
Как построить вариационный ряд в Excel
Вариационный ряд может быть:
— дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
— интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

Построить вариационный ряд и полигон распределения
Решение.
Алгоритм построения вариационного ряда:
1) Откроем таблицы Excel.
2) Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
3) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
4) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

5) Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
6) Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

7) Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
1) выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа — в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
2) Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Рис.1.3. Пример 1. Построение полигона частот

Примечание: можно скачать готовый шаблон построение дискретного вариационного ряда в Excel
Следующая тема: Построение интервального вариационного ряда в Excel.
1. Построение вариационного ряда
Нужно выделить ячейки содержащие результаты эксперимента, и воспользоваться операцией сортировка по возрастанию (либо с панели инструментов, либо через главное меню Данные>Сортировка), и в появившемся окне сообщения – «обнаружены данные выходящие за пределы выделенного диапазона» выбрать действие – «сортировать в пределах указанного выделения»
2. Построение группировочного статистического ряда
Для вычисления абсолютной частоты нужна статистическая функция ЧАСТОТА. При её использовании нужно выполнить следующие действия:
а) выделить весь диапазон ячеек, в которых будет располагаться результат подсчёта частот (т.е. это ячейки под заголовком Абсолютная частота в количестве равном числу промежутков)
b) не снимая выделения, поставить курсор в строку формул и нажать на кнопку вставка функции (чуть левее курсора) или Главное меню – вставка – формула.
с) выбрать функцию ЧАСТОТА
d) ввести Массив_данных – диапазон, содержащий элементы выборки (в файле 2.xls это ячейки) B2:B101
e) ввести Массив_интервалов – диапазон ячеек под заголовком Начало промежутка начиная со строчки, соответствующей промежутку под номером 2 до строчки, соответствующей последнему промежутку.
f) нажмите на кнопку ОК и после закрытия окна для ввода аргументов функции ЧАСТОТА поставьте курсор обратно в строку формул.
g) Нажмите на три кнопки Ctrl+Shift+Enter (сначала на первые две, а потом, не отпуская их, нажмите на Enter).
Примечание. Формулу вычисления абсолютной частоты необходимо ввести как формулу массива. Нажатие комбинации клавиш CTRL+SHIFT+ENTER позволяет определить формулу как формулу массива. Если формула не будет введена как формула массива, единственное значение будет равно 1.
В результате изначально выделенный диапазон будет содержать абсолютные частоты попадания во все промежутка. Проверьте, что сумма всех абсолютных частот равна общему числу элементов выборки (100).
3. Построение гистограммы группировочного статистического ряда
Построим дискретный вариационный ряд
по затратам труда на 1 ц зерна.
Открываем лист Excel,
в ячейку А1 записываем условное обозначение
результативного признака – у, а в ячейки
А2:А31 значения затрат труда на 1 ц зерна.
В ячейки В2:В3 введём наименьшее и
следующее за ним значения признака 0,7
и 0,8; выделим обе ячейки (В2 и В3). Щёлкнем
мышью правый нижний угол выделительной
рамки и потянем вниз до значения 1,5
(наибольшее значение признака). В ячейках
В2:В10 получим варианты признака в
ранжированном порядке. Для определения
частот проделаем следующие шаги:
1.Поставим курсор в ячейку С2.
2.Выберем Вставка,
Функция.
Выберем в категории
Статистические функции
функцию Частота и
нажмём ОК.
3.В поле данных
укажем ячейки А2:А31, а в поле интервалов
В2:В10.
4.Нажмём кнопку ОК.
5.Выделим ячейки
С2:С10.
6.Нажмём F2,
а затем комбинацию клавиш Shift+Ctrl+Enter.
В ячейках С2:С10 появятся
частоты.
Вычислим накопленные
частоты, которые потребуются для
дальнейших расчётов, путём последовательного
суммирования локальных частот (нарастающим
итогом). Так, первая плюс вторая частоты
дают накопленную частоту второго
варианта (1+2=3); прибавляя к ней третью
частоту, получим накопленную частоту
третьего варианта (3+4=7) и т.д.
Скопируем полученный
в Excel
вариационный ряд и построим таблицу.
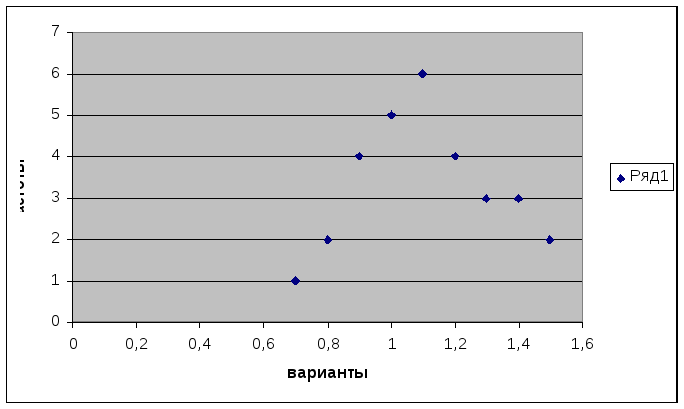
Таблица 2
Дискретный вариационный ряд распределения
затрат труда на 1 ц зерна
|
Варианты |
Частоты |
Накопленные |
|
0,7 |
1 |
1 |
|
0,8 |
2 |
3 |
|
0,9 |
4 |
7 |
|
1,0 |
5 |
12 |
|
1,1 |
6 |
18 |
|
1,2 |
4 |
22 |
|
1,3 |
3 |
25 |
|
1,4 |
3 |
28 |
|
1,5 |
2 |
30 |
Построим
полигон распределения частот с помощью
Мастера
диаграмм.
Выберем точечную диаграмму, соединим
полученные точки отрезками, а крайние
точки с осью абсцисс в точках, отстоящих
от крайних на расстоянии шага.
Р





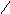 ис.
ис.
1. Полигон распределения сельскохозяйственных
предприятий по затратам труда на 1 ц
зерна
Рассмотрим
построение интервального вариационного
ряда.
Рис. 2. Построение интервального
вариационного ряда
На
листе Excel в ячейку А1 записываем условное
обозначение факторного признака – х,
в ячейки А2:А31 – значения факторного
признака – урожайности озимой пшеницы.
Произведём сортировку данных, для чего
выделяем диапазон данных, выбираем
Данные – Сортировка и в появившемся
окне «Сортировка диапазона» указываем
«по возрастанию», нажимаем ОК. Данные
в ячейках А2:А31 расположатся в ранжированном
порядке по возрастанию признака. По
формуле Стерджесса определяем количество
групп (интервалов). Для вычисления
десятичного логарифма lg30 выбираем
Мастер функций – Математические –
LOG10. В появившемся окне в поле Число
записываем число 30, десятичный логарифм
которого необходимо найти. Нажатием ОК
получаем этот логарифм 1,477121. . Подставляя
числовые данные в формулу (1), получим
число групп (интервалов) 5,9, округляем
до 6. По формуле (2) определяем величину
интервалов – шаг с такой же точностью,
с которой даны исходные данные (в данном
случае с точностью до десятых:
(30-20)/6≈1,7. Следовательно, совокупность
надо разбить на 6 интервалов. Получаем
шаг 1,7. Озаглавим следующие столбцы в
Excel словами «Интервалы», «Частоты»,
«Накопленные частоты», «Середины
интервалов». В ячейку В2 вписываем
минимальное значение признака Хmin=20,
в ячейку В3 формулу =В2+1,7, т.е. минимальное
значение плюс шаг. Копируем эту формулу
на 5 строк вниз. В результате в этих шести
строках (В3:В8) получим верхние границы
всех интервалов. Нижними границами
интервалов будут данные в соседних
верхних ячейках, т.е. для первого интервала
нижней границей будет содержание ячейки
В2, для второго В3 и для шестого В7.
Для
расчёта частот выберем Сервис — Анализ
данных – Гистограмма и нажмём ОК. В
появившемся окне «Гистограмма» в поле
«Входной интервал» копируем исходные
данные (ячейки А2:А31), в поле «Интервал
карманов» — верхние границы интервалов
(ячейки В3:В8), в поле «Выходной интервал»
ячейки частот (С3:С8), нажимаем ОК. В ячейки
D3:D8 будут записаны частоты для всех
шести интервалов. Накопленные частоты
подсчитываем нарастающим итогом.
Для
построения диаграммы необходимо найти
середины интервалов. Для этого вводим
формулу расчёта середины интервала:
![]() ,
,
рассчитаем середину первого интервала.
Копируем формулу для остальных пяти
групп.
Для
построения диаграммы выделяем массив
частот и середин интервалов.
Далее в
Мастере диаграмм выбираем вид диаграммы
— гистограмму определённого вида.
Нажимаем кнопку Далее. В появившемся
окне выбираем вкладку Ряд, удаляем ряд
1, а в поле «Подписи оси х» копируем
середины интервалов. Нажимаем далее, в
появившемся окне выбираем вкладку
Заголовки. В поле «ось х (категорий)»
вписываем название факторного признака
(в данном случае урожайность, ц/га), в
поле «Ось у (значений)» вписываем частоты.
Нажимаем Далее, Готово. Появится
диаграмма, состоящая из столбиков,
отделённых друг от друга некоторым
зазором. Щёлкаем правой кнопкой мыши
на одном из столбиков диаграммы. В
раскрывающемся списке элементов щёлкаем
по кнопке Формат рядов данных. В
появившемся диалоговом окне активизируем
вкладку Параметры и в поле Ширина зазора
устанавливаем значение 0. Нажимаем ОК,
в результате чего гистограмма принимает
стандартный вид.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Создание вариационного
ряда, вариационной кривой, определение среднего значения и среднеквадратичного
отклонения.
Для селекционера,
например, важно знать, сколько зерен содержит колос выведенного (выводимого) им
нового сорта пшеницы. В этой ситуации совершенно ясно, что подсчетом количества
зерен только в одном колосе не обойтись. Для определения числа зерен надо
воспользоваться достаточно большим количеством колосьев, скажем не менее сотни.
Приведем пример математической обработки результатов селекции.
Все поле
пшеницы, которое вырастил селекционер можно на математическом языке назвать
генеральной совокупностью. Подсчитать количество зерен в колосьях всей
генеральной совокупности, очевидно, не представляется возможным, но из всей
генеральной совокупности можно выбрать, скажем, сто колосьев и подсчитать
количество зерен в них. Эти сто колосьев будут называться выборкой из генеральной
совокупности, и они с определенной точностью будут отражать число зерен во всем
поле (генеральной совокупности). Чтобы по данным выборки иметь возможность
судить обо всей генеральной совокупности, она должна быть отобрана случайно.
Так в нашем случае селекционер ни в коем случае не должен отдавать предпочтение
тем или иным колосьям (по размерам, внешнему виду, месту произрастания на поле
и т.п.) в процессе их выборки. Наиболее целесообразно в данной ситуации
совершать выбор колосьев из непрозрачного мешка наугад. У всех выбранных
колосьев производится подсчет числа зерен, и результаты фиксируются в виде ряда
чисел, с которыми в дальнейшем и предстоит совершать математические действия. В
данном примере можно предложить следующую их последовательность.
2.1 Создание вариационного ряда.
Вариационным
рядом называется ранжированный в порядке возрастания или убывания ряд вариантов
с соответствующими им весами (частотами или частностями). Вариационный ряд
будет дискретным, если любые его варианты отличаются на постоянную величину, и
непрерывным, если варианты могут отличатся один от другого на сколь угодно
малую величину.
Иными словами в вариационном ряду
полученные значения располагаются в порядке их увеличения и, если значение
повторяется, то рядом записывается число его повторений. Т.е. в данном примере
по числу зерен в колосьях ряд может выглядеть так (таб. 2):
Таблица 2
|
Число зерен в колосе |
17 |
18 |
19 |
20 |
21 |
22 |
23 |
24 |
25 |
|
Число колосьев |
1 |
2 |
2 |
4 |
6 |
8 |
8 |
9 |
10 |
|
Число зерен в колосе |
26 |
27 |
28 |
29 |
30 |
31 |
32 |
33 |
34 |
|
Число колосьев |
9 |
9 |
9 |
8 |
6 |
4 |
3 |
1 |
1 |
Полученный вариационный ряд
позволяет выявить закономерности распределения колосьев по числу зерен в них.
2.2 Создание вариационной
кривой.
Закономерности распределения
можно представить более наглядно, создав вариационную кривую, называемую
полигоном (рис 3), или представить в виде столбчатой диаграммы, которая здесь
будет называться гистограммой (рис 4).


Из полученных схем уже можно наглядно судить о закономерностях
распределения.
Диаграммы
строятся при помощи «Excel»
так:
Ø Ввести в окно программы данные вариационного
ряда.
Ø Запустить «Мастер диаграмм», нажатием
кнопки  .
.
Ø В графе «тип» выбирать или «гистограмма», или
«график».
Ø Нажать кнопку «Далее».
Ø В «шаге 2 из 4» найти строку с названием
«Диапазон» и щелкнуть по кнопке, расположенной справа от надписи и пустого
поля, при этом «Мастер диаграмм» несколько свернется.
Ø Выделить данные в окне программы (в примере это
значения в ячейках В1 – В18).
Ø Снова щелкнуть по кнопке в «Мастере диаграмм».
«Мастер» развернется. В окне «Мастера» появится эскиз гистограммы или полигона.
Ø В этом же шаге (2 из 4) щелкнуть по закладке с
надписью «Ряд».
Ø В открывшейся страничке найти строчку с надписью
«Подписи оси Х».
Ø Щелкнуть по кнопке справа от надписи и пустого
поля.
Ø Выделить значения в окне программы, которые
будут на диаграмме представляться в качестве данных оси Х. (в примере значения
в ячейках А1 – А18).
Ø Щелкнуть по кнопке в свернутом «Мастере».
Ø Щелкнуть по кнопке «Далее» (шаг 3 из 4).
Ø При необходимости, в графе «Заголовки» выполнить
подписи осей Х и Y, а
так же дать диаграмме название.
Ø Щелкнуть по кнопке далее, затем готово и в
результате получится готовая гистограмма или полигон (рис 3).
2.3 Определение среднего значения признака.
Среднее
значение ряда данных находится обычным образом. Суммируются все значения
признака и делятся на количество этих значений. Т.е. здесь общее число зерен в
100 колосках равно 2551, то среднее значение будет равно 2551/100 = 25.51.
Для определения
среднего значения признака с использованием «Excel» надо выполнить следующие шаги:
Ø Ввести в столбец А окна программы все значения
признака, в том числе и повторяющиеся. Т.е. здесь все 100 значений зерен в
колосках. Ввод можно осуществлять в любой последовательности – по возрастанию,
по убыванию или в разнобой. Введенный массив чисел лучше сохранить, так как он
пригодится для расчета отклонения.
Ø Щелкнуть в окне программы по любой пустой
ячейке. По окончании расчетов в ней появится соответствующее среднее значение.
Ø В меню «Вставка» выбрать «Функция».
Ø В появившемся списке функций выбрать функцию
«СРЗНАЧ».
Ø Щелкнуть по кнопке «ОК». Появится окно
«Аргументы функции».
Ø Щелкнуть по кнопке правее надписи «Число 1» и
поля (окно свернется).
Ø Выделить в окне программы весь числовой массив,
среднее значение которого необходимо определить.
Ø Щелчком по кнопке справа от поля с надписями
развернуть окно «Аргументы функции».
Ø Щелкнуть по кнопке «ОК». В выбранной
предварительно ячейке появится среднее значение массива чисел.
2.4 Определение среднего квадратического
отклонения.
Вариационная кривая имеет
определенную ширину. Нетрудно догадаться, что чем больше ширина вариационной
кривой, тем сильнее разброс значений относительно средней величины.


Как показано на рисунках 5 и 6 при
одном и том же среднем значении, равном 25.51, полигон первого рисунка шире
полигона второго.
Оценить
степень разброса данных относительно среднего значения можно рассчитав значение
дисперсии S2,
или среднее квадратическое отклонение S, равное корню квадратному из дисперсии. Дисперсией вариационного ряда называется
средняя арифметическая квадратов отклонений вариантов от их средней
арифметической. Значением среднего квадратического отклонения пользоваться
удобнее, так как оно выражается в тех же единицах, что и значение признака. Так
среднее квадратическое отклонение данных, представленных графически на первом
полигоне равно 3.70, а на втором полигоне 2.65. Видим, что отклонение первое
больше второго и это как раз и отражается на ширине полигона.
Алгоритм
расчета среднего квадратического отклонения
и дисперсии такой же, как и для расчета среднего арифметического
значения, только в списке функций надо выбрать «СТАНДОТКЛОН» для вычисления отклонения, или «ДИСП» для расчета дисперсии.
При изучении величины, принимающей случайные значения (результатов физических измерений в серии экспериментов, экономических показателей, параметров технологических процессов и т.п.), мы имеем дело с выборками. Выборочное наблюдение – это способ наблюдения, при котором обследуется не вся совокупность значений изучаемой величины, а лишь часть ее, отобранная по определенным правилам выборки и обеспечивающая получение данных, характеризующих всю совокупность в целом.
При выборочном наблюдении обследованию подвергается определенная, заранее обусловленная часть совокупности, а результаты обследования распространяются на всю совокупность.
Ту часть единиц, которая отобрана для наблюдения, принято называть выборочной совокупностью или выборкой, а всю совокупность единиц, из которых производится отбор, – генеральной совокупностью.
Число единиц (элементов) статистической совокупности называется ее объемом. Объем генеральной совокупности обозначается N, а объем выборочной совокупности п.
Качество результатов выборочного наблюдения зависит от того, насколько состав выборки представляет генеральную совокупность, иначе говоря, от того, насколько выборка репрезентативна (представительна).
Элементами выборки (x1 х2, . хп) являются числовые значения, называемые вариантами, которые могут быть дискретными, т.е. изолированными (например, целыми числами), или могут принимать значения из некоторого интервала (а, b).
Вариационный ряд получается из выборки упорядочением по возрастанию (или убыванию) и подсчетом частоты каждого значения. Если вариационный ряд содержит значения признака и соответствующие ему частоты,то такой ряд носит название дискретный вариационный ряд. Если нам известно, что исследуемый показатель может принимать любые значения из некоторого интервала, то строим интервальный вариационный.
Удобнее всего ряды распределения анализировать с помощью их графического изображения, позволяющего судить о форме распределения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма.
Пример 2.1.
Известны следующие данные о результатах сдачи студентами экзамена (в баллах):
| 18 | 16 | 20 | 17 | 19 | 20 | 17 |
| 17 | 12 | 15 | 20 | 18 | 19 | 18 |
| 18 | 16 | 18 | 14 | 14 | 17 | 19 |
| 16 | 14 | 19 | 12 | 15 | 16 | 20 |
Необходимо построить ряд распределения числа студентов по баллу, представить графически результаты.
Введем данные в диапазоне A1: A29, в ячейку A1 введем текст «Балл» (рис.2.6).
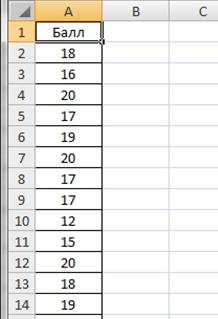
Рисунок 2.6. Баллы успеваемости студентов
Определим наименьший и наибольший балл по выборке. Для этого введем в ячейках С1 и С2 соответственно введем формулы =МИН(A2:A29) и =МАКС(A2:A29). Получим значения 12 и 20 соответственно (рис.2.7).
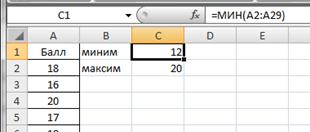
Рисунок 2.7. Минимальный и максимальный балл
Построим вариационный ряд. Для каждого значения необходимо подсчитать частоту. Так как значения признака (балл) отличаются на единицу, то можно воспользоваться следующим способом. В ячейку С4 введем формулу =С1, в С5 соответственно С4+1. Ячейку С5 протянем маркером заполнения (правый нижний угол ячейки) вниз до С12. Результаты представлены на рисунке 2.8.
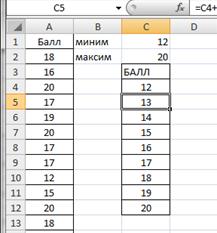
Рисунок 2.8. Значения признака
Вычислим частоту для каждого значения признака. В ячейку D4 введем формулу =СЧЕТЕСЛИ(A$2:A$29;C4) и протянем D4 маркером вниз до заполнения D12. В ячейке D13 просуммируем частоты с помощью формулы =СУММ(D4:D12).
Получим вариационный ряд (значения признака и соответствующие им частоты) на рисунке 2.9.
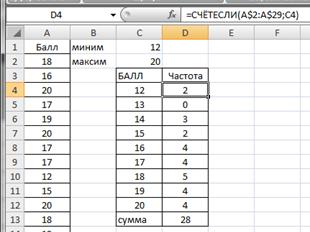
Рис.2.9. Частоты вариационного ряда
Вычислим частость (относительную частоту) для каждого значения признака. В ячейку Е4 введем формулу = D4/D$13. Протянем Е4 маркером заполнения вниз до Е12 (рис.2.10).
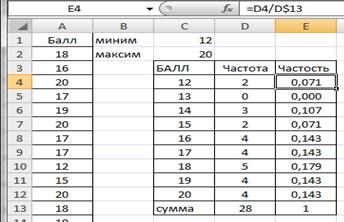
Рисунок 2.10. Частости ряда распределения
Вычислим накопленные частоты. В ячейку F4 введем формулу =D4, а в ячейку F5 – формулу = D5+F4. Протянем F5 маркером заполнения вниз до F12 (рис.2.11).
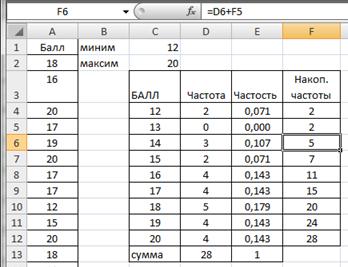
Рисунок 2.11. Накопленные частоты ряда
Построим эмпирическую функцию распределения, т.е. найдем наколенные частости. Выделим F4:F12 и маркером заполнения протянем вправо на соседний столбец (рис.2.12). В G4 получим формулу = Е4, в ячейке G5 формулу =Е5+ G4 и т.д.
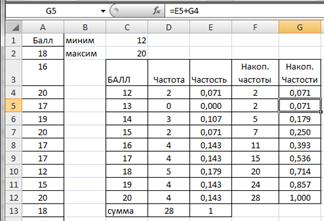
Рисунок 2.12. Накопленные частости ряда
Построим полигон распределения частот и частостей. Выделим диапазон ячеек С4:D12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частот представлен на рисунке 2.13.

Рисунок 2.13. Полигон распределения частот
Выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон Е4:Е12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками и маркерами». Полигон распределения частостей представлен на рисунке 2.14.
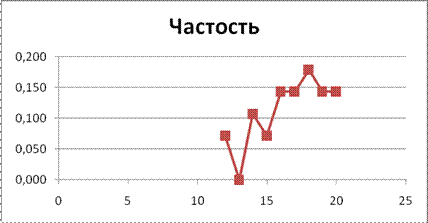
Рисунок 2.14. Полигон распределения частостей
Построим гистограмму распределения частостей, для чего выделим диапазон Е4:Е12, выберем тип диаграммы «Гистограмма». Щелкнем правой кнопкой в области диаграммы, выберем «Выбрать данные», выберете «Ряд» – «Изменить», левой кнопкой щелкнем в строке «Подписи оси Х» и выделим диапазон С4:С12 (рис.2.15).
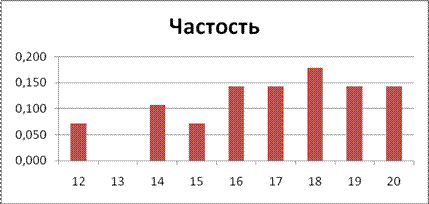
Рисунок 2.15. Гистограмма распределения частостей
Построим кумуляту частостей, для чего выделим диапазон ячеек С4:С12 и, удерживая клавишу CTRL, диапазон G4:G12. Выполним команду меню «Диаграмма» и выберем тип «Точечная», вариант «Точечная с прямыми отрезками». Кумулята представлена на рис.2.16.

Рисунок 2.16. Кумулята
Пример 2.2.
В таблице 2.7 представлены значения процентных ставок по кредитам по 30 коммерческим банкам.
Банковские процентные ставки
| № Банка | Процентная ставка, % |
| 1 | 20,3 |
| 2 | 17,1 |
| 3 | 14,2 |
| 4 | 11,0 |
| 5 | 17,3 |
| 6 | 19,6 |
| 7 | 20,5 |
| 8 | 23,6 |
| 9 | 14,6 |
| 10 | 17,5 |
| 11 | 20,8 |
| 12 | 13,6 |
| 13 | 24,0 |
| 14 | 17,5 |
| 15 | 15,0 |
| 16 | 21,1 |
| 17 | 17,6 |
| 18 | 15,8 |
| 19 | 18,8 |
| 20 | 22,4 |
| 21 | 16,1 |
| 22 | 17,9 |
| 23 | 21,7 |
| 24 | 18,0 |
| 25 | 16,4 |
| 26 | 26,0 |
| 27 | 18,4 |
| 28 | 16,7 |
| 29 | 12,2 |
| 30 | 13,9 |
Построим интервальный вариационный ряд. Для этого вычислим границы интервалов (карманов) с использованием формулы Стэрджесса.
Введем данные в диапазоне A1:A31 (рис.2.17). Определим максимальное и минимальное значения (ячейки С2 и С3 соответственно) так же как и в примере 2.1. Определим число интервалов по формуле Стэрджесса, для чего в ячейку С6 введем формулу =ЦЕЛОЕ(1+3,322*LOG10(30)) (рис.2.18).
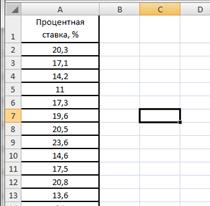
Рисунок 2.17. Процентные ставки банков

Рисунок 2.18. Число интервалов
Вычислим длину интервалов, для чего в ячейке С8 введем формулу =ОКРУГЛ((C3-C2)/C6;2) (рис.2.19).
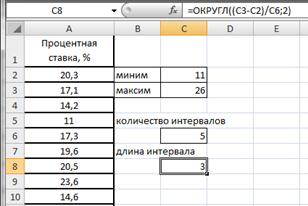
Рисунок 2.19. Длина интервала
Определим нижние и верхние границы интервалов (карманы), для чего в ячейке Е2 запишем формулу =С2, в ячейке Е3 запишем ==E2+$C$8. Протянем Е3 маркером заполнения вниз до Е7 (рис.2.20).
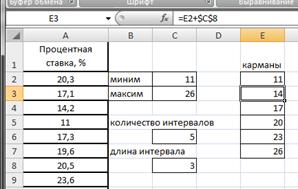
Рисунок 2.20. Границы интервалов
Подсчитаем частоты – в интервал считаем те значения, которые больше нижней границы интервала или равны ей и меньше верхней границы.
Воспользуемся функцией ЧАСТОТА. Для этого в ячейке F2 введем формулу =ЧАСТОТА(A2:A31;E2:E7). Протянем F2 маркером заполнения вниз до F8.
Формулу в этом примере необходимо ввести как формулу массива. Выделим диапазон F2:F8, нажмем клавишу F2, а затем нажмем клавиши CTRL+SHIFT+ВВОД (рис.2.21).
Если формула не будет введена как формула массива, отобразится только одно ее значение в ячейке F2.
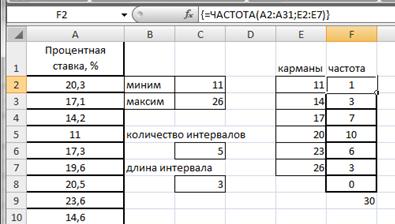
Рисунок 2.21. Частоты значений признака
Также можно воспользоваться средством Пакета анализа (Анализ данных в Office 2007) ГИСТОГРАММА (рис.2.22). Выберем входной интервал, интервал карманов, метки, интегральный процент, поместим результаты на этом же листе (укажем ячейку $H$2).
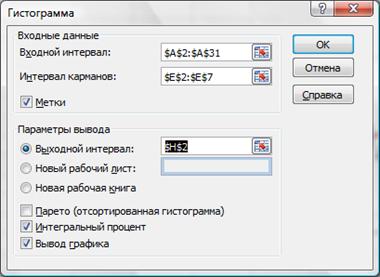
Рисунок 2.22. Построение гистограммы
Полученная гистограмма представлена на рис.2.23.
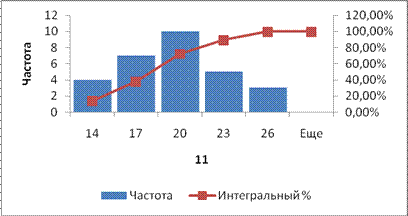
Рис.2.23. Гистограмма частот
Замечание. Если диапазон карманов не был введен, то набор отрезков, равномерно распределенных между минимальным и максимальным значениями данных, будет создан автоматически.
Дата добавления: 2018-11-12 ; просмотров: 1065 | Нарушение авторских прав
Вариационный ряд может быть:
– дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
– интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Рассмотрим пример построения дискретного вариационного ряда.
Пример 1. Имеются данные о количественном составе 60 семей.

Построить вариационный ряд и полигон распределения
Решение .
Алгоритм построения вариационного ряда:
1) Откроем таблицы Excel.
2) Введем массив данных в диапазон А1:L5. Если вы изучаете документ в электронной форме (в формате Word, например), для этого достаточно выделить таблицу с данными и скопировать ее в буфер, затем выделить ячейку А1 и вставить данные – они автоматически займут подходящий диапазон.
3) Подсчитаем объем выборки n – число выборочных данных, для этого в ячейку В7 введем формулу =СЧЁТ(А1:L5). Заметим, что для того, чтобы в формулу ввести нужный диапазон, необязательно вводить его обозначение с клавиатуры, достаточно его выделить.
4) Определим минимальное и максимальное значение в выборке, введя в ячейку В8 формулу =МИН(А1:L5), и в ячейку В9: =МАКС(А1:L5).
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

5) Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17.
6) Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER
Рис.1.2 Пример 1. Построение вариационного ряда

7) Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Построим полигон:
1) выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа – в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
2) Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.
Рис.1.3. Пример 1. Построение полигона частот
В реальных социально-экономических системах нельзя проводить активные эксперименты, поэтому данные обычно представляют собой наблюдения за происходящим процессом, например: курс валюты на бирже в течение месяца, урожайность пшеницы в хозяйстве за 30 лет, производительность труда рабочих за смену и т.д. Результаты наблюдений — это в общем случае ряд чисел, расположенных в беспорядке, который для изучения необходимо упорядочить (проранжи- ровать).
Операция, заключающаяся в расположении значений признака по возрастанию, называется ранжированием опытных данных.
После операции ранжирования опытные данные можно сгруппировать так, чтобы в каждой группе признак принимал одно и то же значение, которое называется вариантом (х,). Число элементов в каждой группе называется частотой варианта («,).
Размахом вариации называется число

где хтах — наибольший вариант;
x min — наименьший вариант.
Сумма всех частот равна определенному числу л, которое называется объемом совокупности:

Отношение частоты данного варианта к объему совокупности называется относительной частотой, или частостью, этого варианта:

Последовательность вариант, расположенных в возрастающем порядке, называется вариационным рядом (вариация — изменение).
Вариационные ряды бывают дискретными и непрерывными. Дискретным вариационным рядом называется ранжированная последовательность вариант с соответствующими частотами и (или) частостями.
Пример 1. В результате тестирования группа из 24 человек набрала баллы: 4, 0, 3, 4, 1, 0, 3, 1, 0, 4, 0, 0, 3, 1, 0, 1, 1, 3, 2, 3, 1, 2, 1, 2. Построить дискретный вариационный ряд.
Решение. Проранжируем исходный ряд, подсчитаем частоту и частость вариант: 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4.
В результате получим дискретный вариационный ряд (табл. 3.10).
Ранжированный ряд успеваемости
Число студентов, л,
Относительная частота, А
В Excel проранжируем исходный ряд. Для этого введем все данные в диапазон А1 :А24 и воспользуемся кнопкой Щ (Сортировка по возрастанию).
Подсчитаем частоту и частость вариант. Построим таблицу в диапазоне D2:G7 (рис. 3.13).

Рис. 3.13. Контекстное меню строки состояния
Рассмотрим два варианта подсчета частот:
- 1) выделим диапазон, в котором находятся нули. Щелкнем в нижней правой части окна Excel правой кнопкой мыши и выберем в контекстном меню вид итога, который по умолчанию будет появляться в итоговой строке при выделении произвольного диапазона (см. рис. 3.13) — количество. Таким образом, последовательно выделяя диапазоны с одинаковыми значениями вариант, мы получим все частоты;
- 2) выполним команду Сервис — Анализ данных — Гистограмма. Заполним диалоговое окно в соответствии с рис. 3.14.

Рис. 3.14. Диалоговое окно инструмента пакета анализа «Гистограмма»
В результате получим таблицу с частотами вариантов и соответствующий график (рис. 3.15).

Рис. 3.15. Результаты применения инструмента «Гистограмма)
Найдем объем выборки, заполнив все частоты вариант в диапазоне ЕЗ:Е7, выделим его левой кнопкой мыши и щелкнем по кнопке ? (автосумма).
В ячейку F3 введем формулу «=ЕЗ/$Е$8», за маркер заполнения (крест в правом нижнем углу ячейки) с помощью мыши скопируем до F7 и выберем кнопку автосумма, в результате получим частоты вариантов и их сумму (1). В ячейку G3 введем частоту варианта 0 — цифру 6 (или ссылку на ячейку, ее содержащую — ЕЗ), в ячейку G4 введем формулу «=G3+E4» и скопируем ее до ячейки G7, в результате получим накопленные частоты. Таким образом, мы получили дискретный вариационный ряд. Естественно, частоты необходимо округлить, но таким образом, чтобы их сумма равнялась 1. Для этого выделим левой кнопкой мыши диапазон частот (F3:F7), щелкнув по правой кнопке, откроем контекстное меню и выполним команду Формат ячеек — Числовой — Число знаков 3 — ОК. Преобразовав обозначения, получим дискретный вариационный ряд, представленный в табл. 3.11.