
Уважаемые коллеги, мы рады предложить вам, разрабатываемый нами учебный курс по программированию ПЛК фирмы Beckhoff с применением среды автоматизации TwinCAT. Курс предназначен исключительно для самостоятельного изучения в ознакомительных целях. Перед любым применением изложенного материала в коммерческих целях просим связаться с нами. Текст из предложенных вам статей скопированный и размещенный в других источниках, должен содержать ссылку на наш сайт heaviside.ru. Вы можете связаться с нами по любым вопросам, в том числе создания для вас систем мониторинга и АСУ ТП.
Типы данных в языках стандарта МЭК 61131-3
Уважаемые коллеги, в этой статье мы будем рассматривать важнейшую для написания программ тему — типы данных. Чтобы читатели понимали, в чем отличие одних типов данных от других и зачем они вообще нужны, мы подробно разберем, каким образом данные представлены в процессоре. В следующем занятии будет большая практическая работа, выполняя которую, можно будет потренироваться объявлять переменные и на практике познакомится с особенностями выполнения математических операций с различными типами данных.
Простые типы данных
В прошлой статье мы научились записывать цифры в двоичной системе счисления. Именно такую систему счисления используют все компьютеры, микропроцессоры и прочая вычислительная техника. Теперь мы будем изучать типы данных.
Любая переменная, которую вы используете в своем коде, будь то показания датчиков, состояние выхода или выхода, состояние катушки или просто любая промежуточная величина, при выполнении программы будет хранится в оперативной памяти. Чтобы под каждую используемую переменную на этапе компиляции проекта была выделена оперативная память, мы объявляем переменные при написании программы. Компиляция, это перевод исходного кода, написанного программистом, в команды на языке ассемблера понятные процессору. Причем в зависимости от вида применяемого процессора один и тот же исходный код может транслироваться в разные ассемблерные команды (вспомним что ПЛК Beckhoff, как и персональные компьютеры работают на процессорах семейства x86).
Как помните, из статьи Знакомство с языком LD, при объявлении переменной необходимо указать, к какому типу данных будет принадлежать переменная. Как вы уже можете понять, число B016 будет занимать гораздо меньший объем памяти чем число 4 C4E5 01E7 7A9016. Также одни и те же операции с разными типами данных будут транслироваться в разные ассемблерные команды. В TwinCAT используются следующие типы данных:
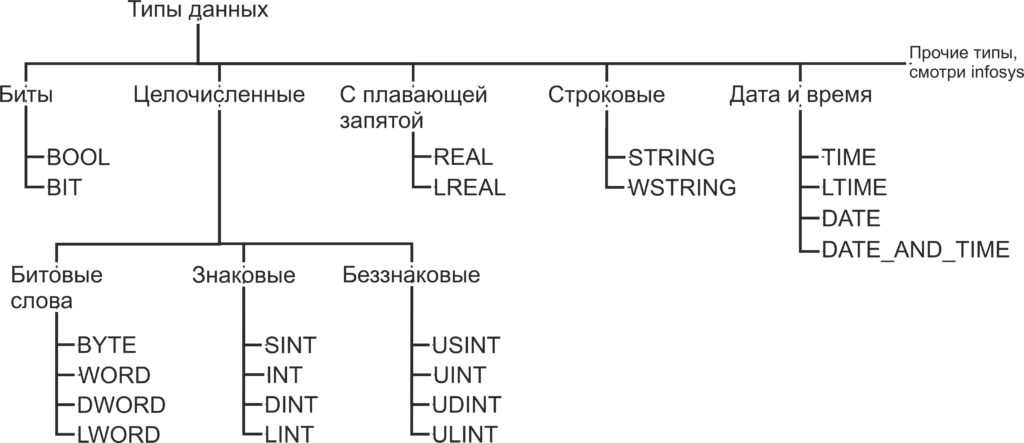
Биты
BOOL — это простейший тип данных, как уже было сказано, этот тип данных может принимать только два значения 0 и 1. Так же в TwinCAT, как и в большинстве языков программирования, эти значения, наравне с 0 и 1, обозначаются как TRUE и FALSE и несут в себе количество информации, соответствующее одному биту. Минимальным объемом данных, который читается из памяти за один раз, является байт, то есть восемь бит. Поэтому, для оптимизации скорости доступа к данным, переменная типа BOOL занимает восемь бит памяти. Для хранения самой переменной используется нулевой бит, а биты с первого по седьмой заполнены нулями. Впрочем, на практике о таком нюансе приходится вспоминать достаточно редко.
BIT — то же самое, что и BOOL, но в памяти занимает 1 бит. Как можно догадаться, операции с этим типом данных медленнее чем с типом BOOL, но он занимает меньше места в памяти. Тип данных BIT отсутствует в стандарте МЭК 61131-3 и поддерживается исключительно в TwinCAT, поэтому стоит отдавать предпочтение типу BOOL, когда у вас нет явных поводов использовать тип BIT.
Целочисленные типы данных
BYTE — тип данных, по размеру соответствующий одному байту. Хоть с типом BYTE можно производить математические операции, но в первую очередь он предназначен для хранения набора из 8 бит. Иногда в таком виде удобнее, чем побитно, передавать данные по цифровым интерфейсам, работать с входами выходами и так далее. С такими вопросами мы будем знакомится далее по мере изучения курса. В переменную типа BYTE можно записать числа из диапазона 0..255 (0..28-1).
WORD — то же самое, что и BYTE, но размером 16 бит. В переменную типа WORD можно записать числа из диапазона 0..65 535 (0..216-1). Тип данных WORD переводится с английского как «слово». Давным-давно термином машинное слово называли группу бит, обрабатываемых вычислительной машиной за один раз. Была уместна фраза «Программа состоит из машинных слов.». Со временем этим термином перестали пользоваться в прямом его значении, и сейчас под термином «машинное слово» обычно подразумевается группа из 16 бит.
DWORD — то же самое, что и BYTE, но размером 32 бит. В переменную типа DWORD можно записать числа из диапазона 0..4 294 967 295 (0..232-1). DWORD — это сокращение от double word, что переводится как двойное слово. Довольно часто буква «D» перед каким-либо типом данных значит, что этот тип данных в два раза длиннее, чем исходный.
LWORD — то же самое, что и BYTE, но размером 64 ;бит. В переменную типа LWORD можно записать числа из диапазона 0..18 446 744 073 709 551 615 (0..264-1). LWORD — это сокращение от long word, что переводится как длинное слово. Приставка «L» перед типом данных, как правило, означает что такой тип имеет длину 64 бита.
SINT — знаковый тип данных, длинной 8 бит. В переменную типа SINT можно записать числа из диапазона -128..127 (-27..27-1). В отличии от всех предыдущих типов данных этот тип данных предназначен для хранения именно чисел, а не набора бит. Слово знаковый в описании типа означает, что такой тип данных может хранить как положительные, так и отрицательные значения. Для хранения знака числа предназначен старший, в данном случае седьмой, разряд числа. Если старший разряд имеет значение 0, то число интерпретируется как положительное, если 1, то число интерпретируется как отрицательное. Приставка «S» означает short, что переводится с английского как короткий. Как вы догадались, SINT короткий вариант типа INT.
USINT — беззнаковый тип данных, длинной 8 бит. В переменную типа USINT можно записать числа из диапазона 0..255 (0..28-1). Приставка «U» означает unsigned, переводится как беззнаковый.
Остальные целочисленные типы аналогичны уже описанным и отличаются только размером. Сведем все целочисленные типы в таблицу.
| Тип данных | Нижний предел | Верхний предел | Занимаемая память |
| BYTE | 0 | 255 | 8 бит |
| WORD | 0 | 65 535 | 16 бит |
| DWORD | 0 | 4 294 967 295 | 32 бит |
| LWORD | 0 | 264-1 | 64 бит |
| SINT | -128 | 127 | 8 бит |
| USINT | 0 | 255 | 8 бит |
| INT | -32 768 | 32 767 | 16 бит |
| UINT | 0 | 65 535 | 16 бит |
| DINT | -2 147 483 648 | 2 147 483 647 | 32 бит |
| UDINT | 0 | 4 294 967 295 | 32 бит |
| LINT | -263 | -263-1 | 64 бит |
| ULINT | 0 | -264-1 | 64 бит |
Выше мы рассматривали целочисленные типы данных, то есть такие типы данных, в которых отсутствует запятая. При совершении математических операций с целочисленными типами данных есть некоторые особенности:
- Округление при делении: округление всегда выполняется вниз. То есть дробная часть просто отбрасывается. Если делимое меньше делителя, то частное всегда будет равно нулю, например, 10/11 = 0.
- Переполнение: если к целочисленной переменной, например, SINT, имеющей значение 255, прибавить 1, переменная переполнится и примет значение 0. Если прибавить 2, переменная примет значение 1 и так далее. При операции 0 — 1 результатом будет 255. Это свойство очень схоже с устройством стрелочных часов. Если сейчас 2 часа, то 5 часов назад было 9 часов. Только шкала часов имеет пределы не 1..12, а 0..255. Иногда такое свойство может использоваться при написании программ, но как правило не стоит допускать переполнения переменных.
Подробно такие нюансы разбираются в пособиях по дискретной математике. Мы на них пока что останавливаться не будем, но о приведенных двух особенностях не стоит забывать при написании программ.
Можно встретить упоминания о данных с фиксированной запятой, это такие данные, в которых количество знаков после запятой строго фиксировано. В TwinCAT типы данных с фиксированной запятой отсутствуют в чистом виде. TwinCAT поддерживает типы данных с плавающей запятой, то есть количество знаков до и после запятой может быть любым в пределах поддерживаемого диапазона.
Типы данных с плавающей запятой
REAL — тип данных с плавающей запятой длинной 32 бита. В переменную типа REAL можно записать числа из диапазона -3.402 82*1038..3.402 82*1038.
LREAL — тип данных с плавающей запятой длинной 64 бита. В переменную типа LREAL можно записать числа из диапазона -1.797 693 134 862 315 8*10308..1.797 693 134 862 315 8*10308.
При присваивании значения типам REAL и LREAL присваиваемое значение должно содержать целую часть, разделительную точку и дробную часть, например, 7.4 или 560.0.
Так же при записи значения типа REAL и LREAL использовать экспоненциальную (научную) форму. Примером экспоненциальной формы записи будет Me+P, в этом примере
- M называется мантиссой.
- e называется экспонентой (от англ. «exponent»), означающая «·10^» («…умножить на десять в степени…»),
- P называется порядком.
Примерами такой формы записи будет:
- 1.64e+3 расшифровывается как 1.64e+3 = 1.64*103 = 1640.
- 9.764e+5 расшифровывается как 9.764e+5 = 9.764*105 = 976400.
- 0.3694e+2 расшифровывается как 0.3694e+2 = 0.3694*102 = 36.94.
Еще один способ записи присваиваемого значения переменной типа REAL и LREAL, это добавить к числу префикс REAL#, например, REAL#7.4 или REAL#560. В таком случае можно не указывать дробную часть.
Старший, 31-й бит переменной типа REAL представляет собой знак. Следующие восемь бит, с 30-го по 23-й отведены под экспоненту. Оставшиеся 23 бита, с 22-го по 0-й используются для записи мантиссы.
В переменной типа LREAL старший, 63-й бит также используется для записи знака. В следующие 11 бит, с 62 по 52-й, записана экспонента. Оставшиеся 52 бита, с 51-го по 0-й, используются для записи мантиссы.
При записи числа с большим количеством значащих цифр в переменные типа REAL и LREAL производится округление. Необходимо не забывать об этом в расчетах, к которым предъявляются строгие требования по точности. Еще одна особенность, вытекающая из прошлой, если вы хотите сравнить два числа типа REAL или LREAL, прямое сравнение мало применимо, так как если в результате округления числа отличаются хоть на малую долю результат сравнения будет FALSE. Чтобы выполнить сравнение более корректно, можно вычесть одно число из другого, а потом оценить больше или меньше модуль получившегося результата вычитания, чем наибольшая допустимая разность. Поведение системы при переполнении переменных с плавающей запятой не определенно стандартом МЭК 61131-3, допускать его не стоит.
Строковые типы данных
STRING — тип данных для хранения символов. Каждый символ в переменной типа STRING хранится в 1 байте, в кодировке Windows-1252, это значит, что переменные такого типа поддерживают только латинские символы. При объявлении переменной количество символов в переменной указывается в круглых или квадратных скобках. Если размер не указан, при объявлении по умолчанию он равен 80 символам. Для данных типа STRING количество содержащихся в переменной символов не ограниченно, но функции для обработки строк могут принять до 255 символов.
Объем памяти, необходимый для переменной STRING, всегда составляет 1 байт на символ +1 дополнительный байт, например, переменная объявленная как «STRING [80]» будет занимать 81 байт. Для присвоения константного значения переменной типа STRING присваемый текст необходимо заключить в одинарные кавычки.
Пример объявления строки на 35 символов:
sVar : STRING(35) := 'This is a String'; (*Пример объявления переменной типа STRING*)
WSTRING — этот тип данных схож с типом STRING, но использует по 2 байта на символ и кодировку Unicode. Это значит что переменные типа WSTRING поддерживают символы кириллицы. Для присвоения константного значения переменной типа WSTRING присваемый текст необходимо заключить в двойные кавычки.
Пример объявления переменной типа WSTRING:
wsVar : WSTRING := "This is a WString"; (*Пример объявления переменной типа WSTRING*)Если значение, присваиваемое переменной STRING или WSTRING, содержит знак доллара ($), следующие два символа интерпретируются как шестнадцатеричный код в соответствии с кодировкой Windows-1252. Код также соответствует кодировке ASCII.
| Код со знаком доллара | Его значение в переменной |
| $<восьмибитное число> | Восьмибитное число интерпретируется как символ в кодировке ISO / IEC 8859-1 |
| ‘$41’ | A |
| ‘$9A’ | © |
| ‘$40’ | @ |
| ‘$0D’, ‘$R’, ‘$r’ | Разрыв строки |
| ‘$0A’, ‘$L’, ‘$l’, ‘$N’, ‘$n’ | Новая строка |
| ‘$P’, ‘$p’ | Конец страницы |
| ‘$T’, ‘$t’ | Табуляция |
| ‘$$’ | Знак доллара |
| ‘$’ ‘ | Одиночная кавычка |
Такое разнообразие кодировок связанно с тем, что у всех из них первые 128 символов соответствуют кодовой таблице ASCII, но в статье для каждого случая кодировка указывалась так же, как она указана в infosys.
Пример:
VAR CONSTANT
sConstA : STRING :='Hello world';
sConstB : STRING :='Hello world $21'; (*Пример объявления переменной типа STRING с спец символом*)
END_VAR
Типы данных времени
TIME — тип данных, предназначенный для хранения временных промежутков. Размер типа данных 32 бита. Этот тип данных интерпретируется в TwinCAT, как переменная типа DWORD, содержащая время в миллисекундах. Нижний допустимый предел 0 (0 мс), верхний предел 4 294 967 295 (49 дней, 17 часов, 2 минуты, 47 секунд, 295 миллисекунд). Для записи значений в переменные типа TIME используется префикс T# и суффиксы d: дни, h: часы, m: минуты, s: секунды, ms: миллисекунды, которые должны располагаться в порядке убывания.
Примеры корректного присваивания значения переменной типа TIME:
TIME1 : TIME := T#14ms;
TIME1 : TIME := T#100s12ms; // Допускается переполнение в старшем отрезке времени.
TIME1 : TIME := t#12h34m15s;Примеры некорректного присваивания значения переменной типа TIME, при компиляции будет выдана ошибка:
TIME1 : TIME := t#5m68s; // Переполнение не в старшем отрезке времени недопустимо
TIME1 : TIME := 15ms; // Пропущен префикс T#
TIME1 : TIME := t#4ms13d; // Не соблюден порядок записи временных отрезокLTIME — тип данных аналогичен TIME, но его размер составляет 64 бита, а временные отрезки хранятся в наносекундах. Нижний допустимый предел 0, верхний предел 213 503 дней, 23 часов, 34 минуты, 33 секунд, 709 миллисекунд, 551 микросекунд и 615 наносекунд. Для записи значений в переменные типа LTIME используется префикс LTIME#. Помимо суффиксов, используемых для записи типа TIME для LTIME, используются µs: микросекунды и ns: наносекунды.
Пример:
LTIME1 : LTIME := LTIME#1000d15h23m12s34ms2us44ns; (*Пример объявления переменной типа LTIME*)TIME_OF_DAY (TOD) — тип данных для записи времени суток. Имеет размер 32 бита. Нижнее допустимое значение 0, верхнее допустимое значение 23 часа, 59 минут, 59 секунд, 999 миллисекунд. Для записи значений в переменные типа TOD используется префикс TIME_OF_DAY# или TOD#, значение записывается в виде <часы : минуты : секунды> . В остальном этот тип данных аналогичен типу TIME.
Пример:
TIME_OF_DAY#15:36:30.123
tod#00:00:00Date — тип данных для записи даты. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106), да, здесь присутствует возможный компьютерный апокалипсис, но учитывая запас по верхнему пределу, эта проблема не слишком актуальна. Для записи значений в переменные типа TOD используется префикс DATE# или D#, значение записывается в виде <год — месяц — дата>. В остальном этот тип данных аналогичен типу TIME.
DATE#1996-05-06
d#1972-03-29DATE_AND_TIME (DT) — тип данных для записи даты и времени. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106, 6:28:15). Для записи значений в переменные типа DT используется префикс DATE_AND_TIME # или DT#, значение записывается в виде <год — месяц — дата — час : минута : секунда>. В остальном этот тип данных аналогичен типу TIME.
DATE_AND_TIME#1996-05-06-15:36:30
dt#1972-03-29-00:00:00На этом раз мы заканчиваем рассмотрение типов данных. Сейчас мы разобрали не все типы данных, остальные можно найти в infosys по пути TwinCAT 3 → TE1000 XAE → PLC → Reference Programming → Data types.
Следующая статья будет целиком состоять из практической работы, мы напишем калькулятор на языке LD.
│
Deutsch (de) │
English (en) │
suomi (fi) │
français (fr) │
русский (ru) │
A word is the processor’s native data unit.
Modern consumer processors have a word width of 64 bits.
Data type
Most run-time libraries provide the native data type of a processor as the Pascal data type word.
It is a subset of all whole numbers (non-negative integers) that can be represented by the processor’s natural data unit size.
On a 64-bit architecture this means a word is an integer within the range [math]displaystyle{ [0,~2^{64}-1] }[/math].
On a 32-bit architecture a word will be an integer in the range [math]displaystyle{ [0,~2^{32}-1] }[/math], and so on, respectively.
In GNU Pascal a word is just an alias for cardinal, which has the same properties regarding possible values.
If a signed integer having the processor’s native size is wanted, the data type integer provides this functionality.
FPC
For source compatibility reasons, FPC defines word in the same way as Turbo Pascal and Delphi: the subrange data type 0..65535.
The high value 65535 is [math]displaystyle{ 2^{16}-1 }[/math].
Thus a system.word occupies two bytes of space.
Subrange data types are stored in a quantity that serves best the goals of performance and memory efficiency.
The processor’s native word size, as defined above, corresponds to different types depending on the purpose you want to use it for:
- the (as of 2022 still undocumented)
system.ALUSintandsystem.ALUUinttypes correspond to the native word size used by the processor’s ALU (arithmetic and logical unit), as defined at the beginning of this page. In general, this type should not be used in high level code. Instead, choose a data type based on the values it should be able to represent, as this is safer and more portable. It is the compiler’s job to generate optimal code. system.CodePtrUIntcorresponds to the size of pointers to code, such as the address of a procedure. This can be different from a pointer to data, e. g. on targets that support multiple memory models.system.PtrUIntcorresponds to the size of pointers to data.
On many platforms, all of these types have the same size, but it is not the case everywhere.
In FPC a smallInt has the same size as a word, but is signed.
| simple data types |
|
|---|---|
| complex data types |
|
stesl писал(а): ↑23 мар 2021, 10:37
Тип Word — это целочисленный беззнаковый тип данных, в два байта. Диапазон 0-65535. Используется везде, где оказывается нужным.
Не путайте Word с UInt (unsigned integer16), он не относится к целочисленным, так как не кодирует числовые значения и не совместим с математическими операциями.
Потому что:
Sergy6661 писал(а): ↑23 мар 2021, 12:54
Вот для упаковки-распаковки битовых переменных и используется в основном.
Но не в основном, а только для этого. Если конечно в конкретном ПЛК не срабатывает неявное преобразование, из-за которого кажется, что Word — это целое число.
Отправлено спустя 21 минуту 7 секунд:
Не, иначе объясню:
Word — это когда ты в 16 бит записал 16 булевых значений, каждый из которых что-то значит в смысле true/false. Например, при управлении сервоприводом или частотником.
Int16, UInt16 — это числа, отдельные биты не представляют интереса (хотя бывают редкие исключения).
Математические операции умеют работать с числами, то есть Add(), Sub(), Mul(), Div() работают с Int16/UInt16, а с Word работает подозрительно, подсвечивает типа «глянь, что за дрянь ты задумал?», но воспринимает как число 0-65535. Извините, правда, зачем вы складываете слово управления частотника с числом -85?
Зато сдвиговые операции и операции со словами типа ANDW(), ORW(), NOT(W), XORW() работают именно со словами и подозрительно с целыми числами.
Это разные типы данных, хотя все они 16 бит.
Word Size and Data Types
A word is the amount of data that a machine can process at one time. This fits into the document analogy that includes characters (usually eight bits) and pages (many words, often 4 or 8KB worth) as other measurements of data. A word is an integer number of bytes for example, one, two, four, or eight. When someone talks about the «n-bits» of a machine, they are generally talking about the machine’s word size. For example, when people say the Pentium is a 32-bit chip, they are referring to its word size, which is 32 bits, or four bytes.
The size of a processor’s general-purpose registers (GPR’s) is equal to its word size. The widths of the components in a given architecture for example, the memory bus are usually at least as wide as the word size. Typically, at least in the architectures that Linux supports, the memory address space is equal to the word size[2]. Consequently, the size of a pointer is equal to the word size. Additionally, the size of the C type long is equal to the word size, whereas the size of the int type is sometimes less than that of the word size. For example, the Alpha has a 64-bit word size. Consequently, registers, pointers, and the long type are 64 bits in length. The int type, however, is 32 bits long. The Alpha can access and manipulate 64 bits, one word at a time.
Further read : http://www.makelinux.com/books/lkd2/ch19lev1sec2
Тип данных "WORD" история происхожения названия какова?
Во многих языка программирование есть тип «WORD», в других есть аналоги только называются по-другому. Может кто знает историю появления названия типа «WORD»? Было бы интересно узнать, поделитесь или подскажите где искать, а то гугл рассказывает только, что мол есть такой тип данных в Delphi.
-
Вопрос заданболее трёх лет назад
-
6149 просмотров
Пригласить эксперта
Это машинное слово.
В зависимости от архитектуры бывает разной длинны 2 байта, 4 байта и т.д.
Собственно происходит он из доассемблерных времен. Когда программы писались в машинных кодах.
Сакральность? — Хм
Вначале Бог создал бит и байт. И из них он создал слово.
И было в слове два байта, и ничего больше не было.
И отделил Бог единицу от нуля…
-
Показать ещё
Загружается…
16 апр. 2023, в 22:36
300 руб./в час
16 апр. 2023, в 21:57
3000 руб./за проект
16 апр. 2023, в 21:48
500 руб./за проект
Минуточку внимания
На занятии рассматриваются основные стандартные типы данных в Паскаль, понятие переменной и константы; объясняется, как работать с арифметическими операциями
Содержание:
- Типы данных в Паскале
- Целочисленные типы данных в Паскаль
- Комментарии в Паскале
- Вещественные типы данных в Паскаль
- Приведение типов
- Константы в Паскале
- «Красивый» вывод целых и вещественных чисел
- Арифметические операции в Паскале
- Порядок выполнения операций
- Стандартные арифметические процедуры и функции Pascal
Типы данных в Паскале
Паскаль — это типизированный язык программирования. Это означает, что переменные, в которых хранятся данные, имеют определенный тип данных. Т.е. программе напрямую надо указать, какие данные могут храниться в той или иной переменной: текстовые данные, числовые данные, если числовые — то целочисленные или дробные, и т.п. Это необходимо в первую очередь для того чтобы компьютер «знал», какие операции можно выполнять с этими переменными и как правильно их выполнять.
Например, сложение текстовых данных, или как это правильно называется в программировании — конкатенация — это обычное слияние строк, тогда как сложение числовых данных происходит поразрядно, кроме того, дробные и целые числа складываются тоже по-разному. То же самое касается и других операций.
Рассмотрим наиболее распространенные в Pascal типы данных.
Целочисленные типы данных в Паскаль
| Тип | Диапазон | Требуемая память (байт) |
| byte | 0..255 | 1 |
| shortint | -128..127 | 1 |
| integer | -32768.. 32767 | 2 |
| word | 0..65535 | 2 |
| longint | -2147483648..2147483647 | 4 |
Нужно иметь в виду, что при написании программ в паскале integer (в переводе с англ. целое) является наиболее часто используемым, так как диапазон значений наиболее востребуем. Если необходим более широкий диапазон, используется longint (long integer, в переводе с англ. длинное целое). Тип byte в Паскале используется, когда нет необходимости работать с отрицательными значениями, то же самое касается и типа word (только диапазон значений здесь значительно больше).
Примеры того, как описываются (объявляются) переменные в Паскале:
| Pascal | PascalABC.NET | ||||
|
|
Результат: имя: Петр, возраст: 17
При использовании PascalABC.NET наиболее часто используются следующие целочисленные типы:
| Тип | Длина, байт | Диапазон допустимых значений |
|---|---|---|
| integer | 4 | -2 147 483 648 .. 2 147 483 647 |
| int64 | 8 | -9 223 372 036 854 775 808 .. 9 223 372 036 854 775 807 |
| BigInteger | переменная | неограниченный |
Комментарии в Паскале
Обратите внимание на то, как используются комментарии в Паскале. В примере комментарии, т.е. служебный текст, который «не видим» для компилятора, заключаются в фигурные скобки {}. Обычно комментарии делаются программистами с целью пояснения фрагментов кода. Для однострочных комментариев можно использовать два слэша //:
{Очень простая программа для вывода слова "Привет"} begin // вывод write('Привет'); end.
Задача 5. Население Москвы равняется а=9000000 жителей. Население Нью-Васюков равняется b=1000 жителей. Напишите программу, которая определяет разницу в числе жителей между двумя городами. Используйте переменные величины.
[Название файла: L1task5.pas]
Вещественные типы данных в Паскаль
Вещественные числа в Паскале и вообще в программировании — это название дробных чисел.
| Тип | Диапазон | Требуемая память (байт) |
| real | 2.9 * 10E-39 .. 1.7 * 10E38 | 6 |
| single | 1.5 * 10 E-45 .. 3.4 * 10E38 | 4 |
| double | 5 * 10E-324 .. 1.7 * 10E308 | 8 |
| extended | 1.9 * 10E-4951 .. 1.1 * 10E4932 | 10 |
Тип real в Паскале — наиболее часто используемый из вещественных типов.
Выше были представлены простые типы данных в Паскаль, к которым относятся:
- Порядковые
- Целые
- Логические
- Символьные
- Перечисляемые
- Интервальные
- Вещественные
Для вывода значений переменных вещественного типа обычно используется форматированный вывод:
в формате используется либо одно число, означающее число позиций, отводимых на это число в экспоненциальной форме; p:=1234.6789; Writeln(p:12); {_1.2346E+004}либо два числа, первое из которых обозначает общий размер поля, отведенного под это число, второе — число знаков после запятой, т.е. точность. p:=1234.6789; Writeln(p:6:2); {1234.68}
Наряду с простыми типами в языке еще используются структурированные типы данных и указатели, которым будут посвящены последующие уроки по Паскалю.
Приведение типов
В pascalABC.Net в некоторых случаях можно значения одного типа присваивать переменным другого типа.
Значения типов данных, которые занимают меньше памяти, можно присвоить переменным типа данных с бОльшей емкостью. Так, возможны следующие приведения:
integer → int64 int64 → real integer → BigInteger
Пример использования операции приведения типов:
var a := 10; // integer var b := 123456789012345; // int64 var c := -3bi; // BigInteger var i := int64(a); // приведение integer → int64 var x := real(b); // приведение int64 → real var p := BigInteger(a); // приведение integer → BigInteger
Обратное приведение с помощью функций
Обратное приведение, т.е. чтобы присвоить значение большей ёмкости переменной типа данных меньшей емкости, следует использовать функции округления. Например:
real → integer
Пример:
## var x := Sqrt(3); // корень квадратный из 3, тип real var a := Trunc(x); // приведение к integer с отсечением дробной части. рез-т 1 var b := Round(x); // приведение к integer с округлением до ближайшего целого. рез-т 2
Константы в Паскале
Зачастую в программе заранее известно, что переменная будет принимать какое-то конкретное значение и не менять его на протяжении выполнения всей программы. В таком случае необходимо использовать константу.
Объявление константы в Паскале происходит до объявления переменных (до служебного слова var) и выглядит следующим образом:
Пример описания константы в Паскале:
| Pascal | PascalABC.NET | ||||
|
|
«Красивый» вывод целых и вещественных чисел
Для того чтобы после вывода значений переменных оставались отступы, чтобы значения не «сливались» друг с другом, принято через двоеточие указывать какое количество символов нужно предусмотреть для вывода значения:

Вывод целых чисел

Вывод вещественных чисел
Арифметические операции в Паскале
| ДЕЙСТВИЕ | РЕЗУЛЬТАТ | СМЫСЛ |
|---|---|---|
| 2 + 3 | 5 | плюс |
| 4 — 1 | 3 | минус |
| 2 * 3 | 6 | умножить |
| 10 / 5 | 2 | разделить |
| 10 ** 2 | 100 | возведение в степень с результатом типа real |
| 17 div 5 | 3 | целочисленное деление |
| 17 mod 5 | 2 | остаток от целочисленного деления |

Порядок выполнения операций
- вычисление выражений в скобках;
- умножение, деление, div, mod слева направо;
- сложение и вычитание слева направо.

Канонический способ:
var a: integer; b: real; begin a := 1; writeln('a := 1; a = ',a); a += 2; // Увеличение на 2 writeln('a += 2; a = ',a); a *= 3; // Умножение на 3 writeln('a *= 3; a = ',a); writeln; b := 6; writeln('b := 6; b = ',b); r /= 2; writeln('b /= 2; b = ',b); end.
Стандартные арифметические процедуры и функции Pascal
Здесь стоит более подробно остановиться на некоторых арифметических операциях.
- Операция
incв Паскале, произносимая как инкремент, это стандартная процедура pascal, которая обозначает увеличение на единицу. - Аналогично работает процедура
Decв Паскале:Dec(x)— уменьшает x на 1 (декремент) илиDec(x,n)— уменьшает x на n. - Оператор
absпредставляет собой модуль числа. Работает следующим образом: - Оператор
divв паскале является часто используемым, так как целый ряд задач связан с действием деление нацело. -
Остаток от деления или оператор
modв pascal тоже незаменим при решении ряда задач. - Заслуживающей внимания является стандартная функция
oddПаскаля, которая определяет, является ли целое число нечетным. Т. е. возвращаетtrue(истина) для нечетных чисел,false(ложь) для четных чисел. - Функция
expв паскале возвращает экспоненту параметра. Записывается какexp(x), где x типа real. - Квадрат числа в Паскале вычисляется при помощи процедуры
sqr. - Операция возведение в степень в Паскале отсутствует как таковая. Но для того чтобы возвести в степень число можно использовать функцию
exp. - Извлечь квадратный корень в Паскале можно при помощи процедуры
sqrt.
Пример операции inc:
1 2 3 |
x:=1; inc(x); {Увеличивает x на 1, т.е. x=2} writeln (х) |
Более сложное использование процедуры inc:
Inc(x,n) где x — порядкового типа, n — целого типа; процедура inc увеличивает x на n.
a:=-9; b:=abs(a); { b = 9}
Пример использования функции odd:
1 2 3 4 |
begin WriteLn(Odd(5)); {True} WriteLn(Odd(4)); {False} end. |
Пример использования процедуры sqr в Pascal:
1 2 3 4 5 |
var x:integer; begin x:=3; writeln(sqr(x)); {ответ 9} end. |
Формула такая: exp(ln(a)*n), где а — число, n — степень (а>0).
Однако в компиляторе pascal abc возведение в степень осуществляется значительно проще:
WriteLn(Power(2,3)); {ответ 8}
Пример использования процедуры sqrt в Pascal:
1 2 3 4 5 |
var x:integer; begin x:=9; writeln(sqrt(x)); {ответ 3} end. |
Задача 6. Известны размеры спичечной коробки: высота — 12.41 см., ширина — 8 см., толщина — 5 см. Вычислить площадь основания коробки и ее объем
(S=ширина * толщина, V=площадь*высота)
[Название файла: L1task6.pas]
Задача 7. В зоопарке три слона и довольно много кроликов, причем количество кроликов часто меняется. Слону положено съедать в сутки сто морковок, а кролику — две. Каждое утро служитель зоопарка сообщает компьютеру количество кроликов. Компьютер в ответ на это должен сообщить служителю общее количество морковок, которые сегодня нужно скормить кроликам и слонам.
[Название файла: L1task7.pas]
Задача 8. Известно, что x кг конфет стоит a рублей. Определите, сколько стоит y кг этих конфет, а также, сколько килограмм конфет можно купить на k рублей. Все значения вводит пользователь.
[Название файла: L1task8.pas]
В приведенных ниже примерах все функции имеют аргументы. Аргументы
m и n имеют целочисленный тип,
a и b – тип real,
x и y – любой из этих типов.
Abs(x) – возвращает абсолютное значение аргумента x; Ceil(x) - возвращает ближайшее целое, не меньшее, чем х; Floor(x) - возвращает ближайшее целое, не превышающее х; Frac(x) - возвращает дробную часть аргумента x; Max(x, y, …) – возвращает максимальное из значений x, y, …; Min(x, y, …) – возвращает минимальное из значений x, y, … ; Random(m) – возвращает случайное число из интервала [0 ; m-1]; Random(a) – возвращает случайное число из интервала [0 ; a); Random(m, n) – возвращает случайное число из интервала [m ; n]; Random(a, b) – возвращает случайное число из интервала [a ; b); Random2(m) – возвращает кортеж из двух случайных чисел в интервале [0 ; m-1]; Random2(a) – возвращает кортеж из двух случайных чисел в интервале [0 ; a); Random2(m, n) – возвращает кортеж из двух случайных чисел в интервале [m ; n]; Random2(a, b) – возвращает кортеж из двух случайных чисел в интервале [a ; b); Random3(m) – возвращает кортеж из трех случайных чисел в интервале [0 ; m-1]; Random3(a, b) – возвращает кортеж из трех случайных чисел в интервале [a ; b); Round(x) - возвращает округленное до целых по правилам арифметики значение типа integer; Round(x, n) - возвращает значение х, округленное до n знаков в дробной части; Sign(x) – возвращает -1 при x < 0, 0 при x = 0 и 1 при x > 0; Sin(x) – возвращает sin(x) типа real; Sqr(a) – возвращает a2; Sqr(m) – возвращает m2 типа int64; Sqrt(x) – возвращает √x типа real; Trunc(a) – возвращает целую часть значения a того же типа
-
07-02-2010
#1

Registered User
what is the WORD datatype?
I had a programming class assignment to make a simple guessing game ( we’re just starting out programming in C) and I read this code that changes the color of the console:
Code:
HANDLE mainwin = GetStdHandle ( STD_OUTPUT_HANDLE ); WORD DefaultColor; CONSOLE_SCREEN_BUFFER_INFO csbiInfo; GetConsoleScreenBufferInfo(mainwin, &csbiInfo); DefaultColor = csbiInfo.wAttributes;I know what each bit does, but I would like to know what the WORD datatype / structure is? ( sorry if I’m not using the correct terminology, I’m just beginning programming, and it’s really fun
) Thanks alot for the help
-
07-02-2010
#2
C++まいる!Cをこわせ!
WORD in a Windows environment is just that — a word. Now the definition of a word is some type of data that is 16 bits (2 bytes) for x86. Typically an alias for short (ONLY guaranteed under Windows!).
Originally Posted by Adak
io.h certainly IS included in some modern compilers. It is no longer part of the standard for C, but it is nevertheless, included in the very latest Pelles C versions.
Originally Posted by Salem
You mean it’s included as a crutch to help ancient programmers limp along without them having to relearn too much.
Outside of your DOS world, your header file is meaningless.
-
07-02-2010
#3
Registered User
Oh ok, thanks
So word is sort of like a string that can only hold to characters? (2 bytes?)
Thanks for the help
-
07-03-2010
#4
Registered User
No, a WORD is just a 2-Byte (unsigned) data type, you can use it for whatever you like.
Windows Data Types (Windows)
-
07-03-2010
#5
C++まいる!Cをこわせ!
When we speak of types such as word, dword, qword, etc, they all refer to a storage unit, or place, where we can store at most n bytes (2, 4, 8 in this case respectively). What exactly you want to store in them is up to you, because to the hardware it’s all bits.
Now, these types are all (usually) represented by integer types (short, int, long long respectively in this case). Originally Posted by Adak
io.h certainly IS included in some modern compilers. It is no longer part of the standard for C, but it is nevertheless, included in the very latest Pelles C versions.
Originally Posted by Salem
You mean it’s included as a crutch to help ancient programmers limp along without them having to relearn too much.
Outside of your DOS world, your header file is meaningless.
-
07-03-2010
#6
Registered User
Oh ok, its starting to make more sense now,
Thanks alot Elysia and DeadPlanet,
+ the link was really helpful as well
-
07-05-2010
#7
Programming Wraith
Short question: Why are data types bigger that BYTE called *WORD? (WORD, DWORD, QWORD … )
Devoted my life to programming…
-
07-05-2010
#8
Just a pushpin.
Short question: Why are data types bigger that BYTE called *WORD? (WORD, DWORD, QWORD … )
A word is the data size that a processor naturally handles. So for a 32-bit processor, it’s theoretically 32 bits (or an int), although x86 processors support 16 and 32 bits equally via the *x and e*x registers.
Since smaller data sizes have to be padded for operations there’s really no speed gain from using e.g. bytes vs. words. So it’s probably more convenient to define data types that are word size rather than byte size — that way you have a much larger int range at no cost of speed.
Therefore Windows has DWORD (double word) and QWORD (quad word), which correspond to 2 words and 4 words respectively (or a 16-bit long int and long long int).Since the modern Windows API really came about in Windows ’95 and that was a 16-bit system, WORD was defined to be a 16-bit data structure (on 16-bit processors, an int, and a short was 8 bits like a char). Hence the 16-bit Windows word. And it stuck on into win32, probably for compatibility reasons.
EDIT: Nevermind the ’95 part, 16-bit started out with DOS, but the point is still valid.
Last edited by bernt; 07-06-2010 at 08:23 AM.
Consider this post signed
-
07-05-2010
#9
Programming Wraith
Devoted my life to programming…

 )
) 
