
Содержание
- Как это работает
- Подключаем внешние данные из интернет
- Импорт внешних данных Excel 2010
- Отличите нового и старого мастера импорта
- Пример работы функции БИЗВЛЕЧЬ при выборке данных из таблицы Excel
- Примеры использования функции БИЗВЛЕЧЬ в Excel
- Тип данных: Числовые значения MS Excel
- Классификация типов данных
- Текстовые значения
- Дата и время
- Логические данные
- Разновидности типов данных
- Число
- Текст
- Ошибки
- Подключение к внешним данным
- Подключение к базе данных
- Импорт данных из базы данных Microsoft Access
- Импорт данных с веб-страницы
- Копировать-вставить данные из Интернета
- Импорт данных из текстового файла
- Импорт данных из другой книги
- Импорт данных из других источников
- Задача для получения данных в Excel
Как это работает
Инструменты для импорта расположены во вкладке меню «Данные». 
Если подключение отключено, перейдите: 
Далее: 
На вкладке «Центр управления» перейдите: 
Подключаем внешние данные из интернет
В Excel 2013 и более поздних версиях, по умолчанию для импорта информации из внешних источников используется надстройка Power Query. Как это работает? Перейдите: 
Пропишите адрес сайта, с которого импортируются данные: 
Выберите что отобразится, нажмите кнопку «Загрузить». 
Информация подгрузится в лист Excel. Работайте с ними как с простым документом: используйте формулы графики, сводные таблицы. 
Для обновления нажмите ПКМ по таблице: 
Или: 
Импорт внешних данных Excel 2010
Перейдите: 
В новом окне пропишите адрес сайта. Получите информацию из областей страницы, где проставлены желтые ярлыки. Отметьте их мышкой, нажмите «Импорт». 
Отметьте пункт «Обновление». Тогда внешняя информация обновится автоматически. 
Отличите нового и старого мастера импорта
Преимущества Power Query:
- Поддерживается работа с большим числом страниц;
- Промежуточная обработка информации перед загрузкой на лист;
- Информация импортируется быстрее.
Как создать базу данных в Excel? Базой данных в программе Excel считается таблица, которая была создана с учетом определенных требований:
- Заголовки таблицы должны находиться в первой строке.
- Любая последующая строка должна содержать хотя бы одну непустую ячейку.
- Объединения ячеек в любых строках запрещены.
- Для каждой ячейки каждого столбца должен быть определен единый тип хранящихся данных.
- Диапазон базы данных должен быть отформатирован в качестве списка и иметь свое имя.
Таким образом, практически любая таблица в Excel может быть преобразована в базу данных. Ее строки являются записями, а столбцы – полями данных.
Функция БИЗВЛЕЧЬ хорошо работает с корректно отформатированными таблицами.
Примеры использования функции БИЗВЛЕЧЬ в Excel
Пример 1. В таблице, которую можно рассматривать как БД, содержатся данные о различных моделях смартфонов. Найти название бренда смартфона, который содержит процессор с минимальным числом ядер.
Вид таблиц данных и критериев:

В ячейке B2 запишем условие отбора данных следующим способом:
=МИН(СТОЛБЕЦ(B1))
Данный вариант записи позволяет унифицировать критерий для поиска данных в изменяющейся таблице (если число записей будет увеличиваться или уменьшаться со временем).
В результате получим следующее:

В ячейке A4 запишем следующую формулу:
Описание аргументов:
- A8:F15 – диапазон ячеек, в которых хранится БД;
- 1 – числовое указание номера поля (столбца), из которого будет выводиться значение (необходимо вывести Бренд);
- A2:F3 – диапазон ячеек, в которых хранится таблица критериев.
Результат вычислений:

При изменении значений в таблице параметров условий мы будем автоматически получать выборку соответственных им результатов.
Тип данных: Числовые значения MS Excel
Числовые значения, в отличие от текстовых, можно и складывать и умножать и вообще, применять к ним весь богатый арсенал экселевских средств по обработке данных. После ввода в пустую ячейку MS Excel, числовые значения выравнивается по правой границе ячейки.
Фактически, к числовым типам данных относятся:
- сами числа (и целые и дробные и отрицательные и даже записанные в виде процентов)
- дата и время
Несколько особенностей числовых типов данных
Если введенное число не помещается в ячейку, то оно будет представлено в экспоненциальной форму представления, здорово пугающей неподготовленных пользователей. Например, гигантское число 4353453453453450 х 54545 в ячейку будет записано в виде 2,37459Е+20. Но, как правило в «жизни» появление «странных чисел» в ячейках excel свидетельствует о простой ошибке.

Если число или дата не помещается в ячейку целиком, вместо цифр в ней появляются символы ###. В этом случае «лечение» ещё более простое — нужно просто увеличить ширину столбца таблицы.
Иногда есть необходимостью записать число как текст, например в случае записи всевозможных артикулов товаров и т.п. дело в том, что если вы запишите 000335 в ячейку, Excel посчитав это значение числом, сразу же удалит нули, превратив артикул в 335. Чтобы этого не произошло, просто поместите число в кавычки — это будет сигналом для Excel, что содержимое ячейки надо воспринимать как текст, то есть выводить также, как его ввел пользователь. Естественно, производить с таким числом математических операций нельзя.
Что представляет собой дата в MS Excel?
Если с числами все более-менее понятно, то даты имеют несколько особенностей, о которых стоит упомянуть. Для начала, что такое «дата» с точки зрения MS Excel? На самом деле все не так уж и просто.
Дата в Excel — это число дней, отсчитанных до сегодняшнего дня, от некой начальной даты. По умолчанию этой начальной датой считается 1 января 1900 года.
А что же текущее время? Ещё интереснее — за точку отсчета каждых суток берется 00:00:00, которое представляется как 1. А дальше, эта единичка уменьшается, по мере того как уменьшается оставшееся в сутках время. Например 12.00 дня это с точки зрения MS Excel 0,5 (прошла половина суток), а 18.00 — 0,25 (прошли 3 четверти суток).
В итоге, дата 17 июня 2019 года, 12:30, «языком экселя» выглядит как 43633 (17.06.19) + 0,52 (12:30), то есть число 43633,52.

Как превратить число в текст? Поместите его в кавычки!
Классификация типов данных
Тип данных — это характеристика информации, хранимой на листе. На основе этой характеристики программа определяет, каким образом обрабатывать то или иное значение.
Типы данных делятся на две большие группы: константы и формулы. Отличие между ними состоит в том, что формулы выводят значение в ячейку, которое может изменяться в зависимости от того, как будут изменяться аргументы в других ячейках. Константы – это постоянные значения, которые не меняются.
В свою очередь константы делятся на пять групп:
- Текст;
- Числовые данные;
- Дата и время;
- Логические данные;
- Ошибочные значения.
Текстовые значения
Текстовый тип содержит символьные данные и не рассматривается Excel, как объект математических вычислений. Это информация в первую очередь для пользователя, а не для программы. Текстом могут являться любые символы, включая цифры, если они соответствующим образом отформатированы. В языке DAX этот вид данных относится к строчным значениям. Максимальная длина текста составляет 268435456 символов в одной ячейке.
Для ввода символьного выражения нужно выделить ячейку текстового или общего формата, в которой оно будет храниться, и набрать текст с клавиатуры. Если длина текстового выражения выходит за визуальные границы ячейки, то оно накладывается поверх соседних, хотя физически продолжает храниться в исходной ячейке.

Дата и время
Ещё одним типом данных является формат времени и даты. Это как раз тот случай, когда типы данных и форматы совпадают. Он характеризуется тем, что с его помощью можно указывать на листе и проводить расчеты с датами и временем. Примечательно, что при вычислениях этот тип данных принимает сутки за единицу. Причем это касается не только дат, но и времени. Например, 12:30 рассматривается программой, как 0,52083 суток, а уже потом выводится в ячейку в привычном для пользователя виде.
Существует несколько видов форматирования для времени:
- ч:мм:сс;
- ч:мм;
- ч:мм:сс AM/PM;
- ч:мм AM/PM и др.

Аналогичная ситуация обстоит и с датами:
- ДД.ММ.ГГГГ;
- ДД.МММ
- МММ.ГГ и др.

Есть и комбинированные форматы даты и времени, например ДД:ММ:ГГГГ ч:мм.

Также нужно учесть, что программа отображает как даты только значения, начиная с 01.01.1900.
Логические данные
Довольно интересным является тип логических данных. Он оперирует всего двумя значениями: «ИСТИНА» и «ЛОЖЬ». Если утрировать, то это означает «событие настало» и «событие не настало». Функции, обрабатывая содержимое ячеек, которые содержат логические данные, производят те или иные вычисления.

Разновидности типов данных
Выделяются две большие группы типов данных:
- константы – неизменные значения;
- формулы – значения, которые меняются в зависимости от изменения других.
В группу “константы” входят следующие типы данных:
- числа;
- текст;
- дата и время;
- логические данные;
- ошибки.
Число
Этот тип данных применяется в различных расчетах. Как следует из названия, здесь предполагается работа с числами, и для которых может быть задан один из следующих форматов ячеек:
- числовой;
- денежный;
- финансовый;
- процентный;
- дробный;
- экспоненциальный.
Формат ячейки можно задать двумя способами:
- Во вкладке “Главная” в группе инструментов “Число” нажимаем по стрелке рядом с текущим значением и в раскрывшемся списке выбираем нужный вариант.

- В окне форматирования (вкладка “Число”), в которое можно попасть через контекстное меню ячейки.



Для каждого из форматов, перечисленных выше (за исключением дробного), можно задать количество знаков после запятой, а для числового – к тому же, включить разделитель групп разрядов.

Чтобы ввести значение в ячейку, достаточно просто выделить ее (с нужным форматом) и набрать с помощью клавиш на клавиатуре нужные символы (либо вставить ранее скопированные данные из буфера обмена). Или можно выделить ячейку, после чего ввести нужные символы в строке формул.
Также можно поступить наоборот – сначала ввести значение в нужной ячейке, а формат поменять после.
Текст
Данный тип данных не предназначен для выполнения расчетов и носит исключительно информационный характер. В качестве текстового значения могут использоваться любые знаки, цифры и т.д.
Ввод текстовой информации происходит таким же образом, как и числовой. Если текст не помещается в рамках выбранной ячейки, он будет перекрывать соседние (если они пустые).

Ошибки
В некоторых случаях пользователь может видеть в Excel ошибки, которые бывают следующих видов:

- #ДЕЛ/О! – результат деления на число 0
- #Н/Д – введены недопустимые данные;
- #ЗНАЧ! – использование неправильного вида аргумента в функции;
- #ЧИСЛО! – неверное числовое значение;
- #ССЫЛКА! – удалена ячейка, на которую ссылалась формула;
- #ИМЯ? – неправильное имя в формуле;
- #ПУСТО! – неправильно указан адрес дапазона.
Подключение к внешним данным
Вы можете получить доступ к внешним источникам через вкладку Данные, группу Получить и преобразовать данные. Подключения к данным хранятся вместе с книгой, и вы можете просмотреть их, выбрав пункт Данные –> Запросы и подключения.
Подключение к данным может быть отключено на вашем компьютере. Для подключения данных пройдите по меню Файл –> Параметры –> Центр управления безопасностью –> Параметры центра управления безопасностью –> Внешнее содержимое. Установите переключатель на одну из опций: включить все подключения к данным (не рекомендуется) или запрос на подключение к данным.

Настройка доступа к внешним данным; чтобы увеличить изображение кликните на нем правой кнопкой мыши и выберите Открыть картинку в новой вкладке
Подробнее о подключении к внешним источникам данных см. Кен Пульс и Мигель Эскобар. Язык М для Power Query. При использовании таблиц, подключенных к данным можно переставлять и удалять столбцы, не изменяя запрос. Excel продолжает сопоставлять запрошенные данные с правильными столбцами. Однако ширина столбцов обычно автоматически устанавливается при обновлении. Чтобы запретить Excel автоматически устанавливать ширину столбцов Таблицы при обновлении, щелкните правой кнопкой мыши в любом месте Таблицы и пройдите по меню Конструктор –> Данные из внешней таблицы –> Свойства, а затем снимите флажок Задать ширину столбца.

Свойства Таблицы, подключенной к внешним данным
Подключение к базе данных
Для подключения к базе данных SQL Server выберите Данные –> Получить данные –> Из базы данных –> Из базы данных SQL Server. Появится мастер подключения к данным, предлагающий элементы управления для указания имени сервера и типа входа, который будет использоваться для открытия соединения. Обратитесь к своему администратору SQL Server или ИТ-администратору, чтобы узнать, как ввести учетные данные для входа.

Подключение к базе данных SQL Server
При импорте данных в книгу Excel их можно загрузить в модель данных, предоставив доступ к ним другим инструментам анализа, таким как Power Pivot.
Существует много различных типов доступных источников данных, и иногда шаблоны соединений по умолчанию, представленные Excel, не работают.
Импорт данных из базы данных Microsoft Access
Мы научимся импортировать данные из базы данных MS Access. Следуйте инструкциям ниже
Шаг 1 – Откройте новую пустую книгу в Excel.
Шаг 2 – Перейдите на вкладку ДАННЫЕ на ленте.
Шаг 3 – Нажмите « Доступ» в группе «Получить внешние данные». Откроется диалоговое окно « Выбор источника данных ».

Шаг 4 – Выберите файл базы данных Access, который вы хотите импортировать. Файлы базы данных Access будут иметь расширение .accdb.

Откроется диалоговое окно «Выбор таблицы», в котором отображаются таблицы, найденные в базе данных Access. Вы можете импортировать все таблицы в базе данных одновременно или импортировать только выбранные таблицы на основе ваших потребностей анализа данных.

Шаг 5 – Установите флажок Включить выбор нескольких таблиц и выберите все таблицы.

Шаг 6 – Нажмите ОК. Откроется диалоговое окно « Импорт данных ».

Как вы заметили, у вас есть следующие опции для просмотра данных, которые вы импортируете в свою рабочую книгу:
- Таблица
- Отчет сводной таблицы
- PivotChart
- Power View Report
У вас также есть возможность – только создать соединение . Далее отчет по сводной таблице выбран по умолчанию.
Excel также дает вам возможность поместить данные в вашу книгу –
- Существующий лист
- Новый лист
Вы найдете еще один флажок, который установлен и отключен. Добавьте эти данные в модель данных . Каждый раз, когда вы импортируете таблицы данных в свою книгу, они автоматически добавляются в модель данных в вашей книге. Вы узнаете больше о модели данных в следующих главах.
Вы можете попробовать каждый из вариантов, чтобы просмотреть импортируемые данные и проверить, как эти данные отображаются в вашей рабочей книге.
-
Если вы выберете « Таблица» , опция «Существующая рабочая таблица» будет отключена, будет выбрана опция « Новая рабочая таблица», и Excel создаст столько таблиц, сколько будет импортировано таблиц из базы данных. Таблицы Excel отображаются в этих таблицах.
-
Если вы выберете Отчет сводной таблицы , Excel импортирует таблицы в рабочую книгу и создаст пустую сводную таблицу для анализа данных в импортированных таблицах. У вас есть возможность создать сводную таблицу на существующем листе или новом листе.
Таблицы Excel для импортированных таблиц данных не будут отображаться в книге. Однако вы найдете все таблицы данных в списке полей сводной таблицы вместе с полями в каждой таблице.
-
Если вы выберете PivotChart , Excel импортирует таблицы в рабочую книгу и создаст пустую PivotChart для отображения данных в импортированных таблицах. У вас есть возможность создать сводную диаграмму на существующем или новом листе.
Таблицы Excel для импортированных таблиц данных не будут отображаться в книге. Однако вы найдете все таблицы данных в списке полей PivotChart вместе с полями в каждой таблице.
-
Если вы выберите Power View Report , Excel импортирует таблицы в рабочую книгу и создаст Power View Report в новой рабочей таблице. В последующих главах вы узнаете, как использовать отчеты Power View для анализа данных.
Таблицы Excel для импортированных таблиц данных не будут отображаться в книге. Однако вы найдете все таблицы данных в списке полей Power View Report вместе с полями в каждой таблице.
-
Если вы выберете опцию – Только создать соединение , между базой данных и вашей книгой будет установлено соединение для передачи данных. Таблицы или отчеты не отображаются в книге. Однако импортированные таблицы по умолчанию добавляются в модель данных в вашей книге.
Вам необходимо выбрать любой из этих параметров в зависимости от вашего намерения импортировать данные для анализа данных. Как вы заметили выше, независимо от выбранной вами опции, данные импортируются и добавляются в модель данных в вашей рабочей книге.
Если вы выберете « Таблица» , опция «Существующая рабочая таблица» будет отключена, будет выбрана опция « Новая рабочая таблица», и Excel создаст столько таблиц, сколько будет импортировано таблиц из базы данных. Таблицы Excel отображаются в этих таблицах.
Если вы выберете Отчет сводной таблицы , Excel импортирует таблицы в рабочую книгу и создаст пустую сводную таблицу для анализа данных в импортированных таблицах. У вас есть возможность создать сводную таблицу на существующем листе или новом листе.
Таблицы Excel для импортированных таблиц данных не будут отображаться в книге. Однако вы найдете все таблицы данных в списке полей сводной таблицы вместе с полями в каждой таблице.
Если вы выберете PivotChart , Excel импортирует таблицы в рабочую книгу и создаст пустую PivotChart для отображения данных в импортированных таблицах. У вас есть возможность создать сводную диаграмму на существующем или новом листе.
Таблицы Excel для импортированных таблиц данных не будут отображаться в книге. Однако вы найдете все таблицы данных в списке полей PivotChart вместе с полями в каждой таблице.
Если вы выберите Power View Report , Excel импортирует таблицы в рабочую книгу и создаст Power View Report в новой рабочей таблице. В последующих главах вы узнаете, как использовать отчеты Power View для анализа данных.
Таблицы Excel для импортированных таблиц данных не будут отображаться в книге. Однако вы найдете все таблицы данных в списке полей Power View Report вместе с полями в каждой таблице.
Если вы выберете опцию – Только создать соединение , между базой данных и вашей книгой будет установлено соединение для передачи данных. Таблицы или отчеты не отображаются в книге. Однако импортированные таблицы по умолчанию добавляются в модель данных в вашей книге.
Вам необходимо выбрать любой из этих параметров в зависимости от вашего намерения импортировать данные для анализа данных. Как вы заметили выше, независимо от выбранной вами опции, данные импортируются и добавляются в модель данных в вашей рабочей книге.
Импорт данных с веб-страницы
Иногда вам может понадобиться использовать данные, которые обновляются на веб-сайте. Вы можете импортировать данные из таблицы на веб-сайте в Excel.
Шаг 1 – Откройте новую пустую книгу в Excel.
Шаг 2 – Перейдите на вкладку ДАННЫЕ на ленте.
Шаг 3 – Нажмите « Из Интернета» в группе « Получить внешние данные ». Откроется диалоговое окно « Новый веб-запрос ».

Шаг 4 – Введите URL-адрес веб-сайта, с которого вы хотите импортировать данные, в поле рядом с адресом и нажмите «Перейти».

Шаг 5 – Данные на сайте появляются. Рядом с данными таблицы будут отображаться желтые значки со стрелками, которые можно импортировать.

Шаг 6 – Нажмите желтые значки, чтобы выбрать данные, которые вы хотите импортировать. Это превращает желтые значки в зеленые поля с галочкой, как показано на следующем снимке экрана.

Шаг 7 – Нажмите кнопку «Импорт» после того, как вы выбрали то, что вы хотите.

Откроется диалоговое окно « Импорт данных ».

Шаг 8 – Укажите, куда вы хотите поместить данные и нажмите Ok.
Шаг 9 – Организовать данные для дальнейшего анализа и / или представления.

Копировать-вставить данные из Интернета
Другой способ получения данных с веб-страницы – копирование и вставка необходимых данных.
Шаг 1 – Вставьте новый лист.
Шаг 2 – Скопируйте данные с веб-страницы и вставьте их на лист.
Шаг 3 – Создайте таблицу с вставленными данными.

Импорт данных из текстового файла
Если у вас есть данные в файлах .txt или .csv или .prn , вы можете импортировать данные из этих файлов, рассматривая их как текстовые файлы. Следуйте инструкциям ниже
Шаг 1 – Откройте новый лист в Excel.
Шаг 2 – Перейдите на вкладку ДАННЫЕ на ленте.
Шаг 3 – Нажмите « Из текста» в группе «Получить внешние данные». Откроется диалоговое окно « Импорт текстового файла ».

Вы можете видеть, что текстовые файлы с расширениями .prn, .txt и .csv принимаются.
Шаг 4 – Выберите файл. Имя выбранного файла появится в поле Имя файла. Кнопка «Открыть» изменится на кнопку «Импорт».

Шаг 5 – Нажмите кнопку «Импорт». Мастер импорта текста – появляется диалоговое окно « Шаг 1 из 3 ».
Шаг 6 – Выберите опцию «С разделителями», чтобы выбрать тип файла, и нажмите «Далее».

Откроется мастер импорта текста – шаг 2 из 3 .
Шаг 7 – В разделе «Разделители» выберите « Другое» .
Шаг 8 – В поле рядом с Другой введите | (Это разделитель в текстовом файле, который вы импортируете).
Шаг 9 – Нажмите Далее.

Откроется мастер импорта текста – шаг 3 из 3 .
Шаг 10 – В этом диалоговом окне вы можете установить формат данных столбца для каждого из столбцов.

Шаг 11. После завершения форматирования данных столбцов нажмите кнопку «Готово». Откроется диалоговое окно « Импорт данных ».

Вы увидите следующее –
-
Таблица выбрана для просмотра и отображается серым цветом. Таблица – единственный вариант просмотра, который у вас есть в этом случае.
-
Вы можете поместить данные либо в существующий рабочий лист, либо в новый рабочий лист.
-
Вы можете установить или не устанавливать флажок Добавить эти данные в модель данных.
-
Нажмите OK после того, как вы сделали выбор.
Таблица выбрана для просмотра и отображается серым цветом. Таблица – единственный вариант просмотра, который у вас есть в этом случае.
Вы можете поместить данные либо в существующий рабочий лист, либо в новый рабочий лист.
Вы можете установить или не устанавливать флажок Добавить эти данные в модель данных.
Нажмите OK после того, как вы сделали выбор.
Данные появятся на указанном вами листе. Вы импортировали данные из текстового файла в книгу Excel.
Импорт данных из другой книги
Возможно, вам придется использовать данные из другой книги Excel для анализа данных, но кто-то другой может поддерживать другую книгу.
Чтобы получать последние данные из другой книги, установите соединение данных с этой книгой.
Шаг 1 – Нажмите DATA> Соединения в группе Соединения на ленте.
Откроется диалоговое окно « Подключения к книге».

Шаг 2. Нажмите кнопку «Добавить» в диалоговом окне «Подключения к книге». Откроется диалоговое окно « Существующие подключения ».

Шаг 3 – Нажмите кнопку Обзор для более … Откроется диалоговое окно « Выбор источника данных ».

Шаг 4 – Нажмите кнопку « Новый источник» . Откроется диалоговое окно мастера подключения к данным .

Шаг 5 – Выберите Other / Advanced в списке источников данных и нажмите Next. Откроется диалоговое окно «Свойства ссылки на данные».

Шаг 6 – Установите свойства канала передачи данных следующим образом –
-
Перейдите на вкладку « Соединение ».
-
Нажмите Использовать имя источника данных.
-
Нажмите стрелку вниз и выберите « Файлы Excel» в раскрывающемся списке.
-
Нажмите ОК.
Перейдите на вкладку « Соединение ».
Нажмите Использовать имя источника данных.
Нажмите стрелку вниз и выберите « Файлы Excel» в раскрывающемся списке.
Нажмите ОК.
Откроется диалоговое окно « Выбрать рабочую книгу ».

Шаг 7 – Найдите место, где у вас есть рабочая книга для импорта. Нажмите ОК.
Откроется диалоговое окно « Мастер подключения к данным » с выбором базы данных и таблицы.
Примечание. В этом случае Excel обрабатывает каждый рабочий лист, который импортируется, как таблицу. Имя таблицы будет именем рабочего листа. Таким образом, чтобы иметь значимые имена таблиц, назовите / переименуйте рабочие листы в зависимости от ситуации.

Шаг 8 – Нажмите Далее. Откроется диалоговое окно мастера подключения к данным с сохранением файла подключения к данным и завершением.

Шаг 9 – Нажмите кнопку Готово. Откроется диалоговое окно « Выбор таблицы ».

Как вы заметили, Name – это имя листа, которое импортируется как тип TABLE. Нажмите ОК.
Соединение данных с выбранной вами рабочей книгой будет установлено.
Импорт данных из других источников
Excel предоставляет вам возможность выбора различных других источников данных. Вы можете импортировать данные из них в несколько шагов.
Шаг 1 – Откройте новую пустую книгу в Excel.
Шаг 2 – Перейдите на вкладку ДАННЫЕ на ленте.
Шаг 3 – Нажмите Из других источников в группе Получить внешние данные.

Появляется выпадающий список с различными источниками данных.

Вы можете импортировать данные из любого из этих источников данных в Excel.
Задача для получения данных в Excel
И для того чтобы более понятно рассмотреть данную возможность, мы это будем делать как обычно на примере. Другими словами допустим, что нам надо выгрузить данные, одной таблицы, из базы SQL сервера, средствами Excel, т.е. без помощи вспомогательных инструментов, таких как Management Studio SQL сервера.
Примечание! Все действия мы будем делать, используя Excel 2010. SQL сервер у нас будет MS Sql 2008.
И для начала разберем исходные данные, допустим, есть база test, а в ней таблица test_table, данные которой нам нужно получить, для примера будут следующими:

Эти данные располагаются в таблице test_table базы test, их я получил с помощью простого SQL запроса select, который я выполнил в окне запросов Management Studio. И если Вы программист SQL сервера, то Вы можете выгрузить эти данные в Excel путем простого копирования (данные не большие), или используя средство импорта и экспорта MS Sql 2008.
Источники
- https://public-pc.com/podklyuchenie-vneshnih-dannyh-v-excel/
- https://exceltable.com/funkcii-excel/vyborka-iz-bazy-dannyh-bizvlech
- http://bussoft.ru/tablichnyiy-redaktor-excel/tipy-dannyh-v-redaktore-elektronnyh-tablicz-ms-excel.html
- https://lumpics.ru/data-types-in-excel/
- https://MicroExcel.ru/tipy-dannyh/
- https://baguzin.ru/wp/glava-8-rabota-s-vneshnimi-dannymi-v-tablitsah-excel/
- https://coderlessons.com/tutorials/bolshie-dannye-i-analitika/izuchite-analiz-dannykh-excel/import-dannykh-v-excel
- https://info-comp.ru/obucheniest/375-excel-get-data-from-sql-server.html
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
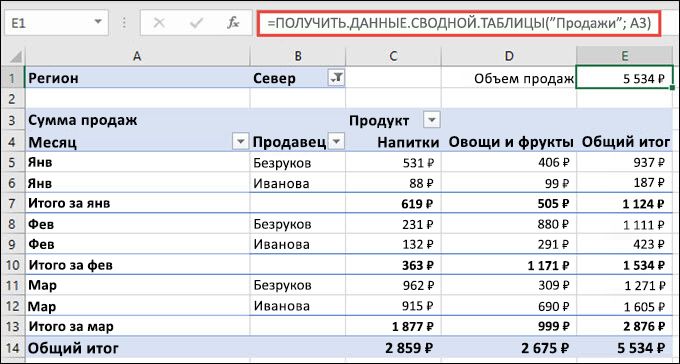
Функция ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ возвращает видимые данные из сводной таблицы.
В этом примере =ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ.(«Продажи»; A3) возвращает общий объем продаж из сводной таблицы:
Синтаксис
ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ(поле_данных; сводная_таблица; [поле1; элемент1; поле2; элемент2]; …)
Аргументы функции ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ описаны ниже.
|
Аргумент |
Описание |
|---|---|
|
поле_данных Обязательно |
Имя поля сводной таблицы, содержащее данные, которые необходимо извлечь. Должно быть заключено в кавычки. |
|
сводная_таблица Обязательно |
Ссылка на ячейку, диапазон ячеек или именованный диапазон ячеек в сводной таблице. Эти сведения используются для определения сводной таблицы, содержащей данные, которые необходимо извлечь. |
|
поле1, элемент1, поле2, элемент2… Необязательно |
От 1 до 126 пар имен полей и элементов, описывающих данные, которые необходимо извлечь. Они могут следовать друг за другом в произвольном порядке. Имена полей и элементов (кроме дат и чисел) должны быть заключены в кавычки. В сводных таблицах OLAP элементы могут содержать исходное имя измерения, а также исходное имя элемента. Пара «поле-элемент» для сводной таблицы OLAP может выглядеть следующим образом: «[Продукт]»;»[Продукт].[Все продукты].[Продовольствие].[Выпечка]» |
Примечания:
-
Можно быстро ввести простую формулу ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ, введя = (знак равенства) в ячейке, в которой должно быть возвращено значение, и затем щелкнув ячейку в сводной таблице, содержащей необходимые данные.
-
Вы можете отключить эту возможность. Для этого нужно выбрать любую ячейку в существующей сводной таблице, а затем перейти к вкладке Анализ сводной таблицы > Сводная таблица > Параметры > и снять флажок у параметра Генерировать функцию ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ.
-
Вычисляемые поля или элементы и дополнительные вычисления могут включаться в расчеты для функции ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ.
-
Аргумент «сводная_таблица» задан как диапазон, включающий несколько сводных таблиц. Данные будут извлекаться из той сводной таблицы, которая была создана последней.
-
Если аргументы «поле» и «элемент» описывают одну ячейку, возвращается значение, содержащееся в этой ячейке, независимо от его типа (строка, число, ошибка или пустая ячейка).
-
Если аргумент «элемент» содержит дату, необходимо представить это значение как порядковый номер или воспользоваться функцией ДАТА, чтобы это значение не изменилось при открытии листа в системе с другими языковыми настройками. Например, элемент, ссылающийся на дату 5 марта 1999 г., можно ввести двумя способами: 36 224 или ДАТА(1999;3;5). Время можно задать в виде десятичных значений или с помощью функции ВРЕМЯ.
-
Если аргумент «сводная_таблица» не является диапазоном, содержащим сводную таблицу, функция ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ возвращает значение ошибки #ССЫЛКА!.
-
Если аргументы не описывают видимое поле или содержат фильтр отчета, в котором не отображаются отфильтрованные данные, функция ПОЛУЧИТЬ.ДАННЫЕ.СВОДНОЙ.ТАБЛИЦЫ возвращает #ССЫЛКА! (значение ошибки).
Примеры
Формулы в примере ниже представляют различные методы извлечения данных из сводной таблицы.
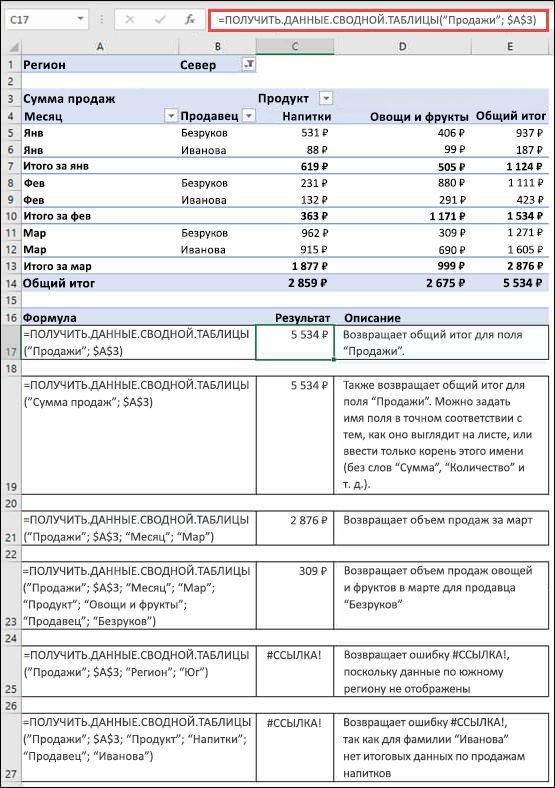
К началу страницы
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Функции Excel (по алфавиту)
Функции Excel (по категориям)
Нужна дополнительная помощь?
Внешние источники данных Excel – это информация, находящаяся за пределами книги: в сервере или другом приложении. К примеру, извлечение тестовых данных или Access. Отображение таких данных возможно при условии подключений (одного или нескольких) к внешним источникам, к примеру таких как SQL Server и Windows Azure Marketplace. Такие подключения дают возможность получить нужные сведения из указанных в подключениях баз данных. При этом, если информация во внешнем источнике обновлена, отображённые в книге данные тоже будут самыми новыми.
Попробуем разобраться в работе системы внешних источников информации Excel. Для начала открывается новый документ. Вкладка «Данные» на главной панели задач имеет раздел получения внешних данных. Имеющиеся возможности получить данные: из Веба, Access, текста, других источников, также «Существующие подключения».
Получение информации возможно лишь при наличии самостоятельно созданной ранее базе данных Access. Следует первым источником данных обозначить тестовый файл (значок «из текста»), поскольку на компьютере проще найти любые тексты, а не базы данных. Выбор источника — «Выбрать», «Ок».
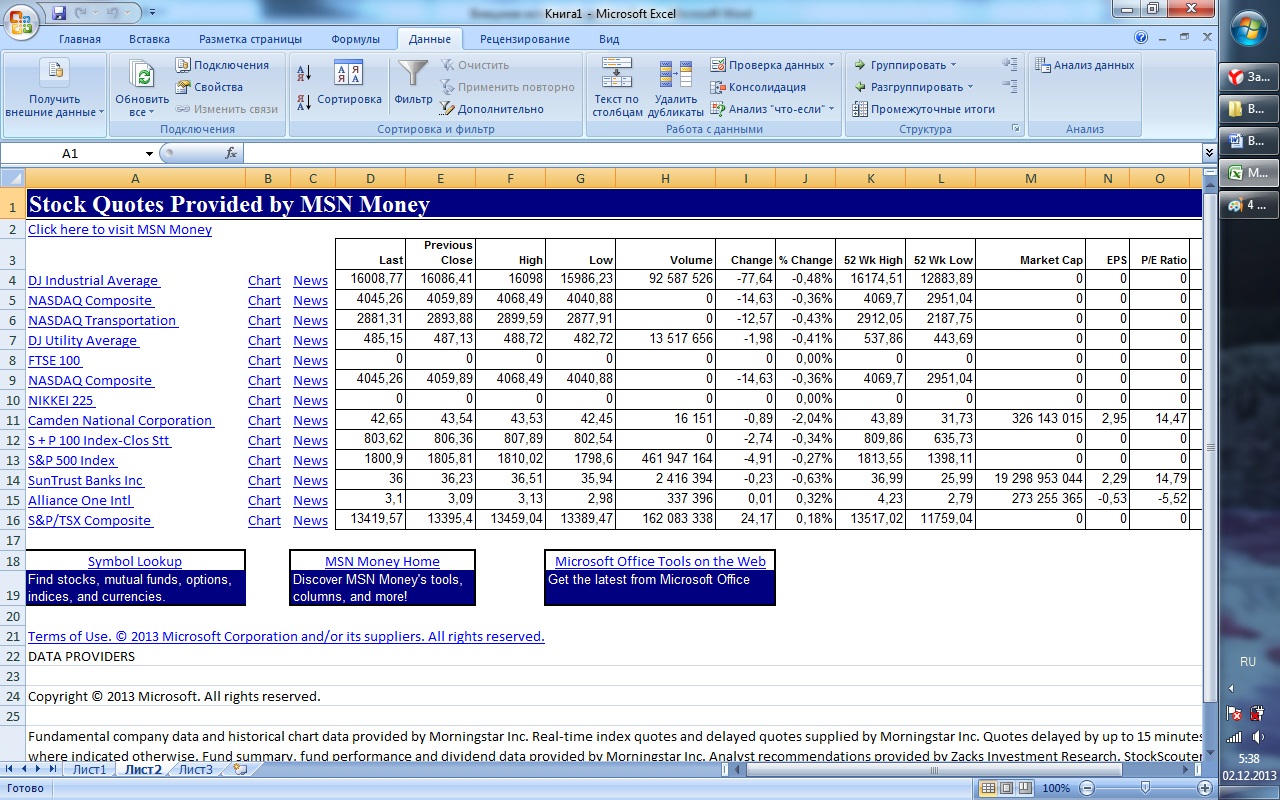
Получение информации из Интернета. Кликнув значок «Из Веба», мы увидим окно веб-запроса. В нём необходимо прописать название необходимого для получения информации сайта. Также можно настроить параметры необходимых данных – значок «Параметры». Выбираем формат файла (RTF, HTML), задаём настройки блоков и включение – отключение параметров дат. После завершения настроек параметров нажимаем «Импорт». Контент сайта должен появиться в книге Excel.
Также источником информации могут стать определённые службы серверов, аналитиков, мастера подключения. Если возникла необходимость сопоставления файла формата XML. Кликаем «Из других источников», после этого – импорт информации XML.
Также у нас есть возможность получения информации из существующих подключений. Выбираем «Получить внешние данные» — «Существующие подключения». Далее – выбор необходимого вида информации – «Открыть». Программа осуществляет поиск информации во внешнем источнике и моделирует её в книге Excel.
6262

Содержание:
- Для чего написана эта статья.
- Получение xlsx-файла по
данным из xml+xsd. - Извлечение xml-таблицы данных из xlsx-файла.
- Краткое описание кода примеров.
- Заключение.
- Ссылки по теме.
Для чего написана эта статья. 

Если вы имеете установленную у Вас серию продуктов из MS Office 2007, Вы наверное
обратили внимание на тип файла «Книга Excel (*.xlsx)«,
имеющегося в диалоге «Сохранить [как/Другие форматы]«,
расширение которого, как и структура содержащихся в нём данных, отличается от
прежнего xls-формата (совместимого с
Excel 97-2003). Этот типа принадлежит к т.н. типам файлов
Office 2007, известных как Office XML Open Format. См. также
статьи Алексея Федорова в разделе: Внешние ссылки по теме.
Ниже приведена таблица форматов, поддерживаемых Excel
из MS Office 2007 с краткими пояснениями к ним
(позаимствована из документации):
| Формат | Расширение | Описание |
|---|---|---|
| Книга Excel | XLSX | Стандартный формат файлов Office Excel 2007 на основе XML. Не сохраняет код VBA-макросов, а также листы макросов Microsoft Excel 4.0 (XLM). |
| Лист Excel (код) | XLSM | Формат файлов Office Excel 2007 на основе XML, поддерживающий сохранение макросов. Сохраняет код VBA-макросов, а также листы макросов Excel 4.0 (XLM). |
| Двоичная книга Excel | XLSB | Формат двоичных файлов Office Excel 2007 (BIFF12). |
| Шаблон | XLTX | Стандартный формат файлов шаблонов Office Excel 2007Excel. Не сохраняет код VBA-макросов, а также листы макросов Microsoft Excel 4.0 (XLM). |
| Шаблон (код) | XLTXM | Формат файлов шаблонов Office Excel 2007Excel, поддерживающий сохранение макросов. Сохраняет код VBA-макросов, а также листы макросов Microsoft Excel 4.0 (XLM). |
| Книга Microsoft Excel 97-2003 |
XLS | Формат двоичных файлов Excel 97 — Excel 2003 (BIFF8). |
| Шаблон Excel 97- Excel 2003 |
XLT | Формат двоичных файлов Excel 97 — Excel 2003 (BIFF8) для хранения шаблонов Excel. |
| Книга Microsoft Excel 5.0/95 |
XLS | Формат двоичных файлов Excel 5.0/95 (BIFF5). |
| XML-таблица 2003 | XML | Формат файлов XML-таблиц 2003 (XMLSS). |
| Данные XML Data | XML | Формат данных XML. |
| Надстройка Microsoft Excel |
XLAM | Формат файлов надстроек Office Excel 2007, обеспечивающих дополнительные возможности программ, создаваемых для исполнения дополнительного кода, на основе XML, и поддерживающих макросы. Поддерживает использование проектов VBA и листов макросов Excel 4.0 (XLM). |
На самом деле, любой файл xlsx-формата представляет собой
zip-файл, содержащий в себе несколько подкаталогов, в которых имеются ряд
файлов с данными в xml(eXtensible Markup Language)-формате. В этом нетрудно
убедиться, если заменить расширение xlsx-файла на
zip и попробовать разархивировать полученный после
переименования zip-файл с помощью какой-нибудь
утилиты, способной это сделать, например используя WinRAR.exe, а в старших версиях OS Windows это можно
также осуществить и с помощью обычного «Проводника» OS
Windows.
Цель данной заметки заключается в том, чтобы на конкретном примере показать способ извлечений
таблицы данных из xlsx-файла, используя
XSLT(eXtensible Stylesheet Language Transformations)-преобразования над xml-данными,
хранящимися в xlsx-файлах. Нами будет проделано две
вещи:
- во-первых, имея некоторую таблицу xml-данных, с
описывающей её структуру xsd-схемой, мы получим
xlsx-файл с этой таблицей в качестве данных, - во-вторых, мы попробуем извлечь таблицу данных из полученного таким образом
xlsx-файла, а для выполнения необходимых
преобразований при этом, мы будем использовать XSLT
с помощью утилиты msxsl.exe или средств, входящих
в MSXML 4.0 Service Pack 2 (Microsoft XML Core Services),
которые
можно свободно и бесплатно загрузить по ссылкам, приведённом мной в разделе: Внешние ссылки по теме.
Получение xlsx-файла по данным
из xml+xsd.
Чтобы самим не придумывать данные для Excel-таблицы, воспользуемся тем, что можно загрузить из
интернета по ссылке: Сопоставление XML-элементов и отмена их сопоставления .
.
Продублирую прямо сюда текст файлов, позаимствованных из этого источника. Итак, там
взяты два файла: Расходы.xml — пример данных,
на основе которых, нами будет построена Excel-таблица и
Расходы.xsd — схема для него.
В файле Расходы.xml имеем следующее:
<?xml
version=«1.0«
encoding=«UTF-8«
standalone=«no«
?>
<Root>
<EmployeeInfo>
<Name>Jane
Winston</Name>
<Date>2001-01-01</Date>
<Code>0001</Code>
</EmployeeInfo>
<ExpenseItem>
<Date>2001-01-01</Date>
<Description>Airfare</Description>
<Amount>500.34</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-01</Date>
<Description>Hotel</Description>
<Amount>200</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-01</Date>
<Description>Taxi
Fare</Description>
<Amount>100.00</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-01</Date>
<Description>Long
Distance Phone Charges</Description>
<Amount>57.89</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-01</Date>
<Description>Food</Description>
<Amount>82.19</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-02</Date>
<Description>Food</Description>
<Amount>17.89</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-02</Date>
<Description>Personal
Items</Description>
<Amount>32.54</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-03</Date>
<Description>Taxi
Fare</Description>
<Amount>75.00</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-03</Date>
<Description>Food</Description>
<Amount>36.45</Amount>
</ExpenseItem>
<ExpenseItem>
<Date>2001-01-03</Date>
<Description>New
Suit</Description>
<Amount>750.00</Amount>
</ExpenseItem>
</Root>
а в файле Расходы.xsd:
<?xml
version=«1.0«
encoding=«UTF-8«
standalone=«no«?>
<xsd:schema
xmlns:xsd=«http://www.w3.org/2001/XMLSchema«>
<xsd:element
name=«Root«>
<xsd:complexType>
<xsd:sequence>
<xsd:element
minOccurs=«0«
maxOccurs=«1«
name=«EmployeeInfo«>
<xsd:complexType>
<xsd:all>
<xsd:element
minOccurs=«0«
maxOccurs=«1«
name=«Name«
type=«xsd:anyType«
/>
<xsd:element
minOccurs=«0«
maxOccurs=«1«
name=«Date«
type=«xsd:anyType«
/>
<xsd:element
minOccurs=«0«
maxOccurs=«1«
name=«Code«
type=«xsd:anyType«
/>
</xsd:all>
</xsd:complexType>
</xsd:element>
<xsd:element
minOccurs=«0«
maxOccurs=«unbounded«
name=«ExpenseItem«>
<xsd:complexType>
<xsd:sequence>
<xsd:element
name=«Date«
type=«xsd:date«
/>
<xsd:element
name=«Description«
type=«xsd:string«
/>
<xsd:element
name=«Amount«
type=«xsd:decimal«
/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:schema>
Далее, создадим на основе данных этих двух файлов таблицу в
Excel из MS Office 2007.
Ниже шаг за шагом и т.с. в картинках показано, как это можно сделать. Но прежде
всего, если у Вас на «Панели
быстрого доступа» отсутствует вкладка «Разработчик», то проделайте действия,
изображённые на Рис.1:

Рис.1
т.е. отметьте пункт «Показывать вкладку «Разработчик» на ленте» в диалоге
«Параметры Excel» и подтвердите изменения, нажав
кнопку «Ok» в правой нижней части окна этого диалога.
Следующим действием загрузим файл-схему Расходы.xsd
в Excel, для чего выполните
пункты, отмеченные красными кружками на Рис.2:

Рис.2
Если всё предшествующее не вызвало никаких ошибок, то в результате Вы должны
получить то, что изображено на Рис.3:

Рис.3
т.е. в правой панели «Источник XML» у Вас должна
появиться древовидная структура полей, описанных в фале-схеме Расходы.xsd.
Следующим действием, мы должны сопоставить данные в области листа книги с
полями загруженной xsd-схемы. Для чего следует мышкой
выделить корневой элемент в правой панели «Источник XML»
(Root в нашем случае) и не отпуская мышки, перетащить
его в ячейку A1 на Лист 1. После чего отпустить кнопку
мыши. Проделав это, мы получим ситуацию, подобную изображённой на Рис.4:

Рис.4
Наконец, попробуем выполнить загрузку/импорт собственно самих данных из файла Расходы.xml,
для чего выделив область данных нашей таблицы на Лист 1 (область ячеек:
A2:F2), воспользуемся кнопкой «Импорт» на закладке «Разработчик» так, как
показано на Рис.5:

Рис.5
Если никаких ошибок при загрузке xml-данных из
файла Расходы.xml не возникло, то вы должны получить ситуацию, изображённую на Рис.6:

Рис.6
Наконец-то мы достигли конечной цели данного этапа, и можем сохранить полученное в виде файла
Книга1.xlsx. Только перед сохранением желательно
удалить пустые лишние листы: Лист 2, Лист 3.
Здесь резонно возникает вопрос: а возможна ли загрузка/импорт табличных
xml-данных в MS Excel 2007 в
случае отсутствия файла xsd-схемы? И ответ здесь: да
возможна. В этом случае, Excel 2007 сам попробует
создать схему/карту Ваших xml-данных, опираясь на
анализ значений самих исходных данных. Что же, попробуем открыть файл Расходы.xml
без предварительной загрузки его файла-схемы Расходы.xsd,
а в возникшем при этом вопросе в диалоге «Открытие XML«, подтвердить пункт «XML-таблица».
На Рис.7 ниже изображена ситуация, которую я получил при таком эксперименте:

Рис.7
Обратите внимание, что в столбцах B и
C тип данных будет соответственно: «Дата» и «Общий» в
отличии от «Текст», которые мы имели выше, т.е. при использовании файла-схемы Расходы.xsd
перед загрузкой xml-данных.
Получив после сохранения файл Книга1.xlsx,
сделайте его копию как файл Книга1.zip, и
разархивируйте последний, включая структуру подкаталогов, с помощью используемого
Вами средства работы с zip-архивами в каталог Книга1.
Если скажем, у Вас имеется установленный WinRAR, то
разархивировать файл Книга.xlsx Вы сможете создав и
выполнив командный файл getContentsUseWinRAR.cmd вот с таким
содержанием:
@echo off
mode con: cp select=1251 > _tmp.txt
"C:Program FilesWinRARWinRAR.exe" X -ad -ibck -o+ Книга1.xlsx
del _tmp.txt
Описание структуры полученных после разархивации подкаталогов/файлов можно найти в ссылках, приведённых мной в
разделе Внешние ссылки по теме,
для дальнейшего нас будут интересовать только полученные после распаковки
xml-файлы,
содержащие как собственно данные, так и описания их типов. К ним относятся:
- ..Книга1xlsharedStrings.xml — общие данные, имеющие тип строка
- ..Книга1xlxmlMaps.xml — файл, содержащий схемы данных
- ..Книга1xltablestable1.xml — описание столбцов таблицы,
включая и типы данных столбцов - ..Книга1xlworksheetssheet1.xml — данные листа, не являющиеся
строками, а также ссылки на общие строковые данные из файла
sharedStrings.xml

Скопируйте перечисленные выше файлы: sharedStrings.xml, xmlMaps.xml, table1.xml и sheet1.xml в отдельный рабочий каталог.
Работой только с этими файлами в отдельном рабочем каталоге мы собственно и
займёмся в дальнейшем.
Извлечение xml-таблицы данных из xlsx-файла.
Прежде всего, попытка выполнить экспорт данных, содержащихся в полученном нами файле Книга1.xlsx,
завершается неудачей, изображённой на рисунке ниже:

Рис.8
Я не нашёл разгадки этой очередной MS-загадки…
 Однако, если бы даже выполнение экспорта таблицы данных из
Однако, если бы даже выполнение экспорта таблицы данных из
xlsx-файла средствами MS Excel
2007 не вызывало бы проблем (например, можно попробовать сохранить содержание листа в формате:
«XML-таблица 2003» и о работе
с данными в рамках этого формата, можно посмотреть здесь: Как получить dbf-таблицы из xls-файла при наличии групп в данных?),
изложенное ниже в этом разделе, может иметь самостоятельный интерес, т.к. позволяет выполнить экспорт
xml-таблицы данных даже в тех случаях, когда у клиента отсутствует
установленный у него на компьютере Excel из MS Office 2007.
Что же, попробуем разобраться во внутреннем представлении
xml-данных, а точнее файлов: sharedStrings.xml, table1.xml и sheet1.xml из
предыдущего раздела, с тем чтобы попытаться всё же выполнить экспорт таблицы
данных.
В полученном нами Книга.zip-файле, начальный
фрагмент файла sharedStrings.xml имеет вид:
<?xml
version=«1.0«
encoding=«UTF-8«
standalone=«yes«?>
<sst
xmlns=«http://schemas.openxmlformats.org/spreadsheetml/2006/main«
count=«46«
uniqueCount=«16«>
<si>
<t>Name</t>
</si>
<si>
<t>Date</t>
</si>
<si>
<t>Code</t>
</si>
<si>
<t>Description</t>
</si>
<si>
<t>Amount</t>
</si>
<si>
<t>Date2</t>
</si>
<si>
<t>Jane
Winston</t>
</si>
<si>
<t>2001-01-01</t>
</si>
<si>
<t>0001</t>
</si>
<si>
<t>Airfare</t>
</si>
<si>
<t>Hotel</t>
</si>
<si>
<t>Taxi
Fare</t>
</si>
<si>
<t>Long
Distance Phone Charges</t>
</si>
…
</sst>
и как не трудно догадаться по названию файла, элементы
<t>…</t> которого, у каждого элемента <si>…</si>
в качестве текста имеют строки из нашей исходной xml-таблицы данных. Точнее,
это заголовки столбцов нашей таблицы, и далее строки-значения данных исходной
таблицы xml-данных. Причём, если непосредственно в
данных одна и та же строка может встретиться несколько раз (как например, строка ‘Jane Winston’ или ‘2001-01-01’), то в
файле sharedStrings.xml такое значение представлено единственным si-элементом.
Забегая слегка вперёд, XPATH-выражение фильтра для
выбора элемента <t>…</t>, содержащего текст у
n-го
элемента <si>…</si>, могло бы выглядеть так: select=»/sst/si[$n]/t»,
где переменная n — имела бы в качестве значения число, означающее
порядковый номер выбираемого si-элемента,
начиная с 1.
В представленном ниже файле table1.xml, нас будет интересовать только
информация о типах данных столбцов таблицы:
<?xml
version=«1.0«
encoding=«UTF-8«
standalone=«yes«?>
<table
xmlns=«http://schemas.openxmlformats.org/spreadsheetml/2006/main«
id=«1«
name=«1«
displayName=«1«
ref=«A1:F11«
tableType=«xml«
totalsRowShown=«0«
connectionId=«1«>
<autoFilter
ref=«A1:F11«/>
<tableColumns
count=«6«>
<tableColumn
id=«1«
uniqueName=«Name«
name=«Name«>
<xmlColumnPr
mapId=«1«
xpath=«/Root/EmployeeInfo/Name«
xmlDataType=«anyType«/>
</tableColumn>
<tableColumn
id=«2«
uniqueName=«Date«
name=«Date«>
<xmlColumnPr
mapId=«1«
xpath=«/Root/EmployeeInfo/Date«
xmlDataType=«anyType«/>
</tableColumn>
<tableColumn
id=«3«
uniqueName=«Code«
name=«Code«>
<xmlColumnPr
mapId=«1«
xpath=«/Root/EmployeeInfo/Code«
xmlDataType=«anyType«/>
</tableColumn>
<tableColumn
id=«4«
uniqueName=«Date«
name=«Date2«>
<xmlColumnPr
mapId=«1«
xpath=«/Root/ExpenseItem/Date«
xmlDataType=«date«/>
</tableColumn>
<tableColumn
id=«5«
uniqueName=«Description«
name=«Description«>
<xmlColumnPr
mapId=«1«
xpath=«/Root/ExpenseItem/Description«
xmlDataType=«string«/>
</tableColumn>
<tableColumn
id=«6«
uniqueName=«Amount«
name=«Amount«>
<xmlColumnPr
mapId=«1«
xpath=«/Root/ExpenseItem/Amount«
xmlDataType=«decimal«/>
</tableColumn>
</tableColumns>
<tableStyleInfo
name=«TableStyleMedium9«
showFirstColumn=«0«
showLastColumn=«0«
showRowStripes=«1«
showColumnStripes=«0«/>
</table>
т.е. значение атрибута xmlDataType у соответствующего элемента tableColumn, в то время как
выбор требуемого столбца можно сделать, опираясь на значение атрибута id,
содержащего в качестве значений порядковый номер столбца, начиная с 1.
Соответствующее XPATH-выражение для выбора типа данных
n-го столбца, могло бы выглядеть так:
select=»/table/tableColumns/tableColumn[@id=$n]/xmlColumnPr/@xmlDataType»
Наконец, рассмотрим содержание файла sheet1.xml
<?xml
version=«1.0«
encoding=«UTF-8«
standalone=«yes«?>
<worksheet
xmlns=«http://schemas.openxmlformats.org/spreadsheetml/2006/main«
xmlns:r=«http://schemas.openxmlformats.org/officeDocument/2006/relationships«>
<sheetPr
codeName=«1«/>
<dimension
ref=«A1:F11«/>
<sheetViews>
<sheetView
tabSelected=«1«
topLeftCell=«C1«
zoomScaleNormal=«100«
workbookViewId=«0«>
<selection
activeCell=«I3«
sqref=«I3«/>
</sheetView>
</sheetViews>
<sheetFormatPr
defaultRowHeight=«15«/>
<cols>
<col
min=«1«
max=«1«
width=«12.85546875«
bestFit=«1«
customWidth=«1«/>
<col
min=«2«
max=«2«
width=«10.42578125«
bestFit=«1«
customWidth=«1«/>
<col
min=«3«
max=«3«
width=«7.7109375«
bestFit=«1«
customWidth=«1«/>
<col
min=«4«
max=«4«
width=«12«
bestFit=«1«
customWidth=«1«/>
<col
min=«5«
max=«5«
width=«27.28515625«
bestFit=«1«
customWidth=«1«/>
<col
min=«6«
max=«6«
width=«10.42578125«
bestFit=«1«
customWidth=«1«/>
</cols>
<sheetData>
<row
r=«1«
spans=«1:6«>
<c
r=«A1«
t=«s«>
<v>0</v>
</c>
<c
r=«B1«
t=«s«>
<v>1</v>
</c>
<c
r=«C1«
t=«s«>
<v>2</v>
</c>
<c
r=«D1«
t=«s«>
<v>5</v>
</c>
<c
r=«E1«
t=«s«>
<v>3</v>
</c>
<c
r=«F1«
t=«s«>
<v>4</v>
</c>
</row>
<row
r=«2«
spans=«1:6«>
<c
r=«A2«
s=«1«
t=«s«>
<v>6</v>
</c>
<c
r=«B2«
s=«1«
t=«s«>
<v>7</v>
</c>
<c
r=«C2«
s=«1«
t=«s«>
<v>8</v>
</c>
<c
r=«D2«
s=«2«>
<v>36892</v>
</c>
<c
r=«E2«
s=«1«
t=«s«>
<v>9</v>
</c>
<c
r=«F2«>
<v>500.34</v>
</c>
</row>
…
</sheetData>
<pageMargins
left=«0.7«
right=«0.7«
top=«0.75«
bottom=«0.75«
header=«0.3«
footer=«0.3«/>
<pageSetup
paperSize=«9«
orientation=«portrait«
r:id=«rId1«/>
<tableParts
count=«1«>
<tablePart
r:id=«rId2«/>
</tableParts>
</worksheet>
На верхнем уровне файл имеет коневой элемент <worksheet>…</worksheet>,
который в свою очередь, содержит элементы: sheetPr, dimension, sheetViews, sheetFormatPr, cols, sheetData, pageMargins, pageSetup, tableParts.
Собственно сами данные (в т.ч. и данные о данных) содержатся в виде списка
дочерних элементов <row>…</row> у элемента <sheetData>…</sheetData>.
Ради сокращения объёма
элементы <row>…</row> с значениями своих атрибутов r=»3″ и до конца (т.е.
до r=»11″ в нашем случае) удалены
из приведённого выше текста, а оставлены только с r=»1″ и r=»2″,
что вполне достаточно, чтобы разобраться в том, как они «устроены».
Разглядывая содержание элементов row (т.е. строк
листа) видим, что каждый из них состоит из набора элементов
<c>…</c>,
(т.е. колонок [или столбцов]),
каждый из которых помимо атрибутов: r [, s, t],
содержит элемент <v>…</v>, текст которого собственно
и представляет из себя значение содержания соответствующей колонки. А
приглядевшись внимательно к значениям элементов <v>…</v>,
можно заметить странность, которая заключается в том, что там, где мы ожидали бы
увидеть текст в виде строки, имеем просто число. Обратите внимание, что атрибут
t у соответствующего элемента
<c>…</c> при этом, имеет значение «s». Однако, вспомнив о
существовании выше рассмотренного нами файла sharedStrings.xml, легко
обнаруживается, что число, используемое в качестве значения у элементов <v>…</v>, есть
ни что иное, как порядковый номер si-элемента в файле sharedStrings.xml,
правда с нумерацией от значения 0, t-элемент которого,
собственно и содержит искомую нами текстовую строку, как значение
колонки/столбца у соответствующей строки из файла sheet1.xml. Этот факт легко
обнаруживается например, у элемента <row>…</row>
при значении его атрибута r=»1″, т.е. когда
дочерние c-элементы должны содержать заголовки
столбцов нашей таблицы… Вот такая нормализация (исключение
дублирования значений) для строк имеет место быть в MS Excel 2007, однако! 
Ну хорошо, а как же теперь всем этим воспользоваться, чтобы «собирать»
разбросанные таким образом значения в один xml-файл,
представляющий собой результат экспорта таблицы данных из
xlsx-файла? На мой взгляд, проще всего воспользоваться технологиями
XSLT, чтобы осуществить это «меньшей кровью». Ниже
показывается как это можно сделать.
В качестве первого шага, попробуем написать XSLT-преобразование,
в котором оставаясь в рамках структуры элемента sheetData
из файла sheet1.xml в результате преобразований, заменим все ссылки на
строки из файла sharedStrings.xml (т.е. элементы <v>…</v>
с числовыми значениями, у которых родительский c-элемент
будет иметь атрибут t=»s»).
XSLT-код такого преобразования мог бы быть следующим:
<?xml
version=«1.0«
encoding=«utf-8«?>
<!— File: extractXlsxData.xslt
—>
<xsl:stylesheet
version=«1.0«
xmlns:xsl=«http://www.w3.org/1999/XSL/Transform«
xmlns:r=«http://schemas.openxmlformats.org/officeDocument/2006/relationships«
xmlns:msxsl=«urn:schemas-microsoft-com:xslt«
exclude-result-prefixes=«xsl
r msxsl«>
<
xsl:output
version=«1.0«
method=«xml«
standalone=«yes«
encoding=«utf-8«/>
<
xsl:param
name=«prmPathToSharedStringsFile«>
<xsl:text></xsl:text>
</xsl:param>
<xsl:variable
name=«varDocSharedStrings«>
<xsl:copy-of
select=«document(concat($prmPathToSharedStringsFile,
‘sharedStrings.xml’))«
/>
</xsl:variable>
<
xsl:template
match=«/«>
<sheetData>
<xsl:apply-templates
select=«/./*[local-name()=’worksheet’]/*[local-name()=’sheetData’]/*«
/>
</sheetData>
</xsl:template>
<
xsl:template
match=«@*|node()«>
<xsl:variable
name=«varLocalName«>
<xsl:value-of
select=«local-name()«
/>
</xsl:variable>
<xsl:choose>
<xsl:when
test=«string-length($varLocalName)>0
and $varLocalName != ‘v’«>
<xsl:element
name=«{$varLocalName}«>
<xsl:for-each
select=«@*«>
<xsl:attribute
name=«{local-name()}«>
<xsl:value-of
select=«.«
/>
</xsl:attribute>
</xsl:for-each>
<xsl:apply-templates
select=«*«
/>
</xsl:element>
</xsl:when>
<xsl:when
test=«$varLocalName=’v’«>
<xsl:choose>
<xsl:when
test=«parent::*/@t=’s’«>
<xsl:variable
name=«varNumSs«>
<xsl:value-of
select=«.«
/>
</xsl:variable>
<v>
<xsl:value-of
select=«msxsl:node-set($varDocSharedStrings)/./*[local-name()=’sst’]/*[local-name()=’si’][number($varNumSs)
+ 1]/*[local-name()=’t’]«
/>
</v>
</xsl:when>
<xsl:otherwise>
<v>
<xsl:value-of
select=«.«
/>
</v>
</xsl:otherwise>
</xsl:choose>
</xsl:when>
<xsl:otherwise>
<xsl:apply-templates
select=«@*|node()«
/>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
</
xsl:stylesheet>
Здесь, кажущиеся утяжелёнными условные XPATH-выражения типа:
/./*[local-name()=’worksheet’]/*[local-name()=’sheetData’]/* вместо прямого
выбора типа: /./worksheet/sheetData/*, на самом деле
необходимы, т.к. обрабатываемые xml-данные, имеют
namespace-ы по умолчанию (default
namespace), а в таких случаях прямое использование названий элементов в XPATH-выражениях
«не работает», в таких случаях приходится использовать относительные пути и
условные выборки.
Для выполнения
XSLT-преобразований, можно воспользоваться бесплатной
утилитой командной строки от Microsoft
msxsl.exe
(см. «Command Line Transformation Utility (msxsl.exe)» в разделе: Внешние ссылки по теме)
и применяя приведённое выше XSLT-преобразование extractXlsxData.xslt над
файлами sharedStrings.xml и sheet1.xml (например,
поместив в командный файл extractToXml.cmd строку: msxsl.exe sheet1.xml extractXlsxData.xslt -o tr.xml) получаем на
выходе tr.xml-файл со следующим содержанием:
<?xml
version=«1.0«
encoding=«utf-8«
standalone=«yes«?>
<sheetData>
<row
r=«1«
spans=«1:6«>
<c
r=«A1«
t=«s«>
<v>Name</v>
</c>
<c
r=«B1«
t=«s«>
<v>Date</v>
</c>
<c
r=«C1«
t=«s«>
<v>Code</v>
</c>
<c
r=«D1«
t=«s«>
<v>Date2</v>
</c>
<c
r=«E1«
t=«s«>
<v>Description</v>
</c>
<c
r=«F1«
t=«s«>
<v>Amount</v>
</c>
</row>
<row
r=«2«
spans=«1:6«>
<c
r=«A2«
s=«1«
t=«s«>
<v>Jane
Winston</v>
</c>
<c
r=«B2«
s=«1«
t=«s«>
<v>2001-01-01</v>
</c>
<c
r=«C2«
s=«1«
t=«s«>
<v>0001</v>
</c>
<c
r=«D2«
s=«2«>
<v>36892</v>
</c>
<c
r=«E2«
s=«1«
t=«s«>
<v>Airfare</v>
</c>
<c
r=«F2«>
<v>500.34</v>
</c>
</row>
…
</sheetData>
Здесь, как и в предыдущем случае, для уменьшения объёма документа оставлены
только две строки (row-элементы с атрибутами r=»1″ и r=»2″),
а остальные данные упущены. Как видим, всё работает так, как и ожидалось!
Однако, обратите внимание на значение даты во второй строке в колонке
D (<c r=»D2″…><v>36892</v></c>).
Хм… дата в xml-представлении не в формате:
YYYY-MM-DD, а в количестве дней с 01.01.1970. Да
уж!… Придётся с этим чего-то делать…
Для выполнения XSLT-преобразований можно пробовать
использовать и другие средства… Например, в MS .NET Framework
2.0, 3.0, C#-код консольного приложения мог бы быть таким:
using System;
using System.Collections.Generic;
using System.Text;
using System.Xml;
using System.Xml.Xsl;
namespace testTranse
{
class
Program
{
const
bool IS_DOCFUNC =
true;
const
bool IS_SCRIPT =
false;
const
bool USE_DEBUG =
false;
const
string XSL_FILE =
«extractXlsxData.xslt»;
const
string INP_FILE =
«sheet1.xml»;
const
string OUT_FILE =
«tr.xml»; static
void Main(string[]
args)
{
bool bIsOk =
false;
try
{
XsltSettings
xsltSettings = new
XsltSettings(IS_DOCFUNC,
IS_SCRIPT);
XslCompiledTransform
xslTrans = new
XslCompiledTransform(USE_DEBUG);
xslTrans.Load(XSL_FILE, xsltSettings,
new XmlUrlResolver());
xslTrans.Transform(INP_FILE, OUT_FILE);
bIsOk = true;
}
catch (Exception
ex)
{
Console.WriteLine(«***
Error: « + ex.ToString());
}
if (bIsOk)
{
Console.WriteLine(«Transformation
successfully completed!»);
}
Console.WriteLine(«Press
any key to continue…»);
Console.ReadKey();
}
}
}
Если будете экспериментировать именно с extractXlsxData.xslt, здесь константе
IS_DOCFUNC
следует присвоить именно true, т.к. в его коде
выполняется загрузка файла sharedStrings.xml, используя
XSLT-функцию document().
Аналогичный MS Visual FoxPro 9.0 код с использованием MSXML 4.0 (Microsoft XML Core Services),
мог бы выглядеть так:
#DEFINE
XML_FILE «sheet1.xml»
#DEFINE
XSL_FILE «extractXlsxData.xslt»
#DEFINE
OUT_FILE «tr.xml»
#
DEFINE
XSL_PRM_NAME «prmPathToSharedStringsFile»
#DEFINE
XSL_PRM_VALUE «»
#
DEFINE
XML_VERS «»
&& or «.4.0» && or «.3.0»
#DEFINE
XMLPI ‘<?xml version=»1.0″
encoding=»windows-1251″ standalone=»yes»?>’
#
DEFINE
SW_NORMAL 1
#DEFINE
CRLF
CHR(13)
+ CHR(10)
SET DEFAULT TO (LEFT(SYS(16),
RAT(«»,
SYS(16))))
LOCAL lcXmlFile
as String;
,lcXslFile as String;
,lcHtmFile as String;
,lbResult as
Boolean
lcXmlFile =
LOWER(FULLPATH(XML_FILE))
lcXslFile = LOWER(FULLPATH(XSL_FILE))
lcOutFile = LOWER(FULLPATH(OUT_FILE))
IF !FILE(lcXslFile)
ERROR
101, lcXslFile
RETURN
lbResult
ENDIF
IF !FILE(lcXmlFile)
ERROR
101, lcXmlFile
RETURN
lbResult
ENDIF
DECLARE INTEGER
ShellExecute
IN
shell32.dll
;
INTEGER hwnd,
;
STRING
@lsOperation, ;
STRING
@lsFile, ;
STRING
@lsParameters, ;
STRING
@lsDirectory, ;
INTEGER
liShowCmd
DECLARE INTEGER GetDesktopWindow
IN
user32.dll
LOCAL
loErr
as Exception;
,lcPROGIDmsxml as
String;
,lcPROGIDmsxsl as
String;
,lcPROGIDmstemp as
String;
,loMsXml as
Msxml2.DOMDocument;
,loMsXsl as
Msxml2.FreeThreadedDOMDocument;
,loMsPrc as
Msxml2.XSLTemplate;
,lobjXSLTProc as
Msxml2.IXSLProcessor;
,lbParseError as Boolean
TRY
*/////////////////////////////////////////////////
*// Try do XML + XSL => OUT transformation
lcPROGIDmsxml = «Msxml2.DOMDocument»
+ XML_VERS
lcPROGIDmsxsl = «Msxml2.FreeThreadedDOMDocument» + XML_VERS
lcPROGIDmstemp = «Msxml2.XSLTemplate» + XML_VERS
loMsXml =
CREATEOBJECT(lcPROGIDmsxml)
loMsXsl =
CREATEOBJECT(lcPROGIDmsxsl)
loMsPrc =
CREATEOBJECT(lcPROGIDmstemp)
*
*— Load XML
WITH
loMsXml
.async = .F.
.load(lcXmlFile)
&& Load XML-file
IF
.parseError.errorCode != 0
lbParseError = .T.
ShowXmlErr(.parseError)
ENDIF
ENDWITH
IF !lbParseError
*
*— Load XSL
WITH
loMsXsl
.async = .F.
.load(lcXslFile)
&& Load XSL-file
IF
.parseError.errorCode != 0
lbParseError = .T.
ShowXmlErr(.parseError)
ENDIF
ENDWITH
ENDIF
IF !lbParseError
*
*— XSLT transformation
loMsPrc.stylesheet =
loMsXsl.documentElement
lobjXSLTProc = loMsPrc.createProcessor()
IF VARTYPE(lobjXSLTProc)
= «O»
lobjXSLTProc.input
= loMsXml
IF
!EMPTY(XSL_PRM_VALUE)
lobjXSLTProc.addParameter(XSL_PRM_NAME, XSL_PRM_VALUE, «»)
ENDIF
IF lobjXSLTProc.transform()
LOCAL
lcOutPut
as String
lcOutPut = lobjXSLTProc.output
IF FILE(lcOutFile)
ERASE
(lcOutFile)
ENDIF
LOCAL lnPosXmlPI
as Number
lnPosXmlPI =
ATC(«?>»,
lcOutPut)
IF
lnPosXmlPI > 0
lcOutPut = XMLPI +
SUBSTRC(lcOutPut, lnPosXmlPI + 2)
ENDIF
LOCAL lnBytes
as Number
lnBytes = 0
lnBytes = STRTOFILE(lcOutPut,
lcOutFile)
IF
lnBytes > 0 AND
FILE(lcOutFile)
LOCAL
lnRetCode
as Number
lnRetCode = 0
lnRetCode = ShellExecute(GetDesktopWindow(), «open», lcOutFile, «», «»,
SW_NORMAL)
IF
lnRetCode > 32
lbResult = .T.
ELSE
ERROR «ShellExecute: errorcode = » +
LTRIM(STR(lnRetCode))
ENDIF
ELSE
ERROR 101, lcOutFile
ENDIF
ELSE
ERROR «Error on XML + XSL => XML
transformation»
ENDIF
ELSE
ERROR «Can not createProcessor()»
ENDIF
ENDIF
CATCH TO loErr
MESSAGEBOX(«Error: » + LTRIM(STR(loErr.ErrorNo))
+ CRLF ;
+ «LineNo: » + LTRIM(STR(loErr.LineNo))
+ CRLF ;
+ «Message: » + loErr.Message,16,
_SCREEN.Caption)
FINALLY
STORE NULL TO ;
loMsXml, loMsXsl, loMsPrc, lobjXSLTProc
ENDTRY
CLEAR DLLS
RETURN lbResult
*/////////////////////////////////////////////////
*// ShowXmlErr
FUNCTION ShowXmlErr
LPARAMETERS
toXmlErr
as
Msxml2.IXMLDOMParseError
IF VARTYPE(toXmlErr)
# ‘O’
RETURN
.F.
ENDIF
LOCAL lcMsg
as String
WITH toXmlErr
lcMsg = «Error loading ‘» +
ALLTRIM(.url)
+ «‘»
lcMsg = lcMsg + CRLF + «Code: » +
TRANSFORM(.errorCode,
‘@0’)
IF
!EMPTY(.reason)
lcMsg = lcMsg + CRLF + «Reason: » +
ALLTRIM(.reason)
ENDIF
IF !EMPTY(.filepos)
lcMsg = lcMsg + CRLF + «Filepos: » +
TRANSFORM(.filepos)
ENDIF
IF !EMPTY(.linepos)
lcMsg = lcMsg + CRLF + «Linepos: » +
TRANSFORM(.linepos)
ENDIF
IF !EMPTY(.line)
lcMsg = lcMsg + CRLF + «Line: » +
TRANSFORM(.line)
ENDIF
IF !EMPTY(.srcText)
lcMsg = lcMsg + CRLF + «Text: » +
ALLTRIM(.srcText)
ENDIF
ENDWITH
MESSAGEBOX(lcMsg, 16,
_SCREEN.Caption)
ENDFUNC
Ну хорошо, удачно осуществив «подгруздку» строк-значений в таблицу
xml-данных, давайте сделаем с этим результатом
чего-нибудь действительно полезное. Например, вторым шагом попробуем написать
код XSLT-преобразования такой, чтобы на выходе у нас
получалось html-представление наших
xml-данных.
В общих чертах, такое преобразование должно выполнять следующее:
используя результат предыдущего шага на входе (файл tr.xml
в нашем случае), а также файл table1.xml для
извлечения информации о типах значений данных в столбцах, сформировать
html-таблицу таким образом, чтобы данные из первой
строки входных данных были бы заголовками столбцов формируемой таблицы, а во
время создания строк выходной таблицы из строк исходных данных начиная со
второй, нами должны быть учтены типы значений столбцов (из файла table1.xml) с тем, чтобы
осуществить соответствующее форматирование значений, если требуется. Также
неплохо было бы выровнять текст в каждой из колонок влево или вправо, в зависимости от типа
данных.
В попытке учесть всё вышеперечисленное, мной написан код вот такого XSLT-преобразования:
<?xml
version=«1.0«
encoding=«utf-8«?>
<!— File: getHtml.xslt—>
<xsl:stylesheet
version=«1.0«
xmlns=«http://www.w3.org/TR/html4«
xmlns:xsl=«http://www.w3.org/1999/XSL/Transform«
xmlns:msxsl=«urn:schemas-microsoft-com:xslt«
xmlns:user=«urn:A9A4A767-327E-4c7d-970B-DC3FF20F6DB5:user-function«
exclude-result-prefixes=«xsl
msxsl user«> <xsl:output
version=«4.0«
method=«html«
indent=«no«
encoding=«utf-8«
doctype-public=«-//W3C//DTD
HTML 4.0 Transitional//EN«
/> <msxsl:script
language=«JScript«
implements-prefix=«user«>
function getDate(newdate)
{
var n, d, s, p, td, tm;
n = parseInt(newdate.toString()) — 1;
d = new Date(0, 0, n);
//s = d.toLocaleDateString();
p = «-«;
td = d.getDate().toString();
if (td.length == 1)
{ td = «0» + td; }
tm = (d.getMonth() + 1).toString();
if (tm.length == 1)
{ tm = «0» + tm; }
s = d.getFullYear().toString() + p
+ tm + p
+ td;
return(s);
}
</msxsl:script>
<xsl:decimal-format
name=«russian«
grouping-separator=«
«
decimal-separator=«,«
/> <xsl:param
name=«prmTableFile«>
<xsl:text>table1.xml</xsl:text>
</xsl:param> <xsl:variable
name=«varDocTable«>
<xsl:copy-of
select=«document($prmTableFile)«/>
</xsl:variable>
<xsl:variable
name=«varTableName«>
<xsl:value-of
select=«msxsl:node-set($varDocTable)/./*[local-name()=’table’]/@displayName«
/>
</xsl:variable> <xsl:template
match=«/«>
<html>
<head>
<meta
name=«vs_targetSchema«
content=«http://schemas.microsoft.com/intellisense/ie5«
/>
<meta
http-equiv=«Content-Type«
content=«text/html;
charset=utf-8« />
<style
type=«text/css«>
<xsl:comment>
h4
{font-family: Verdana, Arial, Helvetica, sans-serif;
font-size: 8.5pt;}
th
{font-family: Verdana, Arial, Helvetica, sans-serif;
font-size: 8.5pt;
color: darkblue;
background-color: WhiteSmoke;}
td
{font-family: Verdana, Arial, Helvetica, sans-serif;
font-size: 8.5pt;}
.even
{font-family: Verdana, Arial, Helvetica, sans-serif;
font-size: 8.5pt;
background-color: Azure;}
</xsl:comment>
</style>
<title>
<xsl:value-of
select=«$varTableName«
/>
</title>
</head>
<body>
<h4>
<xsl:value-of
select=«$varTableName«
/>
</h4>
<table
border=«1«
cellspacing=«0«
cellpadding=«2«>
<xsl:for-each
select=«/./*/row«>
<tr>
<xsl:choose>
<xsl:when
test=«position()=1«>
<xsl:for-each
select=«c/v«>
<th>
<xsl:value-of
select=«.«
/>
</th>
</xsl:for-each>
</xsl:when>
<xsl:otherwise>
<xsl:variable
name=«varClass«>
<xsl:if
test=«position()
mod 2«>
<xsl:text>even</xsl:text>
</xsl:if>
</xsl:variable>
<xsl:for-each
select=«c«>
<xsl:variable
name=«varNumCol«>
<xsl:value-of
select=«position()«/>
</xsl:variable>
<xsl:variable
name=«varType«>
<xsl:value-of
select=«msxsl:node-set($varDocTable)/./*[local-name()=’table’]/*[local-name()=’tableColumns’]/*[local-name()=’tableColumn’
and @id=$varNumCol]/*[local-name()=’xmlColumnPr’]/@xmlDataType«/>
</xsl:variable>
<xsl:call-template
name=«getValue«>
<xsl:with-param
name=«prmClass«
select=«$varClass«
/>
<xsl:with-param
name=«prmType«
select=«$varType«
/>
<xsl:with-param
name=«prmValue«
select=«v«
/>
</xsl:call-template>
</xsl:for-each>
</xsl:otherwise>
</xsl:choose>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template> <xsl:template
name=«getValue«>
<xsl:param
name=«prmClass«
/>
<xsl:param
name=«prmType«
/>
<xsl:param
name=«prmValue«
/>
<td>
<xsl:if
test=«string-length($prmClass)>0«>
<xsl:attribute
name=«class«>
<xsl:value-of
select=«$prmClass«/>
</xsl:attribute>
</xsl:if>
<xsl:attribute
name=«vAlign«>
<xsl:text>top</xsl:text>
</xsl:attribute>
<xsl:if
test=«$prmType=’decimal’
or $prmType=’int’ or $prmType=’date’«>
<xsl:attribute
name=«align«>
<xsl:text>right</xsl:text>
</xsl:attribute>
</xsl:if>
<xsl:choose>
<xsl:when
test=«$prmType=’decimal’«>
<xsl:value-of
select=«format-number($prmValue,
‘### ##0,00’, ‘russian’)«
/>
</xsl:when>
<xsl:when
test=«$prmType=’date’«>
<xsl:variable
name=«varDate«>
<xsl:choose>
<xsl:when
test=«contains($prmValue,
‘-‘)«>
<xsl:value-of
select=«$prmValue«
/>
</xsl:when>
<xsl:otherwise>
<xsl:value-of
select=«user:getDate(string($prmValue))«
/>
</xsl:otherwise>
</xsl:choose>
</xsl:variable>
<xsl:value-of
select=«msxsl:format-date($varDate,
‘dd.MM.yyyy’)« />
</xsl:when>
<xsl:otherwise>
<xsl:value-of
select=«$prmValue«
/>
</xsl:otherwise>
</xsl:choose>
</td>
</xsl:template>
</
xsl:stylesheet>
Применяя это преобразование к данным из файла tr.xml
(т.е к результату, полученному на первом шаге) используя утилиту
msxsl.exe (например, предварительно создав командный
файл convertToHtml.cmd со строкой:
msxsl.exe tr.xml getHtml.xslt -o tr.htm) или используя вышеприведённый C#-код, заменив в нём
соответствующие константы на:
…
const
bool IS_DOCFUNC =
true;
const
bool IS_SCRIPT =
true;
const
bool USE_DEBUG =
false;
const
string XSL_FILE =
«getHtml.xslt»;
const
string INP_FILE =
«tr.xml»;
const
string OUT_FILE =
«tr.htm»;
…
получаем в файле tr.htm вот такой результат:

Рис.9
что в общем-то и соответствует тому, к чему мы стремились…
Пожалуй, полезным будет привести сюда C#-код с
использованием библиотеки C:Program FilesReference AssembliesMicrosoftFrameworkv3.0WindowsBase.dll,
содержащей namespace System.IO.Packaging и позволяющей работать с частями zip-ованых файлов в
MS .Net Framework 2.0, 3.0. Код консольного приложения
с использованием этих возможностей мог бы быть таким:
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
using System.Xml;
using System.Xml.Xsl;
using System.IO.Packaging;
namespace xlsx2html
{
class
Program
{
const
string INPUT_FILE =
«Книга1.xlsx»;
const
string XSLT_SHEET_FILE =
«extractXlsxData.xslt»;
const
string XSLT_HTML_FILE =
«getHtml.xslt»;
const
string ERR_FILE_NOTFOUND =
«Not found file: «;
const
string ERR_PACKAGE_NOTOPEN
= «Not open package for file: «;
const
string
ERR_PACKAGEPART_NOTFOUND = «Not found
PackagePart: «;
const
string ERR_XMLDOC_NOTLOAD =
«Not load XmlDocument: «;
const
string URI_SHARED_STRINGS =
«/xl/sharedStrings.xml»;
const
string URI_FORMAT_SHEET =
«/xl/worksheets/sheet{0}.xml»;
const
string URI_FORMAT_TABLE =
«/xl/tables/table{0}.xml»;
const
int NUMBER_SHEET = 1;
const
int NUMBER_TABLE = 1;static
void Main(string[]
args)
{
string XlsxFile =
INPUT_FILE;
string HtmlFile =
System.String.Empty;
int NumberSheet =
NUMBER_SHEET;
int NumberTable =
NUMBER_TABLE;if (args.Length >
0)
{
XlsxFile = args[0];
}
int nPosLE =
XlsxFile.LastIndexOf(‘.’);
if (nPosLE ==
(-1))
{
XlsxFile += «.xlsx»;
}
if (args.Length >
1)
{
HtmlFile = args[2];
}
else
{
nPosLE = XlsxFile.LastIndexOf(‘.’);
HtmlFile = XlsxFile.Substring(0, nPosLE) +
«.htm»;
}bool bResult =
false;
Package
package = null;
StringBuilder sb
= new
StringBuilder();try
{
if (!File.Exists(XlsxFile))
{
throw (new
FileNotFoundException(ERR_FILE_NOTFOUND
+ XlsxFile));
}
package = Package.Open(XlsxFile);
if (package ==
null)
{
throw (new
NullReferenceException(ERR_PACKAGE_NOTOPEN
+ XlsxFile));
}
if (args.Length >
2)
{
NumberSheet = Convert.ToInt32(args[3]);
}
if (args.Length >
3)
{
NumberTable = Convert.ToInt32(args[4]);
} /////////////////////////////////
// SharedStrings
Uri
UriSharedStrings = new
Uri(URI_SHARED_STRINGS,
UriKind.Relative);
PackagePart
ppSharedStrings = package.GetPart(UriSharedStrings);
if
(ppSharedStrings == null)
{
throw (new
NullReferenceException(ERR_PACKAGEPART_NOTFOUND
+ UriSharedStrings.ToString()));
}
XmlDocument
xmlDocSharedStrings = new
XmlDocument();
xmlDocSharedStrings.Load(ppSharedStrings.GetStream());
if
(xmlDocSharedStrings.DocumentElement ==
null)
{
throw (new
NullReferenceException(ERR_XMLDOC_NOTLOAD
+ UriSharedStrings.ToString()));
} /////////////////////////////////
// Sheet
sb.Length = 0;
sb.AppendFormat(URI_FORMAT_SHEET, NumberSheet);
Uri UriSheet =
new
Uri(sb.ToString(),
UriKind.Relative);
PackagePart
ppSheet = package.GetPart(UriSheet);
if (ppSheet ==
null)
{
throw (new
NullReferenceException(ERR_PACKAGEPART_NOTFOUND
+ UriSheet.ToString()));
}
XmlDocument
xmlDocSheet = new
XmlDocument();
xmlDocSheet.Load(ppSheet.GetStream());
if (xmlDocSheet.DocumentElement == null)
{
throw (new
NullReferenceException(ERR_XMLDOC_NOTLOAD
+ UriSheet.ToString()));
} /////////////////////////////////
// Table
sb.Length = 0;
sb.AppendFormat(URI_FORMAT_TABLE, NumberTable);
Uri UriTable =
new
Uri(sb.ToString(),
UriKind.Relative);
PackagePart
ppTable = package.GetPart(UriTable);
if (ppTable ==
null)
{
throw (new
NullReferenceException(ERR_PACKAGEPART_NOTFOUND
+ UriTable.ToString()));
}
XmlDocument
xmlDocTable = new
XmlDocument();
xmlDocTable.Load(ppTable.GetStream());
if (xmlDocTable.DocumentElement == null)
{
throw (new
NullReferenceException(ERR_XMLDOC_NOTLOAD
+ UriTable.ToString()));
} /////////////////////////////////////////////////////////
// Resolve SharedStrings in sheet
XsltArgumentList
xsltArgListSheet = new
XsltArgumentList();
XslCompiledTransform
xslTransSheet = new
XslCompiledTransform();
xslTransSheet.Load(XSLT_SHEET_FILE);
xsltArgListSheet.AddParam(«prmDocSharedStrings»,
«»,
xmlDocSharedStrings.CreateNavigator());
string
sOutXmlSheet = System.String.Empty;
sb.Length = 0;
using (TextWriter
twSheet = new
StringWriter(sb))
{
xslTransSheet.Transform(xmlDocSheet.CreateNavigator(), xsltArgListSheet,
twSheet);
sOutXmlSheet = sb.ToString();
} /////////////////////////////////////////////////////////
// Convert to html
XmlDocument
xmlDocSheetOut = new
XmlDocument();
xmlDocSheetOut.LoadXml(sOutXmlSheet);
XsltArgumentList
xsltArgListHtml = new
XsltArgumentList();
XsltSettings
xsltSettings = new
XsltSettings(false,
true);
XslCompiledTransform
xslTransHtml = new
XslCompiledTransform();
xslTransHtml.Load(XSLT_HTML_FILE, xsltSettings,
new
XmlUrlResolver());
xsltArgListHtml.AddParam(«prmDocTable»,
«»,
xmlDocTable.CreateNavigator());
string sOutHtml =
System.String.Empty;
sb.Length = 0;
using (TextWriter
twHtml = new
StringWriter(sb))
{
xslTransHtml.Transform(xmlDocSheetOut.CreateNavigator(), xsltArgListHtml,
twHtml);
sOutHtml = sb.ToString();
} /////////////////////////////////////////////////////////
// Write result as html-file
using (TextWriter
twOutHtml = new
StreamWriter(HtmlFile))
{
twOutHtml.Write(sOutHtml);
} package.Close();
package = null;
bResult = true;
}
catch (Exception
ex)
{
Console.WriteLine(«***
Error: « + ex.ToString());
}
if (bResult)
{
Console.WriteLine(«Convert
to html successfully completed!»);
}
Console.WriteLine(«Press
any key to continue…»);
Console.ReadKey();
if
(package !=
null)
{
package.Close();
package =
null;
}
}
}
}
Чтобы воспользоваться этим кодом в MS VS.NET 2005,
создайте консольное приложение на
C# с названием xlsx2html, в Solution Explorer в папку
References добавьте библиотеку C:Program FilesReference AssembliesMicrosoftFrameworkv3.0WindowsBase.dll,
а весь код в Program.cs замените вышеприведённым. В
используемых при этом xslt-файлах: extractXlsxData.xslt
и getHtml.xslt изменён способ подгруздки «дополнительных файлов»,
передаваемых через параметры. Чтобы адаптировать их на новые условия
использования, необходимо внести ряд изменений.
Так, в extractXlsxData.xslt фрагмент кода:
…
<xsl:param
name=«prmPathToSharedStringsFile«>
<xsl:text></xsl:text>
</xsl:param>
<xsl:variable
name=«varDocSharedStrings«>
<xsl:copy-of
select=«document(concat($prmPathToSharedStringsFile,
‘sharedStrings.xml’))«
/>
</xsl:variable>
…
следует изменить на
…
<xsl:param
name=«prmDocSharedStrings«
/>
…
и далее в тексте extractXlsxData.xslt все вхождения varDocSharedStrings
необходимо поменять на
prmDocSharedStrings
Аналогично, в файле getHtml.xslt фрагмент кода:
…
<xsl:param
name=«prmTableFile«>
<xsl:text>table1.xml</xsl:text>
</xsl:param> <xsl:variable
name=«varDocTable«>
<xsl:copy-of
select=«document($prmTableFile)«/>
</xsl:variable>
…
следует изменить на
…
<xsl:param
name=«prmDocTable«
/>
…
и далее в тексте getHtml.xslt все вхождения
varDocTable следует изменить на prmDocTable
Здесь у VFP-программиста может возникнуть
раздражение: мол чего C#-код приводить, если из-под
VFP его нельзя выполнить… и будет неправ… т.к.
использовать библиотеки классов из .NET Framework
из-под VFP всё-таки можно! Один из возможных вариантов
загрузки и использования .NET Framework-сборок описан
на
http://www.west-wind.com/WebLog/posts/104449.aspx — «Hosting the .NET Runtime in Visual FoxPro», by Rick Strahl  . Там же можно загрузить весь код, обеспечивающий поддержку такого подхода. Смысл
. Там же можно загрузить весь код, обеспечивающий поддержку такого подхода. Смысл
предложенного в следующем:
1) Имеется возможность через небольшую прослойку C++кода (Unmanaged API) в
виде Win32API-dll (ClrHost.dll)
- загрузить некоторую/указанную .NET Framework-сборку
- создать экземпляр её некоторого класса
- получить IDispatch-интерфейс последнего и передать его клиенту
2) Rick также написал небольшой C#-код в виде
класса в .NET Framework-сборке (wwDotNetBridge.dll), позволяющего:
- создать экземпляр класса из указанной .NET Framework-сборки и передать его клиенту
- далее, клиент может используя эту ссылку обратиться к методам/свойствам экземпляра класса, через некоторый «обобщённый интерфейс» (серию Invoke-методов, реализованных в
How to get data from a UserForm in Excel, including from: text inputs (TextBox), list boxes (ListBox), drop-down menus (ComboBox), checkboxes (CheckBox), and option buttons (OptionButton).
This tutorial shows you how to get a user’s input from the above controls and put in into the spreadsheet and work with it inside of macros and VBA.
Sections:
Where to Put the Code Examples
Get Data from a TextBox
Get Data from a ListBox
Get Data from a ComboBox
Get Data from a CheckBox
Get Data from a OptionButton
Notes
Where to Put the Code Examples
Ususally, you get data from a UserForm when the user clicks a button that then causes something to happen with the data in the form. As such, we want to put the code that gets the data into the place where code is run when the user clicks the correct button.
Open the UserForm and find the button that you want to cause data to be stored and then double-click it.
Once you double-click it, you should see something like this:
CommandButton2 is the name of the button that I clicked. You must put the code within the Sub section that ends with _Click() just like it does in the image above.
Everything that you put into this code section for CommandButton2 will run when the user clicks that button on the form.
Note: this is the code section for the entire UserForm and all of the controls within it. Once you build-out your form, you will see many different sections of code within here.
The sample file for this tutorial has a few extra code sections and you can look at those to see how data can be pre-populated into the UserForm.
Get Data from a TextBox
TextBox1.TextTextBox1 — name of the TextBox
This gets whatever the user entered into the text box.
Useful Code
'Get input from TextBox
TextBoxValue = TextBox1.Text
'Store input in the worksheet
Sheets("Sheet1").Range("A2").Value = TextBoxValueThis sets the TextBoxValue variable equal to the value contained in the text box.
Once we have that data inside of a variable, we can do anything that we want with it.
In this case, the value will be stored in cell A2 on Sheet1.
Get Data from a ListBox
ListBox1.TextListBox1 — name of the ListBox
This gets whatever the user selected from the list box.
Useful Code
'Get input from ListBox
ListBoxValue = ListBox1.Text
'Store input in the worksheet
Sheets("Sheet1").Range("B2").Value = ListBoxValueThis sets the ListBoxValue variable equal to the selection from the ListBox.
Once we have that data inside of a variable, we can do anything that we want with it.
Here, the value will be stored in cell B2 on Sheet1.
Get Data from a ComboBox
ComboBox1.TextComboBox1 — name of the ComboBox
This gets whatever the user selected from the combo box drop-down menu.
Useful Code
'Get input from ComboBox
ComboBoxValue = ComboBox1.Text
'Store input in the worksheet
Sheets("Sheet1").Range("C2").Value = ComboBoxValueThis sets the ComboBoxValue variable equal to the selection from the ComboBox.
Once we have that data inside of a variable, we can do anything that we want with it.
Here, the value will be stored in cell C2 on Sheet1.
Get Data from a CheckBox
CheckBox1.ValueCheckBox1 — name of the CheckBox
This gets the value of the check box; it can be either True or False.
True — means the box was checked.
False — means the box was not checked.
Useful Code
'Get input from CheckBox
CheckBoxValue = CheckBox1.Value
'Store input in the worksheet
Sheets("Sheet1").Range("D2").Value = CheckBoxValueThis sets the CheckBoxValue variable equal to the True or False value from the CheckBox.
Once we have that data inside of a variable, we can do anything that we want with it.
Here, the value will be stored in cell D2 on Sheet1.
Get Data from a OptionButton
OptionButton1.ValueOptionButton1 — name of the OptionBox that is being checked.
This gets the value of the option box; it can be either True or False.
True — means the option was selected.
False — means the option was not selected.
Useful Code
OptionButtons always come in groups; they are never singular because then you couldn’t de-select them.
As a result of this, the above method for check if an OptionButton was selected or not is rather cumbersome; we don’t want to check each OptionButton separately.
To remedy this, we have to use a loop and the resulting method for figuring out which OptionButton was selected might seem confusing at first.
'Loop through the controls in the form.
For Each FormControl In Me.Controls
'Check only OptionButtons
If TypeName(FormControl) = "OptionButton" Then
' Check the status of the OptionButton.
If FormControl.Value = True Then
OptionButtonValue = FormControl.Caption
Exit For
End If
End If
Next
'Store input in the worksheet
Sheets("Sheet1").Range("E2").Value = OptionButtonValueThe first part of this code loops through all of the controls in the form; then, it looks for controls that are OptionButtons and then it checks to see which OptionButton was selected; once it finds the selected OptionButton, it sets the OptionButtonValue variable equal to the caption of the button.
The Exit For section of the loop simply tells the code to exit the loop once it finds the OptionButton that was selected.
Once the value is put into a variable, we can then work with it. The second part of the code puts the value into cel E2.
Notes
Getting data from most controls is pretty straightforward and simple, using the .Text or .Value method after the name of the control whose data we want to get. The only tricky one is for the OptionButtons since, there, you can only allow the user to select one option per group; now, if you didn’t want to do a loop, you could do the longer, but perhaps more intuitive, process of using a bunch of IF Then statements to check each OptionButton, but once you have more than a few OptionButtons, this becomes a real pain.
This tutorial was meant to be and overview and show you how to get the data from the UserForm in basic circumstances. There are a lot of scenarios that are not covered here, such as mutliple groups of OptionButtons and multiple selections from a ListBox; more advanced topics like that will be covered in their own tutorials.
For now, you should have at least a basic, and working, understanding of how to get data from the UserForm.
Make sure to download the sample file for the tutorial so you can see all of this code in action.