Время на прочтение
5 мин
Количество просмотров 63K
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
import pandas as pd
sales = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'sales')
states = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'states')
Теперь воспользуемся методом .head() датафрейма sales для того чтобы вывести элементы, находящиеся в начале датафрейма:
print(sales.head())
Сравним то, что будет выведено, с тем, что можно видеть в Excel.
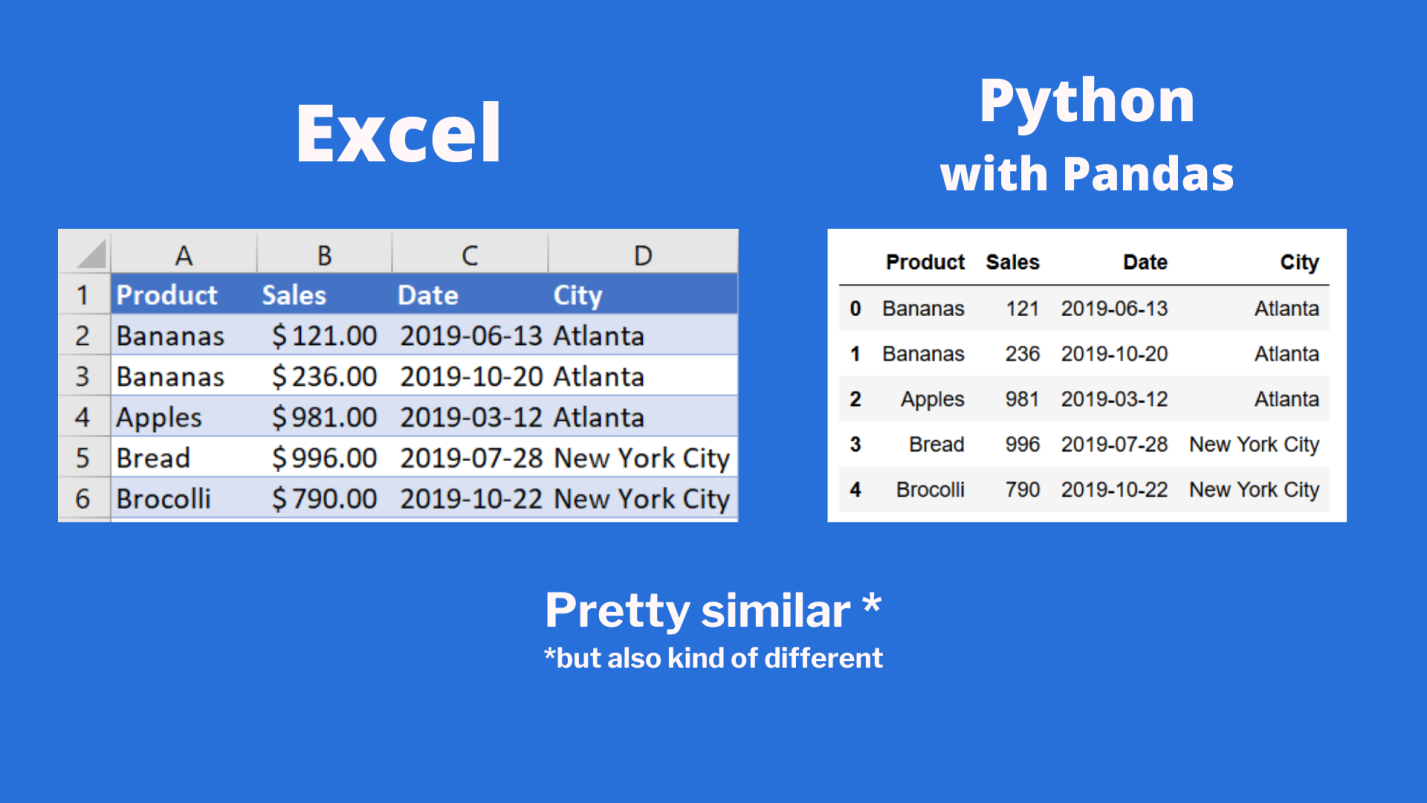
Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
- Нумерация строк в Excel начинается с 1, а в pandas номер (индекс) первой строки равняется 0.
- В Excel столбцы имеют буквенные обозначения, начинающиеся с буквы
A, а в pandas названия столбцов соответствуют именам соответствующих переменных.
Продолжим исследование возможностей pandas, позволяющих решать задачи, которые обычно решают в Excel.
Реализация возможностей Excel-функции IF в Python
В Excel существует очень удобная функция IF, которая позволяет, например, записать что-либо в ячейку, основываясь на проверке того, что находится в другой ячейке. Предположим, нужно создать в Excel новый столбец, ячейки которого будут сообщать нам о том, превышают ли 500 значения, записанные в соответствующие ячейки столбца B. В Excel такому столбцу (в нашем случае это столбец E) можно назначить заголовок MoreThan500, записав соответствующий текст в ячейку E1. После этого, в ячейке E2, можно ввести следующее:
=IF([@Sales]>500, "Yes", "No")
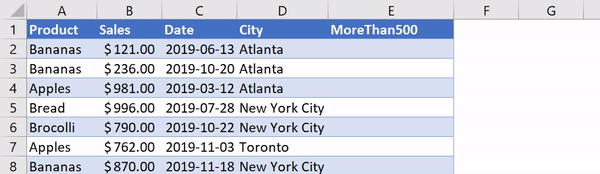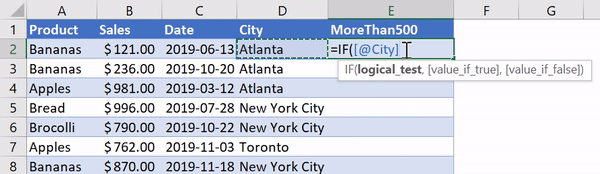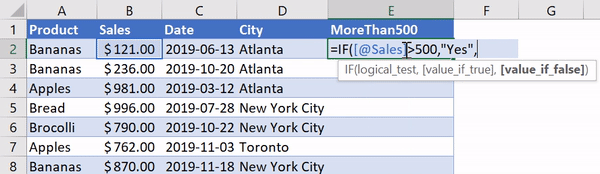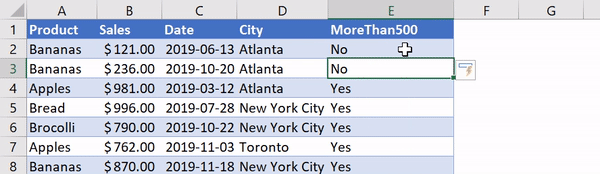
Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
sales['MoreThan500'] = ['Yes' if x > 500 else 'No' for x in sales['Sales']]

Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
В нашем наборе данных, на одном из листов Excel, есть названия городов, а на другом — названия штатов и провинций. Как узнать о том, где именно находится каждый город? Для этого подходит Excel-функция VLOOKUP, с помощью которой можно связать данные двух таблиц. Эта функция работает по принципу левого соединения, когда сохраняется каждая запись из набора данных, находящегося в левой части выражения. Применяя функцию VLOOKUP, мы предлагаем системе выполнить поиск определённого значения в заданном столбце указанного листа, а затем — вернуть значение, которое находится на заданное число столбцов правее найденного значения. Вот как это выглядит:
=VLOOKUP([@City],states,2,false)
Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.

Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
sales = pd.merge(sales, states, how='left', on='City')
Разберём его:
- Первый аргумент метода
merge— это исходный датафрейм. - Второй аргумент — это датафрейм, в котором мы ищем значения.
- Аргумент
howуказывает на то, как именно мы хотим соединить данные. - Аргумент
onуказывает на переменную, по которой нужно выполнить соединение (тут ещё можно использовать аргументыleft_onиright_on, нужные в том случае, если интересующие нас данные в разных датафреймах названы по-разному).
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
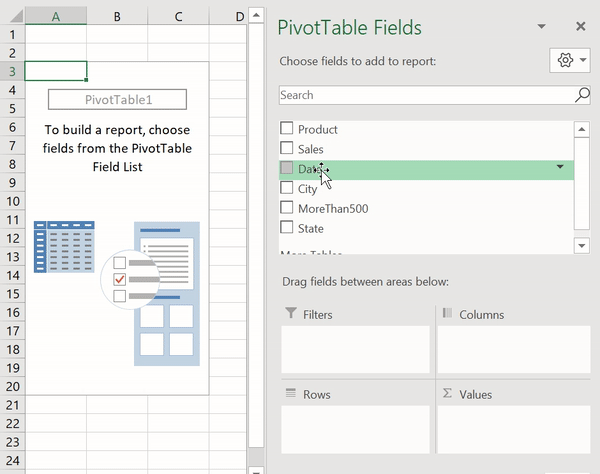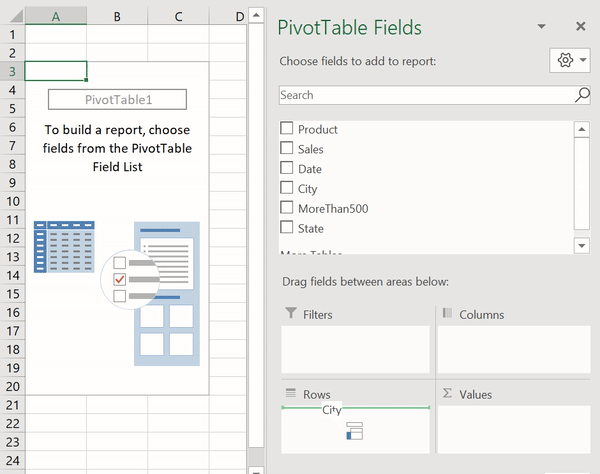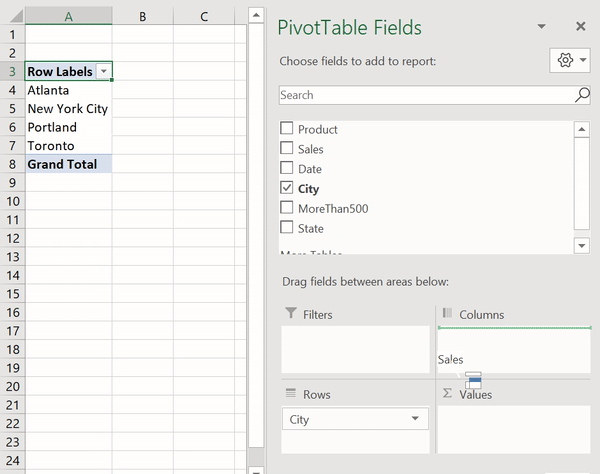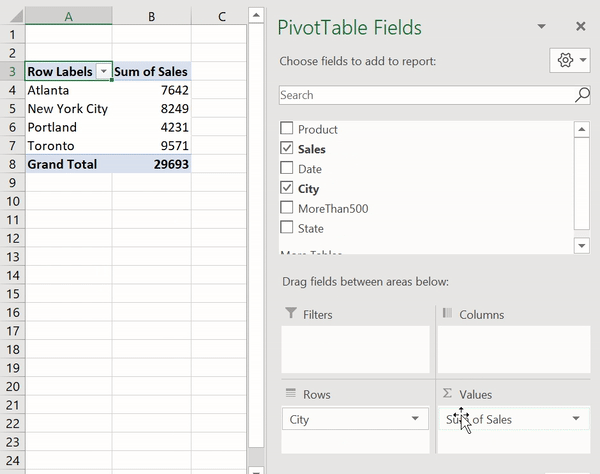
Создание сводной таблицы в Excel
Как видите, для создания подобной таблицы достаточно перетащить поле City в раздел Rows, а поле Sales — в раздел Values. После этого Excel автоматически выведет суммарные продажи для каждого города.
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
sales.pivot_table(index = 'City', values = 'Sales', aggfunc = 'sum')
Разберём его:
- Здесь мы используем метод
sales.pivot_table, сообщая pandas о том, что мы хотим создать сводную таблицу, основанную на датафреймеsales. - Аргумент
indexуказывает на столбец, по которому мы хотим агрегировать данные. - Аргумент
valuesуказывает на то, какие значения мы собираемся агрегировать. - Аргумент
aggfuncзадаёт функцию, которую мы хотим использовать при обработке значений (тут ещё можно воспользоваться функциямиmean,max,minи так далее).
Итоги
Из этого материала вы узнали о том, как импортировать Excel-данные в pandas, о том, как реализовать средствами Python и pandas возможности Excel-функций IF и VLOOKUP, а также о том, как воспроизвести средствами pandas функционал сводных таблиц Excel. Возможно, сейчас вы задаётесь вопросом о том, зачем вам пользоваться pandas, если то же самое можно сделать и в Excel. На этот вопрос нет однозначного ответа. Python позволяет создавать код, который поддаётся тонкой настройке и глубокому исследованию. Такой код можно использовать многократно. Средствами Python можно описывать очень сложные схемы анализа данных. А возможностей Excel, вероятно, достаточно лишь для менее масштабных исследований данных. Если вы до этого момента пользовались только Excel — рекомендую испытать Python и pandas, и узнать о том, что у вас из этого получится.
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.

Last updated on
Jul 18, 2021
In this post you can learn how to read Excel files (ext xls, xlsx etc) with Python and Pandas. We will import one or several sheets from an Excel file to a Pandas DataFrame.
The list of the supported file extensions:
xlsxlsxxlsmxlsbodfodsodt
Note for ods, ods and odt please check: Read Excel(OpenDocument ODS) with Python Pandas
Step 1: Install Pandas and odfpy
Python offers many different modules for reading and manipulating Excel files. In this guide we are going to use pandas and odfpy:
pip install pandas
pip install odfpy
Step 2: Read the one sheet of Excel(XLS) file
Pandas offers a powerful method for reading any type of Excel files read_excel(). It’s pretty easy to be used and requires only the file path:
import pandas as pd
pd.read_excel('animals.xls')
It will read and return all non empty cells from the Excel file:
| Rank | Animal | Maximum speed | Class | Notes | |
|---|---|---|---|---|---|
| 0 | 1 | Peregrine falcon | 389 km/h (242 mph)108 m/s (354 ft/s)[2][6] | Flight-diving | The peregrine falcon is the fastest aerial ani… |
| 1 | 2 | Golden eagle | 240–320 km/h (150–200 mph)67–89 m/s (220–293 f… | Flight-diving | Assuming the maximum size at 1.02 m, its relat… |
| 2 | 3 | White-throated needletail swift | 169 km/h (105 mph)[8][9][10] | Flight | NaN |
| 3 | 4 | Eurasian hobby | 160 km/h (100 mph)[11] | Flight | Can sometimes outfly the swift |
| 4 | 5 | Mexican free-tailed bat | 160 km/h (100 mph)[12] | Flight | It has been claimed to have the fastest horizo… |
| 5 | 6 | Frigatebird | 153 km/h (95 mph) | Flight | The frigatebird’s high speed is helped by its … |
| 6 | 7 | Rock dove (pigeon) | 148.9 km/h (92.5 mph)[13] | Flight | Pigeons have been clocked flying 92.5 mph (148… |
| 7 | 8 | Spur-winged goose | 142 km/h (88 mph)[14] | Flight | NaN |
| 8 | 9 | Gyrfalcon | 128 km/h (80 mph)[citation needed] | Flight | NaN |
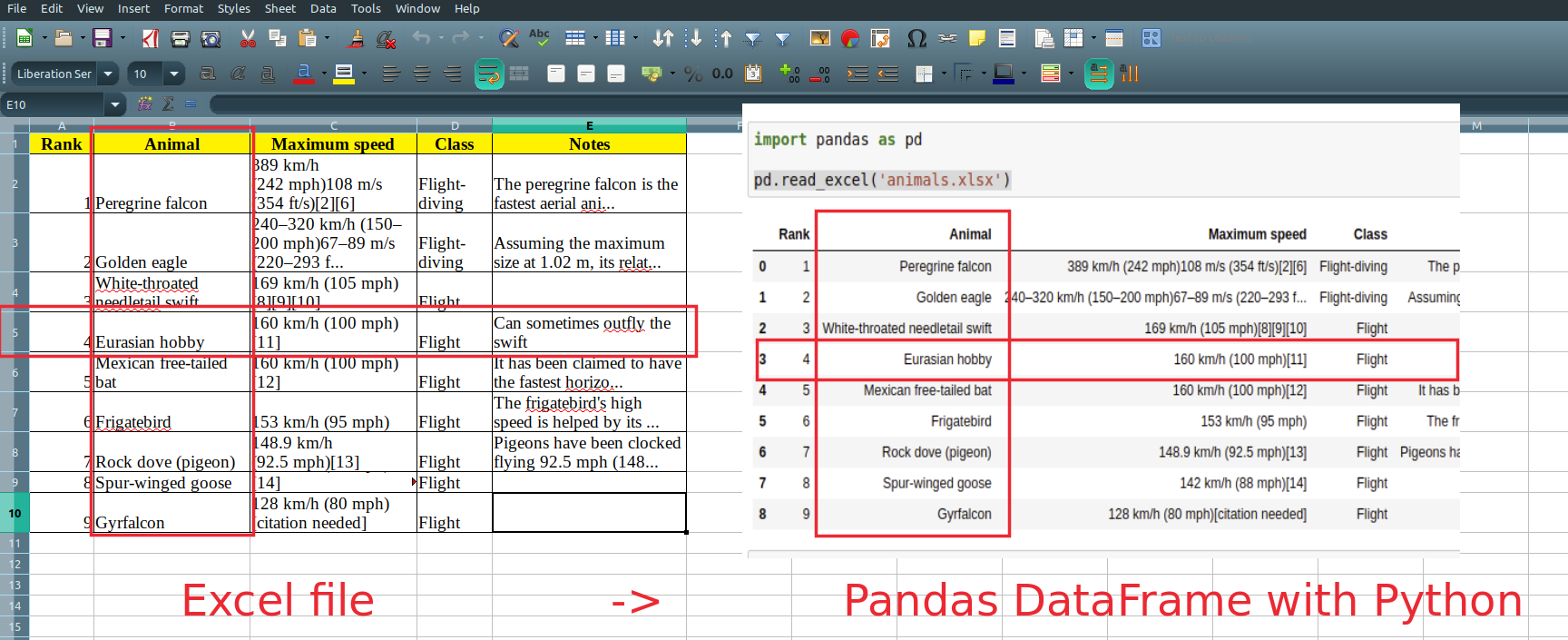
Step 3: Read the second sheet of Excel file by name
If you like to read data from a specific sheet — for example Sheet 2 then you can specify the name as a parameter — sheet_name:
pd.read_excel('animals.xlsx', sheet_name="Sheet2")
Which will result in:
| Blackbuck | Unnamed: 1 | |
|---|---|---|
| 0 | NaN | NaN |
| 1 | Male blackbuck | Male blackbuck |
| 2 | NaN | NaN |
| 3 | Female with young at the National Zoological Park Delhi | Female with young at the National Zoological P… |
| 4 | Conservation status | Conservation status |
| 5 | Least Concern (IUCN 3.1)[1] | Least Concern (IUCN 3.1)[1] |
| 6 | Scientific classification | Scientific classification |
Step 4: Python read excel file — specify columns and rows
If you like to read a range of data and not the whole sheet — read_excel offers several very useful parameters.
Python read excel file select rows
Next code example will show you how to read 3 rows skipping the first two rows. In this way Pandas will read only some rows from the whole sheet:
pd.read_excel('animals.xlsx', skiprows=2, nrows=3)
which will result in:
| 2 | Golden eagle | 240–320 km/h (150–200 mph)67–89 m/s (220–293 f… | Flight-diving | Assuming the maximum size at 1.02 m, its relat… | |
|---|---|---|---|---|---|
| 0 | 3 | White-throated needletail swift | 169 km/h (105 mph)[8][9][10] | Flight | NaN |
| 1 | 4 | Eurasian hobby | 160 km/h (100 mph)[11] | Flight | Can sometimes outfly the swift |
| 2 | 5 | Mexican free-tailed bat | 160 km/h (100 mph)[12] | Flight | It has been claimed to have the fastest horizo… |
Python read excel file select columns
If you like to** work with few columns** and not the whole sheet — then parameter use_cols can be used as shown:
pd.read_excel('animals.xlsx', usecols='C:D')
Python read excel file specify columns and rows
Finally if you like to select a range from specific columns and rows than you can use:
Which will result into:
| 240–320 km/h (150–200 mph)67–89 m/s (220–293 f… | Flight-diving | |
|---|---|---|
| 0 | 169 km/h (105 mph)[8][9][10] | Flight |
| 1 | 160 km/h (100 mph)[11] | Flight |
| 2 | 160 km/h (100 mph)[12] | Flight |
Step 5. Read multiple sheets from Excel file
What if you like to read with Pandas multiple sheets from Excel. It’s possible with pd.read_excel by providing a list of all sheets to be read as follows:
pd.read_excel('animals.xlsx', sheet_name=["Sheet1", "Sheet2"])
Note that a dictionary of
- keys — sheet names
- values — resulted DataFrames
will be returned.
In order to access data you can access it by a sheet name as:
pd.read_excel('animals.xlsx', sheet_name=["Sheet1", "Sheet2"]).get('Sheet1')
which will return the data for Sheet1 as a DataFrame.
Read All Sheets
For loading all sheets from Excel file use sheet_name=None:
pd.read_excel('animals.xlsx', sheet_name=None)
Step 6. Pandas read excel data with conversion, NA values and parsing
Finally let’s check what we can do if we need to convert data, drop or fill missing values, parse dates and numbers.
Pandas offers several parameters for this purpose:
- converters — dict of functions for converting values in certain columns
- keep_default_na — whether or not to include the default NaN values
- parse_dates
- ate_parser — converting a sequence of string columns to an array of datetime instances.
- thousands
- convert_float
You can check the Notebook in the resources for more examples of the above.
Resources
- Python Pandas Reading Excel files
- pandas.read_excel
- Notebook —
Read Excel ODS with Python Pandas
Why learn to work with Excel with Python? Excel is one of the most popular and widely-used data tools; it’s hard to find an organization that doesn’t work with it in some way. From analysts, to sales VPs, to CEOs, various professionals use Excel for both quick stats and serious data crunching.
With Excel being so pervasive, data professionals must be familiar with it. Working with data in Python or R offers serious advantages over Excel’s UI, so finding a way to work with Excel using code is critical. Thankfully, there’s a great tool already out there for using Excel with Python called pandas.
Pandas has excellent methods for reading all kinds of data from Excel files. You can also export your results from pandas back to Excel, if that’s preferred by your intended audience. Pandas is great for other routine data analysis tasks, such as:
- quick Exploratory Data Analysis (EDA)
- drawing attractive plots
- feeding data into machine learning tools like scikit-learn
- building machine learning models on your data
- taking cleaned and processed data to any number of data tools
Pandas is better at automating data processing tasks than Excel, including processing Excel files.
In this tutorial, we are going to show you how to work with Excel files in pandas. We will cover the following concepts.
- setting up your computer with the necessary software
- reading in data from Excel files into pandas
- data exploration in pandas
- visualizing data in pandas using the matplotlib visualization library
- manipulating and reshaping data in pandas
- moving data from pandas into Excel
Note that this tutorial does not provide a deep dive into pandas. To explore pandas more, check out our course.
System Prerequisites
We will use Python 3 and Jupyter Notebook to demonstrate the code in this tutorial.In addition to Python and Jupyter Notebook, you will need the following Python modules:
- matplotlib — data visualization
- NumPy — numerical data functionality
- OpenPyXL — read/write Excel 2010 xlsx/xlsm files
- pandas — data import, clean-up, exploration, and analysis
- xlrd — read Excel data
- xlwt — write to Excel
- XlsxWriter — write to Excel (xlsx) files
There are multiple ways to get set up with all the modules. We cover three of the most common scenarios below.
- If you have Python installed via Anaconda package manager, you can install the required modules using the command
conda install. For example, to install pandas, you would execute the command —conda install pandas. - If you already have a regular, non-Anaconda Python installed on the computer, you can install the required modules using
pip. Open your command line program and execute commandpip install <module name>to install a module. You should replace<module name>with the actual name of the module you are trying to install. For example, to install pandas, you would execute command —pip install pandas. - If you don’t have Python already installed, you should get it through the Anaconda package manager. Anaconda provides installers for Windows, Mac, and Linux Computers. If you choose the full installer, you will get all the modules you need, along with Python and pandas within a single package. This is the easiest and fastest way to get started.
The Data Set
In this tutorial, we will use a multi-sheet Excel file we created from Kaggle’s IMDB Scores data. You can download the file here.
Our Excel file has three sheets: ‘1900s,’ ‘2000s,’ and ‘2010s.’ Each sheet has data for movies from those years.
We will use this data set to find the ratings distribution for the movies, visualize movies with highest ratings and net earnings and calculate statistical information about the movies. We will be analyzing and exploring this data using Python and pandas, thus demonstrating pandas capabilities for working with Excel data in Python.
Read data from the Excel file
We need to first import the data from the Excel file into pandas. To do that, we start by importing the pandas module.
import pandas as pdWe then use the pandas’ read_excel method to read in data from the Excel file. The easiest way to call this method is to pass the file name. If no sheet name is specified then it will read the first sheet in the index (as shown below).
excel_file = 'movies.xls'
movies = pd.read_excel(excel_file)Here, the read_excel method read the data from the Excel file into a pandas DataFrame object. Pandas defaults to storing data in DataFrames. We then stored this DataFrame into a variable called movies.
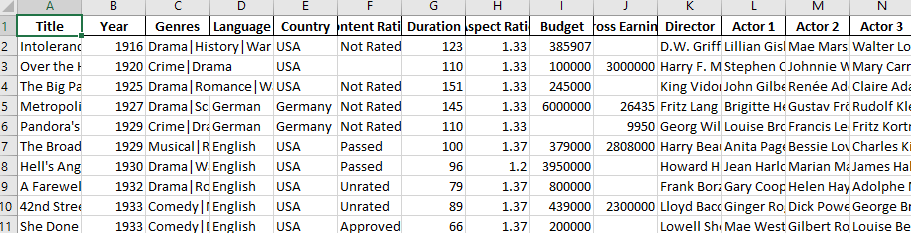
Pandas has a built-in DataFrame.head() method that we can use to easily display the first few rows of our DataFrame. If no argument is passed, it will display first five rows. If a number is passed, it will display the equal number of rows from the top.
movies.head()| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | … | Facebook Likes — Actor 1 | Facebook Likes — Actor 2 | Facebook Likes — Actor 3 | Facebook Likes — cast Total | Facebook likes — Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Intolerance: Love’s Struggle Throughout the Ages | 1916 | Drama|History|War | NaN | USA | Not Rated | 123 | 1.33 | 385907.0 | NaN | … | 436 | 22 | 9.0 | 481 | 691 | 1 | 10718 | 88 | 69.0 | 8.0 |
| 1 | Over the Hill to the Poorhouse | 1920 | Crime|Drama | NaN | USA | NaN | 110 | 1.33 | 100000.0 | 3000000.0 | … | 2 | 2 | 0.0 | 4 | 0 | 1 | 5 | 1 | 1.0 | 4.8 |
| 2 | The Big Parade | 1925 | Drama|Romance|War | NaN | USA | Not Rated | 151 | 1.33 | 245000.0 | NaN | … | 81 | 12 | 6.0 | 108 | 226 | 0 | 4849 | 45 | 48.0 | 8.3 |
| 3 | Metropolis | 1927 | Drama|Sci-Fi | German | Germany | Not Rated | 145 | 1.33 | 6000000.0 | 26435.0 | … | 136 | 23 | 18.0 | 203 | 12000 | 1 | 111841 | 413 | 260.0 | 8.3 |
| 4 | Pandora’s Box | 1929 | Crime|Drama|Romance | German | Germany | Not Rated | 110 | 1.33 | NaN | 9950.0 | … | 426 | 20 | 3.0 | 455 | 926 | 1 | 7431 | 84 | 71.0 | 8.0 |
5 rows × 25 columns
Excel files quite often have multiple sheets and the ability to read a specific sheet or all of them is very important. To make this easy, the pandas read_excel method takes an argument called sheetname that tells pandas which sheet to read in the data from. For this, you can either use the sheet name or the sheet number. Sheet numbers start with zero. If the sheetname argument is not given, it defaults to zero and pandas will import the first sheet.
By default, pandas will automatically assign a numeric index or row label starting with zero. You may want to leave the default index as such if your data doesn’t have a column with unique values that can serve as a better index. In case there is a column that you feel would serve as a better index, you can override the default behavior by setting index_col property to a column. It takes a numeric value for setting a single column as index or a list of numeric values for creating a multi-index.
In the below code, we are choosing the first column, ‘Title’, as index (index=0) by passing zero to the index_col argument.
movies_sheet1 = pd.read_excel(excel_file, sheetname=0, index_col=0)
movies_sheet1.head()| Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | Director | … | Facebook Likes — Actor 1 | Facebook Likes — Actor 2 | Facebook Likes — Actor 3 | Facebook Likes — cast Total | Facebook likes — Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Title | |||||||||||||||||||||
| Intolerance: Love’s Struggle Throughout the Ages | 1916 | Drama|History|War | NaN | USA | Not Rated | 123 | 1.33 | 385907.0 | NaN | D.W. Griffith | … | 436 | 22 | 9.0 | 481 | 691 | 1 | 10718 | 88 | 69.0 | 8.0 |
| Over the Hill to the Poorhouse | 1920 | Crime|Drama | NaN | USA | NaN | 110 | 1.33 | 100000.0 | 3000000.0 | Harry F. Millarde | … | 2 | 2 | 0.0 | 4 | 0 | 1 | 5 | 1 | 1.0 | 4.8 |
| The Big Parade | 1925 | Drama|Romance|War | NaN | USA | Not Rated | 151 | 1.33 | 245000.0 | NaN | King Vidor | … | 81 | 12 | 6.0 | 108 | 226 | 0 | 4849 | 45 | 48.0 | 8.3 |
| Metropolis | 1927 | Drama|Sci-Fi | German | Germany | Not Rated | 145 | 1.33 | 6000000.0 | 26435.0 | Fritz Lang | … | 136 | 23 | 18.0 | 203 | 12000 | 1 | 111841 | 413 | 260.0 | 8.3 |
| Pandora’s Box | 1929 | Crime|Drama|Romance | German | Germany | Not Rated | 110 | 1.33 | NaN | 9950.0 | Georg Wilhelm Pabst | … | 426 | 20 | 3.0 | 455 | 926 | 1 | 7431 | 84 | 71.0 | 8.0 |
5 rows × 24 columns
As you noticed above, our Excel data file has three sheets. We already read the first sheet in a DataFrame above. Now, using the same syntax, we will read in rest of the two sheets too.
movies_sheet2 = pd.read_excel(excel_file, sheetname=1, index_col=0)
movies_sheet2.head()| Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | Director | … | Facebook Likes — Actor 1 | Facebook Likes — Actor 2 | Facebook Likes — Actor 3 | Facebook Likes — cast Total | Facebook likes — Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Title | |||||||||||||||||||||
| 102 Dalmatians | 2000 | Adventure|Comedy|Family | English | USA | G | 100.0 | 1.85 | 85000000.0 | 66941559.0 | Kevin Lima | … | 2000.0 | 795.0 | 439.0 | 4182 | 372 | 1 | 26413 | 77.0 | 84.0 | 4.8 |
| 28 Days | 2000 | Comedy|Drama | English | USA | PG-13 | 103.0 | 1.37 | 43000000.0 | 37035515.0 | Betty Thomas | … | 12000.0 | 10000.0 | 664.0 | 23864 | 0 | 1 | 34597 | 194.0 | 116.0 | 6.0 |
| 3 Strikes | 2000 | Comedy | English | USA | R | 82.0 | 1.85 | 6000000.0 | 9821335.0 | DJ Pooh | … | 939.0 | 706.0 | 585.0 | 3354 | 118 | 1 | 1415 | 10.0 | 22.0 | 4.0 |
| Aberdeen | 2000 | Drama | English | UK | NaN | 106.0 | 1.85 | 6500000.0 | 64148.0 | Hans Petter Moland | … | 844.0 | 2.0 | 0.0 | 846 | 260 | 0 | 2601 | 35.0 | 28.0 | 7.3 |
| All the Pretty Horses | 2000 | Drama|Romance|Western | English | USA | PG-13 | 220.0 | 2.35 | 57000000.0 | 15527125.0 | Billy Bob Thornton | … | 13000.0 | 861.0 | 820.0 | 15006 | 652 | 2 | 11388 | 183.0 | 85.0 | 5.8 |
5 rows × 24 columns
movies_sheet3 = pd.read_excel(excel_file, sheetname=2, index_col=0)
movies_sheet3.head()| Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | Director | … | Facebook Likes — Actor 1 | Facebook Likes — Actor 2 | Facebook Likes — Actor 3 | Facebook Likes — cast Total | Facebook likes — Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Title | |||||||||||||||||||||
| 127 Hours | 2010.0 | Adventure|Biography|Drama|Thriller | English | USA | R | 94.0 | 1.85 | 18000000.0 | 18329466.0 | Danny Boyle | … | 11000.0 | 642.0 | 223.0 | 11984 | 63000 | 0.0 | 279179 | 440.0 | 450.0 | 7.6 |
| 3 Backyards | 2010.0 | Drama | English | USA | R | 88.0 | NaN | 300000.0 | NaN | Eric Mendelsohn | … | 795.0 | 659.0 | 301.0 | 1884 | 92 | 0.0 | 554 | 23.0 | 20.0 | 5.2 |
| 3 | 2010.0 | Comedy|Drama|Romance | German | Germany | Unrated | 119.0 | 2.35 | NaN | 59774.0 | Tom Tykwer | … | 24.0 | 20.0 | 9.0 | 69 | 2000 | 0.0 | 4212 | 18.0 | 76.0 | 6.8 |
| 8: The Mormon Proposition | 2010.0 | Documentary | English | USA | R | 80.0 | 1.78 | 2500000.0 | 99851.0 | Reed Cowan | … | 191.0 | 12.0 | 5.0 | 210 | 0 | 0.0 | 1138 | 30.0 | 28.0 | 7.1 |
| A Turtle’s Tale: Sammy’s Adventures | 2010.0 | Adventure|Animation|Family | English | France | PG | 88.0 | 2.35 | NaN | NaN | Ben Stassen | … | 783.0 | 749.0 | 602.0 | 3874 | 0 | 2.0 | 5385 | 22.0 | 56.0 | 6.1 |
5 rows × 24 columns
Since all the three sheets have similar data but for different recordsmovies, we will create a single DataFrame from all the three DataFrames we created above. We will use the pandas concat method for this and pass in the names of the three DataFrames we just created and assign the results to a new DataFrame object, movies. By keeping the DataFrame name same as before, we are over-writing the previously created DataFrame.
movies = pd.concat([movies_sheet1, movies_sheet2, movies_sheet3])We can check if this concatenation by checking the number of rows in the combined DataFrame by calling the method shape on it that will give us the number of rows and columns.
movies.shape(5042, 24)Using the ExcelFile class to read multiple sheets
We can also use the ExcelFile class to work with multiple sheets from the same Excel file. We first wrap the Excel file using ExcelFile and then pass it to read_excel method.
xlsx = pd.ExcelFile(excel_file)
movies_sheets = []
for sheet in xlsx.sheet_names:
movies_sheets.append(xlsx.parse(sheet))
movies = pd.concat(movies_sheets)If you are reading an Excel file with a lot of sheets and are creating a lot of DataFrames, ExcelFile is more convenient and efficient in comparison to read_excel. With ExcelFile, you only need to pass the Excel file once, and then you can use it to get the DataFrames. When using read_excel, you pass the Excel file every time and hence the file is loaded again for every sheet. This can be a huge performance drag if the Excel file has many sheets with a large number of rows.
Exploring the data
Now that we have read in the movies data set from our Excel file, we can start exploring it using pandas. A pandas DataFrame stores the data in a tabular format, just like the way Excel displays the data in a sheet. Pandas has a lot of built-in methods to explore the DataFrame we created from the Excel file we just read in.
We already introduced the method head in the previous section that displays few rows from the top from the DataFrame. Let’s look at few more methods that come in handy while exploring the data set.
We can use the shape method to find out the number of rows and columns for the DataFrame.
movies.shape(5042, 25)This tells us our Excel file has 5042 records and 25 columns or observations. This can be useful in reporting the number of records and columns and comparing that with the source data set.
We can use the tail method to view the bottom rows. If no parameter is passed, only the bottom five rows are returned.
movies.tail()| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | … | Facebook Likes — Actor 1 | Facebook Likes — Actor 2 | Facebook Likes — Actor 3 | Facebook Likes — cast Total | Facebook likes — Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1599 | War & Peace | NaN | Drama|History|Romance|War | English | UK | TV-14 | NaN | 16.00 | NaN | NaN | … | 1000.0 | 888.0 | 502.0 | 4528 | 11000 | 1.0 | 9277 | 44.0 | 10.0 | 8.2 |
| 1600 | Wings | NaN | Comedy|Drama | English | USA | NaN | 30.0 | 1.33 | NaN | NaN | … | 685.0 | 511.0 | 424.0 | 1884 | 1000 | 5.0 | 7646 | 56.0 | 19.0 | 7.3 |
| 1601 | Wolf Creek | NaN | Drama|Horror|Thriller | English | Australia | NaN | NaN | 2.00 | NaN | NaN | … | 511.0 | 457.0 | 206.0 | 1617 | 954 | 0.0 | 726 | 6.0 | 2.0 | 7.1 |
| 1602 | Wuthering Heights | NaN | Drama|Romance | English | UK | NaN | 142.0 | NaN | NaN | NaN | … | 27000.0 | 698.0 | 427.0 | 29196 | 0 | 2.0 | 6053 | 33.0 | 9.0 | 7.7 |
| 1603 | Yu-Gi-Oh! Duel Monsters | NaN | Action|Adventure|Animation|Family|Fantasy | Japanese | Japan | NaN | 24.0 | NaN | NaN | NaN | … | 0.0 | NaN | NaN | 0 | 124 | 0.0 | 12417 | 51.0 | 6.0 | 7.0 |
5 rows × 25 columns
In Excel, you’re able to sort a sheet based on the values in one or more columns. In pandas, you can do the same thing with the sort_values method. For example, let’s sort our movies DataFrame based on the Gross Earnings column.
sorted_by_gross = movies.sort_values(['Gross Earnings'], ascending=False)Since we have the data sorted by values in a column, we can do few interesting things with it. For example, we can display the top 10 movies by Gross Earnings.
sorted_by_gross["Gross Earnings"].head(10)1867 760505847.0
1027 658672302.0
1263 652177271.0
610 623279547.0
611 623279547.0
1774 533316061.0
1281 474544677.0
226 460935665.0
1183 458991599.0
618 448130642.0
Name: Gross Earnings, dtype: float64We can also create a plot for the top 10 movies by Gross Earnings. Pandas makes it easy to visualize your data with plots and charts through matplotlib, a popular data visualization library. With a couple lines of code, you can start plotting. Moreover, matplotlib plots work well inside Jupyter Notebooks since you can displace the plots right under the code.
First, we import the matplotlib module and set matplotlib to display the plots right in the Jupyter Notebook.
import matplotlib.pyplot as plt%matplotlib inlineWe will draw a bar plot where each bar will represent one of the top 10 movies. We can do this by calling the plot method and setting the argument kind to barh. This tells matplotlib to draw a horizontal bar plot.
sorted_by_gross['Gross Earnings'].head(10).plot(kind="barh")
plt.show()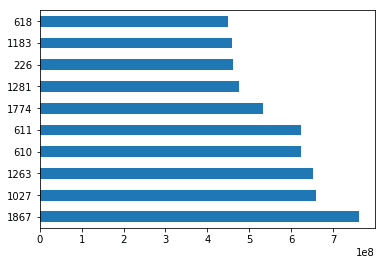
Let’s create a histogram of IMDB Scores to check the distribution of IMDB Scores across all movies. Histograms are a good way to visualize the distribution of a data set. We use the plot method on the IMDB Scores series from our movies DataFrame and pass it the argument.
movies['IMDB Score'].plot(kind="hist")
plt.show()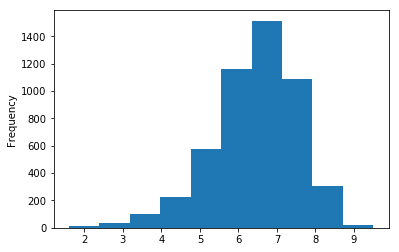
This data visualization suggests that most of the IMDB Scores fall between six and eight.
Getting statistical information about the data
Pandas has some very handy methods to look at the statistical data about our data set. For example, we can use the describe method to get a statistical summary of the data set.
movies.describe()| Year | Duration | Aspect Ratio | Budget | Gross Earnings | Facebook Likes — Director | Facebook Likes — Actor 1 | Facebook Likes — Actor 2 | Facebook Likes — Actor 3 | Facebook Likes — cast Total | Facebook likes — Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4935.000000 | 5028.000000 | 4714.000000 | 4.551000e+03 | 4.159000e+03 | 4938.000000 | 5035.000000 | 5029.000000 | 5020.000000 | 5042.000000 | 5042.000000 | 5029.000000 | 5.042000e+03 | 5022.000000 | 4993.000000 | 5042.000000 |
| mean | 2002.470517 | 107.201074 | 2.220403 | 3.975262e+07 | 4.846841e+07 | 686.621709 | 6561.323932 | 1652.080533 | 645.009761 | 9700.959143 | 7527.457160 | 1.371446 | 8.368475e+04 | 272.770808 | 140.194272 | 6.442007 |
| std | 12.474599 | 25.197441 | 1.385113 | 2.061149e+08 | 6.845299e+07 | 2813.602405 | 15021.977635 | 4042.774685 | 1665.041728 | 18165.101925 | 19322.070537 | 2.013683 | 1.384940e+05 | 377.982886 | 121.601675 | 1.125189 |
| min | 1916.000000 | 7.000000 | 1.180000 | 2.180000e+02 | 1.620000e+02 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 5.000000e+00 | 1.000000 | 1.000000 | 1.600000 |
| 25% | 1999.000000 | 93.000000 | 1.850000 | 6.000000e+06 | 5.340988e+06 | 7.000000 | 614.500000 | 281.000000 | 133.000000 | 1411.250000 | 0.000000 | 0.000000 | 8.599250e+03 | 65.000000 | 50.000000 | 5.800000 |
| 50% | 2005.000000 | 103.000000 | 2.350000 | 2.000000e+07 | 2.551750e+07 | 49.000000 | 988.000000 | 595.000000 | 371.500000 | 3091.000000 | 166.000000 | 1.000000 | 3.437100e+04 | 156.000000 | 110.000000 | 6.600000 |
| 75% | 2011.000000 | 118.000000 | 2.350000 | 4.500000e+07 | 6.230944e+07 | 194.750000 | 11000.000000 | 918.000000 | 636.000000 | 13758.750000 | 3000.000000 | 2.000000 | 9.634700e+04 | 326.000000 | 195.000000 | 7.200000 |
| max | 2016.000000 | 511.000000 | 16.000000 | 1.221550e+10 | 7.605058e+08 | 23000.000000 | 640000.000000 | 137000.000000 | 23000.000000 | 656730.000000 | 349000.000000 | 43.000000 | 1.689764e+06 | 5060.000000 | 813.000000 | 9.500000 |
The describe method displays below information for each of the columns.
- the count or number of values
- mean
- standard deviation
- minimum, maximum
- 25%, 50%, and 75% quantile
Please note that this information will be calculated only for the numeric values.
We can also use the corresponding method to access this information one at a time. For example, to get the mean of a particular column, you can use the mean method on that column.
movies["Gross Earnings"].mean()48468407.526809327Just like mean, there are methods available for each of the statistical information we want to access. You can read about these methods in our free pandas cheat sheet.
Reading files with no header and skipping records
Earlier in this tutorial, we saw some ways to read a particular kind of Excel file that had headers and no rows that needed skipping. Sometimes, the Excel sheet doesn’t have any header row. For such instances, you can tell pandas not to consider the first row as header or columns names. And If the Excel sheet’s first few rows contain data that should not be read in, you can ask the read_excel method to skip a certain number of rows, starting from the top.
For example, look at the top few rows of this Excel file.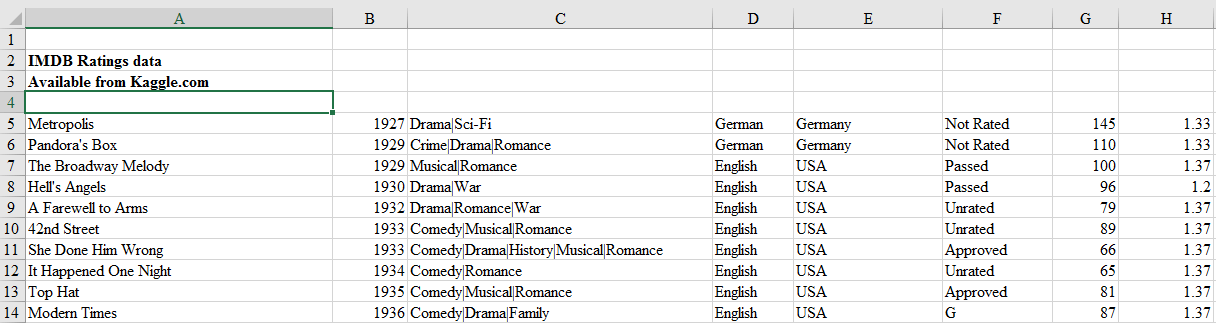
This file obviously has no header and first four rows are not actual records and hence should not be read in. We can tell read_excel there is no header by setting argument header to None and we can skip first four rows by setting argument skiprows to four.
movies_skip_rows = pd.read_excel("movies-no-header-skip-rows.xls", header=None, skiprows=4)
movies_skip_rows.head(5)| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | … | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Metropolis | 1927 | Drama|Sci-Fi | German | Germany | Not Rated | 145 | 1.33 | 6000000.0 | 26435.0 | … | 136 | 23 | 18.0 | 203 | 12000 | 1 | 111841 | 413 | 260.0 | 8.3 |
| 1 | Pandora’s Box | 1929 | Crime|Drama|Romance | German | Germany | Not Rated | 110 | 1.33 | NaN | 9950.0 | … | 426 | 20 | 3.0 | 455 | 926 | 1 | 7431 | 84 | 71.0 | 8.0 |
| 2 | The Broadway Melody | 1929 | Musical|Romance | English | USA | Passed | 100 | 1.37 | 379000.0 | 2808000.0 | … | 77 | 28 | 4.0 | 109 | 167 | 8 | 4546 | 71 | 36.0 | 6.3 |
| 3 | Hell’s Angels | 1930 | Drama|War | English | USA | Passed | 96 | 1.20 | 3950000.0 | NaN | … | 431 | 12 | 4.0 | 457 | 279 | 1 | 3753 | 53 | 35.0 | 7.8 |
| 4 | A Farewell to Arms | 1932 | Drama|Romance|War | English | USA | Unrated | 79 | 1.37 | 800000.0 | NaN | … | 998 | 164 | 99.0 | 1284 | 213 | 1 | 3519 | 46 | 42.0 | 6.6 |
5 rows × 25 columns
We skipped four rows from the sheet and used none of the rows as the header. Also, notice that one can combine different options in a single read statement. To skip rows at the bottom of the sheet, you can use option skip_footer, which works just like skiprows, the only difference being the rows are counted from the bottom upwards.
The column names in the previous DataFrame are numeric and were allotted as default by the pandas. We can rename the column names to descriptive ones by calling the method columns on the DataFrame and passing the column names as a list.
movies_skip_rows.columns = ['Title', 'Year', 'Genres', 'Language', 'Country', 'Content Rating', 'Duration', 'Aspect Ratio', 'Budget', 'Gross Earnings', 'Director', 'Actor 1', 'Actor 2', 'Actor 3', 'Facebook Likes - Director', 'Facebook Likes - Actor 1', 'Facebook Likes - Actor 2', 'Facebook Likes - Actor 3', 'Facebook Likes - cast Total', 'Facebook likes - Movie', 'Facenumber in posters', 'User Votes', 'Reviews by Users', 'Reviews by Crtiics', 'IMDB Score']
movies_skip_rows.head()| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | … | Facebook Likes — Actor 1 | Facebook Likes — Actor 2 | Facebook Likes — Actor 3 | Facebook Likes — cast Total | Facebook likes — Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Metropolis | 1927 | Drama|Sci-Fi | German | Germany | Not Rated | 145 | 1.33 | 6000000.0 | 26435.0 | … | 136 | 23 | 18.0 | 203 | 12000 | 1 | 111841 | 413 | 260.0 | 8.3 |
| 1 | Pandora’s Box | 1929 | Crime|Drama|Romance | German | Germany | Not Rated | 110 | 1.33 | NaN | 9950.0 | … | 426 | 20 | 3.0 | 455 | 926 | 1 | 7431 | 84 | 71.0 | 8.0 |
| 2 | The Broadway Melody | 1929 | Musical|Romance | English | USA | Passed | 100 | 1.37 | 379000.0 | 2808000.0 | … | 77 | 28 | 4.0 | 109 | 167 | 8 | 4546 | 71 | 36.0 | 6.3 |
| 3 | Hell’s Angels | 1930 | Drama|War | English | USA | Passed | 96 | 1.20 | 3950000.0 | NaN | … | 431 | 12 | 4.0 | 457 | 279 | 1 | 3753 | 53 | 35.0 | 7.8 |
| 4 | A Farewell to Arms | 1932 | Drama|Romance|War | English | USA | Unrated | 79 | 1.37 | 800000.0 | NaN | … | 998 | 164 | 99.0 | 1284 | 213 | 1 | 3519 | 46 | 42.0 | 6.6 |
5 rows × 25 columns
Now that we have seen how to read a subset of rows from the Excel file, we can learn how to read a subset of columns.
Reading a subset of columns
Although read_excel defaults to reading and importing all columns, you can choose to import only certain columns. By passing parse_cols=6, we are telling the read_excel method to read only the first columns till index six or first seven columns (the first column being indexed zero).
movies_subset_columns = pd.read_excel(excel_file, parse_cols=6)
movies_subset_columns.head()| Title | Year | Genres | Language | Country | Content Rating | Duration | |
|---|---|---|---|---|---|---|---|
| 0 | Intolerance: Love’s Struggle Throughout the Ages | 1916 | Drama|History|War | NaN | USA | Not Rated | 123 |
| 1 | Over the Hill to the Poorhouse | 1920 | Crime|Drama | NaN | USA | NaN | 110 |
| 2 | The Big Parade | 1925 | Drama|Romance|War | NaN | USA | Not Rated | 151 |
| 3 | Metropolis | 1927 | Drama|Sci-Fi | German | Germany | Not Rated | 145 |
| 4 | Pandora’s Box | 1929 | Crime|Drama|Romance | German | Germany | Not Rated | 110 |
Alternatively, you can pass in a list of numbers, which will let you import columns at particular indexes.
Applying formulas on the columns
One of the much-used features of Excel is to apply formulas to create new columns from existing column values. In our Excel file, we have Gross Earnings and Budget columns. We can get Net earnings by subtracting Budget from Gross earnings. We could then apply this formula in the Excel file to all the rows. We can do this in pandas also as shown below.
movies["Net Earnings"] = movies["Gross Earnings"] - movies["Budget"]Above, we used pandas to create a new column called Net Earnings, and populated it with the difference of Gross Earnings and Budget. It’s worth noting the difference here in how formulas are treated in Excel versus pandas. In Excel, a formula lives in the cell and updates when the data changes — with Python, the calculations happen and the values are stored — if Gross Earnings for one movie was manually changed, Net Earnings won’t be updated.
Let’s use the sort_values method to sort the data by the new column we created and visualize the top 10 movies by Net Earnings.
sorted_movies = movies[['Net Earnings']].sort_values(['Net Earnings'], ascending=[False])sorted_movies.head(10)['Net Earnings'].plot.barh()
plt.show()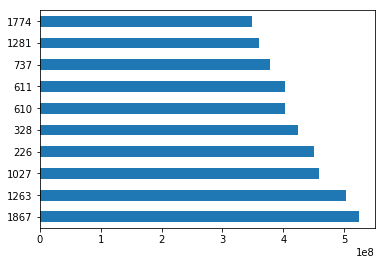
Pivot Table in pandas
Advanced Excel users also often use pivot tables. A pivot table summarizes the data of another table by grouping the data on an index and applying operations such as sorting, summing, or averaging. You can use this feature in pandas too.
We need to first identify the column or columns that will serve as the index, and the column(s) on which the summarizing formula will be applied. Let’s start small, by choosing Year as the index column and Gross Earnings as the summarization column and creating a separate DataFrame from this data.
movies_subset = movies[['Year', 'Gross Earnings']]
movies_subset.head()| Year | Gross Earnings | |
|---|---|---|
| 0 | 1916.0 | NaN |
| 1 | 1920.0 | 3000000.0 |
| 2 | 1925.0 | NaN |
| 3 | 1927.0 | 26435.0 |
| 4 | 1929.0 | 9950.0 |
We now call pivot_table on this subset of data. The method pivot_table takes a parameter index. As mentioned, we want to use Year as the index.
earnings_by_year = movies_subset.pivot_table(index=['Year'])
earnings_by_year.head()| Gross Earnings | |
|---|---|
| Year | |
| 1916.0 | NaN |
| 1920.0 | 3000000.0 |
| 1925.0 | NaN |
| 1927.0 | 26435.0 |
| 1929.0 | 1408975.0 |
This gave us a pivot table with grouping on Year and summarization on the sum of Gross Earnings. Notice, we didn’t need to specify Gross Earnings column explicitly as pandas automatically identified it the values on which summarization should be applied.
We can use this pivot table to create some data visualizations. We can call the plot method on the DataFrame to create a line plot and call the show method to display the plot in the notebook.
earnings_by_year.plot()
plt.show()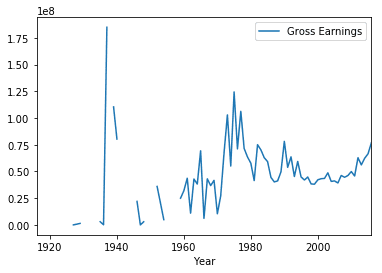
We saw how to pivot with a single column as the index. Things will get more interesting if we can use multiple columns. Let’s create another DataFrame subset but this time we will choose the columns, Country, Language and Gross Earnings.
movies_subset = movies[['Country', 'Language', 'Gross Earnings']]
movies_subset.head()| Country | Language | Gross Earnings | |
|---|---|---|---|
| 0 | USA | NaN | NaN |
| 1 | USA | NaN | 3000000.0 |
| 2 | USA | NaN | NaN |
| 3 | Germany | German | 26435.0 |
| 4 | Germany | German | 9950.0 |
We will use columns Country and Language as the index for the pivot table. We will use Gross Earnings as summarization table, however, we do not need to specify this explicitly as we saw earlier.
earnings_by_co_lang = movies_subset.pivot_table(index=['Country', 'Language'])
earnings_by_co_lang.head()| Gross Earnings | ||
|---|---|---|
| Country | Language | |
| Afghanistan | Dari | 1.127331e+06 |
| Argentina | Spanish | 7.230936e+06 |
| Aruba | English | 1.007614e+07 |
| Australia | Aboriginal | 6.165429e+06 |
| Dzongkha | 5.052950e+05 |
Let’s visualize this pivot table with a bar plot. Since there are still few hundred records in this pivot table, we will plot just a few of them.
earnings_by_co_lang.head(20).plot(kind='bar', figsize=(20,8))
plt.show()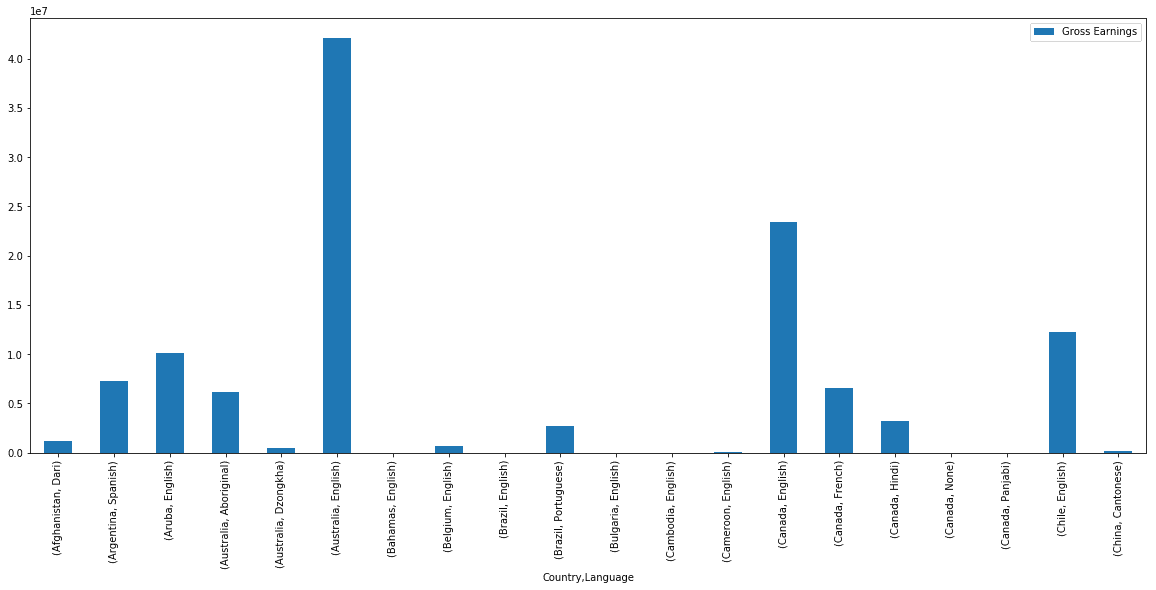
Exporting the results to Excel
If you’re going to be working with colleagues who use Excel, saving Excel files out of pandas is important. You can export or write a pandas DataFrame to an Excel file using pandas to_excel method. Pandas uses the xlwt Python module internally for writing to Excel files. The to_excel method is called on the DataFrame we want to export.We also need to pass a filename to which this DataFrame will be written.
movies.to_excel('output.xlsx')By default, the index is also saved to the output file. However, sometimes the index doesn’t provide any useful information. For example, the movies DataFrame has a numeric auto-increment index, that was not part of the original Excel data.
movies.head()| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | … | Facebook Likes — Actor 2 | Facebook Likes — Actor 3 | Facebook Likes — cast Total | Facebook likes — Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | Net Earnings | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Intolerance: Love’s Struggle Throughout the Ages | 1916.0 | Drama|History|War | NaN | USA | Not Rated | 123.0 | 1.33 | 385907.0 | NaN | … | 22.0 | 9.0 | 481 | 691 | 1.0 | 10718 | 88.0 | 69.0 | 8.0 | NaN |
| 1 | Over the Hill to the Poorhouse | 1920.0 | Crime|Drama | NaN | USA | NaN | 110.0 | 1.33 | 100000.0 | 3000000.0 | … | 2.0 | 0.0 | 4 | 0 | 1.0 | 5 | 1.0 | 1.0 | 4.8 | 2900000.0 |
| 2 | The Big Parade | 1925.0 | Drama|Romance|War | NaN | USA | Not Rated | 151.0 | 1.33 | 245000.0 | NaN | … | 12.0 | 6.0 | 108 | 226 | 0.0 | 4849 | 45.0 | 48.0 | 8.3 | NaN |
| 3 | Metropolis | 1927.0 | Drama|Sci-Fi | German | Germany | Not Rated | 145.0 | 1.33 | 6000000.0 | 26435.0 | … | 23.0 | 18.0 | 203 | 12000 | 1.0 | 111841 | 413.0 | 260.0 | 8.3 | -5973565.0 |
| 4 | Pandora’s Box | 1929.0 | Crime|Drama|Romance | German | Germany | Not Rated | 110.0 | 1.33 | NaN | 9950.0 | … | 20.0 | 3.0 | 455 | 926 | 1.0 | 7431 | 84.0 | 71.0 | 8.0 | NaN |
5 rows × 26 columns
You can choose to skip the index by passing along index-False.
movies.to_excel('output.xlsx', index=False)We need to be able to make our output files look nice before we can send it out to our co-workers. We can use pandas ExcelWriter class along with the XlsxWriter Python module to apply the formatting.
We can do use these advanced output options by creating a ExcelWriter object and use this object to write to the EXcel file.
writer = pd.ExcelWriter('output.xlsx', engine='xlsxwriter')
movies.to_excel(writer, index=False, sheet_name='report')
workbook = writer.bookworksheet = writer.sheets['report']We can apply customizations by calling add_format on the workbook we are writing to. Here we are setting header format as bold.
header_fmt = workbook.add_format({'bold': True})
worksheet.set_row(0, None, header_fmt)Finally, we save the output file by calling the method save on the writer object.
writer.save()As an example, we saved the data with column headers set as bold. And the saved file looks like the image below.
Like this, one can use XlsxWriter to apply various formatting to the output Excel file.
Conclusion
Pandas is not a replacement for Excel. Both tools have their place in the data analysis workflow and can be very great companion tools. As we demonstrated, pandas can do a lot of complex data analysis and manipulations, which depending on your need and expertise, can go beyond what you can achieve if you are just using Excel. One of the major benefits of using Python and pandas over Excel is that it helps you automate Excel file processing by writing scripts and integrating with your automated data workflow. Pandas also has excellent methods for reading all kinds of data from Excel files. You can export your results from pandas back to Excel too if that’s preferred by your intended audience.
On the other hand, Excel is a such a widely used data tool, it’s not a wise to ignore it. Acquiring expertise in both pandas and Excel and making them work together gives you skills that can help you stand out in your organization.
If you’d like to learn more about this topic, check out Dataquest’s interactive Pandas and NumPy Fundamentals course, and our Data Analyst in Python, and Data Scientist in Python paths that will help you become job-ready in around 6 months.
Close: first you call ExcelFile, but then you call the .parse method and pass it the sheet name.
>>> xl = pd.ExcelFile("dummydata.xlsx")
>>> xl.sheet_names
[u'Sheet1', u'Sheet2', u'Sheet3']
>>> df = xl.parse("Sheet1")
>>> df.head()
Tid dummy1 dummy2 dummy3 dummy4 dummy5
0 2006-09-01 00:00:00 0 5.894611 0.605211 3.842871 8.265307
1 2006-09-01 01:00:00 0 5.712107 0.605211 3.416617 8.301360
2 2006-09-01 02:00:00 0 5.105300 0.605211 3.090865 8.335395
3 2006-09-01 03:00:00 0 4.098209 0.605211 3.198452 8.170187
4 2006-09-01 04:00:00 0 3.338196 0.605211 2.970015 7.765058
dummy6 dummy7 dummy8 dummy9
0 0.623354 0 2.579108 2.681728
1 0.554211 0 7.210000 3.028614
2 0.567841 0 6.940000 3.644147
3 0.581470 0 6.630000 4.016155
4 0.595100 0 6.350000 3.974442
What you’re doing is calling the method which lives on the class itself, rather than the instance, which is okay (although not very idiomatic), but if you’re doing that you would also need to pass the sheet name:
>>> parsed = pd.io.parsers.ExcelFile.parse(xl, "Sheet1")
>>> parsed.columns
Index([u'Tid', u'dummy1', u'dummy2', u'dummy3', u'dummy4', u'dummy5', u'dummy6', u'dummy7', u'dummy8', u'dummy9'], dtype=object)
Хотя многие Data Scientist’ы больше привыкли работать с CSV-файлами, на практике очень часто приходится сталкиваться с обычными Excel-таблицами. Поэтому сегодня мы расскажем, как читать Excel-файлы в Pandas, а также рассмотрим основные возможности Python-библиотеки OpenPyXL для чтения метаданных ячеек.
Дополнительные зависимости для возможности чтения Excel таблиц
Для чтения таблиц Excel в Pandas требуются дополнительные зависимости:
- xlrd поддерживает старые и новые форматы MS Excel [1];
- OpenPyXL поддерживает новые форматы MS Excel (.xlsx) [2];
- ODFpy поддерживает свободные форматы OpenDocument (.odf, .ods и .odt) [3];
- pyxlsb поддерживает бинарные MS Excel файлы (формат .xlsb) [4].
Мы рекомендуем установить только OpenPyXL, поскольку он нам пригодится в дальнейшем. Для этого в командной строке прописывается следующая операция:
pip install openpyxl
Затем в Pandas нужно указать путь к Excel-файлу и одну из установленных зависимостей. Python-код выглядит следующим образом:
import pandas as pd
pd.read_excel(io='temp1.xlsx', engine='openpyxl')
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
Читаем несколько листов
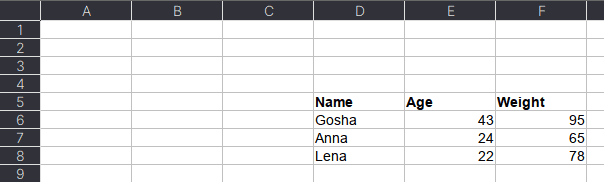
Excel-файл может содержать несколько листов. В Pandas, чтобы прочитать конкретный лист, в аргументе нужно указать sheet_name. Можно указать список названий листов, тогда Pandas вернет словарь (dict) с объектами DataFrame:
dfs = pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
sheet_name=['Sheet1', 'Sheet2'])
dfs
#
{'Sheet1': Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64,
'Sheet2': Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78}
Если таблицы в словаре имеют одинаковые атрибуты, то их можно объединить в один DataFrame. В Python это выглядит так:
pd.concat(dfs).reset_index(drop=True)
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
3 Gosha 43 95
4 Anna 24 65
5 Lena 22 78
Указание диапазонов
Таблицы могут размещаться не в самом начале, а как, например, на рисунке ниже. Как видим, таблица располагается в диапазоне A:F.
Чтобы прочитать такую таблицу, нужно указать диапазон в аргументе usecols. Также дополнительно можно добавить header — номер заголовка таблицы, а также nrows — количество строк, которые нужно прочитать. В аргументе header всегда передается номер строки на единицу меньше, чем в Excel-файле, поскольку в Python индексация начинается с 0 (на рисунке это номер 5, тогда указываем 4):
pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
usecols='D:F',
header=4, # в excel это №5
nrows=3)
#
Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78
Читаем таблицы в OpenPyXL
Pandas прочитывает только содержимое таблицы, но игнорирует метаданные: цвет заливки ячеек, примечания, стили таблицы и т.д. В таком случае пригодится библиотека OpenPyXL. Загрузка файлов осуществляется через функцию load_workbook, а к листам обращаться можно через квадратные скобки:
from openpyxl import load_workbook
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
type(ws)
# openpyxl.worksheet.worksheet.Worksheet
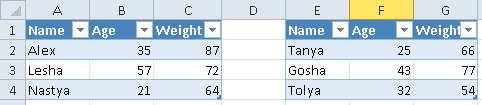
Допустим, имеется Excel-файл с несколькими таблицами на листе (см. рисунок выше). Если бы мы использовали Pandas, то он бы выдал следующий результат:
pd.read_excel(io='temp2.xlsx',
engine='openpyxl')
#
Name Age Weight Unnamed: 3 Name.1 Age.1 Weight.1
0 Alex 35 87 NaN Tanya 25 66
1 Lesha 57 72 NaN Gosha 43 77
2 Nastya 21 64 NaN Tolya 32 54
Можно, конечно, заняться обработкой и привести таблицы в нормальный вид, а можно воспользоваться OpenPyXL, который хранит таблицу и его диапазон в словаре. Чтобы посмотреть этот словарь, нужно вызвать ws.tables.items. Вот так выглядит Python-код:
ws.tables.items()
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
ws.tables.items()
#
[('Таблица1', 'A1:C4'), ('Таблица13', 'E1:G4')]
Обращаясь к каждому диапазону, можно проходить по каждой строке или столбцу, а внутри них – по каждой ячейке. Например, следующий код на Python таблицы объединяет строки в список, где первая строка уходит на заголовок, а затем преобразует их в DataFrame:
dfs = []
for table_name, value in ws.tables.items():
table = ws[value]
header, *body = [[cell.value for cell in row]
for row in table]
df = pd.DataFrame(body, columns=header)
dfs.append(df)
Если таблицы имеют одинаковые атрибуты, то их можно соединить в одну:
pd.concat(dfs)
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
0 Tanya 25 66
1 Gosha 43 77
2 Tolya 32 54
Сохраняем метаданные таблицы
Как указано в коде выше, у ячейки OpenPyXL есть атрибут value, который хранит ее значение. Помимо value, можно получить тип ячейки (data_type), цвет заливки (fill), примечание (comment) и др.
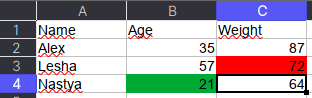
Например, требуется сохранить данные о цвете ячеек. Для этого мы каждую ячейку с числами перезапишем в виде <значение,RGB>, где RGB — значение цвета в формате RGB (red, green, blue). Python-код выглядит следующим образом:
# _TYPES = {int:'n', float:'n', str:'s', bool:'b'}
data = []
for row in ws.rows:
row_cells = []
for cell in row:
cell_value = cell.value
if cell.data_type == 'n':
cell_value = f"{cell_value},{cell.fill.fgColor.rgb}"
row_cells.append(cell_value)
data.append(row_cells)
Первым элементом списка является строка-заголовок, а все остальное уже значения таблицы:
pd.DataFrame(data[1:], columns=data[0])
#
Name Age Weight
0 Alex 35,00000000 87,00000000
1 Lesha 57,00000000 72,FFFF0000
2 Nastya 21,FF00A933 64,00000000
Теперь представим атрибуты в виде индексов с помощью метода stack, а после разобьём все записи на значение и цвет методом str.split:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
)
#
0 1
Name
Alex Age 35 00000000
Weight 87 00000000
Lesha Age 57 00000000
Weight 72 FFFF0000
Nastya Age 21 FF00A933
Weight 64 0000000
Осталось только переименовать 0 и 1 на Value и Color, а также добавить атрибут Variable, который обозначит Вес и Возраст. Полный код на Python выглядит следующим образом:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
.set_axis(['Value', 'Color'], axis=1)
.rename_axis(index=['Name', 'Variable'])
.reset_index()
)
#
Name Variable Value Color
0 Alex Age 35 00000000
1 Alex Weight 87 00000000
2 Lesha Age 57 00000000
3 Lesha Weight 72 FFFF0000
4 Nastya Age 21 FF00A933
5 Nastya Weight 64 00000000
Ещё больше подробностей о работе с таблицами в Pandas, а также их обработке на реальных примерах Data Science задач, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники
- https://xlrd.readthedocs.io/en/latest/
- https://openpyxl.readthedocs.io/en/latest/
- https://github.com/eea/odfpy
- https://github.com/willtrnr/pyxlsb
In this Pandas tutorial, we will learn how to work with Excel files (e.g., xls) in Python. It will provide an overview of how to use Pandas to load xlsx files and write spreadsheets to Excel.
In the first section, we will go through, with examples, how to use Pandas read_excel to; 1) read an Excel file, 2) read specific columns from a spreadsheet, 3) read multiple spreadsheets, and combine them to one dataframe. Furthermore, we are going to learn how to read many Excel files, and how to convert data according to specific data types (e.g., using Pandas dtypes).
When we have done this, we will continue by learning how to use Pandas to write Excel files; how to name the sheets and how to write to multiple sheets. Make sure to check out the newer post about reading xlsx files in Python with openpyxl, as well.
- Read the How to import Excel into R blog post if you need an overview on how to read xlsx files into R dataframes.
How to Install Pandas
Before we continue with this Pandas read and write Excel files tutorial there is something we need to do; installing Pandas (and Python, of course, if it’s not installed). We can install Pandas using Pip, given that we have Pip installed, that is. See here how to install pip.
# Linux Users
pip install pandas
# Windows Users
python pip install pandasCode language: Bash (bash)Note, if pip is telling us that there’s a newer version of pip, we may want to upgrade it. In a recent post, we cover how to upgrade pip to the latest version. Finally, before going on to the next section, you can use pip to install a certain version (i.e., older) of a packages usch as Pandas.
Installing Anaconda Scientific Python Distribution
Another great option is to consider is to install the Anaconda Python distribution. This is really an easy and fast way to get started with computer science. No need to worry about installing the packages you need to do computer science separately.
Both of the above methods are explained in this tutorial. Now, in a more recent blog post, we also cover how to install a Python package using pip, conda, and Anaconda. In that post, you will find more information about installing Python packages.
How to Read Excel Files to Pandas Dataframes:
Can Pandas read xlsx files? The short answer is, of course, “yes”. In this section, we are going to learn how to read Excel files and spreadsheets to Pandas dataframe objects. All examples in this Pandas Excel tutorial use local files. Note, that read_excel also can also load Excel files from a URL to a dataframe. As always when working with Pandas, we have to start by importing the module:
import pandas as pdCode language: Python (python)Now it’s time to learn how to use Pandas read_excel to read in data from an Excel file. The easiest way to use this method is to pass the file name as a string. If we don’t pass any other parameters, such as sheet name, it will read the first sheet in the index. In the first example, we are not going to use any parameters:
# Pandas read xlsx
df = pd.read_excel('MLBPlayerSalaries.xlsx')
df.head()Code language: Python (python)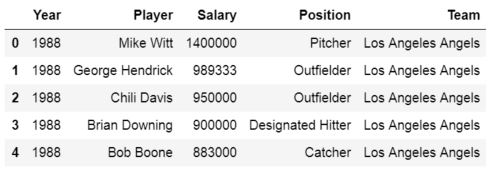
Here, Pandas read_excel method read the data from the Excel file into a Pandas dataframe object. We then stored this dataframe into a variable called df.
When using read_excel Pandas will, by default, assign a numeric index or row label to the dataframe, and as usual, when int comes to Python, the index will start with zero. We may have a reason to leave the default index as it is.
For instance, if your data doesn’t have a column with unique values that can serve as a better index. In case there is a column that would serve as a better index, we can override the default behavior.
Setting the Index Column when Reading xls File
This is done by setting the index_col parameter to a column. It takes a numeric value for setting a single column as index or a list of numeric values for creating a multi-index. In the example below, we use the column ‘Player’ as indices. Note, these are not unique and it may, thus, not make sense to use these values as indices.
df = pd.read_excel('MLBPlayerSalaries.xlsx', sheet_names='MLBPlayerSalaries', index_col='Player')Code language: Python (python)Now, if one or two of your columns, for instance, are objects you use Pandas to_datetime to convert a column, properly.
Importing an Excel File to Pandas in Two Easy Steps:
Time needed: 1 minute.
Here’s a quick answer to the How do you import an Excel file into Python using Pandas? Importing an Excel file into a Pandas dataframe basically only requires two steps, given that we know the path, or URL, to the Excel file:
- Import Pandas
In the script type import pandas as pd

- Use Pandas read_excel method
Next step is to type df = pd.read_excel(FILE_PATH_OR_URL)
Remember to change FILE_PATH_OR_URL to the path or the URL of the Excel file.


Now that we know how easy it is to load an Excel file into a Pandas dataframe we are going to continue with learning more about the read_excel method.
Reading Specific Columns using Pandas read_excel
When using Pandas read_excel we will automatically get all columns from an Excel file. If we, for some reason, don’t want to parse all columns in the Excel file, we can use the parameter usecols. Let’s say we want to create a dataframe with the columns Player, Salary, and Position, only. We can do this by adding 1, 3, and 4 in a list:
cols = [1, 2, 3]
df = pd.read_excel('MLBPlayerSalaries.xlsx', sheet_names='MLBPlayerSalaries', usecols=cols)
df.head()Code language: Python (python)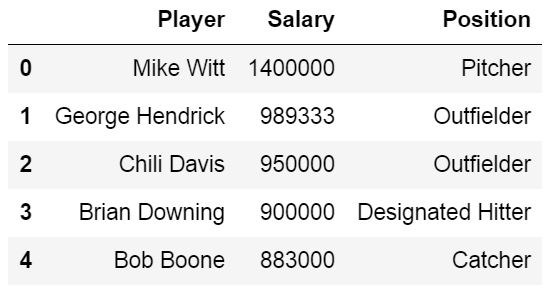
According to the read_excel documentation, we should be able to put in a string. For instance, cols=’Player:Position’ should give us the same results as above.
Handling Missing Data using Pandas read_excel
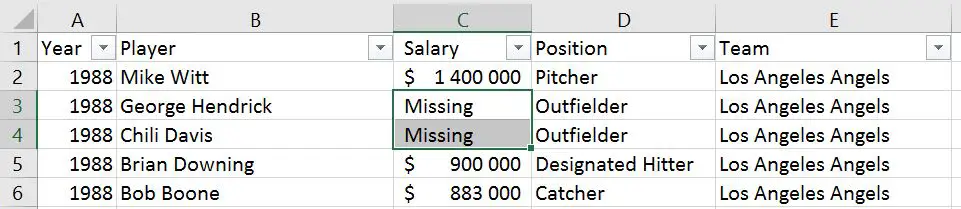
If our data has missing values in some cells and these missing values are coded in some way, like “Missing” we can use the na_values parameter.
Pandas Read Excel Example with Missing Data
In the example below, we are using the parameter na_values and we are putting in a string (i.e., “Missing’):
df = pd.read_excel('MLBPlayerSalaries_MD.xlsx', na_values="Missing", sheet_names='MLBPlayerSalaries', usecols=cols)
df.head()Code language: Python (python)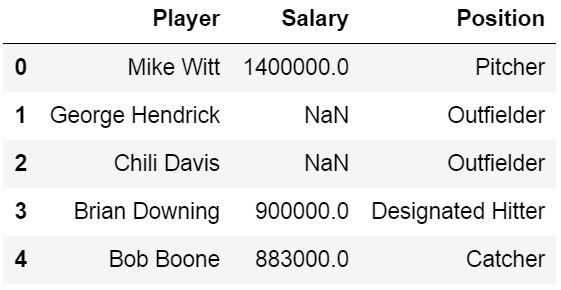
In the read excel examples above we used a dataset that can be downloaded from this page.
- Read the post Data manipulation with Pandas for three methods on data manipulation of dataframes, including missing data.
- Learn easy methods to clean data using Pandas and Pyjanitor
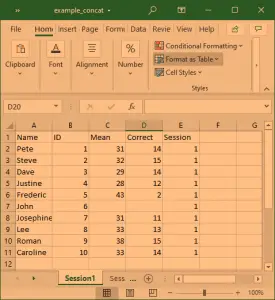
How to Skip Rows when Reading an Excel File
Now we will learn how to skip rows when loading an Excel file using Pandas. For this read excel example, we will use data that can be downloaded here.

In the following Pandas read_excel example we load the sheet ‘session1’, which contains rows that we need to skip (these rows contain some information about the dataset).
We will use the parameter sheet_name=’Session1′ to read the sheet named ‘Session1’ (the example data contains more sheets; e.g., ‘Session2’ will load that sheet). Note, the first sheet will be read if we don’t use the sheet_name parameter. In this example, the important part is the parameter skiprow=2. We use this to skip the first two rows:
df = pd.read_excel('example_sheets1.xlsx', sheet_name='Session1', skiprows=2)
df.head()Code language: Python (python)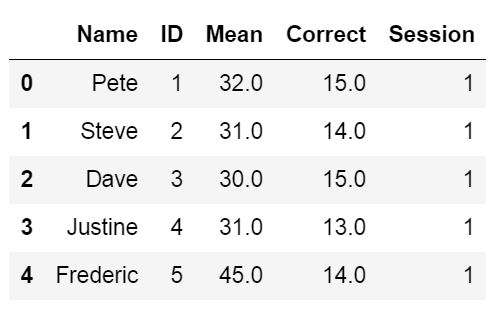
Another way to get Pandas read_excel to read from the Nth row is by using the header parameter. In the example Excel file, we use here, the third row contains the headers and we will use the parameter header=2 to tell Pandas read_excel that our headers are on the third row.
df = pd.read_excel('example_sheets1.xlsx', sheet_name='Session1', header=2)Code language: Python (python)Now, if we want Pandas read_excel to read from the second row, we change the number in the skiprows and header arguments to 2, and so on.
Reading Multiple Excel Sheets to Pandas Dataframes
In this section, of the Pandas read excel tutorial, we are going to learn how to read multiple sheets. Our Excel file, example_sheets1.xlsx’, has two sheets: ‘Session1’, and ‘Session2.’ Each sheet has data from an imagined experimental session. In the next example we are going to read both sheets, ‘Session1’ and ‘Session2’. Here’s how to use Pandas read_excel to read multiple sheets:
df = pd.read_excel('example_sheets1.xlsx',
sheet_name=['Session1', 'Session2'], skiprows=2)Code language: Python (python)By using the parameter sheet_name, and a list of names, we will get an ordered dictionary containing two dataframes:
dfCode language: Python (python)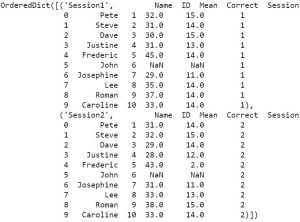
When working with Pandas read_excel we may want to join the data from all sheets (in this case sessions). Merging Pandas dataframes are quite easy; we just use the concat function and loop over the keys (i.e., sheets):
df2 = pd.concat(df[frame] for frame in data.keys())Code language: Python (python)Now in the example Excel file, there is a column identifying the dataset (e.g., session number). However, maybe we don’t have that kind of information in our Excel file. To merge the two dataframes and adding a column depicting which session we can use a for loop:
dfs = []
for framename in data.keys():
temp_df = data[framename]
temp_df['Session'] = framename
dfs.append(temp_df)
df = pd.concat(dfs)Code language: Python (python)In the code above, we start by creating a list and continue by looping through the keys in the list of dataframes. Finally, we create a temporary dataframe and take the sheet name and add it in the column ‘Session’.
Pandas Read Excel: How to Read All Sheets
Now, it is, of course, possible that when we want to read multiple sheets we also want to read all the sheets in the Excel file. That is, if we want to use read_excel to load all sheets from an Excel file to a dataframe it is possible. When reading multiple sheets and we want all sheets we can set the parameter sheet_name to None.
all_sheets_df = pd.read_excel('example_sheets1.xlsx', sheet_name=None)Code language: Python (python)Pandas Read Excel: Reading Many Excel Files
In this section, of the Pandas read excel tutorial, we will learn how to load many files into a Pandas dataframe because, in some cases, we may have a lot of Excel files containing data from, let’s say, different experiments. In Python, we can use the modules os and fnmatch to read all files in a directory. Finally, we use list comprehension to use read_excel on all files we found:
import os, fnmatch
xlsx_files = fnmatch.filter(os.listdir('.'), '*concat*.xlsx')
dfs = [pd.read_excel(xlsx_file) for xlsx_file in xlsx_files]Code language: Python (python)If it makes sense we can, again, use the function concat to merge the dataframes:
df = pd.concat(dfs, sort=False)Code language: Python (python)There are other methods for reading many Excel files and merging them. We can, for instance, use the module glob together with Pandas concat to read multiple xlsx files:
import glob
list_of_xlsx = glob.glob('./*concat*.xlsx')
df = pd.concat(list_of_xlsx)Code language: Python (python)Note, the files in this example, where we read multiple xlsx files using Pandas, are located here. They are named example_concat.xlsx, example_concat1.xlsx, and example_concat3.xlsx and should be added to the same directory as the Python script. Another option, of course, is to add the file path to the files. E.g., if we want to read multiple Excel files, using Pandas read_excel method, and they are stored in a directory called “SimData” we would do as follows:
import glob
list_of_xlsx = glob.glob('./SimData/*concat*.xlsx')
df = pd.concat(list_of_xlsx)Code language: Python (python)Setting the Data Type for Data or Columns
If we need to, we can also, set the data type for the columns when reading Excel files using Pandas. Let’s use Pandas to read the example_sheets1.xlsx again. In the Pandas read_excel example below we use the dtype parameter to set the data type of some of the columns.
df = pd.read_excel('example_sheets1.xlsx',sheet_name='Session1',
header=1,dtype={'Names':str,'ID':str,
'Mean':int, 'Session':str})Code language: Python (python)We can use the method info to see the what data types the different columns have:
df.info()Code language: Python (python)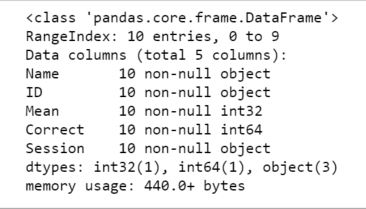
Writing Pandas Dataframes to Excel
Excel files can, of course, be created in Python using Pandas to_excel method. In this section of the post, we will learn how to create an excel file using Pandas. First, before writing an Excel file, we will create a dataframe containing some variables. Before that, we need to import Pandas:
import pandas as pdCode language: Python (python)The next step is to create the dataframe. We will create the dataframe using a dictionary. The keys will be the column names and the values will be lists containing our data:
df = pd.DataFrame({'Names':['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
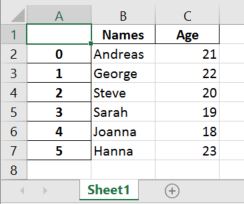
'Age':[21, 22, 20, 19, 18, 23]})Code language: Python (python)In this Pandas write to Excel example, we will write the dataframe to an Excel file using the to_excel method. Noteworthy, when using Pandas to_excel in the code chunk below, we don’t use any parameters.
df.to_excel('NamesAndAges.xlsx')Code language: Python (python)In the Excel file created when using Pandas to_excel is shown below. Evidently, if we don’t use the parameter sheet_name we get the default sheet name, ‘Sheet1’. Now, we can also see that we get a new column in our Excel file containing numbers. These are the index from the dataframe.
If we want our sheet to be named something else and we don’t want the index column we can add the following argument and parameters when we use Pandas to write to Excel:
df.to_excel('NamesAndAges.xlsx', sheet_name='Names and Ages', index=False)Code language: Python (python)Writing Multiple Pandas Dataframes to an Excel File:
In this section, we are going to use Pandas ExcelWriter and Pandas to_excel to write multiple Pandas dataframes to one Excel file. That is if we happen to have many dataframes that we want to store in one Excel file but on different sheets, we can do this easily. However, we need to use Pandas ExcelWriter now:
df1 = pd.DataFrame({'Names': ['Andreas', 'George', 'Steve',
'Sarah', 'Joanna', 'Hanna'],
'Age':[21, 22, 20, 19, 18, 23]})
df2 = pd.DataFrame({'Names': ['Pete', 'Jordan', 'Gustaf',
'Sophie', 'Sally', 'Simone'],
'Age':[22, 21, 19, 19, 29, 21]})
df3 = pd.DataFrame({'Names': ['Ulrich', 'Donald', 'Jon',
'Jessica', 'Elisabeth', 'Diana'],
'Age':[21, 21, 20, 19, 19, 22]})
dfs = {'Group1':df1, 'Group2':df2, 'Group3':df3}
writer = pd.ExcelWriter('NamesAndAges.xlsx', engine='xlsxwriter')
for sheet_name in dfs.keys():
dfs[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()Code language: Python (python)In the code above, we create 3 dataframes and then we continue to put them in a dictionary. Note, the keys are the sheet names and the cell names are the dataframes. After this is done we create a writer object using the xlsxwriter engine. We then continue by looping through the keys (i.e., sheet names) and add each sheet. Finally, the file is saved. Note, the final step is important as leaving this out will not give you the intended results.
Of course, there are other ways to store data. One of them is using JSON files. See the latest tutorial on how to read and write JSON files using Pandas to learn about one way to load and save data in the JSON format.
More resources on how to load data in different formats:
- How to read and write CSV files using Pandas
- How to read and write SPSS files using Python
Summary: How to Work With Excel Files using Pandas
That was it! In this post, we have learned a lot! We have, among other things, learned how to:
- Read Excel files and Spreadsheets using read_excel
- Load Excel files to dataframes:
- Read Excel sheets and skip rows
- Merging many sheets to a dataframe
- Loading many Excel files into one dataframe
- Load Excel files to dataframes:
- Write a dataframe to an Excel file
- Taking many dataframes and writing them to one Excel file with many sheets
Leave a comment below if you have any requests or suggestions on what should be covered next! Check the post A Basic Pandas Dataframe Tutorial for Beginners to learn more about working with Pandas dataframe. That is after you have loaded them from a file (e.g., Excel spreadsheets)
Pandas можно использовать для чтения и записи файлов Excel с помощью Python. Это работает по аналогии с другими форматами. В этом материале рассмотрим, как это делается с помощью DataFrame.
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip.
Если у вас Windows, Linux или macOS:
pip install pandas # или pip3В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
ModuleNotFoundError: No module named 'openpyxl'В таком случае нужно установить недостающие модули:
pip install openpyxl xlsxwriter xlrd # или pip3Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame. А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas. Потом используем словарь для заполнения DataFrame:
import pandas as pd
df = pd.DataFrame({'Name': ['Manchester City', 'Real Madrid', 'Liverpool',
'FC Bayern München', 'FC Barcelona', 'Juventus'],
'League': ['English Premier League (1)', 'Spain Primera Division (1)',
'English Premier League (1)', 'German 1. Bundesliga (1)',
'Spain Primera Division (1)', 'Italian Serie A (1)'],
'TransferBudget': [176000000, 188500000, 90000000,
100000000, 180500000, 105000000]})
Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:
df.to_excel('./teams.xlsx')
А вот и созданный файл Excel:

Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
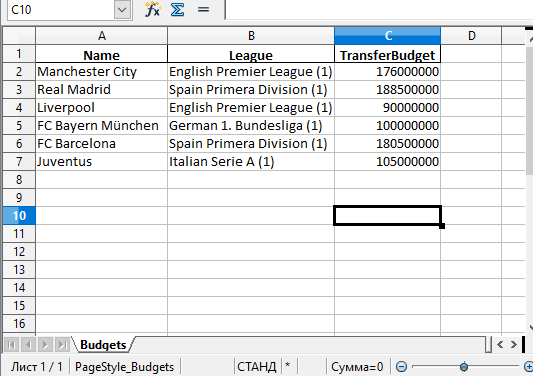
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel():
df.to_excel('./teams.xlsx', sheet_name='Budgets', index=False)
Также можно добавили параметр index со значением False, чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
salaries1 = pd.DataFrame({'Name': ['L. Messi', 'Cristiano Ronaldo', 'J. Oblak'],
'Salary': [560000, 220000, 125000]})
salaries2 = pd.DataFrame({'Name': ['K. De Bruyne', 'Neymar Jr', 'R. Lewandowski'],
'Salary': [370000, 270000, 240000]})
salaries3 = pd.DataFrame({'Name': ['Alisson', 'M. ter Stegen', 'M. Salah'],
'Salary': [160000, 260000, 250000]})
salary_sheets = {'Group1': salaries1, 'Group2': salaries2, 'Group3': salaries3}
writer = pd.ExcelWriter('./salaries.xlsx', engine='xlsxwriter')
for sheet_name in salary_sheets.keys():
salary_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets, где каждый ключ будет названием листа, а значение — объектом DataFrame.
Дальше используем движок xlsxwriter для создания объекта writer. Он и передается функции to_excel().
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
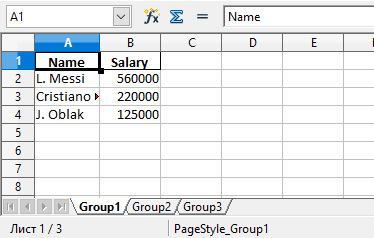
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter, который нужен для работы с классом ExcelWriter. Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save(), которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame. Для этого достаточно воспользоваться функцией read_excel():
top_players = pd.read_excel('./top_players.xlsx')
top_players.head()
Содержимое финального объекта можно посмотреть с помощью функции head().
Примечание:
Этот способ самый простой, но он и способен прочесть лишь содержимое первого листа.
Посмотрим на вывод функции head():
| Name | Age | Overall | Potential | Positions | Club | |
|---|---|---|---|---|---|---|
| 0 | L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| 1 | Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| 2 | J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| 3 | K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| 4 | Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
Pandas присваивает метку строки или числовой индекс объекту DataFrame по умолчанию при использовании функции read_excel().
Это поведение можно переписать, передав одну из колонок из файла в качестве параметра index_col:
top_players = pd.read_excel('./top_players.xlsx', index_col='Name')
top_players.head()
Результат будет следующим:
| Name | Age | Overall | Potential | Positions | Club |
|---|---|---|---|---|---|
| L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
В этом примере индекс по умолчанию был заменен на колонку «Name» из файла. Однако этот способ стоит использовать только при наличии колонки со значениями, которые могут стать заменой для индексов.
Чтение определенных колонок из файла Excel
Иногда удобно прочитать содержимое файла целиком, но бывают случаи, когда требуется получить доступ к определенному элементу. Например, нужно считать значение элемента и присвоить его полю объекта.
Это делается с помощью функции read_excel() и параметра usecols. Например, можно ограничить функцию, чтобы она читала только определенные колонки. Добавим параметр, чтобы он читал колонки, которые соответствуют значениям «Name», «Overall» и «Potential».
Для этого укажем числовой индекс каждой колонки:
cols = [0, 2, 3]
top_players = pd.read_excel('./top_players.xlsx', usecols=cols)
top_players.head()
Вот что выдаст этот код:
| Name | Overall | Potential | |
|---|---|---|---|
| 0 | L. Messi | 93 | 93 |
| 1 | Cristiano Ronaldo | 92 | 92 |
| 2 | J. Oblak | 91 | 93 |
| 3 | K. De Bruyne | 91 | 91 |
| 4 | Neymar Jr | 91 | 91 |
Таким образом возвращаются лишь колонки из списка cols.
В DataFrame много встроенных возможностей. Легко изменять, добавлять и агрегировать данные. Даже можно строить сводные таблицы. И все это сохраняется в Excel одной строкой кода.
Рекомендую изучить DataFrame в моих уроках по Pandas.
Выводы
В этом материале были рассмотрены функции read_excel() и to_excel() из библиотеки Pandas. С их помощью можно считывать данные из файлов Excel и выполнять запись в них. С помощью различных параметров есть возможность менять поведение функций, создавая нужные файлы, не просто копируя содержимое из объекта DataFrame.
Excel sheets are very instinctive and user-friendly, which makes them ideal for manipulating large datasets even for less technical folks. If you are looking for places to learn to manipulate and automate stuff in excel files using Python, look no more. You are at the right place.
Python Pandas With Excel Sheet
In this article, you will learn how to use Pandas to work with Excel spreadsheets. At the end of the article, you will have the knowledge of:
- Necessary modules are needed for this and how to set them up in your system.
- Reading data from excel files into pandas using Python.
- Exploring the data from excel files in Pandas.
- Using functions to manipulate and reshape the data in Pandas.
Installation
To install Pandas in Anaconda, we can use the following command in Anaconda Terminal:
conda install pandas
To install Pandas in regular Python (Non-Anaconda), we can use the following command in the command prompt:
pip install pandas
Getting Started
First of all, we need to import the Pandas module which can be done by running the command: Pandas
Python3
Input File: Let’s suppose the excel file looks like this
Sheet 1:
Sheet 2:
Now we can import the excel file using the read_excel function in Pandas. The second statement reads the data from excel and stores it into a pandas Data Frame which is represented by the variable newData. If there are multiple sheets in the excel workbook, the command will import data of the first sheet. To make a data frame with all the sheets in the workbook, the easiest method is to create different data frames separately and then concatenate them. The read_excel method takes argument sheet_name and index_col where we can specify the sheet of which the data frame should be made of and index_col specifies the title column, as is shown below:
Python3
file =('path_of_excel_file')
newData = pds.read_excel(file)
newData
Output:
Example:
The third statement concatenates both sheets. Now to check the whole data frame, we can simply run the following command:
Python3
sheet1 = pds.read_excel(file,
sheet_name = 0,
index_col = 0)
sheet2 = pds.read_excel(file,
sheet_name = 1,
index_col = 0)
newData = pds.concat([sheet1, sheet2])
newData
Output:
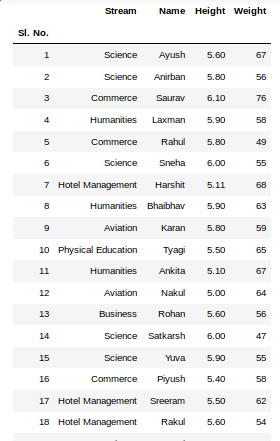
To view 5 columns from the top and from the bottom of the data frame, we can run the command. This head() and tail() method also take arguments as numbers for the number of columns to show.
Python3
newData.head()
newData.tail()
Output:
The shape() method can be used to view the number of rows and columns in the data frame as follows:
Python3
Output:
If any column contains numerical data, we can sort that column using the sort_values() method in pandas as follows:
Python3
sorted_column = newData.sort_values(['Height'], ascending = False)
Now, let’s suppose we want the top 5 values of the sorted column, we can use the head() method here:
Python3
sorted_column['Height'].head(5)
Output:
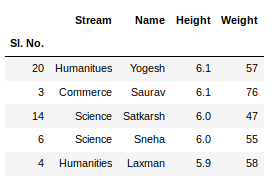
We can do that with any numerical column of the data frame as shown below:
Python3
Output:
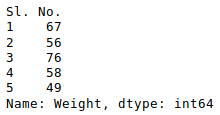
Now, suppose our data is mostly numerical. We can get the statistical information like mean, max, min, etc. about the data frame using the describe() method as shown below:
Python3
Output:
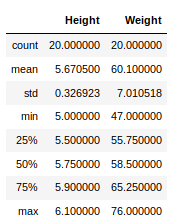
This can also be done separately for all the numerical columns using the following command:
Python3
Output:
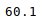
Other statistical information can also be calculated using the respective methods. Like in excel, formulas can also be applied and calculated columns can be created as follows:
Python3
newData['calculated_column'] =
newData[“Height”] + newData[“Weight”]
newData['calculated_column'].head()
Output:
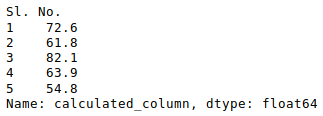
After operating on the data in the data frame, we can export the data back to an excel file using the method to_excel. For this we need to specify an output excel file where the transformed data is to be written, as shown below:
Python3
newData.to_excel('Output File.xlsx')
Output: