
In this tutorial, we’ll compare Excel and Python by looking at how to perform basic analysis tasks across both platforms.
Excel is the most commonly used data analysis software in the world. Why? It’s easy to get the hang of and fairly powerful once you master it. In contrast, Python’s reputation is that it’s more difficult to use, though what you can do with it is once you’ve learned it is almost unlimited.
But how do these two data analysis tools actually compare? Their reputations don’t really reflect reality. In this tutorial, we’ll take a look at some common data analysis tasks to demonstrate how accessible Python data analysis can be.
This tutorial assumes you have an intermediate-level knowledge of Excel, including using formulas and pivot tables.
We’ll be using the Python library pandas, which is designed facilitate data analysis in Python, but you don’t need any Python or pandas knowledge for this tutorial.
Why Use Python vs Excel?
Before we start, you might be wondering why Python is even worth considering. Why couldn’t you just keep using Excel?
Even though Excel is great, there are some areas that make a programming language like Python better for certain types of data analysis. Here are some reasons from our post 9 Reasons Excel Users Should Consider Learning Programming:
- You can read and work with almost any kind of data.
- Automated and repetitive tasks are easier.
- Working with large data sets is much faster and easier.
- It’s easier for others to reproduce and audit your work.
- Finding and fixing errors is easier.
- Python is open source, so you can see what’s behind the libraries you use.
- Advanced statistics and machine learning capabilities.
- Advanced data visualization capabilities.
- Cross-platform stability — your analysis can be run on any computer.
To be clear, we don’t advocate leaving Excel behind — it’s a powerful tool with many uses! But as an Excel user, being able to also leverage the power of Python can save you hours of time and open up career advancement opportunities.
It’s worth remembering the two tools can work well in tandem, and you may find that some tasks are best left in Excel, while others would benefit from the power, flexibility, and transparency that’s offered by Python.
Importing Our Data
Let’s start by familiarizing ourselves with the data we’ll be working with for this tutorial. We’ll use fictional data about a company with salespeople. Here’s what our data looks like in Excel:
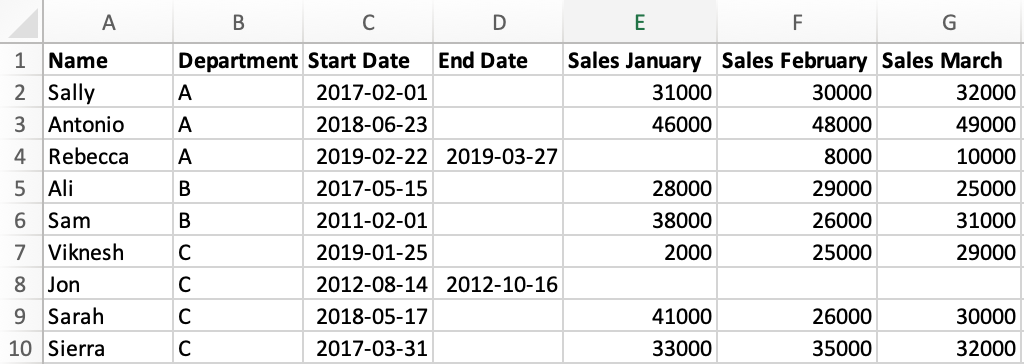
Our data is saved as a CSV file called sales.csv. In order to import our data in pandas, we need to start by importing the pandas library itself.
The code above imports pandas and aliases it to the syntax pd. That may sound complicated, but it’s actually just a kind of nickname — it means that in the future we can just use pd to refer to pandas so that we don’t have to type out the full word each time.
To read our file we use pd.read_csv():
We assigned the result of pd.read_csv() to a variable called sales, which we’ll use to refer to our data. We also put the variable name on its own in the last line of our code, which prints the data in a nicely formatted table.
Immediately, we can notice a few differences between how pandas represents the data vs what we saw in Excel:
- In pandas, the row numbers start at 0 versus 1 in Excel.
- The column names in pandas are taken from the data, versus Excel where columns are labelled using letters.
- Where there is a missing value in the original data, pandas has the placeholder
NaNwhich indicates that the value is missing, or null. - The sales data has a decimal point added to each value, because pandas stores numeric values that include null (
NaN) values as numeric type known as float (this doesn’t effect anything for us, but we just wanted to explain why this is).
Before we learn our first pandas operation, we’ll quickly learn a little about how our data is stored.
Let’s use the type() function to look at the type of our sales variable:
This output tells us that our sales variable is a DataFrame object, which is a specific type of object in pandas. Most of the time in pandas when we want to modify a dataframe, we’ll use special syntax called a dataframe method, which allows us to access specific functionality that relates to the dataframe objects. We’ll see an example of that in a moment when we complete our first task in pandas!
Sorting Data
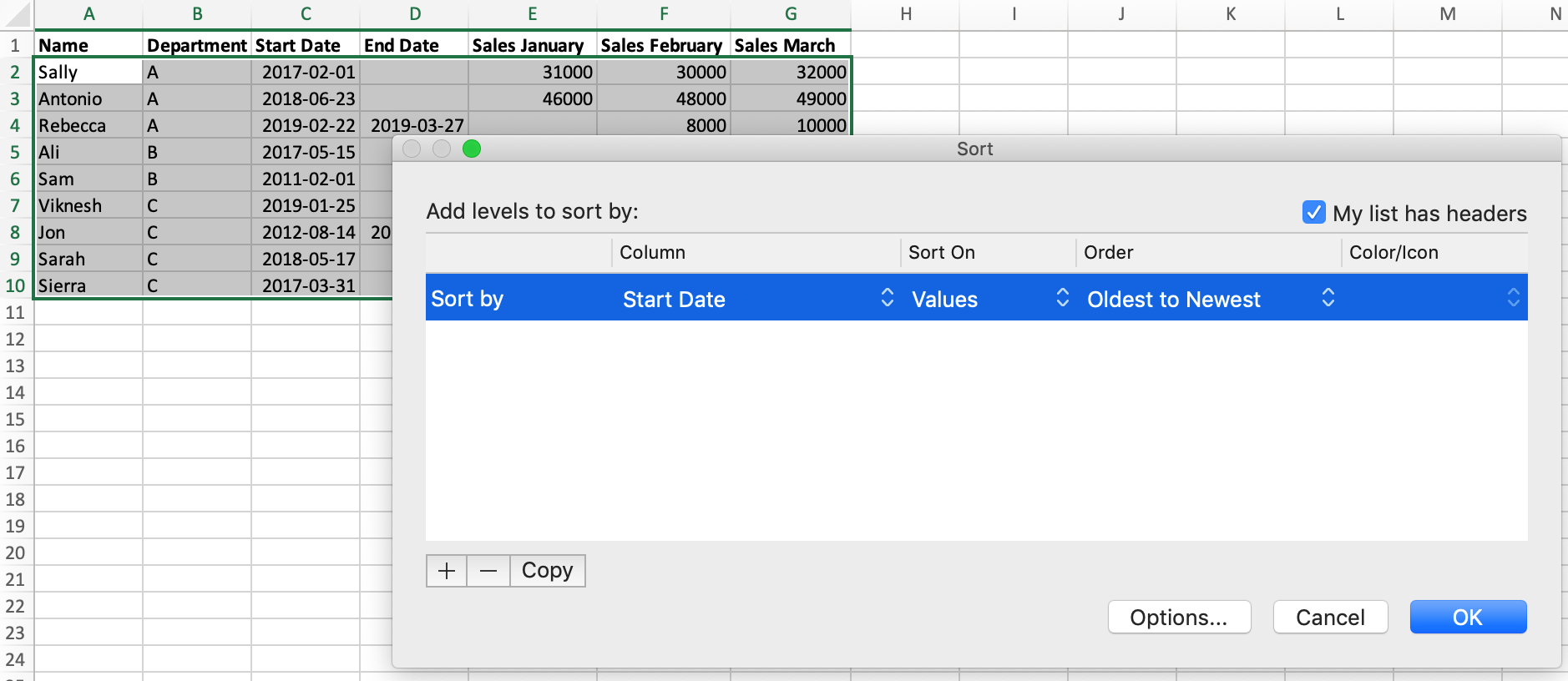
Let’s learn how to sort our data in Excel and Python. Currently, our data isn’t sorted. In Excel, if we wanted to sort our data by the "Start Date" column, we would:
- Select our data.
- Click the ‘Sort’ button on the toolbar.
- Select ‘Start Date’ in the dialog box that opens.
In pandas, we use the DataFrame.sort_values() method. We mentioned methods briefly a moment ago. In order to use them we have to replace DataFrame with the name of the dataframe we want to apply the method to — in this case sales. If you’ve worked with lists in Python, you will be familiar with this pattern from the list.append() method.
We provide the column name to the method to tell it which column to sort by:
The values in our dataframe have been sorted with one simple line of pandas code!
Summing the Sales Values
The last three columns of our data contain sales values for the first three months of the year, known as the first quarter. Our next task will be to sum those values in both Excel and Python.
Let’s start by looking at how we achieve this in Excel:
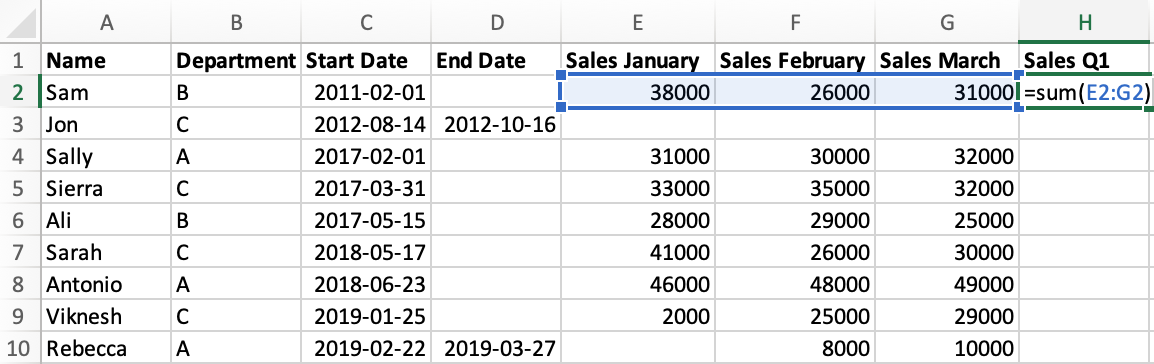
- Enter a new column name
"Sales Q1"in cellH1. - In cell H2, use the
SUM()formula and specify the range of cells using their coordinates. - Drag the formula down to all rows.
In pandas, when we perform an operation it automatically applies it to every row at once. We’ll start by selecting the three column by using their names in a list:
Next, we’ll use the DataFrame.sum() method and specify axis=1, which tells pandas that we want to sum the rows and not the columns. We’ll specify the new column name by providing it inside brackets:
In pandas, the «formula» we used isn’t stored. Instead the resulting values are added directly to our dataframe. If we wanted to make an adjustment to the values in our new column, we’d need to write new code to do it.
Joining Manager Data
In our spreadsheet, we also have a small table of data on who manages each team:
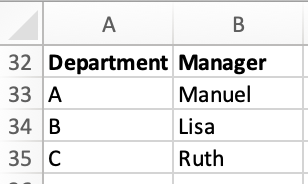
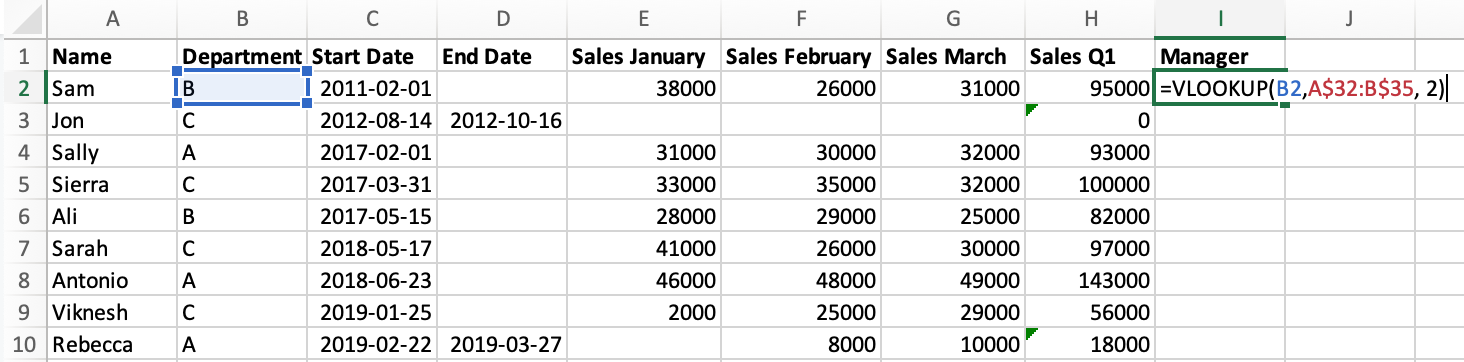
Let’s look at how to join this data in a "Manager" column in Excel and Python. In Excel, we:
- start by adding the column name to cell
I1. - use the
VLOOKUP()formula in cellI2, specifying:- to lookup the value from cell
B2(the Department) - in the selection of manager data, which we specify using coordinates
- and that we want to select the value from the second column of that data.
- to lookup the value from cell
- Click and drag the formula down to all cells.
To work with this data in pandas, first we’ll need to import it from a second CSV, managers.csv:
In order to join mangers data to sales using pandas, we’ll use the pandas.merge() function. We provide the following arguments, in order:
sales: the name of the first, or left, dataframe we want to mergemanagers: the name of the second, or right, dataframe we want to mergehow='left': the method we want to use to join the data. Theleftjoin specifies that no matter what, we want to keep all the rows from our left (first) dataframe.on='Department': The name of the column in both dataframes that we will join on.
If this seems is a bit confusing at first, that’s OK. The model for joining data in Python is different to what is used in Excel, but it’s also a lot more powerful. Note that in Python we get to specify exactly how we join our data using clear syntax and column names.
Adding a Conditional Column
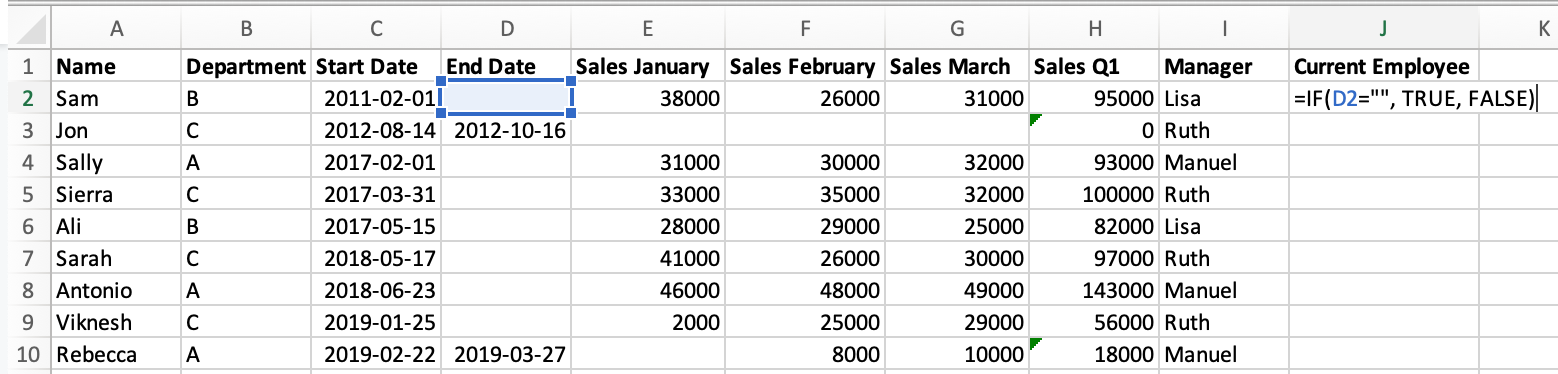
If we look at the "End Date" column, we can see that not all employees are still with the company — those with a missing value are still employed but the rest have left. Our next task will be to create a column which tells us if each salesperson is a current employee. We’ll perform this in Excel and Python.
Starting with Excel, to add this column we:
- Add a new column name to cell
J1. - Use the
IF()formula to check if cellD1(End Date) is empty, and if so fillJ2withTRUE, otherwiseFALSE. - Drag the formula down to the cells below.
In pandas, we use the pandas.isnull() function to check for null values in the "End Date" column, and assign the result to a new column:
Pivot Tables
One of the most powerful Excel features is pivot tables, which facilitate data analysis using aggregation. We’re going to look at two different pivot table applications in Excel and Python.
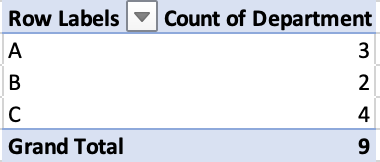
We’ll start with a pivot table in Excel that counts the number of employees in each department:
This operation — counting the number of times a value occurs in a column — is so common that in pandas it has its own syntax: Series.value_counts().
The series type is new to this tutorial, but it’s quite similar to a DataFrame, which we’ve already learned about. Series is just the pandas representation of a single row or column.
Let’s use the pandas method to calculate the number of employees in each department:
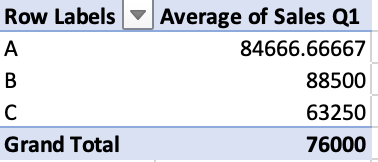
The second pivot table example also aggregates by department, but instead calculates the average Q1 sales:
In order to calculate this in pandas, we’ll use the DataFrame.pivot_table() method. We need to specify some arguments:
index: the column to aggregate by.values: the column we want to use the values for.aggfunc: the aggregation function we want to use, in this case'mean'average.
Excel vs Python: Summary
In this tutorial we learned Python equivalents for the following Excel functionality:
- Sorting data
SUM()VLOOKUP()IF()- Pivot Tables
For each example we looked at, the pandas syntax was of similar complexity to the formulas or menu options you would use in Excel. But Python offers some advantages, like much faster processing of large data sets, more customization and complexity, and more transparency for error-checking and auditing (since everything you’ve done is clearly laid out in code, rather than hidden in cells).
Someone proficient in Excel is more than capable of making the leap to working in Python. Adding Python skills to your skill set will make you a faster and more powerful analyst in the long run, and you’ll discover new workflows that take advantage of both Excel and Python for more efficient and powerful data analysis than you could do with Excel alone.
If you’d like to learn how to analyze data in Python, our Data Analyst in Python path is design to teach you everything you need to know, even if you’ve never coded before. You’ll start with two courses that teach you the Python fundamentals before you move onto learn the pandas library that we’ve worked with in this tutorial.
Время на прочтение
5 мин
Количество просмотров 63K
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
import pandas as pd
sales = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'sales')
states = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'states')
Теперь воспользуемся методом .head() датафрейма sales для того чтобы вывести элементы, находящиеся в начале датафрейма:
print(sales.head())
Сравним то, что будет выведено, с тем, что можно видеть в Excel.
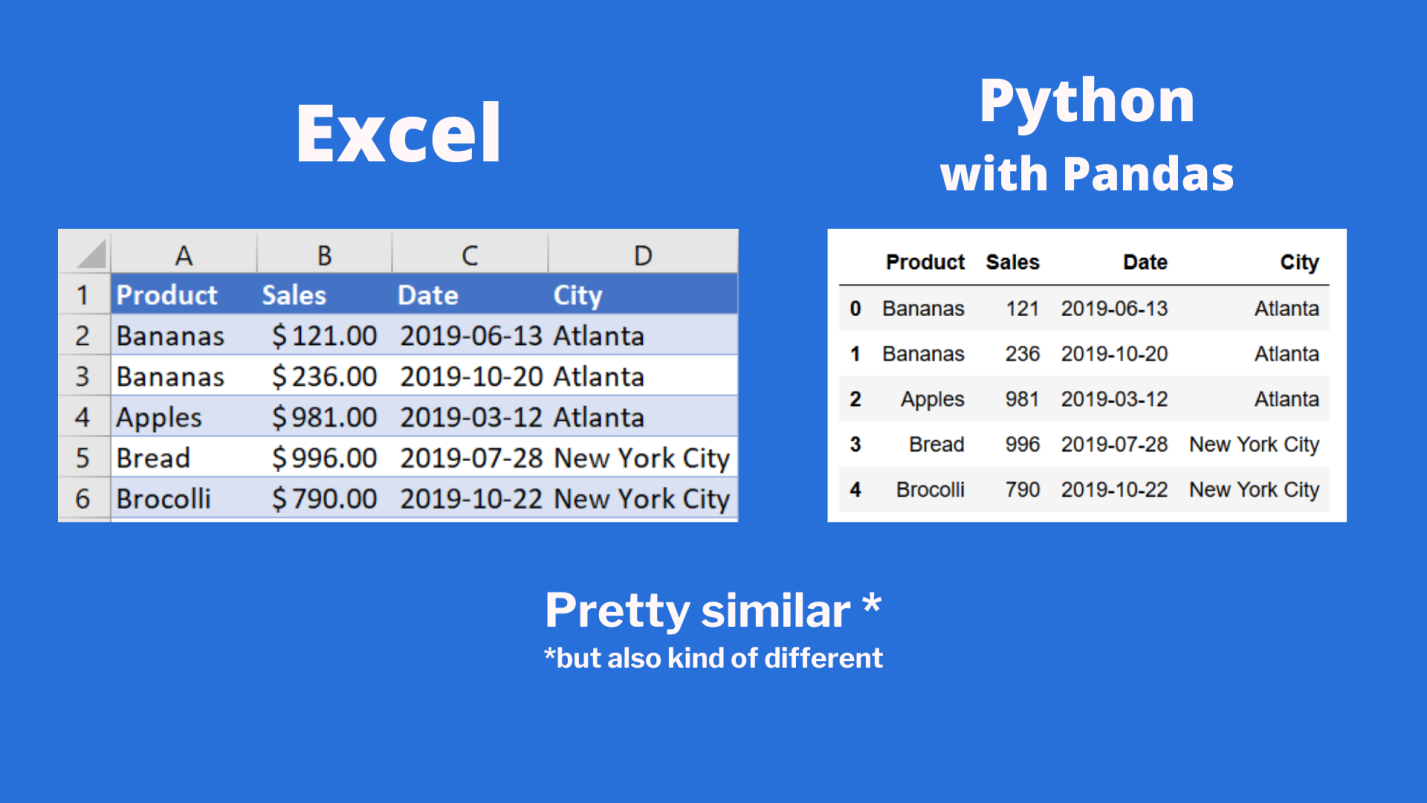
Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
- Нумерация строк в Excel начинается с 1, а в pandas номер (индекс) первой строки равняется 0.
- В Excel столбцы имеют буквенные обозначения, начинающиеся с буквы
A, а в pandas названия столбцов соответствуют именам соответствующих переменных.
Продолжим исследование возможностей pandas, позволяющих решать задачи, которые обычно решают в Excel.
Реализация возможностей Excel-функции IF в Python
В Excel существует очень удобная функция IF, которая позволяет, например, записать что-либо в ячейку, основываясь на проверке того, что находится в другой ячейке. Предположим, нужно создать в Excel новый столбец, ячейки которого будут сообщать нам о том, превышают ли 500 значения, записанные в соответствующие ячейки столбца B. В Excel такому столбцу (в нашем случае это столбец E) можно назначить заголовок MoreThan500, записав соответствующий текст в ячейку E1. После этого, в ячейке E2, можно ввести следующее:
=IF([@Sales]>500, "Yes", "No")
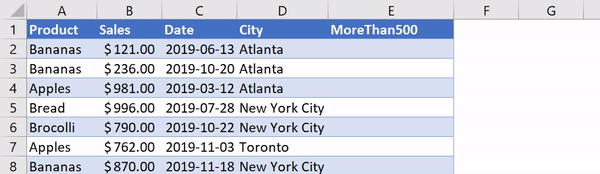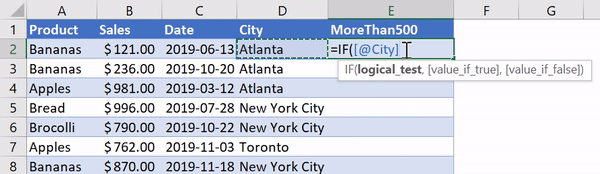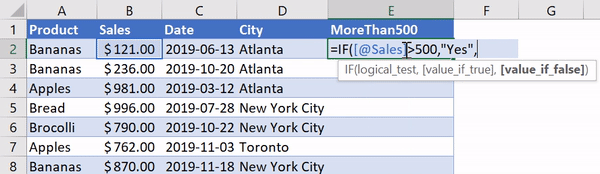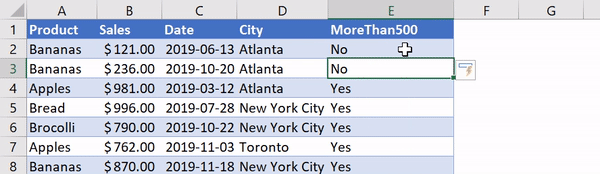
Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
sales['MoreThan500'] = ['Yes' if x > 500 else 'No' for x in sales['Sales']]

Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
В нашем наборе данных, на одном из листов Excel, есть названия городов, а на другом — названия штатов и провинций. Как узнать о том, где именно находится каждый город? Для этого подходит Excel-функция VLOOKUP, с помощью которой можно связать данные двух таблиц. Эта функция работает по принципу левого соединения, когда сохраняется каждая запись из набора данных, находящегося в левой части выражения. Применяя функцию VLOOKUP, мы предлагаем системе выполнить поиск определённого значения в заданном столбце указанного листа, а затем — вернуть значение, которое находится на заданное число столбцов правее найденного значения. Вот как это выглядит:
=VLOOKUP([@City],states,2,false)
Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.

Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
sales = pd.merge(sales, states, how='left', on='City')
Разберём его:
- Первый аргумент метода
merge— это исходный датафрейм. - Второй аргумент — это датафрейм, в котором мы ищем значения.
- Аргумент
howуказывает на то, как именно мы хотим соединить данные. - Аргумент
onуказывает на переменную, по которой нужно выполнить соединение (тут ещё можно использовать аргументыleft_onиright_on, нужные в том случае, если интересующие нас данные в разных датафреймах названы по-разному).
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
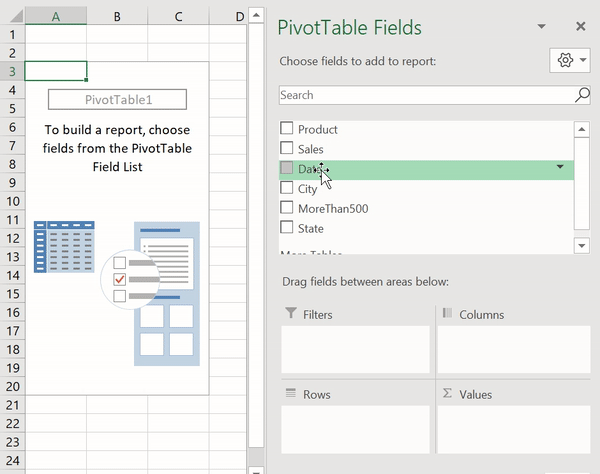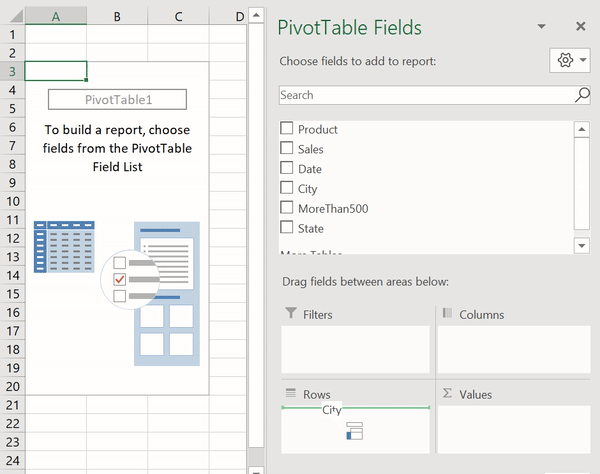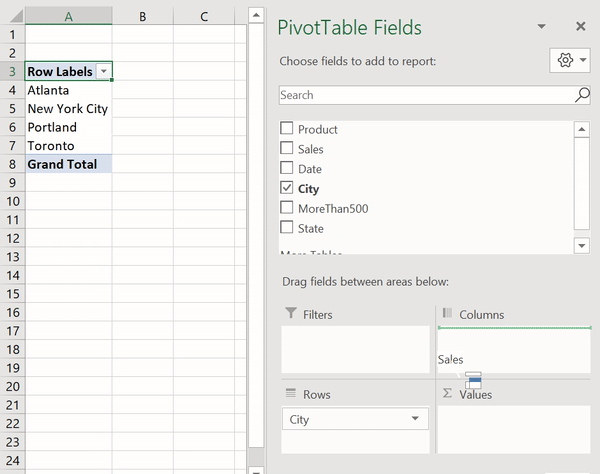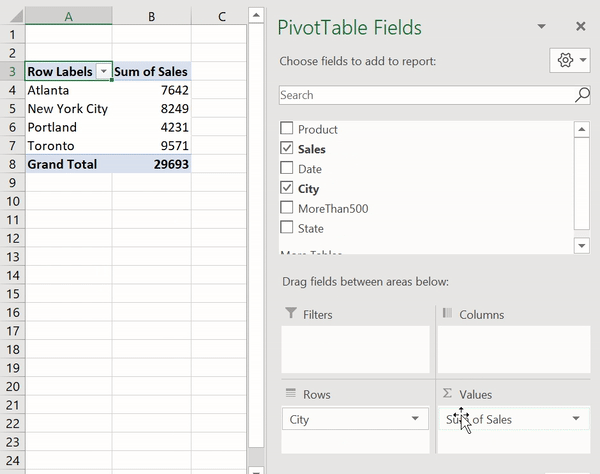
Создание сводной таблицы в Excel
Как видите, для создания подобной таблицы достаточно перетащить поле City в раздел Rows, а поле Sales — в раздел Values. После этого Excel автоматически выведет суммарные продажи для каждого города.
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
sales.pivot_table(index = 'City', values = 'Sales', aggfunc = 'sum')
Разберём его:
- Здесь мы используем метод
sales.pivot_table, сообщая pandas о том, что мы хотим создать сводную таблицу, основанную на датафреймеsales. - Аргумент
indexуказывает на столбец, по которому мы хотим агрегировать данные. - Аргумент
valuesуказывает на то, какие значения мы собираемся агрегировать. - Аргумент
aggfuncзадаёт функцию, которую мы хотим использовать при обработке значений (тут ещё можно воспользоваться функциямиmean,max,minи так далее).
Итоги
Из этого материала вы узнали о том, как импортировать Excel-данные в pandas, о том, как реализовать средствами Python и pandas возможности Excel-функций IF и VLOOKUP, а также о том, как воспроизвести средствами pandas функционал сводных таблиц Excel. Возможно, сейчас вы задаётесь вопросом о том, зачем вам пользоваться pandas, если то же самое можно сделать и в Excel. На этот вопрос нет однозначного ответа. Python позволяет создавать код, который поддаётся тонкой настройке и глубокому исследованию. Такой код можно использовать многократно. Средствами Python можно описывать очень сложные схемы анализа данных. А возможностей Excel, вероятно, достаточно лишь для менее масштабных исследований данных. Если вы до этого момента пользовались только Excel — рекомендую испытать Python и pandas, и узнать о том, что у вас из этого получится.
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.

Многие потенциальные пользователи pandas имеют некоторое представление о программах для работы с электронными таблицами, такими как Excel. На этой странице приведены примеры того, как выполняются различные операции с электронными таблицами с помощью pandas. На этой странице используется терминология Excel и ссылки на документацию Excel, но многое похожим образом делается в Google Таблицах, LibreOffice Calc, Apple Numbers и в другом программном обеспечении для работы с электронными таблицами, совместимом с Excel.
Если вы новичок в pandas, вы можете сначала прочитать 10 Minutes to pandas, чтобы ознакомиться с библиотекой.
Как обычно, импортируем pandas и NumPy следующим образом:
In [1]: import pandas as pd In [2]: import numpy as np
Структуры данных¶
Перевод общей терминологии¶
|
pandas |
Excel |
|---|---|
|
DataFrame |
лист |
|
Series |
столбец |
|
Index |
заголовки строк |
|
строка |
строка |
|
NaN |
пустая ячейка |
DataFrame¶
DataFrame в pandas аналогичен листу в Excel. В то время как книга Excel может содержать несколько листов, DataFrame в pandas существуют независимо друг от друга.
Series¶
Series — это структура данных, представляющая один столбец DataFrame. Работа с Series аналогична работе со столбцом электронной таблицы.
Index¶
У каждого DataFrame и Series есть Index, который является меткой для строк данных. В pandas, если индекс не указан, по умолчанию используется RangeIndex (первая строка = 0, вторая строка = 1 и так далее), аналогично заголовкам или номерам строк в электронных таблицах.
В pandas индекс можно установить на одно или несколько уникальных значений, что похоже на наличие столбца, который используется в качестве идентификатора строки на листе. В отличие от большинства электронных таблиц, эти значения Index могут фактически использоваться для ссылки на строки. (Обратите внимание, это можно сделать в Excel со структурированными ссылками.) Например, в электронных таблицах вы бы ссылались на первую строку как A1:Z1, а в pandas бы использовали populations.loc['Chicago'].
Значения индекса постоянны, поэтому, если вы измените порядок строк в DataFrame, метка для конкретной строки не изменится.
См. документацию по индексированию, чтобы узнать больше о том, как эффективно использовать Index.
Копии и операции на месте¶
Большинство операций pandas возвращают копии Series и DataFrame. Чтобы зафиксировать изменения, вам нужно либо назначить новую переменную:
sorted_df = df.sort_values("col1")
Либо перезаписать исходный объект:
df = df.sort_values("col1")
Примечание
Вы можете столкнуться с аргументом inplace=True, доступным для некоторых методов:
df.sort_values("col1", inplace=True)
Мы не рекомендуем его использовать.
Ввод и вывод данных¶
Построение DataFrame из значений¶
В электронной таблице значения можно вводить непосредственно в ячейки.
DataFrame в pandas можно создать разными способами, но для небольшого количества значений часто бывает удобно указать его как словарь Python, где ключи — это имена столбцов, а значения — это данные.
In [3]: df = pd.DataFrame({"x": [1, 3, 5], "y": [2, 4, 6]}) In [4]: df Out[4]: x y 0 1 2 1 3 4 2 5 6
Чтение данных из внешних источников¶
И Excel, и pandas могут импортировать данные из разных источников в разных форматах.
CSV¶
Давайте загрузим из тестов pandas и отобразим набор данных tips в формате CSV. В Excel вам нужно загрузить, а затем открыть файл CSV. В pandas вы передаете URL-адрес или локальный путь файла CSV в read_csv():
In [5]: url = ( ...: "https://raw.github.com/pandas-dev" ...: "/pandas/main/pandas/tests/io/data/csv/tips.csv" ...: ) ...: In [6]: tips = pd.read_csv(url) In [7]: tips Out[7]: total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 29.03 5.92 Male No Sat Dinner 3 240 27.18 2.00 Female Yes Sat Dinner 2 241 22.67 2.00 Male Yes Sat Dinner 2 242 17.82 1.75 Male No Sat Dinner 2 243 18.78 3.00 Female No Thur Dinner 2 [244 rows x 7 columns]
Подобно Мастеру импорта текста Excel, read_csv в pandas принимает ряд параметров, которые позволяют указать, как нужно проанализировать данные. Например, если бы данные были разделены табуляцией и не имели имен столбцов, команда pandas была бы такой:
tips = pd.read_csv("tips.csv", sep="t", header=None) # alternatively, read_table is an alias to read_csv with tab delimiter tips = pd.read_table("tips.csv", header=None)
Файлы Excel¶
Excel открывает файлы различных форматов Excel двойным щелчком мыши или через меню Открыть. В pandas используются специальные методы для чтения и записи файлов Excel.
Давайте сначала создадим новый файл Excel на основе данных tips из приведенного выше примера:
tips.to_excel("./tips.xlsx")
Если вы хотите впоследствии получить доступ к данным в файле tips.xlsx, вы можете прочитать его так:
tips_df = pd.read_excel("./tips.xlsx", index_col=0)
Вы только что прочитали файл Excel с помощью pandas!
Ограничение вывода¶
Программы для работы с электронными таблицами отображают данные, которые помещаются на экране, а затем позволяют прокручивать их, так что на самом деле нет необходимости ограничивать вывод. В pandas приходится подумать о том, как отображаются DataFrame.
По умолчанию pandas обрезает вывод больших DataFrame, чтобы показать первую и последнюю строки. Это можно переопределить, изменив параметры pandas или используя DataFrame.head() или DataFrame.tail().
In [8]: tips.head(5) Out[8]: total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
Экспорт данных¶
По умолчанию программное обеспечение для работы с электронными таблицами сохраняет файлы в соответствующем формате (.xlsx, .ods и т. д.). Однако вы можете сохранить файл в другом формате.
pandas может создавать файлы Excel, CSV и файлы других форматов.
Операции с данными¶
Операции над столбцами¶
В электронных таблицах формулы часто создаются в отдельных ячейках. а затем перетаскиваются в другие ячейки, чтобы применить аналогичные операции ко всем ячейкам в столбце. В pandas вы можете напрямую выполнять операции над целыми столбцами.
pandas обеспечивает векторизованные операции, указывая отдельные Series в DataFrame. Таким же образом можно назначить новые столбцы. Метод DataFrame.drop() удаляет столбец из DataFrame.
In [9]: tips["total_bill"] = tips["total_bill"] - 2 In [10]: tips["new_bill"] = tips["total_bill"] / 2 In [11]: tips Out[11]: total_bill tip sex smoker day time size new_bill 0 14.99 1.01 Female No Sun Dinner 2 7.495 1 8.34 1.66 Male No Sun Dinner 3 4.170 2 19.01 3.50 Male No Sun Dinner 3 9.505 3 21.68 3.31 Male No Sun Dinner 2 10.840 4 22.59 3.61 Female No Sun Dinner 4 11.295 .. ... ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 13.515 240 25.18 2.00 Female Yes Sat Dinner 2 12.590 241 20.67 2.00 Male Yes Sat Dinner 2 10.335 242 15.82 1.75 Male No Sat Dinner 2 7.910 243 16.78 3.00 Female No Thur Dinner 2 8.390 [244 rows x 8 columns] In [12]: tips = tips.drop("new_bill", axis=1)
Обратите внимание, что нам не пришлось выполнять вычитание по ячейкам — pandas сделал это за нас. См. как создать новые столбцы, производные от существующих столбцов.
Фильтрация¶
В Excel фильтрация осуществляется через графическое меню.
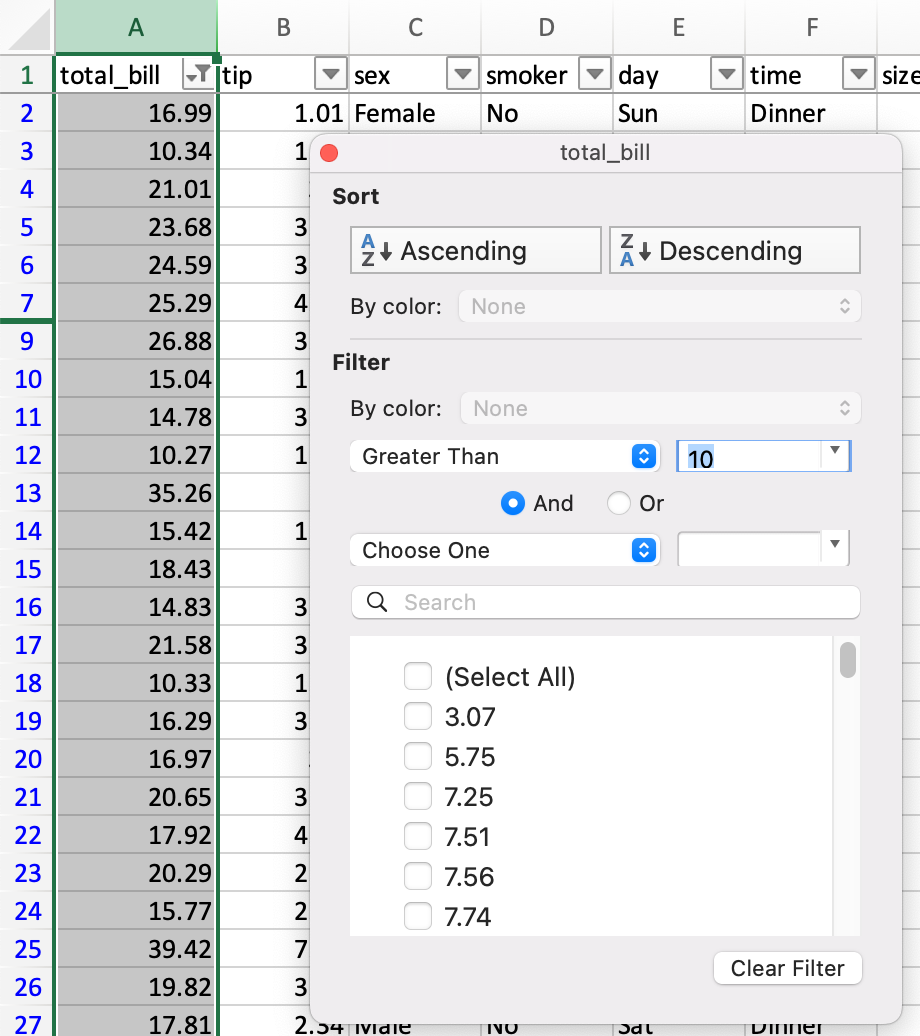
DataFrame можно фильтровать несколькими способами; наиболее интуитивным из них является использование логического индексирования.
In [13]: tips[tips["total_bill"] > 10] Out[13]: total_bill tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 5 23.29 4.71 Male No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [204 rows x 7 columns]
Вышеприведенный оператор просто передает Series объектов True и False в DataFrame, возвращая все строки с True.
In [14]: is_dinner = tips["time"] == "Dinner" In [15]: is_dinner Out[15]: 0 True 1 True 2 True 3 True 4 True ... 239 True 240 True 241 True 242 True 243 True Name: time, Length: 244, dtype: bool In [16]: is_dinner.value_counts() Out[16]: True 176 False 68 Name: time, dtype: int64 In [17]: tips[is_dinner] Out[17]: total_bill tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 1 8.34 1.66 Male No Sun Dinner 3 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [176 rows x 7 columns]
Логика if/then¶
Допустим, мы хотим создать столбец bucket со значениями low и high, в зависимости от того, меньше или больше 10 долларов значение в total_bill.
В электронных таблицах логическое сравнение можно выполнить с помощью условных формул. Мы бы использовали формулу =IF(A2 < 10, "low", "high"), перетащив ее во все ячейки в новом столбце bucket.
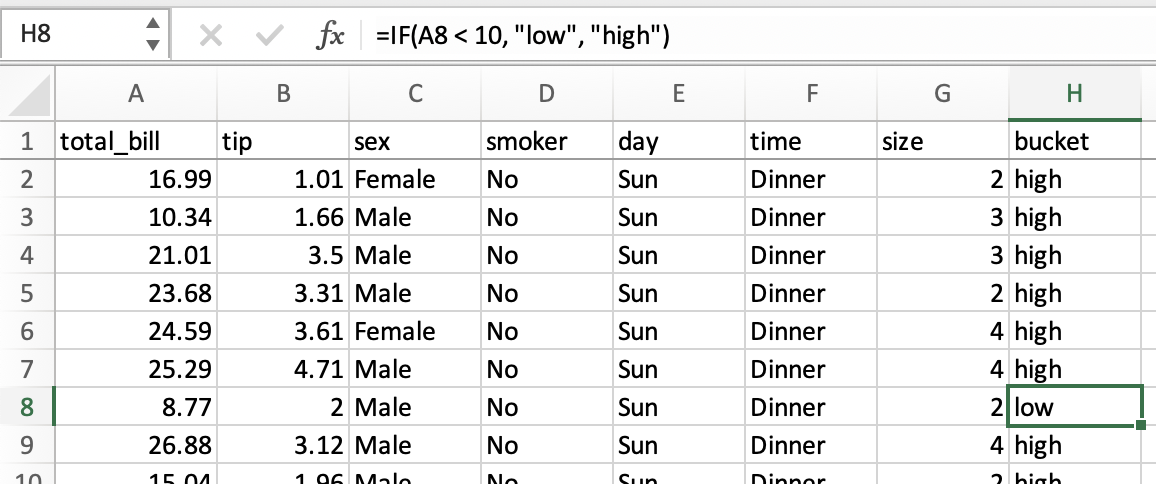
Ту же операцию в pandas можно выполнить с использованием метода where из numpy.
In [18]: tips["bucket"] = np.where(tips["total_bill"] < 10, "low", "high") In [19]: tips Out[19]: total_bill tip sex smoker day time size bucket 0 14.99 1.01 Female No Sun Dinner 2 high 1 8.34 1.66 Male No Sun Dinner 3 low 2 19.01 3.50 Male No Sun Dinner 3 high 3 21.68 3.31 Male No Sun Dinner 2 high 4 22.59 3.61 Female No Sun Dinner 4 high .. ... ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 high 240 25.18 2.00 Female Yes Sat Dinner 2 high 241 20.67 2.00 Male Yes Sat Dinner 2 high 242 15.82 1.75 Male No Sat Dinner 2 high 243 16.78 3.00 Female No Thur Dinner 2 high [244 rows x 8 columns]
Функциональность даты¶
В этом разделе будут упоминаться «даты», но метки времени обрабатываются аналогичным образом.
Функционал даты можно разделить на две части: синтаксический анализ и вывод. В электронных таблицах значения даты обычно анализируются автоматически, хотя существует функция DATEVALUE. В pandas вам нужно явно преобразовать обычный текст в объекты даты и времени, либо при чтении из CSV, либо в DataFrame.
После анализа электронные таблицы отображают даты в формате по умолчанию, хотя формат можно изменить. В pandas при вычислениях над датами их обычно хранят как объекты datetime. Вывод частей дат (например, года) осуществляется в электронных таблицах с помощью функций даты, а в pandas с помощью свойств datetime.
Учитывая date1 и date2 в столбцах A и B электронной таблицы, у вас могут быть следующие формулы:
|
столбец |
формула |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Эквивалентные операции pandas показаны ниже.
In [20]: tips["date1"] = pd.Timestamp("2013-01-15") In [21]: tips["date2"] = pd.Timestamp("2015-02-15") In [22]: tips["date1_year"] = tips["date1"].dt.year In [23]: tips["date2_month"] = tips["date2"].dt.month In [24]: tips["date1_next"] = tips["date1"] + pd.offsets.MonthBegin() In [25]: tips["months_between"] = tips["date2"].dt.to_period("M") - tips[ ....: "date1" ....: ].dt.to_period("M") ....: In [26]: tips[ ....: ["date1", "date2", "date1_year", "date2_month", "date1_next", "months_between"] ....: ] ....: Out[26]: date1 date2 date1_year date2_month date1_next months_between 0 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 1 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 2 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 3 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 4 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> .. ... ... ... ... ... ... 239 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 240 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 241 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 242 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> 243 2013-01-15 2015-02-15 2013 2 2013-02-01 <25 * MonthEnds> [244 rows x 6 columns]
См. более подробную информацию в разделе Time series / date functionality.
Выбор столбцов¶
В электронных таблицах вы можете выбрать нужные столбцы:
-
Скрытие столбцов
-
Удаление столбцов
-
Ссылка на диапазон с одного листа на другой
Поскольку столбцы электронной таблицы обычно именуются в строке заголовка, переименование столбца — это просто изменение текста в заголовочной ячейке.
Аналогичные операции в pandas продемонстрированы ниже.
Сохранить определенные столбцы¶
In [27]: tips[["sex", "total_bill", "tip"]] Out[27]: sex total_bill tip 0 Female 14.99 1.01 1 Male 8.34 1.66 2 Male 19.01 3.50 3 Male 21.68 3.31 4 Female 22.59 3.61 .. ... ... ... 239 Male 27.03 5.92 240 Female 25.18 2.00 241 Male 20.67 2.00 242 Male 15.82 1.75 243 Female 16.78 3.00 [244 rows x 3 columns]
Удалить столбец¶
In [28]: tips.drop("sex", axis=1) Out[28]: total_bill tip smoker day time size 0 14.99 1.01 No Sun Dinner 2 1 8.34 1.66 No Sun Dinner 3 2 19.01 3.50 No Sun Dinner 3 3 21.68 3.31 No Sun Dinner 2 4 22.59 3.61 No Sun Dinner 4 .. ... ... ... ... ... ... 239 27.03 5.92 No Sat Dinner 3 240 25.18 2.00 Yes Sat Dinner 2 241 20.67 2.00 Yes Sat Dinner 2 242 15.82 1.75 No Sat Dinner 2 243 16.78 3.00 No Thur Dinner 2 [244 rows x 6 columns]
Переименовать столбец¶
In [29]: tips.rename(columns={"total_bill": "total_bill_2"}) Out[29]: total_bill_2 tip sex smoker day time size 0 14.99 1.01 Female No Sun Dinner 2 1 8.34 1.66 Male No Sun Dinner 3 2 19.01 3.50 Male No Sun Dinner 3 3 21.68 3.31 Male No Sun Dinner 2 4 22.59 3.61 Female No Sun Dinner 4 .. ... ... ... ... ... ... ... 239 27.03 5.92 Male No Sat Dinner 3 240 25.18 2.00 Female Yes Sat Dinner 2 241 20.67 2.00 Male Yes Sat Dinner 2 242 15.82 1.75 Male No Sat Dinner 2 243 16.78 3.00 Female No Thur Dinner 2 [244 rows x 7 columns]
Сортировка по значениям¶
Сортировка в электронных таблицах осуществляется с помощью диалогового окна сортировки.
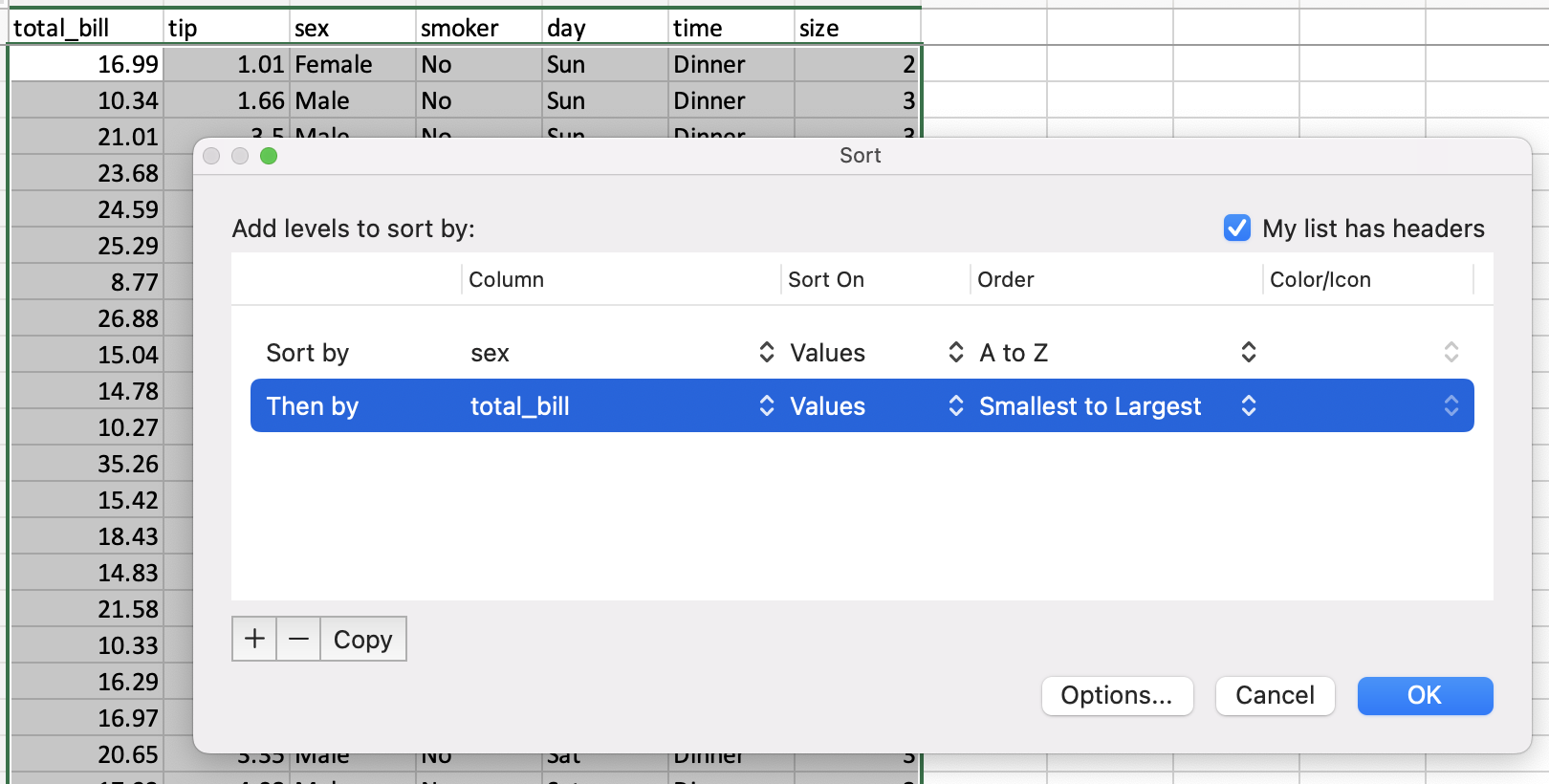
У pandas есть метод DataFrame.sort_values(), который принимает список столбцов для сортировки.
In [30]: tips = tips.sort_values(["sex", "total_bill"]) In [31]: tips Out[31]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns]
Обработка строк¶
Нахождение длины строки¶
В электронных таблицах количество символов в тексте можно узнать с помощью функции LEN. Ее можно использовать вместе с функцией TRIM, если нужно удалить лишние пробелы.
Вы можете узнать длину строки символов с помощью Series.str.len(). В Python 3 все строки являются строками Unicode. len включает конечные пробелы. Используйте len и rstrip, чтобы исключить пробелы в конце.
In [32]: tips["time"].str.len() Out[32]: 67 6 92 6 111 6 145 5 135 5 .. 182 6 156 6 59 6 212 6 170 6 Name: time, Length: 244, dtype: int64 In [33]: tips["time"].str.rstrip().str.len() Out[33]: 67 6 92 6 111 6 145 5 135 5 .. 182 6 156 6 59 6 212 6 170 6 Name: time, Length: 244, dtype: int64
Обратите внимание, что в этом случае множественные пробелы внутри строки останутся, так что функции эквивалентны не на 100%.
Поиск позиции подстроки¶
Функция электронной таблицы FIND возвращает позицию подстроки с первым символ 1.
В pandas вы можете найти положение символа в столбце строк с помощью метода Series.str.find(). find ищет первую позицию подстроки. Если подстрока найдена, метод возвращает ее позицию. Если не найдена, возвращается -1. Имейте в виду, что индексы Python отсчитываются от нуля.
In [34]: tips["sex"].str.find("ale") Out[34]: 67 3 92 3 111 3 145 3 135 3 .. 182 1 156 1 59 1 212 1 170 1 Name: sex, Length: 244, dtype: int64
Изменение регистра¶
В электронных таблицах есть функции UPPER, LOWER и PROPER для преобразование текста в верхний, нижний и заглавный регистр соответственно.
Эквивалентные методы pandas: Series.str.upper(), Series.str.lower() и Series.str.title().
In [40]: firstlast = pd.DataFrame({"string": ["John Smith", "Jane Cook"]}) In [41]: firstlast["upper"] = firstlast["string"].str.upper() In [42]: firstlast["lower"] = firstlast["string"].str.lower() In [43]: firstlast["title"] = firstlast["string"].str.title() In [44]: firstlast Out[44]: string upper lower title 0 John Smith JOHN SMITH john smith John Smith 1 Jane Cook JANE COOK jane cook Jane Cook
Объединение¶
В примерах объединения будут использоваться следующие таблицы:
In [45]: df1 = pd.DataFrame({"key": ["A", "B", "C", "D"], "value": np.random.randn(4)}) In [46]: df1 Out[46]: key value 0 A 0.469112 1 B -0.282863 2 C -1.509059 3 D -1.135632 In [47]: df2 = pd.DataFrame({"key": ["B", "D", "D", "E"], "value": np.random.randn(4)}) In [48]: df2 Out[48]: key value 0 B 1.212112 1 D -0.173215 2 D 0.119209 3 E -1.044236
В Excel объединение таблиц можно выполнить с помощью функции VLOOKUP.
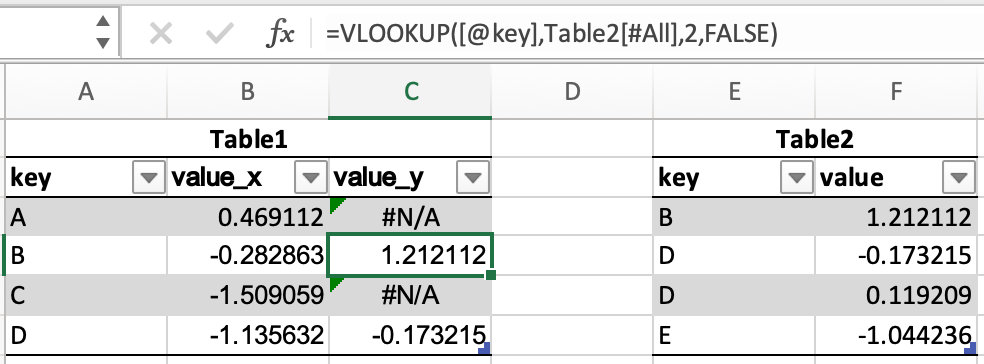
В pandas есть метод DataFrame.merge, который обеспечивает аналогичную функциональность. Данные не нужно сортировать заранее, а различные типы объединений выполняются с помощью ключевого слова how.
In [49]: inner_join = df1.merge(df2, on=["key"], how="inner") In [50]: inner_join Out[50]: key value_x value_y 0 B -0.282863 1.212112 1 D -1.135632 -0.173215 2 D -1.135632 0.119209 In [51]: left_join = df1.merge(df2, on=["key"], how="left") In [52]: left_join Out[52]: key value_x value_y 0 A 0.469112 NaN 1 B -0.282863 1.212112 2 C -1.509059 NaN 3 D -1.135632 -0.173215 4 D -1.135632 0.119209 In [53]: right_join = df1.merge(df2, on=["key"], how="right") In [54]: right_join Out[54]: key value_x value_y 0 B -0.282863 1.212112 1 D -1.135632 -0.173215 2 D -1.135632 0.119209 3 E NaN -1.044236 In [55]: outer_join = df1.merge(df2, on=["key"], how="outer") In [56]: outer_join Out[56]: key value_x value_y 0 A 0.469112 NaN 1 B -0.282863 1.212112 2 C -1.509059 NaN 3 D -1.135632 -0.173215 4 D -1.135632 0.119209 5 E NaN -1.044236
merge имеет ряд преимуществ перед VLOOKUP:
-
Искомое значение не обязательно должно быть в первом столбце таблицы поиска.
-
Если совпадают несколько строк, своя строка будет для каждого совпадения, а не только для первого.
-
Включаются все столбцы из таблицы поиска, а не только указанный столбец.
-
Поддерживаются более сложные операции объединения.
Другие соображения¶
Заполнение ячеек¶
Создайте ряд чисел по заданному шаблону в определенном наборе ячеек. В электронной таблице это можно сделать с помощью Shift + перетаскивания после ввода первого числа, или же путем ввода первых двух или трех значений с последующим перетаскиванием.
В pandas этого можно добиться, создав Series и назначив его нужным ячейкам.
In [57]: df = pd.DataFrame({"AAA": [1] * 8, "BBB": list(range(0, 8))}) In [58]: df Out[58]: AAA BBB 0 1 0 1 1 1 2 1 2 3 1 3 4 1 4 5 1 5 6 1 6 7 1 7 In [59]: series = list(range(1, 5)) In [60]: series Out[60]: [1, 2, 3, 4] In [61]: df.loc[2:5, "AAA"] = series In [62]: df Out[62]: AAA BBB 0 1 0 1 1 1 2 1 2 3 2 3 4 3 4 5 4 5 6 1 6 7 1 7
Удаление дубликатов¶
Excel имеет встроенную функцию удаления повторяющихся значений. Аналогичный функционал поддерживается в pandas с drop_duplicates().
In [63]: df = pd.DataFrame( ....: { ....: "class": ["A", "A", "A", "B", "C", "D"], ....: "student_count": [42, 35, 42, 50, 47, 45], ....: "all_pass": ["Yes", "Yes", "Yes", "No", "No", "Yes"], ....: } ....: ) ....: In [64]: df.drop_duplicates() Out[64]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes In [65]: df.drop_duplicates(["class", "student_count"]) Out[65]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes
Сводные таблицы¶
Сводные таблицы из электронных таблиц могут быть реплицированы в pandas, см. изменение формы и сводные таблицы. Снова используя набор данных tips, давайте найдем среднее вознаграждение в зависимости от масштаба вечеринки и пола официанта.
В Excel мы используем следующую конфигурацию для сводной таблицы:
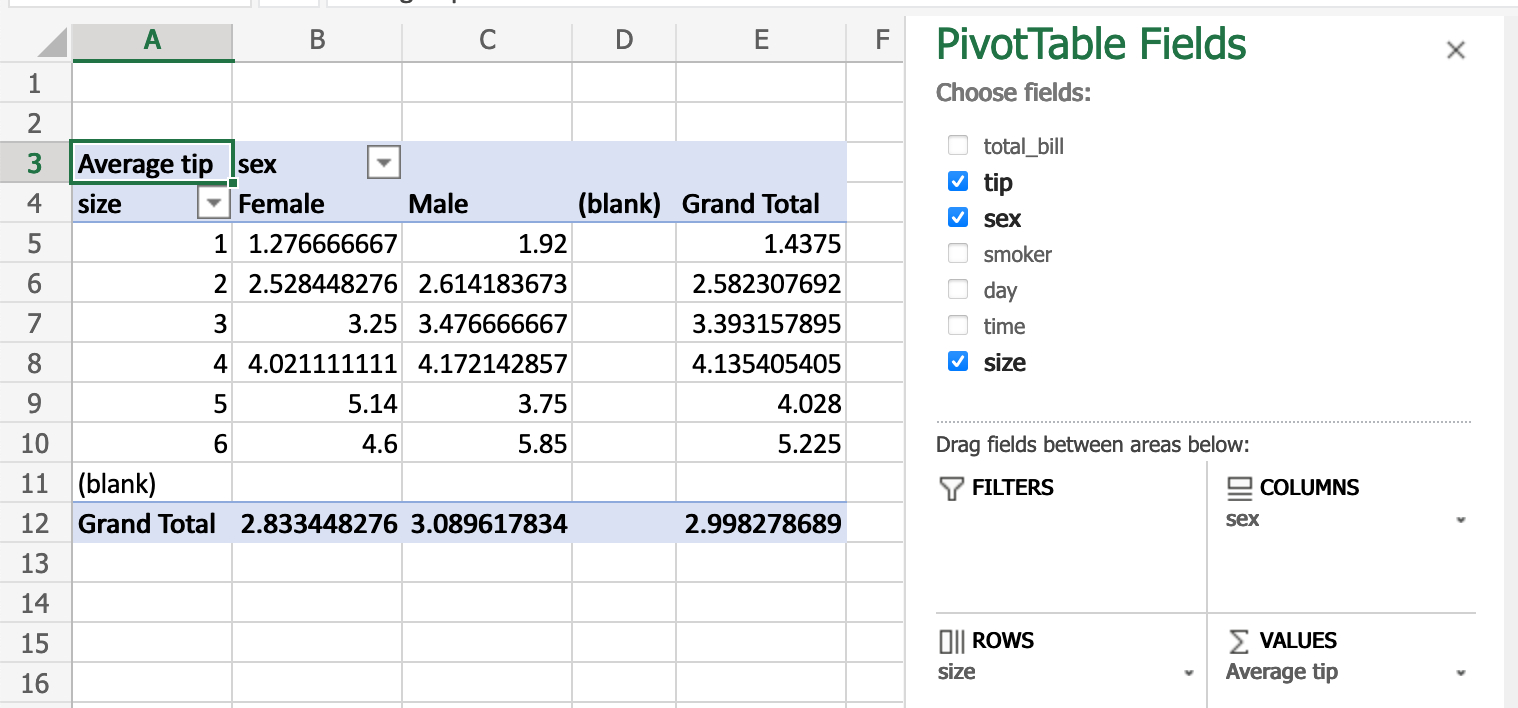
Эквивалент в pandas:
In [66]: pd.pivot_table( ....: tips, values="tip", index=["size"], columns=["sex"], aggfunc=np.average ....: ) ....: Out[66]: sex Female Male size 1 1.276667 1.920000 2 2.528448 2.614184 3 3.250000 3.476667 4 4.021111 4.172143 5 5.140000 3.750000 6 4.600000 5.850000
Добавление строки¶
Предполагая, что мы используем RangeIndex (с номером 0, 1 и т. д.), мы можем использовать concat(), чтобы добавить строку в конец DataFrame.
In [67]: df Out[67]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 2 A 42 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes In [68]: new_row = pd.DataFrame([["E", 51, True]], ....: columns=["class", "student_count", "all_pass"]) ....: In [69]: pd.concat([df, new_row]) Out[69]: class student_count all_pass 0 A 42 Yes 1 A 35 Yes 2 A 42 Yes 3 B 50 No 4 C 47 No 5 D 45 Yes 0 E 51 True
Поиск и замена¶
Диалоговое окно поиска Excel показывает вам подходящие ячейки, одну за другой. В pandas эта операция обычно выполняется для всего столбца или DataFrame с помощью условных выражений.
In [70]: tips Out[70]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns] In [71]: tips == "Sun" Out[71]: total_bill tip sex smoker day time size 67 False False False False False False False 92 False False False False False False False 111 False False False False False False False 145 False False False False False False False 135 False False False False False False False .. ... ... ... ... ... ... ... 182 False False False False True False False 156 False False False False True False False 59 False False False False False False False 212 False False False False False False False 170 False False False False False False False [244 rows x 7 columns] In [72]: tips["day"].str.contains("S") Out[72]: 67 True 92 False 111 True 145 False 135 False ... 182 True 156 True 59 True 212 True 170 True Name: day, Length: 244, dtype: bool
Метод replace() в pandas сопоставим с Replace All в Excel.
In [73]: tips.replace("Thu", "Thursday") Out[73]: total_bill tip sex smoker day time size 67 1.07 1.00 Female Yes Sat Dinner 1 92 3.75 1.00 Female Yes Fri Dinner 2 111 5.25 1.00 Female No Sat Dinner 1 145 6.35 1.50 Female No Thur Lunch 2 135 6.51 1.25 Female No Thur Lunch 2 .. ... ... ... ... ... ... ... 182 43.35 3.50 Male Yes Sun Dinner 3 156 46.17 5.00 Male No Sun Dinner 6 59 46.27 6.73 Male No Sat Dinner 4 212 46.33 9.00 Male No Sat Dinner 4 170 48.81 10.00 Male Yes Sat Dinner 3 [244 rows x 7 columns]
Многие пользуются Excel для анализа данных, но Python лучше подойдет для решения аналитических задач: в нем можно работать с неограниченным количеством данных и написать пару строк кода для сложной операции. Перевели статью Stop Using Excel for Data Analytics: Upgrade to Python Тайлера Фолкмана, руководителя направления ИИ в Branded Entertainment Network, в которой он объясняет, почему стоит перейти на Python.
Да, Excel — важный инструмент для компаний. До сих пор им пользуются аналитики и ученые. Но для большинства задач он не подходит. Вот пять причин, почему пора перестать использовать Excel и перейти на Python.
Причина 1. Масштабирование и автоматизация
Excel хорош, когда нужно за раз проанализировать небольшое количество данных. Но для масштабных вычислений он не подходит. Excel поддерживает данные размером до 1 048 576 строк и до 16 384 столбцов.
Python может масштабироваться до объема памяти. Кроме того, у него есть много инструментов, поддерживающих вычисления и вне памяти устройства. Например, с помощью библиотеки Dask можно масштабировать вычисления для работы на внешнем кластере, а не только на ноутбуке. Если вы уже работали с Pandas (библиотекой для анализа и обработки данных), то тут используется почти такой же код для чтения в формате CSV:

Всего одна строка кода, и вы можете прочесть данные, объем которых превышает размер памяти компьютера. В Excel это сделать невозможно.
Кроме того, Python можно использовать для работы с несколькими источниками данных. Если Excel — это одновременно и хранилище, и вычислительный механизм, то Python полностью независим. Если вы можете найти способ прочитать данные в Python, вы сможете их использовать. У Python много библиотек, поэтому можно анализировать данные из разных источников, будь то CSV, Excel, JSON или SQL.
Наконец, Python незаменим при автоматизации. Этот язык программирования позволяет напрямую подключаться к базе данных и выполнять обновления автоматически. С его помощью можно проводить расчеты, создавать отчеты или динамические дашборды, экономя массу времени. В Excel многое надо вводить вручную, а обновления нельзя автоматизировать.
Читайте также: Кому и для чего нужен Python?
Причина 2. Воспроизводимость
Воспроизводимость — это когда вашу аналитику или визуальный отчет легко может повторить другой человек. Он должен суметь не только перезапустить процессы и получить точно такой же результат, но и пройти те же самые шаги. Воспроизводимость важна при автоматизации, но настроить ее в Excel сложно.
Дело в том, что расчеты в ячейках Excel практически невозможно проверить по любой шкале измерений. Типы данных сбивают с толку — не всегда то, что вы видите, представлено в необработанных данных. Да, в Excel можно использовать VBA (Visual Basic for Applications) и он немного улучшает воспроизводимость.
VBA — это язык программирования, разработанный Microsoft и предназначенный для работы с пакетами Microsoft Office. Он позволяет писать программы прямо в файле и создавать макросы — набор команд для автоматического выполнения задач. При этом не нужно устанавливать среду для разработки — она уже есть в самом Excel.
Но лучше все же потратить время на изучение Python.
Посмотрите на этот документ в Excel:
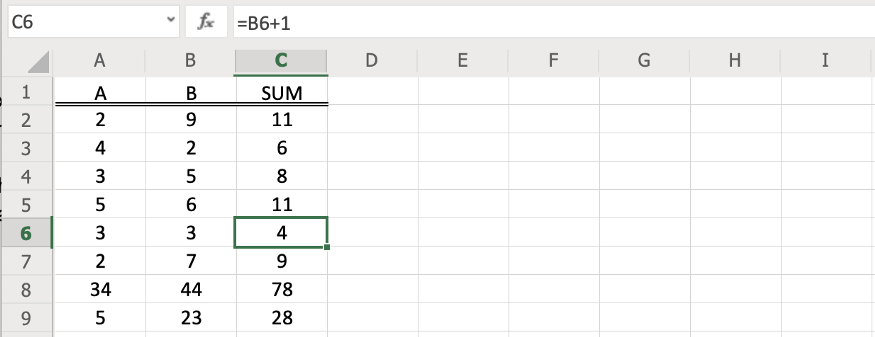
В столбце с sum должна отображаться сумма чисел из столбцов A и B, но как это проверить? Вы можете проверить одну из формул и увидеть, что это на самом деле сумма, но поскольку каждая ячейка тоже может быть формулой, то результат неверный. Если не проверять все вручную, то можно пропустить ошибки.
А в Python эти расчеты выглядели бы так:

Код простой и понятный, с его помощью можно легко проверить, что сумма рассчитана правильно.
C Python вы получаете все инструменты, предназначенные для того, чтобы улучшить воспроизводимость и совместную работу программистов.
Вдобавок ко всему, Python превосходит возможности подключения к данным. С его помощью можно анализировать данные в облаке и мгновенно повторять этот процесс. Git (распределенная система управления версиями), модульное тестирование, документация и стандарты форматирования кода широко распространены в сообществе Python.
В третьей версии Python можно добавить статическую типизацию, чтобы сделать ваш код более понятным. Все эти инструменты упрощают процесс создания кода и обеспечивают его правильное написание. В следующий раз, когда кто-то будет смотреть ваш код, он сможет легко его понять и воспроизвести.
Причина 3. Гибкость навыков
Если вы знаете Excel, это, безусловно, полезный навык, но больше его применить негде. Python же многофункционален. Это не только удобный инструмент для анализа и визуализации данных, но и язык программирования, который можно использовать для чего угодно. Хотите заниматься машинным или глубоким обучением? Создать сайт? Автоматизировать умный дом? Все это можно сделать с помощью Python.
Кроме того, Python намного ближе к другим языкам программирования, чем Excel. Поэтому, зная Python, гораздо легче изучить другие языки. Он открывает больше возможностей, чем Excel.
И, наконец, Python невероятно востребован. По данным Stack Overflow, в 2019 году он стал четвертым по популярности языком программирования в мире среди профессиональных разработчиков ПО, а также первым наиболее востребованным языком программирования. (По данным Stack Overflow на май 2021 года, Python — третий по популярности язык программирования после JavaScript и HTML/CSS.) По оценкам американского сервиса по поиску работы Indeed, средняя зарплата разработчика на Python в США в 2020 году составляла 120 тысяч долларов в год. Неплохо.
Причина 4. Продвинутые инструменты
В Excel есть множество встроенных формул, но они меркнут по сравнению с возможностями Python. У Python не только сотни библиотек, помогающих упростить расширенную статистику и аналитику, но и продвинутые инструменты для визуализации данных.
Это, например, библиотека Matplotlib, Plotly, фреймворк Streamlit и библиотека для статистических графиков Seaborn (все это — инструменты для визуализации данных). С их помощью вы можете прекрасно визуализировать данные, а также создавать интерактивные информационные панели и графики.
Библиотеки Numpy и SciPy поддерживают научные и векторизованные вычисления, линейную алгебру. Библиотека Scikit-learn позволяет применять различные алгоритмы машинного обучения: от дерева принятия решений до градиентного бустинга. Я думаю, xkcd сказал об этом лучше всего:

— Python. Я узнал его вчера вечером! Все так просто! Чтобы запустить программу Hello world, нужно просто напечатать фразу “Hello, world!”.
— Я не знаю… Динамический набор текста? Пробел?
— Присоединяйся к нам! Программирование — это весело! Это совершенно новый мир!
— Но как ты летаешь?
— Я только что набрал import antigravity (импортировать антигравитацию).
— И это все?
— Я также для сравнения попробовал все, что было в аптечке. Но, думаю, причина все же в Python.
Причина 5. Python легко выучить
Учитывая все преимущества Python над Excel, кажется, что он должен быть очень сложным. Но это не так. Посмотрите, как на Java выглядит самая простая программа Hello World:
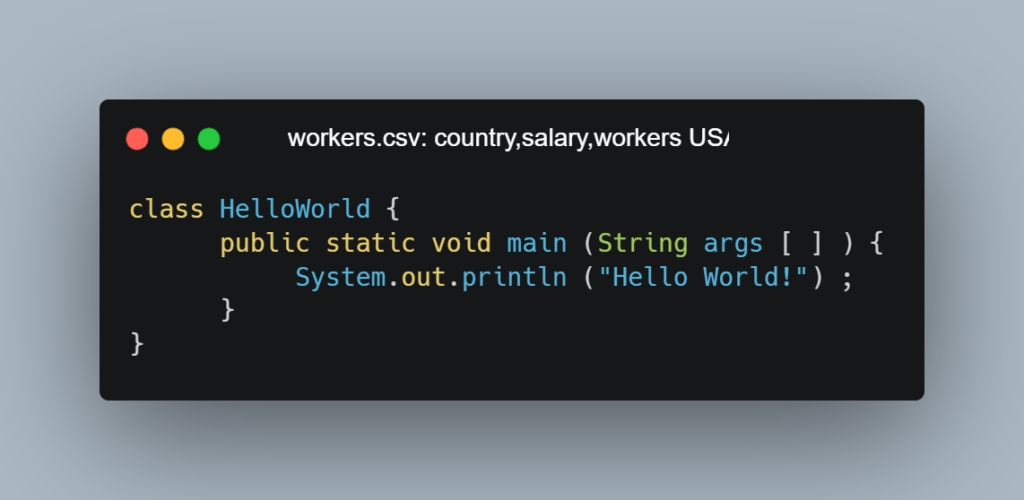
На Python она займет всего одну строку:

Python — один из самых интуитивно понятных языков программирования. Его могут освоить даже те, у кого нет опыта в написании кода. Хотя обучение Excel может оказаться предпочтительнее, выгоды от него гораздо меньше. Python стоит потраченного времени и усилий, и Excel никогда не сможет с ним сравниться из-за универсальности его дизайна. Расскажем немного про основы анализа и визуализации данных в Python.
Как начать использовать Python для анализа данных
Изучим основные команды и операции в Python, которые потребуются при анализе данных. Первый нюанс — Python использует пробелы и не использует точку с запятой, как и другие языки. Вот очень простой пример:

Импорт функций
Мы будем использовать множество библиотек. Некоторые из них предустановлены вместе с Python, а другие придется поставить самостоятельно. Чтобы загрузить библиотеку, используйте оператор импорта (import statement):

Эта команда импортирует класс Counter (счетчик) из библиотеки collections. Counter — полезный инструмент для дата-аналитиков. Он помогает подсчитать, сколько раз элементы появляются в коллекциях, например в списках. Ниже мы написали код, в котором создали список брачных возрастов. Используя Counter, мы можем быстро подсчитать, сколько раз появляется каждый возраст.
Списки на Python
Списки — это полезная структура данных, предназначенная для их хранения. Подробнее изучим их в следующем уроке. Например:
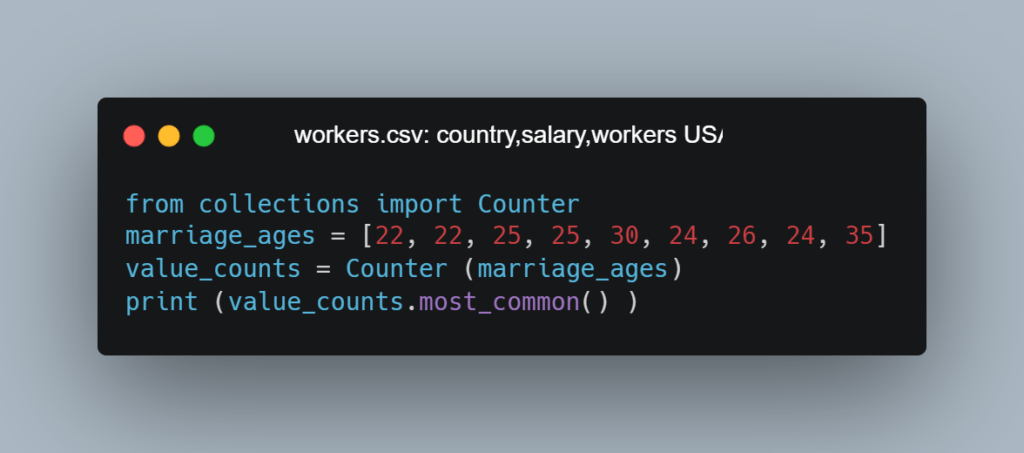
Видно, что мы создали список, содержащий возраст вступления в брак, используя [ ] во второй строке. Затем передали этот список в функцию Counter, чтобы вывести наиболее распространенные значения в виде списка кортежей (tuple).
Кортеж — это неизменяемый список внутри круглых скобок (). Кортежи содержат два элемента: значение и количество раз, когда это значение появлялось в вашем списке. Частота упорядочивает список кортежей. Первым отображается значение с наибольшим числом случаев.
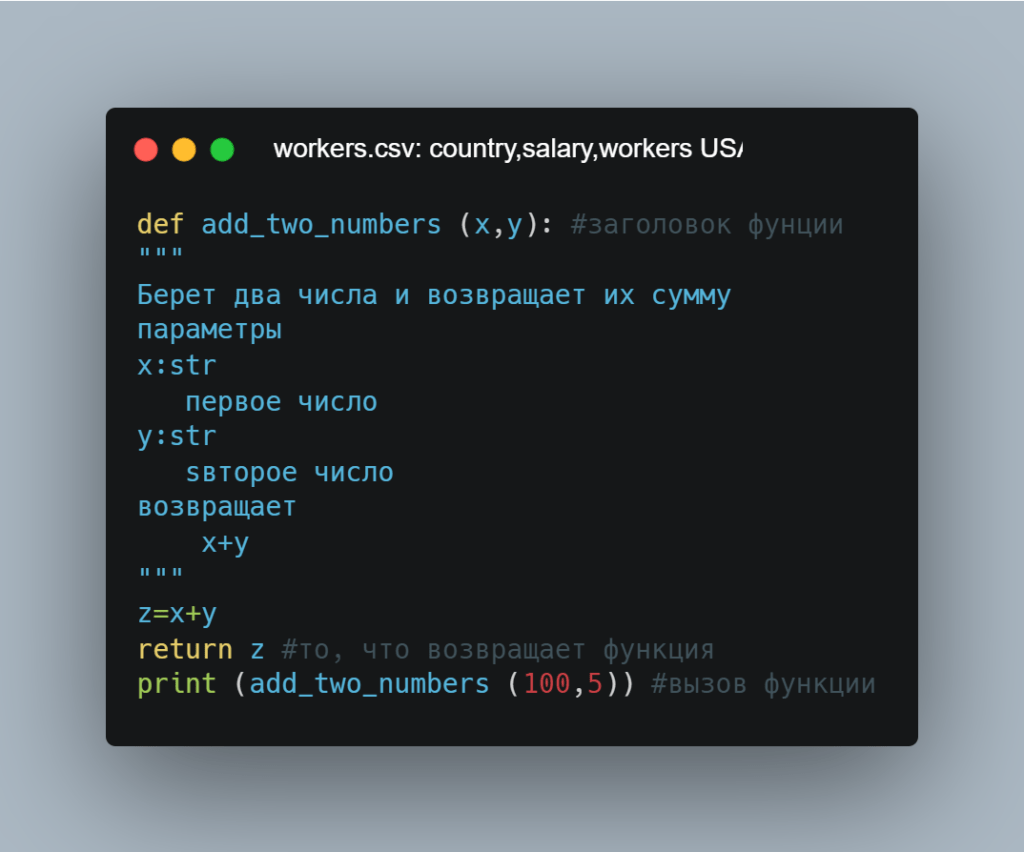
Функции в Python
Функции в Python тоже полезны. Они начинаются с ключевого слова def и названия функции, затем добавляются аргументы в скобках. Вот функция, которая принимает 2 аргумента, x и y, и возвращает sum:
Функции также могут быть анонимными — в них не нужно расписывать всю структуру, указанную выше. Вместо этого можно использовать ключевое слово lambda. Вот та же функция, что и выше, но записанная как анонимная:

Итоги
Пришло время перейти на Python. Больше нет оправданий! Я надеюсь, что эта статья помогла увидеть все преимущества Python и развеять сомнения.
Начать реализацию вашей задачи можно так:
import pandas as pd # pip install pandas
# читаем Excel в Pandas DataFrame
df = pd.read_excel(r'D:downloadисходник.xls', skiprows=1)
# разворачиваем столбцы в строки
d = df.set_index('Ф.И.О.').stack()
...
Получилось:
In [34]: d.reset_index()
Out[34]:
Ф.И.О. level_1 0
0 Иванов М.Е. кв 1
1 Иванов М.Е. пропис 4
2 Иванов М.Е. прож 4
3 Иванов М.Е. Полез площадь 73.5
4 Иванов М.Е. Отопление тариф 1936.54
5 Иванов М.Е. Отопление ГгКал 1.66185
6 Иванов М.Е. Отопление ИТОГО 3218.24
7 Иванов М.Е. ГВС(горячая вода м.куб 23
8 Иванов М.Е. ГВС начисл 2689.16
9 Иванов М.Е. ХВС(холодная вода) м.куб 7
10 Иванов М.Е. ХВС начисл 125.23
11 Иванов М.Е. Стоки м. куб 30
12 Иванов М.Е. Стоки начисл 682.5
13 Иванов М.Е. мусор 169.05
14 Иванов М.Е. ТО жилья 1617
15 Иванов М.Е. ОДН ГВС 0.84735
16 Иванов М.Е. одн гвс руб 99.0721
17 Иванов М.Е. ОДН ХВС 0.766097
18 Иванов М.Е. одн хвс руб 13.7055
19 Иванов М.Е. ОДН СТОКИ 1.61345
.. ... ... ...
165 итого Полез площадь 397.8
166 итого Отопление тариф 0
167 итого Отопление ГгКал 8.99433
168 итого Отопление ИТОГО 17417.9
169 итого ГВС(горячая вода м.куб 36
170 итого ГВС начисл 4209.12
171 итого ХВС(холодная вода) м.куб 61
172 итого ХВС начисл 1091.29
173 итого Стоки начисл 2206.75
174 итого мусор 914.94
175 итого ТО жилья 7956
176 итого ОДН ГВС 4.58607
177 итого одн гвс руб 536.203
178 итого ОДН ХВС 4.1463
179 итого одн хвс руб 74.1773
180 итого ОДН СТОКИ 8.73236
181 итого однстоки руб 198.661
182 итого Кап.рем 2864.16
183 итого ИТОГО 37455.7
184 итого пени за 0
[185 rows x 3 columns]
Далее после фильтрации нудная и кропотливая работа по формированию нужной вам выходной формы… Для этого возможно придется прибегнуть к низкоуровневому программированию на уровне отдельных ячеек Excel — для этого можно воспользоваться openpyxl или xlsxwriter.