
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, we will see how to convert a PDF to Excel or CSV File Using Python. It can be done with various methods, here are we are going to use some methods.
Method 1: Using pdftables_api
Here will use the pdftables_api Module for converting the PDF file into any other format. It’s a simple web-based API, so can be called from any programming language.
Installation:
pip install git+https://github.com/pdftables/python-pdftables-api.git
After Installation, you need an API KEY. Go to PDFTables.com and signup, then visit the API Page to see your API KEY.
For Converting PDF File Into excel File we will use xml() method.
Syntax:
xml(pdf_path, xml_path)
Below is the Implementation:
PDF File Used:

PDF FILE
Python3
import pdftables_api
conversion = pdftables_api.Client('API KEY')
conversion.xlsx("pdf_file_path", "output_file_path")
Output:

EXCEL FILE
Method 2: Using tabula-py
Here will use the tabula-py Module for converting the PDF file into any other format.
Installation:
pip install tabula-py
Before we start, first we need to install java and add a java installation folder to the PATH variable.
- Install java click here
- Add java installation folder (C:Program Files (x86)Javajre1.8.0_251bin) to the environment path variable
Approach:
- Read PDF file using read_pdf() method.
- Then we will convert the PDF files into an Excel file using the to_excel() method.
Syntax:
read_pdf(PDF File Path, pages = Number of pages, **agrs)
Below is the Implementation:
PDF File Used:
PDF FILE
Python3
import tabula
df = tabula.read_pdf("PDF File Path", pages = 1)[0]
df.to_excel('Excel File Path')
Output:

EXCEL FILE
Like Article
Save Article
Last Updated on July 14, 2022 by
In this tutorial, we’ll take a look at how to convert PDF to Excel with Python. If you work with data, the chances are that you have had, or will have to deal with data stored in a .pdf file. It’s difficult to copy a table from PDF and paste it directly into Excel. In most cases, what we copy from the PDF file is text, instead of formatted Excel tables. Therefore, when pasting the data into Excel, we see a chunk of text squeezed into one cell.
Of course, we don’t want to copy and paste individual values one by one into Excel. There are several commercial software that allows PDF to Excel conversion, but they charge a hefty fee. If you are willing to learn a little bit of Python, it takes less than 10 lines of code to achieve a reasonably good result.
We’ll extract the COVID-19 cases by country from the WHO’s website. I’m attaching it here in case the source file gets removed later.
Step 1. Install Python library and Java
tabula-py is a Python wrapper of tabula-java, which can read tables in PDF file. It means that we need to install Java first. The installation takes about 1 minute, and you can follow this link to find the Java installation file for your operating system: https://java.com/en/download/help/download_options.xml.
Once you have Java, install tabula-py with pip:
pip install tabula-pyWe are going to extract the table on page 3 of the PDF file. tabula.read_pdf() returns a list of dataframes. For some reason, tabula detected 8 tables on this page, looking through them, we see that the second table is what we want to extract. Thus we specify that we want to get the second element of that list using [1].
import tabula
df = tabula.read_pdf('data.pdf', pages = 3, lattice = True)[1]If this is your first time installing Java and tabula-py, you might get the following error message when running the above 2 lines of code:
tabula.errors.JavaNotFoundError: `java` command is not found from this Python process.Please ensure Java is installed and PATH is set for `java`Which is due to Java folder is not in the PATH system variable. Simply add your Java installation folder to the PATH variable. I used the default installation, so the Java folder is C:Program Files (x86)Javajre1.8.0_251bin on my laptop.

Now the script should run.
By default, tabula-py will extract tables from PDF file into a pandas dataframe. Let’s take a look at the data by inspecting the first 10 rows with .head(10):

We immediately see two problems with this unprocessed table: the header row contains weird letters “r”, and there are many NaN values. We’ll have to do a little bit further clean up to make the data useful.
Step 2. Clean up the header row
Let’s first clean up the header row. df.columns returns the dataframe header names.

We can replace the “r” in the header by doing the following:
df.columns = df.columns.str.replace('r', ' ').str returns all of the string values of the header, then we can perform the .replace() function to replace “r” with a space. Then, we assign the clean string values back to the dataframe’s header (columns)
Step 3. Remove NaN values
Next, we’ll clean those NaN values, which were created by the function tabula.read_pdf(), for whenever a particular cell is blank. These values cause troubles for us when doing data analysis, so most of the time we’ll remove them. Glancing through the table, it appears we can remove the rows that contain NaN values without losing any data points. Lucky for us, pandas provide a convenient way to remove rows with NaN values.
data = df.dropna()
data.to_excel('data.xlsx')
Putting it all together
import tabula
df = tabula.read_pdf('data.pdf', pages = 3, lattice = True)[1]
df.columns = df.columns.str.replace('r', ' ')
data = df.dropna()
data.to_excel('data.xlsx')Now you see, it takes only 5 lines of code to convert PDF to Excel with Python. It’s simple and powerful. The best part? You control what you want to extract, keep, and change!
PDF — не самый удобный формат для передачи данных, но иногда возникает необходимость извлекать таблицы (или текст). Данный скрипт Python будет особенно полезен в случае, если вам необходимо периодически извлекать данные из однотипных PDF файлов.
Начнём с импорта библиотек, которые мы будем использовать — Pandas (для записи таблиц в CSV/Excel). Непосредственно работать с PDF файлами мы будем с помощью библиотеки tabula. (установка — cmd -> «pip install tabula-py« ; также для работы необходимо установить Java (https://www.java.com/en/download/))
import tabula
import pandas as pdЗадаём путь к файлу в формате PDF, из которого необходимо извлечь табличные данные:
pdf_in = "D:/Folder/File.pdf"Извлекаем все таблицы из файла в переменную PDF в виде вложенных списков.
PDF = tabula.read_pdf(pdf_in, pages='all', multiple_tables=True)
pages=’all’ и multiple_tables=True — необязательные параметры
Далее прописываем пути к Excel/CSV файлам, которые мы хотим получить на выходе:
pdf_out_xlsx = "D:TempFrom_PDF.xlsx"
pdf_out_csv = "D:TempFrom_PDF.csv"Для сохранения в .xlsx мы создаем датафрейм pandas из нашего вложенного списка и используем pandas.DataFrame.to_excel :
PDF = pd.DataFrame(PDF)
PDF.to_excel(pdf_out_xlsx,index=False) Для сохранения в CSV мы можем использовать convert_into из tabula.
tabula.convert_into (input_PDF, pdf_out_csv, pages='all',multiple_tables=True)
print("Done")Скрипт целиком:
# Script to export tables from PDF files
# Requirements:
# Pandas (cmd --> pip install pandas)
# Java (https://www.java.com/en/download/)
# Tabula (cmd --> pip install tabula-py)
# openpyxl (cmd --> pip install openpyxl) to export to Excel from pandas dataframe
import tabula
import pandas as pd
# Path to input PDF file
pdf_in = "D:/Folder/File.pdf" #Path to PDF
# pages and multiple_tables are optional attributes
# outputs df as list
PDF = tabula.read_pdf(pdf_in, pages='all', multiple_tables=True)
#View result
print ('nTables from PDF filen'+str(PDF))
#CSV and Excel save paths
pdf_out_xlsx = "D:TempFrom_PDF.xlsx"
pdf_out_csv = "D:TempFrom_PDF.csv"
# to Excel
PDF = pd.DataFrame(PDF)
PDF.to_excel(pdf_out_xlsx,index=False)
# to CSV
tabula.convert_into (input_PDF, pdf_out_csv, pages='all',multiple_tables=True)
print("Done")
Python has a large set of libraries for handling different types of operations. Through this article, we will see how to convert a pdf file to an Excel file. There are various packages are available in python to convert pdf to CSV but we will use the Tabula-py module. The major part of tabula-py is written in Java that reads the pdf document and converts the python DataFrame into a JSON object.
In order to work with tabula-py, we must have java preinstalled in our system. Now, to convert the pdf file to csv we will follow the steps-
-
First, install the required package by typing pip install tabula-py in the command shell.
-
Now read the file using read_pdf(«file location», pages=number) function. This will return the DataFrame.
-
Convert the DataFrame into an Excel file using tabula.convert_into(‘pdf-filename’, ‘name_this_file.csv’,output_format= «csv», pages= «all»). It generally exports the pdf file into an excel file
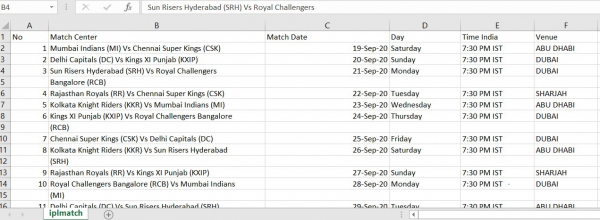
Example
In this example, we have used IPL Match Schedule Document to convert it into an excel file.
# Import the required Module
import tabula
# Read a PDF File
df = tabula.read_pdf("IPLmatch.pdf", pages='all')[0]
# convert PDF into CSV
tabula.convert_into("IPLmatch.pdf", "iplmatch.csv", output_format="csv", pages='all')
print(df)
Output
Running the above code will convert the pdf file into an excel (csv) file.
Updated February 2019
You can convert your PDF to Excel, CSV, XML or HTML with Python using the PDFTables API. Our API will enable you to convert PDFs without uploading each one manually.
In this tutorial, I’ll be showing you how to get the library set up on your local machine and then use it to convert PDF to Excel, with Python.
Here’s an example of a PDF that I’ve converted with the library. In order to properly test the library, make sure you have a PDF handy!
Step 1
If you haven’t already, install Anaconda on your machine from Anaconda website. You can use either Python 3.6.x or 2.7.x, as the PDFTables API works with both. Downloading Anaconda means that pip will also be installed. Pip gives a simple way to install the PDFTables API Python package.
For this tutorial, I’ll be using the Windows Python IDLE Shell, but the instructions are almost identical for Linux and Mac.
Step 2
In your terminal/command line, install the PDFTables Python library with:
pip install git+https://github.com/pdftables/python-pdftables-api.git
If git is not recognised, download it here. Then, run the above command again.
Or if you’d prefer to install it manually, you can download it from python-pdftables-api then install it with:
python setup.py install
Step 3
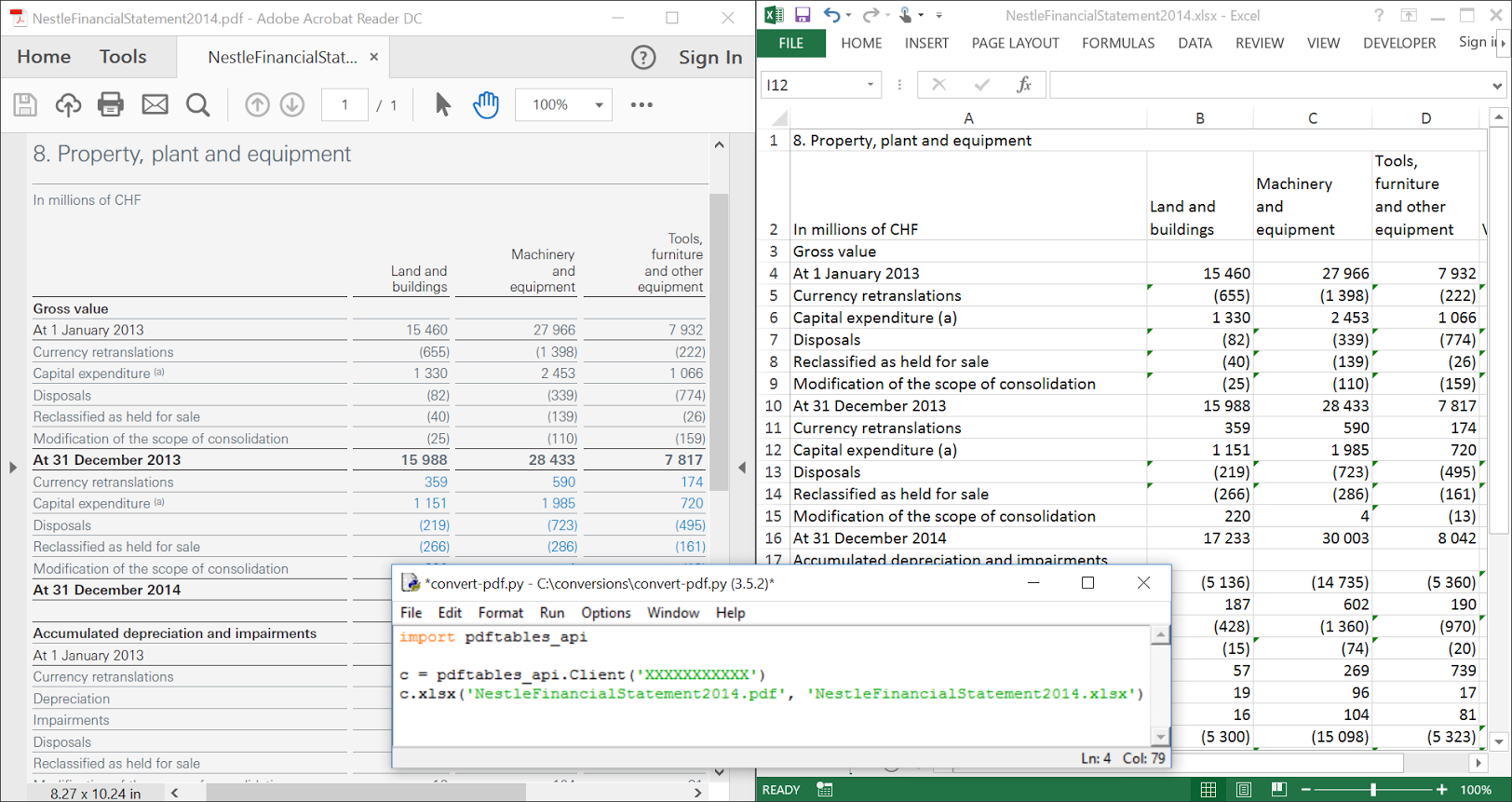
Create a new Python script then add the following code:
import pdftables_api
c = pdftables_api.Client('my-api-key')
c.xlsx('input.pdf', 'output')
#replace c.xlsx with c.csv to convert to CSV
#replace c.xlsx with c.xml to convert to XML
#replace c.xlsx with c.html to convert to HTML
Now, you’ll need to make the following changes to the script:
- Replace
my-api-keywith your PDFTables API key, which you can get here. - Replace
input.pdfwith the PDF you would like to convert. - Replace
outputwith the name you’d like to give the converted document.
Now, save your finished script as convert-pdf.py in the same directory as the PDF document you’d like to convert.
If you don’t understand the script above, see the script overview section.
Step 4
Open your command line/terminal and change your directory (e.g. cd C:/Users/Bob) to the folder you saved your convert-pdf.py script and PDF in, then run the following command:
python convert-pdf.py
To find your converted spreadsheet, navigate to the folder in your file explorer and hey presto, you’ve converted a PDF to Excel or CSV with Python!
Script overview
The first line is simply importing the PDFTables API toolset, so that Python knows what to do when certain actions are called. The second
line is calling the PDFTables API with your unique API key. This means here at PDFTables we know which account is using the API and how many
PDF pages are available. Finally, the third line is telling Python to convert the file with name input.pdf to xlsx and also what
you would like it to be called upon output: output. To convert to CSV, XML or HTML simply change c.xlsx to be c.csv,
c.xml or c.htmlrespectively.
Looking to convert multiple PDF files at once?
Check out our blog post here.
Love PDFTables? Leave us a review on our Trustpilot page!
In this article we will see how to quickly extract a table from a PDF to Excel.
For this tutorial you will need two Python libraries :
- tabula-py
- pandas
To install them, go to your terminal/shell and type these lines of code:
pip install tabula-py
pip install pandasIf you use Google Colab, you can install these libraries directly on it. You just have to add an exclamation mark “!” in front of it, like this:
!pip install tabula-py
!pip install pandas[smartslider3 slider=”10″]
Photo by Aurelien Romain on Unsplash
PDF to Excel (one table only)
First we load the libraries into our text editor :
import tabula
import pandas as pdThen, we will read the pdf with the read_pdf() function of the tabula library.
This function automatically detects the tables in a pdf and converts them into DataFrames. Ideal for converting them into Excel files!
df = tabula.read_pdf('file_path/file.pdf', pages = 'all')[0]We can then check that the table has the expected shape.
df.head()Then convert it to an Excel file !
df.to_excel('file_path/file.xlsx')The entire code :
THE PANE METHOD FOR DEEP LEARNING!
Get your 7 DAYS FREE TRAINING to learn how to create your first ARTIFICIAL INTELLIGENCE!
For the next 7 days I will show you how to use Neural Networks.
You will learn what Deep Learning is with concrete examples that will stick in your head.
BEWARE, this email series is not for everyone. If you are the kind of person who likes theoretical and academic courses, you can skip it.
But if you want to learn the PANE method to do Deep Learning, click here :
import tabula import pandas as pd
df = tabula.read_pdf('file_path/file.pdf', pages = 'all')[0]
df.to_excel('file_path/file.xlsx')
PDF containing several tables
We load the libraries in our text editor :
import tabula
import pandas as pdThen, we will read the pdf with the read_pdf() function of the tabula library.
This function automatically detects the tables in a pdf and converts them into DataFrames. Ideal to convert them then in Excel file !
Here, the variable df will be in fact a list of DataFrame. The first element corresponds to the first table, the second to the second table, etc.
df = tabula.read_pdf('file_path/file.pdf', pages = 'all')To save these tables separately, you will have to use a for loop that will save each table in an Excel file.
for i in range(len(df)):
df[i].to_excel('file_'+str(i)+'.xlsx')The entire code :
import tabula
import pandas as pd
df = tabula.read_pdf('file_path/file.pdf', pages = 'all')
for i in range(len(df)):
df[i].to_excel('file_'+str(i)+'.xlsx')sources:
- Medium
- Photo by Birger Strahl on Unsplash
THE PANE METHOD FOR DEEP LEARNING!
Get your 7 DAYS FREE TRAINING to learn how to create your first ARTIFICIAL INTELLIGENCE!
For the next 7 days I will show you how to use Neural Networks.
You will learn what Deep Learning is with concrete examples that will stick in your head.
BEWARE, this email series is not for everyone. If you are the kind of person who likes theoretical and academic courses, you can skip it.
But if you want to learn the PANE method to do Deep Learning, click here :
I want to convert a pdf file into excel and save it in local via python.
I have converted the pdf to excel format but how should I save it local?
my code:
df = ("./Downloads/folder/myfile.pdf")
tabula.convert_into(df, "test.csv", output_format="csv", stream=True)
![]()
asked Nov 4, 2019 at 9:28
![]()
You can specify your whole output path instead of only output.csv
df = ("./Downloads/folder/myfile.pdf")
output = "./Downloads/folder/test.csv"
tabula.convert_into(df, output, output_format="csv", stream=True)
Hope this answers your question!!!
answered Nov 4, 2019 at 9:41
![]()
skaul05skaul05
2,1143 gold badges17 silver badges25 bronze badges
0
In my case, the script below worked:
import tabula
df = tabula.read_pdf(r'C:UsersuserDownloadsfolder3.pdf', pages='all')
tabula.convert_into(r'C:UsersuserDownloadsfolder3.pdf', r'C:UsersuserDownloadsfoldertest.csv' , output_format="csv",pages='all', stream=True)
![]()
David Buck
3,69335 gold badges33 silver badges35 bronze badges
answered Aug 8, 2020 at 12:48
![]()
i use google collab
install the packege needed
!pip install tabula-py
!pip install pandas
Import the required Module
import tabula
import pandas as pd
Read a PDF File
data = tabula.read_pdf("example.pdf", pages='1')[0] # "all" untuk semua data, pages diisi nomor halaman
convert PDF into CSV
tabula.convert_into("example.pdf", "example.csv", output_format="csv", pages='1') #"all" untuk semua data, pages diisi no halaman
print(data)
to convert to excell file
data1 = pd.read_csv("example.csv")
data1.dtypes
now save to xlsx
data.to_excel('example.xlsx')
answered Feb 23 at 2:02
![]()
1
Documentation says that:
Output file will be saved into output_path
output_path is your second parameter, «test.csv». I guess it works fine, but you are loking it in the wrong folder. It will be located near to your script (to be strict — in current working directory) since you didn’t specify full path.
answered Nov 4, 2019 at 9:43
![]()
QtRoSQtRoS
1,1391 gold badge17 silver badges23 bronze badges
0
PDF to .xlsx file:
for item in df:
list1.append(item)
df = pd.DataFrame(list1)
df.to_excel('outputfile.xlsx', sheet_name='Sheet1', index=True)
answered Apr 8, 2021 at 10:03
![]()
HithHith
495 bronze badges
you can also use camelot in combination with pandas
import camelot
import pandas
tables = camelot.read_pdf(path_to_pdf, flavor='stream',pages='all')
df = pandas.concat([table.df for table in tables])
df.to_csv(path_to_csv)
answered Dec 7, 2022 at 11:31
![]()
smoquetsmoquet
2913 silver badges10 bronze badges