

Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей.
Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
Пример использования парсера для мониторинга цен конкурентов
Дополнительные видеоинструкции, а также подробное описание функционала, можно найти в разделе Справка по программе
В программе можно настроить несколько парсеров (обработчиков сайтов).
Любой из парсеров настраивается и работает независимо от других.
Примеры настроенных парсеров (можно скачать, запустить, посмотреть настройки)
Видеоинструкция (2 минуты), как запустить готовый (уже настроенный) парсер
Настройка программы, — дело не самое простое (для этого, надо хоть немного разбираться в HTML)
Если вам нужен готовый парсер, но вы не хотите разбираться с настройкой,
— закажите настройку парсера разработчику программы. Стоимость настройки под конкретный сайт — от 2000 рублей.
(настройка под заказ выполняется только при условии приобретения лицензии на надстройку «Парсер» (3300 руб)
Инструкция (с видео) по заказу настройки парсера
По всем вопросам, готов проконсультировать вас в Скайпе.
Программа не привязана к конкретному файлу Excel.
Вы в настройках задаёте столбец с исходными данными (ссылками или артикулами),
настраиваете формирование ссылок и подстановку данных с сайта в нужные столбцы,
нажимаете кнопку, — и ваша таблица заполняется данными с сайта.
Программа «Парсер сайтов» может быть полезна для формирования каталога товаров интернет-магазинов,
поиска и загрузки фотографий товара по артикулам (если для получения ссылки на фото, необходимо анализировать страницу товара),
загрузки актуальных данных (цен и наличия) с сайтов поставщиков, и т.д. и т.п.
Справка по программе «Парсер сайтов»
Можно попробовать разобраться с работой программы на примерах настроенных парсеров
Парсить сайты в Excel достаточно просто если использовать облачную версию софта Google Таблицы (Sheets/Doc), которые без труда позволяют использовать мощности поисковика для отправки запросов на нужные сайты.
- Подготовка;
- IMPORTXML;
- IMPORTHTML;
- Обратная конвертация.
Видеоинструкция
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/
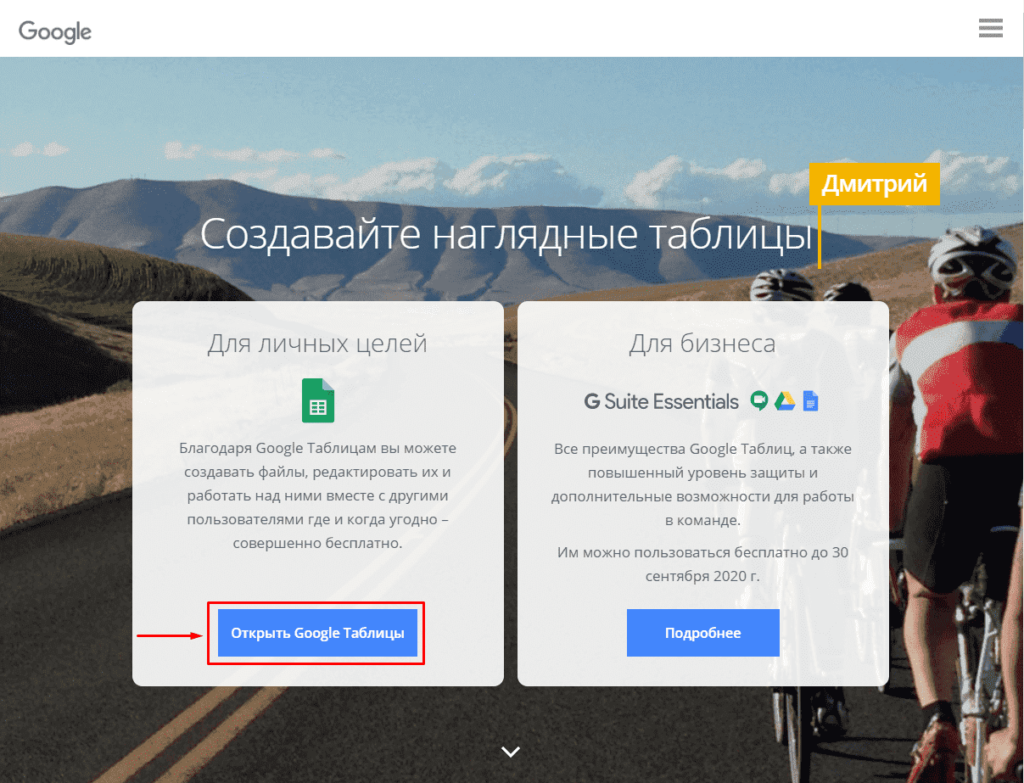
Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).
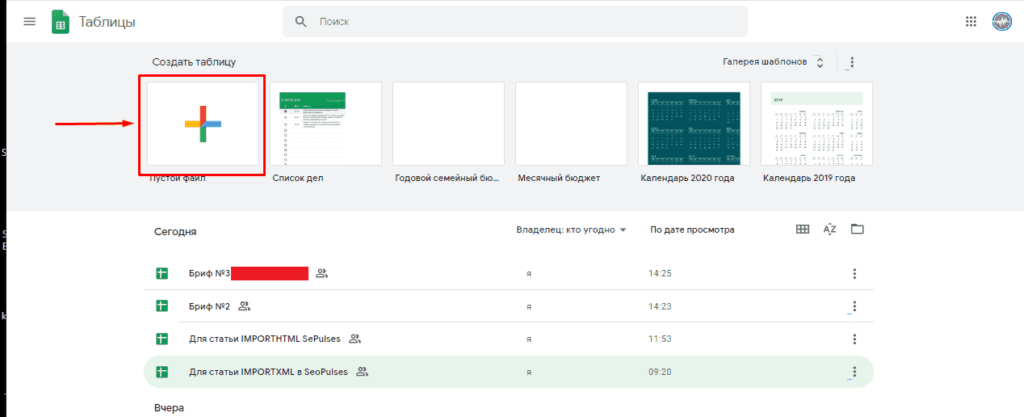
Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML. Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
- IMPORTHTML. Позволяет получить данные из таблиц и списков.
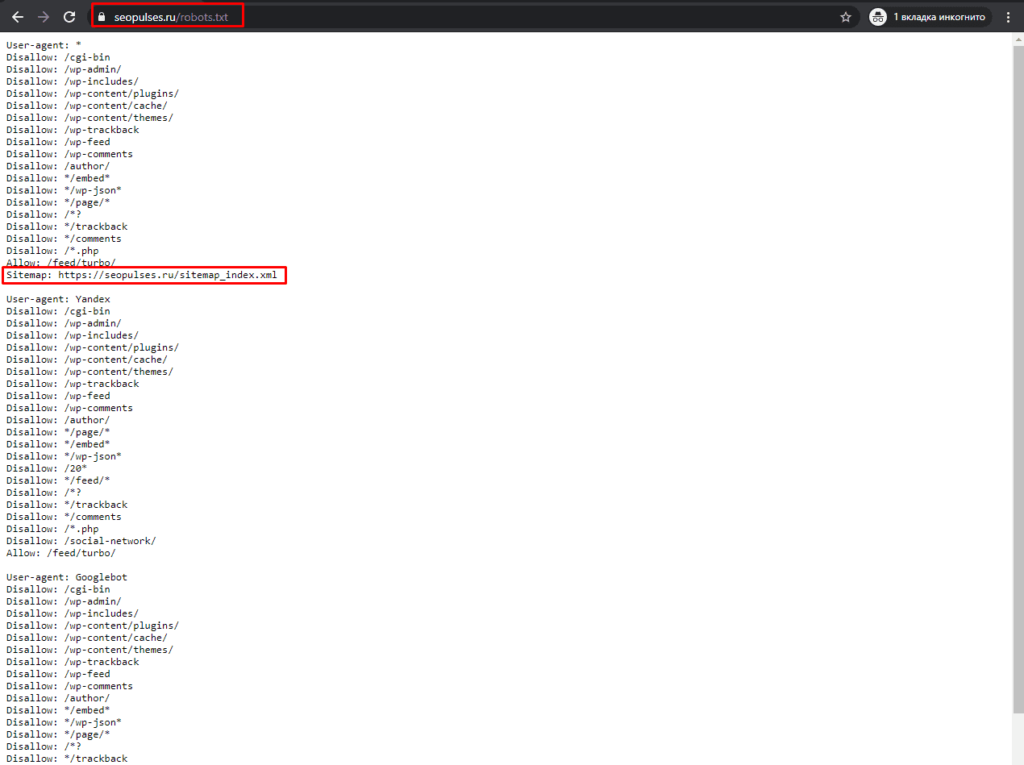
Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:
Нас интересует список постов, поэтому открываем первую ссылку.
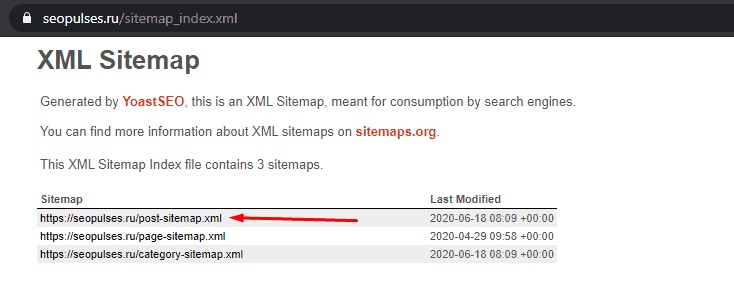
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).
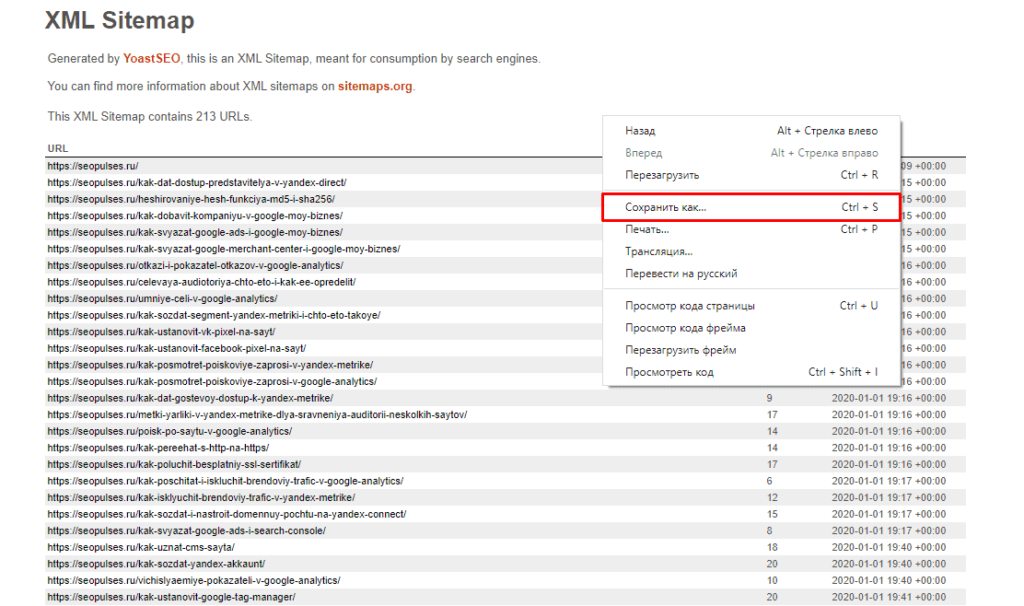
Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.
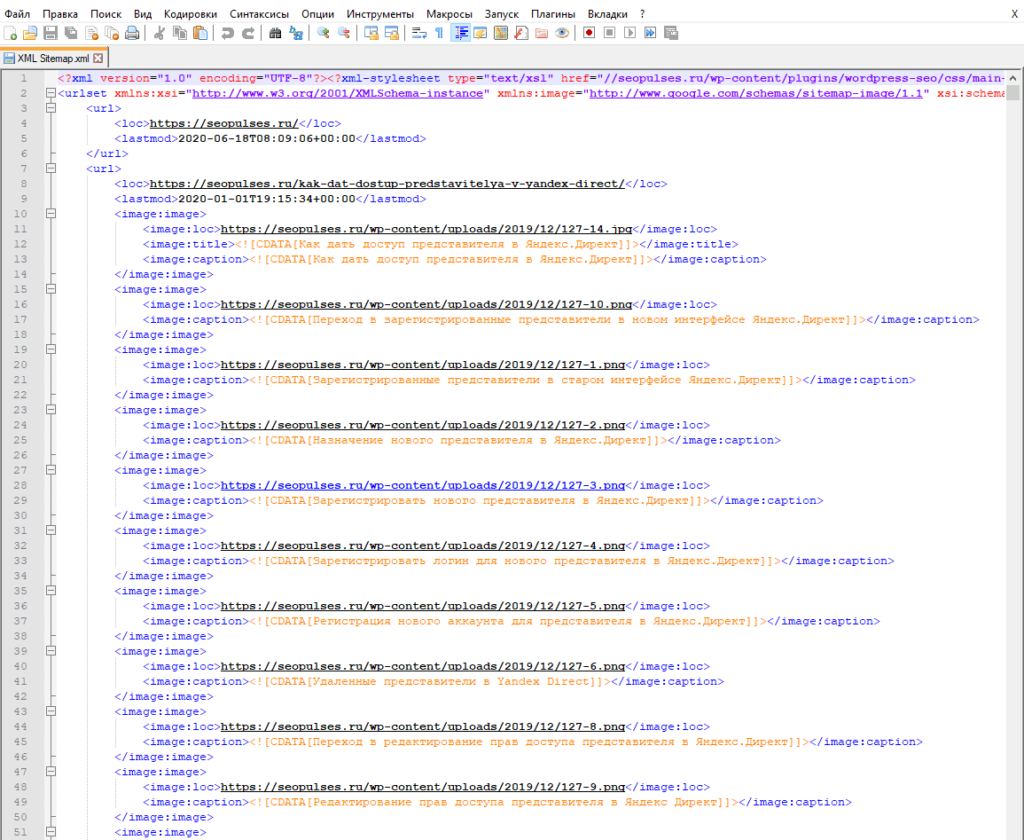
Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.
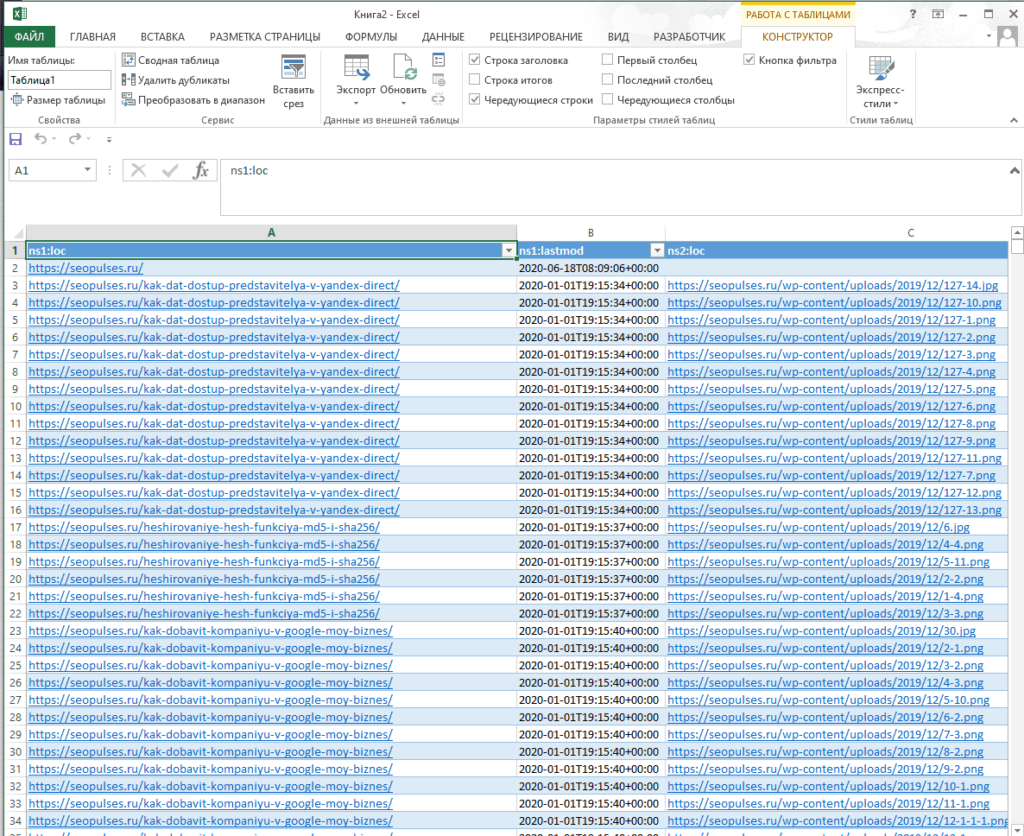
Все готово, можно переходить к методам парсинга.
IPMORTXML для парсинга сайтов в Excel
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – в формате XPath.
С примером можно ознакомиться в:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit#gid=0
Примеры использования IMPORTXML в Google Doc
Парсинг названий
Для работы с парсингом через данную функцию потребуется знание XPATH и составление пути в этом формате. Сделать это можно открыв консоль разработчика. Для примера будет использоваться сайт крупного интернет-магазина и в первую очередь необходимо в Google Chrome открыть окно разработчика кликнув правой кнопкой мыли и в выпавшем меню выбрать «Посмотреть код» (сочетание клавиш CTRL+Shift+I).
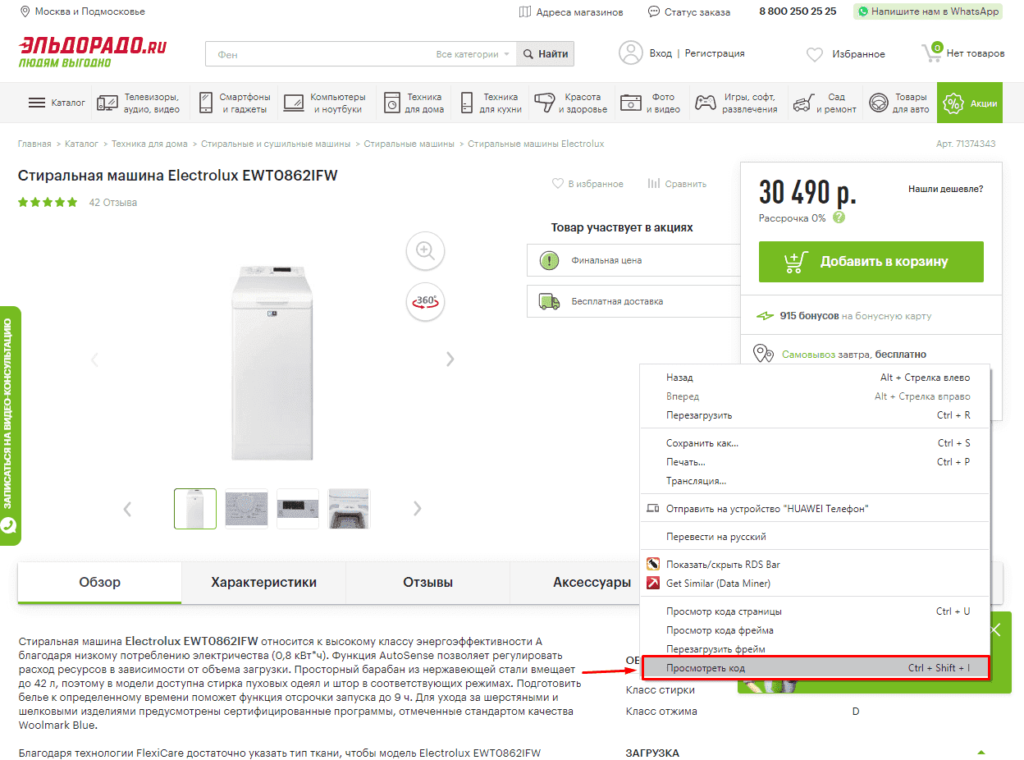
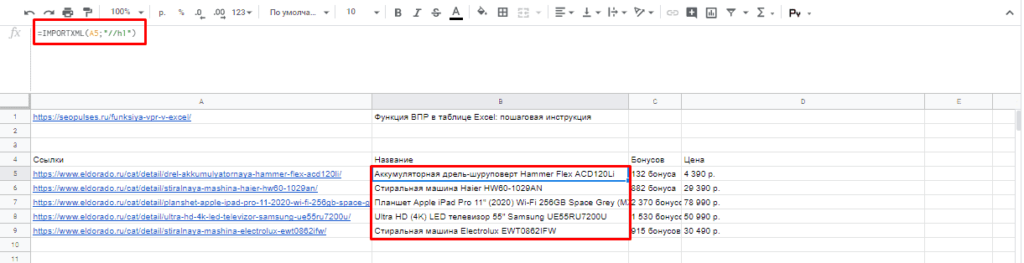
После этого пытаемся получить название товара, которое содержится в H1, единственным на странице, поэтому запрос должен быть:
//h1
И как следствие формула:
=IMPORTXML(A2;»//h1″)
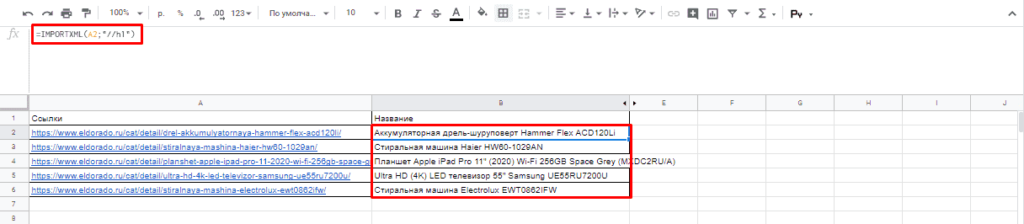
Важно! Запрос XPath пишется в кавычках «запрос».
Парсинг различных элементов
Если мы хотим получить баллы, то нам потребуется обратиться к элементу div с классом product-standart-bonus поэтому получаем:
//div[@class=’product-standart-bonus’]
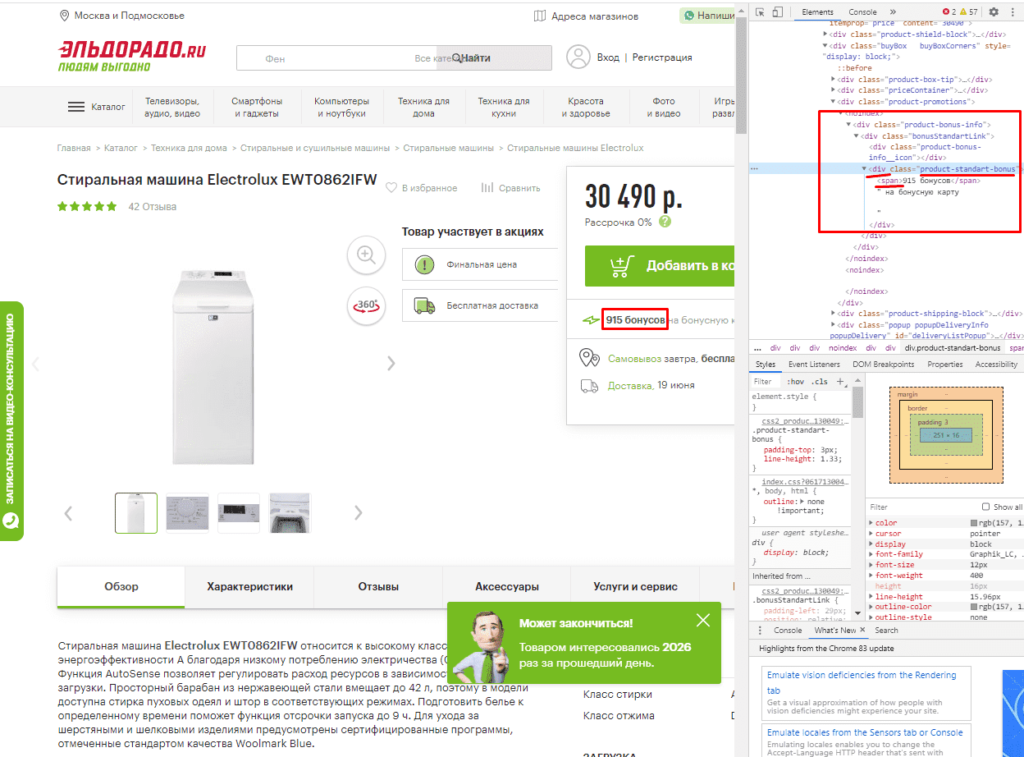
В этом случае первый тег div обозначает то, откуда берутся данные, когда в скобках [] уточняется его уникальность.
Для уточнения потребуется указать тип в виде @class, который может быть и @id, а после пишется = и в одинарных кавычках ‘значение’ пишется запрос.
Однако, нужное нам значение находиться глубже в теге span, поэтому добавляем /span и вводим:
//div[@class=’product-standart-bonus’]/span
В документе:

Парсинг цен без знаний XPath
Если нет знаний XPath и необходимо быстро получить информацию, то требуется выбрав нужный элемент в консоли разработчика кликнуть правой клавишей мыши и в меню выбрать «Copy»-«XPath». Например, при поиске запроса цены получаем:
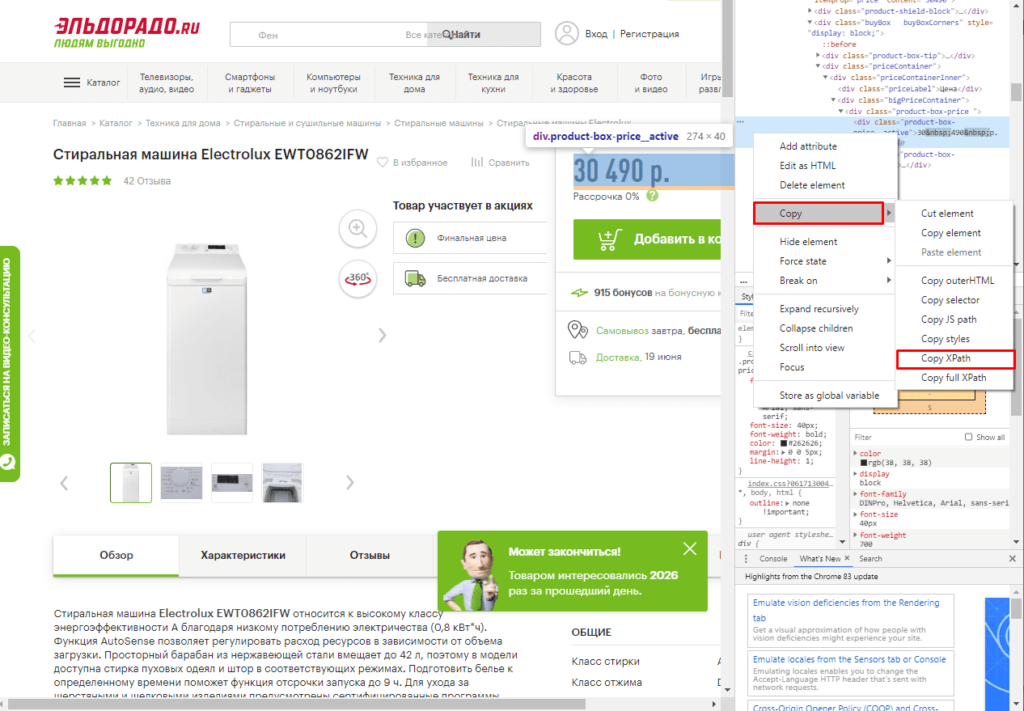
//*[@id=»showcase»]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div/div[1]
Важно! Следует изменить » на одинарные кавычки ‘.
Далее используем ее вместе с IMPORTXML.
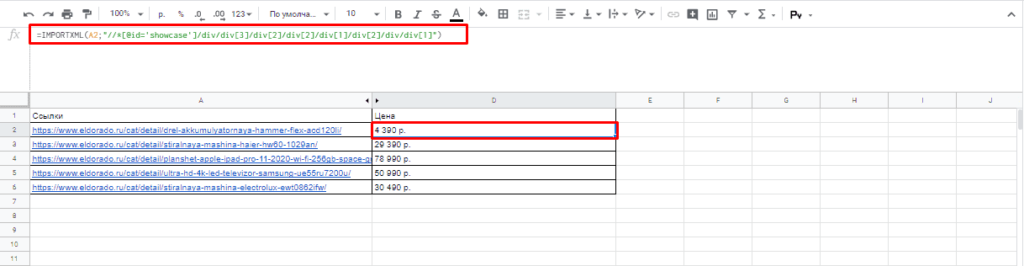
Все готово цены получены.
Простые формулы с IMPORTXML в Google Sheets
Чтобы получить title страницы необходимо использовать запрос:
=IMPORTXML(A3;»//title»)
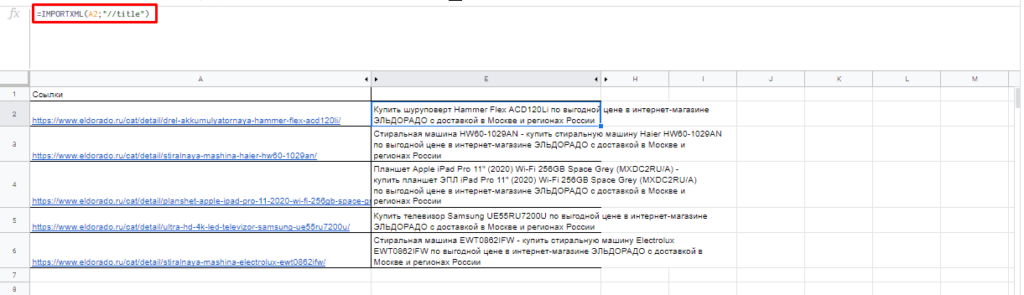
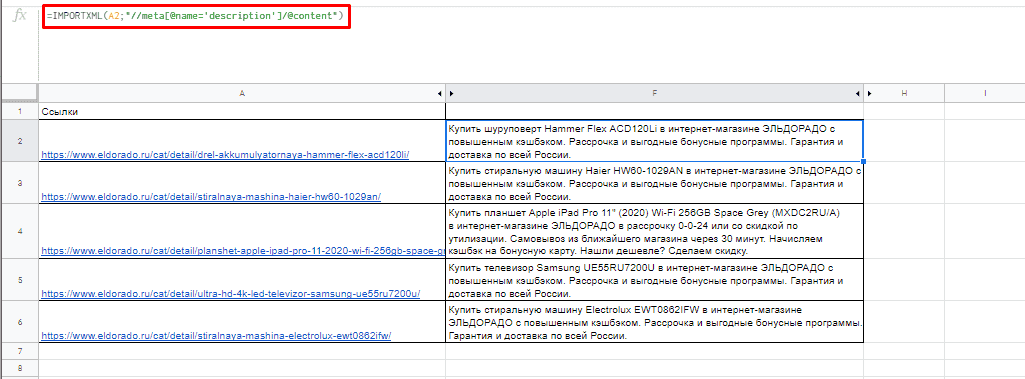
Для вывода description стоит использовать:
=IMPORTXML(A3;»//description»)
Первый заголовок (или любой другой):
=IMPORTXML(A3;»//h1″)

IMPORTHTML для создания парсера веи-ресурсов в Эксель
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос;Индекс)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – может быть в формате «table» или «list», выгружающий таблицу и список, соответственно.
- Индекс – порядковый номер элемента.
С примерами можно ознакомиться в файле:
https://docs.google.com/spreadsheets/d/1GpcGZd7CW4ugGECFHVMqzTXrbxHhdmP-VvIYtavSp4s/edit#gid=0
Пример использования IMPORTHTML в Google Doc
Парсинг таблиц
В примерах будет использоваться данная статья, перейдя на которую можно открыть консоль разработчика (в Google Chrome это можно сделать кликнув правой клавишей мыши и выбрав пункт «Посмотреть код» или же нажав на сочетание клавиш «CTRL+Shift+I»).
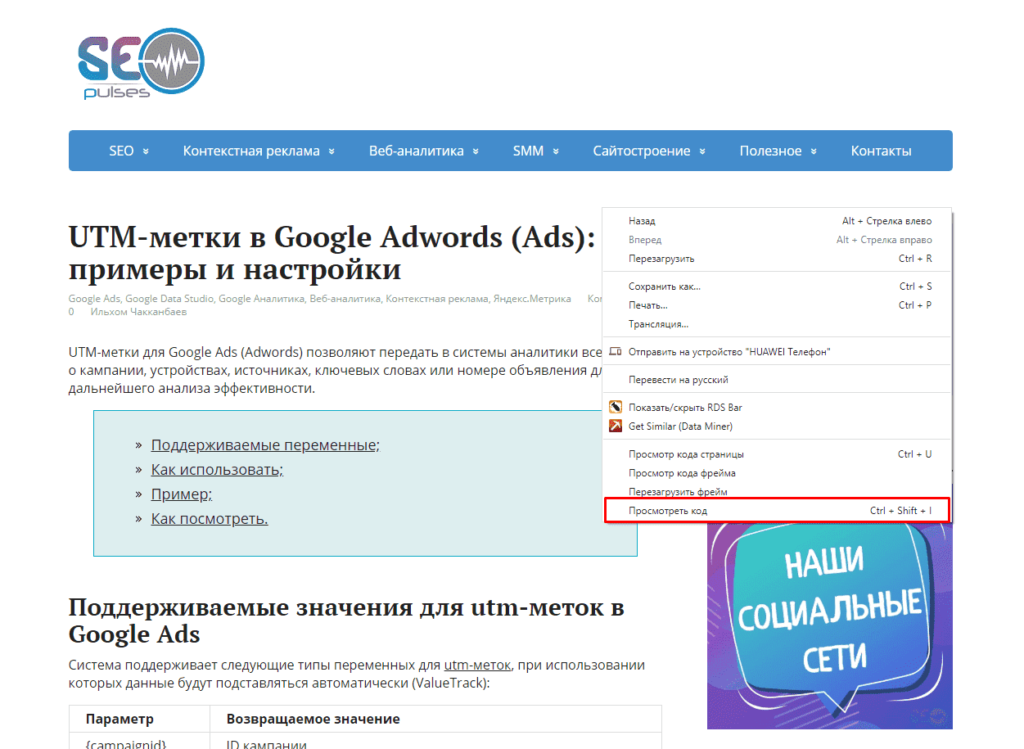
Теперь просматриваем код таблицы, которая заключена в теге <table>.
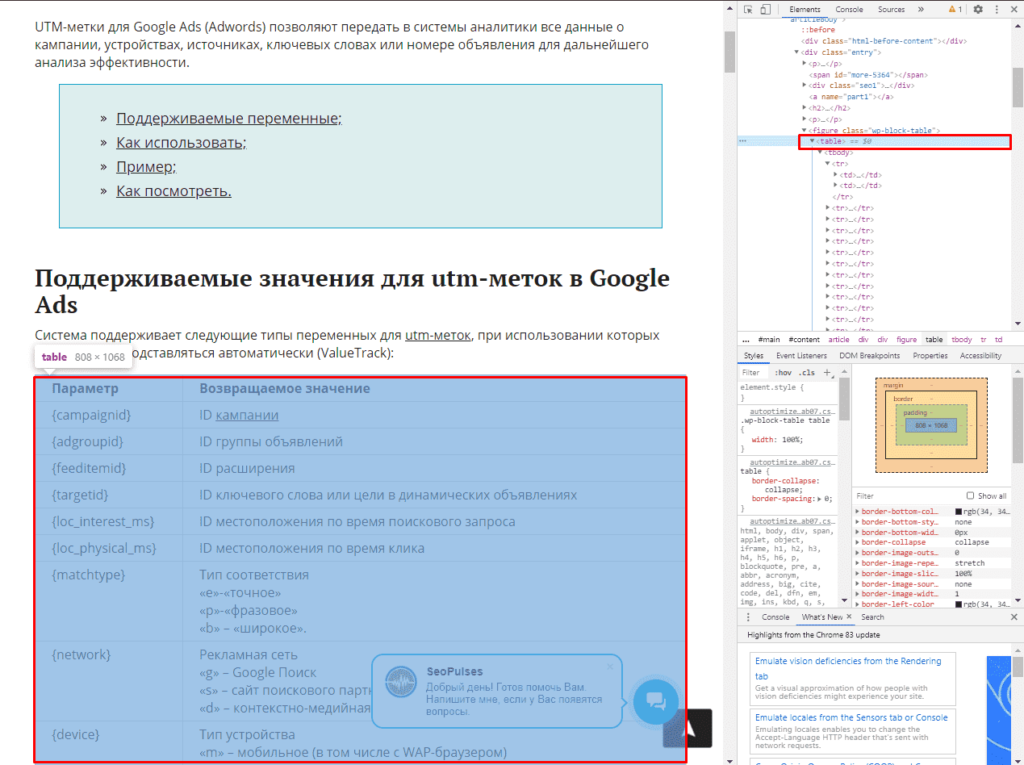
Данный элемент можно будет выгрузить при помощи конструкции:
=IMPORTHTML(A2;»table»;1)
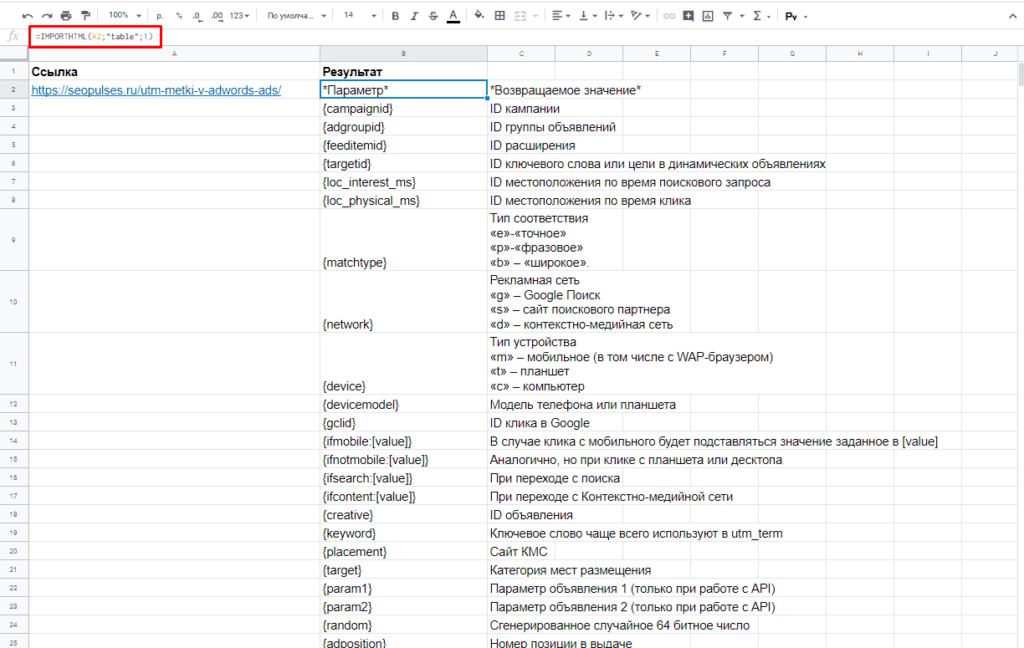
- Где A2 ячейка со ссылкой;
- table позволяет получить данные с таблицы;
- 1 – номер таблицы.
Важно! Сам запрос table или list записывается в кавычках «запрос».
Парсинг списков
Получить список, заключенный в тегах <ul>…</ul> при помощи конструкции.
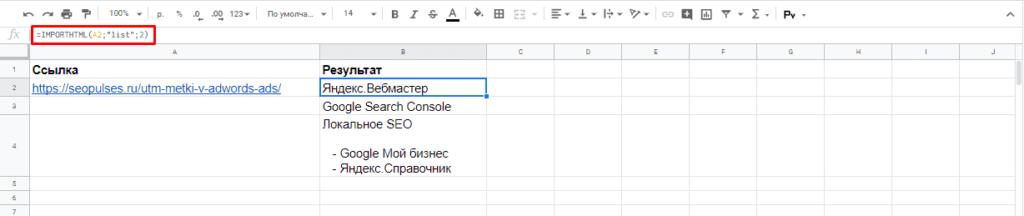
=IMPORTHTML(A2;»list»;1)
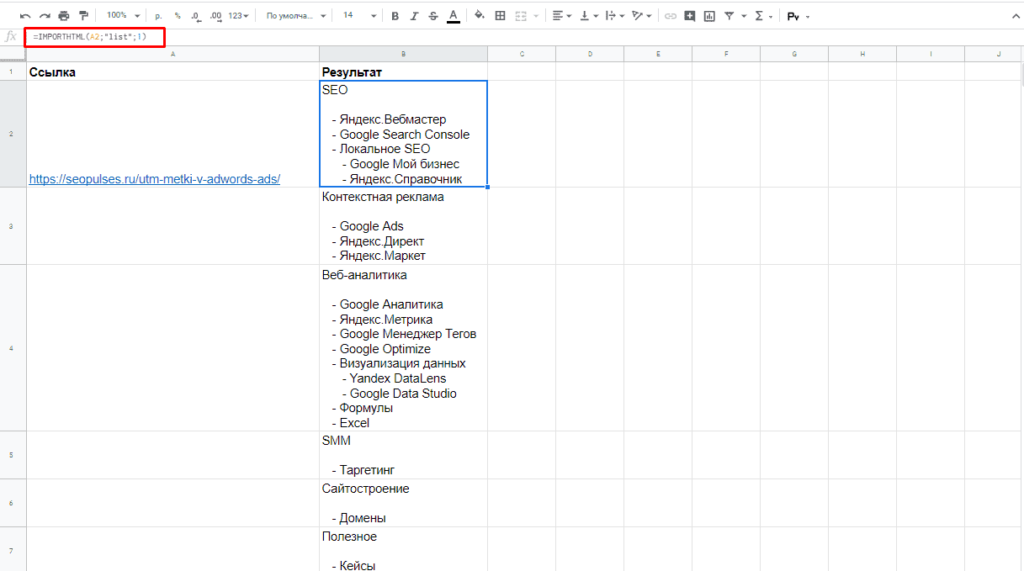
В данном случае речь идет о меню, которое также представлено в виде списка.
Если использовать индекс третей таблицы, то будут получены данные с третей таблицы в меню:
Формула:
=IMPORTHTML(A2;»list»;2)
Все готово, данные получены.
Обратная конвертация
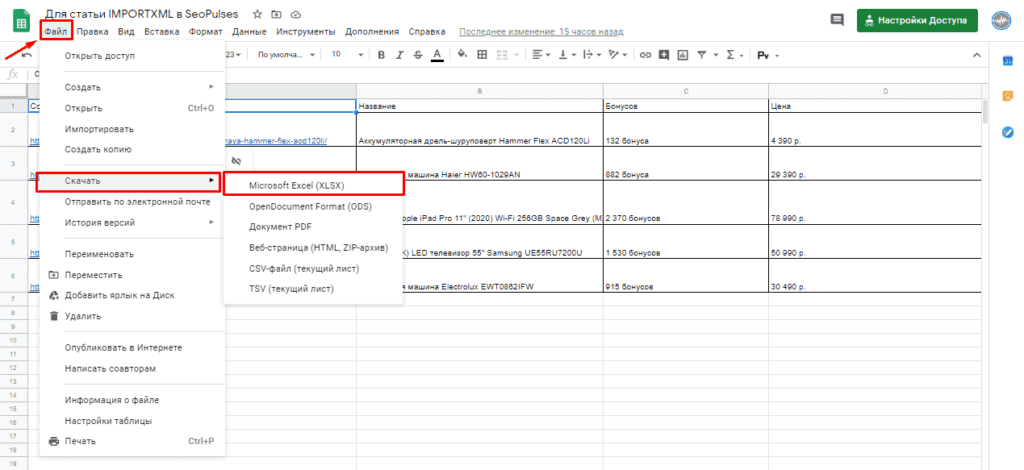
Чтобы превратить Google таблицу в MS Excel потребуется кликнуть на вкладку «Файл»-«Скачать»-«Microsoft Excel».
Все готово, пример можно скачать ниже.
Пример:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit
Парсинг нетабличных данных с сайтов
Проблема с нетабличными данными
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet), вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:

Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:

Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2… или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом <TABLE>, а её аналог — вложенные друг в друга теги-контейнеры <DIV>. Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel.
Тем не менее, есть способ обойти это ограничение 
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:

Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
https://www.wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:

Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data), чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:

… и затем щёлкаем по значку шестерёнки справа от шага Источник (Source), чтобы открыть его параметры:

В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file). Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):

Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:

- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:

Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains), переключаемся в режим Подробнее (Advanced) [2] и вводим наши критерии:

Добавление условий выполняется кнопкой со смешным названием Добавить предложение [3]. И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:

Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: <span class=»price»> через команду Главная — Замена значений (Home — Replace values).
- Разделить получившийся столбец по первому разделителю «>» слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя «<» слева, чтобы отделить полезные данные от тегов:

- Удалить лишние столбцы, а в оставшемся заменить стандартную HTML-конструкцию " на нормальные кавычки.

В итоге получим наши данные в уже гораздо более презентабельном виде:

Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View)) и вводим следующую конструкцию:
= Table.FromRows(List.Split(#»Замененное значение1″[Column1.2.1],3))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:

Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load…)

Вот и все хитрости 
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query
Время на прочтение
10 мин
Количество просмотров 331K

Десктопные/облачные, платные/бесплатные, для SEO, для совместных покупок, для наполнения сайтов, для сбора цен… В обилии парсеров можно утонуть.
Мы разложили все по полочкам и собрали самые толковые инструменты парсинга — чтобы вы могли быстро и просто собрать открытую информацию с любого сайта.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
- Цены. Актуальная задача для интернет-магазинов. Например, с помощью парсинга вы можете регулярно отслеживать цены конкурентов по тем товарам, которые продаются у вас. Или актуализировать цены на своем сайте в соответствии с ценами поставщика (если у него есть свой сайт).
- Товарные позиции: названия, артикулы, описания, характеристики и фото. Например, если у вашего поставщика есть сайт с каталогом, но нет выгрузки для вашего магазина, вы можете спарсить все нужные позиции, а не добавлять их вручную. Это экономит время.
- Метаданные: SEO-специалисты могут парсить содержимое тегов title, description и другие метаданные.
- Анализ сайта. Так можно быстро находить страницы с ошибкой 404, редиректы, неработающие ссылки и т. д.
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
Есть несколько вариантов:
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Но если вы хотите собрать персональные данные пользователей и использовать их для email-рассылок или таргетированной рекламы, это уже будет незаконно (эти данные защищены законом о персональных данных).
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
- Import.io,
- Mozenda (доступна также десктопная версия парсера),
- Octoparce,
- ParseHub.
Из русскоязычных облачных парсеров можно привести такие:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
- ParserOK,
- Datacol,
- Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
- Parsers;
- Scraper;
- Data Scraper;
- Kimono.
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
Эти формулы: IMPORTXML и IMPORTHTML.
IMPORTXML
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Вот так выглядит функция:
IMPORTXML("https://site.com/catalog"; "//a/@href")Функция принимает два значения:
- ссылку на страницу или фид, из которого нужно получить данные;
- второе значение — XPath-запрос (специальный запрос, который указывает, какой именно элемент с данными нужно спарсить).
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.
С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
IMPORTHTML
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)Она принимает три значения:
- Ссылку на страницу, с которой необходимо собрать данные.
- Параметр элемента, который содержит нужные данные. Если хотите собрать информацию из таблицы, укажите «table». Для парсинга списков — параметр «list».
- Число — порядковый номер элемента в коде страницы.
Об использовании 16 функций Google Таблиц для целей SEO читайте в нашей статье. Здесь все очень подробно расписано, с примерами по каждой функции.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Парсеры цен конкурентов
Инструменты для интернет-магазинов, которые хотят регулярно отслеживать цены конкурентов на аналогичные товары. С помощью таких парсеров вы можете указать ссылки на ресурсы конкурентов, сопоставлять их цены с вашими и корректировать при необходимости.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Парсеры для SEO-специалистов
Отдельная категория парсеров — узко- или многофункциональные программы, созданные специально под решение задач SEO-специалистов. Такие парсеры предназначены для упрощения комплексного анализа оптимизации сайта. С их помощью можно:
- анализировать содержимое robots.txt и sitemap.xml;
- проверять наличие title и description на страницах сайта, анализировать их длину, собирать заголовки всех уровней (h1-h6);
- проверять коды ответа страниц;
- собирать и визуализировать структуру сайта;
- проверять наличие описаний изображений (атрибут alt);
- анализировать внутреннюю перелинковку и внешние ссылки;
- находить неработающие ссылки;
- и многое другое.
Пройдемся по нескольким популярным парсерам и рассмотрим их основные возможности и функционал.
Парсер метатегов и заголовков PromoPult
Стоимость: первые 500 запросов — бесплатно. Стоимость последующих запросов зависит от количества: до 1000 — 0,04 руб./запрос; от 10000 — 0,01 руб.
Возможности
С помощью парсера метатегов и заголовков можно собирать заголовки h1-h6, а также содержимое тегов title, description и keywords со своего или чужих сайтов.
Инструмент пригодится при оптимизации своего сайта. С его помощью можно обнаружить:
- страницы с пустыми метатегами;
- неинформативные заголовки или заголовки с ошибками;
- дубли метатегов и т.д.
Также парсер полезен при анализе SEO конкурентов. Вы можете проанализировать, под какие ключевые слова конкуренты оптимизируют страницы своих сайтов, что прописывают в title и description, как формируют заголовки.
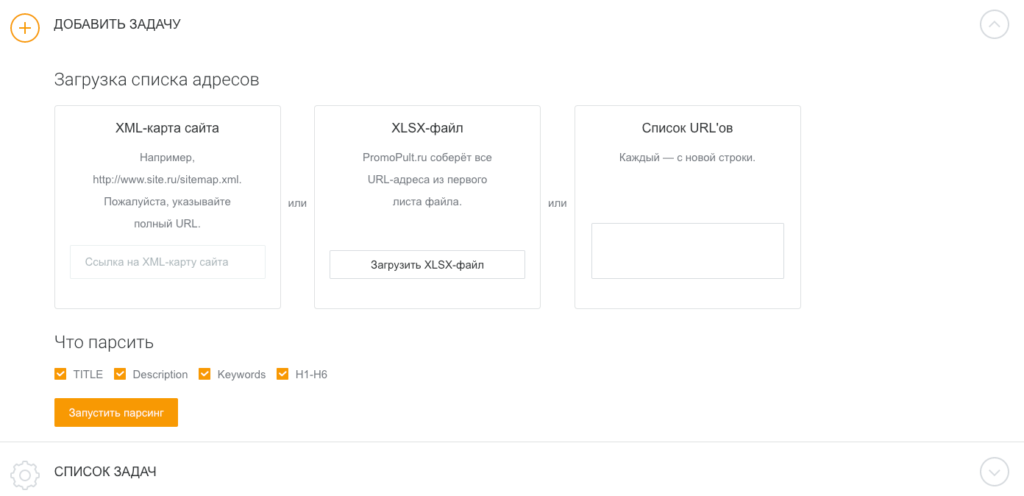
Сервис работает «в облаке». Для начала работы необходимо добавить список URL и указать, какие данные нужно спарсить. URL можно добавить вручную, загрузить XLSX-таблицу со списком адресов страниц, или вставить ссылку на карту сайта (sitemap.xml).
Работа с инструментом подробно описана в статье «Как в один клик собрать мета-теги и заголовки с любого сайта?».
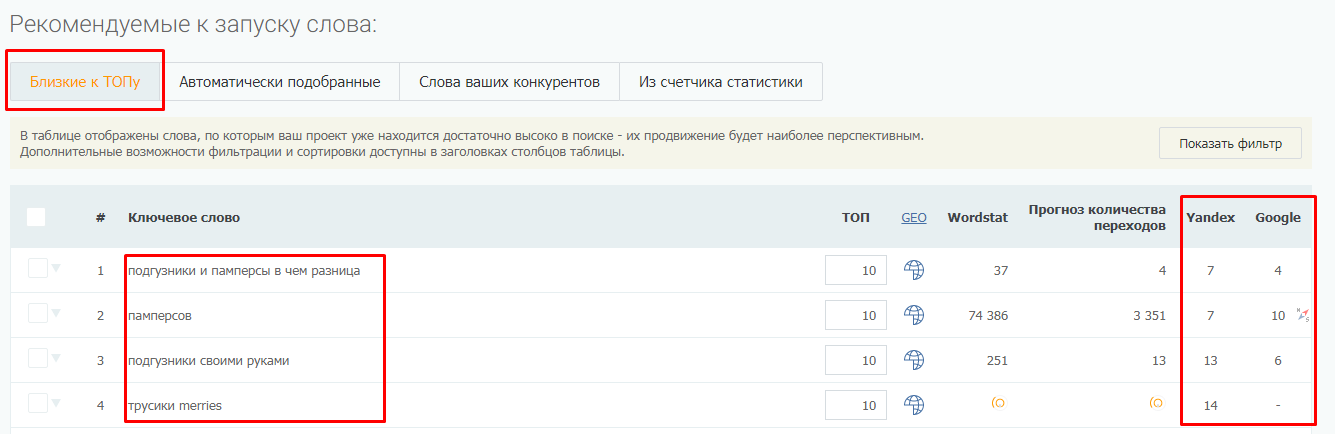
Парсер метатегов и заголовков — не единственный инструмент системы PromoPult для парсинга. В SEO-модуле системы можно бесплатно спарсить ключевые слова, по которым добавленный в систему сайт занимает ТОП-50 в Яндексе/Google.
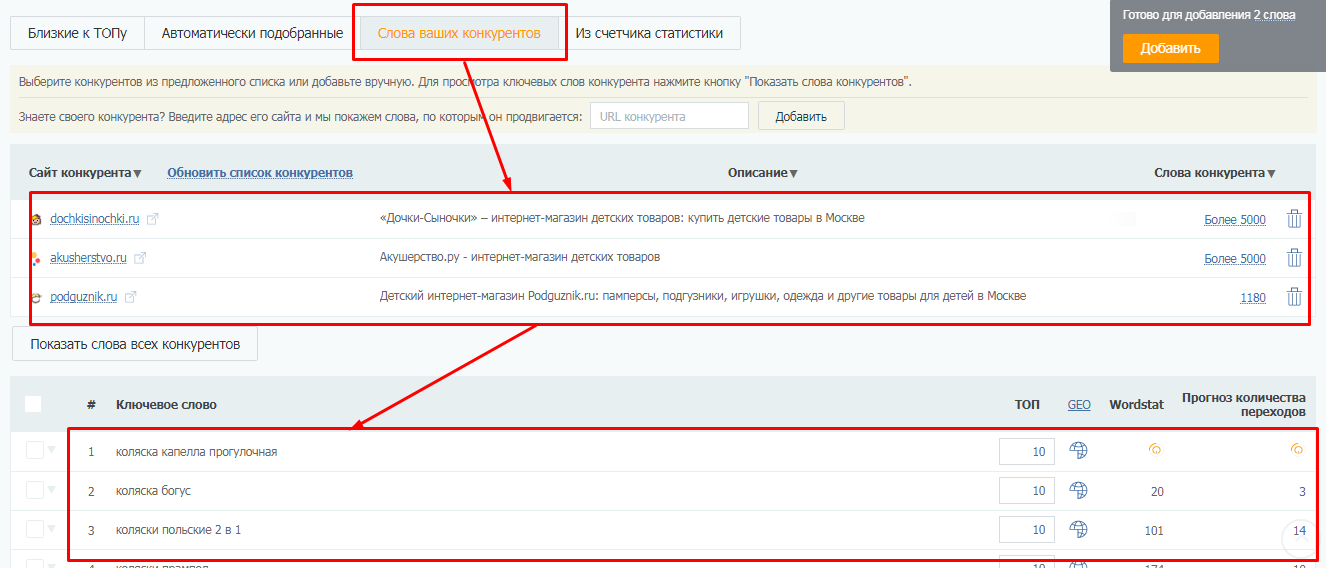
Здесь же на вкладке “Слова ваших конкурентов” вы можете выгрузить ключевые слова конкурентов (до 10 URL за один раз).
Подробно о работе с парсингом ключей в SEO-модуле PromoPult читайте здесь.
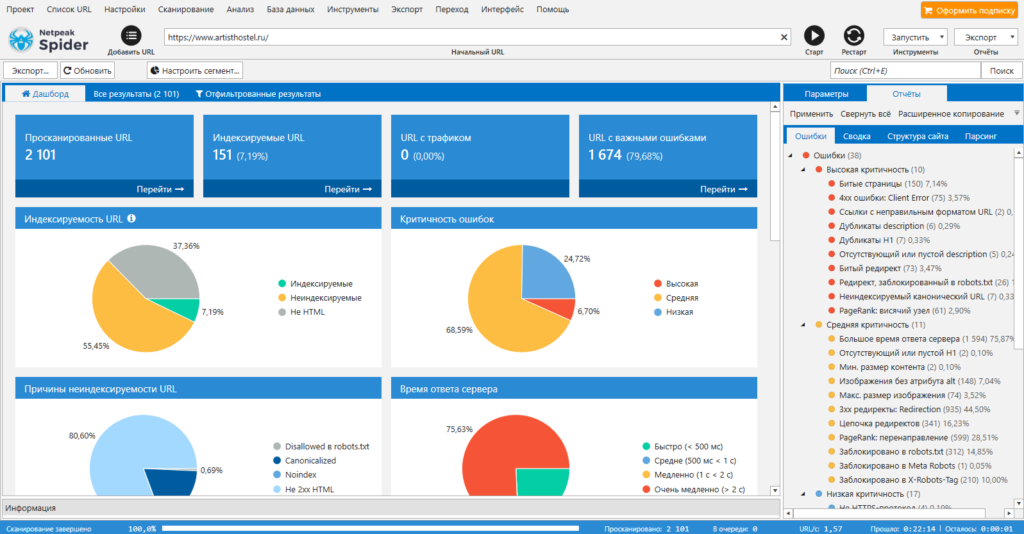
Netpeak Spider
Стоимость: от 19$ в месяц, есть 14-дневный пробный период.
Парсер для комплексного анализа сайтов. С Netpeak Spider можно:
- провести технический аудит сайта (обнаружить битые ссылки, проверить коды ответа страниц, найти дубли и т.д.). Парсер позволяет находить более 80 ключевых ошибок внутренней оптимизации;
- проанализировать основные SEO-параметры (файл robots.txt, проанализировать структуру сайта, проверить редиректы);
- парсить данные с сайтов с помощью регулярных выражений, XPath-запросов и других методов;
- также Netpeak Spider может импортировать данные из Google Аналитики, Яндекс.Метрики и Google Search Console.
Screaming Frog SEO Spider
Стоимость: лицензия на год — 149 фунтов, есть бесплатная версия.
Многофункциональный инструмент для SEO-специалистов, подходит для решения практически любых SEO-задач:
- поиск битых ссылок, ошибок и редиректов;
- анализ мета-тегов страниц;
- поиск дублей страниц;
- генерация файлов sitemap.xml;
- визуализация структуры сайта;
- и многое другое.
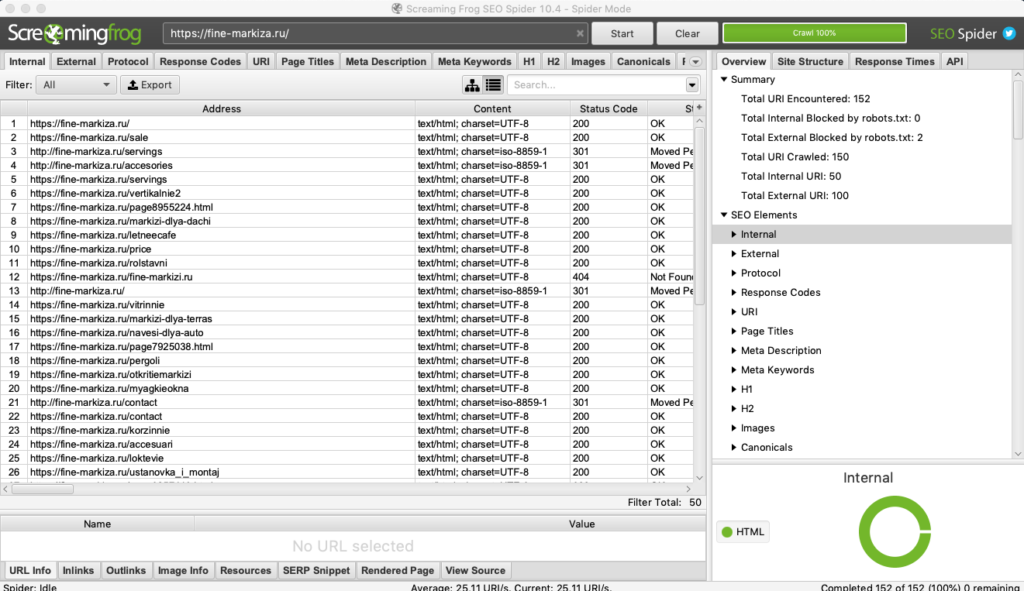
В бесплатной версии доступен ограниченный функционал, а также есть лимиты на количество URL для парсинга (можно парсить всего 500 url). В платной версии таких лимитов нет, а также доступно больше возможностей. Например, можно парсить содержимое любых элементов страниц (цены, описания и т.д.).
Подробно том, как пользоваться Screaming Frog, мы писали в статье «Парсинг любого сайта «для чайников»: ни строчки программного кода».
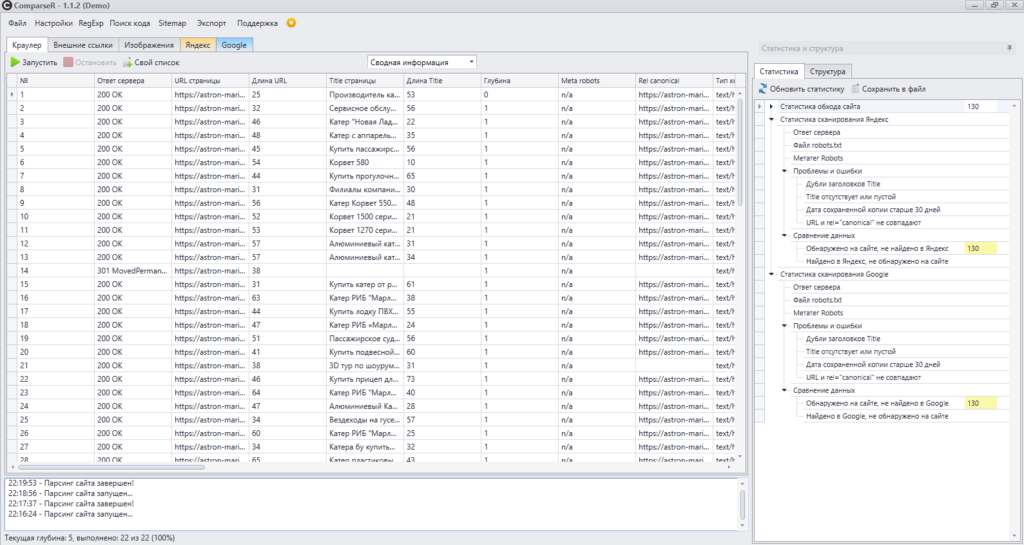
ComparseR
Стоимость: 2000 рублей за 1 лицензию. Есть демо-версия с ограничениями.
Еще один десктопный парсер. С его помощью можно:
- проанализировать технические ошибки на сайте (ошибки 404, дубли title, внутренние редиректы, закрытые от индексации страницы и т.д.);
- узнать, какие страницы видит поисковой робот при сканировании сайта;
- основная фишка ComparseR — парсинг выдачи Яндекса и Google, позволяет выяснить, какие страницы находятся в индексе, а какие в него не попали.
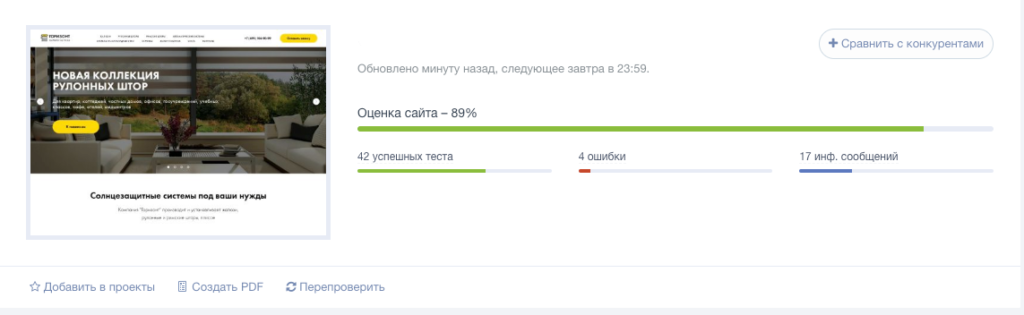
Анализ сайта от PR-CY
Стоимость: платный сервис, минимальный тариф — 990 рублей в месяц. Есть 7-дневная пробная версия с полным доступом к функционалу.
Онлайн-сервис для SEO-анализа сайтов. Сервис анализирует сайт по подробному списку параметров (70+ пунктов) и формирует отчет, в котором указаны:
- обнаруженные ошибки;
- варианты исправления ошибок;
- SEO-чеклист и советы по улучшению оптимизации сайта.
Анализ сайта от SE Ranking
Стоимость: платный облачный сервис. Доступно две модели оплаты: ежемесячная подписка или оплата за проверку.
Стоимость минимального тарифа — 7$ в месяц (при оплате годовой подписки).
Возможности:
- сканирование всех страниц сайта;
- анализ технических ошибок (настройки редиректов, корректность тегов canonical и hreflang, проверка дублей и т.д.);
- поиск страниц без мета-тегов title и description, определение страниц со слишком длинными тегами;
- проверка скорости загрузки страниц;
- анализ изображений (поиск неработающих картинок, проверка наличия заполненных атрибутов alt, поиск «тяжелых» изображений, которые замедляют загрузку страниц);
- анализ внутренних ссылок.
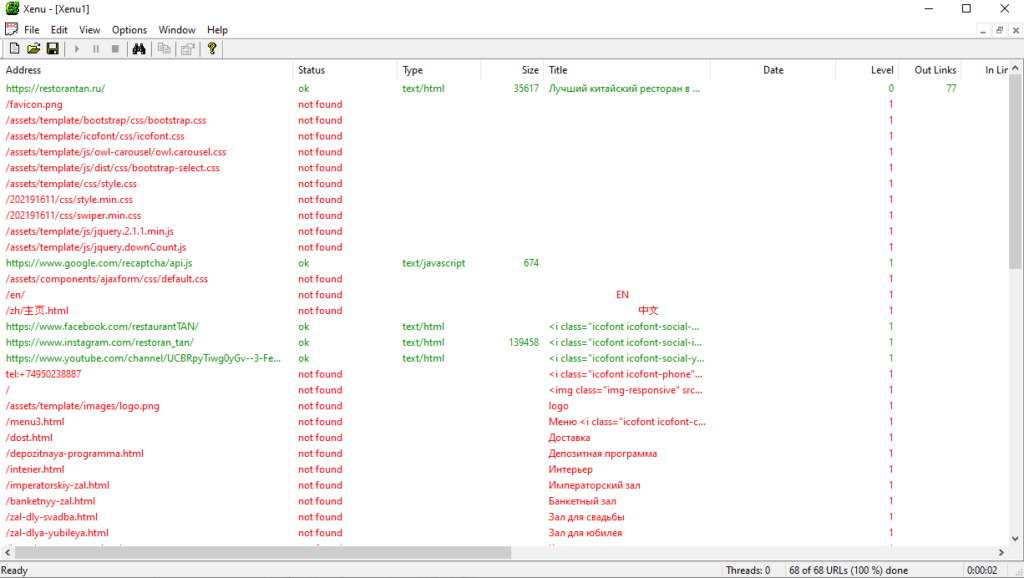
Xenu’s Link Sleuth
Стоимость: бесплатно.
Десктопный парсер для Windows. Используется для парсинга все url, которые есть на сайте:
- ссылки на внешние ресурсы;
- внутренние ссылки (перелинковка);
- ссылки на изображения, скрипты и другие внутренние ресурсы.
Часто применяется для поиска неработающих ссылок на сайте.
A-Parser
Стоимость: платная программа с пожизненной лицензией. Минимальный тарифный план — 119$, максимальный — 279$. Есть демо-версия.
Многофункциональный SEO-комбайн, объединяющий 70+ разных парсеров, заточенных под различные задачи:
- парсинг ключевых слов;
- парсинг данных с Яндекс и Google карт;
- мониторинг позиций сайтов в поисковых системах;
- парсинг контента (текст, изображения, видео) и т.д.
Кроме набора готовых инструментов, можно создать собственный парсер с помощью регулярных выражений, языка запросов XPath или Javascript. Есть доступ по API.

Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
В этой статье расскажу про программы, сервисы и фреймворки для парсинга, которые позволяют собирать данные бесплатно. В подборке представлены как полностью бесплатные инструменты, так и инструменты, предоставляющие ограниченный бесплатный период либо ограниченную функциональность, но в любом случае дают возможности, которых может хватить для решения тех или иных задач.
Парсинг – это автоматизированный процесс сбора данных с сайтов, применяется для сбора контента: цен конкурентов, описаний товаров, контактов для лидов, отзывов и рейтингов, файлов и для любых других задач, когда нужно собрать большой объем информации.
Условно инструменты для парсинга разделяются на две части. Одна из них – это разработка парсинга под задачу, этим занимаются программисты, которые часто используют разные языки программирования, например, Python или JavaScript, чтобы тщательно продумать логику будущего скрипта до деталей, что требует времени и вычислительных ресурсов, но в конечном итоге дает наилучшие результаты. Задачи при таком подходе решаются точно, как нужно, можно собирать данные с необходимыми условиями, скоростью и объемами.
Другая часть — непрофессиональные пользователи, которым приходится выбирать между множеством существующих парсеров, программ или сервисов, каждый из которых включает набор готовых команд и ограничен реализованной функциональностью. Это часто вынуждает пользователей тратить время и деньги на изучение нескольких инструментов в попытке охватить широкий спектр возможных сценариев парсинга сайтов.
Программы для парсинга
Программы стоит выбирать, если вам нужно простое решение с быстрым стартом, не требующее знаний языков программирования. Конечно, использование программ не позволит решить любой кейс и возможности самих программ различны, но тем не менее это отличное решение для простых задач.
1. Screaming Frog SEO Spider
Screaming Frog SEO Spider – популярная программа, специализирующаяся на работе с SEO данными, имеет широчайший функционал для аудита сайтов, полное перечисление возможностей программы займет не одну страницу. При первом знакомстве интерфейс программы может показаться громоздким из-за множества вкладок и окон, но поработав некоторое время становится понятно, что он удобен, вкладки позволяют получить быстрый доступ к отчетам, окна удобно структурируют результаты парсинга.
В бесплатной версии программа предоставляет следующие возможности:
- Поиск нерабочих ссылок и редиректов;
- Сбор заголовков и метаданных;
- Просмотр robot.txt;
- Аудит атрибутов hreflang;
- Обнаружение дубликатов страниц;
- Просмотр Sitemap.
Бесплатная версия ограничена возможностью парсить до 500 URL адресов на сайте и если ваши потребности вписываются в ограничения программы, то внимательно присмотритесь к данному продукту. Screaming Frog быстр в работе, в силу популярности на эту программу написано множество обзоров и разобраться в базовом функционале не составит труда.
Полная версия программы предоставляет возможность парсить не только SEO данные, но и любую другую информацию с сайтов используя XPath (XML Path Language) — язык запросов к элементам XML-документа.
Возможности:
- Быстрая работа;
- Бесплатного функционала хватит для аудита среднего сайта;
- Хорошо документирована;
- Имеет базу туториалов рассказывающих как работать с различными кейсами.
Доступные OS:
- Windows
- macOS;
- Ubuntu.
2. Easy Web Extract
Easy Web Extract дает массу возможностей, позволяющих собирать данные как с простых, так и со сложных сайтов. Программа не требует углубленных знаний программирования для настройки сбора данных, специальный мастер проведет вас по шагам в настройке шаблона парсинга, а для того, чтобы быстро разобраться с настройкой есть видео уроки. Одна из особенностей — вы можете запрограммировать автоматический поиск для определенных товаров и производить сбор только нужных данных. Еще одна особенность программы – сбор в несколько потоков, до 24 различных веб-страниц, это позволит сэкономить ваше время парсинга. Обратная сторона быстрого парсинга – блокировка вашего ip со стороны сайта из-за подозрительной активности, будьте аккуратны.
Некоторые сайты используют методы динамической загрузки данных на стороне клиента для создания асинхронных запросов. Такие данные проблема для простых парсеров, поскольку веб-контент не встроен в исходный HTML код. Easy Web Extract заявляет о возможности сбора таких данных, при тестировании программа справилась не со всеми сайтами, вам нужно проверить эту фичу на нужных вам сайтах.
Ограничения бесплатной версии:
- Доступна 14 дней;
- Парсит только первые 200 результатов;
- Экспортировать можно только первые 50 результатов.
Остальной функционал парсера доступен в бесплатной версии, программу можно использовать для сбора небольших объемов.
Возможности:
- Многопоточность;
- Автоматизированный поиск;
- Наличие шаблонов для сбора;
- Видео уроки для быстрого старта;
- Работа с динамическим содержимым.
Доступные OS:
Программа доступна только под Windows. Так же для работы требуются .NET frameworks 2.0 и Internet Explorer 9.0.
3. FMiner
FMiner – инструмент для парсинга сайтов, работа которого построена на записи ваших действий и последующем воспроизведении записанных сценариев. Созданные таким образом последовательности действий (макросы), можно редактировать в визуальном формате, что позволяет использовать инструмент без знания языков программирования.
Программа работает с динамически подгружаемыми данными (AJAX), поддерживает работу с несколькими потоками, позволяет работать с результатами поиска и несколько выходных форматов. Программа имеет видеоуроки для быстрого старта, но страницы с мануалами не работают и последние обновления на сайте датированы 2015 годом, что говорит о том, что разработчик не следит за продуктом, но установочные файлы доступны и можно загрузить билд для бесплатного использования полнофункциональной версии программы в течении двух недель.
На сайте есть раздел с документацией, рассказывающий в краткой форме возможности и основы работы с программой.
Ограничения бесплатной версии:
- Доступна полнофункциональная версия программы на 14 дней;
Возможности:
- Визуальное программирование и редактирование парсинга;
- Многопоточность;
- Работает с результатами поиска;
- Работа с AJAX;
- Видео уроки для быстрого старта.
Доступные OS:
- Windows;
- Mac OS X.
4. Helium scraper
Helium scraper – еще одна программа для парсинга данных с сайтов. Принцип работы с программой похож на работу с FMiner, только вместо визуального представления планируемых действий программа выводит код. В целом интерфейс при первом знакомстве не такой понятный как у предыдущих программ, но программа предлагает видеоуроки и базу знаний, которые помогут быстро разобраться с основами рабочего процесса.
По функциональности программа похожа на рассмотренные выше, но имеет ряд особенностей. Одно из ключевых заявленных отличий, это возможность работать с базами данных, до 140 Терабайт, конечно это не означает, что другие программы не осилят работу с большими базами данных, но, если планируете собирать много данных, стоит присмотреться к Helium scraper. Еще одна особенность — это возможность работы с API, вы сможете интегрировать запросы в свой проект.
Ограничения бесплатной версии:
- Доступна полнофункциональная версия программы на 10 дней;
Возможности:
- Визуальное редактирование;
- Многопоточность;
- Работает с результатами поиска;
- Работа с динамически подгружаемыми данными;
- Ротация прокси;
- Возможность блокировки изображений или нежелательного контента;
- Видео уроки и база знаний;
- Возможность работать с API;
- Планировщик.
Доступные OS:
Программа доступна только для Windows, требует .NET Framework 4.6.2 и Visual C ++ для Visual Studio 201.
5. WebHarvy
WebHarvy — последняя в нашем списке программ для парсинга, но не последняя, чтобы сделать выбор. Программа предлагает простой визуальный интерфейс для парсинга информации и в этом ее главная фишка – она интуитивно понятна. WebHarvy не подойдет для сложных, разветвленных каталогов, но c более простой структурой она справится легко, вы сможете обрабатывать динамически подгружаемые данные, подключить свои прокси, обработать заранее подготовленный список Url-адресов. Еще одна особенность программы, это возможность применять регулярные выражения к результатам извлечения, например вы быстро сможете очистить нужные данные из html кода, конечно, эта возможность требует знания язык поиска RegExp.
Ограничения бесплатной версии:
- Доступ на 15 дней;
- Собирает данные только с 2 страниц.
В силу ограничения сбора, программа подойдет вам, если нужные данные находятся (или можно вывести) не дальше второй страницы.
Возможности:
- Визуальное редактирование;
- Многопоточность;
- Работает с RegExp;
- Работа с динамически подгружаемыми данными;
- Поддержка прокси;
- Видео уроки;
- Планировщик.
Доступные OS:
Программа доступна только для Windows.
6. Screen-Scraper
Screen-Scraper – программный комплекс для парсинга данных. Программа автоматизирует копирование текста с веб-страниц, переход по ссылкам, ввод данных в формы и их отправку, итерации по страницам результатов поиска, скачивание файлов (PDF, Word, изображения и т. д.). Программа может обрабатывать практически любой сайт, включая сайты, использующие динамически подгружаемые данные AJAX.
Ограничения бесплатной версии:
- Не ограничено по времени;
Программу сложно назвать интуитивно понятной, но на сайте разработчика имеются уроки, которые позволят понять принципы работы и быстро стартовать проект.
Возможности:
- Наличие видео уроков;
- Многопоточность;
- Интеграции через API;
- Работа с динамически подгружаемыми данными;
- Поддержка прокси сервера;
- Возможность писать скрипты на Java, JavaScript и Python.
Доступные OS:
- Windows;
- MacOS;
- Linux.
Облачные сервисы для парсинга
Облачные сервисы, как и программы для парсинга предоставляют доступ к функционалу бесплатно на определенных условиях, и вы можете воспользоваться услугами сервисов для решения своей задачи. Главное отличие от программ – парсинг выполняется на удаленном сервере и не тратит ресурсы вашего компьютера.
7. Octoparse
Octoparse – облачный сервис для парсинга данных с визуальным программированием парсера. Сильные стороны сервиса – множество статей объясняющих как пользоваться сервисом и хорошие лимиты бесплатной версии.
Ограничения бесплатной версии:
- Доступ на 14 дней;
- Неограниченное количество страниц за сканирование;
- Экспорт 10 000 записей;
- 2 одновременных локальных прогона;
- 10 настроенных парсингов;
- Поддержка.
Возможности сервиса:
- Работа с динамически загружаемым контентом;
- Ротация ip;
- Планировщик;
- Работа в облаке 24/7;
- Работа с API.
8. Mozenda
Mozenda – популярный облачный сервис для парсинга сайтов. Сервис предлагает визуальный метод захвата данных, для более сложных сайтов вы сможете использовать запросы XPath, если вы разработчик, то сможете создать сценарий парсинга точно отвечающий вашей задаче. Сервис предлагает месячный демо доступ, для настройки парсинга нужно установить приложение на компьютер, дальнейшая обработка происходит в облаке.
Ограничения бесплатной версии:
- Доступ на 30 дней;
Возможности сервиса:
- Многопоточность;
- Работа с динамически загружаемым контентом;
- Ротация ip;
- Планировщик;
- Уведомления о событиях.
9. Diffbot
Diffbot – облачный сервис для парсинга работающий на алгоритмах машинного обучения и компьютерного зрения. Сервис автоматически определяет тип страницы URL-адресов и возвращает найденные данные для поддерживаемых типов страниц (статьи, карточки товара, изображения, обсуждения или видео).
Ограничения бесплатной версии:
- Доступ на 14 дней;
- Один запрос в секунду;
- Доступ для одного пользователя.
Возможности сервиса:
- Автоматическое нахождение контента для парсинга;
- Ротация ip;
- Работа в облаке 24/7;
- Работа с API.
10. Scraper api
Scraper api – сервис для парсинга требующий программирования. Особенность сервиса Scraper API меняет IP-адреса с каждым запросом из пула включающего миллионы прокси через десятки интернет-провайдеров и автоматически повторяет неудачные запросы, тем самым гарантирует сбор нужных данных. Scraper API также обрабатывает CAPTCHA. Парсинг осуществляется через безголовый браузер.
Ограничения бесплатной версии:
- 1000 бесплатных вызовов;
Сервис подойдет в случае, если вы умеете программировать на одном из языков, NodeJS, Python, Ruby или PHP и вам нужно получить данные с сайта с высокой степенью защиты.
Возможности сервиса:
- 40+ миллионов IP-адресов;
- 12+ геолокаций;
- Неограниченная пропускная способность;
- Работа с javascript содержимым.
11. Scrapy Cloud от Scrapinghub
Scrapy Cloud — это проверенная в боях облачная платформа для запуска парсеров, требующая знания языков программирования и предоставляющая гибкие инструменты для создания проектов со сложной логикой. Сервис предлагает интересный бесплатный тариф с безлимитным количеством данных, ограниченно только время работы – 1час.
Ограничения бесплатной версии:
- 1 час работы;
Сервис подойдет в случае, если вы умеете программировать и ваш проект содержит сложную логику для извлечения данных.
Возможности сервиса:
- Работа с динамическим содержимым;
- Поддержка прокси;
- Мультипоточность;
- Поддержка API.
12. ScrapingBee
ScrapingBee – сервис для парсинга сайтов использующий безголовый браузер и ротацию прокси. Сервис может рендерить Javascript, это позволяет парсить любой веб-сайт, даже одностраничники использующие React, Angulars, Vue.js или любые другие библиотеки. Большой пул прокси серверов поможет снизить вероятность блокировки и увеличить скорость сбора данных благодаря одновременному использованию нескольких браузеров.
Ограничения бесплатной версии:
- 1000 бесплатных вызовов API;
Сервис требует программирования скриптов (CURL, Python, NodeJS, Java, Ruby, Php, Go), подойдет в случае сложной, кастомизируемой логики для извлечения данных и необходимости рендеринга JavaScript.
Возможности сервиса:
- Рендеринг JavaScript;
- Поддержка прокси;
- Мультипоточность;
- Поддержка API запросов.
13. Apify
Apify – сервис для парсинга данных построенный по принципу магазина готовых решений. По сути, это шаблоны, настроенные на самые популярные кейсы: сбор данных с Amazon, Instagram, Booking и т.д. Работа происходит через обращение к API сервиса, все представленные шаблоны сопровождаются документацией, и вы можете поменять запрос, чтобы он в точности соответствовал вашей задаче.
Ограничения бесплатной версии:
- 10 единиц для сканирования (единицы позволяют сканировать разное количество страниц JavaScript и HTML страниц в месяц);
- Хранение данных 7 дней;
- 30 прокси серверов (только 1 месяц).
Сервис требует умения вызова API, подойдет для парсинга популярных сайтов, имеет хорошие лимиты для бесплатного использования.
Возможности сервиса:
- Рендеринг JavaScript;
- Ротация прокси;
- Мультипоточность;
- Работа через API.
14. Web Scraper
Web Scraper – сервис для парсинга который максимально упрощает извлечение данных с сайтов. Настройка парсера, происходит в визуальном редакторе посредством указания того, какие элементы нужно собирать, программирование не требуется. Web Scraper позволяет создавать карты сайта из различных типов селекторов. Эта система позволяет в последующем адаптировать извлечение данных к разным структурам сайта.
Ограничения бесплатной версии:
- Только локальное использование;
- Динамические данные;
- Работа с JavaScript;
- Экспорт в CSV.
Возможности сервиса:
- Рендеринг JavaScript;
- Ротация прокси;
- Планировщик;
- Мультипоточность;
- Работа через API.
15. CrawlMonster
CrawlMonster – инструмент для парсинга SEO показателей сайта, вы можете сканировать, хранить и получать доступ к SEO-данным вашего веб-сайта, таким как контент сайта, исходный код, статусы страниц, распространенные ошибки, проблемы безопасности и многие другие.
Ограничения бесплатной версии:
- 1 пользователь;
- 100 URL-адресов;
- 1 сайт;
- Нет планировщика;
- Ограниченные возможности.
Возможности сервиса:
- Комплексный технический SEO-анализ;
- Архитектурный анализ;
- Анализ эффективности SEO;
- Отслеживание проблем;
- Анализ безопасности веб-сайта;
- Мониторинг сайта в реальном времени;
- Инструменты SEO-отчетности.
16. eScraper
eScraper – сервис позволяющий парсить любые сайты, ориентирован на электронную коммерцию и имеет простые интеграции с магазинами построенными на Magento, PrestaShop, WooCommerce или Shopify. Работает с динамически загружаемым контентом, например, раскрывающиеся списки, разделы “показать больше”, “следующая страница”, чекбоксы.
Ограничения бесплатной версии:
- 100 URL-адресов.
Возможности сервиса:
- Парсинг без программирования;
- Планировщик;
- Множество интеграций с eCommerce платформами.
17. 80legs
80legs – сервис для парсинга построенный на основе шаблонов. Приложения для сканирования 80legs используют методы Javascript, которые вы можете изменить в соответствии с любыми вашими требованиями к парсингу. Вы можете настроить, какие данные будут обрабатываться и по каким ссылкам переходить с каждого просканированного URL. Вы также можете использовать приложения для сканирования 80legs по умолчанию для сбора любых данных HTML, таких как ссылки, ключевые слова, метатеги и многое другое.
Ограничения бесплатной версии:
- Одно сканирование за раз;
- До 10 000 страниц;
- Требуется привязка банковской карты.
Возможности сервиса:
- Рендеринг JavaScript;
- Ротация прокси;
- Автоматическое определение скорости парсинга;
- API.
18. Phantom Buster
Phantom Buster – облачный сервис для сбора данных, предлагающий готовые решения для основных социальных сетей и других сайтов, например, Facebook, Twitter, Instagram, LinkedIn и т.д. Парсинг при помощи сервиса не требует умения программировать и позволяет легко выполнять стандартные для социальных сетей кейсы в автоматической режиме, такие как автоматическое отслеживание профилей, авто-лайки постов, отправка индивидуальных сообщений, прием заявок.
Ограничения бесплатной версии:
- Один слот (настройка парсинга);
- 10 минут в день.
Возможности сервиса:
- Готовые шаблоны;
- Автоматизация действий;
- Планировщик.
19. Webhose
Webhose – сервис специализируется на новостных источниках, включая блоги, форумы, радиостанции. API новостей Webhose обеспечивает прямой доступ к данным в реальном времени с глобальных новостных сайтов и предоставляет доступ к огромной базе исторических данных. Интересная особенность сервиса — API к данным даркнета.
Ограничения бесплатной версии:
- 10 дней.
Сервис подойдет, если вам нужно получать данные из новостных источников и есть необходимость в исторических данных.
Возможности сервиса:
- Работа через API;
- Специализация на новостных источниках;
- Исторические данные.
20. Parsers
Parsers – сервис парсинга, извлекает данные из HTML страниц и импортирует их в excel, xls, xlsx, csv, json, xml файл. Сервис настраивается через расширение для браузера. Особенность сервиса – нужно выбрать необходимый тип данных только на одной, самой детальной странице сайта, далее технология сервиса найдет похожие страницы на сайте и извлечет необходимые данные. Парсинг работает автоматически на основе машинного обучения, нет необходимости указывать все страницы, каталоги и другие настройки.
Ограничения бесплатной версии:
- 1000 страниц за запуск;
- Один сайт одновременно;
- 10 запросов одновременно.
Сервис подойдет, если вам нужно получать данные из новостных источников и есть необходимость в исторических данных.
Возможности сервиса:
- Работа через API;
- Планировщик;
- Машинное обучение при определении страниц для парсинга.
21. Agenty
Agenty – сервис работающий через расширение для браузера Chrome. Очень простое в использовании расширение для парсинга данных с помощью CSS-селекторов с функцией «укажи и щелкни» с предварительным просмотром извлеченных данных в реальном времени и быстрого экспорта данных в JSON / CSV / TSV.
Ограничения бесплатной версии:
- 14 дней;
- 100 страниц.
Возможности сервиса:
- Автоматическая ротация IP-адресов;
- Визуальная настройка парсинга;
- Пакетная обработка Url-адресов;
- Планировщик;
- Интеграции с сервисами хранения и Google таблицами.
22. Grepsr
Grepsr – расширение для браузера Chrome позволяющее простыми методами визуального программирования собирать данные с сайтов. Сервис предлагает интуитивно понятный интерфейс, API для автоматизации действий и интеграции с популярными системами управления документами, такими как Dropbox, Google Drive, Amazon S3, Box, также доступна выгрузка на FTP.
Ограничения бесплатной версии:
- 1000 записей в месяц;
- 500 записей за прогон;
- 5 запусков в месяц;
- 3 отчета в месяц.
Возможности сервиса:
- Интеграции с сервисами хранения;
- Визуальная настройка парсинга;
- Планировщик;
- Доступ к API.
23. Web Robots
Web Robots – сервис работающий как расширение для браузера Chrome. Сервис прост в использовании, имеет интерфейс для визуального захвата данных, разобраться с ним не составит особого труда, главное преимущество – сервис автоматизирует действия. Функциональность сервиса так же проста, парсер подойдет для самых простых задач.
Ограничения бесплатной версии:
- Ограничений для расширения нет;
Возможности сервиса:
- Визуальная настройка парсинга;
- Автоматически находит и извлекает данные.
24. Data miner
Data miner – сервис парсинга данных работающий через расширения для браузеров Google Chrome и Microsoft Edge, помогает собирать данные с различных сайтов с помощью визуального интерфейса. В Data Miner есть более 40 000 общедоступных шаблонов для множества самых популярных сайтов. Используя эти шаблоны, вы можете получить нужные данные в несколько щелчков мыши. Еще одна особенность – сервис позволяет работать со списком адресов, вы можете загрузить нужные страницы и быстро получить результат.
Ограничения бесплатной версии:
- Можно парсить до 500 страниц абсолютно бесплатно;
Возможности сервиса:
- Визуальная настройка парсинга;
- Пакетная обработка URL-адресов;
- Работа с динамически подгружаемыми данными.
25. Scraper.AI
Scraper.AI – сервис парсинга данных работающий как расширения для браузеров Chrome, Firefox и Edge. Ключевая особенность Scraper.AI — это визуальное программирование парсера, не требующее работы с кодом. Так же сервис предлагает готовые шаблоны, которые настроены на сбор данных в Facebook, Instagram и Twitter.
Ограничения бесплатной версии:
- 3 месяца бесплатной работы;
- Не более 50 страниц.
Возможности сервиса:
- Визуальная настройка парсинга;
- Планировщик;
- Работа с динамически подгружаемыми данными;
- Уведомления.
Бесплатные фреймворки (библиотеки) для парсинга
Для использования фреймворков необходимо обладать знаниями языков программирования и в некоторых случаях нужны обособленные вычислительные мощности, использование библиотек для парсинга поможет реализовать задачу любой сложности и точно настроить проект под задачу.
26. Scrapy
Scrapy – это фреймворк для парсинга с открытым исходным кодом. Фреймворк написан на языке программирования Python и это одно из самых часто применяемых решений для сбора данных. Одно из основных преимуществ Scrapy – асинхронная обработка запросов. Это означает, что Scrapy не нужно ждать, пока запрос будет завершен и обработан, он может отправлять другие запросы или выполнять другие действия в этот же момент времени. Это также означает, что запросы могут выполняться, даже если при обработке какого-либо запроса возникает ошибка.
Это позволяет выполнять очень быстрый обход (одновременную отправку нескольких запросов отказоустойчивым способом), Scrapy также дает контроль над другими параметрами парсинга. Вы можете делать такие вещи как установка задержки загрузки между каждым запросом, ограничение количества одновременных запросов для каждого домена или IP-адреса и даже использовать расширение с автоматическим определением времени парсинга.
Scrapy имеет подробную документацию и большое комьюнити.
27. BeautifulSoup
BeautifulSoup – еще один фреймворк на языке Python для парсинга данных из HTML и XML документов, имеет подробную документацию, требует дополнительных библиотек для открытия ссылок и сохранения результатов сбора данных. Он более прост по сравнению со Scrapy, BeautifulSoup стоит использовать, если задача не подразумевает распределение данных, не требуется реализация сложной логики, не нужно использовать прокси. Так же отличительная черта BeautifulSoup низкий порог входа, библиотека подойдет программистам даже с начальными знаниями, множество мануалов способствует быстрому освоению.
28. Jaunt
Jaunt – это бесплатная библиотека Java для парсинга, автоматизации и запросов JSON. Библиотека предоставляет быстрый и сверхлегкий безголовый браузер (без графического интерфейса). Браузер предоставляет функции парсинга данных, доступ к DOM и контроль над каждым HTTP-запросом — ответом.
Возможности Jaunt:
- Выполнять парсинг веб-страниц и извлекать данные JSON;
- Работать с формами и таблицами;
- Контролировать / обрабатывать отдельные HTTP-запросы / ответы;
- Интерфейс с REST API или веб-приложениями (JSON, HTML, XHTML или XML).
29. Selenium
Selenium — это набор инструментов для автоматизации веб-браузеров с открытым исходным кодом, объединяет набор инструментов для управления, развертывания, записи и воспроизведения действия.
Сценарии могут быть написаны на различных языках Python, Java, C#, JavaScript, Ruby. Selenium настоящий комбайн для парсинга, позволяющий объединять не только браузеры, но и вычислительные мощности для решения задач. Этот инструмент стоит использовать, если перед вами стоят большие задачи и есть ресурсы для их реализации.
30. Grab
Grab — фреймворк на языке Python для написания веб-парсеров. Grab помогает создавать парсеры различной сложности, от простых 5-строчных скриптов, до сложных и асинхронных поисковых роботов, способных обрабатывать миллионы страниц. Фреймворк предлагает API для выполнения сетевых запросов и последующей обработки контента, например, для взаимодействия с деревом DOM HTML- документа.
Библиотека Grab состоит из двух основных частей:
- Единый API запроса / ответа, позволяющий строить сетевой запрос, выполнять его и работать с полученными данными. API — оболочка библиотек pycurl и lxml.
- API-интерфейс Spider для создания асинхронных поисковых роботов. Вы пишете классы, которые определяют обработчики для каждого типа сетевого запроса. Каждый обработчик может создавать новые сетевые запросы. Сетевые запросы обрабатываются одновременно с пулом асинхронных веб-сокетов.
Платный сервис в заключении
В заключении расскажу о сервисе парсинга развитием которого я занимаюсь – iDatica. Компания занимаемся разработкой парсинга под задачи клиента. Мы очищаем и визуализируем данные, сопоставляем (матчим) товары, делаем это качественно, под ключ.
У нас нет бесплатного тарифа, почему нужны наши услуги, если есть готовые и даже бесплатные сервисы? Если коротко – сервисы требуют людей, которые будут с ними работать, требуют время на изучение функционала и не во всех случаях способны справиться с требования заказчика. Мы решаем все эти задачи.
Если говорить более развернуто — мы поможем, когда сервис, который вы используете не может собрать данные с нужного сайта, например, большинство даже платных версий сервисов из списка, при тестировании не справились с парсингом Яндекс.Маркет, а защищаются от парсинга практически все товарные каталоги. Мы напишем логику парсинга под ваш запрос, например, сначала найти на сайте определенные товары, выбрать категории, бренды, или парсинг под сайт с нестандартной структурой. Мы сравним ваши товары и товары конкурентов с максимальной точностью, в противовес — автоматические машинные алгоритмы сравнения товаров часто не отрабатывают на 100% и потребуют ручной доработки с вашей стороны, а часть сервисов потребует с самого начала сопоставлять ваши товары и товары конкурентов. Все это выливается в оплату сервиса, оплату труда сотрудника, который работает с сервисом, время на обучение, а если сервис в конечном итоге не справится, в потраченное время и необходимость искать новый вариант. Выбирая работу с нами, вы просто будете получать нужный результат.