
This tutorial will help you set up and interpret a Quantile regression in Excel using the XLSTAT software.
Not sure this is the modeling feature you are looking for? Check out this guide.
Dataset for running a Quantile Regression
The data have been obtained in Lewis T. and Taylor L.R. (1967). Introduction to Experimental Ecology, New York: Academic Press, Inc.. They concern 237 children, described by their Gender, Age in months, Height in inches (1 inch = 2.54 cm), and Weight in pounds (1 pound = 0.45 kg).
Goal of this tutorial on Quantile Regression
Using the Quantile Regression, we want to find out how the weight of the children varies with their gender (a qualitative variable that takes value f or m), their height and their age, and to verify if a linear model makes sense. The Quantile Regression method belongs to a larger family of models called GLM (Generalized Linear Models) as do the ANCOVA.
The specificity of Quantile Regression with respect to these other methods is to provide an estimate of conditional quantiles of the dependent variable instead of conditional mean. In this way, Quantile Regression permits to give a more accurate quality assessment based on a quantile analysis.
The parameter estimates in QR linear models have the same interpretation as those of any other linear model, as rates of change. Therefore, in a similar way to the ordinary least squares (OLS) model, the coefficients of the QR model can be interpreted as the rate of change of some quantile of the dependent variable distribution per unit change in the value of some regressor.
Moreover, as in ANCOVA, it’s possible to mix qualitative and quantitative explanatory variables. In three other tutorials on linear regression this dataset is also used, with the Height (Linear Regression), the Height and the Age (ANOVA) and then the Height, the Age and the Gender (ANCOVA) as explanatory variables.
Setting up a Quantile Regression
After opening XLSTAT, select the XLSTAT / Modeling data / Quantile Regression command (see below).

Once you’ve clicked on the button, the Quantile Regression dialog box appears. Select the data on the Excel sheet. The Dependent variable (or variable to model) is here the Weight.
The quantitative explanatory variables are the height and the age. The qualitative variable is the gender. As we selected the column title for the variables, we leave the option Variable labels activated. The other options have been left at their default value.

The computations begin once you have clicked on OK. The results will then be displayed.
In this study, we want to focus the analysis on quantiles for which the coefficients of the quantile regression are quite far from those of the ANCOVA.
In the following example, since no a-priori information giving quantiles of interest are assumed, a two-step analysis of the data is preferred and produced.
First, as an exploratory step, the Quantile Process can be selected to get an overview and thus detect some quantiles of interest to focus on next.
Before beginning, we recall the main results of ANCOVA applied on this dataset :

Interpreting the results of the first step of Quantile Regression : the Quantile Process computation
For this preliminary step, only general results are supplied (more options are available in the second step).
First, it can be noticed that around the median, the results are of the same order than those of the ANCOVA (for the mean) :

Now, if we focus on the Age and Height, their contribution seems to be stronger in the evaluation of the weight of the biggest children (alpha>0.9):

whereas some other quantile regression results suggest that the Gender has a greater effect on the weight of the slimest ones (alpha<0.1):

Obviously, the quantiles we are interested in belong to the intervals [0.9 , 1] and [0, 0.1].
It’s also easy and quick to confirm these impressions visualizing the illustrative charts displayed at the end of the analysis :



Then, in a second step, the quantile Selection : 0.95 and 0.05 is done via the Excel sheet.
Interpreting the results of the second step of Quantile Regression: the Quantile Selection computation
This first table displays the goodness of fit coefficients of the model for a specific quantile. The R² (coefficient of determination) indicates the % of variability of the dependant variable which is explained by the explanatory variables. The closer to 1 the R² is, the better the fit.

In this particular case, 91.6 % of the variability of the Weight is explained by the Height, the Age and the Gender. The remainder of the variability is due to some effects (other explanatory variables) that have not been or that could not be measured during this experiment. We can guess that some genetic and nutritive effects are involved, but it might be that simply by transforming the available variables we could obtain some better results.
It is important to examine the results of the model significance table (see below). The results enable us to determine whether or not the explanatory variables bring significant information (null hypothesis H0) to the model. In other words, it’s a way of asking yourself whether it is valid to use this quantile to describe the whole population, or whether the information brought by the explanatory variables is of value or not.

Three tests are used : Maximum Likelihood, Lagrange Multipliers and Wald. Given the fact that the probability corresponding to the Chi² value is lower than 0.0001, it means that we would be taking a lower than 0.01% risk in assuming that the null hypothesis (no effect of the two explanatory variables) is wrong. Therefore, we can conclude with confidence that the three variables do bring a significant amount of information.
The following table gives details on the model. This table is helpful when predictions are needed, or when you need to compare the coefficients of the model for a given population with the ones obtained for another population.

The next table shows a part of the predictions and the residuals. It enables us to take a closer look at each of the standardized residuals.

The chart below shows the predicted values versus the observed values :

Conclusion for this Quantile Regression
As a conclusion, the Height, the Age and the Gender allow us to explain more than 90% of the variability of the Weight. A significant amount of information is explained by the Quantile Regression model we have used.
Was this article useful?
- Yes
- No
Рассмотрим вычисление квантилей для некоторых функций распределений, представленных в
MS
EXCEL
.
Понятие
Квантиля
основано на определении
Функции распределения
. Поэтому, перед изучением
Квантилей
рекомендуем освежить в памяти понятия из статьи
Функция распределения вероятности
.
Содержание статьи:
- Определение
- Квантили специальных видов
- Квантили стандартного нормального распределения
- Квантили распределения Стьюдента
- Квантили распределения ХИ-квадрат
- Квантили F-распределения
- Квантили распределения Вейбулла
- Квантили экспоненциального распределения
Сначала дадим формальное определение
квантиля,
затем приведем примеры их вычисления в MS EXCEL.
Определение
Пусть случайная величина
X
, имеет
функцию распределения
F
(
x
).
α-квантилем
(
альфа-
квантиль,
x
a
,
квантиль
порядка
α, нижний
α-
квантиль
) называют решение уравнения
x
a
=F
-1
(α), где
α
— вероятность, что случайная величина х примет значение меньшее или равное x
a
, т.е. Р(х<= x
a
)=
α.
Из определения ясно, что нахождение
квантиля
распределения является обратной операцией нахождения вероятности. Т.е. если при вычислении
функции распределения
мы находим вероятность
α,
зная x
a
, то при нахождении
квантиля
мы, наоборот, ищем
x
a
зная
α
.
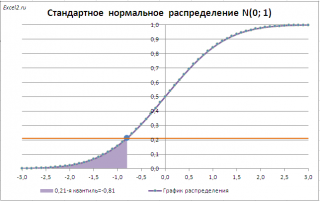
Чтобы пояснить определение, используем график функции
стандартного нормального распределения
(см.
файл примера Лист Определение
):
Примечание
: О построении графиков в MS EXCEL можно прочитать статью
Основные типы диаграмм в MS EXCEL
.
Например, с помощью графика вычислим 0,21-ю
квантиль
, т.е. такое значение случайной величины, что Р(X<=x
0,21
)=0,21.
Для этого найдем точку пересечения горизонтальной линии на уровне вероятности равной 0,21 с
функцией распределения
. Абсцисса этой точки равна -0,81. Соответственно, 0,21-я
квантиль
равна -0,81. Другими словами, вероятность того, что случайная величина, распределенная
стандартному нормальному закону,
примет значение
меньше
-0,81, равна 0,21 (21%).
Примечание
: При вычислении
квантилей
в MS EXCEL используются
обратные функции распределения
:
НОРМ.СТ.ОБР()
,
ЛОГНОРМ.ОБР()
,
ХИ2.ОБР(),
ГАММА.ОБР()
и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье
Распределения случайной величины в MS EXCEL
.
Точное значение
квантиля
в нашем случае можно найти с помощью формулы
=НОРМ.СТ.ОБР(0,21)
СОВЕТ
: Процедура вычисления
квантилей
имеет много общего с вычислением
процентилей
выборки
(см. статью
Процентили в MS EXCEL
).
Квантили специальных видов
Часто используются
Квантили
специальных видов:
-
процентили
x
p/100
, p=1, 2, 3, …, 99 -
квартили
x
p/4
, p=1, 2, 3 -
медиана
x
1/2
В качестве примера вычислим
медиану (0,5-квантиль)
логнормального распределения
LnN(0;1) (см.
файл примера лист Медиана
).
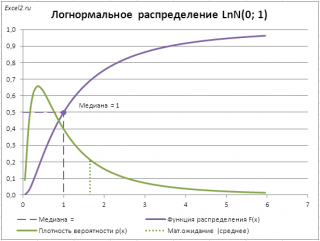
Это можно сделать с помощью формулы
=ЛОГНОРМ.ОБР(0,5; 0; 1)
Квантили стандартного нормального распределения
Необходимость в вычислении квантилей
стандартного нормального распределения
возникает при
проверке статистических гипотез
и при
построении доверительных интервалов.
Примечание
: Про
проверку статистических гипотез
см. статью
Проверка статистических гипотез в MS EXCEL
. Про
построение доверительных интервалов
см. статью
Доверительные интервалы в MS EXCEL
.
В данных задачах часто используется специальная терминология:
Нижний квантиль уровня
альфа
(
α
percentage point)
;
Верхний квантиль уровня альфа (upper
α
percentage point)
;
Двусторонние квантили уровня
альфа
.
Нижний квантиль уровня альфа
— это обычный
α-квантиль.
Чтобы пояснить название «
нижний» квантиль
, построим график
плотности вероятности
и
функцию вероятности
стандартного нормального
распределения
(см.
файл примера лист Квантили
).
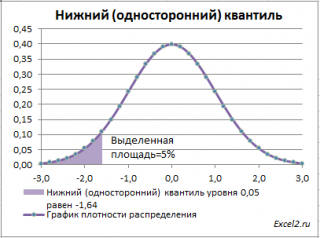
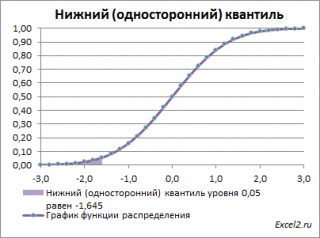
Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение меньше
α-квантиля
. Из определения
квантиля
эта вероятность равна
α
. Из графика
функции распределения
становится понятно, откуда происходит название »
нижний квантиль» —
выделенная область расположена в нижней части графика.
Для
α=0,05,
нижний 0,05-квантиль
стандартного нормального распределения
равен -1,645. Вычисления в MS EXCEL можно сделать по формуле:
=НОРМ.СТ.ОБР(0,05)
Однако, при
проверке гипотез
и построении
доверительных интервалов
чаще используется «верхний»
α-квантиль.
Покажем почему.
Верхним
α
—
квантилем
называют такое значение x
α
, для которого вероятность, того что случайная величина X примет значение
больше или равное
x
α
равна
альфа:
P(X>= x
α
)=
α
. Из определения понятно, что
верхний альфа
—
квантиль
любого распределения равен
нижнему (1-
α)
—
квантилю.
А для распределений, у которых
функция плотности распределения
является четной функцией,
верхний
α
—
квантиль
равен
нижнему
α
—
квантилю
со знаком минус
.
Это следует из свойства четной функции f(-x)=f(x), в силу симметричности ее относительно оси ординат.
Действительно, для
α=0,05,
верхний 0,05-квантиль
стандартного нормального распределения
равен 1,645. Т.к.
функция плотности вероятности
стандартного нормального
распределения
является четной функцией, то вычисления в MS EXCEL
верхнего квантиля
можно сделать по двум формулам:
=НОРМ.СТ.ОБР(1-0,05)
=-НОРМ.СТ.ОБР(0,05)
Почему применяют понятие
верхний
α
—
квантиль?
Только из соображения удобства, т.к. он при
α<0,5
всегда положительный (в случае
стандартного нормального
распределения
). А при проверке гипотез
α
равно
уровню значимости
, который обычно берут равным 0,05, 0,1 или 0,01. В противном случае, в процедуре
проверки гипотез
пришлось бы записывать условие отклонения
нулевой гипотезы
μ>μ
0
как Z
0
>Z
1-
α
, подразумевая, что Z
1-
α
–
обычный
квантиль
порядка
1-
α
(или как Z
0
>-Z
α
). C верхнем квантилем эта запись выглядит проще Z
0
>Z
α
.
Примечание
: Z
0
— значение
тестовой статистики
, вычисленное на основе
выборки
. Подробнее см. статью
Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна)
.
Чтобы пояснить название «
верхний»
квантиль
, построим график
плотности вероятности
и
функцию вероятности
стандартного нормального
распределения
для
α=0,05.
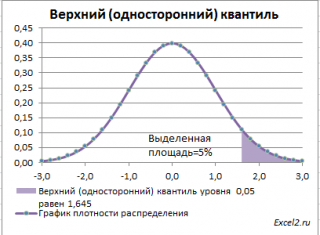
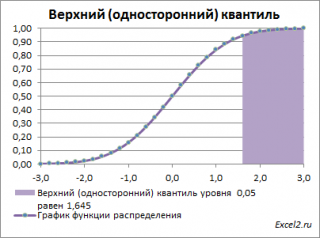
Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение больше
верхнего 0,05-квантиля
, т.е.
больше
значения 1,645. Эта вероятность равна 0,05.
На графике
плотности вероятности
площадь выделенной области равна 0,05 (5%) от общей площади под графиком (равна 1). Из графика
функции распределения
становится понятно, откуда происходит название «верхний»
квантиль
—
выделенная область расположена в верхней части графика. Если Z
0
больше
верхнего квантиля
, т.е. попадает в выделенную область, то
нулевая гипотеза
отклоняется.
Также при
проверке двухсторонних гипотез
и построении соответствующих
доверительных интервалов
иногда используется понятие «двусторонний»
α-квантиль.
В этом случае условие отклонения
нулевой гипотезы
звучит как |Z
0
|>Z
α
/2
, где Z
α
/2
–
верхний
α/2-квантиль
. Чтобы не писать
верхний
α/2-квантиль
, для удобства используют «двусторонний»
α-квантиль.
Почему двусторонний? Как и в предыдущих случаях, построим график
плотности вероятности стандартного нормального распределения
и график
функции распределения
.
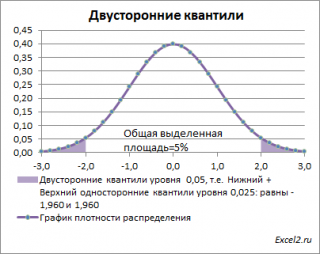
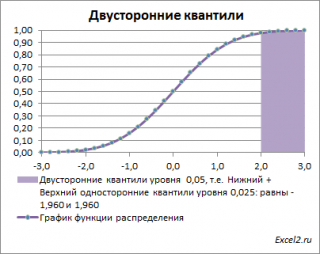
Невыделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение
между
нижним квантилем уровня α
/2 и
верхним квантилем
уровня α
/2, т.е. будет между значениями -1,960 и 1,960 при α=0,05. Эта вероятность равна в нашем случае 1-(0,05/2+0,05/2)=0,95. Если Z
0
попадает в одну из выделенных областей, то
нулевая гипотеза
отклоняется.
Вычислить
двусторонний
0,05
—
квантиль
это можно с помощью формул MS EXCEL:
=НОРМ.СТ.ОБР(1-0,05/2)
или
=-НОРМ.СТ.ОБР(0,05/2)
Другими словами,
двусторонние α-квантили
задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью α.
Квантили распределения Стьюдента
Аналогичным образом
квантили
вычисляются и для
распределения Стьюдента
. Например, вычислять
верхний
α/2-
квантиль
распределения Стьюдента с
n
-1 степенью свободы
требуется, если проводится
проверка двухсторонней гипотезы
о
среднем значении
распределения при
неизвестной
дисперсии
(
см. эту статью
).
Для
верхних квантилей
распределения Стьюдента
часто используется запись t
α/2,n-1
. Если такая запись встретилась в статье про
проверку гипотез
или про построение
доверительного интервала
, то это именно
верхний квантиль
.
Примечание
:
Функция плотности вероятности распределения Стьюдента
, как и
стандартного нормального распределения
, является четной функцией.
Чтобы вычислить в MS EXCEL
верхний
0,05/2
—
квантиль
для t-распределения с 10 степенями свободы (или тоже самое
двусторонний
0,05-квантиль
), необходимо записать формулу
=СТЬЮДЕНТ.ОБР.2Х(0,05; 10)
или
=СТЬЮДРАСПОБР(0,05; 10)
или
=СТЬЮДЕНТ.ОБР(1-0,05/2; 10)
или
=-СТЬЮДЕНТ.ОБР(0,05/2; 10)
.2X означает 2 хвоста, т.е.
двусторонний квантиль
.
Квантили распределения ХИ-квадрат
Вычислять
квантили
распределения ХИ-квадрат
с
n
-1 степенью свободы
требуется, если проводится
проверка гипотезы
о
дисперсии нормального распределения
(см. статью
Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения
).
При
проверке таких гипотез
также используются
верхние квантили.
Например, при
двухсторонней гипотезе
требуется вычислить 2
верхних
квантиля
распределения
ХИ
2
: χ
2
α/2,n-1
и
χ
2
1-
α/2,n-1
. Почему требуется вычислить два
квантиля
, не один, как при
проверке гипотез о среднем
, где используется
стандартное нормальное распределение
или
t-распределение
?
Дело в том, что в отличие от
стандартного нормального распределения
и
распределения Стьюдента
, плотность распределения
ХИ
2
не является четной (симметричной относительно оси х). У него все
квантили
больше 0, поэтому
верхний альфа-квантиль
не равен
нижнему (1-альфа)-квантилю
или по-другому:
верхний альфа-квантиль
не равен
нижнему альфа-квантилю
со знаком минус.
Чтобы вычислить
верхний
0,05/2
—
квантиль
для
ХИ
2
-распределения
с
числом степеней свободы
10, т.е.
χ
2
0,05/2,n-1
, необходимо в MS EXCEL записать формулу
=ХИ2.ОБР.ПХ(0,05/2; 10)
или
=ХИ2.ОБР(1-0,05/2; 10)
Результат равен 20,48. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике
функции распределения
.
Чтобы вычислить
верхний
(1-0,05/2)-
квантиль
при том же
числе степеней свободы
, т.е.
χ
2
1-0,05/2,n-1
и необходимо записать формулу
=ХИ2.ОБР.ПХ(1-0,05/2; 10)
или
=ХИ2.ОБР(0,05/2; 10)
Результат равен 3,25.
Квантили F-распределения
Вычислять
квантили
распределения Фишера
с
n
1
-1 и
n
2
-1 степенями свободы
требуется, если проводится
проверка гипотезы
о равенстве
дисперсий двух нормальных распределений
(см. статью
Двухвыборочный тест для дисперсии: F-тест в MS EXCEL
).
При
проверке таких гипотез
используются, как правило,
верхние квантили.
Например, при
двухсторонней гипотезе
требуется вычислить 2
верхних
квантиля
F
-распределения:
F
α/2,n1-1,
n
2
-1
и
F
1-α/2,n1-1,
n
2
-1
. Почему требуется вычислить два
квантиля
, не один, как при
проверке гипотез о среднем
? Причина та же, что и для распределения ХИ
2
– плотность
F-распределения
не является четной
.
Эти
квантили
нельзя выразить один через другой как для
стандартного нормального распределения
.
Верхний альфа-квантиль
F
-распределения
не равен
нижнему альфа-квантилю
со знаком минус.
Чтобы вычислить
верхний
0,05/2-квантиль
для
F
-распределения
с
числом степеней свободы
10 и 12, необходимо записать формулу
=F.ОБР.ПХ(0,05/2;10;12) =FРАСПОБР(0,05/2;10;12) =F.ОБР(1-0,05/2;10;12)
Результат равен 3,37. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике
функции распределения
.
Квантили распределения Вейбулла
Иногда
обратная функция распределения
может быть представлена в явном виде с помощью элементарных функций, например как для
распределения Вейбулла
. Напомним, что функция этого распределения задается следующей формулой:
![]()
После логарифмирования обеих частей выражения, выразим x через соответствующее ему значение F(x) равное P:
![]()
Примечание
: Вместо обозначения
α-квантиль
может использоваться
p
—
квантиль.
Суть от этого не меняется.
Это и есть обратная функция, которая позволяет вычислить
P
—
квантиль
(
p
—
quantile
). Для его вычисления в формуле нужно подставить известное значение вероятности P и вычислить значение х
p
(вероятность того, что случайная величина Х примет значение меньше или равное х
p
равна P).
Квантили экспоненциального распределения
Задача
:
Случайная величина имеет
экспоненциальное распределение
:
![]()
Требуется выразить
p
-квантиль
x
p
через параметр распределения λ и заданную вероятность
p
.
Примечание
: Вместо обозначения
α-квантиль
может использоваться
p-квантиль
. Суть от этого не меняется.
Решение
: Вспоминаем, что
p
-квантиль
– это такое значение x
p
случайной величины X, для которого P(X<=x
p
)=
p
. Т.е. вероятность, что случайная величина X примет значение меньше или равное x
p
равна
p
. Запишем это утверждение с помощью формулы:
![]()
По сути, мы записали
функцию вероятности экспоненциального распределения
: F(x
p
)=
p
.
Из определения
квантиля
следует, что для его нахождения нам потребуется
обратная функция распределения
.
Проинтегрировав вышеуказанное выражение, получим:
![]()
Используя это уравнение, выразим x
p
через λ и вероятность
p
.
![]()
Конечно, явно выразить
обратную функцию распределения
можно не для всех
функций распределений
.
Содержание
- Медиана и квартили
- Математическое описание
- Среднее значение
- Отклонение от среднего
- Квантиль
- Построение интервалов
- Двусторонний доверительный интервал
- Первый квартиль
- Третий квартиль
- Квартили непрерывного распределения
- Квартили в MS EXCEL
- Моменты случайной величины
- Статистический анализ роста доли дохода в Excel за период
- Анализ статистики случайно сгенерированных чисел в Excel
- Расчет квартилей в R и SAS
- Расчет децилей для дискретного ряда
- Квантили специальных видов
- Квантили стандартного нормального распределения
- Квантили распределения Стьюдента
- Квантили распределения ХИ-квадрат

![]()
Квантили нормального распределения
Основная статья: Медиана (статистика)
- 0,25-квантиль называется первым (или нижним) квартилем (от лат. quarta — четверть);
- 0,5-квантиль называется медианой (от лат. mediāna — середина) или вторым квартилем
- 0,75-квантиль называется третьим (или верхним) квартилем.
Интерквартильным размахом (англ. Interquartile range) называется разность между третьим и первым квартилями. Интерквартильный размах является характеристикой разброса распределения величины и является робастным аналогом дисперсии. Вместе, медиана и интерквартильный размах могут быть использованы вместо математического ожидания и дисперсии в случае распределений с большими выбросами, либо при невозможности вычисления последних.
Математическое описание
Смотря на закон распределения, мы можем понять, какова вероятность того или иного события, можем сказать, какова вероятность, что произойдёт группа событий, а в этой статье мы рассмотрим, как наши выводы “на глаз” перевести в математически обоснованное утверждение.
Крайне важное определение: математическое ожидание – это площадь под графиком распределения. Если мы говорим о дискретном распределении – это сумма событий умноженных на соответсвующие вероятности, также известно как момент:
(2) E(X) = Σ(pi•Xi) E – от английского слова Expected (ожидание)
Для математического ожидания справедливы равенства:
(3) E(X + Y) = E(X) + E(Y)
(4) E(X•Y) = E(X) • E(Y)
Момент степени k:
(5) νk = E(Xk)
Центральный момент степени k:
(6) μk = E[X – E(X)]k
Среднее значение
Среднее значение (μ) закона распределения – это математическое ожидание случайной величины (случайная величина – это событие), например, сколько в среднем посетителей заходит в магазин в час:
| Кол-во посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Количество наблюдений | 114 | 115 | 52 | 52 | 24 | 13 | 30 |
| Таблица 1. Количество посетителей в час |
График 1. Количество посетителей в час
Чтобы найти среднее значение всех результатов необходимо сложить всё вместе и разделить на количество результатов:
μ = (114 • 0 + 115 • 1 + 52 • 2 + 52 • 3 + 24 • 4 + 13 • 5 + 30 • 6) / 400 = 716/400 = 1.79
То же самое мы можем проделать используя формулу 2:
μ = M(X) = Σ(Xi•pi) = 0 • 0.29 + 1 • 0.29 + 2 • 0.13 + 3 • 0.13 + 4 • 0.06 + 5 • 0.03 + 6 • 0.08 = 1.79 Момент первой степени, формула (5)
Собственно, формула 2 представляет собой среднее арифметическое всех значений
Итог: в среднем, 1.79 посетителя в час
| Количество посетителей | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Вероятность (%) | 28.5 | 28.8 | 13 | 13 | 6 | 3.3 | 7.5 |
| Таблица 2. Закон распределения количества посетителей |
Отклонение от среднего
Посмотрите на это распределение, можно предположить, что в среднем случайная величина равна 100±5, поскольку кажется, что таких значений несравнимо больше чем тех, что меньше 95 или больше 105:
График 2. График функции вероятности. Распределение ≈ 100±5
Среднее значение по формуле (2): μ = 99.95, но как посчитать, насколько далеко все значения находятся от среднего? Вам должна быть знакома запись 100±5. Что бы получить это значение ±, нам необходимо определить диапазон значений вокруг среднего. И мы могли бы использовать в качестве меры удалённости “разность” между средним и случайными величинами:
(7) xi – μ
но сумма таких расстояний, а следовательно и любое производное от этого числа, будет равно нулю, поэтому в качестве меры выбрали квадрат разниц между величинами и средним значением:
(8) (xi – μ)2
Соответственно, среднее значение удалённости – это математическое ожидание квадратов удалённости:
(9) σ2 = E[(X – E(X))2] Поскольку вероятности любой удалённости равносильны – вероятность каждого из них – 1/n, откуда: (10) σ2 = E[(X – E(X))2] = ∑[(Xi – μ)2]/n Она же формула центрального момента (6) второй степени
σ возведена в квадрат, поскольку вместо расстояний мы взяли квадрат расстояний. σ2 называется дисперсией. Корень из дисперсии называется средним квадратическим отклонением, или среднеквадратическим отклоненим, и его используют в качестве меры разброса:
(11) μ±σ
(12) σ = √(σ2) = √[∑[(Xi – μ)2]/n]
Возвращаясь к примеру, посчитаем среднеквадратическое отклонение для графика 2:
σ = √(∑(x-μ)2/n) = √{[(90 – 99.95)2 + (91 – 99.95)2 + (92 – 99.95)2 + (93 – 99.95)2 + (94 – 99.95)2 + (95 – 99.95)2 + (96 – 99.95)2 + (97 – 99.95)2 + (98 – 99.95)2 + (99 – 99.95)2 + (100 – 99.95)2 + (101 – 99.95)2 + (102 – 99.95)2 + (103 – 99.95)2 + (104 – 99.95)2 + (105 – 99.95)2 + (106 – 99.95)2 + (107 – 99.95)2 + (108 – 99.95)2 + (109 – 99.95)2 + (110 – 99.95)2]/21} = 6.06
Итак, для графика 2 мы получили:
X = 99.95±6.06 ≈ 100±6 , что немного отличается от полученного “на глаз”
Квантиль
График 3. Функция распределения. Медиана
График 4. Функция распределения. 4-квантиль или квартиль
График 5. Функция распределения. 0.34-квантиль
Для анализа функции распределения ввели понятие квантиль. Квантиль – это случайная величина при заданном уровне вероятности, т.е.: квантиль для уровня вероятности 50% – это случайная величина на графике плотности вероятности, которая имеет вероятность 50%. На примере с графиком 3, квантиль уровня 0.5 = 99 (ближайшее значение, поскольку распределение дискретно и события со значением 99.3 просто не существует)
- 2-квантиль – медиана
- 4-квантиль – квартиль
- 10-квантиль – дециль
- 100-квантиль – перцентиль
То есть, если мы говорим о дециле (10-квантиле), то это означает, что мы разбили график на 10 частей, что соответствует девяти линяям, и для каждого дециля нашли значение случайной величины.
Также, используется обозначение x-квантиль, где х – дробное число, например, 0.34-квантиль, такая запись означает значение случайной величины при p = 0.34.
Для дискретного распределения квантиль необходимо выбирать следующим образом: квантиль гарантирует вероятность, поэтому, если рассчитанный квантиль не совпадает с одним и значений, необходимо выбирать меньшее значение.
Построение интервалов
Квантили используют для построения доверительных интервалов, которые необходимы для исследования статистики не одного конкретного события (например, интерес – случайное число = 98), а для группы событий (например, интерес – случайное число между 96 и 99). Доверительный интервал бывает двух видов: односторонний и двусторонний. Параметр доверительного интервала – уровень доверия. Уровень доверия означает процент событий, которые можно считать успешными.
Двусторонний доверительный интервал
Двусторонний доверительный интервал строится следующим образом: мы задаёмся уровнем значимости, например, 10%, и выделяем область на графике так, что 90% всех событий попадут в эту область. Поскольку интервал двусторонний, то мы отсекаем по 5% с каждой стороны, т.е. мы ищем 5й перцентиль, 95й перцентиль и значения случайной величины между ними будут являться доверительной областью, значения за пределами доверительной области называются “критическая область“
Первый квартиль
Значение квартиля Q1 находится в интервале 68,98 – 71,70, соответствующего частоте fQ1 = 150:4 = 37,5
Третий квартиль
Значение квартиля находится в интервале 68,98 – 71,70, соответствующего частоте fQ3 = (3*150):4 = 112,5
Квартили непрерывного распределения
Если функция распределения F (х) случайной величины х непрерывна, то 1-й квартиль является решением уравнения F(х) =0,25, второй – F(х) =0,5, а третий F(х) =0,75.
Примечание : Подробнее о Функции распределения см. статью Функция распределения и плотность вероятности в MS EXCEL .
Если известна функция плотности вероятности p (х) , то 1-й квартиль можно найти из уравнения: ![]()
Например, решив аналитическим способом это уравнение для Логнормального распределения lnN(μ; σ 2 ), получим, что медиана (2-й квартиль ) вычисляется по формуле e μ или в MS EXCEL =EXP(μ). При μ=1, медиана равна 2,718. 
Обратите внимание на точку Функции распределения , для которой F(х)=0,5 (см. картинку выше или файл примера , лист Квартиль-распределение) . Абсцисса этой точки равна 2,718. Это и есть значение 2-го квартиля ( медианы ), что естественно совпадает с ранее вычисленным значением по формуле e μ .
Примечание : Напомним, что интеграл от функции плотности вероятности по всей области задания случайной величины равен единице: ![]()
Поэтому, линии квартилей ( х=квартиль ) делят площадь под графиком функции плотности вероятности на 4 равные части.
Квартили в MS EXCEL
Чтобы вычислить в MS EXCEL квартили заданного распределения необходимо использовать соответствующую обратную функцию распределения .
При вычислении квартилей в MS EXCEL используются обратные функции распределения : НОРМ.СТ.ОБР() , ЛОГНОРМ.ОБР() , ХИ2.ОБР() , ГАММА.ОБР() и т.д. Подробнее о распределениях, представленных в MS EXCEL, можно прочитать в статье Распределения случайной величины в MS EXCEL .
Например, в MS EXCEL 1-й квартиль для логнормального распределения LnN(1;1) можно вычислить по формуле =ЛОГНОРМ.ОБР(0,25;1;1) , а 3-й квартиль для стандартного нормального распределения по формуле =НОРМ.СТ.ОБР(0,75) .
Моменты случайной величины
Моменты случайно величины описывают различные аспекты характера и формы нашего распределения.
#1 — первый момент случайной величины — среднее значение данных, которое показывает место распределения.
#2 — второй момент случайной величины — дисперсия, которая показывает разброс распределения. Большие значения имеют больший размах, чем маленькие.
#3 — третий момент случайной величины — коэффициент асимметрии — мера того, насколько неравномерным является распределение. Коэффициент асимметрии положителен, если распределение наклонено влево и левый хвост короче правого. То есть среднее значение находится правее. И наоборот:

#4 — четвертый момент случайной величины — коэффициент эксцесса, который описывает то, насколько толстый хвост и насколько острый пик распределения. Этот коэффициент показывает, насколько вероятно найти точки экстремума в данных. Чем выше значение, тем вероятнее выбросы. Это похоже на разброс (дисперсию), но между ними есть отличия.

Как видно на графике, чем выше значение пики, тем выше коэффициент эксцесса, т.е. у верхней кривой коэффициент эксцесса выше, чем у нижней.
Статистический анализ роста доли дохода в Excel за период
Пример 2. В таблице приведены данные о доходах предпринимателя за год. Доказать, что примерно 75% значений меньше, чем третий квартиль доходов.
Вид исходной таблицы:

Определим 3-й по формуле:


Определим соотношение чисел, меньше полученного числа, к общему количеству значений по формуле:
=СЧЁТЕСЛИ(B2:B13;”<“&B15)/СЧЁТ(B2:B13)
Полученные результаты:

Анализ статистики случайно сгенерированных чисел в Excel
Пример 3. Имеется диапазон случайных чисел, отсортированный в порядке возрастания. Определить соотношение суммы чисел, которые меньше 1-го квартиля, к сумме чисел, которые превышают значение 1-го квартиля.
Чтобы сгенерировать случайное число в Excel воспользуемся функцией:
=СЛУЧМЕЖДУ(0;1000)
После генерации отсортируем случайно сгенерированные числа по возрастанию. Вид исходной таблицы данных со случайными числами:

Формула для расчета имеет следующий вид (формула массива CTRL+SHIFT+ENTER):
Функции СУММ с вложенными функциями ЕСЛИ выполняют расчет суммы только тех чисел, которые меньше и больше соответственно значения, возвращаемого функцией для исследуемого диапазона. Из полученных значений вычисляется частное. Результат расчетов:

Общая сумма чисел исследуемого диапазона, которые меньше 1-го квартиля, составляет всего 8,57% от общей суммы чисел, которые больше 1-го квартиля.
Расчет квартилей в R и SAS
Функция quantile в R использует все девять алгоритмов расчета квантилей, в соответствии с нумерацией, предложенной Hyndman and Fan в работе 1996 г. (рис. 15; если вы не знакомы с R, рекомендую начать с Алексей Шипунов. Наглядная статистика. Используем R!). Квантиль при i-м методе расчета:
![]()
где i – номер метода, 1 ≤ i ≤ 9, (j–m)/n ≤ p < (j–m+1)/n, хj – j-ый порядковый элемент упорядоченного ряда, n – размер выборки, γ является функцией двух параметров: j = floor(np + m) и g = np + m – j, где floor – функция возвращающая наибольшее целое, но всё еще меньшее, чем аргумент функции (аналог в Excel – ОКРВНИЗ.МАТ), m – константа, определяемая типом алгоритма расчета квантиля. Если вас интересуют подробности, обратитесь к справочной системе R.
SAS предлгает 5 методов расчета квантилей.

Расчет децилей для дискретного ряда
-
Определяем номер дециля по формуле:
 ,
, -
Если номер дециля – целое число, то значение дециля будет равно величине элемента ряда, которое обладает накопленной частотой равной номеру дециля. Например, если номер дециля равен 20, его значение будет равно значению признака с S =20 (накопленной частотой равной 20).
 ,
,Если номер дециля – нецелое число, то дециль попадает между двумя наблюдениями. Значением дециля будет сумма, состоящая из значения элемента, для которого накопленная частота равна целому значению номера дециля, и указанной части (нецелая часть номера дециля) разности между значением этого элемента и значением следующего элемента.
Например, если номер дециля равна 20,25, дециль попадает между 20-м и 21-м наблюдениями, и его значение будет равно значению 20-го наблюдения плюс 1/4 разности между значением 20-го и 21-го наблюдений.
Квантили специальных видов
Часто используются Квантили специальных видов:
- процентили x p/100 , p=1, 2, 3, …, 99
- квартили x p/4 , p=1, 2, 3
- медиана x 1/2
В качестве примера вычислим медиану (0,5-квантиль) логнормального распределения LnN(0;1) (см. файл примера лист Медиана ). 
Это можно сделать с помощью формулы =ЛОГНОРМ.ОБР(0,5; 0; 1)
Квантили стандартного нормального распределения
Необходимость в вычислении квантилей стандартного нормального распределения возникает при проверке статистических гипотез и при построении доверительных интервалов.
Примечание : Про проверку статистических гипотез см. статью Проверка статистических гипотез в MS EXCEL . Про построение доверительных интервалов см. статью Доверительные интервалы в MS EXCEL .
В данных задачах часто используется специальная терминология:
- Нижний квантиль уровня альфа ( α percentage point)
- Верхний квантиль уровня альфа (upper α percentage point)
- Двусторонние квантили уровня альфа .
Нижний квантиль уровня альфа – это обычный α-квантиль. Чтобы пояснить название « нижний» квантиль , построим график плотности вероятности и функцию вероятности стандартного нормального распределения (см. файл примера лист Квантили ).


Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение меньше α-квантиля . Из определения квантиля эта вероятность равна α . Из графика функции распределения становится понятно, откуда происходит название ” нижний квантиль” – выделенная область расположена в нижней части графика.
Для α=0,05, нижний 0,05-квантиль стандартного нормального распределения равен -1,645. Вычисления в MS EXCEL можно сделать по формуле:
=НОРМ.СТ.ОБР(0,05)
Однако, при проверке гипотез и построении доверительных интервалов чаще используется “верхний” α-квантиль. Покажем почему.
Верхним α – квантилем называют такое значение x α , для которого вероятность, того что случайная величина X примет значение больше или равное x α равна альфа: P(X>= x α )= α . Из определения понятно, что верхний альфа – квантиль любого распределения равен нижнему (1- α) – квантилю. А для распределений, у которых функция плотности распределения является четной функцией, верхний α – квантиль равен нижнему α – квантилю со знаком минус . Это следует из свойства четной функции f(-x)=f(x), в силу симметричности ее относительно оси ординат.
Действительно, для α=0,05, верхний 0,05-квантиль стандартного нормального распределения равен 1,645. Т.к. функция плотности вероятности стандартного нормального распределения является четной функцией, то вычисления в MS EXCEL верхнего квантиля можно сделать по двум формулам:
=НОРМ.СТ.ОБР(1-0,05)
=-НОРМ.СТ.ОБР(0,05)
Почему применяют понятие верхний α – квантиль? Только из соображения удобства, т.к. он при α всегда положительный (в случае стандартного нормального распределения ). А при проверке гипотез α равно уровню значимости , который обычно берут равным 0,05, 0,1 или 0,01. В противном случае, в процедуре проверки гипотез пришлось бы записывать условие отклонения нулевой гипотезы μ>μ 0 как Z 0 >Z 1- α , подразумевая, что Z 1- α – обычный квантиль порядка 1- α (или как Z 0 >-Z α ). C верхнем квантилем эта запись выглядит проще Z 0 >Z α .
Примечание : Z 0 – значение тестовой статистики , вычисленное на основе выборки . Подробнее см. статью Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна) .
Чтобы пояснить название « верхний» квантиль , построим график плотности вероятности и функцию вероятности стандартного нормального распределения для α=0,05.


Выделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение больше верхнего 0,05-квантиля , т.е. больше значения 1,645. Эта вероятность равна 0,05.
На графике плотности вероятности площадь выделенной области равна 0,05 (5%) от общей площади под графиком (равна 1). Из графика функции распределения становится понятно, откуда происходит название “верхний” квантиль – выделенная область расположена в верхней части графика. Если Z 0 больше верхнего квантиля , т.е. попадает в выделенную область, то нулевая гипотеза отклоняется.
Также при проверке двухсторонних гипотез и построении соответствующих доверительных интервалов иногда используется понятие “двусторонний” α-квантиль. В этом случае условие отклонения нулевой гипотезы звучит как |Z 0 |>Z α /2 , где Z α /2 – верхний α/2-квантиль . Чтобы не писать верхний α/2-квантиль , для удобства используют “двусторонний” α-квантиль. Почему двусторонний? Как и в предыдущих случаях, построим график плотности вероятности стандартного нормального распределения и график функции распределения .


Невыделенная площадь на рисунке соответствует вероятности, что случайная величина примет значение между нижним квантилем уровня α /2 и верхним квантилем уровня α /2, т.е. будет между значениями -1,960 и 1,960 при α=0,05. Эта вероятность равна в нашем случае 1-(0,05/2+0,05/2)=0,95. Если Z 0 попадает в одну из выделенных областей, то нулевая гипотеза отклоняется.
Вычислить двусторонний 0,05 – квантиль это можно с помощью формул MS EXCEL: =НОРМ.СТ.ОБР(1-0,05/2) или =-НОРМ.СТ.ОБР(0,05/2)
Другими словами, двусторонние α-квантили задают интервал, в который рассматриваемая случайная величина попадает с заданной вероятностью α.
Квантили распределения Стьюдента
Аналогичным образом квантили вычисляются и для распределения Стьюдента . Например, вычислять верхний α/2- квантиль распределения Стьюдента с n -1 степенью свободы требуется, если проводится проверка двухсторонней гипотезы о среднем значении распределения при неизвестной дисперсии ( см. эту статью ).
Для верхних квантилей распределения Стьюдента часто используется запись t α/2,n-1 . Если такая запись встретилась в статье про проверку гипотез или про построение доверительного интервала , то это именно верхний квантиль .
Примечание : Функция плотности вероятности распределения Стьюдента , как и стандартного нормального распределения , является четной функцией.
Чтобы вычислить в MS EXCEL верхний 0,05/2 – квантиль для t-распределения с 10 степенями свободы (или тоже самое двусторонний 0,05-квантиль ), необходимо записать формулу =СТЬЮДЕНТ.ОБР.2Х(0,05; 10) или =СТЬЮДРАСПОБР(0,05; 10) или =СТЬЮДЕНТ.ОБР(1-0,05/2; 10) или =-СТЬЮДЕНТ.ОБР(0,05/2; 10)
.2X означает 2 хвоста, т.е. двусторонний квантиль .
Квантили распределения ХИ-квадрат
Вычислять квантили распределения ХИ-квадрат с n -1 степенью свободы требуется, если проводится проверка гипотезы о дисперсии нормального распределения (см. статью Проверка статистических гипотез в MS EXCEL о дисперсии нормального распределения ).
При проверке таких гипотез также используются верхние квантили. Например, при двухсторонней гипотезе требуется вычислить 2 верхних квантиля распределения ХИ 2 : χ 2 α/2,n-1 и χ 2 1- α/2,n-1 . Почему требуется вычислить два квантиля , не один, как при проверке гипотез о среднем , где используется стандартное нормальное распределение или t-распределение ?
Дело в том, что в отличие от стандартного нормального распределения и распределения Стьюдента , плотность распределения ХИ 2 не является четной (симметричной относительно оси х). У него все квантили больше 0, поэтому верхний альфа-квантиль не равен нижнему (1-альфа)-квантилю или по-другому: верхний альфа-квантиль не равен нижнему альфа-квантилю со знаком минус.
Чтобы вычислить верхний 0,05/2 – квантиль для ХИ 2 -распределения с числом степеней свободы 10, т.е. χ 2 0,05/2,n-1 , необходимо в MS EXCEL записать формулу =ХИ2.ОБР.ПХ(0,05/2; 10) или =ХИ2.ОБР(1-0,05/2; 10)
Результат равен 20,48. .ПХ означает правый хвост распределения, т.е. тот который расположен вверху на графике функции распределения .
Чтобы вычислить верхний (1-0,05/2)- квантиль при том же числе степеней свободы , т.е. χ 2 1-0,05/2,n-1 и необходимо записать формулу =ХИ2.ОБР.ПХ(1-0,05/2; 10) или =ХИ2.ОБР(0,05/2; 10)
Результат равен 3,25.
Источники
- https://dic.academic.ru/dic.nsf/ruwiki/291015
- https://k-tree.ru/articles/statistika/analiz_dannyh/svoistva_raspredeleniia
- https://univer-nn.ru/zadachi-po-statistike-primeri/kvartili-v-statistike/
- https://excel2.ru/articles/kvartili-i-interkvartilnyy-interval-iqr-v-ms-excel
- https://nuancesprog.ru/p/3307/
- https://exceltable.com/funkcii-excel/primery-funkcii-kvartil
- https://baguzin.ru/wp/kvartil-kakie-formuly-rascheta-ispol/
- https://studfile.net/preview/5316597/page:4/
- https://excel2.ru/articles/kvantili-raspredeleniy-ms-excel
August 27, 2013 by abhid90210
0
According to Wikipedia, for discrete distributions, there is no universally agreed method of calculating a Quantile, however in Excel one can simply use PERCENTILE function to calculate any arbitrary quantile.
e.g.: to calculate 1 to 10th deciles:
 1st decile is the 0.1 percentile, hence the C2/10 in the formula at D2.
1st decile is the 0.1 percentile, hence the C2/10 in the formula at D2.
Similarly 1st Quartile is 0.25 percentile and so on.
Leave a Reply
Enter your comment here…
Fill in your details below or click an icon to log in:
![]()
Email (required) (Address never made public)
Name (required)
Website
![]()
You are commenting using your WordPress.com account.
( Log Out /
Change )
![]()
You are commenting using your Twitter account.
( Log Out /
Change )
You are commenting using your Facebook account.
( Log Out /
Change )
Cancel
Connecting to %s
Notify me of new comments via email.
Notify me of new posts via email.
Квартиль — одна из статистик, используемая при описании выборок (подробнее о различных статистиках см. Определение среднего значения, вариации и формы распределения. Описательные статистики). В то время как медиана разделяет упорядоченный массив пополам, квартили разбивают набор данных на четыре части. Первый квартиль – это число, разделяющее выборку на две части: 25% элементов меньше, а 75% — больше значения первого квартиля. Третий квартиль — это число, разделяющее выборку также на две части: 75% элементов меньше, а 25% — больше третьего квартиля.

Рис. 1. 5-числовые сводки: М – медиана, Н1 и Н2 – сгибы (они же квартили)
Скачать заметку в формате Word или pdf, примеры в формате Excel (файл содержит код VBA).
Для расчета квартилей в Excel2007 и более ранних версиях использовалась функция КВАРТИЛЬ. Начиная с версии Excel2010 применяются две функции: КВАРТИЛЬ.ВКЛ и КВАРТИЛЬ.ИСКЛ (функция КВАРТИЛЬ оставлена для совмещения с более ранними версиями Excel; эта функция возвращает те же значения, что и КВАРТИЛЬ.ВКЛ). Эти две функции возвращают различные значения, но я нигде не нашел, какой алгоритм они используют при расчетах. Замечу, что для корректной работы функций данные можно не упорядочивать.
Изучение литературы показало, что в отличие от большинства других статистик, единодушия в методике расчета квартилей нет)) Я нашел упоминание о девяти различных подходах…
Начнем с метода Джона Тьюки, описанного им в, уже ставшем классическом, труде Анализ результатов наблюдений. Разведочный анализ, изданном в 1977 г. Он начинает с введения трех сводок, характеризующих выборку: минимальное, максимальное значения и медиана. Далее он продолжает: «Если мы хотим добавить еще два числа, чтобы образовать 5-числовую сводку, то естественно определять их подсчетом до половины расстояния от каждого из концов к медиане. Процесс нахождения медианы, а затем и этих новых значений можно представить себе, как складывание листа бумаги. Поэтому эти новые значения естественно назвать сгибами» (англ. – hinge; рис. 1). Мы их называем квартилями.
Такие рисунки выглядят очень аккуратно, если число элементов выборки N = 4k + 1, например, 9, 13, 17… Но как быть, если в выборке 12 или 19 элементов? Наглядную картину представил Jon Peltier в серии заметок в своем блоге. Упорядочим элементы случайной выборки и разместим их над линейкой (рис. 2; случайная выборка, элементы которой упорядочены называется вариационным рядом). Серые числа под линейкой – индекс ряда (Джон зачем-то в качестве выборки – над линейкой – взял ряд целых чисел; наверное, чтобы запутать нас). Красное число над рядом – значение сводки; если оно дробное, значит полученное значение является интерполяцией между соседними значениями. Мы определяем медиану, как среднее значение набора данных, а первую квартиль – как медиану нижней половины данных.

Рис. 2. Инклюзивные квартили
Когда Джон Тьюки впервые предложил такой подход, он решил, что медиана (если число элементов в выборке нечетное) должна быть включена как в нижнюю (левую на рисунке), так и в верхнюю половинку данных при определении медиан этих половинок, то есть сгибов. Поэтому такой подход и называется инклюзивным (с включением).
Эксклюзивный подход. Некоторым статистикам не нравится, что медиана учитывается дважды. Они решили, что сгибы должны быть определены как медианы верхней и нижней половин набора данных, из которых срединное значение исключено (рис. 3). Такой взгляд отстаивали Moore и McCabe, или кратко M&M. Если набор данных содержит четное количество значений, инклюзивные и эксклюзивные квартили равны, так как нет элемента выборки (соответствующего центральной медиане), который можно было бы включить или исключить из рассмотрения. Для нечетного числа элементов, инклюзивные сгибы всегда ближе к медиане.

Рис. 3. Эксклюзивные квартили
Третий подход – компромисс между Тьюки и М&M – называется Эмпирическая функции распределения или Интегральная функция распределения (английская аббревиатура CDF). В случае нечетного числа значений в наборе данных, следует включить или исключить медиану, ориентируясь на то, чтобы оставшиеся половинки содержали нечетное число элементов. Например, если в выборке 9 элементов, медиану следует включить, а при 11 элементах – исключить. В обоих случаях половинки будут содержать по 5 элементов. Преимущество этого компромисса заключается в том, что в качестве значения квартиля всегда получается один из элементов набора данных (а не среднее значение двух соседних элементов). CDF является методом по умолчанию в статистическом пакете SAS.
Все возможные случаи N. Мы не всегда можем изобразить данные в W-образной форме, как на рис. 1, поэтому удобнее пользоваться линейкой. В общем случае возможны четыре варианта по числу элементов в выборке: N = 4k, N = 4k + 1, N = 4k + 2, N = 4k + 3… и три подхода к расчету квартилей: Тьюки, M&M, CDF (рис. 4–7).

Рис. 4. Число элементов в выборке N = 4k; все три метода дают одинаковые значения квартилей

Рис. 5. Число элементов в выборке N = 4k + 1; M&M дает значения, отстоящие дальше от медианы

Рис. 6. Число элементов в выборке N = 4k + 2; все три метода дают одинаковые значения квартилей

Рис. 7. Число элементов в выборке N = 4k + 3
Методы интерполяции. Помимо трех описанных выше методов, применяют и целый ряд индексных алгоритмов. Мы рассмотрим три из них. Первый индекс во всех методах равен 0, а последний – N–1, N, N + 1. Например, для N=8 индексированные ряды представлены на рис. 8.

Рис. 8. Индексные ряды на основе N–1, N и N + 1 для N = 8
Положение перцентиля р – доля длины индексной линии, или р(N–1), рN, р(N+1), соответственно. р = 0,25 соответствует первому квартилю, а р = 0,75 – третьему. Ниже наглядно представлен расчет квартилей при различном числе элементов в выборке и трех методах интерполяции на основе N–1, N и N + 1 (рис. 9, 11–13). Обратите внимание, что рассчитанные числа (по формулам справа от линеек) являются не значениями квартилей, а значениями индексов квартилей. Над линейками показано значение квартилей для ряда значений {1, 2, 3, 4, 5, 6, 7, 8}.

Рис. 9. Число элементов в выборке N = 4k
Если, например, наша выборка {2, 3, 5, 8, 11, 12, 14, 17}, то расчет квартилей на основе N–1-метода даст индексы 1,75, 3,5 и 5,25, и значения квартилей 4,5, 9,5 и 12,5 (рис. 10).

Рис. 10. От индексов к значениям квартилей для N–1-метода и N = 4k

Рис. 11. Число элементов в выборке N = 4k + 1

Рис. 12. Число элементов в выборке N = 4k + 2

Рис. 13. Число элементов в выборке N = 4k + 3
Какой алгоритм считать стандартным для вычисления квартилей?
В 1996 году Роб Дж. Хиндман и Янан Фан опубликовали статью в American Statistician под названием Квантили выборок в статистических пакетах. В ней они рассматривали различные алгоритмы расчета квантилей (квартили – это частный случай квантилей). Их целью было указать методологию, которая могла бы стать стандартом для поставщиков статистического программного обеспечения, чтобы расчет квартилей не зависел от типа пакета. В статье они описали девять методов для расчета квантилей. Таблица показывает некоторые статистические пакеты и используемые в них алгоритмы (рис. 14; таблица, этот раздел заметки и код VBA ниже базируются на тексте с сайта Bacon Bits). Обратите внимание, что R и Maple применяют весь спектр алгоритмов.

Рис. 14. Алгоритмы, используемые в статистических пакетах
Кстати, Хиндман и Фан в завершении своей статьи рекомендовали метод 8 в качестве стандарта для статистических пакетов. По их мнению, этот метод оценки квантиля не зависит от распределения, что делает его наиболее приемлемым для расчета.
Расчет квартилей в Excel
Функция Excel КВАРТИЛЬ.ИСКЛ использует следующую формулу для расчета квартилей:
![]()
где Qp – p-й квантиль: p = 0 – для минимального значения, 0,25 – для первого квартиля, 0,5 – для медианы, 0,75 – для третьего квартиля, 1 – для максимального значения;
x – индекс квантиля (может быть дробным); x = (n+1)p, где n – число элементов в выборке; обратите внимание на (n+1), поэтому метод и называется N+1-интерполяция;
i – индекс элемента в упорядоченной выборке; самое большое целое всё еще меньшее, чем x;
A1, A2, …, Ai, Ai+1, …, An – элементы случайной выборки, упорядоченной по возрастанию.
Формула для КВАРТИЛЬ.ВКЛ отличается только методом расчета х: x = (n-1)p+1; обратите внимание на (n–1), поэтому метод называется N–1-интерполяция. Подробнее с работой формул можно ознакомиться в приложенном Excel-файле на листе Формулы.
Расчет квартилей в R и SAS
Функция quantile в R использует все девять алгоритмов расчета квантилей, в соответствии с нумерацией, предложенной Hyndman and Fan в работе 1996 г. (рис. 15; если вы не знакомы с R, рекомендую начать с Алексей Шипунов. Наглядная статистика. Используем R!). Квантиль при i-м методе расчета:
![]()
где i – номер метода, 1 ≤ i ≤ 9, (j–m)/n ≤ p < (j–m+1)/n, хj – j-ый порядковый элемент упорядоченного ряда, n – размер выборки, γ является функцией двух параметров: j = floor(np + m) и g = np + m – j, где floor – функция возвращающая наибольшее целое, но всё еще меньшее, чем аргумент функции (аналог в Excel – ОКРВНИЗ.МАТ), m – константа, определяемая типом алгоритма расчета квантиля. Если вас интересуют подробности, обратитесь к справочной системе R.
SAS предлгает 5 методов расчета квантилей. И вновь за подробностями я отсылаю вас к справочной системе.

Рис. 15. Расчет квартилей в R девятью способами
Расчет квартилей в Excel любым методом с помощью VBA
Ниже представлен код пользовательской функции, которая позволяет воспроизвести любой из шести методов, перечисленных в таблице на рис. 14. Даже если у вас Excel 2007, и вам недоступна функция КВАРТИЛЬ.ИСКЛ, вы сможете рассчитать квартиль шестым методом с помощью этой функции.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
Function Quantile(MyRange As Range, p As Double, Optional m As Variant) ‘Mike Alexander: www.datapigtechnologies.com ‘Based on Code originally posted by Jerry W. Lewis (former Excel MVP) ‘********************************************************************* ‘This function will replicate various quantile calcuations found ‘in statistical software packages. ‘Calculation is determined by the Hyndman—Fan method used. ‘Hyndman-Fan Method 4 Replicates: ‘SAS(PCTLDEF=1), R(type=4), Maple(method=3) ‘Hyndman-Fan Method 5 Replicates: R(type=5), Maple(method=4) ‘Hyndman—Fan Method 6 Replicates: Excel(QUARTILE.EXC), SAS(PCTLDEF=4), ‘R(type=6), Minitab, SPSS, BMDP, JMP, Maple(method=5) ‘Hyndman—Fan Method 7 Replicates: Excel (QUARTILE and QUARTILE.INC), ‘R(type=7), S-Plus, Maxima, Maple(method=6) ‘Hyndman—Fan Method 8 Replicates: R(type=8), Maple(method=7) ‘Hyndman-Fan Method 9 Replicates: R(type=9), Maple(method=8) ‘********************************************************************** ‘Call function from Excel Spreadhseet by entering ‘=Quantile(Range, p, m) ‘Enter p as the fraction of the population ‘(.25 for quartile 1, .75 for quartile 3, etc....) ‘Enter m as the Hyndman-Fan Quantile method number (4, 5, 6, 7, 8 or 9) ‘If m is left blank, the function will use method 6 by default ‘********************************************************************** Dim n As Long Dim i As Long Dim QDef As Double Dim x As Double ‘Identify method and set the interpolation basis used Select Case m Case Is = 4 QDef = 0 Case Is = 5 QDef = 0.5 Case Is = 6 QDef = p Case Is = 7 QDef = 1 — p Case Is = 8 QDef = (p + 1) / 3 Case Is = 9 QDef = (p + 1.5) / 4 Case Else ‘Use Hyndman-Fan 6 by default QDef = p End Select ‘Count values within MyRange and calculate the required position index n = WorksheetFunction.Count(MyRange) x = n * p + QDef i = WorksheetFunction.Max(WorksheetFunction.Min(Fix(x), n), 1) ‘Perform interpolation and return answer If (x — i) >= 0 And i < n Then Quantile = (1 — (x — i)) * WorksheetFunction.Small(MyRange, i) + _ (x — i) * WorksheetFunction.Small(MyRange, i + 1) Else Quantile = WorksheetFunction.Small(MyRange, i) End If End Function |
После того, как вставите код в стандартный модуль книги, вы сможете использовать функцию (рис. 16): =Quantile(MyRange; P; M), где MyRange – диапазон, включающий выборку (можно оставить его неупорядоченным); Р – статистика: 0 – минимум, 0,25 – 1-й квартиль, 0,5 – медиана, 0,75 – 3-й квартиль, 1 – максимум; возможно введение иных значений в диапазоне от 0 до 1; М – номер метода из таблицы на рис. 14.

Рис. 16. Синтаксис пользовательской функции Quantile
В таблице (рис. 17) приведен расчет квартилей по всем методам. Обратите внимание, как метод 8 (который Хиндман и Фан рекомендуют в качестве стандарта) вычисляет квартили, которые ложатся между значениями, вычисляемыми по методам 6 и 7. Действительно, метод 8 дает наиболее сбалансированный набор квартилей.

Рис. 17. Значения квартилей, вычисленные различными методами
Сравнение алгоритмов вычисления квартилей
Стандартом де-факто вычисления квартилей в статистических пакетах и Excel является метод 6 на основе N+1-интерполяции. Если вы хотите, чтобы ваши данные были одинаковыми при использовании различных инструментов, используйте именно этот метод. В Excel он лежит в основе работы функции КВАРТИЛЬ.ИСКЛ. К сожалению, этот метод приводит к увеличению межквартильного интервала. Для нашего примера (рис. 17) с 13,0 до 15,5. Если сравнить все пять методов расчета (рис. 18), то видно, что минимальный межквартильный интервал соответствует методу 7, а максимальный – методу 6. На что это влияет мы рассмотрим в заметке Визуализация статистических данных с помощью диаграммы ящик с усами. Если же вы используете только Excel рекомендую метод 7 на основе N–1-интерполяции. Это позволит вам оперировать с самым узким межквартильным интервалом.

Рис. 18. Влияние алгоритма расчета квартилей на межквартильный интервал; цифры от 5 до 9 – номера методов