
Получить первое непустое значение в столбце или строке
Чтобы получить первое значение (первая ячейка, которая не пуста, без учета ошибок) из диапазона из одного столбца или одной строки, вы можете использовать формулу, основанную на ИНДЕКС и МАТЧ функции. Однако, если вы не хотите игнорировать ошибки из вашего диапазона, вы можете добавить функцию ISBLANK к приведенной выше формуле.
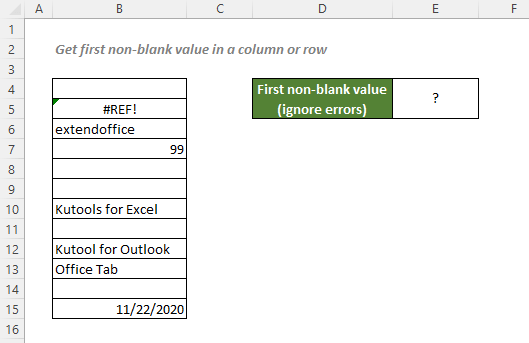
Получить первое непустое значение в столбце или строке, игнорируя ошибки
Получить первое непустое значение в столбце или строке, включая ошибки
Получить первое непустое значение в столбце или строке, игнорируя ошибки
Чтобы получить первое непустое значение в списке как показано выше игнорирование ошибок, вы можете использовать функцию ИНДЕКС, чтобы найти непустые ячейки. Затем вы можете использовать ПОИСКПОЗ, чтобы найти его положение, и которое будет передано в другой ИНДЕКС, чтобы получить значение в этой позиции.
Общий синтаксис
=INDEX(range,MATCH(TRUE,INDEX((range<>0),0),0))
- ассортимент: Диапазон из одного столбца или одной строки, в котором должна быть возвращена первая непустая ячейка с текстовыми или числовыми значениями при игнорировании ошибок.
Чтобы получить первое непустое значение в списке без учета ошибок, скопируйте или введите формулу ниже в ячейку E4 и нажмите Enter чтобы получить результат:
= ИНДЕКС (B4: B15, ПОИСКПОЗ (ИСТИНА; ИНДЕКС ((B4: B15<> 0), 0), 0))
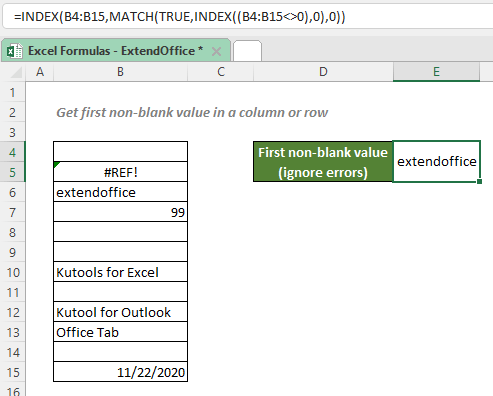
Пояснение формулы
=INDEX(B4:B15,MATCH(TRUE,INDEX((B4:B15<>0),0),0))
- ИНДЕКС ((B4: B15 <> 0), 0): Фрагмент оценивает каждое значение в диапазоне B4: B15. Если ячейка пуста, она вернет FLASE; Если ячейка содержит ошибку, сниппет сам вернет ошибку; И если ячейка содержит число или текст, будет возвращено ИСТИНА. Поскольку row_num аргумент этой формулы ИНДЕКС: 0, поэтому фрагмент вернет массив значений для всего столбца следующим образом: {ЛОЖЬ; # ССЫЛКА!; ИСТИНА; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ИСТИНА; ИСТИНА; ЛОЖЬ; ИСТИНА}.
- МАТЧ (ИСТИНА;ИНДЕКС ((B4: B15 <> 0), 0), 0) = МАТЧ (ИСТИНА;{ЛОЖЬ; # ССЫЛКА!; ИСТИНА; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ИСТИНА; ИСТИНА; ЛОЖЬ; ИСТИНА}, 0): Наблюдения и советы этой статьи мы подготовили на основании опыта команды match_type 0 заставляет функцию ПОИСКПОЗ возвращать позицию первого точного ИСТИНА в массиве. Итак, функция вернет 3.
- ИНДЕКС (B4: B15,МАТЧ (ИСТИНА;ИНДЕКС ((B4: B15 <> 0), 0), 0)) = ИНДЕКС (B4: B15;3): Затем функция ИНДЕКС возвращает 3rd значение в диапазоне B4: B15, Которая является extendoffice.
Получить первое непустое значение в столбце или строке, включая ошибки
Чтобы получить первое непустое значение в списке, включая ошибки, вы можете просто использовать функцию ISBLANK, чтобы проверить ячейки в списке, являются ли они пустыми или нет. Затем ИНДЕКС вернет первое непустое значение в соответствии с позицией, предоставленной ПОИСКПОЗ.
Общий синтаксис
=INDEX(range,MATCH(FALSE,ISBLANK(range),0))
√ Примечание. Это формула массива, требующая ввода с помощью Ctrl + Shift + Enter.
- ассортимент: Диапазон из одного столбца или одной строки, в котором должна быть возвращена первая непустая ячейка с текстом, числами или значениями ошибки.
Чтобы получить первое непустое значение в списке, включая ошибки, скопируйте или введите формулу ниже в ячейку E7 и нажмите Ctrl + Shift + Enter чтобы получить результат:
= ИНДЕКС (B4: B15, ПОИСКПОЗ (ЛОЖЬ; ЕСТЬ ПУСТО (B4: B15), 0))
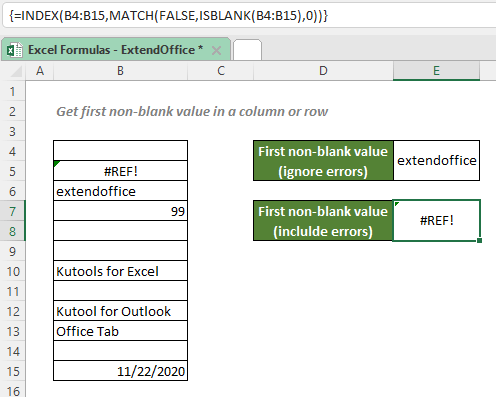
Пояснение формулы
=INDEX(B4:B15,MATCH(FALSE,ISBLANK(B4:B15),0))
- ISBLANK (B4: B15): Функция ISBLANK проверяет, находятся ли ячейки в диапазоне B4: B15 пустые или нет. Если да, будет возвращено ИСТИНА; В противном случае будет возвращено ЛОЖЬ. Итак, функция сгенерирует такой массив: {ИСТИНА; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ}.
- МАТЧ (ЛОЖЬ;ISBLANK (B4: B15), 0) = МАТЧ (ЛОЖЬ;{ИСТИНА; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ}, 0): Наблюдения и советы этой статьи мы подготовили на основании опыта команды match_type 0 заставляет функцию ПОИСКПОЗ возвращать позицию первого точного НЕПРАВДА в массиве. Итак, функция вернет 2.
- ИНДЕКС (B4: B15,МАТЧ (ЛОЖЬ;ISBLANK (B4: B15), 0)) = ИНДЕКС (B4: B15;2): Затем функция ИНДЕКС возвращает 2ое значение в диапазоне B4: B15, Которая является #REF!.
Связанные функции
Функция ИНДЕКС в Excel
Функция ИНДЕКС Excel возвращает отображаемое значение на основе заданной позиции из диапазона или массива.
Функция ПОИСКПОЗ в Excel
Функция ПОИСКПОЗ в Excel ищет определенное значение в диапазоне ячеек и возвращает относительное положение значения.
Связанные формулы
Точное совпадение с ИНДЕКСОМ и ПОИСКПОЗ
Если вам нужно найти информацию, указанную в Excel, о конкретном продукте, фильме или человеке и т. Д., Вы должны хорошо использовать комбинацию функций ИНДЕКС и ПОИСКПОЗ.
Получить первое текстовое значение в столбце
Чтобы получить первое текстовое значение из диапазона с одним столбцом, вы можете использовать формулу, основанную на функциях ИНДЕКС и ПОИСКПОЗ, а также формулу, основанную на функции ВПР.
Найдите первое частичное совпадение с помощью подстановочных знаков
Есть случаи, когда вам нужно получить позицию первого частичного совпадения, которое содержит определенное число в диапазоне числовых значений в Excel. В этом случае формула ПОИСКПОЗ и ТЕКСТ, содержащая звездочку (*), подстановочный знак, который соответствует любому количеству символов, окажет вам услугу. И если вам также нужно знать точное значение в этой позиции, вы можете добавить в формулу функцию ИНДЕКС.
Найдите первое частичное совпадение
Есть случаи, когда вам нужно получить позицию первого частичного совпадения, которое содержит определенное число в диапазоне числовых значений в Excel. В этом случае формула ПОИСКПОЗ и ТЕКСТ, содержащая звездочку (*), подстановочный знак, который соответствует любому количеству символов, окажет вам услугу. И если вам также нужно знать точное значение в этой позиции, вы можете добавить в формулу функцию ИНДЕКС.
Лучшие инструменты для работы в офисе
Kutools for Excel — Помогает вам выделиться из толпы
Хотите быстро и качественно выполнять свою повседневную работу? Kutools for Excel предлагает 300 мощных расширенных функций (объединение книг, суммирование по цвету, разделение содержимого ячеек, преобразование даты и т. д.) и экономит для вас 80 % времени.
- Разработан для 1500 рабочих сценариев, помогает решить 80% проблем с Excel.
- Уменьшите количество нажатий на клавиатуру и мышь каждый день, избавьтесь от усталости глаз и рук.
- Станьте экспертом по Excel за 3 минуты. Больше не нужно запоминать какие-либо болезненные формулы и коды VBA.
- 30-дневная неограниченная бесплатная пробная версия. 60-дневная гарантия возврата денег. Бесплатное обновление и поддержка 2 года.
")
Вкладка Office — включение чтения и редактирования с вкладками в Microsoft Office (включая Excel)
- Одна секунда для переключения между десятками открытых документов!
- Уменьшите количество щелчков мышью на сотни каждый день, попрощайтесь с рукой мыши.
- Повышает вашу продуктивность на 50% при просмотре и редактировании нескольких документов.
- Добавляет эффективные вкладки в Office (включая Excel), точно так же, как Chrome, Firefox и новый Internet Explorer.
")
|
caustic  Пользователь Сообщений: 342 |
Собственно, Функция поискпоз — находит всегда последнюю-нижнюю позицию. |
|
caustic Пользователь Сообщений: 342 |
Спасибо Но, я имел в виду поиск по числам (правый столбец). |
|
Формула массива |
|
|
caustic Пользователь Сообщений: 342 |
{quote}{login=}{date=31.07.2009 10:42}{thema=}{post}Формула массива Спасибо — но не подойдет, т.к. мне нужна позиция в диапазоне а не номер строки. |
|
А не то чтобы позиция первого сверху непустого значения в списке всегда будет первой, т.е. равной 1? |
|
|
caustic Пользователь Сообщений: 342 |
{quote}{login=KL}{date=31.07.2009 11:42}{thema=}{post}А не то чтобы позиция первого сверху непустого значения в списке всегда будет первой, т.е. равной 1?{/post}{/quote} Ну в списке она будет первой, если непустая. для решения вот этой задачи: http://www.planetaexcel.ru/forum.php?thread_id=8944 |
|
{quote}{login=CaustiC}{date=31.07.2009 09:55}{thema=Как найти позицию первого сверху непустого значения в списке?}{post}Функция поискпоз — находит всегда последнюю-нижнюю позицию.{/post}{/quote} Это — неправда. ПОИСКПОЗ находит последнюю позицию только в случае поиска с приблизительным совпадением, а так первую. Посмотрел файл с примером, оказывается речь о позиции в диапазоне. Как насчет этого? =СУММПРОИЗВ(ПОИСКПОЗ(ИСТИНА;D6:D12>0;0)) |
|
|
{quote}{login=KL}{date=31.07.2009 11:49}{thema=Re: Как найти позицию первого сверху непустого значения в списке?}{post}{quote}{login=CaustiC}{date=31.07.2009 09:55}{thema=Как найти позицию первого сверху непустого значения в списке?}{post}Функция поискпоз — находит всегда последнюю-нижнюю позицию.{/post}{/quote} Это — неправда. ПОИСКПОЗ находит последнюю позицию только в случае поиска с приблизительным совпадением, а так первую. Посмотрел файл с примером, оказывается речь о позиции в диапазоне. Как насчет этого? =СУММПРОИЗВ(ПОИСКПОЗ(ИСТИНА;D6:D12>0;0)){/post}{/quote} Блин! Ну вы монстры какие то! |
|
|
KL Подскажи — ка сделать так чтобы не по одному столбцу а по нескольким расчитывалось? |
|
|
Например вот так, но это крайне ресурсоемкая формула массива (ввод с помощью {Ctrl+Shift+Enter}), если диапазон большой, то пересчет может сильно замедлиться: =МИН(ЕСЛИ(D6:F12>0;СТРОКА(D6:F12)))-СТРОКА(D6)+1 |
|
|
=СУММПРОИЗВ(ПОИСКПОЗ(ИСТИНА;ДЛСТР(D6:D12&E6:E12&F6:F12)>0;0)) вопрос-оффтоп: этот вариант наверное быстрее, т к поиски заканчиваются при нахождении непустого значения, так? |
|
|
А, собственно, там суммпроизв не нужен. |
|
|
слэн  Пользователь Сообщений: 5192 |
разница между менее 1%, но есть.. |
|
Не, меня интересует разница между =ПОИСКПОЗ(ИСТИНА;ДЛСТР(D6:D12&E6:E12&F6:F12)>0;0) и =МИН(ЕСЛИ(D6:F12>0;СТРОКА(D6:F12)))-СТРОКА(D6)+1 Можешь глянуть пожалуйста? кстати, а каким макросом(или чем?) вы засекаете время пересчёта? |
|
|
Сейчас снова вдалеке от компа, но… |
|
|
Как я и предполагал, в MSO2007 (на моей машине), для полностью заполненного числами диапазона 1000 х 3, формула «=МИН(ЕСЛИ(D6:F12>0;СТРОКА(D6:F12)))-СТРОКА(D6)+1» на 35% быстрее, чем «=ПОИСКПОЗ(ИСТИНА;ДЛСТР(D6:D12&E6:E12&F6:F12)>0;0)» |
|
 Разница сокращается по мере опустения диапазона, при пустом диапазоне с данными в последней строке скорости практически одинаковые.
Разница сокращается по мере опустения диапазона, при пустом диапазоне с данными в последней строке скорости практически одинаковые.|
{quote}{login=}{date=31.07.2009 01:52}{thema=}{post}кстати, а каким макросом(или чем?) вы засекаете время пересчёта?{/post}{/quote} см. надстройку RangeCalc.zip здесь: http://www.decisionmodels.com/downloads.htm Очень важно: перед проведением замеров, обязательно менять режим пересчета на ручной, иначе данные будут искаженными! |
|
|
слэн Пользователь Сообщений: 5192 |
|
|
{quote}{login=CaustiC}{date=31.07.2009 11:03}{thema=Re: }{post}{quote}{login=}{date=31.07.2009 10:42}{thema=}{post}Формула массива Спасибо — но не подойдет, т.к. мне нужна позиция в диапазоне а не номер строки.{/post}{/quote} |
|
|
caustic Пользователь Сообщений: 342 |
#20 03.08.2009 08:47:05 Начал пристраивать но заметил что если значений в таблице нет, то. показывает (-5) caustic |
Здравствуйте, форумчане! В Excel-e не новичок, пользуюсь давно, но вот перемкнуло:  не получается построить формулу, выбирающую значение из первой непустой ячейки столбца. До сих пор использовал макросы или обходные пути, но чувствую, что должно быть более простое и быстрое решение. Устроит любая форма адресации — ссылка, смещение, номер строки. Заранее спасибо!
не получается построить формулу, выбирающую значение из первой непустой ячейки столбца. До сих пор использовал макросы или обходные пути, но чувствую, что должно быть более простое и быстрое решение. Устроит любая форма адресации — ссылка, смещение, номер строки. Заранее спасибо! 
Позицию первой непустой ячейки можно вернуть так:
=ПОИСКПОЗ(«?»;A1:A10&»»;) — формула массива (текст и числа)
или:
=ПОИСКПОЗ(«*»;A1:A10  — обычная формула (только текст)
— обычная формула (только текст)
Ну и соответственно возврат самих значений:
=ВПР(«?»;A1:A10&»»;1;) — формула массива (текст и числа) — возвращает числа также в виде текста.
и
=ВПР(«*»;A1:A10;1;) — обычная формула (только текст)
Webmoney: E350157549801 Z116603216205 R268084006579
Не «массивная» формула для поиска номера строки:
=СУММПРОИЗВ(ПОИСКПОЗ(«*?*»;(«»&A1:A23);0))
Даже самый простой вопрос можно превратить в огромную проблему. Достаточно не уметь формулировать вопросы…
www.excel-vba.ru
Просто СПАСИБО [+оказать+]
Считаешь СПАСИБО мало? Яндекс.Деньги: 41001332272872; WM: R298726502453
Ну раз такое дело, во еще 
=ПРОСМОТР(«»;A1:A10&»»;A2:A11)
Webmoney: E350157549801 Z116603216205 R268084006579
Цитата: Axacal от 27.06.2011, 13:40
Формула =ПРОСМОТР(«»;A1:A10&»»;A2:A11) на столбце со смещанным содержимым (пустые клетки, текст, числа) вообще ведет себя некорректно.
У меня работает, см. вложение.
Заодно добавил ещё свой вариантик формулы, который не предлагали ранее.
Цитата: Axacal от 27.06.2011, 13:40
Что означает приклеивание амперсандом пробела к адресу массива (A1:A10&»»)?
Замена пустых строк строками нулевой длинны.
Еще вариант немассивной:
=ПОИСКПОЗ("*?";ИНДЕКС(""&A1:A23;);)
ЦитироватьКстати, что означает приклеивание амперсандом пробела к адресу массива (A1:A10&»»)?
цифры в массиве становятся текстовыми данными

Хочется добавить:
Сцепляется не с пробелом, а со строкой нулевой длины.
Для корректной работы формулы: =ПРОСМОТР(«»;A1:A10&»»;A2:A11) требуется хотябы одна пустая верхняя ячейка.
Webmoney: E350157549801 Z116603216205 R268084006579
Возникла похожая, но «обратная» задача: найти первую пустую строку.
В принципе, мне удались решения с доп. столбцом и с формулой массива, но хочется упростить задачу.
Есть ли у кого-нибудь идеи?
пока придумалась такая формула массива:
=СУММ(C4:ИНДЕКС(C4:$C$13;ПОИСКПОЗ(» «;» «&B4:$B$13;0))*D4:ИНДЕКС(D4:$D$13;ПОИСКПОЗ(» «;» «&B4:$B$13;0)))
Даже самый простой вопрос можно превратить в огромную проблему. Достаточно не уметь формулировать вопросы…
www.excel-vba.ru
Просто СПАСИБО [+оказать+]
Считаешь СПАСИБО мало? Яндекс.Деньги: 41001332272872; WM: R298726502453
На чтение 7 мин. Просмотров 30k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Это глава из книги Билла Джелена Гуру Excel расширяют горизонты: делайте невозможное с Microsoft Excel.
Задача: требуется формула, которая позволяла найти первое непустое значение в строке, т.е., возвращала бы номер первой непустой ячейки в строке. Предположим, что данные представлены в столбцах С:K (рис. 1).
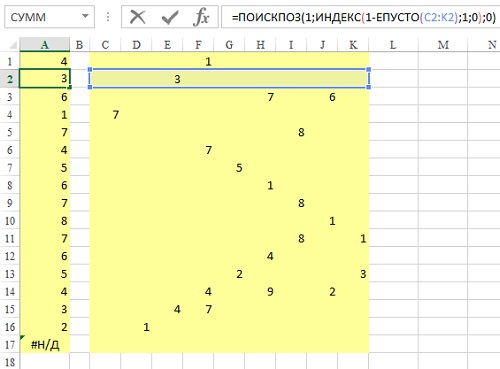
Рис. 1. Формула находит первую непустую ячейку в каждой строке и возвращает ее номер в массиве
Скачать заметку в формате Word или pdf, примеры в формате Excel
Решение: формула в А2: =ПОИСКПОЗ(1;ИНДЕКС(1-ЕПУСТО(C2:K2);1;0);0). Хотя эта формула имеет дело с массивом ячеек, она в конечном счете возвращает одно значение, так что использовать при вводе нажатие Ctrl+Shift+Enter не требуется (о формулах массива см. Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel).
Рассмотрим работу формулы подробнее. Функция ЕПУСТО возвращает ИСТИНА, если ячейка является пустой, и ЛОЖЬ, если ячейка – не пустая. Посмотрите на строку данных в С2:К2. ЕПУСТО(С2:К2) возвратит массив: {ИСТИНА;ИСТИНА;ЛОЖЬ;ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА}.
Обратите внимание, что далее этот массив вычитается из 1. При попытке использовать значения ИСТИНА и ЛОЖЬ в математической формуле, значение ИСТИНА интерпретируется как 1, а значение ЛОЖЬ – как 0. Задавая 1-ЕПУСТО(С2:К2), вы преобразуете массив логических значений ИСТИНА/ЛОЖЬ в числовую последовательность нулей и единиц: {0;0;1;0;0;0;0;0;0}.
Итак, фрагмент формулы 1-ЕПУСТО(С2:К2) возвращает массив {0;0;1;0;0;0;0;0;0}. Это немного странно, так как от такого фрагмента Excel ожидает, что вернется одно значение. Странно, но не смертельно. Функция ИНДЕКС также обычно возвращает одно значение. Но вот, что написано в Справке Excel: Если указать в качестве аргумента номер_строки или номер_столбца значение 0 (ноль), функция ИНДЕКС возвратит массив значений для целого столбца или целой строки соответственно. Чтобы использовать значения, возвращенные как массив, введите функцию ИНДЕКС как формулу массива в горизонтальный диапазон ячеек для строки и в вертикальный — для столбца.
Если функция ИНДЕКС возвращает массив, ее можно использовать внутри других функций, ожидающих, что аргумент является массивом.
Итак, указав в качестве третьего аргумента функции ИНДЕКС(1-ЕПУСТО(C2:K2);1;0) значение ноль, мы получим массив {0;0;1;0;0;0;0;0;0}.
Функция ПОИСКПОЗ выполняет поиск искомого значения в одномерном массиве и возвращает относительную позицию первого найденного совпадения. Формула =ПОИСКПОЗ(1,МАССИВ,0) просит Excel найти номер ячейки в МАССИВЕ, которая содержит первую встретившуюся единицу. Функция ПОИСКПОЗ определяет в каком столбце содержится первая непустая ячейка. Когда вы просите ПОИСКПОЗ найти первую 1 в массиве {0;0;1;0;0;0;0;0;0}, она возвращает 3.
Итак =ПОИСКПОЗ(1;ИНДЕКС(1-ЕПУСТО(C2:K2);1;0);0) превращается в =ПОИСКПОЗ(1;{0;0;1;0;0;0;0;0;0};0) и возвращает результат 3.
В этот момент, вы знаете, что третий столбец строки С2:К2 содержит первое непустое значение. Отсюда довольно просто, используя функцию ИНДЕКС, узнать само это первое непустое значение: =ИНДЕКС(МАССИВ;1;3) или =ИНДЕКС(C2:K2;1;ПОИСКПОЗ(1;ИНДЕКС(1-ЕПУСТО(C2:K2);1;0);0)).
Результат: 3

Рис. 2. Формула находит первую непустую ячейку в каждой строке и возвращает значение этой ячейки
Дополнительные сведения: если все ячейки пустые, то формула возвращает ошибку #Н/Д.
Альтернативные стратегии: когда вы из единицы вычитаете значение ЕПУСТО, вы преобразуете логические значения ИСТИНА/ЛОЖЬ в числовые 1/0. Вы могли бы пропустить этот шаг, но тогда вам придется искать ЛОЖЬ в качестве первого аргумента функция ПОИСКПОЗ: =ИНДЕКС(C2:K2;1;ПОИСКПОЗ(ЛОЖЬ;ИНДЕКС(ЕПУСТО(C2:K2);1;0);0)).
Источник.