
Поиск последней непустой ячейки в строке или столбце функцией ПРОСМОТР
На практике часто возникает необходимость быстро найти значение последней (крайней) непустой ячейки в строке или столбце таблицы. Предположим, для примера, что у нас есть вот такая таблица с данными продаж по нескольким филиалам:

Задача: найти значение продаж в последнем месяце по каждому филиалу, т.е. для Москвы это будет 78, для Питера — 41 и т.д.
Если бы в нашей таблице не было пустых ячеек, то путь к решению был бы очевиден — можно было бы посчитать количество заполненных ячеек в каждой строке и брать потом ячейку с этим номером. Но филиалы работают неравномерно: Москва простаивала в марте и августе, филиал в Тюмени открылся только с апреля и т.д., поэтому такой способ не подойдет.
Универсальным решением будет использование функции ПРОСМОТР (LOOKUP):

У этой функции хитрая логика:
- Она по очереди (слева-направо) перебирает непустые ячейки в диапазоне (B2:M2) и сравнивает каждую из них с искомым значением (9999999).
- Если значение очередной проверяемой ячейки совпало с искомым, то функция останавливает просмотр и выводит содержимое ячейки.
- Если точного совпадения нет и очередное значение меньше искомого, то функция переходит к следующей ячейке в строке.
Легко сообразить, что если в качестве искомого значения задать достаточно большое число, то функция пройдет по всей строке и, в итоге, выдаст содержимое последней проверенной ячейки. Для компактности, можно указать искомое число в экспоненциальном формате, например 1E+11 (1*1011 или сто миллиардов).
Если в таблице не числа, а текст, то идея остается той же, но «очень большое число» нужно заменить на «очень большой текст»:

Применительно к тексту, понятие «большой» означает код символа. В любом шрифте символы идут в следующем порядке возрастания кодов:
- латиница прописные (A-Z)
- латиница строчные (a-z)
- кириллица прописные (А-Я)
- кириллица строчные (а-я)
Поэтому строчная «я» оказывается буквой с наибольшим кодом и слово из нескольких подряд «яяяяя» будет, условно, «очень большим словом» — заведомо «большим», чем любое текстовое значение из нашей таблицы.
Вот так. Не совсем очевидное, но красивое и компактное решение. Для поиска последней непустой ячейки в столбцах работает тоже «на ура».
Ссылки по теме
- Поиск и подстановка по нескольким условиям (ВПР по 2 и более критериям)
- Поиск ближайшего похожего текста (max совпадений символов)
- Двумерный поиск в таблице (ВПР 2D)
I am having a lot of difficulty trying to come up with a way to ‘parse’ and ‘order’ my excel spreadsheet. What I essentially need to do is get the last non empty cell from every row and cut / paste it a new column.
I was wondering if there is an easy way to do this?
I appreciate any advice. Many thanks in advance!
asked Jul 6, 2013 at 18:50
![]()
AnchovyLegendAnchovyLegend
12k35 gold badges144 silver badges229 bronze badges
4
Are your values numeric or text (or possibly both)?
For numbers get last value with this formula in Z2
=LOOKUP(9.99E+307,A2:Y2)
or for text….
=LOOKUP("zzz",A2:Y2)
or for either…
=LOOKUP(2,1/(A2:Y2<>""),A2:Y2)
all the formulas work whether you have blanks in the data or not……
answered Jul 6, 2013 at 21:15
![]()
barry houdinibarry houdini
45.5k8 gold badges63 silver badges80 bronze badges
3
Okay, from what you’ve given if I understood correctly, you can use this formula in cell J1 and drag it down for the other rows below this cell:
=INDEX(A1:I1,1,COUNTA(A1:I1))
This assumes that the ‘longest row’ goes up to the column I.
answered Jul 6, 2013 at 19:27
![]()
JerryJerry
70.1k13 gold badges99 silver badges143 bronze badges
1
You can also use OFFSET. You don’t need to specify an ending column, you can just reference the entire row.
=OFFSET(1:1,0,COUNTA(1:1)-1,1,1)
answered Jul 11, 2013 at 14:29
![]()
grandocugrandocu
3261 silver badge4 bronze badges
Найдем номер строки последней заполненной ячейки в столбце и списке. По номеру строки найдем и само значение.
Рассмотрим диапазон значений, в который регулярно заносятся новые данные.
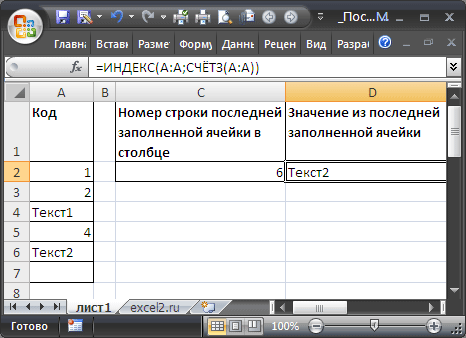
Диапазон без пропусков и начиная с первой строки
В случае, если в столбце значения вводятся, начиная с первой строки и без пропусков, то определить номер строки последней заполненной ячейки можно формулой:
=СЧЁТЗ(A:A))
Формула работает для числовых и текстовых диапазонов (см.
Файл примера
)
Значение из последней заполненной ячейки в столбце выведем с помощью функции
ИНДЕКС()
:
=ИНДЕКС(A:A;СЧЁТЗ(A:A))
Ссылки на целые столбцы и строки достаточно ресурсоемки и могут замедлить пересчет листа. Если есть уверенность, что при вводе значений пользователь не выйдет за границы определенного диапазона, то лучше указать ссылку на диапазон, а не на столбец. В этом случае формула будет выглядеть так:
=ИНДЕКС(A1:A20;СЧЁТЗ(A1:A20))
Диапазон без пропусков в любом месте листа
Если список, в который вводятся значения расположен в диапазоне
E8:E30
(т.е. не начинается с первой строки), то формулу для определения номера строки последней заполненной ячейки можно записать следующим образом:
=СЧЁТЗ(E9:E30)+СТРОКА(E8)
Формула
СТРОКА(E8)
возвращает номер строки заголовка списка. Значение из последней заполненной ячейки списка выведем с помощью функции
ИНДЕКС()
:
=ИНДЕКС(E9:E30;СЧЁТЗ(E9:E30))
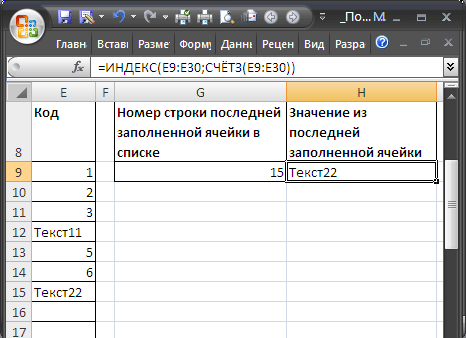
Диапазон с пропусками (числа)
В случае
наличия пропусков
(пустых строк) в столбце, функция
СЧЕТЗ()
будет возвращать неправильный (уменьшенный) номер строки: оно и понятно, ведь эта функция подсчитывает только значения и не учитывает
пустые
ячейки.
Если диапазон заполняется
числовыми
значениями, то для определения номера строки последней заполненной ячейки можно использовать формулу
=ПОИСКПОЗ(1E+306;A:A;1)
. Пустые ячейки и текстовые значения игнорируются.
Так как в качестве просматриваемого массива указан целый столбец (
A:A
), то функция
ПОИСКПОЗ()
вернет номер последней заполненной строки. Функция
ПОИСКПОЗ()
(с третьим параметром =1) находит позицию наибольшего значения, которое меньше или равно значению первого аргумента (1E+306). Правда, для этого требуется, чтобы массив был
отсортирован
по возрастанию. Если он не отсортирован, то эта функция возвращает позицию последней заполненной строки столбца, т.е. то, что нам нужно.
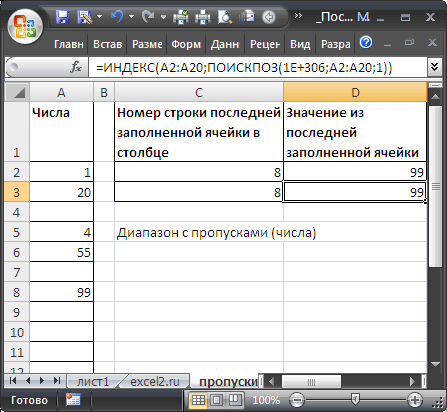
Чтобы вернуть значение в последней заполненной ячейке списка, расположенного в диапазоне
A2:A20
, можно использовать формулу:
=ИНДЕКС(A2:A20;ПОИСКПОЗ(1E+306;A2:A20;1))
Диапазон с пропусками (текст)
В случае необходимости определения номера строки последнего
текстового
значения (также при наличии пропусков), формулу нужно переделать:
=ПОИСКПОЗ(«*»;$A:$A;-1)
Пустые ячейки, числа и текстовое значение
Пустой текст
(«») игнорируются.
Диапазон с пропусками (текст и числа)
Если столбец содержит и
текстовые и числовые значения
, то для определения номера строки последней заполненной ячейки можно предложить универсальное решение:
=МАКС(ЕСЛИОШИБКА(ПОИСКПОЗ(«*»;$A:$A;-1);0); ЕСЛИОШИБКА(ПОИСКПОЗ(1E+306;$A:$A;1);0))
Функция
ЕСЛИОШИБКА()
нужна для подавления ошибки возникающей, если столбец
A
содержит только текстовые или только числовые значения.
Другим универсальным решением является
формула массива
:
=МАКС(СТРОКА(A1:A20)*(A1:A20<>»»))
Или
=МАКС(СТРОКА(A1:A20)*НЕ(ЕПУСТО(A1:A20)))
После ввода
формулы массива
нужно нажать
CTRL + SHIFT + ENTER
. Предполагается, что значения вводятся в диапазон
A1:A20
. Лучше задать фиксированный диапазон для поиска, т.к. использование в
формулах массива
ссылок на целые строки или столбцы является достаточно ресурсоемкой задачей.
Значение из последней заполненной ячейки, в этом случае, выведем с помощью функции
ДВССЫЛ()
:
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*(A1:A20<>»»)))
Или
=ДВССЫЛ(«A»&МАКС(СТРОКА(A1:A20)*НЕ(ЕПУСТО(A1:A20))))
Как обычно, после ввода
формулы массива
нужно нажать
CTRL + SHIFT + ENTER
вместо
ENTER
.
СОВЕТ:
Как видно, наличие пропусков в диапазоне существенно усложняет подсчет. Поэтому имеет смысл при заполнении и проектировании таблиц придерживаться правил приведенных в статье
Советы по построению таблиц
.

Для того, чтобы «вытащить» последнее непустое значение в строке, содержащей как пустые, так и непустые ячейки, можно воспользоваться функцией ПРОСМОТР с определенными «настройками» диапазонов.
Такая задача может возникнуть при поиске последней цены закупки в хронологическом порядке, последних данных транзакции и т.п.
Для этого:
- В столбце с нашими будущими результатами вводим =ПРОСМОТР( и нажимаем fx.

- В предложенных режимах функции выбираем первый – «искомое_значение;просматриваемый_вектор;вектор_результатов» и нажимаем ОК.
- Далее заполняем аргументы. Функция ПРОСМОТР имеет очень интересную особенность. Если она не находит требуемые искомые значения, то она возвращает последнее справа в указанном диапазоне. Диапазон для поиска находится в просматриваемом векторе. Его мы преобразуем таким образом, чтобы результатами были либо значения, либо ошибки.
Вводя конструкцию 1/(ДИАПАЗОН<>””) (диапазон, не равный пустым ячейкам), мы получим последовательность {1; #ДЕЛ/0…..}. Это даст нам возможность исключить из поиска пустые ячейки. Т.к. в просматриваемом векторе теперь заведомо будут отсутствовать любые искомые значения (кроме «1», ее вводить нельзя), то в искомое значение вводим любое число – например «1111». - В вектор результатов вводим тот же диапазон, но без ограничений, т.е. диапазон с частью нашей строки.
- Заканчиваем ввод нажатием на ОК и «протягиваем» формулу на все строки.
- Для указанного примера, вся последовательность будет иметь вид:




=ПРОСМОТР(1111111111;1/(B3:F3<>»»);B3:F3), ее можно скопировать в строку формул и перенастроить под первую строку вашей таблицы, изменяя диапазон B3:F3 в векторах.
Если материал Вам понравился или даже пригодился, Вы можете поблагодарить автора, переведя определенную сумму по кнопке ниже:
(для перевода по карте нажмите на VISA и далее «перевести»)
Предположим, что вы часто обновляете таблицу, добавляя новые данные в ее столбцы. Вам, возможно, понадобится способ ссылаться на последнее значение в определенном столбце (последнее введенное значение).
В таблице на рис. 114.1 отслеживаются значения трех фондов в столбцах B:D. Обратите внимание, что информация поступает не в одно и то же время. Цель состоит в том, чтобы получить сумму самых последних данных по каждому фонду. Эти значения рассчитываются в диапазоне G4:G6.

Рис. 114.1. Таблица, из которой необходимо получить значение последней непустой ячейки в столбцах B:D
Формулы в G4, G5 и G6 следующие:
=ИНДЕКС(B:B;СЧЁТЗ(B:B))
=ИНДЕКС(C:C;СЧЁТЗ(C:C))
=ИНДЕКС(D:D;СЧЁТЗ(D:D))
Формулы применяют функции СЧЁТЗ для подсчета количества непустых ячеек в столбце С. Это значение используется в качестве второго аргумента функции ИНДЕКС. Например, в столбце В последнее значение в строке равно 6, СЧЁТЗ возвращает 6, а функция ИНДЕКС возвращает шестое значение в столбце.
Предыдущие формулы работают в большинстве, но не во всех случаях. Если в столбце одна или несколько пустых ячеек разбросаны, то определение последней непустой ячейки — немного более сложная задача, поскольку функция СЧЁТЗ не подсчитывает пустые ячейки.
Следующая формула массива возвращает содержимое последней непустой ячейки в первых 500 строках из столбца С, даже если он включает пустые ячейки: =ИНДЕКС(C1:C500;МАКС(СТОЛБЕЦ(C1:C500)*(C1:C500<>""))).
Нажмите Ctrl+Shift+Enter (а не просто Enter), чтобы ввести формулу массива.
Вы можете, конечно, изменить формулу для работы с любым другим столбцом, кроме С. Для этого поменяйте четыре ссылки на столбец С на другой, который вам нужен. Если последняя непустая ячейка была в строке, идущей за 500 первыми строками, вам необходимо изменить два экземпляра значения 500 на большее число. Чем меньше строк ссылается в формуле, тем быстрее выполняется расчет.
Следующая формула массива подобна предыдущей, но возвращает последнюю непустую ячейку в строке (в данном случае в строке 1): =ИНДЕКС(1:1;МАКС(СТОЛБЕЦ(1:1)*(1:1<>""))). Чтобы использовать эту формулу для различных строк, измените три ссылки на строки 1:1 так, чтобы она соответствовала правильному количеству строк.