
 Есть 3 способа расчета значений полинома в Excel:
Есть 3 способа расчета значений полинома в Excel:
- 1-й способ с помощью графика;
- 2-й способ с помощью функции Excel =ЛИНЕЙН();
- 3-й способ с помощью Forecast4AC PRO;
Подробнее о полиноме и способе его расчета в Excel далее в нашей статье.
Полиномиальный тренд применяется для описания значений временных рядов, попеременно возрастающих и убывающих. Полином отлично подходит для анализа большого набора данных нестабильной величины (например, продажи сезонных товаров).
Что такое полином? Полином — это степенная функция y=ax2+bx+c (полином второй степени) и y=ax3+bx2+cx+d (полином третей степени) и т.д. Степень полинома определяет количество экстремумов (пиков), т.е. максимальных и минимальных значений на анализируемом промежутке времени.
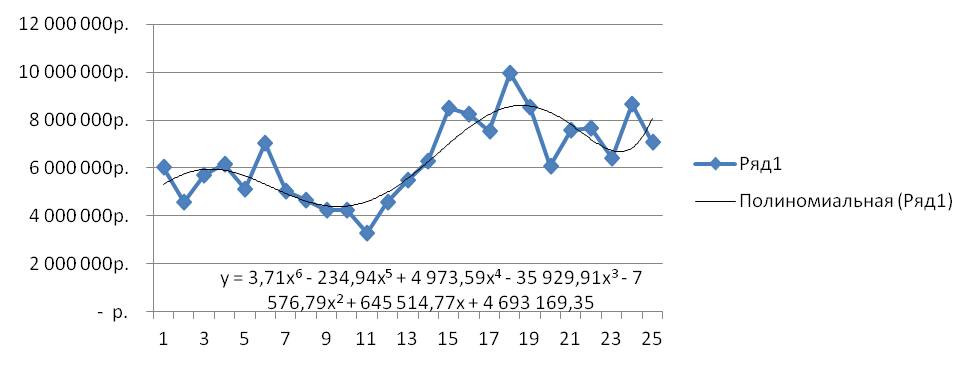
У полинома второй степени y=ax2+bx+c один экстремум (на графике ниже 1 максимум).
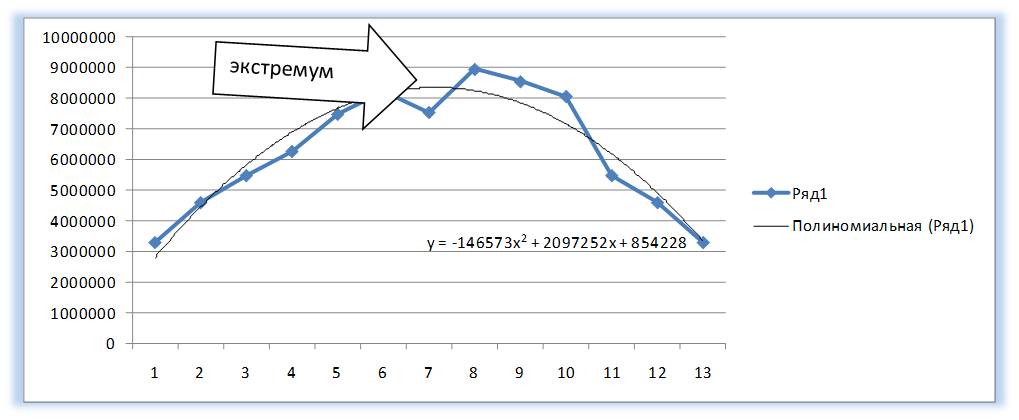
У Полинома третьей степени y=ax3+bx2+cx+d может быть один или два экстремума.
Один экстремум
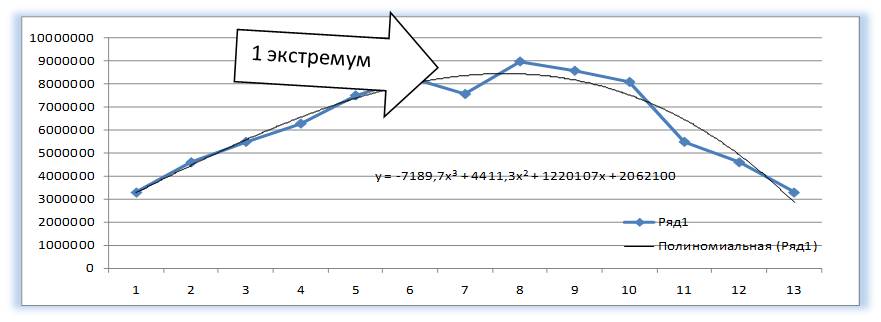
Два экстремума
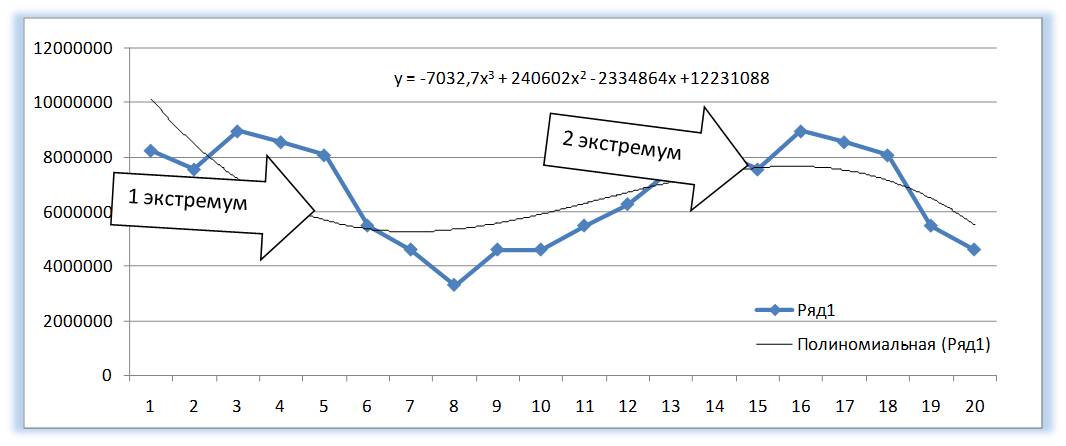
У Полинома четвертой степени не более трех экстремумов и т.д.
Как рассчитать значения полинома в Excel?
Есть 3 способа расчета значений полинома в Excel:
- 1-й способ с помощью графика;
- 2-й способ с помощью функции Excel =ЛИНЕЙН;
- 3-й способ с помощью Forecast4AC PRO;
1-й способ расчета полинома — с помощью графика
Выделяем ряд со значениями и строим график временного ряда.
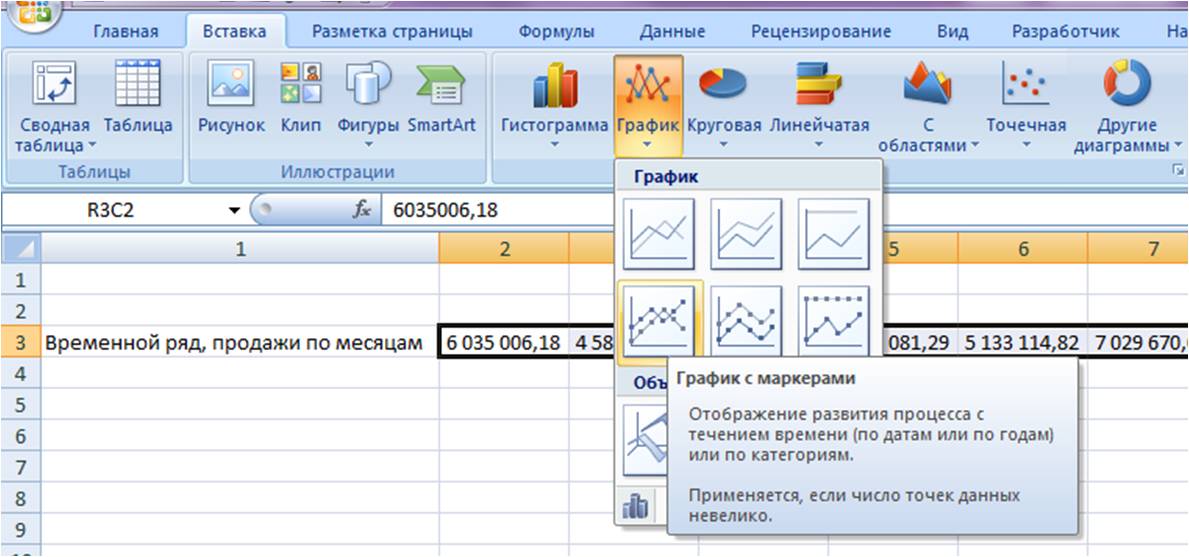
На график добавляем полином 6-й степени.
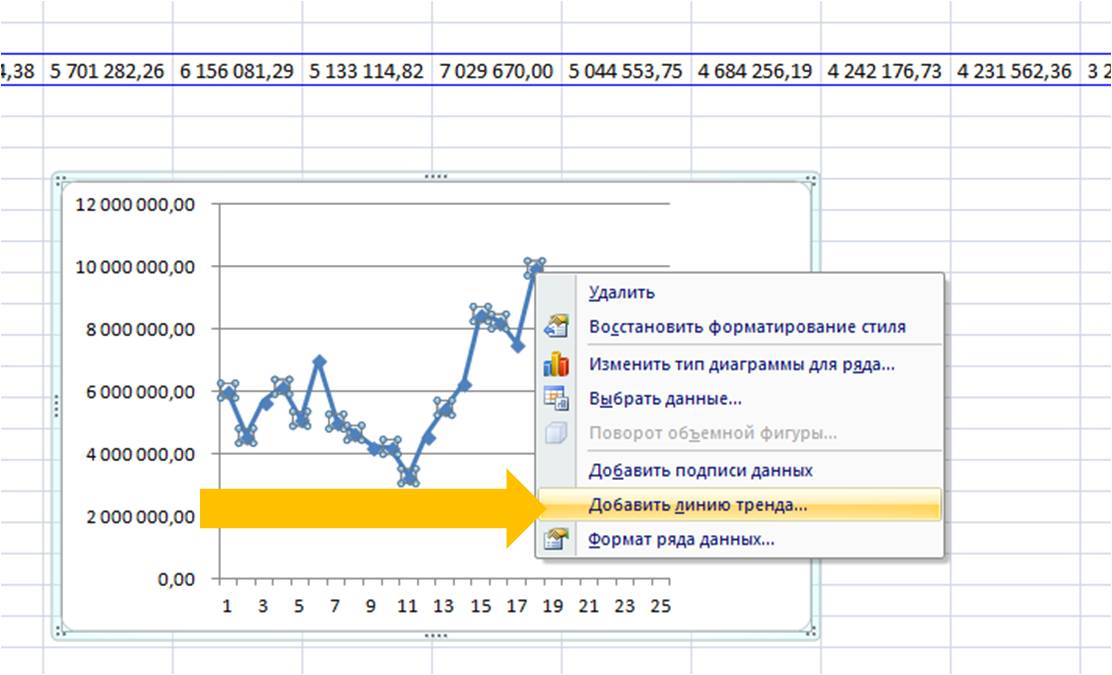
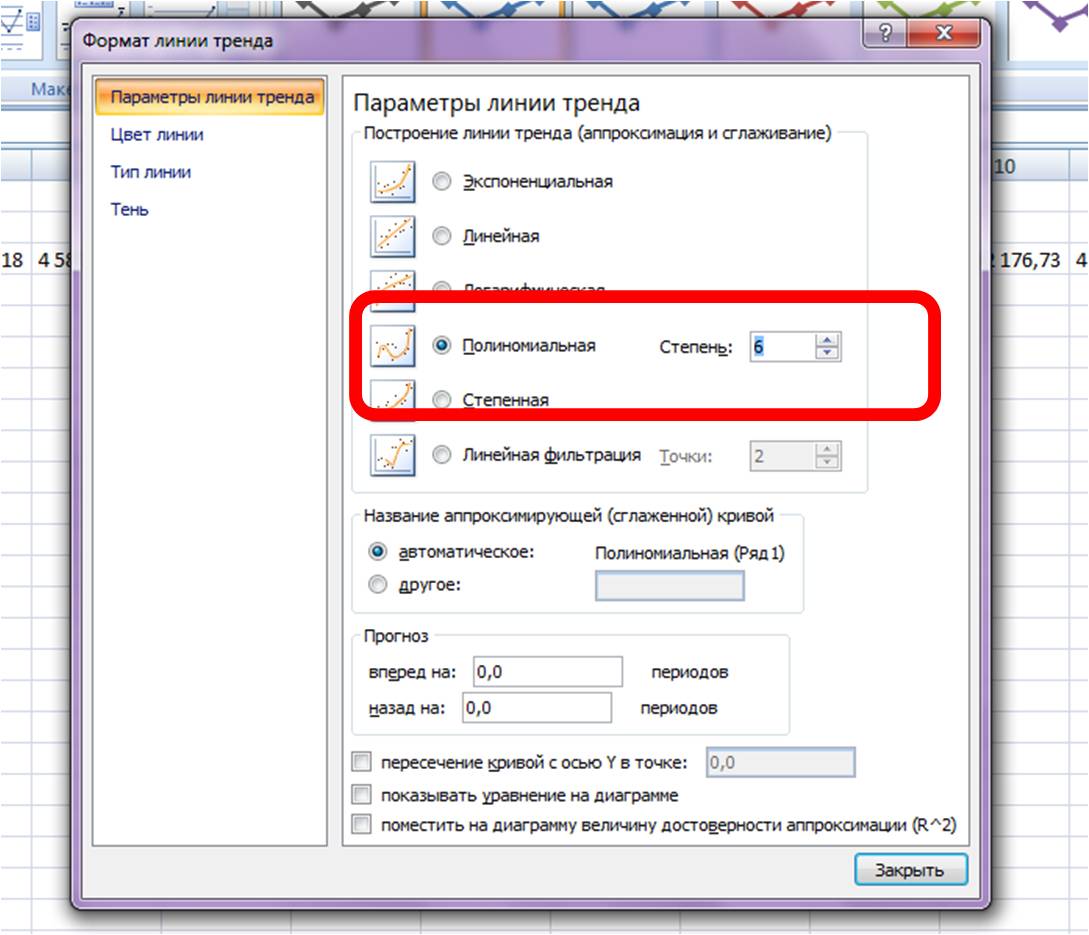
Затем в формате линии тренда ставим галочку «показать уравнение на диаграмме»
После этого уравнение выводится на график y = 3,7066x6 — 234,94x5 + 4973,6x4 — 35930x3 — 7576,8x2 + 645515x + 5E+06. Для того чтобы последний коэффициент сделать читаемым, мы зажимаем левую кнопку мыши и выделяем уравнение полинома
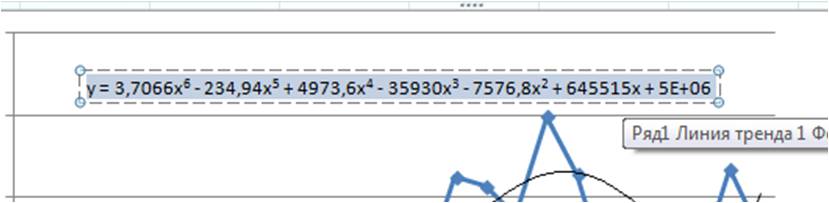
Нажимаем правой кнопкой и выбираем «формат подписи линии тренда»
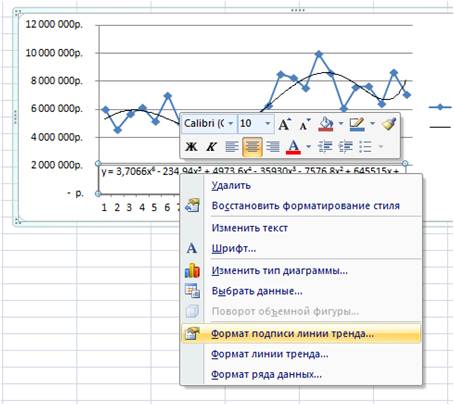
В настройках подписи линии тренда выбираем число и в числовых форматах выбираем «Числовой».
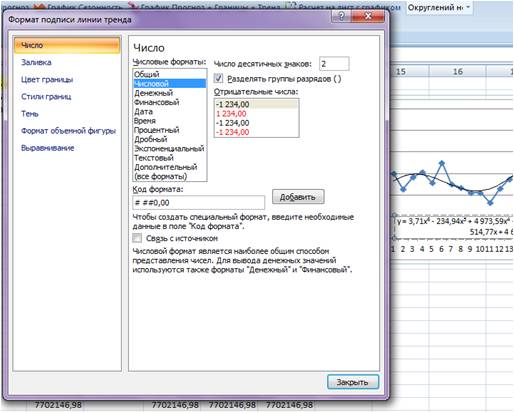
Получаем уравнение полинома в читаемом формате:
y = 3,71x6 — 234,94x5 + 4 973,59x4 — 35 929,91x3 — 7 576,79x2 + 645 514,77x + 4 693 169,35
Из этого уравнения берем коэффициенты a, b, c, d, g, m, v, и вводим в соответствующие ячейки Excel

Каждому периоду во временном ряду присваиваем порядковый номер, который будем подставлять в уравнение вместо X.

Рассчитаем значения полинома для каждого периода. Для этого вводим формулу полинома y = 3,71x6 — 234,94x5 + 4 973,59x4 — 35 929,91x3 — 7 576,79x2 + 645 514,77x + 4 693 169,35 в первую ячейку и фиксируем ссылки на коэффициенты тренда (см. статью как зафиксировать ссылки)
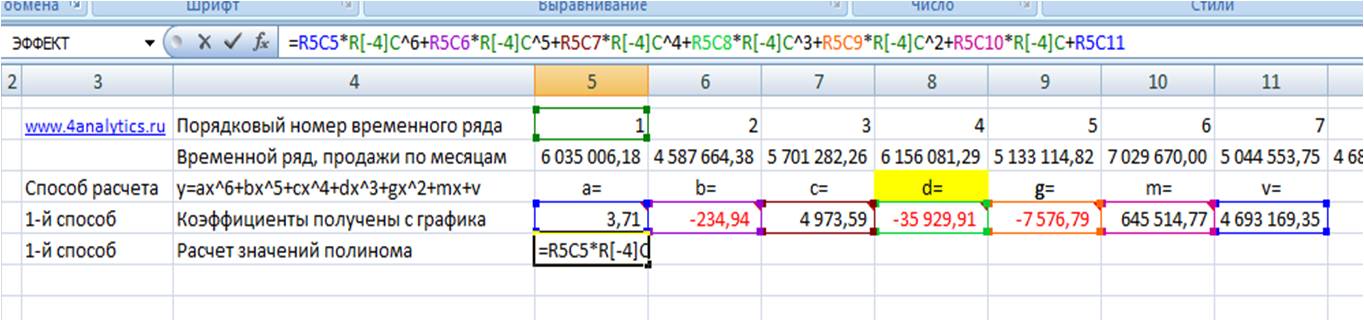
Получаем формулу следующего вида:
=R2C8*RC[-3]^6+R3C8*RC[-3]^5+R4C8*RC[-3]^4+R5C8*RC[-3]^3+R6C8*RC[-3]^2+R7C8*RC[-3]+R8C8
в которой коэффициенты тренда зафиксированы и вместо «x» мы подставляем ссылку на номер текущего временного ряда (для первого значение 1, для второго 2 и т.д.)
Также «X» возводим в соответствующую степень (значок в Excel «^» означает возведение в степень)
=R2C8*RC[-3]^6+R3C8*RC[-3]^5+R4C8*RC[-3]^4+R5C8*RC[-3]^3+R6C8*RC[-3]^2+R7C8*RC[-3]+R8C8
Теперь протягиваем формулу до конца временного ряда и получаем рассчитанные значения полиномиального тренда для каждого периода.
Скачать файл с примером расчета значений полинома.
2-й способ расчета полинома в Excel — функция ЛИНЕЙН()
Рассчитаем коэффициенты линейного тренда с помощью стандартной функции Excel =ЛИНЕЙН()
Для расчета коэффициентов в формулу =ЛИНЕЙН(известные значения y, известные значения x, константа, статистика) вводим:
- «известные значения y» (объёмы продаж за периоды),
- «известные значения x» (порядковый номер временного ряда),
- в константу ставим «1»,
- в статистику «0»
Получаем следующего вида формулу:
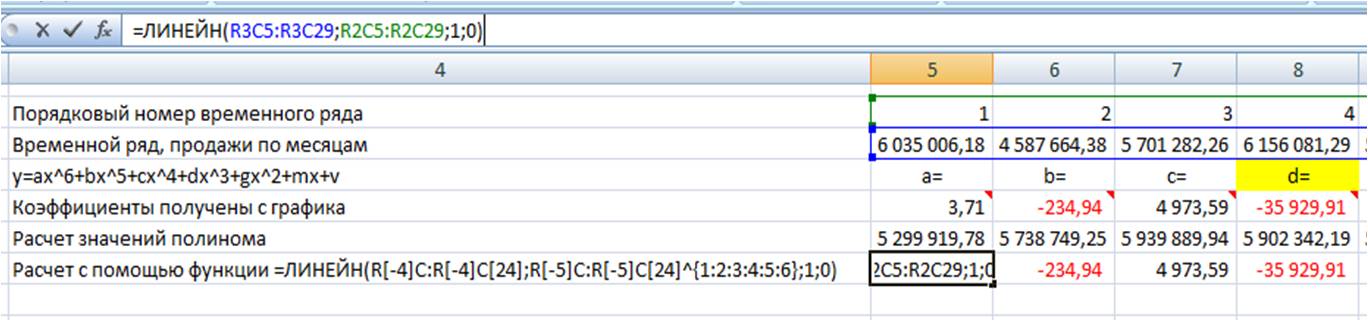
=ЛИНЕЙН(R[-4]C:R[-4]C[24];R[-5]C:R[-5]C[24];1;0),
Теперь, чтобы формула Линейн() рассчитала коэффициенты полинома, нам в неё надо дописать степень полинома, коэффициенты которого мы хотим рассчитать.
Для этого в часть формулы с «известными значениями x» вписываем степень полинома:
- ^{1:2:3:4:5:6} — для расчета коэффициентов полинома 6-й степени
- ^{1:2:3:4:5} — для расчета коэффициентов полинома 5-й степени
- ^{1:2} — для расчета коэффициентов полинома 2-й степени
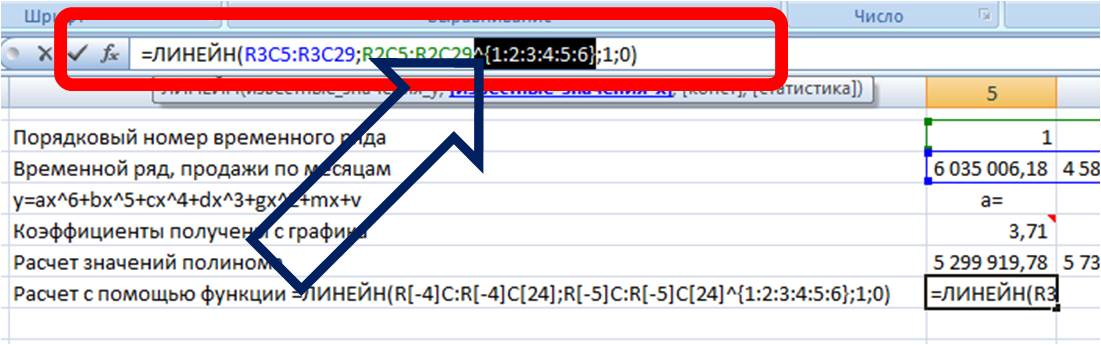
Получаем формулу следующего вида:
=ЛИНЕЙН(R[-4]C:R[-4]C[24]; R[-5]C:R[-5]C[24]^{1:2:3:4:5:6}; 1; 0)
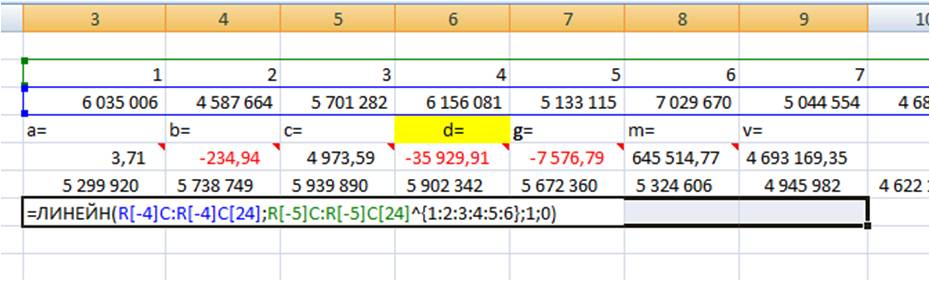
Вводим формулу в ячейку, получаем 3,71 —- значение (a) для полинома 6-й степени y=ax^6+bx^5+cx^4+dx^3+gx^2+mx+v
Для того, чтобы Excel рассчитал все 7 коэффициентов полинома 6-й степени y=ax^6+bx^5+cx^4+dx^3+gx^2+mx+v, необходимо:
1. Установить курсор в ячейку с формулой и выделить 7 соседних ячеек справа, как на рисунке:

2. Нажать на клавишу F2
3. Затем одновременно — клавиши CTRL + SHIFT + ВВОД (т.е. ввести формулу массива, как это сделать читайте подробно в статье «Как ввести формулу массива»)

Получаем 7 коэффициентов полиномиального тренда 6-й степени.
Рассчитаем значения полиномиального тренда с помощью полученных коэффициентов. Подставляем в уравнение y=3,7* x ^ 6 -234,9* x ^ 5 +4973,5* x ^ 4 -35929,9 * x^3 -7576,7 * x^2 +645514,7* x +4693169,3 номера периодов X, для которых хотим рассчитать значения полинома.
Каждому периоду во временном ряду присваиваем порядковый номер, который будем подставлять в уравнение полинома вместо X.
Рассчитаем значения полиномиального тренда для каждого периода. Для этого вводим формулу полинома в первую ячейку и фиксируем ссылки на коэффициенты тренда (см. статью как зафиксировать ссылки)
Получаем формулу следующего вида:
=R2C8*RC[-3]^6+R3C8*RC[-3]^5+R4C8*RC[-3]^4+R5C8*RC[-3]^3+R6C8*RC[-3]^2+R7C8*RC[-3]+R8C8
в которой коэффициенты тренда зафиксированы и вместо «x» мы подставляем ссылку на номер текущего временного ряда (для первого значение 1, для второго 2 и т.д.)
Также «X» возводим в соответствующую степень (значок в Excel «^» означает возведение в степень)
=R2C8*RC[-3]^6+R3C8*RC[-3]^5+R4C8*RC[-3]^4+R5C8*RC[-3]^3+R6C8*RC[-3]^2+R7C8*RC[-3]+R8C8
Теперь протягиваем формулу до конца временного ряда и получаем рассчитанные значения полиномиального тренда для каждого периода.
Скачать файл с примером расчета значений полинома.
2-й способ точнее, чем первый, т.к. коэффициенты тренда мы получаем без округления, а также этот расчет быстрее.
3-й способ расчета значений полиномиальных трендов — Forecast4AC PRO
Устанавливаем курсор в начало временного ряда
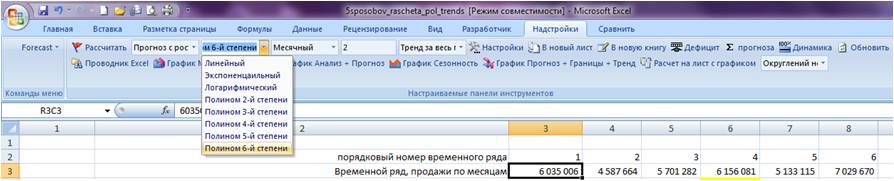
Заходим в настройки Forecast4AC PRO, выбираем «Прогноз с ростом и сезонностью», «Полином 6-й степени», нажимаем кнопку «Рассчитать».
Заходим в лист с пошаговым расчетом «ForPol6», находим строку «Сложившийся тренд»:
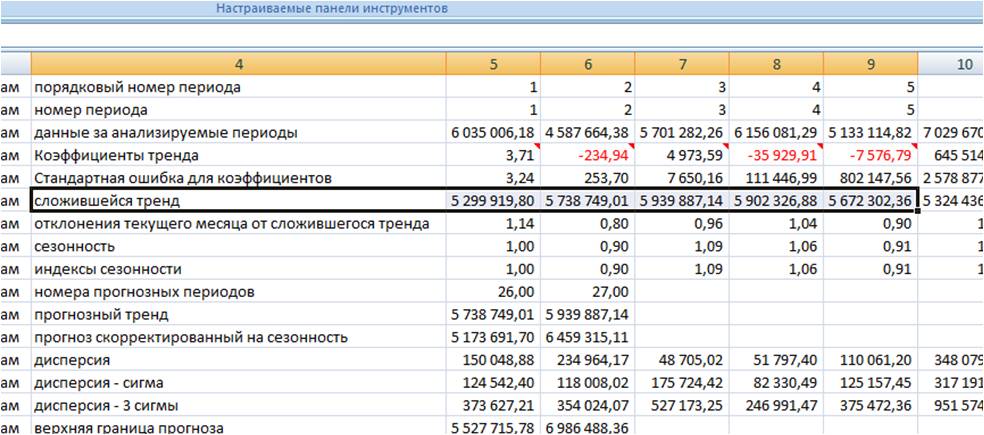
Копируем значения в наш лист.
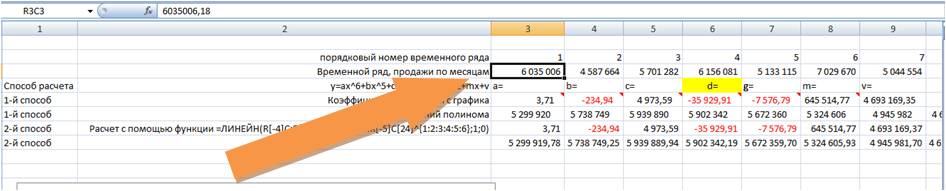
Получаем значения полинома 6-й степени, рассчитанные 3 способами с помощью:
Скачать файл с примером расчета значений полинома.
- Коэффициентов полиномиального тренда выведенных на график;
- Коэффициентов полинома рассчитанных с помощью функцию Excel =ЛИНЕЙН
- и с помощью Forecast4AC PRO одним нажатием клавиши, легко и быстро.
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
3 способа расчета полинома в Excel.
Автор: Алексей Батурин.
Есть 3 способа расчета значений полинома в Excel:
- 1-й способ с помощью графика;
- 2-й способ с помощью функции Excel =ЛИНЕЙН();
- 3-й способ с помощью Forecast4AC PRO;
Подробнее о полиноме и способе его расчета в Excel далее в нашей статье.
Полиномиальный тренд применяется для описания значений временных рядов, попеременно возрастающих и убывающих. Полином отлично подходит для анализа большого набора данных нестабильной величины (например, продажи сезонных товаров).
Что такое полином? Полином — это степенная функция y=ax 2 +bx+c (полином второй степени) и y=ax 3 +bx 2 +cx+d (полином третей степени) и т.д. Степень полинома определяет количество экстремумов (пиков), т.е. максимальных и минимальных значений на анализируемом промежутке времени.
У полинома второй степени y=ax 2 +bx+c один экстремум (на графике ниже 1 максимум).
У Полинома третьей степени y=ax 3 +bx 2 +cx+d может быть один или два экстремума.
Один экстремум
Два экстремума
У Полинома четвертой степени не более трех экстремумов и т.д.
Как рассчитать значения полинома в Excel?
Есть 3 способа расчета значений полинома в Excel:
- 1-й способ с помощью графика;
- 2-й способ с помощью функции Excel =ЛИНЕЙН;
- 3-й способ с помощью Forecast4AC PRO;
1-й способ расчета полинома — с помощью графика
Выделяем ряд со значениями и строим график временного ряда.
На график добавляем полином 6-й степени.
Затем в формате линии тренда ставим галочку «показать уравнение на диаграмме»
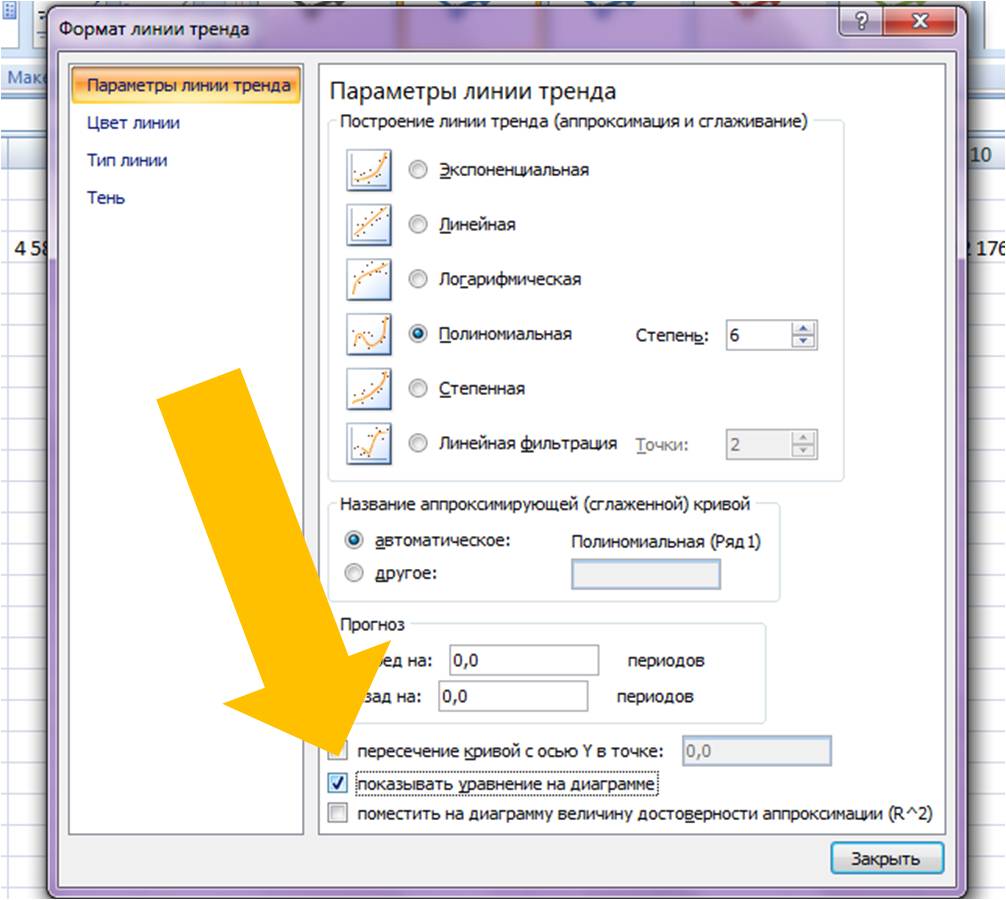
После этого уравнение выводится на график y = 3,7066x 6 — 234,94x 5 + 4973,6x 4 — 35930x 3 — 7576,8x 2 + 645515x + 5E+06 . Для того чтобы последний коэффициент сделать читаемым, мы зажимаем левую кнопку мыши и выделяем уравнение полинома
Нажимаем правой кнопкой и выбираем «формат подписи линии тренда»
В настройках подписи линии тренда выбираем число и в числовых форматах выбираем «Числовой».
Получаем уравнение полинома в читаемом формате:
y = 3,71x 6 — 234,94x 5 + 4 973,59x 4 — 35 929,91x 3 — 7 576,79x 2 + 645 514,77x + 4 693 169,35
Из этого уравнения берем коэффициенты a, b, c, d, g, m, v, и вводим в соответствующие ячейки Excel
Каждому периоду во временном ряду присваиваем порядковый номер, который будем подставлять в уравнение вместо X.
Рассчитаем значения полинома для каждого периода. Для этого вводим формулу полинома y = 3,71x 6 — 234,94x 5 + 4 973,59x 4 — 35 929,91x 3 — 7 576,79x 2 + 645 514,77x + 4 693 169,35 в первую ячейку и фиксируем ссылки на коэффициенты тренда (см. статью как зафиксировать ссылки)
Получаем формулу следующего вида:
= R2C8 *RC[-3]^6+ R3C8 *RC[-3]^5+ R4C8 *RC[-3]^4+ R5C8 *RC[-3]^3+ R6C8 *RC[-3]^2+ R7C8 *RC[-3]+ R8C8
в которой коэффициенты тренда зафиксированы и вместо «x» мы подставляем ссылку на номер текущего временного ряда (для первого значение 1, для второго 2 и т.д.)
Также «X» возводим в соответствующую степень (значок в Excel «^» означает возведение в степень)
=R2C8*RC[-3] ^6 +R3C8*RC[-3] ^5 +R4C8*RC[-3] ^4 +R5C8*RC[-3] ^3 +R6C8*RC[-3] ^2 +R7C8*RC[-3]+R8C8
Теперь протягиваем формулу до конца временного ряда и получаем рассчитанные значения полиномиального тренда для каждого периода.
2-й способ расчета полинома в Excel — функция ЛИНЕЙН()
Рассчитаем коэффициенты линейного тренда с помощью стандартной функции Excel =ЛИНЕЙН()
Для расчета коэффициентов в формулу =ЛИНЕЙН(известные значения y, известные значения x, константа, статистика) вводим:
- «известные значения y» (объёмы продаж за периоды),
- «известные значения x» (порядковый номер временного ряда),
- в константу ставим «1»,
- в статистику «0»
Получаем следующего вида формулу:
Теперь, чтобы формула Линейн() рассчитала коэффициенты полинома, нам в неё надо дописать степень полинома, коэффициенты которого мы хотим рассчитать.
Для этого в часть формулы с «известными значениями x» вписываем степень полинома:
- ^ <1:2:3:4:5:6>— для расчета коэффициентов полинома 6-й степени
- ^ <1:2:3:4:5>— для расчета коэффициентов полинома 5-й степени
- ^ <1:2>— для расчета коэффициентов полинома 2-й степени
Получаем формулу следующего вида:
Вводим формулу в ячейку, получаем 3,71 —- значение (a) для полинома 6-й степени y=ax^6+bx^5+cx^4+dx^3+gx^2+mx+v
Для того, чтобы Excel рассчитал все 7 коэффициентов полинома 6-й степени y=ax^6+bx^5+cx^4+dx^3+gx^2+mx+v, необходимо:
1. Установить курсор в ячейку с формулой и выделить 7 соседних ячеек справа, как на рисунке:
2. Нажать на клавишу F2
3. Затем одновременно — клавиши CTRL + SHIFT + ВВОД (т.е. ввести формулу массива, как это сделать читайте подробно в статье «Как ввести формулу массива»)
Получаем 7 коэффициентов полиномиального тренда 6-й степени.
Рассчитаем значения полиномиального тренда с помощью полученных коэффициентов. Подставляем в уравнение y=3,7* x ^ 6 -234,9* x ^ 5 +4973,5* x ^ 4 -35929,9 * x^3 -7576,7 * x^2 +645514,7* x +4693169,3 номера периодов X, для которых хотим рассчитать значения полинома.
Каждому периоду во временном ряду присваиваем порядковый номер, который будем подставлять в уравнение полинома вместо X.
Рассчитаем значения полиномиального тренда для каждого периода. Для этого вводим формулу полинома в первую ячейку и фиксируем ссылки на коэффициенты тренда (см. статью как зафиксировать ссылки)
Получаем формулу следующего вида:
= R2C8 *RC[-3]^6+ R3C8 *RC[-3]^5+ R4C8 *RC[-3]^4+ R5C8 *RC[-3]^3+ R6C8 *RC[-3]^2+ R7C8 *RC[-3]+ R8C8
в которой коэффициенты тренда зафиксированы и вместо «x» мы подставляем ссылку на номер текущего временного ряда (для первого значение 1, для второго 2 и т.д.)
Также «X» возводим в соответствующую степень (значок в Excel «^» означает возведение в степень)
=R2C8*RC[-3] ^6 +R3C8*RC[-3] ^5 +R4C8*RC[-3] ^4 +R5C8*RC[-3] ^3 +R6C8*RC[-3] ^2 +R7C8*RC[-3]+R8C8
Теперь протягиваем формулу до конца временного ряда и получаем рассчитанные значения полиномиального тренда для каждого периода.
2-й способ точнее, чем первый, т.к. коэффициенты тренда мы получаем без округления, а также этот расчет быстрее.
3-й способ расчета значений полиномиальных трендов — Forecast4AC PRO
Устанавливаем курсор в начало временного ряда
Заходим в настройки Forecast4AC PRO, выбираем «Прогноз с ростом и сезонностью», «Полином 6-й степени», нажимаем кнопку «Рассчитать».
Заходим в лист с пошаговым расчетом «ForPol6», находим строку «Сложившийся тренд»:
Копируем значения в наш лист.
Получаем значения полинома 6-й степени, рассчитанные 3 способами с помощью:
- Коэффициентов полиномиального тренда выведенных на график;
- Коэффициентов полинома рассчитанных с помощью функцию Excel =ЛИНЕЙН
- и с помощью Forecast4AC PRO одним нажатием клавиши, легко и быстро.
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:
- Novo Forecast Lite — автоматический расчет прогноза в Excel .
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Множественная регрессия в EXCEL
history 26 января 2019 г.
-
Группы статей
- Статистический анализ
Рассмотрим использование MS EXCEL для прогнозирования переменной Y на основании нескольких переменных Х, т.е. множественную регрессию.
Перед прочтением этой статьи рекомендуется освежить в памяти простую линейную регрессию – прогнозирование на основе значений только одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Множественного регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Множественный регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Прогнозирование единственной переменной Y на основании значений 2-х или более переменных Х называется множественной регрессией .
Множественная линейная регрессионная модель (Multiple Linear Regression Model) имеет вид Y=β 0 +β 1 *X 1 +β 2 *X 2 +…+β k *X k +ε. В этом случае переменная Y зависит от k поясняющих переменных Х, т.е. регрессоров . ε — случайная ошибка . Модель является линейной относительно неизвестных параметров β.
Оценка неизвестных параметров
В этой статье рассмотрим модель с 2-мя регрессорами. Сначала введем необходимые обозначения и понятия множественной регрессии.
Для описания зависимости Y от 2-х переменных линейная модель имеет вид:
Параметры этой модели β i нам неизвестны, но их можно оценить, используя случайную выборку (измеренные значения переменной Y от заданных Х). Оценки параметров модели (β 0 , β 1 , β 2 ) обычно вычисляются методом наименьших квадратов (МНК) , который минимизирует сумму квадратов ошибок прогнозирования (критерий минимизации в англоязычной литературе обозначают как SSE – Sum of Squared Errors).
Ошибка ε имеет случайную природу и имеет свою функцию распределения со средним значением =0 и дисперсией σ 2 .
Оценки b 1 и b 2 называются коэффициентами регрессии , они определяют влияние соответствующей переменной X, когда все остальные независимые переменные остаются неизменными .
Сдвиг (intercept) или постоянный член b 0 , определяет прогнозируемое значение Y, когда все поясняющие переменные Х равны 0 (часто сдвиг не имеет физического смысла в рамках модели и обусловлен лишь математическими вычислениями МНК ).
Вычислив оценки, полученные методом МНК, позволяют прогнозировать значения переменной Y:
Примечание : Для случая 2-х регрессоров, все спрогнозированные значения переменной Y будут лежать в плоскости (в плоскости регрессии ).
В качестве примера рассмотрим технологический процесс изготовления нити:
Инженер, на основе имеющегося опыта, предположил, что прочность нити Y зависит от концентрации исходного раствора (Х 1 ) и температуры реакции (Х 2 ), и соответствует модели линейной регрессии. Для нахождения комбинации переменных Х, при которых Y принимает максимальное значение, необходимо определить коэффициенты регрессии, сделав выборку.
В MS EXCEL коэффициенты множественной регрессии удобнее всего вычислить с помощью функции ЛИНЕЙН() . Это сделано в файле примера на листе Коэффициенты . Чтобы вычислить оценки:
- выделите 3 ячейки в одной строке (т.к. мы рассматриваем случай 2-х регрессоров, то будут вычислены 2 коэффициента регрессии + величина сдвига = 3 значения, для вывода которых понадобится 3 ячейки). Пусть это будет диапазон С8:Е8 ;
- в Строке формул введите = ЛИНЕЙН(D20:D50;B20:C50) . Предполагается, что в столбце В содержатся прогнозируемые значения Y (в нашей модели это Прочность нити), в столбцах С и D содержатся значения контролируемых параметров Х (Х1 – Концентрация в столбце С и Х2 – Температура в столбце D).
- нажмите CTRL+SHIFT+ENTER (т.к. это формула массива ).
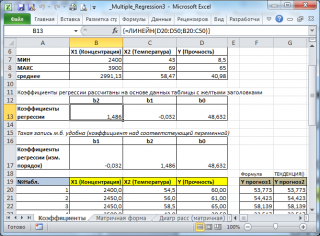
В левой ячейке будет рассчитано значение коэффициента регрессии b 2 для переменной Х2, в средней ячейке — значение коэффициента регрессии b 1 для переменной Х1, в правой – сдвиг . Обратите внимание, что порядок вывода коэффициентов регрессии обратный по отношению к расположению столбцов с данными соответствующих переменных Х (вычисленный коэффициент b 2 располагается левее по отношению к b 1 , тогда как значения переменной Х2 располагаются правее значений переменной Х1). Это может привести к путанице, поэтому лучше разместить коэффициенты над соответствующими столбцами с данными, как это сделано в строке 17 файла примера .
Примечание : В принципе без функции ЛИНЕЙН() можно обойтись, записав альтернативные формулы. Для этого в файле примера на листе Коэффициенты в столбцах I : K вычислены отклонения значений переменных Х 1i , Х 2i , Y i от их средних значений 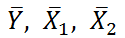 , т.е.:
, т.е.: 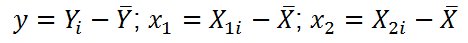
Далее коэффициенты регрессии рассчитываются по следующим формулам (эти формулы справедливы только при прогнозировании по 2-м независимым переменным Х):
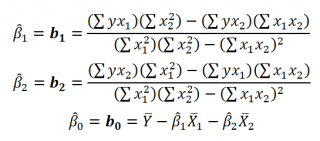
При прогнозировании по 3-м и более независимым переменным Х формулы для вычисления коэффициентов регрессии значительно усложняются, поэтому следует использовать матричный подход.
В файле примера на листе Матричная форма выполнены расчеты коэффициентов регрессии с помощью матричного подхода.
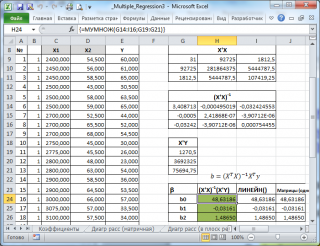
Расчет можно произвести как пошагово, так и одной формулой массива :
Коэффициенты регрессии (вектор b ) в этом случае вычисляются по формуле b =(X T X) -1 (X T Y) или в другом виде записи b =(X ’ X) -1 (X ’ Y)
Под Х подразумевается матрица, состоящая из столбцов значений переменной Х с дополнительным столбцом единиц, а под Y – вектор-столбец значений Y.
Диаграмма рассеяния
В случае простой линейной регрессии (один регрессор, т.е. одна переменная Х) для визуализации связи между прогнозируемым значением Y и переменной Х строят диаграмму рассеяния (двумерную).
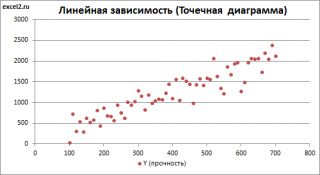
В случае множественной линейной регрессии двумерную диаграмму рассеяния можно построить только для анализа влияния каждого отдельного регрессора на Y (при этом остальные Х не меняются), т.е. так называемую Матричную диаграмму рассеивания (См. файл примера лист Диагр расс (матричная) ).
К сожалению, такую диаграмму трудно интерпретировать.
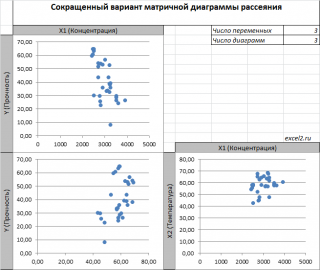
Более того, матричная диаграмма может вводить в заблуждение (см. Introduction to linear regression analysis / D . C . Montgomery , E . A . Peck , G . G . Vining , раздел 3.2.5 ), демонстрируя наличие или отсутствие линейной взаимосвязи между отдельным регрессором X i и Y.
Для случая с 2-мя регрессорами можно предложить альтернативный вид матричной диаграммы рассеяния . В стандартной диаграмме рассеяния строятся проекции на координатные плоскости Х1;Х2, Y;X1 и Y;X2. Однако, если взглянуть на точки относительно плоскости регрессии , то картину, на мой взгляд, будет проще интерпретировать.
Сравним две матричные диаграммы рассеяния (см. файл примера на листе «Диагр расс (в плоск регрессии)» , построенные для одних и тех же наблюдений. Первая – стандартная,

вторая представляет собой вид сверху на плоскость регрессии и 2 вида вдоль плоскости.
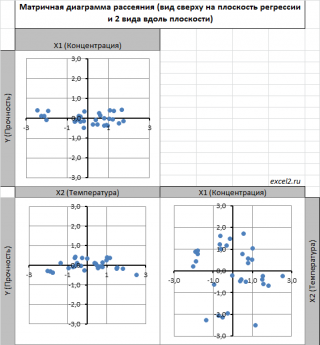
На второй диаграмме становится очевидно, что разброс точек относительно плоскости регрессии совсем не большой и поэтому, скорее всего, построенная модель является полезной, а выбранные 2 переменные Х позволяют прогнозировать Y (конечно, для подтверждения этой гипотезы нужно провести процедуру F-теста ).
Несколько слов о построении альтернативной матричной диаграммы рассеяния:
- Перед построением необходимо нормировать значения наблюдений (для каждой переменной вычесть среднее и разделить на стандартное отклонение ). В этом случае практически все точки на диаграммах будут находится в диапазоне +/-3 (по аналогии со стандартным нормальным распределением , 99% значений которого лежат в пределах +/-3 сигма). В этом случае, на диаграмме можно фиксировать мин/макс значений осей, чтобы EXCEL автоматически не модифицировал масштаб осей при изменении данных (это не всегда удобно);
- Теперь координаты точек необходимо рассчитать в системе отсчета относительно плоскости регрессии (в которой плоскость Оху’ совпадает с плоскостью регрессии). Для этого необходимо найти матрицу вращения , например, через вращение приводящее к совмещению нормали к плоскости регрессии и вектора оси Z (0;0;1);
- Новые координаты позволяют построить альтернативную матричную диаграмму. Кроме того, для удобства можно вращать систему координат вокруг новой оси Z, чтобы нагляднее представить себе распределение точек относительно плоскости регрессии (для этого использована Полоса прокрутки в ячейках Q31:S31 ).
Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
После того, как нами были найдены тем или иным способом коэффициенты регрессии можно приступать к вычислению прогнозных значений Y на основе заданных значений переменных Х.
Уравнение прогнозирования или уравнение регрессии в случае 2-х независимых переменных (регрессоров) записывается в виде:
Примечание: В MS EXCEL прогнозное значение Y для заданных Х 1 и Х 2 можно также предсказать с помощью функции ТЕНДЕНЦИЯ() . При этом 2-й аргумент будет ссылкой на столбцы, содержащие все значения переменных Х 1 и Х 2 , а 3-й аргумент функции должен быть ссылкой на диапазон ячеек, содержащий 2 значения Х (Х 1i и Х 2i ) для выбранного наблюдения i (см. файл примера, лист Коэффициенты, столбец G ). Функция ПРЕДСКАЗ() , использованная нами в простой регрессии, не работает в случае множественной регрессии .
Найдя прогнозное значение Y, мы, таким образом, вычислим его точечную оценку. Понятно, что фактическое значение Y, полученное при наблюдении, будет, скорее всего, отличаться от этой оценки. Чтобы ответить на вопрос о том, на сколько хорошо мы можем предсказывать новые значения Y, нам потребуется построить доверительный интервал этой оценки, т.е. диапазон в котором с определенной заданной вероятностью, скажем 95%, мы ожидаем новое значение Y.
Доверительные интервалы построим при фиксированном Х для:
- нового наблюдения Y;
- среднего значения Y (интервал будет уже, чем для отдельного нового наблюдения)
Как и в случае простой линейной регрессии , для построения доверительных интервалов нам потребуется сначала вычислить стандартную ошибку модели (standard error of the model) , которая приблизительно показывает насколько велика ошибка предсказания значений переменной Y на основании значений переменных Х.
Для вычисления стандартной ошибки оценивают дисперсию ошибки ε, т.е. сигма^2 (ее часто обозначают как MS Е либо MSres ) . Затем, вычислив из полученной оценки квадратный корень, получим Стандартную ошибку регрессии (часто обозначают как SEy или sey ).
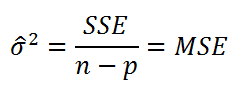
где SSE – сумма квадратов значений ошибок модели ei=yi — ŷi ( Sum of Squared Errors ). MSE означает Mean Square of Errors (среднее квадратов ошибок, точнее остатков).
Величина n-p – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y, р – количество оцениваемых параметров модели). В случае простой множественной регрессии с 2-мя регрессорами число степеней свободы равно n-3, т.к. при построении плоскости регрессии было оценено 3 параметра модели b (т.е. на это было «потрачено» 3 степени свободы ).
В MS EXCEL стандартную ошибку SEy можно вычислить формулы (см. файл примера, лист Статистика ):
Стандартная ошибка нового наблюдения Y при заданных значениях Х (вектор Хi) вычисляется по формуле:
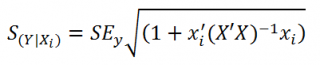
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
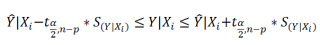
где α (альфа) – уровень значимости (обычно принимают равным 0,05=5%)
р – количество оцениваемых параметров модели (в нашем случае = 3)
n-p – число степеней свободы
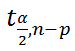 – квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
– квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
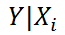 – прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
– прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
Стандартная ошибка среднего значения Y при заданных значениях Х (вектор Хi) будет меньше, чем стандартная ошибка отдельного наблюдения. Вычисления производятся по формуле:
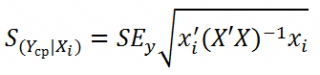
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
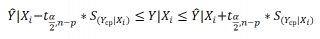
Прогнозное значение Yi (точечная оценка) используется тоже, что и для отдельного наблюдения.
Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
В разделе Оценка неизвестных параметров мы получили точечные оценки коэффициентов регрессии . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ) коэффициентов регрессии .
Стандартная ошибка коэффициента регрессии b j (обозначается se ( b j ) ) вычисляется на основании стандартной ошибки по следующей формуле:
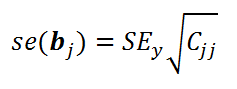
где C jj является диагональным элементом матрицы (X ’ X) -1 . Для коэффициента сдвига b 0 индекс j=1 (верхний левый элемент), для b 1 индекс j=2, b 2 индекс j=3 (нижний правый элемент).
SEy – стандартная ошибка регрессии (см. выше ).
В MS EXCEL стандартные ошибки коэффициентов регрессии можно вычислить с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. статью Функция MS EXCEL ЛИНЕЙН() .
Применяя матричный подход стандартные ошибки можно вычислить и через обычные формулы (точнее через формулу массива , см. файл примера лист Статистика ):
= КОРЕНЬ(СУММКВРАЗН(E13:E43;F13:F43) /(n-p)) *КОРЕНЬ (ИНДЕКС (МОБР (МУМНОЖ(ТРАНСП(B13:D43);(B13:D43)));j;j))
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
где t – это t-значение , которое можно вычислить с помощью формулы = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) для уровня значимости 0,05.
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии b j . Здесь мы считаем, что коэффициент регрессии b j имеет распределение Стьюдента с n-p степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Проверка гипотез
Когда мы строим модель, мы предполагаем, что между Y и переменными X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X, возможен, когда все коэффициенты регрессии β равны 0.
Чтобы убедиться, что вычисленная нами оценка коэффициентов регрессии не обусловлена лишь случайностью (они не случайно отличны от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что линейной связи нет, т.е. ВСЕ β=0. В качестве альтернативной гипотезы Н 1 принимают, что ХОТЯ БЫ ОДИН коэффициент β <>0.
Процедура проверки значимости множественной регрессии, приведенная ниже, является обобщением дисперсионного анализа , использованного нами в случае простой линейной регрессии (F-тест) .
Если нулевая гипотеза справедлива, то тестовая F -статистика имеет F-распределение со степенями свободы k и n — k -1 , т.е. F k, n-k-1 :
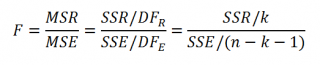
Проверку значимости регрессии можно также осуществить через вычисление p -значения . В этом случае вычисляют вероятность того, что случайная величина F примет значение F 0 (это и есть p-значение ), затем сравнивают p-значение с заданным уровнем значимости α (альфа) . Если p-значение больше уровня значимости , то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В MS EXCEL для проверки гипотезы через p -значение используйте формулу =F.РАСП.ПХ(F 0 ;k;n-k-1) файл примера лист Статистика , где показано эквивалентность обоих подходов проверки значимости регрессии).
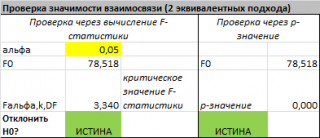
В MS EXCEL критическое значение для заданного уровня значимости F 1-альфа, k, n-k-1 можно вычислить по формуле = F.ОБР(1- альфа;k;n-k-1) или = F.ОБР.ПХ(альфа;k; n-k-1) . Другими словами требуется вычислить верхний альфа- квантиль F -распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F 0 > F 1-альфа, k, n-k-1 мы имеем основание для отклонения нулевой гипотезы.
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Надстройка , которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
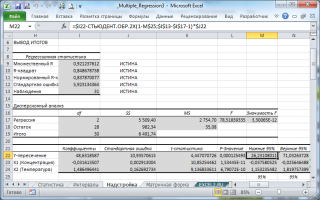
Генерация данных для множественной регрессии с помощью заданного тренда
Иногда, бывает удобно сгенерировать значения наблюдений, имея заданный тренд.
Для решения этой задачи нам потребуется:
- задать значения регрессоров в нужном диапазоне (значения переменных Х);
- задать коэффициенты регрессии ( b );
- задать тренд (вычислить значения Y= b0 +b1 * Х 1 + b2 * Х 2 );
- задать величину разброса Y вокруг тренда (варианты: случайный разброс в заданных границах или заданная фигура, например, круг)
Все вычисления выполнены в файле примера, лист Тренд для случая 2-х регрессоров. Там же построены диаграммы рассеяния .
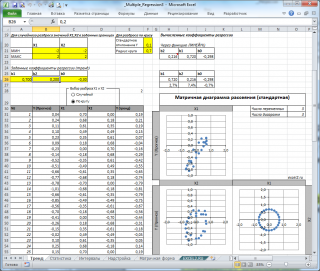
Коэффициент детерминации
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью ( SSR ) / Общая изменчивость ( SST ).
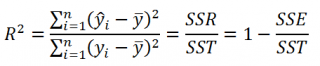
Этот показатель можно вычислить с помощью функции ЛИНЕЙН() :
При добавлении в модель новой объясняющей переменной Х, коэффициент детерминации будет всегда расти. Поэтому, рост коэффициента детерминации не может служить основанием для вывода о том, что новая модель (с дополнительным регрессором) лучше прежней.
Более подходящей статистикой, которая лишена указанного недостатка, является нормированный коэффициент детерминации (Adjusted R-squared):
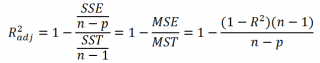
где p – число независимых регрессоров (вычисления см. файл примера лист Статистика ).
Нелинейная регрессия в Excel
Нелинейная регрессия в Excel
Добрый день, уважаемые читатели блога! Сегодня мы поговорим о нелинейных регрессиях. Решение линейных регрессий можно посмотреть по ССЫЛКЕ.
Данный способ применяется, в основном, в экономическом моделировании и прогнозировании. Его цель – пронаблюдать и выявить зависимости между двумя показателями.
Основными типами нелинейных регрессий являются:
- полиномиальные (квадратичная, кубическая);
- гиперболическая;
- степенная;
- показательная;
- логарифмическая.
Также могут применяться различные комбинации. Например, для аналитики временных рядов в банковской сфере, страховании, демографических исследованиях используют кривую Гомпцера, которая является разновидностью логарифмической регрессии.
В прогнозировании с помощью нелинейных регрессий главное выяснить коэффициент корреляции, который покажет нам есть ли тесная взаимосвязь меду двумя параметрами или нет. Как правило, если коэффициент корреляции близок к 1, значит связь есть, и прогноз будет довольно точен. Ещё одним важным элементом нелинейных регрессий является средняя относительная ошибка (А), если она находится в промежутке
На этом, пожалуй, теоретический блок мы закончим и перейдём к практическим вычислениям.
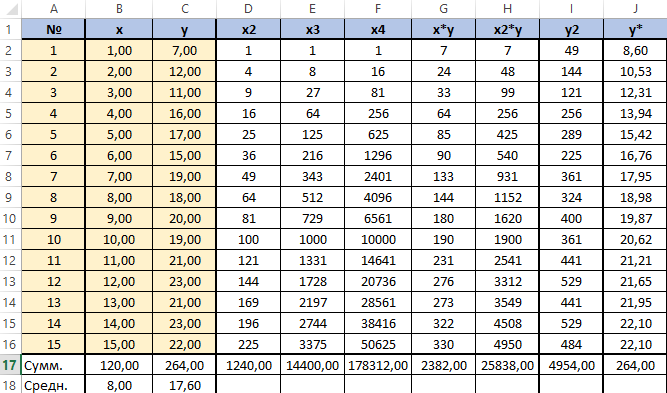
У нас имеется таблица продаж автомобилей за промежуток 15 лет (обозначим его X), количество шагов измерений будет аргумент n, также имеется выручка за эти периоды (обозначим её Y), нам нужно спрогнозировать какова будет выручка в дальнейшем. Построим следующую таблицу:

Для исследования нам потребуется решить уравнение (зависимости Y от X): y=ax 2 +bx+c+e. Это парная квадратичная регрессия. Применим в этом случае метод наименьших квадратов, для выяснения неизвестных аргументов — a, b, c. Он приведёт к системе алгебраических уравнений вида:

Для решения этой системы воспользуемся, к примеру, методом Крамера. Видим, что входящие в систему суммы являются коэффициентами при неизвестных. Для их вычисления добавим в таблицу несколько столбцов (D,E,F,G,H) и подпишем соответственно смыслу вычислений — в столбце D возведём x в квадрат, в E в куб, в F в 4 степень, в G перемножим показатели x и y, в H возведём x в квадрат и перемножим с y.
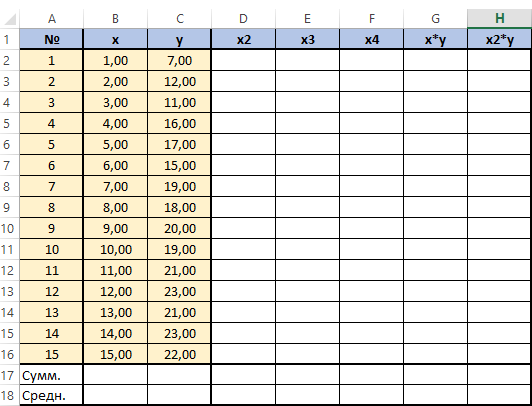
Получится заполненная нужными для решения уравнения таблица вида.
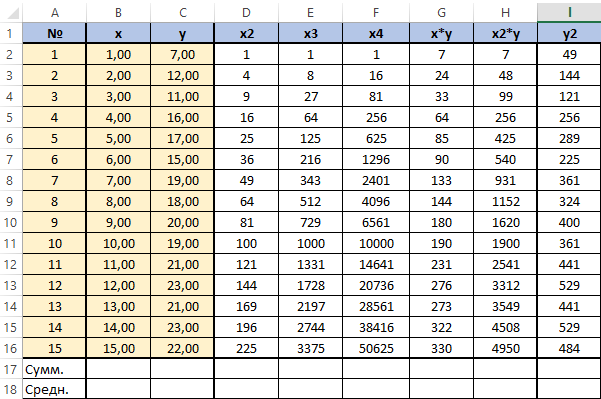
Далее посчитаем суммы по каждому столбцу — воспользуемся ∑ в программе Excel.
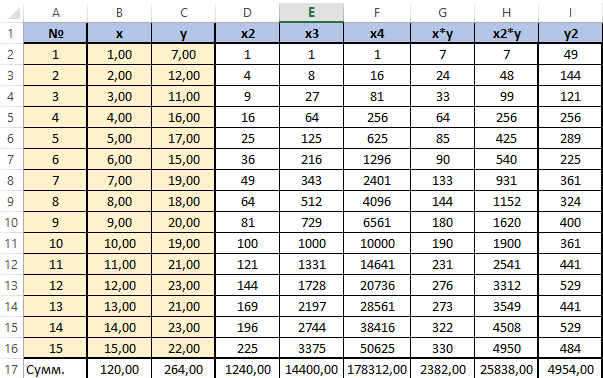
Сформируем матрицу A системы, состоящую из коэффициентов при неизвестных в левых частях уравнений. Поместим её в ячейку А22 и назовём «А=«. Следуем той системе уравнений, которую мы избрали для решения регрессии.
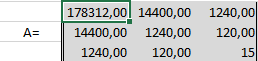
То есть, в ячейку B21 мы должны поместить сумму столбца, где возводили показатель X в четвёртую степень — F17. Просто сошлёмся на ячейку — «=F17». Далее нам необходима сумма столбца где возводили X в куб — E17, далее идём строго по системе. Таким образом, нам необходимо будет заполнить всю матрицу.
В соответствии с алгоритмом Крамера наберём матрицу А1, подобную А, в которой вместо элементов первого столбца должны размещаться элементы правых частей уравнений системы. То есть сумма столбца X в квадрате умноженная на Y, сумма столбца XY и сумма столбца Y.

Также нам понадобятся ещё две матрицы — назовём их А2 и А3 в которых второй и третий столбцы будут состоять из коэффициентов правых частей уравнений. Картина будет такова.
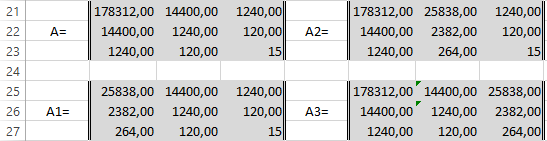
Следуя избранному алгоритму, нам нужно будет вычислить значения определителей (детерминантов, D) полученных матриц. Воспользуемся формулой МОПРЕД. Результаты разместим в ячейках J21:K24.

Расчёт коэффициентов уравнения по Крамеру будем производить в ячейках напротив соответствующих детерминантов по формуле: a (в ячейке M22) — «=K22/K21»; b (в ячейке M23) — «=K23/K21»; с (в ячейке M24) — «=K24/K21».

Получим наше искомое уравнение парной квадратичной регрессии:
y=-0,074x 2 +2,151x+6,523
Оценим тесноту линейной связи индексом корреляции.
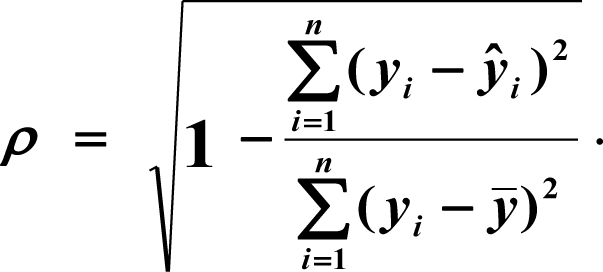
Для вычисления добавим в таблицу дополнительный столбец J (назовём его y*). Расчёта будет следующей (согласно полученному нами уравнению регрессии) — «=$m$22*B2*B2+$M$23*B2+$M$24». Поместим её в ячейку J2. Останется протянуть вниз маркер автозаполнения до ячейки J16.
Для вычисления сумм (Y-Y усредненное) 2 добавим в таблицу столбцы K и L с соответствующими формулами. Среднее по столбцу Y посчитаем с помощью функции СРЗНАЧ.
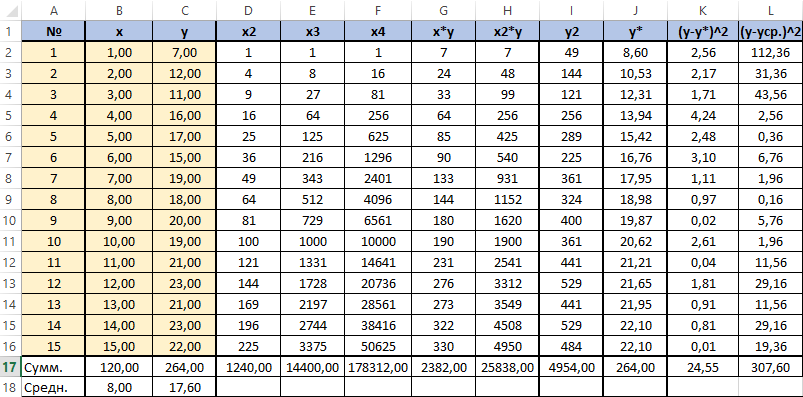
В ячейке K25 разместим формулу подсчёта индекса корреляции — «=КОРЕНЬ(1-(K17/L17))».
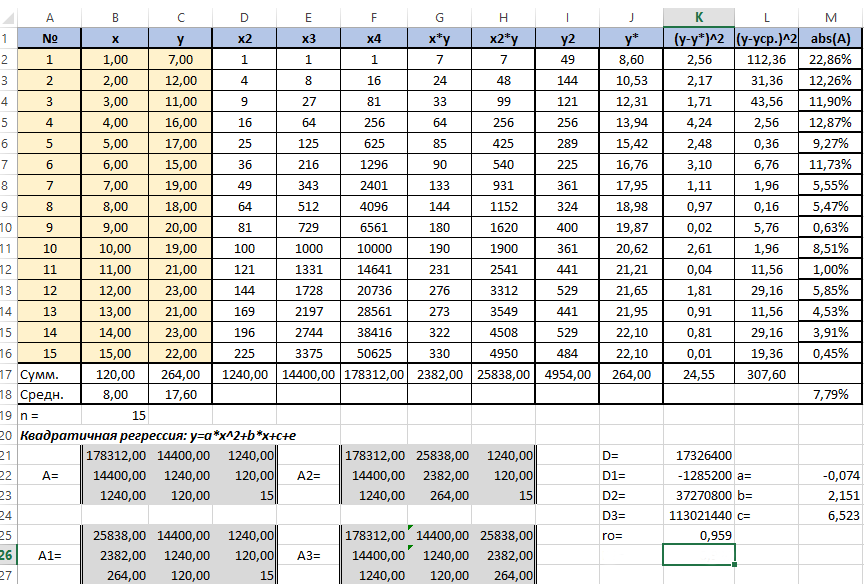
Видим, что значение 0,959 очень близко к 1, значит между продажами и годами есть тесная нелинейная связь.
Осталось оценить качество подгонки полученного квадратичного уравнения регрессии (индекс детерминации). Он рассчитывается по формуле квадрата индекса корреляции. То есть формула в ячейке K26 будет очень проста — «=K25*K25».
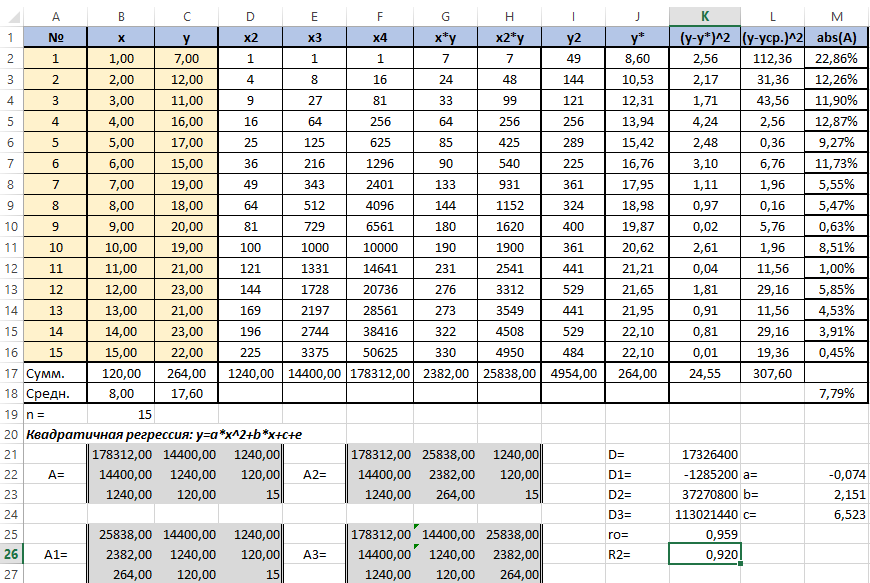
Коэффициент 0,920 близок к 1, что свидетельствует о высоком качестве подгонки.
Последним действием будет вычисление относительной ошибки. Добавим столбец и внесём туда формулу: «=ABS((C2-J2)/C2), ABS — модуль, абсолютное значение. Протянем маркером вниз и в ячейке M18 выведем среднее значение (СРЗНАЧ), назначим ячейкам процентный формат. Полученный результат — 7,79% находится в пределах допустимых значений ошибки
Если возникнет необходимость, по полученным значениям мы можем построить график.
источники:
http://excel2.ru/articles/mnozhestvennaya-regressiya-v-ms-excel
http://pcandlife.ru/nelineinaya-regressiya-v-excel/
Содержание
- Выполнение аппроксимации
- Способ 1: линейное сглаживание
- Способ 2: экспоненциальная аппроксимация
- Способ 3: логарифмическое сглаживание
- Способ 4: полиномиальное сглаживание
- Способ 5: степенное сглаживание
- Вопросы и ответы

Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Урок: Как построить линию тренда в Excel
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
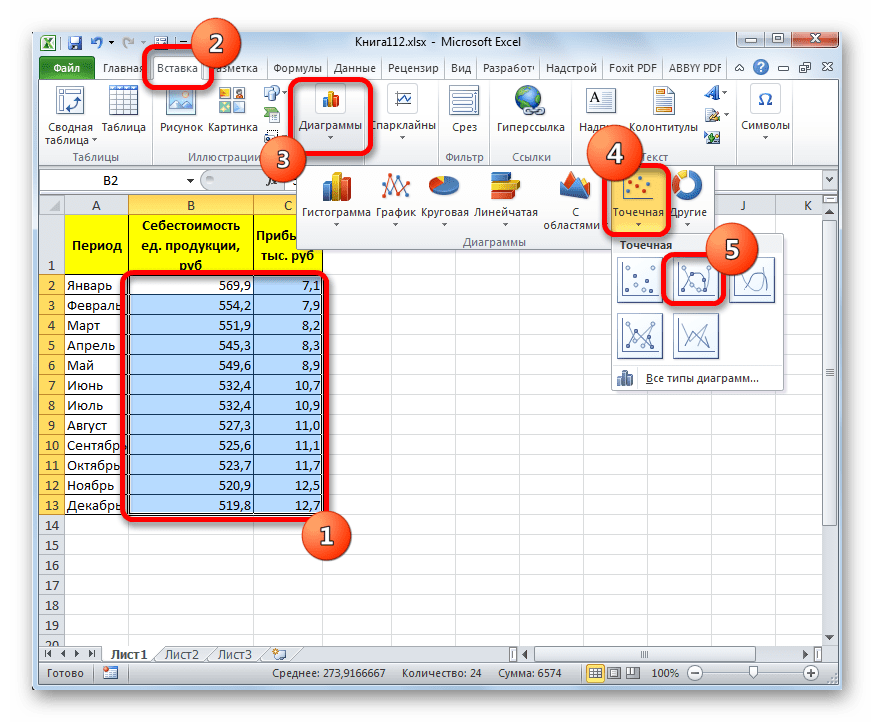
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
- Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.
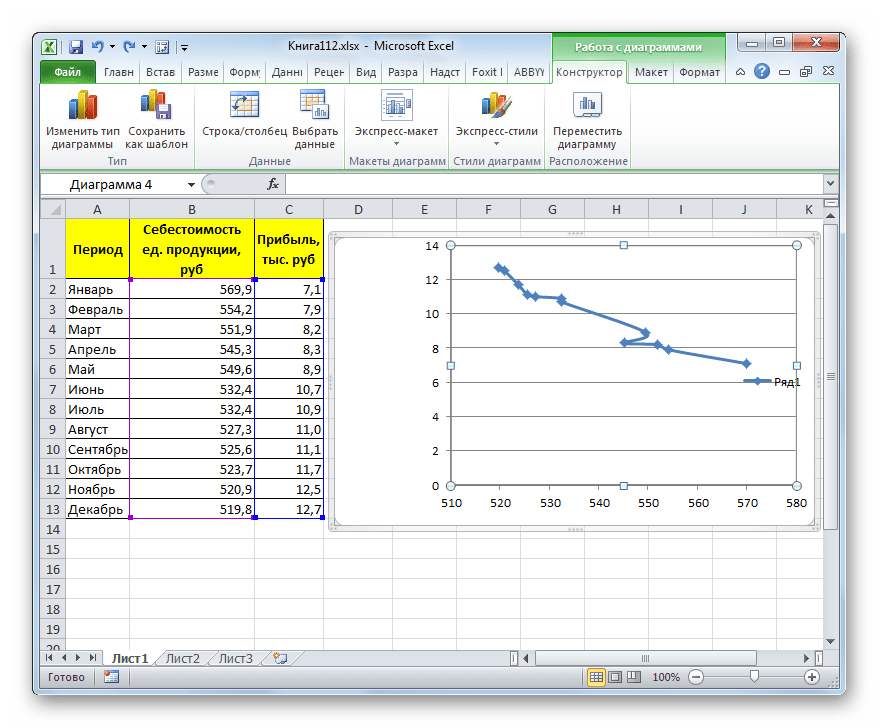
- График построен.
- Для добавления линии тренда выделяем его кликом правой кнопки мыши. Появляется контекстное меню. Выбираем в нем пункт «Добавить линию тренда…».

Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
- Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
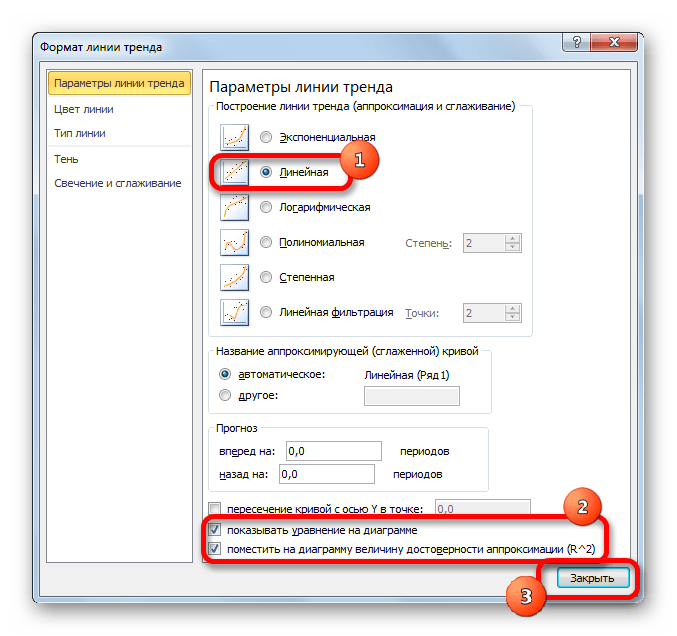
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
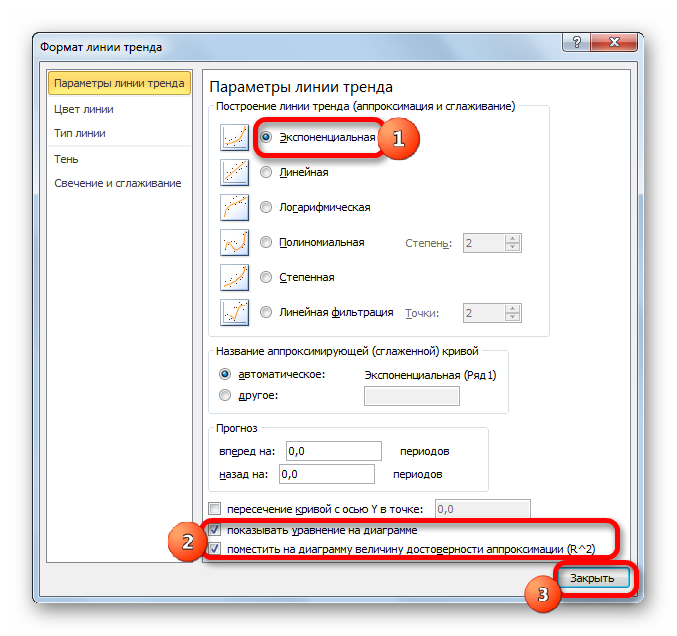
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от 0 до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.

После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
- Как видим, на графике линия тренда построена. При линейной аппроксимации она обозначается черной прямой полосой. Указанный вид сглаживания можно применять в наиболее простых случаях, когда данные изменяются довольно быстро и зависимость значения функции от аргумента очевидна.

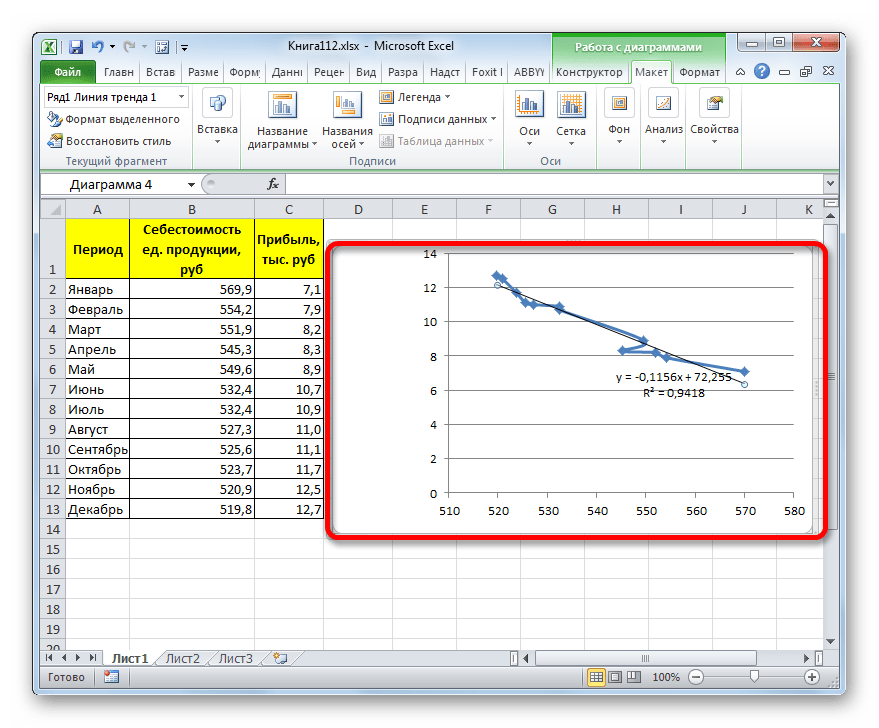
Сглаживание, которое используется в данном случае, описывается следующей формулой:
y=ax+b
В конкретно нашем случае формула принимает такой вид:
y=-0,1156x+72,255
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
- Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
- После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
- После этого линия тренда будет построена на графике. Как видим, при использовании данного метода она имеет несколько изогнутую форму. При этом уровень достоверности равен 0,9592, что выше, чем при использовании линейной аппроксимации. Экспоненциальный метод лучше всего использовать в том случае, когда сначала значения быстро изменяются, а потом принимают сбалансированную форму.
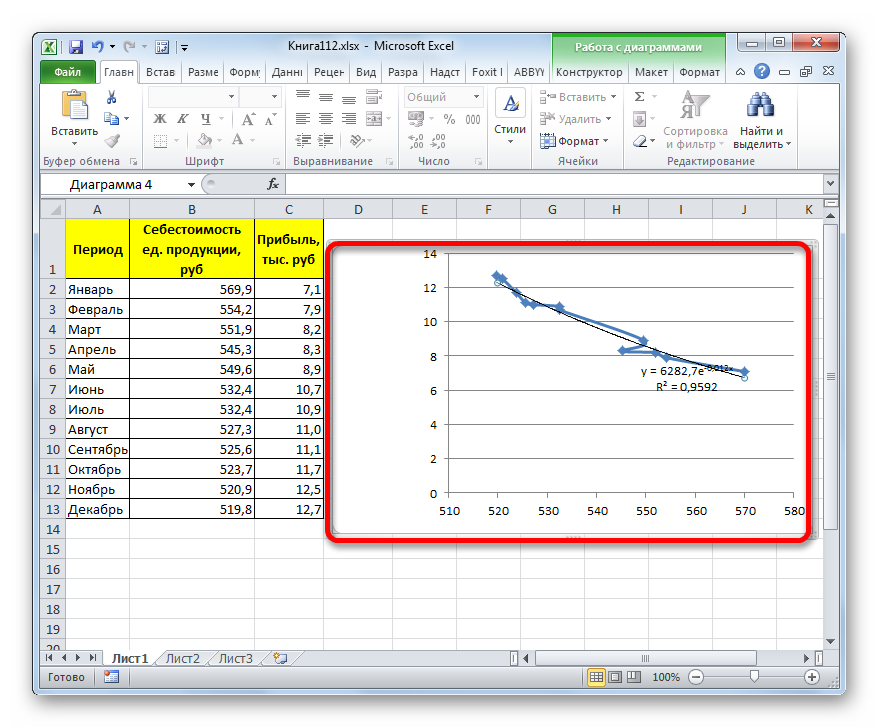
Общий вид функции сглаживания при этом такой:
y=be^x
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
y=6282,7*e^(-0,012*x)
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
- Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
- Происходит процедура построения линии тренда с логарифмической аппроксимацией. Как и в предыдущем случае, такой вариант лучше использовать тогда, когда изначально данные быстро изменяются, а потом принимают сбалансированный вид. Как видим, уровень достоверности равен 0,946. Это выше, чем при использовании линейного метода, но ниже, чем качество линии тренда при экспоненциальном сглаживании.
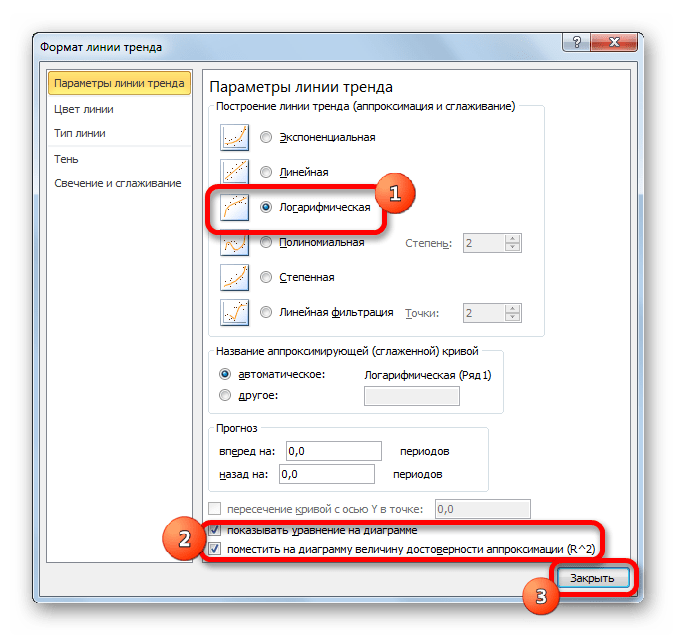
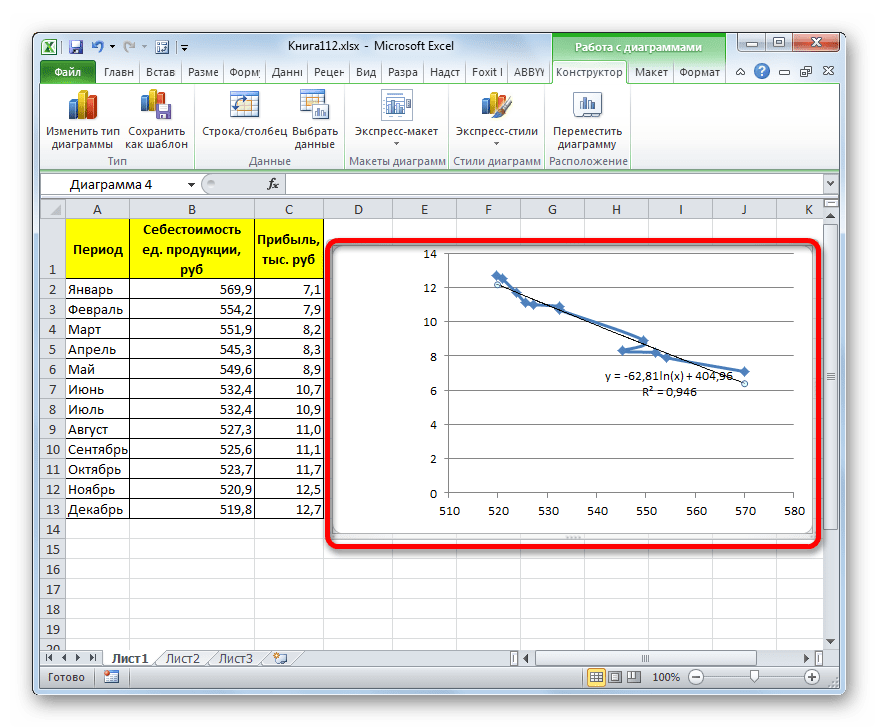
В общем виде формула сглаживания выглядит так:
y=a*ln(x)+b
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
y=-62,81ln(x)+404,96
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
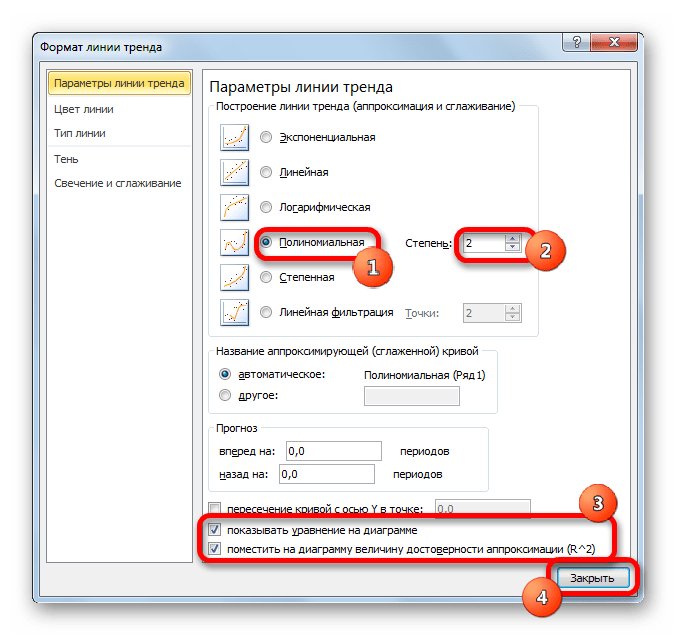
- Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».
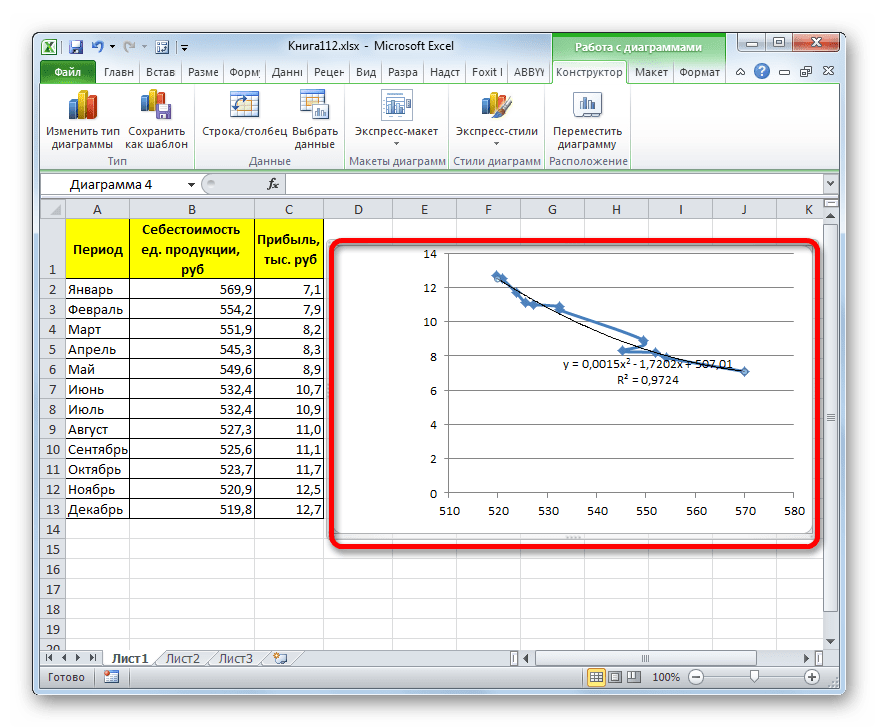
- Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.

Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
y=a1+a1*x+a2*x^2+…+an*x^nВ нашем случае формула приняла такой вид:
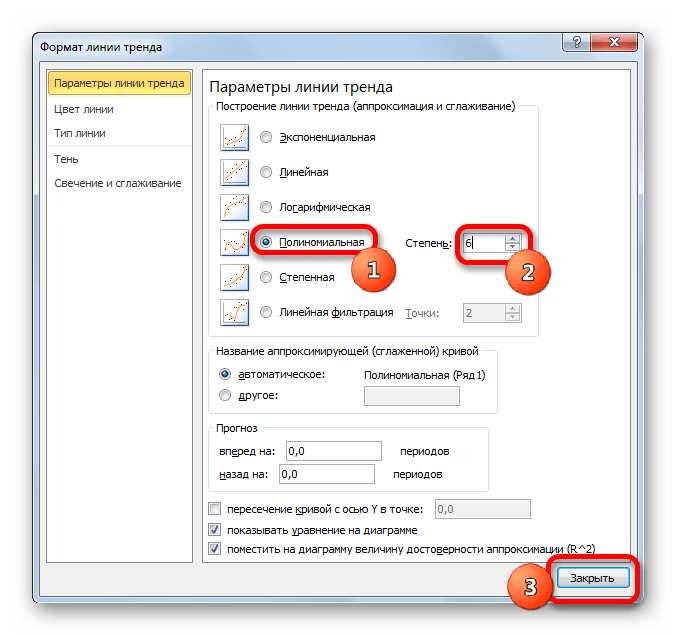
y=0,0015*x^2-1,7202*x+507,01 - Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.
- Как видим, после этого наша линия тренда приняла форму ярко выраженной кривой, у которой число максимумов равно шести. Уровень достоверности повысился ещё больше, составив 0,9844.
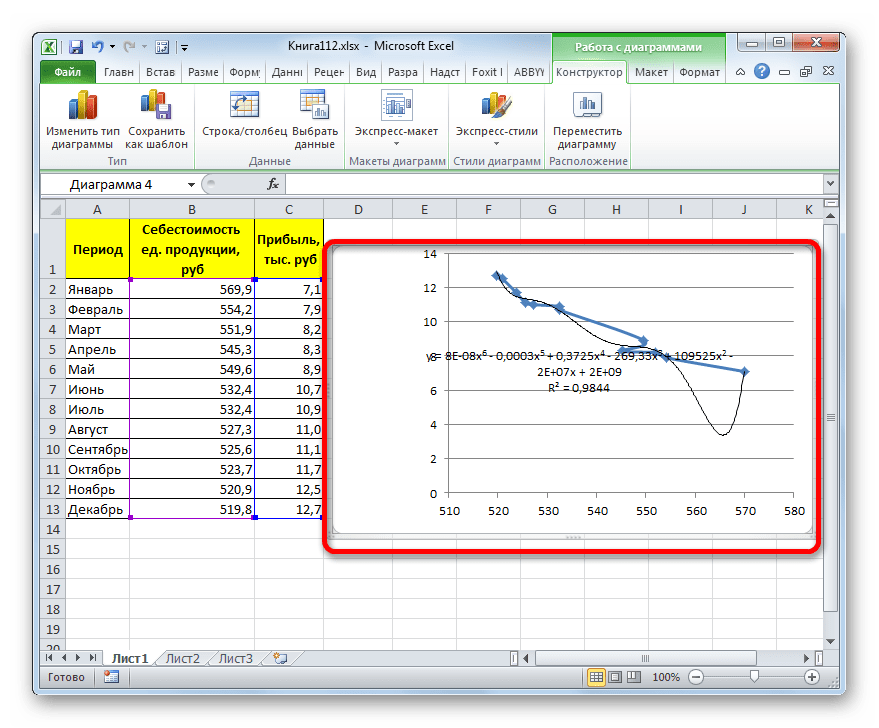
Формула, которая описывает данный тип сглаживания, приняла следующий вид:
y=8E-08x^6-0,0003x^5+0,3725x^4-269,33x^3+109525x^2-2E+07x+2E+09
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
- Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
- Программа формирует линию тренда. Как видим, в нашем случае она представляет собой линию с небольшим изгибом. Уровень достоверности равен 0,9618, что является довольно высоким показателем. Из всех вышеописанных способов уровень достоверности был выше только при использовании полиномиального метода.
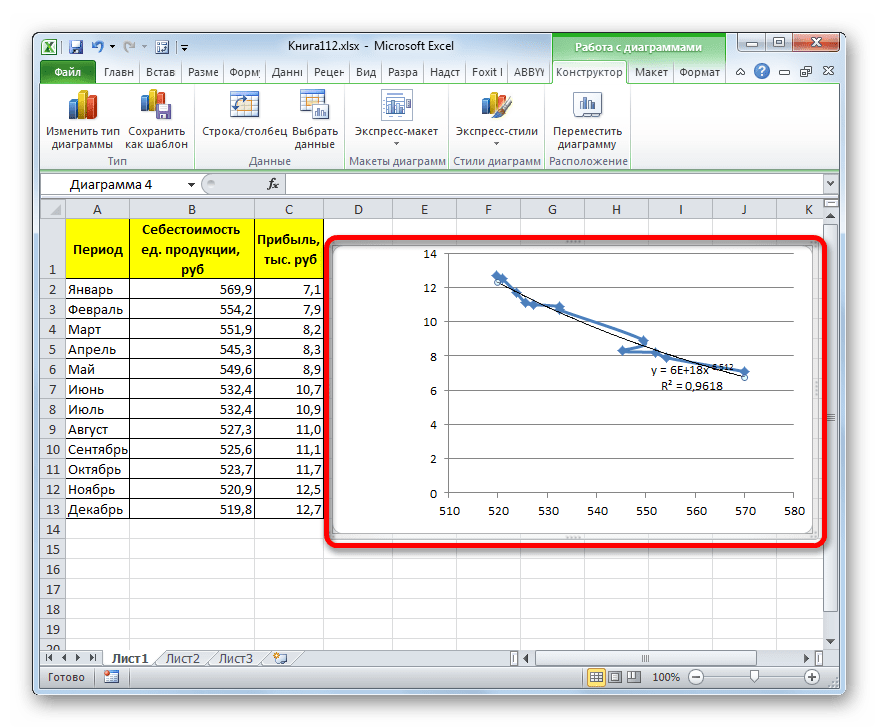
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
y=bx^n
В конкретно нашем случае она выглядит так:
y = 6E+18x^(-6,512)
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
17 авг. 2022 г.
читать 1 мин
Вы можете использовать функцию ЛИНЕЙН() в Excel, чтобы подобрать полиномиальную кривую с определенной степенью.
Например, вы можете использовать следующий базовый синтаксис, чтобы подогнать полиномиальную кривую со степенью 3:
=LINEST( known_ys , known_xs ^{1, 2, 3})
Функция возвращает массив коэффициентов, описывающих полиномиальную подгонку.
В следующем пошаговом примере показано, как использовать эту функцию для подбора полиномиальной кривой в Excel.
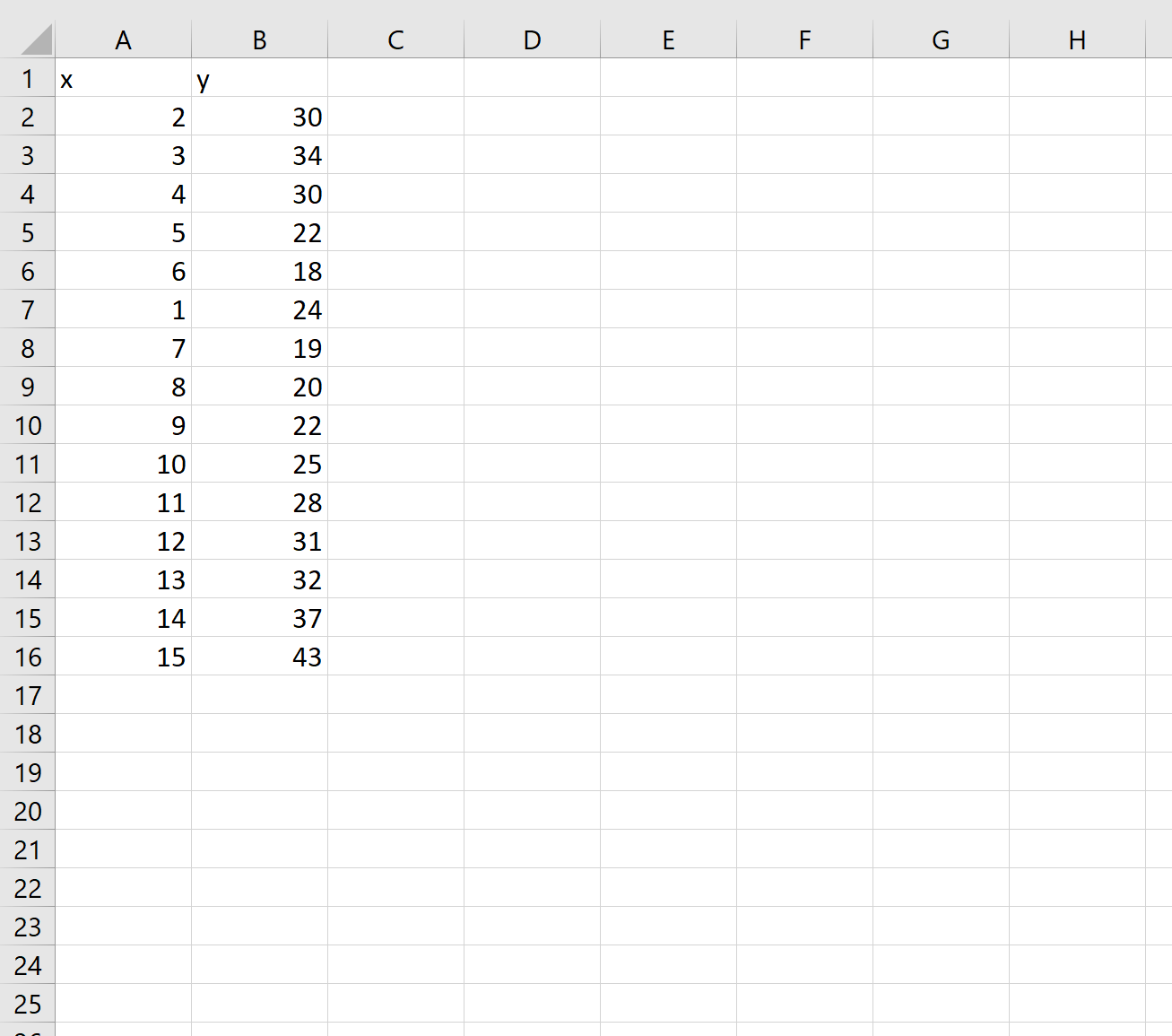
Шаг 1: Создайте данные
Во-первых, давайте создадим некоторые данные для работы:
Шаг 2: Подберите полиномиальную кривую
Далее воспользуемся функцией ЛИНЕЙН() , чтобы подобрать полиномиальную кривую степени 3 к набору данных:
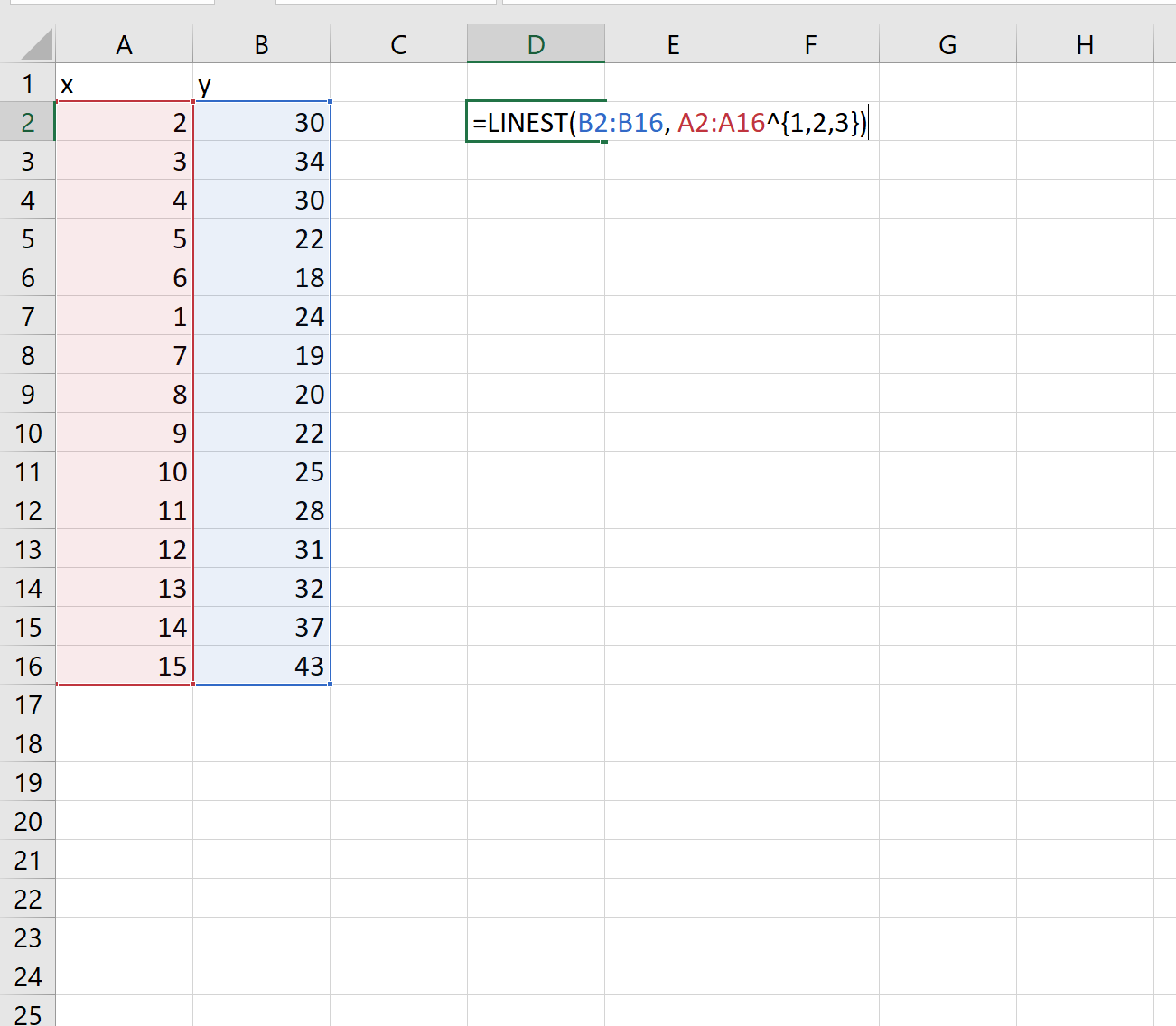
Шаг 3: Интерпретация полиномиальной кривой
Как только мы нажмем ENTER , появится массив коэффициентов:
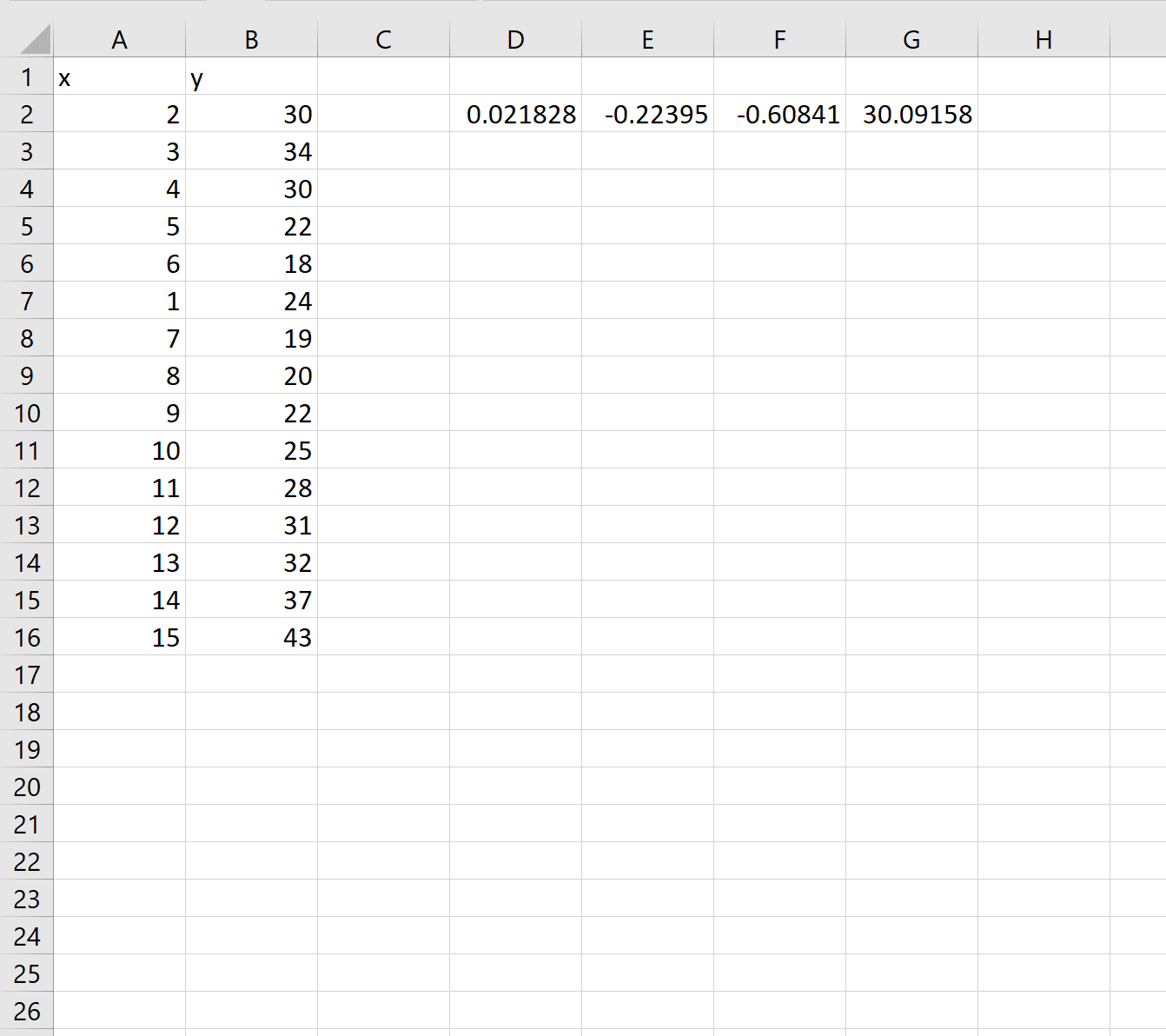
Используя эти коэффициенты, мы можем построить следующее уравнение, описывающее взаимосвязь между x и y:
у = 0,0218x 3 – 0,2239x 2 – 0,6084x + 30,0915
Мы также можем использовать это уравнение для вычисления ожидаемого значения y на основе значения x.
Например, предположим, что x = 4. Ожидаемое значение y будет следующим:
у = 0,0218(4) 3 – 0,2239(4) 2 – 0,6084(4) + 30,0915 = 25,47
Дополнительные ресурсы
Как выполнить полиномиальную регрессию в Excel
Как выполнить квадратичную регрессию в Excel
Как добавить квадратную линию тренда в Excel
|
Уважаемые сопланетники! Столкнулся с проблемой, прошу помочь. Для аппроксимации передаточной характеристики измерительных приборов часто используют полином. С точки зрения электроники — это очень удобный способ, требующий от МК относительно мало ресурсов и предоставляющий очень хорошую точность. Для получения коэффициентов однофакторного полинома я традиционно использовал встроенную в Excel функцию ЛИНЕЙН. Однако в имеющейся в данный момент задаче выяснилось, что погрешность аппроксимации этим способом очень высока, — значительно выше, чем при использовании математических пакетов или линии тренда графика в Excel. Предположив, что проблема в некорректном использовании функции ЛИНЕЙН, перешерстил интернет, пробовал сторонние файлы. Оказалось, проблема известная, и связана она с алгоритмом работы этой функции (подробности я не понял, в математике не очень). Я взял одну и ту же выборку и сравнил четыре способа получения коэффициентов:
первый способ (ЛИНЕЙН) даёт примерно в 1,5…2 раза бОльшую погрешность, чем другие . и ЛИНЕЙН , и Agraph дают погрешность в 4 раза больше , чем два последних . Хотелось бы все действия максимально автоматизировать и привязать к Excel. Возможно, можно как-то исхитриться и заставить ЛИНЕЙН работать по другому? p.s. Движок запрещает грузить файлы свыше 100к, поэтому нарезал скринов. |
|






|
МатросНаЗебре Пользователь Сообщений: 5516 |
#2 03.12.2021 14:29:35 Коэффициенты можно найти формулами:
И через VBA.
Изменено: МатросНаЗебре — 03.12.2021 15:02:39 |
||||
|
tutochkin  Пользователь Сообщений: 559 |
#3 03.12.2021 14:47:41
Да, есть. тут выкладывал решение
Однако обратите внимание, что далеко не всегда коэфф-ты вытаскиваются верно. Я в практике с таким не сталкивался, но такое имеет место быть Тут выкладывали проблему. Поэтому в своих расчётах применяю кусочную интерполяцию… Изменено: tutochkin — 03.12.2021 15:02:10 |
||||
|
Алексей Назаров  Пользователь Сообщений: 24 |
#4 07.12.2021 11:23:02 Благодарю за подсказки, пробую использовать. На VBA не писал очень давно, попал в ступор. Пытаюсь например, так, получаю ошибку:
Чувствую, не учёл какую-то мелочь, а сообразить не могу.. |
||
|
tutochkin Пользователь Сообщений: 559 |
#5 07.12.2021 13:06:23 Алексей Назаров,
Изменено: tutochkin — 07.12.2021 13:07:24 |
||
|
Цель — получить коэффициенты аппроксимирующего полинома 5-6 порядка по исходной выборке, находящейся в книге Excel. Почему именно Excel — в ней я собираю данные с измерительных приборов (с помощью VBA), управляю внешними устройствами (с помощью VBA же), обрабатываю полученные данные и т.п., и любой прыжок в сторону превращается в неудобный костыль… И при экспериментах часто вариантов данных очень много, каждый нужно обработать, проверить и т.п. Изменено: Алексей Назаров — 08.12.2021 10:17:38 |
|
|
tutochkin Пользователь Сообщений: 559 |
#7 07.12.2021 13:54:31 Алексей Назаров, ну вытащить коэфф-ты из того что я выше привёл совсем не сложно — они там уже есть (матрица с). Однако они не будет отличаться от =ИНДЕКС(ЛИНЕЙН(F4:F13;E4:E13^{1;2;3;4;5;6});1;1) , проверено
Понятие точности относительно. Вот на рисунке несколько видов интерполяции через одни и те-же опорные точки…. А какая разница в промежутках
Изменено: tutochkin — 07.12.2021 14:16:00 |
||||


|
Алексей Назаров Пользователь Сообщений: 24 |
#8 07.12.2021 13:58:25 Ага, уже что-то получается! На команду
Получаю результат: 4,7737E-38 * X ^ 6 -5,455E-30 * X ^ 5 + 2,1638E-22 * X ^ 4 -3,0827E-15 * X ^ 3 + 0 * X ^ 2 + 0 * X ^ 1 + 5512600 Осталось «раздербанить» строку на составляющие, но есть одно большое НО: в результате всего 5 значащих цифр….. Кроме того, значения коэффициентов отличаются… Теоретически, как здесь: |
||

|
tutochkin Пользователь Сообщений: 559 |
#9 07.12.2021 15:01:02
Так этот макрос и выводит полную формулу… Там же написано — «‘ Программа формирования текста уравнения по всем точкам»
Так это в макросе и прописано… Format(Application.Index(WorksheetFunction.LinEst(yn, xn, True, True), 1, k), «0.####E+») увеличивайте, или вообще удалите.
=ИНДЕКС(Koef($D$5:$D$12;$E$5:$E$12;6);1;G5) — вывод элементов
Да, это известная проблема при больших Х. Изменено: tutochkin — 07.12.2021 15:17:32 |
||||||||||||

|
Алексей Назаров Пользователь Сообщений: 24 |
#10 08.12.2021 09:48:48
Какой инженер читает инструкции? )))
Да, благодарю, разрядность получил.
Сейчас попробую
К сожалению…. В самом первом сообщении в этой ветке я постарался подробно расписать, почему именно меня не удовлетворяют коэффициенты, полученные функцией ЛИНЕЙН. И цель этой ветки была следующей: Спасибо за помощь, буду пробовать дальше. tutochkin , два последних фрагмента кода — это что? Дают ли они коэффициенты, отличные от ЛИНЕЙН, или то же самое? |
||||||||
|
Алексей Назаров Пользователь Сообщений: 24 |
#11 08.12.2021 09:52:34
Боюсь, большие Х здесь не главная причина.
Вы привели пример интерполяции, у меня — аппроксимация, причём количество точек не просто превышает порядок полинома, оно составляет от нескольких десятков до нескольких тысяч. В измерительных устройствах является стандартом де-факто использование именно полиномиальной аппроксимации. Фактически, этот способ полностью и меня удовлетворяет, остался один нюанс — нужно выработать инструмент для удобного расчёта адекватных коэффициентов. )) P.S. Сейчас попробую разобраться в примерах МатросНаЗебре , может, здесь что получится. |
||||
|
tutochkin Пользователь Сообщений: 559 |
#12 08.12.2021 11:09:11
так я про это и писал:
а куда 4…20мА дели ?
Вот это зря. |
||||||||
|
Алексей Назаров Пользователь Сообщений: 24 |
#13 08.12.2021 12:06:10
4..20 кануло в лету.
Виноват, исправлюсь! ))) Сейчас разбираюсь со свойством .DataLabel.Text, пытаюсь корректно выдернуть из него данные. |
||||
|
tutochkin Пользователь Сообщений: 559 |
#14 08.12.2021 13:03:54
Да вот не правда. 99% КИПиА на новых станциях на нём. Все метраны ДД ДИ (да и Метран-280, Метран-2700) на 4-20 с харт протоколом. Сименс аналогично. А вот потом уже идёт преобразование хоть по среднемедианному хоть по среднеарефметическому. Но это не суть. Для моих работ выковыривание из лэйблов никуда не годится, посему не рассматривалось. |
||
|
Алексей Назаров Пользователь Сообщений: 24 |
#15 08.12.2021 13:20:40
Вот именно, что с HART протоколом, т.е. от 4-20 осталось, фактически, только питание и характеристики физического уровня передачи данных.
Это не преобразование, это усреднение/фильтрация, её делают, в зависимости от конкретного применения.
Для моих годится всё, что НОРМАЛЬНО РАБОТАЕТ. Сейчас разбираюсь с .DataLabel.Text, данные получить удаётся, но либо при пошаговом выполнении кода, либо, если в тексте есть ошибка, вызывающая остановку компилятора. После пропуска ошибки данные и появляются. (((
|
||||||||
|
tutochkin Пользователь Сообщений: 559 |
#16 08.12.2021 13:26:21
Ну во первых вы так и не показали как считаете погрешность. Во вторых — интерполируйте кусочным способом и получите в узлах 0-ю погрешность. |
||
|
Алексей Назаров Пользователь Сообщений: 24 |
#17 08.12.2021 14:29:14
Под погрешностью аппроксимации я имею в виду максимальную разницу между любой точкой экспериментальных данных и соответствующей точкой, вычисленной по полиному, построенному по этим данным. В том числе и между узлами. Например, для проверки качества полинома можем сделать 1000 измерений, по 100 точкам (каждой 10-й) построить полином, а погрешность проверить по всем 1000 точкам. И между узлами погрешность не менее важна, чем в узлах! Кусочно-линейную пробовали, но при разумном количестве точек (не более нескольких десятков) погрешность аппроксимации наших данных превышает 0,03%, а нужно не более 0,01%. |
||
|
tutochkin Пользователь Сообщений: 559 |
#18 08.12.2021 14:45:35
При кусочной интерполяции в узловых точках погрешность нулевая. Точно так же как и при интерполяцией сплайном. Между узлов зависит от типа функции интерполяции и граничных условий. Рисунки приводил выше.
Т.е. вы с помощью аппроксимации фильтруете точки и говорите о погрешности аппроксимации? Серьёзно? Не пробовали в начале хотя бы по медианному фильтру откинуть шумы? |
||||
|
Алексей Назаров Пользователь Сообщений: 24 |
#19 08.12.2021 15:46:31
Мне не важна погрешность в узловых точках, важна В ЛЮБОЙ точке в заданном интервале. И этого КЛ не обеспечивает.
Не фильтрую, Вы не так поняли (или я неясно объяснил), но при исследовании иногда это использую.
Тут согласен, полноценные (даже сильно урезанные) файлы в лимит не влазят, а кидать на файлообменники не с руки было. |
||||||
|
tutochkin Пользователь Сообщений: 559 |
#20 08.12.2021 17:09:14
А Вы?
Чушь. Говорю как человек почти 20 лет занимающийся экспериментами на энергетическом оборудовании. Включая проведение гарантийных испытаний турбин Siemens и GE. Хорошим является только верный метод. А остальное называется подгон под условия. |
||||
|
Алексей Назаров Пользователь Сообщений: 24 |
#21 09.12.2021 08:48:06
Вы читаете через строчку. аппроксимации (а не о полной погрешности измерений), и везде старался это подчёркивать. Во-вторых, даже если говорить о полной погрешности, то параметры определяются на готовом изделии по эталонному прибору. На любой промежуточной точке , включая рекомендованные ГОСТами для данных СИ.
На первом графике числа по оси Y обрезаны, извините, недоглядел. Шум +-2…3 емзр от полного значения 30000…150000 это примерно 0,01…0,0015% от измеренного значения. т.е. не более 0,002%FS, это немного ниже, чем 50%? Кстати, и ошибка аппроксимации (по коэффициентам Октавы и линии тренда) в данном случае максимальная около 1,9ЕМЗР, т.е. находится на уровне шумов эталонного прибора. Думаю, при использовании более высокоточного СИ и погрешность аппроксимации будет ниже.
Вот именно, Вы занимаетесь метрологией, а я нормативными актами и МИ не особо ограничен, я больше исследователь-разработчик. В любом случае спасибо Вам за помощь, что помогли разобраться. Хоть этот метод нам и не подошёл, но отрицательный результат — тоже результат! P.S. Добавил файлы с выборками. Прикрепленные файлы
Изменено: Алексей Назаров — 09.12.2021 08:57:15 |
||||||
|
О, вроде получилось загрузить файл на 260 кБ, а ранее выше 100 не получалось. |
|
|
МатросНаЗебре Пользователь Сообщений: 5516 |
#23 09.12.2021 10:21:46 Вариант, возвращающий коэффициенты полинома.
|
||
|
tutochkin Пользователь Сообщений: 559 |
#24 09.12.2021 10:34:37
Я так и не увидел как Вы её считаете. Судя по приложенному файлу — контроль отклонений в заданных точках.
Это Вы про меня? Серьёзно?
Я не занимаюсь метрологией. Но моя работа требует знаний по средствам измерений, как раз из-за того что некоторые делают на глаз, а потом баланс расходов не сходится. |
||||||

|
alenco Пользователь Сообщений: 24 |
#25 09.12.2021 10:57:53 МатросНаЗебре, большое спасибо за (почти) правильно работающий код! У меня вылезает ошибка 9 (Subscript out of range) на строке
После замены формата числа на экспоненциальный
ошибка пропала, но и признаки работы ограничились перерисовкой экрана… Попробовал тормознуть код перед
И… вуаля! Осталась мелочь — обойтись без остановки кода. Такая проблема обсуждалась, например, здесь , здесь , попадалось и на других форумах, но панацеи никто не знает. Изменено: alenco — 09.12.2021 11:00:48 |
||||||
|
tutochkin Пользователь Сообщений: 559 |
#26 09.12.2021 11:13:56
И Вас ничего не смущает? |
||

|
alenco Пользователь Сообщений: 24 |
#27 09.12.2021 11:23:50
Судя по скрину, всё увидели и даже для своего варианта посчитали?
Не знаю, с функцией kus_interp я не знаком. Я когда-то пробовал КЛ на своих выборках, при небольшом количестве опорных точек (по моему, 10 или 20, уже не помню) она дала приличную погрешность. Дальше не заморачивался, остановился полностью на полиномах, по образцу предприятий, с кем мы работаем. Изменено: alenco — 09.12.2021 11:24:26 |
||||
|
alenco Пользователь Сообщений: 24 |
#28 09.12.2021 11:27:14
Кроме малого количества значащих цифр на вашем скрине — ничего. Если Вы про необходимость остановки кода — я верю, что эта проблема будет решена. Изменено: alenco — 09.12.2021 11:31:18 |
||
|
tutochkin Пользователь Сообщений: 559 |
#29 09.12.2021 12:01:05
Читайте не через строчку — давал вариант. Урезанный правда, только с линейным вариантом, но давал.
У как всё запущено… А ещё на глаз погрешности определяете. А зачем сменили Имя-фамилию на ник? |
||||

|
МатросНаЗебре Пользователь Сообщений: 5516 |
#30 09.12.2021 13:20:31 Вариант, вычисляющий коэффициенты через решение системы линейных уравнений. Точность хуже, чем у метода, через уравнение из линии тренда. Вероятно, точность теряется при работе с длинными числами.
Изменено: МатросНаЗебре — 09.12.2021 14:35:22 |
||