Хотя многие Data Scientist’ы больше привыкли работать с CSV-файлами, на практике очень часто приходится сталкиваться с обычными Excel-таблицами. Поэтому сегодня мы расскажем, как читать Excel-файлы в Pandas, а также рассмотрим основные возможности Python-библиотеки OpenPyXL для чтения метаданных ячеек.
Дополнительные зависимости для возможности чтения Excel таблиц
Для чтения таблиц Excel в Pandas требуются дополнительные зависимости:
- xlrd поддерживает старые и новые форматы MS Excel [1];
- OpenPyXL поддерживает новые форматы MS Excel (.xlsx) [2];
- ODFpy поддерживает свободные форматы OpenDocument (.odf, .ods и .odt) [3];
- pyxlsb поддерживает бинарные MS Excel файлы (формат .xlsb) [4].
Мы рекомендуем установить только OpenPyXL, поскольку он нам пригодится в дальнейшем. Для этого в командной строке прописывается следующая операция:
pip install openpyxl
Затем в Pandas нужно указать путь к Excel-файлу и одну из установленных зависимостей. Python-код выглядит следующим образом:
import pandas as pd
pd.read_excel(io='temp1.xlsx', engine='openpyxl')
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
Читаем несколько листов
Excel-файл может содержать несколько листов. В Pandas, чтобы прочитать конкретный лист, в аргументе нужно указать sheet_name. Можно указать список названий листов, тогда Pandas вернет словарь (dict) с объектами DataFrame:
dfs = pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
sheet_name=['Sheet1', 'Sheet2'])
dfs
#
{'Sheet1': Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64,
'Sheet2': Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78}
Если таблицы в словаре имеют одинаковые атрибуты, то их можно объединить в один DataFrame. В Python это выглядит так:
pd.concat(dfs).reset_index(drop=True)
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
3 Gosha 43 95
4 Anna 24 65
5 Lena 22 78
Указание диапазонов
Таблицы могут размещаться не в самом начале, а как, например, на рисунке ниже. Как видим, таблица располагается в диапазоне A:F.
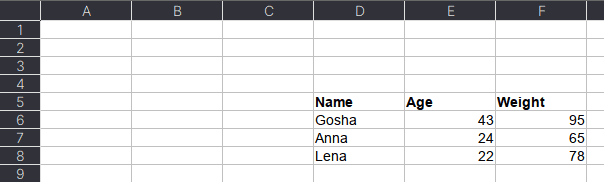
Чтобы прочитать такую таблицу, нужно указать диапазон в аргументе usecols. Также дополнительно можно добавить header — номер заголовка таблицы, а также nrows — количество строк, которые нужно прочитать. В аргументе header всегда передается номер строки на единицу меньше, чем в Excel-файле, поскольку в Python индексация начинается с 0 (на рисунке это номер 5, тогда указываем 4):
pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
usecols='D:F',
header=4, # в excel это №5
nrows=3)
#
Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78
Читаем таблицы в OpenPyXL
Pandas прочитывает только содержимое таблицы, но игнорирует метаданные: цвет заливки ячеек, примечания, стили таблицы и т.д. В таком случае пригодится библиотека OpenPyXL. Загрузка файлов осуществляется через функцию load_workbook, а к листам обращаться можно через квадратные скобки:
from openpyxl import load_workbook
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
type(ws)
# openpyxl.worksheet.worksheet.Worksheet
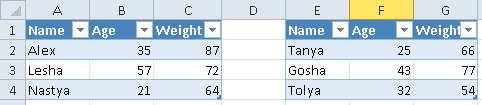
Допустим, имеется Excel-файл с несколькими таблицами на листе (см. рисунок выше). Если бы мы использовали Pandas, то он бы выдал следующий результат:
pd.read_excel(io='temp2.xlsx',
engine='openpyxl')
#
Name Age Weight Unnamed: 3 Name.1 Age.1 Weight.1
0 Alex 35 87 NaN Tanya 25 66
1 Lesha 57 72 NaN Gosha 43 77
2 Nastya 21 64 NaN Tolya 32 54
Можно, конечно, заняться обработкой и привести таблицы в нормальный вид, а можно воспользоваться OpenPyXL, который хранит таблицу и его диапазон в словаре. Чтобы посмотреть этот словарь, нужно вызвать ws.tables.items. Вот так выглядит Python-код:
ws.tables.items()
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
ws.tables.items()
#
[('Таблица1', 'A1:C4'), ('Таблица13', 'E1:G4')]
Обращаясь к каждому диапазону, можно проходить по каждой строке или столбцу, а внутри них – по каждой ячейке. Например, следующий код на Python таблицы объединяет строки в список, где первая строка уходит на заголовок, а затем преобразует их в DataFrame:
dfs = []
for table_name, value in ws.tables.items():
table = ws[value]
header, *body = [[cell.value for cell in row]
for row in table]
df = pd.DataFrame(body, columns=header)
dfs.append(df)
Если таблицы имеют одинаковые атрибуты, то их можно соединить в одну:
pd.concat(dfs)
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
0 Tanya 25 66
1 Gosha 43 77
2 Tolya 32 54
Сохраняем метаданные таблицы
Как указано в коде выше, у ячейки OpenPyXL есть атрибут value, который хранит ее значение. Помимо value, можно получить тип ячейки (data_type), цвет заливки (fill), примечание (comment) и др.
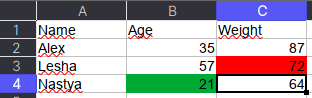
Например, требуется сохранить данные о цвете ячеек. Для этого мы каждую ячейку с числами перезапишем в виде <значение,RGB>, где RGB — значение цвета в формате RGB (red, green, blue). Python-код выглядит следующим образом:
# _TYPES = {int:'n', float:'n', str:'s', bool:'b'}
data = []
for row in ws.rows:
row_cells = []
for cell in row:
cell_value = cell.value
if cell.data_type == 'n':
cell_value = f"{cell_value},{cell.fill.fgColor.rgb}"
row_cells.append(cell_value)
data.append(row_cells)
Первым элементом списка является строка-заголовок, а все остальное уже значения таблицы:
pd.DataFrame(data[1:], columns=data[0])
#
Name Age Weight
0 Alex 35,00000000 87,00000000
1 Lesha 57,00000000 72,FFFF0000
2 Nastya 21,FF00A933 64,00000000
Теперь представим атрибуты в виде индексов с помощью метода stack, а после разобьём все записи на значение и цвет методом str.split:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
)
#
0 1
Name
Alex Age 35 00000000
Weight 87 00000000
Lesha Age 57 00000000
Weight 72 FFFF0000
Nastya Age 21 FF00A933
Weight 64 0000000
Осталось только переименовать 0 и 1 на Value и Color, а также добавить атрибут Variable, который обозначит Вес и Возраст. Полный код на Python выглядит следующим образом:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
.set_axis(['Value', 'Color'], axis=1)
.rename_axis(index=['Name', 'Variable'])
.reset_index()
)
#
Name Variable Value Color
0 Alex Age 35 00000000
1 Alex Weight 87 00000000
2 Lesha Age 57 00000000
3 Lesha Weight 72 FFFF0000
4 Nastya Age 21 FF00A933
5 Nastya Weight 64 00000000
Ещё больше подробностей о работе с таблицами в Pandas, а также их обработке на реальных примерах Data Science задач, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники
- https://xlrd.readthedocs.io/en/latest/
- https://openpyxl.readthedocs.io/en/latest/
- https://github.com/eea/odfpy
- https://github.com/willtrnr/pyxlsb
The new version of Pandas uses the following interface to load Excel files:
read_excel('path_to_file.xls', 'Sheet1', index_col=None, na_values=['NA'])
but what if I don’t know the sheets that are available?
For example, I am working with excel files that the following sheets
Data 1, Data 2 …, Data N, foo, bar
but I don’t know N a priori.
Is there any way to get the list of sheets from an excel document in Pandas?
![]()
denfromufa
5,97612 gold badges77 silver badges138 bronze badges
asked Jul 31, 2013 at 17:57
![]()
You can still use the ExcelFile class (and the sheet_names attribute):
xl = pd.ExcelFile('foo.xls')
xl.sheet_names # see all sheet names
xl.parse(sheet_name) # read a specific sheet to DataFrame
see docs for parse for more options…
![]()
answered Jul 31, 2013 at 18:01
![]()
Andy HaydenAndy Hayden
353k101 gold badges619 silver badges531 bronze badges
3
You should explicitly specify the second parameter (sheetname) as None. like this:
df = pandas.read_excel("/yourPath/FileName.xlsx", None);
«df» are all sheets as a dictionary of DataFrames, you can verify it by run this:
df.keys()
result like this:
[u'201610', u'201601', u'201701', u'201702', u'201703', u'201704', u'201705', u'201706', u'201612', u'fund', u'201603', u'201602', u'201605', u'201607', u'201606', u'201608', u'201512', u'201611', u'201604']
please refer pandas doc for more details: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html
answered Aug 10, 2017 at 1:59
![]()
3
The easiest way to retrieve the sheet-names from an excel (xls., xlsx) is:
tabs = pd.ExcelFile("path").sheet_names
print(tabs)
Then to read and store the data of a particular sheet (say, sheet names are «Sheet1», «Sheet2», etc.), say «Sheet2» for example:
data = pd.read_excel("path", "Sheet2")
print(data)
![]()
answered Aug 12, 2021 at 20:13
![]()
This is the fastest way I have found, inspired by @divingTobi’s answer. All The answers based on xlrd, openpyxl or pandas are slow for me, as they all load the whole file first.
from zipfile import ZipFile
from bs4 import BeautifulSoup # you also need to install "lxml" for the XML parser
with ZipFile(file) as zipped_file:
summary = zipped_file.open(r'xl/workbook.xml').read()
soup = BeautifulSoup(summary, "xml")
sheets = [sheet.get("name") for sheet in soup.find_all("sheet")]
answered Sep 6, 2019 at 21:10
![]()
S.E.AS.E.A
1211 silver badge3 bronze badges
#It will work for Both '.xls' and '.xlsx' by using pandas
import pandas as pd
excel_Sheet_names = (pd.ExcelFile(excelFilePath)).sheet_names
#for '.xlsx' use only openpyxl
from openpyxl import load_workbook
excel_Sheet_names = (load_workbook(excelFilePath, read_only=True)).sheet_names
![]()
Suraj Rao
29.3k11 gold badges96 silver badges103 bronze badges
answered Dec 7, 2021 at 11:58
![]()
1
I have tried xlrd, pandas, openpyxl and other such libraries and all of them seem to take exponential time as the file size increase as it reads the entire file. The other solutions mentioned above where they used ‘on_demand’ did not work for me. If you just want to get the sheet names initially, the following function works for xlsx files.
def get_sheet_details(file_path):
sheets = []
file_name = os.path.splitext(os.path.split(file_path)[-1])[0]
# Make a temporary directory with the file name
directory_to_extract_to = os.path.join(settings.MEDIA_ROOT, file_name)
os.mkdir(directory_to_extract_to)
# Extract the xlsx file as it is just a zip file
zip_ref = zipfile.ZipFile(file_path, 'r')
zip_ref.extractall(directory_to_extract_to)
zip_ref.close()
# Open the workbook.xml which is very light and only has meta data, get sheets from it
path_to_workbook = os.path.join(directory_to_extract_to, 'xl', 'workbook.xml')
with open(path_to_workbook, 'r') as f:
xml = f.read()
dictionary = xmltodict.parse(xml)
for sheet in dictionary['workbook']['sheets']['sheet']:
sheet_details = {
'id': sheet['@sheetId'],
'name': sheet['@name']
}
sheets.append(sheet_details)
# Delete the extracted files directory
shutil.rmtree(directory_to_extract_to)
return sheets
Since all xlsx are basically zipped files, we extract the underlying xml data and read sheet names from the workbook directly which takes a fraction of a second as compared to the library functions.
Benchmarking: (On a 6mb xlsx file with 4 sheets)
Pandas, xlrd: 12 seconds
openpyxl: 24 seconds
Proposed method: 0.4 seconds
Since my requirement was just reading the sheet names, the unnecessary overhead of reading the entire time was bugging me so I took this route instead.
answered May 27, 2019 at 5:43
![]()
3
Building on @dhwanil_shah ‘s answer, you do not need to extract the whole file. With zf.open it is possible to read from a zipped file directly.
import xml.etree.ElementTree as ET
import zipfile
def xlsxSheets(f):
zf = zipfile.ZipFile(f)
f = zf.open(r'xl/workbook.xml')
l = f.readline()
l = f.readline()
root = ET.fromstring(l)
sheets=[]
for c in root.findall('{http://schemas.openxmlformats.org/spreadsheetml/2006/main}sheets/*'):
sheets.append(c.attrib['name'])
return sheets
The two consecutive readlines are ugly, but the content is only in the second line of the text. No need to parse the whole file.
This solution seems to be much faster than the read_excel version, and most likely also faster than the full extract version.
answered Jul 1, 2019 at 14:01
![]()
divingTobidivingTobi
1,9349 silver badges24 bronze badges
1
If you:
- care about performance
- don’t need the data in the file at execution time.
- want to go with conventional libraries vs rolling your own solution
Below was benchmarked on a ~10Mb xlsx, xlsb file.
xlsx, xls
from openpyxl import load_workbook
def get_sheetnames_xlsx(filepath):
wb = load_workbook(filepath, read_only=True, keep_links=False)
return wb.sheetnames
Benchmarks: ~ 14x speed improvement
# get_sheetnames_xlsx vs pd.read_excel
225 ms ± 6.21 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
3.25 s ± 140 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
xlsb
from pyxlsb import open_workbook
def get_sheetnames_xlsb(filepath):
with open_workbook(filepath) as wb:
return wb.sheets
Benchmarks: ~ 56x speed improvement
# get_sheetnames_xlsb vs pd.read_excel
96.4 ms ± 1.61 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
5.36 s ± 162 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Notes:
- This is a good resource —
http://www.python-excel.org/ xlrdis no longer maintained as of 2020
answered Nov 9, 2020 at 21:24
![]()
Glen ThompsonGlen Thompson
8,7834 gold badges49 silver badges50 bronze badges
from openpyxl import load_workbook
sheets = load_workbook(excel_file, read_only=True).sheetnames
For a 5MB Excel file I’m working with, load_workbook without the read_only flag took 8.24s. With the read_only flag it only took 39.6 ms. If you still want to use an Excel library and not drop to an xml solution, that’s much faster than the methods that parse the whole file.
answered Jun 4, 2020 at 20:54
![]()
flutefreak7flutefreak7
2,2915 gold badges28 silver badges38 bronze badges
-
With the load_workbook readonly option, what was earlier seen as a execution seen visibly waiting for many seconds happened with milliseconds. The solution could however be still improved.
import pandas as pd from openpyxl import load_workbook class ExcelFile: def __init__(self, **kwargs): ........ ..... self._SheetNames = list(load_workbook(self._name,read_only=True,keep_links=False).sheetnames) -
The Excelfile.parse takes the same time as reading the complete xls in order of 10s of sec. This result was obtained with windows 10 operating system with below package versions
C:>python -V Python 3.9.1 C:>pip list Package Version --------------- ------- et-xmlfile 1.0.1 numpy 1.20.2 openpyxl 3.0.7 pandas 1.2.3 pip 21.0.1 python-dateutil 2.8.1 pytz 2021.1 pyxlsb 1.0.8 setuptools 49.2.1 six 1.15.0 xlrd 2.0.1
answered Apr 8, 2021 at 12:19
![]()
if you read excel file
dfs = pd.ExcelFile('file')
then use
dfs.sheet_names
dfs.parse('sheetname')
another variant
df = pd.read_excel('file', sheet_name='sheetname')
![]()
Dominique
15.9k15 gold badges52 silver badges104 bronze badges
answered Aug 10, 2021 at 5:12
![]()
import pandas as pd
path = "\DB\Expense\reconcile\"
file_name = "202209-v01.xlsx"
df = pd.read_excel(path + file_name, None)
print(df)
sheet_names = list(df.keys())
# print last sheet name
print(sheet_names[len(sheet_names)-1])
last_month = df.get(sheet_names[len(sheet_names)-1])
print(last_month)
answered Nov 8, 2022 at 0:00
![]()
Время на прочтение
5 мин
Количество просмотров 63K
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
import pandas as pd
sales = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'sales')
states = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'states')
Теперь воспользуемся методом .head() датафрейма sales для того чтобы вывести элементы, находящиеся в начале датафрейма:
print(sales.head())
Сравним то, что будет выведено, с тем, что можно видеть в Excel.
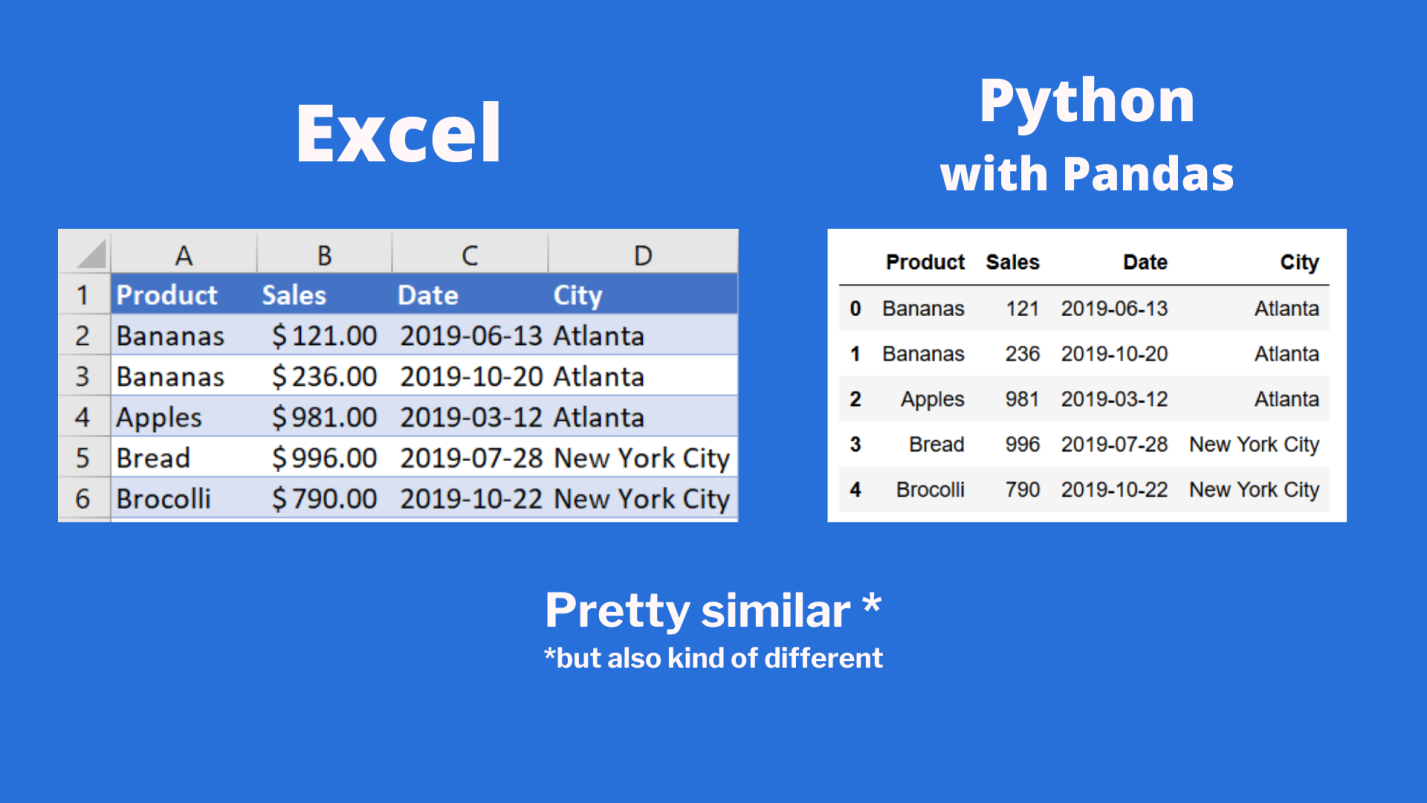
Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
- Нумерация строк в Excel начинается с 1, а в pandas номер (индекс) первой строки равняется 0.
- В Excel столбцы имеют буквенные обозначения, начинающиеся с буквы
A, а в pandas названия столбцов соответствуют именам соответствующих переменных.
Продолжим исследование возможностей pandas, позволяющих решать задачи, которые обычно решают в Excel.
Реализация возможностей Excel-функции IF в Python
В Excel существует очень удобная функция IF, которая позволяет, например, записать что-либо в ячейку, основываясь на проверке того, что находится в другой ячейке. Предположим, нужно создать в Excel новый столбец, ячейки которого будут сообщать нам о том, превышают ли 500 значения, записанные в соответствующие ячейки столбца B. В Excel такому столбцу (в нашем случае это столбец E) можно назначить заголовок MoreThan500, записав соответствующий текст в ячейку E1. После этого, в ячейке E2, можно ввести следующее:
=IF([@Sales]>500, "Yes", "No")
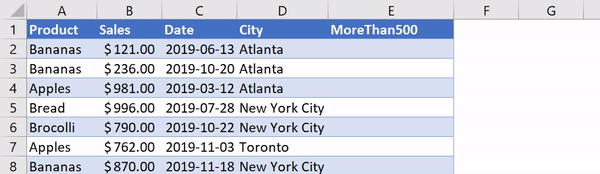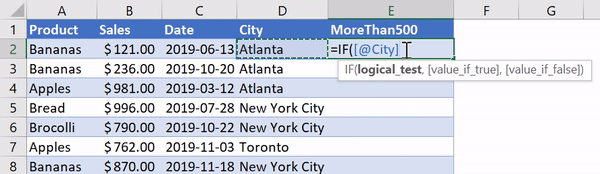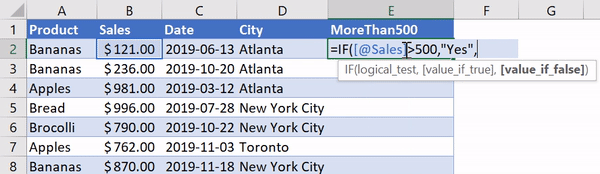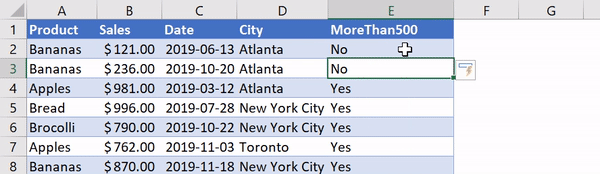
Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
sales['MoreThan500'] = ['Yes' if x > 500 else 'No' for x in sales['Sales']]

Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
В нашем наборе данных, на одном из листов Excel, есть названия городов, а на другом — названия штатов и провинций. Как узнать о том, где именно находится каждый город? Для этого подходит Excel-функция VLOOKUP, с помощью которой можно связать данные двух таблиц. Эта функция работает по принципу левого соединения, когда сохраняется каждая запись из набора данных, находящегося в левой части выражения. Применяя функцию VLOOKUP, мы предлагаем системе выполнить поиск определённого значения в заданном столбце указанного листа, а затем — вернуть значение, которое находится на заданное число столбцов правее найденного значения. Вот как это выглядит:
=VLOOKUP([@City],states,2,false)
Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.

Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
sales = pd.merge(sales, states, how='left', on='City')
Разберём его:
- Первый аргумент метода
merge— это исходный датафрейм. - Второй аргумент — это датафрейм, в котором мы ищем значения.
- Аргумент
howуказывает на то, как именно мы хотим соединить данные. - Аргумент
onуказывает на переменную, по которой нужно выполнить соединение (тут ещё можно использовать аргументыleft_onиright_on, нужные в том случае, если интересующие нас данные в разных датафреймах названы по-разному).
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
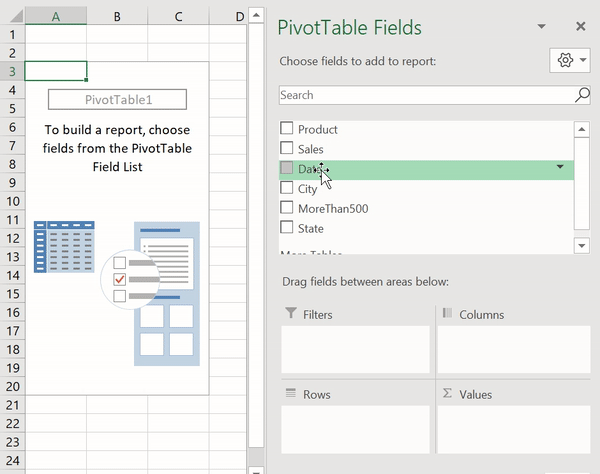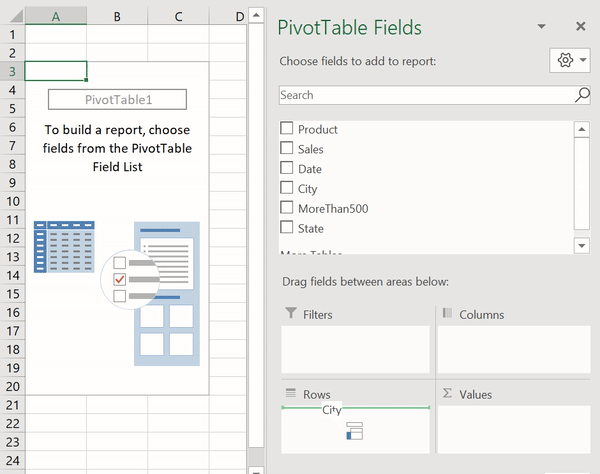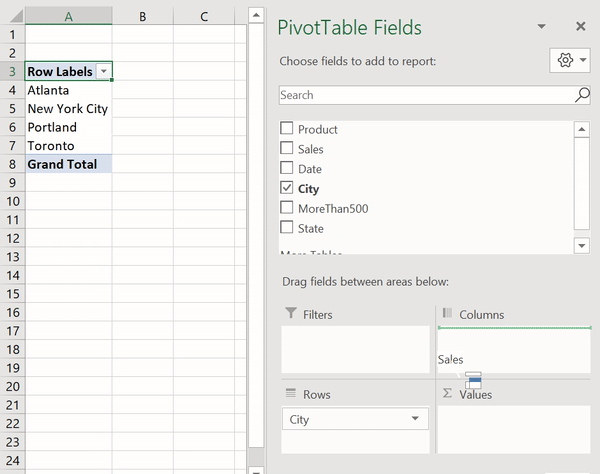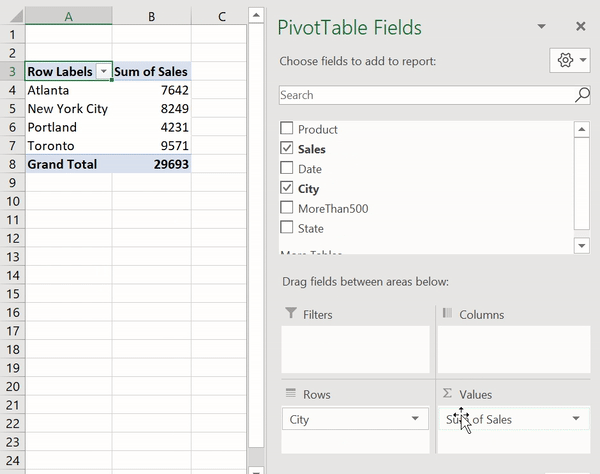
Создание сводной таблицы в Excel
Как видите, для создания подобной таблицы достаточно перетащить поле City в раздел Rows, а поле Sales — в раздел Values. После этого Excel автоматически выведет суммарные продажи для каждого города.
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
sales.pivot_table(index = 'City', values = 'Sales', aggfunc = 'sum')
Разберём его:
- Здесь мы используем метод
sales.pivot_table, сообщая pandas о том, что мы хотим создать сводную таблицу, основанную на датафреймеsales. - Аргумент
indexуказывает на столбец, по которому мы хотим агрегировать данные. - Аргумент
valuesуказывает на то, какие значения мы собираемся агрегировать. - Аргумент
aggfuncзадаёт функцию, которую мы хотим использовать при обработке значений (тут ещё можно воспользоваться функциямиmean,max,minи так далее).
Итоги
Из этого материала вы узнали о том, как импортировать Excel-данные в pandas, о том, как реализовать средствами Python и pandas возможности Excel-функций IF и VLOOKUP, а также о том, как воспроизвести средствами pandas функционал сводных таблиц Excel. Возможно, сейчас вы задаётесь вопросом о том, зачем вам пользоваться pandas, если то же самое можно сделать и в Excel. На этот вопрос нет однозначного ответа. Python позволяет создавать код, который поддаётся тонкой настройке и глубокому исследованию. Такой код можно использовать многократно. Средствами Python можно описывать очень сложные схемы анализа данных. А возможностей Excel, вероятно, достаточно лишь для менее масштабных исследований данных. Если вы до этого момента пользовались только Excel — рекомендую испытать Python и pandas, и узнать о том, что у вас из этого получится.
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.

В Python данные из файла Excel считываются в объект DataFrame. Для этого используется функция read_excel() модуля pandas.
Лист Excel — это двухмерная таблица. Объект DataFrame также представляет собой двухмерную табличную структуру данных.
- Пример использования Pandas read_excel()
- Список заголовков столбцов листа Excel
- Вывод данных столбца
- Пример использования Pandas to Excel: read_excel()
- Чтение файла Excel без строки заголовка
- Лист Excel в Dict, CSV и JSON
- Ресурсы

Предположим, что у нас есть документ Excel, состоящий из двух листов: «Employees» и «Cars». Верхняя строка содержит заголовок таблицы.

Ниже приведен код, который считывает данные листа «Employees» и выводит их.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Employees')
# print whole sheet data
print(excel_data_df)
Вывод:
EmpID EmpName EmpRole 0 1 Pankaj CEO 1 2 David Lee Editor 2 3 Lisa Ray Author
Первый параметр, который принимает функция read_excel ()— это имя файла Excel. Второй параметр (sheet_name) определяет лист для считывания данных.
При выводе содержимого объекта DataFrame мы получаем двухмерные таблицы, схожие по своей структуре со структурой документа Excel.
Чтобы получить список заголовков столбцов таблицы, используется свойство columns объекта Dataframe. Пример реализации:
print(excel_data_df.columns.ravel())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Мы можем получить данные из столбца и преобразовать их в список значений. Пример:
print(excel_data_df['EmpName'].tolist())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Можно указать имена столбцов для чтения из файла Excel. Это потребуется, если нужно вывести данные из определенных столбцов таблицы.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print(excel_data_df)
Вывод:
Car Name Car Price 0 Honda City 20,000 USD 1 Bugatti Chiron 3 Million USD 2 Ferrari 458 2,30,000 USD
Если в листе Excel нет строки заголовка, нужно передать его значение как None.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Numbers', header=None)
Если вы передадите значение заголовка как целое число (например, 3), тогда третья строка станет им. При этом считывание данных начнется со следующей строки. Данные, расположенные перед строкой заголовка, будут отброшены.
Объект DataFrame предоставляет различные методы для преобразования табличных данных в формат Dict , CSV или JSON.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print('Excel Sheet to Dict:', excel_data_df.to_dict(orient='record'))
print('Excel Sheet to JSON:', excel_data_df.to_json(orient='records'))
print('Excel Sheet to CSV:n', excel_data_df.to_csv(index=False))
Вывод:
Excel Sheet to Dict: [{'Car Name': 'Honda City', 'Car Price': '20,000 USD'}, {'Car Name': 'Bugatti Chiron', 'Car Price': '3 Million USD'}, {'Car Name': 'Ferrari 458', 'Car Price': '2,30,000 USD'}]
Excel Sheet to JSON: [{"Car Name":"Honda City","Car Price":"20,000 USD"},{"Car Name":"Bugatti Chiron","Car Price":"3 Million USD"},{"Car Name":"Ferrari 458","Car Price":"2,30,000 USD"}]
Excel Sheet to CSV:
Car Name,Car Price
Honda City,"20,000 USD"
Bugatti Chiron,3 Million USD
Ferrari 458,"2,30,000 USD"
- Документы API pandas read_excel()
Дайте знать, что вы думаете по этой теме материала в комментариях. Мы крайне благодарны вам за ваши комментарии, дизлайки, подписки, лайки, отклики!
Excel sheets are very instinctive and user-friendly, which makes them ideal for manipulating large datasets even for less technical folks. If you are looking for places to learn to manipulate and automate stuff in excel files using Python, look no more. You are at the right place.
Python Pandas With Excel Sheet
In this article, you will learn how to use Pandas to work with Excel spreadsheets. At the end of the article, you will have the knowledge of:
- Necessary modules are needed for this and how to set them up in your system.
- Reading data from excel files into pandas using Python.
- Exploring the data from excel files in Pandas.
- Using functions to manipulate and reshape the data in Pandas.
Installation
To install Pandas in Anaconda, we can use the following command in Anaconda Terminal:
conda install pandas
To install Pandas in regular Python (Non-Anaconda), we can use the following command in the command prompt:
pip install pandas
Getting Started
First of all, we need to import the Pandas module which can be done by running the command: Pandas
Python3
Input File: Let’s suppose the excel file looks like this
Sheet 1:
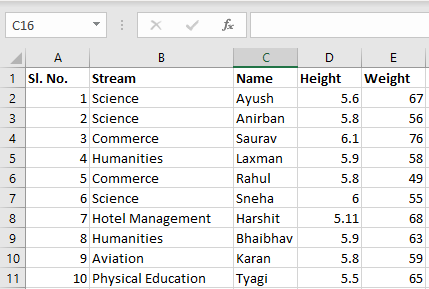
Sheet 2:
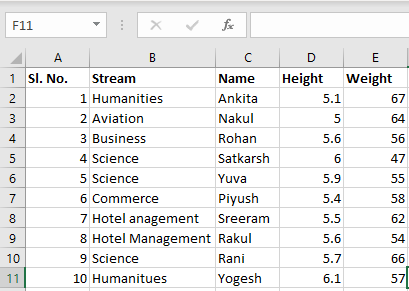
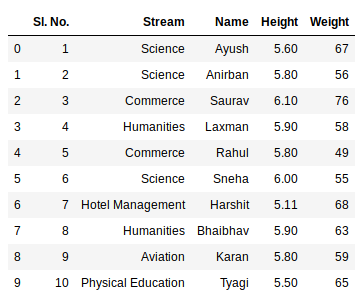
Now we can import the excel file using the read_excel function in Pandas. The second statement reads the data from excel and stores it into a pandas Data Frame which is represented by the variable newData. If there are multiple sheets in the excel workbook, the command will import data of the first sheet. To make a data frame with all the sheets in the workbook, the easiest method is to create different data frames separately and then concatenate them. The read_excel method takes argument sheet_name and index_col where we can specify the sheet of which the data frame should be made of and index_col specifies the title column, as is shown below:
Python3
file =('path_of_excel_file')
newData = pds.read_excel(file)
newData
Output:
Example:
The third statement concatenates both sheets. Now to check the whole data frame, we can simply run the following command:
Python3
sheet1 = pds.read_excel(file,
sheet_name = 0,
index_col = 0)
sheet2 = pds.read_excel(file,
sheet_name = 1,
index_col = 0)
newData = pds.concat([sheet1, sheet2])
newData
Output:
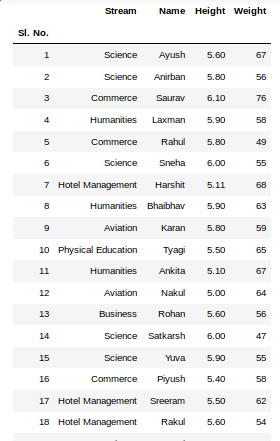
To view 5 columns from the top and from the bottom of the data frame, we can run the command. This head() and tail() method also take arguments as numbers for the number of columns to show.
Python3
newData.head()
newData.tail()
Output:
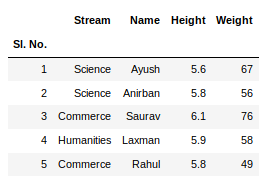
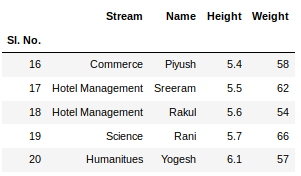
The shape() method can be used to view the number of rows and columns in the data frame as follows:
Python3
Output:
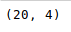
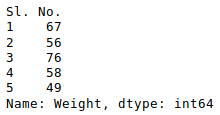
If any column contains numerical data, we can sort that column using the sort_values() method in pandas as follows:
Python3
sorted_column = newData.sort_values(['Height'], ascending = False)
Now, let’s suppose we want the top 5 values of the sorted column, we can use the head() method here:
Python3
sorted_column['Height'].head(5)
Output:
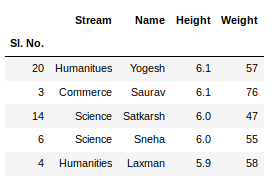
We can do that with any numerical column of the data frame as shown below:
Python3
Output:
Now, suppose our data is mostly numerical. We can get the statistical information like mean, max, min, etc. about the data frame using the describe() method as shown below:
Python3
Output:
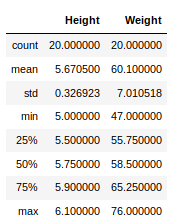
This can also be done separately for all the numerical columns using the following command:
Python3
Output:
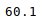
Other statistical information can also be calculated using the respective methods. Like in excel, formulas can also be applied and calculated columns can be created as follows:
Python3
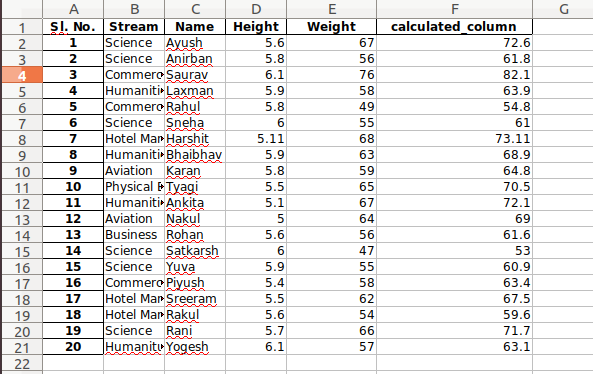
newData['calculated_column'] =
newData[“Height”] + newData[“Weight”]
newData['calculated_column'].head()
Output:
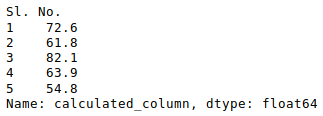
After operating on the data in the data frame, we can export the data back to an excel file using the method to_excel. For this we need to specify an output excel file where the transformed data is to be written, as shown below:
Python3
newData.to_excel('Output File.xlsx')
Output: