
С помощью модуля python-docx можно создавать и изменять документы MS Word с расширением .docx. Чтобы установить этот модуль, выполняем команду
> pip install python-docx
При установке модуля надо вводить python-docx, а не docx (это другой модуль). В то же время при импортировании модуля python-docx следует использовать import docx, а не import python-docx.
Чтение документов MS Word
Файлы с расширением .docx обладают развитой внутренней структурой. В модуле python-docx эта структура представлена тремя различными типами данных. На самом верхнем уровне объект Document представляет собой весь документ. Объект Document содержит список объектов Paragraph, которые представляют собой абзацы документа. Каждый из абзацев содержит список, состоящий из одного или нескольких объектов Run, представляющих собой фрагменты текста с различными стилями форматирования.

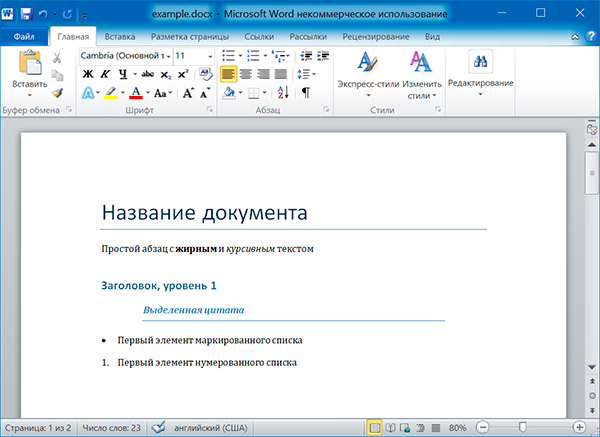
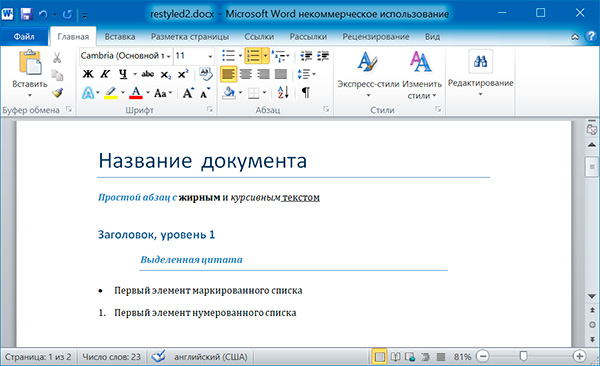
import docx doc = docx.Document('example.docx') # количество абзацев в документе print(len(doc.paragraphs)) # текст первого абзаца в документе print(doc.paragraphs[0].text) # текст второго абзаца в документе print(doc.paragraphs[1].text) # текст первого Run второго абзаца print(doc.paragraphs[1].runs[0].text)
6 Название документа Простой абзац с жирным и курсивным текстом Простой абзац с
Получаем весь текст из документа:
text = [] for paragraph in doc.paragraphs: text.append(paragraph.text) print('n'.join(text))
Название документа Простой абзац с жирным и курсивным текстом Заголовок, уровень 1 Выделенная цитата Первый элемент маркированного списка Первый элемент нумерованного списка
Стилевое оформление
В документах MS Word применяются два типа стилей: стили абзацев, которые могут применяться к объектам Paragraph, стили символов, которые могут применяться к объектам Run. Как объектам Paragraph, так и объектам Run можно назначать стили, присваивая их атрибутам style значение в виде строки. Этой строкой должно быть имя стиля. Если для стиля задано значение None, то у объекта Paragraph или Run не будет связанного с ним стиля.
Стили абзацев
NormalBody TextBody Text 2Body Text 3CaptionHeading 1Heading 2Heading 3Heading 4Heading 5Heading 6Heading 7Heading 8Heading 9Intense QuoteListList 2List 3List BulletList Bullet 2List Bullet 3List ContinueList Continue 2List Continue 3List NumberList Number 2List Number 3List ParagraphMacro TextNo SpacingQuoteSubtitleTOCHeadingTitle
Стили символов
EmphasisStrongBook TitleDefault Paragraph FontIntense EmphasisSubtle EmphasisIntense ReferenceSubtle Reference
paragraph.style = 'Quote' run.style = 'Book Title'
Атрибуты объекта Run
Отдельные фрагменты текста, представленные объектами Run, могут подвергаться дополнительному форматированию с помощью атрибутов. Для каждого из этих атрибутов может быть задано одно из трех значений: True (атрибут активизирован), False (атрибут отключен) и None (применяется стиль, установленный для данного объекта Run).
bold— Полужирное начертаниеunderline— Подчеркнутый текстitalic— Курсивное начертаниеstrike— Зачеркнутый текст
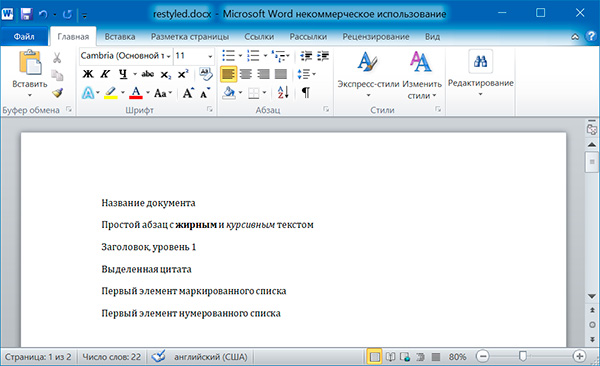
Изменим стили для всех параграфов нашего документа:
import docx doc = docx.Document('example.docx') # изменяем стили для всех параграфов for paragraph in doc.paragraphs: paragraph.style = 'Normal' doc.save('restyled.docx')
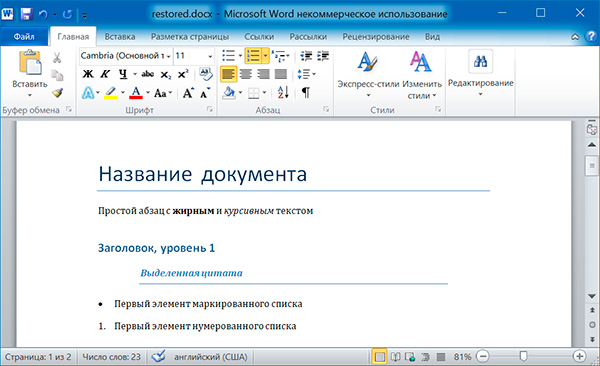
А теперь восстановим все как было:
import docx os.chdir('C:\example') doc1 = docx.Document('example.docx') doc2 = docx.Document('restyled.docx') # получаем из первого документа стили всех абзацев styles = [] for paragraph in doc1.paragraphs: styles.append(paragraph.style) # применяем стили ко всем абзацам второго документа for i in range(len(doc2.paragraphs)): doc2.paragraphs[i].style = styles[i] doc2.save('restored.docx')
Изменим форматирвание объектов Run второго абзаца:
import docx doc = docx.Document('example.docx') # добавляем стиль символов для runs[0] doc.paragraphs[1].runs[0].style = 'Intense Emphasis' # добавляем подчеркивание для runs[4] doc.paragraphs[1].runs[4].underline = True doc.save('restyled2.docx')
Запись докуменов MS Word
Добавление абзацев осуществляется вызовом метода add_paragraph() объекта Document. Для добавления текста в конец существующего абзаца, надо вызвать метод add_run() объекта Paragraph:
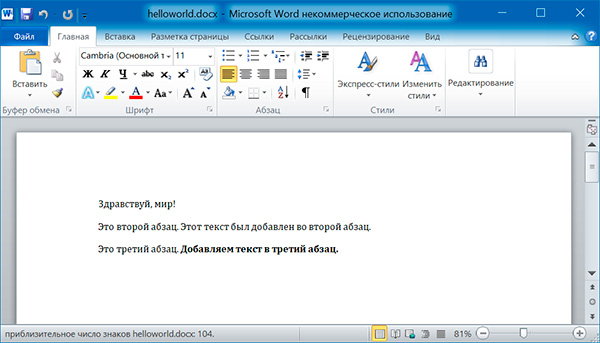
import docx doc = docx.Document() # добавляем первый параграф doc.add_paragraph('Здравствуй, мир!') # добавляем еще два параграфа par1 = doc.add_paragraph('Это второй абзац.') par2 = doc.add_paragraph('Это третий абзац.') # добавляем текст во второй параграф par1.add_run(' Этот текст был добавлен во второй абзац.') # добавляем текст в третий параграф par2.add_run(' Добавляем текст в третий абзац.').bold = True doc.save('helloworld.docx')
Оба метода, add_paragraph() и add_run() принимают необязательный второй аргумент, содержащий строку стиля, например:
doc.add_paragraph('Здравствуй, мир!', 'Title')
Добавление заголовков
Вызов метода add_heading() приводит к добавлению абзаца, отформатированного в соответствии с одним из возможных стилей заголовков:
doc.add_heading('Заголовок 0', 0) doc.add_heading('Заголовок 1', 1) doc.add_heading('Заголовок 2', 2) doc.add_heading('Заголовок 3', 3) doc.add_heading('Заголовок 4', 4)
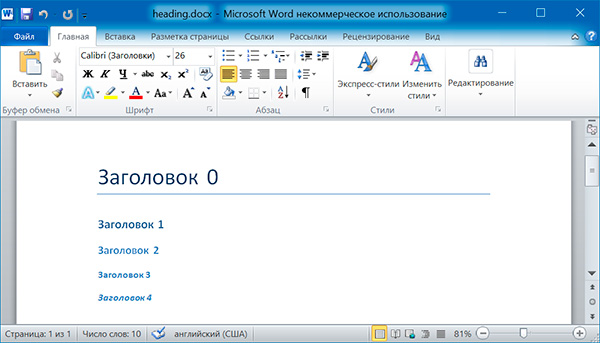
Аргументами метода add_heading() являются строка текста и целое число от 0 до 4. Значению 0 соответствует стиль заголовка Title.
Добавление разрывов строк и страниц
Чтобы добавить разрыв строки (а не добавлять новый абзац), нужно вызвать метод add_break() объекта Run. Если же требуется добавить разрыв страницы, то методу add_break() надо передать значение docx.enum.text.WD_BREAK.PAGE в качестве единственного аргумента:
import docx doc = docx.Document() doc.add_paragraph('Это первая страница') doc.paragraphs[0].runs[0].add_break(docx.enum.text.WD_BREAK.PAGE) doc.add_paragraph('Это вторая страница') doc.save('pages.docx')
Добавление изображений
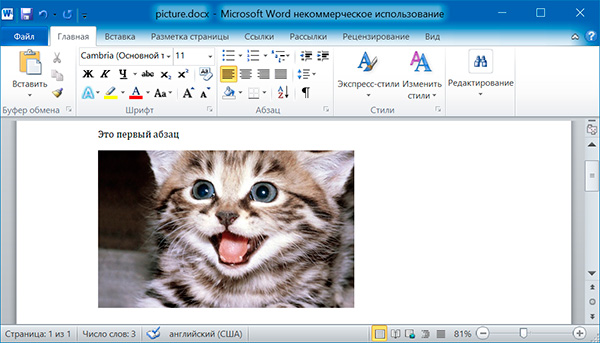
Метод add_picture() объекта Document позволяет добавлять изображения в конце документа. Например, добавим в конец документа изображение kitten.jpg шириной 10 сантиметров:
import docx doc = docx.Document() doc.add_paragraph('Это первый абзац') doc.add_picture('kitten.jpg', width = docx.shared.Cm(10)) doc.save('picture.docx')
Именованные аргументы width и height задают ширину и высоту изображения. Если их опустить, то значения этих аргументов будут определяться размерами самого изображения.
Добавление таблицы
import docx doc = docx.Document() # добавляем таблицу 3x3 table = doc.add_table(rows = 3, cols = 3) # применяем стиль для таблицы table.style = 'Table Grid' # заполняем таблицу данными for row in range(3): for col in range(3): # получаем ячейку таблицы cell = table.cell(row, col) # записываем в ячейку данные cell.text = str(row + 1) + str(col + 1) doc.save('table.docx')
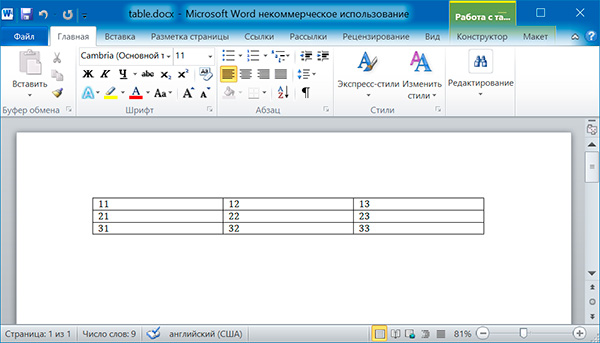
import docx doc = docx.Document('table.docx') # получаем первую таблицу в документе table = doc.tables[0] # читаем данные из таблицы for row in table.rows: string = '' for cell in row.cells: string = string + cell.text + ' ' print(string)
11 12 13 21 22 23 31 32 33
Дополнительно
- Документация python-docx
Поиск:
MS • Python • Web-разработка • Word • Модуль
Каталог оборудования
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Производители
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Функциональные группы
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Prerequisite: Working with .docx module
Word documents contain formatted text wrapped within three object levels. The Lowest level-run objects, middle level-paragraph objects, and highest level-document object. So, we cannot work with these documents using normal text editors. But, we can manipulate these word documents in python using the python-docx module. Pip command to install this module is:
pip install python-docx
Python docx module allows user to manipulate docs by either manipulating the existing one or creating a new empty document and manipulating it. It is a powerful tool as it helps you to manipulate the document to a very large extend. You can also manipulate the font size, colour and its style using this module.
Font Size
To increase/decrease the font size of the text you have to first create a paragraph object then you have to use add_run() method to add content. You can directly use add_paragraph() method to add paragraph but if you want to increase/decrease the font size of the text you have to use add_run() as all the block-level formatting is done by using add_paragraph() method while all the character-level formatting is done by using add_run().
Now to set a new font size we will use .font.size method. This is the method of the font object and is used to set the new font size of the text.
Syntax: para.font.size = Length
Parameter:
Length: It defines the size of the font. It can be in inches, pt or cm.
Example 1: Setting the font size of the text in a paragraph.
Python3
import docx
from docx.shared import Pt
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
doc.add_heading('Increased Font Size Paragraph:', 3)
para = doc.add_paragraph().add_run(
'GeeksforGeeks is a Computer Science portal for geeks.')
para.font.size = Pt(12)
doc.add_heading('Normal Font Size Paragraph:', 3)
doc.add_paragraph(
'GeeksforGeeks is a Computer Science portal for geeks.')
doc.save('gfg.docx')
Output:

Font Colour
To apply a font colour to the text you have to first create a paragraph object then you have to use add_run() method to add content. You can directly use add_paragraph() method to add paragraph but if you want to apply a font colour to a text you have to use add_run() as all the block-level formatting is done by using add_paragraph() method while all the character-level formatting is done by using add_run().
To set the colour to the font we will make us of the RGBColor() object which takes hexadecimal input of the colour and sets the same colour to the text.
Syntax: para.font.color.rgb = RGBColor([RGB Colour Value in Hexadecimal])
Parameter:
RGB Colour Value: It is the hexadecimal value of the colour you want to set. It is given in the form of R, G, B as input.
Note: You have to add ‘from docx.shared import RGBColor‘ import statement before calling RGBColor() function in your code.
Example 2: Adding colour to the text in the paragraph.
Python3
import docx
from docx.shared import RGBColor
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
doc.add_heading('Font Colour:', 3)
para = doc.add_paragraph().add_run(
'GeeksforGeeks is a Computer Science portal for geeks.')
para.font.color.rgb = RGBColor(0x22, 0x8b, 0x22)
doc.save('gfg.docx')
Output:

Font Style
To set a new font style for the text you have to first create a paragraph object then you have to use add_run() method to add content. You can directly use add_paragraph() method to add paragraph but if you want to set a new font style of the text you have to use add_run() as all the block-level formatting is done by using add_paragraph() method while all the character-level formatting is done by using add_run().
Now to set a new font name we will use .font.name method. This is the method of the font object and is used to set the new font name for the text.
Syntax: para.font.name = String s
Parameter:
String s: It is the name of the new font style. If you give any random name as input string then default style is adopted for the text.
Example 3: Setting a new font name for a paragraph.
Python3
import docx
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
doc.add_heading('Font Style: Roboto', 3)
para = doc.add_paragraph().add_run(
'GeeksforGeeks is a Computer Science portal for geeks.')
para.font.name = 'Roboto'
doc.add_heading('Font Style: Default [Cambria]', 3)
doc.add_paragraph(
'GeeksforGeeks is a Computer Science portal for geeks.')
doc.save('gfg.docx')
Output:

Bold Text
To set the text to bold you have to set it true.
doc.bold = True
To highlight a specific word the bold needs to be set True along with its add_run() statement.
add_run(" text ").bold=True
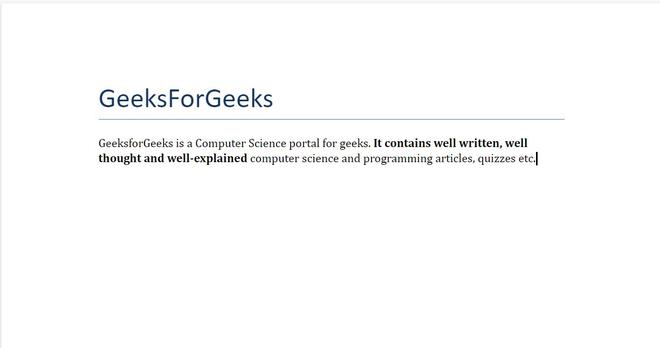
Example 1: Applying bold to a complete paragraph.
Python3
import docx
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
para = doc.add_paragraph()
bold_para = para.add_run(
)
bold_para.bold = True
doc.save('gfg.docx')
Output:

Document gfg.docx
Example 2: Applying bold to a specific word or phrase.
Python3
import docx
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
para = doc.add_paragraph(
)
para.add_run(
).bold = True
para.add_run()
doc.save('gfg.docx')
Output:
Document gfg.docx
Italics Text
To set the text to italics you have to set it true.
doc.italic = True
To make some specific word(s) italics, it needs to be set True along with its add_run() statement.
add_run(" text ").italic=True
Example 3: Applying italics to a complete paragraph.
Python3
import docx
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
para = doc.add_paragraph()
italic_para = para.add_run(
)
italic_para.italic = True
doc.save('gfg.docx')
Output:

Document gfg.docx
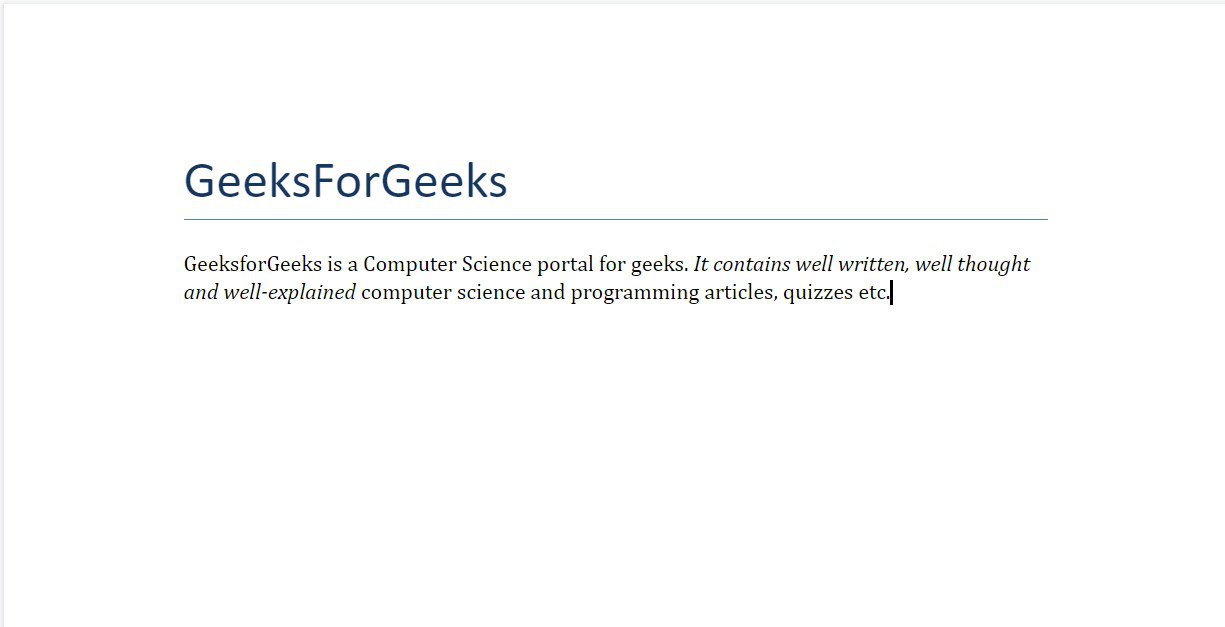
Example 4: Applying italics to a specific word or phrase.
Python3
import docx
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
para = doc.add_paragraph(
)
para.add_run(
).italic = True
para.add_run()
doc.save('gfg.docx')
Output:
Document gfg.docx
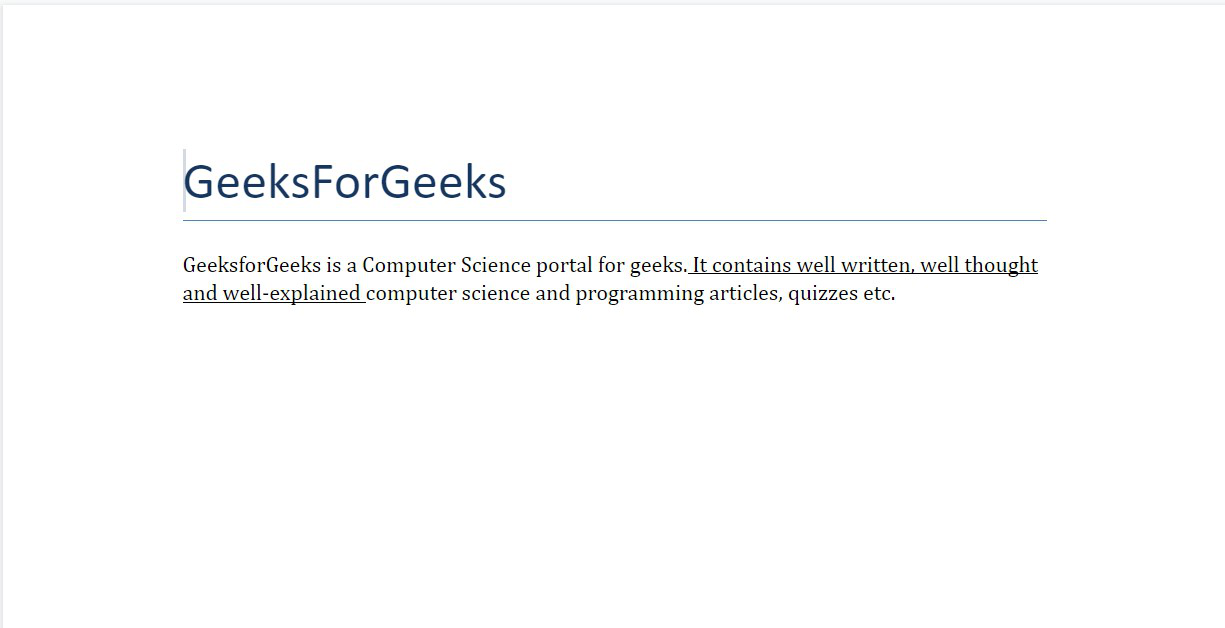
Underlined Text
To apply to underline to a text you have to set it true.
doc.underline = True
To underline a specific part, underline needs to set a True along with its add_run() function
add_run("text").underline=True
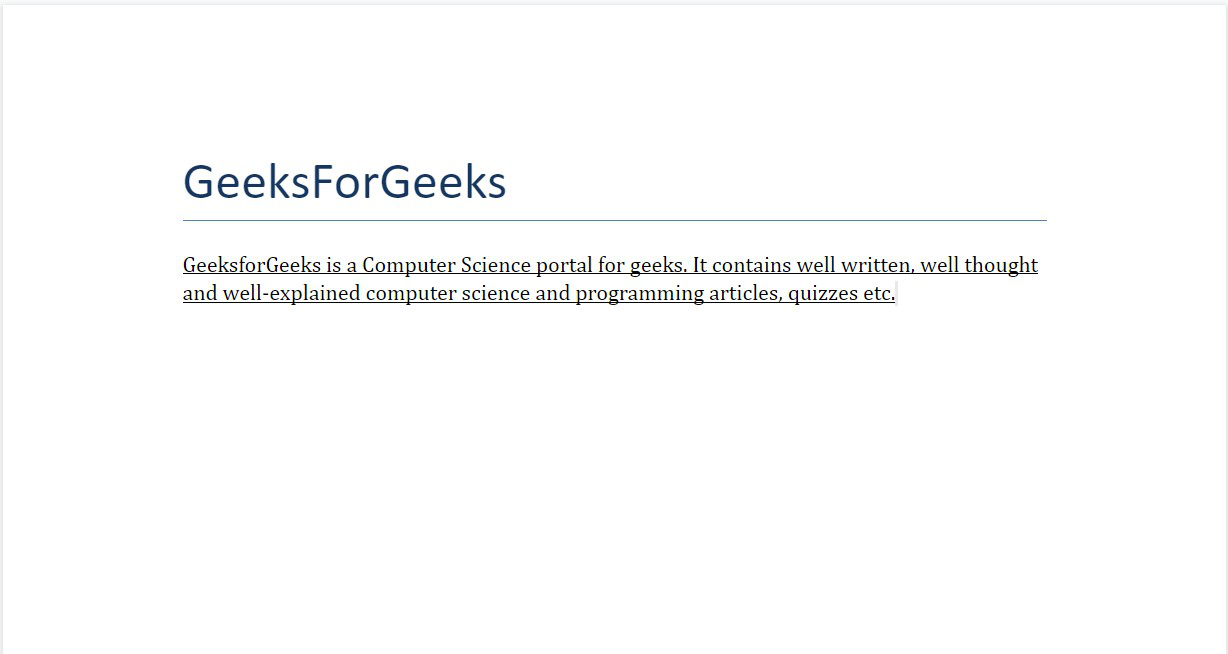
Example 5: Applying underline to a complete paragraph.
Python3
import docx
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
para = doc.add_paragraph()
underline_para = para.add_run(
)
underline_para.underline = True
doc.save('gfg.docx')
Output:
Document gfg.docx
Example 6: Applying underline to a specific word or phrase.
Python3
import docx
doc = docx.Document()
doc.add_heading('GeeksForGeeks', 0)
para = doc.add_paragraph(
)
para.add_run(
).underline = True
para.add_run()
doc.save('gfg.docx')
Output:
Document gfg.docx
Python Docx is a python library for creation and modification of Microsoft Word documents. It offers a variety of operations to create new documents and other word operations like working with text, images, shapes, tables and many other document features. New document can be created and existing documents can also be modified using python docx. For getting started, first install python docx on your system using pip or source.
# using pip
pip install python-docx
# using easy_install
easy_install python-docx
# or build from source
tar xvzf python-docx-{version}.tar.gz
cd python-docx-{version}
python setup.py installNow we can work with basic of python docx for word document creation.
Getting Started
First, we can create an empty document where we can write any text or other data.
# import docx document
from docx import Document
# initialize a document
document = Document()Or if there is some existing document, it can also be opened using Document() in python docx by providing path of document.
document = Document(doc_path)Next we work with python docx functions to add data to document.
Working with Text
Python-Docx offers different options like paragraph, heading and other options for simple text.
Headings are paragraphs with different text size and style based on its level defined while creating heading. Heading level ranges from 0-9 based on text size where 0 is biggest font heading. Here are some examples of headings.
# title heading
document.add_heading("This is a level 1 heading", 0)
# Add other heading levels
document.add_heading("This is a level 2 heading", 2)
document.add_heading("This is a level 3 heading", 3)
document.add_heading("This is a level 5 heading", 5)
document.add_heading("This is a level 7 heading", 7)
document.add_heading("This is a level 9 heading", 9)
Paragraph has different properties depending on its placement and it divides content accordingly to its lines. Paragraphs has different style and alignment options to create a document with specified text locations and styles.
paragraph = document.add_paragraph("TensorFlow is a free and open-source software library for machine learning and artificial intelligence.")Paragraphs can be updated/modified with new text or alignment options.
# add more text
paragraph.add_run(" It can be used across a range of tasks for ")
# add text with styles
paragraph.add_run('training model ').bold = True # added text with bold
paragraph.add_run('and inference.').italic = True # added italic textParagraphs can have other styles like quotes and other styles.
document.add_paragraph('Intense quote', style='I have no special talent')Paragraph Alignment
Paragraph alignments like horizontal alignment, indentation and other features like line spacing can also be applied to paragraphs. First lets work with horizontal alignment.
from docx.enum.text import WD_ALIGN_PARAGRAPH
# Check previous alignment
print("Previous alignment", paragraph.paragraph_format.alignment)
# Align paragraph center
paragraph.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTERIndentation is horizontal space between paragraph and its container edges. In python-docx we can specify details in Inches so we import function and can indent in direction.
from docx.shared import Inches
paragraph_r = document.add_paragraph('This is some random paragraph for testing indentation on both (left and right) side of paragraph.')
# only first line indent
paragraph.paragraph_format.first_line_indent = Inches(0.5)
# paragraph indent
paragraph_r.paragraph_format.left_indent = Inches(0.5) # apply 0.5 inch left indentation
paragraph_r.paragraph_format.right_indent = Inches(1) # apply 1 inch right indentationLine spacing is also part of paragraph formating and is easy to use.
from docx.shared import Pt
paragraph.paragraph_format.line_spacing = Pt(18)Working with Fonts
Different font styles like color, font family and other modifications can also be applied. Here we create a paragraph and change its font size and font family.
# font modifications
para_font = document.add_paragraph()
run = para_font.add_run('This is a paragraph with different font styles.n')
run.font.size = Pt(14) # font size
run.font.name = 'Courier New' # font nameWe can also apply colors and other attributes like bold, italice, underline etc.
from docx.shared import RGBColor
# add underlined text with blue color
url = para_font.add_run("http://google.com")
url.font.color.rgb = RGBColor(0x00, 0x00, 0xFF)
url.font.underline = True # font underlineHere is the output for all the code we have written for paragraphs.

Now we can export document and write it to directory.
# save document
document.save("paragraphs.docx")There are a lot of other features of python docx like working with lists and nested lists, images, tables, header and footers and other operations. For this, you can check other posts that will be published soon or check official python-docx documentation.
https://python-docx.readthedocs.io/en/latest/
Время прочтения: 9 мин.
Во время подготовки и проведения аудиторских проверок часто возникает потребность проанализировать большое количество документов, актов и иных материалов. Давайте рассмотрим, как можно автоматизировать этот процесс на примере библиотеки docx, способной обрабатывать документы в формате .docx.
Для установки библиотеки в командной строке необходимо ввести:
> pip install python-docxПосле успешной установки библиотеки, её нужно импортировать в Python. Обратите внимание, что несмотря на то, что для установки использовалось название python-docx, при импорте следует называть библиотеку docx:
import docxКак правило, мы обращаемся к автоматизации, когда нам нужно извлечь нужную информацию не из одного, а сразу из многих документов. Чтобы иметь возможность обработать все документы, для начала нужно собрать список таких документов. Здесь сможет помочь библиотека os, с помощью которой можно рекурсивно обойти директории, в которых хранятся документы. Предположим, что все они находятся внутри директории, где расположен скрипт:
import os
paths = []
folder = os.getcwd()
for root, dirs, files in os.walk(folder):
for file in files:
if file.endswith('docx') and not file.startswith('~'):
paths.append(os.path.join(root, file))
Мы прошли по всем директориям и занесли в список paths все файлы с расширением .docx. Файлы, начинавшиеся с тильды, игнорировались (эти временные файлы возникают лишь тогда, когда в Windows открыт какой-либо из документов). Теперь, когда у нас уже есть список всех документов, можно начинать с ними работать:
for path in paths:
doc = docx.Document(path)
В блоке выше на каждом шаге цикла в переменную doc записывается экземпляр, представляющий собой весь документ. Мы можем посмотреть основные свойства такого документа:
properties = doc.core_properties
print('Автор документа:', properties.author)
print('Автор последней правки:', properties.last_modified_by)
print('Дата создания документа:', properties.created)
print('Дата последней правки:', properties.modified)
print('Дата последней печати:', properties.last_printed)
print('Количество сохранений:', properties.revision)
Из основных свойств можно получить автора документа, основные даты, количество сохранений документа и пр. Обратите внимание, что даты и время будут указаны в часовом поясе UTC+0.
Теперь поговорим о том, как можно проанализировать содержимое документа. Файлы с расширением docx обладают развитой внутренней структурой, которая в библиотеке docx представлена следующими объектами:
- Объект Document, представляющий собой весь документ
- Список объектов Paragraph – абзацы документа
- Список объектов Run – фрагменты текста с различными стилями форматирования (курсив, цвет шрифта и т.п.)
- Список объектов Table – таблицы документа
- Список объектов Row – строки таблицы
- Список объектов Cell – ячейки в строке
- Список объектов Column – столбцы таблицы
- Список объектов Cell – ячейки в столбце
- Список объектов Row – строки таблицы
- Список объектов InlineShape – иллюстрации документа
- Список объектов Paragraph – абзацы документа
Работа с текстом документа
Для начала давайте разберёмся, как работать с текстом документа. В библиотеке docx это возможно через обращение к абзацам документа. Можно получить как сам текст абзаца, так и его характеристики: тип выравнивания, величину отступов и интервалов, положение на странице.
Очень часто стоит задача получить весь текст из документа для дальнейшей обработки. Чтобы это сделать, достаточно лишь перебрать все абзацы документа:
text = []
for paragraph in doc.paragraphs:
text.append(paragraph.text)
print('n'.join(text))
Как мы видим, для получения текста абзаца нужно просто обратиться к объекту paragraph.text. Но что же делать, если нужно извлечь только абзацы с определёнными характеристиками и далее работать именно с ними? Рассмотрим основные характеристики абзацев, которые можно проанализировать.
В первую очередь, можно получить стиль выравнивания абзацев в документе:
for paragraph in doc.paragraphs:
print('Выравнивание абзаца:', paragraph.alignment)
Значения alignment будут соответствовать одному из основных стилей выравнивания: LEFT (0), CENTER (1), RIGHT (2) или JUSTIFY (3). Однако если пользователь не установил стиль выравнивания, значение параметра alignment будет None.
Кроме того, можно получить и значения отступов у абзацев документа:
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
print('Отступ перед абзацем:', formatting.space_before)
print('Отступ после абзаца:', formatting.space_after)
print('Отступ слева:', formatting.left_indent)
print('Отступ справа:', formatting.right_indent)
print('Отступ первой строки абзаца:', formatting.first_line_indent)
Как и в предыдущем примере, если отступы не были установлены, значения параметров будут None. В остальных случаях они будут представлены в виде целого числа в формате EMU (английские метрические единицы). Этот формат позволяет конвертировать число как в метрическую, так и в английскую систему мер. Привести полученные числа в привычный формат довольно просто, достаточно просто добавить нужные единицы исчисления после параметра (например, formatting.space_before.cm или formatting.space_before.pt). Главное помнить, что такое преобразование нельзя применять к значениям None.
Наконец, можно посмотреть на положение абзаца на странице. В меню Абзац… на вкладке Положение на странице находятся четыре параметра, значения которых также можно посмотреть при помощи библиотеки docx:
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
print('Не отрывать от следующего абзаца:', formatting.keep_with_next)
print('Не разрывать абзац:', formatting.keep_together)
print('Абзац с новой страницы:', formatting.page_break_before)
print('Запрет висячих строк:', formatting.widow_control)
Параметры будут иметь значение None для случаев, когда пользователь не устанавливал на них галочки, и True, если устанавливал.
Мы рассмотрели основные способы, которыми можно проанализировать абзац в документе. Но бывают ситуации, когда мы точно знаем, что информация, которую нужно извлечь, написана курсивом или выделена определённым цветом. Как быть в таком случае?
Можно получить список фрагментов с различными стилями форматирования (список объектов Run). Попробуем, к примеру, извлечь все фрагменты, написанные курсивом:
for paragraph in doc.paragraphs:
for run in paragraph.runs:
if run.italic:
print(run.text)
Очень просто, не так ли? Посмотрим, какие ещё стили форматирования можно извлечь:
for paragraph in doc.paragraphs:
for run in paragraph.runs:
print('Полужирный текст:', run.bold)
print('Подчёркнутый текст:', run.underline)
print('Зачёркнутый текст:', run.strike)
print('Название шрифта:', run.font.name)
print('Цвет текста, RGB:', run.font.color.rgb)
print('Цвет заливки текста:', run.font.highlight_color)
Если пользователь не менял стиль форматирования (отсутствует подчёркивание, используется стандартный шрифт и т.п.), параметры будут иметь значение None. Но если стиль определённого параметра изменялся, то:
- параметры italic, bold, underline, strike будут иметь значение True;
- параметр font.name – наименование шрифта;
- параметр font.color.rgb – код цвета текста в RGB;
- параметр font.highlight_color – наименование цвета заливки текста.
Делая цикл по фрагментам стоит иметь ввиду, что фрагменты с одинаковым форматированием могут быть разбиты на несколько, если в них встречаются символы разных типов (буквенные символы и цифры, кириллица и латиница).
Абзацы и их фрагменты могут быть оформлены в определённом стиле, соответствующем стилям Word (например, Normal, Heading 1, Intense Quote). Чем это может быть полезно? К примеру, обращение к стилям абзаца может пригодиться при выделении нумерованных или маркированных списков. Каждый элемент таких списков считается отдельным абзацев, однако каждому из них приписан особый стиль – List Paragraph. С помощью кода ниже можно извлечь только элементы списков:
for paragraph in doc.paragraphs:
if paragraph.style.name == 'List Paragraph':
print(paragraph.text)
Чтобы закрепить полученные знания, давайте разберём менее тривиальный случай. Предположим, что у нас есть множество документов с похожей структурой, из которых нужно извлечь названия продуктов. Проанализировав документы, мы установили, что продукты встречаются только в абзацах, начинающихся с новой страницы и выровненных по ширине. Притом сами названия написаны с использованием полужирного начертания, шрифт Arial Narrow. Посмотрим, как можно проанализировать документы:
for path in paths:
doc = docx.Document(path)
product_names = []
for paragraph in doc.paragraphs:
formatting = paragraph.paragraph_format
if formatting.page_break_before and paragraph.alignment == 3:
product_name, is_sequential = '', False
for run in paragraph.runs:
if run.bold and run.font.name == 'Arial Narrow':
is_sequential = True
product_name += run.text
elif is_sequential == True:
product_names.append(product_name)
product_name, is_sequential = '', False
В блоке кода выше последовательно обрабатываются все файлы из списка paths, преобразовываемые в ходе обработки в объект Document. В каждом документе происходит перебор абзацев и выполняются проверки: абзац должен начинаться с новой страницы и быть выровненным по ширине. Если проверки прошли успешно, внутри абзаца происходит уже перебор фрагментов с различными типами форматированием и проверки на начертание и шрифт.
Обратим внимание на переменную is_sequential, которая помогает определить, идут ли фрагменты, прошедшие проверку, друг за другом. Фрагменты с символами разных типов (буквы и числа, кириллица и латиница) разбиваются на несколько, но поскольку в названии продукта одновременно могут встретиться символы всех типов, все последовательно идущие фрагменты соединяются в один. Он и заносится в результирующий список product_names.
Работа с таблицами
Мы рассмотрели способы, которыми можно обрабатывать текст в документах, а теперь давайте перейдём к обработке таблиц. Любую таблицу можно перебирать как по строкам, так и по столбцам. Посмотрим, как можно построчно получить текст каждой ячейки в таблице:
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
print(cell.text)
Если же во второй строке заменить rows на columns, то можно будет аналогичным образом прочитать таблицу по столбцам. Текст в ячейках таблицы тоже состоит из абзацев. Если мы захотим проанализировать абзацы или фрагменты внутри ячейки, то можно будет воспользоваться всеми методами объектов Paragraph и Run.
Часто может понадобиться проанализировать только таблицы, содержащие определённые заголовки. Попробуем, например, выделить из документа только таблицы, у которых в строке заголовка присутствуют названия Продукт и Стоимость. Для таких таблиц построчно распечатаем все значения из ячеек:
for table in doc.tables:
for index, row in enumerate(table.rows):
if index == 0:
row_text = list(cell.text for cell in row.cells)
if 'Продукт' not in row_text or 'Стоимость' not in row_text:
break
for cell in row.cells:
print(cell.text)
Также нам может понадобиться определить, какие из ячеек в таблице являются объединёнными. Стандартной функции для этого нет, однако мы можем воспользоваться тем, что нам доступно положение ячейки от каждого из краев таблицы:
for table in doc.tables:
unique, merged = set(), set()
for row in table.rows:
for cell in row.cells:
tc = cell._tc
cell_loc = (tc.top, tc.bottom, tc.left, tc.right)
if cell_loc in unique:
merged.add(cell_loc)
else:
unique.add(cell_loc)
print(merged)
Воспользовавшись этим кодом, можно получить все координаты объединённых ячеек для каждой из таблиц документа. Кроме того, разница координат tc.top и tc.bottom показывает, сколько строк в объединённой ячейке, а разница tc.left и tc.right – сколько столбцов.
Наконец, рассмотрим возможность выделения из таблиц ячеек, в которых фон окрашен в определённый цвет. Для этого понадобится с помощью регулярных выражений посмотреть на xml-код ячейки:
import re
pattern = re.compile('w:fill="(S*)"')
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
match = pattern.search(cell._tc.xml)
if match:
if match.group(1) == 'FFFF00':
print(cell.text)
В этом блоке кода мы выделили только те ячейки, фон которых был окрашен в жёлтый цвет (#FFFF00 в формате RGB).
Работа с иллюстрациями
В библиотеке docx также реализована возможность работы с иллюстрациями документа. Стандартными способами можно посмотреть только на размеры изображений:
for shape in doc.inline_shapes:
print(shape.width, shape.height)
Однако при помощи сторонней библиотеки docx2txt и анализа xml-кода абзацев становится возможным не только выгрузить все иллюстрации документов, но и определить, в каком именно абзаце они встречались:
import os
import docx
import docx2txt
for path in paths:
splitted = os.path.split(path)
folders = [os.path.splitext(splitted[1])[0]]
while splitted[0]:
splitted = os.path.split(splitted[0])
folders.insert(0, splitted[1])
images_path = os.path.join('images', *folders)
os.makedirs(images_path, exist_ok=True)
doc = docx.Document(path)
docx2txt.process(path, images_path)
rels = {}
for rel in doc.part.rels.values():
if isinstance(rel._target, docx.parts.image.ImagePart):
rels[rel.rId] = os.path.basename(rel._target.partname)
for paragraph in doc.paragraphs:
if 'Graphic' in paragraph._p.xml:
for rId in rels:
if rId in paragraph._p.xml:
print(os.path.join(images_path, rels[rId]))
print(paragraph.text)
В этом блоке мы выводим путь к изображению, которое сохранено на диске, и текст параграфа, в котором встретилось изображение. Все изображения находятся внутри директории images, а именно — в поддиректориях, соответствующих расположению исходного файла Word.