

Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей.
Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
Пример использования парсера для мониторинга цен конкурентов
Дополнительные видеоинструкции, а также подробное описание функционала, можно найти в разделе Справка по программе
В программе можно настроить несколько парсеров (обработчиков сайтов).
Любой из парсеров настраивается и работает независимо от других.
Примеры настроенных парсеров (можно скачать, запустить, посмотреть настройки)
Видеоинструкция (2 минуты), как запустить готовый (уже настроенный) парсер
Настройка программы, — дело не самое простое (для этого, надо хоть немного разбираться в HTML)
Если вам нужен готовый парсер, но вы не хотите разбираться с настройкой,
— закажите настройку парсера разработчику программы. Стоимость настройки под конкретный сайт — от 2000 рублей.
(настройка под заказ выполняется только при условии приобретения лицензии на надстройку «Парсер» (3300 руб)
Инструкция (с видео) по заказу настройки парсера
По всем вопросам, готов проконсультировать вас в Скайпе.
Программа не привязана к конкретному файлу Excel.
Вы в настройках задаёте столбец с исходными данными (ссылками или артикулами),
настраиваете формирование ссылок и подстановку данных с сайта в нужные столбцы,
нажимаете кнопку, — и ваша таблица заполняется данными с сайта.
Программа «Парсер сайтов» может быть полезна для формирования каталога товаров интернет-магазинов,
поиска и загрузки фотографий товара по артикулам (если для получения ссылки на фото, необходимо анализировать страницу товара),
загрузки актуальных данных (цен и наличия) с сайтов поставщиков, и т.д. и т.п.
Справка по программе «Парсер сайтов»
Можно попробовать разобраться с работой программы на примерах настроенных парсеров
Парсить сайты в Excel достаточно просто если использовать облачную версию софта Google Таблицы (Sheets/Doc), которые без труда позволяют использовать мощности поисковика для отправки запросов на нужные сайты.
- Подготовка;
- IMPORTXML;
- IMPORTHTML;
- Обратная конвертация.
Видеоинструкция
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/
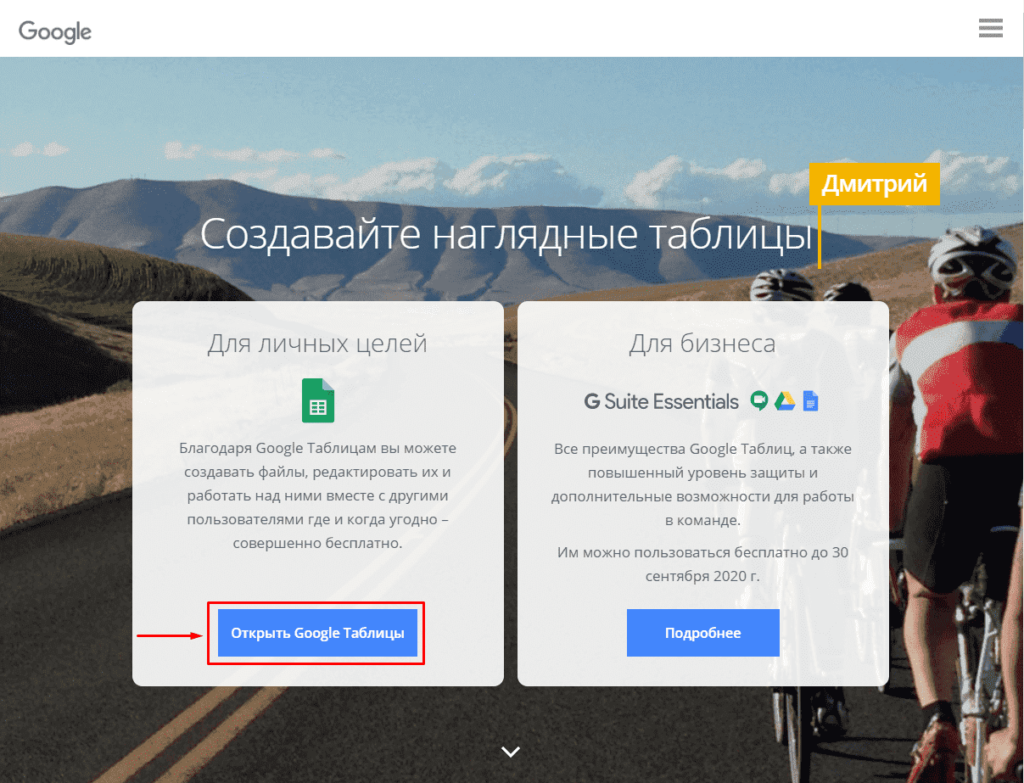
Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).
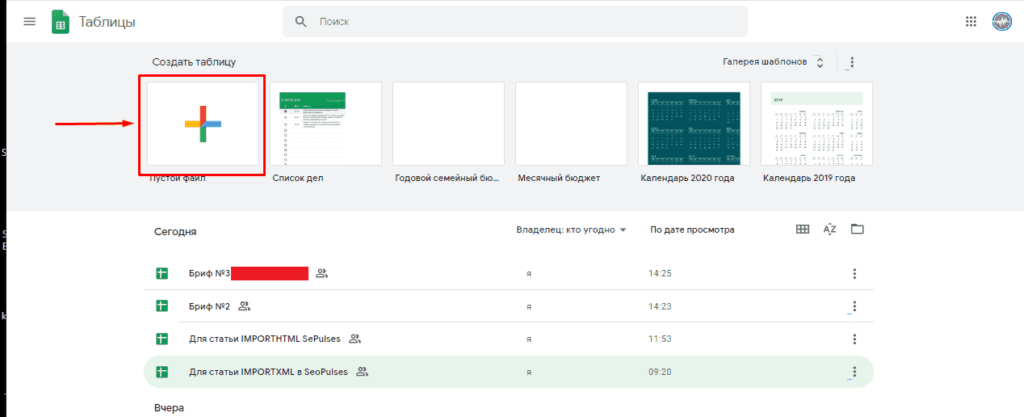
Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML. Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
- IMPORTHTML. Позволяет получить данные из таблиц и списков.
Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:
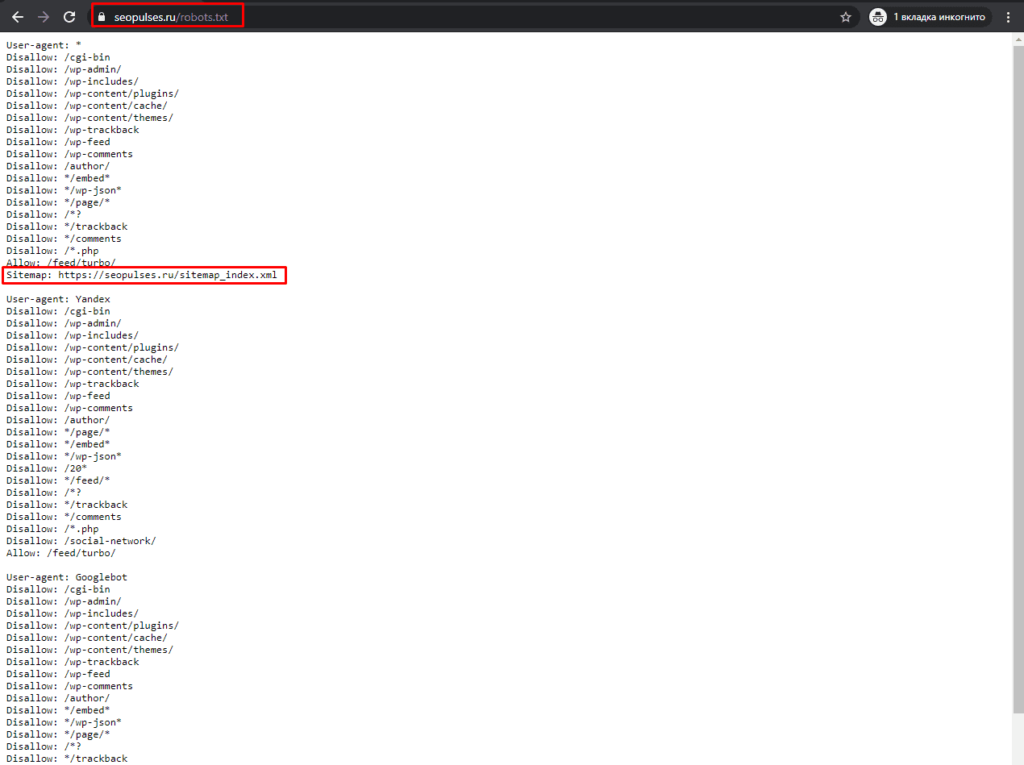
Нас интересует список постов, поэтому открываем первую ссылку.
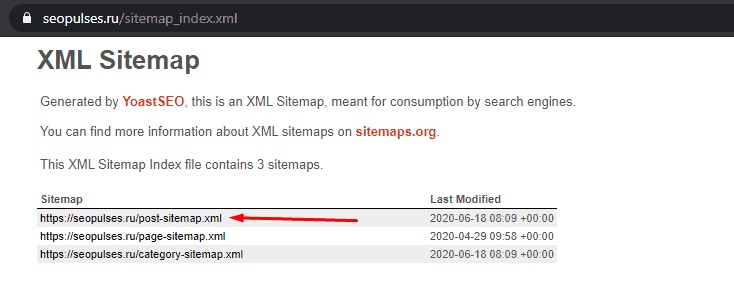
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).
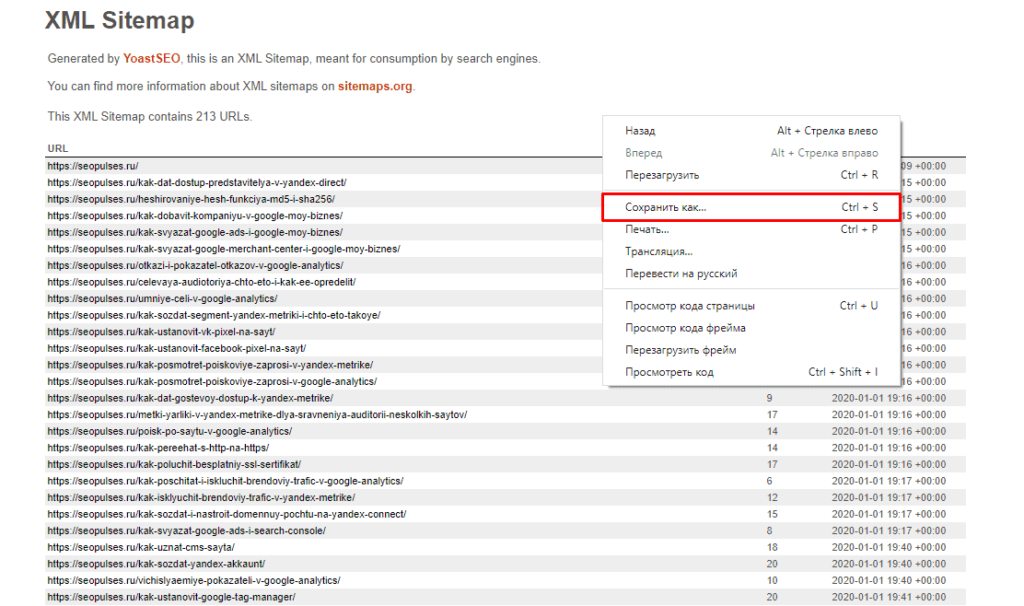
Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.
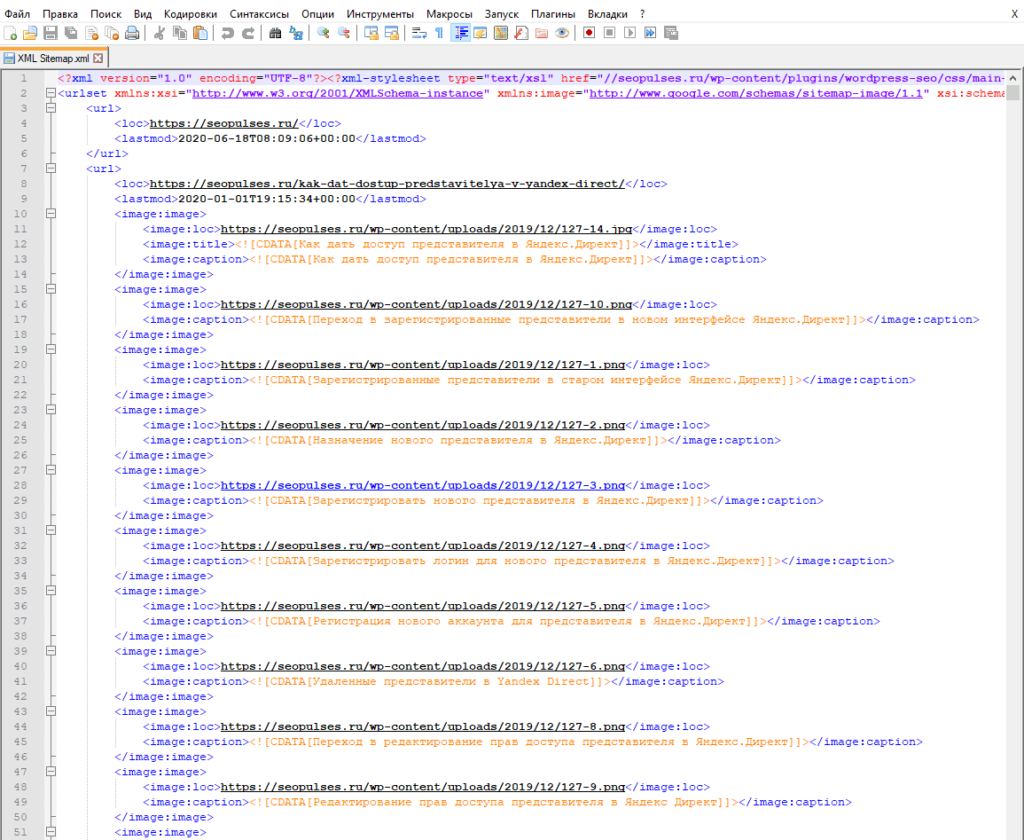
Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.
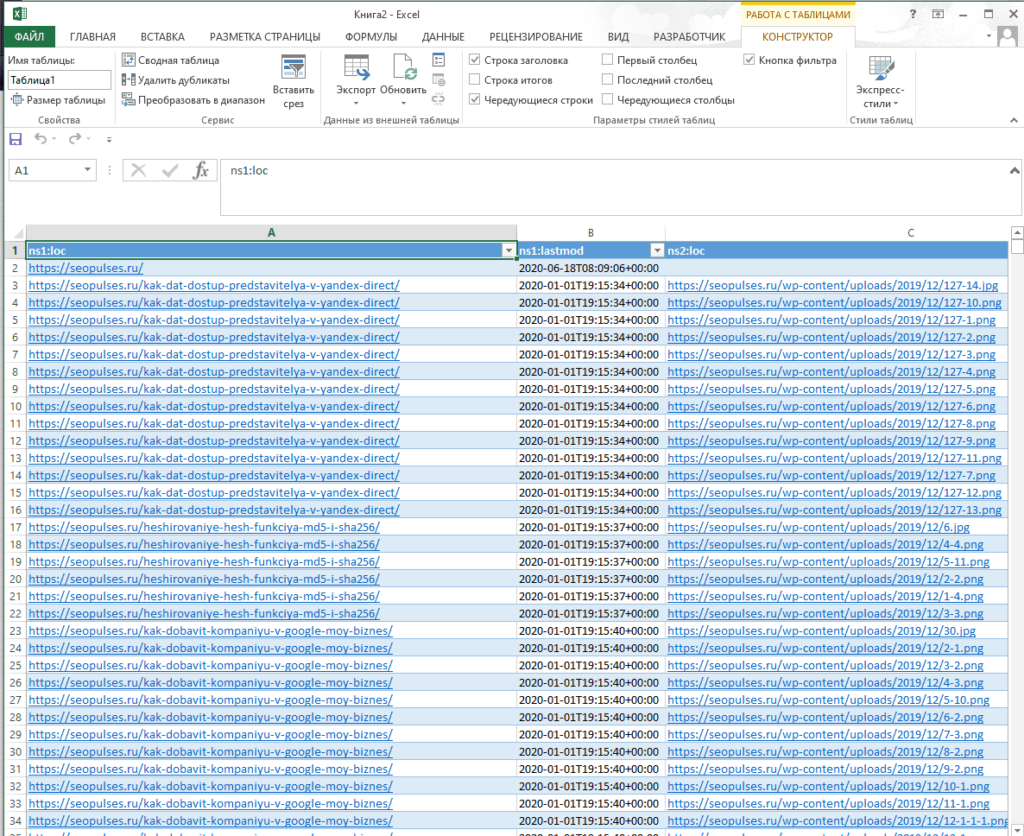
Все готово, можно переходить к методам парсинга.
IPMORTXML для парсинга сайтов в Excel
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – в формате XPath.
С примером можно ознакомиться в:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit#gid=0
Примеры использования IMPORTXML в Google Doc
Парсинг названий
Для работы с парсингом через данную функцию потребуется знание XPATH и составление пути в этом формате. Сделать это можно открыв консоль разработчика. Для примера будет использоваться сайт крупного интернет-магазина и в первую очередь необходимо в Google Chrome открыть окно разработчика кликнув правой кнопкой мыли и в выпавшем меню выбрать «Посмотреть код» (сочетание клавиш CTRL+Shift+I).
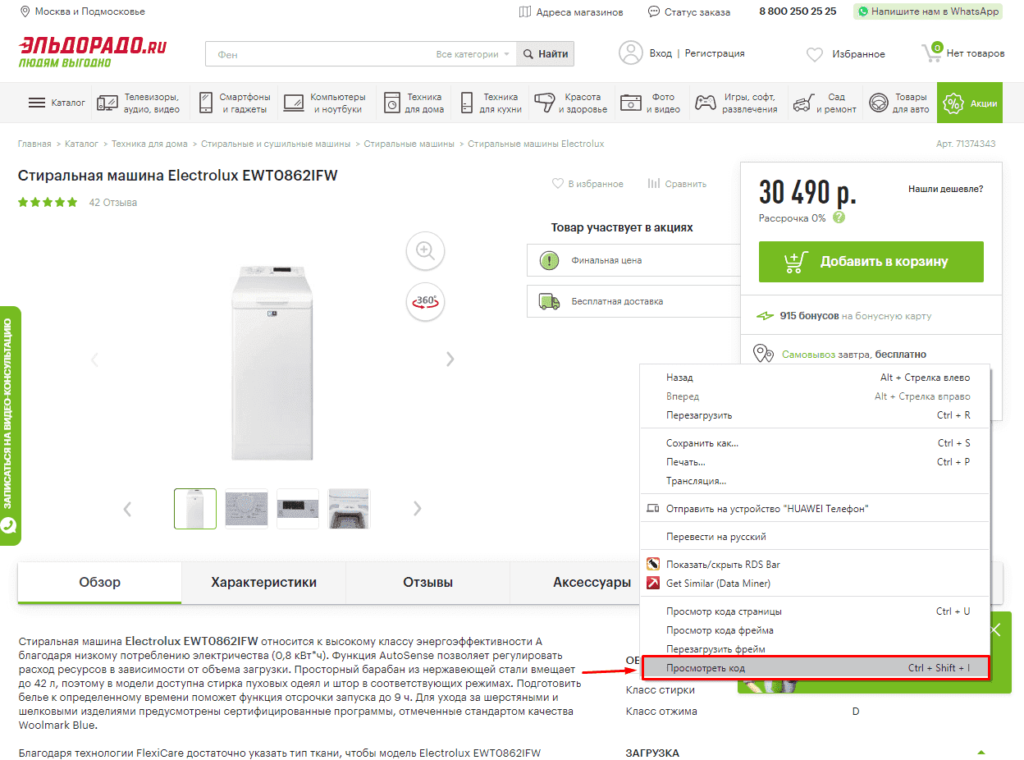
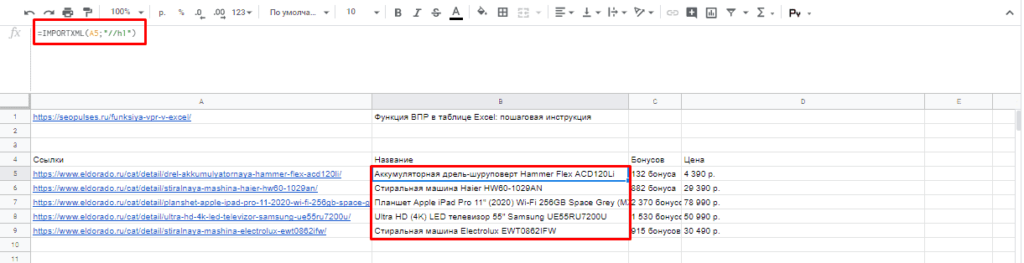
После этого пытаемся получить название товара, которое содержится в H1, единственным на странице, поэтому запрос должен быть:
//h1
И как следствие формула:
=IMPORTXML(A2;»//h1″)
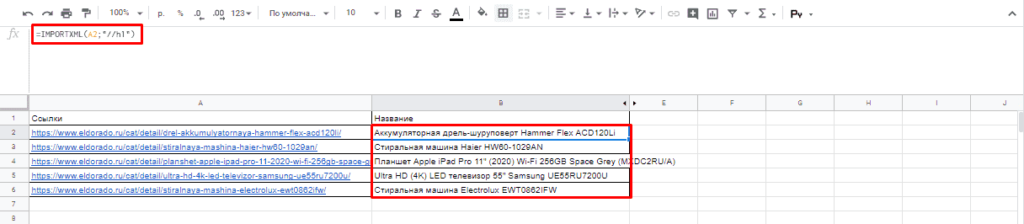
Важно! Запрос XPath пишется в кавычках «запрос».
Парсинг различных элементов
Если мы хотим получить баллы, то нам потребуется обратиться к элементу div с классом product-standart-bonus поэтому получаем:
//div[@class=’product-standart-bonus’]
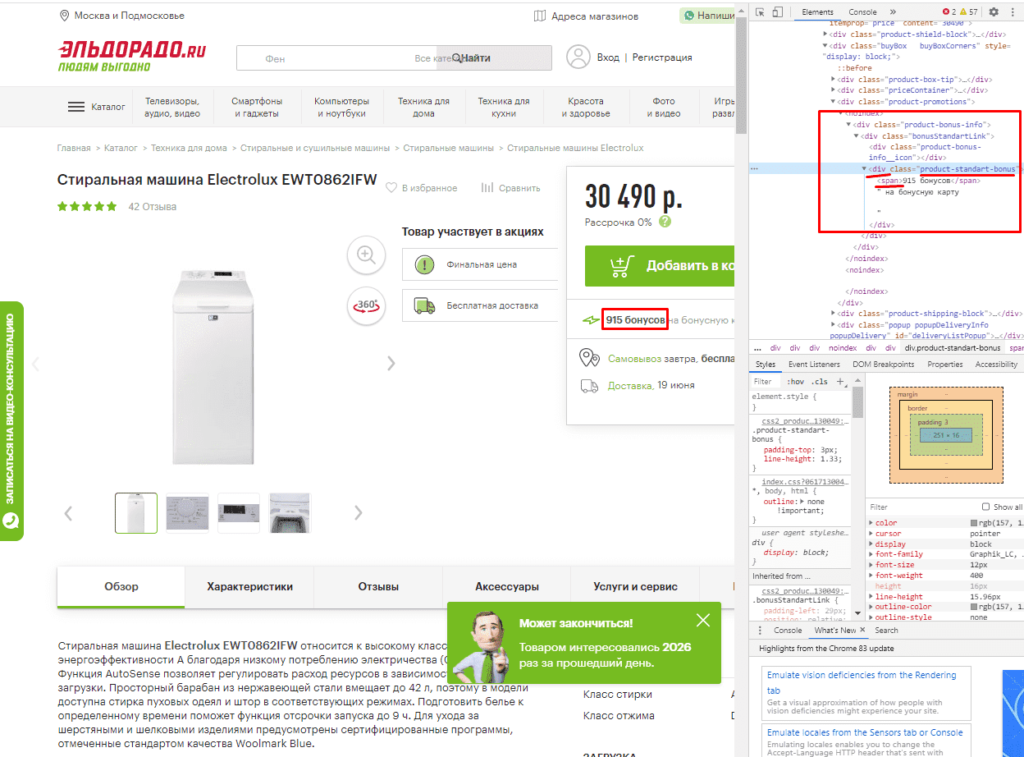
В этом случае первый тег div обозначает то, откуда берутся данные, когда в скобках [] уточняется его уникальность.
Для уточнения потребуется указать тип в виде @class, который может быть и @id, а после пишется = и в одинарных кавычках ‘значение’ пишется запрос.
Однако, нужное нам значение находиться глубже в теге span, поэтому добавляем /span и вводим:
//div[@class=’product-standart-bonus’]/span
В документе:

Парсинг цен без знаний XPath
Если нет знаний XPath и необходимо быстро получить информацию, то требуется выбрав нужный элемент в консоли разработчика кликнуть правой клавишей мыши и в меню выбрать «Copy»-«XPath». Например, при поиске запроса цены получаем:
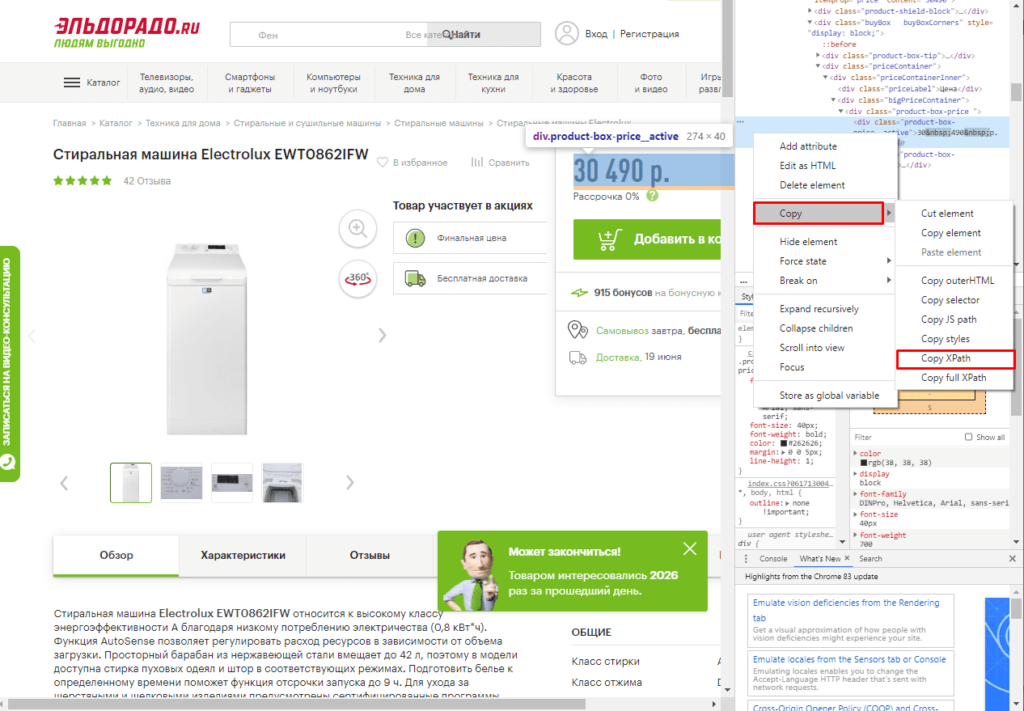
//*[@id=»showcase»]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div/div[1]
Важно! Следует изменить » на одинарные кавычки ‘.
Далее используем ее вместе с IMPORTXML.
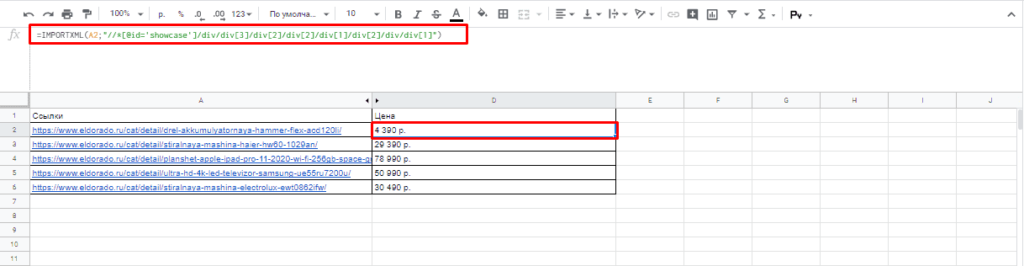
Все готово цены получены.
Простые формулы с IMPORTXML в Google Sheets
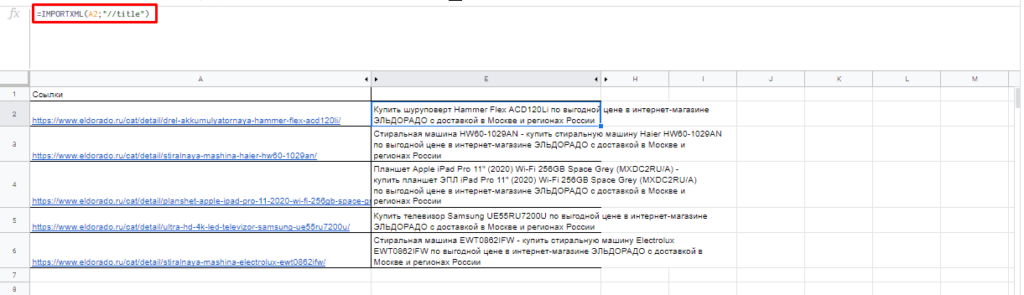
Чтобы получить title страницы необходимо использовать запрос:
=IMPORTXML(A3;»//title»)
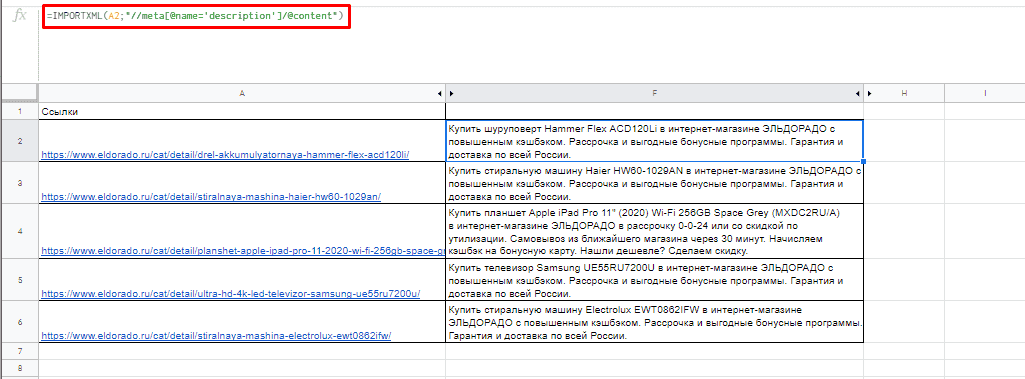
Для вывода description стоит использовать:
=IMPORTXML(A3;»//description»)
Первый заголовок (или любой другой):
=IMPORTXML(A3;»//h1″)

IMPORTHTML для создания парсера веи-ресурсов в Эксель
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос;Индекс)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – может быть в формате «table» или «list», выгружающий таблицу и список, соответственно.
- Индекс – порядковый номер элемента.
С примерами можно ознакомиться в файле:
https://docs.google.com/spreadsheets/d/1GpcGZd7CW4ugGECFHVMqzTXrbxHhdmP-VvIYtavSp4s/edit#gid=0
Пример использования IMPORTHTML в Google Doc
Парсинг таблиц
В примерах будет использоваться данная статья, перейдя на которую можно открыть консоль разработчика (в Google Chrome это можно сделать кликнув правой клавишей мыши и выбрав пункт «Посмотреть код» или же нажав на сочетание клавиш «CTRL+Shift+I»).
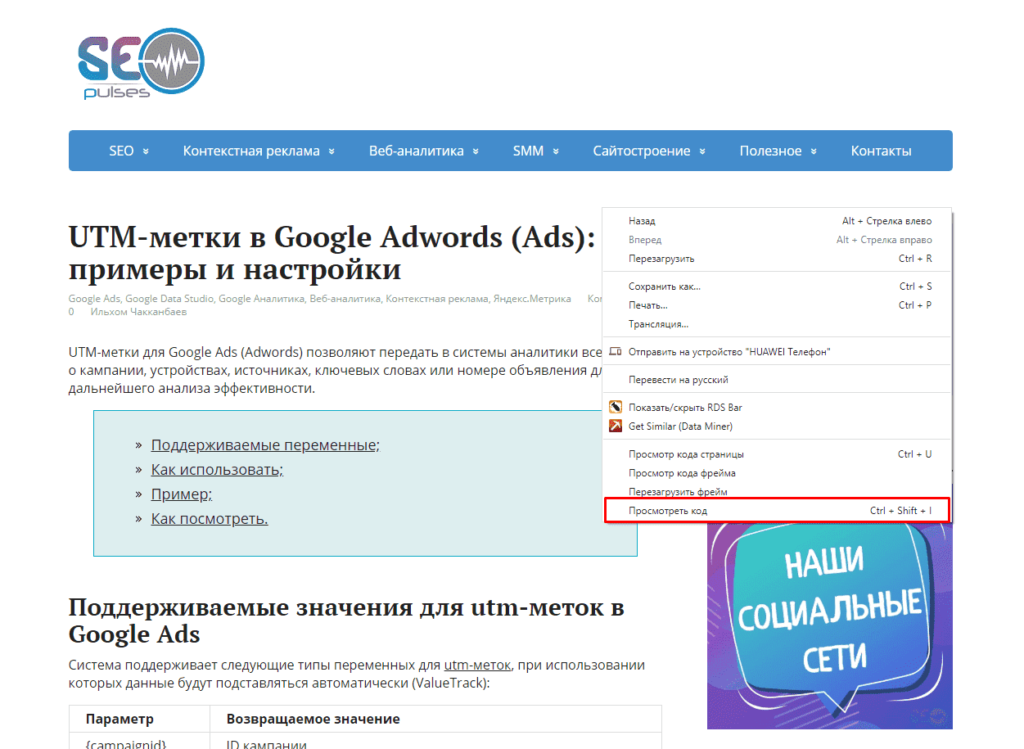
Теперь просматриваем код таблицы, которая заключена в теге <table>.
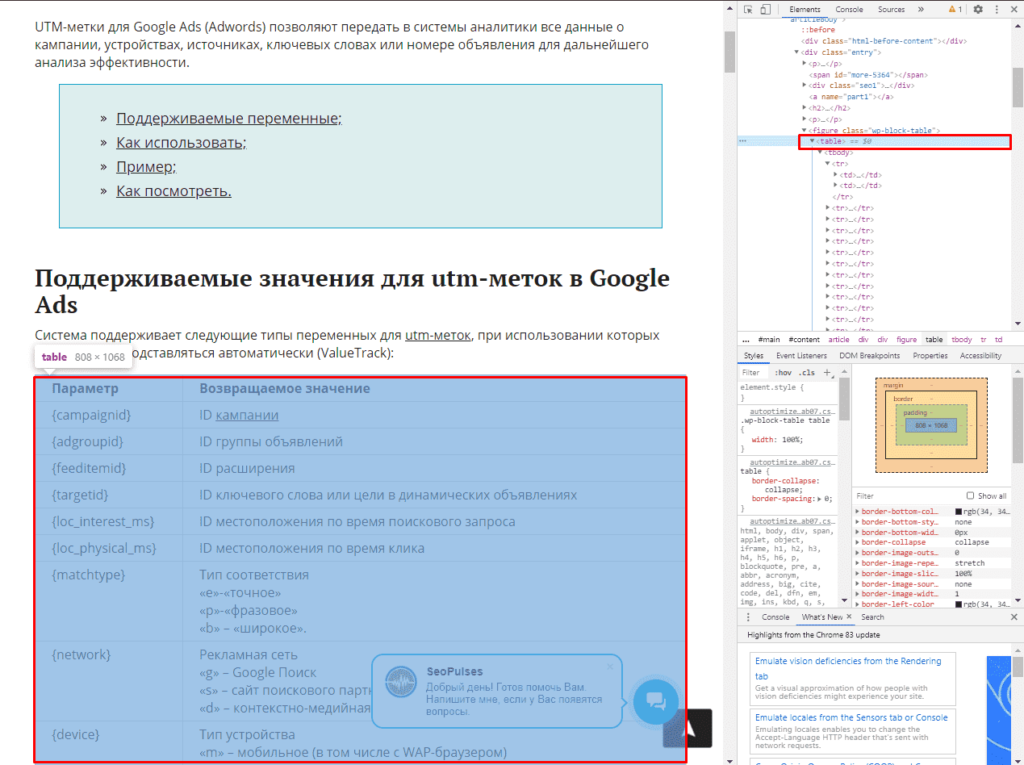
Данный элемент можно будет выгрузить при помощи конструкции:
=IMPORTHTML(A2;»table»;1)
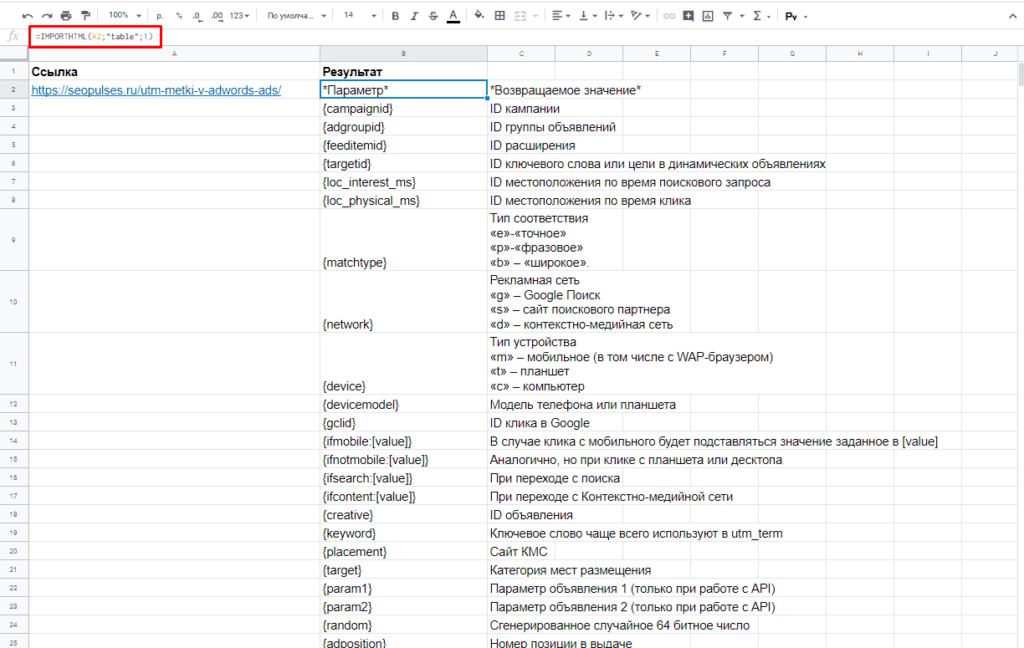
- Где A2 ячейка со ссылкой;
- table позволяет получить данные с таблицы;
- 1 – номер таблицы.
Важно! Сам запрос table или list записывается в кавычках «запрос».
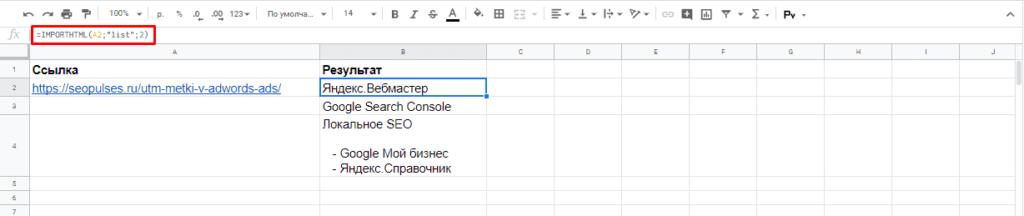
Парсинг списков
Получить список, заключенный в тегах <ul>…</ul> при помощи конструкции.
=IMPORTHTML(A2;»list»;1)
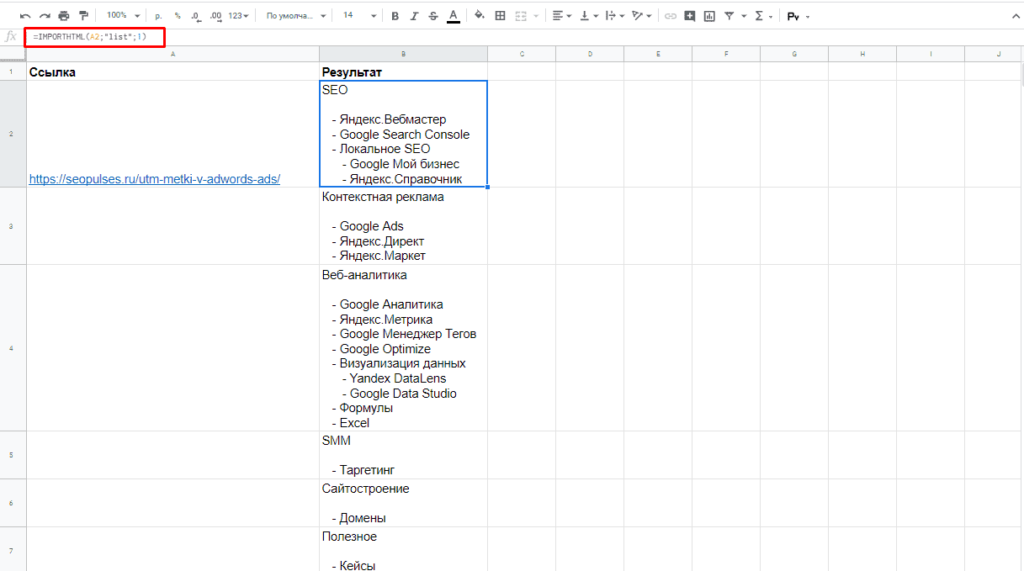
В данном случае речь идет о меню, которое также представлено в виде списка.
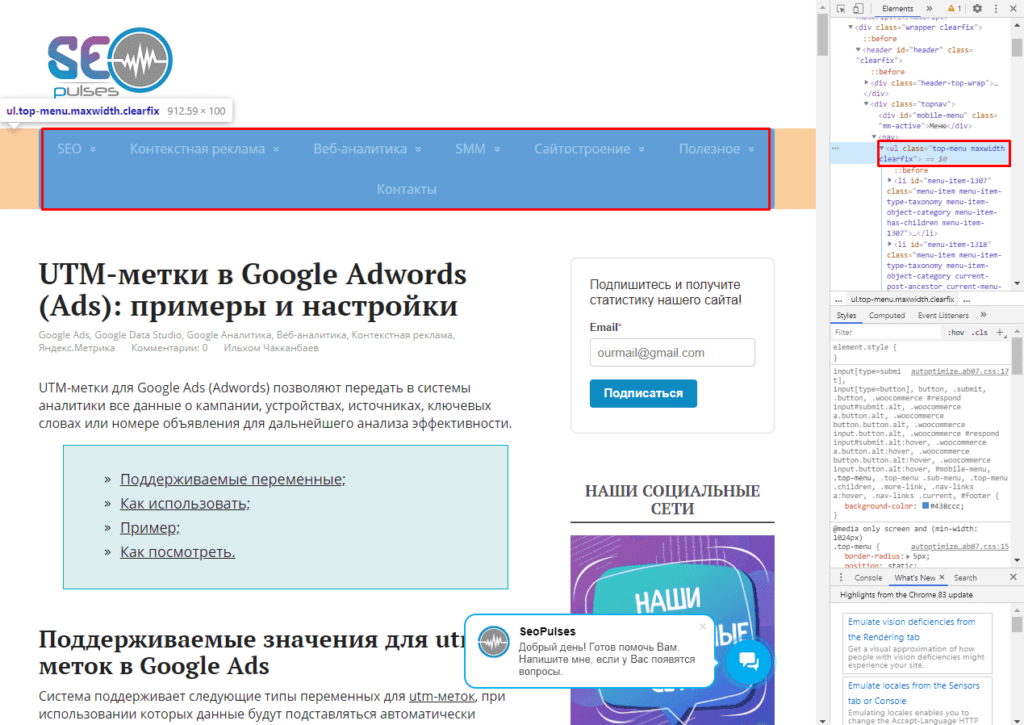
Если использовать индекс третей таблицы, то будут получены данные с третей таблицы в меню:
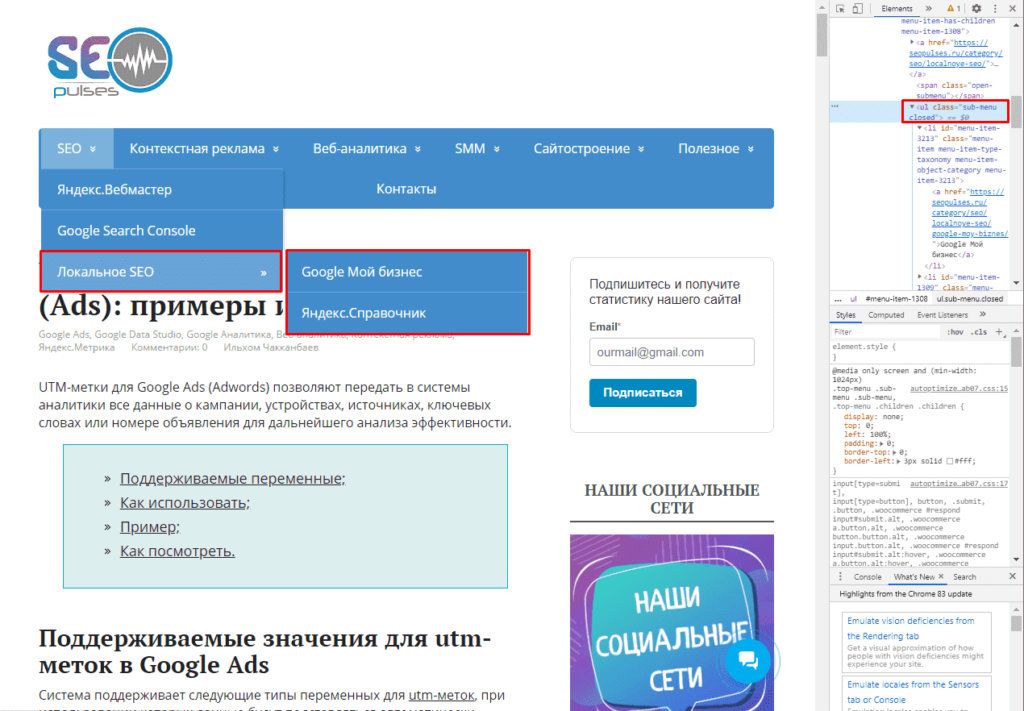
Формула:
=IMPORTHTML(A2;»list»;2)
Все готово, данные получены.
Обратная конвертация
Чтобы превратить Google таблицу в MS Excel потребуется кликнуть на вкладку «Файл»-«Скачать»-«Microsoft Excel».
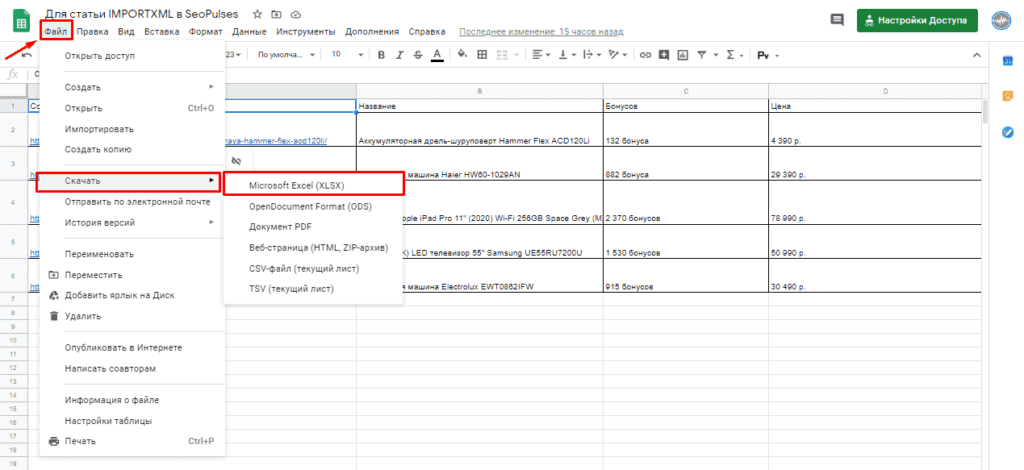
Все готово, пример можно скачать ниже.
Пример:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit
Парсинг нетабличных данных с сайтов
Проблема с нетабличными данными
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet), вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:

Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:

Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2… или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом <TABLE>, а её аналог — вложенные друг в друга теги-контейнеры <DIV>. Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel.
Тем не менее, есть способ обойти это ограничение 
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:

Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
https://www.wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:

Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data), чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:

… и затем щёлкаем по значку шестерёнки справа от шага Источник (Source), чтобы открыть его параметры:

В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file). Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):

Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:

- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:

Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains), переключаемся в режим Подробнее (Advanced) [2] и вводим наши критерии:

Добавление условий выполняется кнопкой со смешным названием Добавить предложение [3]. И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:

Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: <span class=»price»> через команду Главная — Замена значений (Home — Replace values).
- Разделить получившийся столбец по первому разделителю «>» слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя «<» слева, чтобы отделить полезные данные от тегов:

- Удалить лишние столбцы, а в оставшемся заменить стандартную HTML-конструкцию " на нормальные кавычки.

В итоге получим наши данные в уже гораздо более презентабельном виде:

Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View)) и вводим следующую конструкцию:
= Table.FromRows(List.Split(#»Замененное значение1″[Column1.2.1],3))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:

Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load…)

Вот и все хитрости 
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query
На первый взгляд Excel и парсинг понятия несовместимые. Как с помощью табличного редактора можно получать информацию из сети? И ведь многие недооценивают Excel, а это вполне посильная задача для него. При этом все делается стандартными методами без необходимости дополнительно что-то устанавливать/настраивать.
Разберем на конкретном примере по получению информации с сайта Минюста, а именно, нам необходим перечень действующих адвокатов Российской Федерации. Кнопки «выгрузить списочно всех адвокатов» — конечно же, нет. На официальном сайте http://lawyers.minjust.ru/ выводится по 20 адвокатов на 1 странице, всего 74 754 страниц, итого на выходе мы должны получить чуть меньше 150 тыс. адвокатов.
Для начала открываем VBA и создаем объект InternetExplorer, посредством которого будем получать данные.
Затем надо определить, как будем переходить между страницами на сайте – для этого просматриваем элемент перехода на следующую страницу. Ссылка между станицами отличается значением в конце и соответствует номеру страницы – 1.
Имея информацию о ссылке страницы — осуществляем их перебор, загружаем в InternetExplorer и забираем все данные со страницы.
В коде страницы представлена структура таблицы со всеми столбцами, которые нам необходимы: реестровый номер, ФИО адвоката, субъект РФ, номер удостоверения, текущий статус.
Для получения этой информации с помощью ключевых слов осуществляем поиск по тегам и забираем требуемые данные.
В итоге получаем список всех адвокатов в таблицу Excel для дальнейшей обработки.
Пользовательские функции VBA Excel для парсинга сайтов, html-страниц и файлов, возвращающие их текстовое содержимое. Примеры записи текста в переменную.
Парсинг html-страниц (msxml2.xmlhttp)
Пользовательская функция GetHTML1 (VBA Excel) для извлечения (парсинга) текстового содержимого из html-страницы сайта по ее URL-адресу с помощью объекта «msxml2.xmlhttp»:
|
Function GetHTML1(ByVal myURL As String) As String On Error Resume Next With CreateObject(«msxml2.xmlhttp») .Open «GET», myURL, False .send Do: DoEvents: Loop Until .readyState = 4 GetHTML1 = .responseText End With End Function |
Парсинг сайтов (WinHttp.WinHttpRequest.5.1)
Пользовательская функция GetHTML2 (VBA Excel) для извлечения (парсинга) текстового содержимого из html-страницы сайта по ее URL-адресу с помощью объекта «WinHttp.WinHttpRequest.5.1»:
|
Function GetHTML2(ByVal myURL As String) As String On Error Resume Next With CreateObject(«WinHttp.WinHttpRequest.5.1») .Open «GET», myURL, False .send Do: DoEvents: Loop Until .readyState = 4 GetHTML2 = .responseText End With End Function |
Парсинг файлов (ADODB.Stream)
Пользовательская функция GetText (VBA Excel) для извлечения (парсинга) текстового содержимого из файла (.txt, .csv, .mhtml), сохраненного на диск компьютера, по его полному имени (адресу) с помощью объекта «ADODB.Stream»:
|
Function GetText(ByVal myFile As String) As String On Error Resume Next With CreateObject(«ADODB.Stream») .Charset = «utf-8» .Open .LoadFromFile myFile GetText = .ReadText .Close End With End Function |
Примеры записи текста в переменную
Общая формула записи текста, извлеченного с помощью пользовательских функций VBA Excel, в переменную:
|
Dim htmlText As String htmlText = GetHTML1(«Адрес сайта (html-страницы)») htmlText = GetHTML2(«Адрес сайта (html-страницы)») htmlText = GetText(«Полное имя файла») |
Конкретные примеры:
|
htmlText = GetHTML1(«https://internettovary.ru/nabor-dlya-vyrashchivaniya-veshenki/») htmlText = GetHTML2(«https://internettovary.ru/nabor-dlya-vyrashchivaniya-veshenki/») htmlText = GetText(«C:UsersEvgeniyDownloadsНовый текстовый документ.txt») htmlText = GetText(«C:UsersEvgeniyDownloadsИспользование msxml2.xmlhttp в Excel VBA.mhtml») |
В понятие «парсинг», кроме извлечения текстового содержимого сайтов, html-страниц или файлов, входит поиск и извлечение конкретных данных из всего полученного текстового содержимого.
Пример извлечения email-адресов из текста, присвоенного переменной, смотрите в последнем параграфе статьи: Регулярные выражения (объекты, свойства, методы).
Парсинг содержимого тегов
Извлечение содержимого тегов с помощью метода getElementsByTagName объекта HTMLFile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Sub Primer1() Dim myHtml As String, myFile As Object, myTag As Object, myTxt As String ‘Извлекаем содержимое html-страницы в переменную myHtml с помощью функции GetHTML1 myHtml = GetHTML1(«https://internettovary.ru/sadovaya-nozhovka-sinitsa/») ‘Создаем объект HTMLFile Set myFile = CreateObject(«HTMLFile») ‘Записываем в myFile текст из myHtml myFile.body.innerHTML = myHtml ‘Присваиваем переменной myTag коллекцию одноименных тегов, имя которого ‘указанно в качестве аргумента метода getElementsByTagName Set myTag = myFile.getElementsByTagName(«p») ‘Выбираем, содержимое какого тега по порядку, начинающегося с 0, нужно извлечь myTxt = myTag(5).innerText MsgBox myTxt ‘Большой текст может не уместиться в MsgBox, тогда для просмотра используйте окно Immediate ‘Debug.Print myTxt End Sub |
С помощью этого кода извлекается текст, расположенный между открывающим и закрывающим тегами. В примере — это текст 6-го абзаца (p) между 5-й (нумерация с 0) парой отрывающего <p> и закрывающего </p> тегов.
Примеры тегов, используемых в html: "p", "title", "h1", "h2", "table", "div", "script".
Пример извлечения содержимого тега "title":
|
Sub Primer2() Dim myHtml As String, myFile As Object, myTag As Object, myTxt As String myHtml = GetHTML1(«https://internettovary.ru/sadovaya-nozhovka-sinitsa/») Set myFile = CreateObject(«HTMLFile») myFile.body.innerHTML = myHtml Set myTag = myFile.getElementsByTagName(«title») myTxt = myTag(0).innerText MsgBox myTxt End Sub |
Парсинг содержимого Id
Извлечение текстового содержимого html-элементов, имеющих уникальный идентификатор — Id, с помощью метода getElementById объекта HTMLFile:
|
Sub Primer3() Dim myHtml As String, myFile As Object, myTag As Object, myTxt As String myHtml = GetHTML1(«https://internettovary.ru/sadovaya-nozhovka-sinitsa/») Set myFile = CreateObject(«HTMLFile») myFile.body.innerHTML = myHtml ‘Присваиваем переменной myTag html-элемент по указанному в скобках Id Set myTag = myFile.getElementById(«attachment_465») ‘Присваиваем переменной myTxt текстовое содержимое html-элемента с Id myTxt = myTag.innerText MsgBox myTxt ‘Большой текст может не уместиться в MsgBox, тогда для просмотра используйте окно Immediate ‘Debug.Print myTxt End Sub |
Для реализации представленных здесь примеров могут понадобиться дополнительные библиотеки. В настоящее время у меня подключены следующие (к данной теме могут относиться последние шесть):
- Visual Basic For Applications
- Microsoft Excel 16.0 Object Library
- OLE Automation
- Microsoft Office 16.0 Object Library
- Microsoft Forms 2.0 Object Library
- Ref Edit Control
- Microsoft Scripting Runtime
- Microsoft Word 16.0 Object Library
- Microsoft Windows Common Controls 6.0 (SP6)
- Microsoft ActiveX Data Objects 6.1 Library
- Microsoft ActiveX Data Objects Recordset 6.0 Library
- Microsoft HTML Object Library
- Microsoft Internet Controls
- Microsoft Shell Controls And Automation
- Microsoft XML, v6.0
С этим набором библиотек все примеры работают. Тестирование проводилось в VBA Excel 2016.