
There is no simple built-in string function that does what you’re looking for, but you could use the more powerful regular expressions:
import re
[m.start() for m in re.finditer('test', 'test test test test')]
#[0, 5, 10, 15]
If you want to find overlapping matches, lookahead will do that:
[m.start() for m in re.finditer('(?=tt)', 'ttt')]
#[0, 1]
If you want a reverse find-all without overlaps, you can combine positive and negative lookahead into an expression like this:
search = 'tt'
[m.start() for m in re.finditer('(?=%s)(?!.{1,%d}%s)' % (search, len(search)-1, search), 'ttt')]
#[1]
re.finditer returns a generator, so you could change the [] in the above to () to get a generator instead of a list which will be more efficient if you’re only iterating through the results once.
![]()
answered Jan 12, 2011 at 2:43
![]()
moinudinmoinudin
132k45 gold badges189 silver badges214 bronze badges
9
>>> help(str.find)
Help on method_descriptor:
find(...)
S.find(sub [,start [,end]]) -> int
Thus, we can build it ourselves:
def find_all(a_str, sub):
start = 0
while True:
start = a_str.find(sub, start)
if start == -1: return
yield start
start += len(sub) # use start += 1 to find overlapping matches
list(find_all('spam spam spam spam', 'spam')) # [0, 5, 10, 15]
No temporary strings or regexes required.
![]()
answered Jan 12, 2011 at 3:13
![]()
Karl KnechtelKarl Knechtel
61k11 gold badges97 silver badges144 bronze badges
6
Here’s a (very inefficient) way to get all (i.e. even overlapping) matches:
>>> string = "test test test test"
>>> [i for i in range(len(string)) if string.startswith('test', i)]
[0, 5, 10, 15]
answered Jan 12, 2011 at 2:48
![]()
thkalathkala
83.2k23 gold badges155 silver badges199 bronze badges
3
Use re.finditer:
import re
sentence = input("Give me a sentence ")
word = input("What word would you like to find ")
for match in re.finditer(word, sentence):
print (match.start(), match.end())
For word = "this" and sentence = "this is a sentence this this" this will yield the output:
(0, 4)
(19, 23)
(24, 28)
answered Feb 3, 2016 at 19:01
![]()
IdosIdos
15k14 gold badges58 silver badges72 bronze badges
2
Again, old thread, but here’s my solution using a generator and plain str.find.
def findall(p, s):
'''Yields all the positions of
the pattern p in the string s.'''
i = s.find(p)
while i != -1:
yield i
i = s.find(p, i+1)
Example
x = 'banananassantana'
[(i, x[i:i+2]) for i in findall('na', x)]
returns
[(2, 'na'), (4, 'na'), (6, 'na'), (14, 'na')]
answered Dec 23, 2015 at 23:09
![]()
AkiRossAkiRoss
11.5k6 gold badges59 silver badges85 bronze badges
3
You can use re.finditer() for non-overlapping matches.
>>> import re
>>> aString = 'this is a string where the substring "is" is repeated several times'
>>> print [(a.start(), a.end()) for a in list(re.finditer('is', aString))]
[(2, 4), (5, 7), (38, 40), (42, 44)]
but won’t work for:
In [1]: aString="ababa"
In [2]: print [(a.start(), a.end()) for a in list(re.finditer('aba', aString))]
Output: [(0, 3)]
![]()
AnukuL
5751 gold badge7 silver badges21 bronze badges
answered Jan 12, 2011 at 2:55
![]()
Chinmay KanchiChinmay Kanchi
61.8k22 gold badges86 silver badges114 bronze badges
2
Come, let us recurse together.
def locations_of_substring(string, substring):
"""Return a list of locations of a substring."""
substring_length = len(substring)
def recurse(locations_found, start):
location = string.find(substring, start)
if location != -1:
return recurse(locations_found + [location], location+substring_length)
else:
return locations_found
return recurse([], 0)
print(locations_of_substring('this is a test for finding this and this', 'this'))
# prints [0, 27, 36]
No need for regular expressions this way.
answered Nov 1, 2013 at 3:16
![]()
Cody PiersallCody Piersall
8,1742 gold badges42 silver badges57 bronze badges
2
If you’re just looking for a single character, this would work:
string = "dooobiedoobiedoobie"
match = 'o'
reduce(lambda count, char: count + 1 if char == match else count, string, 0)
# produces 7
Also,
string = "test test test test"
match = "test"
len(string.split(match)) - 1
# produces 4
My hunch is that neither of these (especially #2) is terribly performant.
answered Sep 24, 2014 at 21:12
![]()
jstaabjstaab
3,28925 silver badges40 bronze badges
1
this is an old thread but i got interested and wanted to share my solution.
def find_all(a_string, sub):
result = []
k = 0
while k < len(a_string):
k = a_string.find(sub, k)
if k == -1:
return result
else:
result.append(k)
k += 1 #change to k += len(sub) to not search overlapping results
return result
It should return a list of positions where the substring was found.
Please comment if you see an error or room for improvment.
answered Apr 1, 2015 at 9:23
![]()
ThurinesThurines
1111 silver badge3 bronze badges
This does the trick for me using re.finditer
import re
text = 'This is sample text to test if this pythonic '
'program can serve as an indexing platform for '
'finding words in a paragraph. It can give '
'values as to where the word is located with the '
'different examples as stated'
# find all occurances of the word 'as' in the above text
find_the_word = re.finditer('as', text)
for match in find_the_word:
print('start {}, end {}, search string '{}''.
format(match.start(), match.end(), match.group()))
answered Jul 6, 2018 at 9:34
![]()
Bruno VermeulenBruno Vermeulen
2,8152 gold badges15 silver badges27 bronze badges
This thread is a little old but this worked for me:
numberString = "onetwothreefourfivesixseveneightninefiveten"
testString = "five"
marker = 0
while marker < len(numberString):
try:
print(numberString.index("five",marker))
marker = numberString.index("five", marker) + 1
except ValueError:
print("String not found")
marker = len(numberString)
![]()
wingerse
3,6201 gold badge26 silver badges56 bronze badges
answered Sep 1, 2014 at 12:48
![]()
Andrew HAndrew H
46610 silver badges22 bronze badges
You can try :
>>> string = "test test test test"
>>> for index,value in enumerate(string):
if string[index:index+(len("test"))] == "test":
print index
0
5
10
15
answered Feb 27, 2018 at 6:44
![]()
Harsha BiyaniHarsha Biyani
7,0049 gold badges37 silver badges61 bronze badges
You can try :
import re
str1 = "This dress looks good; you have good taste in clothes."
substr = "good"
result = [_.start() for _ in re.finditer(substr, str1)]
# result = [17, 32]
answered Oct 25, 2021 at 10:13
![]()
2
When looking for a large amount of key words in a document, use flashtext
from flashtext import KeywordProcessor
words = ['test', 'exam', 'quiz']
txt = 'this is a test'
kwp = KeywordProcessor()
kwp.add_keywords_from_list(words)
result = kwp.extract_keywords(txt, span_info=True)
Flashtext runs faster than regex on large list of search words.
answered Sep 28, 2018 at 17:29
![]()
Uri GorenUri Goren
13.1k6 gold badges56 silver badges108 bronze badges
This function does not look at all positions inside the string, it does not waste compute resources. My try:
def findAll(string,word):
all_positions=[]
next_pos=-1
while True:
next_pos=string.find(word,next_pos+1)
if(next_pos<0):
break
all_positions.append(next_pos)
return all_positions
to use it call it like this:
result=findAll('this word is a big word man how many words are there?','word')
answered Jan 13, 2020 at 12:39
![]()
0
src = input() # we will find substring in this string
sub = input() # substring
res = []
pos = src.find(sub)
while pos != -1:
res.append(pos)
pos = src.find(sub, pos + 1)
answered May 16, 2020 at 17:05
![]()
mascaimascai
9551 gold badge7 silver badges26 bronze badges
1
Whatever the solutions provided by others are completely based on the available method find() or any available methods.
What is the core basic algorithm to find all the occurrences of a
substring in a string?
def find_all(string,substring):
"""
Function: Returning all the index of substring in a string
Arguments: String and the search string
Return:Returning a list
"""
length = len(substring)
c=0
indexes = []
while c < len(string):
if string[c:c+length] == substring:
indexes.append(c)
c=c+1
return indexes
You can also inherit str class to new class and can use this function
below.
class newstr(str):
def find_all(string,substring):
"""
Function: Returning all the index of substring in a string
Arguments: String and the search string
Return:Returning a list
"""
length = len(substring)
c=0
indexes = []
while c < len(string):
if string[c:c+length] == substring:
indexes.append(c)
c=c+1
return indexes
Calling the method
newstr.find_all(‘Do you find this answer helpful? then upvote
this!’,’this’)
answered Feb 15, 2018 at 20:02
![]()
This is solution of a similar question from hackerrank. I hope this could help you.
import re
a = input()
b = input()
if b not in a:
print((-1,-1))
else:
#create two list as
start_indc = [m.start() for m in re.finditer('(?=' + b + ')', a)]
for i in range(len(start_indc)):
print((start_indc[i], start_indc[i]+len(b)-1))
Output:
aaadaa
aa
(0, 1)
(1, 2)
(4, 5)
![]()
answered Jan 20, 2020 at 22:47
![]()
if you want to use without re(regex) then:
find_all = lambda _str,_w : [ i for i in range(len(_str)) if _str.startswith(_w,i) ]
string = "test test test test"
print( find_all(string, 'test') ) # >>> [0, 5, 10, 15]
answered Nov 5, 2021 at 8:38
![]()
WangSungWangSung
2092 silver badges5 bronze badges
Here’s a solution that I came up with, using assignment expression (new feature since Python 3.8):
string = "test test test test"
phrase = "test"
start = -1
result = [(start := string.find(phrase, start + 1)) for _ in range(string.count(phrase))]
Output:
[0, 5, 10, 15]
answered Apr 8, 2022 at 10:06
![]()
MikeMike
1132 silver badges6 bronze badges
I think the most clean way of solution is without libraries and yields:
def find_all_occurrences(string, sub):
index_of_occurrences = []
current_index = 0
while True:
current_index = string.find(sub, current_index)
if current_index == -1:
return index_of_occurrences
else:
index_of_occurrences.append(current_index)
current_index += len(sub)
find_all_occurrences(string, substr)
Note: find() method returns -1 when it can’t find anything
![]()
SUTerliakov
4,3633 gold badges15 silver badges34 bronze badges
answered Oct 13, 2022 at 20:06
![]()
ulas.kesikulas.kesik
861 silver badge4 bronze badges
The pythonic way would be:
mystring = 'Hello World, this should work!'
find_all = lambda c,s: [x for x in range(c.find(s), len(c)) if c[x] == s]
# s represents the search string
# c represents the character string
find_all(mystring,'o') # will return all positions of 'o'
[4, 7, 20, 26]
>>>
![]()
perror
6,95316 gold badges59 silver badges83 bronze badges
answered Apr 10, 2018 at 19:40
![]()
2
if you only want to use numpy here is a solution
import numpy as np
S= "test test test test"
S2 = 'test'
inds = np.cumsum([len(k)+len(S2) for k in S.split(S2)[:-1]])- len(S2)
print(inds)
answered Jun 10, 2021 at 16:46
![]()
please look at below code
#!/usr/bin/env python
# coding:utf-8
'''黄哥Python'''
def get_substring_indices(text, s):
result = [i for i in range(len(text)) if text.startswith(s, i)]
return result
if __name__ == '__main__':
text = "How much wood would a wood chuck chuck if a wood chuck could chuck wood?"
s = 'wood'
print get_substring_indices(text, s)
answered Mar 16, 2017 at 1:14
![]()
黄哥Python培训黄哥Python培训
2392 silver badges5 bronze badges
1
def find_index(string, let):
enumerated = [place for place, letter in enumerate(string) if letter == let]
return enumerated
for example :
find_index("hey doode find d", "d")
returns:
[4, 7, 13, 15]
![]()
answered Nov 8, 2020 at 13:49
![]()
1
Not exactly what OP asked but you could also use the split function to get a list of where all the substrings don’t occur. OP didn’t specify the end goal of the code but if your goal is to remove the substrings anyways then this could be a simple one-liner. There are probably more efficient ways to do this with larger strings; regular expressions would be preferable in that case
# Extract all non-substrings
s = "an-example-string"
s_no_dash = s.split('-')
# >>> s_no_dash
# ['an', 'example', 'string']
# Or extract and join them into a sentence
s_no_dash2 = ' '.join(s.split('-'))
# >>> s_no_dash2
# 'an example string'
Did a brief skim of other answers so apologies if this is already up there.
answered May 19, 2021 at 13:43
![]()
als0052als0052
3893 silver badges12 bronze badges
def count_substring(string, sub_string):
c=0
for i in range(0,len(string)-2):
if string[i:i+len(sub_string)] == sub_string:
c+=1
return c
if __name__ == '__main__':
string = input().strip()
sub_string = input().strip()
count = count_substring(string, sub_string)
print(count)
answered Jun 2, 2021 at 3:24
![]()
2
I runned in the same problem and did this:
hw = 'Hello oh World!'
list_hw = list(hw)
o_in_hw = []
while True:
o = hw.find('o')
if o != -1:
o_in_hw.append(o)
list_hw[o] = ' '
hw = ''.join(list_hw)
else:
print(o_in_hw)
break
Im pretty new at coding so you can probably simplify it (and if planned to used continuously of course make it a function).
All and all it works as intended for what i was doing.
Edit: Please consider this is for single characters only, and it will change your variable, so you have to create a copy of the string in a new variable to save it, i didnt put it in the code cause its easy and its only to show how i made it work.
answered Jun 25, 2021 at 20:18
![]()
By slicing we find all the combinations possible and append them in a list and find the number of times it occurs using count function
s=input()
n=len(s)
l=[]
f=input()
print(s[0])
for i in range(0,n):
for j in range(1,n+1):
l.append(s[i:j])
if f in l:
print(l.count(f))
![]()
barbsan
3,39811 gold badges21 silver badges28 bronze badges
answered Jul 30, 2019 at 11:44
![]()
2
To find all the occurence of a character in a give string and return as a dictionary
eg: hello
result :
{‘h’:1, ‘e’:1, ‘l’:2, ‘o’:1}
def count(string):
result = {}
if(string):
for i in string:
result[i] = string.count(i)
return result
return {}
or else you do like this
from collections import Counter
def count(string):
return Counter(string)
answered Apr 30, 2022 at 8:00
![]()
Many times while working with strings, we have problems dealing with substrings. This may include the problem of finding all positions of a particular substrings in a string. Let’s discuss certain ways in which this task can be performed.
Method #1 : Using list comprehension + startswith() This task can be performed using the two functionalities. The startswith function primarily performs the task of getting the starting indices of substring and list comprehension is used to iterate through the whole target string.
Python3
test_str = "GeeksforGeeks is best for Geeks"
test_sub = "Geeks"
print("The original string is : " + test_str)
print("The substring to find : " + test_sub)
res = [i for i in range(len(test_str)) if test_str.startswith(test_sub, i)]
print("The start indices of the substrings are : " + str(res))
Output :
The original string is : GeeksforGeeks is best for Geeks The substring to find : Geeks The start indices of the substrings are : [0, 8, 26]
Time Complexity: O(n*m), where n is the length of the original string and m is the length of the substring to find
Auxiliary Space: O(k), where k is the number of occurrences of the substring in the string
Method #2 : Using re.finditer() The finditer function of the regex library can help us perform the task of finding the occurrences of the substring in the target string and the start function can return the resultant index of each of them.
Python3
import re
test_str = "GeeksforGeeks is best for Geeks"
test_sub = "Geeks"
print("The original string is : " + test_str)
print("The substring to find : " + test_sub)
res = [i.start() for i in re.finditer(test_sub, test_str)]
print("The start indices of the substrings are : " + str(res))
Output :
The original string is : GeeksforGeeks is best for Geeks The substring to find : Geeks The start indices of the substrings are : [0, 8, 26]
Method #3 : Using find() and replace() methods
Python3
test_str = "GeeksforGeeks is best for Geeks"
test_sub = "Geeks"
print("The original string is : " + test_str)
print("The substring to find : " + test_sub)
res=[]
while(test_str.find(test_sub)!=-1):
res.append(test_str.find(test_sub))
test_str=test_str.replace(test_sub,"*"*len(test_sub),1)
print("The start indices of the substrings are : " + str(res))
Output
The original string is : GeeksforGeeks is best for Geeks The substring to find : Geeks The start indices of the substrings are : [0, 8, 26]
Time Complexity: O(n*m), where n is the length of the original string and m is the length of the substring to find.
Auxiliary Space: O(k), where k is the number of occurrences of the substring in the string.
Method #4 : Using find()
The find() method is used to find the index of the first occurrence of the substring in the string. We start searching for the substring from the beginning of the string and continue searching until the substring is not found in the remaining part of the string. If the substring is found, we add its start index to the list of indices and update the start index to start searching for the next occurrence of the substring.
Python3
def find_substring_indices(string, substring):
indices = []
start_index = 0
while True:
index = string.find(substring, start_index)
if index == -1:
break
else:
indices.append(index)
start_index = index + 1
return indices
string = "GeeksforGeeks is best for Geeks"
substring = "Geeks"
indices = find_substring_indices(string, substring)
print("The original string is:", string)
print("The substring to find:", substring)
print("The start indices of the substrings are:", indices)
Output
The original string is: GeeksforGeeks is best for Geeks The substring to find: Geeks The start indices of the substrings are: [0, 8, 26]
Time complexity: O(nm)
Auxiliary space: O(1)
Method #5: Using string slicing and while loop
- Initialize an empty list to store the indices of all occurrences of the substring.
- Set the starting index i to 0.
- Use a while loop to keep searching for the substring in the string.
- Inside the while loop, use the find() method to find the first occurrence of the substring in the string, starting from the current index i.
- If find() returns -1, it means that there are no more occurrences of the substring in the string, so break out of the loop.
- If find() returns a non-negative value, append the index of the first character of the substring to the list, and update the starting index i to the next character after the end of the substring.
- Repeat steps 4-6 until there are no more occurrences of the substring in the string.
- Return the list of indices.
Python3
def find_all_substrings(string, substring):
indices = []
i = 0
while i < len(string):
j = string.find(substring, i)
if j == -1:
break
indices.append(j)
i = j + len(substring)
return indices
test_str = "GeeksforGeeks is best for Geeks"
test_sub = "Geeks"
print(find_all_substrings(test_str, test_sub))
Time complexity: O(nm), where n is the length of the string and m is the length of the substring.
Auxiliary space: O(k), where k is the number of occurrences of the substring in the string.
Method #6 : Using re.finditer() and reduce():
Algorithm:
1. Import the required modules – re and functools.
2.Initialize the input string test_str and the substring to be searched test_sub.
3.Use re.finditer() to find all the occurrences of the substring test_sub in the string test_str.
4. Use reduce() to get the start indices of all the occurrences found in step 3.
5. The lambda function inside the reduce() takes two arguments – the first one is the list x that accumulates the start 6.indices and the second one is the Match object y returned by finditer(). The function adds the start index of the 7.current Match object to the list x.
8. Convert the final result to a string and print it.
Python3
import re
from functools import reduce
test_str = "GeeksforGeeks is best for Geeks"
test_sub = "Geeks"
occurrences = re.finditer(test_sub, test_str)
res = reduce(lambda x, y: x + [y.start()], occurrences, [])
print("The start indices of the substrings are : " + str(res))
Output
The start indices of the substrings are : [0, 8, 26]
Time Complexity: O(n), where n is the length of the input string.
Auxiliary Space: O(m), where m is the number of occurrences of the substring in the input string. This is because we need to store the start indices of all the occurrences in a list.
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Check if a Python String Contains a Substring
If you’re new to programming or come from a programming language other than Python, you may be looking for the best way to check whether a string contains another string in Python.
Identifying such substrings comes in handy when you’re working with text content from a file or after you’ve received user input. You may want to perform different actions in your program depending on whether a substring is present or not.
In this tutorial, you’ll focus on the most Pythonic way to tackle this task, using the membership operator in. Additionally, you’ll learn how to identify the right string methods for related, but different, use cases.
Finally, you’ll also learn how to find substrings in pandas columns. This is helpful if you need to search through data from a CSV file. You could use the approach that you’ll learn in the next section, but if you’re working with tabular data, it’s best to load the data into a pandas DataFrame and search for substrings in pandas.
How to Confirm That a Python String Contains Another String
If you need to check whether a string contains a substring, use Python’s membership operator in. In Python, this is the recommended way to confirm the existence of a substring in a string:
>>>
>>> raw_file_content = """Hi there and welcome.
... This is a special hidden file with a SECRET secret.
... I don't want to tell you The Secret,
... but I do want to secretly tell you that I have one."""
>>> "secret" in raw_file_content
True
The in membership operator gives you a quick and readable way to check whether a substring is present in a string. You may notice that the line of code almost reads like English.
When you use in, the expression returns a Boolean value:
Trueif Python found the substringFalseif Python didn’t find the substring
You can use this intuitive syntax in conditional statements to make decisions in your code:
>>>
>>> if "secret" in raw_file_content:
... print("Found!")
...
Found!
In this code snippet, you use the membership operator to check whether "secret" is a substring of raw_file_content. If it is, then you’ll print a message to the terminal. Any indented code will only execute if the Python string that you’re checking contains the substring that you provide.
The membership operator in is your best friend if you just need to check whether a Python string contains a substring.
However, what if you want to know more about the substring? If you read through the text stored in raw_file_content, then you’ll notice that the substring occurs more than once, and even in different variations!
Which of these occurrences did Python find? Does capitalization make a difference? How often does the substring show up in the text? And what’s the location of these substrings? If you need the answer to any of these questions, then keep on reading.
Generalize Your Check by Removing Case Sensitivity
Python strings are case sensitive. If the substring that you provide uses different capitalization than the same word in your text, then Python won’t find it. For example, if you check for the lowercase word "secret" on a title-case version of the original text, the membership operator check returns False:
>>>
>>> title_cased_file_content = """Hi There And Welcome.
... This Is A Special Hidden File With A Secret Secret.
... I Don't Want To Tell You The Secret,
... But I Do Want To Secretly Tell You That I Have One."""
>>> "secret" in title_cased_file_content
False
Despite the fact that the word secret appears multiple times in the title-case text title_cased_file_content, it never shows up in all lowercase. That’s why the check that you perform with the membership operator returns False. Python can’t find the all-lowercase string "secret" in the provided text.
Humans have a different approach to language than computers do. This is why you’ll often want to disregard capitalization when you check whether a string contains a substring in Python.
You can generalize your substring check by converting the whole input text to lowercase:
>>>
>>> file_content = title_cased_file_content.lower()
>>> print(file_content)
hi there and welcome.
this is a special hidden file with a secret secret.
i don't want to tell you the secret,
but i do want to secretly tell you that i have one.
>>> "secret" in file_content
True
Converting your input text to lowercase is a common way to account for the fact that humans think of words that only differ in capitalization as the same word, while computers don’t.
Now that you’ve converted the string to lowercase to avoid unintended issues stemming from case sensitivity, it’s time to dig further and learn more about the substring.
Learn More About the Substring
The membership operator in is a great way to descriptively check whether there’s a substring in a string, but it doesn’t give you any more information than that. It’s perfect for conditional checks—but what if you need to know more about the substrings?
Python provides many additonal string methods that allow you to check how many target substrings the string contains, to search for substrings according to elaborate conditions, or to locate the index of the substring in your text.
In this section, you’ll cover some additional string methods that can help you learn more about the substring.
By using in, you confirmed that the string contains the substring. But you didn’t get any information on where the substring is located.
If you need to know where in your string the substring occurs, then you can use .index() on the string object:
>>>
>>> file_content = """hi there and welcome.
... this is a special hidden file with a secret secret.
... i don't want to tell you the secret,
... but i do want to secretly tell you that i have one."""
>>> file_content.index("secret")
59
When you call .index() on the string and pass it the substring as an argument, you get the index position of the first character of the first occurrence of the substring.
But what if you want to find other occurrences of the substring? The .index() method also takes a second argument that can define at which index position to start looking. By passing specific index positions, you can therefore skip over occurrences of the substring that you’ve already identified:
>>>
>>> file_content.index("secret", 60)
66
When you pass a starting index that’s past the first occurrence of the substring, then Python searches starting from there. In this case, you get another match and not a ValueError.
That means that the text contains the substring more than once. But how often is it in there?
You can use .count() to get your answer quickly using descriptive and idiomatic Python code:
>>>
>>> file_content.count("secret")
4
You used .count() on the lowercase string and passed the substring "secret" as an argument. Python counted how often the substring appears in the string and returned the answer. The text contains the substring four times. But what do these substrings look like?
You can inspect all the substrings by splitting your text at default word borders and printing the words to your terminal using a for loop:
>>>
>>> for word in file_content.split():
... if "secret" in word:
... print(word)
...
secret
secret.
secret,
secretly
In this example, you use .split() to separate the text at whitespaces into strings, which Python packs into a list. Then you iterate over this list and use in on each of these strings to see whether it contains the substring "secret".
Now that you can inspect all the substrings that Python identifies, you may notice that Python doesn’t care whether there are any characters after the substring "secret" or not. It finds the word whether it’s followed by whitespace or punctuation. It even finds words such as "secretly".
That’s good to know, but what can you do if you want to place stricter conditions on your substring check?
Find a Substring With Conditions Using Regex
You may only want to match occurrences of your substring followed by punctuation, or identify words that contain the substring plus other letters, such as "secretly".
For such cases that require more involved string matching, you can use regular expressions, or regex, with Python’s re module.
For example, if you want to find all the words that start with "secret" but are then followed by at least one additional letter, then you can use the regex word character (w) followed by the plus quantifier (+):
>>>
>>> import re
>>> file_content = """hi there and welcome.
... this is a special hidden file with a secret secret.
... i don't want to tell you the secret,
... but i do want to secretly tell you that i have one."""
>>> re.search(r"secretw+", file_content)
<re.Match object; span=(128, 136), match='secretly'>
The re.search() function returns both the substring that matched the condition as well as its start and end index positions—rather than just True!
You can then access these attributes through methods on the Match object, which is denoted by m:
>>>
>>> m = re.search(r"secretw+", file_content)
>>> m.group()
'secretly'
>>> m.span()
(128, 136)
These results give you a lot of flexibility to continue working with the matched substring.
For example, you could search for only the substrings that are followed by a comma (,) or a period (.):
>>>
>>> re.search(r"secret[.,]", file_content)
<re.Match object; span=(66, 73), match='secret.'>
There are two potential matches in your text, but you only matched the first result fitting your query. When you use re.search(), Python again finds only the first match. What if you wanted all the mentions of "secret" that fit a certain condition?
To find all the matches using re, you can work with re.findall():
>>>
>>> re.findall(r"secret[.,]", file_content)
['secret.', 'secret,']
By using re.findall(), you can find all the matches of the pattern in your text. Python saves all the matches as strings in a list for you.
When you use a capturing group, you can specify which part of the match you want to keep in your list by wrapping that part in parentheses:
>>>
>>> re.findall(r"(secret)[.,]", file_content)
['secret', 'secret']
By wrapping secret in parentheses, you defined a single capturing group. The findall() function returns a list of strings matching that capturing group, as long as there’s exactly one capturing group in the pattern. By adding the parentheses around secret, you managed to get rid of the punctuation!
Using re.findall() with match groups is a powerful way to extract substrings from your text. But you only get a list of strings, which means that you’ve lost the index positions that you had access to when you were using re.search().
If you want to keep that information around, then re can give you all the matches in an iterator:
>>>
>>> for match in re.finditer(r"(secret)[.,]", file_content):
... print(match)
...
<re.Match object; span=(66, 73), match='secret.'>
<re.Match object; span=(103, 110), match='secret,'>
When you use re.finditer() and pass it a search pattern and your text content as arguments, you can access each Match object that contains the substring, as well as its start and end index positions.
You may notice that the punctuation shows up in these results even though you’re still using the capturing group. That’s because the string representation of a Match object displays the whole match rather than just the first capturing group.
But the Match object is a powerful container of information and, like you’ve seen earlier, you can pick out just the information that you need:
>>>
>>> for match in re.finditer(r"(secret)[.,]", file_content):
... print(match.group(1))
...
secret
secret
By calling .group() and specifying that you want the first capturing group, you picked the word secret without the punctuation from each matched substring.
You can go into much more detail with your substring matching when you use regular expressions. Instead of just checking whether a string contains another string, you can search for substrings according to elaborate conditions.
Using regular expressions with re is a good approach if you need information about the substrings, or if you need to continue working with them after you’ve found them in the text. But what if you’re working with tabular data? For that, you’ll turn to pandas.
Find a Substring in a pandas DataFrame Column
If you work with data that doesn’t come from a plain text file or from user input, but from a CSV file or an Excel sheet, then you could use the same approach as discussed above.
However, there’s a better way to identify which cells in a column contain a substring: you’ll use pandas! In this example, you’ll work with a CSV file that contains fake company names and slogans. You can download the file below if you want to work along:
When you’re working with tabular data in Python, it’s usually best to load it into a pandas DataFrame first:
>>>
>>> import pandas as pd
>>> companies = pd.read_csv("companies.csv")
>>> companies.shape
(1000, 2)
>>> companies.head()
company slogan
0 Kuvalis-Nolan revolutionize next-generation metrics
1 Dietrich-Champlin envisioneer bleeding-edge functionalities
2 West Inc mesh user-centric infomediaries
3 Wehner LLC utilize sticky infomediaries
4 Langworth Inc reinvent magnetic networks
In this code block, you loaded a CSV file that contains one thousand rows of fake company data into a pandas DataFrame and inspected the first five rows using .head().
After you’ve loaded the data into the DataFrame, you can quickly query the whole pandas column to filter for entries that contain a substring:
>>>
>>> companies[companies.slogan.str.contains("secret")]
company slogan
7 Maggio LLC target secret niches
117 Kub and Sons brand secret methodologies
654 Koss-Zulauf syndicate secret paradigms
656 Bernier-Kihn secretly synthesize back-end bandwidth
921 Ward-Shields embrace secret e-commerce
945 Williamson Group unleash secret action-items
You can use .str.contains() on a pandas column and pass it the substring as an argument to filter for rows that contain the substring.
When you’re working with .str.contains() and you need more complex match scenarios, you can also use regular expressions! You just need to pass a regex-compliant search pattern as the substring argument:
>>>
>>> companies[companies.slogan.str.contains(r"secretw+")]
company slogan
656 Bernier-Kihn secretly synthesize back-end bandwidth
In this code snippet, you’ve used the same pattern that you used earlier to match only words that contain secret but then continue with one or more word character (w+). Only one of the companies in this fake dataset seems to operate secretly!
You can write any complex regex pattern and pass it to .str.contains() to carve from your pandas column just the rows that you need for your analysis.
Conclusion
Like a persistent treasure hunter, you found each "secret", no matter how well it was hidden! In the process, you learned that the best way to check whether a string contains a substring in Python is to use the in membership operator.
You also learned how to descriptively use two other string methods, which are often misused to check for substrings:
.count()to count the occurrences of a substring in a string.index()to get the index position of the beginning of the substring
After that, you explored how to find substrings according to more advanced conditions with regular expressions and a few functions in Python’s re module.
Finally, you also learned how you can use the DataFrame method .str.contains() to check which entries in a pandas DataFrame contain a substring .
You now know how to pick the most idiomatic approach when you’re working with substrings in Python. Keep using the most descriptive method for the job, and you’ll write code that’s delightful to read and quick for others to understand.
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Check if a Python String Contains a Substring
In this Python tutorial, we will learn how to find all occurrences of a substring in a string.
Table Of Contents
- Find all occurrences of a substring using count()
- Find all occurrences of a substring using startswith()
- Find all occurrences of a substring using finditer()
- Summary
The count() method is used to count the total occurrences of the given substring in a string. It takes three parameters.
Syntax:
string.count(substring,start,end)
Parameters
1. substring is the string to be counted
2. start is an optional parameter that takes an integer such that counting is started from the given index position.
3. end is an optional parameter that takes an integer such that counting is ended up to the given index position.
Advertisements
It returns the number of occurrences of substring in from index positions start to end in the calling string object.
Example 1:
In this example, we will count the substring-“Python”.
# String
string1="""Python programming language. Python is object-oriented,
Python supports database connectivity and Python supports
List,set, tuple and dictionary"""
# Get the total number of occurrences - Python
num = string1.count("Python")
print(num)
Output:
4
We can see that “Python” occurred 4 times in the string.
Example 2:
In this example, we will count the substring-“Python” from a particular position.
# String
string1="""Python programming language. Python is object-oriented,
Python supports database connectivity and Python supports
List,set, tuple and dictionary"""
# Get the total number of occurrences -
# Python from 1st position to 20th position
num = string1.count("Python",0,19)
print(num)
# Get the total number of occurrences -
# Python from 21st position to 65th position
num = string1.count("Python",20,64)
print(num)
Output:
1 2
We can see that “Python” occurred 1 time from the 1st position to the 20th position in the string and 2 times from the 21st position to the 65th position.
Find all occurrences of a substring using startswith()
The startswith() method is used to return the starting index of a particular substring. If we want to return all occurrence indices, we have to use list comprehension.
Syntax:
[iterator for iterator in range(len(string)) if string.startswith(substring, iterator)]
Parameters
1. substring is the string to be counted
2. iterator represents the position
To return the total number of occurrences, then we can apply the len() function to it.
Syntax:
len([iterator for iterator in range(len(string)) if string.startswith(substring, iterator)])
Example 1:
In this example, we will get the starting indices of the substring-“Python” and return the total number of occurrences.
# String
string1="""Python programming language. Python is object-oriented,
Python supports database connectivity and Python supports
List,set, tuple and dictionary"""
# Get the all indexpositions where substring "Python" exist in the string
indices = [i for i in range(len(string1)) if string1.startswith("Python", i)]
print(indices)
# Get the total number of occurrences of "Python"
num = len([i for i in range(len(string1)) if string1.startswith("Python", i)])
print(num)
Output:
[0, 29, 57, 99] 4
We can see that “Python” occurred 4 times in the string and starting indices were also returned.
Example 2:
In this example, we will get the starting indices of the substring-“supports” and return the total number of occurrences.
# String
string1="""Python programming language. Python is object-oriented,
Python supports database connectivity and Python supports
List,set, tuple and dictionary"""
# Get the all indexpositions where substring "supports" exist in the string
indices = [i for i in range(len(string1)) if string1.startswith("supports", i)]
print(indices)
# Get the total number of occurrences of "supports"
num = len([i for i in range(len(string1)) if string1.startswith("supports", i)])
print(num)
Output:
[64, 106] 2
We can see that “supports” occurred 2 times in the string and starting indices were also returned.
Find all occurrences of a substring using finditer()
The finditer() method is available in the re module which is used to return the starting index of a particular substring using the start() method. If we want to return all occurrence indices, we have to use list comprehension and iterate the string using an iterator.
Syntax:
[iterator.start() for iterator in re.finditer(substring, string)]
Parameters
1. substring is the string to be counted
2. string is the actual string
It returns a sequence a list of index positions where substring exists in the string. To return the total number of occurrences, then we can apply the len() function to it.
Example 1:
In this example, we will get the starting indices of the substring-“Python” and return the total number of occurrences.
import re
# String
string1="""Python programming language. Python is object-oriented,
Python supports database connectivity and Python supports
List,set, tuple and dictionary"""
# Get the all indexpositions where substring "Python" exist in the string
indices = [i.start() for i in re.finditer("Python", string1)]
print(indices)
# Get the total number of occurrences of "Python"
num = len(indices)
print(num)
Output:
[0, 29, 57, 99] 4
We can see that “Python” occurred 4 times in the string and starting indices were also returned.
Example 2:
In this example, we will get the starting indices of the substring-“supports” and return the total number of occurrences.
import re
# String
string1="""Python programming language. Python is object-oriented,
Python supports database connectivity and Python supports
List,set, tuple and dictionary"""
# Get the all indexpositions where substring "supports" exist in the string
indices = [i.start() for i in re.finditer("supports", string1)]
print(indices)
# Get the total number of occurrences of "supports"
num = len(indices)
print(num)
Output:
[64, 106] 2
We can see that “supports” occurred 2 times in the string and starting indices were also returned.
Summary
We have seen how to find and return the total number of occurrences of a particular substring using count(), startswith(), and finditer() methods. The startswith() and finditer() methods used list comprehension to return all the occurrences.
In this Python tutorial, we will discuss everything on Python find substring in string with a few more examples.
Python provides several methods to find substrings in a string. Here we will discuss 12 different methods to check if Python String contains a substring.
- Using the in operator
- Using The find() method
- Using the index() method
- Using the re module
- Using the startswith() method
- Using the endswith() method
- Using the split() method
- Using the partition() method
- Using the count() method
- Using the rfind() method
- Using the list comprehension
- Using the re.findall()
Method-1: Using the in operator
The in operator is one of the simplest and quickest ways to check if a substring is present in a string. It returns True if the substring is found and False otherwise.
# Define the main string
string = "I live in USA"
# Define the substring to be searched
substring = "USA"
# Use 'in' operator to check if substring is present in string
if substring in string:
print("Substring found")
else:
print("Substring not found")The above code checks if a given substring is present in a given string.
- The main string is stored in the variable string and the substring to be searched is stored in the variable substring.
- The code uses the in operator to check if the substring is present in the string. If it is, the code outputs “Substring found” to the console. If not, the code outputs “Substring not found”.

Read: Slicing string in Python + Examples
Method-2: Using The find() method
The find() method is another simple way to find substrings in a string. It returns the index of the first occurrence of the substring in the string. If the substring is not found, it returns -1.
# Define the main string
string = "I live in USA"
# Define the substring to be searched
substring = "USA"
# Use the find() method to get the index of the substring
index = string.find(substring)
# Check if the substring is found
if index != -1:
print("Substring found at index", index)
else:
print("Substring not found")The above code uses the find() method to search for the index of a given substring in a given string.
- The find() method is used to search for the index of the substring in the string, and the result is stored in the variable index.
- If the substring is found, the index will be set to the index of the first character of the substring in the string. If the substring is not found, index will be set to -1.
- The code then checks if index is not equal to -1. If it is not, the substring was found and the code outputs “Substring found at index” followed by the value of the index.
- If the index is equal to -1, the substring was not found and the code outputs “Substring not found”.

Read: Convert string to float in Python
Method-3: Using the index() method
The index() method is similar to the find() method, but it raises a ValueError exception if the substring is not found in the string.
# Search for substring in a given string
string = "I live in USA"
# The substring we want to search for
substring = "live"
# Use try-except block to handle potential ValueError if substring is not found
try:
# Find the index of the substring in the string using the index() method
index = string.index(substring)
# Print a success message with the index of the substring
print("Substring found at index", index)
except ValueError:
# If the substring is not found, print a message indicating that it was not found
print("Substring not found")The code above is checking if a given substring is present in a string.
- The input string is “I live in USA” and the substring we want to search for is “live”.
- The code uses a try-except block to handle the potential error of not finding the substring in the string.
- The index() method is used to find the index of the substring in the string. If the substring is found, the code prints a message indicating the index of the substring in the string.
- If the substring is not found, a ValueError is raised, which is caught by the except block, and a message indicating that the substring was not found is printed.

Read: Append to a string Python + Examples
Method-4: Using the re module
The re (regular expression) module provides powerful methods for matching and searching for substrings in a string.
# Use the re module for pattern matching
import re
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "in"
# Use the search() method from the re module to find a match
match = re.search(substring, string)
# Check if a match was found
if match:
# If a match was found, print a success message
print("Substring found")
else:
# If no match was found, print a failure message
print("Substring not found")
The code above is checking if a given substring is present in a string using regular expressions (regex).
- The first line import re imports the re module which provides functions for pattern matching in strings.
- The input string is “I live in USA” and the substring we want to search for is “in”. The code then uses the re.search() method to find a match between the substring and the input string.
- The re.search() method returns a match object if there is a match between the substring and the input string, otherwise it returns None.
- The code then uses an if statement to check if a match was found. If a match was found, the code prints a message indicating that the substring was found.
- If no match was found, the code prints a message indicating that the substring was not found.

Read: Python compare strings
Method-5: Using the startswith() method
The startswith() method returns True if the string starts with the specified substring and False otherwise.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "I"
# Use the startswith() method to check if the string starts with the substring
if string.startswith(substring):
# If the string starts with the substring, print a success message
print("Substring found")
else:
# If the string does not start with the substring, print a failure message
print("Substring not found")
The code above checks if a given substring is at the beginning of a string.
- The input string is “I live in USA” and the substring we want to search for is “I”. The code uses the startswith() method to check if the input string starts with the substring.
- The startswith() method returns True if the input string starts with the substring and False otherwise. The code then uses an if statement to check the result of the startswith() method.
- If the input string starts with the substring, the code prints a message indicating that the substring was found. If the input string does not start with the substring, the code prints a message indicating that the substring was not found.

Read: Python program to reverse a string with examples
Method-6: Using the endswith() method
The endswith() method is similar to the startswith() method, but it returns True if the string ends with the specified substring and False otherwise.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "USA"
# Use the endswith() method to check if the string ends with the substring
if string.endswith(substring):
# If the string ends with the substring, print a success message
print("Substring found")
else:
# If the string does not end with the substring, print a failure message
print("Substring not found")The code above checks if a given substring is at the end of a string.
- The input string is “I live in USA” and the substring we want to search for is “USA”. The code uses the endswith() method to check if the input string ends with the substring.
- The endswith() method returns True if the input string ends with the substring and False otherwise. The code then uses an if statement to check the result of the endswith() method.
- If the input string ends with the substring, the code prints a message indicating that the substring was found. If the input string does not end with the substring, the code prints a message indicating that the substring was not found.

Read: Python string formatting with examples.
Method-7: Using the split() method
The split() method splits a string into a list of substrings based on a specified delimiter. The resulting substrings can then be searched for the desired substring.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "USA"
# Split the string into substrings using the split() method and store the result in a list
substrings = string.split(" ")
# Check if the substring is in the list of substrings
if substring in substrings:
# If the substring is in the list, print a success message
print("Substring found")
else:
# If the substring is not in the list, print a failure message
print("Substring not found")
The code above checks if a given substring is contained within a string.
- The input string is “I live in USA” and the substring we want to search for is “USA”. The code splits the input string into substrings using the split() method and stores the result in a list substrings.
- The split() method splits a string into substrings using a specified delimiter (in this case, a space character).
- Next, the code uses the
inoperator to check if the substring is in the list of substrings. If the substring is in the list, the code prints a message indicating that the substring was found. - If the substring is not in the list, the code prints a message indicating that the substring was not found.

Method-8: Using the partition() method
The partition() method splits a string into a tuple of three substrings: the substring before the specified delimiter, the specified delimiter, and the substring after the specified delimiter.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "I"
# Use the partition() method to split the string into three parts
before, delimiter, after = string.partition(" ")
# Check if the first part of the split string is equal to the substring
if before == substring:
# If the first part is equal to the substring, print a success message
print("Substring found")
else:
# If the first part is not equal to the substring, print a failure message
print("Substring not found")
The code above checks if a given substring is at the beginning of a string.
The input string is “I live in USA” and the substring we want to search for is “I”. The code uses the partition() method to split the input string into three parts:
- The part before the specified delimiter, the delimiter itself, and the part after the delimiter. In this case, the delimiter is a space character.
- The partition() method returns a tuple with three elements: the part before the delimiter, the delimiter itself, and the part after the delimiter.
- The code uses tuple unpacking to assign the three parts to the variables before, delimiter, and after.
- Next, the code uses an if statement to check if the first part of the split string (i.e., before) is equal to the substring.
- If the first part is equal to the substring, the code prints a message indicating that the substring was found. If the first part is not equal to the substring, the code prints a message indicating that the substring was not found.

Method-9: Using the count() method
The count() method returns the number of times a substring appears in a string.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "live"
# Use the count() method to count the number of times the substring appears in the string
count = string.count(substring)
# Print the result
print("Substring found", count, "times")The code above counts the number of times a given substring appears in a string.
- The input string is “I live in USA” and the substring we want to search for is “live”. The code uses the count() method to count the number of times the substring appears in the string.
- Finally, the code uses the print() function to print the result, indicating how many times the substring was found in the string.

Method-10: Using the rfind() method
The rfind() method is similar to the find() method, but it returns the index of the last occurrence of the substring in the string. If the substring is not found, it returns -1.
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "USA"
# Use the rfind() method to find the last index of the substring in the string
index = string.rfind(substring)
# Check if the substring was found
if index != -1:
# If the substring was found, print the index
print("Substring found at index", index)
else:
# If the substring was not found, print a message
print("Substring not found")The code above searches for the last occurrence of a given substring in a string.
- The input string is “I live in USA” and the substring we want to search for is “USA”. The code uses the rfind() method to find the last index of the substring in the string.
- The rfind() method returns the index of the last occurrence of the substring in the string, or -1 if the substring is not found. So the code checks if the returned value is not equal to -1, indicating that the substring was found in the string.
- Finally, the code uses the print() function to print the result, indicating the index of the last occurrence of the substring in the string.

Method-11: Using the list comprehension
# The string we want to search in
string = "I live in USA"
# The substring we want to search for
substring = "USA"
# Use a list comprehension to find if the substring exists in the string split into words
result = [word for word in string.split() if word == substring]
# Check if the result list is not empty
if result:
# If the result list is not empty, the substring was found
print("Substring found")
else:
# If the result list is empty, the substring was not found
print("Substring not found")
The code above checks if a given substring exists in a string.
- The input string is “I live in USA” and the substring we want to search for is “USA”. The code uses a list comprehension to create a list of words from the input string, where each word is checked if it is equal to the given substring.
- The list comprehension iterates over the words in the input string, which is split using the split() method, and adds the word to the result list if it is equal to the given substring.
- Finally, the code uses an if statement to check if the result list is not empty. If the result list is not empty, it means that the substring was found in the input string, so the code prints “Substring found”.
- If the result list is empty, the substring was not found in the input string, so the code prints “Substring not found”.

Method-12: Using the re.findall()
The re.findall() function returns a list of all non-overlapping matches of the specified pattern within the string. We can use this function to find all occurrences of a substring within a string by specifying the substring as the pattern.
# Import the regular expression library 're'
import re
# The input text to search for the substring
text = "I live in USA"
# The substring to search for in the text
substring = "USA"
# Find all occurrences of the substring in the text using the 'findall' method from the 're' library
result = re.findall(substring, text)
# Print the result
print(result)In the above code, the regular expression library re is imported and used to find all occurrences of the given substring “USA” in the input text “I live in USA”.
- The re.findall method is used to search for all occurrences of the substring in the text and return them as a list.
- Finally, the result is printed on the console.
You may like the following Python examples:
- How to concatenate strings in python
- Find Last Number in String in Python
- Find first number in string in Python
In this Python tutorial, we learned, Python find substring in string using the below methods:
- Python find substring in string using the in operator
- Python find substring in string using The find() method
- Python find substring in string using the index() method
- Python find substring in string using the re module
- Python find substring in string using the startswith() method
- Python find substring in string using the endswith() method
- Python find substring in string using the split() method
- Python find substring in string using the partition() method
- Python find substring in string using the count() method
- Python find substring in string using the rfind() method
- Python find substring in string using the list comprehension
- Python find substring in string using the re.findall()

Python is one of the most popular languages in the United States of America. I have been working with Python for a long time and I have expertise in working with various libraries on Tkinter, Pandas, NumPy, Turtle, Django, Matplotlib, Tensorflow, Scipy, Scikit-Learn, etc… I have experience in working with various clients in countries like United States, Canada, United Kingdom, Australia, New Zealand, etc. Check out my profile.
16 ответов
Нет простой встроенной строковой функции, которая делает то, что вы ищете, но вы можете использовать более мощные регулярные выражения:
import re
[m.start() for m in re.finditer('test', 'test test test test')]
#[0, 5, 10, 15]
Если вы хотите найти совпадающие совпадения, lookahead сделает это:
[m.start() for m in re.finditer('(?=tt)', 'ttt')]
#[0, 1]
Если вы хотите получить обратное вскрытие без перекрытий, вы можете комбинировать положительные и отрицательные образы в виде следующего вида:
search = 'tt'
[m.start() for m in re.finditer('(?=%s)(?!.{1,%d}%s)' % (search, len(search)-1, search), 'ttt')]
#[1]
re.finditer возвращает генератор, поэтому вы можете изменить [] в приведенном выше re.finditer на () чтобы получить генератор вместо списка, который будет более эффективен, если вы будете только повторять результаты один раз.
marcog
12 янв. 2011, в 03:25
Поделиться
>>> help(str.find)
Help on method_descriptor:
find(...)
S.find(sub [,start [,end]]) -> int
Таким образом, мы можем сами его построить:
def find_all(a_str, sub):
start = 0
while True:
start = a_str.find(sub, start)
if start == -1: return
yield start
start += len(sub) # use start += 1 to find overlapping matches
list(find_all('spam spam spam spam', 'spam')) # [0, 5, 10, 15]
Никаких временных строк или регулярных выражений не требуется.
Karl Knechtel
12 янв. 2011, в 04:02
Поделиться
Здесь (очень неэффективный) способ получить все (т.е. даже совпадение):
>>> string = "test test test test"
>>> [i for i in range(len(string)) if string.startswith('test', i)]
[0, 5, 10, 15]
thkala
12 янв. 2011, в 04:17
Поделиться
Вы можете использовать re.finditer() для совпадающих совпадений.
>>> import re
>>> aString = 'this is a string where the substring "is" is repeated several times'
>>> print [(a.start(), a.end()) for a in list(re.finditer('is', aString))]
[(2, 4), (5, 7), (38, 40), (42, 44)]
но не будет работать:
In [1]: aString="ababa"
In [2]: print [(a.start(), a.end()) for a in list(re.finditer('aba', aString))]
Output: [(0, 3)]
Chinmay Kanchi
12 янв. 2011, в 03:44
Поделиться
Опять старый поток, но здесь мое решение использует генератор и обычный str.find.
def findall(p, s):
'''Yields all the positions of
the pattern p in the string s.'''
i = s.find(p)
while i != -1:
yield i
i = s.find(p, i+1)
Пример
x = 'banananassantana'
[(i, x[i:i+2]) for i in findall('na', x)]
возвращает
[(2, 'na'), (4, 'na'), (6, 'na'), (14, 'na')]
AkiRoss
24 дек. 2015, в 00:23
Поделиться
Приходите, давайте возместим вместе.
def locations_of_substring(string, substring):
"""Return a list of locations of a substring."""
substring_length = len(substring)
def recurse(locations_found, start):
location = string.find(substring, start)
if location != -1:
return recurse(locations_found + [location], location+substring_length)
else:
return locations_found
return recurse([], 0)
print(locations_of_substring('this is a test for finding this and this', 'this'))
# prints [0, 27, 36]
Нет необходимости в регулярных выражениях таким образом.
Cody Piersall
01 нояб. 2013, в 04:53
Поделиться
Это старый поток, но я заинтересовался и хотел поделиться своим решением.
def find_all(a_string, sub):
result = []
k = 0
while k < len(a_string):
k = a_string.find(sub, k)
if k == -1:
return result
else:
result.append(k)
k += 1 #change to k += len(sub) to not search overlapping results
return result
Он должен вернуть список позиций, в которых была найдена подстрока.
Прокомментируйте, если вы видите ошибку или комнату для улучшения.
Thurines
01 апр. 2015, в 09:49
Поделиться
Если вы ищете только один символ, это будет работать:
string = "dooobiedoobiedoobie"
match = 'o'
reduce(lambda count, char: count + 1 if char == match else count, string, 0)
# produces 7
Кроме того,
string = "test test test test"
match = "test"
len(string.split(match)) - 1
# produces 4
Моя догадка заключается в том, что ни один из них (особенно # 2) не ужасен.
jstaab
24 сен. 2014, в 21:41
Поделиться
Этот поток немного стар, но это сработало для меня:
numberString = "onetwothreefourfivesixseveneightninefiveten"
testString = "five"
marker = 0
while marker < len(numberString):
try:
print(numberString.index("five",marker))
marker = numberString.index("five", marker) + 1
except ValueError:
print("String not found")
marker = len(numberString)
Andrew H
01 сен. 2014, в 14:16
Поделиться
Это делает трюк для меня, используя re.finditer
import re
text = 'This is sample text to test if this pythonic '
'program can serve as an indexing platform for '
'finding words in a paragraph. It can give '
'values as to where the word is located with the '
'different examples as stated'
# find all occurances of the word 'as' in the above text
find_the_word = re.finditer('as', text)
for match in find_the_word:
print('start {}, end {}, search string '{}''.
format(match.start(), match.end(), match.group()))
Bruno Vermeulen
06 июль 2018, в 10:13
Поделиться
Вы можете попробовать:
>>> string = "test test test test"
>>> for index,value in enumerate(string):
if string[index:index+(len("test"))] == "test":
print index
0
5
10
15
Harsha B
27 фев. 2018, в 08:13
Поделиться
Независимо от решений, предоставляемых другими, полностью зависит от доступного метода find() или любых доступных методов.
Каков основной базовый алгоритм для поиска всех вхождений подстрока в строке?
def find_all (строка, подстрока): "" Функция: Возврат всего индекса подстроки в строку Аргументы: Строка и строка поиска Возврат: возврат списка "" length = len (подстрока) с = 0 indexes = [] в то время как c < Len (строка): if string [c: c + length] == substring: indexes.append(с) с = с + 1 индексы возврата
Код>
Вы также можете наследовать класс str новому классу и можете использовать эту функцию ниже.
class newstr (str):
def find_all (строка, подстрока): "" Функция: Возврат всего индекса подстроки в строку Аргументы: Строка и строка поиска Возврат: возврат списка "" length = len (подстрока) с = 0 indexes = [] в то время как c < Len (строка): if string [c: c + length] == substring: indexes.append(с) с = с + 1 индексы возврата
Код>
Вызов метода
newstr.find_all ( «Вы находите этот ответ полезным?» это!», ‘this’)
naveen raja
15 фев. 2018, в 21:37
Поделиться
RaySaraiva
01 дек. 2018, в 20:23
Поделиться
При поиске большого количества ключевых слов в документе используйте flashtext
from flashtext import KeywordProcessor
words = ['test', 'exam', 'quiz']
txt = 'this is a test'
kwp = KeywordProcessor()
kwp.add_keywords_from_list(words)
result = kwp.extract_keywords(txt, span_info=True)
Flashtext работает быстрее, чем регулярное выражение в большом списке поисковых слов.
Uri Goren
28 сен. 2018, в 19:20
Поделиться
Питонический путь:
mystring = 'Hello World, this should work!'
find_all = lambda c,s: [x for x in range(c.find(s), len(c)) if c[x] == s]
# s represents the search string
# c represents the character string
find_all(mystring,'o') # will return all positions of 'o'
[4, 7, 20, 26]
>>>
Harvey
10 апр. 2018, в 21:38
Поделиться
посмотрите ниже код
#!/usr/bin/env python
# coding:utf-8
'''黄哥Python'''
def get_substring_indices(text, s):
result = [i for i in range(len(text)) if text.startswith(s, i)]
return result
if __name__ == '__main__':
text = "How much wood would a wood chuck chuck if a wood chuck could chuck wood?"
s = 'wood'
print get_substring_indices(text, s)
黄哥Python培训
16 март 2017, в 01:52
Поделиться
Ещё вопросы
- 0Есть ли в PHP библиотека преобразования голоса для 3gpp в mp4
- 1cvxpy: ‘sum_entries’ не определен
- 1Использование RenderPartial для назначения значений свойств модели
- 0Чек возвращается как объект
- 1Изменение размера изображения в JLabel
- 0jQuery — API видимости окна для продолжения работы
- 0Сочетание CSS-селекторов с несколькими идентификаторами страниц
- 1Таблица Angular 2 не обновляется, когда коллбэк обновляет коллекцию, таймер обновляет всю коллекцию
- 1альтернатива для Javadoc? [Дубликат]
- 0Масштабирование уже нарисованного QPolygonF на чертеже
- 0Странный неразрешенный внешний символ в C ++ / CLI
- 1Kivy Popup показывает фоновые виджеты
- 1Сервер Simple C # SSL: учетные данные, предоставленные для пакета, не были распознаны
- 0Почему связанная таблица не обновляется должным образом, используя hibernate?
- 0Моделирование броска костей с использованием структуры
- 0SQL: исключить пользователей, где хотя бы одна строка совпадает
- 0Моя программа работает нормально, но мой учитель хочет, чтобы она была более эффективной
- 1Как повторно заархивировать файл ODT в C # и сделать его читабельным?
- 0Обнаружить переполнение в поле ввода
- 1Можно ли сохранить версию миниатюры в файловой системе? какова общая практика?
- 1AmChart умножает значения даты
- 0Центрирование по CSS
- 1Загрузка текста richTextBox в массив
- 1DbContext с Ninject ADO.NET
- 0Как разбить строку JSON
- 1ASP.NET Publishing со старой ссылкой на сборку
- 1Производитель приложений Google — Гиперссылки
- 0Классный производный дизайн
- 0Пользовательский фильтр в Angular
- 0Мой массив массивов символов сохраняет только последнюю введенную строку
- 0Если (случайного) слова нет, полностью повторить / перезапустить функцию?
- 0Рисование холста в элементе, который был только что добавлен
- 0Вызов метода jQuery из контроллера
- 0Где в Codeigniter я могу определить, находится ли пользователь на мобильном устройстве?
- 0Как я могу сделать перетаскиваемый элемент, который находится в таблице?
- 1Эффективная замена всех неподдерживаемых символов в строке [дубликаты]
- 1Как открыть проект из GitHub в Android-студии? Проблемы с Maven и Android поддержки библиотек.
- 0Как обработать результаты json typeahead.js перед переходом к шаблону (hogan.js)?
- 1Необходимо расшифровать ответ SAML
- 0Как получить значение из текстовых полей шаблона кендо в угловой массив
- 0Непрозрачность IE8 на PNG прозрачный
- 0Расчет возраста в PHP с использованием SQL
- 0Заполнитель ввода не работает с angular и ui.router
- 0Простая проверка формы JavaScript не вернет true
- 1Есть ли способ узнать, был ли «blur» вызван «element.blur ()» или это было «фактическое» blur?
- 0MySQL исключение «соединение потеряно во время запроса», «сервер MySQL пропал» и «команда не синхронизирована»
- 1Как разделить строку на несколько строк отдельных символов
- 0Как получить значение первого тд таблицы, используя JQuery?
- 0MYSQL ON DUPLICATE KEY вставить что-то еще
- 1java.security.cert.CertPathValidatorException: доверенная привязка для пути сертификации не найдена
In this post, you’ll learn how to find an index of a substring in a string, whether it’s the first substring or the last substring. You’ll also learn how to find every index of a substring in a string.
Knowing how to work with strings is an important skill in your Python journey. You’ll learn how to create a list of all the index positions where that substring occurs.
The Quick Answer:
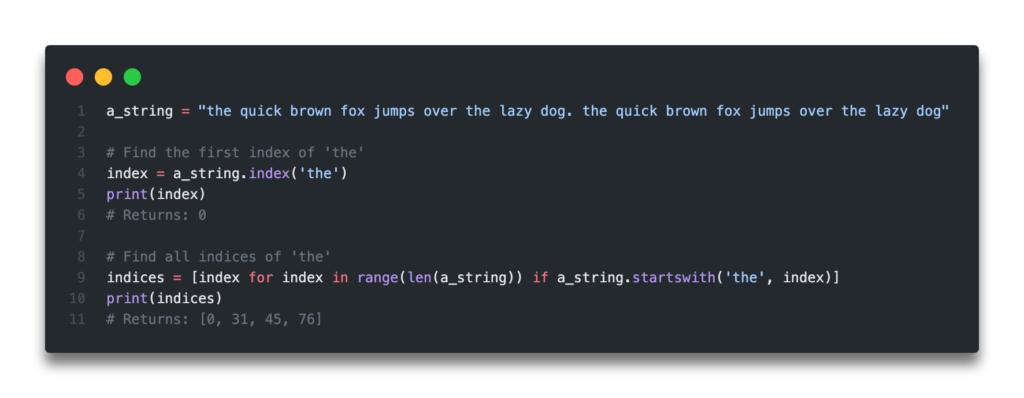
How to Use Python to Find the First Index of a Substring in a String
If all you want to do is first index of a substring in a Python string, you can do this easily with the str.index() method. This method comes built into Python, so there’s no need to import any packages.
Let’s take a look at how you can use Python to find the first index of a substring in a string:
a_string = "the quick brown fox jumps over the lazy dog. the quick brown fox jumps over the lazy dog"
# Find the first index of 'the'
index = a_string.index('the')
print(index)
# Returns: 0We can see here that the .index() method takes the parameter of the sub-string that we’re looking for. When we apply the method to our string a_string, the result of that returns 0. This means that the substring begins at index position 0, of our string (i.e., it’s the first word).
Let’s take a look at how you can find the last index of a substring in a Python string.
How to Use Python to Find the Last Index of a Substring in a String
There may be many times when you want to find the last index of a substring in a Python string. To accomplish this, we cannot use the .index() string method. However, Python comes built in with a string method that searches right to left, meaning it’ll return the furthest right index. This is the .rindex() method.
Let’s see how we can use the str.rindex() method to find the last index of a substring in Python:
a_string = "the quick brown fox jumps over the lazy dog. the quick brown fox jumps over the lazy dog"
# Find the last index of 'the'
index = a_string.rindex('the')
print(index)
# Returns: 76In the example above, we applied the .rindex() method to the string to return the last index’s position of our substring.
How to Use Regular Expression (Regex) finditer to Find All Indices of a Substring in a Python String
The above examples both returned different indices, but both only returned a single index. There may be other times when you may want to return all indices of a substring in a Python string.
For this, we’ll use the popular regular expression library, re. In particular, we’ll use the finditer method, which helps you find an iteration.
Let’s see how we can use regular expressions to find all indices of a substring in a Python string:
import re
a_string = "the quick brown fox jumps over the lazy dog. the quick brown fox jumps over the lazy dog"
# Find all indices of 'the'
indices_object = re.finditer(pattern='the', string=a_string)
indices = [index.start() for index in indices_object]
print(indices)
# Returns: [0, 31, 45, 76]This example has a few more moving parts. Let’s break down what we’ve done step by step:
- We imported
reand set up our variablea_stringjust as before - We then use
re.finditerto create an iterable object containing all the matches - We then created a list comprehension to find the
.start()value, meaning the starting index position of each match, within that - Finally, we printed our list of index start positions
In the next section, you’ll learn how to use a list comprehension in Python to find all indices of a substring in a string.
How to Use a Python List Comprehension to Find All Indices of a Substring in a String
Let’s take a look at how you can find all indices of a substring in a string in Python without using the regular expression library. We’ll accomplish this by using a list comprehension.
Want to learn more about Python list comprehensions? Check out my in-depth tutorial about Python list comprehensions here, which will teach you all you need to know!
Let’s see how we can accomplish this using a list comprehension:
a_string = "the quick brown fox jumps over the lazy dog. the quick brown fox jumps over the lazy dog"
# Find all indices of 'the'
indices = [index for index in range(len(a_string)) if a_string.startswith('the', index)]
print(indices)
# Returns: [0, 31, 45, 76]Let’s take a look at how this list comprehension works:
- We iterate over the numbers from 0 through the length of the list
- We include the index position of that number if the substring that’s created by splitting our string from that index onwards, begins with our letter
- We get a list returned of all the instances where that substring occurs in our string
In the final section of this tutorial, you’ll learn how to build a custom function to return the indices of all substrings in our Python string.
Check out some other Python tutorials on datagy, including our complete guide to styling Pandas and our comprehensive overview of Pivot Tables in Pandas!
How to Build a Custom Function to Find All Indices of a Substring in a String in Python
Now that you’ve learned two different methods to return all indices of a substring in Python string, let’s learn how we can turn this into a custom Python function.
Why would we want to do this? Neither of the methods demonstrated above are really immediately clear a reader what they accomplish. This is where a function would come in handy, since it allows a future reader (who may, very well, be you!) know what your code is doing.
Let’s get started!
# Create a custom function to return the indices of all substrings in a Python string
a_string = "the quick brown fox jumps over the lazy dog. the quick brown fox jumps over the lazy dog"
def find_indices_of_substring(full_string, sub_string):
return [index for index in range(len(full_string)) if full_string.startswith(sub_string, index)]
indices = find_indices_of_substring(a_string, 'the')
print(indices)
# Returns: [0, 31, 45, 76]In this sample custom function, we use used our list comprehension method of finding the indices of all substrings. The reason for this is that it does not create any additional dependencies.
Conclusion
In this post, you leaned how to use Python to find the first index, the last index, and all indices of a substring in a string. You learned how to do this with regular string methods, with regular expressions, list comprehensions, as well as a custom built function.
To learn more about the re.finditer() method, check out the official documentation here.