
Productivity is
the ability to form new words after existing patterns which are
readily understood by the speakers of a language. The most important
and the most productive ways of word-formation are affixation,
conversion,
word-composition
and abbreviation
(contraction).
In the course of time the productivity of this or that way of
word-formation may change. Sound
interchange
or gradation
(blood −
to bleed, to abide − abode, to strike − stroke) was
a productive way of word building in old English and is important for
a diachronic study of the English language. It has lost its
productivity in Modern English and no new word can be coined by means
of sound gradation. Affixation on the contrary was productive in Old
English and is still one of the most productive ways of word building
in Modern English.
3. Affixation. General characteristics of suffixes and prefixes.
The process of affixation
consists
in coining a new word by adding an affix or several affixes to some
root morpheme.
Suffixation
is more productive than prefixation.
In Modern English suffixation is characteristic of noun and adjective
formation, while prefixation is typical of verb formation (incoming,
trainee, principal, promotion).
From
the etymological point of view affixes are classified into the same
two large groups as words: native
and
borrowed (see
Lecture
1; Table 2).
It would be wrong, though, to suppose that affixes are borrowed in
the same way and for the same reasons as words. The
term borrowed
affixes
is not very exact as affixes are never
borrowed as such, but only as parts of loan words. To enter the
morphological system of the English language a borrowed affix has to
meet certain conditions. The borrowing of the affixes is possible
only if the number of words containing this affix is considerable, if
its meaning and function are definite and clear enough, and also if
its structural pattern corresponds to the structural patterns already
existing in the language.
If
these conditions are fulfilled, the foreign affix may even become
productive and combine with native stems or borrowed stems within the
system of English vocabulary like
-able <
Lat
-abilis
in
such words as laughable
or
unforgettable
and
unforgivable.
The
English words balustrade,
brigade, cascade are
borrowed from French. On the analogy with these in the English
language itself such words as blockade
are
coined.
Affixes are usually divided
into living
and dead
affixes.
Living affixes are easily separated from the stem (care-ful).
Dead affixes have become fully merged with the stem and can be
singled out by a diachronic analysis of the development of the word
(admit
− L.
ad+mittere).
Affixes can also be
classified into productive
and
non-productive
types. By productive
affixes
we mean the ones, which take part in deriving new words in this
particular period of language development. The best way to identify
productive affixes is to look for them among neologisms
and
so-called nonce-words,
i.e. words
coined and used only for this particular occasion. The latter are
usually formed on the level of living speech and reflect the most
productive and progressive patterns in word-building:
unputdownable thrill;
“I
don’t
like Sunday evenings: I feel so Mondayish”;
Professor Pringle was a
thinnish, baldish, dispeptic-lookingish
cove with an eye like a haddock. (From Right-Ho,
Jeeves by
P.G. Wodehouse)
In many cases the choice of
the affixes is a means of differentiating meaning:
uninterested −
disinterested;
distrust − mistrust.
One should not confuse the
productivity of affixes with their frequency of occurrence. There are
quite a number of high-frequency affixes which, nevertheless, are no
longer used in word-derivation (e. g. the adjective-forming native
suffixes -ful,
-ly; the
adjective-forming suffixes of Latin origin -ant,
-ent, -al which
are quite frequent).
Unlike
roots, affixes are always bound forms. The difference between
suffixes and prefixes, it will be remembered, is not confined to
their respective position, suffixes being “fixed after” and
prefixes “fixed before” the stem. It also concerns their function
and meaning.
A
suffix
is
a derivational morpheme following the stem and forming a new
derivative in a different part of speech or a different word class,
сf.
-en,
-y, -less in
hearten,
hearty, heartless. When
both the underlying and the resultant forms belong to the same part
of speech, the suffix serves to differentiate between
lexico-grammatical classes by rendering some very general
lexico-grammatical meaning. For instance, both -ify
and
-er
are
verb suffixes, but the first characterises causative verbs, such as
horrify,
purify, rarefy, simplify, whereas
the second is mostly typical of frequentative verbs: flicker,
shimmer, twitter and
the like.
If we realise that suffixes
render the most general semantic component of the word’s lexical
meaning by marking the general class of phenomena to which the
referent of the word belongs, the reason why suffixes are as a rule
semantically fused with the stem stands explained.
A
prefix
is a derivational morpheme standing before the root and modifying
meaning, cf. hearten
—
dishearten.
It
is only with verbs and statives that a prefix may serve to
distinguish one part of speech from another, like in earth
n
—
unearth
v,
sleep
n
—
asleep
(stative).
It
is interesting that as a prefix en-
may
carry the same meaning of being or bringing into a certain state as
the suffix -en,
сf.
enable,
encamp, endanger,
endear, enslave and
fasten,
darken, deepen, lengthen, strengthen.
Preceding
a verb stem, some prefixes express the difference between a
transitive and an intransitive verb: stay
v
and outstay
(sb)
vt. With a few exceptions prefixes modify the stem for time (pre-,
post-), place
(in-,
ad-) or
negation (un-,
dis-) and
remain semantically rather independent of the stem.
An
infix
is an affix placed within the word, like -n-
in
stand.
The
type is not productive. An affix should not be confused with a
combining form.
A
combining form is also a bound form but it can be distinguished from
an affix historically by the fact that it is always borrowed from
another language, namely, from Latin or Greek, in which it existed as
a free form, i.e. a separate word, or also as a combining form. They
differ from all other borrowings in that they occur in compounds and
derivatives that did not exist in their original language but were
formed only in modern times in English, Russian, French, etc., сf.
polyclinic,
polymer;
stereophonic, stereoscopic, telemechanics, television. Combining
forms
are mostly international. Descriptively a combining form differs from
an affix, because it can occur as one constituent of a form whose
only other constituent is an affix, as in graphic,
cyclic.
Also
affixes are characterised either by preposition with respect to the
root (prefixes) or by postposition (suffixes), whereas the same
combining
form may occur in both positions. Cf.
phonograph,
phonology and
telephone,
microphone, etc.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Lecture №3. Productive and Non-productive Ways of Word-formation in Modern English
Productivity is the ability to form new words after existing patterns which are readily understood by the speakers of language. The most important and the most productive ways of word-formation are affixation, conversion, word-composition and abbreviation (contraction). In the course of time the productivity of this or that way of word-formation may change. Sound interchange or gradation (blood-to bleed, to abide-abode, to strike-stroke) was a productive way of word building in old English and is important for a diachronic study of the English language. It has lost its productivity in Modern English and no new word can be coined by means of sound gradation. Affixation on the contrary was productive in Old English and is still one of the most productive ways of word building in Modern English.
WORDBUILDING
Word-building is one of the main ways of enriching vocabulary. There are four main ways of word-building in modern English: affixation, composition, conversion, abbreviation. There are also secondary ways of word-building: sound interchange, stress interchange, sound imitation, blends, back formation.
AFFIXATION
Affixation is one of the most productive ways of word-building throughout the history of English. It consists in adding an affix to the stem of a definite part of speech. Affixation is divided into suffixation and prefixation.
Suffixation
The main function of suffixes in Modern English is to form one part of speech from another, the secondary function is to change the lexical meaning of the same part of speech. (e.g. «educate» is a verb, «educator» is a noun, and music» is a noun, «musical» is also a noun or an adjective). There are different classifications of suffixes :
1. Part-of-speech classification. Suffixes which can form different parts of speech are given here :
a) noun-forming suffixes, such as: —er (criticizer), —dom (officialdom), —ism (ageism),
b) adjective-forming suffixes, such as: —able (breathable), less (symptomless), —ous (prestigious),
c) verb-forming suffixes, such as —ize (computerize) , —ify (minify),
d) adverb-forming suffixes , such as : —ly (singly), —ward (tableward),
e) numeral-forming suffixes, such as —teen (sixteen), —ty (seventy).
2. Semantic classification. Suffixes changing the lexical meaning of the stem can be subdivided into groups, e.g. noun-forming suffixes can denote:
a) the agent of the action, e.g. —er (experimenter), —ist (taxist), -ent (student),
b) nationality, e.g. —ian (Russian), —ese (Japanese), —ish (English),
c) collectivity, e.g. —dom (moviedom), —ry (peasantry, —ship (readership), —ati (literati),
d) diminutiveness, e.g. —ie (horsie), —let (booklet), —ling (gooseling), —ette (kitchenette),
e) quality, e.g. —ness (copelessness), —ity (answerability).
3. Lexico—grammatical character of the stem. Suffixes which can be added to certain groups of stems are subdivided into:
a) suffixes added to verbal stems, such as: —er (commuter), —ing (suffering), — able (flyable), —ment (involvement), —ation (computerization),
b) suffixes added to noun stems, such as: —less (smogless), —ful (roomful), —ism (adventurism), —ster (pollster), —nik (filmnik), —ish (childish),
c) suffixes added to adjective stems, such as: —en (weaken), —ly (pinkly), —ish (longish), —ness (clannishness).
4. Origin of suffixes. Here we can point out the following groups:
a) native (Germanic), such as —er,-ful, —less, —ly.
b) Romanic, such as : —tion, —ment, —able, —eer.
c) Greek, such as : —ist, —ism, -ize.
d) Russian, such as —nik.
5. Productivity. Here we can point out the following groups:
a) productive, such as: —er, —ize, —ly, —ness.
b) semi-productive, such as: —eer, —ette, —ward.
c) non-productive , such as: —ard (drunkard), —th (length).
Suffixes can be polysemantic, such as: —er can form nouns with the following meanings: agent, doer of the action expressed by the stem (speaker), profession, occupation (teacher), a device, a tool (transmitter). While speaking about suffixes we should also mention compound suffixes which are added to the stem at the same time, such as —ably, —ibly, (terribly, reasonably), —ation (adaptation from adapt). There are also disputable cases whether we have a suffix or a root morpheme in the structure of a word, in such cases we call such morphemes semi-suffixes, and words with such suffixes can be classified either as derived words or as compound words, e.g. —gate (Irangate), —burger (cheeseburger), —aholic (workaholic) etc.
Prefixation
Prefixation is the formation of words by means of adding a prefix to the stem. In English it is characteristic for forming verbs. Prefixes are more independent than suffixes. Prefixes can be classified according to the nature of words in which they are used: prefixes used in notional words and prefixes used in functional words. Prefixes used in notional words are proper prefixes which are bound morphemes, e.g. un— (unhappy). Prefixes used in functional words are semi-bound morphemes because they are met in the language as words, e.g. over— (overhead) (cf. over the table). The main function of prefixes in English is to change the lexical meaning of the same part of speech. But the recent research showed that about twenty-five prefixes in Modern English form one part of speech from another (bebutton, interfamily, postcollege etc).
Prefixes can be classified according to different principles:
1. Semantic classification:
a) prefixes of negative meaning, such as: in— (invaluable), non— (nonformals), un— (unfree) etc,
b) prefixes denoting repetition or reversal actions, such as: de— (decolonize), re— (revegetation), dis— (disconnect),
c) prefixes denoting time, space, degree relations, such as: inter— (interplanetary) , hyper— (hypertension), ex— (ex-student), pre— (pre-election), over— (overdrugging) etc.
2. Origin of prefixes:
a) native (Germanic), such as: un-, over-, under— etc.
b) Romanic, such as: in-, de-, ex-, re— etc.
c) Greek, such as: sym-, hyper— etc.
When we analyze such words as adverb, accompany where we can find the root of the word (verb, company) we may treat ad-, ac— as prefixes though they were never used as prefixes to form new words in English and were borrowed from Romanic languages together with words. In such cases we can treat them as derived words. But some scientists treat them as simple words. Another group of words with a disputable structure are such as: contain, retain, detain and conceive, receive, deceive where we can see that re-, de-, con— act as prefixes and —tain, —ceive can be understood as roots. But in English these combinations of sounds have no lexical meaning and are called pseudo-morphemes. Some scientists treat such words as simple words, others as derived ones. There are some prefixes which can be treated as root morphemes by some scientists, e.g. after— in the word afternoon. American lexicographers working on Webster dictionaries treat such words as compound words. British lexicographers treat such words as derived ones.
COMPOSITION
Composition is the way of word building when a word is formed by joining two or more stems to form one word. The structural unity of a compound word depends upon: a) the unity of stress, b) solid or hyphеnated spelling, c) semantic unity, d) unity of morphological and syntactical functioning. These are characteristic features of compound words in all languages. For English compounds some of these factors are not very reliable. As a rule English compounds have one uniting stress (usually on the first component), e.g. hard-cover, best—seller. We can also have a double stress in an English compound, with the main stress on the first component and with a secondary stress on the second component, e.g. blood—vessel. The third pattern of stresses is two level stresses, e.g. snow—white, sky—blue. The third pattern is easily mixed up with word-groups unless they have solid or hyphеnated spelling.
Spelling in English compounds is not very reliable as well because they can have different spelling even in the same text, e.g. war—ship, blood—vessel can be spelt through a hyphen and also with a break, insofar, underfoot can be spelt solidly and with a break. All the more so that there has appeared in Modern English a special type of compound words which are called block compounds, they have one uniting stress but are spelt with a break, e.g. air piracy, cargo module, coin change, penguin suit etc. The semantic unity of a compound word is often very strong. In such cases we have idiomatic compounds where the meaning of the whole is not a sum of meanings of its components, e.g. to ghostwrite, skinhead, brain—drain etc. In nonidiomatic compounds semantic unity is not strong, e. g., airbus, to bloodtransfuse, astrodynamics etc.
English compounds have the unity of morphological and syntactical functioning. They are used in a sentence as one part of it and only one component changes grammatically, e.g. These girls are chatter-boxes. «Chatter-boxes» is a predicative in the sentence and only the second component changes grammatically. There are two characteristic features of English compounds:
a) Both components in an English compound are free stems, that is they can be used as words with a distinctive meaning of their own. The sound pattern will be the same except for the stresses, e.g. «a green-house» and «a green house». Whereas for example in Russian compounds the stems are bound morphemes, as a rule.
b) English compounds have a two-stem pattern, with the exception of compound words which have form-word stems in their structure, e.g. middle-of-the-road, off—the—record, up—and—doing etc. The two-stem pattern distinguishes English compounds from German ones.
WAYS OF FORMING COMPOUND WORDS
Compound words in English can be formed not only by means of composition but also by means of:
a) reduplication, e.g. too—too, and also by means of reduplication combined with sound interchange , e.g. rope-ripe,
b) conversion from word-groups, e.g. to micky—mouse, can—do, makeup etc,
c) back formation from compound nouns or word-groups, e.g. to bloodtransfuse, to fingerprint etc ,
d) analogy, e.g. lie—in (on the analogy with sit-in) and also phone—in, brawn—drain (on the analogy with brain—drain) etc.
CLASSIFICATIONS OF ENGLISH COMPOUNDS
1. According to the parts of speech compounds are subdivided into:
a) nouns, such as: baby-moon, globe-trotter,
b) adjectives, such as : free-for-all, power-happy,
c) verbs, such as : to honey-moon, to baby-sit, to henpeck,
d) adverbs, such as: downdeep, headfirst,
e) prepositions, such as: into, within,
f) numerals, such as : fifty—five.
2. According to the way components are joined together compounds are divided into: a) neutral, which are formed by joining together two stems without any joining morpheme, e.g. ball—point, to windowshop,
b) morphological where components are joined by a linking element: vowels «o» or «i» or the consonant «s», e.g. («astrospace», «handicraft», «sportsman»),
c) syntactical where the components are joined by means of form-word stems, e.g. here-and-now, free-for-all, do-or-die.
3. According to their structure compounds are subdivided into:
a) compound words proper which consist of two stems, e.g. to job-hunt, train-sick, go-go, tip-top,
b) derivational compounds, where besides the stems we have affixes, e.g. ear—minded, hydro-skimmer,
c) compound words consisting of three or more stems, e.g. cornflower—blue, eggshell—thin, singer—songwriter,
d) compound-shortened words, e.g. boatel, VJ—day, motocross, intervision, Eurodollar, Camford.
4. According to the relations between the components compound words are subdivided into:
a) subordinative compounds where one of the components is the semantic and the structural centre and the second component is subordinate; these subordinative relations can be different: with comparative relations, e.g. honey—sweet, eggshell—thin, with limiting relations, e.g. breast—high, knee—deep, with emphatic relations, e.g. dog—cheap, with objective relations, e.g. gold—rich, with cause relations, e.g. love—sick, with space relations, e.g. top—heavy, with time relations, e.g. spring—fresh, with subjective relations, e.g. foot—sore etc
b) coordinative compounds where both components are semantically independent. Here belong such compounds when one person (object) has two functions, e.g. secretary-stenographer, woman-doctor, Oxbridge etc. Such compounds are called additive. This group includes also compounds formed by means of reduplication, e.g. fifty-fifty, no-no, and also compounds formed with the help of rhythmic stems (reduplication combined with sound interchange) e.g. criss-cross, walkie-talkie.
5. According to the order of the components compounds are divided into compounds with direct order, e.g. kill—joy, and compounds with indirect order, e.g. nuclear—free, rope—ripe.
CONVERSION
Conversion is a characteristic feature of the English word-building system. It is also called affixless derivation or zero-suffixation. The term «conversion» first appeared in the book by Henry Sweet «New English Grammar» in 1891. Conversion is treated differently by different scientists, e.g. prof. A.I. Smirntitsky treats conversion as a morphological way of forming words when one part of speech is formed from another part of speech by changing its paradigm, e.g. to form the verb «to dial» from the noun «dial» we change the paradigm of the noun (a dial, dials) for the paradigm of a regular verb (I dial, he dials, dialed, dialing). A. Marchand in his book «The Categories and Types of Present-day English» treats conversion as a morphological-syntactical word-building because we have not only the change of the paradigm, but also the change of the syntactic function, e.g. I need some good paper for my room. (The noun «paper» is an object in the sentence). I paper my room every year. (The verb «paper» is the predicate in the sentence). Conversion is the main way of forming verbs in Modern English. Verbs can be formed from nouns of different semantic groups and have different meanings because of that, e.g.:
a) verbs have instrumental meaning if they are formed from nouns denoting parts of a human body e.g. to eye, to finger, to elbow, to shoulder etc. They have instrumental meaning if they are formed from nouns denoting tools, machines, instruments, weapons, e.g. to hammer, to machine-gun, to rifle, to nail,
b) verbs can denote an action characteristic of the living being denoted by the noun from which they have been converted, e.g. to crowd, to wolf, to ape,
c) verbs can denote acquisition, addition or deprivation if they are formed from nouns denoting an object, e.g. to fish, to dust, to peel, to paper,
d) verbs can denote an action performed at the place denoted by the noun from which they have been converted, e.g. to park, to garage, to bottle, to corner, to pocket,
e) verbs can denote an action performed at the time denoted by the noun from which they have been converted e.g. to winter, to week-end.
Verbs can be also converted from adjectives, in such cases they denote the change of the state, e.g. to tame (to become or make tame), to clean, to slim etc.
Nouns can also be formed by means of conversion from verbs. Converted nouns can denote: a) instant of an action e.g. a jump, a move,
b) process or state e.g. sleep, walk,
c) agent of the action expressed by the verb from which the noun has been converted, e.g. a help, a flirt, a scold,
d) object or result of the action expressed by the verb from which the noun has been converted, e.g. a burn, a find, a purchase,
e) place of the action expressed by the verb from which the noun has been converted, e.g. a drive, a stop, a walk.
Many nouns converted from verbs can be used only in the Singular form and denote momentaneous actions. In such cases we have partial conversion. Such deverbal nouns are often used with such verbs as: to have, to get, to take etc., e.g. to have a try, to give a push, to take a swim.
CRITERIA OF SEMANTIC DERIVATION
In cases of conversion the problem of criteria of semantic derivation arises: which of the converted pair is primary and which is converted from it. The problem was first analized by prof. A.I. Smirnitsky. Later on P.A. Soboleva developed his idea and worked out the following criteria:
1. If the lexical meaning of the root morpheme and the lexico-grammatical meaning of the stem coincide the word is primary, e.g. in cases pen — to pen, father — to father the nouns are names of an object and a living being. Therefore in the nouns «pen» and «father» the lexical meaning of the root and the lexico-grammatical meaning of the stem coincide. The verbs «to pen» and «to father» denote an action, a process therefore the lexico-grammatical meanings of the stems do not coincide with the lexical meanings of the roots. The verbs have a complex semantic structure and they were converted from nouns.
2. If we compare a converted pair with a synonymic word pair which was formed by means of suffixation we can find out which of the pair is primary. This criterion can be applied only to nouns converted from verbs, e.g. «chat» n. and «chat» v. can be compared with «conversation» – «converse».
3. The criterion based on derivational relations is of more universal character. In this case we must take a word-cluster of relative words to which the converted pair belongs. If the root stem of the word-cluster has suffixes added to a noun stem the noun is primary in the converted pair and vica versa, e.g. in the word-cluster: hand n., hand v., handy, handful the derived words have suffixes added to a noun stem, that is why the noun is primary and the verb is converted from it. In the word-cluster: dance n., dance v., dancer, dancing we see that the primary word is a verb and the noun is converted from it.
SUBSTANTIVIZATION OF ADJECTIVES
Some scientists (Yespersen, Kruisinga) refer substantivization of adjectives to conversion. But most scientists disagree with them because in cases of substantivization of adjectives we have quite different changes in the language. Substantivization is the result of ellipsis (syntactical shortening) when a word combination with a semantically strong attribute loses its semantically weak noun (man, person etc), e.g. «a grown-up person» is shortened to «a grown-up». In cases of perfect substantivization the attribute takes the paradigm of a countable noun, e.g. a criminal, criminals, a criminal’s (mistake), criminals’ (mistakes). Such words are used in a sentence in the same function as nouns, e.g. I am fond of musicals. (musical comedies). There are also two types of partly substantivized adjectives: 1) those which have only the plural form and have the meaning of collective nouns, such as: sweets, news, finals, greens; 2) those which have only the singular form and are used with the definite article. They also have the meaning of collective nouns and denote a class, a nationality, a group of people, e.g. the rich, the English, the dead.
«STONE WALL» COMBINATIONS
The problem whether adjectives can be formed by means of conversion from nouns is the subject of many discussions. In Modern English there are a lot of word combinations of the type, e.g. price rise, wage freeze, steel helmet, sand castle etc. If the first component of such units is an adjective converted from a noun, combinations of this type are free word-groups typical of English (adjective + noun). This point of view is proved by O. Yespersen by the following facts:
1. «Stone» denotes some quality of the noun «wall».
2. «Stone» stands before the word it modifies, as adjectives in the function of an attribute do in English.
3. «Stone» is used in the Singular though its meaning in most cases is plural, and adjectives in English have no plural form.
4. There are some cases when the first component is used in the Comparative or the Superlative degree, e.g. the bottomest end of the scale.
5. The first component can have an adverb which characterizes it, and adjectives are characterized by adverbs, e.g. a purely family gathering.
6. The first component can be used in the same syntactical function with a proper adjective to characterize the same noun, e.g. lonely bare stone houses.
7. After the first component the pronoun «one» can be used instead of a noun, e.g. I shall not put on a silk dress, I shall put on a cotton one.
However Henry Sweet and some other scientists say that these criteria are not characteristic of the majority of such units. They consider the first component of such units to be a noun in the function of an attribute because in Modern English almost all parts of speech and even word-groups and sentences can be used in the function of an attribute, e.g. the then president (an adverb), out-of-the-way villages (a word-group), a devil-may-care speed (a sentence). There are different semantic relations between the components of «stone wall» combinations. E.I. Chapnik classified them into the following groups:
1. time relations, e.g. evening paper,
2. space relations, e.g. top floor,
3. relations between the object and the material of which it is made, e.g. steel helmet,
4. cause relations, e.g. war orphan,
5. relations between a part and the whole, e.g. a crew member,
6. relations between the object and an action, e.g. arms production,
7. relations between the agent and an action e.g. government threat, price rise,
8. relations between the object and its designation, e.g. reception hall,
9. the first component denotes the head, organizer of the characterized object, e.g. Clinton government, Forsyte family,
10. the first component denotes the field of activity of the second component, e.g. language teacher, psychiatry doctor,
11. comparative relations, e.g. moon face,
12. qualitative relations, e.g. winter apples.
ABBREVIATION
In the process of communication words and word-groups can be shortened. The causes of shortening can be linguistic and extra-linguistic. By extra-linguistic causes changes in the life of people are meant. In Modern English many new abbreviations, acronyms, initials, blends are formed because the tempo of life is increasing and it becomes necessary to give more and more information in the shortest possible time. There are also linguistic causes of abbreviating words and word-groups, such as the demand of rhythm, which is satisfied in English by monosyllabic words. When borrowings from other languages are assimilated in English they are shortened. Here we have modification of form on the basis of analogy, e.g. the Latin borrowing «fanaticus» is shortened to «fan» on the analogy with native words: man, pan, tan etc. There are two main types of shortenings: graphical and lexical.
Graphical abbreviations
Graphical abbreviations are the result of shortening of words and word-groups only in written speech while orally the corresponding full forms are used. They are used for the economy of space and effort in writing. The oldest group of graphical abbreviations in English is of Latin origin. In Russian this type of abbreviation is not typical. In these abbreviations in the spelling Latin words are shortened, while orally the corresponding English equivalents are pronounced in the full form, e.g. for example (Latin exampli gratia), a.m. – in the morning (ante meridiem), No – number (numero), p.a. – a year (per annum), d – penny (dinarius), lb – pound (libra), i. e. – that is (id est) etc.
Some graphical abbreviations of Latin origin have different English equivalents in different contexts, e.g. p.m. can be pronounced «in the afternoon» (post meridiem) and «after death» (post mortem). There are also graphical abbreviations of native origin, where in the spelling we have abbreviations of words and word-groups of the corresponding English equivalents in the full form. We have several semantic groups of them: a) days of the week, e.g. Mon – Monday, Tue – Tuesday etc
b) names of months, e.g. Apr – April, Aug – August etc.
c) names of counties in UK, e.g. Yorks – Yorkshire, Berks – Berkshire etc
d) names of states in USA, e.g. Ala – Alabama, Alas – Alaska etc.
e) names of address, e.g. Mr., Mrs., Ms., Dr. etc.
f) military ranks, e.g. capt. – captain, col. – colonel, sgt – sergeant etc.
g) scientific degrees, e.g. B.A. – Bachelor of Arts, D.M. – Doctor of Medicine. (Sometimes in scientific degrees we have abbreviations of Latin origin, e.g., M.B. – Medicinae Baccalaurus).
h) units of time, length, weight, e.g. f./ft – foot/feet, sec. – second, in. – inch, mg. – milligram etc.
The reading of some graphical abbreviations depends on the context, e.g. «m» can be read as: male, married, masculine, metre, mile, million, minute, «l.p.» can be read as long-playing, low pressure.
Initial abbreviations
Initialisms are the bordering case between graphical and lexical abbreviations. When they appear in the language, as a rule, to denote some new offices they are closer to graphical abbreviations because orally full forms are used, e.g. J.V. – joint venture. When they are used for some duration of time they acquire the shortened form of pronouncing and become closer to lexical abbreviations, e.g. BBC is as a rule pronounced in the shortened form. In some cases the translation of initialisms is next to impossible without using special dictionaries. Initialisms are denoted in different ways. Very often they are expressed in the way they are pronounced in the language of their origin, e.g. ANZUS (Australia, New Zealand, United States) is given in Russian as АНЗУС, SALT (Strategic Arms Limitation Talks) was for a long time used in Russian as СОЛТ, now a translation variant is used (ОСВ – Договор об ограничении стратегических вооружений). This type of initialisms borrowed into other languages is preferable, e.g. UFO – НЛО, CП – JV etc. There are three types of initialisms in English:
a) initialisms with alphabetical reading, such as UK, BUP, CND etc
b) initialisms which are read as if they are words, e.g. UNESCO, UNO, NATO etc.
c) initialisms which coincide with English words in their sound form, such initialisms are called acronyms, e.g. CLASS (Computor-based Laboratory for Automated School System). Some scientists unite groups b) and c) into one group which they call acronyms. Some initialisms can form new words in which they act as root morphemes by different ways of wordbuilding:
a) affixation, e.g. AVALism, ex- POW, AIDSophobia etc.
b) conversion, e.g. to raff, to fly IFR (Instrument Flight Rules),
c) composition, e.g. STOLport, USAFman etc.
d) there are also compound-shortened words where the first component is an initial abbreviation with the alphabetical reading and the second one is a complete word, e.g. A-bomb, U-pronunciation, V -day etc. In some cases the first component is a complete word and the second component is an initial abbreviation with the alphabetical pronunciation, e.g. Three -Ds (Three dimensions) – стереофильм.
Abbreviations of words
Abbreviation of words consists in clipping a part of a word. As a result we get a new lexical unit where either the lexical meaning or the style is different form the full form of the word. In such cases as «fantasy» and «fancy», «fence» and «defence» we have different lexical meanings. In such cases as «laboratory» and «lab», we have different styles. Abbreviation does not change the part-of-speech meaning, as we have it in the case of conversion or affixation, it produces words belonging to the same part of speech as the primary word, e.g. prof. is a noun and professor is also a noun. Mostly nouns undergo abbreviation, but we can also meet abbreviation of verbs, such as to rev. from to revolve, to tab from to tabulate etc. But mostly abbreviated forms of verbs are formed by means of conversion from abbreviated nouns, e.g. to taxi, to vac etc. Adjectives can be abbreviated but they are mostly used in school slang and are combined with suffixation, e.g. comfy, dilly etc. As a rule pronouns, numerals, interjections. conjunctions are not abbreviated. The exceptions are: fif (fifteen), teen-ager, in one’s teens (apheresis from numerals from 13 to 19). Lexical abbreviations are classified according to the part of the word which is clipped. Mostly the end of the word is clipped, because the beginning of the word in most cases is the root and expresses the lexical meaning of the word. This type of abbreviation is called apocope. Here we can mention a group of words ending in «o», such as disco (dicotheque), expo (exposition), intro (introduction) and many others. On the analogy with these words there developed in Modern English a number of words where «o» is added as a kind of a suffix to the shortened form of the word, e.g. combo (combination) – небольшой эстрадный ансамбль, Afro (African) – прическа под африканца etc. In other cases the beginning of the word is clipped. In such cases we have apheresis, e.g. chute (parachute), varsity (university), copter (helicopter), thuse (enthuse) etc. Sometimes the middle of the word is clipped, e.g. mart (market), fanzine (fan magazine) maths (mathematics). Such abbreviations are called syncope. Sometimes we have a combination of apocope with apheresis, when the beginning and the end of the word are clipped, e.g. tec (detective), van (vanguard) etc. Sometimes shortening influences the spelling of the word, e.g. «c» can be substituted by «k» before «e» to preserve pronunciation, e.g. mike (microphone), Coke (coca-cola) etc. The same rule is observed in the following cases: fax (facsimile), teck (technical college), trank (tranquilizer) etc. The final consonants in the shortened forms are substituded by letters characteristic of native English words.
NON-PRODUCTIVE WAYS OF WORDBUILDING
SOUND INTERCHANGE
Sound interchange is the way of word-building when some sounds are changed to form a new word. It is non-productive in Modern English, it was productive in Old English and can be met in other Indo-European languages. The causes of sound interchange can be different. It can be the result of Ancient Ablaut which cannot be explained by the phonetic laws during the period of the language development known to scientists, e.g. to strike – stroke, to sing – song etc. It can be also the result of Ancient Umlaut or vowel mutation which is the result of palatalizing the root vowel because of the front vowel in the syllable coming after the root (regressive assimilation), e.g. hot — to heat (hotian), blood — to bleed (blodian) etc. In many cases we have vowel and consonant interchange. In nouns we have voiceless consonants and in verbs we have corresponding voiced consonants because in Old English these consonants in nouns were at the end of the word and in verbs in the intervocalic position, e.g. bath – to bathe, life – to live, breath – to breathe etc.
STRESS INTERCHANGE
Stress interchange can be mostly met in verbs and nouns of Romanic origin: nouns have the stress on the first syllable and verbs on the last syllable, e.g. `accent — to ac`cent. This phenomenon is explained in the following way: French verbs and nouns had different structure when they were borrowed into English, verbs had one syllable more than the corresponding nouns. When these borrowings were assimilated in English the stress in them was shifted to the previous syllable (the second from the end). Later on the last unstressed syllable in verbs borrowed from French was dropped (the same as in native verbs) and after that the stress in verbs was on the last syllable while in nouns it was on the first syllable. As a result of it we have such pairs in English as: to af«fix -`affix, to con`flict- `conflict, to ex`port -`export, to ex`tract — `extract etc. As a result of stress interchange we have also vowel interchange in such words because vowels are pronounced differently in stressed and unstressed positions.
SOUND IMITATION
It is the way of word-building when a word is formed by imitating different sounds. There are some semantic groups of words formed by means of sound imitation:
a) sounds produced by human beings, such as : to whisper, to giggle, to mumble, to sneeze, to whistle etc.
b) sounds produced by animals, birds, insects, such as: to hiss, to buzz, to bark, to moo, to twitter etc.
c) sounds produced by nature and objects, such as: to splash, to rustle, to clatter, to bubble, to ding-dong, to tinkle etc.
The corresponding nouns are formed by means of conversion, e.g. clang (of a bell), chatter (of children) etc.
BLENDS
Blends are words formed from a word-group or two synonyms. In blends two ways of word-building are combined: abbreviation and composition. To form a blend we clip the end of the first component (apocope) and the beginning of the second component (apheresis) . As a result we have a compound- shortened word. One of the first blends in English was the word «smog» from two synonyms: smoke and fog which means smoke mixed with fog. From the first component the beginning is taken, from the second one the end, «o» is common for both of them. Blends formed from two synonyms are: slanguage, to hustle, gasohol etc. Mostly blends are formed from a word-group, such as: acromania (acronym mania), cinemaddict (cinema adict), chunnel (channel, canal), dramedy (drama comedy), detectifiction (detective fiction), faction (fact fiction) (fiction based on real facts), informecial (information commercial), Medicare (medical care), magalog (magazine catalogue) slimnastics (slimming gymnastics), sociolite (social elite), slanguist (slang linguist) etc.
BACK FORMATION
It is the way of word-building when a word is formed by dropping the final morpheme to form a new word. It is opposite to suffixation, that is why it is called back formation. At first it appeared in the language as a result of misunderstanding the structure of a borrowed word. Prof. Yartseva explains this mistake by the influence of the whole system of the language on separate words. E.g. it is typical of English to form nouns denoting the agent of the action by adding the suffix -er to a verb stem (speak- speaker). So when the French word «beggar» was borrowed into English the final syllable «ar» was pronounced in the same way as the English —er and Englishmen formed the verb «to beg» by dropping the end of the noun. Other examples of back formation are: to accreditate (from accreditation), to bach (from bachelor), to collocate (from collocation), to enthuse (from enthusiasm), to compute (from computer), to emote (from emotion), to televise (from television) etc.
As we can notice in cases of back formation the part-of-speech meaning of the primary word is changed, verbs are formed from nouns.
23
Modern English Word-Formation
C H A P T E R I
The ways in which new words are
formed, and the factors which govern their acceptance into the language, are
generally taken very much for granted by the average speaker. To understand a
word, it is not necessary to know how it is constructed, whether it is simple
or complex, that is, whether or not it can be broken down into two or more
constituents. We are able to use a word which is new to us when we find out
what object or notion it denotes. Some words, of course, are more ‘transparent’
than others. For example, in the words unfathomable and indescribable
we recognize the familiar pattern of negative prefix + transitive word +
adjective-forming suffix on which many words of similar form are constructed.
Knowing the pattern, we can easily guess their meanings – ‘cannot be fathomed’
and ‘cannot be described’ – although we are not surprised to find other
similar-looking words, for instance unfashionable and unfavourable
for which this analysis will not work. We recognize as ‘transparent’ the
adjectives unassuming and unheard-of, which taking for granted
the fact that we cannot use assuming and heard-of. We accept as
quite natural the fact that although we can use the verbs to pipe, to
drum and to trumpet, we cannot use the verbs to piano
and to violin.
But when we meet new coinages, like tape-code,
freak-out, shutup-ness and beautician, we may not readily
be able to explain our reactions to them. Innovations in vocabulary are capable
of arousing quite strong feelings in people who may otherwise not be in the
habit of thinking very much about language. Quirk[1]
quotes some letter to the press of a familiar kind, written to protest about
‘horrible jargon’, such as breakdown, ‘vile’ words like transportation,
and the ‘atrocity’ lay-by.
Many linguists agree over the fact
that the subject of word-formation has not until recently received very much
attention from descriptive grammarians of English, or from scholars working in
the field of general linguistics. As a collection of different processes
(compounding, affixation, conversion, backformation, etc.) about which, as a
group, it is difficult to make general statements, word-formation usually makes
a brief appearance in one or two chapters of a grammar. Valerie Adams
emphasizes two main reasons why the subject has not been attractive to
linguists: its connections with the non-linguistic world of things and ideas,
for which words provide the names, and its equivocal position as between
descriptive and historical studies. A few brief remarks, which necessarily
present a much over-simplified picture, on the course which linguistics has
taken in the last hundred years will make this easier.
The nineteenth century, the period of
great advances in historical and comparative language study, saw the first
claims of linguistics to be a science, comparable in its methods with the
natural sciences which were also enjoying a period of exciting discovery. These
claims rested on the detailed study, by comparative linguists, of formal
correspondences in the Indo-European languages, and their realization that such
study depended on the assumption of certain natural ‘laws’ of sound change. As
Robins[2] observes in his discussion of the
linguistics of the latter part of the nineteenth century:
The history of a language is traced
through recorded variations in the forms and meanings of its words, and
languages are proved to be related by reason of their possession of worlds
bearing formal and semantic correspondences to each other such as cannot be
attributed to mere chance or to recent borrowing. If sound change were not
regular, if word-forms were subject to random, inexplicable, and unmotivated
variation in the course of time, such arguments would lose their validity and
linguistic relations could only be established historically by extralinguistic
evidence such as is provided in the Romance field of languages descended from
Latin.
The rise and development in the
twentieth century of synchronic descriptive linguistics meant a shift of
emphasis from historical studies, but not from the idea of linguistics as a
science based on detailed observation and the rigorous exclusion of all
explanations depended on extralinguistic factors. As early as 1876, Henry Sweet
had written:
Before history must come a knowledge of what exists.
We must learn to observe things as they are, without regard to their origin,
just as a zoologist must learn to describe accurately a horse or any other
animal. Nor would the mere statements that the modern horse is a descendant of
a three-toed marsh quadruped be accepted as an exhausted description… Such
however is the course being pursued by most antiquarian philologists.[3]
The most influential scholar
concerned with the new linguistics was Ferdinand de Saussure, who emphasized
the distinction between external linguistics – the study of the effects on a
language of the history and culture of its speakers, and internal linguistics –
the study of its system and rules. Language, studied synchronically, as a
system of elements definable in relation to one another, must be seen as a
fixed state of affairs at a particular point of time. It was internal
linguistics, stimulated by de Saussure’s works, that was to be the main concern
of the twentieth-century scholars, and within it there could be no place for
the study of the formation of words, with its close connection with the
external world and its implications of constant change. Any discussion of new
formations as such means the abandonment of the strict distinction between
history and the present moment. As Harris expressed in his influential Structural
Linguistics[4]:
‘The methods of descriptive linguistics cannot treat of the productivity of
elements since that is a measure of the difference between our corpus and some
future corpus of the language.’ Leonard Bloomfield, whose book Language[5]
was the next work of major influence after that of de Saussure, re-emphasized
the necessity of a scientific approach, and the consequent difficulties in the
way of studying ‘meaning’, and until the middle of the nineteen-fifties,
interest was centered on the isolating of minimal segments of speech, the
description of their distribution relative to one another, and their
organization into larger units. The fundamental unit of grammar was not the
word but a smaller unit, the morpheme.
The next major change of emphasis in
linguistics was marked by the publication in 1957 of Noam Chomsky’s Syntactic
Structures[6].
As Chomsky stated it, the aim of linguistics was now seen to be ‘to make
grammatical explanations parallel in achievement to the behavior of the speaker
who, on the basis of a finite and accidental experience with language can
produce and understand an indefinite number of new sentences’[7].
The idea of productivity, or creativity, previously excluded from linguistics,
or discussed in terms of probabilities in the effort to maintain the view of
language as existing in a static state, was seen to be of central importance.
But still word-formation remained a topic neglected by linguists, and for
several good reasons. Chomsky made explicit the distinction, fundamental to
linguistics today (and comparable to that made by de Saussure between langue,
the system of a language, and parole, the set of utterances of the
language), between linguistic competence, ‘the speaker-hearer’s knowledge of
his language’ and performance, ‘the actual use of language in concrete
situations’[8].
Linked with this distinction are the notions of ‘grammaticalness’ and
‘acceptability’; in Chomsky’s words, ‘Acceptability is a concept that belongs
to the study of competence’[9].
A ‘grammatical’ utterance is one which may be generated and interpreted by the
rules of the grammar; an ‘acceptable’ utterance is one which is ‘perfectly
natural and immediately comprehensible… and in no way bizarre or outlandish’[10].
It is easy to show, as Chomsky does, that a grammatical sentence may not be
acceptable. For instance, this is the cheese the rat the cat caught stole
appears ‘bizarre’ and unacceptable because we have difficulty in working it
out, not because it breaks any grammatical rules. Generally, however, it is to
be expected that grammaticalness and acceptability will go hand in hand where
sentences are concerned.
The ability to make and understand
new words is obviously as much a part of our linguistic competence as the
ability to make and understand new sentences, and so, as Pennanen[11]
points out, ‘it is an obvious gap in transformational grammars not to have made
provision for treating word-formation.’ But, as we have already noticed, we may
readily thing of words, like to piano and to violin, against
which we can invoke no rule, but which are definitely ‘unacceptable’ for no
obvious reason. The incongruence of grammaticality and acceptability that is,
is far greater where words are concerned than where sentences are concerned. It
is so great, in fact, that the exercise of setting out the ‘rules’ for forming
words has so far seemed to many linguists to be out of questionable usefulness.
The occasions on which we would have to describe the output of such rules as ‘grammatical
but non-occurring’[12]
are just too numerous. And there are further difficulties in treating new words
like new sentences. A novel word (like handbook or partial) may
attract unwelcome attention to itself and appear to be the result of the breaking
of rules rather than of their application. And besides, the more accustomed to
the word we become, the more likely we are to find it acceptable, whether it is
‘grammatical’ or not – or perhaps we should say, whether or not is was
‘grammatical’ at the time it was first formed, since a new word once
formed, often becomes merely a member of an inventory; its formation is a
historical event, and the ‘rule’ behind it may then appear irrelevant.
What exactly is a word? From Lewis
Carroll onwards, this apparently simple question has bedeviled countless word
buffs, whether they are participating in a game of Scrabble or writing an
article for the Word Ways linguistic magazine. To help the reader decide what
constitutes a word, A. Ross Eckler[13]
suggests a ranking of words in decreasing order of admissibility. A logical way
to rank a word is by the number of English-speaking people who can recognize it
in speech or writing, but this is obviously impossible to ascertain.
Alternatively, one can rank a word by its number of occurrences in a selected
sample of printed material. H. Kucera and W.N. Francis’s Computational
Analysis of Present-day English[14]
is based on one million words from sources in print in 1961. Unfortunately, the
majority of the words in Webster’s Unabridged[15]
do not appear even once in this compilation – and the words which do not appear
are the ones for which a philosophy of ranking is most urgently needed.
Furthermore, the written ranking will differ from the recognition ranking;
vulgarities and obscenities will rank much higher in the latter than in the
former.
A detailed, word-by-word ranking is
an impossible dream, but a ranking based on classes of words may be within our
grasp. Ross Eckler[16]
proposes the following classes: (1) words appearing in one more standard
English-language dictionaries, (2) non-dictionary words appearing in print in
several different contexts, (3) words invented to fill a specific need and
appearing but once in print.
Most people are willing to admit as
words all uncapitalized, unlabeled entries in, say, Webster’s New International
Dictionary, Third Edition (1961). Intuitively, one recognizes that words become
less admissible as they move in any or all of three directions: as they become
more frequently capitalized, as they become the jargon of smaller groups
(dialect, technical, scientific), and as they become archaic or obsolete. These
classes have no definite boundaries – is a word last used in 1499 significantly
more obsolete than a word last used in 1501? Is a word known to 100,000
chemists more admissible than a word known to 90,000 Mexican-Americans? Each
linguist will set his own boundaries.
The second class consists of
non-dictionary words appearing in print in a number of sources. There are many
non-dictionary words in common use; some logologists would like to draw a wider
circle to include these. Such words can be broadly classified into: (1)
neologisms and common words overlooked by dictionary-makers, (2) geographical
place names, (3) given names and surnames.
Dmitri Borgmann[17]
points out that the well-known words uncashed, ex-wife and duty-bound
appear in no dictionaries (since 1965, the first of these has appeared in the
Random House Unabridged). Few people would exclude these words. Neologisms
present a more awkward problem since some may be so ephemeral that they never
appear in a dictionary. Perhaps one should read Pope’s dictum «Be not the
first by whom the new are tried, nor yet the last to lay the old aside.»
Large treasure-troves of geographic
place names can be found in The Times Atlas of the World[18]
(200,000 names), and the Rand McNally Commercial Atlas and Marketing Guide[19]
(100,000 names). These are not all different, and some place names are already
dictionary words. All these can be easily verified by other readers; however,
some will feel uneasy about admitting as a word the name, say, of a small
Albanian town which possibly has never appeared in any English-language text
outside of atlases.
Given names appear in the appendix of
many dictionaries. Common given names such as Edward or Cornelia ought to be
admitted as readily as common geographical place names such as Guatemala, but
this set does not add much to the logological stockpile.
Family surnames at first blush appear
to be on the same footing as geographical place names. However, one must be
careful about sources. Biographical dictionaries and Who’s Who are adequate
references, but one should be cautious citing surnames appearing only in
telephone directories. Once a telephone directory is supplanted by a later
edition, it is difficult to locate copies for verifying surname claims.
Further, telephone directories are not immune to nonce names coined by
subscribers for personal reasons. A good index of the relative admissibility of
surnames is the number of people in the United States bearing that surname. An
estimate of this could be obtained from computer tapes of the Social Security
Administration; in 1957 they issued a pamphlet giving the number of Social
Security accounts associated with each of the 1500 most common family names.
The third and final class of words
consists of nonce words, those invented to fill a specific need, and appearing
only once (or perhaps only in the work of the author favoring the word). Few
philologists feel comfortable about admitting these. Nonce words range from
coinages by James Joyce and Edgar Allan Poe (X-ing a Paragraph) to
interjections in comic strips (Agggh! Yowie!). Ross Eckler and Daria
Abrossimova suggest that misspellings in print should be included here also.
In the book “Beyond Language”, Dmitri
Borgmann proposes that the philologist be prepared to admit words that may
never have appeared in print. For example, Webster’s Second lists eudaemony as
well as the entry «Eudaimonia, eudaimonism, eudaimonist, etc.» From
this he concludes that EUDAIMONY must exist and should be admitted as a word.
Similarly, he can conceive of sentences containing the word GRACIOUSLY’S («There are ten graciously’s in
Anna Karenina») and SAN DIEGOS («Consider the luster that the San Diegos of our
nation have brought to the US»). In short, he argues that these words
might plausibly be used in an English-language sentence, but does not assert
any actual usage. His criterion for the acceptance of a word seems to be its
philological uniqueness (EUDAIMONY is a short word containing all five vowels and Y).
The available linguistic literature
on the subject cites various types and ways of forming words. Earlier books,
articles and monographs on word-formation and vocabulary growth in general used
to mention morphological, syntactic and lexico-semantic types of
word-formation. At present the classifications of the types of word-formation
do not, as a rule, include lexico-semantic word-building. Of interest is the
classification of word-formation means based on the number of motivating bases
which many scholars follow. A distinction is made between two large classes of
word-building means: to Class I belong the means of building words having one
motivating base (e.g. the noun doer is composed of the base do-
and the suffix —er), which Class II includes the means of building words
containing more than one motivating base. They are all based on compounding
(e.g. compounds letter-opener, e-mail, looking-glass).
Most linguists in special chapters and manuals devoted to
English word-formation consider as the chief processes of English
word-formation affixation, conversion and compounding.
Apart from these, there is a number
of minor ways of forming words such as back-formation, sound interchange,
distinctive stress, onomatopoeia, blending, clipping, acronymy.
Some of the ways of forming words in
present-day English can be restored to for the creation of new words whenever
the occasion demands – these are called productive ways of forming words,
other ways of forming words cannot now produce new words, and these are
commonly termed non—productive or unproductive. R. S.
Ginzburg gives the example of affixation having been a productive way of
forming new words ever since the Old English period; on the other hand,
sound-interchange must have been at one time a word-building means but in
Modern English (as we have mentioned above) its function is actually only to
distinguish between different classes and forms of words.
It follows that productivity of
word-building ways, individual derivational patterns and derivational affixes
is understood as their ability of making new words which all who speak English
find no difficulty in understanding, in particular their ability to create what
are called occasional words or nonce-words[20]
(e.g. lungful (of smoke), Dickensish (office), collarless
(appearance)). The term suggests that a speaker coins such words when he needs
them; if on another occasion the same word is needed again, he coins it afresh.
Nonce-words are built from familiar language material after familiar patterns.
Dictionaries, as a rule, do not list occasional words.
The delimitation between productive
and non-productive ways and means of word-formation as stated above is not,
however, accepted by all linguists without reserve. Some linguists consider it
necessary to define the term productivity of a word-building means more
accurately. They hold the view that productive ways and means of word-formation
are only those that can be used for the formation of an unlimited number of new
words in the modern language, i.e. such means that “know no bounds” and easily
form occasional words. This divergence of opinion is responsible for the
difference in the lists of derivational affixes considered productive in
various books on English lexicology.
Nevertheless, recent investigations
seem to prove that productivity of derivational means is relative in many
respects. Moreover there are no absolutely productive means; derivational
patterns and derivational affixes possess different degrees of productivity.
Therefore it is important that conditions favouring productivity and the degree
if productivity of a particular pattern or affix should be established. All
derivational patterns experience both structural and semantic constraints. The
fewer are the constraints, the higher is the degree of productivity, the
greater is the number of new words built on it. The two general constraints
imposed on all derivational patterns are: the part of speech in which the
pattern functions and the meaning attached to it which conveys the regular
semantic correlation between the two classes of words. It follows that each
part of speech is characterized by a set of productive derivational patterns
peculiar to it. Three degrees of productivity are distinguished for
derivational patterns and individual derivational affixes: (1) highly
productive, (2) productive or semi-productive and (3) non-productive.
R. S. Ginzburg[21]
says that productivity of derivational patterns and affixes should not be
identified with the frequency of occurrence in speech, although there may be
some interrelation between then. Frequency of occurrence is characterized by
the fact that a great number of words containing a given derivational affix are
often used in speech, in particular in various texts. Productivity is
characterized by the ability of a given suffix to make new words.
In linguistic literature there is
another interpretation of derivational productivity based on a quantitative
approach. A derivational pattern or a derivational affix are qualified as
productive provided there are in the word-stock dozens and hundreds of derived
words built on the pattern or with the help of the suffix in question. Thus
interpreted, derivational productivity is distinguished from word-formation
activity by which is meant the ability of an affix to produce new words, in
particular occasional words or nonce-words. For instance, the agent suffix –er
is to be qualified both as a productive and as an active suffix: on the one hand,
the English word-stock possesses hundreds of nouns containing this suffix (e.g.
writer, reaper, lover, runner, etc.), on the other hand, the suffix –er
in the pattern v + –er à N is freely used to coin an unlimited number
of nonce-words denoting active agents (e.g. interrupter, respecter, laugher,
breakfaster, etc.).
The adjective suffix –ful is
described as a productive but not as an active one, for there are hundreds of
adjectives with this suffix (e.g. beautiful, hopeful, useful, etc.), but
no new words seem to be built with its help.
For obvious reasons, the noun-suffix –th in terms of
this approach is to be regarded both as a non-productive and a non-active one.
Now let us consider the basic ways of
forming words in the English language.
Affixation is generally defined as the
formation of words by adding derivational affixes to different types of bases.
Derived words formed by affixation may be the result of one or several
applications of word-formation rule and thus the stems of words making up a
word-cluster enter into derivational relations of different degrees. The zero
degree of derivation is ascribed to simple words, i.e. words whose stem is
homonymous with a word-form and often with a root-morpheme (e.g. atom,
haste, devote, anxious, horror, etc.). Derived words whose bases are built
on simple stems and thus are formed by the application of one derivational
affix are described as having the first degree of derivation (e.g. atomic,
hasty, devotion, etc.). Derived words formed by two consecutive stages of
coining possess the second degree of derivation (e.g. atomical, hastily,
devotional, etc.), and so forth.
In conformity with the division of
derivational affixes into suffixes and prefixes affixation is subdivided into suffixation
and prefixation. Distinction is naturally made between prefixal and
suffixal derivatives according to the last stage of derivation, which
determines the nature of the immediate constituents of the pattern that signals
the relationship of the derived word with its motivating source unit, e.g. unjust
(un– + just), justify (just + –ify), arrangement
(arrange + –ment), non-smoker (non– + smoker). Words like reappearance,
unreasonable, denationalize, are often qualified as prefixal-suffixal
derivatives. R. S. Ginzburg[22]
insists that this classification is relevant only in terms of the constituent
morphemes such words are made up of, i.e. from the angle of morphemic analysis.
From the point of view of derivational analysis, such words are mostly either
suffixal or prefixal derivatives, e.g. sub-atomic = sub– + (atom
+ –ic), unreasonable = un– + (reason + –able), denationalize = de– +
(national + –ize), discouragement = (dis– + courage) + –ment.
A careful study of a great many
suffixal and prefixal derivatives has revealed an essential difference between
them. In Modern English, suffixation is mostly characteristic of noun and
adjective formation, while prefixation is mostly typical of verb formation. The
distinction also rests on the role different types of meaning play in the
semantic structure of the suffix and the prefix. The part-of-speech meaning has
a much greater significance in suffixes as compared to prefixes which possess
it in a lesser degree. Due to it, a prefix may be confined to one part of
speech as, for example, enslave, encage, unbutton, or may function in
more that one part of speech as over– in overkind, overfeed,
overestimation. Unlike prefixes, suffixes as a rule function in any one
part of speech often forming a derived stem of a different part of speech as
compared with that of the base, e.g. careless – care; suitable – suit,
etc. Furthermore, it is necessary to point out that a suffix closely knit
together with a base forms a fusion retaining less of its independence that a
prefix which is as a general rule more independent semantically, e.g. reading
– ‘the act of one who reads’; ‘ability to read’; and to re-read – ‘to read
again’.
Prefixation is the formation of words with the
help of prefixes. The interpretation of the terms prefix and prefixation now firmly
rooted in linguistic literature has undergone a certain evolution. For
instance, some time ago there were linguists who treated prefixation as part of
word-composition (or compounding). The greater semantic independence of
prefixes as compared with suffixes led the linguists to identify prefixes with
the first component part of a compound word.
At present the majority of scholars
treat prefixation as an integral part of word-derivation regarding prefixes as
derivational affixes which differ essentially both from root-morphemes and
non-derivational prepositive morphemes. Opinion sometimes differs concerning
the interpretation of the functional status of certain individual groups of
morphemes which commonly occur as first component parts of words. H. Marchand[23],
for instance, analyses words like to overdo, to underestimate as
compound verbs, the first component of which are locative particles, not
prefixes. In a similar way he interprets words like income, onlooker,
outhouse qualifying them as compounds with locative particles as first
elements.
R. S. Ginzburg[24]
states there are about 51 prefixes in the system of Modern English
word-formation.
Unlike suffixation, which is usually more closely bound
up with the paradigm of a certain part of speech, prefixation is considered to
be more neutral in this respect. It is significant that in linguistic
literature derivational suffixes are always divided into noun-forming,
adjective-forming and so on; prefixes, however, are treated differently. They
are described either in alphabetical order or sub-divided into several classes
in accordance with their origin,. Meaning or function and never according to
the part of speech.
Prefixes may be classified on
different principles. Diachronically distinction is made between prefixes of
native and foreign origin. Synchronically prefixes may be classified:
(1) According to the class of words they
preferably form. Recent investigations allow one to classify prefixes according
to this principle. It must be noted that most of the 51 prefixes of Modern
English function in more than one part of speech forming different structural
and structural-semantic patterns. A small group of 5 prefixes may be referred
to exclusively verb-forming (en–, be–, un–, etc.).
(2) As to the type of lexical-grammatical
character of the base they are added to into: (a) deverbal, e.g. rewrite,
outstay, overdo, etc.; (b) denominal, e.g. unbutton, detrain,
ex-president, etc. and (c) deadjectival, e.g. uneasy, biannual, etc.
It is interesting that the most productive prefixal pattern for adjectives is
the one made up of the prefix un– and the base built either on
adjectival stems or present and past participle, e.g. unknown, unsmiling,
untold, etc.
(3) Semantically prefixes fall into mono–
and polysemantic.
(4) As to the generic denotational
meaning there are different groups that are distinguished in linguistic
literature: (a) negative prefixes such as un–, non–, in–, dis–, a–,
im–/in–/ir– (e.g. employment à unemployment, politician à non-politician, correct à incorrect, advantage à disadvantage, moral à amoral, legal à illegal, etc.); (b) reversative of privative
prefixes, such as un–, de–, dis–, dis– (e.g. tie à untie, centralize à decentralize, connect à disconnect, etc.); (c) pejorative prefixes,
such as mis–, mal–, pseudo– (e.g. calculate à miscalculate, function à malfunction, scientific à pseudo-scientific, etc.); (d) prefixes of time and
order, such as fore–, pre–, post–, ex– (e.g. see à foresee, war à pre-war, Soviet à post-Soviet, wife à ex-wife, etc.); (e) prefix of repetition re–
(e.g. do à redo, type à retype, etc.); (f) locative prefixes such
as super–, sub–, inter–, trans– (e.g. market à supermarket, culture à subculture, national à international, Atlantic à trans-Atlantic, etc.).
(5) When viewed from the angle of their
stylistic reference, English prefixes fall into those characterized by neutral
stylistic reference and those possessing quite a definite stylistic
value. As no exhaustive lexico-stylistic classification of English prefixes
has yet been suggested, a few examples can only be adduced here. There is no
doubt, for instance, that prefixes like un–, out–, over–, re–, under–
and some others can be qualified as neutral (e. g. unnatural, unlace,
outgrow, override, redo, underestimate, etc.). On the other hand, one can
hardly fail to perceive the literary-bookish character of such prefixes as pseudo–,
super–, ultra–, uni–, bi– and some others (e. g. pseudo-classical,
superstructure, ultra-violence, unilateral, bifocal, etc.).
Sometimes one
comes across pairs of prefixes one of which is neutral, the other is
stylistically coloured. One example will suffice here: the prefix over–
occurs in all functional styles, the prefix super– is peculiar to
the style of scientific prose.
(6) Prefixes may be also
classified as to the degree of productivity into highly-productive,
productive and non-productive.
Suffixation is the formation of
words with the help of suffixes. Suffixes usually modify the lexical meaning
of the base and transfer words to a different part of speech. There are
suffixes however, which do not shift words from one part of speech into
another; a suffix of this kind usually transfers a word into a different
semantic group, e. g. a concrete noun becomes an abstract one, as is the case
with child—childhood, friend—friendship, etc.
Chains of suffixes
occurring in derived words having two and more suffixal morphemes are sometimes
referred to in lexicography as compound suffixes: –ably = –able + –ly
(e. g. profitably, unreasonably) –ical–ly = –ic + –al + –ly
(e. g. musically, critically); –ation = –ate + –ion (e. g.
fascination, isolation) and some others. Compound suffixes do not
always present a mere succession of two or more suffixes arising out of several
consecutive stages of derivation. Some of them acquire a new quality operating
as a whole unit. Let us examine from this point of view the suffix –ation
in words like fascination, translation, adaptation and the like. Adaptation
looks at first sight like a parallel to fascination, translation.
The latter however are first-degree derivatives built with the suffix –ion
on the bases fascinate–, translate–. But there is no base adaptate–,
only the shorter base adapt–. Likewise damnation,
condemnation, formation, information and many others
are not matched by shorter bases ending in –ate, but only by still
shorter ones damn–, condemn–, form–, inform–. Thus, the suffix –ation
is a specific suffix of a composite nature. It consists of two suffixes –ate
and –ion, but in many cases functions as a single unit in first-degree
derivatives. It is referred to in linguistic literature as a coalescent suffix
or a group suffix. Adaptation is then a derivative of the first
degree of derivation built with the coalescent suffix on the base adapt–.
Of interest is also the
group-suffix –manship consisting of the suffixes –man and
–ship. It denotes a superior quality, ability of doing something
to perfection, e. g. authormanship, quotemanship, lipmanship, etc.
It also seems appropriate
to make several remarks about the morphological changes that sometimes
accompany the process of combining derivational morphemes with bases. Although
this problem has been so far insufficiently investigated, some observations
have been made and some data collected. For instance, the noun-forming suffix –ess
for names of female beings brings about a certain change in the phonetic shape
of the correlative male noun provided the latter ends in –er, –or, e.g.
actress (actor), sculptress (sculptor), tigress (tiger), etc. It may be
easily observed that in such cases the sound [∂] is contracted in
the feminine nouns.
Further, there are
suffixes due to which the primary stress is shifted to the syllable immediately
preceding them, e.g. courageous (courage), stability (stable), investigation
(investigate), peculiarity (peculiar), etc. When added to a base
having the suffix –able/–ible as its component, the suffix –ity
brings about a change in its phonetic shape, namely the vowel [i] is
inserted between [b] and [l], e. g. possible à possibility, changeable
à changeability, etc. Some suffixes attract the primary stress on
to themselves, there is a secondary stress on the first syllable in words with
such suffixes, e. g. ’employ’ee (em’ploy), govern’mental (govern),
‘pictu’resque (picture).
There are different
classifications of suffixes in linguistic literature, as suffixes may be
divided into several groups according to different principles:
(1) The first principle of
classification that, one might say, suggests itself is the part of speech
formed. Within the scope of the part-of-speech classification suffixes
naturally fall into several groups such as:
a)
noun-suffixes,
i.e. those forming or occurring in nouns, e. g. –er, –dom, –ness, –ation, etc.
(teacher, Londoner, freedom, brightness, justification, etc.);
b) adjective-suffixes, i.e.
those forming or occurring in adjectives, e. g. –able, –less, –ful, –ic,
–ous, etc. (agreeable, careless, doubtful, poetic, courageous, etc.);
c) verb-suffixes, i.e. those
forming or occurring in verbs, e. g. –en, –fy, –ize (darken, satisfy,
harmonize, etc.);
d) adverb-suffixes, i.e.
those forming or occurring in adverbs, e. g. –ly, –ward (quickly, eastward,
etc.).
(2) Suffixes may also be
classified into various groups according to the lexico-grammatical character of
the base the affix is usually added to. Proceeding from this principle one may
divide suffixes into:
a)
deverbal
suffixes (those added to the verbal base), e. g. –er, –ing, –ment, –able, etc.
(speaker, reading, agreement, suitable, etc.);
b) denominal suffixes (those
added to the noun base), e. g. –less, –ish, –ful, –ist, –some, etc.
(handless, childish, mouthful, violinist, troublesome, etc.);
c) de-adjectival suffixes
(those affixed to the adjective base), e. g. –en, –ly, –ish, –ness, etc.
(blacken, slowly, reddish, brightness, etc.).
(3) A classification of
suffixes may also be based on the criterion of sense expressed by a set of
suffixes. Proceeding from this principle suffixes are classified into various
groups within the bounds of a certain part of speech. For instance, noun-suffixes
fall into those denoting:
a)
the
agent of an action, e. g. –er, –ant (baker, dancer, defendant, etc.);
b) appurtenance, e. g. –an,
–ian, –ese, etc. (Arabian, Elizabethan, Russian, Chinese,
Japanese, etc.);
c) collectivity, e. g. –age,
–dom, –ery (–ry), etc. (freightage, officialdom, peasantry,
etc.);
d) diminutiveness, e. g. –ie,
–let, –ling, etc. (birdie, girlie, cloudlet, squirreling,
wolfing, etc.).
(4) Still another
classification of suffixes may be worked out if one examines them from the
angle of stylistic reference. Just like prefixes, suffixes are also
characterized by quite a definite stylistic reference falling into two basic
classes:
a)
those
characterized by neutral stylistic reference such as –able, –er, –ing,
etc.;
Suffixes with
neutral stylistic reference may occur in words of different lexico-stylistic
layers. As for suffixes of the second class they are restricted in use to quite
definite lexico-stylistic layers of words, in particular to terms, e.g. rhomboid,
asteroid, cruciform, cyclotron, synchrophasotron, etc.
(5) Suffixes are also
classified as to the degree of their productivity.
Distinction is usually
made between dead and living affixes. Dead affixes are described as those which are no longer felt in
Modern English as component parts of words; they have so fused with the base of
the word as to lose their independence completely. It is only by special
etymological analysis that they may be singled out, e. g. –d in dead,
seed, –le, –l, –el in bundle, sail, hovel; –ock in hillock; –lock
in wedlock; –t in flight, gift, height. It is quite
clear that dead suffixes are irrelevant to present-day English word-formation,
they belong in its diachronic study.
Living
affixes may be easily singled out from a word, e. g. the noun-forming suffixes –ness,
–dom, –hood, –age, –ance, as in darkness, freedom, childhood,
marriage, assistance, etc. or the adjective-forming suffixes –en, –ous,
–ive, –ful, –y as in wooden, poisonous, active, hopeful, stony, etc.
However, not
all living derivational affixes of Modern English possess the ability to coin
new words. Some of them may be employed to coin new words on the spur of the
moment, others cannot, so that they are different from the point of view of
their productivity. Accordingly they fall into two basic classes — productive
and non-productive word-building affixes.
It has been
pointed out that linguists disagree as to what is meant by the productivity of
derivational affixes.
Following the
first approach all living affixes should be considered productive in varying
degrees from highly-productive (e. g. –er, –ish, –less, re–, etc.)
to non-productive (e. g. –ard, –cy, –ive, etc.).
Consequently
it becomes important to describe the constraints imposed on and the factors
favouring the productivity of affixational patterns and individual affixes. The
degree of productivity of affixational patterns very much depends on the
structural, lexico-grammatical and semantic nature of bases and the meaning of
the affix. For instance, the analysis of the bases from which the suffix –ize
can derive verbs reveals that it is most productive with noun-stems,
adjective-stems also favour ifs productivity, whereas verb-stems and
adverb-stems do not, e. g. criticize (critic), organize (organ), itemize
(item), mobilize (mobile), localize (local), etc. Comparison of the
semantic structure of a verb in –ize with that of the base it is built
on shows that the number of meanings of the stem usually exceeds that of the
verb and that its basic meaning favours the productivity of the suffix –ize
to a greater degree than its marginal meanings, e. g. to characterize —
character, to moralize — moral, to dramatize — drama, etc.
The treatment
of certain affixes as non-productive naturally also depends on the concept of
productivity. The current definition of non-productive derivational affixes as
those which cannot hg used in Modern English for the coining of new words is
rather vague and maybe interpreted in different ways. Following the definition
the term non-productive refers only to the affixes unlikely to be used for the
formation of new words, e. g. –ous, –th, fore– and some others (famous,
depth, foresee).
If one
accepts the other concept of productivity mentioned above, then non-productive
affixes must be defined as those that cannot be used for the formation of
occasional words and, consequently, such affixes as –dom, –ship, –ful, –en,
–ify, –ate and many others are to be regarded as non-productive.
The theory of
relative productivity of derivational affixes is also corroborated by some
other observations made on English word-formation. For instance, different
productive affixes are found in different periods of the history of the
language. It is extremely significant, for example, that out of the seven
verb-forming suffixes of the Old English period only one has survived up to the
present time with a very low degree of productivity, namely the suffix –en
(e. g. to soften, to darken, to whiten).
A derivational
affix may become productive in just one meaning because that meaning is
specially needed by the community at a particular phase in its history. This
may be well illustrated by the prefix de– in the sense of ‘undo what has
been done, reverse an action or process’, e. g. deacidify (paint spray),
decasualize (dock labour), decentralize (government or management), deration
(eggs and butter), de-reserve (medical students), desegregate (coloured
children), and so on.
Furthermore,
there are cases when a derivational affix being nonproductive in the
non-specialized section of the vocabulary is used to coin scientific or
technical terms. This is the case, for instance, with the suffix –ance
which has been used to form some terms in Electrical Engineering, e. g. capacitance,
impedance, reactance. The same is true of the suffix –ity
which has been used to form terms in physics, and chemistry such as alkalinity,
luminosity, emissivity and some others.
Conversion, one of the principal
ways of forming words in Modern English is highly productive in replenishing
the English word-stock with new words. The term conversion, which some
linguists find inadequate, refers to the numerous cases of phonetic identity
of word-forms, primarily the so-called initial forms, of two words belonging to
different parts of speech. This may be illustrated by the following cases: work
— to work; love — to love; paper — to paper; brief — to brief, etc. As
a rule we deal with simple words, although there are a few exceptions, e.g. wireless
— to wireless.
It will be
recalled that, although inflectional categories have been greatly reduced in
English in the last eight or nine centuries, there is a certain difference on
the morphological level between various parts of speech, primarily between
nouns and verbs. For instance, there is a clear-cut difference in Modern
English between the noun doctor and the verb to doctor —
each exists in the language as a unity of its word-forms and variants, not as
one form doctor. It is true that some of the forms are identical
in sound, i.e. homonymous, but there is a great distinction between them, as
they are both grammatically and semantically different.
If we regard
such word-pairs as doctor — to doctor, water — to water, brief — to brief
from the angle of their morphemic structure, we see that they are all
root-words. On the derivational level, however, one of them should be referred
to derived words, as it belongs to a different part of speech and is understood
through semantic and structural relations with the other, i.e. is motivated by
it. Consequently, the question arises: what serves as a word-building means in
these cases? It would appear that the noun is formed from the verb (or vice
versa) without any morphological change, but if we probe deeper into the
matter, we inevitably come to the conclusion that the two words differ in the
paradigm. Thus it is the paradigm that is used as a word-building means. Hence,
we may define conversion as the formation of a new word through changes in its
paradigm.
It is
necessary to call attention to the fact that the paradigm plays a significant
role in the process of word-formation in general and not only in the case of
conversion. Thus, the noun cooker (in gas-cooker) is formed from
the word to cook not only by the addition of the suffix –er, but also by
the change in its paradigm. However, in this case, the role played by the
paradigm as a word-building means is less obvious, as the word-building suffix
–er comes to the fore. Therefore, conversion is characterized not simply
by the use of the paradigm as a word-building means, but by the formation of a
new word solely by means of changing its paradigm. Hence, the change of
paradigm is the only word-building means of conversion. As a paradigm is a
morphological category conversion can be described as a morphological way of
forming words.
Compounding or word-composition is one of
the productive types of word-formation in Modern
English. Composition like all other ways of deriving words has its own peculiarities
as to the means used, the nature of bases and their distribution, as to the
range of application, the scope of semantic classes and the factors conducive
to productivity.
Compounds, as
has been mentioned elsewhere, are made up of two ICs which are both
derivational bases. Compound words are inseparable vocabulary units. They are
formally and semantically dependent on the constituent bases and the semantic
relations between them which mirror the relations between the motivating units.
The ICs of compound words represent bases of all three structural types. The
bases built on stems may be of different degree of complexity as, for example,
week-end, office-management, postage-stamp, aircraft-carrier,
fancy-dress-maker, etc. However, this complexity of structure of
bases is not typical of the bulk of Modern English compounds.
In this
connection care should be taken not to confuse compound words with polymorphic
words of secondary derivation, i.e. derivatives built according to an affixal
pattern but on a compound stem for its base such as, e. g. school-mastership
([n + n] + suf), ex-housewife (prf + [n + n]), to weekend, to spotlight ([n
+ n] + conversion).
Structurally compound words are
characterized by the specific order and arrangement in which bases follow one
another. The order in which the two bases are placed within a compound is
rigidly fixed in Modern English and it is the second IC that makes the
head-member of the word, i.e. its structural and semantic centre. The
head-member is of basic importance as it preconditions both the
lexico-grammatical and semantic features of the first component. It is of interest
to note that the difference between stems (that serve as bases in compound
words) and word-forms they coincide with is most obvious in some
compounds, especially in compound adjectives. Adjectives like long, wide,
rich are characterized by grammatical forms of degrees of comparison
longer, wider, richer. The corresponding stems functioning as
bases in compound words lack grammatical independence and forms proper to the
words and retain only the part-of-speech meaning; thus compound adjectives
with adjectival stems for their second components, e. g. age-long, oil-rich,
inch-wide, do not form degrees of comparison as the compound adjective
oil-rich does not form them the way the word rich does,
but conforms to the general rule of polysyllabic adjectives and has analytical
forms of degrees of comparison. The same difference between words and stems is
not so noticeable in compound nouns with the noun-stem for the second
component.
Phonetically compounds are also
marked by a specific structure of their own. No phonemic changes of bases occur
in composition but the compound word acquires a new stress pattern, different
from the stress in the motivating words, for example words key and
hole or hot and house each
possess their own stress but when the stems of these words are brought together
to make up a new compound word, ‘keyhole — ‘a hole in a lock into
which a key fits’, or ‘hothouse — ‘a heated building for growing
delicate plants’, the latter is given a different stress pattern — a unity
stress on the first component in our case. Compound words have three stress
patterns:
a)
a
high or unity stress on the first component as in ‘honeymoon, ‘doorway,
etc.
b) a double stress, with a
primary stress on the first component and a weaker, secondary stress on the
second component, e. g. ‘blood-ֻvessel, ‘mad-ֻdoctor, ‘washing-ֻmachine,
etc.
c)
It is
not infrequent, however, for both ICs to have level stress as in, for instance,
‘arm-‘chair, ‘icy-‘cold, ‘grass-‘green, etc.
Graphically most compounds have two
types of spelling — they are spelt either solidly or with a hyphen. Both types
of spelling when accompanied by structural and phonetic peculiarities serve as
a sufficient indication of inseparability of compound words in contradistinction
to phrases. It is true that hyphenated spelling by itself may be sometimes
misleading, as it may be used in word-groups to emphasize their phraseological
character as in e. g. daughter-in-law, man-of-war, brother-in-arms or in
longer combinations of words to indicate the semantic unity of a string of
words used attributively as, e.g., I-know-what-you’re-going-to-say
expression, we-are-in-the-know jargon, the young-must-be-right attitude.
The two types of spelling typical of compounds, however, are not rigidly
observed and there are numerous fluctuations between solid or hyphenated
spelling on the one hand and spelling with a break between the components on
the other, especially in nominal compounds of the n+n type. The spelling
of these compounds varies from author to author and from dictionary to
dictionary. For example, the words war-path, war-time, money-lender are
spelt both with a hyphen and solidly; blood-poisoning, money-order,
wave-length, war-ship— with a hyphen and with a break; underfoot,
insofar, underhand—solidly and with a break[25]. It is noteworthy that new compounds
of this type tend to solid or hyphenated spelling. This inconsistency of
spelling in compounds, often accompanied by a level stress pattern (equally
typical of word-groups) makes the problem of distinguishing between compound
words (of the n + n type in particular) and word-groups especially difficult.
In this connection it
should be stressed that Modern English nouns (in the Common Case, Sg.) as has
been universally recognized possess an attributive function in which they are
regularly used to form numerous nominal phrases as, e. g. peace years,
stone steps, government office, etc. Such variable nominal phrases
are semantically fully derivable from the meanings of the two nouns and are
based on the homogeneous attributive semantic relations unlike compound words.
This system of nominal phrases exists side by side with the specific and numerous
class of nominal compounds which as a rule carry an additional semantic component
not found in phrases.
It is also important to
stress that these two classes of vocabulary units — compound words and free
phrases — are not only opposed but also stand in close correlative relations to
each other.
Semantically compound words are
generally motivated units. The meaning of the compound is first of all derived
from the combined lexical meanings of its components. The semantic peculiarity
of the derivational bases and the semantic difference between the base and the
stem on which the latter is built is most obvious in compound words. Compound
words with a common second or first component can serve as illustrations. The
stem of the word board is polysemantic and its multiple meanings
serve as different derivational bases, each with its own selective range for
the semantic features of the other component, each forming a separate set of
compound words, based on specific derivative relations. Thus the base board
meaning ‘a flat piece of wood square or oblong’ makes a set of compounds chess-board,
notice-board, key-board, diving-board, foot-board, sign-board; compounds
paste-board, cardboard are built on the base meaning ‘thick,
stiff paper’; the base board– meaning ‘an authorized body of men’,
forms compounds school-board, board-room. The same can be
observed in words built on the polysemantic stem of the word foot. For
example, the base foot– in foot-print, foot-pump, foothold,
foot-bath, foot-wear has the meaning of ‘the terminal part of the leg’, in
foot-note, foot-lights, foot-stone the base foot– has the meaning of
‘the lower part’, and in foot-high, foot-wide, footrule — ‘measure of
length’. It is obvious from the above-given examples that the meanings of the
bases of compound words are interdependent and that the choice of each is
delimited as in variable word-groups by the nature of the other IC of the word.
It thus may well be said that the combination of bases serves as a kind of
minimal inner context distinguishing the particular individual lexical meaning
of each component. In this connection we should also remember the significance
of the differential meaning found in both components which becomes especially
obvious in a set of compounds containing identical bases.
Compound words can be
described from different points of view and consequently may be classified
according to different principles. They may be viewed from the point of view:
(1) of general relationship
and degree of semantic independence of components;
(2) of the parts of speech
compound words represent;
(3) of the means of
composition used to link the two ICs together;
(4) of the type of ICs that
are brought together to form a compound;
(5) of the correlative
relations with the system of free word-groups.
From the point of view of
degree of semantic independence there are two types of relationship between
the ICs of compound words that are generally recognized in linguistic
literature: the relations of coordination and subordination, and accordingly
compound words fall into two classes: coordinative compounds (often
termed copulative or additive) and subordinative (often termed
determinative).
In coordinative
compounds the two ICs are semantically equally important as in fighter-bomber,
oak-tree, girl-friend, Anglo-American. The constituent bases belong to the
same class and той often to the same semantic group. Coordinative compounds make up
a comparatively small group of words. Coordinative compounds fall into three
groups:
a)
Reduplicative compounds which are made
up by the repetition of the same base as in goody-goody, fifty-fifty,
hush-hush, pooh-pooh. They are all only partially motivated.
b) Compounds formed by
joining the phonically variated rhythmic twin forms which either
alliterate with the same initial consonant but vary the vowels as in chit-chat,
zigzag, sing-song, or rhyme by varying the initial consonants as in clap-trap,
a walky-talky, helter-skelter. This subgroup stands very much apart. It is
very often referred to pseudo-compounds and considered by some linguists
irrelevant to productive word-formation owing to the doubtful morphemic status
of their components. The constituent members of compound words of this subgroup
are in most cases unique, carry very vague or no lexical meaning of their own,
are not found as stems of independently functioning words. They are motivated
mainly through the rhythmic doubling of fanciful sound-clusters.
Coordinative compounds of both subgroups (a, b) are
mostly restricted to the colloquial layer, are marked by a heavy emotive
charge and possess a very small degree of productivity.
c)
The
bases of additive compounds such as a queen-bee, an actor-manager,
unlike the compound words of the first two subgroups, are built on stems of the
independently functioning words of the same part of speech. These bases often
semantically stand in the genus-species relations. They denote a person or an
object that is two things at the same time. A secretary-stenographer is
thus a person who is both a stenographer and a secretary, a
bed-sitting-room (a bed-sitter) is both a bed-room and a
sitting-room at the same time. Among additive compounds there is a specific
subgroup of compound adjectives one of ICs of which is a bound root-morpheme.
This group is limited to the names of nationalities such as Sino-Japanese,
Anglo-Saxon, Afro-Asian, etc.
Additive compounds of this group are mostly fully
motivated but have a very limited degree of productivity.
However it
must be stressed that though the distinction between coordinative and subordinative
compounds is generally made, it is open to doubt and there is no hard and fast
border-line between them. On the contrary, the border-line is rather vague. It
often happens that one and the same compound may with equal right be
interpreted either way — as a coordinative or a subordinative compound, e. g. a
woman-doctor may be understood as ‘a woman who is at the same time a
doctor’ or there can be traced a difference of importance between the
components and it may be primarily felt to be ‘a doctor who happens to be a
woman’ (also a mother-goose, a clock-tower).
In
subordinative compounds the components are neither structurally nor
semantically equal in importance but are based on the domination of the
head-member which is, as a rule, the second IC. The second IC thus is the
semantically and grammatically dominant part of the word, which preconditions
the part-of-speech meaning of the whole compound as in stone-deaf, age-long which
are obviously adjectives, a wrist-watch, road-building, a baby-sitter
which are nouns.
Functionally
compounds are viewed as words of different parts of speech. It is the
head-member of the compound, i.e. its second IC that is indicative of the
grammatical and lexical category the compound word belongs to.
Compound words
are found in all parts of speech, but the bulk of compounds are nouns and
adjectives. Each part of speech is characterized by its set of derivational
patterns and their semantic variants. Compound adverbs, pronouns and
connectives are represented by an insignificant number of words, e. g. somewhere,
somebody, inside, upright, otherwise moreover, elsewhere, by means of, etc.
No new compounds are coined on this pattern. Compound pronouns and adverbs
built on the repeating first and second IC like body, ever, thing make
closed sets of words
SOME
+
BODY
ANY
THING
EVERY
ONE
NO
WHERE
On the whole
composition is not productive either for adverbs, pronouns or for connectives.
Verbs are of
special interest. There is a small group of compound verbs made up of the
combination of verbal and adverbial stems that language retains from earlier
stages, e. g. to bypass, to inlay, to offset. This type according
to some authors, is no longer productive and is rarely found in new compounds.
There are
many polymorphic verbs that are represented by morphemic sequences of two
root-morphemes, like to weekend, to gooseflesh, to spring-clean, but
derivationally they are all words of secondary derivation in which the
existing compound nouns only serve as bases for derivation. They are often
termed pseudo-compound verbs. Such polymorphic verbs are presented by two
groups:
(1) verbs formed by means of
conversion from the stems of compound nouns as in to spotlight from a
spotlight, to sidetrack from a side-track, to handcuff from
handcuffs, to blacklist from a blacklist, to pinpoint from a
pin-point;
(2) verbs formed by
back-derivation from the stems of compound nouns, e. g. to baby-sit from
a baby-sitter, to playact from play-acting, to housekeep from
house-keeping, to spring-clean from spring-cleaning.
From the point of view of the means by which the components
are joined together, compound words may be classified into:
(1) Words formed by merely
placing one constituent after another in a definite order which thus is
indicative of both the semantic value and the morphological unity of the
compound, e. g. rain-driven, house-dog, pot-pie (as opposed to
dog-house, pie-pot). This means of linking the components is typical of the
majority of Modern English compounds in all parts of speech.
As to the
order of components, subordinative compounds are often classified as:
a)
asyntactic compounds in which the
order of bases runs counter to the order in which the motivating words can be
brought together under the rules of syntax of the language. For example, in
variable phrases adjectives cannot be modified by preceding adjectives and
noun modifiers are not placed before participles or adjectives, yet this kind
of asyntactic arrangement is typical of compounds, e. g. red-hot,
bluish-black, pale-blue, rain-driven, oil-rich. The asyntactic order is
typical of the majority of Modern English compound words;
b) syntactic compounds whose
components are placed in the order that resembles the order of words in free
phrases arranged according to the rules of syntax of Modern English. The order
of the components in compounds like blue-bell, mad-doctor, blacklist (
a + n ) reminds one of the order and arrangement of the corresponding words
in phrases a blue bell, a mad doctor, a black list ( A + N ),
the order of compounds of the type door-handle, day-time, spring-lock
( n + n ) resembles the order of words in nominal phrases with
attributive function of the first noun ( N + N ), e. g. spring time,
stone steps, peace movement.
(2) Compound words whose ICs
are joined together with a special linking-element — the linking vowels
[ou] and occasionally [i] and the linking consonant [s/z] — which is indicative
of composition as in, for example, speedometer, tragicomic, statesman.
Compounds of this type can be both nouns and adjectives, subordinative and
additive but are rather few in number since they are considerably restricted by
the nature of their components. The additive compound adjectives linked with
the help of the vowel [ou] are limited to the names of nationalities and
represent a specific group with a bound root for the first component, e. g. Sino-Japanese,
Afro-Asian, Anglo-Saxon.
In
subordinative adjectives and nouns the productive linking element is also [ou]
and compound words of the type are most productive for scientific terms. The
main peculiarity of compounds of the type is that their constituents are
nonassimilated bound roots borrowed mainly from classical languages, e. g. electro-dynamic,
filmography, technophobia, videophone, sociolinguistics, videodisc.
A small group
of compound nouns may also be joined with the help of linking consonant [s/z],
as in sportsman, landsman, saleswoman, bridesmaid. This small
group of words is restricted by the second component which is, as a rule, one
of the three bases man–, woman–, people–. The commonest of them is man–.
Compounds may be also
classified according to the nature of the bases and the interconnection with
other ways of word-formation into the so-called compounds proper and
derivational compounds.
Derivational compounds, e. g. long-legged,
three-cornered, a break-down, a pickpocket differ from compounds
proper in the nature of bases and their second IC. The two ICs of the compound
long-legged — ‘having long legs’ — are the suffix –ed meaning
‘having’ and the base built on a free word-group long legs whose
member words lose their grammatical independence, and are reduced to a single
component of the word, a derivational base. Any other segmentation of such
words, say into long– and legged– is impossible because
firstly, adjectives like *legged do not exist in Modern English
and secondly, because it would contradict the lexical meaning of these words.
The derivational adjectival suffix –ed converts this newly formed base into a
word. It can be graphically represented as long legs à [ (long–leg) + –ed]
à long–legged. The suffix –ed becomes the grammatically and
semantically dominant component of the word, its head-member. It imparts its
part-of-speech meaning and its lexical meaning thus making an adjective that
may be semantically interpreted as ‘with (or having) what is denoted by the
motivating word-group’. Comparison of the pattern of compounds proper like baby-sitter,
pen-holder
[ n + ( v + –er ) ] with the pattern of
derivational compounds like long-legged [ (a + n) + –ed ] reveals
the difference: derivational compounds are formed by a derivational means, a
suffix in case if words of the long-legged type, which is applied
to a base that each time is formed anew on a free word-group and is not
recurrent in any other type if words. It follows that strictly speaking words
of this type should be treated as pseudo-compounds or as a special group of
derivatives. They are habitually referred to derivational compounds because of
the peculiarity of their derivational bases which are felt as built by composition,
i.e. by bringing together the stems of the member-words of a phrase which lose
their independence in the process. The word itself, e. g. long-legged,
is built by the application of the suffix, i.e. by derivation and thus may
be described as a suffixal derivative.
Derivational compounds or
pseudo-compounds are all subordinative and fall into two groups according to
the type of variable phrases that serve as their bases and the derivational
means used:
a)
derivational
compound adjectives formed with the help of the highly-productive adjectival suffix
–ed applied to bases built on attributive phrases of the A + N, Num + N,
N + N type, e. g. long legs, three corners, doll face. Accordingly
the derivational adjectives under discussion are built after the patterns [
(a + n ) + –ed], e. g. long-legged, flat-chested, broad-minded;
[ ( пит + n) + –ed], e. g. two-sided,
three-cornered; [ (n + n ) + –ed], e. g. doll-faced,
heart-shaped.
b) derivational compound nouns formed mainly by conversion applied
to bases built on three types of variable phrases — verb-adverb phrase,
verbal-nominal and attributive phrases.
The commonest type of
phrases that serves as derivational bases for this group of derivational
compounds is the V + Adv type of word-groups as in, for instance, a
breakdown, a breakthrough, a castaway, a layout. Semantically derivational
compound nouns form lexical groups typical of conversion, such as an act
or instance of the action, e. g. a holdup — ‘a
delay in traffic’’ from to hold up — ‘delay, stop by use of force’; a
result of the action, e. g. a breakdown — ‘a failure in machinery
that causes work to stop’ from to break down — ‘become disabled’;
an active agent or recipient of the action, e. g. cast-offs
— ‘clothes that he owner will not wear again’ from to cast off — ‘throw
away as unwanted’; a show-off — ‘a person who shows off’ from to show
off — ‘make a display of one’s abilities in order to impress people’.
Derivational compounds of this group are spelt generally solidly or with a
hyphen and often retain a level stress. Semantically they are motivated by
transparent derivative relations with the motivating base built on the
so-called phrasal verb and are typical of the colloquial layer of vocabulary.
This type of derivational compound nouns is highly productive due to the
productivity of conversion.
The semantic subgroup of
derivational compound nouns denoting agents calls for special mention. There is
a group of such substantives built on an attributive and verbal-nominal type of
phrases. These nouns are semantically only partially motivated and are marked
by a heavy emotive charge or lack of motivation and often belong to terms as,
for example, a kill-joy, a wet-blanket — ‘one who kills enjoyment’; a turnkey
— ‘keeper of the keys in prison’; a sweet-tooth — ‘a person who
likes sweet food’; a red-breast — ‘a bird called the robin’. The
analysis of these nouns easily proves that they can only be understood as the
result of conversion for their second ICs cannot be understood as their
structural or semantic centres, these compounds belong to a grammatical and
lexical groups different from those their components do. These compounds are
all animate nouns whereas their second ICs belong to inanimate objects. The
meaning of the active agent is not found in either of the components but is
imparted as a result of conversion applied to the word-group which is thus
turned into a derivational base.
These compound nouns are
often referred to in linguistic literature as «bahuvrihi»
compounds or exocentric compounds, i.e. words whose semantic head is outside
the combination. It seems more correct to refer them to the same group of
derivational or pseudo-compounds as the above cited groups.
This small group of
derivational nouns is of a restricted productivity, its heavy constraint lies
in its idiomaticity and hence its stylistic and emotive colouring.
The linguistic analysis
of extensive language data proves that there exists a regular correlation
between the system of free phrases and all types of subordinative (and
additive) compounds[26].
Correlation embraces both the structure and the meaning of compound words, it
underlies the entire system of productive present-day English composition
conditioning the derivational patterns and lexical types of compounds.
[1]
Randolph Quirk, Ian Svortik. Investigating Linguistic Acceptability.
Walter de Gruyter. Inc., 1966. P. 127-128.
[2]
Robins, R. H. A short history of linguistics. London: Longmans, 1967. P.
183.
[3]
Henry Sweet, History of Language. Folcroft Library Editions,1876. P.
471.
[4]
Zellig S. Harris, Structural Linguistics. University of Chicago Press,
1951. P. 255.
[5]
Leonard Bloomfield, Language. New York, 1933
[6]
Noam Avram Chomsky, Syntactic Structures. Berlin, 1957.
[7]
Ibidem, p. 15.
[8]
Ibidem, p. 4.
[9]
Ibidem, p. 11.
[10]
Ibidem, p. 10.
[11]
Jukka Pennanen, Aspects of Finnish Grammar. Pohjoinen, 1972. P. 293.
[12]
K. Zimmer, Levels of Linguistic Description. Chicago, 1964. P. 18.
[13]
A. Ross Eckler’s letters to Daria Abrossimova, 2001.
[14]
Kucera, H. & Francis, W. N. Computational analysis of present-day
American English. University Press of New England, 1967.
[15] Webster’s Encyclopedic Unabridged Dictionary of the English
Language. Random House Value Pub. 1996.
[16]
A. Ross Eckler’s letters to Daria Abrossimova, 2001.
[17]
Dmitri Borgmann. Beyond Language. Charles Scribner’s Sons. 1965.
[18] The Times Atlas of the World. Times Books. 1994.
[19] Rand McNally Commercial Atlas and Marketing Guide. Rand
McNally & Co. 2000.
[20]
Prof. Smirnitsky calls them “potential words” in his book on English Lexicology
(p. 18).
[21] Ginzburg R. A Course in Modern
English Lexicology. Moscow, 1979. P. 113.
[22]
Ibidem. P. 114-115.
[23] Marchand H. Studies in Syntax and Word-Formation. Munich, 1974.
[24] Ginzburg R. A Course in Modern
English Lexicology. Moscow, 1979. P. 115.
[25]
The spelling is given according to Webster’s New Collegiate Dictionary,
1956 and H.C. Wyld. The Universal English Dictionary, 1952.
[26]
Prof. A. I. Smirnitsky as far back as the late forties pointed out the rigid
parallelism existing between free word-groups and derivational compound
adjectives which he termed “grammatical compounds”.
According to Смирницкий, word-formation is the system of derivative types of words and the process of creating new words from the material available in the language. Words are formed after certain structural and semantic patterns. The main two types of word-formation are: word-derivation and word-composition(compounding).
The degree of productivity of word-formation and factors that favor it make an important aspect of synchronic description of every derivational pattern within the two types of word-formation. The two general restrictions imposed on the derivational patterns are: 1. the part of speech in which the pattern functions; 2. the meaning which is attached to it.
Three degrees of productivity are distinguished for derivational patterns and individual derivational affixes: highly productive, productive or semi-productive and non-productive.
Productivity of derivational patterns and affixes shouldn’t be identified with frequency of occurrence in speech (e.g.-er — worker, -ful – beautiful are active suffixes because they are very frequently used. But if -er is productive, it is actively used to form new words, while -ful is non-productive since no new words are built).
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ № 6
Morphological, phonetical and semantic motivation
A new meaning of a word is always motivated. Motivation — is the connection between the form of the word (i.e. its phonetic, morphological composition and structural pattern) and its meaning. Therefore a word may be motivated phonetically, morphologically and semantically.
Phoneticallymotivated words are not numerous. They imitate the sounds (e.g. crash, buzz, ring). Or sometimes they imitate quick movement (e.g. rain, swing).
Morphologicalmotivation is expressed through the relationship of morphemes => all one-morpheme words aren’t motivated. The words like «matter» are called non-motivated or idiomatic while the words like «cranberry» are partially motivated because structurally they are transparent, but «cran» is devoid of lexical meaning; «berry» has its lexical meaning.
Semantic motivation is the relationship between the direct meaning of the word and other co-existing meanings or lexico-semantic variants within the semantic structure of a polysemantic word (e.g. «root»— «roots of evil» — motivated by its direct meaning, «the fruits of peace» — is the result).
Motivation is a historical category and it may fade or completely disappear in the course of years.
Classification of compounds
The meaning of a compound word is made up of two components: structural meaning of a compound and lexical meaning of its constituents.
Compound words can be classified according to different principles.
1. According to the relations between the ICs compound words fall into two classes: 1) coordinative compounds and 2) subordinative compounds.
In coordinative compounds the two ICs are semantically equally important. The coordinative compounds fall into three groups:
a) reduplicative compounds which are made up by the repetition of the same base, e.g. pooh-pooh (пренебрегать), fifty-fifty;
b) compounds formed by joining the phonically variated rhythmic twin forms, e.g. chit-chat, zig-zag (with the same initial consonants but different vowels); walkie-talkie (рация), clap-trap (чепуха) (with different initial consonants but the same vowels);
c) additive compounds which are built on stems of the independently functioning words of the same part of speech, e.g. actor-manager, queen-bee.
In subordinative compounds the components are neither structurally nor semantically equal in importance but are based on the domination of the head-member which is, as a rule, the second IС, e.g. stone-deaf, age-long. The second IС preconditions the part-of-speech meaning of the whole compound.
2.
According to the part of speech compounds represent they fall into:
1) compound nouns, e.g. sunbeam, maidservant;
2) compound adjectives, e.g. heart-free, far-reaching;
3) compound pronouns, e.g. somebody, nothing;
4) compound adverbs, e.g. nowhere, inside;
5) compound verbs, e.g. to offset, to bypass, to mass-produce.
From the diachronic point of view many compound verbs of the present-day language are treated not as compound verbs proper but as polymorphic verbs of secondary derivation. They are termed pseudo-compounds and are represented by two groups: a) verbs formed by means of conversion from the stems of compound nouns, e.g. to spotlight (from spotlight); b) verbs formed by back-derivation from the stems of compound nouns, e.g. to babysit (from baby-sitter).
However synchronically compound verbs correspond to the definition of a compound as a word consisting of two free stems and functioning in the sentence as a separate lexical unit. Thus, it seems logical to consider such words as compounds by right of their structure.
3. According to the means of composition compound words are classified into:
1) compounds composed without connecting elements, e.g. heartache, dog-house;
2)compounds composed with the help of a vowel or a consonant as a linking element, e.g. handicraft, speedometer, statesman;
3) compounds composed with the help of linking elements represented by preposition or conjunction stems, e.g. son-in-law, pepper-and-salt.
4. According to the type of bases that form compounds the following classes can be singled out:
1) compounds proper that are formed by joining together bases built on the stems or on the word-forms with or without a linking element, e.g. door-step, street-fighting;
2) derivational compounds that are formed by joining affixes to the bases built on the word-groups or by converting the bases built on the word-groups into other parts of speech, e.g. long-legged —> (long legs) + -ed; a turnkey —> (to turn key) + conversion. Thus, derivational compounds fall into two groups: a) derivational compounds mainly formed with the help of the suffixes -ed and -er applied to bases built, as a rule, on attributive phrases, e.g. narrow-minded, doll-faced, lefthander; b) derivational compounds formed by conversion applied to bases built, as a rule, on three types of phrases — verbal-adverbial phrases (a breakdown), verbal-nominal phrases (a kill-joy) and attributive phrases (a sweet-tooth).
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ № 7
Diachronic and synchronic approaches to polysemy
Diachronically, polysemy is understood as the growth and development of the semantic structure of the word. Historically we differentiate between the primary and secondary meanings of words.
The relation between these meanings isn’t only the one of order of appearance but it is also the relation of dependence = > we can say that secondary meaning is always the derived meaning (e.g. dog – 1. animal, 2. despicable person)
Synchronically it is possible to distinguish between major meaning of the word and its minor meanings. However it is often hard to grade individual meaning of the word in order of their comparative value (e.g. to get the letter — получить письмо; to get to London — прибыть в Лондон — minor).
The only more or less objective criterion in this case is the frequency of occurrence in speech (e.g. table – 1. furniture, 2. food). The semantic structure is never static and the primary meaning of a word may become synchronically one of the minor meanings and vice versa. Stylistic factors should always be taken into consideration
Polysemy of words: «yellow»- sensational (Am., sl.)
The meaning which has the highest frequency is the one representative of the whole semantic structure of the word. The Russian equivalent of «a table» which first comes to your mind and when you hear this word is ‘cтол» in the meaning «a piece of furniture». And words that correspond in their major meanings in two different languages are referred to as correlated words though their semantic structures may be different.
Primary meaning — historically first.
Major meaning — the most frequently used meaning of the word synchronically.
10.1. The morphological structure of English words.
10.2. Definition of word-formation. Synchronic and diachronic approaches to word formation.
10.3. Main units of word-formation. Derivational analysis.
10.4. Ways of word-formation.
10.5. Functional approach to word-formation.
10.6. The communicative aspect of word-formation.
10.1. Structurally, words are divisible into smaller units which are called morphemes. Morphemes are the smallest indivisible two-facet (significant) units. A morpheme exists only as a constituent part of the word.
One morpheme may have different phonemic shapes, i.e. it is represented by allomorphs (its variants),
e.g. in please, pleasure, pleasant [pli: z], [ple3-], [plez-] are allomorphs of one morpheme.
Semantically, all morphemes are classified into roots and affixes. The root is the lexical centre of the word, its basic part; it has an individual lexical meaning,
e.g. in help, helper, helpful, helpless, helping, unhelpful — help- is the root.
Affixes are used to build stems; they are classified into prefixes and suffixes; there are also infixes. A prefix precedes the root, a suffix follows it; an infix is inserted in the body of the word,
e.g. prefixes: re -think, mis -take, dis -cover, over -eat, ex -wife;
suffixes: danger- ous, familiar- ize, kind- ness, swea- ty etc.
Structurally, morphemes fall into: free morphemes, bound morphemes, semi-bound (semi-free) morphemes.
A free morpheme is one that coincides with a stem or a word-form. A great many root-morphemes are free,
e.g. in friendship the root -friend — is free as it coincides with a word-form of the noun friend.
A bound morpheme occurs only as a part of a word. All affixes are bound morphemes because they always make part of a word,
e.g. in friendship the suffix -ship is a bound morpheme.
Some root morphemes are also bound as they always occur in combination with other roots and/or affixes,
e.g. in conceive, receive, perceive — ceive — is a bound root.
To this group belong so-called combining forms, root morphemes of Greek and Latin origin,
e.g. tele -, mega, — logy, micro -, — phone: telephone, microphone, telegraph, etc.
Semi-bound morphemes are those that can function both as a free root morpheme and as an affix (sometimes with a change of sound form and/or meaning),
e.g. proof, a. » giving or having protection against smth harmful or unwanted» (a free root morpheme): proof against weather;
-proof (in adjectives) » treated or made so as not to be harmed by or so as to give protection against» (a semi-bound morpheme): bulletproof, ovenproof, dustproof, etc.
Morphemic analysis aims at determining the morphemic (morphological) structure of a word, i.e. the aim is to split the word into morphemes and state their number, types and the pattern of arrangement. The basic unit of morphemic analysis is the morpheme.
In segmenting words into morphemes, we use the method of Immediate and Unltimate Constituents. At each stage of the analysis, a word is broken down into two meaningful parts (ICs, i.e. Immediate Constituents). At the next stage, each IC is broken down into two smaller meaningful elements. The analysis is completed when we get indivisible constituents, i.e. Ultimate Constituents, or morphs, which represent morphemes in concrete words,
e.g. 
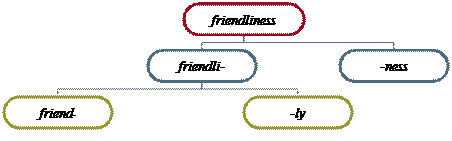
Friend-, -ly, -ness are indivisible into smaller meaningful units, so they are Ultimate Constituents (morphs) and the word friendliness consists of 3 morphemes: friend-+-li+-ness.
There are two structural types of words at the morphemic level of analysis: monomorphic (non-segmentable, indivisible) and polymorphic words (segmentable, divisible). The former consist only of a root morpheme, e.g. cat, give, soon, blue, oh, three. The latter consist of two or more morphemes, e.g. disagreeableness is a polymorphic word which consists of four morphemes, one root and three affixes: dis- + -agree- + -able + -ness. The morphemic structure is Pr + R + Sf1 + Sf2.
10.2. Word-Formation (W-F) is building words from available linguistic material after certain structural and semantic patterns. It is also a branch of lexicology that studies the process of building words as well as the derivative structure of words, the patterns on which they are built and derivational relations between words.
Synchronically, linguists study the system of W-F at a given time; diachronically, they are concerned with the history of W-F, and the history of building concrete words. The results of the synchronic and the diachronic analysis may not always coincide,
e.g. historically, to beg was derived from beggar, but synchronically the noun beggar is considered derived from the verb after the pattern v + -er/-ar → N, as the noun is structurally and semantically more complex. Cf. also: peddle- ← -pedlar/peddler, lie ← liar.
10.3. The aim of derivational analysis is to determine the derivational structure of a word, i.e. to state the derivational pattern after which it is built and the derivational base (the source of derivation).
Traditionally, the basic units of derivational analysis are: the derived word (the derivative), the derivational base, the derivational pattern, the derivational affix.
The derivational base is the source of a derived word, i.e. a stem, a word-form, a word-group (sometimes even a sentence) which motivates the derivative semantically and on which the latter is based structurally,
e.g. in dutifully the base is dutiful-, which is a stem;
in unsmiling it is the word-form smiling (participle I);
in blue-eyed it is the word-group blue eye.
In affixation, derivational affixes are added to derivational bases to build new words, i.e. derivatives. They repattern the bases, changing them structurally and semantically. They also mark derivational relations between words,
e.g. in encouragement en- and -ment are derivational affixes: a prefix and a suffix; they are used to build the word encouragement: (en- + courage) + -ment.
They also mark the derivational relations between courage and encourage, encourage and encouragement.
A derivational pattern is a scheme (a formula) describing the structure of derived words already existing in the language and after which new words may be built,
e.g. the pattern of friendliness is a+ -ness- → N, i.e. an adjective stem + the noun-forming suffix -ness.
Derivationally, all words fall into two classes: simple (non-derived) words and derivatives. Simple words are those that are non-motivated semantically and independent of other linguistic units structurally, e.g. boy, run, quiet, receive, etc. Derived words are motivated structurally and semantically by other linguistic units, e.g. to spam, spamming, spammer, anti-spamming are motivated by spam.
Each derived word is characterized by a certain derivational structure. In traditional linguistics, the derivational structure is viewed as a binary entity, reflecting the relationship between derivational bases and derivatives and consisting of a stem and a derivational affix,
e.g. the structure of nationalization is nationaliz- + -ation
(described by the formula, or pattern v + -ation → N).
But there is a different point of view. In modern W-F, the derivational structure of a word is defined as a finite set of derivational steps necessary to produce (build) the derived word,
e.g. [(nation + -al) + — ize ] + -ation.
To describe derivational structures and derivational relations, it is convenient to use the relator language and a system of oriented graphs. In this language, a word is generated by joining relators to the amorphous root O. Thus, R1O describes the structure of a simple verb (cut, permiate); R2O shows the structure of a simple noun (friend, nation); R3O is a simple adjective (small, gregarious) and R4O is a simple adverb (then, late).
e.g. The derivational structure of nationalization is described by the R-formula R2R1R3R2O; the R-formula of unemployment is R2R2R1O (employ → employment → unemployment).
In oriented graphs, a branch slanting left and down » /» correspond to R1; a vertical branch » I» corresponds to R2; a branch slanting right and down » » to R3, and a horizontal right branch to R4.
 Thus we can show the derivational structure of unemployment like this:
Thus we can show the derivational structure of unemployment like this:
and dutifulness like this:
Words whose derivational structures can be described by one R-formula are called monostructural, e.g. dutifulness, encouragement; words whose derivational structures can be described by two (or more) R-formulas are polystructural,
e.g. disagreement R2R2R1O / R2R1R1O
(agree → disagree → disagreement R2R1R1O or
agree → agreement → disagreement R2R2R1O)
There are complex units of word-formation. They are derivational clusters and derivational sets.
A derivational cluster is a group of words that have the same root and are derivationally related. The structure of a cluster can be shown with the help of a graph,
 e.g. READ
e.g. READ
reread read
misreadreaderreadable
reading
readership ∙ unreadable
A derivational set is a group of words that are built after the same derivational pattern,
e.g. n + -ish → A: mulish, dollish, apish, bookish, wolfish, etc,
Table TWO TYPES OF STRUCTURAL ANALYSIS
| MORPHEMIC ANALYSIS | DERIVATIONAL ANALYSIS | |
| AIM | to find out the morphemic structure (composition) | to determine the derivational structure |
| BASIC UNITS | morphemes (roots and affixes) | derived word, derivational pattern, derivational base, derivational step, derivational means (e.g. affix) |
| RESULTS: CLASSES OF WORDS | monomorphic (non-segmentable) and polymorphic (segmentable) words | simple and derived words |
| EXAMPLES | 1. cut, v. and cut, n. are monomorphic (root) words | 1. cut, v. is a simple word (R1O); cut, n. is derived from it (R2R1O) |
| 2. encouragement, unemployment consist of three morphemes and have the same morphemic composition: Pr + R + Sf | 2. encouragement and unemployment have different derivational structures: v + -ment → N (R2R1R2O) and un- + n → N (R2R2R1O) |
10.4. Traditionally, the following ways of W-F are distinguished:
affixation, compounding, conversion, shortening, blending, back-formation. Sound interchange, sound imitation, distinctive stress, lexicalization, coinage certainly do not belong to word-formation as no derivational patterns are used.
Affixation is formation of words by adding derivational affixes to derivational bases. Affixation is devided into prefixation and suffixation,
e.g. the following prefixes and suffixes are used to build words with negative or opposite meanings: un-, non-, a-, contra-, counter-, de-, dis-, in-, mis-, -less, e.g. non-toxic.
Compounding is building words by combining two (or more) derivational bases (stems or word-forms),
e.g. big -ticket (= expensive), fifty-fifty, laid-back, statesman.
Among compounds, we distinguish derivational compounds, formed by adding a derivational affix (usu. a suffix) to a word group,
e.g. heart-shaped (= shaped like a heart), stone-cutter (= one who cuts stone).
Conversion consists in making a word from some existing word by transferring it into another part of speech. The new word acquires a new paradigm; the sound form and the morphimic composition remain unchanged. The most productive conversion patterns are n → V (i.e. formation of verbs from noun-stems), v → N (formation of nouns from verb stems), a → V (formation of verbs from adjective stems),
e.g. a drink, a do, a go, a swim: Have another try.
to face, to nose, to paper, to mother, to ape;
to cool, to pale, to rough, to black, to yellow, etc.
Nouns and verbs can be converted from other parts of speech, too, for example, adverbs: to down, to out, to up; ifs and buts.
Shortening consists in substituting a part for a whole. Shortening may result in building new lexical items (i.e. lexical shortenings) and so-called graphic abbreviations, which are not words but signs representing words in written speech; in reading, they are substituted by the words they stand for,
e.g. Dr = doctor, St = street, saint, Oct = 0ctober, etc.
Lexical shortenings are produced in two ways:
(1) clipping, i.e. a new word is made from a syllable (or two syllables) of the original word,
e.g. back-clippings: pro ← professional, chimp ← chimpanzee,
fore-clippings: copter ← helicopter, gator ← alligator,
fore-and-aft clippings: duct ← deduction, tec ← detective,
(2) abbreviation, i.e. a new word is made from the initial letters of the original word or word-group. Abbreviations are devided into letter-based initialisms (FBI ← the Federal Bureau of Investigation) and acronyms pronounced as root words (AIDS, NATO).
Blending is building new words, called blends, fusions, telescopic words, or portmanteau words, by merging (usu.irregular) fragments of two existing words,
e.g. biopic ← biography + picture, alcoholiday ← alcohol + holiday.
Back-formation is derivation of new words by subtracting a real or supposed affix (usu. a suffix) from existing words (on analogy with existing derivational pairs),
e.g. to enthuse ← enthusiasm, to intuit ← intuition.
Sound interchange and distinctive stress are not ways of word-formation. They are ways of distinguishing words or word forms,
e.g. food -feed, speech — speak, life — live;
‘ insult, n. — in ‘ sult, v., ‘ perfect, a. — per ‘ fect, v.
Sound interchange may be combined with affixation and/or the shift of stress,
e.g. strong — strength, wide — width.
10.5. Productivity and activity of derivational ways and means.
Productivity and activity in W-F are close but not identical. By productivity of derivational ways/types/patterns/means we mean ability to derive new words,
e.g. The suffix -er/ the pattern v + -er → N is highly productive.
By activity we mean the number of words derived with the help of a certain derivational means or after a derivational pattern,
e.g. — er is found in hundreds of words so it is active.
Sometimes productivity and activity go together, but they may not always do.
| DERIVATIONAL MEANS | EXAMPLE | PRODUCTIVITY | ACTIVITY |
| -ly | nicely | + | + |
| -ous | dangerous | _ | + |
| -th | breadth | _ | _ |
In modern English, the most productive way of W-P is affixation (suffixation more so than prefixation), then comes compounding, shortening takes third place, with conversion coming fourth.
Productivity may change historically. Some derivational means / patterns may be non-productive for centuries or decades, then become productive, then decline again,
e.g. In the late 19th c. US -ine was a popular feminine suffix on the analogy of heroine, forming such words as actorine, doctorine, speakerine. It is not productive or active now.
|
Практические расчеты на срез и смятие При изучении темы обратите внимание на основные расчетные предпосылки и условности расчета… |
Функция спроса населения на данный товар Функция спроса населения на данный товар: Qd=7-Р. Функция предложения: Qs= -5+2Р,где… |
Аальтернативная стоимость. Кривая производственных возможностей В экономике Буридании есть 100 ед. труда с производительностью 4 м ткани или 2 кг мяса… |
Вычисление основной дактилоскопической формулы Вычислением основной дактоформулы обычно занимается следователь. Для этого все десять пальцев разбиваются на пять пар… |




|
Билет №7 (1 вопрос) Язык как средство общения и форма существования национальной культуры. Русский литературный язык как нормированная и обработанная форма общенародного языка Важнейшая функция языка — коммуникативная функция, т.е. функция общения Язык представлен в двух своих разновидностях… Патристика и схоластика как этап в средневековой философии Основной задачей теологии является толкование Священного писания, доказательство существования Бога и формулировка догматов Церкви… Основные симптомы при заболеваниях органов кровообращения При болезнях органов кровообращения больные могут предъявлять различные жалобы: боли в области сердца и за грудиной, одышка, сердцебиение, перебои в сердце, удушье, отеки, цианоз головная боль, увеличение печени, слабость… |
Потенциометрия. Потенциометрическое определение рН растворов Потенциометрия — это электрохимический метод исследования и анализа веществ, основанный на зависимости равновесного электродного потенциала Е от активности (концентрации) определяемого вещества в исследуемом растворе… Гальванического элемента При контакте двух любых фаз на границе их раздела возникает двойной электрический слой (ДЭС), состоящий из равных по величине, но противоположных по знаку электрических зарядов… Сущность, виды и функции маркетинга персонала Перснал-маркетинг является новым понятием. В мировой практике маркетинга и управления персоналом он выделился в отдельное направление лишь в начале 90-х гг.XX века… |