
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Pandas can read, filter, and re-arrange small and large datasets and output them in a range of formats including Excel. In this article, we will be dealing with the conversion of .csv file into excel (.xlsx).
Pandas provide the ExcelWriter class for writing data frame objects to excel sheets.
Syntax:
final = pd.ExcelWriter('GFG.xlsx')
Example:
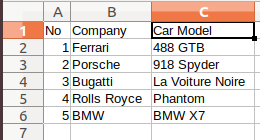
Sample CSV File:
Python3
import pandas as pd
df_new = pd.read_csv('Names.csv')
GFG = pd.ExcelWriter('Names.xlsx')
df_new.to_excel(GFG, index=False)
GFG.save()
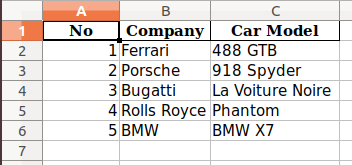
Output:
Method 2:
The read_* functions are used to read data to pandas, the to_* methods are used to store data. The to_excel() method stores the data as an excel file. In the example here, the sheet_name is named passengers instead of the default Sheet1. By setting index=False the row index labels are not saved in the spreadsheet.
Python3
import pandas as pd
df = pd.read_csv("./weather_data.csv")
df.to_excel("weather.xlsx", sheet_name="Testing", index=False)
Like Article
Save Article
Pandas is a third-party python module that can manipulate different format data files, such as CSV, JSON, Excel, Clipboard, HTML format, etc. This example will tell you how to use Pandas to read/write CSV files, and how to save the pandas.DataFrame object to an excel file.
1. How To Use Pandas In Python Application.
1.1 Install Python Pandas Module.
- First, you should make sure the python pandas module has been installed using the pip show pandas command in a terminal. If it shows can not find the pandas module in the terminal, you need to run the pip install pandas command to install it.
$ pip show pandas WARNING: Package(s) not found: pandas $ pip install pandas Collecting pandas Downloading pandas-1.2.3-cp37-cp37m-macosx_10_9_x86_64.whl (10.4 MB) |████████████████████████████████| 10.4 MB 135 kB/s Collecting pytz>=2017.3 Downloading pytz-2021.1-py2.py3-none-any.whl (510 kB) |████████████████████████████████| 510 kB 295 kB/s Requirement already satisfied: numpy>=1.16.5 in /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages (from pandas) (1.20.1) Requirement already satisfied: python-dateutil>=2.7.3 in /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages (from pandas) (2.8.1) Requirement already satisfied: six>=1.5 in /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages (from python-dateutil>=2.7.3->pandas) (1.15.0) Installing collected packages: pytz, pandas Successfully installed pandas-1.2.3 pytz-2021.1 - Because this example will save data to an excel file with the python pandas module, so it should install the python XlsxWriter module also. Run the command pip show XlsxWriter to see whether the python XlsxWriter module has been installed or not, if not you should run the pip install XlsxWriter to install it.
$ pip show XlsxWriter WARNING: Package(s) not found: XlsxWriter $ pip install XlsxWriter Collecting XlsxWriter Downloading XlsxWriter-1.3.7-py2.py3-none-any.whl (144 kB) |████████████████████████████████| 144 kB 852 kB/s Installing collected packages: XlsxWriter Successfully installed XlsxWriter-1.3.7
1. 2 Import Python Pandas Module In Python Source File.
- This is very simple, just add the import pandas command at the beginning of the python source file to import it, then you can use it’s various methods.
2. Read CSV File Use Pandas.
- To read a CSV file using python pandas is very easy, you just need to invoke the pandas module’s read_csv method with the CSV file path. The returned object is a pandas.DataFrame object. It represents the whole data of the CSV file, you can use its various method to manipulate the data such as order, query, change index, columns, etc.
data_frame = pandas.read_csv(csv_file)
- You can pass an encoding parameter to the read_csv() method to specify the CSV file text character encoding.
data_frame = pandas.read_csv(csv_file, encoding='gbk')
- Now you can call the returned DataFrame object’s head(n) method to get the first n rows of the text in the CSV file.
data_frame.head(n)
3. Pandas Write Data To CSV File.
- After you edit the data in the pandas.DataFrame object, you can call its to_csv method to save the new data into a CSV file.
data_frame.to_csv(csv_file_path)
4. Pandas Write Data To Excel File.
- Create a file writer using pandas.ExcelWriter method.
excel_writer = pandas.ExcelWriter(excel_file_path, engine='xlsxwriter')
- Call DataFrame object’s to_excel method to set the DataFrame data to a special excel file sheet.
data_frame.to_excel(excel_writer, 'Employee Info')
- Call the writer’s save method to save the data to an excel file.
excel_writer.save()
5. Python Pandas DataFrame Operation Methods.
5.1 Sort DataFrame Data By One Column.
- Please note the data column name is case sensitive.
data_frame.sort_values(by=['Salary'], ascending=False)
5.2 Query DataFrame Data In A Range.
- The below python code will query a range of data in the DataFrame object.
data_frame = data_frame.loc[(data_frame['Salary'] > 10000) & (data_frame['Salary'] < 20000)]
6. Python Pandas Read/Write CSV File And Save To Excel File Example.
- Below is the content of this example used source CSV file, the file name is employee_info.csv.
Name,Hire Date,Salary jerry,2010-01-01,16000 tom,2011-08-19,6000 kevin,2009-02-08,13000 richard,2012-03-19,5000 jackie,2015-06-08,28000 steven,2008-02-01,36000 jack,2006-09-19,8000 gary,2018-01-16,19000 john,2017-10-01,16600
- The example python file name is CSVExcelConvertionExample.py, it contains the below functions.

- read_csv_file_by_pandas(csv_file).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") ======================================================================================================== Execution output: ------------------data frame all---------------------- Name Hire Date Salary 0 jerry 2010-01-01 16000 1 tom 2011-08-19 6000 2 kevin 2009-02-08 13000 3 richard 2012-03-19 5000 4 jackie 2015-06-08 28000 5 steven 2008-02-01 36000 6 jack 2006-09-19 8000 7 gary 2018-01-16 19000 8 john 2017-10-01 16600 ------------------data frame index---------------------- RangeIndex(start=0, stop=9, step=1) ------------------set Name column as data frame index---------------------- Index(['jerry', 'tom', 'kevin', 'richard', 'jackie', 'steven', 'jack', 'gary', 'john'], dtype='object', name='Name') ------------------data frame columns---------------------- Index(['Hire Date', 'Salary'], dtype='object') ------------------data frame values---------------------- [['2010-01-01' 16000] ['2011-08-19' 6000] ['2009-02-08' 13000] ['2012-03-19' 5000] ['2015-06-08' 28000] ['2008-02-01' 36000] ['2006-09-19' 8000] ['2018-01-16' 19000] ['2017-10-01' 16600]] ------------------data frame hire date series---------------------- Name jerry 2010-01-01 tom 2011-08-19 kevin 2009-02-08 richard 2012-03-19 jackie 2015-06-08 steven 2008-02-01 jack 2006-09-19 gary 2018-01-16 john 2017-10-01 Name: Hire Date, dtype: object ------------------select multiple columns from data frame---------------------- Salary Hire Date Name jerry 16000 2010-01-01 tom 6000 2011-08-19 kevin 13000 2009-02-08 richard 5000 2012-03-19 jackie 28000 2015-06-08 steven 36000 2008-02-01 jack 8000 2006-09-19 gary 19000 2018-01-16 john 16600 2017-10-01 - write_to_csv_file_by_pandas(csv_file_path, data_frame).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame # Write pandas.DataFrame object to a csv file. def write_to_csv_file_by_pandas(csv_file_path, data_frame): data_frame.to_csv(csv_file_path) print(csv_file_path + ' has been created.') if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") write_to_csv_file_by_pandas("./employee_info_new.csv", data_frame) ================================================================================================================ Execution output: ./employee_info_new.csv has been created. - write_to_excel_file_by_pandas(excel_file_path, data_frame).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame # Write pandas.DataFrame object to an excel file. def write_to_excel_file_by_pandas(excel_file_path, data_frame): excel_writer = pandas.ExcelWriter(excel_file_path, engine='xlsxwriter') data_frame.to_excel(excel_writer, 'Employee Info') excel_writer.save() print(excel_file_path + ' has been created.') if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") write_to_excel_file_by_pandas("./employee_info_new.xlsx", data_frame) ========================================================================================== Execution output: ./employee_info_new.xlsx has been created. - sort_data_frame_by_string_column(data_frame).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame # Sort the data in DataFrame object by name that data type is string. def sort_data_frame_by_string_column(data_frame): data_frame = data_frame.sort_values(by=['Name']) print("--------------Sort data format by string column---------------") print(data_frame) if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") sort_data_frame_by_string_column(data_frame) ==================================================================================================== Execution output: --------------Sort data format by string column--------------- Hire Date Salary Name gary 2018-01-16 19000 jack 2006-09-19 8000 jackie 2015-06-08 28000 jerry 2010-01-01 16000 john 2017-10-01 16600 kevin 2009-02-08 13000 richard 2012-03-19 5000 steven 2008-02-01 36000 tom 2011-08-19 6000 - sort_data_frame_by_datetime_column(data_frame).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame # Sort DataFrame data by Hire Date that data type is datetime. def sort_data_frame_by_datetime_column(data_frame): data_frame = data_frame.sort_values(by=['Hire Date']) print("--------------Sort data format by date column---------------") print(data_frame) if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") sort_data_frame_by_datetime_column(data_frame) =========================================================================================== Execution output: --------------Sort data format by date column--------------- Hire Date Salary Name jack 2006-09-19 8000 steven 2008-02-01 36000 kevin 2009-02-08 13000 jerry 2010-01-01 16000 tom 2011-08-19 6000 richard 2012-03-19 5000 jackie 2015-06-08 28000 john 2017-10-01 16600 gary 2018-01-16 19000 - sort_data_frame_by_number_column(data_frame).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame # Sort DataFrame data by Salary that data type is number. def sort_data_frame_by_number_column(data_frame): data_frame = data_frame.sort_values(by=['Salary'], ascending=False) print("--------------Sort data format by number column desc---------------") print(data_frame) if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") sort_data_frame_by_number_column(data_frame) ================================================================================ Execution output: --------------Sort data format by number column desc--------------- Hire Date Salary Name steven 2008-02-01 36000 jackie 2015-06-08 28000 gary 2018-01-16 19000 john 2017-10-01 16600 jerry 2010-01-01 16000 kevin 2009-02-08 13000 jack 2006-09-19 8000 tom 2011-08-19 6000 richard 2012-03-19 5000 - get_data_in_salary_range(data_frame).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame # Get DataFrame data list in salary range. def get_data_in_salary_range(data_frame): data_frame = data_frame.loc[(data_frame['Salary'] > 10000) & (data_frame['Salary'] < 20000)] data_frame = data_frame.sort_values(by=['Salary']) print("-------------- Employee info whose salary between 10000 and 20000---------------") print(data_frame) if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") get_data_in_salary_range(data_frame) ============================================================================================================== Execution output: -------------- Employee info whose salary between 10000 and 20000--------------- Hire Date Salary Name kevin 2009-02-08 13000 jerry 2010-01-01 16000 john 2017-10-01 16600 gary 2018-01-16 19000 - get_data_in_hire_date_range(data_frame).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame # Get DataFrame data list in hire date range. def get_data_in_hire_date_range(data_frame): min_hire_date = '2010-01-01' max_hire_date = '2017-01-01' data_frame = data_frame.loc[(data_frame['Hire Date'] > min_hire_date) & (data_frame['Hire Date'] < max_hire_date)] data_frame = data_frame.sort_values(by=['Hire Date']) print("-------------- Employee info whose Hire Date between 2010/01/01 and 2017/01/01---------------") print(data_frame) if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") get_data_in_hire_date_range(data_frame) ==================================================================================================== Execution output: -------------- Employee info whose Hire Date between 2010/01/01 and 2017/01/01--------------- Hire Date Salary Name tom 2011-08-19 6000 richard 2012-03-19 5000 jackie 2015-06-08 28000 - get_data_in_name_range(data_frame).
import pandas import os import glob # Read csv file use pandas module. def read_csv_file_by_pandas(csv_file): data_frame = None if(os.path.exists(csv_file)): data_frame = pandas.read_csv(csv_file) print("------------------data frame all----------------------") print(data_frame) print("------------------data frame index----------------------") print(data_frame.index) data_frame = data_frame.set_index('Name') print("------------------set Name column as data frame index----------------------") print(data_frame.index) print("------------------data frame columns----------------------") print(data_frame.columns) print("------------------data frame values----------------------") print(data_frame.values) print("------------------data frame hire date series----------------------") print(data_frame['Hire Date']) print("------------------select multiple columns from data frame----------------------") print(data_frame[['Salary', 'Hire Date']]) else: print(csv_file + " do not exist.") return data_frame # Get DataFrame data list in name range. def get_data_in_name_range(data_frame): start_name = 'jerry' end_name = 'kevin' # First sort the data in the data_frame by Name column. data_frame = data_frame.sort_values(by=['Name']) # Because the Name column is the index column, so use the value in loc directly. data_frame = data_frame.loc[start_name:end_name] print("-------------- Employee info whose Name first character between jerry and kevin---------------") print(data_frame) if __name__ == '__main__': data_frame = read_csv_file_by_pandas("./employee_info.csv") get_data_in_name_range(data_frame) ==================================================================================================== Execution output: -------------- Employee info whose Name first character between jerry and kevin--------------- Hire Date Salary Name jerry 2010-01-01 16000 john 2017-10-01 16600 kevin 2009-02-08 13000 - convert_csv_to_excel_in_folder(folder_path): You can see the below section 7 to see this function detail python source code.
7. How To Convert Multiple CSV Files In A Folder To Excel File.
- The comment-95168 wants to convert some CSV files in a directory to Excel files automatically. Below is the example code which can implement this function.
import pandas import os import glob ''' This function will convert all the CSV files in the folder_path to Excel files. ''' def convert_csv_to_excel_in_folder(folder_path): # Loop all the CSV files under the path. for csv_file in glob.glob(os.path.join(folder_path, '*.csv')): # If the CSV file exist. if(os.path.exists(csv_file)): # Get the target excel file name and path. excel_file_path = csv_file.replace(".csv", ".xlsx") # Read the CSV file by python pandas module read_csv method. data_frame = pandas.read_csv(csv_file) # Create an excel writer object. excel_writer = pandas.ExcelWriter(excel_file_path, engine='xlsxwriter') # Add a work sheet in the target excel file. data_frame.to_excel(excel_writer, 'sheet_1') # Save the target excel file. excel_writer.save() print(excel_file_path + ' has been created.') else: print(csv_file + " do not exist.") if __name__ == '__main__': convert_csv_to_excel_in_folder(".") ==================================================================================================== Execution output: ./employee_info_new.xlsx has been created. ./employee_info.xlsx has been created.
In this quick guide, you’ll see the complete steps to convert a CSV file to an Excel file using Python.
To start, here is a simple template that you can use to convert a CSV to Excel using Python:
import pandas as pd read_file = pd.read_csv (r'Path where the CSV file is storedFile name.csv') read_file.to_excel (r'Path to store the Excel fileFile name.xlsx', index = None, header=True)
In the next section, you’ll see how to apply this template in practice.
Step 1: Install the Pandas package
If you haven’t already done so, install the Pandas package. You can use the following command to install the Pandas package (under Windows):
pip install pandas
Step 2: Capture the path where the CSV file is stored
Next, capture the path where the CSV file is stored on your computer.
Here is an example of a path where a CSV file is stored:
C:UsersRonDesktopTestProduct_List.csv
Where ‘Product_List‘ is the current CSV file name, and ‘csv‘ is the file extension.
Step 3: Specify the path where the new Excel file will be stored
Now, you’ll need to specify the path where the new Excel file will be stored. For example:
C:UsersRonDesktopTestNew_Products.xlsx
Where ‘New_Products‘ is the new file name, and ‘xlsx‘ is the Excel file extension.
Step 4: Convert the CSV to Excel using Python
For this final step, you’ll need to use the following template to perform the conversion:
import pandas as pd read_file = pd.read_csv (r'Path where the CSV file is storedFile name.csv') read_file.to_excel (r'Path to store the Excel fileFile name.xlsx', index = None, header=True)
Here is the complete syntax for our example (note that you’ll need to modify the paths to reflect the location where the files will be stored on your computer):
import pandas as pd read_file = pd.read_csv (r'C:UsersRonDesktopTestProduct_List.csv') read_file.to_excel (r'C:UsersRonDesktopTestNew_Products.xlsx', index = None, header=True)
Run the code in Python and the new Excel file (i.e., New_Products) will be saved at your specified location.
In this article, we will show you how to convert a CSV File (Comma Separated Values) to an excel file using the pandas module in python.
Assume we have taken an excel file with the name ExampleCsvFile.csv containing some random text. We will return a CSV File after converting the given excel file into a CSV file.
ExampleCsvFile.csv
| Player Name | Age | Type | Country | Team | Runs | Wickets |
|---|---|---|---|---|---|---|
| Virat Kohli | 33 | Batsman | India | Royal Challengers Bangalore | 6300 | 20 |
| Bhuvneshwar Kumar | 34 | Batsman | India | Sun Risers Hyderabad | 333 | 140 |
| Mahendra Singh Dhoni | 39 | Batsman | India | Chennai Super Kings | 4500 | 0 |
| Rashid Khan | 28 | Bowler | Afghanistan | Gujarat Titans | 500 | 130 |
| Hardik Pandya | 29 | All rounder | India | Gujarat Titans | 2400 | 85 |
| David Warner | 34 | Batsman | Australia | Delhi Capitals | 5500 | 12 |
| Kieron Pollard | 35 | All rounder | West Indies | Mumbai Indians | 3000 | 67 |
| Rohit Sharma | 33 | Batsman | India | Mumbai Indians | 5456 | 20 |
| Kane Williamson | 33 | Batsman | New Zealand | Sun Risers Hyderabad | 3222 | 5 |
| Kagiso Rabada | 29 | Bowler | South Africa | Lucknow Capitals | 335 | 111 |
Method 1: Converting CSV to Excel without Displaying Index values
Algorithm (Steps)
Following are the Algorithm/steps to be followed to perform the desired task −
-
Import the pandas module (Pandas is a Python open-source data manipulation and analysis package.This module can read, filter, and rearrange small and large datasets in Excel, JSON, and CSV formats.)
-
Create a variable to store the path of the CSV file after reading a file using the pandas read_csv() function (loads a CSV file as a pandas dataframe).
-
Create an output excel file with the pandas ExcelWriter() class (To save a DataFrame to an Excel sheet, use the pandas ExcelWriter() class. This class is typically used to save multiple sheets and append data to an existing Excel sheet.
Pandas ExcelWriter Highlights If xlsxwriter is installed, it is used by default; otherwise, openpyxl is used).
-
Convert the CSV file to an excel file using the to_excel() function (To export the DataFrame to an excel file, use the to_excel() function. The target file name must be specified when writing a single object to an excel file) without displaying index values by passing the index as False as an argument. Here index=False indicates no index values are displayed.
-
Use the save() function (saves the file) to save the result/output excel file.
Example
The following program converts the CSV file into an excel file without displaying index values −
import pandas as pd cvsDataframe = pd.read_csv('ExampleCsvFile.csv') resultExcelFile = pd.ExcelWriter('ResultExcelFile.xlsx') cvsDataframe.to_excel(resultExcelFile, index=False) resultExcelFile.save()
Output
On executing, the above program a new Excel file (resultExcelFile.csv) will be created with data from the CSV file.
In this program, we read a CSV file containing some random dummy data as a data frame using the pandas read_csv() function, and then we created a new excel file and converted the above CSV data frame to excel using the to excel() function. If we pass the index as a false argument, the output excel file removes the index row at the start. If no index parameter is given, it adds an index row at the beginning of the excel sheet and then we save the resultant excel file using the save() function to apply the changes.
Method 2: Converting CSV to Excel With Displaying Index values
Algorithm (Steps)
Following are the Algorithm/steps to be followed to perform the desired task −
-
load the CSV as a pandas data frame.
-
Convert the CSV file to an excel file by passing the index as True as an argument to the excel() function and displaying index values. index=True means that index values are shown here.
-
Use the save() function (saves the file) to save the result/output excel file.
-
Read the output Excel file with the read_excel() function (loads an Excel file as a pandas data frame) and convert it to a data frame object with the pandas module’s DataFrame() function.
-
Show/display the data frame object.
Example
The following program converts the CSV file into an excel file with displaying index values −
import pandas as pd cvsDataframe = pd.read_csv('ExampleCsvFile.csv') resultExcelFile = pd.ExcelWriter('ResultExcelFile.xlsx') cvsDataframe.to_excel(resultExcelFile, index=True) resultExcelFile.save() excelDataframe=pd.read_excel('ResultExcelFile.xlsx') print(excelDataframe)
Output
Unnamed: 0 Player Name Age Type Country
0 0 Virat Kohli 33 Batsman India
1 1 Bhuvneshwar Kumar 34 Batsman India
2 2 Mahendra Singh Dhoni 39 Batsman India
3 3 Rashid Khan 28 Bowler Afghanistan
4 4 Hardik Pandya 29 All rounder India
5 5 David Warner 34 Batsman Australia
6 6 Kieron Pollard 35 All rounder West Indies
7 7 Rohit Sharma 33 Batsman India
8 8 Kane Williamson 33 Batsman New Zealand
9 9 Kagiso Rabada 29 Bowler South Africa
Team Runs Wickets
0 Royal Challengers Bengaluru 6300 20
1 Sun Risers Hyderabad 333 140
2 Chennai Super Kings 4500 0
3 Gujarat Titans 500 130
4 Gujarat Titans 2400 85
5 Delhi Capitals 5500 12
6 Mumbai Indians 3000 67
7 Mumbai Indians 5456 20
8 Sun Risers Hyderabad 3222 5
9 Lucknow Capitals 335 111
Here we passed the index as a true as an argument, the result excel file adds the index row at the start and then we save the resultant excel file using the save() function to apply the changes. Then we converted the excel file to a data frame to see if the values from the CSV file were copied into the Excel file.
Conclusion
In this tutorial, we learned how to read a CSV file, then how to convert it to an Excel file and remove the index or add indices at the start of the excel file, and finally how to convert the Excel file to a pandas data frame.
Problem Formulation
💡 Challenge: Given a CSV file. How to convert it to an excel file in Python?
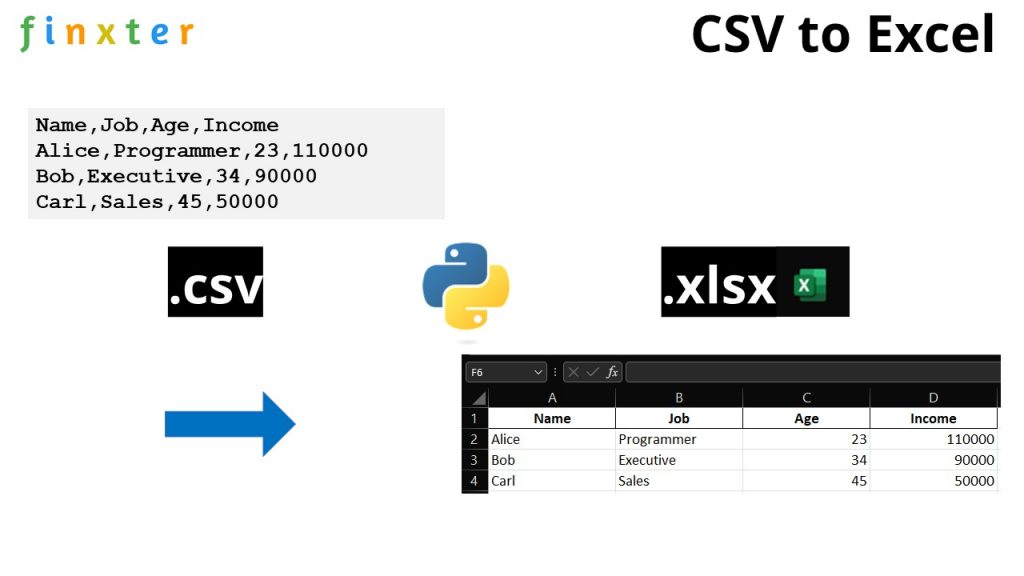
We create a folder with two files, the file csv_to_excel.py and my_file.csv. We want to convert the CSV file to an excel file so that after running the script csv_to_excel.py, we obtain the third file my_file.csv in our folder like so:

All methods discussed in this tutorial show different code snippets to put into csv_to_excel.py so that it converts the CSV to XLSX in Python.
Method 1: 5 Easy Steps in Pandas
The most pythonic way to convert a .csv to an .xlsx (Excel) in Python is to use the Pandas library.
- Install the
pandaslibrary withpip install pandas - Install the
openpyxllibrary that is used internally by pandas withpip install openpyxl - Import the
pandaslibray withimport pandas as pd - Read the CSV file into a DataFrame
dfby using the expressiondf = pd.read_csv('my_file.csv') - Store the DataFrame in an Excel file by calling
df.to_excel('my_file.xlsx', index=None, header=True)
import pandas as pd
df = pd.read_csv('my_file.csv')
df.to_excel('my_file.xlsx', index=None, header=True)
Note that there are many ways to customize the to_excel() function in case
- you don’t need a header line,
- you want to fix the first line in the Excel file,
- you want to format the cells as numbers instead of strings, or
- you have an index column in the original CSV and want to consider it in the Excel file too.
If you want to do any of those, feel free to read our full guide on the Finxter blog here:
🌍 Tutorial: Pandas DataFrame.to_excel() – An Unofficial Guide to Saving Data to Excel
Also, we’ve recorded a video on the ins and outs of this method here:
pd.to_excel() – An Unofficial Guide to Saving Data to Excel
Let’s have a look at an alternative to converting a CSV to an Excel file in Python:
Method 2: Modules csv and openpyxl
To convert a CSV to an Excel file, you can also use the following approach:
- Import the
csvmodule - Import the
openpyxlmodule - Read the CSV file into a list of lists, one inner list per row, by using the
csv.reader()function - Write the list of lists to the Excel file by using the workbook representation of the
openpyxllibrary. - Get the active worksheet by calling
workbook.active - Write to the worksheet by calling
worksheet.append(row)and append one list of values, one value per cell.
The following function converts a given CSV to an Excel file:
import csv
import openpyxl
def csv_to_excel(csv_filename, excel_filename):
# Read CSV file
csv_data = []
with open(csv_filename) as f:
csv_data = [row for row in csv.reader(f)]
# Write to Excel file
workbook = openpyxl.workbook.Workbook()
worksheet = workbook.active
for row in csv_data:
worksheet.append(row)
workbook.save(excel_filename)
if __name__ == "__main__":
csv_to_excel("my_file.csv", "my_file.xlsx")
This is a bit more fine-granular approach and it allows you to modify each row in the code or even write additional details into the Excel worksheet.
More Python CSV Conversions
🐍 Learn More: I have compiled an “ultimate guide” on the Finxter blog that shows you the best method, respectively, to convert a CSV file to JSON, Excel, dictionary, Parquet, list, list of lists, list of tuples, text file, DataFrame, XML, NumPy array, and list of dictionaries.
Where to Go From Here?
Enough theory. Let’s get some practice!
Coders get paid six figures and more because they can solve problems more effectively using machine intelligence and automation.
To become more successful in coding, solve more real problems for real people. That’s how you polish the skills you really need in practice. After all, what’s the use of learning theory that nobody ever needs?
You build high-value coding skills by working on practical coding projects!
Do you want to stop learning with toy projects and focus on practical code projects that earn you money and solve real problems for people?
🚀 If your answer is YES!, consider becoming a Python freelance developer! It’s the best way of approaching the task of improving your Python skills—even if you are a complete beginner.
If you just want to learn about the freelancing opportunity, feel free to watch my free webinar “How to Build Your High-Income Skill Python” and learn how I grew my coding business online and how you can, too—from the comfort of your own home.
Join the free webinar now!

While working as a researcher in distributed systems, Dr. Christian Mayer found his love for teaching computer science students.
To help students reach higher levels of Python success, he founded the programming education website Finxter.com that has taught exponential skills to millions of coders worldwide. He’s the author of the best-selling programming books Python One-Liners (NoStarch 2020), The Art of Clean Code (NoStarch 2022), and The Book of Dash (NoStarch 2022). Chris also coauthored the Coffee Break Python series of self-published books. He’s a computer science enthusiast, freelancer, and owner of one of the top 10 largest Python blogs worldwide.
His passions are writing, reading, and coding. But his greatest passion is to serve aspiring coders through Finxter and help them to boost their skills. You can join his free email academy here.