
- Подробности
- Создано 13 Июль 2011
| Содержание |
|---|
| Описание примеров |
| Применение метода |
| Суммирование по одному ключевому полю |
| Суммирование по нескольким критериям |
| Поиск по одному критерию |
| Поиск по нескольким критериям |
| Выборка по одному критерию |
| Выборка вариантов |
| Заключение |
Одним из самых популярных методов использования электронных таблиц является обработка данных, полученных из учетных систем. Современные базы данных, используемые учетными системами в качестве хранилища информации, способны накапливать и обрабатывать в собственных структурах десятки, а иногда сотни тысяч информационных записей в день. Средства анализа в системах управления базами данных реализуются либо на программном уровне, либо через специальные интерфейсы и языки запросов. Электронные таблицы позволяют эффективно обработать данные без знания языков программирования и других технических средств.
Методы переноса данных в Excel могут быть различны:
- Копирование-вставка результатов запросов
- Использование стандартных процедур импорта (например, Microsoft Query) для формирования данных на рабочих листах
- Использование программных средств для доступа к базам данных с последующим переносом информации в диапазоны ячеек
- Непосредственный доступ к данным без копирования информации на рабочие листы
- Подключение к OLAP-кубам
Данные, полученные из учетных систем, обычно характеризуются большим объемом – количество строк может составлять десятки тысяч, количество столбцов при этом часто невелико, так как языки запросов к базам данным сами имеют ограничение на одновременно выводимое количество полей.
Обработка этих данных в Excel может вестись различными методами. Выделим основные способы работы:
- Обработка данных стандартными средствами интерфейса Excel
- Анализ данных при помощи сводных таблиц и диаграмм
- Консолидация данных при помощи формул рабочего листа
- Выборка данных и заполнение шаблонов для получения отчета
- Программная обработка данных
Правильность выбора способа работы с данными зависит от конкретной задачи. У каждого метода есть свои преимущества и недостатки.
В данной статье будут рассмотрены способы консолидации и выборки данных при помощи стандартных формул Excel.
Описание примеров
Примеры к статье построены на основе демонстрационной базы данных, которую можно скачать с сайта Microsoft
http://www.microsoft.com/download/en/details.aspx?displaylang=en&id=19704
Выгруженный из этой базы данных набор записей сформирован при помощи Microsoft Query.
Данные не несут специальной смысловой нагрузки и используются только в качества произвольного набора записей, имеющих несколько ключевых полей.

Файл nwdata_sums.xls используется для версий Excel 2000-2003
Файл nwdata_sums.xlsx имеет некоторые отличия и используется для версий Excel 2007-2010.
Первый лист data содержит исходные данные, остальные – примеры различных формул для обработки информации.
Ячейки, окрашенные в серый цвет, содержат служебные формулы. Ячейки желтого цвета содержат ключевые значения, которые могут быть изменены.
Применение метода
Очевидно, самым простым и удобным методом обработки больших объемов данных с точки зрения пользователя являются сводные таблицы. Этот интерфейс специально создавался для подобного рода задач, способен работать с различными источниками данных, поддерживает интерфейсные методы фильтрации, группировки, сортировки, а также автоматической агрегации данных различными способами.
Проблема при консолидации данных при помощи сводных таблиц появляются, если предполагается дальнейшая работа с этими агрегированными данными. Например, сравнить или дополнить данные из двух разных сводных таблиц (как вариант: объемы продаж и прайс листы). В таком случае обычно прибегают к методу копирования значений из сводных таблиц в промежуточные диапазоны с дальнейшим применением формул поиска (VLOOKUP/HLOOKUP). Очевидно, что проблема возникает при обновлении исходных данных (например, при добавлении новых строк) – требуется заново копировать результаты консолидации из сводной таблицы. Другим, с нашей точки зрения, не совсем корректным методом решения является применение функций поиска непосредственно к диапазонам, которые занимают сводные таблицы. Это может привести к неверному поиску при обновлении не только данных, но и внешнего вида сводной таблицы.
Еще один классический пример непригодности применения сводной таблицы – это требование формирования отчета в заранее предопределенном виде («начальство требует в такой форме и никак иначе»). Возможностей настройки сводной таблицы зачастую недостаточно для предоставления произвольной формы. В данном случае пользователи также обычно используют копирование результатов агрегирования в качестве значений.
Самым правильным методом обработки данных в приведенных случаях, с нашей точки зрения, является применение функций рабочего листа для консолидации данных. Этот метод требует иногда больших затрат времени на создание формул, но зато в дальнейшем при изменении исходных данных отчеты будут обновляться автоматически. Файлы примеров показывают различные варианты применения функция рабочего листа для обработки данных.
Суммирование по одному ключевому полю
Таблицы с формулами на листе SUM показывают вариант решения задачи консолидации данных по одному ключевому значению.

Две верхние таблицы на листе демонстрируют возможности стандартной функции SUMIF, которая как раз и предназначена для суммирования с проверкой одного критерия.
SUM!B5
=SUMIF(data!$H:$H;A5;data!$M:$M)
SUM!B11
=SUMIF(data!$Z:$Z;A11;data!$M:$M)
Нижние таблицы показывают возможности другой редко используемой функции DSUM
SUM!B19
=DSUM(data!$A$1:$AJ$2156;"Quantity";D18:D19)
Первый параметр определяет рабочий диапазон данных. Причем верхняя строка диапазона должна содержать заголовки полей. Второй параметр указывает наименование поля (столбца) для суммирования. Третий параметр ссылается на диапазон условий суммирования. Этот диапазон должен состоять как минимум из двух строк, верхняя строка – поле критерия, вторая и последующие — условия.
В другом варианте указания условий именем поля в этом диапазоне можно пренебречь, задав его прямо в тексте условия:
SUM!B28
=DSUM(data!$A$1:$AJ$2156;"Quantity";D27:D28)
SUM!D28
Здесь data!Z2 означает ссылку на текущую строку данных, а не на конкретную ячейку, так как используется относительная ссылка. К сожалению, нельзя указать в третьем параметры ссылку на одну ячейку – строка заголовка полей все равно требуется, хотя и может быть пустой.
В принципе, функции типа DSUM являются устаревшим методом работы с данными, в подавляющем большинстве случаев лучше использовать SUMIF, SUMPRODUCT или формулы обработки массивов. Но иногда их применение может дать хороший результат, например, при совместном использовании с интерфейсной возможностью «расширенный фильтр» – в обоих случаях используется одинаковое описание условий через дополнительные диапазоны.
Суммирование по нескольким критериям
Таблицы с формулами на листе SUM2 показывают вариант суммирования по нескольким критериям.

Первый вариант решения использует дополнительно подготовленный столбец обработанных исходных данных. В реальных задачах логичнее добавлять такой столбец с формулами непосредственно на лист данных.
SUM!D5
=SUMIF(A:A;B5 & ";" & C5;data!M:M)
Операция «&» используется для соединения строк. Можно также вместо этого оператора использовать функцию CONCATENATE. Промежуточный символ «;» (или любой другой служебный символ) необходим для обеспечения уникальности сцепленных строковых значений.
Пример: Есть, если два поля с перечнем слов. Пары слов «СТОЛ»-«ОСЬ» и «СТО»-«ЛОСЬ» дают одинаковый ключ «СТОЛОСЬ». Что соответственно даст неверный результат при консолидации данных. При использовании служебного символа комбинации ключей будут уникальны «СТОЛ;ОСЬ» и «СТО;ЛОСЬ», что обеспечит корректность вычислений.
Использовать подобную методику создания уникального ключа можно не только для строковых, но и для числовых целочисленных полей.
Второй пример – это популярный вариант использования функции SUMPRODUCT с проверкой условий в виде логического выражения:
SUM!D13
=SUMPRODUCT((data!$H$2:$H$3000=B13)*(data!$Z$2:$Z$3000=C13)*data!$M$2:$M$3000)
Обрабатываются все ячейки диапазона (data!$M$2:$M$3000), но для тех ячеек, где условия не выполняются, в суммирование попадает нулевое значение (логическая константа FALSE приводится к числу «0»). Такое использование этой функции близко по смыслу к формулам обработки массива, но не требует ввода через Ctrl+Shift+Enter.
Третий пример аналогичен, описанному использованию функций DSUM для листа SUM, но в нем для диапазона условий использовано несколько полей.
SUM!D21
=DSUM(data!$A$1:$AJ$2156;"Quantity";F20:G21)
Четвертый пример – это использование функций обработки массивов.
SUM!D32
{=SUM(IF(data!$H$2:$H$3000=B32;IF(data!$Z$2:$Z$3000=C32;data!$M$2:$M$3000)))}
Обработка массивов является самым гибким вариантом проверки условий. Но имеет очень сложную запись, трудно воспринимается пользователем и работает медленнее стандартных функций.
Пятый пример содержится только в файле формата Excel 2007 (xlsx). Он показывает возможности новой стандартной функции
SUMIFS
SUM!D40
=SUMIFS(data!$M$2:$M$3000;data!$H$2:$H$3000;B40;data!$Z$2:$Z$3000;C40)
Поиск по одному критерию
Таблицы с формулами на листе SEARCH предназначены для поиска по ключевому полю с выборкой другого поля в качестве результата.

Первый вариант – это использование популярной функции VLOOKUP.
SEARCH!B5
=VLOOKUP(A5;data!$H$1:$M$3000;6;0)
Во втором вариант использовать VLOOKUP нельзя, так как результирующее поле находится слева от искомого. В данном случае используется сочетание функций MATCH+OFFSET.
SEARCH!C13
=MATCH(A13;data!$Z$1:$Z$3000;0)
SEARCH!B13
=OFFSET(data!$M$1;C13-1;0)
Первая функция ищет нужную строку, вторая возвращает нужное значение через вычисляемую адресацию.
Поиск по нескольким критериям
Таблицы с формулами на листе SEARCH2 предназначены для поиска по нескольким ключевым полям.

В первом варианте используется техника использования служебного столбца, описанная в примере к листу SUM2:
SEARCH2!Е5
=VLOOKUP(C5 & ";" & D5;$A$1:$B$3000;2;0)
Второй вариант работы сложнее. Используется обработка массива, который образуется при помощи функций вычисляемой адресации:
SEARCH2!Е 12
{=OFFSET(data!$M$1;MATCH(C13 & ";" & D13; data!$H$1:$H$3000 & ";" & data!$Z$1:$Z$3000;0)-1;0)}
Четвертый и пятый параметр в функции OFFSET используется для образования массива и определяет его размерность в строках и столбцах.
Выборка по одному критерию
Таблица на листе SELECT показывает вариант фильтрации данных через формулы.

Предварительно определяется количество строк в выборке:
SELECT!С4
=COUNTIF(data!$H:$H;$A$5)
Служебный столбец содержит формулы для определения номеров строк для фильтра. Первая строка ищется через простую функцию:
SELECT!С5
=MATCH($A$5;data!$H$1:$H$3000;0)
Вторая и последующие строки ищутся в вычисляемом диапазоне с отступом от предыдущей найденной строки:
SELECT!С6
=MATCH($A$5;OFFSET(data!$H$1;C5;0; ROWS(data!$H$1:$H$3000)-C5;1);0)+C5
Результат выдается через функцию вычисляемой адресации:
SELECT!B6
=IF(ISNA(C6);"";OFFSET(data!$M$1;C6-1;0))
Вместо функции проверки наличия ошибки ISNA можно сравнивать текущую строку с максимальным количеством, так как это сделано в столбце A.
Для организации выборок при помощи формул необходимо знать максимально возможное количество строк в фильтре, чтобы создать в них формулы.
Выборка вариантов
Самый сложный вариант выборки по ключевому полю представлен на листе SELECT2. Формулы сами определяют все доступные ключевые значения второго критерия.

Первый служебный столбец содержит сцепленные строки ключевых полей. Второй столбец проверяет соответствие первому ключу и оставляет значение второго ключевого поля:
SELECT2!B2
=IF(LEFT(A2;LEN($D$5)) & ";" = $D$5 & ";"; data!Z2;"")
Третий служебный столбец проверяет значение второго ключа на уникальность:
SELECT2!C2
=IF(B2="";0;IF(ISNA(MATCH(B2;B$1:B1;0));COUNTIF(C$1:C1;">0")+1;0))
Результирующий столбец второго ключа ProductName ищет уникальные значения в служебном столбце C:
SELECT2!E5
=IF(ISNA(MATCH(ROWS($5:5);$C$1:$C$3000;0));"";OFFSET($B$1;MATCH(ROWS($5:5);$C$1:$C$3000;0)-1;0))
Столбец Quantity просто суммирует данные по двум критериям, используя технику, описанную на листе SUM2.
SELECT2!F5
=IF(E5="";"";SUMPRODUCT((data!$H$2:$H$3000=D5)*(data!$Z$2:$Z$3000=E5)*data!$M$2:$M$3000))
Заключение
Использование функций рабочего листа для консолидации и выборки данных является эффективным методом построения отчетов с обновляемым источником исходных данных. Недостатками этого метода являются повышенные требования к пользователю в части создания сложных формул, а также низкая производительность в сравнении, например, со сводными таблицами. Последний недостаток зависит от объема исходных данных, сложности формул консолидации и технических возможностей компьютера. В критических случаях рекомендуется использовать ручной режим пересчета формул рабочей книги Excel.
Смотри также
» Работа с ненормализированными данными
В приложении к статье файл с простой задачей суммирования диапазона по различным условиям. Как ни странно, подобные задачи…
» Простые формулы
В приложенном файле несколько примеров использования простых функций Excel нестандартным способом.
» Обработка больших объемов данных. Часть 3. Сводные таблицы
Третья статья, посвященная обработке больших объемов данных с помощью Excel, описывает преимущества использования сводных таблиц….
» Обработка больших объемов данных. Часть 2. Интерфейс
В статье систематизируются простые приемы обработки больших объемов данных при помощи стандартных методов интерфейса Excel. Информация…
» Суммирование несвязанных диапазонов
При обработке больших таблиц иногда возникает потребность получить итоговые значения на основе данных, расположенных в диапазонах…
Excel открывает большие возможности в обработке массива цифр и строк. Сегодня мы разберем, как в excel обработать большой объем данных. В этой части мы не будем разбирать макросы. Цель этой статьи — научиться работать с самыми доступными и простыми формулами excel, которые помогут выполнить нашу работу в большинстве случаев.
Статья будет разделена на 2 части. Содержание первой части, представлена ниже. Начнем без теории. Вряд ли она вам интересна.
Содержание:
- Как в excel найти повторяющееся значение
- Как в excel быстро удалить дублирующиеся строки
- Работа со сводной таблицей в excel
- Как в excel «подтянуть» данные из другого листа или файла
- Что такое функции правсимв и левсимв и как их применять
Как в excel найти повторяющееся значение
В своде данных мы можем столкнуться с проблемой, когда нам нужно из большого количества строк быстро найти повторяющиеся строки. Ведь в одной строке может быть одно значение, а во второй, по такому же наименованию товара, дубль или другое значение.
Возьмем таблицу. В столбец Е ставим равно и затем, в поиске «Другие функции» ищем нужную нам формулу (см. рис 1)
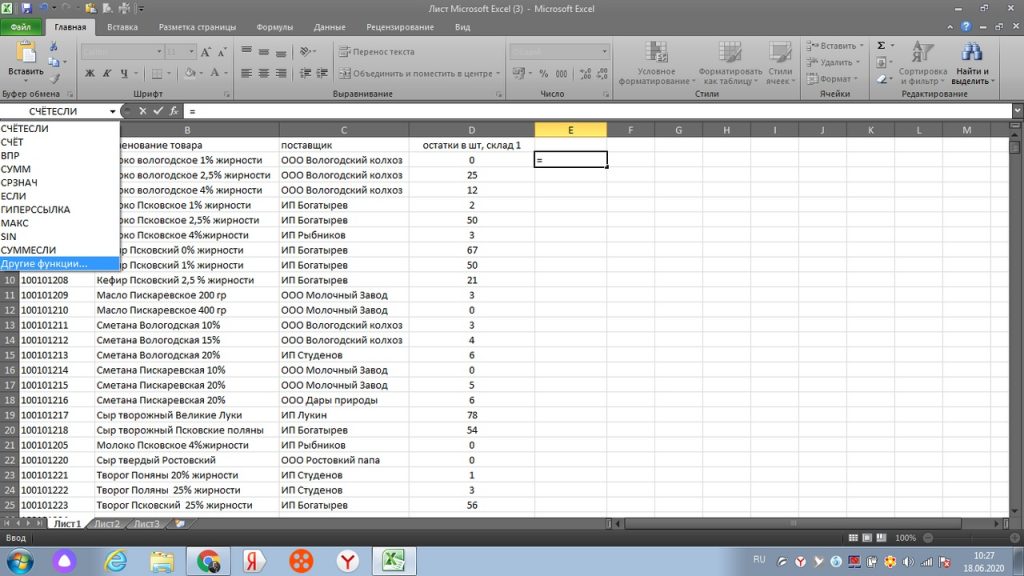
Для поиска повторяющегося значения, в данном случае, в коде товара по столбцу А, мы будем пользоваться простой формулой = СЧЕТЕСЛИ
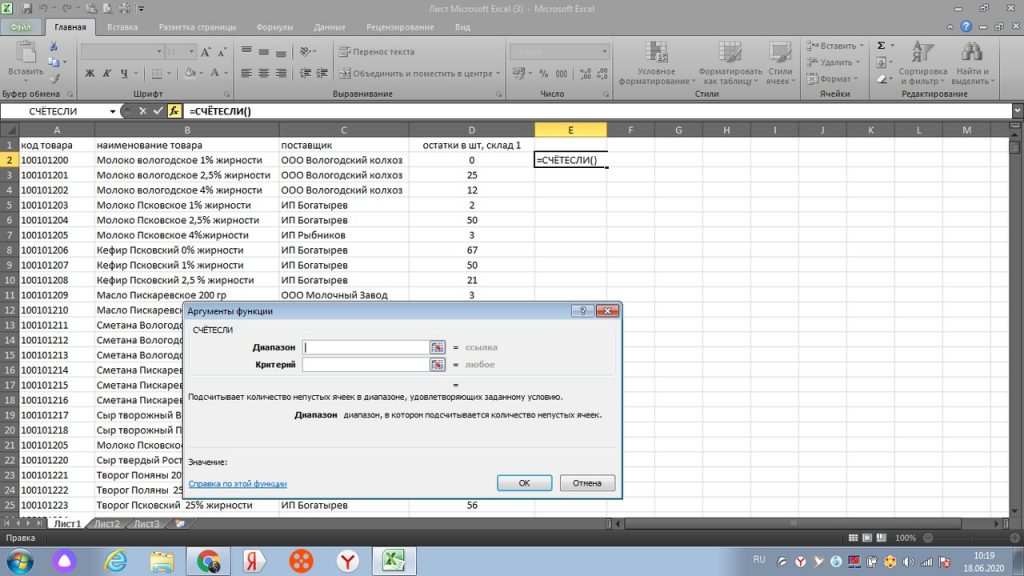
Выделяем весь столбец «А», и в диапазоне аргументов функций ( маленькое голубое окошко посреди экрана), у нас появляется А:А, то есть весь выделенный диапазон по этому столбцу. см. рис 3.
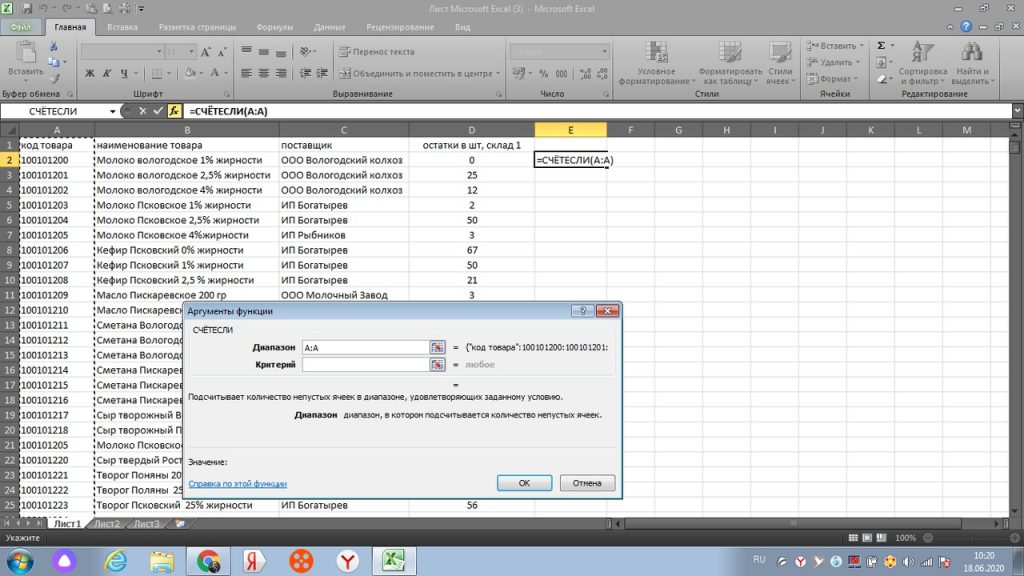
Переходим в окно «критерий», и выделяем только первую строку по коду товара. У нас она отразится, как А2. см. рис. 3.
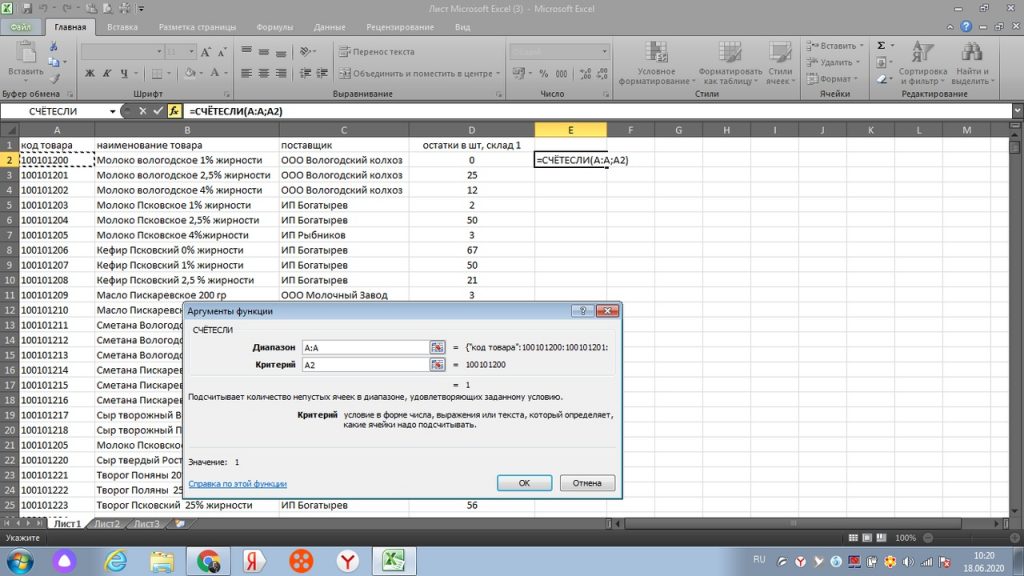
Далее, нажимаем «ок», и в столбце «Е» появляется цифра 1. Это значит, что по товару 100101200 Молоко Вологодское 1% жирности, только один такой товар, нет дублей. См. рис 5.
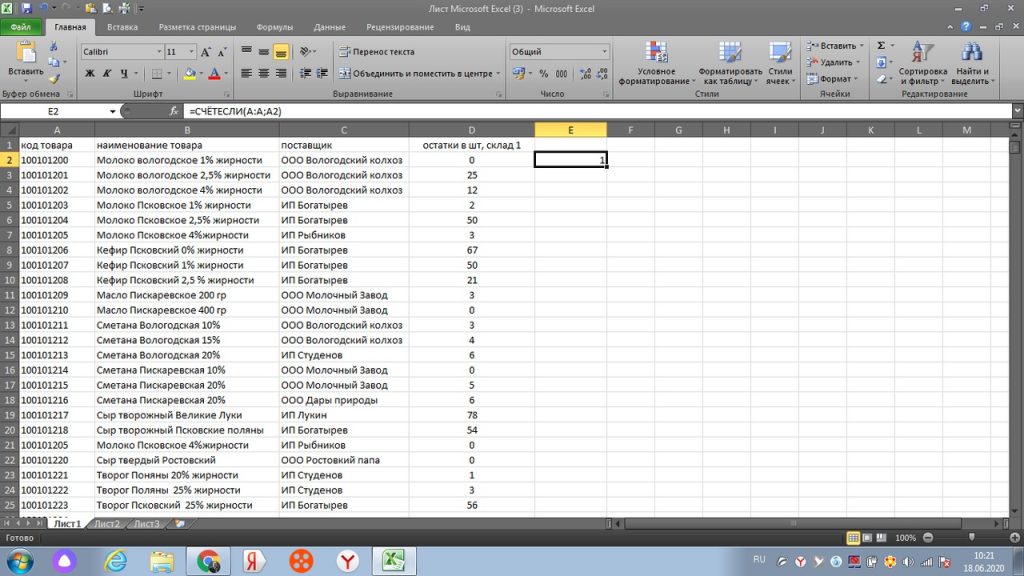
«Протягиваем» значения по столбцу «Е» вниз, и мы получаем результат, а именно, какие товары у нас имеют дубль в нашем списке, см рис 6. У нас проявилось 2 одинаковых товара, (их excel обозначил цифрой 2), которые, для наглядности вручную выделил желтым.
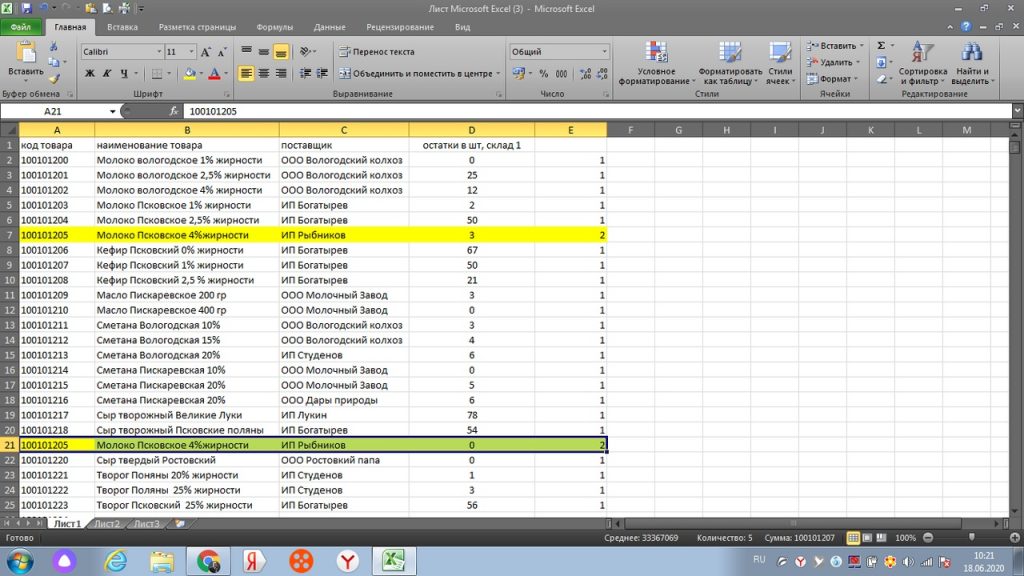
Если бы у нас было три одинаковых товара в списке, то excel, соответственно, проставил цифру 3. И так далее. Уже через простой фильтр, можно выделить, все, что больше 1 и увидеть полную картину.
Как в excel удалить дублирующиеся строки
По сути, метод, указанный выше, уже выполняет наш запрос. Однако, если Вам не нужны данные с повторяющихся строк, а требуется просто их удалить, тогда есть наиболее простой способ быстрого удаления дублей.
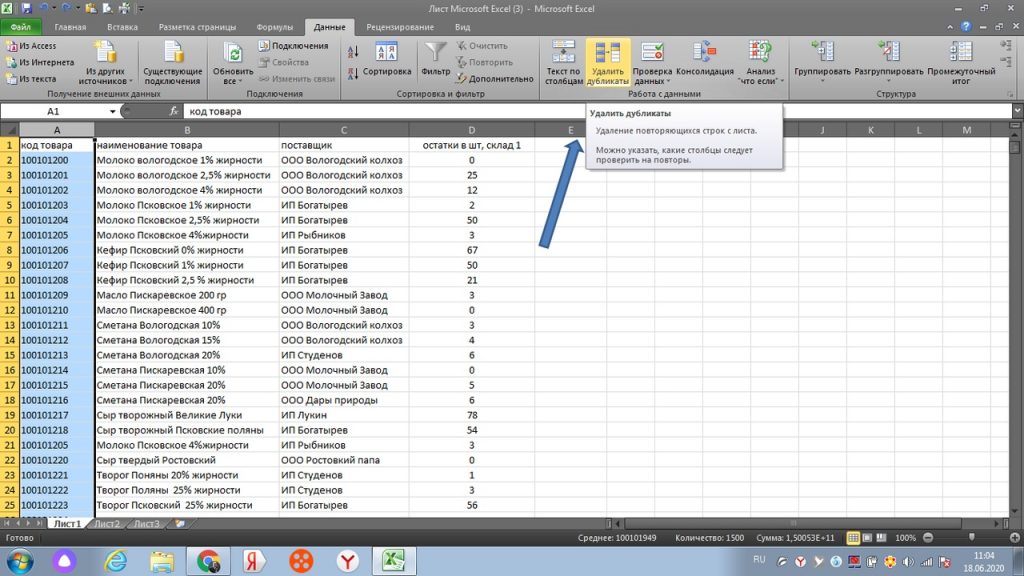
Мы воспользуемся функцией, которая уже встроена в панель excel. См. на панели закладку » ДАННЫЕ». Наша функция так и называется «Удалить дубликаты».
Мы выделяем область поиска, у нас это вновь столбец А. См рис 7.
(В более поздней версии excel, можно все находить через поисковое окно.)
Далее нам просто нужно подтвердить удаление. Однако, для наглядности, выделил зеленым те задвоенные строки, которые у нас есть. Это строка 7 и 21. См рис 8.
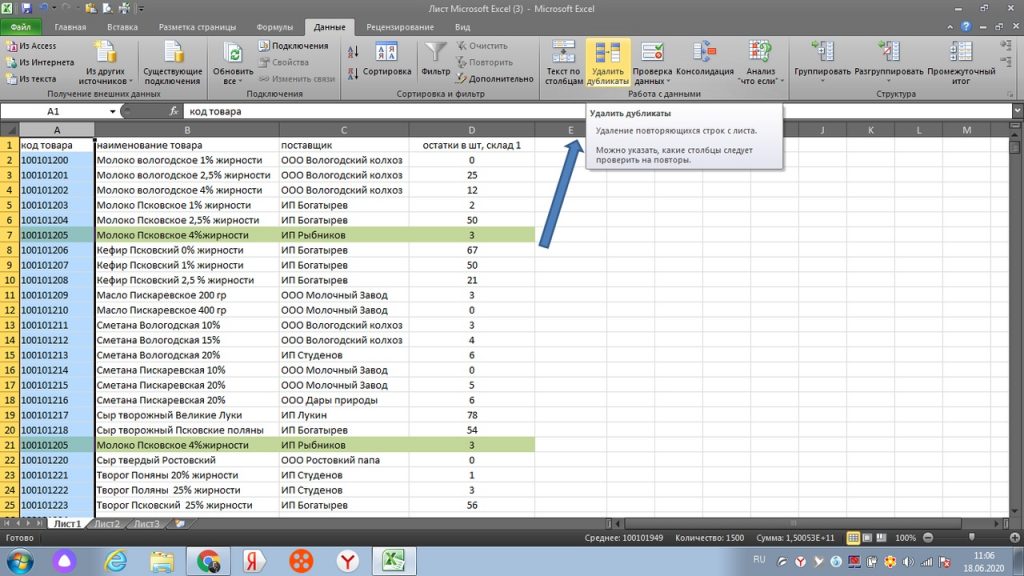
Теперь на панели жмем кнопку «удалить дубликаты». У нас появляется окошко. Здесь нам автоматически предлагает удалить всю горизонтальную строку, то есть «автоматически расширить выделенный диапазон». Жмем на кнопку «удалить дубликаты». См рис 9
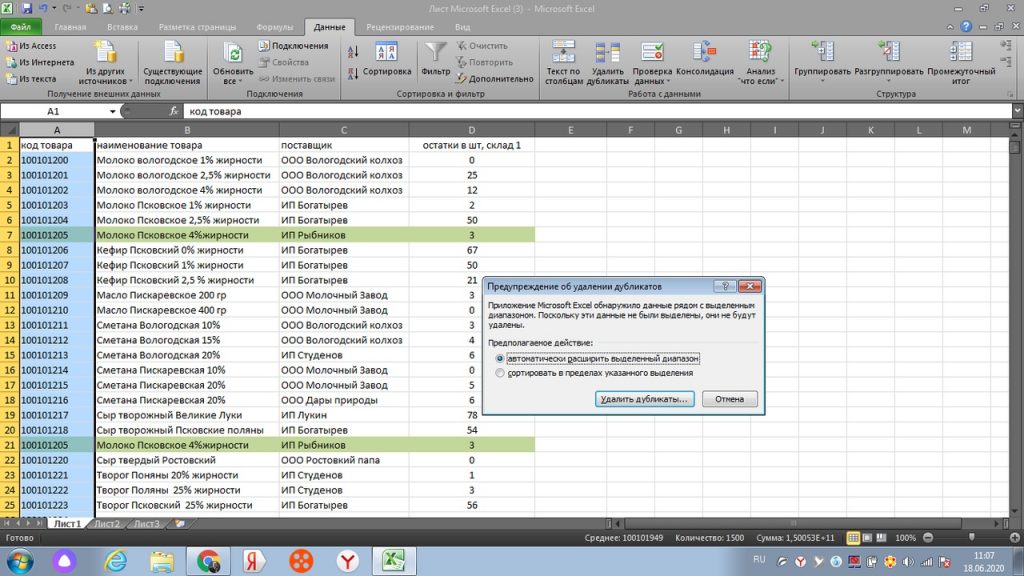
После этого мы видим, что указаны столбцы отмеченные галочками, которые будут удалены по дублирующейся горизонтальной строке. См. рис 10. Мы жмем «ок».
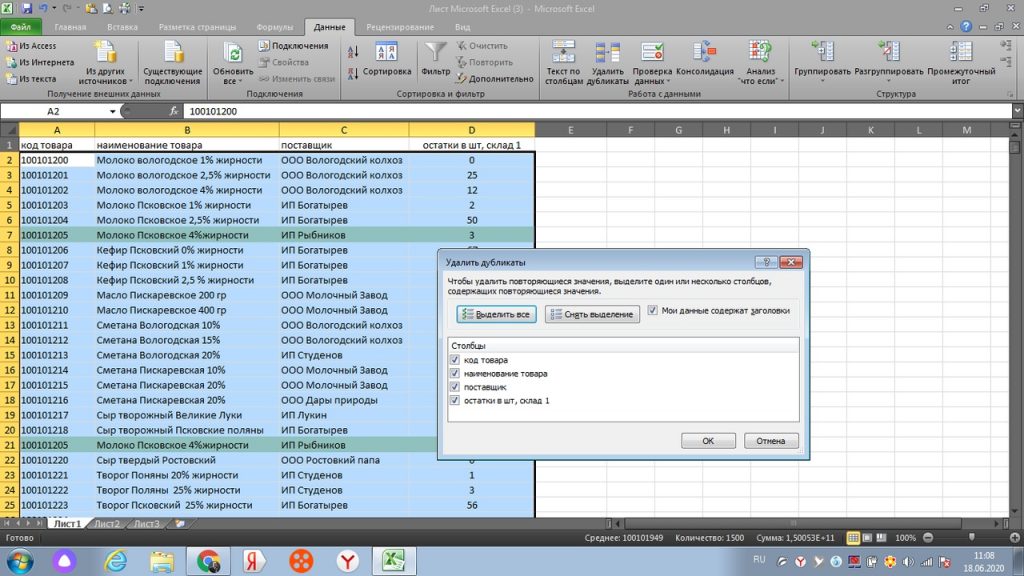
Все. Теперь мы видим окно с оповещением, что дубль в количестве 1 строки был удален. Теперь, на месте 21-ой строки по товару-дублю, появился следующий товар из нижнего списка. См. рис 11.
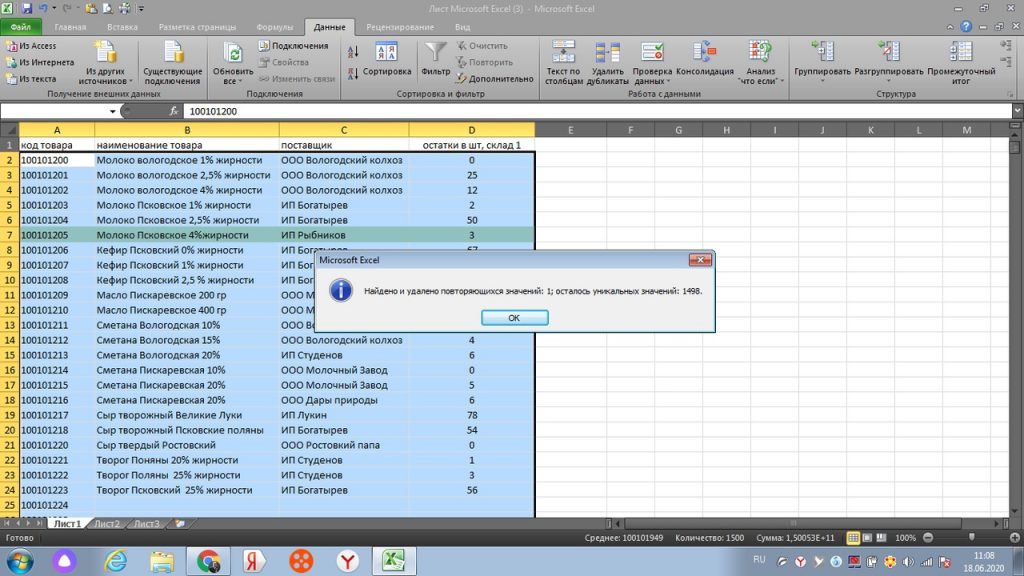
Исходя из описания, может показаться, что по времени занимает не меньше, чем в первом варианте, но на самом деле это не так. Я просто эту функцию расписал очень подробно.
Как в excel обработать большой объем данных, сводная таблица
Сводная таблица служит для объединения разрозненной информации воедино. Сегодня мы также научимся это делать. Здесь нет ничего сложного. К примеру нам требуется, сколько же у нас есть одного и того же товара, не по брендам, а по виду товара.
Смотрим нашу таблицу. В панели инструментов ищем закладку «ВСТАВКА». Под панелью инструментов, в верхнем левом углу, появляется иконка, которая так и называется «Сводная таблица». см. рис 12. (Или ищем ее в поиске новой версии excel)
Мы выделяем все столбцы или столбцы интересующих нас значений.
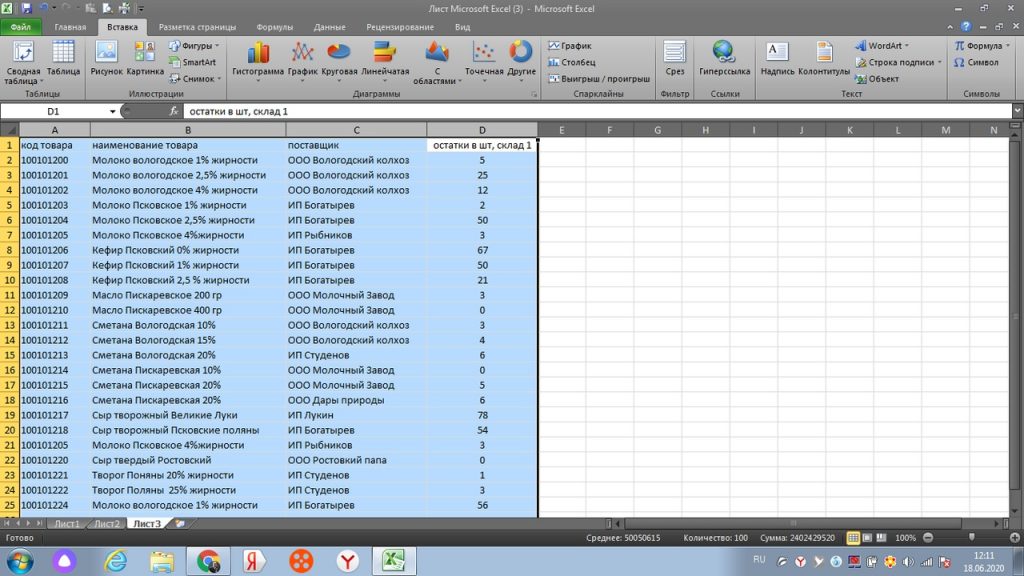
Затем нажимаем на иконку «сводная таблица». У нас выходит окошко, в котором выделен диапазон столбцов. По умолчанию, excel предлагает сводную таблицу вынести на новый лист. см. рис 13. Мы так и делаем.
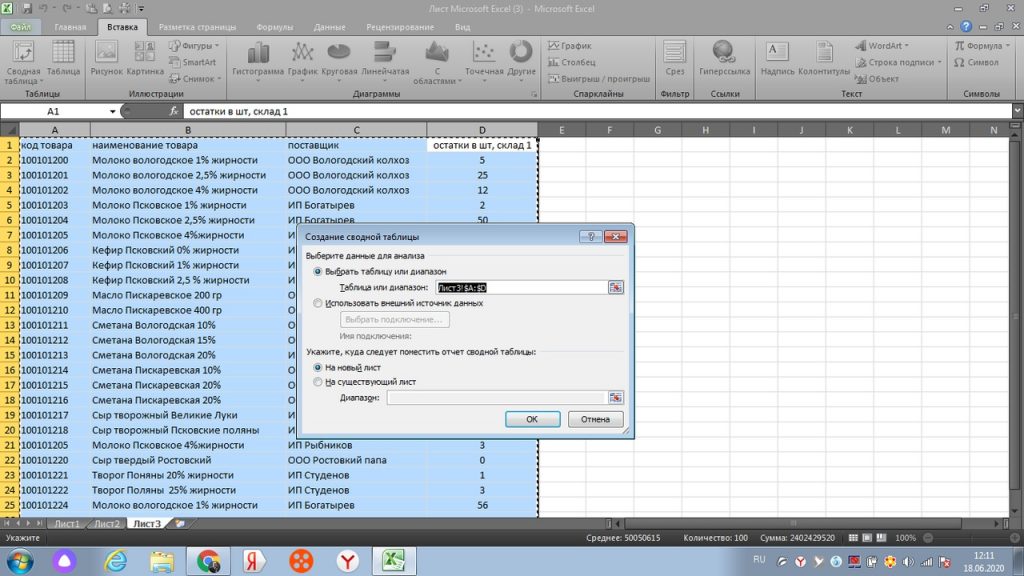
Подтверждаем команду нажав кнопку «ок». Получаем на новом листе нашей страницы excel возможность построения сводной таблицы, см рис 14.
Теперь мы выбираем нужные нам значения из правого верхнего участка. Раз мы договорились, что нам нужно знать сколько у нас товара по одному наименованию, то выбираем галкой наименование товара. См. рис 15.
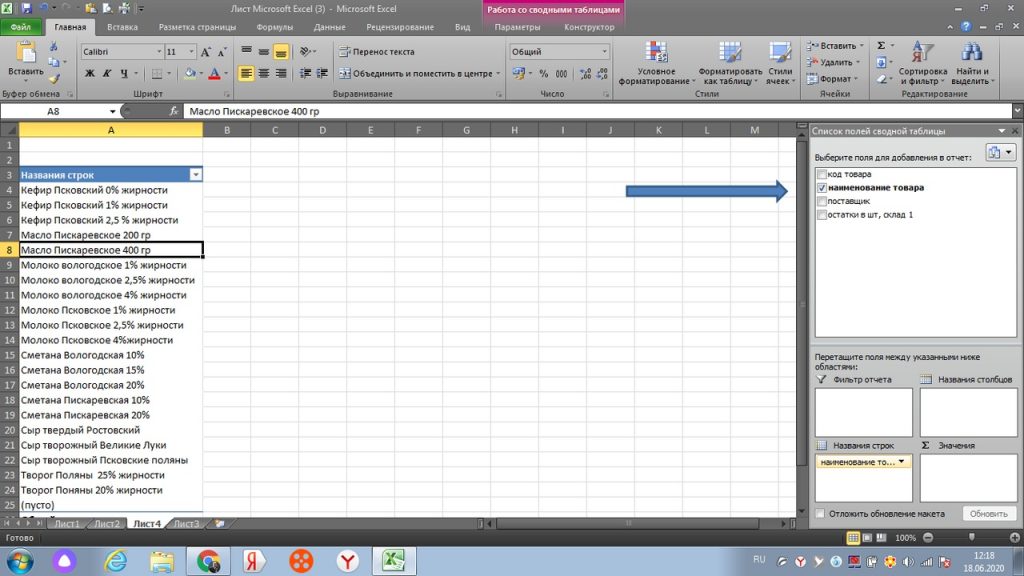
По аналогии, мы ставим галку напротив количества (остатки в шт, склад 1).
При этом, перемещаем данные с количеством не в окно «название строк», а в окно «Значения». см. рис 16
Здесь мы видим, что у нас появился дополнительный столбец, но пока не по количеству штук каждого товара, а по количеству строк. Далее мы делаем следующую операцию.
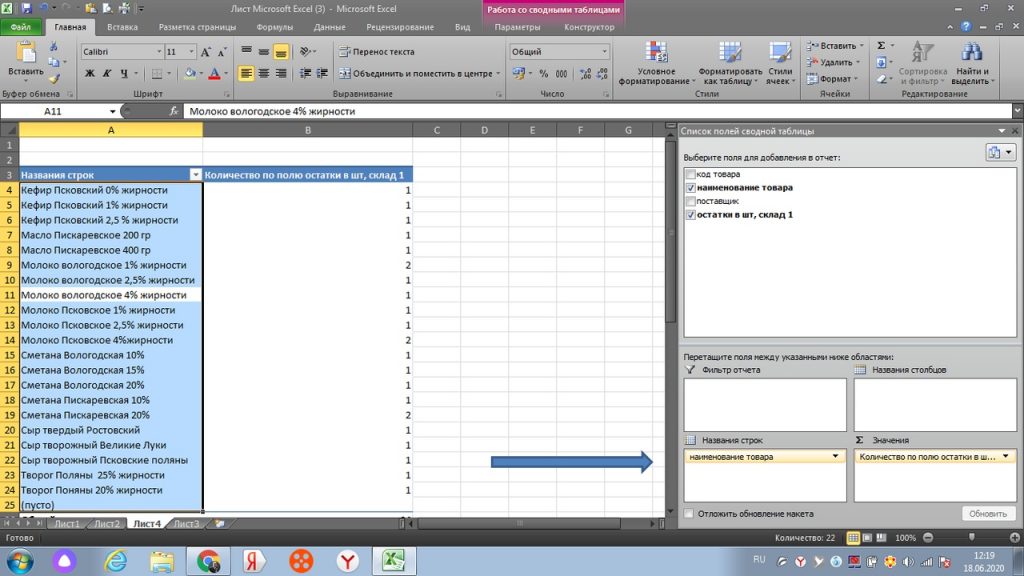
Правой клавишей мыши нажимаем на столбец с количеством. См. рис 17. У нас открывается окно, где в строке ИТОГИ ПО, мы ставим галку не по количеству (строк), как на картинке, а по сумме.
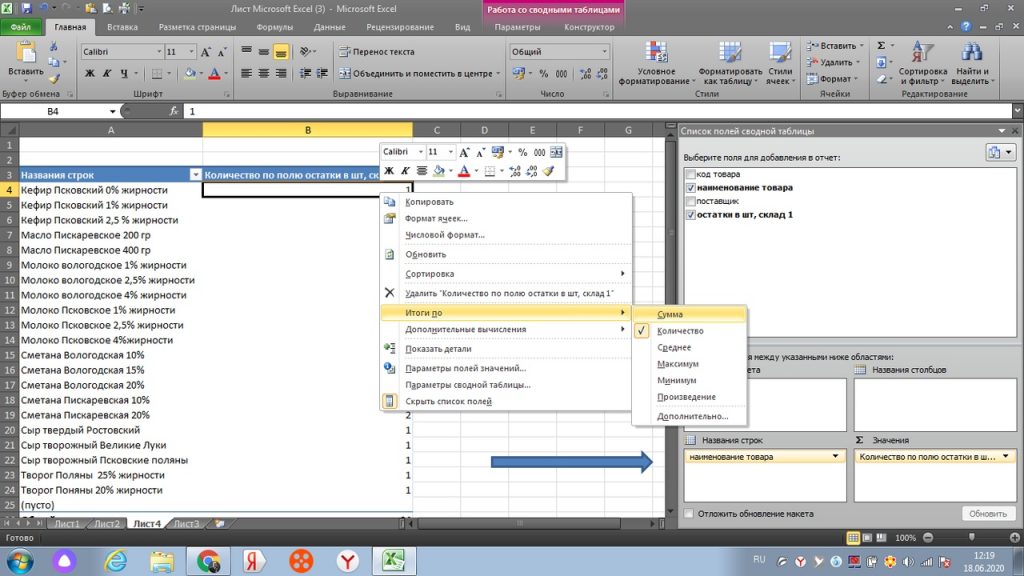
Теперь мы получаем именно сведенное количество по каждому товару. См рис 18.
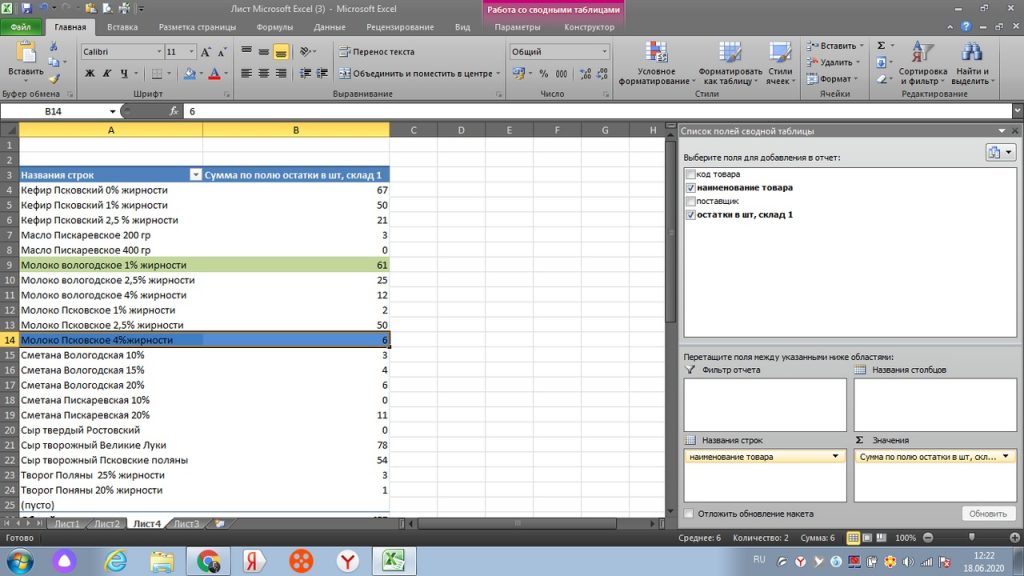
Для сравнения и наглядности, возвращаемся в исходный лист, (см. рис 19) и мы видим:
одинаковые товары по наименованию, помеченные синим цветом 3+3 = 6 штук.
одинаковые товары, помеченные зеленым 5+56 = 61 штука.
Тоже самое у нас в сводной таблице ( рис 18), 6 и 61 штука.
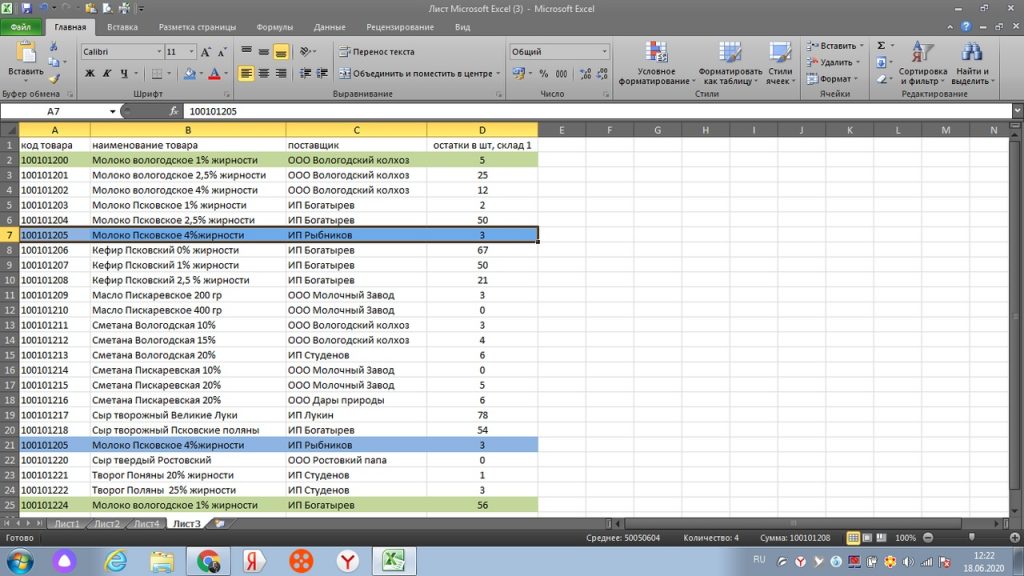
В сводную таблицу можно добавить поставщика и так далее. Можно ее сделать более сложной в плане количества учитываемый столбцов. Это уже дело необходимости и практики. Один-два раза сделаете, поймете суть. Потом, навык, как в excel обработать большой объем данных на уровне сводной таблицы, уже никогда не забудете.
Как в excel подтянуть данные из одного диапазона в другой, с помощью функции ВПР
Будет логичным, если сразу же покажу, как в excel «подтянуть» данные из другого листа или файла, в другой. Для этого есть замечательная функция ВПР. Мы разберем, как пользоваться этим на уже знакомых нам данных.
К примеру, Вам нужно свести цифры воедино с другого магазина, склада заявки на один лист Excel. Это делается по ключевому значению, которое должно быть во всех источниках данных. Это может быть уникальный код товара или его наименование.
Сразу оговорюсь по наименованию или текстовому значению, функция ВПР бескомпромиссна.
Если в наименовании товара есть пробел или точка, (любое отклонение) то для нее это будет уже другое значение.
Также необходимо, что бы все источники были в одном формате. Если мы говорим о числах, то в числовом формате.
Итак, у нас есть исходный файл, на листе 1, (см. рис 20)
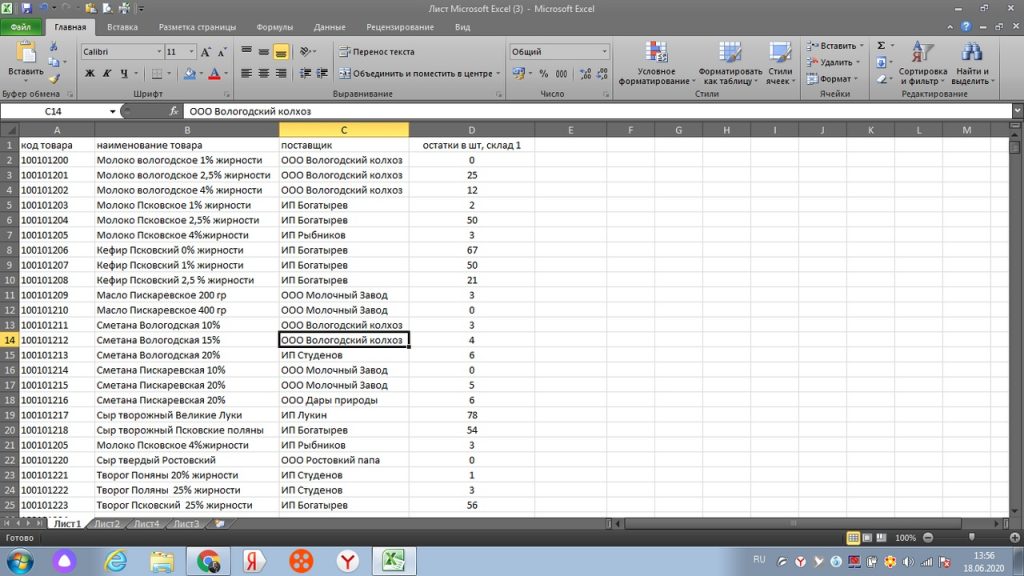
Из листа 2, (рис 21) мы будем подтягивать цифры в лист 1. Обратите внимание, что количества на листах разное. Строки также могут быть смещены в списке или перемешаны, поэтому, простым сложением одной цифры с другой нам не обойтись.
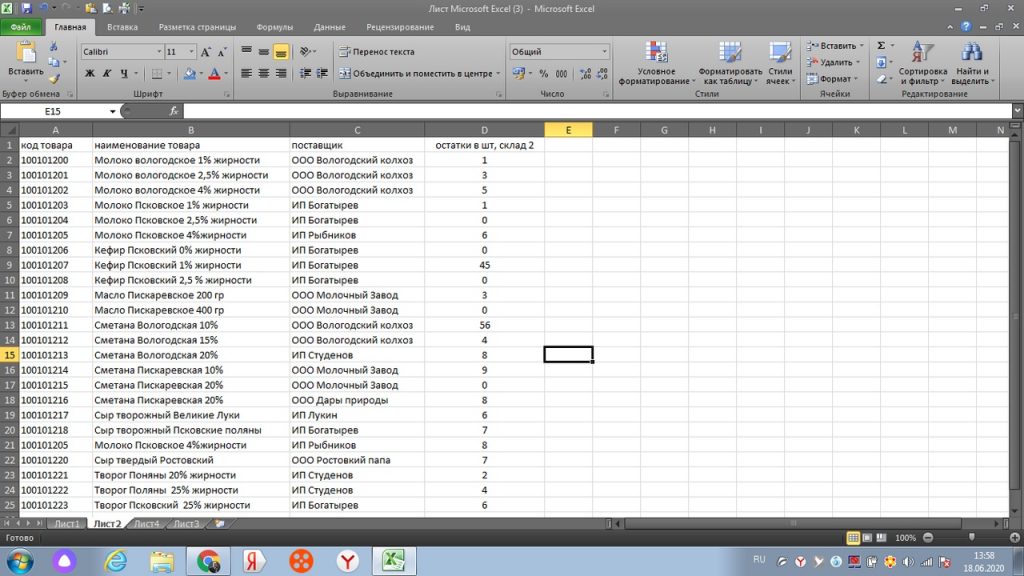
Для нас данные на листе 1 те, к которым нужно подтянуть другие значения. Также действуем через знак равно «=». В левом верхнем углу, через поиск других функций, находим ВПР, см рис 22.
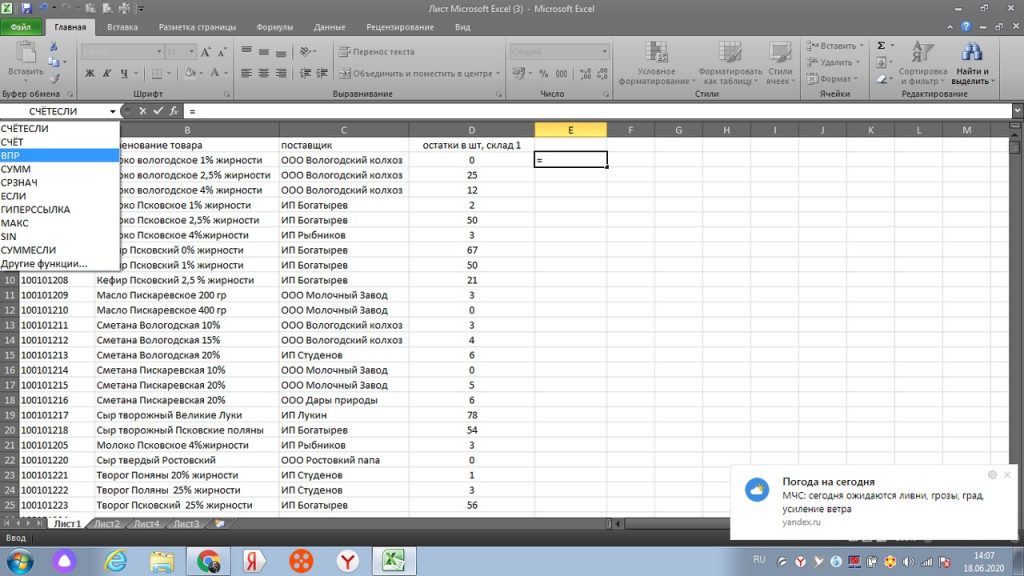
Затем, у нас открывается окно и мы выделяем весь столбец А, то есть искомое значение. Оно в новом окне выделяется, как А:А, см рис 23.
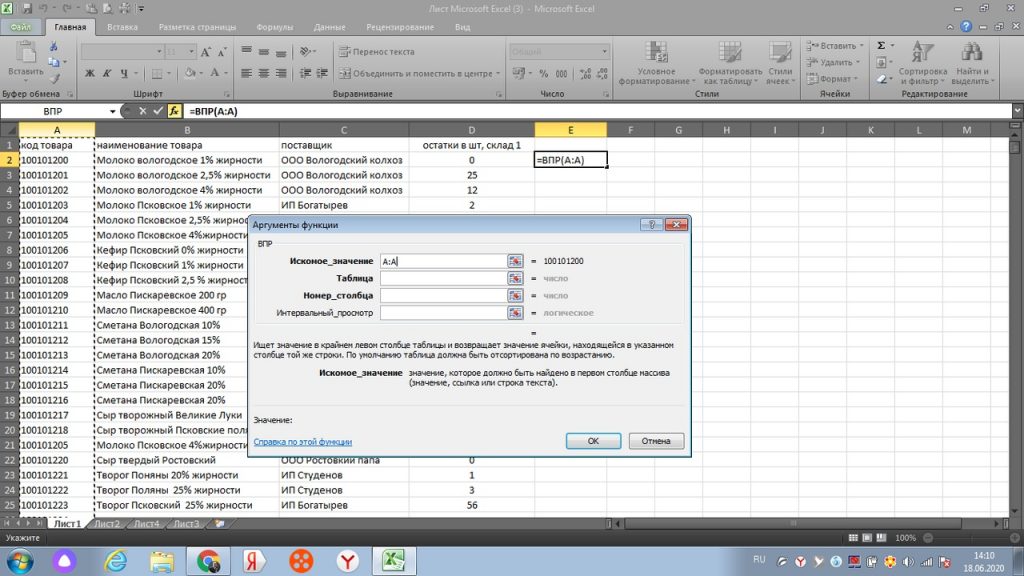
Далее, мышкой переходим в самом окошке на вторую строку «таблица», только после этого переходим на лист 2 нашего файла.
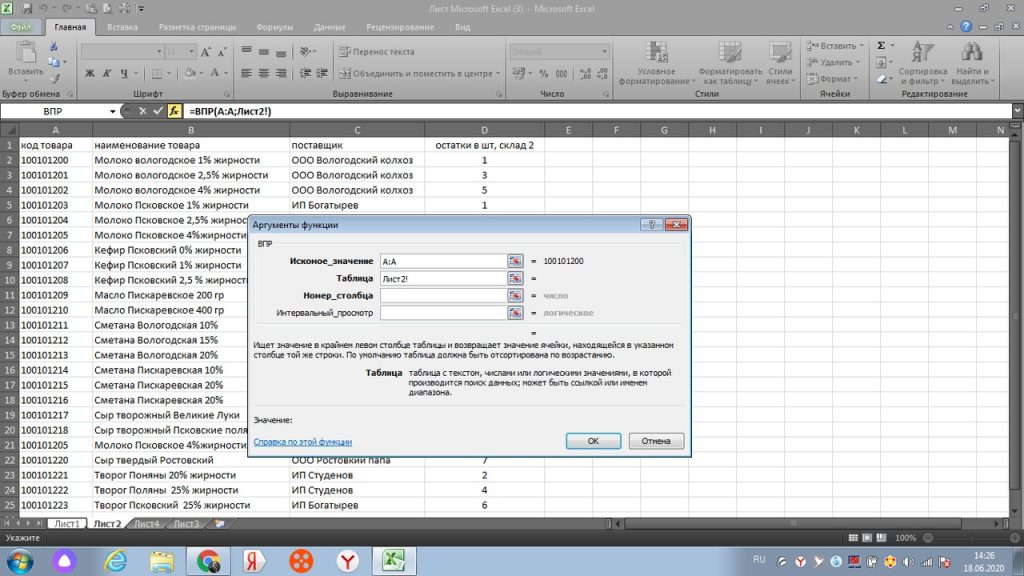
И от столбца «А» выделяем и протягиваем к столбцу с количеством. В данном случае, к столбцу «D», см рис 25.
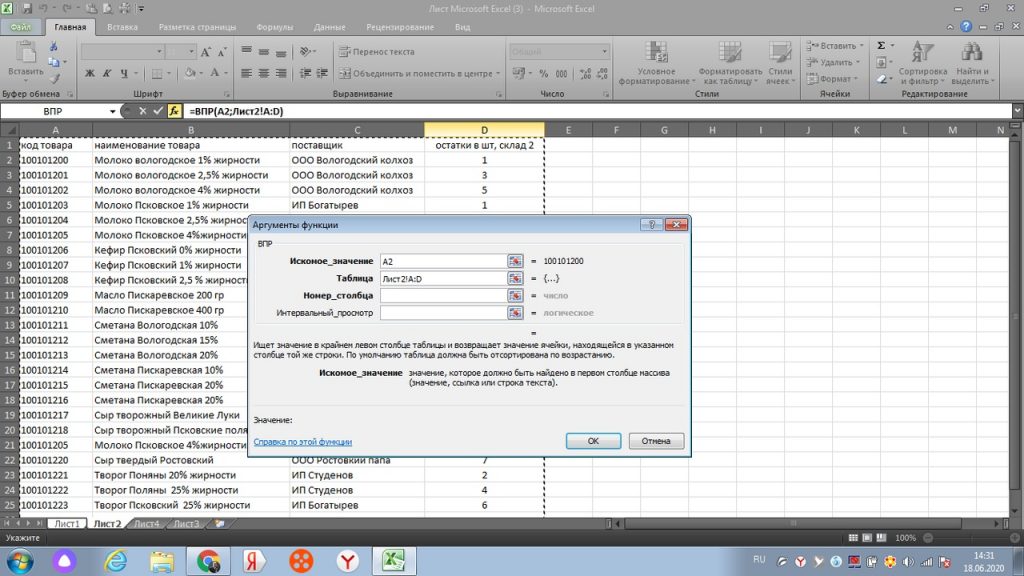
Столбец D, это четвертый столбец начиная с искомого значения, то есть с кода товара в столбце А.
Поэтому, мы ставим в третьем поле окошка «номер столбца» цифру 4. и в поле «интервальный просмотр» всего ноль. В итоге у нас получается заполненное окошко, см рис 26.
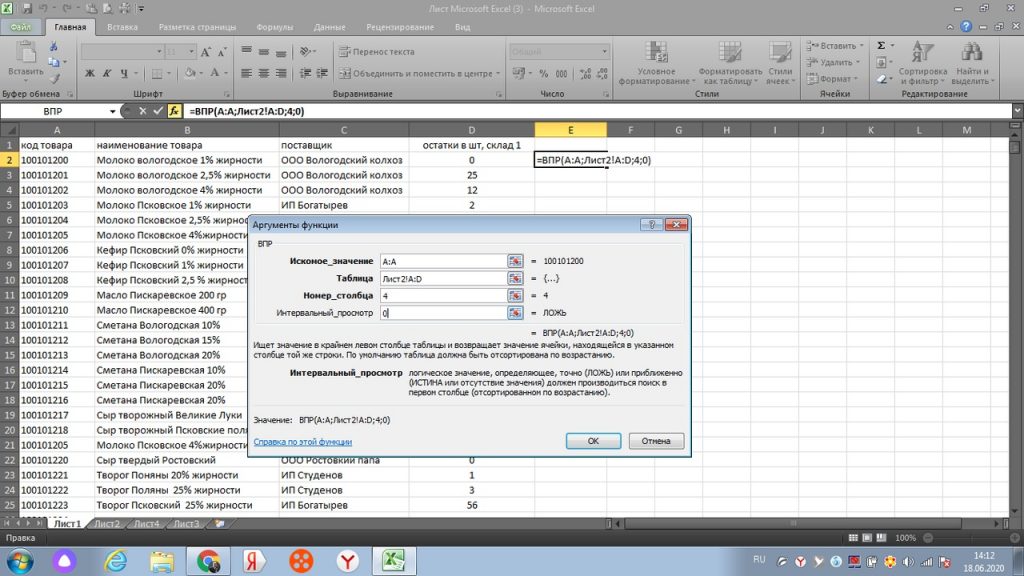
Нажимаем «ок», и получаем подтянутую цифру со второго листа, по коду товара 100101200. см. рис 27.
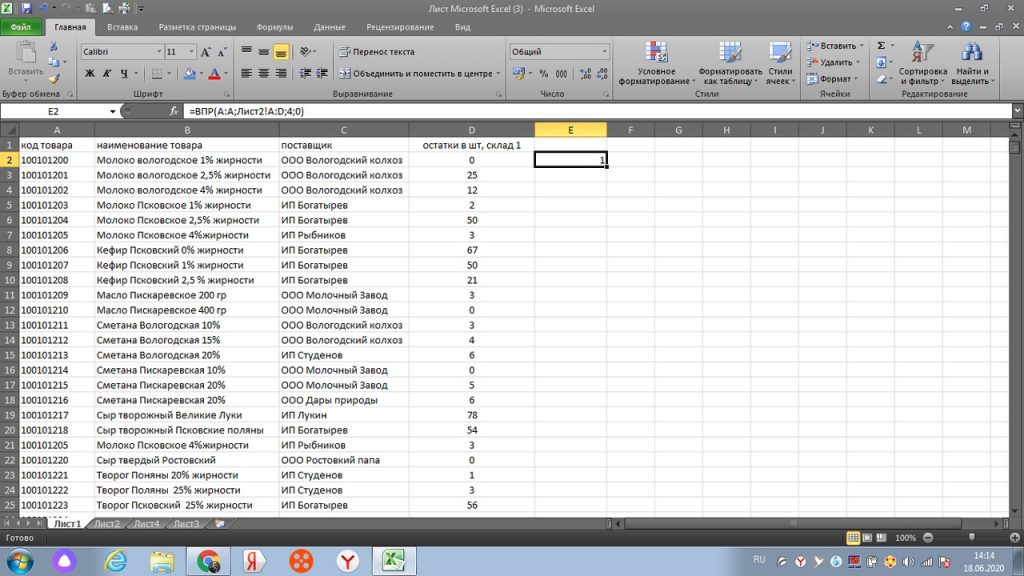
Протягиваем значение вниз, столбец D заполняется цифрами с листа 2. см. рис 28. Здесь нам остается просто сложить одни цифры с другими простой формулой сложения и протянуть вниз.
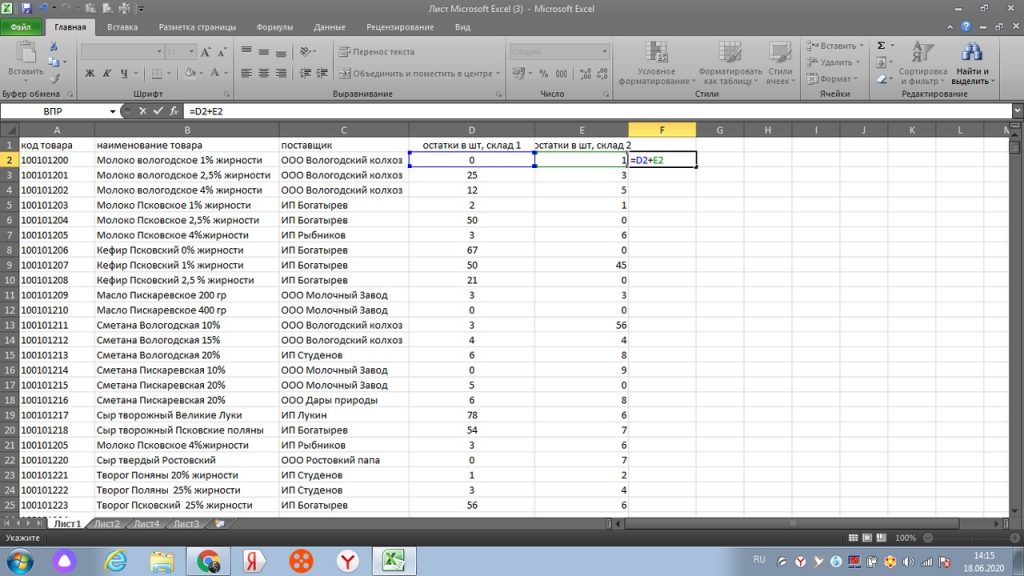
Таким образом, мы можем подтянуть значение из большого массива данных, которое вручную искать долго и не целесообразно, если есть функция ВПР.
Важный момент. Если Вы подтягиваете из другого файла, то файлы должны быть сохранены. И еще. Формулы подтянутых значений остаются. Вам нужна цифры привести в значения или не удалять и не менять значения, которые Вы подтягивали.
Как в excel обработать большой объем данных, функция правсимв и левсимв
Бывает, что необходимо для работы с функцией ВПР, привести искомые значения, и значение которые мы подтягиваем в единую форму. Как мы говорили выше, для ВПР любое отклонение, даже пробел, это уже другое значение.
Для этого, нам в помощь функция excel: правсимв и левсимв. То есть с помощью этой функции можно слева или справа нашего значения, например наименования товара, убрать лишние знаки.
Итак,, нам нужно взять только часть от полного наименования. Смотрим наш рис 29, к примеру, нам нужно только слово «молоко». Мы также в окне поиска формул ищем = левсимв.
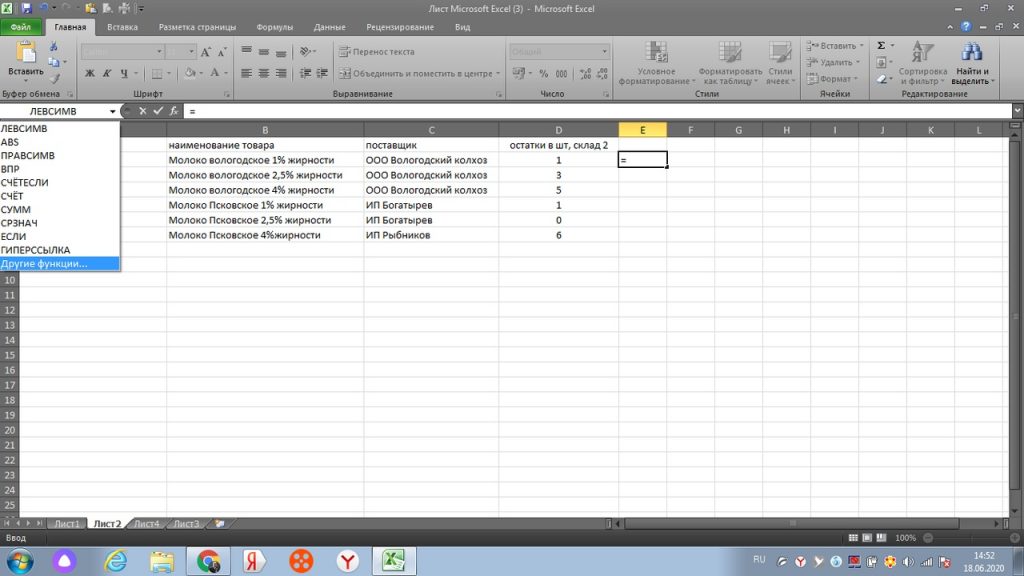
У нас появляется окошко, см рис 30.
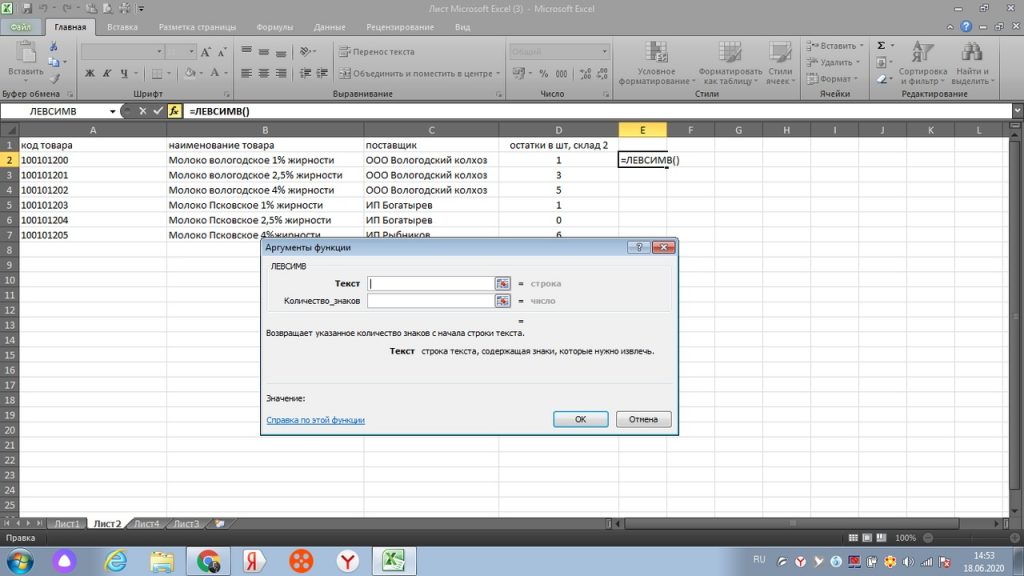
Мы выделяем интересующий нас столбец «В», в строке «текст» он появляется как В:В, см рис 31.
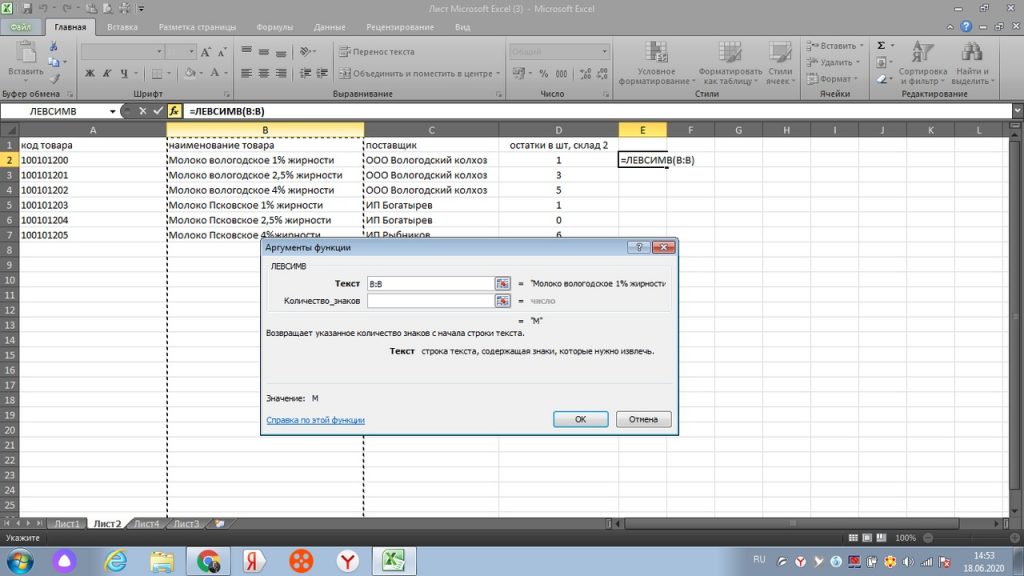
Далее, в строку «количество знаков» мы ставим ту цифру, сколько букв или символов содержит слово или слова с пробелом начиная с левой стороны. Если нам нужно только слово «молоко», то в нем, с учетом пробела 7 букв, поэтому, ставим цифру 7. См. рис 32.
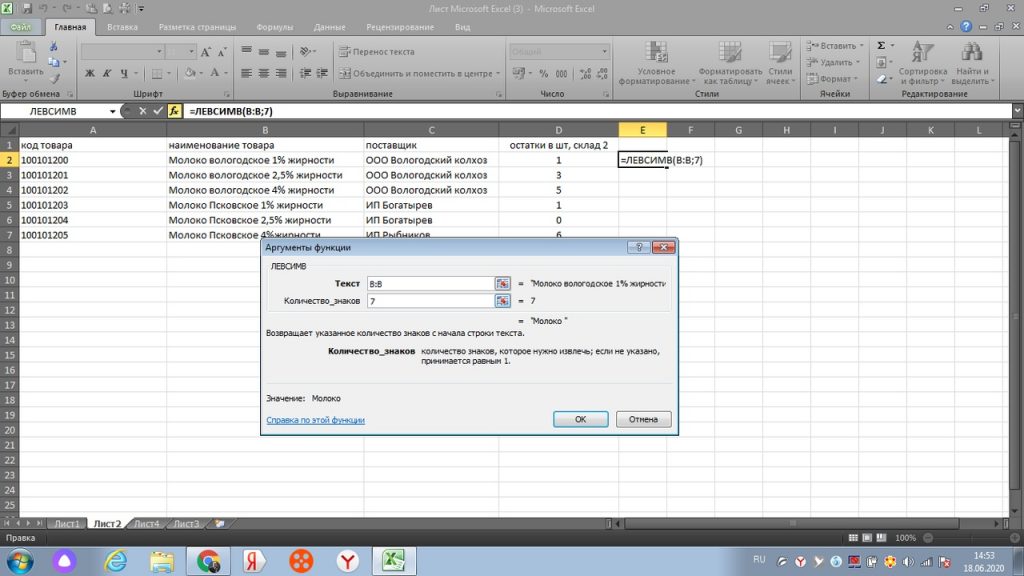
Вот и обрезалось наше наименование только в нужное нам слово, см. рис 33.
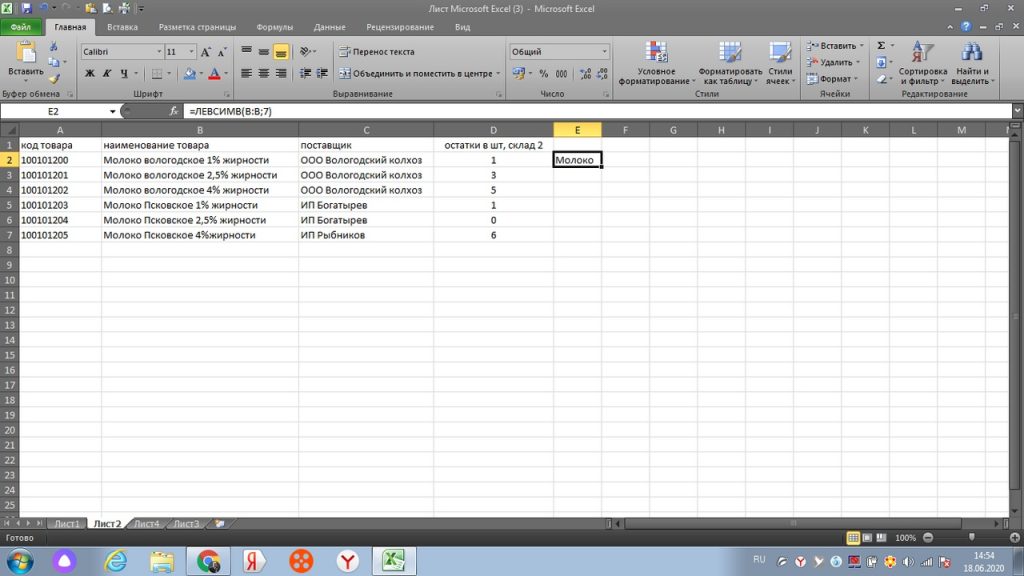
Теперь остается только «протянуть» вниз, и все значения с первыми 7-ю символами с левой стороны, будут в нашей таблице., см рис 34.
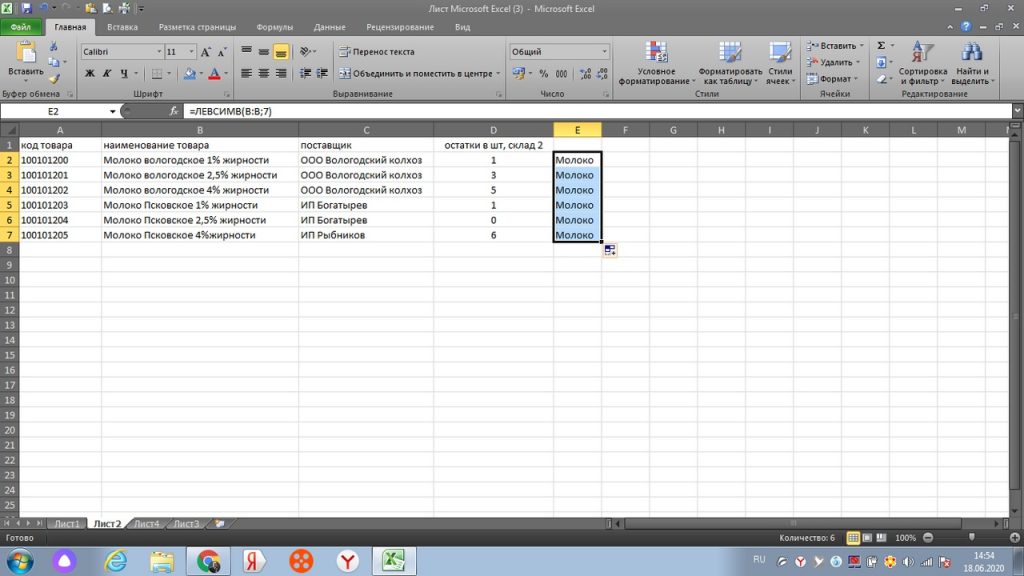
По аналогии, можно пользоваться функцией ПРАВСИМВ. Здесь все тоже самое, только символы оставляет с правой стороны. Эту функцию часто применяют на числовых значениях, когда код имеет дополнительные обозначения или отделяется, например точкой.
Заключение
Я отдельно сделал статью, как в excel вести учет и планирование товарных запасов. Ели интересно, статью можно почитать здесь.
Чтобы не утяжелять прочтение, разделю материал на две части. В следующей части пойдет речь о том, как в excel обработать большой объем данных с помощью функции СЦЕПИТЬ, построения графиков и диаграмм. Как автоматически подсветить значения верхнего или нижнего порога, и как седлать пароль на страницу или всю книгу в excel, и так далее.
Надеюсь материал был полезным, всего Вам хорошего. Успехов!
Работа с большими файлами экселя
Время на прочтение
5 мин
Количество просмотров 50K
Что такое большой файл? Ну так чтобы реально большой? В бытность свою я думал, что это файлик на 50-60 тыс строк записей. И оставался я бы в таком неведении до сих пор, но пришлось выполнять один проект, в котором надо было работать с файлами на 600-800 тыс строк. Хождение по мукам — под катом:
Что сначала
А сначала, друзья мои, ринулись мы в самое простое, что можно придумать. Interop.Excell, и все дела. Казалось. Ага, щаз. Как показали тестовые испытания, данный способ открытия приводил к тому, что за час было прочитано 200 тыс строк экселя, приложение активно потребляло оперативку, и раздвигало плечами остальные процессы на машине. Кончилось все ожидаемо, но следственный эксперимент надо было довести до конца — на 260 тысячах приложение свалилось в OutOfMemory на машине с 4 Гб. Стало понятно, что в лоб решить проблему не получится
Google it
Сколько нам открытий чудных… Гугль привел, как ни странно, в msdn, где я познакомился с двумя методами открытия очень больших файлов: DOM и SAX. Уж за давностью времен не вспомню, но какой то из них отвалился по причине опостылевшей уже на тот момент OutOfMemory, а второй был совершенно неюзабелен в плане доступа к данным. Почему — читаем ниже.
Из чего же, из чего же
Сделаны наши эксельки. Ни для кого, кто решил копнуть формат чуть глубже, не станет секретом, что в отличие от бинарным xls, xlsx — по сути zip архив с данными. Достаточно поменять расширение ручками и распаковать архив в папку — и мы получим всю внутреннюю структуру документа, что есть не что иное, как набор xml файлов и сопутствующей информации. Как оказалось, в корневом xml нет текстовых данных. Вместо этого мы имеем набор индексов, которые ссылаются на вспомогательный файл, в котором представлены пары «ключ/значение» Одним из вышеприведенных способов открыть то файл можно, но при этом нужно копаться в сопутствующих файлах и вытаскивать из них текстовые значения. Мрак.
И отступила тьма
После долгих мытарств и стенаний родилось следующее:
Наши любимые юзинги, которые некоторые личности забывают указывать:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.OleDb;
using System.IO;
using System.Linq;
using DocumentFormat.OpenXml;
using DocumentFormat.OpenXml.Packaging;
using DocumentFormat.OpenXml.Spreadsheet;* This source code was highlighted with Source Code Highlighter.
Собственно, сам код:
public delegate void MessageHave(string message);public delegate void _DataLoaded(List<string> data);public delegate void _NewProcent(int col);public static _DataLoaded DataLoaded;public static _NewProcent NewProcent;public static MessageHave MessageHave_Event;public static void ReadData(object data)
{
//Приводим объект с переданной парой "имя файла"-"выбранный лист экселя"
var keyValuePair = (KeyValuePair<string, string>)data;
using (var cnn = new OleDbConnection(@"Provider=Microsoft.ACE.OLEDB.12.0;Data Source=" +
keyValuePair.Key + @";Extended Properties=""Excel 12.0;HDR=No;IMEX=1""")
)
{
int calc = 1000;
MessageHave_Event("Открытие соединения провайдера");
cnn.Open();
try
{
var cmd = new OleDbCommand(String.Format("select * from [{0}]", keyValuePair.Value), cnn);
using (OleDbDataReader dr = cmd.ExecuteReader())
{
var lines = new List<string>();
int id = 0;
if (dr != null)
while (dr.Read())
{
string text = "";
for (int i = 0; i < dr.FieldCount; ++i)
{
if (dr[i] != null)
text += dr[i] + "^";//добавляем разделитель между ячейками
else
text += "^";
}
lines.Add(text);id++;
if (id == calc)
{
NewProcent(id);
calc += 1000;
}
}
DataLoaded(lines);
}
cnn.Close();
}
catch (Exception ex)
{
MessageHave_Event("Exception: " + ex.Message);
cnn.Close();
}
}
}* This source code was highlighted with Source Code Highlighter.
Код показал производительность порядка 15-20 минут на файлах в 600-800 тыс строк записей.
Если кому то реализация покажется кривой — сильно не пинать  Выслушаю все комментарии
Выслушаю все комментарии
во-первых, с такими большими таблицами не сталкивался.
действительно большие объемы у нас хранятся в БД, в ексель — максимум было тысяч 40, да и это — исключение.
но пару слов сказать имею, пока модераторы не почистили флуд
имхо, ВСЁ очень сильно зависит от того, какие это таблицы, что в них хранится, как часто меняется/добавляется, как данные используются и т.п.
во-первых,
настораживают приведенные ТС слова о том, что таблицу в 80+ тыс. строк, содержащую формулы в 17 столбцах, часто фильтруют.
при фильтрации ексель автоматически запускает пересчет (как минимум — листа, а если есть ссылки с других листов — то и там тоже). данные при этом могут и не меняться.
нужно тщательно посмотреть каждую из 17 формул — нужна ли она, используется ли, от каких полей таблицы зависит и насколько часто пересчитывается.
возможно, после этого некоторые или даже все формулы можно будет заменить на значения, по мере надобности рассчитываемые макросом и хранящиеся в таблице в виде значений.
во-вторых,
в таблицах такого рода очень вредно иметь УФ, да и любое другое форматирование (кроме необходимых в отдельных случаях форматов «текстовый» и «дата»).
никаких рамочек, никаких цветовых выделений (фона или шрифта), стандартный шрифт стандартного размера и начертания.
в-третьих,
стоит подумать — а нужно ли работать с такой таблицей непосредственно в таблице?
существует богатый инструментарий — SQL-запросы, сводные, юзер-формы и т.п…
идеальный вариант — когда большая таблица и не видна никому, и недоступна.
а обновление и выборка данных идет через макросы и запросы — имхо, гораздо более быстрые способы, чем встроенные фильтры.
ну и нормализация таблиц не помешает. и адекватное использование сортировки или индексации (правда, индексацию придется делать и поддерживать самостоятельно).
пс. excel-ok, если хотите — могу посмотреть вашу таблицу и сделать более конкретные предложения, особенно при наличии более подробных описаний и комментариев — что, как и почему вы с ней делаете
ппс. на случай согласия — предупреждаю: у меня экс’2003, 2007-10 ставить пока не собираюсь, так что лучше обрезать табличку, но не слишком сильно — иначе будут не очень заметен эффект.
пппс. бесплатно — не могу (принципиально, а не из-за жадности)
ппппс. резвизиты в подписи.
Таблицы Excel — очень мощный инструмент. В них больше 470 скрытых функций. Поначалу это пугает: кажется, на то, чтобы разобраться со всем, уйдут годы. На самом деле это не так. Всего десятка функций и горячих клавиш уже хватит для того, чтобы сильно упростить себе жизнь. Расскажем о некоторых из них (скоро стартует второй поток курса «Магия Excel»).
Интерфейс
Настраиваем панель быстрого доступа
Начнем с самого простого — добавления самых часто используемых опций на панель быстрого доступа. Чтобы сделать это, заходите в параметры Excel — «Настроить ленту» — и ищите в параметрах «Панель быстрого доступа».
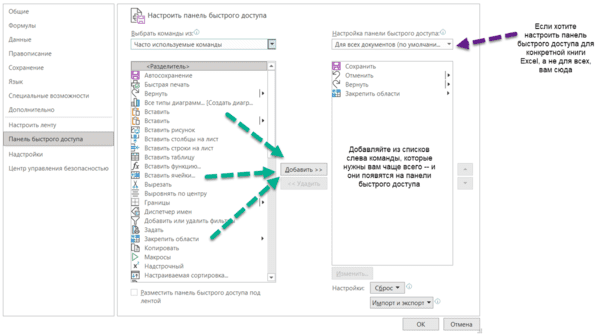
Опции, перенесенные на панель быстрого доступа, будут доступны при работе со всеми вашими книгами Excel (хотя можно ее настроить и отдельно для любой книги). Так что если пользуетесь какими-то командами и инструментами постоянно — добавляйте их туда.
Другой вариант — просто щелкнуть по инструменту на ленте правой кнопкой мыши и нажать «Добавить…»:
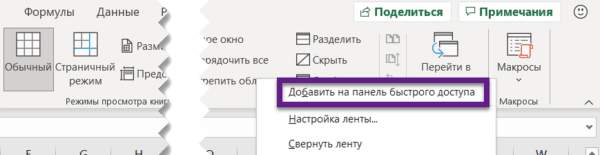
Перемещаемся по ленте без мышки
Нажмите на Alt. На ленте инструментов появились цифры и буквы — у каждого инструмента на панели быстрого доступа и у каждой вкладки на ленте соответственно:
Нажмите на клавиатуре любую из букв — попадете на соответствующую вкладку на ленте, а там каждый инструмент в свою очередь тоже будет подписан. Так можно быстро вызвать нужные опции, не трогая мышку.

Ввод данных
Теперь давайте рассмотрим несколько инструментов для быстрого ввода данных.
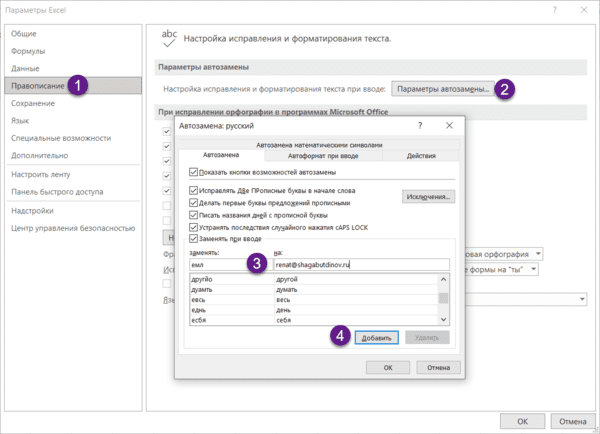
Автозамена
Если вам часто нужно вводить какое-то словосочетание, адрес, емейл и так далее — придумайте для него короткое обозначение и добавьте в список автозамены в Параметрах:
Прогрессия
Если нужно заполнить столбец или строку последовательностью чисел или дат, введите в ячейку первое значение и затем воспользуйтесь этим инструментом:
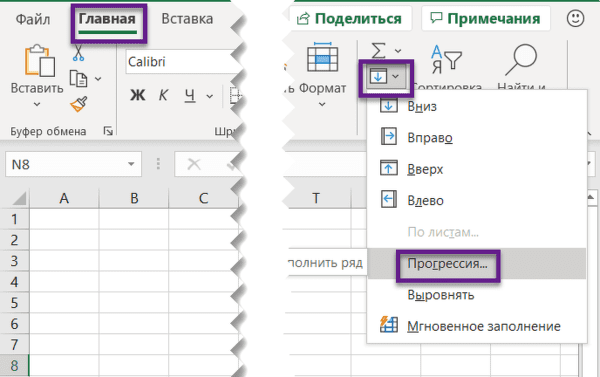
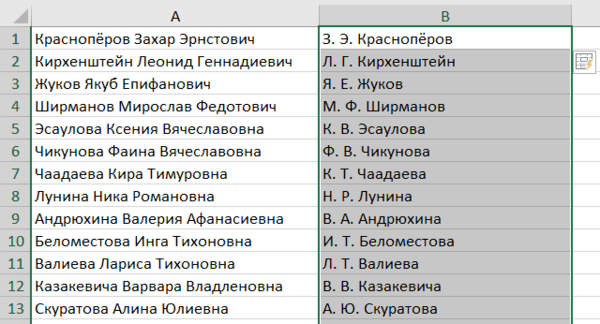
Протягивание
Представьте, что вам нужно извлечь какие-то данные из целого столбца или переписать их в другом виде (например, фамилию с инициалами вместо полных ФИО). Задайте Excel одну ячейку с образцом — что хотите получить:
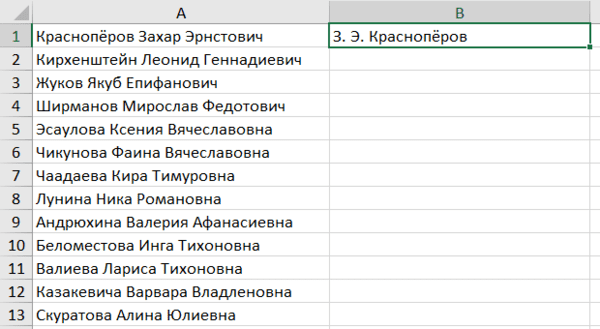
Выделите все ячейки, которые хотите заполнить по образцу, — и нажмите Ctrl+E. И магия случится (ну, в большинстве случаев).
Проверка ошибок
Проверка данных позволяет избежать ошибок при вводе информации в ячейки.
Какие бывают типовые ошибки в Excel?
- Текст вместо чисел
- Отрицательные числа там, где их быть не может
- Числа с дробной частью там, где должны быть целые
- Текст вместо даты
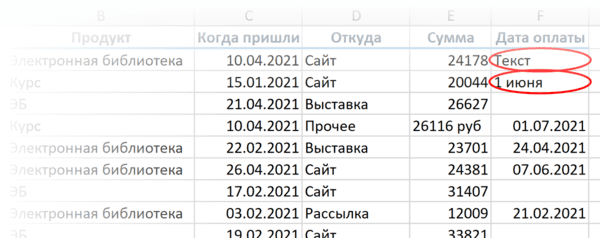
- Разные варианты написания одного и того же значения. Например, сокращения («ЭБ» вместо «Электронная библиотека»), лишние пробелы в конце текстового значения или между словами — всего этого достаточно, чтобы превратить текстовые значения в разные и, соответственно, чтобы они обрабатывались Excel некорректно.
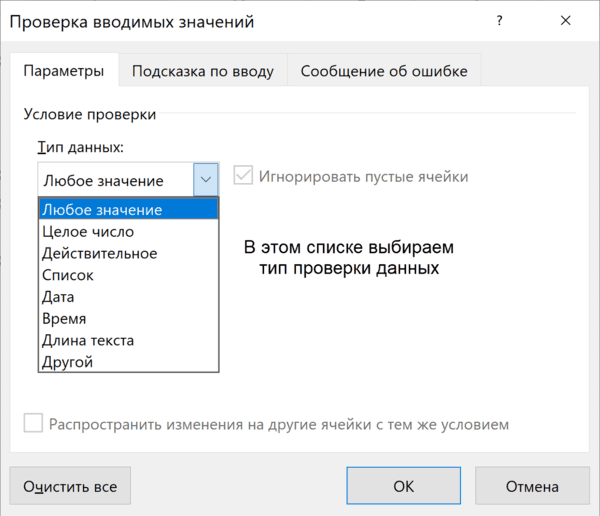
Инструмент проверки данных
Чтобы использовать инструмент проверки данных, нужно выделить ячейки, к которым хотите его применить, выбрать на ленте «Данные» → «Проверка данных» и настроить параметры проверки в диалоговом окне:
Если в графе «Сообщение об ошибке» вы выбрали вариант «Остановка», то после проверки в ячейки нельзя будет ввести значения, не соответствующие заданному правилу.
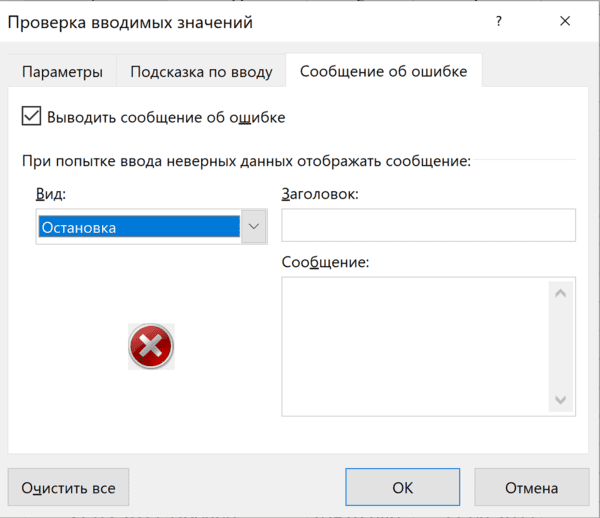
Если же вы выбрали «Предупреждение» или «Сообщение», то при попытке ввести неверные данные будет появляться предупреждение, но его можно будет проигнорировать и все равно ввести что угодно.
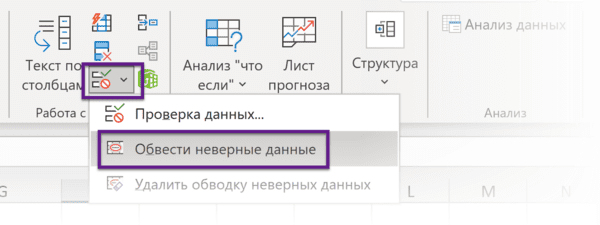
Еще неверные данные можно обвести, чтобы точно увидеть, где есть ошибки:
Удаление пробелов
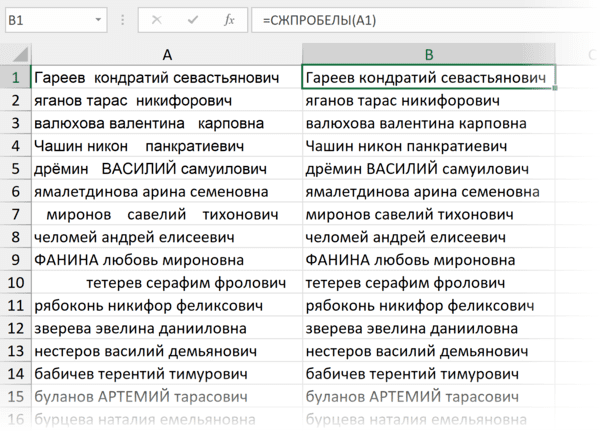
Для удаления лишних пробелов (в начале, в конце и всех кроме одного между слов) используйте функцию СЖПРОБЕЛЫ / TRIM. Ее единственный аргумент — текст (ссылка на ячейку с текстом, как правило).
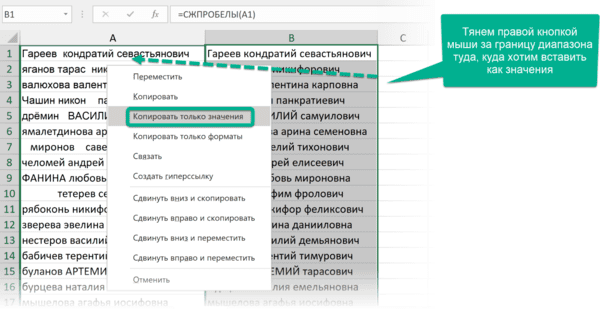
Если после очистки данных функцией СЖПРОБЕЛЫ или другой обработки вам не нужен исходный столбец, вставьте данные, полученные в отдельном столбце с помощью функций, как значения на место исходных данных, а столбец с формулой удалите:
Дата и время
За любой датой в Excel скрывается целое число. Датой его делает формат.
Аналогично со временем: одна единица — это день, а часть единицы (число от 0 до 1) — время, то есть часть дня.
Это не значит, что так имеет смысл вводить даты и время в ячейки, вводите их в любом из стандартных форматов — Excel сразу отформатирует их как даты:
ДД.ММ.ГГГГ
ДД/ММ/ГГГГ
ГГГГ-ММ-ДД
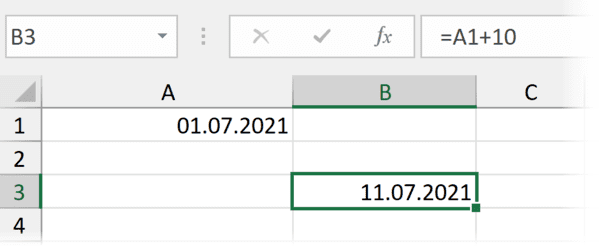
С датами можно производить операции вычитания и сложения.
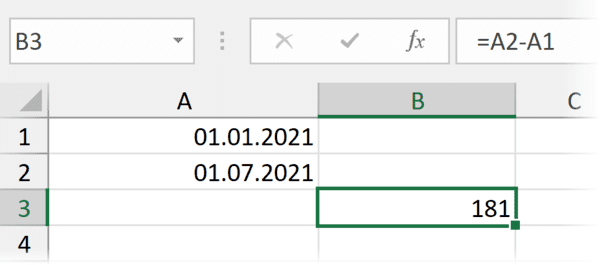
Вычесть из одной даты другую, чтобы получить разницу в днях (результатом вычитания будет число — количество дней.
Прибавить к дате число — и получить дату, которая наступит через соответствующее количество дней.
Поиск и подстановка значений
Функция ВПР / VLOOKUP
Функция ВПР / VLOOKUP (вертикальный просмотр) нужна, чтобы связать несколько таблиц — «подтянуть» данные из одной в другую по какому-то ключу (например, названию товара или бренда, фамилии сотрудника или клиента, номеру транзакции).
=ВПР (что ищем; таблица с данными, где «что ищем» должно быть в первом столбце; номер столбца таблицы, из которого нужны данные; [интервальный просмотр])
У нее есть два режима работы: интервальный просмотр и точный поиск.
Интервальный просмотр — это поиск интервала, в который попадает число. Если у вас прогрессивная шкала налога или скидок, нужно конвертировать оценку из одной системы в другую и так далее — используется именно этот режим. Для интервального просмотра нужно пропустить последний аргумент ВПР или задать его равным единице (или ИСТИНА).
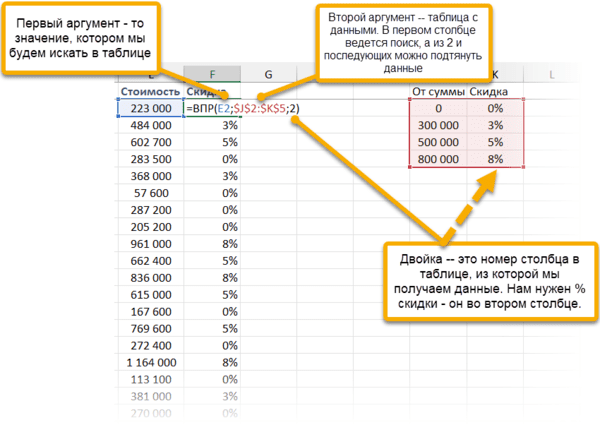
В большинстве случаев мы связываем таблицы по текстовым ключам — в таком случае нужно обязательно явным образом указывать последний аргумент «интервальный_просмотр» равным нулю (или ЛОЖЬ). Только тогда функция будет корректно работать с текстовыми значениями.
Функции ПОИСКПОЗ / MATCH и ИНДЕКС / INDEX
У ВПР есть существенный недостаток: ключ (искомое значение) обязан быть в первом столбце таблицы с данными. Все, что левее этого столбца, через ВПР «подтянуть» невозможно.
В реальных условиях структура таблиц бывает разной и не всегда возможно изменить порядок столбцов. Поэтому важно уметь работать с любой структурой.
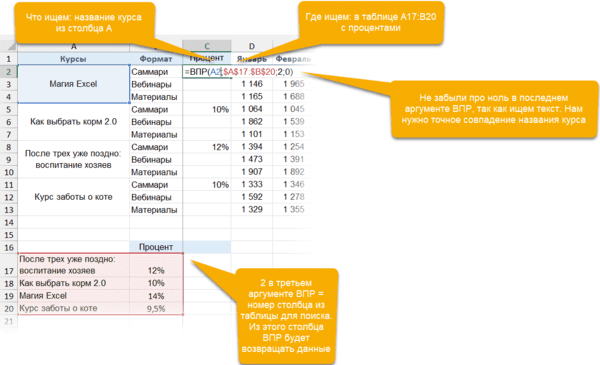
Функция ПОИСКПОЗ / MATCH определяет порядковый номер значения в диапазоне. Ее синтаксис:
=ПОИСКПОЗ (что ищем; где ищем ; 0)
На выходе — число (номер строки или столбца в рамках диапазона, в котором находится искомое значение).
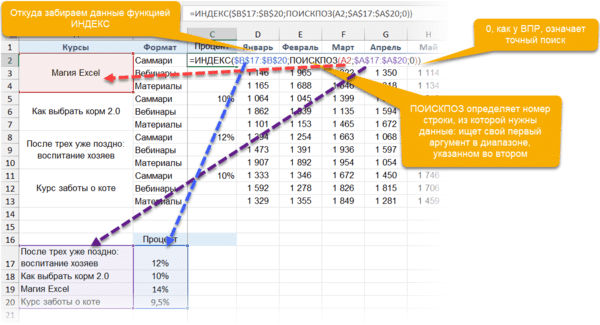
ИНДЕКС / INDEX выполняет другую задачу — возвращает элемент по его номеру.
=ИНДЕКС(диапазон, из которого нужны данные; порядковый номер элемента)
Соответственно, мы можем определить номер строки, в котором находится искомое значение, с помощью ПОИСКПОЗ. А затем подставить этот номер в ИНДЕКС на место второго аргумента, чтобы получить данные из любого нужного нам столбца.
Получается следующая конструкция:
=ИНДЕКС(диапазон, из которого нужны данные; ПОИСКПОЗ (что ищем; где ищем ; 0))
Оформление
Нужно оформить ячейки в книге Excel в едином стиле? Для этого есть одноименный инструмент — «Стили».
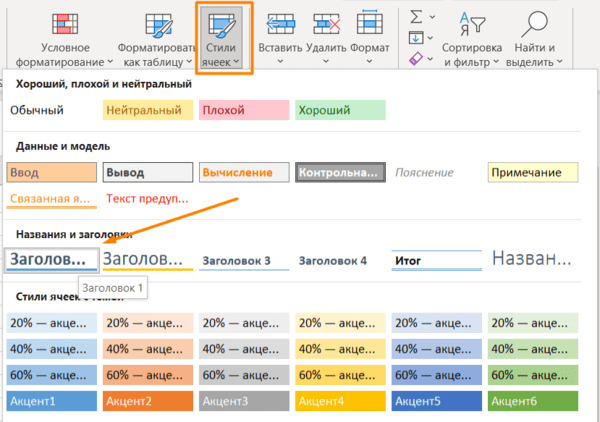
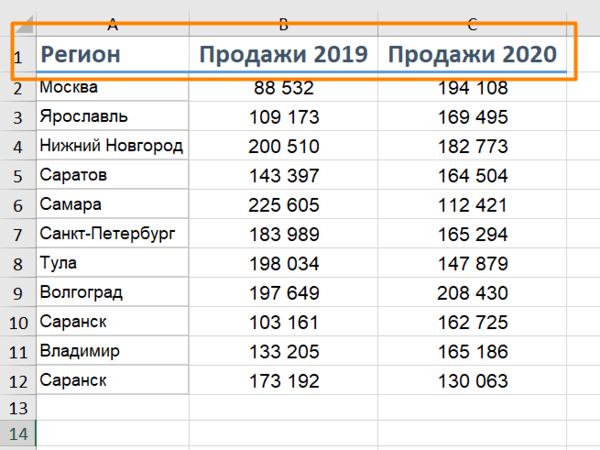
На ленте инструментов нажмите на «Стили ячеек» и выберите подходящий. Он будет применен к выделенным ячейкам:
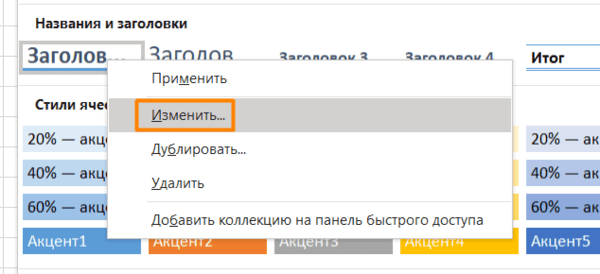
А самое главное — если вы применили стиль ко многим ячейкам (например, ко всем заголовкам на 20 листах книги Excel) и захотели что-то переделать, щелкните правой кнопкой мыши и нажмите «Изменить». Изменения будут применены ко всем нужным ячейкам в документе.
На курсе «Магия Excel» будет два модуля — для новичков и продвинутых. Записывайтесь→
Фото на обложке отсюда