
Время на прочтение
8 мин
Количество просмотров 15K
Для языка Java (как, впрочем, и для любого другого языка программирования) всё еще не придумали более простого и действенного способа генерации документов docx, чем библиотека Apache POI. В конце нулевых появился сей высокоуровнеый API, позволящий говорить с формируемым документом не на языке разметки XML, а с помощью удобных полей и выводов.
Судя по моим Google-запросам на протяжении более чем года сообщество пользователей этой библиотеки продержалось года этак до 2012, в то время как новые версии библиотеки всё еще появляются на главной странице проекта. Не на все вопросы, касающиеся формирования самого примитивного документа, есть ответы в документации или stackoverflow, не говоря уже о текстах на русском языке. Постараемся компенсировать этот недостаток данных для тех, кому это может понадобиться.
Основные классы API
XWPFDocument — целостное представление Word документа. В нём не только содержится xml-код, интерпретируемый редакторами (Word, LibreOffice), но также содержатся и методы для определения метаданных отображения — набора стилей, сносок и т.п. В этой статье поговорим о первом, так как работа с метаданными не так явно задокументирована, к тому же многие редакторы успешно справляются с отображением документа и без подсказок.
Итак, предположим, у вас на руках есть (ненужный) файл docx. Преобразуем его в файл zip (осторожно, обратное преобразование путем переименования zip -> docx может сделать файл недоступным для вашего редактора(!)), в получившемся архиве откроем папку word, а в ней — файл document.xml. Перед нами xml-представление word-файла, которое также можно было бы получить через Apache POI, с меньшими трудностями.
File file = new File("C:/username/document.docx");
FileInputStream fis = new FileInputStream(file.getAbsolutePath());
XWPFDocument document = new XWPFDocument(fis); // Вот и объект описанного нами класса
String documentLine = document.getDocument().toString();
Для того, чтобы поближе познакомиться с содержимым документа, придется вооружиться еще двумя классами API: XWPFParagraph и XWPFTable.
XWPFParagraph — как следует из названия, представляет собой параграф документа. Расположен он может быть как внутри XWPFDocument,
document.getParagraphs();
XWPFParagraph lastParagraph = document.createParagraph();так и внутри таблицы (если точнее — внутри ячейки таблицы, вложенной в ряд таблицы, вложенного непосредственно в таблицу).
document.createTable().createRow().createCell().addParagraph();Параграф предоставляет изрядный набор информации для вёрстки и размещения текста. Официальная документация на этот счёт достаточно красноречива: отступы слева и справа, сверху и снизу, в том числе и между строками, добавление гиперссылок и границ для параграфа.
XWPFTable — класс, олицетворяющий таблицу. Также как и в XWPFParagraph, XWPFTable можно добавлять к самому документу и к ячейке таблицы (создавая, тем самым, таблицу внутри таблицы). Семантика в таком случае чуточку усложняется.
XWPFTable table = document.createTable(); //Здесь всё просто, создаем таблицу в документе и работаем с ней.
XWPFCell cell = table.createRow().createCell();//Добавим к таблице ряд, к ряду - ячейку, и используем её.
XWPFTable innerTable = new XWPFTable(cell.getCTTc().addNewTbl(), cell, 2, 2); // Воспользуемся конструктором для добавления таблицы - возьмем cell и её внутренние свойства, а так же зададим число рядов и колонок вложенной таблицы
cell.insertTable(cell.getTables().size(), innerTable);
XWPFRun — набор данных о выводе текста внутри параграфа. Находится может только внутри параграфа, создается через вызов метода параграфа-родителя:
paragraph.createRun();
Из нескольких «ранов», как я предпочитаю их называть, и состоит целый параграф текста в Word. Каждый «ран» имеет свою настройку шрифта, его цвета и размера, а также стилизации. Через добавление различных «ранов», подчиняющихся разметке параграфа, можно выводить тексты с совершенно разной стилизацией.
Как становится видно из обзора классов, перенос, скажем, css-стиля в документ будет связан с дополнительной сложностью: часть свойств необходимо будет применить к параграфу docx, часть — к объекту класса XWPFRun.
Итак, библиотека легла в External Libraries/jar лежит под рукой, пора творить.
Создадим документ, добавим таблицу 2х2 и параграф.
XWPFDocument document = new XWPFDocument();
XWPFTable table = document.createTable(2, 2);
XWPFParagraph paragraph = document.createParagraph();
fillTable(table);
fillParagraph(paragraph);
Заполним параграф, добавив ран для вывода текста. После перевода строки стилизация параграфа будет потеряна, и в Word новый параграф будет выведен без красной строки.
void fillParagraph(XWPFParagraph paragraph) {
paragraph.setIndent(20);
XWPFRun run = paragraph.createRun();
run.setFontSize(12);
run.setFontFamily("Times New Roman");
run.setText("My text");
run.addBreak();
run.setText("New line");
}
Теперь займёмся заполнением таблицы. Мы можем обращаться не только к уже созданным элементам, но и вызвать у сформированной таблицы метод для добавления рядов или колонок.
void fillTable(XWPFTable table) {
XWPFRow firstRow = table.getRows().get(0);
XWPFRow secondRow = table.getRows().get(1);
XWPFRow thirdRow = table.createRow();
fillRow(firstRow);
}
Опускаемся глубже, на уровень ряда таблицы. Именно в таком порядке предстаёт разбор таблицы в Apache POI — сначала ряды, потом клетки. Напрямую из таблицы можно получить лишь количество колонок в таблице:
table.getColBandSize();
Итак, ряд.
void fillRow(XWPFRow row) {
List<XWPFTableCell> cellsList = row.getCells();
cellsList.forEach(cell -> fillParagraph(cell.createParagraph()));
}
Оказавшись в ячейке двигаться глубже уже некуда, поэтому можно снова вызвать наш дуболомный метод по заполнению параграфа, предварительно создав его в таблице.
Итак, можно легко уловить суть структуры документа в Word: вкладывай одно в другое и предоставляй доступ (в том числе и к созданию новых экземпляров). К сожалению, далеко не всегда есть возможность получить последний элемент во вложенной коллекции. Чаще всего приходится пользоваться такими вот ухищрениями:
XWPFRun lastRunOfParagraph = paragraph.getRuns(paragraph.getRuns().size() - 1);
Хорошо, с содержимым таблицы разобрались. Что если нам нужно явно уточнить ширину таблицы, а не оставлять её для волной интерпретации редактора?
Для некоторых на первый взгляд числовых значений, например, ширины таблицы, в Apache POI существуют целые классы.
CTTblWidth widthRepr = table.getCTTbl().getTblPr().addNewTblW();
widthRepr.setType(STTblWidth.DXA);
widthRepr.setW(BigInteger.valueOf(4000));
С помощью типа укажем, какая именно ширина нам нужна: auto, pct или dxa. В первом случае таблицы займёт всю предоставленную ей ширину, во втором — процент от всей ширины, указанный позже методом setW. В нашем же случае вмешиватеся специальная единица измерения — dxa, равная 1/20 точки.
Классы, подобные CTTblWidth, используются повсеместно: для определения ширины страницы (PgSize), ширины ячейки и др.
Единцы измерения в Apache POI
В хорошем документе всё выверенно и расчерчено идеально, вплоть до самого пикселя. Возможно, в теории можно сделать всё средствами Apache POI и без углубления в тему единиц измерения, но лучше уделить им внимание сразу, чтобы избежать недопониманий в духе «почему это схлопнулось» и «когда переместил картинку в word на один сантиметр».
О поддержке сантиметров и остальной метрической системы тут остается только мечтать. Это резонно (каждый шрифт уникален, у каждого редактора своя специфика), но дико неудобно. Придется прибегнуть ко множеству конвертаций, если вы хотите задавать отступы (ведь именно в сантиметрах мы привыкли видеть их в word) в сантиметрах. Итак, указав тип измерения dxa для некоторой ширины, как описно в параграфе выше, мы получаем в распоряжение некоторое точное значение, но абсолютно не представляем как им воспользоваться. Для перевода в сантиметры на stackoverflow есть формула. Для всего остального существует класс Units. В нем определены как методы для перевода единиц измерения, так и сами соотношения между значениями.
Запись готового документа
Для записи в конечный файл есть удобный метод XWPFDocument — write. На вход принимается поток, в который пойдёт запись.
document.write(new FileOutputStream(new File("/path/to/file.docx")));
Если готовый документ нужно куда-то передать можно подать в качестве аргумента не File-, а ByteArrayOutputStream.
Информация об элементе отображения в формате xml
Имея документ, отображающийся корректно в определенном редакторе, полезно было бы узнать как именно представлен необходимый параграф или другой элемент. Для этого определенны специальные методы, возвращающие объекты классов пакета org.openxmlformats.schemas.wordprocessingml.x2006.main. Из названия (wordprocessingml) видно, что данный набор классов используется только для работы с документами word. Например, для xlsx документов есть пакет spreadsheetml, некоторые классы которого очень и очень похожи на классы wordprocessingml, поэтому конвертация между форматами достаточно затруднена.
paragraph.getCTP();
table.getCTTbl();
Так, пустой параграф будет иметь скромное представление
<xml-fragment/>Пустая таблица покажет больше интересного.
<xml-fragment xmlns:main="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<main:tblPr>
<main:tblW main:w="0" main:type="auto"/>
<main:tblBorders>
<main:top main:val="single"/>
<main:left main:val="single"/>
<main:bottom main:val="single"/>
<main:right main:val="single"/>
<main:insideH main:val="single"/>
<main:insideV main:val="single"/>
</main:tblBorders>
</main:tblPr>
<main:tr>
<main:tc>
<main:p/>
</main:tc>
<main:tc>
<main:p/>
</main:tc>
</main:tr>
<main:tr>
<main:tc>
<main:p/>
</main:tc>
<main:tc>
<main:p/>
</main:tc>
</main:tr>
<main:tr>
<main:tc>
<main:p/>
</main:tc>
<main:tc>
<main:p/>
</main:tc>
</main:tr>
</xml-fragment>
Что здесь интересного? Свойства tblPr — всевозможные свойства таблицы. Внутри уже описанная ширина таблицы (установлена 0, но свойство «auto» все равно выведет таблицу в приемлимой, автоматической ширине). Также tblBorders — набор информации о границах таблицы. Далее идёт явно выраженное представление внутренностей таблицы. tr — ряд таблицы, внутри вложенны tc. Внутри tc оказался бы набор вложенный параграфов, если бы мы добавили хотя бы один.
Попробуем пополнить параграф информацией и посмотреть что из этого получится.
XWPFParagraph xwpfParagraph = document.getParagraphs().get(0);
xwpfParagraph.setFirstLineIndent(10);
XWPFRun run = xwpfParagraph.createRun();
run.setFontFamily("Times New Roman");
run.setText("New text");Получаем:
<xml-fragment xmlns:main="http://schemas.openxmlformats.org/wordprocessingml/2006/main">
<main:pPr>
<main:ind main:firstLine="10"/>
</main:pPr>
<main:r>
<main:rPr>
<main:rFonts main:ascii="Times New Roman" main:hAnsi="Times New Roman" main:cs="Times New Roman" main:eastAsia="Times New Roman"/>
</main:rPr>
<main:t>New text</main:t>
</main:r>
</xml-fragment>Здесь ситуация ровно такая же: объект с мета-информацией (в него добавлена информация об отступе красной строки, который мы вложили в коде), а так же само содержимое: там размещается список «ранов». В первый и единственный мы добавили текст и информацию о шрифте. Эта информация также разделилась внутри «рана» — информация о шрифте попала в rPr, сам текст — в элемент t.
Вместо вывода
Apache POI предоставляет удобный, и, что не менее важно, бесплатный API для работы с документами. В нем непросто добиться единого отображения во всех редакторах (Office Online и LibreOffice обязательно будут выглядеть иначе), есть множество неудобств с единицами измерения, а так же непонятно где и какие свойства в элементах должны находиться. Тем не менее, работа с этими свойствами подчинена логике, а возможность подглядеть в xml не нарушая эту логику делает разработку гораздо более удобной.
package ua.com.prologistic;
import org.apache.poi.xwpf.model.XWPFHeaderFooterPolicy;
import org.apache.poi.xwpf.usermodel.ParagraphAlignment;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTP;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTR;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTSectPr;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTText;
import java.io.FileOutputStream;
public class WordWorker {
public static void main(String[] args) {
try {
// создаем модель docx документа,
// к которой будем прикручивать наполнение (колонтитулы, текст)
XWPFDocument docxModel = new XWPFDocument();
CTSectPr ctSectPr = docxModel.getDocument().getBody().addNewSectPr();
// получаем экземпляр XWPFHeaderFooterPolicy для работы с колонтитулами
XWPFHeaderFooterPolicy headerFooterPolicy = new XWPFHeaderFooterPolicy(docxModel, ctSectPr);
// создаем верхний колонтитул Word файла
CTP ctpHeaderModel = createHeaderModel(
«Верхний колонтитул — создано с помощью Apache POI на Java :)»
);
// устанавливаем сформированный верхний
// колонтитул в модель документа Word
XWPFParagraph headerParagraph = new XWPFParagraph(ctpHeaderModel, docxModel);
headerFooterPolicy.createHeader(
XWPFHeaderFooterPolicy.DEFAULT,
new XWPFParagraph[]{headerParagraph}
);
// создаем нижний колонтитул docx файла
CTP ctpFooterModel = createFooterModel(«Просто нижний колонтитул»);
// устанавливаем сформированый нижний
// колонтитул в модель документа Word
XWPFParagraph footerParagraph = new XWPFParagraph(ctpFooterModel, docxModel);
headerFooterPolicy.createFooter(
XWPFHeaderFooterPolicy.DEFAULT,
new XWPFParagraph[]{footerParagraph}
);
// создаем обычный параграф, который будет расположен слева,
// будет синим курсивом со шрифтом 25 размера
XWPFParagraph bodyParagraph = docxModel.createParagraph();
bodyParagraph.setAlignment(ParagraphAlignment.RIGHT);
XWPFRun paragraphConfig = bodyParagraph.createRun();
paragraphConfig.setItalic(true);
paragraphConfig.setFontSize(25);
// HEX цвет без решетки #
paragraphConfig.setColor(«06357a»);
paragraphConfig.setText(
«Prologistic.com.ua — новые статьи по Java и Android каждую неделю. Подписывайтесь!»
);
// сохраняем модель docx документа в файл
FileOutputStream outputStream = new FileOutputStream(«F:/Apache POI Word Test.docx»);
docxModel.write(outputStream);
outputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(«Успешно записан в файл»);
}
private static CTP createFooterModel(String footerContent) {
// создаем футер или нижний колонтитул
CTP ctpFooterModel = CTP.Factory.newInstance();
CTR ctrFooterModel = ctpFooterModel.addNewR();
CTText cttFooter = ctrFooterModel.addNewT();
cttFooter.setStringValue(footerContent);
return ctpFooterModel;
}
private static CTP createHeaderModel(String headerContent) {
// создаем хедер или верхний колонтитул
CTP ctpHeaderModel = CTP.Factory.newInstance();
CTR ctrHeaderModel = ctpHeaderModel.addNewR();
CTText cttHeader = ctrHeaderModel.addNewT();
cttHeader.setStringValue(headerContent);
return ctpHeaderModel;
}
}
Apache POI and File stream is the root concept to create a Word document. Apache POI Is an API provided by Apache foundation which is a collection of different java libraries. This facility gives the library to read, write, and manipulate different Microsoft files such as Excel sheets, PowerPoint, and Word files. There are two types basically older version including ‘.doc’, ‘.ppt’ while newer versions of files as ‘.docx’, ‘.pptx’. There are two ways to deal with Apache POI as mentioned below:
Here zip file is taken for consideration and also if the operating system is Windows, zip files should be preferred. It is a simple java project so binary distribution API is used. In the process of creating the document, several paragraphs will be inserted as a sample to display output and will be providing styles to paragraphs such as font color, font name, and font size.
Now in order to create a Word file without using Microsoft Word, there is a java interface called Spire and if there is a need to create a PDF document without using Adobe Acrobat then it can be done with the use of an interface known as ‘E-Ice blue’. Here ‘Spire.doc’ must have to be imported as per problem statement as all dealing is in word format.
Spire.Doc for Java is a professional Java Word API that enables Java applications to create, convert, manipulate, and print Word documents without using Microsoft Office. It will be imported as a reference for this program as a reference.
Syntax: For importing libraries in java of Spire
import Spire.Doc.jar ;
Additionally, there is another Java API for PDF format as discussed above ‘E-Ice Blue’ that enables developers to read, write, convert, and print PDF documents in Java applications without using Adobe Acrobat. Similarly, a PowerPoint API allows developers to create, read, edit, convert, and print PowerPoint files within Java applications.
Now, just like any class Apache POI contains classes and methods to work on. Major components of Apache POI are discussed below to understand the internal working of a file, how it is been generated without Word with help of classes and methods. There are basically two versions of files been present in Word itself.

File Streams in Java itself is an abstract class so it has three classes InputStreamClass, OutputStreamClass, and ByteStreamClass to operational execution. When an I/O occurs through byte data is called Byte handling and when an I/O stream occurs with character stream then it is called file handling process with byte stream. Remember the base reference for the newer version of files is from Word version 3.5 onwards.

Approach:
- File Handling provides how to read from and write to a file in Java. Java provides the basic input/output package for reading and writing streams. java.io package allows doing all the input and output tasks in java. Further, in detail is explained below under file streams in java.
- Java contains an in-built package org.apache.poi.xwpf.usermodel which can be imported into the environment, providing a wide range of functionalities involved with documents. This package provides a class XWPFDocument which can be used to work with ‘.docx’ files. The other required package involves File for processing and working with files and FileOutputStream to establish a connection and create the corresponding file. It also stimulates the procedure of writing contents onto the specified file location. A blank document can be created and stored at the local storage using these packages. The connection needs to be closed after writing the contents.

Algorithm: To create a blank Word file
- Creating a blank document using file methods.
- Specifying the path or directory where the blank document is to be created.
- Writing to the document in the file stream.
- Writings contents to the document.
- Close the file connection.
Implementation: The following Java code illustrates this procedure: Here it is a simple Apache implementation program so no need to introduce Maven libraries to the program:
Java
import java.io.File;
import java.io.FileOutputStream;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
public class GFG {
public static void main(String[] args) throws Exception
{
XWPFDocument xwpfdocument = new XWPFDocument();
File file = new File("C:/blankdocument.docx");
FileOutputStream ostream
= new FileOutputStream(file);
xwpfdocument.write(ostream);
ostream.close();
}
}
Output: The code creates a blank document file in the local directory as specified by the programmer in the code.
![]()
Пару месяцев назад мне нужно было создать динамический документ Word с несколькими таблицами и абзацами. В прошлом я использовал POI для этого, но мне было трудно это использовать, и он не очень хорошо работает при создании более сложных документов. Так что для этого проекта, после некоторых поисков, я решил использовать docx4j . Docx4j, в соответствии с их сайтом является:
«Docx4j – это библиотека Java для создания и управления файлами Microsoft Open XML (Word docx, Powerpoint pptx и Excel xlsx).
Это похоже на Microsoft OpenXML SDK, но для Java. »
В этой статье я покажу вам пару примеров, которые вы можете использовать для создания контента для текстовых документов. Более конкретно мы рассмотрим следующие два примера:
- Загрузите шаблон документа Word, чтобы добавить содержимое и сохранить как новый документ.
- Добавить абзацы в этот шаблон документа
- Добавить таблицы в этот шаблон документа
Общий подход заключается в том, чтобы сначала создать документ Word, который содержит макет и основные стили вашего окончательного документа. В этом документе вам необходимо добавить заполнители (простые строки), которые мы будем использовать для поиска и замены реальным контентом.
Например, очень простой шаблон выглядит так:
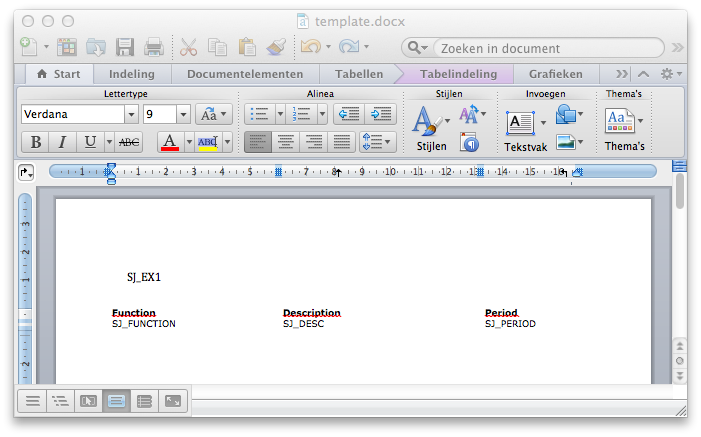
В этой статье мы покажем вам, как вы можете заполнить это, чтобы получить это:
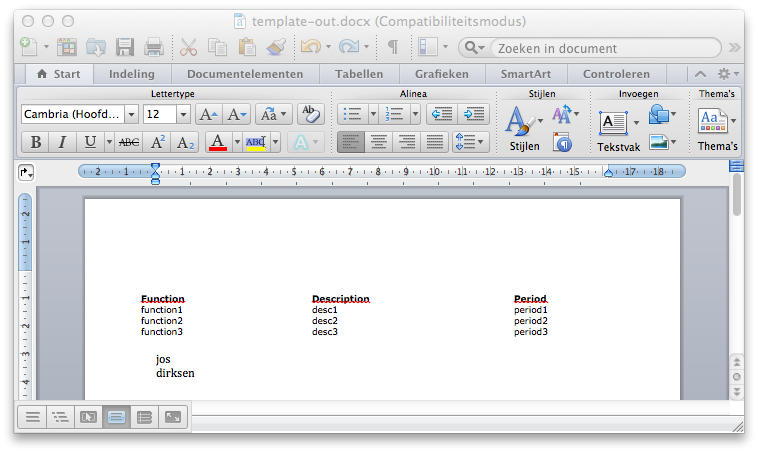
Загрузите шаблон документа Word, чтобы добавить содержимое и сохранить как новый документ.
Обо всем по порядку. Давайте создадим простой текстовый документ, который мы можем использовать в качестве шаблона. Для этого просто откройте Word, создайте новый документ и сохраните его как template.docx. Это слово шаблон, который мы будем использовать для добавления контента. Первое, что нам нужно сделать, это загрузить этот документ с помощью docx4j. Вы можете сделать это с помощью следующего фрагмента кода Java:
|
1 2 3 4 |
|
Это вернет объект Java, представляющий полный (на данный момент) пустой документ. Теперь мы можем использовать API Docx4J для добавления, удаления и изменения содержимого в этом текстовом документе. Docx4J имеет несколько вспомогательных классов, которые вы можете использовать для просмотра этого документа. Я сам написал пару помощников, которые позволяют легко найти конкретные заполнители и заменить их реальным контентом. Давайте посмотрим на одного из них. Эта операция является оберткой вокруг пары операций JAXB, которая позволяет вам искать через определенный элемент и все его дочерние элементы для определенного класса. Например, вы можете использовать это, чтобы получить все таблицы в документе, все строки в таблице и многое другое.
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 |
|
Ничего сложного, но действительно полезно. Давайте посмотрим, как мы можем использовать эту операцию. В этом примере мы просто заменим простой текстовый заполнитель другим значением. Это, например, то, что вы будете использовать для динамической установки заголовка документа. Сначала добавьте пользовательский заполнитель в созданный вами шаблон слова. Я буду использовать SJ_EX1 для этого. Мы заменим это значение на наше имя. Основные текстовые элементы в docx4j представлены классом org.docx4j.wml.Text. Чтобы заменить этот простой заполнитель, все что нам нужно сделать, это вызвать этот метод:
|
01 02 03 04 05 06 07 08 09 10 |
|
Это будет искать все элементы текста в документе, и те, которые соответствуют, заменяются на значение, которое мы указываем. Теперь все, что нам нужно сделать, это записать документ обратно в файл.
|
1 2 3 4 |
|
Не так сложно, как вы можете видеть.
С помощью этой настройки мы также можем добавить более сложный контент в наши текстовые документы. Самый простой способ определить, как добавить конкретный контент, – просмотреть исходный код XML документа word. Это скажет вам, какие оболочки нужны и как Word маршаллизирует XML. В следующем примере мы рассмотрим, как добавить полный абзац.
Добавить абзацы в этот шаблон документа
Вы можете спросить, зачем нам нужно добавлять абзацы? Мы уже можем добавить текст, и не является ли абзац просто большим фрагментом текста? Ну да и нет. Абзац действительно выглядит как большой кусок текста, но вам нужно принять во внимание разрывы строк. Если вы добавите элемент «Текст», как мы делали ранее, и добавите в текст разрывы строк, они не будут отображаться. Когда вы хотите разрывы строк, вам нужно создать новый абзац. К счастью, с Docx4j это также очень легко сделать.
Мы сделаем это, выполнив следующие шаги:
- Найти абзац для замены из шаблона
- Разбить входной текст на отдельные строки
- Для каждой строки создайте новый абзац на основе абзаца из шаблона
- Удалить оригинальный абзац
Не должно быть слишком сложно с вспомогательными методами, которые у нас уже есть.
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
В этом методе мы заменяем содержимое абзаца предоставленным текстом, а затем добавляем новые абзацы к аргументу, указанному в addTo.
|
1 2 3 4 |
|
Если вы запустите это с большим количеством контента в вашем шаблоне слов, вы заметите, что абзацы появятся внизу вашего документа. Причина в том, что абзацы добавляются обратно в основной документ. Если вы хотите, чтобы ваши абзацы добавлялись в определенное место в вашем документе (что обычно требуется), вы можете поместить их в таблицу без полей 1 × 1. Эта таблица считается родительской для абзаца, и в нее можно добавить новые абзацы.
Добавить таблицы в этот шаблон документа
Последний пример, который я хотел бы показать, – это как добавить таблицы в шаблон слова. На самом деле, лучшим описанием было бы то, как вы можете заполнить предопределенные таблицы в вашем шаблоне слов. Как и в случае с простым текстом и абзацами, мы заменим заполнители. Для этого примера добавьте простую таблицу в ваш текстовый документ (который вы можете стилизовать по своему усмотрению). К этой таблице добавьте 1 фиктивную строку, которая служит шаблоном для контента. В коде мы будем искать эту строку, копировать ее и заменять содержимое новыми строками из кода Java следующим образом:
- найдите таблицу, которая содержит одно из наших ключевых слов
- скопировать строку, которая служит шаблоном строки
- для каждой строки данных добавьте строку в таблицу на основе шаблона строки
- удалить исходную строку шаблона
Такой же подход, как мы показали и для абзацев. Сначала давайте посмотрим, как мы предоставим данные для замены. Для этого примера я просто предоставляю набор хеш-карт, которые содержат имя замещающего элемента и значение для его замены. Я также предоставляю токены для замены, которые можно найти в строке таблицы.
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 |
|
Теперь, как выглядит этот метод replaceTable.
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
Этот метод находит таблицу, получает первую строку и для каждой предоставленной карты добавляет новую строку в таблицу. Перед возвратом удаляет строку шаблона. Этот метод использует два помощника: addRowToTable и getTemplateTable. Сначала рассмотрим этот последний:
|
01 02 03 04 05 06 07 08 09 10 11 12 |
|
Эта функция просто смотрит, содержит ли таблица один из наших заполнителей. Если так, то эта таблица возвращается. Операция addRowToTable также очень проста.
|
01 02 03 04 05 06 07 08 09 10 11 12 |
|
Этот метод копирует наш шаблон и заменяет заполнители в этой строке шаблона предоставленными значениями. Эта копия добавлена в таблицу. Вот и все. С помощью этого фрагмента кода мы можем заполнять произвольные таблицы в нашем текстовом документе, сохраняя при этом макет и стиль таблиц.
Вот и все для этой статьи. С помощью абзацев и таблиц вы можете создавать множество различных типов документов, и это точно соответствует типу документов, которые чаще всего генерируются. Этот же подход можно использовать и для добавления контента другого типа в текстовые документы.
Справка: Создавайте сложные документы Word (.docx) программно с помощью docx4j от нашего партнера JCG Йоса Дирксена из блога Smart Java .