
Чтобы поисковые функции Excel: ВПР, ГПР и ПОИСКПОЗ выполняли точный поиск с точным совпадением искомого и проверяемого значения ячеек или возвращали ошибку, в последнем третьем их аргументе должно быть указано – ЛОЖЬ или 0. При этом независимо отсортирован ли просматриваемый список значений или нет.
Формула приблизительного поиска неточных совпадений в Excel
Поисковые функции Excel предназначенные для выборки значений из таблиц позволяют находить данные также если необходимо найти приблизительное значение. Но только в сортированных списках значений таблицы по возрастанию.
Ниже на рисунке проиллюстрировано метод расчета суммы налога. Таблица процентных ставок налога не содержит всевозможные варианты, а только некоторые определенные их границы пределов. Сначала необходимо определить, в котором диапазоне границ налоговой ставки будет находится зарплата того или иного сотрудника. А далее следует использовать полученную информацию из найденного наиболее близкого значения для налоговых расчетов:
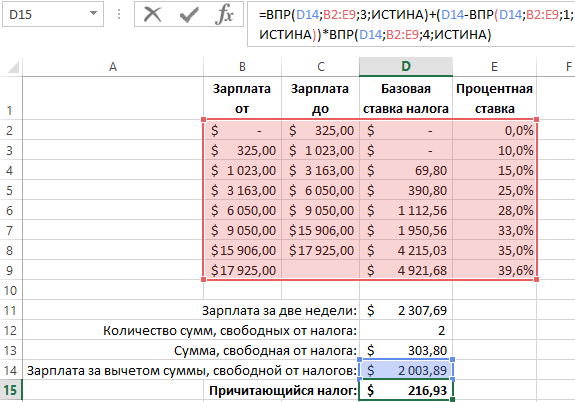
Формула использует три функции ВПР для считывания 3-х значений с таблицы. В последнем аргументе каждой функции находится логическое значение ИСТИНА. Это значит, что необходимо найти приблизительное значение, а необязательно точное совпадение.
Чтобы любая поисковая функция выборки в Excel: ВПР, ГПР либо ПОИСКПОЗ со значением ИСТИНА в третьем аргументе возвращала правильный результат вычисления, данные в просматриваемом столбце (в данном примере это диапазон ячеек B2:B9) должны быть отсортированы по возрастанию. Функция ВПР поочередно проверяет все значения и закончит поиск, если следующее значение будет больше чем искомое. После чего поиск прекращается. Вот почему нужно сортировать исходный диапазон по возрастанию. Таким способом найдено наибольшее значение, которое одновременно с тем меньше чем искомое.
Внимание! Поиск приблизительного соответствия значений с помощью поисковых функций Excel не предоставляют возможность находить максимально приближенное значение. Возвращается лишь только наибольшее число, которое является меньшим от искомого. Даже если очередное проверяемое значение является максимально приблизительным к искомому значению.
Внимание! Если данные в просматриваемом функцией столбце не отсортированы по возрастанию, поисковая функция при выборке вернет не ошибку, а только лишь ошибочный результат (что еще хуже ошибки)! Функции, предназначенные для приблизительного поиска соответствий, используют в своих алгоритмах бинарный метод. Согласно этому алгоритму поиск начинается от середины столбца, а в процессе происходит проверка находится ли искомое значение в верхней или нижней части. Когда определена более подходящая часть столбца, она снова делится на половину и снова проверяется от своей середины. Данный процесс повторяется пока не будет найден результат.
Поэтому бинарный поиск по неотсортированным диапазонам значений с большой вероятностью может привести к тому, что поисковая функция выберет неправильную половину просматриваемого столбца и возвратит ошибочное значение (при этом без кода ошибки).
В выше приведенном примере функция ВПР закончит поиск на второй строке просматриваемого столбца так как число 1023 является наибольшим числом, которое меньше от искомого числа 2003,89. Условно формулу можно разделить на 3, которые последовательно выполняют следующие операции:
- Первая функция ВПР возвращает базовую налоговую ставку с третьего столбца таблицы, то есть число 69,80.
- Следующая функция ВПР ищет тоже самое приблизительное значение для числа 2003,89, но уже по первому столбцу «Зарплата от». После чего найденное приближенное значение вычитаемое от искомого.
- Третья функция ВПР возвращает процентную ставку с четвертого столбца таблицы. Полученная ставка умножается на чистую зарплату netto – после всех вычетов, а результат прибавляется к базовой ставке.
Когда все функции ВПР возвратят свои результаты, выполняются следующие арифметические вычисления с числами:
=69,80+(2003,89-1023,00)*15,0%
Поиск данных с приблизительным совпадением выполняется существенно быстрее чем при точном поиске. При точном совпадении поисковая функция должна проверять по очереди содержимое каждой ячейки в просматриваемом столбце. Если вы уверенны что исходные данные просматриваемого столбца отсортированы по возрастанию, можно ускорить точный поиск указав в третьем аргументе поисковой функции значение ИСТИНА. В случаи приблизительного совпадения значений, всегда будет найдено точное значение с точным совпадением с искомым. Главное, чтобы оно действительно фактически присутствовало в списке значений, а сам список было отсортирован по возрастанию.
Пример формулы для приблизительного поиска ИНДЕКС и ПОИСКПОЗ в Excel
Любые поисковые функции для выборки можно заменить формулой из комбинации функций ИНДЕКС и ПОИСКПОЗ. Последний аргумент функции ПОИСКПОЗ позволяет переключатся между приблизительными и точным поиском, подобно как в функциях ВПР и ГПР. Но отличительным преимуществом функции ПОИСКПОЗ является возможность выполнять поиск с приблизительным совпадением при отсортированных значениях по убыванию.
Ниже на рисунке приведена та же таблица с налоговыми ставками, но отсортирована по убыванию. Новая формула в ячейке … использует формулу функций ИНДЕКС и ПОИСКПОЗ возвращает правильный результат:
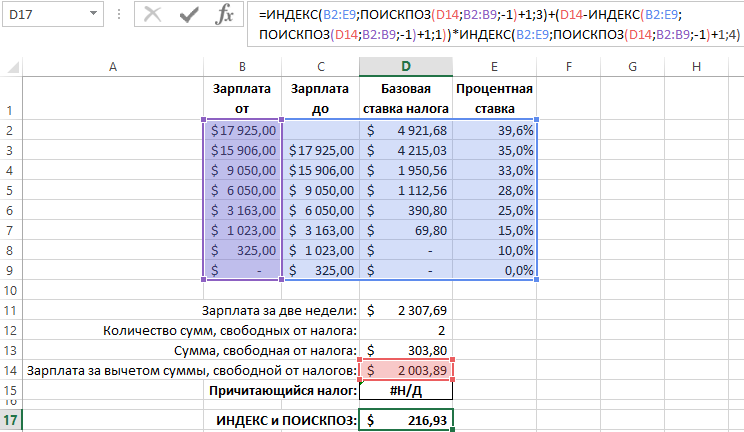
Старая формула с функциями ВПР в таком случае возвращает ошибку #Н/Д! вместо итогового результата в ячейке D15. Так получается потому что функция ВПР начинает свой поиск от среднего значения просматриваемого столбца, после чего определяет, что искомое значение является меньшим. Поэтому она анализирует только верхнюю часть столбца. Та как значения отсортированы по убыванию, то в первой половине столбца уж точно не найдется значения меньше чем искомое.
В тоже время новая формула в ячейке D17 возвращает правильный итоговый результат вычислений.
В отличии от других поисковых функций последним аргументом функции ПОИСКПОЗ может быть и отрицательное число, а точнее одно из трех вариантов: -1, 0, 1:
- Отрицательное значение -1 используется в случаях работы с данными отсортированными по убыванию. Функция возвращает из просматриваемого столбца наименьшее значение, которое является большим по отношению к искомому. Нельзя использовать отрицательную единицу с минусом (-1) в третьем аргументе для поисковых функций выборки данных ВПР и ГПР. Там нет соответственного режима работы функции.
- Значение 0 используется для обработки неотсортированных списков данных, с целью поиска точного совпадения значений с искомым. Поведение функции ПОИСКПОЗ с нулевым значением в третьем аргументе (0) – соответствует поведению функций ВПР и ГПР с тратим аргументом равному ЛОЖЬ или 0.
- Значение 1 применяется к спискам данных отсортированных по возрастанию. В таком случае функция возвращает из просматриваемого столбца наибольшее значение, которое меньше от искомого. Положительное число 1 в третьем аргументе функции ПОИСКПОЗ работает аналогично как ИСТИНА или 1 для функций ВПР и ГПР в этом же аргументе.
Так как функция ПОИСКПОЗ с последним аргументом равным отрицательному число -1 ищет значение больше чем искомое к возвращаемому результату следует добавить число +1, чтобы получить правильный номер строки для функции ИНДЕКС.
Совет: Попробуйте использовать новые функции ПРОСМОТРX и XMATCH, а также улучшенные версии функций, описанные в этой статье. Эти новые функции работают в любом направлении и возвращают точные совпадения по умолчанию, что упрощает и упрощает работу с ними по сравнению с предшественниками.
Предположим, у вас есть список номеров офисов, и вам нужно знать, какие сотрудники работают в каждом из них. Таблица очень угрюмая, поэтому, возможно, вам кажется, что это сложная задача. С функцией подытов на самом деле это довольно просто.
Функции ВВ., а также ИНДЕКС и ВЫБОРПОЗ — одни из самых полезных функций в Excel.
Примечание: Мастер подметок больше не доступен в Excel.
Ниже в качестве примера по выбору вы можете найти пример использования в этой области.
=ВПР(B2;C2:E7,3,ИСТИНА)
В этом примере B2 является первым аргументом —элементом данных, который требуется для работы функции. В случае СРОТ ВЛ.В.ОВ этот первый аргумент является искомой значением. Этот аргумент может быть ссылкой на ячейку или фиксированным значением, таким как «кузьмина» или 21 000. Вторым аргументом является диапазон ячеек C2–:E7, в котором нужно найти и найти значение. Третий аргумент — это столбец в диапазоне ячеек, содержащий ищите значение.
Четвертый аргумент необязателен. Введите истина или ЛОЖЬ. Если ввести ИСТИНА или оставить аргумент пустым, функция возвращает приблизительное совпадение значения, указанного в качестве первого аргумента. Если ввести ЛОЖЬ, функция будет соответствовать значению, заведомо первому аргументу. Другими словами, если оставить четвертый аргумент пустым или ввести ИСТИНА, это обеспечивает большую гибкость.
В этом примере показано, как работает функция. При вводе значения в ячейку B2 (первый аргумент) в результате поиска в ячейках диапазона C2:E7 (2-й аргумент) выполняется поиск в ней и возвращается ближайшее приблизительное совпадение из третьего столбца в диапазоне — столбца E (третий аргумент).
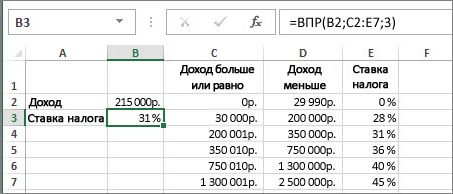
Четвертый аргумент пуст, поэтому функция возвращает приблизительное совпадение. Иначе потребуется ввести одно из значений в столбец C или D, чтобы получить какой-либо результат.
Если вы хорошо разучились работать с функцией ВГТ.В.В., то в равной степени использовать ее будет легко. Вы вводите те же аргументы, но выполняется поиск в строках, а не в столбцах.
Использование индекса и MATCH вместо ВРОТ
При использовании функции ВПРАВО существует ряд ограничений, которые действуют только при использовании функции ВПРАВО. Это означает, что столбец, содержащий и look up, всегда должен быть расположен слева от столбца, содержащего возвращаемого значения. Теперь, если ваша таблица не построена таким образом, не используйте В ПРОСМОТР. Используйте вместо этого сочетание функций ИНДЕКС и MATCH.
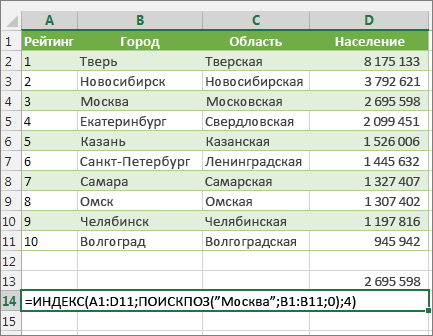
В данном примере представлен небольшой список, в котором искомое значение (Воронеж) не находится в крайнем левом столбце. Поэтому мы не можем использовать функцию ВПР. Для поиска значения «Воронеж» в диапазоне B1:B11 будет использоваться функция ПОИСКПОЗ. Оно найдено в строке 4. Затем функция ИНДЕКС использует это значение в качестве аргумента поиска и находит численность населения Воронежа в четвертом столбце (столбец D). Использованная формула показана в ячейке A14.
Дополнительные примеры использования индексов и MATCH вместо В ПРОСМОТР см. в статье билла Https://www.mrexcel.com/excel-tips/excel-vlookup-index-match/ Билла Джилена (Bill Jelen), MVP корпорации Майкрософт.
Попробуйте попрактиковаться
Если вы хотите поэкспериментировать с функциями подытовки, прежде чем попробовать их с собственными данными, вот примеры данных.
Пример работы с ВЛОКОНПОМ
Скопируйте следующие данные в пустую таблицу.
Совет: Прежде чем врезать данные в Excel, установите для столбцов A–C ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Плотность |
Вязкость |
Температура |
|
0,457 |
3,55 |
500 |
|
0,525 |
3,25 |
400 |
|
0,606 |
2,93 |
300 |
|
0,675 |
2,75 |
250 |
|
0,746 |
2,57 |
200 |
|
0,835 |
2,38 |
150 |
|
0,946 |
2,17 |
100 |
|
1,09 |
1,95 |
50 |
|
1,29 |
1,71 |
0 |
|
Формула |
Описание |
Результат |
|
=ВПР(1,A2:C10,2) |
Используя приблизительное соответствие, функция ищет в столбце A значение 1, находит наибольшее значение, которое меньше или равняется 1 и составляет 0,946, а затем возвращает значение из столбца B в той же строке. |
2,17 |
|
=ВПР(1,A2:C10,3,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 1, находит наибольшее значение, которое меньше или равняется 1 и составляет 0,946, а затем возвращает значение из столбца C в той же строке. |
100 |
|
=ВПР(0,7,A2:C10,3,ЛОЖЬ) |
Используя точное соответствие, функция ищет в столбце A значение 0,7. Поскольку точного соответствия нет, возвращается сообщение об ошибке. |
#Н/Д |
|
=ВПР(0,1,A2:C10,2,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 0,1. Поскольку 0,1 меньше наименьшего значения в столбце A, возвращается сообщение об ошибке. |
#Н/Д |
|
=ВПР(2,A2:C10,2,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 2, находит наибольшее значение, которое меньше или равняется 2 и составляет 1,29, а затем возвращает значение из столбца B в той же строке. |
1,71 |
Пример ГВ.Г.В.В.
Скопируйте всю таблицу и вставьте ее в ячейку A1 пустого листа Excel.
Совет: Прежде чем врезать данные в Excel, установите для столбцов A–C ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Оси |
Подшипники |
Болты |
|
4 |
4 |
9 |
|
5 |
7 |
10 |
|
6 |
8 |
11 |
|
Формула |
Описание |
Результат |
|
=ГПР(«Оси»;A1:C4;2;ИСТИНА) |
Поиск слова «Оси» в строке 1 и возврат значения из строки 2, находящейся в том же столбце (столбец A). |
4 |
|
=ГПР(«Подшипники»;A1:C4;3;ЛОЖЬ) |
Поиск слова «Подшипники» в строке 1 и возврат значения из строки 3, находящейся в том же столбце (столбец B). |
7 |
|
=ГПР(«П»;A1:C4;3;ИСТИНА) |
Поиск буквы «П» в строке 1 и возврат значения из строки 3, находящейся в том же столбце. Так как «П» найти не удалось, возвращается ближайшее из меньших значений: «Оси» (в столбце A). |
5 |
|
=ГПР(«Болты»;A1:C4;4) |
Поиск слова «Болты» в строке 1 и возврат значения из строки 4, находящейся в том же столбце (столбец C). |
11 |
|
=ГПР(3;{1;2;3:»a»;»b»;»c»;»d»;»e»;»f»};2;ИСТИНА) |
Поиск числа 3 в трех строках константы массива и возврат значения из строки 2 того же (в данном случае — третьего) столбца. Константа массива содержит три строки значений, разделенных точкой с запятой (;). Так как «c» было найдено в строке 2 того же столбца, что и 3, возвращается «c». |
c |
Примеры индекса и match
В последнем примере функции ИНДЕКС и MATCH совместно возвращают номер счета с наиболее ранней датой и соответствующую дату для каждого из пяти городов. Так как дата возвращается как число, для ее формата используется функция ТЕКСТ. Функция ИНДЕКС использует результат, возвращенный функцией ПОИСКПОЗ, как аргумент. Сочетание функций ИНДЕКС и ПОИСКПОЗ используется в каждой формуле дважды — сперва для возврата номера счета, а затем для возврата даты.
Скопируйте всю таблицу и вставьте ее в ячейку A1 пустого листа Excel.
Совет: Перед тем как вировать данные в Excel, установите для столбцов A–D ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Счет |
Город |
Дата выставления счета |
Счет с самой ранней датой по городу, с датой |
|
3115 |
Казань |
07.04.12 |
=»Казань = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Казань»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Казань»,$B$2:$B$33,0),3),»m/d/yy») |
|
3137 |
Казань |
09.04.12 |
=»Орел = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Орел»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Орел»,$B$2:$B$33,0),3),»m/d/yy») |
|
3154 |
Казань |
11.04.12 |
=»Челябинск = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Челябинск»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Челябинск»,$B$2:$B$33,0),3),»m/d/yy») |
|
3191 |
Казань |
21.04.12 |
=»Нижний Новгород = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Нижний Новгород»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Нижний Новгород»,$B$2:$B$33,0),3),»m/d/yy») |
|
3293 |
Казань |
25.04.12 |
=»Москва = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Москва»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Москва»,$B$2:$B$33,0),3),»m/d/yy») |
|
3331 |
Казань |
27.04.12 |
|
|
3350 |
Казань |
28.04.12 |
|
|
3390 |
Казань |
01.05.12 |
|
|
3441 |
Казань |
02.05.12 |
|
|
3517 |
Казань |
08.05.12 |
|
|
3124 |
Орел |
09.04.12 |
|
|
3155 |
Орел |
11.04.12 |
|
|
3177 |
Орел |
19.04.12 |
|
|
3357 |
Орел |
28.04.12 |
|
|
3492 |
Орел |
06.05.12 |
|
|
3316 |
Челябинск |
25.04.12 |
|
|
3346 |
Челябинск |
28.04.12 |
|
|
3372 |
Челябинск |
01.05.12 |
|
|
3414 |
Челябинск |
01.05.12 |
|
|
3451 |
Челябинск |
02.05.12 |
|
|
3467 |
Челябинск |
02.05.12 |
|
|
3474 |
Челябинск |
04.05.12 |
|
|
3490 |
Челябинск |
05.05.12 |
|
|
3503 |
Челябинск |
08.05.12 |
|
|
3151 |
Нижний Новгород |
09.04.12 |
|
|
3438 |
Нижний Новгород |
02.05.12 |
|
|
3471 |
Нижний Новгород |
04.05.12 |
|
|
3160 |
Москва |
18.04.12 |
|
|
3328 |
Москва |
26.04.12 |
|
|
3368 |
Москва |
29.04.12 |
|
|
3420 |
Москва |
01.05.12 |
|
|
3501 |
Москва |
06.05.12 |
На чтение 10 мин Просмотров 13.9к. Опубликовано 31.07.2020
Содержание
- 5 thoughts on “ «ВПР» по частичному совпадению ”
- Проверяем условие для полного совпадения текста.
- ЕСЛИ + СОВПАД
- Использование функции ЕСЛИ с частичным совпадением текста.
- ЕСЛИ + ПОИСК
- ЕСЛИ + НАЙТИ
- Примеры использования функции ПОИСКПОЗ в Excel
- Формула для поиска неточного совпадения текста в Excel
- Сравнение двух таблиц в Excel на наличие несовпадений значений
- Поиск ближайшего большего знания в диапазоне чисел Excel
- Особенности использования функции ПОИСКПОЗ в Excel
Спустя катастрофически большой промежуток времени с момента публикации моего последнего поста, решил поделиться супер крутой, на мой взгляд, Excel-формулой, узнав о которой, начинаешь удивляться, как же раньше-то я жил без нее. Но, должен сказать, авторство ее создания не мое, а вероятнее всего принадлежит англоязычному ресурсу, о котором я скажу ниже.
Кто более-менее часто работает с массивами данных в Excel почти наверняка знает про функцию ВПР (см. мою статью) или ИНДЕКС+ПОИСКПОЗ, которые решают достаточно частую задачу по объединению двух наборов данных по каким-либо совпадающим значениям. И действительно, использование этих функций решает задачи по сопоставлению и объединению данных в 90% случаев. Если бы не одно но — данные, по которым производится объединение, действительно должны именно совпадать. Но бывают случаи, когда требуется сопоставление по частичному совпадению. Да, в ВПР есть поиск по приблизительному совпадению, но работает он не совсем прозрачно, а потому предугадать, почему было подобрано одно похожее слово, а не другое, может быть невозможно не просто. Как вы поняли, эту прелюдию я затеял не просто так, а для того, чтобы рассказать, как же решить такую задачу при помощи Excel.
Предположим, у нас есть список товаров, которые надо как-то сгруппировать:





5 thoughts on “ «ВПР» по частичному совпадению ”
На форуме SQL.ru мне подсказали еще одно очень изящное решение этой задачи, посмотреть его можно здесь:
http://www.sql.ru/forum/actualutils.aspx?action=gotomsg&t > Спасибо большое, Казанский (автор совета)!
Игорь, спасибо Вам огромное за эту «бронебойную» формулу. Весь интернет «перелопатила» в поиске решения своей задачи и только Вы мне помогли на 100%. Всё работает как часики. Удачи Вам, успешной работы и ещё больше таких гениальных решений.
Ольга, спасибо большое за Ваш комментарий! Справедливости ради надо сказать, что идея этой формулы не моя, а обнаружил я ее на сайте Exceljet
Игорь, добрый день!
Формула прекрасная, но есть ли какая-нибудь ее вариация, которая может находить и подставлять несколько значений сразу?
Например, в строке указаны два производителя холодильников, LG и Samsung
Можно ли вывести их в ячейку через запятую?
Добрый день, Артём!
Спасибо за ваш комментарий и прошу прощения за медленный ответ. Вопрос интересный, но с ходу у меня на него ответа, увы, нет, а по времени довольно сильно ограничен. Если будет свободное время, попробую поломать голову на эту тему
Рассмотрим использование функции ЕСЛИ в Excel в том случае, если в ячейке находится текст.
Будьте особо внимательны в том случае, если для вас важен регистр, в котором записаны ваши текстовые значения. Функция ЕСЛИ не проверяет регистр – это делают функции, которые вы в ней используете. Поясним на примере.
Проверяем условие для полного совпадения текста.
Проверку выполнения доставки организуем при помощи обычного оператора сравнения «=».
=ЕСЛИ(G2=»выполнено»,ИСТИНА,ЛОЖЬ)
При этом будет не важно, в каком регистре записаны значения в вашей таблице.

Если же вас интересует именно точное совпадение текстовых значений с учетом регистра, то можно рекомендовать вместо оператора «=» использовать функцию СОВПАД(). Она проверяет идентичность двух текстовых значений с учетом регистра отдельных букв.
Вот как это может выглядеть на примере.

Обратите внимание, что если в качестве аргумента мы используем текст, то он обязательно должен быть заключён в кавычки.
ЕСЛИ + СОВПАД
В случае, если нас интересует полное совпадение текста с заданным условием, включая и регистр его символов, то оператор «=» нам не сможет помочь.
Но мы можем использовать функцию СОВПАД (английский аналог — EXACT).
Функция СОВПАД сравнивает два текста и возвращает ИСТИНА в случае их полного совпадения, и ЛОЖЬ — если есть хотя бы одно отличие, включая регистр букв. Поясним возможность ее использования на примере.
Формула проверки выполнения заказа в столбце Н может выглядеть следующим образом:

Как видите, варианты «ВЫПОЛНЕНО» и «выполнено» не засчитываются как правильные. Засчитываются только полные совпадения. Будет полезно, если важно точное написание текста — например, в артикулах товаров.
Использование функции ЕСЛИ с частичным совпадением текста.
Выше мы с вами рассмотрели, как использовать текстовые значения в функции ЕСЛИ. Но часто случается, что необходимо определить не полное, а частичное совпадение текста с каким-то эталоном. К примеру, нас интересует город, но при этом совершенно не важно его название.
Первое, что приходит на ум – использовать подстановочные знаки «?» и «*» (вопросительный знак и звездочку). Однако, к сожалению, этот простой способ здесь не проходит.
ЕСЛИ + ПОИСК
Нам поможет функция ПОИСК (в английском варианте – SEARCH). Она позволяет определить позицию, начиная с которой искомые символы встречаются в тексте. Синтаксис ее таков:
=ПОИСК(что_ищем, где_ищем, начиная_с_какого_символа_ищем)
Если третий аргумент не указан, то поиск начинаем с самого начала – с первого символа.
Функция ПОИСК возвращает либо номер позиции, начиная с которой искомые символы встречаются в тексте, либо ошибку.
Но нам для использования в функции ЕСЛИ нужны логические значения.
Здесь нам на помощь приходит еще одна функция EXCEL – ЕЧИСЛО. Если ее аргументом является число, она возвратит логическое значение ИСТИНА. Во всех остальных случаях, в том числе и в случае, если ее аргумент возвращает ошибку, ЕЧИСЛО возвратит ЛОЖЬ.
В итоге наше выражение в ячейке G2 будет выглядеть следующим образом:
Еще одно важное уточнение. Функция ПОИСК не различает регистр символов.

ЕСЛИ + НАЙТИ
В том случае, если для нас важны строчные и прописные буквы, то придется использовать вместо нее функцию НАЙТИ (в английском варианте – FIND).
Синтаксис ее совершенно аналогичен функции ПОИСК: что ищем, где ищем, начиная с какой позиции.
Изменим нашу формулу в ячейке G2

То есть, если регистр символов для вас важен, просто замените ПОИСК на НАЙТИ.
Итак, мы с вами убедились, что простая на первый взгляд функция ЕСЛИ дает нам на самом деле много возможностей для операций с текстом.
Функция ПОИСКПОЗ в Excel используется для поиска точного совпадения или ближайшего (меньшего или большего заданному в зависимости от типа сопоставления, указанного в качестве аргумента) значения заданному в массиве или диапазоне ячеек и возвращает номер позиции найденного элемента.
Примеры использования функции ПОИСКПОЗ в Excel
Например, имеем последовательный ряд чисел от 1 до 10, записанных в ячейках B1:B10. Функция =ПОИСКПОЗ(3;B1:B10;0) вернет число 3, поскольку искомое значение находится в ячейке B3, которая является третьей от точки отсчета (ячейки B1).
Данная функция удобна для использования в случаях, когда требуется вернуть не само значение, содержащееся в искомой ячейке, а ее координату относительно рассматриваемого диапазона. В случае использования для констант массивов, которые могут быть представлены как массивы элементов «ключ» — «значение», функция ПОИСКПОЗ возвращает значение ключа, который явно не указан.
Например, массив <«виноград»;»яблоко»;»груша»;»слива»>содержит элементы, которые можно представить как: 1 – «виноград», 2 – «яблоко», 3 – «груша», 4 – «слива», где 1, 2, 3, 4 – ключи, а названия фруктов – значения. Тогда функция =ПОИСКПОЗ(«яблоко»;<«виноград»;»яблоко»;»груша»;»слива»>;0) вернет значение 2, являющееся ключом второго элемента. Отсчет выполняется не с 0 (нуля), как это реализовано во многих языках программирования при работе с массивами, а с 1.
Функция ПОИСКПОЗ редко используется самостоятельно. Ее целесообразно применять в связке с другими функциями, например, ИНДЕКС.
Формула для поиска неточного совпадения текста в Excel
Пример 1. Найти позицию первого частичного совпадения строки в диапазоне ячеек, хранящих текстовые значения.
Вид исходной таблицы данных:
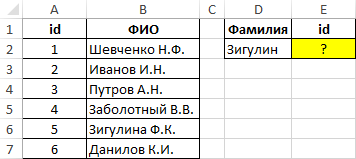
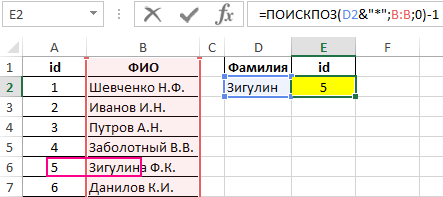
Для нахождения позиции текстовой строки в таблице используем следующую формулу:
Из полученного значения вычитается единица для совпадения результата с id записи в таблице.
Сравнение двух таблиц в Excel на наличие несовпадений значений
Пример 2. В Excel хранятся две таблицы, которые на первый взгляд кажутся одинаковыми. Было решено сравнить по одному однотипному столбцу этих таблиц на наличие несовпадений. Реализовать способ сравнения двух диапазонов ячеек.
Вид таблицы данных:
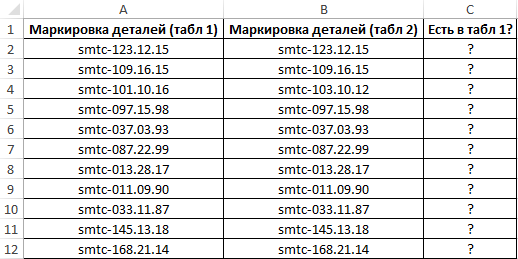
Для сравнения значений, находящихся в столбце B:B со значениями из столбца A:A используем следующую формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ выполняет поиск логического значения ИСТИНА в массиве логических значений, возвращаемых функцией СОВПАД (сравнивает каждый элемент диапазона A2:A12 со значением, хранящимся в ячейке B2, и возвращает массив результатов сравнения). Если функция ПОИСКПОЗ нашла значение ИСТИНА, будет возвращена позиция его первого вхождения в массив. Функция ЕНД возвратит значение ЛОЖЬ, если она не принимает значение ошибки #Н/Д в качестве аргумента. В этом случае функция ЕСЛИ вернет текстовую строку «есть», иначе – «нет».
Чтобы вычислить остальные значения «протянем» формулу из ячейки C2 вниз для использования функции автозаполнения. В результате получим:
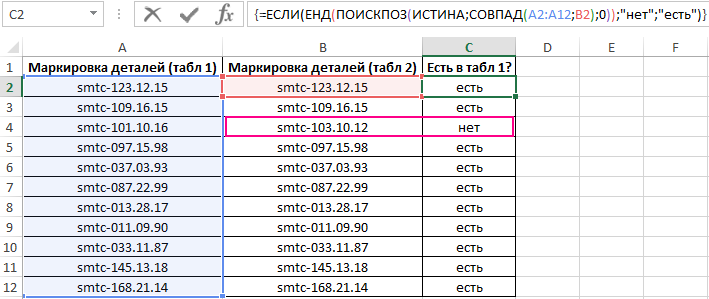
Как видно, третьи элементы списков не совпадают.
Поиск ближайшего большего знания в диапазоне чисел Excel
Пример 3. Найти ближайшее меньшее числу 22 в диапазоне чисел, хранящихся в столбце таблицы Excel.
Вид исходной таблицы данных:
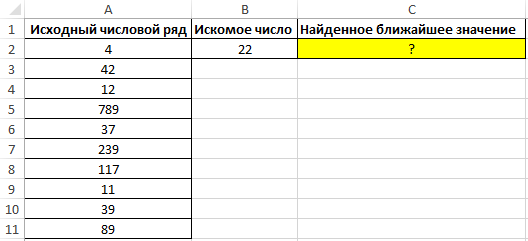
Для поиска ближайшего большего значения заданному во всем столбце A:A (числовой ряд может пополняться новыми значениями) используем формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ возвращает позицию элемента в столбце A:A, имеющего максимальное значение среди чисел, которые больше числа, указанного в ячейке B2. Функция ИНДЕКС возвращает значение, хранящееся в найденной ячейке.
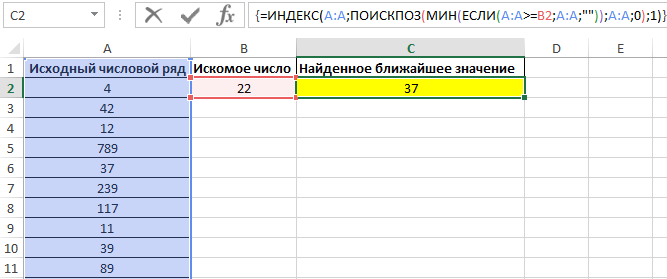
Для поиска ближайшего меньшего значения достаточно лишь немного изменить данную формулу и ее следует также ввести как массив (CTRL+SHIFT+ENTER):
Особенности использования функции ПОИСКПОЗ в Excel
Функция имеет следующую синтаксическую запись:
=ПОИСКПОЗ( искомое_значение;просматриваемый_массив; [тип_сопоставления])
- искомое_значение – обязательный аргумент, принимающий текстовые, числовые значения, а также данные логического и ссылочного типов, который используется в качестве критерия поиска (для сопоставления величин или нахождения точного совпадения);
- просматриваемый_массив – обязательный аргумент, принимающий данные ссылочного типа (ссылки на диапазон ячеек) или константу массива, в которых выполняется поиск позиции элемента согласно критерию, заданному первым аргументом функции;
- [тип_сопоставления] – необязательный для заполнения аргумент в виде числового значения, определяющего способ поиска в диапазоне ячеек или массиве. Может принимать следующие значения:
- -1 – поиск наименьшего ближайшего значения заданному аргументом искомое_значение в упорядоченном по убыванию массиве или диапазоне ячеек.
- 0 – (по умолчанию) поиск первого значения в массиве или диапазоне ячеек (не обязательно упорядоченном), которое полностью совпадает со значением, переданным в качестве первого аргумента.
- 1 – Поиск наибольшего ближайшего значения заданному первым аргументом в упорядоченном по возрастанию массиве или диапазоне ячеек.
- Если в качестве аргумента искомое_значение была передана текстовая строка, функция ПОИСКПОЗ вернет позицию элемента в массиве (если такой существует) без учета регистра символов. Например, строки «МоСкВа» и «москва» являются равнозначными. Для различения регистров можно дополнительно использовать функцию СОВПАД.
- Если поиск с использованием рассматриваемой функции не дал результатов, будет возвращен код ошибки #Н/Д.
- Если аргумент [тип_сопоставления] явно не указан или принимает число 0, для поиска частичного совпадения текстовых значений могут быть использованы подстановочные знаки («?» — замена одного любого символа, «*» — замена любого количества символов).
- Если в объекте данных, переданном в качестве аргумента просматриваемый_массив, содержится два и больше элементов, соответствующих искомому значению, будет возвращена позиция первого вхождения такого элемента.
Поиск совпадений в Excel
Рассмотрим одну из полезных опций, предлагаемую программой Microsoft Excel. Кстати, лицензионную версию этой программы вы можете купить в нашем интернет-магазине со скидкой. Цены и версии можно посмотреть здесь.
Сегодня речь пойдет об «Условном форматировании». Оно предназначено для выделения ячеек таблицы, имеющих общие черты. Это может быть идентичный шрифт, значения, фон и т.д. Данная операция предусматривает различные конфигурации: строгость проверки, содержание совпадений, их тождественность и вариативность.
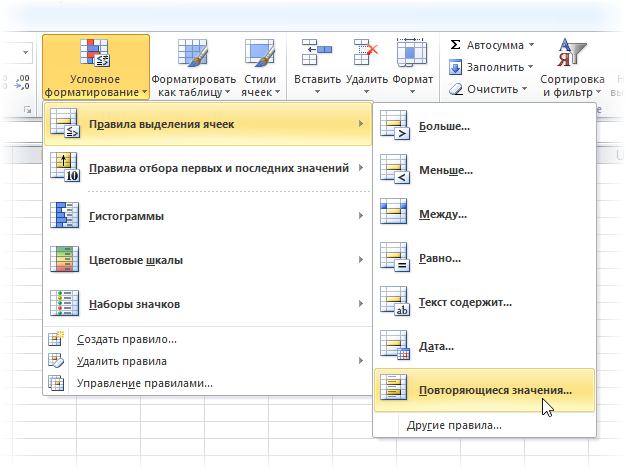
- Начнем с запуска программы Microsoft Excel, содержащую необходимую нам таблицу. Следом выделяем диапазон ячеек, нуждающихся в обработке. Речь идет об общности столбцов и ячеек, формирующих часть таблицы, либо несколько несвязанных между собой областей таблицы.
- Далее нам потребуется пройти следующий путь:
- меню Excel, работаем во вкладке «ГЛАBНАЯ».
- Находим в группе команд «CТИЛИ».
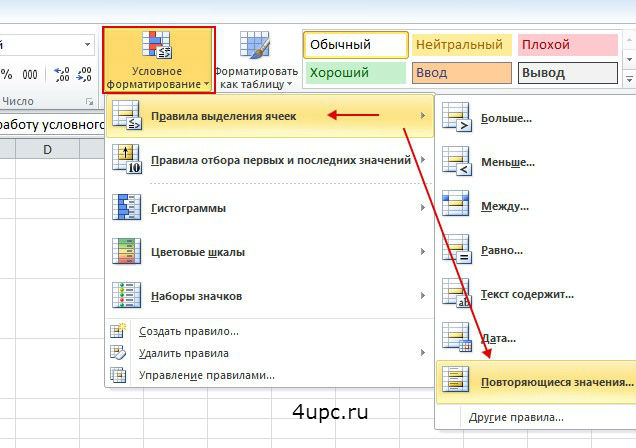
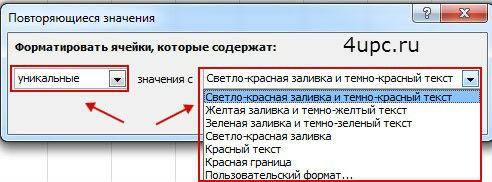
- В открывшемся списке отмечаем «УСЛOВНОЕ ФОРМАТИРОВАНИЕ». Нас интересует пункт «ПОВТОРЯЮЩИЕСЯ ЗНАЧЕНИЯ».
- В разделе «ПРАВИЛА BЫДЕЛЕНИЯ ЯЧЕЕК». При необходимости выбираем в списке «ПOВТОРЯЮЩИЕСЯ», что позволит отметить все ячейки в интересующей нас области, имеющие одно и более повторений.

- Выбрав вариант «УНИКАЛЬНЫЕ», мы увидим ячейки с уникальным значением или содержанием.
- Программа имеет широкую линейку возможностей, в частности: можно выбрать подсветку ячеек, попавших в отбор, предусмотрен вариант выбора фона заливки (программа предоставляет 6 цветовых решений), вариации шрифтов и табличных рамок. Возможен выбор «ПОЛЬЗОВАТЕЛЬСКОГО ФОРМАТА», который позволяет создать свой вариант оформления ячеек. Для отмены выборки совпадающих ячеек нажмите ОК.
Использование функции «РАВНО»
Если нужные для выделения ячейки имеют совершенно конкретное значение, воспользуйтесь пунктом «РАВНО» в списке «УСЛОВНОЕ ФОРМАТИРОВАНИЕ», находящееся в разделе «ПРАВИЛА ВЫДЕЛЕНИЯ ЯЧЕЕК». В открывшемся диалоговом окне отметьте интересующие вас ячейки, требующие выявления дубликатов, при этом их адрес появится в соседнем диалоговом окне. Овладев этими нехитрыми навыками, вы сможете значительно сократить время на обработку табличных данных и группировку общих значений.
Видео: Поиск совпадений в Excel
Пример функции ПОИСКПОЗ для поиска совпадения значений в Excel
Функция ПОИСКПОЗ в Excel используется для поиска точного совпадения или ближайшего (меньшего или большего заданному в зависимости от типа сопоставления, указанного в качестве аргумента) значения заданному в массиве или диапазоне ячеек и возвращает номер позиции найденного элемента.
Примеры использования функции ПОИСКПОЗ в Excel
Например, имеем последовательный ряд чисел от 1 до 10, записанных в ячейках B1:B10. Функция =ПОИСКПОЗ(3;B1:B10;0) вернет число 3, поскольку искомое значение находится в ячейке B3, которая является третьей от точки отсчета (ячейки B1).
Данная функция удобна для использования в случаях, когда требуется вернуть не само значение, содержащееся в искомой ячейке, а ее координату относительно рассматриваемого диапазона. В случае использования для констант массивов, которые могут быть представлены как массивы элементов «ключ» — «значение», функция ПОИСКПОЗ возвращает значение ключа, который явно не указан.
Например, массив <«виноград»;»яблоко»;»груша»;»слива»>содержит элементы, которые можно представить как: 1 – «виноград», 2 – «яблоко», 3 – «груша», 4 – «слива», где 1, 2, 3, 4 – ключи, а названия фруктов – значения. Тогда функция =ПОИСКПОЗ(«яблоко»;<«виноград»;»яблоко»;»груша»;»слива»>;0) вернет значение 2, являющееся ключом второго элемента. Отсчет выполняется не с 0 (нуля), как это реализовано во многих языках программирования при работе с массивами, а с 1.
Функция ПОИСКПОЗ редко используется самостоятельно. Ее целесообразно применять в связке с другими функциями, например, ИНДЕКС.
Формула для поиска неточного совпадения текста в Excel
Пример 1. Найти позицию первого частичного совпадения строки в диапазоне ячеек, хранящих текстовые значения.
Вид исходной таблицы данных:
Для нахождения позиции текстовой строки в таблице используем следующую формулу:
Из полученного значения вычитается единица для совпадения результата с id записи в таблице.
Сравнение двух таблиц в Excel на наличие несовпадений значений
Пример 2. В Excel хранятся две таблицы, которые на первый взгляд кажутся одинаковыми. Было решено сравнить по одному однотипному столбцу этих таблиц на наличие несовпадений. Реализовать способ сравнения двух диапазонов ячеек.
Вид таблицы данных:
Для сравнения значений, находящихся в столбце B:B со значениями из столбца A:A используем следующую формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ выполняет поиск логического значения ИСТИНА в массиве логических значений, возвращаемых функцией СОВПАД (сравнивает каждый элемент диапазона A2:A12 со значением, хранящимся в ячейке B2, и возвращает массив результатов сравнения). Если функция ПОИСКПОЗ нашла значение ИСТИНА, будет возвращена позиция его первого вхождения в массив. Функция ЕНД возвратит значение ЛОЖЬ, если она не принимает значение ошибки #Н/Д в качестве аргумента. В этом случае функция ЕСЛИ вернет текстовую строку «есть», иначе – «нет».
Чтобы вычислить остальные значения «протянем» формулу из ячейки C2 вниз для использования функции автозаполнения. В результате получим:
Как видно, третьи элементы списков не совпадают.
Поиск ближайшего большего знания в диапазоне чисел Excel
Пример 3. Найти ближайшее меньшее числу 22 в диапазоне чисел, хранящихся в столбце таблицы Excel.
Вид исходной таблицы данных:
Для поиска ближайшего большего значения заданному во всем столбце A:A (числовой ряд может пополняться новыми значениями) используем формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ возвращает позицию элемента в столбце A:A, имеющего максимальное значение среди чисел, которые больше числа, указанного в ячейке B2. Функция ИНДЕКС возвращает значение, хранящееся в найденной ячейке.
Для поиска ближайшего меньшего значения достаточно лишь немного изменить данную формулу и ее следует также ввести как массив (CTRL+SHIFT+ENTER):
Особенности использования функции ПОИСКПОЗ в Excel
Функция имеет следующую синтаксическую запись:
=ПОИСКПОЗ( искомое_значение;просматриваемый_массив; [тип_сопоставления])
- искомое_значение – обязательный аргумент, принимающий текстовые, числовые значения, а также данные логического и ссылочного типов, который используется в качестве критерия поиска (для сопоставления величин или нахождения точного совпадения);
- просматриваемый_массив – обязательный аргумент, принимающий данные ссылочного типа (ссылки на диапазон ячеек) или константу массива, в которых выполняется поиск позиции элемента согласно критерию, заданному первым аргументом функции;
- [тип_сопоставления] – необязательный для заполнения аргумент в виде числового значения, определяющего способ поиска в диапазоне ячеек или массиве. Может принимать следующие значения:
- -1 – поиск наименьшего ближайшего значения заданному аргументом искомое_значение в упорядоченном по убыванию массиве или диапазоне ячеек.
- 0 – (по умолчанию) поиск первого значения в массиве или диапазоне ячеек (не обязательно упорядоченном), которое полностью совпадает со значением, переданным в качестве первого аргумента.
- 1 – Поиск наибольшего ближайшего значения заданному первым аргументом в упорядоченном по возрастанию массиве или диапазоне ячеек.
- Если в качестве аргумента искомое_значение была передана текстовая строка, функция ПОИСКПОЗ вернет позицию элемента в массиве (если такой существует) без учета регистра символов. Например, строки «МоСкВа» и «москва» являются равнозначными. Для различения регистров можно дополнительно использовать функцию СОВПАД.
- Если поиск с использованием рассматриваемой функции не дал результатов, будет возвращен код ошибки #Н/Д.
- Если аргумент [тип_сопоставления] явно не указан или принимает число 0, для поиска частичного совпадения текстовых значений могут быть использованы подстановочные знаки («?» — замена одного любого символа, «*» — замена любого количества символов).
- Если в объекте данных, переданном в качестве аргумента просматриваемый_массив, содержится два и больше элементов, соответствующих искомому значению, будет возвращена позиция первого вхождения такого элемента.
Поиск совпадений в двух списках
Тема сравнения двух списков поднималась уже неоднократно и с разных сторон, но остается одной из самых актуальных везде и всегда. Давайте рассмотрим один из ее аспектов — подсчет количества и вывод совпадающих значений в двух списках. Предположим, что у нас есть два диапазона данных, которые мы хотим сравнить:
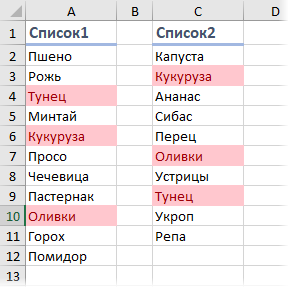
Для удобства, можно дать им имена, чтобы потом использовать их в формулах и ссылках. Для этого нужно выделить ячейки с элементами списка и на вкладке Формулы нажать кнопку Менеджер Имен — Создать (Formulas — Name Manager — Create) . Также можно превратить таблицы в «умные» с помощью сочетания клавиш Ctrl + T или кнопки Форматировать как таблицу на вкладке Главная (Home — Format as Table) .
Подсчет количества совпадений
Для подсчета количества совпадений в двух списках можно использовать следующую элегантную формулу:
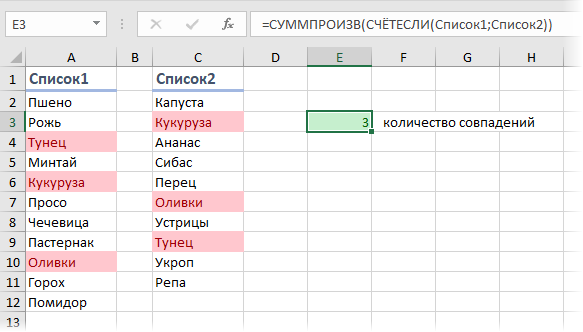
В английской версии это будет =SUMPRODUCT(COUNTIF(Список1;Список2))
Давайте разберем ее поподробнее, ибо в ней скрыто пару неочевидных фишек.
Во-первых, функция СЧЁТЕСЛИ (COUNTIF) . Обычно она подсчитывает количество искомых значений в диапазоне ячеек и используется в следующей конфигурации:
=СЧЁТЕСЛИ( Где_искать ; Что_искать )
Обычно первый аргумент — это диапазон, а второй — ячейка, значение или условие (одно!), совпадения с которым мы ищем в диапазоне. В нашей же формуле второй аргумент — тоже диапазон. На практике это означает, что мы заставляем Excel перебирать по очереди все ячейки из второго списка и подсчитывать количество вхождений каждого из них в первый список. По сути, это равносильно целому столбцу дополнительных вычислений, свернутому в одну формулу:
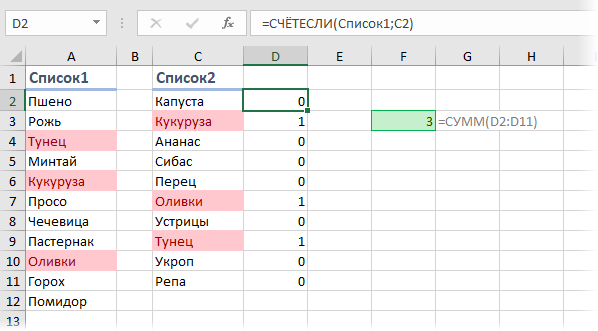
Во-вторых, функция СУММПРОИЗВ (SUMPRODUCT) здесь выполняет две функции — суммирует вычисленные СЧЁТЕСЛИ совпадения и заодно превращает нашу формулу в формулу массива без необходимости нажимать сочетание клавиш Ctrl + Shift + Enter . Формула массива необходима, чтобы функция СЧЁТЕСЛИ в режиме с двумя аргументами-диапазонами корректно отработала свою задачу.
Вывод списка совпадений формулой массива
Если нужно не просто подсчитать количество совпадений, но и вывести совпадающие элементы отдельным списком, то потребуется не самая простая формула массива:
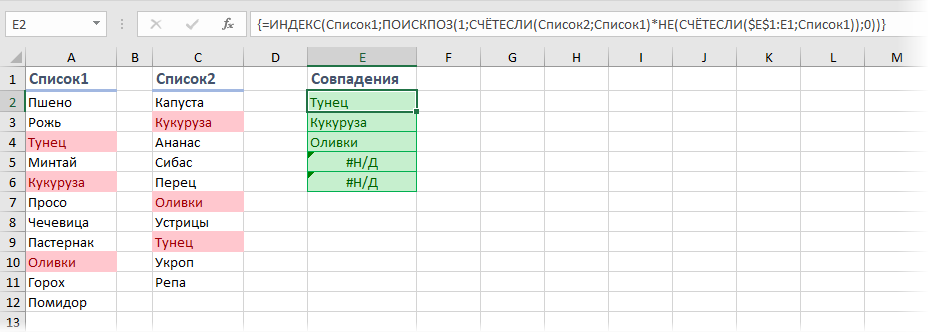
В английской версии это будет, соответственно:
Логика работы этой формулы следующая:
- фрагмент СЧЁТЕСЛИ(Список2;Список1), как и в примере до этого, ищет совпадения элементов из первого списка во втором
- фрагмент НЕ(СЧЁТЕСЛИ($E$1:E1;Список1)) проверяет, не найдено ли уже текущее совпадение выше
- и, наконец, связка функций ИНДЕКС и ПОИСКПОЗ извлекает совпадающий элемент
Не забудьте в конце ввода этой формулы нажать сочетание клавиш Ctrl + Shift + Enter , т.к. она должна быть введена как формула массива.
Возникающие на избыточных ячейках ошибки #Н/Д можно дополнительно перехватить и заменить на пробелы или пустые строки «» с помощью функции ЕСЛИОШИБКА (IFERROR) .
Вывод списка совпадений с помощью слияния запросов Power Query
На больших таблицах формула массива из предыдущего способа может весьма ощутимо тормозить, поэтому гораздо удобнее будет использовать Power Query. Это бесплатная надстройка от Microsoft, способная загружать в Excel 2010-2013 и трансформировать практически любые данные. Мощь и возможности Power Query так велики, что Microsoft включила все ее функции по умолчанию в Excel начиная с 2016 версии.
Для начала, нам необходимо загрузить наши таблицы в Power Query. Для этого выделим первый список и на вкладке Данные (в Excel 2016) или на вкладке Power Query (если она была установлена как отдельная надстройка в Excel 2010-2013) жмем кнопку Из таблицы/диапазона (From Table) :
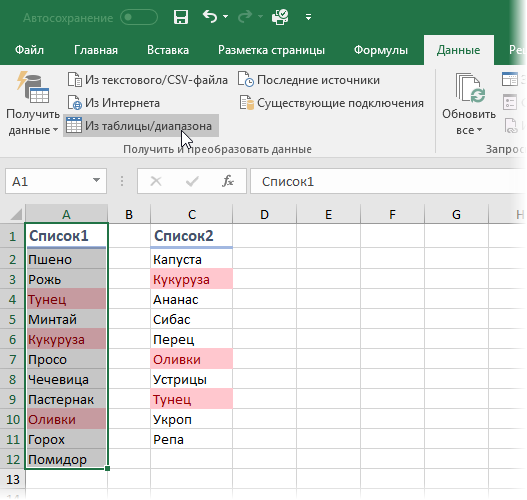
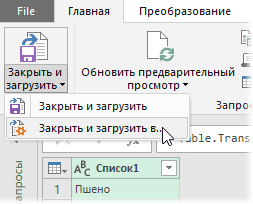
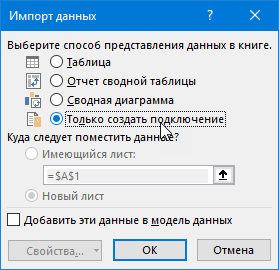
Excel превратит нашу таблицу в «умную» и даст ей типовое имя Таблица1. После чего данные попадут в редактор запросов Power Query. Никаких преобразований с таблицей нам делать не нужно, поэтому можно смело жать в левом верхнем углу кнопку Закрыть и загрузить — Закрыть и загрузить в. (Close & Load To. ) и выбрать в появившемся окне Только создать подключение (Create only connection) :
Затем повторяем то же самое со вторым диапазоном.
И, наконец, переходим с выявлению совпадений. Для этого на вкладке Данные или на вкладке Power Query находим команду Получить данные — Объединить запросы — Объединить (Get Data — Merge Queries — Merge) :
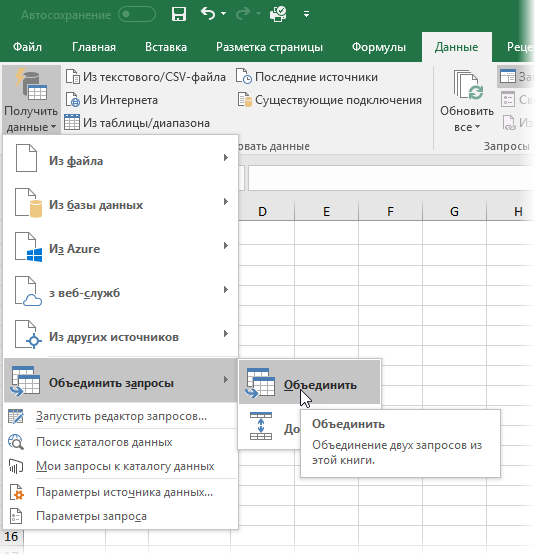
В открывшемся окне делаем три вещи:
- выбираем наши таблицы из выпадающих списков
- выделяем столбцы, по которым идет сравнение
- выбираем Тип соединения = Внутреннее (Inner Join)
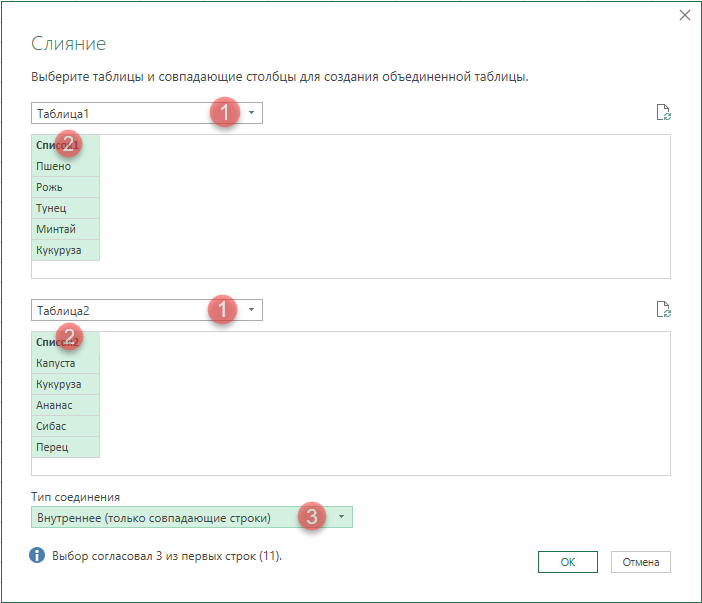
После нажатия на ОК на экране останутся только совпадающие строки:
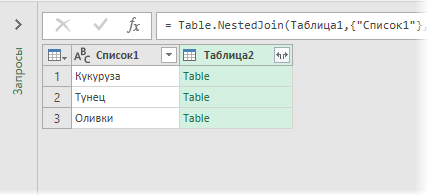
Ненужный столбец Таблица2 можно правой кнопкой мыши удалить, а заголовок первого столбца переименовать во что-то более понятное (например Совпадения). А затем выгрузить полученную таблицу на лист, используя всё ту же команду Закрыть и загрузить (Close & Load) :
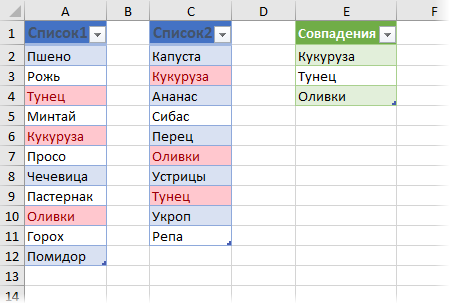
Если значения в исходных таблицах в будущем будут изменяться, то необходимо не забыть обновить результирующий список совпадений правой кнопкой мыши или сочетанием клавиш Ctrl + Alt + F5 .
Макрос для вывода списка совпадений
Само-собой, для решения задачи поиска совпадений можно воспользоваться и макросом. Для этого нажмите кнопку Visual Basic на вкладке Разработчик (Developer) . Если ее не видно, то отобразить ее можно через Файл — Параметры — Настройка ленты (File — Options — Customize Ribbon) .
В окне редактора Visual Basic нужно добавить новый пустой модуль через меню Insert — Module и затем скопировать туда код нашего макроса:
Воспользоваться добавленным макросом очень просто. Выделите, удерживая клавишу Ctrl , оба диапазона и запустите макрос кнопкой Макросы на вкладке Разработчик (Developer) или сочетанием клавиш Alt + F8 . Макрос попросит указать ячейку, начиная с которой нужно вывести список совпадений и после нажатия на ОК сделает всю работу:
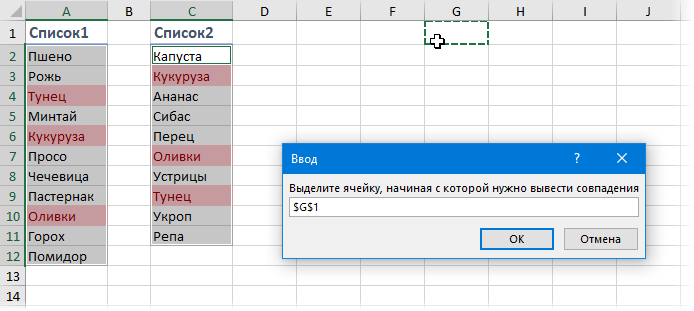
Более совершенный макрос подобного типа есть, кстати, в моей надстройке PLEX для Microsoft Excel.
Совпадение в столбцах Excel
Сегодня расскажу как искать совпадение в столбцах Excel. Разберем все тонкости на примерах.
Задача 1: Есть 6 текстов в 6 ячейках. Необходимо узнать, какие из них уникальные, а какие повторяются.
Использовать будем Условное форматирование.
- Выбираем ячейки, которые необходимо сравнить;
- Во вкладке Главная переходим «Условное форматирование -> Правила выделения ячеек -> Повторяющиеся значения»;
Выскакивает новое окно и в таблице начинают подсвечиваться ячейки, которые повторяются.
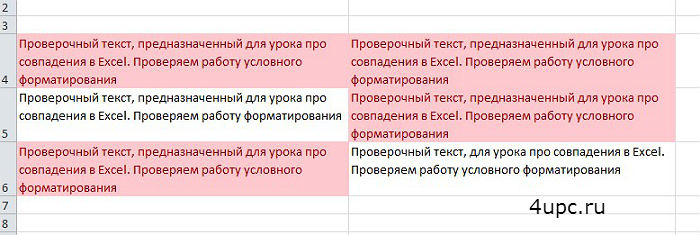
В этом окне вы можете выбрать две настройки: подсвечивать Повторяющиеся или Уникальные ячейки, а также какую подсветку при этом использовать — граница, текст, цвет текста, фон или своя уникальная.
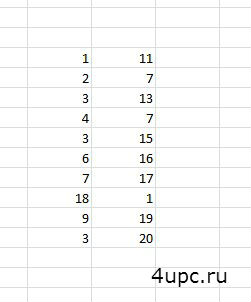
Рассмотрим еще пример. Необходимо сравнить два столбца в Excel на совпадения. Есть таблица, в которой также есть совпадения, но уже числовые.
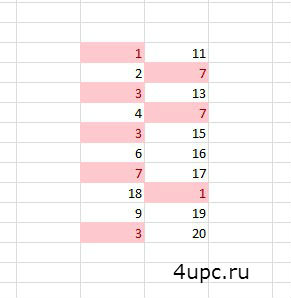
Выбираем таблицу и заходим в Повторяющиеся значения. Все совпадения будут подсвечены.
Можно, например, найти совпадения в одном столбце. Для этого достаточно перед применением опции выделить только его.

Ну и как я говорил выше, из выпадающего списка вы можете выделять не только повторяющиеся ячейки, но и уникальные.
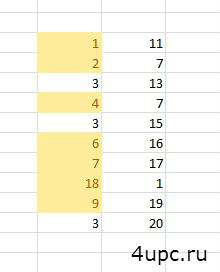
Искать таким образом можно буквы, слова, символы, тексты и т.д.
Как сравнить два столбца в Excel на совпадения
Пожалуй, каждый, кто работает с данными в Excel сталкивается с вопросом как сравнить два столбца в Excel на совпадения и различия. Существует несколько способов как это сделать. Давайте рассмотрим подробней каждый из них.
Как сравнить два столбца в Excel по строкам
Сравнивая два столбца с данными часто необходимо сравнивать данные в каждой отдельной строке на совпадения или различия. Сделать такой анализ мы можем с помощью функции ЕСЛИ . Рассмотрим как это работает на примерах ниже.
Пример 1. Как сравнить два столбца на совпадения и различия в одной строке
Для того, чтобы сравнить данные в каждой строке двух столбцов в Excel напишем простую формулу ЕСЛИ . Вставлять формулу следует в каждую строку в соседнем столбце, рядом с таблицей, в которой размещены основные данные. Создав формулу для первой строки таблицы, мы сможем ее протянуть/скопировать на остальные строки.
Для того чтобы проверить, содержат ли два столбца одной строки одинаковые данные нам потребуется формула:
=ЕСЛИ(A2=B2; “Совпадают”; “”)
Формула, определяющая различия между данными двух столбцов в одной строке будет выглядеть так:
=ЕСЛИ(A2<>B2; “Не совпадают”; “”)
Мы можем уместить проверку на совпадения и различия между двумя столбцами в одной строке в одной формуле:
=ЕСЛИ(A2=B2; “Совпадают”; “Не совпадают”)
=ЕСЛИ(A2<>B2; “Не совпадают”; “Совпадают”)
Пример результата вычислений может выглядеть так:

Для того чтобы сравнить данные в двух столбцах одной строки с учетом регистра следует использовать формулу:
=ЕСЛИ(СОВПАД(A2,B2); “Совпадает”; “Уникальное”)
Как сравнить несколько столбцов на совпадения в одной строке Excel
В Excel есть возможность сравнить данные в нескольких столбцах одной строки по следующим критериям:
- Найти строки с одинаковыми значениями во всех столбцах таблицы;
- Найти строки с одинаковыми значениями в любых двух столбцах таблицы;
Пример1. Как найти совпадения в одной строке в нескольких столбцах таблицы
Представим, что наша таблица состоит из нескольких столбцов с данными. Наша задача найти строки в которых значения совпадают во всех столбцах. В этом нам помогут функции Excel ЕСЛИ и И . Формула для определения совпадений будет следующей:
=ЕСЛИ(И(A2=B2;A2=C2); “Совпадают”; ” “)

Если в нашей таблице очень много столбцов, то более просто будет использовать функцию СЧЁТЕСЛИ в сочетании с ЕСЛИ :
=ЕСЛИ(СЧЁТЕСЛИ($A2:$C2;$A2)=3;”Совпадают”;” “)
В формуле в качестве “5” указано число столбцов таблицы, для которой мы создали формулу. Если в вашей таблице столбцов больше или меньше, то это значение должно быть равно количеству столбцов.
Пример 2. Как найти совпадения в одной строке в любых двух столбцах таблицы
Представим, что наша задача выявить из таблицы с данными в несколько столбцов те строки, в которых данные совпадают или повторяются как минимум в двух столбцах. В этом нам помогут функции ЕСЛИ и ИЛИ . Напишем формулу для таблицы, состоящей из трех столбцов с данными:
=ЕСЛИ(ИЛИ(A2=B2;B2=C2;A2=C2);”Совпадают”;” “)

В тех случаях, когда в нашей таблице слишком много столбцов – наша формула с функцией ИЛИ будет очень большой, так как в ее параметрах нам нужно указать критерии совпадения между каждым столбцом таблицы. Более простой способ, в этом случае, использовать функцию СЧЁТЕСЛИ .
=ЕСЛИ(СЧЁТЕСЛИ(B2:D2;A2)+СЧЁТЕСЛИ(C2:D2;B2)+(C2=D2)=0; “Уникальная строка”; “Не уникальная строка”)
Первая функция СЧЁТЕСЛИ вычисляет количество столбцов в строке со значением в ячейке А2 , вторая функция СЧЁТЕСЛИ вычисляет количество столбцов в таблице со значением из ячейки B2 . Если результат вычисления равен “0” – это означает, что в каждой ячейке, каждого столбца, этой строки находятся уникальные значения. В этом случае формула выдаст результат “Уникальная строка”, если нет, то “Не уникальная строка”.

Как сравнить два столбца в Excel на совпадения
Представим, что наша таблица состоит из двух столбцов с данными. Нам нужно определить повторяющиеся значения в первом и втором столбцах. Для решения задачи нам помогут функции ЕСЛИ и СЧЁТЕСЛИ .
=ЕСЛИ(СЧЁТЕСЛИ($B:$B;$A5)=0; “Нет совпадений в столбце B”; “Есть совпадения в столбце В”)

Эта формула проверяет значения в столбце B на совпадение с данными ячеек в столбце А.
Если ваша таблица состоит из фиксированного числа строк, вы можете указать в формуле четкий диапазон (например, $B2:$B10 ). Это позволит ускорить работу формулы.
Как сравнить два столбца в Excel на совпадения и выделить цветом
Когда мы ищем совпадения между двумя столбцами в Excel, нам может потребоваться визуализировать найденные совпадения или различия в данных, например, с помощью выделения цветом. Самый простой способ для выделения цветом совпадений и различий – использовать “Условное форматирование” в Excel. Рассмотрим как это сделать на примерах ниже.
Поиск и выделение совпадений цветом в нескольких столбцах в Эксель
В тех случаях, когда нам требуется найти совпадения в нескольких столбцах, то для этого нам нужно:
- Выделить столбцы с данными, в которых нужно вычислить совпадения;
- На вкладке “Главная” на Панели инструментов нажимаем на пункт меню “Условное форматирование” -> “Правила выделения ячеек” -> “Повторяющиеся значения”;
- Во всплывающем диалоговом окне выберите в левом выпадающем списке пункт “Повторяющиеся”, в правом выпадающем списке выберите каким цветом будут выделены повторяющиеся значения. Нажмите кнопку “ОК”:
- После этого в выделенной колонке будут подсвечены цветом совпадения:

Поиск и выделение цветом совпадающих строк в Excel
Поиск совпадающих ячеек с данными в двух, нескольких столбцах и поиск совпадений целых строк с данными это разные понятия. Обратите внимание на две таблицы ниже:
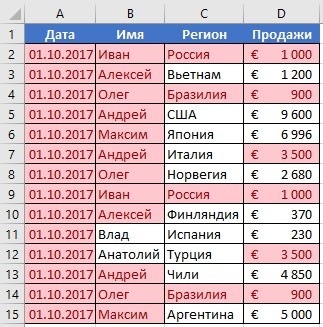
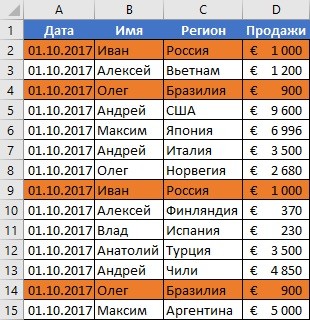
В таблицах выше размещены одинаковые данные. Их отличие в том, что на примере слева мы искали совпадающие ячейки, а справа мы нашли целые повторяющие строчки с данными.
Рассмотрим как найти совпадающие строки в таблице:
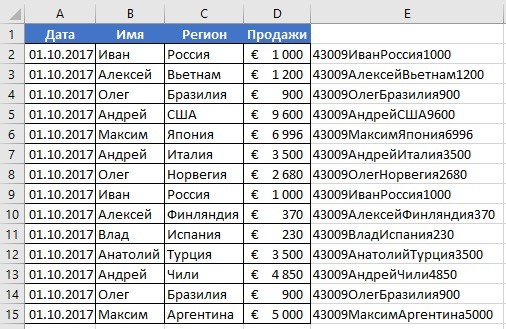
- Справа от таблицы с данными создадим вспомогательный столбец, в котором напротив каждой строки с данными проставим формулу, объединяющую все значения строки таблицы в одну ячейку:
=A2&B2&C2&D2
Во вспомогательной колонке вы увидите объединенные данные таблицы:
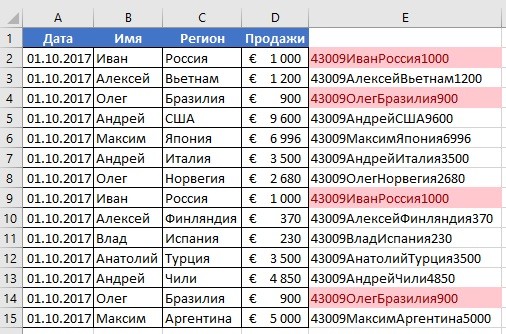
Теперь, для определения совпадающих строк в таблице сделайте следующие шаги:
- Выделите область с данными во вспомогательной колонке (в нашем примере это диапазон ячеек E2:E15 );
- На вкладке “Главная” на Панели инструментов нажимаем на пункт меню “Условное форматирование” -> “Правила выделения ячеек” -> “Повторяющиеся значения”;
- Во всплывающем диалоговом окне выберите в левом выпадающем списке “Повторяющиеся”, в правом выпадающем списке выберите каким цветом будут выделены повторяющиеся значения. Нажмите кнопку “ОК”:
- После этого в выделенной колонке будут подсвечены дублирующиеся строки:
На примере выше, мы выделили строки в созданной вспомогательной колонке.
Но что, если нам нужно выделить цветом строки не во вспомогательном столбце, а сами строки в таблице с данными?
Для этого сделаем следующее:
- Так же как и в примере выше создадим вспомогательный столбец, в каждой строке которого проставим следующую формулу:
=A2&B2&C2&D2
Таким образом, мы получим в одной ячейке собранные данные всей строки таблицы:
- Теперь, выделим все данные таблицы (за исключением вспомогательного столбца). В нашем случае это ячейки диапазона A2:D15 ;
- Затем, на вкладке “Главная” на Панели инструментов нажмем на пункт “Условное форматирование” -> “Создать правило”:
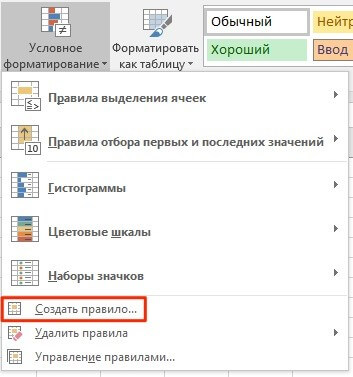
- В диалоговом окне “Создание правила форматирования” кликните на пункт “Использовать формулу для определения форматируемых ячеек” и в поле “Форматировать значения, для которых следующая формула является истинной” вставьте формулу:
=СЧЁТЕСЛИ($E$2:$E$15;$E2)>1
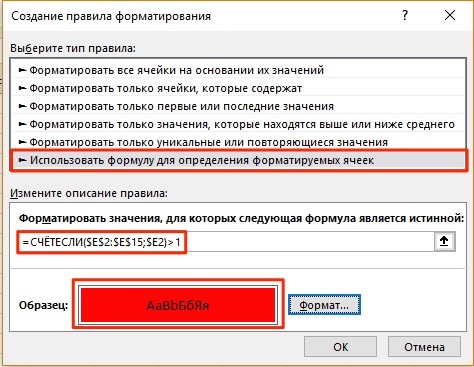
- Не забудьте задать формат найденных дублированных строк.
Эта формула проверяет диапазон данных во вспомогательной колонке и при наличии повторяющихся строк выделяет их цветом в таблице:
На чтение 4 мин. Просмотров 2.4k.
Для того, чтобы найти приближенное соответствие на основе более одного критерия, вы можете использовать формулу массива, основанную на ИНДЕКС и ПОИСКПОЗ, с помощью функции ЕСЛИ.

Пример формулы в G7:
{ = ИНДЕКС (D5:D10; ПОИСКПОЗ (G6; ЕСЛИ( B5:B10 = G5; С5:С10);1))}
Целью данной формулы является найти размер кошки, если известен ее вес.
По сути, это просто формула ИНДЕКС/ПОИСКПОЗ. Проблемой в данном случае является то, что нам нужно «отсеивать» посторонние записи в таблице.
Это делается с помощью простой функции ЕСЛИ:
ЕСЛИ( B5:B10 = G5; С5:С10 )
Она входит в функцию ПОИСКПОЗ как массив. Значение поиска для совпадений происходит от G6, который содержит вес (7 кг в примере).
Обратите внимание, что совпадение настроено для приблизительного совпадения, установив тип_сопоставления = 1, это нужно сортировки С5:С10.
ПОИСКПОЗ возвращает позицию веса в массиве, и передается ИНДЕКСУ как номер строки. Поисковый_массив для ИНДЕКСА размеры в D5:D10, так ИНДЕКС получает размер, соответствующий положению генерируемого совпадением (номер 6 в показанном примере).
Содержание
- Базовый ИНДЕКС ПОИСКПОЗ с приближенным сопоставлением
- Базовый ИНДЕКС ПОИСКПОЗ, точное совпадение
- Чувствительное к регистру совпадение
- Точный поиск соответствия с ИНДЕКС и ПОИСКПОЗ
Базовый ИНДЕКС ПОИСКПОЗ с приближенным сопоставлением
= ИНДЕКС( класс; ПОИСКПОЗ( балл; баллы; 1))
Этот пример показывает, как использовать ИНДЕКС и ПОИСКПОЗ для получения класса из таблицы на основе заданного балла. Для этого требуется «приближенное соответствие», так как маловероятно , что реальная оценка существует в таблице.

Обратите внимание , что последний аргумент 1 (эквивалент ИСТИНЫ), что позволяет ПОИСКПОЗ выполнить приблизительное совпадение на значения , перечисленные в порядке возрастания. В этой конфигурации, ПОИСКПОЗ возвращает позицию первого значения, которое меньше или равно значению перекодировки.
Базовый ИНДЕКС ПОИСКПОЗ, точное совпадение
= ИНДЕКС( данные; ПОИСКПОЗ( значение; поиск_столбца ; ЛОЖЬ); столбец )
Эта формула использует ПОИСКПОЗ, чтобы получить позицию строки «Истории Игрушек» в таблице, и ИНДЕКС для извлечения значения в этой строке в колонке 2.

Обратите внимание, что последний аргумент имеет значение 0, что заставляет ПОИСКПОЗ найти точное совпадение.
ИНДЕКС с одним столбцом
В приведенном выше примере, ИНДЕКС получает массив, который содержит все данные в таблице. Тем не менее, вы можете легко переписать формулы для работы только с одним столбцом, что избавляет от необходимости указывать номер столбца:
= ИНДЕКС (С5:C9; ПОИСКПОЗ (H4; B5:B9;0)) // год
= ИНДЕКС (D5:D9; ПОИСКПОЗ (H4; B5:B9;0)) // ранг
= ИНДЕКС (E5:E9; ПОИСКПОЗ (H4; B5:B9;0)) // продажи
В каждом случае ИНДЕКС принимает массив одного столбца, который соответствует данным его извлечений, и ПОИСКПОЗ поставляет номер строки.
Чувствительное к регистру совпадение
{ = ПОИСКПОЗ (ИСТИНА; СОВПАД (диапазон; значение); 0)}
Для выполнения чувствительного к регистру совпадения, вы можете использовать функцию СОВПАД вместе с ПОИСКПОЗ в формуле массива.

Сама по себе функция ПОИСКПОЗ не чувствительна к регистру, поэтому следующая формула получает 1:
= ПОИСКПОЗ («ИВАН»; B5:B11; 0 )
Чтобы добавить чувствительность к регистру, мы используем функцию СОВПАД:
СОВПАД ( B5:B11; E4 )
Которая получает массив истина/ложь значения:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ}
Этот массив переходит в функции ПОИСКПОЗ как массив. Для поиска, мы используем значение ИСТИНА с ПОИСКПОЗ, установленным в режим точного соответствия путем установки тип_сопоставления к нулю.
= ПОИСКПОЗ (ИСТИНА; { ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ}; 0 )
ПОИСКПОЗ затем получает позицию первого найденного истинного значения: 4.
Точный поиск соответствия с ИНДЕКС и ПОИСКПОЗ
{= ИНДЕКС (данные;ПОИСКПОЗ (ИСТИНА; СОВПАД(текст1; текст2 );0 ); номер_столбца )}
Если вам нужно сделать, чувствительный к регистру поиск, вы можете сделать это с помощью формулы массива, которая использует ИНДЕКС, ПОИСКПОЗ и СОВПАД функции.

В примере, мы используем следующую формулу
={ИНДЕКС (B5:D12; ПОИСКПОЗ (ИСТИНА; СОВПАД (F5;B5:B12);0);3)}
Эта формула будет извлекать текст и числовые значения. Если вы хотите получить только числа, вы можете использовать формулу, основанную на СУММПРОИЗВ.