
I want to create a dictionary from the values, i get from excel cells,
My code is below,
wb = xlrd.open_workbook('foo.xls')
sh = wb.sheet_by_index(2)
for i in range(138):
cell_value_class = sh.cell(i,2).value
cell_value_id = sh.cell(i,0).value
and I want to create a dictionary, like below, that consists of the values coming from the excel cells;
{'class1': 1, 'class2': 3, 'class3': 4, 'classN':N}
Any idea on how I can create this dictionary?
![]()
asked Jan 7, 2013 at 12:31
![]()
or you can try pandas
from pandas import *
xls = ExcelFile('path_to_file.xls')
df = xls.parse(xls.sheet_names[0])
print df.to_dict()
![]()
james
4,0172 gold badges30 silver badges35 bronze badges
answered Jan 7, 2013 at 12:38
![]()
rootroot
75.4k25 gold badges108 silver badges119 bronze badges
1
d = {}
wb = xlrd.open_workbook('foo.xls')
sh = wb.sheet_by_index(2)
for i in range(138):
cell_value_class = sh.cell(i,2).value
cell_value_id = sh.cell(i,0).value
d[cell_value_class] = cell_value_id
answered Jan 7, 2013 at 12:34
![]()
eumiroeumiro
204k34 gold badges297 silver badges261 bronze badges
4
This script allows you to transform an excel data table to a list of dictionaries:
import xlrd
workbook = xlrd.open_workbook('foo.xls')
workbook = xlrd.open_workbook('foo.xls', on_demand = True)
worksheet = workbook.sheet_by_index(0)
first_row = [] # The row where we stock the name of the column
for col in range(worksheet.ncols):
first_row.append( worksheet.cell_value(0,col) )
# transform the workbook to a list of dictionaries
data =[]
for row in range(1, worksheet.nrows):
elm = {}
for col in range(worksheet.ncols):
elm[first_row[col]]=worksheet.cell_value(row,col)
data.append(elm)
print data
![]()
answered Jan 27, 2016 at 10:35
![]()
khelili milianakhelili miliana
3,6801 gold badge15 silver badges27 bronze badges
You can use Pandas to do this. Import pandas and Read the excel as a pandas dataframe.
import pandas as pd
file_path = 'path_for_your_input_excel_sheet'
df = pd.read_excel(file_path, encoding='utf-16')
You can use pandas.DataFrame.to_dict to convert a pandas dataframe to a dictionary. Find the documentation for the same here
df.to_dict()
This would give you a dictionary of the excel sheet you read.
Generic Example :
df = pd.DataFrame({'col1': [1, 2],'col2': [0.5, 0.75]},index=['a', 'b'])
>>> df
col1 col2
a 1 0.50
b 2 0.75
>>> df.to_dict()
{'col1': {'a': 1, 'b': 2}, 'col2': {'a': 0.5, 'b': 0.75}}
answered Dec 26, 2018 at 10:02
![]()
If you want to convert your Excel data into a list of dictionaries in python using pandas,
Best way to do that:
excel_file_path = 'Path to your Excel file'
excel_records = pd.read_excel(excel_file_path)
excel_records_df = excel_records.loc[:, ~excel_records.columns.str.contains('^Unnamed')]
records_list_of_dict=excel_records_df.to_dict(orient='record')
Print(records_list_of_dict)
answered May 8, 2021 at 10:13
![]()
I’d go for:
wb = xlrd.open_workbook('foo.xls')
sh = wb.sheet_by_index(2)
lookup = dict(zip(sh.col_values(2, 0, 138), sh.col_values(0, 0, 138)))
answered Jan 7, 2013 at 12:47
![]()
Jon ClementsJon Clements
137k32 gold badges244 silver badges277 bronze badges
There is also a PyPI package for that: https://pypi.org/project/sheet2dict/
It is parsing excel and csv files and returning it as an array of dictionaries.
Each row is represented as a dictionary in the array.
Like this way :
Python 3.9.0 (default, Dec 6 2020, 18:02:34)
[Clang 12.0.0 (clang-1200.0.32.27)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
# Import the library
>>> from sheet2dict import Worksheet
# Create an object
>>> ws = Worksheet()
# return converted rows as dictionaries in the array
>>> ws.xlsx_to_dict(path='Book1.xlsx')
[
{'#': '1', 'question': 'Notifications Enabled', 'answer': 'True'},
{'#': '2', 'question': 'Updated', 'answer': 'False'}
]
answered Feb 8, 2021 at 10:23
![]()
Tomas PytelTomas Pytel
1882 silver badges14 bronze badges
0
if you can convert it to csv this is very suitable.
import dataconverters.commas as commas
filename = 'test.csv'
with open(filename) as f:
records, metadata = commas.parse(f)
for row in records:
print 'this is row in dictionary:'+row
![]()
answered Feb 10, 2015 at 18:34
![]()
hamedhamed
1,2651 gold badge15 silver badges18 bronze badges
If you use, openpyxl below code might help:
import openpyxl
workbook = openpyxl.load_workbook("ExcelDemo.xlsx")
sheet = workbook.active
first_row = [] # The row where we stock the name of the column
for col in range(1, sheet.max_column+1):
first_row.append(sheet.cell(row=1, column=col).value)
data =[]
for row in range(2, sheet.max_row+1):
elm = {}
for col in range(1, sheet.max_column+1):
elm[first_row[col-1]]=sheet.cell(row=row,column=col).value
data.append(elm)
print (data)
credit to: Python Creating Dictionary from excel data
answered May 14, 2021 at 10:17
![]()
I tried a lot of ways but this is the most effective way I found:
import pyexcel as p
def read_records():
records = p.get_records(file_name="File")
products = [row for row in records]
return products
![]()
Antoine
1,3914 gold badges20 silver badges26 bronze badges
answered Nov 30, 2022 at 7:53
![]()

In this article, you will see everything about how to convert excel to Dictionary in Python with the help of examples. Most of the time you will need to convert excel files to python dictionaries to perform some operations on the data.
Prerequisites
Before going further into this article you will need to install the following packages using the pip command, If you have already installed then you can ignore them.
pip install pandas
pip install openpyxlHeadings of Contents
- 1 Convert excel file to Dictionary in Python
- 1.1 Excel File
- 1.2 First method
- 1.3 Second method
- 1.4 Conclusion
Convert excel file to Dictionary in Python
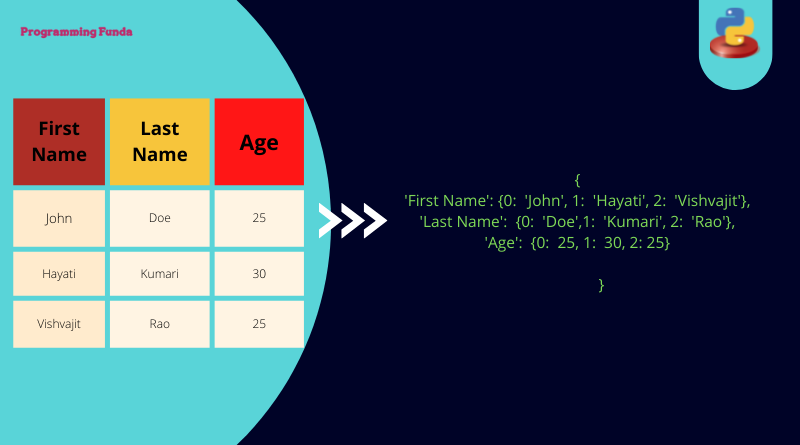
Here we will know the total of two ways to convert excel files to dictionaries, As you know Python is one of the most popular programming languages for data science and Python has the capability of processing large excel files and manipulating their data as per requirements.
Most of the time you want to perform some operations on excel file data, then you have an option to convert the excel file into a Python dictionary.
So, let’s see the two best approaches to converting excel to a dictionary in Python.
Excel File
We have an excel file students.xlsx with the following data, as you can see in the below screenshot.
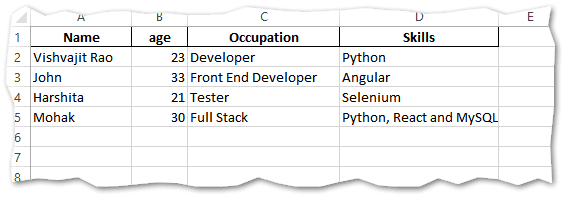
First method
Here we are going to use the pandas read_excel() method to read data from excel files and use the to_dict() method to convert data to dictionaries.
Example
import pandas as pd
# convert into dataframe
df = pd.read_excel("students.xlsx")
# convert into dictionary
dict = df.to_dict()
print(dict)Output
{'Name': {0: 'Vishvajit Rao', 1: 'John', 2: 'Harshita', 3: 'Mohak'},
'Occupation': {0: 'Developer',
1: 'Front End Developer',
2: 'Tester',
3: 'Full Stack'},
'Skills': {0: 'Python',
1: 'Angular',
2: 'Selenium',
3: 'Python, React and MySQL'},
'age': {0: 23, 1: 33, 2: 21, 3: 30}}
Second method
Again, Here we are going to use the pandas ExcelFile() method to read data from excel files and use the to_dict() method to convert data to Dictionary.
Example
excel = pd.ExcelFile("students.xlsx")
data = excel.parse(excel.sheet_names[0])
print(data.to_dict())Output
{'Name': {0: 'Vishvajit Rao', 1: 'John', 2: 'Harshita', 3: 'Mohak'},
'Occupation': {0: 'Developer',
1: 'Front End Developer',
2: 'Tester',
3: 'Full Stack'},
'Skills': {0: 'Python',
1: 'Angular',
2: 'Selenium',
3: 'Python, React and MySQL'},
'age': {0: 23, 1: 33, 2: 21, 3: 30}}- How to convert Dictionary to Excel
Conclusion
So, we have seen all about how to convert excel to dictionaries in Python with the help of examples. This is one of the most important concepts especially when you want to convert your excel file data to a python dictionary to perform some operations in a Pythonic way. You can follow any approach from the above methods to convert excel to a dictionary in Python.
I hope this article will help you. if you like this article, please share and keep visiting for further interesting articles.
Thanks for your valuable time … 👏👏👏
About the Author: Admin

Programming Funda aims to provide the best programming tutorials to all programmers. All tutorials are designed for beginners as well as professionals.
Programming Funda explains any programming article well with easy examples so that you programmer can easily understand what is really going on here.
View all post by Admin | Website
В Python данные из файла Excel считываются в объект DataFrame. Для этого используется функция read_excel() модуля pandas.
Лист Excel — это двухмерная таблица. Объект DataFrame также представляет собой двухмерную табличную структуру данных.
- Пример использования Pandas read_excel()
- Список заголовков столбцов листа Excel
- Вывод данных столбца
- Пример использования Pandas to Excel: read_excel()
- Чтение файла Excel без строки заголовка
- Лист Excel в Dict, CSV и JSON
- Ресурсы

Предположим, что у нас есть документ Excel, состоящий из двух листов: «Employees» и «Cars». Верхняя строка содержит заголовок таблицы.

Ниже приведен код, который считывает данные листа «Employees» и выводит их.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Employees')
# print whole sheet data
print(excel_data_df)
Вывод:
EmpID EmpName EmpRole 0 1 Pankaj CEO 1 2 David Lee Editor 2 3 Lisa Ray Author
Первый параметр, который принимает функция read_excel ()— это имя файла Excel. Второй параметр (sheet_name) определяет лист для считывания данных.
При выводе содержимого объекта DataFrame мы получаем двухмерные таблицы, схожие по своей структуре со структурой документа Excel.
Чтобы получить список заголовков столбцов таблицы, используется свойство columns объекта Dataframe. Пример реализации:
print(excel_data_df.columns.ravel())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Мы можем получить данные из столбца и преобразовать их в список значений. Пример:
print(excel_data_df['EmpName'].tolist())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Можно указать имена столбцов для чтения из файла Excel. Это потребуется, если нужно вывести данные из определенных столбцов таблицы.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print(excel_data_df)
Вывод:
Car Name Car Price 0 Honda City 20,000 USD 1 Bugatti Chiron 3 Million USD 2 Ferrari 458 2,30,000 USD
Если в листе Excel нет строки заголовка, нужно передать его значение как None.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Numbers', header=None)
Если вы передадите значение заголовка как целое число (например, 3), тогда третья строка станет им. При этом считывание данных начнется со следующей строки. Данные, расположенные перед строкой заголовка, будут отброшены.
Объект DataFrame предоставляет различные методы для преобразования табличных данных в формат Dict , CSV или JSON.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print('Excel Sheet to Dict:', excel_data_df.to_dict(orient='record'))
print('Excel Sheet to JSON:', excel_data_df.to_json(orient='records'))
print('Excel Sheet to CSV:n', excel_data_df.to_csv(index=False))
Вывод:
Excel Sheet to Dict: [{'Car Name': 'Honda City', 'Car Price': '20,000 USD'}, {'Car Name': 'Bugatti Chiron', 'Car Price': '3 Million USD'}, {'Car Name': 'Ferrari 458', 'Car Price': '2,30,000 USD'}]
Excel Sheet to JSON: [{"Car Name":"Honda City","Car Price":"20,000 USD"},{"Car Name":"Bugatti Chiron","Car Price":"3 Million USD"},{"Car Name":"Ferrari 458","Car Price":"2,30,000 USD"}]
Excel Sheet to CSV:
Car Name,Car Price
Honda City,"20,000 USD"
Bugatti Chiron,3 Million USD
Ferrari 458,"2,30,000 USD"
- Документы API pandas read_excel()
Дайте знать, что вы думаете по этой теме материала в комментариях. Мы крайне благодарны вам за ваши комментарии, дизлайки, подписки, лайки, отклики!
Мы можем использовать функцию read_excel() модуля pandas для чтения данных файла Excel в объекте DataFrame.
Если вы посмотрите на лист Excel, это двухмерная таблица. Объект DataFrame также представляет собой двумерную табличную структуру данных.
Содержание
- 1. Пример
- 2. Список заголовков столбцов таблицы Excel
- 3. Печать данных столбца
- 4. Пример использования команды read_excel()
- 5. Чтение файла без строки заголовка
- 6. Excel Sheet в Dict, CSV и JSON
1. Пример
Допустим, у нас есть файл Excel с двумя листами – «Employees» и «Cars». Верхняя строка содержит заголовок таблицы.

Вот пример для чтения данных таблицы «Employees» и их печати.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Employees')
# print whole sheet data
print(excel_data_df)
Вывод:
EmpID EmpName EmpRole 0 1 Pankaj CEO 1 2 David Lee Editor 2 3 Lisa Ray Author
- Первый параметр – это имя файла Excel.
- Параметр sheet_name определяет лист, который будет считан из файла Excel.
- Когда мы печатаем объект DataFrame, на выходе получается двумерная таблица. Это похоже на записи в Excel.
2. Список заголовков столбцов таблицы Excel
Мы можем получить список заголовков столбцов, используя свойство columns объекта dataframe.
print(excel_data_df.columns.ravel())
Вывод:
['EmpID' 'EmpName' 'EmpRole']
3. Печать данных столбца
Мы можем получить данные столбца и преобразовать их в список значений.
print(excel_data_df['EmpName'].tolist())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Мы можем указать имена столбцов для чтения из файла Excel. Это полезно, когда вас интересуют только несколько столбцов таблицы Excel.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print(excel_data_df)
Вывод:
Car Name Car Price 0 Honda City 20,000 USD 1 Bugatti Chiron 3 Million USD 2 Ferrari 458 2,30,000 USD
5. Чтение файла без строки заголовка
Если на листе Excel нет строки заголовка, передайте значение параметра заголовка как None.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Numbers', header=None)
Если вы передадите значение заголовка как целое число, скажем, 3. Тогда третья строка будет рассматриваться как строка заголовка, и значения будут считываться со следующей строки. Все данные до строки заголовка будут отброшены.
6. Excel Sheet в Dict, CSV и JSON
Объект DataFrame имеет различные служебные методы для преобразования табличных данных в форматы Dict, CSV или JSON.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print('Excel Sheet to Dict:', excel_data_df.to_dict(orient='record'))
print('Excel Sheet to JSON:', excel_data_df.to_json(orient='records'))
print('Excel Sheet to CSV:n', excel_data_df.to_csv(index=False))
Вывод:
Excel Sheet to Dict: [{'Car Name': 'Honda City', 'Car Price': '20,000 USD'}, {'Car Name': 'Bugatti Chiron', 'Car Price': '3 Million USD'}, {'Car Name': 'Ferrari 458', 'Car Price': '2,30,000 USD'}]
Excel Sheet to JSON: [{"Car Name":"Honda City","Car Price":"20,000 USD"},{"Car Name":"Bugatti Chiron","Car Price":"3 Million USD"},{"Car Name":"Ferrari 458","Car Price":"2,30,000 USD"}]
Excel Sheet to CSV:
Car Name,Car Price
Honda City,"20,000 USD"
Bugatti Chiron,3 Million USD
Ferrari 458,"2,30,000 USD"
( 5 оценок, среднее 2 из 5 )
Хотя многие Data Scientist’ы больше привыкли работать с CSV-файлами, на практике очень часто приходится сталкиваться с обычными Excel-таблицами. Поэтому сегодня мы расскажем, как читать Excel-файлы в Pandas, а также рассмотрим основные возможности Python-библиотеки OpenPyXL для чтения метаданных ячеек.
Дополнительные зависимости для возможности чтения Excel таблиц
Для чтения таблиц Excel в Pandas требуются дополнительные зависимости:
- xlrd поддерживает старые и новые форматы MS Excel [1];
- OpenPyXL поддерживает новые форматы MS Excel (.xlsx) [2];
- ODFpy поддерживает свободные форматы OpenDocument (.odf, .ods и .odt) [3];
- pyxlsb поддерживает бинарные MS Excel файлы (формат .xlsb) [4].
Мы рекомендуем установить только OpenPyXL, поскольку он нам пригодится в дальнейшем. Для этого в командной строке прописывается следующая операция:
pip install openpyxl
Затем в Pandas нужно указать путь к Excel-файлу и одну из установленных зависимостей. Python-код выглядит следующим образом:
import pandas as pd
pd.read_excel(io='temp1.xlsx', engine='openpyxl')
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
Читаем несколько листов
Excel-файл может содержать несколько листов. В Pandas, чтобы прочитать конкретный лист, в аргументе нужно указать sheet_name. Можно указать список названий листов, тогда Pandas вернет словарь (dict) с объектами DataFrame:
dfs = pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
sheet_name=['Sheet1', 'Sheet2'])
dfs
#
{'Sheet1': Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64,
'Sheet2': Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78}
Если таблицы в словаре имеют одинаковые атрибуты, то их можно объединить в один DataFrame. В Python это выглядит так:
pd.concat(dfs).reset_index(drop=True)
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
3 Gosha 43 95
4 Anna 24 65
5 Lena 22 78
Указание диапазонов
Таблицы могут размещаться не в самом начале, а как, например, на рисунке ниже. Как видим, таблица располагается в диапазоне A:F.
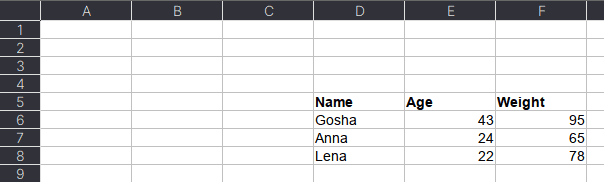
Чтобы прочитать такую таблицу, нужно указать диапазон в аргументе usecols. Также дополнительно можно добавить header — номер заголовка таблицы, а также nrows — количество строк, которые нужно прочитать. В аргументе header всегда передается номер строки на единицу меньше, чем в Excel-файле, поскольку в Python индексация начинается с 0 (на рисунке это номер 5, тогда указываем 4):
pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
usecols='D:F',
header=4, # в excel это №5
nrows=3)
#
Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78
Читаем таблицы в OpenPyXL
Pandas прочитывает только содержимое таблицы, но игнорирует метаданные: цвет заливки ячеек, примечания, стили таблицы и т.д. В таком случае пригодится библиотека OpenPyXL. Загрузка файлов осуществляется через функцию load_workbook, а к листам обращаться можно через квадратные скобки:
from openpyxl import load_workbook
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
type(ws)
# openpyxl.worksheet.worksheet.Worksheet
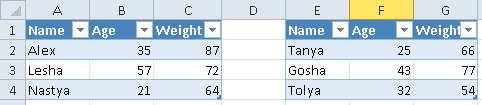
Допустим, имеется Excel-файл с несколькими таблицами на листе (см. рисунок выше). Если бы мы использовали Pandas, то он бы выдал следующий результат:
pd.read_excel(io='temp2.xlsx',
engine='openpyxl')
#
Name Age Weight Unnamed: 3 Name.1 Age.1 Weight.1
0 Alex 35 87 NaN Tanya 25 66
1 Lesha 57 72 NaN Gosha 43 77
2 Nastya 21 64 NaN Tolya 32 54
Можно, конечно, заняться обработкой и привести таблицы в нормальный вид, а можно воспользоваться OpenPyXL, который хранит таблицу и его диапазон в словаре. Чтобы посмотреть этот словарь, нужно вызвать ws.tables.items. Вот так выглядит Python-код:
ws.tables.items()
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
ws.tables.items()
#
[('Таблица1', 'A1:C4'), ('Таблица13', 'E1:G4')]
Обращаясь к каждому диапазону, можно проходить по каждой строке или столбцу, а внутри них – по каждой ячейке. Например, следующий код на Python таблицы объединяет строки в список, где первая строка уходит на заголовок, а затем преобразует их в DataFrame:
dfs = []
for table_name, value in ws.tables.items():
table = ws[value]
header, *body = [[cell.value for cell in row]
for row in table]
df = pd.DataFrame(body, columns=header)
dfs.append(df)
Если таблицы имеют одинаковые атрибуты, то их можно соединить в одну:
pd.concat(dfs)
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
0 Tanya 25 66
1 Gosha 43 77
2 Tolya 32 54
Сохраняем метаданные таблицы
Как указано в коде выше, у ячейки OpenPyXL есть атрибут value, который хранит ее значение. Помимо value, можно получить тип ячейки (data_type), цвет заливки (fill), примечание (comment) и др.
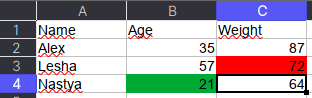
Например, требуется сохранить данные о цвете ячеек. Для этого мы каждую ячейку с числами перезапишем в виде <значение,RGB>, где RGB — значение цвета в формате RGB (red, green, blue). Python-код выглядит следующим образом:
# _TYPES = {int:'n', float:'n', str:'s', bool:'b'}
data = []
for row in ws.rows:
row_cells = []
for cell in row:
cell_value = cell.value
if cell.data_type == 'n':
cell_value = f"{cell_value},{cell.fill.fgColor.rgb}"
row_cells.append(cell_value)
data.append(row_cells)
Первым элементом списка является строка-заголовок, а все остальное уже значения таблицы:
pd.DataFrame(data[1:], columns=data[0])
#
Name Age Weight
0 Alex 35,00000000 87,00000000
1 Lesha 57,00000000 72,FFFF0000
2 Nastya 21,FF00A933 64,00000000
Теперь представим атрибуты в виде индексов с помощью метода stack, а после разобьём все записи на значение и цвет методом str.split:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
)
#
0 1
Name
Alex Age 35 00000000
Weight 87 00000000
Lesha Age 57 00000000
Weight 72 FFFF0000
Nastya Age 21 FF00A933
Weight 64 0000000
Осталось только переименовать 0 и 1 на Value и Color, а также добавить атрибут Variable, который обозначит Вес и Возраст. Полный код на Python выглядит следующим образом:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
.set_axis(['Value', 'Color'], axis=1)
.rename_axis(index=['Name', 'Variable'])
.reset_index()
)
#
Name Variable Value Color
0 Alex Age 35 00000000
1 Alex Weight 87 00000000
2 Lesha Age 57 00000000
3 Lesha Weight 72 FFFF0000
4 Nastya Age 21 FF00A933
5 Nastya Weight 64 00000000
Ещё больше подробностей о работе с таблицами в Pandas, а также их обработке на реальных примерах Data Science задач, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники
- https://xlrd.readthedocs.io/en/latest/
- https://openpyxl.readthedocs.io/en/latest/
- https://github.com/eea/odfpy
- https://github.com/willtrnr/pyxlsb