
- Download source files — 1.74 MB
- Visual Studio .NET Files (Not 2003) — 788 Kb
Introduction
As with the previous word versions of the networks, this one is merely an extension of the code that has gone before except perhaps more so. This network could have been written without any extra classes being added at all. In fact, the Self Organizing Network Word Pattern class that was written for this example is never used as I reuse classes from the Back Propagation network.
I wont go into detail about the classes here as they add nothing that hasn’t been said before. If anyone wishes to use them, they are provided in their own file. However, for the sake of completeness, I will go through the details of how the network is used here, so that if anyone wants to look it up, there isn’t a sudden break with the way the rest of the code is documented.
The Self Organizing Word Network
The Self Organizing Word Network basically implements the same functionality as the Self Organizing Network.


For details on implementation, see the base class descriptions above.
Training
The training loop for the Self Organizing Word Network consists of two loops, one for the training and one for the test. The additional loop that was used for the Self Organizing Network has been omitted from the Word version as I didn’t feel it was required.

for( nIteration=0; nIteration<nNumberOfSonTwoIterations; nIteration++ ) { for( int i=0; i<patterns.Count; i++ ) { for( int n=0; n<20; n++ ) { ( ( BasicNode )sonTest.Nodes[ n ] ).SetValue( Values.NodeValue, ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( n ) ); } soNetwork.Run(); netWorkText.AppendText( "." ); } soNetwork.Learn(); soNetwork.Epoch(); log.Log( DebugLevelSet.Progress, "Iteration number " + nIteration.ToString() + " produced a winning node at " + soNetwork.WinningHorizontalPos + " Horizontal and " + soNetwork.WinningVerticalPos + " vertical, winning node value = " + soNetwork.GetWinningNodeValue( soNetwork.WinningHorizontalPos, soNetwork.WinningVerticalPos ) + "n", ClassName ); netWorkText.AppendText( "nIteration number " + nIteration.ToString() + " produced a winning node at " + soNetwork.WinningHorizontalPos + " Horizontal and " + soNetwork.WinningVerticalPos + " vertical, winning node value = " + soNetwork.GetWinningNodeValue( soNetwork.WinningHorizontalPos, soNetwork.WinningVerticalPos ) + "n" ); } netWorkText.AppendText( "Saving the networkn" ); FileStream xmlstream = new FileStream( "selforganizingnetworktwo.xml", FileMode.Create, FileAccess.Write, FileShare.ReadWrite, 8, true ); XmlWriter xmlWriter = new XmlTextWriter( xmlstream, System.Text.Encoding.UTF8 ); xmlWriter.WriteStartDocument(); soNetwork.Save( xmlWriter ); xmlWriter.WriteEndDocument(); xmlWriter.Close(); FileStream readStream = new FileStream( "selforganizingnetworktwo.xml", FileMode.Open, FileAccess.Read, FileShare.ReadWrite, 8, true ); XmlReader xmlReader = new XmlTextReader( readStream ); netWorkText.AppendText( "Loading the networkn" ); SelfOrganizingNetworkWordNetwork sonTest = new SelfOrganizingNetworkWordNetwork( log ); sonTest.Load( xmlReader ); xmlReader.Close(); StringBuilder strDataDisplay = new StringBuilder( "" ); ArrayList arrayOutput = new ArrayList(); SelfOrganizingNetworkData data; netWorkText.AppendText( "Completed the test ... now reprocessing the orginal data through the loaded networkn " ); for( int i=0; i<patterns.Count; i++ ) { for( int n=0; n<20; n++ ) { ( ( BasicNode )sonTest.Nodes[ n ] ).SetValue( Values.NodeValue, ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( n ) ); } sonTest.Run(); strDataDisplay.Remove( 0, strDataDisplay.Length ); strDataDisplay.Append( "Run Called at " + i.ToString() + " Network Values are :- Composite Value = " + sonTest.GetPosition( Values.Composite ) + ", Horizontal Value = " + sonTest.GetPosition( Values.Row ) + ", Vertical Value = " + sonTest.GetPosition( Values.Column ) + ", Current Winning Horizontal Position = " + sonTest.WinningHorizontalPos + ", Current Winning Vertical Position " + sonTest.WinningVerticalPos + ", Inputs = " + ((BasicNode)sonTest.Nodes[0]).NodeValues[Values.NodeValue].ToString() + "," + ((BasicNode)sonTest.Nodes[1]).NodeValues[Values.NodeValue].ToString() + ", Winning Node Value = " + sonTest.GetWinningNodeValue( sonTest.WinningHorizontalPos, sonTest.WinningVerticalPos ) + "n" ); strDataDisplay.Append( " String Data :- " ); for( int n=0; n<( ( AdalineWordPattern )patterns[ i ] ).InputSize(); n++ ) { strDataDisplay.Append( ( ( AdalineWordPattern )patterns[ i ] ).InputValue( n ) + " " ); } netWorkText.AppendText( strDataDisplay.ToString() ); data = new SelfOrganizingNetworkData(); data.CompositeValue = ( int )sonTest.GetPosition( Values.Composite ); data.Data = strDataDisplay.ToString(); arrayOutput.Add( data ); }
The first loop performs the training of the network for the required number of iterations, which in this example is five hundred. The code then loads the patterns value for the words into the NodeValue section of the node. Note, I use the AdalineWord pattern for this as well as reuse some of the earlier functions for loading the file. This is done for this demo to reduce the amount of cut and paste code that is used, although if you were developing an application using the Self Organizing Network Word files then you would need to write this yourself.
The Learn and Epoch functions are then called at the end of each iteration. The Learn function updates the nodes surrounding the winning node the area of which is controlled by the neighborhood size variable.
The code then does what by now should be standard saving and reloading of the network and then reruns it through an identical loop without calling the Learn or the Epoch functions, with the results of the output using the same formatting code as the Self organizing Network.

Saving And Loading
Saving and Loading is done using the same XML format as everywhere else and looks like:
<?xml version="1.0" encoding="utf-8"?>
<SelfOrganizingNetworkWordNetwork>
<SelfOrganizingNetwork>
<HorizontalSize>10</HorizontalSize>
<VerticalSize>10</VerticalSize>
<InitialLearningRate>0.5</InitialLearningRate>
<LearningRate>0.01</LearningRate>
<FinalLearningRate>0.01</FinalLearningRate>
<InitialNeighborhoodSize>5</InitialNeighborhoodSize>
<FinalNeighborhoodSize>1</FinalNeighborhoodSize>
<NeighborhoodDecrement>100</NeighborhoodDecrement>
<NeighborhoodSize>1</NeighborhoodSize>
<NumberOfIterations>500</NumberOfIterations>
<Iterations>500</Iterations>
<WinningHorizontalPosition>7</WinningHorizontalPosition>
<WinningVerticalPosition>0</WinningVerticalPosition>
<NumberOfNodes>20</NumberOfNodes>
<InputLayer>
<BasicNode>
<Identifier>0</Identifier>
<NodeValue>0.1074</NodeValue>
<NodeError>0</NodeError>
<Bias>
<BiasValue>1</BiasValue>
</Bias>
</BasicNode>
through to ...
<BasicNode>
<Identifier>19</Identifier>
<NodeValue>0.2406</NodeValue>
<NodeError>0</NodeError>
<Bias>
<BiasValue>1</BiasValue>
</Bias>
</BasicNode>
</InputLayer>
<KohonenLayer>
<SelfOrganizingNetworkNode>
<BasicNode>
<Identifier>20</Identifier>
<NodeValue>36.7925330599203</NodeValue>
<NodeValue>0.01</NodeValue>
<NodeError>0</NodeError>
<Bias>
<BiasValue>1</BiasValue>
</Bias>
</BasicNode>
</SelfOrganizingNetworkNode>
through to ....
<SelfOrganizingNetworkNode>
<BasicNode>
<Identifier>2099</Identifier>
<NodeValue>36.793609556095</NodeValue>
<NodeValue>0.01</NodeValue>
<NodeError>0</NodeError>
<Bias>
<BiasValue>1</BiasValue>
</Bias>
</BasicNode>
</SelfOrganizingNetworkNode>
<SelfOrganizingNetworkLink>
<BasicLink>
<Identifier23</Identifier>
<LinkValue>8.38539366591963</LinkValue>
<InputNodeID>2</InputNodeID>
<OutputNodeID>20</OutputNodeID>
</BasicLink>
</SelfOrganizingNetworkLink>
through to ....
<SelfOrganizingNetworkLink>
<BasicLink>
<Identifier>2119</Identifier>
<LinkValue>8.72511583748183</LinkValue>
<InputNodeID>19</InputNodeID>
<OutputNodeID>2099</OutputNodeID>
</BasicLink>
</SelfOrganizingNetworkLink>
</KohonenLayer>
</SelfOrganizingNetwork>
</SelfOrganizingNetworkWordNetwork>
Testing
The testing portions of the code are located under the Run menu for the Neural Net Tester program. The test for this program is the «Load And Run Self Organizing Network 2» menu option. This will load the file that resembles the one above. I say resembles as the linkage values wont be exactly the same any two times running.
The menu option will load and run the SelfOrganizingNetworkOne.wrk file and generate the log Load And Run Self Organizing Network One.xml which can be viewed using the LogViewer that is part of the neural net tester program.
The display will show an output similar to that found when running the Adaline networks and is described in understanding the output below.
The quick guide is:
- Menu :- Run/Load And Run Self Organizing Network 2:- Loads the saved Self Organizing network from the disk and then runs it against the origin-of-the-species.txt file.
- Menu :- Train/Self Organizing Network 2 :- Trains the network from scratch using the sample file which by default is originpart.txt.
- Menu :- Options/Self Organizing Network 2 Options :- Brings up a dialog that allows you to set certain parameters for the running of the network.
Options

As with the previous Self organizing Network, the Learning Rate is reduced as the program progresses. This is why the first two options are the starting or initial Learning Rate and the Final Rate. The Neighborhood which is the range of updated nodes when a Learn is called is reduced as the program progresses as well as the learning rate.
The neighborhood decrement is the number of iterations to perform before a reduction in the neighborhood size and the Number Of Iterations is the amount of times that you want the program to run through the training loop.
Fun And Games
The main problem with the output of this code (well, my main problem anyway) is just what exactly does it mean? The code is meant as an experiment just to see what turns up although actually interpreting the answers then becomes a problem in itself that raises another and perhaps the most important question of: Do the answers given by the network tell us anything about the book and the words in the book or do they merely tell us something about the nature of the words used in a mathematical sense? I personally can’t decide on this one although I have a deep suspicion that the answer will be more to do with the nature of the numbers used, which when you get down to it are chosen in a perfectly arbitrary fashion. But then again, what if the technique can be used to tell us something about the book itself and the nature of how the book is written and if it works on this book, what about other books. It could possibly be quite fascinating, it could equally possibly be a complete waste of time. The problem brings me back to once again interpreting the data in a meaningful way.
At present, I don’t have any answers to this at all. It’s something that requires more research, and possibly, a mathematician having a go at it before a sensible answer is found.
History
- 7 July 2003 :- Initial release.
- 1 December 2003 :- Review and edit for CP conformance.
References
- Tom Archer (2001) Inside C#, Microsoft Press
- Jeffery Richter (2002) Applied Microsoft .NET Framework Programming, Microsoft Press
- Charles Peltzold (2002) Programming Microsoft Windows With C#, Microsoft Press
- Robinson et al (2001) Professional C#, Wrox
- William R. Staneck (1997) Web Publishing Unleashed Professional Reference Edition, Sams.net
- Robert Callan, The Essence Of Neural Networks (1999) Prentice Hall
- Timothy Masters, Practical Neural Network Recipes In C++ (1993) Morgan Kaufmann (Academic Press)
- Melanie Mitchell, An Introduction To Genetic Algorithms (1999) MIT Press
- Joey Rogers, Object-Orientated Neural Networks in C++ (1997) Academic Press
- Simon Haykin Neural Networks A Comprehensive Foundation (1999) Prentice Hall
- Bernd Oestereich (2002) Developing Software With UML Object-Orientated Analysis And Design In Practice, Addison Wesley
- R Beale & T Jackson (1990) Neural Computing An Introduction, Institute Of Physics Publishing.
Thanks
Special thanks go to anyone involved in TortoiseCVS for version control.
All UML diagrams were generated using Metamill version 2.2.
word-rnn-tensorflow

Multi-layer Recurrent Neural Networks (LSTM, RNN) for word-level language models in Python using TensorFlow.
Mostly reused code from https://github.com/sherjilozair/char-rnn-tensorflow which was inspired from Andrej Karpathy’s char-rnn.
Requirements
- Tensorflow 1.1.0rc0
Basic Usage
To train with default parameters on the tinyshakespeare corpus, run:
To sample from a trained model
To pick using beam search, use the --pick parameter. Beam search can be
further customized using the --width parameter, which sets the number of beams
to search with. For example:
python sample.py --pick 2 --width 4
Sample output
Word-RNN
LEONTES:
Why, my Irish time?
And argue in the lord; the man mad, must be deserved a spirit as drown the warlike Pray him, how seven in.
KING would be made that, methoughts I may married a Lord dishonour
Than thou that be mine kites and sinew for his honour
In reason prettily the sudden night upon all shalt bid him thus again. times than one from mine unaccustom'd sir.
LARTIUS:
O,'tis aediles, fight!
Farewell, it himself have saw.
SLY:
Now gods have their VINCENTIO:
Whipt fearing but first I know you you, hinder truths.
ANGELO:
This are entitle up my dearest state but deliver'd.
DUKE look dissolved: seemeth brands
That He being and
full of toad, they knew me to joy.
Char-RNN
ESCALUS:
What is our honours, such a Richard story
Which you mark with bloody been Thilld we'll adverses:
That thou, Aurtructs a greques' great
Jmander may to save it not shif theseen my news
Clisters it take us?
Say the dulterout apy showd. They hance!
AnBESS OF GUCESTER:
Now, glarding far it prick me with this queen.
And if thou met were with revil, sir?
KATHW:
I must not my naturation disery,
And six nor's mighty wind, I fairs, if?
Messenger:
My lank, nobles arms;
Beam search
Beam search differs from the other --pick options in that it does not greedily
pick single words; rather, it expands the most promising nodes and keeps a
running score for each beam.
Word-RNN (with beam search)
# python sample.py --prime "KING RICHARD III:" -n 100 --pick 2 --width 4
KING RICHARD III:
you, and and and and have been to be hanged, I am not to be touched?
Provost:
A Bohemian born, for tying his own train,
Forthwith by all that converses more with a crow-keeper;
I have drunk, Broach'd with the acorn cradled. Follow.
FERDINAND:
Who would not be conducted.
BISHOP OF ELY:
If you have been a-bed an acre of barren ground, hath holy;
I warrant, my lord restored of noon.
ISABELLA:
'Save my master and his shortness whisper me to the pedlar;
Money's a medler.
That I will pamper it to complain.
VOLUMNIA:
Indeed, I am
Word-RNN (without beam search)
# python sample.py --prime "KING RICHARD III:" -n 100
KING RICHARD III:
marry, so and unto the wind have yours;
And thou Juliet, sir?
JULIET:
Well, wherefore speak your disposition cousin;
May thee flatter.
My hand will answer him;
e not to your Mariana Below these those and take this life,
That stir not light of reason.
The time Lucentio keeps a root from you.
Cursed be his potency,
It was my neighbour till the birth and I drank stay.
MENENIUS:
Here's the matter,
I know take this sour place,
they know allegiance Had made you guilty.
You do her bear comfort him between him or our noble bosom he did Bolingbroke's
Projects
If you have any project using this word-rnn, please let us know. I’ll list up your project here.
- http://bot.wpoem.com/ (Simple poem generator in Korean)
Contribution
Your comments (issues) and PRs are always welcome.
- Download source files — 1.74 MB
- Visual Studio .NET Files (Not 2003) — 788 Kb
Introduction
The Adaline Word Network is an experimental network of my own. It came about when I was wondering if a network could be made to understand words. Not as in being able to give a dictionary definition, well not yet anyway, but as separate items of data. Of course, the main problem with this was that the networks all function through numbers. So I had to come up with a way of getting words to be represented by unique numbers. The idea I came up with was that each character of the word is represented on the computer as an ASCII value, so all I had to do was use the value for each letter. But then, there was the problem that certain words would amount to the same value, which required a way of changing the letter value enough so that no two words could arrive at the same value. The way I did this was to multiply each letter in the word by the value of its position in the word. So the first letter would be its character value multiplied by one and so on. I still think it’s possible that two words will come up with the same value, but it gives me a starting point to try some experiments and see where it ends up.
The Adaline Word Node Class
The AdalineWordNode class inherits from the AdalineNode class and overrides the Transfer function changing the test value to test if the total value generated by the Run function is less than 0.5. Other than this (and the saving and loading code), the AdalineWordNode uses the code from the AdalineNode class.
if( dValue < 0.5 ) return -1.0; return 1.0;
The Adaline Word Link Class
The AdalineWordLink class inherits from the AdalineLink class and apart from the saving and loading code, the class makes one change and that is to set the starting weight for the link to a random value between 0 and 1 instead of between -1 and 1. ( See Fun And Games section for an explanation )
arrayLinkValues[ Values.Weight ] = Values.Random( 0, 1 );
The Adaline Word Neuron Class
The AdalineWordNeuron class inherits directly from the BasicNeuron class and the only changes are to allow it to use the AdalineWordLink and AdalineWordNode classes.
The Adaline Pattern Class
The AdalinePattern class inherits directly from the Pattern class and slightly changes the way in which the class works. This is necessary as the pattern array now holds words and not values. These words need to be converted to values and this is done through the GetInSetAt function which contains the code:
double dValue = 0; string strTemp = arrayInSet[ nID ].ToString(); for( int i=0; i<strTemp.Length; i++ ) { dValue += strTemp[ i ] * ( i+1 ); } dValue = dValue / 10000;
which gives me a double value for the word which will be mostly unique.
The OnDoAdaline2 Function
As they both use the same algorithm, the OnDoAdaline2 function is very similar to the function that creates the first Adaline network.
FileInfo info = new FileInfo( "Neural Network Tester.xml" ); if( info.Exists == true ) { info.Delete(); } log = new Logger( "Neural Network Tester.xml", "NeuralNetworkTester", true ); ArrayList patterns = LoadAdaline2TrainingFile(); AdalineWordNeuron neuron = new AdalineWordNeuron( log, new BasicNode( log ), new BasicNode( log ), new BiasNode( log ), new AdalineWordNode( log, dLearningRateOfAdalineTwo ) ); int nIteration = 0; int nGood = 0; while( nGood < nNumberOfItemsInAdalineWordFile ) { nGood = 0; for( int i=0; i<nNumberOfItemsInAdalineWordFile; i++ ) { netWorkText.AppendText( "Setting the Node Data to, Pattern " + i.ToString() + " word 1 = " + ( ( AdalineWordPattern )patterns[ i ] ).InputValue( 0 ) + " value = " + ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 0 ).ToString() + " word 2 = " + ( ( AdalineWordPattern )patterns[ i ] ).InputValue( 1 ) + " value = " + ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 1 ).ToString() + " output value = " + ( ( AdalineWordPattern )patterns[ i ] ).OutSet[ 0 ].ToString() + "n" ); neuron.InputNodeOne.SetValue( neuron.Node.Values.NodeValue, ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 0 ) ); neuron.InputNodeTwo.SetValue( neuron.Node.Values.NodeValue, ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 1 ) ); neuron.Node.Run( neuron.Node.Values.NodeValue ); if( ( ( Pattern )patterns[ i ] ).OutputValue( 0 ) != neuron.Node.GetValue( neuron.Node.Values.NodeValue ) ) { log.Log( DebugLevelSet.Errors, "Learn called at number " + i.ToString() + " Pattern value = " + ( ( Pattern )patterns[ i ] ).OutputValue( 0 ).ToString() + " Neuron value = " + neuron.Node.GetValue( neuron.Node.Values.NodeValue ), "Form1" ); netWorkText.AppendText( "Learn called at number " + i.ToString() + " Pattern value = " + ( ( Pattern )patterns[ i ] ).OutputValue( 0 ).ToString() + " Neuron value = " + neuron.Node.GetValue( neuron.Node.Values.NodeValue ) + "n" ); neuron.Node.Learn(); break; } else nGood++; } log.Log( DebugLevelSet.Progress, "Iteration number " + nIteration.ToString() + " produced " + nGood.ToString() + " Good values out of " + nNumberOfItemsInAdalineWordFile.ToString(), "Form1" ); netWorkText.AppendText( "Iteration number " + nIteration.ToString() + " produced " + nGood.ToString() + " Good values out of " + nNumberOfItemsInAdalineWordFile.ToString() + "n" ); nIteration++; } for( int i=0; i<nNumberOfItemsInAdalineWordFile; i++ ) { neuron.InputNodeOne.SetValue( neuron.Node.Values.NodeValue, ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 0 ) ); neuron.InputNodeTwo.SetValue( neuron.Node.Values.NodeValue, ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 1 ) ); neuron.Node.Run( neuron.Node.Values.NodeValue ); netWorkText.AppendText( "Pattern " + i.ToString() + " Input = ( " + ( string )( ( AdalineWordPattern )patterns[ i ] ).InSet[ 0 ] + "," + ( string )( ( AdalineWordPattern )patterns[ i ] ).InSet[ 1 ] + " ) Adaline = " + neuron.Node.GetValue( neuron.Node.Values.NodeValue ) + " Actual = " + ( ( AdalineWordPattern )patterns[ i ] ).OutSet[ 0 ].ToString() + "n" ); } FileStream xmlstream = new FileStream( "adalinewordnetwork.xml", FileMode.Create, FileAccess.Write, FileShare.ReadWrite, 8, true ); XmlWriter xmlWriter = new XmlTextWriter( xmlstream, System.Text.Encoding.UTF8 ); xmlWriter.WriteStartDocument(); neuron.Save( xmlWriter ); xmlWriter.WriteEndDocument(); xmlWriter.Close(); FileStream readStream = new FileStream( "adalinewordnetwork.xml", FileMode.Open, FileAccess.Read, FileShare.ReadWrite, 8, true ); XmlReader xmlReader = new XmlTextReader( readStream ); AdalineWordNeuron neuron2 = new AdalineWordNeuron( log, new BasicNode( log ), new BasicNode( log ), new BiasNode( log ), new AdalineWordNode( log ) ); neuron2.Load( xmlReader ); xmlReader.Close(); for( int i=0; i<nNumberOfItemsInAdalineWordFile; i++ ) { neuron2.InputNodeOne.SetValue( neuron.Node.Values.NodeValue, ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 0 ) ); neuron2.InputNodeTwo.SetValue( neuron.Node.Values.NodeValue, ( ( AdalineWordPattern )patterns[ i ] ).GetInSetAt( 1 ) ); neuron2.Node.Run( neuron.Node.Values.NodeValue ); netWorkText.AppendText( "Pattern " + i.ToString() + " Input = ( " + ( string )( ( AdalineWordPattern )patterns[ i ] ).InSet[ 0 ] + "," + ( string )( ( AdalineWordPattern )patterns[ i ] ).InSet[ 1 ] + " ) Adaline = " + neuron2.Node.GetValue( neuron2.Node.Values.NodeValue ) + " Actual = " + ( ( AdalineWordPattern )patterns[ i ] ).OutSet[ 0 ].ToString() + "n" ); }
As you can see, the code here is very similar to the code that generates the first Adaline network. The code loops through the number of words in the Adaline word file and trains the network by calling Learn if the Run does not get the answer correct.
The next section runs the training variables through the code again to make sure that it has learned its task properly. The reason I did this was because, originally, the code was running till it got everything correct, but then getting everything wrong when I loaded the file and ran it again. The reason for this was to do with the loading of the file, not loading the link values correctly. Finally, the code will save the network and then load the network into a new neuron and run the data through the new neuron, outputting its responses to the display window.
Training
As mentioned before, the Adaline word relies heavily on the Adaline network, so the picture that depicts the training for the Adaline network is valid here.

This shows the way in which the Run function processes its data by going through the input data and multiplying it by the weight value.

The above shows the transition function for the Adaline network, but apart from the comparison being for less than 0.5, there is no difference.
Saving And Loading
As with the rest of the Neural Network Library, the Adaline Word Network is saved as an XML file to the disk, so that once trained, it can be used and loaded at will.
="1.0"="utf-8" <AdalineWordNeuron> <BasicNeuron> <BasicNode> <Identifier>0</Identifier> <NodeValue>0.2175</NodeValue> <NodeError>0</NodeError> </BasicNode> <BasicNode> <Identifier>1</Identifier> <NodeValue>0.114</NodeValue> <NodeError>0</NodeError> </BasicNode> <BiasNode> <BasicNode> <Identifier>2</Identifier> <NodeValue>1</NodeValue> <NodeError>0</NodeError> </BasicNode> </BiasNode> </BasicNeuron> <AdalineWordNode> <AdalineNode> <BasicNode> <Identifier>3</Identifier> <NodeValue>-1</NodeValue> <NodeValue>0.223333</NodeValue> <NodeError>-2</NodeError> </BasicNode> </AdalineNode> </AdalineWordNode> <AdalineWordLink< <BasicLink> <Identifier>4</Identifier> <LinkValue>-3.70488132032844</LinkValue> <InputNodeID>0</InputNodeID> <OutputNodeID>3</OutputNodeID> </BasicLink> </AdalineWordLink> <AdalineWordLink> <BasicLink> <Identifier>5</Identifier> <LinkValue>5.06800087718808</LinkValue> <InputNodeID>1</InputNodeID> <OutputNodeID>3</OutputNodeID> </BasicLink> </AdalineWordLink> <AdalineWordLink> <BasicLink> <Identifier>6</Identifier> <LinkValue>0.184749753453698</LinkValue> <InputNodeID>2</InputNodeID> <OutputNodeID>3</OutputNodeID> </BasicLink> </AdalineWordLink> </AdalineWordNeuron>
Testing
For the purposes of testing, the Adaline word class appears as the Adaline 2 network on the menus. Its option on the train menu is the Train Adaline 2 option which will run the code listed above. When it comes to the Generate menu, there is an option to generate an Adaline working file that is saved as AdalineWordWorkingFile.wrk. This generate operation reads all the words from the adaline word file which is just a text file that contains words that the Adaline will use.
The adalinewordfile.dat file that contains the words that the Adaline sample uses to generate a file can be added to through setting the options for the Adaline 2 program in the options menu although there is nothing to prevent anyone from just opening the adalinewordfile.dat and editing it in Notepad as it is a simple text file.
The generate operation will then read all the words from the file and create the AdalineWordWorkingFile.wrk by randomly selecting two words from the file and calculating the desired output before writing all the information to the file. This information is in exactly the same format at as the adword.trn file that is used to train the Adaline word network, so if you fancy changing the training data to see what happens, simply cut and paste the contents between the files.
The quick guide is
- Menu :- Generate/Generate Adaline Two Working File :- Generates the file that is used for the Adaline Load and run menu option.
- Menu :- Run/Load And Run Adaline Two :- Loads the Adaline Word saved network from the disk and then runs it against the Adaline word working file.
- Menu :- Train/Train Adaline 2 :- Trains the network from scratch using the current adword.trn Adaline word training file and then saves it to disk.
- Menu :- Options Adaline 2 Options :- Brings up a dialog that allows you to set certain parameters for the running of the Adaline word network, as well as containing a facility to allow you to add words to the Adaline word file. (AdalineWordFile.dat)
Options

The main options that can be set for the Adaline Two network are the Number of Items in the file which is set by default at 100 and the learning rate. There is also the provision to allow testing using a bias value which is a value of 1 at the transfer function. There is also the option to add more words to the file that the Adaline two network uses.

Understanding The Output
Training
Pattern ID = 1 Input Value 0.1587 = metal Input Value 0.0616 = red Output Value metal = -1 Pattern ID = 2 Input Value 0.2215 = rabbit Input Value 0.114 = slow Output Value rabbit = -1 Pattern ID = 3 Input Value 0.0641 = cat Input Value 0.1594 = steel Output Value steel = 1 Pattern ID = 4 Input Value 0.1074 = wood Input Value 0.1611 = white Output Value white = 1
As with the previous Adaline Network, the Adaline Word Network begins by loading the Pattern array with the values to be put to the network with the only difference being that the values in this case are the words. The output shows the word that is being put to the network and its corresponding calculated value.
Iteration number 7 produced 2 Good values out of 100. Setting the Node Data to, Pattern 0 word 1 = metal value = 0.1587 word 2 = red value = 0.0616 output value = -1 Setting the Node Data to, Pattern 1 word 1 = rabbit value = 0.2215 word 2 = slow value = 0.114 output value = -1 Setting the Node Data to, Pattern 2 word 1 = cat value = 0.0641 word 2 = steel value = 0.1594 output value = 1 Learn called at number 2 Pattern value = 1 Neuron value = -1
The above shows a portion of the training code for the Adaline Word Network as it finishes one iteration and begins another. As with the previous Adaline Network example, on discovering an error, the Learn function is called and a new iteration is started.
Iteration number 250 produced 100 Good values out of 100 Pattern 0 Input = ( metal,red ) Adaline = -1 Actual = -1 Pattern 1 Input = ( rabbit,slow ) Adaline = -1 Actual = -1 Pattern 2 Input = ( cat,steel ) Adaline = 1 Actual = 1 Pattern 3 Input = ( wood,white ) Adaline = 1 Actual = 1
Once the network has successfully trained with the examples, it then saves the network and loads it into a completely new network object and then performs a test with the same data to prove that everything has worked correctly.
Running
Generating Adaline Word File... Please Wait Adaline File Generated Pattern ID = 101 Input Value 0.2348 = yellow Input Value 0.0617 = and Output Value yellow = -1 Pattern ID = 102 Input Value 0.1091 = lion Input Value 0.1536 = black Output Value black = 1
When you load and run the Adaline Word network, the code generates a new file to ensure that the running data is different from the training data. Once the data is loaded, it then runs it against the network. Note that for the Adaline word network, the data being loaded into the pattern array is not output to the screen, so the only output is the final results of the run.
Fun And Games
Implementation of this network has not been easy from the start. The first problem being how to define a way that a word could create a number that would be unique and then how to crowbar it into the learning algorithm. The original idea behind this was to give each letter a value based on its ASCII value multiplied by its place in the word. This gives me a good starting point but I end up with a number that is something like 631, which is a bit off the testing of between -1 and 1. So the idea from there was just to stick a «0.» before the number which can be made to work, sort of, apart from the minor technical detail that, if a value came out at 1100, once it had the «0.» stuck in front of it, it would be considered smaller by the code than the value 0.631. This certainly wasn’t the desired result and was generally too confusing.
A solution to this was to divide the resulting number by 1000 which would mean that the value 631 would resolve to 0.0631 and the value of 1100 would resolve to 0.11 which would preserve the integrity of the initial values so that the value that was originally the highest value would still be the highest value and the values would remain linearly separable which is of great importance when dealing with an Adaline network as it only works correctly on linearly separable values.
Next, seeing as the transfer values of -1 and 1 were out, as the numbers would never originally be in the negative, the transfer values were changed so that the values were between 0 and 1. The only problem with this though was trying to set the learning rate to a value sufficient to be able to distinguish between two numbers where the difference could be as low as 0.0001. This presents a problem in the training of the network although not in the running of the network. Once the network has learnt what it is supposed to do, it works fine, but it can get stuck in training on numbers that are very close together during training. The quickest solution is to generate a new training file by generating a test file and simply cutting and pasting the contents of the file into the training file (adalineword.trn). Though, I have to admit that this sometimes just takes lots of patience. Unless you are really interested in watching numbers move across the screen, the best way to test this program is use the load and run Adaline two option from the Run menu.
History
- 2nd July 2003 :- Initial release
- 7th July 2003 :- Can’t remember
- 30th October 2003 :- Review and edit for CP conformance
References
- Tom Archer (2001) Inside C#, Microsoft Press
- Jeffery Richter (2002) Applied Microsoft .NET Framework Programming, Microsoft Press
- Charles Peltzold (2002) Programming Microsoft Windows With C#, Microsoft Press
- Robinson et al (2001) Professional C#, Wrox
- William R. Staneck (1997) Web Publishing Unleashed Professional Reference Edition, Sams.net
- Robert Callan, The Essence Of Neural Networks (1999) Prentice Hall
- Timothy Masters, Practical Neural Network Recipes In C++ (1993) Morgan Kaufmann (Academic Press)
- Melanie Mitchell, An Introduction To Genetic Algorithms (1999) MIT Press
- Joey Rogers, Object-Orientated Neural Networks in C++ (1997) Academic Press
- Simon Haykin, Neural Networks A Comprehensive Foundation (1999) Prentice Hall
- Bernd Oestereich (2002) Developing Software With UML Object-Orientated Analysis And Design In Practice, Addison Wesley
- R Beale & T Jackson (1990) Neural Computing An Introduction, Institute Of Physics Publishing
Thanks
Special thanks go to anyone involved in TortoiseCVS for version control.
All UML diagrams were generated using Metamill version 2.2.
This member has not yet provided a Biography. Assume it’s interesting and varied, and probably something to do with programming.

Contents
- 1 Introduction
- 2 What is Word Embeddings?
- 3 What is Word2Vec Model?
- 4 Word2Vec Architecture
- 4.1 i) Continuous Bag of Words (CBOW) Model
- 4.2 ii) Skip-Gram Model
- 4.3 CBOW vs Skip-Gram Word2Vec Model
- 5 Word2Vec using Gensim Library
- 5.1 Installing Gensim Library
- 6 Working with Pretrained Word2Vec Model in Gensim
- 6.1 i) Download Pre-Trained Weights
- 6.2 ii) Load Libraries
- 6.3 iii) Load Pre-Trained Weights
- 6.4 iv) Checking Vectors of Words
- 6.5 iv) Most Similar Words
- 6.6 v) Word Analogies
- 7 Training Custom Word2Vec Model in Gensim
- 7.1 i) Understanding Syntax of Word2Vec()
- 7.2 ii) Dataset for Custom Training
- 7.3 iii) Loading Libraries
- 7.4 iii) Loading of Dataset
- 7.5 iv) Text Preprocessing
- 7.6 v) Train CBOW Word2Vec Model
- 7.7 v) Train Skip-Gram Word2Vec Model
- 7.8 v) Visualizing Word Embeddings
- 7.8.1 a) Visualize Word Embeddings for CBOW
- 7.8.2 b) Visualize Word Embeddings for Skip-Gram
Introduction
In this article, we will see the tutorial for doing word embeddings with the word2vec model in the Gensim library. We will first understand what is word embeddings and what is word2vec model. Then we will see its two types of architectures namely the Continuous Bag of Words (CBOW) model and Skip Gram model. Finally, we will explain how to use the pre-trained word2vec model and how to train a custom word2vec model in Gensim with your own text corpus. And as a bonus, we will also cover the visualization of our custom word2vec model.
What is Word Embeddings?
Machine learning and deep learning algorithms cannot work with text data directly, hence they need to be converted into numerical representations. In NLP, there are techniques like Bag of Words, Term Frequency, TF-IDF, to convert text into numeric vectors. However, these classical techniques do not represent the semantic relationship relationships between the texts in numeric form.
This is where word embedding comes into play. Word Embeddings are numeric vector representations of text that also maintain the semantic and contextual relationships within the words in the text corpus.
In such representation, the words that have stronger semantic relationships are closer to each other in the vector space. As you can see in the below example, the words Apple and Mango are close to each other as they both have many similar features of being fruit. Similarly, the words King and Queen are close to each other because they are similar in the royal context.

Ad
What is Word2Vec Model?
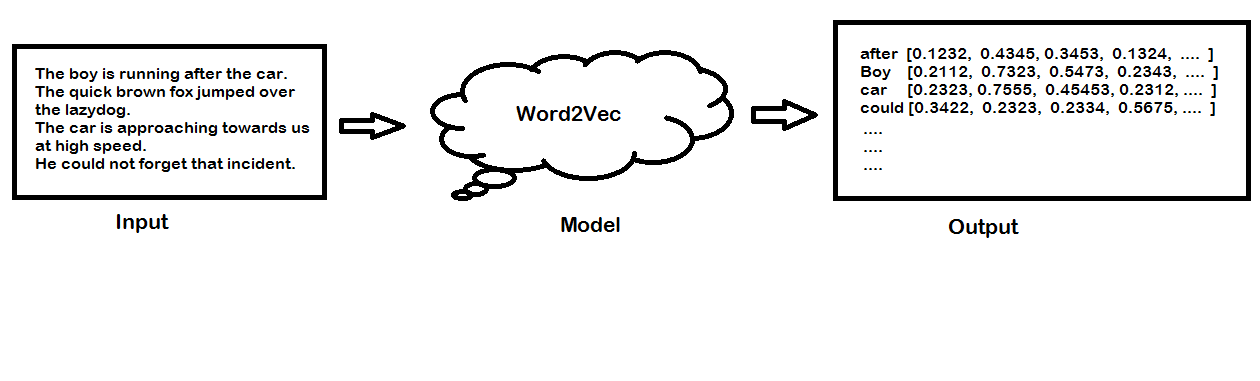
Word2vec is a popular technique for creating word embedding models by using neural network. The word2vec architectures were proposed by a team of researchers led by Tomas Mikolov at Google in 2013.
The word2vec model can create numeric vector representations of words from the training text corpus that maintains the semantic and syntactic relationship. A very famous example of how word2vec preserves the semantics is when you subtract the word Man from King and add Woman it gives you Queen as one of the closest results.
King – Man + Woman ≈ Queen
You may think about how we are doing addition or subtraction with words but do remember that these words are represented by numeric vectors in word2vec so when you apply subtraction and addition the resultant vector is closer to the vector representation of Queen.
In vector space, the word pair of King and Queen and the pair of Man and Woman have similar distances between them. This is another way putting that word2vec can draw the analogy that if Man is to Woman then Kind is to Queen!

The publicly released model of word2vec by Google consists of 300 features and the model is trained in the Google news dataset. The vocabulary size of the model is around 1.6 billion words. However, this might have taken a huge time for the model to be trained on but they have applied a method of simple subsampling approach to optimize the time.
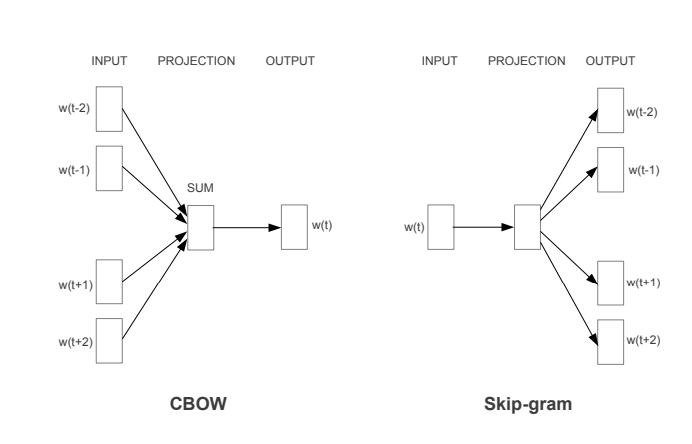
Word2Vec Architecture
The paper proposed two word2vec architectures to create word embedding models – i) Continuous Bag of Words (CBOW) and ii) Skip-Gram.
i) Continuous Bag of Words (CBOW) Model
In the continuous bag of words architecture, the model predicts the current word from the surrounding context words. The length of the surrounding context word is the window size that is a tunable hyperparameter. The model can be trained by a single hidden layer neural network.
Once the neural network is trained, it results in the vector representation of the words in the training corpus. The size of the vector is also a hyperparameter that we can accordingly choose to produce the best possible results.
ii) Skip-Gram Model
In the skip-gram model, the neural network is trained to predict the surrounding context words given the current word as input. Here also the window size of the surrounding context words is a tunable parameter.
When the neural network is trained, it produces the vector representation of the words in the training corpus. Hera also the size of the vector is a hyperparameter that can be experimented with to produce the best results.
CBOW vs Skip-Gram Word2Vec Model
- CBOW model is trained by predicting the current word by giving the surrounding context words as input. Whereas the Skip-Gram model is trained by predicting the surrounding context words by providing the central word as input.
- CBOW model is faster to train as compared to the Skip-Gram model.
- CBOW model works well to represent the more frequently appearing words whereas Skip-Gram works better to represent less frequent rare words.
For details and information, you may refer to the original word2vec paper here.
Word2Vec using Gensim Library
Gensim is an open-source python library for natural language processing. Working with Word2Vec in Gensim is the easiest option for beginners due to its high-level API for training your own CBOW and SKip-Gram model or running a pre-trained word2vec model.
Installing Gensim Library
Let us install the Gensim library and its supporting library python-Levenshtein.
In[1]:
pip install gensim pip install python-Levenshtein
In the below sections, we will show you how to run the pre-trained word2vec model in Gensim and then show you how to train your CBOW and SKip-Gram.
(All the examples are shown with Genism 4.0 and may not work with Genism 3.x version)
Working with Pretrained Word2Vec Model in Gensim
i) Download Pre-Trained Weights
We will use the pre-trained weights of word2vec that was trained on Google New corpus containing 3 billion words. This model consists of 300-dimensional vectors for 3 million words and phrases.
The weight can be downloaded from this link. It is a 1.5GB file so make sure you have enough space to save it.
ii) Load Libraries
We load the required Gensim libraries and modules as shown below –
In[2]:
import gensim from gensim.models import Word2Vec,KeyedVectors
iii) Load Pre-Trained Weights
Next, we load our pre-trained weights by using the KeyedVectors.load_word2vec_format() module of Gensim. Make sure to give the right path of pre-trained weights in the first parameter. (In our case, it is saved in the current working directory)
In[3]:
model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin.gz',binary=True,limit=100000)
iv) Checking Vectors of Words
We can check the numerical vector representation just like the below example where we have shown it for the word man.
In[4]:
vec = model['man'] print(vec)
Out[4]:
[ 0.32617188 0.13085938 0.03466797 -0.08300781 0.08984375 -0.04125977 -0.19824219 0.00689697 0.14355469 0.0019455 0.02880859 -0.25 -0.08398438 -0.15136719 -0.10205078 0.04077148 -0.09765625 0.05932617 0.02978516 -0.10058594 -0.13085938 0.001297 0.02612305 -0.27148438 0.06396484 -0.19140625 -0.078125 0.25976562 0.375 -0.04541016 0.16210938 0.13671875 -0.06396484 -0.02062988 -0.09667969 0.25390625 0.24804688 -0.12695312 0.07177734 0.3203125 0.03149414 -0.03857422 0.21191406 -0.00811768 0.22265625 -0.13476562 -0.07617188 0.01049805 -0.05175781 0.03808594 -0.13378906 0.125 0.0559082 -0.18261719 0.08154297 -0.08447266 -0.07763672 -0.04345703 0.08105469 -0.01092529 0.17480469 0.30664062 -0.04321289 -0.01416016 0.09082031 -0.00927734 -0.03442383 -0.11523438 0.12451172 -0.0246582 0.08544922 0.14355469 -0.27734375 0.03662109 -0.11035156 0.13085938 -0.01721191 -0.08056641 -0.00708008 -0.02954102 0.30078125 -0.09033203 0.03149414 -0.18652344 -0.11181641 0.10253906 -0.25976562 -0.02209473 0.16796875 -0.05322266 -0.14550781 -0.01049805 -0.03039551 -0.03857422 0.11523438 -0.0062561 -0.13964844 0.08007812 0.06103516 -0.15332031 -0.11132812 -0.14160156 0.19824219 -0.06933594 0.29296875 -0.16015625 0.20898438 0.00041771 0.01831055 -0.20214844 0.04760742 0.05810547 -0.0123291 -0.01989746 -0.00364685 -0.0135498 -0.08251953 -0.03149414 0.00717163 0.20117188 0.08300781 -0.0480957 -0.26367188 -0.09667969 -0.22558594 -0.09667969 0.06494141 -0.02502441 0.08496094 0.03198242 -0.07568359 -0.25390625 -0.11669922 -0.01446533 -0.16015625 -0.00701904 -0.05712891 0.02807617 -0.09179688 0.25195312 0.24121094 0.06640625 0.12988281 0.17089844 -0.13671875 0.1875 -0.10009766 -0.04199219 -0.12011719 0.00524902 0.15625 -0.203125 -0.07128906 -0.06103516 0.01635742 0.18261719 0.03588867 -0.04248047 0.16796875 -0.15039062 -0.16992188 0.01831055 0.27734375 -0.01269531 -0.0390625 -0.15429688 0.18457031 -0.07910156 0.09033203 -0.02709961 0.08251953 0.06738281 -0.16113281 -0.19628906 -0.15234375 -0.04711914 0.04760742 0.05908203 -0.16894531 -0.14941406 0.12988281 0.04321289 0.02624512 -0.1796875 -0.19628906 0.06445312 0.08935547 0.1640625 -0.03808594 -0.09814453 -0.01483154 0.1875 0.12792969 0.22753906 0.01818848 -0.07958984 -0.11376953 -0.06933594 -0.15527344 -0.08105469 -0.09277344 -0.11328125 -0.15136719 -0.08007812 -0.05126953 -0.15332031 0.11669922 0.06835938 0.0324707 -0.33984375 -0.08154297 -0.08349609 0.04003906 0.04907227 -0.24121094 -0.13476562 -0.05932617 0.12158203 -0.34179688 0.16503906 0.06176758 -0.18164062 0.20117188 -0.07714844 0.1640625 0.00402832 0.30273438 -0.10009766 -0.13671875 -0.05957031 0.0625 -0.21289062 -0.06542969 0.1796875 -0.07763672 -0.01928711 -0.15039062 -0.00106049 0.03417969 0.03344727 0.19335938 0.01965332 -0.19921875 -0.10644531 0.01525879 0.00927734 0.01416016 -0.02392578 0.05883789 0.02368164 0.125 0.04760742 -0.05566406 0.11572266 0.14746094 0.1015625 -0.07128906 -0.07714844 -0.12597656 0.0291748 0.09521484 -0.12402344 -0.109375 -0.12890625 0.16308594 0.28320312 -0.03149414 0.12304688 -0.23242188 -0.09375 -0.12988281 0.0135498 -0.03881836 -0.08251953 0.00897217 0.16308594 0.10546875 -0.13867188 -0.16503906 -0.03857422 0.10839844 -0.10498047 0.06396484 0.38867188 -0.05981445 -0.0612793 -0.10449219 -0.16796875 0.07177734 0.13964844 0.15527344 -0.03125 -0.20214844 -0.12988281 -0.10058594 -0.06396484 -0.08349609 -0.30273438 -0.08007812 0.02099609]
iv) Most Similar Words
We can get the list of words similar to the given words by using the most_similar() API of Gensim.
In[5]:
model.most_similar('man')
Out[5]:
[(‘woman’, 0.7664012908935547),
(‘boy’, 0.6824871301651001),
(‘teenager’, 0.6586930155754089),
(‘teenage_girl’, 0.6147903203964233),
(‘girl’, 0.5921714305877686),
(‘robber’, 0.5585119128227234),
(‘teen_ager’, 0.5549196600914001),
(‘men’, 0.5489763021469116),
(‘guy’, 0.5420035123825073),
(‘person’, 0.5342026352882385)]
In[6]:
model.most_similar('PHP')
Out[6]:
[(‘ASP.NET’, 0.7275794744491577),
(‘Visual_Basic’, 0.6807329654693604),
(‘J2EE’, 0.6805503368377686),
(‘Drupal’, 0.6674476265907288),
(‘NET_Framework’, 0.6344218254089355),
(‘Perl’, 0.6339991688728333),
(‘MySQL’, 0.6315538883209229),
(‘AJAX’, 0.6286270618438721),
(‘plugins’, 0.6174636483192444),
(‘SQL’, 0.6123985052108765)]
v) Word Analogies
Let us now see the real working example of King-Man+Woman of word2vec in the below example. After doing this operation we use most_similar() API and can see Queen is at the top of the similarity list.
In[7]:
vec = model['king'] - model['man'] + model['women'] model.most_similar([vec])
Out[7]:
[(‘king’, 0.6478992700576782),
(‘queen’, 0.535493791103363),
(‘women’, 0.5233659148216248),
(‘kings’, 0.5162314772605896),
(‘queens’, 0.4995364248752594),
(‘princes’, 0.46233269572257996),
(‘monarch’, 0.45280295610427856),
(‘monarchy’, 0.4293173849582672),
(‘crown_prince’, 0.42302510142326355),
(‘womens’, 0.41756653785705566)]
Let us see another example, this time we do INR – India + England and amazingly the model returns the currency GBP in the most_similar results.
In[8]:
vec = model['INR'] - model ['India'] + model['England'] model.most_similar([vec])
Out[8]:
[(‘INR’, 0.6442341208457947),
(‘GBP’, 0.5040826797485352),
(‘England’, 0.44649264216423035),
(‘£’, 0.43340998888015747),
(‘Â_£’, 0.4307197630405426),
(‘£_#.##m’, 0.42561301589012146),
(‘GBP##’, 0.42464491724967957),
(‘stg’, 0.42324796319007874),
(‘EUR’, 0.418365478515625),
(‘€’, 0.4151178002357483)]
Training Custom Word2Vec Model in Gensim
i) Understanding Syntax of Word2Vec()
It is very easy to train custom wor2vec model in Gensim with your own text corpus by using Word2Vec() module of gensim.models by providing the following parameters –
- sentences: It is an iterable list of tokenized sentences that will serve as the corpus for training the model.
- min_count: If any word has a frequency below this, it will be ignored.
- workers: Number of CPU worker threads to be used for training the model.
- window: It is the maximum distance between the current and predicted word considered in the sentence during training.
- sg: This denotes the training algorithm. If sg=1 then skip-gram is used for training and if sg=0 then CBOW is used for training.
- epochs: Number of epochs for training.
These are just a few parameters that we are using, but there are many other parameters available for more flexibility. For full syntax check the Gensim documentation here.
ii) Dataset for Custom Training
For the training purpose, we are going to use the first book of the Harry Potter series – “The Philosopher’s Stone”. The text file version can be downloaded from this link.
iii) Loading Libraries
We will be loading the following libraries. TSNE and matplotlib are loaded to visualize the word embeddings of our custom word2vec model.
In[9]:
# For Data Preprocessing import pandas as pd # Gensim Libraries import gensim from gensim.models import Word2Vec,KeyedVectors # For visualization of word2vec model from sklearn.manifold import TSNE import matplotlib.pyplot as plt %matplotlib inline
iii) Loading of Dataset
Next, we load the dataset by using the pandas read_csv function.
In[10]:
df = pd.read_csv('HarryPotter.txt', delimiter = "n",header=None)
df.columns = ['Line']
df
Out[10]:
| Line | |
|---|---|
| 0 | / |
| 1 | THE BOY WHO LIVED |
| 2 | Mr. and Mrs. Dursley, of number four, Privet D… |
| 3 | were proud to say that they were perfectly nor… |
| 4 | thank you very much. They were the last people… |
| … | … |
| 6757 | “Oh, I will,” said Harry, and they were surpri… |
| 6758 | the grin that was spreading over his face. “ T… |
| 6759 | know we’re not allowed to use magic at home. I’m |
| 6760 | going to have a lot of fun with Dudley this su… |
| 6761 | Page | 348 |
6762 rows × 1 columns
iv) Text Preprocessing
For preprocessing we are going to use gensim.utils.simple_preprocess that does the basic preprocessing by tokenizing the text corpus into a list of sentences and remove some stopwords and punctuations.
gensim.utils.simple_preprocess module is good for basic purposes but if you are going to create a serious model, we advise using other standard options and techniques for robust text cleaning and preprocessing.
- Also Read – 11 Techniques of Text Preprocessing Using NLTK in Python
In[11]:
preprocessed_text = df['Line'].apply(gensim.utils.simple_preprocess) preprocessed_text
Out[11]:
0 []
1 [the, boy, who, lived]
2 [mr, and, mrs, dursley, of, number, four, priv...
3 [were, proud, to, say, that, they, were, perfe...
4 [thank, you, very, much, they, were, the, last...
...
6757 [oh, will, said, harry, and, they, were, surpr...
6758 [the, grin, that, was, spreading, over, his, f...
6759 [know, we, re, not, allowed, to, use, magic, a...
6760 [going, to, have, lot, of, fun, with, dudley, ...
6761 [page]
Name: Line, Length: 6762, dtype: object
v) Train CBOW Word2Vec Model
This is where we train the custom word2vec model with the CBOW technique. For this, we pass the value of sg=0 along with other parameters as shown below.
The value of other parameters is taken with experimentations and may not produce a good model since our goal is to explain the steps for training your own custom CBOW model. You may have to tune these hyperparameters to produce good results.
In[12]:
model_cbow = Word2Vec(sentences=preprocessed_text, sg=0, min_count=10, workers=4, window =3, epochs = 20)
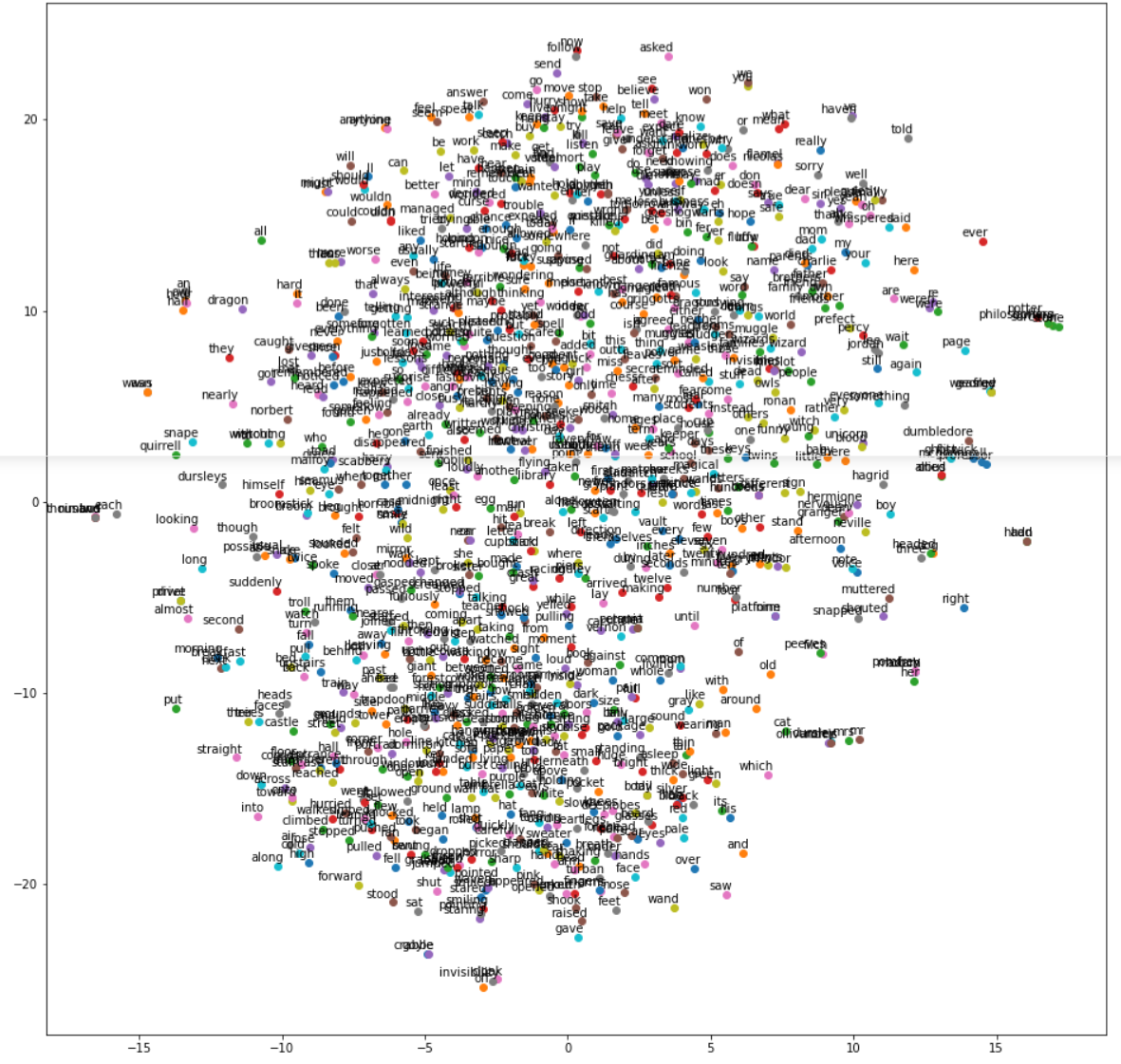
Once the training is complete we can quickly check an example of finding the most similar words to “harry”. It actually does a good job to list out other character’s names that are close friends of Harry Potter. Is it not cool!
In[13]:
model_cbow.wv.most_similar("harry")
Out[13]:
[(‘ron’, 0.8734568953514099),
(‘neville’, 0.8471445441246033),
(‘hermione’, 0.7981335520744324),
(‘hagrid’, 0.7969962954521179),
(‘malfoy’, 0.7925101518630981),
(‘she’, 0.772059977054596),
(‘seamus’, 0.6930352449417114),
(‘quickly’, 0.692932665348053),
(‘he’, 0.691251814365387),
(‘suddenly’, 0.6806278228759766)]
v) Train Skip-Gram Word2Vec Model
For training word2vec with skip-gram technique, we pass the value of sg=1 along with other parameters as shown below. Again, these hyperparameters are just for experimentation and you may like to tune them for better results.
In[14]:
model_skipgram = Word2Vec(sentences =preprocessed_text, sg=1, min_count=10, workers=4, window =10, epochs = 20)
Again, once training is completed, we can check how this model works by finding the most similar words for “harry”. But this time we see the results are not as impressive as the one with CBOW.
In[15]:
model_skipgram.wv.most_similar("harry")
Out[15]:
[(‘goblin’, 0.5757830142974854),
(‘together’, 0.5725131630897522),
(‘shaking’, 0.5482161641120911),
(‘he’, 0.5105234980583191),
(‘working’, 0.5037856698036194),
(‘the’, 0.5015968084335327),
(‘page’, 0.4912668466567993),
(‘story’, 0.4897386431694031),
(‘furiously’, 0.4880291223526001),
(‘then’, 0.47639384865760803)]
v) Visualizing Word Embeddings
The word embedding model created by wor2vec can be visualized by using Matplotlib and the TNSE module of Sklearn. The below code has been referenced from the Kaggle code by Jeff Delaney here and we have just modified the code to make it compatible with Gensim 4.0 version.
In[16]:
def tsne_plot(model): "Creates and TSNE model and plots it" labels = [] tokens = [] for word in model.wv.key_to_index: tokens.append(model.wv[word]) labels.append(word) tsne_model = TSNE(perplexity=40, n_components=2, init='pca', n_iter=2500, random_state=23) new_values = tsne_model.fit_transform(tokens) x = [] y = [] for value in new_values: x.append(value[0]) y.append(value[1]) plt.figure(figsize=(16, 16)) for i in range(len(x)): plt.scatter(x[i],y[i]) plt.annotate(labels[i], xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom') plt.show()
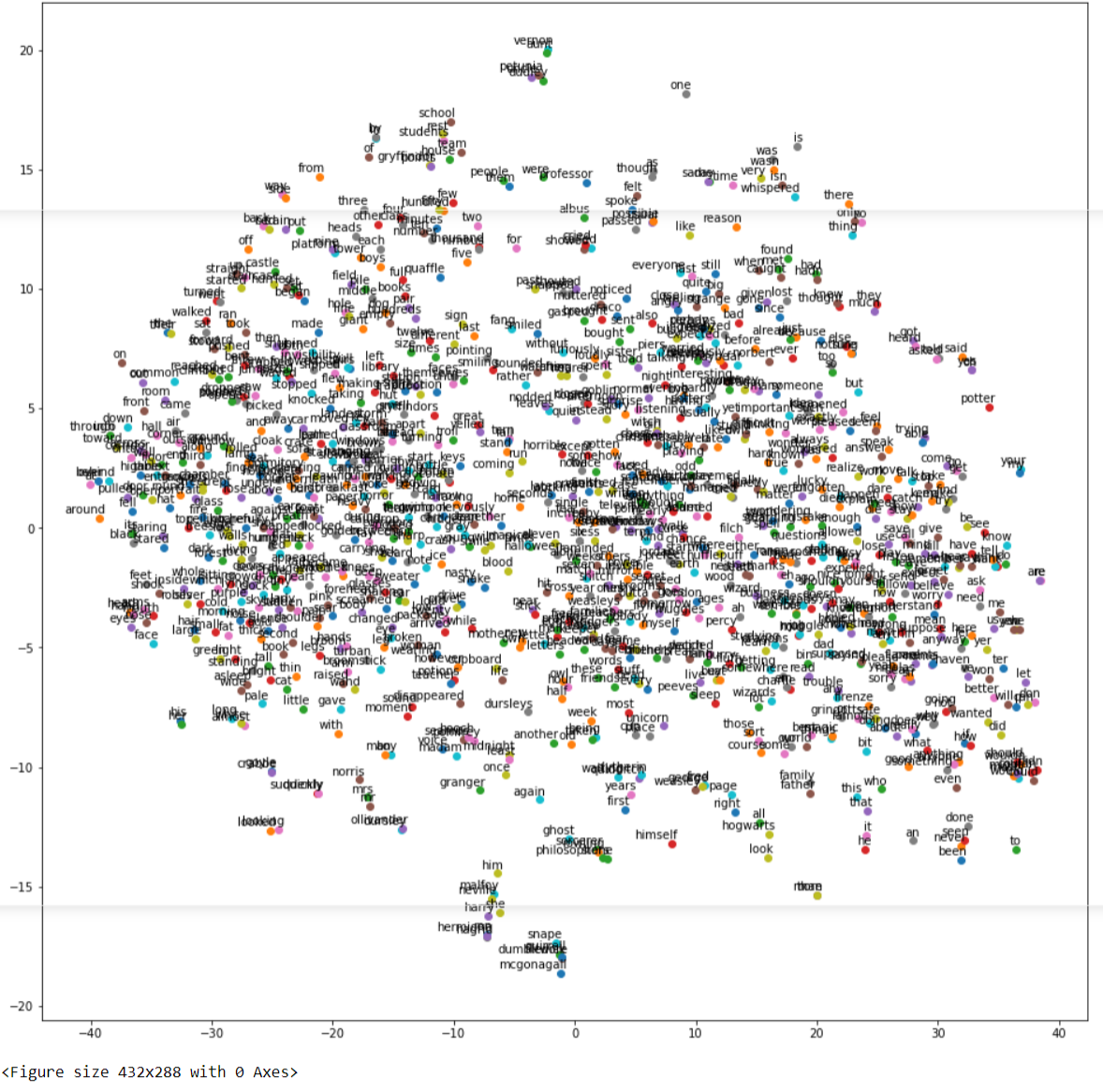
a) Visualize Word Embeddings for CBOW
Let us visualize the word embeddings of our custom CBOW model by using the above custom function.
In[17]:
tsne_plot(model_cbow)
Out[17]:
b) Visualize Word Embeddings for Skip-Gram
Let us visualize the word embeddings of our custom Skip-Gram model by using the above custom function.
In[18]:
tsne_plot(model_skipgram)
Out[18]:
Project description
Introduction
This python package can be used to extract context-enriched implicit word networks as described by Spitz and Gertz. The theoretical background is explained in the following publications:
- Spitz, A. (2019). Implicit Entity Networks: A Versatile Document Model. Heidelberg University Library. https://doi.org/10.11588/HEIDOK.00026328
- Spitz, A., & Gertz, M. (2018). Exploring Entity-centric Networks in Entangled News Streams. In Companion of the The Web Conference 2018 on The Web Conference 2018 — WWW ’18. Companion of the The Web Conference 2018. ACM Press. https://doi.org/10.1145/3184558.3188726
Dependencies
This project uses models from the spaCy and sentence_transformers package. These packages are not installed automatically. You can use the following commands to install them.
pip install sentence_transformers pip install spacy python -m spacy download en_core_web_sm
Example Usage
import spacy as sp import implicit_word_network as wn # Path to text file path = "data.txt" # Entities to search for in corpus entity_types = ["PERSON", "LOC", "NORP", "ORG", "WORK_OF_ART"] c = 2 # Cut-off parameter # Importing data ... D = wn.readDocuments(path) # Parsing data ... nlp = sp.load("en_core_web_sm") D_parsed = wn.parseDocuments(D, entity_types, nlp=nlp) # Converting parsing results ... D_mat = wn.createCorpMat(D_parsed) # Building graph ... V, Ep = wn.buildGraph(D_mat, c)
Download files
Download the file for your platform. If you’re not sure which to choose, learn more about installing packages.