
1. Настройка пакета для выполнения регрессионного анализа
Процедуры корреляционно-регрессионного анализа выполняются в табличном процессоре с помощью модуля «Пакет анализа». Для подключения этого модуля с помощью команды СЕРВИС – НАДСТРОЙКИ выведите окно НАДСТРОЙКИ и включите надстройку ПАКЕТ АНАЛИЗА.

Рис. 11. Диалоговое окно Надстройки меню Сервис.
После выполнения этой процедуры в ниспадающем меню пункта СЕРВИС появится команда АНАЛИЗ ДАННЫХ.

Рис. 12. Лист ППП «Excel» пункт меню Сервис команда Анализ данных.
2. Расчет показателей описательной статистики
Для проверки требований, предъявляемых к исходным данным, следует рассчитать ряд показателей, характеризующих эти данные (среднее значение, дисперсия и т. д.). Эти характеристики данных можно получить, воспользовавшись функцией СЕРВИС — АНАЛИЗ ДАННЫХ – ОПИСАТЕЛЬНАЯ СТАТИСТИКА.

Рис. 13. Диалоговое окно АНАЛИЗ ДАННЫХ.
После выбора требуемой функции откроется окно ОПИСАТЕЛЬНАЯ СТАТИСТИКА.

Рис. 14. Диалоговое окно ОПИСАТЕЛЬНАЯ статистика.
Для расчета показателей описательной статистики в окне «Входной интервал» укажите область ячеек электронной таблицы, где расположены анализируемые данные (исследуемый показатель и все факторы). Желательно в эту область включить ячейки с обозначениями переменных (Х0, Х1, …, Хр) для комфортного восприятия результатов вычислений. Если метки данных (обозначения переменных) учтены, то в области ВХОДНЫЕ ДАННЫЕ включите опцию «Метки в первой строке». Затем в области «Параметры вывода» укажите, куда должны быть выведены результаты расчетов (Новый лист либо Выходной интервал И верхняя левая ячейка области электронной таблицы, где должны быть размещены результаты).
В области «Параметры вывода» включите опцию «Итоговая статистика» и выполните процедуру.
В полученных результатах расчетов удалите повторяющуюся информацию (многократное повторение названий статистик) и рассчитайте для каждого показателя коэффициенты вариации (по среднему значению и стандартному отклонению).
3. Выявление тесноты связи и закона зависимости между факторами и результирующим показателем (анализ полей корреляции)
Для построения полей корреляции (диаграмм рассеивания) используйте команду ВСТАВКА – ДИАГРАММА – ТОЧЕЧНАЯ (вариант без соединения точек) либо мастер диаграмм. В результате выполнения этой команды появится окно МАСТЕР ДИАГРАММ (шаг 2 из 4):

Рис. 15. Диалоговое окно Мастера диаграмм.
В окне Диапазон укажите область столбца электронной таблицы, где находится массив данных для фактора, и через точку с запятой область данных по результирующему показателю. Щелкните мышкой по кнопке ДАЛЕЕ. В результате появится окно следующего 3 шага. В соответствующих окнах введите заголовок графика и названия осей; разместите график на рабочем листе. Постройте графики, отражающие влияние каждого фактора на исследуемый показатель.

Рис. 16. Диалоговое окно Мастера диаграмм – Параметры диаграммы.
Элементы корреляционной матрицы получите, воспользовавшись функцией СЕРВИС — АНАЛИЗ ДАННЫХ — КОРРЕЛЯЦИЯ. В результате будет открыто окно АНАЛИЗ ДАННЫХ.

Рис. 17. Диалоговое окно Анализ данных.
После выбора требуемой функции откроется окно КОРРЕЛЯЦИЯ.

Рис. 18. Диалоговое окно Корреляция.
В окне «Входной интервал» задайте область ячеек электронной таблицы, где расположены анализируемые данные (исследуемый показатель и все факторы). В эту область так же включите ячейки с обозначениями переменных (Х0, Х1, …, Хр). Если метки учтены в области данных, то в окне КОРРЕЛЯЦИЯ включите опцию «Метки в первой строке». Затем в области «Параметры вывода» укажите левую верхнюю ячейку области электронной таблицы, куда должна быть выведена корреляционная матрица.
Анализируя корреляционную матрицу, сделайте выводы о том, как сильно связаны факторы между собой и с исследуемым показателем. Если обнаружены коллинеарные (мультиколлинеарные) факторы, то для дальнейшего анализа следует оставить только один из этих факторов. Проводя анализ взаимосвязей показателей по корреляционной матрице, необходимо помнить о том, что парные коэффициенты корреляции — это показатели тесноты связи для линейных зависимостей.
4. Расчет параметров регрессионной модели
Вид регрессионной модели обосновывают двумя путями: теоретическим и эмпирическим. В первом случае используют качественные рассуждения о законе связи между исследуемым показателем и каждым из факторов, а также результаты других исследователей по построению аналогичных регрессионных моделей. При эмпирическом подходе выводы о форме связи делают на основе анализа фактических данных, представленных в виде первичных полей корреляции.
Чаще всего для анализа используют линейный вид модели или модель, которую можно привести к линейному виду путем некоторых преобразований и замены переменных.
Для расчета параметров регрессионной модели воспользуйтесь функцией СЕРВИС — АНАЛИЗ ДАННЫХ — РЕГРЕССИЯ. В результате появится окно АНАЛИЗ ДАННЫХ. В этом окне выберите инструмент анализа РЕГЕРССИЯ.

Рис. 19. Диалоговое окно Анализ данных.
После щелчка мышкой по кнопке ОК на экране появится окно РЕГРЕССИЯ.

Рис. 20. Диалоговое окно Регрессия.
В этом окне в области «Входной интервал Y» укажите область ячеек, где находятся данные исследуемого показателя, в области «Входной интервал X» — область ячеек с данными по всем факторам. Желательно при этом учитывать обозначения переменных. Если метки данных включены при определении области переменных, то включите опцию «Метки».
Чтобы получить данные для расчета средней относительной ошибки аппроксимации, в этом диалоговом окне поставьте флажок рядом с опцией ОСТАТКИ.
В результате использования функции СЕРВИС — АНАЛИЗ ДАННЫХ — РЕГРЕССИЯ будут получены не только параметры модели, но и показатели, позволяющие оценить надежность построенной модели.
5. Исключение из модели факторов, оказывающих несущественной влияние
Все факторы, влияние которых на исследуемый показатель несущественно, должны быть исключены из модели. Влияние фактора следует считать несущественным, если соответствующий коэффициент регрессии статистически не значим, то есть его можно приравнять нулю. Коэффициент регрессии ![]() следует считать статистически значимым (не равным нулю), если фактическая величина критерия Стьюдента будет больше табличного значения этого критерия. Табличное значение критерия Стьюдента можно найти, воспользовавшись в Excel мастером функций
следует считать статистически значимым (не равным нулю), если фактическая величина критерия Стьюдента будет больше табличного значения этого критерия. Табличное значение критерия Стьюдента можно найти, воспользовавшись в Excel мастером функций ![]() .
.
После обращения к мастеру функций на экране появится окно «Мастер функций – шаг 1 из 2».

Рис. 21. Диалоговое окно Мастера функций.
В левой части этого окна выберите категорию функций «Статистические», в правой части, используя бегунок, выберите функцию «СТЬЮДРАСПРОБР» и щелкните мышкой по кнопке ОК. В результате появится окно для задания параметров этой функции. В этом окне «Вероятность» – уровень значимости ![]() (
(![]() = 1-
= 1-![]()
![]() , где
, где ![]() — доверительная вероятность).
— доверительная вероятность).

Рис. 22. Диалоговое окно функции Стьюдраспобр.
Уровень значимости ![]() обычно принимают равным 0,05; число степеней свободы
обычно принимают равным 0,05; число степеней свободы ![]() =
= ![]() (где
(где ![]() — число наблюдений,
— число наблюдений, ![]() — число параметров регрессионной модели).
— число параметров регрессионной модели).
Если в модели присутствует несколько несущественных факторов, то первым следует исключить тот фактор, для которого табличное значение критерия Стьюдента ![]() намного больше
намного больше ![]() . Несущественно влияющий фактор убирают из совокупности наблюдений и пересчитывают параметры регресcионной модели и ее характеристики. Для модели, полученной на втором шаге, заново проверяют статистическую значимость коэффициентов регресcии. Если вновь обнаружен фактор, оказывающий несущественное влияние на анализируемый показатель, то этот фактор также исключают из модели. Отсев факторов из модели выполняют до тех пор, пока в ней останутся только факторы, оказывающие сильное влияние на
. Несущественно влияющий фактор убирают из совокупности наблюдений и пересчитывают параметры регресcионной модели и ее характеристики. Для модели, полученной на втором шаге, заново проверяют статистическую значимость коэффициентов регресcии. Если вновь обнаружен фактор, оказывающий несущественное влияние на анализируемый показатель, то этот фактор также исключают из модели. Отсев факторов из модели выполняют до тех пор, пока в ней останутся только факторы, оказывающие сильное влияние на ![]() .
.
Чтобы убедиться в том, что из модели были исключены факторы, оказывающие слабое влияние на исследуемый показатель, сравните величины коэффициентов детерминации первого и последнего шагов. Их различие будет незначительным.
6. Проверка надежности регрессионной модели
Вывод о статистической значимости модели в целом делают по ![]() — критерию. Если фактическая величина критерия Фишера окажется больше табличного значения, то полученная модель статистически значима и полно описывает изменение исследуемого показателя под действием факторов, присутствующих в модели.
— критерию. Если фактическая величина критерия Фишера окажется больше табличного значения, то полученная модель статистически значима и полно описывает изменение исследуемого показателя под действием факторов, присутствующих в модели.
Теоретическое значение ![]() — критерия также можно получить с помощью мастера функций
— критерия также можно получить с помощью мастера функций ![]() . Для этого в окне «Мастер функций – шаг 1 из 2» следует выбрать функцию FРАСПОБР.
. Для этого в окне «Мастер функций – шаг 1 из 2» следует выбрать функцию FРАСПОБР.

Рис. 23. Диалоговое окно Мастера функций.
В окне выбранной функции задайте требуемые параметры.

Рис. 24. Диалоговое окно функции Fраспобр.
«Вероятность» – уровень значимости ![]()
![]() (обычно принимают равным 0,05); «Число_степеней свободы1» — это число факторов, присутствующих в модели, «Число_степеней свободы2» определяют как разность между числом наблюдений и числом параметров модели.
(обычно принимают равным 0,05); «Число_степеней свободы1» — это число факторов, присутствующих в модели, «Число_степеней свободы2» определяют как разность между числом наблюдений и числом параметров модели.
Если Fрасч > Fтабл, то построенная модель считается статистически надежной, а следовательно, правильно отражает закон изменения исследуемого показателя под действием факторов, присутствующих в модели.
7. Проверка адекватности регрессионной модели
Среднюю относительную ошибку аппроксимации пользователь должен рассчитать самостоятельно по формуле  , где
, где ![]() фактические (расчетные) значения исследуемого показателя.
фактические (расчетные) значения исследуемого показателя.
Если модель используют для целей анализа, допустима величина средней относительной ошибки до 10%, при применении модели для прогнозирования ошибка не должна быть больше 4%.
Для этого рядом с остатками следует добавить столбец фактических значений исследуемого показателя и выполнить ряд промежуточных расчетов.
8. Интерпретация полученных результатов
На этом этапе разрабатывают рекомендации об использовании результатов регрессионного анализа. Анализируют коэффициенты регрессии в натуральном и стандартизованном масштабе, а также коэффициенты эластичности.
Коэффициент регрессии в натуральном масштабе ![]() показывает, на сколько своих единиц измерения в среднем изменится исследуемый показатель
показывает, на сколько своих единиц измерения в среднем изменится исследуемый показатель ![]() при увеличении
при увеличении ![]() — го фактора на единицу своего измерения. При этом влияние остальных факторов находится на среднем уровне; свободный член уравнения характеризует изменение показателя за счет изменения факторов, неучтенных в модели.
— го фактора на единицу своего измерения. При этом влияние остальных факторов находится на среднем уровне; свободный член уравнения характеризует изменение показателя за счет изменения факторов, неучтенных в модели.
В связи с тем, что факторы имеют различный физический смысл и различные единицы измерения, коэффициенты регрессии ![]() нельзя сравнивать между собой и, следовательно, невозможно определить, какой из факторов оказывает наибольшее влияние. Для устранения различий в единицах измерения применяют частные коэффициенты эластичности, рассчитываемые по формуле:
нельзя сравнивать между собой и, следовательно, невозможно определить, какой из факторов оказывает наибольшее влияние. Для устранения различий в единицах измерения применяют частные коэффициенты эластичности, рассчитываемые по формуле:  , где
, где ![]() — средние значения
— средние значения ![]() — го фактора и исследуемого показателя,
— го фактора и исследуемого показателя, ![]() — коэффициент регрессии, стоящий при переменной
— коэффициент регрессии, стоящий при переменной ![]() в многофакторном уравнении регрессии. Как известно, коэффициент эластичности характеризующие на сколько % в среднем изменится
в многофакторном уравнении регрессии. Как известно, коэффициент эластичности характеризующие на сколько % в среднем изменится ![]() При увеличении j-го фактора на 1% при фиксированном положении других факторов.
При увеличении j-го фактора на 1% при фиксированном положении других факторов.
При определении степени влияния отдельных факторов необходим показатель, который бы учитывал влияние анализируемых факторов с учетом различий в уровне их колеблемости. Таким показателем является коэффициент регрессии в стандартизированном масштабе  Коэффициент
Коэффициент ![]() показывает на какую часть своего среднеквадратического отклонения изменится
показывает на какую часть своего среднеквадратического отклонения изменится ![]() при изменении j-го фактора на одно свое среднеквадратическое отклонение при фиксированном значении остальных факторов. Уравнение регрессии в стандартизированном масштабе :
при изменении j-го фактора на одно свое среднеквадратическое отклонение при фиксированном значении остальных факторов. Уравнение регрессии в стандартизированном масштабе : ![]() где
где 
Границы влияния фактора на исследуемый показатель рассчитываются по формуле ![]() (левая граница)
(левая граница) ![]() (правая граница), где
(правая граница), где ![]() — доверительные полуинтервалы.
— доверительные полуинтервалы.
| < Предыдущая | Следующая > |
|---|
Содержание
- Решение с помощью ППП Excel
- Запуск надстройки Power Pivot для Excel
- Откройте окно Power Pivot.
- Устранение неполадок: исчезновение ленты Power Pivot
- Решение задач с помощью ППП Excel (инструмент Регрессия)
Решение с помощью ППП Excel




![]()
![]()
Задача 3.3 Динамика выпуска продукции Швеции характеризуется данными (млн. долл.), представленными в табл. 3.3.1.
1. Для определения параметров линейного тренда по методу наименьших квадратов используется статистическая функция ЛИНЕЙН, для определения экспоненциального тренда – ЛГРФПРИБЛ. В качестве зависимой переменной в данном примере выступает время (t = 1, 2, …, n). Приведем результаты вычисления функции ЛИНЕЙН и ЛГРФПРИБЛ (рис. 3.1 и 3.2).

Рис. 3.1 Результат вычисления функции ЛИНЕЙН

Рис. 3.2 Результат вычисления функции ЛГРФПРИБЛ
Запишем уравнение линейного и экспоненциального тренда, используя данные рис. 3.1 и 3.2:


2. Построение графиков осуществляется с помощью Мастера диаграмм.
Порядок построения следующий:
1) введите исходные данные или откройте существующий файл, содержащий анализируемые данные;
2) активизируйте Мастер диаграмм любым из следующих способов:
а) в главном меню выберите Вставка / Диаграмма;
б) на панели инструментов Стандартная щелкните по кнопке Мастер диаграмм;
3) в окне Тип выберите График (рис. 3.3); вид графика выберите в поле рядом со списком типов. Щелкните по кнопке Далее;

Рис. 3.3 Диалоговое окно Мастера диаграмм: тип диаграммы
4) заполните диапазон данных, как показано на рис. 3.4. Установите флажок размещения данных в столбцах (строках). Щелкните по кнопке Далее;

Рис. 3.4 Диалоговое окно Мастера диаграмм: источник данных
5) заполните параметры диаграммы на разных закладках (рис. 3.5): название диаграммы и осей, значение осей, линии сетки, параметры легенды, таблица и подписи данных. Щелкните по кнопке Далее;

Рис. 3.5 Диалоговое окно Мастера диаграмм: параметры диаграммы
6) укажите место размещения диаграммы на отдельном или имеющемся листе (рис. 3.6). Щелкните по кнопке Далее. Готовая диаграмма, отражающая динамику уровня изучаемого ряда, представлена на рис. 3.7.

Рис. 3.6 Диалоговое окно Мастера диаграмм: размещение диаграммы
 Рис. 3.7 Динамика выпуска продукции
Рис. 3.7 Динамика выпуска продукции
В ППП MS Excel линия тренда может быть добавлена в диаграмму с областями гистограммы или в график. Для этого:
1) выделите область построения диаграммы; в главном меню выберите Диаграмма / Добавить линию тренда;
2) в появившемся диалоговом окне (рис. 3.8) выберите вид линии тренда и задайте соответствующие параметры. Для полиномиального тренда необходимо задать степень аппроксимирующего полинома, для скользящего среднего – количество точек усреднения.
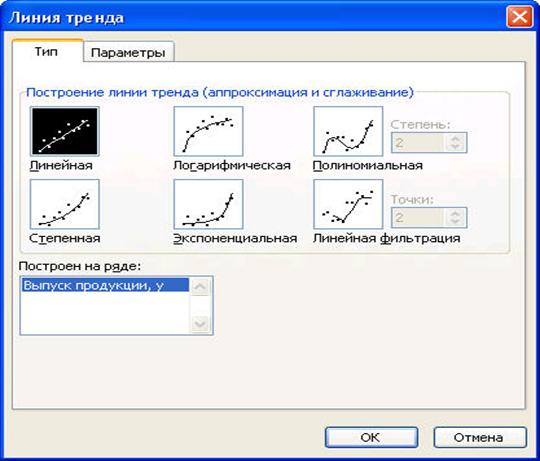
Рис. 3.8 Диалоговое окно типов линий тренда
В качестве дополнительной информации на диаграмме можно отобразить уравнение регрессии и значение среднеквадратического отклонения, установив соответствующие флажки на закладке Параметры (рис. 8.9). Щелкните по кнопке ОК.
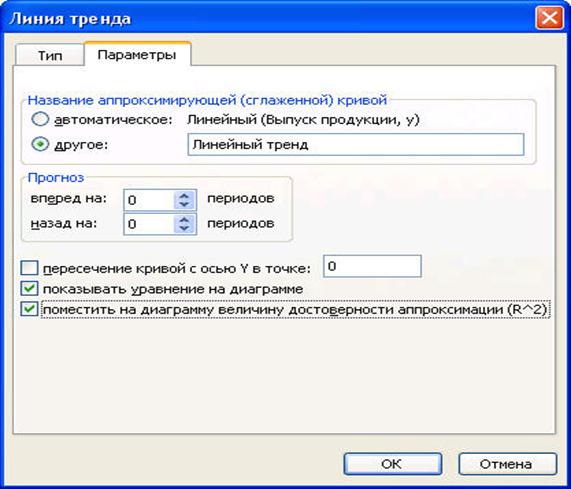
Рис. 3.9 Диалоговое окно параметров линии тренда
На рис. 3.10-3.14 представлены различные виды трендов, описывающие исходные данные задачи.

Рис.3.10 Линейный тренд

Рис.3.11 Логарифмический тренд

Рис.3.12 Полиномиальный тренд


Рис.3.14 Экспоненциальный тренд
3. Сравним значения  (или R 2 ) по разным уравнениям трендов:
(или R 2 ) по разным уравнениям трендов:
полиномиальный 6-й степени —  =0,9728; экспоненциальный — =0,9647;
=0,9728; экспоненциальный — =0,9647;
линейный — =0,8841; степенной — =0,8470; логарифмический — =0,5886.
Исходные данные лучше всего описывает полином 6-й степени. Следовательно, в рассматриваемом примере для прогнозных значений следует использовать полиномиальное уравнение.
Контрольные вопросы
1. Каковы основные элементы временного ряда?
2. В чем состоит задача эконометрического анализа временного ряда?
3. Перечислите основные виды трендов.
4. Что представляют собой параметры линейного и экспоненциального трендов?
5. Что такое аддитивная модель временного ряда? Перечислите этапы ее построения.
6. Как строится мультипликативная модель временного ряда?
7. Что такое скорректированная сезонная компонента и для чего она применяется?
8. Как выбрать наиболее предпочтительный тренд?
9. Пояснить особенности применения аддитивных и мультипликативных моделей.
10. Поясните расчет сезонной компоненты в аддитивных и мультипликативных моделях временных рядов.
Пример варианта промежуточного тестирования
1. Прогнозное значение уровня временного ряда в аддитивной модели равно:
а) разности трендового значения и значения сезонной компоненты;
б) трендовому значению;
в) случайному значению;
г) сумме трендового значения, случайного значения и значения сезонной компоненты.
д) сумме трендового и случайного значения.
2. На основе помесячных данных о числе раскрытых преступлений за последние два года была построена аддитивная модель временного ряда. Скорректированное значение сезонной компоненты за январь – S=-2, уравнение тренда:  . На основе модели число раскрытых преступлений на январь следующего года составит:
. На основе модели число раскрытых преступлений на январь следующего года составит:
3. Для описания темпов роста заработной платы были рассмотрены следующие виды трендов: экспоненциальный, полиномиальный 8 степени, линейный, степенной и логарифмический. Значения коэффициентов детерминации для каждого тренда составляют соответственно:
Понравилась статья? Добавь ее в закладку (CTRL+D) и не забудь поделиться с друзьями:
Источник
Запуск надстройки Power Pivot для Excel
Power Pivot — это надстройка, с помощью которую можно выполнять мощный анализ данных в Excel. Надстройка встроена в определенные версии Office, но по умолчанию не включена.
Список версий Office, которые включают Power Pivot, а также список версий, в которых их нет, см. в вопросе Где Power Pivot?
Вот как можно включить Power Pivot перед первым использованием.
Перейдите на вкладку Файл > Параметры > Надстройки.
В поле Управление выберите Надстройки COM и нажмите Перейти.
Установите флажок Microsoft Office Power Pivot и нажмите кнопку ОК. Если установлены другие версии Power Pivot, то они будут также перечислены в списке надстроек COM. Выберите надстройку Power Pivot для Excel.
На ленте появится вкладка Power Pivot.

Откройте окно Power Pivot.
Щелкните Power Pivot.
На этой вкладке можно работать со сводными таблицами, вычисляемыми полями и ключевыми показателями эффективности Power Pivot, а также создавать связанные таблицы.
Нажмите кнопку Управление.

Откроется окно Power Pivot. Здесь вы можете нажать кнопку «Внешние данные», чтобы использовать мастер импорта таблиц для фильтрации данных при их добавлении в файл, создания связей между таблицами, обогащения данных вычислениями и выражениями и создании сводных таблиц и сводных диаграмм на их основе.
Устранение неполадок: исчезновение ленты Power Pivot
В редких случаях лента Power Pivot исчезает из меню, когда Excel определяет, что надстройка нарушает его работу. Это может произойти, если Excel неожиданно завершает работу при открытом окне Power Pivot. Чтобы восстановить меню Power Pivot:
Выберите Файл > Параметры > Надстройки.
В поле Управление выберите Отключенные объекты > Перейти.
Выберите Microsoft OfficePower Pivot и нажмите кнопку Включить.
Если не удается восстановить ленту Power Pivot, выполнив указанные выше действия, или лента исчезает, когда вы закрываете и снова открываете Excel, сделайте следующее:
откройте меню Пуск > Выполнить и введите команду regedit;
В редакторе реестра разверните следующий раздел:
Для Excel 2013: HKEY_CURRENT_USER > Software > Microsoft > Office > 15.0 > User Settings.
Для Excel 2016: HKEY_CURRENT_USER > Software > Microsoft > Office > 16.0 > User Settings
щелкните правой кнопкой мыши PowerPivotExcelAddin, а затем нажмите Удалить;
вернитесь в верхнюю часть редактора реестра;
разверните раздел HKEY_CURRENT_USER > Software > Microsoft > Office > Excel > Addins;
щелкните правой кнопкой мыши PowerPivotExcelClientAddIn.NativeEntry.1, а затем нажмите Удалить;
закройте редактор реестра;
включите надстройку, выполнив действия, описанные в начале этой статьи.
Источник
Решение задач с помощью ППП Excel (инструмент Регрессия)
Эта операция проводится с помощью инструмента анализа данных Регрессия. Для этого:
1. В главном меню последовательно выберите пункты Сервис/Анализ данных/Регрессия. Щелкните по кнопке ОК;
2. Заполните диалоговое окно ввода данных и параметров вывода (рис.1.7):
Входной интервал У – диапазон, содержащий данные результативного признака;
Входной интервал Х – диапазон, содержащий данные факторов независимого признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона.
Если необходимо получить информацию и графики остатков, установите соответствующие флажки в диалоговом окне.
Щелкните по кнопке ОК.
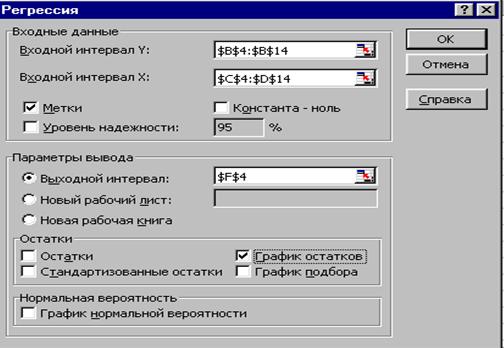
Рис. 1.7. Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных вышеприведенного примера представлены на рис 1.8.
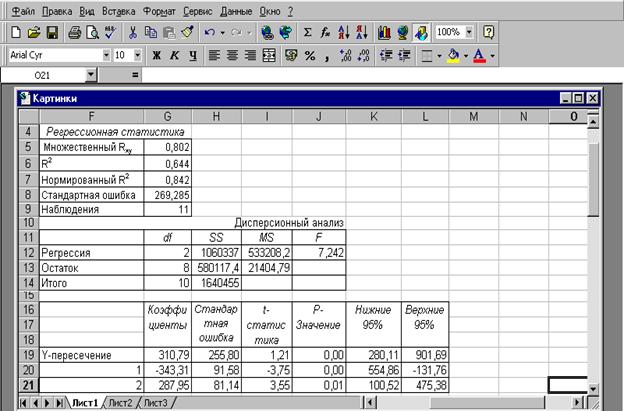
Рис. 1.8. Результат применения инструмента Регрессия
По результатам вычислений составим уравнение множественной регрессии вида
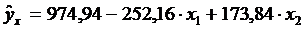 .
.
Критерий Стьюдента t — статистики имеют расчетные значения:
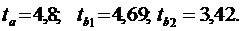
Табличное значение критерия Стьюдента составляет tтабл. = 2,31 при 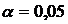 . Расчетные значения критерия Стьюдента больше его табличных значений, следовательно, можно сделать вывод о существенности параметров уравнения.
. Расчетные значения критерия Стьюдента больше его табличных значений, следовательно, можно сделать вывод о существенности параметров уравнения.
Контрольные задания
Задание к задачам 1- 6.
Используя ППП Exsel:
1. Рассчитайте парные коэффициенты корреляции и сделайте по ним вывод.
2. Постройте множественное уравнение регрессии с полным перечнем факторов и сделайте экономическую интерпретацию его параметров.
3. Оцените статистическую значимость множественного уравнения в целом и его параметров.
4. Оцените качество построенной модели, используя ошибку аппроксимации и коэффициент множественной детерминации.
5. Рассчитайте средние и частные коэффициенты эластичности, а также частные коэффициенты корреляции, выполните анализ.
Имеются данные о рентабельности производства шерсти по 18 административным районам области за год:
х1 — настриг шерсти с одной овцы, кг;
х2 — затраты на 1 центнера шерсти, человеко – часов;
х3 — себестоимость 1 центнера, руб;
у – уровень рентабельности, %.
Таблица 1.24 – Рентабельность производства шерсти
| № района | х1 | х2 | х3 | у |
| 1 | 1,3 | 574,1 | 7815,3 | 64,2 |
| 2 | 1,4 | 1156,3 | 8441,9 | 76,9 |
| 3 | 0,5 | 1333,3 | 5604,2 | 67,7 |
| 4 | 1,9 | 712,1 | 4862,7 | 83,9 |
| 5 | 1,6 | 1276,9 | 8817,3 | 81,0 |
| 6 | 1,3 | 563,8 | 9301,8 | 100,0 |
| 7 | 0,4 | 1000,0 | 11200,0 | 87,4 |
| 8 | 1,7 | 516,5 | 11312,5 | 78,2 |
| 9 | 0,4 | 285,7 | 8550,3 | 88,3 |
| 10 | 1,5 | 428,6 | 19521,7 | 90,0 |
| 11 | 0,9 | 725,0 | 5417,6 | 86,4 |
| 12 | 0,7 | 328,4 | 5709,5 | 90,0 |
| 13 | 1,4 | 738,5 | 14660,4 | 92,9 |
| 14 | 1,0 | 556,8 | 7301,2 | 52,1 |
| 15 | 1,8 | 193,5 | 9052,8 | 92,6 |
| 16 | 0,5 | 729,7 | 20157,9 | 90,5 |
| 17 | 1,2 | 322,8 | 16052,6 | 94,8 |
| 18 | 1,1 | 403,5 | 9034,5 | 72,1 |
Имеются данные об уровне убыточности производства мяса птицы по 20 административным районам области за год:
х1— затраты на 1 центнера прироста, человеко – часов;
х2 — затраты на 1 центнера прироста, руб.;
х3 — себестоимость 1 центнера, руб.;
у – уровень убыточности, %.
Таблица 1.25 – Уровень убыточности производства мяса птицы
| № района | х1 | х2 | х3 | у |
| 1 | 46,9 | 3517,7 | 3655,1 | 42,7 |
| 2 | 136,3 | 4432,6 | 3047,2 | 36,1 |
| 3 | 114,8 | 3878,0 | 3243,6 | 35,3 |
| 4 | 247,4 | 8324,7 | 5839,9 | 52,5 |
| 5 | 192,4 | 5162,6 | 1546,5 | 23,2 |
| 6 | 10,1 | 2860,8 | 2976,0 | 39,7 |
| 7 | 108,5 | 4290,6 | 2562,5 | 31,7 |
| 8 | 142,7 | 8046,7 | 4600,4 | 57,3 |
| 9 | 99,1 | 3370,8 | 4888,9 | 63,6 |
| 10 | 153,8 | 5547,4 | 3871,4 | 31,4 |
| 11 | 115,3 | 4599,7 | 2806,9 | 14,2 |
| 12 | 63,0 | 2589,3 | 2852,1 | 53,2 |
| 13 | 107,1 | 5902,9 | 2904,8 | 35,9 |
| 14 | 111,3 | 6754,1 | 3178,3 | 25,7 |
| 15 | 86,9 | 4904,2 | 4702,1 | 59,0 |
| 16 | 110,8 | 4719,2 | 7122,3 | 61,6 |
| 17 | 200,6 | 8462,1 | 2871,8 | 36,8 |
| 18 | 136,7 | 5830,3 | 6070,3 | 53,7 |
| 19 | 87 | 2619,6 | 4711,3 | 61,4 |
| 20 | 107,4 | 2198,2 | 4400,0 | 30,3 |
Имеются данные об уровне рентабельности и удельном весе продукции собственного производства и покупной в товарообороте 15 предприятий общественного питания за год:
х1— удельный вес в товарообороте продукции собственного производства, %;
х2 — удельный вес в товарообороте покупной продукции, %;
у – уровень рентабельности, %.
Таблица 1. 26 – Уровень рентабельности предприятий общественного питания
Имеются данные об уровне рентабельности и показателям хозяйственной деятельности по 15 торговым предприятиям за год:
х1— производительность труда, у. е.;
х3 – относительный уровень издержек обращения, %;
у – уровень рентабельности, %.
Таблица 1. 27 – Уровень рентабельности торговых предприятий
| № предпр. | х1 | х2 | х3 | у |
| 1 | 7134 | 149 | 14,91 | 5,2 |
| 2 | 5415 | 142 | 15,05 | 4,41 |
| 3 | 7633 | 151 | 14,77 | 5,23 |
| 4 | 10259 | 165 | 11,55 | 6,72 |
| 5 | 14620 | 175 | 9,21 | 7,14 |
| 6 | 8736 | 155 | 14,2 | 4,4 |
| 7 | 5590 | 144 | 16,23 | 3,78 |
| 8 | 10212 | 165 | 11,97 | 6,83 |
| 9 | 11586 | 171 | 13,05 | 6,07 |
| 10 | 9156 | 161 | 13,45 | 6,1 |
| 11 | 12501 | 173 | 10,13 | 7,1 |
| 12 | 11274 | 168 | 12,33 | 6,21 |
| 13 | 7700 | 150 | 15,23 | 3,7 |
| 14 | 9383 | 160 | 13,95 | 5,55 |
| 15 | 12255 | 170 | 10,17 | 6,9 |
Имеются данные об уровне рентабельности и показателям хозяйственной деятельности по 15 предприятиям общественного питания за год:
х1— удельный вес в товарообороте продукции собственного производства, %;
х2 — удельный вес в товарообороте покупной продукции, %;
х3 – трудоемкость в расчете на 100000 у. е. товарооборота, чел.;
х4– относительный уровень издержек обращения, %;
у – уровень рентабельности, %.
| № пред. | Х1 | х2 | х3 | х4 | у |
| 1 | 56,6 | 43,4 | 28 | 31,51 | 7,92 |
| 2 | 51,6 | 48,4 | 27 | 30,2 | 8,17 |
| 3 | 48,5 | 51,5 | 22 | 29,1 | 8,0 |
| 4 | 63,2 | 36,8 | 38 | 32,79 | 7,04 |
| 5 | 47,6 | 52,4 | 30 | 26,44 | 9,14 |
| 6 | 60,8 | 39,2 | 35 | 37,16 | 9,0 |
| 7 | 32,2 | 67,8 | 24 | 26,04 | 9,13 |
| 8 | 53,2 | 46,8 | 25 | 31,91 | 7,81 |
| 9 | 41,6 | 58,4 | 29 | 27,13 | 9,17 |
| 10 | 76,1 | 23,9 | 43 | 29,3 | 9,01 |
| 11 | 43,6 | 56,4 | 31 | 33,7 | 6,43 |
| 12 | 52,8 | 47,2 | 30 | 36,44 | 5,64 |
| 13 | 50,0 | 50,0 | 37 | 31,3 | 7,75 |
| 14 | 43,4 | 56,6 | 28 | 31,65 | 7,7 |
| 15 | 47,6 | 52,4 | 24 | 27,09 | 7,02 |
Имеются данные об уровне трудоемкости товарооборота и показателям хозяйственной деятельности по 15 предприятиям общественного питания за год:
х1— удельный вес в товарообороте продовольственных товаров, %;
х2 – удельный вес в товарообороте непродовольственных товаров, %;
х3 – удельный вес товарооборота общественного питания, %;
у – уровень трудоемкости товарооборота, %.
Таблица 1. 29 – Уровень трудоемкости товарооборота
| № пред. | Х1 | х2 | х3 | у |
| 1 | 82,1 | 17,9 | 5,9 | 9 |
| 2 | 76,2 | 23,8 | 10,6 | 10 |
| 3 | 80,3 | 19,7 | 5,5 | 12 |
| 4 | 84,9 | 15,1 | 15,0 | 14 |
| 5 | 81,2 | 18,8 | 7,0 | 8 |
| 6 | 81,5 | 18,5 | 12,7 | 9 |
| 7 | 85,2 | 14,8 | 11,3 | 14 |
| 8 | 77,8 | 22,2 | 6,9 | 10 |
| 9 | 82,2 | 17,8 | 8,1 | 12 |
| 10 | 82,3 | 17,7 | 17,0 | 12 |
| 11 | 80,1 | 19,9 | 6,9 | 11 |
| 12 | 76,0 | 24,0 | 5,7 | 10 |
| 13 | 77,3 | 22,7 | 9,7 | 11 |
| 14 | 74,5 | 25,5 | 12,7 | 9 |
| 15 | 73,5 | 26,5 | 7,4 | 8 |
Контрольные вопросы
1. Назовите, в чем состоит спецификация модели множественной регрессии.
2. Сформулируйте требования, предъявляемые к факторам для включения их в модель множественной регрессии.
3. К каким трудностям приводит мультиколлинеарность факторов, включенных в модель, и как они могут быть разрешены?
4. Назовите методы устранения мультиколлинеарности факторов.
5. Что означает взаимодействие факторов и как оно может быть представлено графически?
6. Назовите способы оценки параметров множественной регрессии?
7. Приведите порядок вычисления параметров множественной модели методом наименьших квадратов.
8. В чем заключается метод оценки параметров уравнения множественной регрессии с использованием стандартизованных переменных?
9. Как интерпретируются коэффициенты множественной регрессии степенной модели?
10. Как интерпретируются коэффициенты множественной регрессии линейной модели?
11. Какие эконометрические параметры используются для оценки сравнительной силы воздействия факторов на результат?
12. Как рассчитываются коэффициенты множественной корреляции и детерминации?
13. Для чего используются частные коэффициенты эластичности и как их рассчитать?
14. Каково назначение частной корреляции при построении множественного уравнения регрессии?
15. Составьте матрицу частных коэффициентов корреляции разного порядка для регрессионной модели с четырьмя факторами.
16. Как оценить статистическую значимость множественной модели в целом?
17. Как оценить статистическую значимость параметров уравнения множественной регрессии?
18. Что такое частный критерий Фишера и для чего он рассчитывается?
19. Как связаны между собой критерий Стьюдента, используемый для оценки статистической значимости коэффициентов регрессии, и частные критерии Фишера?
20. При каких условиях строится уравнение множественной регрессии с фиктивными переменными?
21. Как трактуются коэффициенты модели, построенной только на фиктивных переменных?
22. Сформулируйте основные предпосылки применения МНК для построения регрессионной модели.
23. Как можно проверить наличие гомо – или гетероскедастичности остатков?
24. Как оценивается отсутствие автокорреляции остатков при построении статистической регрессионной модели?
Тесты
1. Частные коэффициенты (или индексы) корреляции характеризуют
а) тесноту связи между у и всеми факторами, включенными в модель;
б) качество построенной модели;
в) тесноту связи между у и соответствующим фактором х при устранении
влияния других включенных в модель факторов;
г) статистическую значимость коэффициентов чистой регрессии.
2. Коэффициент чистой регрессии признается статистически значимым, если:
а) F част хi F табл.;
в) F част хi = 1; г) F част хi> 0.
3. Модель вида y = f (x1,x2, …, xn)представляет собой:
а) множественную регрессию;
б) одномерный временной ряд;
в) простую регрессию;
г) аддитивную модель временного ряда.
4. Допустимый предел средней ошибки аппроксимации ( 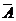 ) составляет
) составляет
а) от – 1 до +1; б) от 0 до + 1; в) от – 1 до 0; г) до (8-10)%.
5. Средний коэффициент эластичности ( 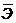 ) показывает
) показывает
а) долю дисперсии, объясненную регрессией, в общей дисперсии результативного признака;
б) средний процент изменения результата от своего среднего значения при изменении фактора на 1% от своего среднего значения;
в) статистическую значимость уравнения регрессии;
г) нет правильного ответа.
6. Известно, что при фиксированном значении х3 ме6жду величинами х1 и х2 существует положительная связь. Какое значение имеет частный коэффициент корреляции r x1x2,x3?
а) — 0,8; б) 0; в) 0,4; г) 1,3.
7. Множественный коэффициент корреляции для двухфакторного уравнения, построенного по 20 наблюдениям, равен 0,85. Чему равен критерий Фишера?
а) 8,74; б) 12,13; в) 22,13; г) 122,14.
8. Имеется уравнение в линеаризованном виде ln y = 0,1274 -0,2143* ln x1 +2,8254* ln x2. Естественная форма данного уравнения будет иметь вид:
в) у = 1,136*х1 -0,2143 * х2 2,8254 ; г) у = 1,136*0,2143х1 * 2,8254х2.
9. Оцените статистическую значимость коэффициентов регрессии в уравнении у = 30 +10*х1 + 8* х2, построенном по 19 наблюдениям, если их стандартные ошибки равны mb1 = 2.5; mb2= 4.
а) коэффициент регрессии b1 статистически значим, а b2 — нет;
б) оба коэффициента регрессии статистически значимы;
в) коэффициент регрессии b2 статистически значим, а b1 — нет;
г) оба коэффициента регрессии статистически незначимы.
10. Множественный коэффициент корреляции ryx1x2 = 0,963, парные коэффициент корреляции ryx1 = 0,428 и ryx2 = 0,962. чему равны частные критерии Фишера Fx1 и Fx2? 7
11. Множественный коэффициент детерминации R 2 = 0.927. парные коэффициент корреляции ryx1 = 0,428 и ryx2 = 0,962. Чему равны критерии Стьюдента tb1 и tb2, рассчитанные для 10 наблюдений?
в) tb = 9,44 ; tb2 = 1,44; г) tb = 8,94 ; tb2 = 0.74.
12. Производственная функция характеризуется уравнением ln Р = 0,552 + 0,2761 ln Z + 0.5211 ln K. Средние коэффициенты эластичности равны
а) Э(Z) = 0,552 ; Э(K) = 0,2761; б) Э(Z) = 0,2761 ; Э(K) = 0,5211;
в) Э(Z) = 0,5211 ; Э(K) = 0,522; г) Э(Z) = 0,2761 ; Э(K) = 0,522.
13. Как интерпретируются коэффициенты множественной регрессии степенной функции?
а) являются средними коэффициентами эластичности;
б) являются коэффициентами чистой регрессии;
в) являются свободными членами;
г) нет правильного ответа.
14. Имеются данные Σу = 8,564; Σх1 = 743,5; Σх2 = 32606; Σх1*у = 639,393; Σх2*у = 27983; Σх1 2 = 55451; . Σх2 2 = 1,07*10 8 ; +Σх1* х2 = 2428731. Чему равны параметры двухфакторной модели, построенной по 10 наблюдениям?
а) а= 2,5; b1 = 0,164; b2= -0,0034; б) а=-0,25; b1=1,64; b2= 0,034;
в) а= — 0,25; b1 = 0,0164; b2=-0,000034; г) а=-0,78; b1=0,164; b2=0,064.
15. В чем смысл средней ошибки аппроксимации?
а) Абсолютное отклонение расчетного значения результативного признака от его фактического значения;
б) среднее отклонение расчетного значения результативного признака от его фактического значения, выраженного в %;
в) среднее отклонение расчетного значения результативного признака от его среднего значения;
г) среднее отклонение расчетного значения результативного признака от его среднего значения, выраженное в %.
16. Назовите методы устранения мультиколлинеарности факторов.
а) исключение из модели одного или нескольких факторов; преобразование факторов; переход к совмещенным уравнениям регрессии;
б) исключение из модели одного или нескольких факторов; преобразование факторов; переход к совмещенным уравнениям регрессии или к уравнениям регрессии приведенной формы;
в) исключение из модели одного или нескольких факторов; переход к совмещенным уравнениям регрессии или к уравнениям регрессии приведенной формы;
г) исключение из модели одного или нескольких факторов; преобразование факторов; переход к уравнениям регрессии приведенной формы.
17. С какой целью рассчитываются частные коэффициенты эластичности для уравнения множественной регрессии?
а) они могут быть использованы для принятия решений относительно развития конкретных регионов;
б) они могут быть использованы для определения спроса и потребления;
в) они могут быть использованы для принятия решений в среднем по регионам;
г) нет полного ответа.
18. Сформулируйте требования, предъявляемые к факторам для включения их в модель множественной регрессии
а) факторы не должны быть мультиколлинеарны; факторы не должны быть фиктивными;
б) они должны быть количественно измеримы; факторы не должны быть интеркоррелированы;
в) факторы не должны находиться в тесной линейной зависимости; факторы не должны быть фиктивными;
г) факторы должны находиться в тесной линейной зависимости ; факторы должны быть количественно измеримы.
19. Каким образом оценивается статистическая значимость мультиколлинеарности факторов?
а) по критерию Фишера; б) по критерию Стьюдента;
в) по величине χ 2 ; г) все ответы правильные.
20. Каков смысл коэффициентов регрессии в логарифмической регрессионной модели?
а) коэффициенты регрессии являются эластичностями переменной у по переменных х1, х2 … хn.;
б) коэффициенты регрессии показывают среднее изменение переменной у при изменении переменным х1, х2 … хn на единицу;
в) коэффициенты регрессии показывают среднее изменение переменной у при изменении соответствующей переменной на единицу и неизменном среднем уровне других факторов;
г) коэффициенты регрессии показывают темпы прироста переменной у по переменных х1, х2 … хn.
21. Средние коэффициенты эластичности для уравнения у(х) = -294 +44,15х1+13,21х2 составят … при условии, что средние значения признаков равны :х1 = 4,45; х2 = 19,5; у=160.
а) 1,23; 1,61; б) 0,77; 1,45;
в) 2,43; 3,56; г) 3,42; 2,71.
22. Мультиколлинеарность – это связь между …
а) векторами; б) процессами; в) признаками; г) явлениями.
23. После расчета неизвестных параметров модели следует:
а) определить состав включенных в модель регрессии переменных;
б) оценить адекватность и точность модели;
в) выбрать функцию, связывающую результативный признак и факторные признаки;
г) рассчитать интервальные прогнозные оценки.
24. В каких случаях во множественной регрессии используются фиктивные переменные?
а) если фактор имеет количественные уровни;
б) если фактор имеет качественные уровни;
в) если в уравнение вводится 2 и более факторов;
г) если факторы мультиколлинеарны.
25. Адекватность эконометрической модели – это …
а) способность модели описывать выходные параметры с относительной погрешностью не более некоторого заданного значения δ;
б) возможность модели обеспечить минимальное совпадение фактических и теоретических значений;
в) способность отразить в достаточной мере выходные параметры, которые отвечают поставленной цели;
г) возможность установить соотношения между внешними и выходными параметрами путем исследования на внешние воздействия.
26. Множественная корреляция – это …
а) связь между двумя показателями;
б) связь между несколькими факторами и одним результативным признаком;
в) связь между одним фактором и результативным признаком при исключении других факторов;
г) связь между одним фактором и несколькими результативными признаками.
27. Система нормальных уравнений вида 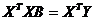 используется для оценки
используется для оценки
а) коэффициентов регрессионного уравнения;
б) временного сдвига двух переменных;
в) коэффициента детерминации;
г) статистической значимости параметров модели.
Дата добавления: 2018-02-15 ; просмотров: 856 ; Мы поможем в написании вашей работы!
Источник
ППП EXCEL
Следует отметить,
что применение встроенных функций ГСЧ
ППП EXCEL
целесообразно лишь в том случае, когда
вероятности реализации всех значений
случайной величины считаются одинаковыми.
В этом случае для
имитации значений требуемой переменной
можно воспользоваться математическими
функциями СЛЧИС()
или СЛУЧМЕЖДУ().
Форматы функций приведены в табл.3.
Таблица 3.
Математические функции для генерации
случайных чисел
|
Наименование функции |
Формат функции |
|
|
Оригинальная версия |
Локализованная версия |
|
|
RAND |
СЛЧИС |
СЛЧИС() — не имеет аргументов |
|
RANDBETWEEN |
СЛУЧМЕЖДУ |
СЛУЧМЕЖДУ(нижн_граница; верхн_граница) |
Функция СЛЧИС()
Функция СЛЧИС()
возвращает равномерно распределенное
случайное число E, большее, либо равное
0 и меньшее 1, т.е.: 0 ≤E< 1. Вместе с тем,
путем несложных преобразований, с ее
помощью можно получить любое случайное
вещественное число. Например, чтобы
получить случайное число между a и b,
достаточно задать в любой ячейке ЭТ
следующую формулу:
=СЛЧИС()*(b-a)+a
Эта функция не
имеет аргументов. Если в ЭТ установлен
режим автоматических вычислений,
принятый по умолчанию, то возвращаемый
функцией результат будет изменяться
всякий раз, когда происходит ввод или
корректировка данных. В режиме ручных
вычислений пересчет всей ЭТ осуществляется
только после нажатия клавиши [F9].
Настройка режима
управления вычислениями производится
установкой соответствующего флажка в
подпункте «Вычисления» пункта
«Параметры» темы «Сервис»
главного меню.
В целом применение
данной функции при решении задач
финансового анализа ограничено рядом
специфических приложений. Однако ее
удобно использовать в некоторых случаях
для генерации значений вероятности
событий, а также вещественных чисел.
Функция
СЛУЧМЕЖДУ(нижн_граница; верхн_граница)
Как следует из
названия этой функции, она позволяет
получить случайное число из заданного
интервала. При этом тип возвращаемого
числа (т.е. вещественное или целое)
зависит от типа заданных аргументов.
В качестве примера,
сгенерируем случайное значение для
переменной Q (объем выпуска продукта).
Согласно табл.1, эта переменная принимает
значения из диапазона 150 — 300.
Введите в любую
ячейку ЭТ формулу:
=СЛУЧМЕЖДУ(150;300)…..(Результат:210)
(Вы можете получить
другой результат — любое число из
заданного диапазона)
Если задать
аналогичные формулы для переменных P и
V, а также формулу для вычисления NPV и
скопировать их требуемое число раз,
можно получить генеральную совокупность,
содержащую различные значения исходных
показателей и полученных результатов.
После этого нетрудно рассчитать
соответствующие параметры распределения
и провести вероятностный анализ.
Замечание:
Перед тем, как приступить к разработке
шаблонов рабочих таблиц описанного
выше примера, рекомендуется установить
в ЭТ режим вычислений ручным способом.
Для этого необходимо
выполнить следующие действия:
— Выбрать в главном
меню пункт «Сервис».
— Выбрать «Параметры»
подпункт «Вычисления».
— Установить флажок
«Вручную» и нажать кнопку «ОК».
Разработка
шаблонов.
Отведем для
проводимого эксперимента в рабочей
книге ППП EXCEL два листа.
Первый лист –
«Имитация», — предназначен для построения
генеральной совокупности эксперимента.
Определенные в данном листе формулы и
собственные имена ячеек приведены в
табл.4. табл.5.
На втором листе
моделируются результаты эксперимента.
Формулы, необходимые для заполнения
ячеек результатов эксперимента, приведены
в табл.6., табл.7.
Оформите шаблоны
рабочих листов ЭТ, рис.1, рис.2.
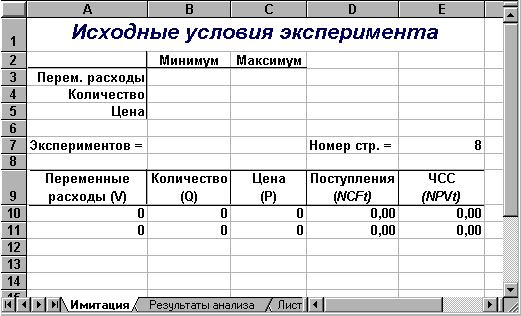
Рис.1. Лист «Имитация»
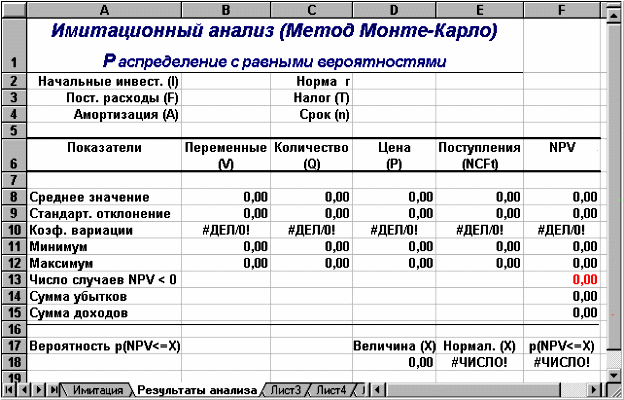
Рис.2. Лист «Результаты
анализа»
Функция
ЧПС(ставка;значение1;значение2;
…)
Возвращает величину
чистой приведенной стоимости инвестиции,
используя ставку дисконтирования, а
также стоимости будущих выплат
(отрицательные значения) и поступлений
(положительные значения).
Ставка — ставка
дисконтирования за один период.
Значение1, значение2,
… — от 1 до 29 аргументов, представляющих
расходы и доходы.
-
Значение1, значение2,
… должны быть равномерно распределены
во времени, выплаты должны осуществляться
в конце каждого периода. -
ЧПС использует
порядок аргументов значение1, значение2,
… для определения порядка поступлений
и платежей. Убедитесь в том, что ваши
платежи и поступления введены в
правильном порядке. -
Аргументы, которые
являются числами, пустыми ячейками,
логическими значениями или текстовыми
представлениями чисел, учитываются;
аргументы, которые являются значениями
ошибки или текстами, которые не могут
быть преобразованы в числа, игнорируются. -
Если аргумент
является массивом или ссылкой, то
учитываются только числа. Пустые ячейки,
логические значения, текст или значения
ошибок в массиве или ссылке игнорируются. -
Считается, что
инвестиция, значение которой вычисляет
функция ЧПС, начинается за один
период до даты денежного взноса (значение
1) и заканчивается с последним денежным
потоком в списке аргументов функции.
Вычисления функции ЧПС базируются на
будущих денежных потоках. Если первый
денежный взнос приходится на начало
первого периода, то первое значение
следует добавить к результату функции
ЧПС cо
знаком минус, но не включать в список
аргументов.
Примечание: а)
в стандартной функции ЧПС (табл..4), под
записью: NCFt[D10(D11)],
следует понимать значения поступлений
(NCF),
повторяющихся в формуле через (;) n
раз, где n
– срок инвестиций проекта.
б)
формула в ячейке Е10 листа «Имитация»
имеет вид:
=ЧПС(Результат!$D$2;D10;D10;D10;D10;D10)-Результат!$B$2
Первая часть листа
(блок ячеек А1:Е7) предназначена для ввода
диапазонов изменений ключевых переменных,
значения которых будут генерироваться
в процессе проведения эксперимента. В
ячейке В7 задается общее число имитаций
(экспериментов). Формула, заданная в
ячейке Е7, вычисляет номер последней
строки выходного блока, в который будут
помещены полученные значения. Смысл
этой формулы будет раскрыт позже.
Вторая часть листа
(блок ячеек А9:Е11) предназначена для
проведения имитации. Формулы в ячейках
А10:С11 генерируют значения для
соответствующих переменных с учетом
заданных в ячейках В3:С5 диапазонов их
изменений.
Обратите внимание!
При указании
нижней и верхней границы изменений
используется абсолютная адресация
ячеек.
Формулы в ячейках
D10:E11 вычисляют величину потока платежей
и его чистую современную стоимость
соответственно.
Обратите внимание!
Значения
постоянных переменных берутся из листа
шаблона — «Результаты анализа».
Лист «Результаты
анализа» кроме значений постоянных
переменных содержит также функции,
вычисляющие параметры распределения
изменяемых (Q, V, P) и результатных (NCF, NPV)
переменных, значения которых выбираются
из листа «Имитация».
Например, по формуле
«=СРЗНАЧ(Перемененные расходы)»
определяется среднее значение переменных
расходов на проект, полученных в
результате имитационного эксперимента.
Исходные данные эксперимента берутся
с листа «Имитация»: блок ячеек от ячейки
А10
до ячейки, координаты которой определяются
формулой ячейки Е7
листа «Имитация»: =B7+10-2
.
Определенные для
данного листа формулы и собственные
имена ячеек приведены в табл. 6 и табл.7.
Общий вид листа показан на рис.2.



Данные для
нахождения средних значений, минимума,
максимума и пр. (табл. 3) берутся из листа
«Имитация»
Поскольку формулы
листа содержат ряд новых функций,
приведем необходимые пояснения.
Функции МИН()
и МАКС()
вычисляют минимальное и максимальное
значение для массива данных из блока
ячеек, указанного в качестве их аргумента.
Имена и диапазоны этих блоков приведены
в табл.7.
Функция СЧЕТЕСЛИ()
осуществляет подсчет количества ячеек
в указанном блоке, значения которых
удовлетворяют заданному условию. Функция
имеет следующий формат:
=СЧЕТЕСЛИ(блок;
«условие»).
В данном случае,
заданная в ячейке F13, функция СЧЕТЕСЛИ()
осуществляет подсчет количества
отрицательных значений NPV, содержащихся
в блоке ячеек ЧСС (см. табл.7).
Механизм действия
функции СУММЕСЛИ() аналогичен функции
СЧЕТЕСЛИ(). Отличие заключается лишь в
том, что эта функция суммирует значения
ячеек в указанном блоке, если они
удовлетворяют заданному условию. Функция
имеет следующий формат:
=СУММЕСЛИ(блок;
«условие»).
В данном случае,
заданные в ячейках F14 и F15 функции
осуществляют подсчет суммы отрицательных
(ячейка F14) и положительных (ячейка F15)
значений NPV, содержащихся в блоке ЧСС.
Смысл этих расчетов будет объяснен
позже.
Две последние
формулы (ячейки Е18 и F18) предназначены
для проведения вероятностного анализа
распределения NPV и требуют небольшого
теоретического отступления.
В рассматриваемом
примере было сделано допущение, что
ключевые переменные Q, V, P независимы и
равномерно распределены. Однако какое
распределение при этом будет иметь
результатная величина — показатель NPV,
заранее определить нельзя.
Одно из возможных
решений этой проблемы — попытаться
аппроксимировать неизвестное распределение
каким-либо известным способом. При этом
в качестве приближения удобнее всего
использовать нормальное распределение.
Это связано с тем, что в соответствии с
центральной предельной теоремой теории
вероятностей при выполнении определенных
условий сумма большого числа случайных
величин имеет распределение, приблизительно
соответствующее нормальному.
В прикладном
анализе для целей аппроксимации широко
применяется частный случай нормального
распределения — т.н. стандартное нормальное
распределение. Математическое ожидание
стандартно распределенной случайной
величины Z
равно 0: M(Z)=0.
График этого распределения симметричен
относительно оси ординат и оно
характеризуется всего одним параметром
— стандартным отклонением
![]()
,
равным 1.
Приведение случайной
переменной Х к стандартно распределенной
величине Z осуществляется с помощью
т.н. нормализации — вычитания средней и
последующего деления на стандартное
отклонение:
|
|
(1) |
Для вычисления
вероятностей по значению нормализованной
величины Z используются специальные
статистические таблицы.
В ППП EXCEL подобные
вычисления осуществляются с помощью
статистических функций НОРМАЛИЗАЦИЯ()
и НОРМСТРАСП().
Функция
НОРМАЛИЗАЦИЯ(x; среднее; станд_откл)
Эта функция
возвращает нормализованное значение
Z величины X,
на основании которого затем вычисляется
искомая вероятность p(X).
Она реализует соотношение (1). Функция
требует задания трех аргументов:
X
— нормализуемое значение;
среднее —
математическое ожидание случайной
величины X;
станд_откл —
стандартное отклонение.
Полученное значение
Z является аргументом для следующей
функции — НОРМСТРАСП().
Функция
НОРМСТРАСП(Z)
Эта функция
возвращает стандартное нормальное
распределение, т.е. вероятность того,
что случайная нормализованная величина
X
будет меньше или равна X.
Она имеет всего один аргумент — Z,
вычисляемый функцией НОРМАЛИЗАЦИЯ().
Нетрудно заметить,
что эти функции следует использовать
в тандеме. При этом наиболее эффективным
и компактным способом их задания является
указание функции НОРМАЛИЗАЦИЯ() в
качестве аргумента функции — НОРМСТРАСП(),
т.е.:
=НОРМСТРАСП(НОРМАЛИЗАЦИЯ(x;
среднее; станд_откл)).
С целью повышения
наглядности, в проектируемом шаблоне
функции заданы раздельно (ячейки Е18 и
F18).
Сформируйте данный
шаблон и сохраните его на магнитном
диске.
Приступаем к
имитационному эксперименту.
Для его проведения
необходимо выполнить следующие шаги.
Ввести значения
постоянных переменных (табл.2) в ячейки
В2:В4 и D2:D4 листа «Результаты анализа».
Ввести значения
диапазонов изменений ключевых переменных
(табл.1) в ячейки В3:С5 листа «Имитация».
Задать в ячейке
В7 требуемое число экспериментов.
Установить курсор
в ячейку А11 и вставить необходимое число
строк в шаблон (номер последней строки
будет вычислен в Е7).
Скопировать формулы
блока А10:Е10 требуемое количество раз.
Перейти к листу
«Результаты анализа» и проанализировать
полученные результаты.
Обратите
внимание на диапазоны рабочих ячеек
листа «Результаты анализа» при вычислениях
среднего значения, стандартного
отклонения и пр.: диапазоны соответствующих
ячеек должны соответствовать диапазонам
данных листа «Имитация».
Рассмотрим
реализацию выделенных шагов более
подробно. Выполнение первых трех пунктов
не должно вызвать особых затруднений.
Введите значения постоянных переменных
в ячейки В2:В4 листа «Результаты
анализа». Введите значения диапазонов
изменений ключевых переменных в ячейки
В3:С5 листа «Имитация». Укажите в
ячейке В7 число проводимых экспериментов,
например — 500. Установите табличный
курсор в ячейку А11.
На следующем шаге
необходимо вставить в шаблон нужное
количество строк (498) (Поскольку первая
и последняя строка блока уже определены,
число вставляемых строк равно: 500 — 2 =
498). Однако выделение такого количества
строк при помощи указателя мыши —
достаточно трудоемкая операция. К
счастью ППП EXCEL предоставляет более
эффективные процедуры для выполнения
подобных операций. В частности, в данном
случае можно воспользоваться операцией
перехода, которую также удобно применять
и для выделения больших диапазонов
ячеек.
Выделите и скопируйте
в буфер обмена блок ячеек А10:Е10.
Установите табличный
курсор в ячейку А11.
Нажмите функциональную
клавишу [F5]. На экране появится окно
диалога «Переход» (рис.3).
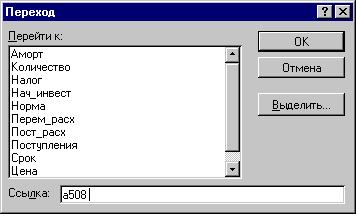
Рис.3. Окно диалога «Переход»
Для перехода к
нужному участку электронной таблицы
достаточно указать в поле «Ссылка»
адрес или имя соответствующей ячейки
(блока). В данном случае, таким адресом
будет любая ячейка последней вставляемой
строки, номер которой вычислен в ячейке
Е7 (508). Например, в качестве адреса
перехода может быть указана ячейка
А508.
Введите в поле
«Ссылка» адрес: А508 и нажмите
комбинацию клавиш [SHIFT]
+
[ENTER].
Результатом выполнения этих действий
будет выделение блока А11:А508. После чего
осуществите вставку строк, записанных
в буфере обмена, любым из известных вам
способов.
Нажмите клавишу
[Esc],
затем [F9].
Результатом
выполнения этих действий будет заполнение
блока А10:Е509 случайными значениями
ключевых переменных V, Q, P и результатами
вычислений величин NCF и NPV. Фрагмент
результатов имитации, приведен на рис.4
(Необходимо все время помнить о случайной
природе эксперимента. Полученные вами
результаты будут отличаться от
приведенных). Соответствующие проведенному
эксперименту результаты анализа
приведены на рис.5.
Нетрудно заметить,
что по результатам имитационного анализа
коэффициент вариации (0,68) меньше 1. Таким
образом, риск данного проекта в целом
ниже среднего риска инвестиционного
портфеля фирмы.
Результаты
вероятностного анализа показывают, что
шанс получить отрицательную величину
NPV не превышает 7%.
Еще больший оптимизм
внушают результаты анализа распределения
чистых поступлений от проекта NCF. Величина
стандартного отклонения здесь составляет
всего 42% от среднего значения. Таким
образом, с вероятностью более 90% можно
утверждать, что поступления от проекта
будут положительными величинами.
Р
ис.4.
Результаты имитации
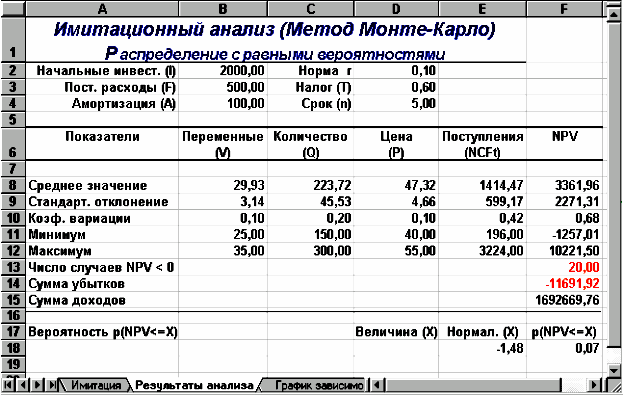
Рис.5. Результаты
анализа
Сумма всех
отрицательных значений NPV в полученной
генеральной совокупности (ячейка F14)
может быть интерпретирована как чистая
стоимость неопределенности для инвестора
в случае принятия проекта. Аналогично
сумма всех положительных значений NPV
(ячейка F15) может трактоваться как чистая
стоимость неопределенности для инвестора
в случае отклонения проекта. Несмотря
на всю условность этих показателей, в
целом они представляют собой индикаторы
целесообразности проведения дальнейшего
анализа.
В данном случае
они наглядно демонстрируют несоизмеримость
суммы возможных убытков по отношению
к общей сумме доходов (-11691,92 и 1692669,76
соответственно).
На практике одним
из важнейших этапов анализа результатов
имитационного эксперимента является
исследование зависимостей между
ключевыми параметрами. Известно, что
количественная оценка вариации
исследуемых параметров напрямую зависит
от степени корреляции между случайными
величинами.
Оценим степени
взаимосвязи исследуемых параметров
визуально (графически). С это целью
построим графики (рис.6) распределения
значений ключевых параметров V, P и Q,
построенных на основе 65 имитаций.
Нетрудно заметить,
что в целом, вариация значений всех трех
параметров носит случайный характер,
что подтверждает принятую ранее гипотезу
о их независимости. Для сравнения ниже
приведен график распределений потока
платежей NCF и величины NPV (рис.7).
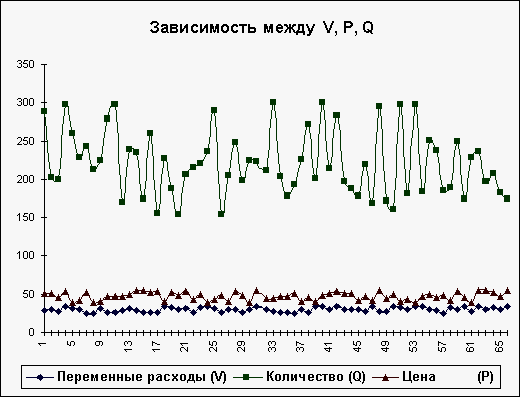
Рис.6 Распределение
значений параметров V, P и Q
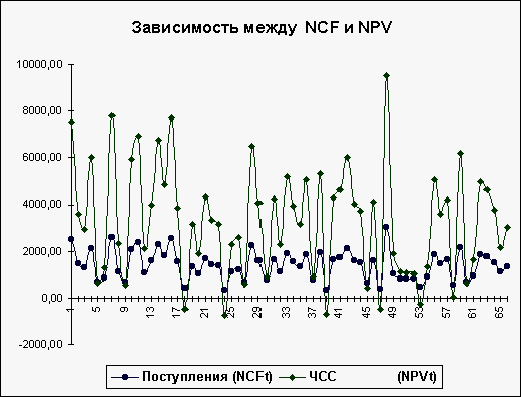
Рис.7. Зависимость
между NCF и NPV
Как и следовало
ожидать, направления колебаний здесь
в точности совпадают и между этими
величинами существует сильная
корреляционная связь, очень близкая к
1.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #