
Хитрости »
15 Май 2011 512328 просмотров
Как найти значение в другой таблице или сила ВПР
- Задача и её решение при помощи ВПР
- Описание аргументов ВПР
- Что важно всегда помнить при работе с ВПР
- Как избежать ошибки #Н/Д(#N/A) в ВПР?
- Как при помощи ВПР искать значение по строке, а не столбцу?
- Решение при помощи ПОИСКПОЗ
- Работа с критериями длиннее 255 символов
Если в двух словах, то ВПР позволяет сравнить данные двух таблиц на основании значений из одного столбца.
Чтобы чуть лучше понять принцип работы ВПР лучше начать с некоего практического примера. Возьмем две таблицы:

рис.1
На картинке выше для удобства они показаны рядом, но на самом деле могут быть расположены на разных листах и даже в разных книгах. Таблицы по сути одинаковые, но фамилии в них расположены в разном порядке, и к тому же в одной заполнены все столбцы, а во второй столбцы ФИО и Отдел. И из первой таблицы необходимо подставить во вторую дату для каждой фамилии. Для трех записей это не проблема и руками сделать — все очевидно. Но в жизни это таблицы на тысячи записей и поиск с подстановкой данных вручную может занять не один час. Вот где ВПР(VLOOKUP) будет весьма кстати. Все, что необходимо — записать в ячейку
C2
второй таблицы(туда, куда необходимо подставить даты из первой таблицы) такую формулу:
=ВПР($A2;Лист1!$A$1:$C$4;3;0)
=VLOOKUP($A2,Лист1!$A$1:$C$4,3,0)
Записать формулу можно либо непосредственно в ячейку, либо воспользовавшись диспетчером функций, выбрав в категории Ссылки и массивы(References & Arrays) функцию ВПР(VLOOKUP) и по отдельности указав нужные критерии. Теперь копируем(
Ctrl
+
C
) ячейку с формулой(С2), выделяем все ячейки столбца
С
до конца данных и вставляем(
Ctrl
+
V
).
Теперь разберем поподробнее саму функцию, её аргументы и некоторые особенности.
ВПР ищет заданное нами значение(аргумент искомое_значение) в первом столбце указанного диапазона(аргумент таблица). Поиск значения всегда происходит сверху вниз(собственно, поэтому функция и называется ВПР: Вертикальный ПРосмотр). Как только функция находит заданное значение — поиск прекращается, ВПР берет строку с найденным значением и смотрит на аргумент номер_столбца. Именно из этого столбца берётся значение, которое мы и видим как итог работы функции. Т.е. в нашем конкретном случае, для ячейки С2 второй таблицы, функция берет фамилию «Петров С.А.»(ячейка $A2 второй таблицы) и ищет её в первом столбце указанной таблицы(Лист1!$A$1:$C$4), т.е. в столбце А. Как только находит(это ячейка А3)
ВПР может вернуть только одно значений — первое, подходящее под критерий. Если искомое значение не найдено(отсутствует в таблице), то результатом функции будет ошибка #Н/Д(#N/A). Не надо этого бояться — это даже полезно. Вы точно будете знать, каких записей нет и таким образом можете сравнивать две таблицы друг с другом. Иногда получается так, что Вы видите: данные есть в обеих таблицах, но ВПР выдает #Н/Д. Значит данные в Ваших таблицах не идентичны. В какой-то из них есть лишние неприметные пробелы(обычно перед значением или после), либо знаки кириллицы перемешаны со знаками латиницы. Так же #Н/Д будет, если критерии числа и в искомой таблице они записаны как текст(как правило в левом верхнем углу такой ячейки появляется зеленый треугольничек), а в итоговой — как числа. Или наоборот.
Описание аргументов ВПР
- Искомое_значение($A2) — это то значение из одной таблицы, которые мы ищем в другой таблице. Т.е. для первой записи второй таблицы это будет Петров С.А.. Здесь можно указать либо непосредственно текст критерия(в этом случае он должен быть в кавычках — =ВПР(«Петров С.А»;Лист1!$A$1:$C$4;3;0), либо ссылку на ячейку, с данным текстом(как в примере функции). Есть небольшой нюанс: так же можно применять символы подстановки: «*» и «?». Это очень удобно, если необходимо найти значения лишь по части строки. Например, можно не вводить полностью «Петров С.А», а ввести лишь фамилию и знак звездочки — «Петров*». Тогда будет выведена любая запись, которая начинается на «Петров». Если же надо найти запись, в которой в любом месте строки встречается фамилия «Петров», то можно указать так: «*петров*». Если хотите найти фамилию Петров и неважно какие инициалы будут у имени-отчества(если ФИО записаны в виде Иванов И.И.), то здесь в самый раз такой вид: «Иванов ?.?.».
Часто необходимо для каждой строки указать свое значение(в столбце А Фамилии и надо их все найти). В таком случае всегда указываются ссылки на ячейки столбца А. Например, в ячейке A2 записано: Иванов. Так же известно, что Иванов есть в другой таблице, но после фамилии могут быть записаны и имя и отчество(или еще что-то). Но нам нужно найти только строку, которая начинается на фамилию. Тогда необходимо записать следующим образом: A2&»*». Эта запись будет равнозначна «Иванов*». В A2 записано Иванов, амперсанд(&) используется для объединения в одну строку двух текстовых значений. Звездочка в кавычках (как и положено быть тексту внутри формулы). Таким образом и получаем:
A2&»*» =>
«Иванов»&»*» =>
«Иванов*»
А полная формула в итоге будет выглядеть так: =ВПР(A2&»*»;Лист1!$A$1:$C$4;3;0)
Очень удобно, если значений для поиска много.
Если надо определить есть ли хоть где-то слово в строке, то звездочки ставим с обеих сторон: «*»&A1&»*» - Таблица(Лист1!$A$1:$C$4) — указывается диапазон ячеек, в первом столбце которых будет просматриваться аргумент Искомое_значение. Диапазон должен содержать данные от первой ячейки с данными до самой последней. Это не обязательно должен быть указанный в примере диапазон. Если строк 100, то Лист1!$A$2:$C$100. Диапазон в аргументе таблица всегда должен быть «закреплен», т.е. содержать знаки доллара($) перед названием столбцов и перед номерами строк(Лист1!$A$1:$C$4).
- Номер_столбца(3) — указывается номер столбца в аргументе Таблица, значения из которого нам необходимо записать в итоговую ячейку в качестве результата. В примере это Дата принятия — т.е. столбец №3. Если бы нужен был отдел, то необходимо было бы указать номер столбца 2, а если бы нам понадобилось просто сравнить есть ли фамилии одной таблицы в другой, то можно было бы указать и 1. Номер столбца всегда указывается числом и не должен быть больше числа столбцов в аргументе Таблица.
если аргумент Таблица имеет слишком большое кол-во столбцов и необходимо вернуть результат из последнего столбца, то совсем необязательно высчитывать их количество. Можно использовать формулу, которая подсчитывает количество столбцов в указанном диапазоне: =ВПР($A2;Лист1!$A$1:$C$4;ЧИСЛСТОЛБ(Лист1!$A$1:$C$4);0). К слову в данном случае Лист1! тоже можно убрать, т.к. функция ЧИСЛОСТОЛБ просто подсчитывает количество столбцов в переданном ей диапазоне и неважно на каком он листе: =ВПР($A2;Лист1!$A$1:$C$4;ЧИСЛСТОЛБ($A$1:$C$4);0).
- Интервальный_просмотр(0) — очень интересный аргумент. Может быть равен либо ИСТИНА либо ЛОЖЬ. Так же допускается указать 1 или 0. 1 = ИСТИНА, 0 = ЛОЖЬ. Если в ВПР указать данный параметр равный 0 или ЛОЖЬ, то будет происходить поиск точного соответствия заданному Искомому_значению. Это не имеет никакого отношения к знакам подстановки(«*» и «?»). Если же использовать 1 или ИСТИНА, то…Совсем в двух словах не объяснить. Если вкратце — ВПР будет искать наиболее похожее значение, подходящее под Искомомое_значение. Иногда очень полезно. Правда, если использовать данный параметр, то необходимо, чтобы список в аргументе Таблица был отсортирован по возрастанию. Обращаю внимание на то, что сортировка необходима только в том случае, если аргумент Интервальный_просмотр равен ИСТИНА или 1. Если же 0 или ЛОЖЬ — сортировка не нужна. Этот аргумент необходимо использовать осторожно — не стоит указывать 1 или ИСТИНА, если нужно найти точное соответствие и уж тем более не стоит использовать, если не понимаете принцип его работы.
Подробнее про работу ВПР с интервальным просмотром, равным 1 или ИСТИНА можно ознакомиться в статье ВПР и интервальный просмотр(range_lookup)
- Таблица всегда должна начинаться с того столбца, в котором ищем Искомое_значение. Т.е. ВПР не умеет искать значение во втором столбце таблицы, а значение возвращать из первого. В лучшем случае ничего найдено не будет и получим ошибку #Н/Д(#N/A), а в худшем результат будет совсем не тот, который должен быть
- аргумент Таблица должен быть «закреплен», т.е. содержать знаки доллара($) перед названием столбцов и перед номерами строк(Лист1!$A$1:$C$4). Это и есть закрепление(если точнее, то это называется абсолютной ссылкой на диапазон). Как это делается. Выделяете текст ссылки и жмете клавишу F4 до тех пор, пока не увидите, что и перед обозначением имени столбца и перед номером строки не появились доллары. Если этого не сделать, то при копировании формулы из одной ячейки в остальные аргумент Таблица будет «съезжать» и результат может быть совсем не таким, какой ожидался(в лучшем случае получите ошибку #Н/Д(#N/A)
- номер_столбца не должен превышать общее кол-во столбцов в аргументе таблица, а сама Таблица соответственно должна содержать столбцы от первого(в котором ищем) до последнего(из которого необходимо возвращать значения). В примере указана Лист1!$A$1:$C$4 — всего 3 столбца(A, B, C). Значит не получится вернуть значение из столбца D(4), т.к. в таблице только три столбца. Т.е. если мы запишем формулу так: =ВПР($A2;Лист1!$A$1:$C$4;4;0) — мы получим ошибку #ССЫЛКА!(#REF!).
Если аргументом Таблица указан диапазон $B$1:$C$4 и необходимо вернуть данные из столбца С, то правильно будет указать номер столбца 2. Т.к. аргумент Таблица($B$1:$C$4) содержит только два столбца — В и С. Если же попытаться указать номер столбца 3(каким по счету он является на листе), то получим ошибку #ССЫЛКА!(#REF!), т.к. третьего столбца в указанном диапазоне просто нет.
Многие наверняка заметили, что на картинке у меня попутаны отделы для ФИО(в обеих таблицах ФИО относятся к разным отделам). Это не ошибка записи. В прилагаемом к статье примере показано, как можно одной формулой подставить и отделы и даты, не меняя вручную аргумент Номер_столбца: =ВПР($A2;Лист1!$A$1:$C$4;СТОЛБЕЦ();0). Такой подход сработает, если в обеих таблицах одинаковый порядок столбцов.
Как избежать ошибки #Н/Д(#N/A) в ВПР?
Еще частая проблема — многие не хотят видеть #Н/Д результатом, если совпадение не найдено. Это можно обойти при помощи специальных функций.
Для пользователей Excel 2003 и старше:
=ЕСЛИ(ЕНД(ВПР($A2;Лист1!$A$1:$C$4;3;0));»»;ВПР($A2;Лист1!$A$1:$C$4;3;0))
=IF(ISNA(VLOOKUP($A2,Лист1!$A$1:$C$4,3,0)),»»,VLOOKUP($A2,Лист1!$A$1:$C$4,3,0))
Теперь если ВПР не найдет совпадения, то ячейка будет пустой.
А пользователям версий Excel 2007 и выше будет удобнее использовать функцию
ЕСЛИОШИБКА(IFERROR)
:
=ЕСЛИОШИБКА(ВПР($A2;Лист1!$A$1:$C$4;3;0);»»)
=IFERROR(VLOOKUP($A2,Лист1!$A$1:$C$4,3,0);»»)
Подробнее про различие между использованием ЕСЛИ(ЕНД и ЕСЛИОШИБКА я разбирал в статье: Как в ячейке с формулой вместо ошибки показать 0
Но я бы не рекомендовал использовать
ЕСЛИОШИБКА(IFERROR)
, не убедившись, что ошибки появляются только для реально отсутствующих значений. Иногда ВПР может вернуть #Н/Д и в других ситуациях:
- искомое значение состоит более чем из 255 символов(решение этой проблемы приведено ниже в этой статье: Работа с критериями длиннее 255 символов)
- искомое значение является числом с большим кол-вом знаков после запятой. Excel не может правильно воспринимать такие числа и в итоге ВПР может вернуть ошибку. Правильным решением здесь будет округлить искомое значение хотя бы до 4-х или 5-ти знаков после запятой(конечно, если это допустимо):
=ВПР(ОКРУГЛ($A2;5);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(ROUND($A2,2),Лист1!$A$1:$C$4,3,0) - искомое значение содержит специальные или непечатаемые символы.
В этом случае придется либо избавиться от непечатаемых символов в искомом аргументе:
=ВПР(ПЕЧСИМВ($A2);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(CLEAN($A2),Лист1!$A$1:$C$4,3,0)
либо добавить перед всеми специальными символами(такими как звездочка или вопр.знак) знак тильды(~), чтобы сделать эти знаки просто знаками, а не знаками специального значения(так же работа со специальными(служебными) символами описывалась в статье: Как заменить/удалить/найти звездочку). Добавить символ перед знаком той же тильды можно при помощи функции ПОДСТАВИТЬ(SUBSTITUTE):
=ВПР(ПОДСТАВИТЬ($A2;»~»;»~~»);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(SUBSTITUTE(A2,»~»,»~~»),Лист1!$A$1:$C$4,3,0)
Если необходимо добавить тильду сразу перед несколькими знаками, то делает это обычно так(на примере подстановки одновременно для тильды и звездочки):
=ВПР(ПОДСТАВИТЬ(ПОДСТАВИТЬ($A2;»~»;»~~»);»*»;»~*»);Лист1!$A$1:$C$4;3;0)
=VLOOKUP(SUBSTITUTE(SUBSTITUTE(A2,»~»,»~~»),»*»,»~*»),Лист1!$A$1:$C$4,3,0)
На самом деле ответ будет коротким — ВПР всегда ищет сверху вниз. Слева направо она не умеет. Но зато слева направо умеет искать её сестра ГПР(HLookup) — Горизонтальный
ПР
осмотр.
ГПР ищет заданное значение(аргумент
искомое_значение
) в первой строке указанного диапазона(аргумент
таблица
) и возвращает для него значение из строки таблицы, указанной аргументом номер_строки. Поиск значения всегда происходит слева направо и заканчивается сразу, как только значение найдено. Если значение не найдено, функция возвращает значение ошибки
#Н/Д(#N/A)
.
Если надо найти значение «Иванов» в строке 2 и вернуть значение из строки 5 в таблице
A2:H10
, то формула будет выглядеть так:
=ГПР(«Иванов»;$A$2:$H$10;5;0)
=HLOOKUP(«Иванов»,$A$2:$H$10,5,0)
Все правила и синтаксис функции точно такие же, как у ВПР:
-в искомом значении можно применять символы астерикса(*) и вопр.знака(?) — «Иванов*»;
-таблица должна быть закреплена —
$A$2:$H$10
;
-интервальный просмотр работает по тому же принципу(0 или ЛОЖЬ точный просмотр слева-направо, 1 или ИСТИНА — интервальный).
Общий принцип работы
ПОИСКПОЗ(MATCH)
очень похож на ВПР — функция ищет заданное значение в массиве (в столбце или строке) и возвращает его позицию(порядковый номер в заданном массиве). Т.е. ищет
Искомое_значение
в аргументе
Просматриваемый_массив
и в качестве результата выдает номер позиции найденного значения в
Просматриваемом_массиве
. Именно номер позиции, а не само значение. Если бы мы хотели применить её для таблицы выше, то она была бы такой:
=ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0)
=MATCH($A2,Лист1!$A$1:$A$4,0)
- Искомое_значение($A2) — непосредственно значение или ссылка на ячейку с искомым значением. Если опираться на пример выше — то это ФИО. Здесь все ровно так же, как и с ВПР. Так же допустимы символы подстановки * и ? и ровно в таком же исполнении.
- Просматриваемый_массив(Лист1!$A$1:$A$4) — указывается ссылка на столбец, в котором необходимо найти искомое значение. В отличии от той же ВПР, где указывается целая таблица, это должен быть именно один столбец, в котором мы собираемся искать Искомое_значение. Если попытаться указать более одного столбца, то функция вернет ошибку.Справедливости ради надо отметить, что можно указать либо столбец, либо строку
- Тип_сопоставления(0) — то же самое, что и Интервальный_просмотр в ВПР. С теми же особенностями. Отличается разве что возможностью поиска наименьшего от искомого или наибольшего.
С основным разобрались. Но ведь нам надо вернуть не номер позиции, а само значение. Значит ПОИСКПОЗ в чистом виде нам не подходит. По крайней мере одна, сама по себе. Но если её использовать вместе с функцией ИНДЕКС(INDEX)(которая возвращает из указанного диапазона значение на пересечении заданных строки и столбца) — то это то, что нам нужно и даже больше.
=ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0);2)
Такая формула результатом вернет то же, что и ВПР.
Аргументы функции ИНДЕКС
Массив(Лист1!$A$2:$C$4). В качестве этого аргумента мы указываем диапазон, из которого хотим получить значения. Может быть как один столбец, так и несколько. В случае, если столбец один, то последний аргумент функции указывать не обязательно или он всегда будет равен 1(столбец-то всего один). К слову — данный аргумент может совершенно не совпадать с тем, который мы указываем в аргументе Просматриваемый_массив функции ПОИСКПОЗ.
Далее идут Номер_строки и Номер_столбца. Именно в качестве Номера_строки мы и подставляем ПОИСКПОЗ, которая возвращает нам номер позиции в массиве. На этом все и строится. ИНДЕКС возвращает значение из Массива, которое находится в указанной строке(Номер_строки) Массива и указанном столбце(Номер_столбца), если столбцов более одного. Важно знать, что в данной связке кол-во строк в аргументе Массив функции ИНДЕКС и кол-во строк в аргументе Просматриваемый_массив функции ПОИСКПОЗ должно совпадать. И начинаться с одной и той же строки. Это в обычных случаях, если не преследуются иные цели.
Так же как и в случае с ВПР, ИНДЕКС в случае не нахождения искомого значения возвращает #Н/Д. И обойти подобные ошибки можно так же:
Для всех версий Excel(включая 2003 и раньше):
=ЕСЛИ(ЕНД(ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0));»»;ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$2:$A$4;0);2))
Для версий 2007 и выше:
=ЕСЛИОШИБКА(ИНДЕКС(Лист1!$A$1:$C$4;ПОИСКПОЗ($A2;Лист1!$A$1:$A$4;0);2);»»)
Есть у ИНДЕКС-ПОИСКПОЗ и еще одно преимущество перед ВПР. Дело в том, что ВПР не может искать значения, длина строки которых содержит более 255 символов. Это случается редко, но случается. Можно, конечно, обмануть ВПР и урезать критерий:
=ВПР(ПСТР($A2;1;255);ПСТР(Лист1!$A$1:$C$4;1;255);3;0)
но это формула массива. Да и к тому же далеко не всегда такая формула вернет нужный результат. Если первые 255 символов идентичны первым 255 символам в таблице, а дальше знаки различаются — формула этого уже не увидит. Да и возвращает формула исключительно текстовые значения, что в случаях, когда возвращаться должны числа, не очень удобно.
Поэтому лучше использовать такую хитрую формулу:
=ИНДЕКС(Лист1!$A$1:$C$4;СУММПРОИЗВ(ПОИСКПОЗ(ИСТИНА;Лист1!$A$1:$A$4=$A2;0));2)
Здесь я в формулах использовал одинаковые диапазоны для удобочитаемости, но в примере для скачивания они различаются от указанных здесь.
Сама формула построена на возможности функции СУММПРОИЗВ преобразовывать в массивные вычисления некоторых функций внутри неё. В данном случае ПОИСКПОЗ ищет позицию строки, в которой критерий равен значению в строке. Подстановочные символы здесь применить уже не получится.
Ну и все же я рекомендовал бы Вам прочитать подробнее про данные функции в справке.
В прилагаемом к статье примере Вы найдете примеры использования всех описанных случаев и пример того, почему ИНДЕКС и ПОИСКПОЗ порой предпочтительнее ВПР.
Скачать пример
 Tips_All_VLookUp.xls (26,0 KiB, 17 437 скачиваний)
Tips_All_VLookUp.xls (26,0 KiB, 17 437 скачиваний)
Так же см.:
ВПР и интервальный просмотр(range_lookup)
ВПР по двум и более критериям
ВПР с возвратом всех значений
ВПР с поиском по нескольким листам
![]() ВПР_МН
ВПР_МН
![]() ВПР_ВСЕ_КНИГИ
ВПР_ВСЕ_КНИГИ
Как заменить/удалить/найти звездочку?
Статья помогла? Поделись ссылкой с друзьями!
![]() Видеоуроки
Видеоуроки
Поиск по меткам
Access
apple watch
Multex
Power Query и Power BI
VBA управление кодами
Бесплатные надстройки
Дата и время
Записки
ИП
Надстройки
Печать
Политика Конфиденциальности
Почта
Программы
Работа с приложениями
Разработка приложений
Росстат
Тренинги и вебинары
Финансовые
Форматирование
Функции Excel
акции MulTEx
ссылки
статистика
Skip to content
В этой статье мы рассмотрим разные подходы к одной из самых распространенных и, по моему мнению, важных задач в Excel — как найти в ячейках и в столбцах таблицы повторяющиеся значения.
Работая с большими наборами данных в Excel или объединяя несколько небольших электронных таблиц в более крупные, вы можете столкнуться с большим числом одинаковых строк.
И сегодня я хотел бы поделиться несколькими быстрыми и эффективными методами выявления дубликатов в одном списке. Эти решения работают во всех версиях Excel 2016, Excel 2013, 2010 и ниже. Вот о чём мы поговорим:
- Поиск повторяющихся значений включая первые вхождения
- Поиск дубликатов без первых вхождений
- Определяем дубликаты с учетом регистра
- Как извлечь дубликаты из диапазона ячеек
- Как обнаружить одинаковые строки в таблице данных
- Использование встроенных фильтров Excel
- Применение условного форматирования
- Поиск совпадений при помощи встроенной команды «Найти»
- Определяем дубликаты при помощи сводной таблицы
- Duplicate Remover — быстрый и эффективный способ найти дубликаты
Самой простой в использовании и вместе с тем эффективной в данном случае будет функция СЧЁТЕСЛИ (COUNTIF). С помощью одной только неё можно определить не только неуникальные позиции, но и их первые появления в столбце. Рассмотрим разницу на примерах.
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача — найти их, то следующая формула для вас:
=СЧЁТЕСЛИ(A:A; A2)>1
Где А2 — первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.

Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте
=СЧЕТЕСЛИ($A$2:$A$8, A2)>1
Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что — уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;»Дубликат»;»Уникальное»)
Если же вам нужно, чтобы формула указывала только на дубли, замените «Уникальное» на пустоту («»):

=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;»Дубликат»;»»)

В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми. То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
=ЕСЛИ(СЧЁТЕСЛИ($A$2:$A2; A2)>1;»Дубликат»;»»)
На скриншоте ниже вы видите эту формулу в деле.

Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент — они не чувствительны к регистру. Быть может, для вас это не принципиально. Но если в ваших данных абв, Абв и АБВ — это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
{=ЕСЛИ(СУММ((—СОВПАД($A$2:$A$17;A2)))<=1;»»;»Дубликат»)}
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (—).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:

Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Как извлечь дубликаты из диапазона.
Формулы, которые мы описывали выше, позволяют находить дубликаты в определенном столбце. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных.
Рассмотрим это на примере числовой матрицы. К сожалению, с символьными значениями этот метод не работает.

При помощи формулы массива
{=ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ(НАИМЕНЬШИЙ(ЕСЛИ( СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11);СТРОКА($1:$100)); НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));»»);СТРОКА()-1))}
вы можете получить упорядоченный по возрастанию список дубликатов. Для этого введите это выражение в нужную ячейку и нажмите Ctrl+Alt+Enter.
Затем протащите маркер заполнения вниз на сколько это необходимо.
Чтобы убрать сообщения об ошибке, когда дублирующиеся значения закончатся, можно использовать функцию ЕСЛИОШИБКА:
=ЕСЛИОШИБКА(ИНДЕКС(НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИОШИБКА(ЕСЛИ(ПОИСКПОЗ( НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));НАИМЕНЬШИЙ(ЕСЛИ(СЧЁТЕСЛИ($A$2:$E$11;$A$2:$E$11)>1;$A$2:$E$11); СТРОКА($1:$100));0)=СТРОКА($1:$100);СТРОКА($1:$100));»»);СТРОКА()-1));»»)
Также обратите внимание, что приведенное выше выражение рассчитано на то, что оно будет записано во второй строке. Соответственно выше него будет одна пустая строка.
Поэтому если вам нужно разместить его, к примеру, в ячейке K4, то выражение СТРОКА()-1 в конце замените на СТРОКА()-3.
Обнаружение повторяющихся строк
Мы рассмотрели, как обнаружить одинаковые данные в отдельных ячейках. А если нужно искать дубликаты-строки?
Есть один метод, которым можно воспользоваться, если вам нужно просто выделить одинаковые строки, но не удалять их.
Итак, имеются данные о товарах и заказчиках.
Создадим справа от наших данных формулу, объединяющую содержание всех расположенных слева от нее ячеек.
Предположим, что данные хранятся в столбцах А:C. Запишем в ячейку D2:
=A2&B2&C2
Добавим следующую формулу в ячейку E2. Она отобразит, сколько раз встречается значение, полученное нами в столбце D:
=СЧЁТЕСЛИ(D:D;D2)
Скопируем вниз для всех строк данных.
В столбце E отображается количество появлений этой строки в столбце D. Неповторяющимся строкам будет соответствовать значение 1. Повторам строкам соответствует значение больше 1, указывающее на то, сколько раз такая строка была найдена.
Если вас не интересует определенный столбец, просто не включайте его в выражение, находящееся в D. Например, если вам хочется обнаружить совпадающие строки, не учитывая при этом значение Заказчик, уберите из объединяющей формулы упоминание о ячейке С2.
Обнаруживаем одинаковые ячейки при помощи встроенных фильтров Excel.
Теперь рассмотрим, как можно обойтись без формул при поиске дубликатов в таблице. Быть может, кому-то этот метод покажется более удобным, нежели написание выражений Excel.
Организовав свои данные в виде таблицы, вы можете применять к ним различные фильтры. Фильтр в таблице вы можете установить по одному либо по нескольким столбцам. Давайте рассмотрим на примере.
В первую очередь советую отформатировать наши данные как «умную» таблицу. Напомню: Меню Главная – Форматировать как таблицу.
После этого в строке заголовка появляются значки фильтра. Если нажать один из них, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с этим выбором.
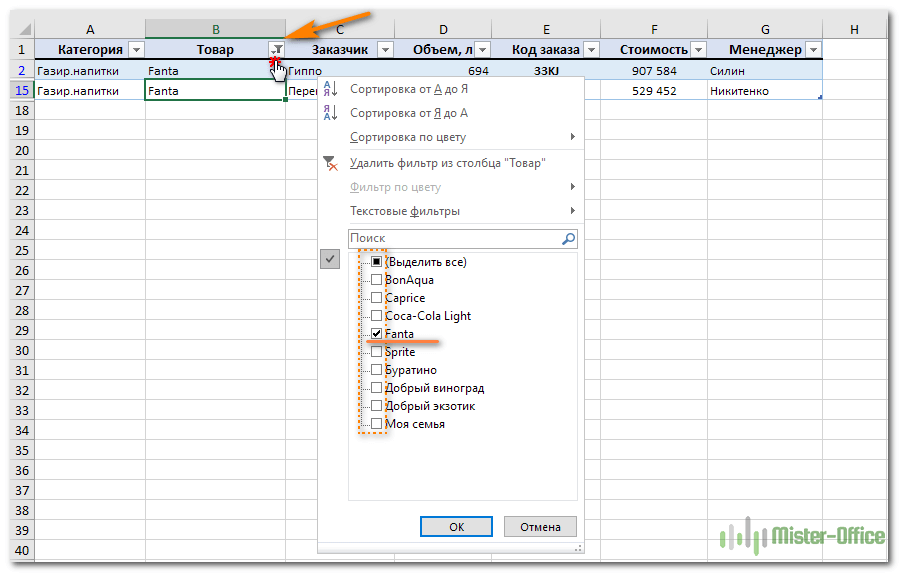
Вы можете убрать галочку с пункта «Выделить все», а затем отметить один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные значения. Так можно обнаружить дубликаты, если они есть. И все готово для их быстрого удаления.
Но при этом вы видите дубли только по отфильтрованному. Если данных много, то искать таким способом последовательного перебора будет несколько утомительно. Ведь слишком много раз нужно будет устанавливать и менять фильтр.
Используем условное форматирование.
Выделение цветом по условию – весьма важный инструмент Excel, о котором достаточно подробно мы рассказывали.
Сейчас я покажу, как можно в Экселе найти дубли ячеек, просто их выделив цветом.
Как показано на рисунке ниже, выбираем Правила выделения ячеек – Повторяющиеся. Неуникальные данные будут подсвечены цветом.
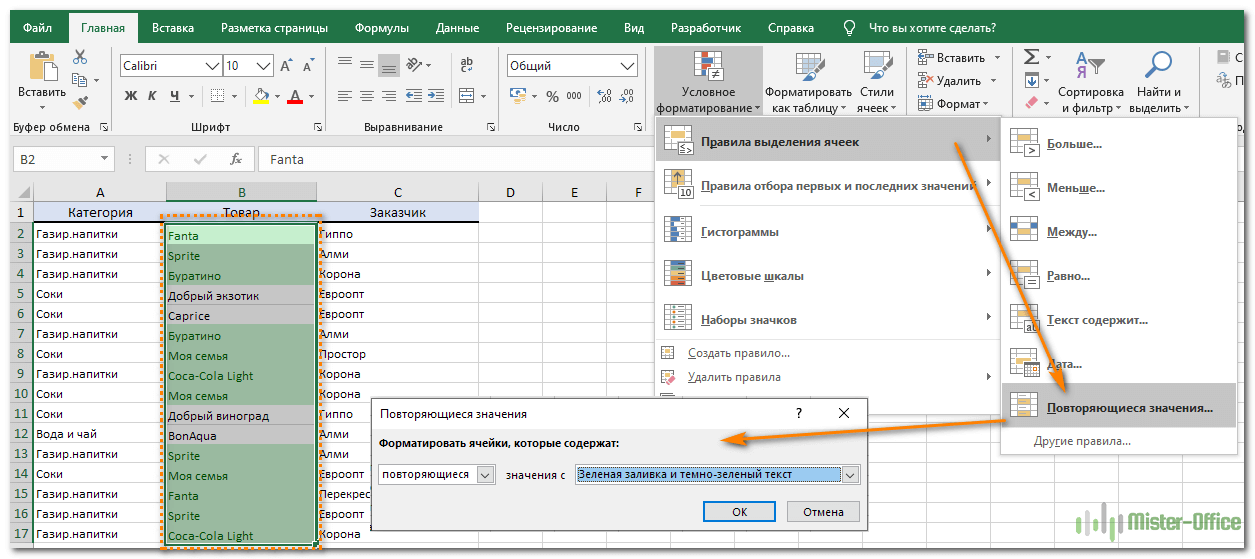
Но здесь мы не можем исключить первые появления – подсвечивается всё.
Но эту проблему можно решить, использовав формулу условного форматирования.
=СЧЁТЕСЛИ($B$2:$B2; B2)>1

Результат работы формулы выденения повторяющихся значений вы видите выше. Они выделены зелёным цветом.
Чтобы освежить память, можете руководствоваться нашим материалом «Как изменить цвет ячейки в зависимости от значения».
Поиск совпадений при помощи команды «Найти».
Еще один простой, но не слишком технологичный способ – использование встроенного поиска.
Зайдите на вкладку Главная и кликните «Найти и выделить». Откроется диалоговое окно, в котором можно ввести что угодно для поиска в таблице. Чтобы избежать опечаток, можете скопировать искомое прямо из списка данных.
Затем нажимаем «Найти все», и видим все найденные дубликаты и места их расположения, как на рисунке чуть ниже.

В случае, когда объём информации очень велик и требуется ускорить работу поиска, предварительно выделите столбец или диапазон, в котором нужно искать, и только после этого начинайте работу. Если этого не сделать, Excel будет искать по всем имеющимся данным, что, конечно, медленнее.
Этот метод еще более трудоемкий, нежели использование фильтра. Поэтому применяют его выборочно, только для отдельных значений.
Как применить сводную таблицу для поиска дубликатов.
Многие считают сводные таблицы слишком сложным инструментом, чтобы постоянно им пользоваться. На самом деле, не все так запутано, как кажется. Для новичков рекомендую к ознакомлению наше руководство по созданию и работе со сводными таблицами.
Для более опытных – сразу переходим к сути вопроса.
Создаем новый макет сводной таблицы. А затем в качестве строк и значений используем одно и то же поле. В нашем случае – «Товар». Поскольку название товара – это текст, то для подсчета таких значений Excel по умолчанию использует функцию СЧЕТ, то есть подсчитывает количество. А нам это и нужно. Если будет больше 1, значит, имеются дубликаты.

Вы наблюдаете на скриншоте выше, что несколько товаров дублируются. И что нам это дает? А далее мы просто можем щелкнуть мышкой на любой из цифр, и на новом листе Excel покажет нам, как получилась эта цифра.
К примеру, откуда взялись 3 дубликата Sprite? Щелкаем на цифре 3, и видим такую картину:

Думаю, этот метод вполне можно использовать. Что приятно – никаких формул не требуется.
Duplicate Remover — быстрый и эффективный способ найти дубликаты в Excel
Теперь, когда вы знаете, как использовать формулы для поиска повторяющихся значений в Excel, позвольте мне продемонстрировать вам еще один быстрый, эффективный и без всяких формул способ: инструмент Duplicate Remover для Excel.
Этот универсальный инструмент может искать повторяющиеся или уникальные значения в одном столбце или же сравнивать два столбца. Он может находить, выбирать и выделять повторяющиеся записи или целые повторяющиеся строки, удалять найденные дубли, копировать или перемещать их на другой лист. Я думаю, что пример практического использования может заменить очень много слов, так что давайте перейдем к нему.
Как найти повторяющиеся строки в Excel за 2 быстрых шага
Сначала посмотрим в работе наиболее простой инструмент — быстрый поиск дубликатов Quick Dedupe. Используем уже знакомую нам таблицу, в которой мы выше искали дубликаты при помощи формул:

Как видите, в таблице несколько столбцов. Чтобы найти повторяющиеся записи в этих трех столбцах, просто выполните следующие действия:
- Выберите любую ячейку в таблице и нажмите кнопку Quick Dedupe на ленте Excel. После установки пакета Ultimate Suite для Excel вы найдете её на вкладке Ablebits Data в группе Dedupe. Это наиболее простой инструмент для поиска дубликатов.
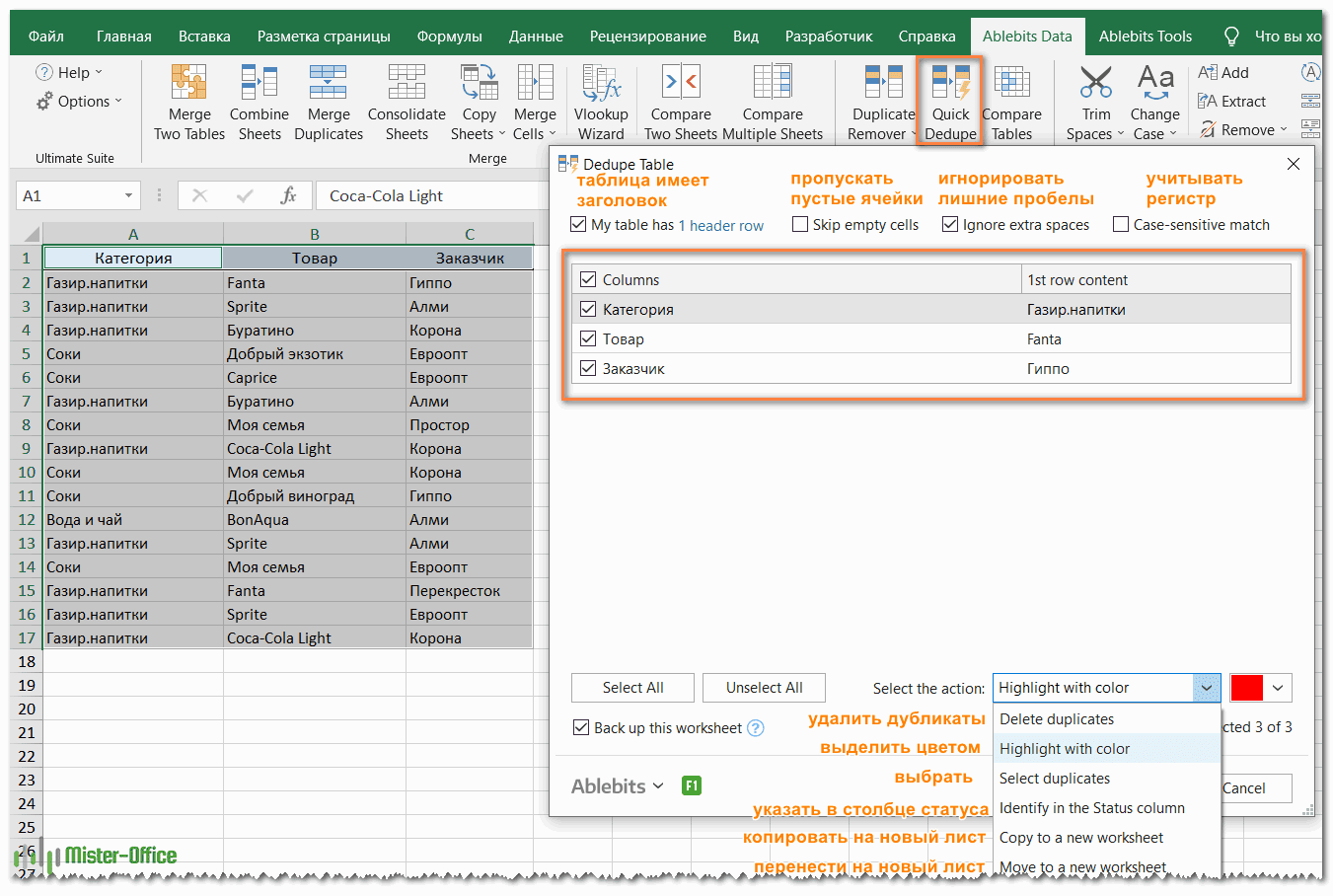
- Интеллектуальная надстройка возьмет всю таблицу и попросит вас указать следующие две вещи:
- Выберите столбцы для проверки дубликатов (в данном примере это все 3 столбца – категория, товар и заказчик).
- Выберите действие, которое нужно выполнить с дубликатами. Поскольку наша цель — выявить повторяющиеся строки, я выбрал «Выделить цветом».
Помимо выделения цветом, вам доступен ряд других опций:
- Удалить дубликаты
- Выбрать дубликаты
- Указать их в столбце статуса
- Копировать дубликаты на новый лист
- Переместить на новый лист
Нажмите кнопку ОК и подождите несколько секунд. Готово! И никаких формул 😊.
Как вы можете видеть на скриншоте ниже, все строки с одинаковыми значениями в первых 3 столбцах были обнаружены (первые вхождения не идентифицируются как дубликаты).

Если вам нужны дополнительные возможности для работы с дубликатами и уникальными значениями, используйте мастер удаления дубликатов Duplicate Remover, который может найти дубликаты с первыми вхождениями или без них, а также уникальные значения. Подробные инструкции приведены ниже.
Мастер удаления дубликатов — больше возможностей для поиска дубликатов в Excel.
В зависимости от данных, с которыми вы работаете, вы можете не захотеть рассматривать первые экземпляры идентичных записей как дубликаты. Одно из возможных решений — использовать разные формулы для каждого сценария, как мы обсуждали в этой статье выше. Если же вы ищете быстрый, точный метод без формул, попробуйте мастер удаления дубликатов — Duplicate Remover. Несмотря на свое название, он не только умеет удалять дубликаты, но и производит с ними другие полезные действия, о чём мы далее поговорим подробнее. Также умеет находить уникальные значения.
- Выберите любую ячейку в таблице и нажмите кнопку Duplicate Remover на вкладке Ablebits Data.
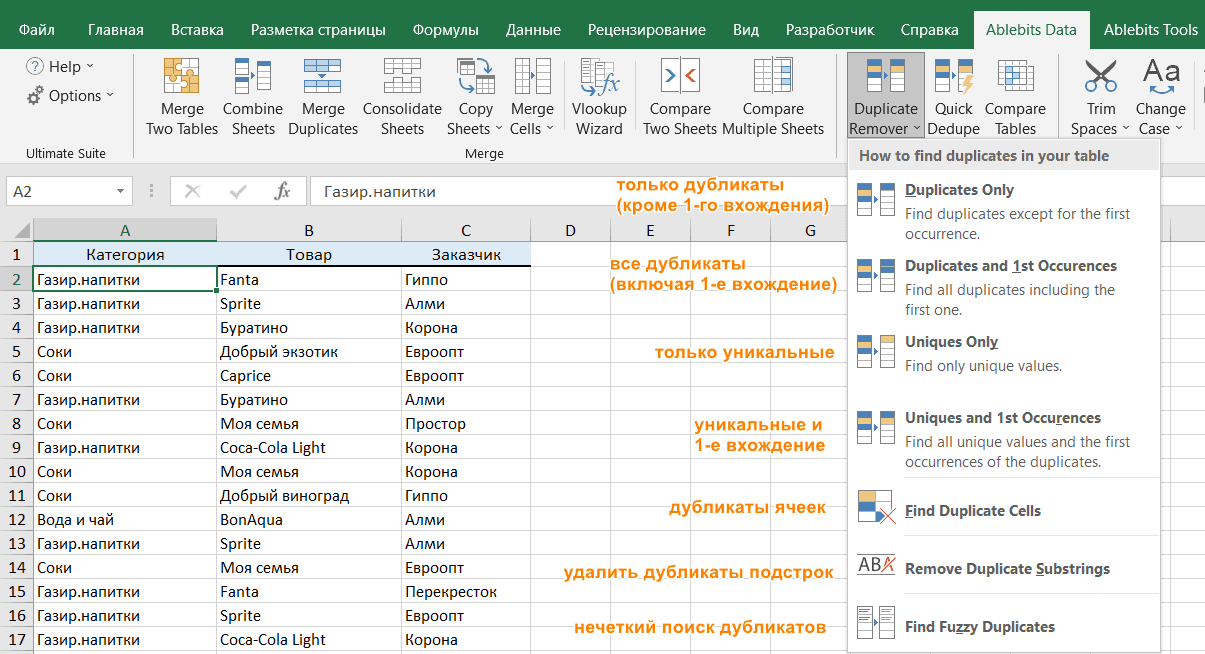
- Вам предложены 4 варианта проверки дубликатов в вашем листе Excel:
- Дубликаты без первых вхождений повторяющихся записей.
- Дубликаты с 1-м вхождением.
- Уникальные записи.
- Уникальные значения и 1-е повторяющиеся вхождения.
В этом примере выберем второй вариант, т.е. Дубликаты + 1-е вхождения:

- Теперь выберите столбцы, в которых вы хотите проверить дубликаты. Как и в предыдущем примере, мы возьмём первые 3 столбца:
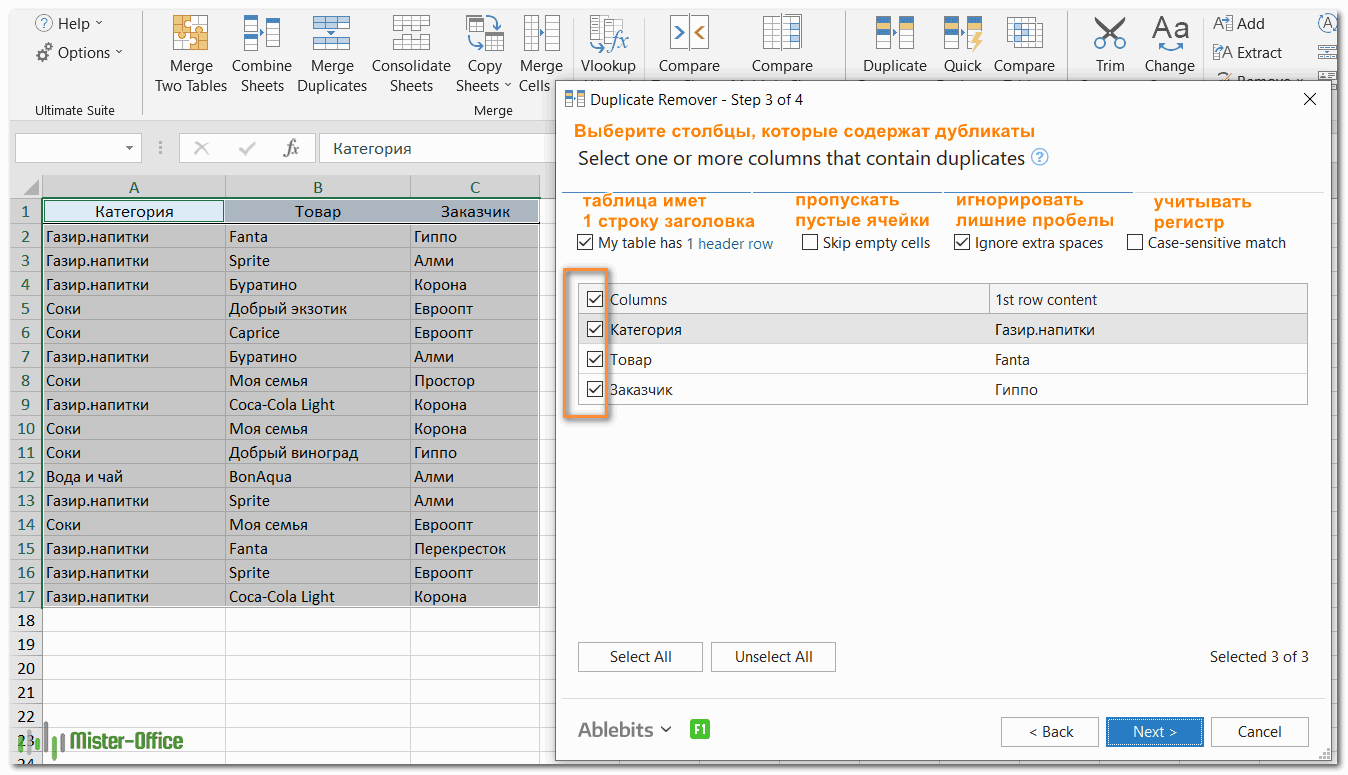
- Наконец, выберите действие, которое вы хотите выполнить с дубликатами. Как и в случае с инструментом быстрого поиска дубликатов, мастер Duplicate Remover может идентифицировать, выбирать, выделять, удалять, копировать или перемещать повторяющиеся данные.

Поскольку цель этого примера – продемонстрировать различные способы определения дубликатов в Excel, давайте отметим параметр «Выделить цветом» (Highlight with color) и нажмите Готово.
Мастеру Duplicate Remover требуется всего лишь несколько секунд, чтобы проверить вашу таблицу и показать результат:

Как видите, результат аналогичен предыдущему. Но здесь мы выделили дубликаты, включая и первое появление повторяющихся записей.
Никаких формул, никакого стресса, никаких ошибок — всегда быстрые и безупречные результаты 
Итак, мы с вам научились различными способами обнаруживать повторяющиеся записи в таблице Excel. В следующих статьях разберем, что мы с этим можем полезного сделать.
Если вы хотите попробовать эти инструменты для поиска дубликатов в таблицах Excel, вы можете загрузить полнофункциональную ознакомительную версию программы. Будем очень признательны за ваши отзывы в комментариях!
Как найти повторяющиеся или уникальные значения в двух столбцах на двух листах?
Может быть, сравнить два диапазона на одном листе и выяснить, что повторяющиеся или уникальные значения легко для большинства из вас, но если два диапазона находятся на двух разных листах, как вы можете быстро найти повторяющиеся и уникальные значения в этих двух диапазонах ? В этом уроке вы найдете несколько быстрых решений.
Сравните два одинаковых столбца заголовка в двух электронных таблицах с формулой в Excel
Сравните два диапазона в двух электронных таблицах с VBA
Сравните два диапазона в двух электронных таблицах с Kutools for Excel
 Сравните два одинаковых столбца заголовка в двух электронных таблицах с формулой в Excel
Сравните два одинаковых столбца заголовка в двух электронных таблицах с формулой в Excel
С помощью формулы в Excel вы можете сравнить два одинаковых столбца заголовка, как показано ниже на разных листах, и найти повторяющиеся и уникальные значения:
1. Набрав эту формулу = СЧЁТЕСЛИ (Лист1! $ A: $ A; A1) в пустой ячейке, которая находится рядом с диапазоном на листе 3. См. снимок экрана:

2. Нажмите Enter на клавиатуре, а затем перетащите маркер заполнения, чтобы заполнить диапазон, который вы хотите сравнить с диапазоном на Листе 1. (Номер Ноль означает повторяющиеся значения в двух диапазонах, а Номер 1 означает уникальные значения в Листе 3, но не в Листе 1)

Советы:
1. Эта формула может сравнивать только два столбца с одинаковым заголовком в двух электронных таблицах.
2. Если вы хотите найти уникальные значения в Sheet1, но не в Sheet3, вам необходимо ввести приведенную выше формулу =СЧЁТЕСЛИ (Лист3! $ A: $ A; A1) в Sheet1.
Сравните два диапазона в двух электронных таблицах с VBA
1. Держать ALT и нажмите F11 на клавиатуре, чтобы открыть Microsoft Visual Basic для приложений окно.
2. Нажмите Вставить > Модули, и скопируйте VBA в модуль.
VBA: сравнить два диапазона в двух таблицах
Sub CompareRanges () 'Обновление 20130815 Dim WorkRng1 как диапазон, WorkRng2 как диапазон, Rng1 как диапазон, Rng2 как диапазон xTitleId = "KutoolsforExcel" Установить WorkRng1 = Application.InputBox ("Range A:", xTitleId, "", Type: = 8 ) Установите WorkRng2 = Application.InputBox ("Range B:", xTitleId, Type: = 8) Для каждого Rng1 в WorkRng1 rng1Value = Rng1.Value для каждого Rng2 в WorkRng2 Если rng1Value = Rng2.Value Тогда Rng1.Interior.Color = VBA .RGB (255, 0, 0) Выйти за конец, если следующий следующий конец Sub
3. Нажмите Run или нажмите F5 для запуска VBA.
4. На экране отображается диалоговое окно, и вы должны выбрать один диапазон, с которым хотите сравнить. Смотрите скриншот:

5. Нажмите Ok и другое диалоговое окно отображается для выбора второго диапазона. Смотрите скриншот:
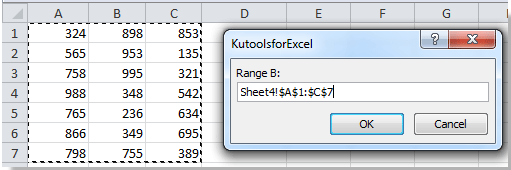
6. Нажмите Ok, а повторяющиеся значения как в диапазоне A, так и в диапазоне B выделяются красным фоном в диапазоне A. См. снимок экрана:

Советы: с помощью этого VBA вы можете сравнивать два диапазона как на одном, так и на разных листах.
Сравните два диапазона в двух электронных таблицах с Kutools for Excel
Если формула вам не удобна, а VBA вам сложно, вы можете попробовать Kutools for Excel‘s Сравнить диапазоны функции.
Kutools for Excel включает более 300 удобных инструментов Excel. Бесплатная пробная версия без ограничений в течение 30 дней. Получить сейчас
Пожалуйста, примените Сравнить диапазоны функция, нажав Кутулс > Сравнить диапазоны. Смотрите скриншот:
Сравните с двумя столбцами на разных листах:
1. Нажмите Кутулс > Сравнить диапазоны, на экране отобразится диалоговое окно. Смотрите скриншот:
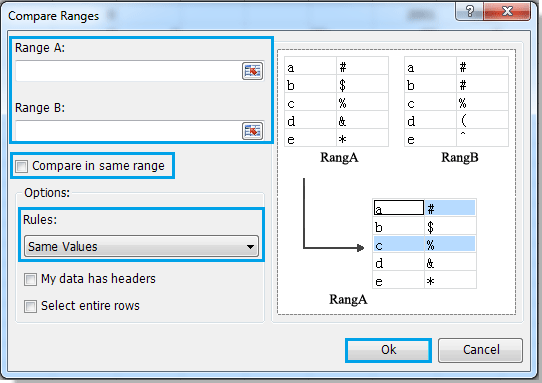
2. Укажите диапазоны и правила, сделайте следующее:
Оставьте Сравнить в том же диапазоне снимите флажок и выберите два диапазона, нажав Диапазон А и Диапазон B, см. снимок экрана:


Укажите те же значения или разные значения, которые вы хотите найти, в раскрывающемся списке в разделе «Правила»;
3. Нажмите Ok. Всплывающее диалоговое окно сообщает вам, что выбраны те же значения.

4. Нажмите Ok во всплывающем диалоговом окне. В диапазоне A выбираются одинаковые значения между двумя диапазонами.
Сравните два диапазона в электронных таблицах
Если у вас есть два диапазона в двух таблицах, как показано ниже, и вы хотите сравнить их и узнать разные значения, вы можете сделать следующее:
1. Нажмите Кутулс > Сравнить диапазоны, на экране отобразится диалоговое окно.
2. Укажите диапазоны и правила, сделайте следующее:
Оставлять Сравнить в том же диапазоне снимите флажок и выберите два диапазона, нажав Диапазон А и Диапазон B;
Укажите различные значения, которые вы хотите найти, в раскрывающемся списке в разделе «Правила»;
Проверить, что у моих данных есть заголовки in Опции раздел;
3. Нажмите Ok. Всплывающее диалоговое окно сообщает вам, что выбраны те же значения.
4. Нажмите Ok во всплывающем диалоговом окне. Выбираются разные значения в диапазоне А. Смотрите скриншот:

Если вы хотите узнать разные значения в диапазоне B листа Sheet2, вам нужно поменять местами два диапазона.
Сравнить диапазоны функция также может сравнивать диапазоны на одном листе. Щелкните здесь, чтобы узнать больше о сравнительных диапазонах.
Относительные статьи:
- Найдите уникальные значения между двумя столбцами
- Найдите повторяющиеся значения в двух столбцах
- Удалите дубликаты и замените пустыми ячейками
- Отфильтровать уникальные записи из выбранного столбца
Лучшие инструменты для работы в офисе
Kutools for Excel Решит большинство ваших проблем и повысит вашу производительность на 80%
- Снова использовать: Быстро вставить сложные формулы, диаграммы и все, что вы использовали раньше; Зашифровать ячейки с паролем; Создать список рассылки и отправлять электронные письма …
- Бар Супер Формулы (легко редактировать несколько строк текста и формул); Макет для чтения (легко читать и редактировать большое количество ячеек); Вставить в отфильтрованный диапазон…
- Объединить ячейки / строки / столбцы без потери данных; Разделить содержимое ячеек; Объединить повторяющиеся строки / столбцы… Предотвращение дублирования ячеек; Сравнить диапазоны…
- Выберите Дубликат или Уникальный Ряды; Выбрать пустые строки (все ячейки пустые); Супер находка и нечеткая находка во многих рабочих тетрадях; Случайный выбор …
- Точная копия Несколько ячеек без изменения ссылки на формулу; Автоматическое создание ссылок на несколько листов; Вставить пули, Флажки и многое другое …
- Извлечь текст, Добавить текст, Удалить по позиции, Удалить пробел; Создание и печать промежуточных итогов по страницам; Преобразование содержимого ячеек в комментарии…
- Суперфильтр (сохранять и применять схемы фильтров к другим листам); Расширенная сортировка по месяцам / неделям / дням, периодичности и др .; Специальный фильтр жирным, курсивом …
- Комбинируйте книги и рабочие листы; Объединить таблицы на основе ключевых столбцов; Разделить данные на несколько листов; Пакетное преобразование xls, xlsx и PDF…
- Более 300 мощных функций. Поддерживает Office/Excel 2007-2021 и 365. Поддерживает все языки. Простое развертывание на вашем предприятии или в организации. Полнофункциональная 30-дневная бесплатная пробная версия. 60-дневная гарантия возврата денег.
")
Вкладка Office: интерфейс с вкладками в Office и упрощение работы
- Включение редактирования и чтения с вкладками в Word, Excel, PowerPoint, Издатель, доступ, Visio и проект.
- Открывайте и создавайте несколько документов на новых вкладках одного окна, а не в новых окнах.
- Повышает вашу продуктивность на 50% и сокращает количество щелчков мышью на сотни каждый день!
")
|
Jojojojo 0 / 0 / 0 Регистрация: 17.03.2015 Сообщений: 68 |
||||
|
1 |
||||
|
03.12.2016, 21:32. Показов 19470. Ответов 6 Метки нет (Все метки)
Доброго всем вечера.
Очень давно был опыт работы с макросами, но размышляя над этой задачей даже не знаю как это правильно сделать.
0 |

|
15136 / 6410 / 1730 Регистрация: 24.09.2011 Сообщений: 9,999 |
|
|
03.12.2016, 21:50 |
2 |
|
Jojojojo, во второй таблице в свободном столбце (F, судя по описанию) формулу В свободном столбце большой таблицы формулу Код =ЕЧИСЛО(ПОИСКПОЗ(B1&C1&D1&E1;[ИмяВторогоФайла.xls]ИмяЛиста!F:F;0)) Отфильтровать по ИСТИНА, покрасить видимые.
1 |
|
0 / 0 / 0 Регистрация: 17.03.2015 Сообщений: 68 |
|
|
03.12.2016, 22:57 [ТС] |
3 |
|
Казанский, Большое спасибо, но в процессе тестов выявилась проблема опечатков в некоторых ячейках. 1 список вручную отрабатывал в течении 2-3 часов, было 130 совпадений, а при данном методе прошло только 119, 11 из-за ошибок в написании.
0 |
|
15136 / 6410 / 1730 Регистрация: 24.09.2011 Сообщений: 9,999 |
|
|
04.12.2016, 17:02 |
4 |
|
Jojojojo, файл-пример приложите (или 2 файла в архиве). Код =ИЛИ(ЕСЛИ(E2=Лист2!$E$2:$E$3;(B2=Лист2!$B$2:$B$3)*(C2=Лист2!$C$2:$C$3)+(C2=Лист2!$C$2:$C$3)*(D2=Лист2!$D$2:$D$3)+(B2=Лист2!$B$2:$B$3)*(D2=Лист2!$D$2:$D$3))) Здесь Лист2 — лист, в котором ищутся совпадения. Вместо «3» везде должен быть номер последней строки (мне хватило фантазии на 2 строки данных).
1 |
|
0 / 0 / 0 Регистрация: 17.03.2015 Сообщений: 68 |
|
|
04.12.2016, 20:01 [ТС] |
5 |
|
Казанский, Выслал архив в личку
0 |
|
Jojojojo 0 / 0 / 0 Регистрация: 17.03.2015 Сообщений: 68 |
||||
|
08.12.2016, 10:32 [ТС] |
6 |
|||
|
Так и не дождавшись ответа работа дошла до момента, когда нужно в одном документе сравнивать значения на Лист1 А1 с массивом значений Лист2 столбец А, и если есть совпадения то на листе 1 в столбце I ставить заранее вводимое число.
но он даже не пытается рассматривать это как формулу
0 |

|
6875 / 2807 / 533 Регистрация: 19.10.2012 Сообщений: 8,562 |
|
|
08.12.2016, 10:54 |
7 |
|
Чтоб рассматривал нужно:
1 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
08.12.2016, 10:54 |
|
Помогаю со студенческими работами здесь Объединение строк в разных таблицах по условию Объединение строк в разных таблицах по условию SQL- запрос. Поиск одинаковых значений полей в таблицах Есть 3 таблицы: 1.проданные товары, 2.продавец, 3.покупатель: Поиск совпадений в разных таблицах sql Подскажите, пожалуйста, решение. Есть 2 таблицы А и В. Количество полей… Искать еще темы с ответами Или воспользуйтесь поиском по форуму: 7 |
Поиск совпадений в двух списках
Тема сравнения двух списков поднималась уже неоднократно и с разных сторон, но остается одной из самых актуальных везде и всегда. Давайте рассмотрим один из ее аспектов — подсчет количества и вывод совпадающих значений в двух списках. Предположим, что у нас есть два диапазона данных, которые мы хотим сравнить:

Для удобства, можно дать им имена, чтобы потом использовать их в формулах и ссылках. Для этого нужно выделить ячейки с элементами списка и на вкладке Формулы нажать кнопку Менеджер Имен — Создать (Formulas — Name Manager — Create). Также можно превратить таблицы в «умные» с помощью сочетания клавиш Ctrl+T или кнопки Форматировать как таблицу на вкладке Главная (Home — Format as Table).
Подсчет количества совпадений
Для подсчета количества совпадений в двух списках можно использовать следующую элегантную формулу:

В английской версии это будет =SUMPRODUCT(COUNTIF(Список1;Список2))
Давайте разберем ее поподробнее, ибо в ней скрыто пару неочевидных фишек.
Во-первых, функция СЧЁТЕСЛИ (COUNTIF). Обычно она подсчитывает количество искомых значений в диапазоне ячеек и используется в следующей конфигурации:
=СЧЁТЕСЛИ(Где_искать; Что_искать)
Обычно первый аргумент — это диапазон, а второй — ячейка, значение или условие (одно!), совпадения с которым мы ищем в диапазоне. В нашей же формуле второй аргумент — тоже диапазон. На практике это означает, что мы заставляем Excel перебирать по очереди все ячейки из второго списка и подсчитывать количество вхождений каждого из них в первый список. По сути, это равносильно целому столбцу дополнительных вычислений, свернутому в одну формулу:

Во-вторых, функция СУММПРОИЗВ (SUMPRODUCT) здесь выполняет две функции — суммирует вычисленные СЧЁТЕСЛИ совпадения и заодно превращает нашу формулу в формулу массива без необходимости нажимать сочетание клавиш Ctrl+Shift+Enter. Формула массива необходима, чтобы функция СЧЁТЕСЛИ в режиме с двумя аргументами-диапазонами корректно отработала свою задачу.
Вывод списка совпадений формулой массива
Если нужно не просто подсчитать количество совпадений, но и вывести совпадающие элементы отдельным списком, то потребуется не самая простая формула массива:

В английской версии это будет, соответственно:
=INDEX(Список1;MATCH(1;COUNTIF(Список2;Список1)*NOT(COUNTIF($E$1:E1;Список1));0))
Логика работы этой формулы следующая:
- фрагмент СЧЁТЕСЛИ(Список2;Список1), как и в примере до этого, ищет совпадения элементов из первого списка во втором
- фрагмент НЕ(СЧЁТЕСЛИ($E$1:E1;Список1)) проверяет, не найдено ли уже текущее совпадение выше
- и, наконец, связка функций ИНДЕКС и ПОИСКПОЗ извлекает совпадающий элемент
Не забудьте в конце ввода этой формулы нажать сочетание клавиш Ctrl+Shift+Enter, т.к. она должна быть введена как формула массива.
Возникающие на избыточных ячейках ошибки #Н/Д можно дополнительно перехватить и заменить на пробелы или пустые строки «» с помощью функции ЕСЛИОШИБКА (IFERROR).
Вывод списка совпадений с помощью слияния запросов Power Query
На больших таблицах формула массива из предыдущего способа может весьма ощутимо тормозить, поэтому гораздо удобнее будет использовать Power Query. Это бесплатная надстройка от Microsoft, способная загружать в Excel 2010-2013 и трансформировать практически любые данные. Мощь и возможности Power Query так велики, что Microsoft включила все ее функции по умолчанию в Excel начиная с 2016 версии.
Для начала, нам необходимо загрузить наши таблицы в Power Query. Для этого выделим первый список и на вкладке Данные (в Excel 2016) или на вкладке Power Query (если она была установлена как отдельная надстройка в Excel 2010-2013) жмем кнопку Из таблицы/диапазона (From Table):

Excel превратит нашу таблицу в «умную» и даст ей типовое имя Таблица1. После чего данные попадут в редактор запросов Power Query. Никаких преобразований с таблицей нам делать не нужно, поэтому можно смело жать в левом верхнем углу кнопку Закрыть и загрузить — Закрыть и загрузить в… (Close & Load To…) и выбрать в появившемся окне Только создать подключение (Create only connection):


Затем повторяем то же самое со вторым диапазоном.
И, наконец, переходим с выявлению совпадений. Для этого на вкладке Данные или на вкладке Power Query находим команду Получить данные — Объединить запросы — Объединить (Get Data — Merge Queries — Merge):

В открывшемся окне делаем три вещи:
- выбираем наши таблицы из выпадающих списков
- выделяем столбцы, по которым идет сравнение
- выбираем Тип соединения = Внутреннее (Inner Join)

После нажатия на ОК на экране останутся только совпадающие строки:

Ненужный столбец Таблица2 можно правой кнопкой мыши удалить, а заголовок первого столбца переименовать во что-то более понятное (например Совпадения). А затем выгрузить полученную таблицу на лист, используя всё ту же команду Закрыть и загрузить (Close & Load):

Если значения в исходных таблицах в будущем будут изменяться, то необходимо не забыть обновить результирующий список совпадений правой кнопкой мыши или сочетанием клавиш Ctrl+Alt+F5.
Макрос для вывода списка совпадений
Само-собой, для решения задачи поиска совпадений можно воспользоваться и макросом. Для этого нажмите кнопку Visual Basic на вкладке Разработчик (Developer). Если ее не видно, то отобразить ее можно через Файл — Параметры — Настройка ленты (File — Options — Customize Ribbon).
В окне редактора Visual Basic нужно добавить новый пустой модуль через меню Insert — Module и затем скопировать туда код нашего макроса:
Sub Find_Matches_In_Two_Lists()
Dim coll As New Collection
Dim rng1 As Range, rng2 As Range, rngOut As Range
Dim i As Long, j As Long, k As Long
Set rng1 = Selection.Areas(1)
Set rng2 = Selection.Areas(2)
Set rngOut = Application.InputBox(Prompt:="Выделите ячейку, начиная с которой нужно вывести совпадения", Type:=8)
'загружаем первый диапазон в коллекцию
For i = 1 To rng1.Cells.Count
coll.Add rng1.Cells(i), CStr(rng1.Cells(i))
Next i
'проверяем вхождение элементов второго диапазона в коллекцию
k = 0
On Error Resume Next
For j = 1 To rng2.Cells.Count
Err.Clear
elem = coll.Item(CStr(rng2.Cells(j)))
If CLng(Err.Number) = 0 Then
'если найдено совпадение, то выводим со сдвигом вниз
rngOut.Offset(k, 0) = rng2.Cells(j)
k = k + 1
End If
Next j
End Sub
Воспользоваться добавленным макросом очень просто. Выделите, удерживая клавишу Ctrl, оба диапазона и запустите макрос кнопкой Макросы на вкладке Разработчик (Developer) или сочетанием клавиш Alt+F8. Макрос попросит указать ячейку, начиная с которой нужно вывести список совпадений и после нажатия на ОК сделает всю работу:

Более совершенный макрос подобного типа есть, кстати, в моей надстройке PLEX для Microsoft Excel.
Ссылки по теме
- Поиск различий в двух списках Excel
- Слияние двух списков без дубликатов (3 способа)
- Что такое макросы, как их использовать, куда копировать код макросов на Visual Basic