
У Word есть мощные возможности поиска, которые позволяют искать вам текст, числа, форматы, параграфы, разрывы страниц, использовать подстановочные символы, коды полей и многое другое. Используя подстановочные символы, вы можете искать просто всё что угодно в вашем документе. Поскольку функция поиска совмещена с заменой, то вы можете также выполнять весьма замысловатые преобразования текста.
Прежде чем мы приступим, поясню пару терминов, которые могут быть не совсем понятными для вас.
Регулярное выражение — это условное обозначение критериев, которым должна соответствовать искомая строка. С помощью регулярных выражений можно найти множество строк или слов, соответствующих заданным условиям.
Подстановочные символы (wildcards) — это * (звёздочка), . (точка) и ? (знак вопроса), которые имеют в регулярных выражениях специальное значение. Например, символ * (звёздочка) обозначает любое количество любых символов, а ? (знак вопроса) означает любой один символ.
Давайте начнём знакомство с продвинутыми возможностями поиска в Word!
Как использовать подстановочные символы в продвинутом поиске
В ленте Word переключитесь на вкладку «Главная» и нажмите кнопку «Заменить»:

В окне «Найти и заменить» кликните «Больше >>», чтобы развернуть диалоговое окно и увидеть дополнительные опции. Если вы увидели кнопку «<< Меньше», значит всё прошло удачно.

В раскрывшемся окне для показа опций поиска, включите флажок «Подстановочные знаки».
Обратите внимание, что после того, как вы включили опцию «Подстановочные знаки», Word сразу под полем «Найти:» показывает, что эта опция включена. Также когда выбран флажок «Подстановочные знаки», некоторые опции становятся недоступными для включения, а именно: «Учитывать регистр», «Только слово целиком», «Учитывать префикс», «Учитывать суффикс».
Теперь нажмите кнопку «Специальный» для просмотра списка подстановочных знаков.
В Word доступны следующие подстановочные символы:
| Символ | Значение |
|---|---|
| ? | Любой знак |
| [-] | Символ в диапазоне |
| < | В начале слова |
| > | В конце слова |
| () | Выражение — единая последовательность символов. Также применяется для обратных ссылок |
| [!] | Не |
| {;} | Число вхождений |
| @ | Предыдущий 1 или более |
| * | Любое число знаков |
| ^t | Знак табуляции |
| ^^ | Знак крышки |
| ^n | Знак столбца |
| ^+ | Длинное тире |
| ^= | Короткое тире |
| ^g | Графический объект |
| ^l | Разрыв строки |
| ^m | Разрыв страницы / раздела |
| ^~ | Неразрывный дефис |
| ^s | Неразрывный пробел |
| ^- | Мягкий перенос |
Наконец выберите подстановочный символ для вставки в ваши критерии поиска. После выбора подстановочного знака, символ добавляется в строку поиска. Когда запомните значения, вы также можете использовать клавиатуру для ввода символов вместо вставки их путём выбора из списка. Меню «Специальный» работает как справка в случае если вы не помните, какие доступны специальные символы и их значения.
Готовые увидеть как работают подстановочные символы? Давайте ознакомимся с конкретными примерами использования регулярных выражений и подстановочных символов в Word.
Для чего используются подстановочные символы?
В меню «Специальный» содержит много специальных символов, которые вы можете использовать для поиска по документу Word, но на самом деле не все они являются подстановочными символами. Большинство из них нужны для поиска каких-то специфичных и, иногда, скрытых символов Word, таких как пробелы, разного вида тире, разрывы страницы.
Здесь мы заострим внимание в первую очередь на подстановочных знаках, которые означают один или более символов текста или модифицируют поиск на основе другого символа в вашем поиске.
Использование звёздочки для указания любого количества символов
Скорее всего, самым часто используемым подстановочным символом для вас станет звёздочка. Она означает, что вы хотите найти любое количество символов. Например, чтобы найти все слова, начинающиеся с «отм», напечатайте «отм*» в строке поиска и затем кликните кнопку «Найти далее». Наше регулярное выражение означает любое количество букв (* звёздочка), следующих после «отм».
В качестве альтернативы ввода символа звёздочки с клавиатуры, вы можете использовать выбор специального символа из списка подстановочных знаком. Вначале наберите «отм» в строке «Найти». Поставьте галочку «Подстановочные знаки». Затем кликните кнопку «Специальный» и выберите «Любое число символов». После этого нажмите кнопку «Найти далее»:
Word оценивает поиск и показывает вам первое вхождение, которое он найдёт в документе. Продолжайте кликать «Найти далее», чтобы найти все части текста, которые соответствуют вашему поисковому термину.
Вы должны помнить важную вещь: при включении подстановочных знаков, поиск автоматически становится чувствительным к регистру (такова особенность регулярных выражений, частью которых являются подстановочные символы). Поэтому поиск «отм*» и «Отм*» даст различные результаты.
Использование знака вопроса для поиска определённого количества символов
В то время как звёздочка означает любое количество символов, знак вопроса в регулярном выражении означает единичный (один) символ. Например, если «отм*» будет искать строки начинающиеся с «отм» за которыми идёт любое количество символов, то «отм?» будет искать строки, начинающиеся с «отм», за которой идёт только один символ.
Как и звёздочку, знак вопроса можно использовать в любой части слова — в том числе в начале и в середине.
Также можно использовать вместе несколько знаков вопроса вместе, тогда они будут обозначать несколько букв.
Например, регулярное выражение для поиска «о?о?о» оно означает букву «о», за которой идёт любой символ, затем снова идёт буква «о», затем опять любой символ и затем опять буква «о» найдёт следующие слова:
- потоков
- многополосных
- многополосных
- которое
- правового
- такового
- такого основания
Можно найти слова с четырьмя буквами «о», шаблон «о?о?о?о»:
- которого
- многополосных
Или с тремя буквами «а», шаблон «а?а?а»:
- наказания
- задача
- аппарата
- высказана
- началах
Необязательно использовать одинаковые буквы — составляйте выражения под ваши задачи.
Например, чтобы найти слова, в которых первая буква «з», затем идёт любой другой символ, а затем буква «к» и вновь любой символ, шаблон для поиска «з?к?» найдёт:
- закономерности
- законодательно
Использование знака собачка (@) и фигурных скобок ({ and}) для поиска вхождений предыдущего символа
Вы можете использовать знак собачка (@) для указания одного или более вхождения предыдущего символа. Например, «ro@t» найдёт все слова, которые начинаются на «ro» и заканчиваются на «t» и которые имеют любое количество букв «o» между этими частями. Поэтому по этим условиям поиска будут найдены слова «rot», «root» и даже «roooooot».
Для большего контроля поиска предыдущих символов, вы можете использовать фигурные скобки, внутри которые укажите точное число вхождений предыдущего символа, который вы хотите найти. Например, поиск «ro{2}t» найдёт «root», но не найдёт «rot» или «roooooot».
Также поддерживает синтаксис вида {n;} — означает искать количество вхождений символа более n раз; {;m} — означает искать количество вхождений символа менее m раз; {n;m} — означает искать количество вхождений символа более n раз, но менее m раз.
Чтобы показать более практический пример, немного забежим вперёд, следующий поиск использует набор символов (будут рассмотрены в этой статье чуть ниже), в результате, будут найдены все слова, в которых подряд идут четыре согласных буквы:
[бвгджзйклмнпрстфхцчшщ]{4}
Использование угловых скобок (< и >) для обозначения начала и конца слова
Думаю, вы заметили, особенно когда составляли поисковые запросы со звёздочкой, что пробел считается за обычный символ и могут быть найдены довольно неожиданные фрагменты большого размера, либо фрагменты, состоящие из двух слов. Вы можете использовать угловые скобки (символы «больше чем» и «меньше чем») для обозначения начала и конца слова поиска. Например, вы можете искать «<но>» и Word найдёт все вхождения «но», но не найдёт слова вроде «новости», «законодатель».
Это довольно полезно, но эта техника становится более мощной, когда вы комбинируете её с другими подстановочными символами. Например, с помощью «<з????>» вы можете найти все слова, которые начинаются на «з» и состоят ровно из пяти букв.
Вам необязательно использовать обе угловые скобки в паре. Вы можете обозначить просто только начало или конец слова, используя только одну соответствующую скобку. Например «ство>» найдёт слова
- руководство
- множество
- средство
- количество
Использование квадратных скобок ([ и ]) для поиска определённых символов или диапазонов символов
Вы можете использовать квадратные скобки для указания любых символов или диапазонов символов. Например «[а]» будет искать любые вхождения буквы «а».
В следующем примере, будет искаться строка, которая начинается на «р», затем идёт любая гласная, а затем снова буква «р»: «р[аеиоуэюя]р»
Далее аналогичный пример, но между буквами «р» должно быть две любых гласных: «р[аеиоуэюя]{2}р», будет найдено, к примеру, слово «приоритет».
Вы также можете искать квадратные скобки для поиска диапазонов символов, например «[a-z]» найдёт любую из этих букв в нижнем регистре. Поиск «[0-9]» найдёт любую из этих цифр.
Пример р[а-и]{2}р найдёт строку, которая начинается и заканчивается на букву «р» между которыми две любые буквы из указанного диапазона.
Следующий пример довольно сложный, но при этом и довольно интересный:
[А-Я]{1}[а-я0-9 ,-]{1;}.
В начале строки должна стоят любая заглавная буква ([А-Я]) ровно один раз ({1}). Затем должны идти маленькие буквы, цифры, пробелы, запятые и тире ([а-я0-9 ,-]) хотя бы один раз и более ({1;}), в самом конце должна стоять точка (.)
Думаю вы догадались, что это регулярное выражение которое будет искать предложения. Перечислены не все возможные символы, поэтому не будут найдены предложения, содержащие кавычки и некоторые другие символы, а также вопросительные и восклицательные предложения.
То есть вы можете комбинировать подстановочные символы и дополнять их кванторами количества, а затем это всё комбинировать любое количество раз, пока не получите желаемый результат. На самом деле, это довольно сложно — почти как программирование, поскольку требует абстрактного мышления.
Использование скобок для группировки поисковых терминов в последовательности
Вы можете использовать круглые скобки в вашем поиске для группировки последовательностей символов.
Можно использовать довольно простые шаблоны, например «(го){3;}» найдёт строки, в которых «го» встречается три и более раза подряд.
Но настоящую силу эта конструкция покажет при использовании в операциях поиска и замены.
Показанная далее техника называется «обратные ссылки». Начнём с конкретного примера, чтобы было проще понять. Предположим, нам нужно во всём документе поменять местами два слова, допустим, имя и фамилию. К примеру, во всём тексте множество раз упоминается «Милосердов Алексей», а нам нужно, чтобы было «Алексей Милосердов».
Для этого в строке поиска мы вставляем «(Милосердов) (Алексей)», а в строке «Заменить на» пишем «2 1».
Скобки не участвуют в поиске, то есть в результате будет искаться фраза «Милосердов Алексей» При этом то, что было найдено в первых скобках, будет присвоено как значение «1», а то, что было найдено во вторых скобках, станет значением «2». При этом найденная строка заменится на «Алексей Милосердов».
Можно сделать по-другому, допустим вместо фамилии и имени, я хочу заменить на фамилию и инициалы, тогда в строке поиска я ищу «(Милосердов) (Алексей)», а в строке «Заменить на» пишу «1 А.В.».
В скобках можно писать не только слова, там могут использоваться подстановочные символы в разных сочетаниях, а также кванторы количества. Когда находится целая фраза, то Word автоматически пронумеровывает эти группы слева направо (это происходит «под капотом» — мы это не видим), поэтому в поле «Заменить на» мы можем использовать эти группы по их номеру, перед которым нужно поставить обратный слэш.
Рассмотрим более жизненный пример. Допустим, у нас по всему документу имеются даты вида 31.12.2019 (то есть в формате день.месяц.год), а мы хотим чтобы все эти даты были в формате 2019.12.31 (то есть год.месяц.день).
Тогда для поиска любых дат составляем регулярное выражение с подстановочными символами:
«[0-9]{2}.[0-9]{2}.[0-9]{4}»
«[0-9]» — это диапазон, обозначающий все цифры, «{2}» — это квантор количества, который говорит, что предыдущий символ должен встречаться ровно два раза. То есть будет искаться строка длиной ровно два символа, состоящая из цифр. Затем идёт точка, затем снова аналогичная строка и точка, и в конце строка из четырёх цифр.
Строка подходит для поиска, но чтобы были созданы обратные ссылки, мы заключаем нужные нам элементы в круглые скобки: «([0-9]{2}).([0-9]{2}).([0-9]{4})» — она будет работать точно также, как и предыдущая.
Теперь составляем строку «Заменить на». В начале идёт год, то есть третья группа, она обозначается как «3», затем точка, затем вторая группа, затем опять точка и затем первая группа, получаем «3.2.1».
Используйте обратный слэш () если вам нужно искать символы, которые являются подстановочными знаками
А что если вам нужно найти в документе символ, который используется как подстановочный? Например, если вам нужно найти звёздочку? Если просто её вставите, то она сработает как подстановочный знак и будет найдено всё что угодно. Есть два способа искать символы в их буквальном значении.
Первый способ, это снять галочку с опции «Подстановочные знаки» перед выполнением поиска. Но если вы не хотите это делать, вы можете использовать обратный слэш () перед этим символом. Например, чтобы найти буквальный знак вопроса при включённых «Подстановочных знаках», введите в поле Поиск «?».
Заключение
Вы можете делать весьма сложные поиски и замены комбинируя подстановочные символы в ваших поисках в Word, поэтому продолжайте пробовать с ними. После того, как вы действительно разберётесь, какой потенциал несут регулярные выражения, вы сможете увеличить вашу продуктивность. Нам только следует порекомендовать вам не делать большие операции поиска и замены одновременно для всего документа, если у вас нет полной уверенности что ваши подстановочные символы делают именно то, что вы задумали. Также рекомендуется для этого использовать тестовые копии документов.
Связанные статьи:
- Как в Microsoft Word сделать массовую замену или удаление текста (74%)
- Как убрать лишние пробелы в Microsoft Word (74%)
- Как выделить текст цветом в Word (66.3%)
- Как вставить музыкальный символ, ноты в Word (57.7%)
- Как напечатать диапазон страниц документа Word из нескольких разделов (57.7%)
- Как добавить линию над текстом в Word (RANDOM — 50%)
| 01 |
Все кто когда-либо сталкивался с подстановочными символами (Wildcards) знают, что это достаточно убогая попытка реализовать в VBA механизм подобный регулярным выражениям в других более развитых языках. Помимо более скудных возможностей (я уже не говорю о невозможности указания количества «ноль-или-один») данный механизм также ограничен и в сложности выстраиваемых выражений, и те кто пытался решить более-менее сложные задачи не раз сталкивался с ошибкой Поле «Найти» содержит слишком сложное выражение с использованием подстановочных символов. Отсюда и возникла необходимость воспользоваться более могущественным инструментом — регулярными выражениями. |
| 02 | VBA |
1 Dim objRegExp, matches, match Set objRegExp = CreateObject(«VBScript.RegExp») With objRegExp |
| 03 |
Здесь, конечно, каждый кодер обрадуется — вызываем Replace и все ок! |
| 04 | VBA |
1 Set matches = objRegExp.Replace(ActiveDocument.Content, «replacementstring») |
| 05 |
Но при запуске, конечно же, будет выдана ошибка. Это связано с тем, что метод Replace объекта VBScript.RegExp принимает на вход первым параметром строковую переменную, а не объект (в нашем случае ActiveDocument.Content), и возвращает этот метод также измененную строку, а не вносит изменение во входящую, отсюда и танцы с бубнами: |
| 06 | VBA |
1 Set matches = objRegExp.Execute(ActiveDocument.Content) For Each match In matches |
| 07 |
Ну хорошо, скажете вы, ну а если нам нужно переформатировать данные по аналогии с выражениями типа $1-$3-$2 (т. н. «обратные ссылки» в регулярных выражениях), т. е. как к примеру из 926-5562214 получить +7 (926) 556-22-14. Это тоже достаточно просто, здесь они тоже есть — единственное отличие — нумерация найденных групп начинается не с нуля, а единицы — $1. Давайте пока отвлечемся от нашего документа и посмотрим как это можно сделать с обычной строковой переменной: |
| 08 | VBA |
1 Dim objRegExp, matches, match Set objRegExp = CreateObject(«VBScript.RegExp») Dim strSearch As String With objRegExp .pattern = «8(d{3})-(d{3})(d{2})(d{2})» End With strResult = objRegExp.Replace(strSearch, «+7 ($1) $2-$3-$4») Debug.Print strResult |
| 09 | На заметку: |
12 строка выделена для того чтобы подчеркнуть каким образом было разделено указание на подгруппы ($2, $3 и $4), ведь выражение (d{3})(d{2})(d{2}) эквивалентно (d{7}). Но во втором случае, рекурсивный запрос содержал бы все 7 цифр. |
Изучайте регулярные выражения! |
| 10 |
Но поскольку, как уже говорилось выше, вместо входной строки у нас объект ActiveDocument.Content, такой метод не подойдет для работы. Придется пойти на хитрость — объединить два предыдущих кода: |
| 11 | VBA |
1 Set objRegExp = CreateObject(«VBScript.RegExp») With objRegExp Set matches = objRegExp.Execute(ActiveDocument.Content) Dim strReplacement As String For Each match In matches strReplacement = objRegExp.Replace(match.Value, «+7 ($1) $2-$3-$4») With matchRange.Find |
| 12 |
Оборачиваем в оболочку-функцию и, вуаля: |
| 13 | VBA |
1 Sub ВыполнитьГруппуПреобразований_RegExp() End Sub Sub ВыполнитьГруппуПреобразований_RegExp() … Private Sub Выполнить_RegExp(pattern As String, patternExpr As String) With objRegExp Set matches = objRegExp.Execute(ActiveDocument.Content) Dim strReplacement As String For Each match In matches strReplacement = objRegExp.Replace(match.Value, patternExpr) With matchRange.Find Private Sub Выполнить_RegExp(pattern As String, patternExpr As String) … |
| 14 |
Нельзя умолчать о существовании, к сожалению, некоторых ограничений в синтаксисе регулярных выражений при использовании объекта VBScript.RegExp в VBA. Эти ограничения провоцируют ошибку Run-time error ‘5017’ Application-defined or object-defined error. Вот некоторые из них: |
| 15 |
|
| 17 |
Похожие запросы:
|
Майкрософт почемуто свои регулярки на называет “wildcards”
Примеры
Поиск
| Описание | Найти |
|---|---|
| Найти все русские буквы в документе | [А‐ЯЁа‐яё] |
| Найти все русские аббревиатуры, длиной от 2 до 8 символов | <[А‐ЯЁ]{2;8}> |
| Найти все, что в фигурных скобках | {*} |
| Найти все ссылки на нормативные документы вида “{некоторый текст}” | {[a‐zA‐Z0‐9‐.]@} |
| Найти все даты в документе | [0‐3][0‐9][‐./][0‐1][0‐9][‐./][0‐9]{2;4} |
| Поиск всех разрывов страниц, переносов строки.т.д. | [^11^12^13] |
| Поиск KKS-кода систем (FH1 специфична) | <[A‐CF‐NPQSX][A‐HJ‐NP‐Z][A‐HJ‐Z] |
| Поиск ККS-кода арматуры (FH1 специфична) | <[A‐CJ‐NPQSX][A‐HJ‐NP‐Z][A‐HJ‐Z][0‐9,//(/)]@AA[0‐9,//(/)]{1;20} |
| Поиск ККSкодов оборудования с кодом отказа для ВАБ (FH1 специфична) | <[A‐Z]{3}[0‐9,//(/)]@[A‐Z]{2}[0‐9,//(/)]@[A‐GI‐MP‐TVW][A‐Z][A‐FH‐MO‐Y]> |
| Поиск кодов функций вида ”AC3b_31D” (FH1 специфична) | <[A‐Z][A‐Z][0‐9][a‐z]_[0‐9][0‐9A‐Z]{1;2}> |
| Поиск вида: [1], [1015], [3,4,9] | [[0‐9‐, ]{1;12}] |
| Найти все шифры документов (FH1 специфична) | <FH1.*.[ER]> |
Замена
| Описание | Найти | Заменить на |
|---|---|---|
| Заменить в десятичных числах запятую на точку | ([!,]<[0‐9]@),([0‐9Ee]@>) | 1.2 |
| Удалить пустые строки | (^0013){2;} | 1 |
| Удалить подряд идущие пробелы | ^0032{2;} | ^0032 |
| Замена двух или более пробелов на табуляцию | ^0032{2;} | ^0009 |
| Удалить пробел перед знаком препинания (.,:;!? итд) | ^0032([.,:;!?]) | 1 |
| Замена пробела между цифрой и буквой (английской или русской) на не разбиваемый пробел | ([0‐9])^0032([A‐Za‐zА‐яЁё]) | 1^s2 |
| Замена дефиса перед цифрой на минус | ‐([0‐9]) | ^01501 |
| Замена круглых скобок вокруг 1ой цифры на квадратные | (([0‐9])) | [1] |
| Замена пробела между цифрами на не разбиваемый пробел | ([0‐9])^0032([0‐9]) | 1^s2 |
| Удалить фигурные скобки вокруг “{A}” | {([A‐Z])} | 1 |
| Заменить “4.5.4.1” на “7.5.4.1”. Проводит замену первой цифры | ([!*])4. | 17. |
- Download demo — 63.16 KB
- Download source — 91.13 KB
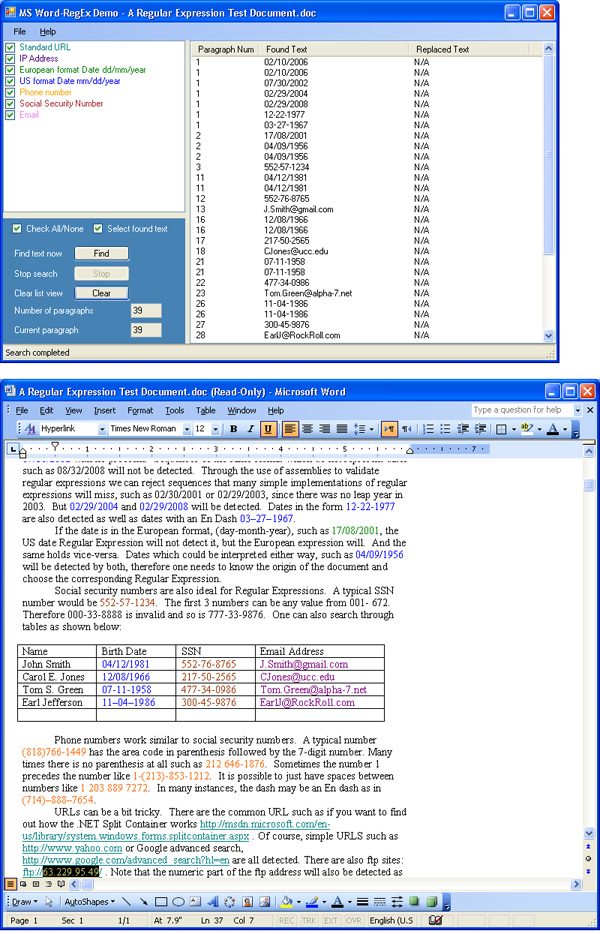
Prerequisites
In order to run the sample application, the Microsoft .NET Framework 2.0 or higher must be installed. In addition, Microsoft Office 2003 or higher must be installed along with the Microsoft Office 2003 Primary Interop Assemblies (PIAs) redistributable. These PIAs are installed if one performs a full install of Microsoft Office 2003, or you can get them for free from Microsoft.
For more information on how to install and use the Primary Interop Assemblies in .NET programs, please refer to this link.
I would like to emphasize that one does not need Visual Tools for Office to run or modify this program.
Introduction
Regular Expressions are a very powerful tool for text processing. Sophisticated expressions can be used to find all kinds of patterns of text. Regular Expression engines are integrated into many text editors. Most Regular Expression examples show how to manipulate either ASCII or Unicode text. In addition to editors that handle the standard text formats mentioned previously, there are millions (or probably billions) of documents encoded in one of Microsoft’s many Office formats, such as WORD format (doc), Rich Text Format (RTF), and Excel (XLS). While one can perform searches in Microsoft Office documents using Regular Expressions through the use of Smart Tags, its implementation is cumbersome for many document processing purposes. In this article, I will present a simple methodology of applying the power of Regular Expressions to Microsoft Word documents through the use of the Microsoft .NET Framework. The methodology makes use of the System.Text.RegularExpressions namespace and the Microsoft Word interop assemblies to realize this solution. In addition, through the use of dynamically loadable assemblies, every Regular Expression match can be validated to ensure that the match is correct. For example, it is quite easy to write a Regular Expression for a numerical date of the form 02/07/2007 for February 7, 2007. But to include in the Regular Expression checks for invalid dates such as 04/31/2002 or 02/30/2007 is quite difficult without code that performs such checks.
In future articles, I plan to present ways of using Regular Expressions to perform sophisticated text search and replace algorithms through the use of the MSOFFICE interop assemblies and .NET technologies. I will also apply these techniques to other MSOFFICE documents such as EXCEL.
Background
Support for Regular Expressions for Microsoft applications first appeared in Word 97. Its implementation was quite tedious because the syntax used differed significantly from the Regular Expression Standard. Microsoft realized the shortfalls in their implementation, and reintroduced Regular Expressions as part of their Smart Tags library 2.0, which was first available with Microsoft Office 2003. Smart Tags, of which Regular Expression operations form a small part, represented a generalized, integrated way to enable users to present data from their documents. However, due to its non-intuitive, complicated manner, Microsoft itself admits in their MSDN Web site that a poll showed developers have not taken the necessary steps to develop them or use the Microsoft .NET Framework to do so. Please refer to this MSDN article for more information: Realize the Potential of Office 2003 by Creating Smart Tags in Managed Code. The focus of this article is devising a simple, yet powerful way of using Regular Expressions (along with validation code).
Using the Code
On startup, the program reads the XML file Searches.XML. This file contains information for all built-in Regular Expression searches. Included in this XML file are searches for URLs, IP addresses, US dates, European dates, US phone numbers, and email addresses. One can add as many search options as she or he wants to this file. Each search option can be activated by placing a check by the desired search.
Each search group contains the following information in the XML file:
- Search Regex – The Regular Expression used in the search
- Indentifier – The search title that appears in the check listbox
- FindColor – The color used to highlight the found text in the document
- Action – The operation used (this version only supports Find)
- PlugInName – The name of the assembly associated with the search. If no assembly is associated, “None” is used.
- PlugInFunction – The function called for this search block that is found in its plug-in assembly
- Description – The description text that is displayed in the check list box
Finding the Text
MSWordRegExDemo contains methods which manipulate the Microsoft Word or RTF document using automation by way of the Microsoft Word interop assembly. All of these methods are contained in the DocumentEngine class. The two main Microsoft Word objects that are used in this application are:
Word.Application app; Word.Document theDoc;
To open the document, we perform the following call which is triggered by the file open event in the GUI:
public void OpenDocument(string documentName) { object optional = Missing.Value; object visible = true; object fileName = documentName; if (app == null) app = new Word.Application(); app.Visible = true; try { theDoc = app.Documents.Open(ref fileName, ref optional, ref optional, ref optional, ref optional, ref optional, ref optional, ref optional, ref optional, ref optional, ref optional, ref visible, ref optional, ref optional, ref optional, ref optional); paraCount = theDoc.Paragraphs.Count; } catch(Exception ex) { MessageBox.Show(ex.Message + ": Error opening document"); } }
The first step is converting the text of the Word document into Text. Once we have the document in the text domain, we can perform a Regular Expression search on the text and see if there are any matches. See below:
docText = docEngine.GetRng(currentParaNum).Text;
If one or more matches occur, we then take the match text and feed it through the Microsoft Word.Find function. In searching for text, we need to select a text range to import into text. I have chosen the paragraph range specifier. This means that we will loop through the document paragraph by paragraph, performing our searches on each paragraph. For short documents, we could select the entire range of the document. If we wanted to iterate through footnotes, Word provides a footnote range. To get the range of each paragraph, the following function is used:
public Word.Range GetRng(int nParagraphNumber) { try { return theDoc.Paragraphs[nParagraphNumber].Range; } catch (System.Runtime.InteropServices.COMException ex) { MessageBox.Show(ex.Message + "nParagraph Number: " + nParagraphNumber.ToString() + " does not exist."); return null; } }
The main function which performs the «find» of text is RegularExpressionFind.
public void RegularExpressionFind(int paraNum, string docText, SearchStruct selSearchStruct, out List<hitinfo /> hits) { HitInfo hitInfo = new HitInfo(); hits = new List<hitinfo />(); System.Text.RegularExpressions.Regex r; Word.WdColor color = GetSearchColor(selSearchStruct.TextColor); r = new Regex(selSearchStruct.RegExpression); MatchCollection matches = r.Matches(docText); if (matches.Count == 0) return; try { if (!LoadSearchAssembly(selSearchStruct.PlugInName, selSearchStruct.PlugInFunction)) return; } catch (Exception ex) { throw ex; } int index = 0; int startSearchPos = GetRng(paraNum).Start; foreach (Match match in matches) { if (hasValidationAssembly) { Object[] objList = new Object[1]; objList[0] = (Object)match; if (!Convert.ToBoolean(validationMethod.Invoke (assemblyInstance, objList))) continue; } index = docText.IndexOf(match.Value, index); string matchStr = docText.Substring(index, match.Value.Length); index += matchStr.Length - 1; FindTextInDoc(OperationMode.DotNetRegExMode, paraNum, matchStr, color, startSearchPos, out startSearchPos, out hitInfo.StartDocPosition); hitInfo.Text = match.Value; hits.Add(hitInfo); } }
First, we search for the Regular Expression in the imported paragraph, by using the Regex .NET functions.
r = new Regex(selSearchStruct.RegExpression); MatchCollection matches = r.Matches(docText); if (matches.Count == 0) return;
If there is a match, we load the search assembly if it has not already been loaded, and perform additional validation on the match.
try { if (!LoadSearchAssembly(selSearchStruct.PlugInName, selSearchStruct.PlugInFunction)) return; }
The following method dynamically loads the validation assembly for the Regular Expression, if one exists. If the assembly was previously loaded, the LoadFrom method will return it.
public bool LoadSearchAssembly(string plugginName, string plugInFunction) { try { if (plugginName.ToLower() == "none") { hasValidationAssembly = false; return true; } hasValidationAssembly = true; string plugginPath = Path.GetDirectoryName (Application.ExecutablePath) + @"Plugins" + plugginName; if (!File.Exists(plugginPath)) throw new Exception("Cannot find path to assembly: " + plugginName); Assembly a = Assembly.LoadFrom(plugginPath); Type[] types = a.GetTypes(); validationMethod = types[0].GetMethod(plugInFunction); assemblyInstance = Activator.CreateInstance(types[0]); return true; } catch (Exception ex) { MessageBox.Show(ex.Message); return false; } }
Below is the assembly that validates a numerical date:
namespace SaelSoft.RegExPlugIn.NumericalDateValidator { public class NumericalDateValidatorClass { int month = 0; int day = 0; int year = 0; public bool ValidateUSDate(Match matchResult) { if (matchResult.Groups.Count < 3) return false; int nResult = 0; if (int.TryParse(matchResult.Groups[1].ToString(), out nResult)) month = nResult; else return false; if (int.TryParse(matchResult.Groups[2].ToString(), out nResult)) day = nResult; else return false; if (int.TryParse(matchResult.Groups[3].ToString(), out nResult)) year = nResult; else return false; return CommonDateValidation(); } public bool ValidateEuropeanDate(Match matchResult) { if (matchResult.Groups.Count < 3) return false; int nResult = 0; if (int.TryParse(matchResult.Groups[1].ToString(), out nResult)) month = nResult; else return false; if (int.TryParse(matchResult.Groups[2].ToString(), out nResult)) day = nResult; else return false; if (int.TryParse(matchResult.Groups[3].ToString(), out nResult)) year = nResult; else return false; return CommonDateValidation(); } private bool CommonDateValidation() { if (day == 31 && (month == 4 || month == 6 || month == 9 || month == 11)) { return false; } else if (day >= 30 && month == 2) { return false; } else if (month == 2 && day == 29 && !(year % 4 == 0 && (year % 100 != 0 || year % 400 == 0))) { return false; } else { return true; } } }
Finally, if we have a real match, we perform a search for the match string in the Word document by calling the DocumentEngine function, FindTextInDoc.
internal bool FindTextInDoc(OperationMode opMode, int currentParaNum, string textToFind, Word.WdColor color, int start, out int end, out int textStartPoint) { string strFind = textToFind; textStartPoint = 0; Word.Range rngDoc = GetRng(currentParaNum); if (start >= rngDoc.End) { end = 0; return false; } rngDoc.Start = start; rngDoc.Find.ClearFormatting(); rngDoc.Find.Forward = true; rngDoc.Find.Text = textToFind; object caseSensitive = "1"; object missingValue = Type.Missing; object matchWildCards = Type.Missing; if (opMode == OperationMode.Word97Mode) matchWildCards = "1"; rngDoc.Find.Execute(ref missingValue, ref caseSensitive, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue, ref missingValue); if (hilightText) rngDoc.Select(); end = rngDoc.End + 1; textStartPoint = rngDoc.Start; if (rngDoc.Find.Found) { rngDoc.Font.Color = color; return true; } return false; }
Points of Interest
The DocumentEngine class makes use of Microsoft Office events in order to detect the situation when the user closes the Microsoft Word document that was loaded by the application. When the Quit event is invoked, the app and the document objects are set to NULL. They are reinitialized when the user opens a new document.
public DocumentEngine() { app = new Word.Application(); ((Word.ApplicationEvents4_Event)app).Quit += new Microsoft.Office. Interop.Word.ApplicationEvents4_QuitEventHandler(App_Quit); } private void App_Quit() { app = null; theDoc = null; }
This project can serve as the first step of a complex document processing application for Microsoft Word and RTF documents. Basically, everything that can be accomplished with Regular Expressions with ASCII or UNICODE files can now be done almost as easily for *.doc and *.rtf files. In my next article, I will show how, by means of dynamic assemblies, we can perform complex formatting using Regular Expressions.
For more online information on Microsoft Office Interop Assemblies, please refer to MSDN.
For Further Investigation
For those who would like to find out more information on regular expressions and Microsoft Office automation, I recommend the follow excellent books: Mastering Regular Expressions by Jeffrey E. F. Freidl, and Visual Studio Tools for Office — Using C# with Excel, Word, Outlook, and Infoview by Eric Carter and Eric Lippert.
History
- 13th June, 2008: First version
- 14th June, 2008: Fixed the *.sln (solution files) so it is a bit tidier
- 16th June, 2008: Added a
ColorCheckedBoxListcomponent (subclassed fromCheckeListBox) to so it would be able to see which color corresponds to which Regular Expression match.
Drag and Drop functionality also added.
Есть почти книга в Word, где часть текста оформлена жирным, курсивным начертанием, подчёркиванием, в общем, всё, как надо. Нужно для всего форматированного текста сделать соответствующие HTML-теги, чтобы потом использовать текст в вебе.
Сохранение, страницы как HTML даёт желаемый результат, но там вылезает множество всякой приблуды, которую нужно вычищать, в общем, всё не слава Богу.
Короче, пришёл я к статье о регулярных выражениях в функции «Найти и Заменить», написал конструкцию, только ищет она отдельные слова, а не словосочетания. Скрин прилагается:
В общем, поскольку изучить VBA пока что выглядит не тривиальной задачей, возникает вопрос: как вычислить форматированный текст (отдельными словами и словосочетаниям, с любыми знаками до и после) и обрамить его HTML-тегами. Если регулярка — то направление, то какова должна быть её конструкция?
Что я примерно ожидаю в итоге:
Lorem ipsum dolor <b>sit amet, eu</b> eirmod offendit eos, te <i>wisi</i> voluptua vel.