
Поиск последнего вхождения (инвертированный ВПР)
Все классические функции поиска и подстановки типа ВПР (VLOOKUP), ГПР (HLOOKUP), ПОИСКПОЗ (MATCH) и им подобные имеют одну важную особенность — они ищут от начала к концу, т.е. слева-направо или сверху-вниз по исходным данным. Как только находится первое подходящее совпадение — поиск останавливается и найденным оказывается только первое вхождение нужного нам элемента.
Что же делать, если нам требуется найти не первое, а последнее вхождение? Например, последнюю сделку по клиенту, последний платёж, самую свежую заявку и т.д.?
Способ 1. Поиск последней строки формулой массива
Если в исходной таблице нет столбца с датой или порядковым номером строки (заказа, платежа…), то наша задача сводится, по сути, к поиску последней строки, удовлетворяющей заданному условию. Реализовать подобное можно вот такой формулой массива:

Здесь:
- Функция ЕСЛИ (IF) проверяет по очереди все ячейки в столбце Клиент и выводит номер строки, если в ней лежит нужное нам имя. Номер строки на листе нам даёт функция СТРОКА (ROW), но поскольку нам нужен номер строки в таблице, то дополнительно приходится вычитать 1, т.к. у нас в таблице есть шапка.
- Затем функция МАКС (MAX) выбирает из сформированного набора номеров строк максимальное значение, т.е. номер самой последней строки клиента.
- Функция ИНДЕКС (INDEX) выдаёт содержимое ячейки с найденным последним номером из любого другого требуемого столбца таблицы (Код заказа).
Всё это нужно вводить как формулу массива, т.е.:
- В Office 365 с последними установленными обновлениями и поддержкой динамических массивов — можно просто жать Enter.
- Во всех остальных версиях после ввода формулы придется нажимать сочетание клавиш Ctrl+Shift+Enter, что автоматически добавит к ней фигурные скобки в строке формул.
Способ 2. Обратный поиск новой функцией ПРОСМОТРХ
Я уже писал большую статью с видео про новую функцию ПРОСМОТРХ (XLOOKUP), которая появилась в последних версиях Office на замену старушке ВПР (VLOOKUP). При помощи ПРОСМОТРХ наша задача решается совершенно элементарно, т.к. для этой функции (в отличие от ВПР) можно явно задавать направление поиска: сверху-вниз или снизу-вверх — за это отвечает её последний аргумент (-1):

Способ 3. Поиск строки с последней датой
Если в исходных данных у нас есть столбец с порядковым номером или датой, играющей аналогичную роль, то задача видоизменяется — нам требуется найти уже не последнюю (самую нижнюю) строку с совпадением, а строку с самой поздней (максимальной) датой.
Как это сделать с помощью классических функций я уже подробно разбирал, а теперь давайте попробуем использовать мощь новых функций динамических массивов. Исходную таблицу для пущей красоты и удобства тоже заранее преобразуем в «умную» с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table).
С их помощью этой «убойной парочки» наша задача решается весьма изящно:

Здесь:
- Сначала функция ФИЛЬТР (FILTER) отбирает только те строки из нашей таблицы, где в столбце Клиент — нужное нам имя.
- Потом функция СОРТ (SORT) сортирует отобранные строки по убыванию даты, чтобы самая последняя сделка оказалась сверху.
- Функция ИНДЕКС (INDEX) извлекает первую строку, т.е. выдает нужную нам последнюю сделку.
- И, наконец, внешняя функция ФИЛЬТР убирает из результатов лишние 1-й и 3-й столбцы (Код заказа и Клиент) и оставляет только дату и сумму. Для этого используется массив констант {0;1;0;1}, определяющий какие именно столбцы мы хотим (1) или не хотим (0) выводить.
Способ 4. Поиск последнего совпадения в Power Query
Ну, и для полноты картины, давайте рассмотрим вариант решения нашей задачи обратного поиска с помощью надстройки Power Query. С её помощью всё решается очень быстро и красиво.
1. Преобразуем нашу исходную таблицу в «умную» с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table).
2. Загружаем её в Power Query кнопкой Из таблицы/диапазона на вкладке Данные (Data — From Table/Range).
3. Сортируем (через выпадающий список фильтра в шапке) нашу таблицу по убыванию даты, чтобы самые последние сделки оказались сверху.
4. На вкладке Преобразование выбираем команду Группировать по (Transform — Group By) и задаем группировку по клиентам, а в качестве агрегирующей функции выбираем вариант Все строки (All rows). Назвать новый столбец можно как угодно — например Подробности.

После группировки получим список уникальных имен наших клиентов и в столбце Подробности — таблицы со всеми сделками каждого из них, где первой строкой будет идти самая последняя сделка, которая нам и нужна:

5. Добавляем новый вычисляемый столбец кнопкой Настраиваемый столбец на вкладке Добавить столбец (Add column — Add custom column) и вводим следующую формулу:

Здесь Подробности — это столбец, откуда мы берем таблицы по клиентам, а {0} — это номер строки, которую мы хотим извлечь (нумерация строк в Power Query начинается с нуля). Получаем столбец с записями (Record), где каждая запись — первая строка из каждой таблицы:

Осталось развернуть содержимое всех записей кнопкой с двойными стрелками в шапке столбца Последняя сделка, выбрав нужные столбцы:

… и удалить потом ненужный более столбец Подробности щёлкнув по его заголовку правой кнопкой мыши — Удалить столбцы (Remove columns).
После выгрузки результатов на лист через Главная — Закрыть и загрузить — Закрыть и загрузить в (Home — Close & Load — Close & Load to…) получим вот такую симпатичную таблицу со списком последних сделок, как и хотели:

При изменении исходных данных результаты нужно не забыть обновить, щёлкнув по ним правой кнопкой мыши — команда Обновить (Refresh) или сочетанием клавиш Ctrl+Alt+F5.
Ссылки по теме
- Функция ПРОСМОТРХ — наследник ВПР
- Как использовать новые функции динамических массивов СОРТ, ФИЛЬТР и УНИК
- Поиск последней непустой ячейки в строке или столбце функцией ПРОСМОТР
На чтение 7 мин. Просмотров 30k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Есть лог звонков, по нему в excel делаю табличку со статистикой звонков, с какого номера, сколько исходящих звонков и хотел добавить во сколько был первый звонок, во сколько последний.
В excel знания поверхностные, да и не только в нём, выручает google, быстро нашёл решение для первого звонка и быстро применил его
=ИНДЕКС(PBX!F:F;ПОИСКПОЗ(B6;PBX!C:C;0))
всё проще простого, ПОИСКПОЗ ищет номер телефона B6 в столбце PBX!C:C с точным совпадением 0, получается в итоге номер строки, где первый раз встречается этот номер телефона и с помощью ИНДЕКС, получаю время из столбца PBX!F:F и найденной строки.
=ИНДЕКС(PBX!F:F;ПОИСКПОЗ(2;1/(PBX!C:C=B6)))
а это решение из google для второй задачи, найти время последнего звонка, я тоже быстро применил его и это работает, но я не могу понять, как это работает.
Вместо аргумента по которому производится поиск здесь «2», почему два, зачем два, непонятно, а диапазон где искать задаётся с помощью 1/(PBX!C:C=B6), что тоже мне непонятно.
Может мне кто нибудь популярно, на пальцах объяснить, как работает эта формула =ИНДЕКС(PBX!F:F;ПОИСКПОЗ(2;1/(PBX!C:C=B6)))?
-
Вопрос заданболее трёх лет назад
-
3956 просмотров
Skip to content
В статье предлагается несколько различных формул для выполнения поиска в двумерном массиве значений Excel. Просмотрите эти варианты и выберите наиболее для вас подходящий.
При поиске данных в электронных таблицах Excel чаще всего вы будете искать вертикально в столбцах или горизонтально в строках. Но иногда вам нужно просматривать сразу два условия – как строки, так и столбцы. Другими словами, вы стремитесь найти значение на пересечении определенной строки и столбца. Это называется матричным поиском (также известным как двумерный или поиск в диапазоне). Далее показано, как это можно сделать различными способами.
- Поиск в массиве при помощи ИНДЕКС ПОИСКПОЗ
- Формула ВПР и ПОИСКПОЗ для поиска в диапазоне
- Функция ПРОСМОТРX для поиска в строках и столбцах
- Формула СУММПРОИЗВ для поиска по строке и столбцу
- Поиск в матрице с именованными диапазонами
Поиск в массиве при помощи ИНДЕКС ПОИСКПОЗ
Самый популярный способ выполнить двусторонний поиск в Excel — использовать комбинацию ИНДЕКС с двумя ПОИСКПОЗ. Это разновидность классической формулы ПОИСКПОЗ ИНДЕКС , к которой вы добавляете еще одну функцию ПОИСКПОЗ, чтобы получить номера строк и столбцов:
ИНДЕКС( массив_данных ; ПОИСКПОЗ( значение_вертикальное ; диапазон_поиска_столбец ; 0), ПОИСКПОЗ( значение_горизонтальное ; диапазон_поиска_строка ; 0))
В этом способе, как и во всех остальных, мы используем поиск по двум условиям. Первое из них должно обнаружить совпадение в определенном столбце (в заголовках строк), а второе – в определенной строке (то есть, в заголовках столбцов). В результате мы имеем строку и столбец, которые соответствуют заданным условиям. А на пересечении их как раз и будут находиться искомые данные.
В качестве примера составим формулу для получения количества проданного товара за определённый период времени из таблицы, которую вы можете видеть ниже. Для начала определим все аргументы:
- Массив_данных — B2:E11 (ячейки данных, не включая заголовки строк и столбцов)
- Значение_вертикальное — H1 (целевой товар)
- Диапазон_поиска_столбец – A2:A11 (заголовки строк: названия напитков)
- Значение_горизонтальное — H2 (целевой период)
- Диапазон_поиска_строка — B1:E1 (заголовки столбцов: временные периоды)
Соедините все аргументы вместе, и вы получите следующую формулу для поиска числа в диапазоне:
=ИНДЕКС(B2:E11; ПОИСКПОЗ(H1;A2:A11;0); ПОИСКПОЗ(H2;B1:E1;0))

Как работает эта формула?
Хотя на первый взгляд это может показаться немного сложным, логика здесь простая. Функция ИНДЕКС извлекает значение из массива данных на основе номеров строк и столбцов, а две функции ПОИСКПОЗ предоставляют ей эти номера:
ИНДЕКС( B2:E11; номер_строки ; номер_столбца )
Здесь мы используем способность ПОИСКПОЗ возвращать относительную позицию значения в искомом массиве .
Итак, чтобы получить номер строки, мы ищем нужный нам товар (H1) в заголовках строк (A2:A11):
ПОИСКПОЗ(H1;A2:A11;0)
Чтобы получить номер столбца, мы ищем нужную нам неделю (H2) в заголовках столбцов (B1:E1):
ПОИСКПОЗ(H2;B1:E1;0)
В обоих случаях мы ищем точное совпадение, присваивая третьему аргументу значение 0.
В этом примере первое ПОИСКПОЗ возвращает 2, потому что нужный товар (Sprite) находится в ячейке A3, которая является второй по счёту в диапазоне A2:A11. Второй ПОИСКПОЗ возвращает 3, так как «Неделя 3» находится в ячейке D1, которая является третьей ячейкой в B1:E1.
С учетом вышеизложенного формула сводится к:
ИНДЕКС(B2:E11; 2 ; 3 )
Она возвращает число на пересечении второй строки и третьего столбца в матрице B2:E4, то есть в ячейке D3.
Думаю, вы понимаете, что аналогичным образом можно производить поиск в двумерном массиве Excel не только числа, но и текста. Тип данных здесь не имеет значения.
Формула ВПР и ПОИСКПОЗ для поиска в диапазоне
Другой способ выполнить матричный поиск в Excel — использовать комбинацию функций ВПР и ПОИСКПОЗ:
ВПР( значение_вертикальное ; массив_данных ; ПОИСКПОЗ( значение_горизонтальное , диапазон_поиска_строка , 0), ЛОЖЬ)
Для нашего образца таблицы формула принимает следующий вид:
=ВПР(H1; A2:E11; ПОИСКПОЗ(H2;A1:E1;0); ЛОЖЬ)
Где:
- Массив_данных — B2:E11 (ячейки данных, не включая заголовки строк и столбцов)
- Значение_вертикальное — H1 (целевой товар)
- Значение_горизонтальное — H2 (целевой период)
- Диапазон_поиска_строка — А1:E1 (заголовки столбцов: временные периоды)

Основой формулы является функция ВПР, настроенная на точное совпадение (последний аргумент имеет значение ЛОЖЬ). Она ищет заданное значение (H1) в первом столбце массива (A2:E11) и возвращает данные из другого столбца в той же строке. Чтобы определить, из какого столбца вернуть значение, вы используете функцию ПОИСКПОЗ, которая также настроена на точное совпадение (последний аргумент равен 0):
ПОИСКПОЗ(H2;A1:E1;0)
ПОИСКПОЗ ищет текст из H2 в заголовках столбцов (A1:E1) и указывает относительное положение найденной ячейки. В нашем случае нужная неделя (3-я) находится в D1, которая является четвертой по счету в массиве поиска. Итак, число 4 идет в аргумент номер_столбца функции ВПР:
=ВПР(H1; A2:E11; 4; ЛОЖЬ)
Далее ВПР находит точное совпадение H1 со значением в A3 и возвращает значение из 4-го столбца в той же строке, то есть из ячейки D3.
Важное замечание! Чтобы формула работала корректно, диапазон_поиска (A2:E11) функции ВПР и диапазон_поиска (A1:E1) функции ПОИСКПОЗ должны иметь одинаковое количество столбцов. Иначе число, переданное в номер_столбца, будет неправильным (не будет соответствовать положению столбца в массиве данных).
Функция ПРОСМОТРX для поиска в строках и столбцах
Недавно Microsoft представила еще одну функцию в Excel, которая призвана заменить все существующие функции поиска, такие как ВПР, ГПР и ИНДЕКС+ПОИСКПОЗ. Помимо прочего, ПРОСМОТРX может смотреть на пересечение определенной строки и столбца:
ПРОСМОТРX( значение_вертикальное ; диапазон_поиска_столбец ; ПРОСМОТРX( значение_горизонтальное ; диапазон_поиска_строка ; массив_данных ))
Для нашего примера набора данных формула выглядит следующим образом:
=ПРОСМОТРX(H1; A2:A11; ПРОСМОТРX(H2; B1:E1; B2:E11))

Примечание. В настоящее время ПРОСМОТРX — это функция, доступная только подписчикам Office 365 и более поздних версий.
В формуле используется функция ПРОСМОТРX для возврата всей строки или столбца. Внутренняя функция ищет целевой период времени в строке заголовка и возвращает все значения для этой недели (в данном примере для 3-й). Эти значения переходят в аргумент возвращаемый_массив внешнего ПРОСМОТРX:
=ПРОСМОТРX(H1; A2:A11; {544:87:488:102:87:433:126:132:111:565})
Внешняя функция ПРОСМОТРX ищет нужный товар в заголовках столбцов и извлекает значение из той же позиции из возвращаемого_массива.
Формула СУММПРОИЗВ для поиска по строке и столбцу
Функция СУММПРОИЗВ чрезвычайно универсальна — она может делать множество вещей, выходящих за рамки ее предназначения, особенно когда речь идет об оценке нескольких условий.
Чтобы найти значение на пересечении определенных строки и столбца, используйте эту общую формулу:
СУММПРОИЗВ ( диапазон_поиска_столбец = значение_вертикальное ) * ( диапазон_поиска_строка = значение_горизонтальное), массив_данных )
Чтобы выполнить поиск данных в массиве по строке и столбцу в нашем наборе данных, формула выглядит следующим образом:
=СУММПРОИЗВ((A2:A11=H1)*(B1:E1=H2); B2:E11)
Приведенный ниже вариант также будет работать:
=СУММПРОИЗВ((A2:A11=H1)*(B1:E1=H2)*B2:E11)

Теперь поясним подробнее. В начале мы сравниваем два значения поиска с заголовками строк и столбцов (целевой товар в H1 со всеми наименованиями в A2: A11 и целевой период времени в H2 со всеми неделями в B1: E1):
(A2:A11=H1)*(B1:E1=H2)
Это дает нам два массива значений ИСТИНА и ЛОЖЬ, где ИСТИНА означает совпадения:
{ЛОЖЬ:ИСТИНА:ЛОЖЬ:ЛОЖЬ:ЛОЖЬ:ЛОЖЬ:ЛОЖЬ:ЛОЖЬ:ЛОЖЬ:ЛОЖЬ}) * ({ЛОЖЬ;ЛОЖЬ;ИСТИНА;ЛОЖЬ}
Операция умножения преобразует значения ИСТИНА и ЛОЖЬ в 1 и 0 и создает матрицу из 4 столбцов и 10 строк (строки разделяются двоеточием, а каждый столбец данных — точкой с запятой):
{0;0;0;0:0;0;1;0:0;0;0;0:0;0;0;0:0;0;0;0:0;0;0;0:0;0;0;0:0;0;0;0:0;0;0;0:0;0;0;0}
Функция СУММПРОИЗВ умножает элементы приведенного выше массива на элементы B2:E4, находящихся в тех же позициях:
{0;0;0;0:0;0;1;0:0;0;0;0:0;0;0;0:0;0;0;0:0;0;0;0:0;0; 0;0:0;0;0;0:0;0;0;0:0;0;0;0} * {455;345;544;366:65;77;87;56:766; 655;488;865:129;66;102;56:89;141;87;89:566;511;433;522:154; 144;126; 162:158;165;132;155:112;143;111; 125:677;466;565;766})
И поскольку умножение на ноль дает в результате ноль, остается только элемент, соответствующий 1 в первом массиве:
=СУММПРОИЗВ({0;0;0;0:0;0;87;0:0;0;0;0:0;0;0;0:0;0;0;0:0; 0;0;0:0;0;0;0:0;0;0;0:0;0;0;0:0;0;0;0})
Наконец, СУММПРОИЗВ складывает все элементы результирующего массива и возвращает значение 87.
Примечание . Если в вашей таблице несколько заголовков строк и/или столбцов с одинаковыми именами, итоговый массив будет содержать более одного числа, отличного от нуля. И все эти числа будут суммированы. В результате вы получите сумму значений, удовлетворяющую обоим критериям. Это то, что отличает формулу СУММПРОИЗВ от ПОИСКПОЗ и ВПР, которые возвращают только первое найденное совпадение.
Поиск в матрице с именованными диапазонами
Еще один достаточно простой способ поиска в массиве в Excel — использование именованных диапазонов. Рассмотрим пошагово:
Шаг 1. Назовите столбцы и строки
Самый быстрый способ назвать каждую строку и каждый столбец в вашей таблице:
- Выделите всю таблицу (в нашем случае A1:E11).
- На вкладке « Формулы » в группе « Определенные имена » щелкните « Создать из выделенного » или нажмите комбинацию клавиш Ctrl + Shift + F3.
- В диалоговом окне « Создание имени из выделенного » выберите « в строке выше » и « в столбце слева» и нажмите «ОК».

Это автоматически создает имена на основе заголовков строк и столбцов. Однако есть пара предостережений:
- Если ваши заголовки столбцов и/или строк являются числами или содержат определенные символы, которые не разрешены в именах Excel, то имена для таких столбцов и строк не будут созданы. Чтобы просмотреть список созданных имен, откройте Диспетчер имен (
Ctrl + F3). Если некоторые имена отсутствуют, определите их вручную. - Если некоторые из ваших заголовков строк или столбцов содержат пробелы, то они будут заменены символами подчеркивания, например, Неделя_1.
Шаг 2. Создание формулы поиска по матрице
Чтобы получить значение из матрицы на пересечении определенной строки и столбца, просто введите одну из следующих общих формул в пустую ячейку:
=имя_строки имя_столбца
Или наоборот:
=имя_столбца имя_строки
Например, чтобы получить продажу Sprite в 3-й неделе, используйте выражение:
=Sprite неделя_3
То есть, имена диапазонов здесь разделены пробелом, который в данном случае является оператором пересечения массивов.
Если кому-то нужны более подробные инструкции, опишем весь процесс пошагово:
- В ячейке, в которой вы хотите отобразить результат, введите знак равенства (=).
- Начните вводить имя целевой строки, Sprite. После того, как вы введете пару символов, Excel отобразит все существующие имена, соответствующие вашему вводу. Дважды щелкните нужное имя, чтобы ввести его в формулу.
- После имени строки введите пробел , который в данном случае работает как оператор пересечения.
- Введите имя целевого столбца ( в нашем случае неделя_3 ).
- Как только будут введены имена строки и столбца, Excel выделит соответствующую строку и столбец в вашей таблице, и вы нажмете Enter, чтобы завершить ввод:

Ваш поиск нужной ячейки в массиве выполнен, найден результат 87.
Вот какими способами можно выполнять поиск в массиве значений – в строках и столбцах таблицы Excel. Я благодарю вас за чтение и надеюсь еще увидеть вас в нашем блоге.
Еще несколько материалов по теме:
 Поиск ВПР нескольких значений по нескольким условиям — В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке. При использовании Microsoft… Поиск ИНДЕКС ПОИСКПОЗ по нескольким условиям — В статье показано, как выполнять быстрый поиск с несколькими условиями в Excel с помощью ИНДЕКС и ПОИСКПОЗ. Хотя Microsoft Excel предоставляет специальные функции для вертикального и горизонтального поиска, опытные пользователи… ИНДЕКС ПОИСКПОЗ как лучшая альтернатива ВПР — В этом руководстве показано, как использовать ИНДЕКС и ПОИСКПОЗ в Excel и чем они лучше ВПР. В нескольких недавних статьях мы приложили немало усилий, чтобы объяснить основы функции ВПР новичкам и предоставить…
Поиск ВПР нескольких значений по нескольким условиям — В статье показаны способы поиска (ВПР) нескольких значений в Excel на основе одного или нескольких условий и возврата нескольких результатов в столбце, строке или в отдельной ячейке. При использовании Microsoft… Поиск ИНДЕКС ПОИСКПОЗ по нескольким условиям — В статье показано, как выполнять быстрый поиск с несколькими условиями в Excel с помощью ИНДЕКС и ПОИСКПОЗ. Хотя Microsoft Excel предоставляет специальные функции для вертикального и горизонтального поиска, опытные пользователи… ИНДЕКС ПОИСКПОЗ как лучшая альтернатива ВПР — В этом руководстве показано, как использовать ИНДЕКС и ПОИСКПОЗ в Excel и чем они лучше ВПР. В нескольких недавних статьях мы приложили немало усилий, чтобы объяснить основы функции ВПР новичкам и предоставить…  Поиск в массиве при помощи ПОИСКПОЗ — В этой статье объясняется с примерами формул, как использовать функцию ПОИСКПОЗ в Excel. Также вы узнаете, как улучшить формулы поиска, создав динамическую формулу с функциями ВПР и ПОИСКПОЗ. В Microsoft…
Поиск в массиве при помощи ПОИСКПОЗ — В этой статье объясняется с примерами формул, как использовать функцию ПОИСКПОЗ в Excel. Также вы узнаете, как улучшить формулы поиска, создав динамическую формулу с функциями ВПР и ПОИСКПОЗ. В Microsoft…  Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…
Функция ИНДЕКС в Excel — 6 примеров использования — В этом руководстве вы найдете ряд примеров формул, демонстрирующих наиболее эффективное использование ИНДЕКС в Excel. Из всех функций Excel, возможности которых часто недооцениваются и используются недостаточно, ИНДЕКС определенно занимает место…  Функция СУММПРОИЗВ с примерами формул — В статье объясняются основные и расширенные способы использования функции СУММПРОИЗВ в Excel. Вы найдете ряд примеров формул для сравнения массивов, условного суммирования и подсчета ячеек по нескольким условиям, расчета средневзвешенного значения…
Функция СУММПРОИЗВ с примерами формул — В статье объясняются основные и расширенные способы использования функции СУММПРОИЗВ в Excel. Вы найдете ряд примеров формул для сравнения массивов, условного суммирования и подсчета ячеек по нескольким условиям, расчета средневзвешенного значения…  Средневзвешенное значение — формула в Excel — В этом руководстве демонстрируются два простых способа вычисления средневзвешенного значения в Excel — с помощью функции СУММ (SUM) или СУММПРОИЗВ (SUMPRODUCT в английском варианте). В одной из предыдущих статей мы…
Средневзвешенное значение — формула в Excel — В этом руководстве демонстрируются два простых способа вычисления средневзвешенного значения в Excel — с помощью функции СУММ (SUM) или СУММПРОИЗВ (SUMPRODUCT в английском варианте). В одной из предыдущих статей мы…
Рассмотрим таблицу продаж, состоящую из столбцов Дата продажи и Сумма. Т.к. в день может быть несколько продаж, то столбец с датами содержит повторы. Задав в качестве критерия поиска дату, найдем номер строки, в которой содержится дата и сумма последней продажи (т.е. последний повтор даты, указанной в критерии). Найдем сумму первой и последней продажи в этот день.
Пусть таблица продаж размещена в диапазоне
A7:B41
. Даты продажи отсортированы по возрастанию.
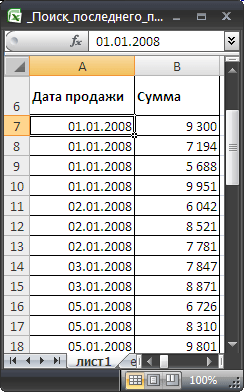
Задача
Определим Сумму первой и последней продажи в заданный день (см.
файл примера
)
Решение
Для удобства определим
Именованный диапазон
Весь_диапазон_Дат
как ссылку на диапазон
=лист1!$A$7:$A$41
Дату продажи (ячейка
D7
) будем выбирать с помощью
Выпадающего списка
.
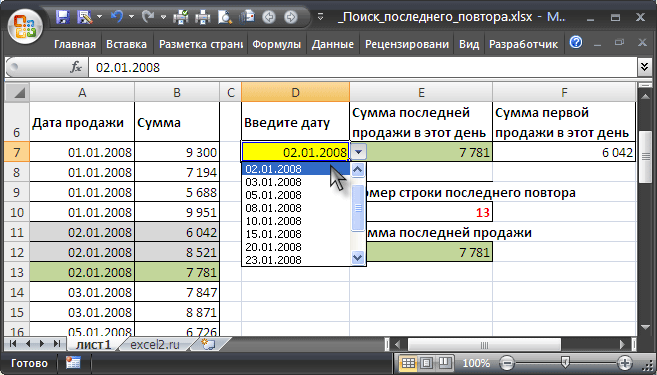
Это будет гарантировать, что в качестве критерия для поиска будут введены только даты из таблицы. Т.к. даты в таблице повторяются, а
Выпадающий список
не должен содержать повторы, то для источника строк
Выпадающего списка
сформируем в столбце
H
список
Уникальных значений
.
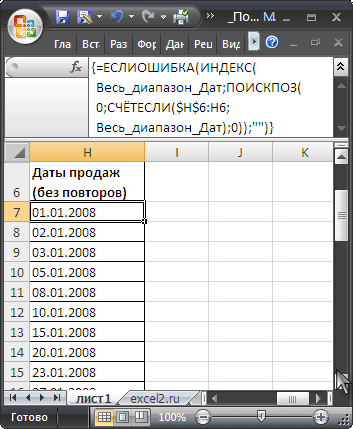
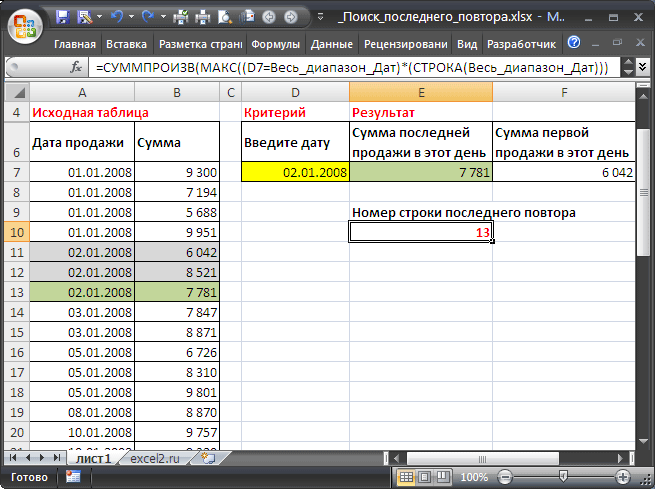
Сумму первой продажи найдем с помощью стандартной функции
ВПР()
с критерием ЛОЖЬ (точное совпадение) :
=ВПР(D7;A7:B41;2;ЛОЖЬ)
В случае повторяющихся значений функция
ВПР()
с критерием ЛОЖЬ возвращает первое (сверху) найденное значение, то что нам и требуется.
Сумму первой продажи найдем с помощью стандартной функции
ВПР()
с критерием ИСТИНА (приблизительное совпадение) :
=ВПР(D7;A7:B41;2;ИСТИНА)
В случае повторяющихся значений функция
ВПР()
с критерием ИСТИНА возвращает наибольшее найденное значение, которое меньше или равно, чем искомое значение. Т.к. перечень дат
сортирован
по возрастанию и искомое значение заведомо имеется в списке, то найденное значение как раз и будет последним повтором даты, указанной в качестве критерия.
В файле примера с помощью
Условного форматирования
серым фоном выделены строки, содержащие информацию о продажах в указанный день. Строка с последней продажей в этот день выделена зеленым фоном.
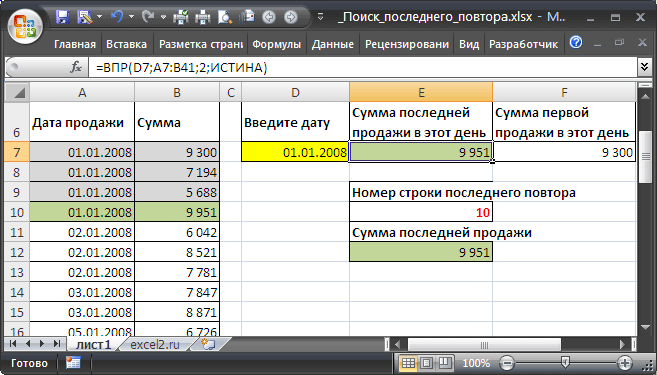
Альтернативное решение
Решить задачу можно также с помощью формулы, которая определит строку содержащую последний повтор (т.е. последнюю продажу в заданный день):
=СУММПРОИЗВ(МАКС((D7=Весь_диапазон_Дат)*(СТРОКА(Весь_диапазон_Дат))))
Формула разместим в ячейке
E10
. Этапы вычислений можно легко увидеть с помощью
клавиши
F9
(выделите в
Строке формул
,
например, выражение
D2=Весь_диапазон_Дат
, нажмите
F9
, вместо формулы отобразится ее результат).
А сумму последней продажи в заданный день можно найти с помощью функции
ИНДЕКС()
:
=ИНДЕКС(B7:B41;E10-СТРОКА(B6))