
Skip to content
Очень часто наши требования к поиску данных не ограничиваются одним условием. К примеру, нам нужна выручка по магазину за определенный месяц, количество конкретного товара, проданного определенному покупателю и т.д. Обычными средствами функции ВПР эту задачу решить сложно и даже не всегда возможно. Ведь там предусмотрено использование только одного критерия поиска.
Мы предложим вам несколько вариантов решения проблемы поиска по нескольким условиям.
- ВПР по нескольким условиям с использованием дополнительного столбца.
- ВПР по двум условиям при помощи формулы массива.
- ВПР по нескольким критериям с применением массивов — способ 2.
- Двойной ВПР при помощи ИНДЕКС + ПОИСКПОЗ
- Достойная замена – функция СУММПРОИЗВ.
ВПР по нескольким условиям с использованием дополнительного столбца.
Задачу, рассмотренную в предыдущем примере, можно решить и другим способом – без использования формулы массива. Ведь работа с массивами многим представляется сложной и недоступной для понимания. Дополнительный столбец для поиска по нескольким условиям будет в определенном отношении более простым вариантом.
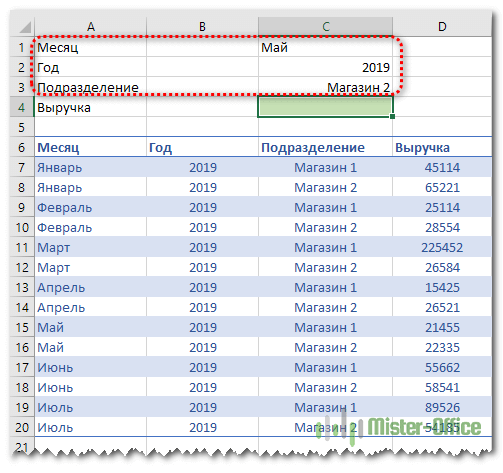
Итак, необходимо выбрать значение выручки за определенный месяц, год и по нужному магазину. В итоге имеем 3 условия отбора.
Сразу по трем столбцам функция ВПР искать не может. Поэтому нам нужно объединить их в один. И, поскольку поиск производится всегда в крайнем левом (первом) столбце, то нужно добавить его в нашу таблицу тоже слева.
Вставляем перед таблицей с данными дополнительный столбец A. Затем при помощи оператора & объединяем в нем содержимое B,C и D. Записываем в А7
=B7&C7&D7
и копируем в находящиеся ниже ячейки.
Формула поиска в D4 будет выглядеть:
=ВПР(D1&D2&D3;A7:E20;5;0)
В диапазон поиска включаем и наш дополнительный столбец. Критерий поиска – также объединение 3 значений. И извлекаем результат из 5 колонки.
Все работает, однако вид несколько портит дополнительный столбец. В крайнем случае, его можно скрыть, используя контекстное меню по нажатию правой кнопки мыши.

Вид станет приятнее, а на результаты это никак не повлияет.
ВПР по двум условиям при помощи формулы массива.
У нас есть таблица, в которой записана выручка по каждому магазину за день. Мы хотим быстро найти сумму продаж по конкретному магазину за определенный день.
Для этого в верхней части нашего листа запишем критерии поиска: дата и магазин. В ячейке B3 будем выводить сумму выручки.
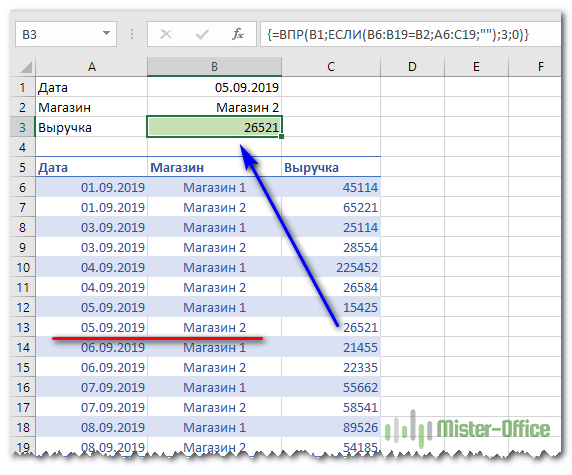
Формула в B3 выглядит следующим образом:
{=ВПР(B1;ЕСЛИ(B6:B19=B2;A6:C19;»»);3;0)}
Обратите внимание на фигурные скобки, которые означают, что это формула массива. То есть наша функция ВПР работает не с отдельными значениями, а разу с массивами данных.
Разберем процесс подробно.
Мы ищем дату, записанную в ячейке B1. Но вот только разыскивать мы ее будем не в нашем исходном диапазоне данных, а в немного видоизмененном. Для этого используем условие
ЕСЛИ(B6:B19=B2;A6:C19;»»)
То есть, в том случае, если наименование магазина совпадает с критерием в ячейке B2, мы оставляем исходные значения из нашего диапазона. А если нет – заменяем их на пробелы. И так по каждой строке.
В результате получим вот такой виртуальный массив данных на основе нашей исходной таблицы:

Как видите, строки, в которых ранее был «Магазин 1», заменены на пустые. И теперь искать нужную дату мы будем только среди информации по «Магазин 2». И извлекать значения выручки из третьей колонки.
С такой работой функция ВПР вполне справится.
Такой ход стал возможен путем применения формулы массива. Поэтому обратите особое внимание: круглые скобки в формуле писать руками не нужно! В ячейке B3 вы записываете формулу
=ВПР(B1;ЕСЛИ(B6:B19=B2;A6:C19;»»);3;0)
И затем нажимаете комбинацию клавиш CTRL+Shift+Enter. При этом Excel поймет, что вы хотите ввести формулу массива и сам подставит скобки.
Таким образом, функция ВПР поиск по двум столбцам производит в 2 этапа: сначала мы очищаем диапазон данных от строк, не соответствующих одному из условий, при помощи функции ЕСЛИ и формулы массива. А затем уже в этой откорректированной информации производим обычный поиск по одному только второму критерию при помощи ВПР.
Чтобы упростить работу в будущем и застраховать себя от возможных ошибок при добавлении новой информации о продажах, мы рекомендуем использовать «умную» таблицу. Она автоматически подстроит свой размер с учетом добавленных строк, и никакие ссылки в формулах не нужно будет менять.

Вот как это будет выглядеть.
ВПР по нескольким критериям с применением массивов — способ 2.
Выше мы уже рассматривали, как при помощи формулы массива можно организовать поиск ВПР с несколькими условиями. Предлагаем еще один способ.
Условия возьмем те же, что и в предыдущем примере.
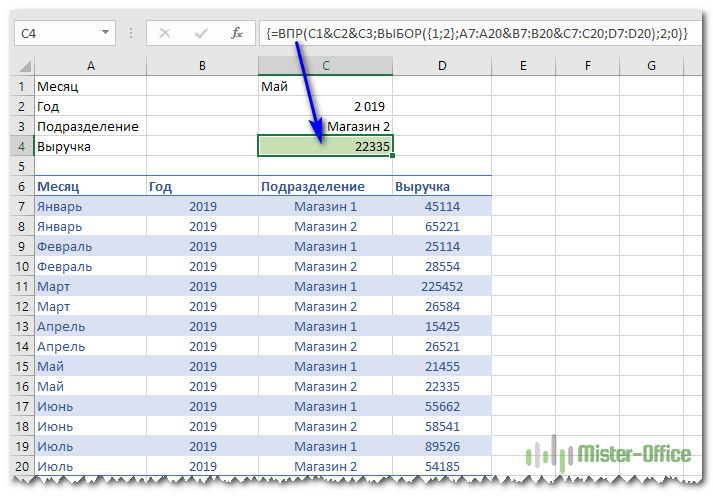
Формулу в С4 введем такую:
=ВПР(C1&C2&C3;ВЫБОР({1;2};A7:A20&B7:B20&C7:C20;D7:D20);2;0)
Естественно, не забываем нажать CTRL+Shift+Enter.
Теперь давайте пошагово разберем, как это работает.
Наше задача здесь – также создать дополнительный столбец для работы функции ВПР. Только теперь мы создаем его не на листе рабочей книги Excel, а виртуально.
Как и в предыдущем примере, мы ищем текст из объединенных в одно целое условий поиска.
Далее определяем данные, среди которых будем искать.
ВЫБОР({1;2};A7:A20&B7:B20&C7:C20;D7:D20)
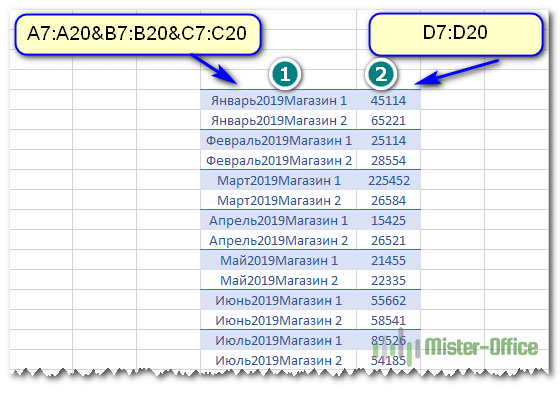
Конструкция вида A7:A20&B7:B20&C7:C20;D7:D20 создает 2 элемента. Первый – это объединение колонок A, B и C из исходных данных. Если помните, то же самое мы делали в нашем дополнительном столбце. Второй D7:D20 – это значения, одно из которых нужно в итоге выбрать.
Функция ВЫБОР позволяет из этих элементов создать массив. {1,2} как раз и означает, что нужно взять сначала первый элемент, затем второй, и объединить их в виртуальную таблицу – массив.
В первой колонке этой виртуальной таблицы мы будем искать, а из второй – извлекать результат.
Таким образом, для работы функции ВПР с несколькими условиями мы вновь используем дополнительный столбец. Только создаем его не реально, а виртуально.
Двойной ВПР при помощи ИНДЕКС + ПОИСКПОЗ
Далее речь у нас пойдет уже не о функции ВПР, но задачу мы будем решать ту же самую. В качестве критерия поиска нам опять нужно использовать несколько условий.
Существуют, пожалуй, даже более гибкие решения, нежели функция ВПР. Это комбинация функций ИНДЕКС + ПОИСКПОЗ.
Область их применения очень велика, о чем бы также будем рассказывать на сайте mister-office.ru.
А пока вернемся вновь к нашей задаче.

Формула в С4 теперь выглядит так:
=ИНДЕКС(D7:D20;ПОИСКПОЗ(1;(A7:A20=C1)*(B7:B20=C2)*(C7:C20=C3);0))
И не забываем при вводе нажать CTRL+Shift+Enter! Это формула массива.
Теперь давайте разбираться, как это работает.
Функция ИНДЕКС в нашем случае позволяет извлечь элемент из списка по его порядковому номеру. Список – это диапазон D7:D20, где записаны суммы выручки. А вот порядковый номер, который нужно извлечь, мы определяем при помощи ПОИСКПОЗ.
Синтаксис здесь следующий:
ПОИСКПОЗ(что_ищем; где_ищем; тип_поиска)
Тип поиска ставим 0, то есть точное совпадение. В нашем случае мы будем искать 1. Далее мы определим массив, в котором будем работать.
Выражение (A7:A20=C1)*(B7:B20=C2)*(C7:C20=C3) позволит создать виртуальную таблицу примерно такого вида:

Как видите, первоначально мы последовательно сравниваем каждое значение с нашим критерием отбора. В столбце А у нас записаны месяцы – сравниваем их с месяцем-критерием из ячейки C1. В случае совпадения получаем ИСТИНА, иначе – ЛОЖЬ. Аналогично последовательно проверяем год и название магазина. А затем просто перемножаем значения. Поскольку логические переменные для Excel – это либо 0, либо 1, то произведение их может быть равно 1 только в том случае, если мы имеем по каждой колонке ИСТИНА (то есть,1). Во всех остальных случаях получаем 0.
Убеждаемся, что цифра 1 встречается только единожды.
При помощи ПОИСКПОЗ определяем, на какой позиции она находится. На какой позиции находится 1, на той же позиции находится в массиве и искомая сумма выручки. В нашем случае это 10-я.
Далее при помощи ИНДЕКС извлекаем 10-ю по счету выручку.

Таким образом мы выбрали значение по нескольким условиям без использования функции ВПР.
Достойная замена – функция СУММПРОИЗВ.
У нас есть данные о продажах нескольких менеджеров в различных регионах. Нужно сделать выборку по дате, менеджеру и региону.
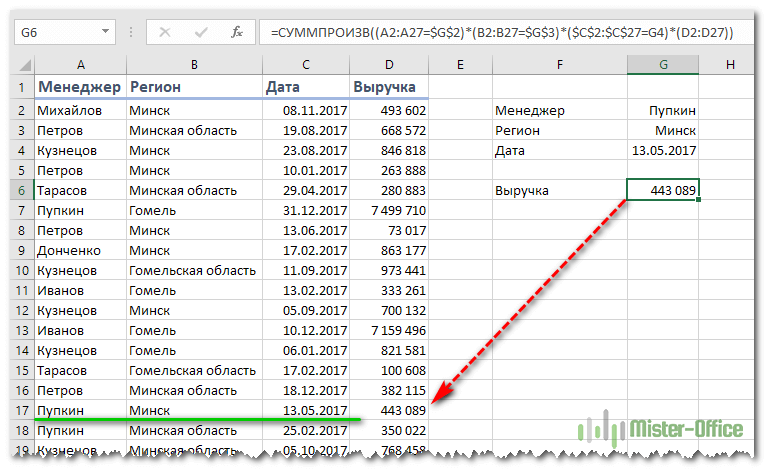
Поясним расчеты.
Выражение
=СУММПРОИЗВ((A2:A27=$G$2)*(B2:B27=$G$3)*($C$2:$C$27=G4)*(D2:D27))
Работает как формула массива, хотя по факту таковой не является. В этом заключается замечательное свойство функции СУММПРОИЗВ, о которой мы еще много будем говорить в других статьях.
Последовательно по каждой строке диапазона от 2-й до 27-й она проверяет совпадение каждого соответствующего значения с критерием поиска. Эти результаты перемножаются между собой и в итоге еще умножаются на сумму выручки. Если среди трех условий будет хотя бы одно несовпадение, то итогом будет 0. В случае совпадения сумма выручки трижды умножится на 1.
Затем все эти 27 произведений складываются, и результатом будет выручка нужного менеджера в каком-то регионе за определенную дату.
В качестве бонуса можно продолжить этот пример и рассчитать общую сумму продаж менеджера в определенном регионе.

Для этого из формулы просто уберем сравнение по дате.
=СУММПРОИЗВ((A2:A27=$G$2)*(B2:B27=$G$3)*(D2:D27))
Кстати, возможен и другой вариант расчета с этой же функцией:
=СУММПРОИЗВ(—(A2:A27=$G$2);—(B2:B27=$G$3);(D2:D27))
Итак, мы рассмотрели примеры использования функции ВПР с двумя и с несколькими условиями. А также обнаружили, что этой ценной функции есть замечательная альтернатива.
[the_ad_group id=»48″]
Примеры использования функции ВПР:
Совет: Попробуйте использовать новые функции ПРОСМОТРX и XMATCH, а также улучшенные версии функций, описанные в этой статье. Эти новые функции работают в любом направлении и возвращают точные совпадения по умолчанию, что упрощает и упрощает работу с ними по сравнению с предшественниками.
Предположим, у вас есть список номеров офисов, и вам нужно знать, какие сотрудники работают в каждом из них. Таблица очень угрюмая, поэтому, возможно, вам кажется, что это сложная задача. С функцией подытов на самом деле это довольно просто.
Функции ВВ., а также ИНДЕКС и ВЫБОРПОЗ — одни из самых полезных функций в Excel.
Примечание: Мастер подметок больше не доступен в Excel.
Ниже в качестве примера по выбору вы можете найти пример использования в этой области.
=ВПР(B2;C2:E7,3,ИСТИНА)
В этом примере B2 является первым аргументом —элементом данных, который требуется для работы функции. В случае СРОТ ВЛ.В.ОВ этот первый аргумент является искомой значением. Этот аргумент может быть ссылкой на ячейку или фиксированным значением, таким как «кузьмина» или 21 000. Вторым аргументом является диапазон ячеек C2–:E7, в котором нужно найти и найти значение. Третий аргумент — это столбец в диапазоне ячеек, содержащий ищите значение.
Четвертый аргумент необязателен. Введите истина или ЛОЖЬ. Если ввести ИСТИНА или оставить аргумент пустым, функция возвращает приблизительное совпадение значения, указанного в качестве первого аргумента. Если ввести ЛОЖЬ, функция будет соответствовать значению, заведомо первому аргументу. Другими словами, если оставить четвертый аргумент пустым или ввести ИСТИНА, это обеспечивает большую гибкость.
В этом примере показано, как работает функция. При вводе значения в ячейку B2 (первый аргумент) в результате поиска в ячейках диапазона C2:E7 (2-й аргумент) выполняется поиск в ней и возвращается ближайшее приблизительное совпадение из третьего столбца в диапазоне — столбца E (третий аргумент).
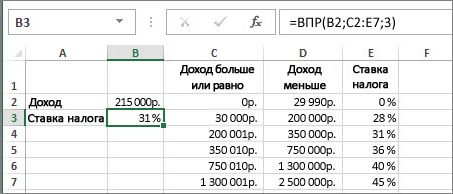
Четвертый аргумент пуст, поэтому функция возвращает приблизительное совпадение. Иначе потребуется ввести одно из значений в столбец C или D, чтобы получить какой-либо результат.
Если вы хорошо разучились работать с функцией ВГТ.В.В., то в равной степени использовать ее будет легко. Вы вводите те же аргументы, но выполняется поиск в строках, а не в столбцах.
Использование индекса и MATCH вместо ВРОТ
При использовании функции ВПРАВО существует ряд ограничений, которые действуют только при использовании функции ВПРАВО. Это означает, что столбец, содержащий и look up, всегда должен быть расположен слева от столбца, содержащего возвращаемого значения. Теперь, если ваша таблица не построена таким образом, не используйте В ПРОСМОТР. Используйте вместо этого сочетание функций ИНДЕКС и MATCH.
В данном примере представлен небольшой список, в котором искомое значение (Воронеж) не находится в крайнем левом столбце. Поэтому мы не можем использовать функцию ВПР. Для поиска значения «Воронеж» в диапазоне B1:B11 будет использоваться функция ПОИСКПОЗ. Оно найдено в строке 4. Затем функция ИНДЕКС использует это значение в качестве аргумента поиска и находит численность населения Воронежа в четвертом столбце (столбец D). Использованная формула показана в ячейке A14.
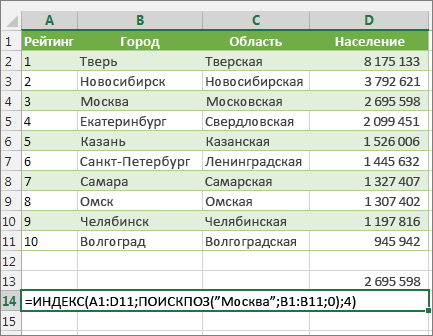
Дополнительные примеры использования индексов и MATCH вместо В ПРОСМОТР см. в статье билла Https://www.mrexcel.com/excel-tips/excel-vlookup-index-match/ Билла Джилена (Bill Jelen), MVP корпорации Майкрософт.
Попробуйте попрактиковаться
Если вы хотите поэкспериментировать с функциями подытовки, прежде чем попробовать их с собственными данными, вот примеры данных.
Пример работы с ВЛОКОНПОМ
Скопируйте следующие данные в пустую таблицу.
Совет: Прежде чем врезать данные в Excel, установите для столбцов A–C ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Плотность |
Вязкость |
Температура |
|
0,457 |
3,55 |
500 |
|
0,525 |
3,25 |
400 |
|
0,606 |
2,93 |
300 |
|
0,675 |
2,75 |
250 |
|
0,746 |
2,57 |
200 |
|
0,835 |
2,38 |
150 |
|
0,946 |
2,17 |
100 |
|
1,09 |
1,95 |
50 |
|
1,29 |
1,71 |
0 |
|
Формула |
Описание |
Результат |
|
=ВПР(1,A2:C10,2) |
Используя приблизительное соответствие, функция ищет в столбце A значение 1, находит наибольшее значение, которое меньше или равняется 1 и составляет 0,946, а затем возвращает значение из столбца B в той же строке. |
2,17 |
|
=ВПР(1,A2:C10,3,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 1, находит наибольшее значение, которое меньше или равняется 1 и составляет 0,946, а затем возвращает значение из столбца C в той же строке. |
100 |
|
=ВПР(0,7,A2:C10,3,ЛОЖЬ) |
Используя точное соответствие, функция ищет в столбце A значение 0,7. Поскольку точного соответствия нет, возвращается сообщение об ошибке. |
#Н/Д |
|
=ВПР(0,1,A2:C10,2,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 0,1. Поскольку 0,1 меньше наименьшего значения в столбце A, возвращается сообщение об ошибке. |
#Н/Д |
|
=ВПР(2,A2:C10,2,ИСТИНА) |
Используя приблизительное соответствие, функция ищет в столбце A значение 2, находит наибольшее значение, которое меньше или равняется 2 и составляет 1,29, а затем возвращает значение из столбца B в той же строке. |
1,71 |
Пример ГВ.Г.В.В.
Скопируйте всю таблицу и вставьте ее в ячейку A1 пустого листа Excel.
Совет: Прежде чем врезать данные в Excel, установите для столбцов A–C ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Оси |
Подшипники |
Болты |
|
4 |
4 |
9 |
|
5 |
7 |
10 |
|
6 |
8 |
11 |
|
Формула |
Описание |
Результат |
|
=ГПР(«Оси»;A1:C4;2;ИСТИНА) |
Поиск слова «Оси» в строке 1 и возврат значения из строки 2, находящейся в том же столбце (столбец A). |
4 |
|
=ГПР(«Подшипники»;A1:C4;3;ЛОЖЬ) |
Поиск слова «Подшипники» в строке 1 и возврат значения из строки 3, находящейся в том же столбце (столбец B). |
7 |
|
=ГПР(«П»;A1:C4;3;ИСТИНА) |
Поиск буквы «П» в строке 1 и возврат значения из строки 3, находящейся в том же столбце. Так как «П» найти не удалось, возвращается ближайшее из меньших значений: «Оси» (в столбце A). |
5 |
|
=ГПР(«Болты»;A1:C4;4) |
Поиск слова «Болты» в строке 1 и возврат значения из строки 4, находящейся в том же столбце (столбец C). |
11 |
|
=ГПР(3;{1;2;3:»a»;»b»;»c»;»d»;»e»;»f»};2;ИСТИНА) |
Поиск числа 3 в трех строках константы массива и возврат значения из строки 2 того же (в данном случае — третьего) столбца. Константа массива содержит три строки значений, разделенных точкой с запятой (;). Так как «c» было найдено в строке 2 того же столбца, что и 3, возвращается «c». |
c |
Примеры индекса и match
В последнем примере функции ИНДЕКС и MATCH совместно возвращают номер счета с наиболее ранней датой и соответствующую дату для каждого из пяти городов. Так как дата возвращается как число, для ее формата используется функция ТЕКСТ. Функция ИНДЕКС использует результат, возвращенный функцией ПОИСКПОЗ, как аргумент. Сочетание функций ИНДЕКС и ПОИСКПОЗ используется в каждой формуле дважды — сперва для возврата номера счета, а затем для возврата даты.
Скопируйте всю таблицу и вставьте ее в ячейку A1 пустого листа Excel.
Совет: Перед тем как вировать данные в Excel, установите для столбцов A–D ширину в 250 пикселей и нажмите кнопку «Перенос текста» (вкладка «Главная», группа «Выравнивание»).
|
Счет |
Город |
Дата выставления счета |
Счет с самой ранней датой по городу, с датой |
|
3115 |
Казань |
07.04.12 |
=»Казань = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Казань»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Казань»,$B$2:$B$33,0),3),»m/d/yy») |
|
3137 |
Казань |
09.04.12 |
=»Орел = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Орел»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Орел»,$B$2:$B$33,0),3),»m/d/yy») |
|
3154 |
Казань |
11.04.12 |
=»Челябинск = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Челябинск»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Челябинск»,$B$2:$B$33,0),3),»m/d/yy») |
|
3191 |
Казань |
21.04.12 |
=»Нижний Новгород = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Нижний Новгород»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Нижний Новгород»,$B$2:$B$33,0),3),»m/d/yy») |
|
3293 |
Казань |
25.04.12 |
=»Москва = «&ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Москва»,$B$2:$B$33,0),1)& «, Дата выставления счета: » & ТЕКСТ(ИНДЕКС($A$2:$C$33,ПОИСКПОЗ(«Москва»,$B$2:$B$33,0),3),»m/d/yy») |
|
3331 |
Казань |
27.04.12 |
|
|
3350 |
Казань |
28.04.12 |
|
|
3390 |
Казань |
01.05.12 |
|
|
3441 |
Казань |
02.05.12 |
|
|
3517 |
Казань |
08.05.12 |
|
|
3124 |
Орел |
09.04.12 |
|
|
3155 |
Орел |
11.04.12 |
|
|
3177 |
Орел |
19.04.12 |
|
|
3357 |
Орел |
28.04.12 |
|
|
3492 |
Орел |
06.05.12 |
|
|
3316 |
Челябинск |
25.04.12 |
|
|
3346 |
Челябинск |
28.04.12 |
|
|
3372 |
Челябинск |
01.05.12 |
|
|
3414 |
Челябинск |
01.05.12 |
|
|
3451 |
Челябинск |
02.05.12 |
|
|
3467 |
Челябинск |
02.05.12 |
|
|
3474 |
Челябинск |
04.05.12 |
|
|
3490 |
Челябинск |
05.05.12 |
|
|
3503 |
Челябинск |
08.05.12 |
|
|
3151 |
Нижний Новгород |
09.04.12 |
|
|
3438 |
Нижний Новгород |
02.05.12 |
|
|
3471 |
Нижний Новгород |
04.05.12 |
|
|
3160 |
Москва |
18.04.12 |
|
|
3328 |
Москва |
26.04.12 |
|
|
3368 |
Москва |
29.04.12 |
|
|
3420 |
Москва |
01.05.12 |
|
|
3501 |
Москва |
06.05.12 |
Функция ВПР может использоваться для поиска значения по строке в таблице в определённом массиве данных. Синтаксис нашей функции имеет следующий вид:
ВПР (искомое значение; диапазон поиска; номер столбца с входным значением; 0 (ЛОЖЬ) или 1 (ИСТИНА)).
ЛОЖЬ – точное значение, ИСТИНА – приблизительное значение.
Простейшая задача для функции ВПР. Например, у нас есть список лекарственных препаратов. Наша первая задача – найти стоимость препарата Хепилор.
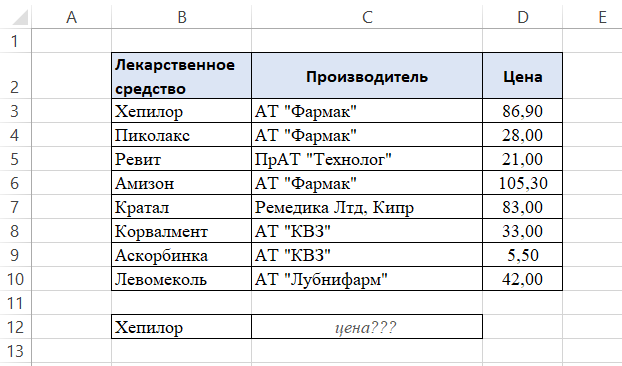
В ячейке С12 начинаем писать функцию:
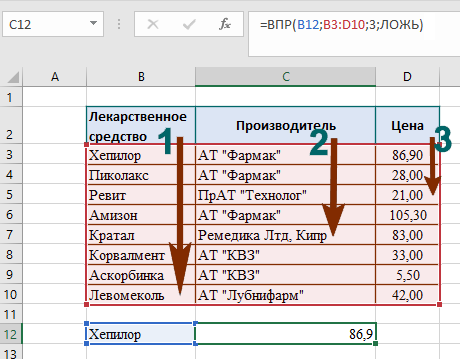
- B12 – поскольку нам нужен Хепилор, выбираем ячейку с предварительно написанным названием искомого лекарства.
- Далее выбираем диапазон данных B3:D10, где функция будет совершать поиск нужного нам значения. Крайний левый столбец диапазона должен содержать в себе искомый критерий, по которому производится поиск значения.
- Следующий шаг – указать номер столбца в массиве B3:D10, из которого будет считана информация на одной строке с Хепилором. Столбцы нумеруются слева направо в самом диапазоне, в нашем примере первый столбец – В, но не А, поскольку А лежит вне области диапазона.
Поиск по столбце «Производитель» будет работать точно так же, нужно просто указать последовательность столбца, где находится нужная нам информация – заменяем цифру «3» в формуле (ячейка С27) на цифру «2»:
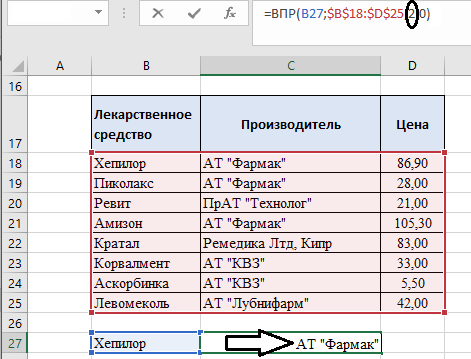
Есть определённая особенность, связанная со столбцами. Иногда в Excel-файле в таблицах некоторые ячейки объединяют. На картинке ниже в формуле на месте порядкового номера столбца у нас написана цифра «3», но результат – название производителя, а не цена, как в первом примере:
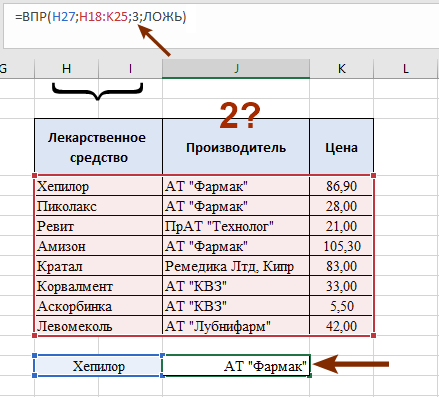
Произошел сдвиг нумерации столбцов как раз из-за наличия объединения ячеек в столбце «Лекарственное средство»: мы объединяли столбцы «H» и «I», зрительно столбец «Лекарственное средство» — это первый столбец, а «Производитель» — второй, НО формула нумерует их следующим образом:
- H – первый;
- I – второй;
- J – третий;
- K – четвертый.
Использование функции ВПР для поиска по критерию в данном примере кажется не совсем уместной, ведь любую информацию о продукте можно сразу прочитать без поиска, но когда диапазон вмещает сотни, тысячи названий, она значительно ускорит процесс и сэкономит очень много времени сравнительно с самостоятельным поиском.
Использование функции ВПР для работы с несколькими таблицами и другими функциями
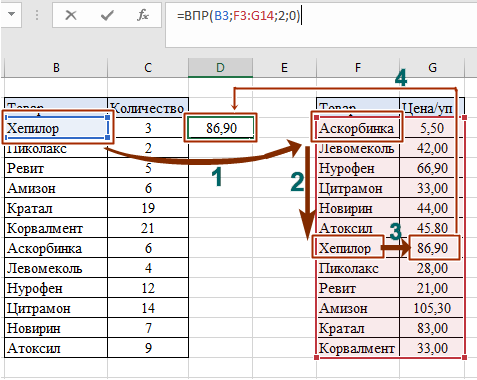
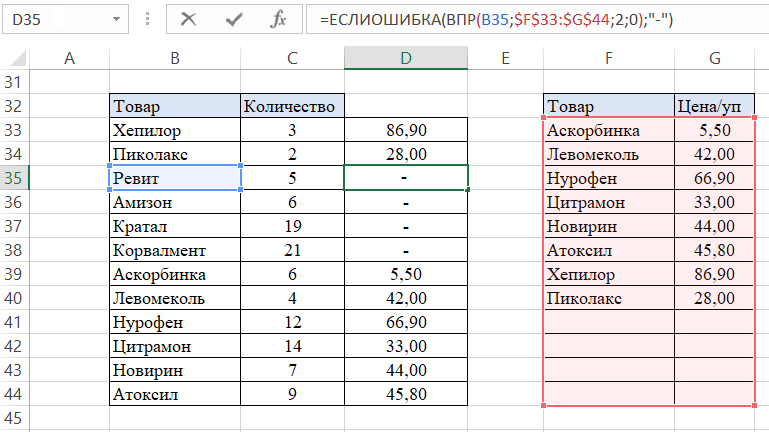
В следующем примере рассмотрим, как ещё мы можем использовать функцию для поиска и получения информации по критериям и комбинирование функции с функцией ЕСЛИОШИБКА. Например, мы имеем два отчета – отчет о количестве товара и отчет о цене за единицу товара, которые нам необходимы для подсчета стоимости. Опять же, с небольшим количеством данных это вполне можно сделать вручную, но, когда мы имеем большой объем, справиться с этим скорее и эффективнее нам поможет функция ВПР. В ячейке D3 начинаем писать функцию:
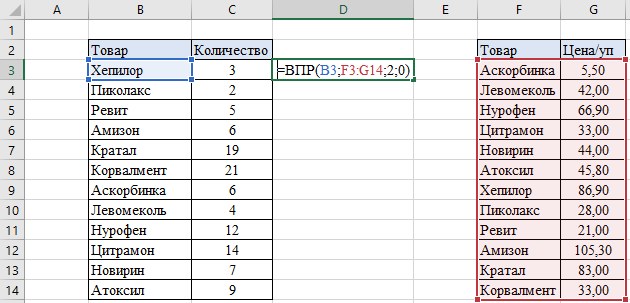
- B3 – критерий, по котором проводим поиск данных.
- F3:G14 – диапазон, по котором наша функция будет осуществлять поиск совпадения критерия и данных по строке.
- Цифра «2» — номер столбца с нужной нам информацией по критерию.
- Цифра «0» (или можно использовать слово «ЛОЖЬ») — для точности результатов.
Таким образом, когда мы задаем формуле искомый критерий, она начинает поиск совпадений с верхней ячейки первого столбца (шаг 1 на картинке). Затем функция «читает» все критерии сверху вниз, пока не найдет точное совпадение (шаг 2). Когда ВПР дойдет до Хепилора, она отсчитает нужное количество столбцов вправо (шаг 3) и выдаст нам искомое значение для критерия – цену 86,90 (шаг 4):
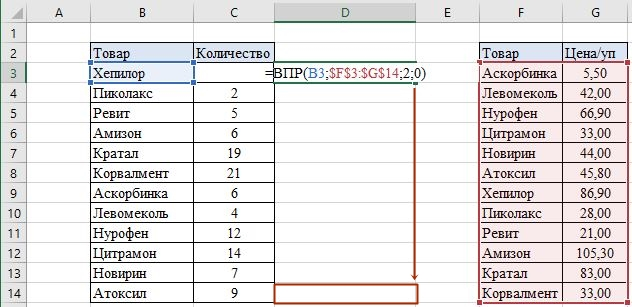
Но сейчас у нас есть данные только по первому критерию. Для того чтобы заполнить третий столбец D первой таблицы до конца, нужно просто скопировать функцию до последнего критерия. Однако, на этом этапе для корректной работы диапазон, где совершается поиск, нужно закрепить, иначе массив данных «съедет» вниз и у нас ничего не получится. Для этого используем абсолютные ссылки для диапазона в ячейке D3 – выделяем курсором диапазон F3:G14 и нажимаем клавишу F4, после чего совершаем копирование формулы до конца таблицы:
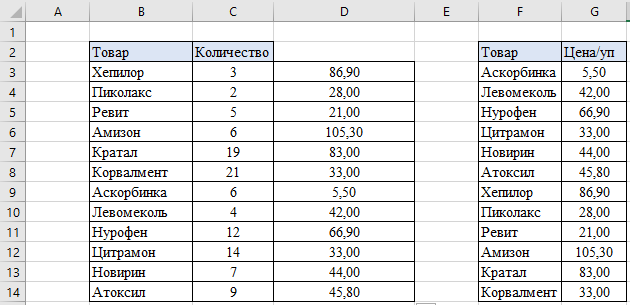
В итоге мы получаем необходимый нам результат:
Однако, наш пример базировался на полном соответствии критериев с обеих таблиц – одинаковое количество товаров, одинаковые наименования. Но что, если, например, убрать последние четыре товара с отчета по ценам за упаковку? Тогда у нас будет ошибка #Н/Д в первой таблице в тех позициях, которые находятся на одной строке с искомым критерием:
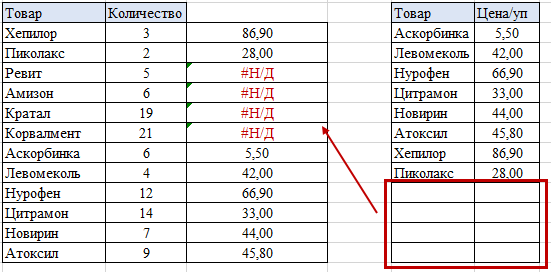
Если вас не устраивает такое содержание ячеек, можно заменить значение ошибки. Для этого комбинируем функцию ВПР с функцией ЕСЛИОШИБКА. Синтаксис функции ЕСЛИОШИБКА(значение, значение_если_ошибка), таким образом значением у нас будет наша использованная функция ВПР, а значением если ошибка – то, что мы хотим видеть вместо #Н/Д, например, прочерк, но обязательно взятый в кавычки:
В результате мы получим красиво оформленную таблицу с надлежащим видом:
Использование приблизительного значения
Не всегда критерий, по которому происходит поиск, должен совпадать в таблицах точь-в-точь. Иногда будет достаточно некоторого диапазона, в который будет входить искомый критерий. Например, у нас есть список сотрудников с их показателями выполнения плана продаж и система мотивации, которая показывает нам сколько процентов премии от оклада заработали сотрудники:
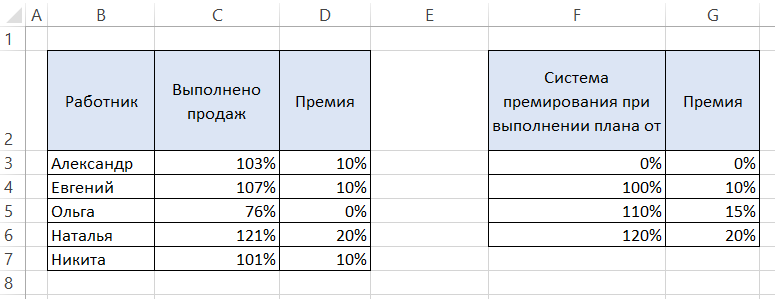
Как видим, размер премии зависит от того диапазона по системе премирования, куда попал показатель выполнения продаж конкретного сотрудника. Мы видим, что если план выполнен менее, чем на 100% — премия не присваивается, а если на 107% (выше 100%, но меньше 110%), тогда сотрудник получает премию размером 10%. Описанные показатели премии нам нужно вписать с помощью функции ВПР в столбец «Премия» первой таблицы, только на этот раз критерий будет находиться в определённом диапазоне.
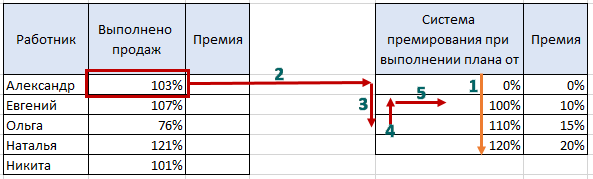
Для корректной работы нужно убедиться, что границы диапазонов во второй таблице крайнего левого столбца размещены по возрастанию сверху вниз (шаг 1). Формула берёт выбранный нами критерий и осуществляет поиск в первом столбце второй таблицы (шаг 2), просматривая все значения сверху вниз (шаг 3). Как только функция находит первое значение, которое превышает критерий с первой таблицы, делает «шаг назад» (шаг 4) и считывает значение, которое соответствует найденому критерию (шаг 5). Иными словами, при неточном поиске функция ВПР ищет меньшее значение для искомого критерия:
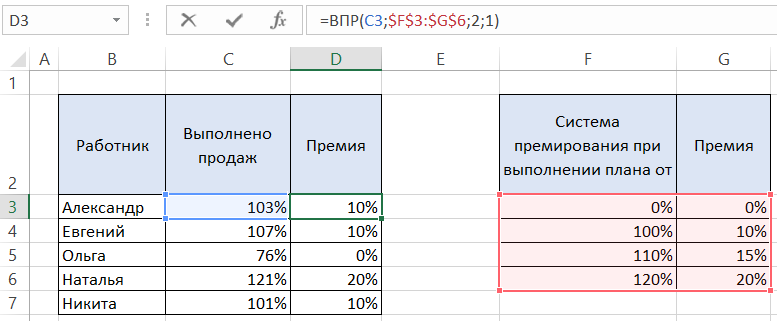
Таким образом, наша функция будет выглядеть так:
И результат использования функции ВПР с приблизительным поиском имеет вот такой результат:
 Скачать все пошаговые примеры функции ВПР в Excel
Скачать все пошаговые примеры функции ВПР в Excel
Например, сотрудник Ольга имеет премию размером 0%, поскольку она выполнила 76% продаж, тоесть перевыполнила план на 0%. А сотрудник Наталья совершила продажи на 21% выше нормы и была премирована на 20%, что мы и видим, если сравнить самостоятельно данные с двух таблиц.
На этих примерах применение функции ВПР не заканчивается, есть много других задач, с которыми удобно справляться этой функцией. Она облегчает работу с большим массивом данных, минимизирует ошибки сравнительно с самостоятельными расчетами, проста в понимании и применении.
Самый быстрый ВПР
Если в ваших таблицах всего лишь несколько десятков строк, то, скорее всего, эта статья не будет для вас актуальной. На таких небольших объемах данных любой способ будет работать достаточно шустро, чтобы вы этого не замечали. Если же число строк в ваших списках измеряется тысячами, да и самих таблиц не одна-две, то время мучительного ожидания на пересчете формул в Excel может доходить до нескольких минут.
В этом случае, правильный выбор функции, применяемой для связывания таблиц, играет решающую роль — разница в производительности между ними, как мы увидим далее, может составлять более 20 раз!
Когда я писал свою первую книжку пять лет назад, то уже делал сравнительный скоростной тест различных способов поиска и подстановки данных функциями ВПР, ИНДЕКС+ПОИСКПОЗ, СУММЕСЛИ и др. С тех пор сменилось три версии Office, появились надстройки Power Query и Power Pivot, кардинально изменившие весь процесс работы с данными. А в прошлом году ещё и обновился вычислительный движок Excel, получив поддержку динамических массивов и новые функции ПРОСМОТРХ, ФИЛЬТР и т.п.
Так что пришла пора снова взяться за секундомер и выяснить — кто же самый быстрый. Ну и, заодно, проверить — какие способы поиска и подстановки данных в Excel вы знаете 
Подопытный кролик
Тест будем проводить на следующем примере:

Это книга Excel с одним листом, где расположены две таблицы: отгрузки (500 000 строк) и прайс-лист (600 строк). Наша задача — подставить цены из прайс-листа в таблицу отгрузок. Для каждого способа будем вводить формулу в ячейку С2 и копировать вниз на весь столбец, замеряя время, которое потребуется Excel, чтобы просчитать весь столбец из полумиллиона ячеек. Полученные значения, безусловно, зависят от множества факторов (поколение процессора, объем оперативной памяти, текущая загрузка системы, версия Office и т.д.), но нам важны не конкретные цифры, а, скорее, их сравнение друг с другом. Важно понимать прожорливость каждого способа и их ограничения.
Способ 1. ВПР
Сначала — классика Легендарная функция вертикального просмотра — ВПР (VLOOKUP), которая приходит в голову первой в подобных ситуациях:

Здесь участвуют следующие аргументы:
- B2 — искомое значение, т.е. название товара, который мы хотим найти в прайс-листе
- $G$2:$H$600 — закреплённая знаками доллара (чтобы не сползала при копировании формулы вниз) абсолютная ссылка на прайс
- 2 — номер столбца в прайс-листе, откуда мы хотим взять цену
- 0 или ЛОЖЬ — переключение в режим поиска точного соответствия, когда любое некорректное название товара (например, ФОНЕРА) в столбце B в таблице отгрузок приведёт к появлению ошибки #Н/Д как результата работы функции.
Время вычисления = 4,3 сек.
Способ 2. ВПР с выделением столбцов целиком
Многие пользователи, применяя ВПР, во втором аргументе этой функции, где нужно задать поисковую таблицу (прайс), выделяют не ограниченный диапазон ($G$2:$H$600), а сразу столбцы G:H целиком. Это проще, быстрее, позволяет не думать про F4 и то, что завтра прайс-лист может быть на несколько строк больше. Формула в этом случае выглядит тоже компактнее:

В старых версиях Excel такое выделение не сильно влияло на скорость вычислений, но сейчас (неожиданно для меня, признаюсь) результат получился в разы хуже предыдущего.
Время вычисления = 14,5 сек.
Однако.
Способ 3. ИНДЕКС и ПОИСКПОЗ
Следующей после ВПР ступенью эволюции для многих пользователей Microsoft Excel обычно является переход на использование связки функций ИНДЕКС (INDEX) и ПОИСКПОЗ (MATCH). Выглядит эта формула так:

Здесь:
Функция ИНДЕКС извлекает из заданного в первом аргументе диапазона (столбца $H$2:$H$600 с ценами в прайс-листе) содержимое ячейки с заданным номером. А номер этот, в свою очередь, определяется функцией ПОИСКПОЗ, у которой три аргумента:
- Что нужно найти — название товара из B2
- Где мы это ищем — столбец с названиями товаров в прайсе ($G$2:$G$600)
- Режим поиска: 0 — точный, 1 или -1 — приблизительный с округлением в меньшую или большую сторону, соответственно.
Формула выходит чуть сложнее, но, при этом имеет несколько ощутимых преимуществ перед классической ВПР, а именно:
- Не нужно отсчитывать номер столбца (как в третьем аргументе ВПР).
- Можно извлекать данные, которые находятся левее столбца, где просходит поиск.
По скорости, однако же, этот способ проигрывает ВПР почти в два раза:
Время вычисления = 7,8 сек.
Если же, вдобавок, полениться и выделять не ограниченные диапазоны, а столбцы целиком:

… то результат получается совсем печальный:
Время вычисления = 28,5 сек.
28 секунд, Карл! В 6 раз медленнее ВПР!
Способ 4. СУММЕСЛИ
Если нужно найти не текстовые, а именно числовые данные (как в нашем случае — цену), то вместо ВПР вполне можно использовать функцию СУММЕСЛИ (SUMIF). Изначально она задумывалась как инструмент для выборочного суммирования данных по условию (найди и сложи мне все продажи кабелей, например), но можно заставить её искать нужный нам товар и в прайс-листе. Если грузы в нём не повторяются, то суммировать будет не с чем и эта функция просто выведет искомое значение:

Здесь:
- Первый аргумент СУММЕСЛИ — это диапазон проверяемых ячеек, т.е. названия товаров в прайсе ($G$2:$G$600).
- Второй аргумент (B2) — что мы ищем.
- Третий аргумент — диапазон ячеек с ценами $H$2:$H$600, числа из которых мы хотим просуммировать, если в соседних ячейках проверяемого диапазона есть искомое значение.
Очевидным минусом такого подхода является то, что он работает только с числами. Также этот способ не удобен, если прайс-лист находится в отдельном файле — придется всё время держать его открытым, т.к. функция СУММЕСЛИ не умеет брать данные из закрытых книг, в отличие от ВПР, для которой это не проблема.
В плюсы же можно записать удобство при поиске сразу по нескольким столбцам — для этого идеально подходит более продвинутая версия этой функции — СУММЕСЛИМН (SUMIFS). Скорость вычислений же, при этом, весьма посредственная:
Время вычисления = 12,8 сек.
При выделении столбцов целиком, т.е. использовании формулы вида =СУММЕСЛИ(G:G; B2; H:H) всё ещё хуже:
Время вычисления = 41,7 сек.
Это самый плохой результат в нашем тесте.
Способ 5. СУММПРОИЗВ
Этот подход сейчас встречается не часто, но всё ещё достаточно регулярно. Обычно так любят извращаться пользователи старой школы, ещё хорошо помнящие те времена, когда в Excel было всего 255 столбцов и 56 цветов
Суть этого метода заключается в использовании функции СУММПРОИЗВ (SUMPRODUCT), изначально предназначенной для поэлементного перемножения нескольких диапазонов с последующим суммированием полученных произведений. В нашем случае, вместо одного из массивов будет выступать условие, а вторым будут цены:

Выражение ($G$2:$G$600=B2), по сути, проверяет каждое название груза в прайс-листе на предмет соответствия искомому значению (ФАНЕРА ПР). Результатом каждого сравнения будет логическое значение ИСТИНА (TRUE) или ЛОЖЬ (FALSE), что в Excel интерпретируется как 1 и 0, соответственно. Последующее умножение этих нулей и единиц на цены оставит в живых цену только того товара, который нам, в данном случае, и нужен.
Эта формула является, по сути, формулой массива, но не требует нажатия обычного для них сочетания клавиш Ctrl+Shift+Enter, т.к. функция СУММПРОИЗВ поддерживает массивы уже сама по себе. Возможно, по этой же причине (формулы массива всегда медленнее, чем обычные) такой скорость пересчёта такой формулы — не очень:
Время вычисления = 11,8 сек.
К плюсам же такого подхода можно отнести:
- Совместимость с любыми, самыми древними версиями Excel.
- Возможность задавать сложные условия (и несколько)
- Способность этой формулы работать с данными из закрытых файлов, если добавить перед ней двойное бинарное отрицание (два подряд знака «минус»). СУММЕСЛИМН таким похвастаться не может.
Способ 6. ПРОСМОТР
Ещё один относительно экзотический способ поиска и подстановки данных, наравне с ВПР — это использование функции ПРОСМОТР (LOOKUP). Только не перепутайте её с новой, буквально, на днях появившейся функцией ПРОСМОТРХ (XLOOKUP) — про неё мы поговорим дальше особо. Функция ПРОСМОТР существовала в Excel начиная с самых ранних версий и тоже вполне может решить нашу задачу:

Здесь:
- B2 — название груза, которое мы ищем
- $G$2:$G$600 — одномерный диапазон-вектор (столбец или строка), где мы ищем совпадение
- $H$2:$H$600 — такого же размера диапазон, откуда нужно вернуть найденный результат (цену)
На первый взгляд всё выглядит очень удобно и логично, но всю картину портят два неочевидных момента:
- Эта функция требует обязательной сортировки прайс-листа по возрастанию (алфавиту) и без этого не работает.
- Если в таблице отгрузок искомое значение будет написано с опечаткой (например, АГЕДОЛ вместо АГИДОЛ), то функция ПРОСМОТР выдаст не ошибку #Н/Д, а цену для ближайшего предыдущего товара:

При работе с неидеальными данными в реальном мире это гарантированно создаст проблемы, как вы понимаете.
Скорость же вычислений у функции ПРОСМОТР (LOOKUP) весьма приличная:
Время вычисления = 7,6 сек.
Способ 7. Новая функция ПРОСМОТРХ
Эта функция пришла с одним из недавних обновлений пока только пользователям Office 365 и пока отсутствует во всех остальных версиях (Excel 2010, 2013, 2016, 2019). По сравнению с классической ВПР у этой функции есть масса преимуществ (упрощенный синтаксис, возможность искать не только сверху-вниз, возможность сразу задать значение вместо #Н/Д и т.д.) Формула для решения нашей задачи будет выглядеть в этом случае так:

Если не брать в расчёт необязательные 4,5,6 аргументы, то синтаксис этой функции полностью совпадает с её предшественником — функцией ПРОСМОТР (LOOKUP). Скорость вычислений при тестировании на наши 500000 строк тоже оказалась аналогичной:
Время вычисления = 7,6 сек.
Почти в два раза медленнее, чем у ВПР, вместо которой Microsoft предлагает теперь использовать ПРОСМОТРХ. Жаль.
И, опять же, если полениться и выделить диапазоны в прайс-листе целыми столбцами:

… то скорость падает до совершенно неприличных уже значений:
Время вычисления = 28,3 сек.
А если на динамических массивах?
Прошлогоднее (осень 2019) обновление вычислительного движка Microsoft Excel добавило ему поддержку динамических массивов (Dynamic Arrays), о которых я уже писал. Это принципиально новый подход к работе с данными, который можно использовать почти с любыми классическими функциями Excel. На примере ВПР это будет выглядеть так:

Разница с классическим вариантом в том, что первым аргументом ВПР здесь выступает не одно искомое значение (а формулу потом нужно копировать вниз на остальные строки), а сразу весь массив из полумиллиона грузов B2:B500000, цены для которых мы хотим найти. Формула при этом сама распространяется вниз, занимая требуемое количество ячеек.
Скорость пересчета в таком варианте меня, откровенно говоря, ошеломила — пауза между нажатием на Enter после ввода формулы и получением результатов почти отсутствовала.
Время вычисления = 1 сек.
Что интересно, и новая ПРОСМОТРХ, и старая ПРОСМОТР, и связка ИНДЕКС+ПОИСКПОЗ в таком режиме тоже были очень быстрыми — время вычислений не больше 1 секунды! Фантастика.
А вот олдскульные подходы на основе СУММПРОИЗВ и СУММЕСЛИ(МН) с динамическими массивами работать отказались 
Что с умными таблицами?
Обрадовавшись фантастическим результатам, полученным на динамических массивах, я решил вдогон попробовать протестировать разницу в скорости при работе с обычными и «умными» таблицами. Я имею ввиду те самые «красивые таблицы», в которые вы можете преобразовать ваш диапазон с помощью команды Форматировать как таблицу на вкладке Главная (Home — Format as Table) или с помощью сочетания клавиш Ctrl+T.
Если предварительно превратить наши отгрузки и прайс в «умные» (по умолчанию они получат имена Таблица1 и Таблица2, соответственно), то формула с той же ВПР будет выглядеть как:

Здесь:
- [@Груз] — ссылка на ячейку B2, означающая, в данном случае, что нужно взять значение из той же строки из столбца Груз текущей умной таблицы.
- Таблица2 — ссылка на прайс-лист
Жирным плюсом такого подхода будет возможность легко добавлять данные в наши таблицы в будущем. При дописывании новых строк в отгрузки или к прайс-листу, наши «умные» таблицы будут растягиваться автоматически.
Скорость же, как выяснилось, тоже вырастает очень значительно и примерно равна скорости работы на динамических массивах:
Время вычисления = 1 сек.
У меня есть подозрение, что дело тут не в самих «умных» таблицах, а всё в том же обновлении вычислительного движка, т.к. на старых версиях Excel такого прироста в скорости на умных таблицах я не помню.
Бонус. Запрос Power Query
Замерять, так замерять! Давайте, для полноты картины, сравним наши перечисленные способы еще и с запросом Power Query, который тоже может решить нашу задачу. Кто-то скажет, что некорректно сравнивать пересчёт формул с механизмом обновления запроса, но мне, откровенно говоря, просто самому было интересно — кто быстрее?
Итак:
- Превращаем обе наши таблицы в «умные» с помощью команды Форматировать как таблицу на вкладке Главная (Home — Format as Table) или с помощью сочетания клавиш Ctrl+T.
- По очереди загружаем таблицы в Power Query с помощью команды Данные — Из таблицы / диапазона (Data — From Table/Range).
- После загрузки в Power Query возвращаемся обратно в Excel, оставляя загруженные данные как подключение. Для этого в окне Power Query выбираем Главная — Закрыть и загрузить — Закрыть и загрузить в… — Только создать подключение (Home — Close&Load — Close&Load to… — Only create connection).
- После того, как обе исходные таблицы будут загружены как подключения, создадим ещё один, третий запрос, который будет объединять их между собой, подставляя цены из прайса в отгрузки. Для этого на вкладке Данные выберем Получить данные / Создать запрос — Объединить запросы — Объединить (Get Data / New Query — Merge queries — Merge):

- В открывшемся окне выберем исходные таблицы в выпадающих списках и выделим столбцы, по которым произойдет связывание:

- После нажатия на ОК мы вернемся в окно Power Query, где увидим нашу таблицу отгрузок с добавленным к ней столбцом, где в каждой ячейке будет лежать фрагмент прайс-листа, соответствующий этому грузу. Развернем вложенные таблицы с помощью кнопки с двойными стрелками в шапке столбца, выбрав нужные нам данные (цены):

- Останется выгрузить готовую таблицу обратно на лист с помощью уже знакомой команды Главная — Закрыть и загрузить (Home — Close&Load).



В отличие от формул, запросы Power Query не обновляются автоматически «на лету», а требуют щелчка правой кнопкой мыши по таблице (или запросу в правой панели) и выбору команды Обновить (Refresh). Также можно воспользоваться командой Обновить все (Refresh All) на вкладке Данные (Data).
Время обновления = 8,2 сек.
Итоговая таблица и выводы
Если вы честно дочитали до этого места, то какие-то выводы, наверное, уже сделали самостоятельно. Если же пропустили все детали и сразу перешли к итогам, то вот вам общая результирующая таблица по скорости всех методов:

Само-собой, у каждого из нас свои предпочтения, задачи и тараканы, но для себя я сформулировал выводы после этого тестирования так:
- ВПР всё ещё главная рабочая лошадка. После прошлогодних обновлений, ускоряющих ВПР, и осенних обновлений вычислительного движка, эта функция заиграла новыми красками и даёт жару по-полной.
- Не нужно лениться и выделять столбцы целиком — для всех способов без исключения это ухудшает результаты почти в 3 раза.
- Экзотические способы из прошлого типа СУММПРОИЗВ и СУММЕСЛИ — в топку. Они работают очень медленно и, вдобавок, не поддерживают динамические массивы.
- Динамические массивы и умные таблицы — это будущее.
К сожалению, у меня не было возможностей полноценно протестировать эти методы на старых версиях Excel и на Excel for Mac (запускать эмуляцию Office на виртуальной машине и тестировать скорость — не есть правильно). Буду благодарен, если вы сможете найти время, чтобы прогнать эти способы на своих ПК и версиях и поделитесь результатами и своими мыслями в комментариях, чтобы вместе мы смогли составить полную картину.
Ссылки по теме
- Как использовать функцию ВПР для подстановки значений в Excel
- Функция ПРОСМОТРХ как наследник ВПР
- 5 вариантов использования функции ИНДЕКС
Прочитав статью, вы не только узнаете, как найти данные в таблице Excel и извлечь их в другую, но и приёмы, которые можно применять вместе с функцией ВПР.

Батьянов Денис на правах гостевого автора рассказывает в этом посте о том, как найти данные в одной таблице Excel и извлечь их в другую, а также открывает все секреты функции вертикального просмотра.
При работе в Excel очень часто возникает потребность найти данные в одной таблице и извлечь их в другую. Если вы ещё не умеете это делать, то, прочитав статью, вы не только научитесь этому, но и узнаете, при каких условиях вы сможете выжать из системы максимум быстродействия. Рассмотрено большинство весьма эффективных приёмов, которые стоит применять совместно с функцией ВПР.
Даже если вы годами используете функцию ВПР, то с высокой долей вероятности эта статья будет вам полезна и не оставит равнодушным. Я, например, будучи IT-специалистом, а потом и руководителем в IT, пользовался VLOOKUP 15 лет, но разобраться со всеми нюансами довелось только сейчас, когда я на профессиональной основе стал обучать людей Excel.
ВПР — это аббревиатура от вертикального просмотра. Аналогично и VLOOKUP — Vertical LOOKUP. Уже само название функции намекает нам, что она производит поиск в строках таблицы (по вертикали — перебирая строки и фиксируя столбец), а не в столбцах (по горизонтали — перебирая столбцы и фиксируя строку). Надо заметить, что у ВПР есть сестра — гадкий утёнок, которая никогда не станет лебедем, — это функция ГПР (HLOOKUP). ГПР, в противоположность ВПР, производит горизонтальный поиск, однако концепция Excel (да и вообще концепция организации данных) подразумевает, что ваши таблицы имеют небольшое количество столбцов и гораздо большее количество строк. Именно поэтому поиск по строкам нам требуется во много раз чаще, чем по столбцам. Если вы в Excel слишком часто пользуетесь функцией ГПР, то, вполне вероятно, что вы чего-то не поняли в этой жизни.
Синтаксис
Функция ВПР имеет четыре параметра:
=ВПР( <ЧТО> ; <ГДЕ> ; <НОМЕР_СТОЛБЦА> [;<ОТСОРТИРОВАНО>] ), тут:
<ЧТО> — искомое значение (редко) или ссылка на ячейку, содержащую искомое значение (подавляющее большинство случаев);
<ГДЕ> — ссылка на диапазон ячеек (двумерный массив), в ПЕРВОМ (!) столбце которого будет осуществляться поиск значения параметра <ЧТО>;
<НОМЕР_СТОЛБЦА> — номер столбца в диапазоне, из которого будет возвращено значение;
<ОТСОРТИРОВАНО> — это очень важный параметр, который отвечает на вопрос, а отсортирован ли по возрастанию первый столбец диапазона <ГДЕ>. В случае, если массив отсортирован, мы указываем значение ИСТИНА (TRUE) или 1, в противном случае — ЛОЖЬ (FALSE) или 0. В случае, если данный параметр опущен, он по умолчанию становится равным 1.
Держу пари, что многие из тех, кто знает функцию ВПР как облупленную, прочитав описание четвёртого параметра, могут почувствовать себя неуютно, так как они привыкли видеть его в несколько ином виде: обычно там идёт речь о точном соответствии при поиске (ЛОЖЬ или 0) либо же о диапазонном просмотре (ИСТИНА или 1).
Вот сейчас надо напрячься и читать следующий абзац несколько раз, пока не прочувствуете смысл сказанного до конца. Там важно каждое слово. Примеры помогут разобраться.
Как же конкретно работает формула ВПР
- Вид формулы I. Если последний параметр опущен или указан равным 1, то ВПР предполагает, что первый столбец отсортирован по возрастанию, поэтому поиск останавливается на той строке, которая непосредственно предшествует строке, в которой находится значение, превышающее искомое. Если такой строки не найдено, то возвращается последняя строка диапазона.
- Вид формулы II. Если последний параметр указан равным 0, то ВПР последовательно просматривает первый столбец массива и сразу останавливает поиск, когда найдено первое точное соответствие с параметром <ЧТО>, в противном случае возвращается код ошибки #Н/Д (#N/A).
Схемы работы формул
ВПР тип I
ВПР тип II
Следствия для формул вида I
- Формулы можно использовать для распределения значений по диапазонам.
- Если первый столбец <ГДЕ> содержит повторяющиеся значения и правильно отсортирован, то будет возвращена последняя из строк с повторяющимися значениями.
- Если искать значение заведомо большее, чем может содержать первый столбец, то можно легко находить последнюю строку таблицы, что бывает довольно ценно.
- Данный вид вернёт ошибку #Н/Д, только если не найдёт значения меньше или равное искомому.
- Понять, что формула возвращает неправильные значения, в случае если ваш массив не отсортирован, довольно затруднительно.
Следствия для формул вида II
Если искомое значение встречается в первом столбце массива несколько раз, то формула выберет первую строку для последующего извлечения данных.
Производительность работы функции ВПР
Вы добрались до кульминационного места статьи. Казалось бы, ну какая разница, укажу ли я в качестве последнего параметра ноль или единицу? В основном все указывают, конечно же, ноль, так как это довольно практично: не надо заботиться о сортировке первого столбца массива, сразу видно, найдено значение или нет. Но если у вас на листе несколько тысяч формул ВПР (VLOOKUP), то вы заметите, что ВПР вида II работает медленно. При этом обычно все начинают думать:
- мне нужен более мощный компьютер;
- мне нужна более быстрая формула, например, многие знают про ИНДЕКС+ПОИСКПОЗ (INDEX+MATCH), которая якобы быстрее на жалкие 5–10%.
И мало кто думает, что стоит только начать использовать ВПР вида I и обеспечить любыми способами сортировку первого столбца, как скорость работы ВПР возрастёт в 57 раз. Пишу прописью — В ПЯТЬДЕСЯТ СЕМЬ РАЗ! Не на 57%, а на 5 700%. Данный факт я проверил вполне надёжно.
Секрет такой быстрой работы кроется в том, что на отсортированном массиве можно применять чрезвычайно эффективный алгоритм поиска, который носит название бинарного поиска (метод деления пополам, метод дихотомии). Так вот ВПР вида I его применяет, а ВПР вида II ищет без какой-либо оптимизации вообще. То же самое относится и к функции ПОИСКПОЗ (MATCH), которая включает в себя аналогичный параметр, а также и к функции ПРОСМОТР (LOOKUP), которая работает только на отсортированных массивах и включена в Excel ради совместимости с Lotus 1-2-3.
Недостатки формулы
Недостатки ВПР очевидны: во-первых, она ищет только в первом столбце указанного массива, а во-вторых, только справа от данного столбца. А как вы понимаете, вполне может случиться так, что столбец, содержащий необходимую информацию, окажется слева от столбца, в котором мы будем искать. Этого недостатка лишена уже упомянутая связка формул ИНДЕКС+ПОИСКПОЗ (INDEX+MATCH), что делает её наиболее гибким решением по извлечению данных из таблиц в сравнении с ВПР (VLOOKUP).
Некоторые аспекты применения формулы в реальной жизни
Диапазонный поиск
Классическая иллюстрация к диапазонному поиску — задача определения скидки по размеру заказа.
Поиск текстовых строк
Безусловно, ВПР ищет не только числа, но и текст. При этом надо принимать во внимание, что регистр символов формула не различает. Если использовать символы подстановки, то можно организовать нечёткий поиск. Есть два символа подстановки: «?» — заменяет один любой символ в текстовой строке, «*» — заменяет любое количество любых символов.
Борьба с пробелами
Часто поднимается вопрос, как решить проблему лишних пробелов при поиске. Если справочную таблицу ещё можно вычистить от них, то первый параметр формулы ВПР не всегда зависит от вас. Поэтому если риск засорения ячеек лишними пробелами присутствует, то можно применять для очистки функции СЖПРОБЕЛЫ (TRIM).
Разный формат данных
Если первый параметр функции ВПР ссылается на ячейку, которая содержит число, но которое хранится в ячейке в текстовом виде, а первый столбец массива содержит числа в правильном формате, то поиск будет неудачным. Возможна и обратная ситуация. Проблема легко решается переводом параметра 1 в необходимый формат:
=ВПР(−−D7; Продукты!$A$2:$C$5; 3; 0) — если D7 содержит текст, а таблица — числа;
=ВПР(D7 & «»); Продукты!$A$2:$C$5; 3; 0) — и наоборот.
Кстати, перевести текст в число можно сразу несколькими способами, выбирайте:
- Двойное отрицание —D7.
- Умножение на единицу D7*1.
- Сложение с нулём D7+0.
- Возведение в первую степень D7^1.
Перевод числа в текст производится через сцепку с пустой строкой, которая заставляет Excel преобразовать тип данных.
Как подавить выдачу #Н/Д
Это очень удобно делать при помощи функции ЕСЛИОШИБКА (IFERROR).
Например: =ЕСЛИОШИБКА( ВПР(D7; Продукты!$A$2:$C$5; 3; 0); «»).
Если ВПР вернёт код ошибки #Н/Д, то ЕСЛИОШИБКА его перехватит и подставит параметр 2 (в данном случае пустая строка), а если ошибки не произошло, то эта функция сделает вид, что её вообще нет, а есть только ВПР, вернувший нормальный результат.
Массив <ГДЕ>
Часто забывают ссылку массива сделать абсолютной, и при протягивании массив «плывёт». Помните, что вместо A2:C5 следует использовать $A$2:$C$5.
Хорошей идеей является размещение справочного массива на отдельном листе рабочей книги. Не путается под ногами, да и сохраннее будет.
Ещё более хорошей идеей будет объявление этого массива в виде именованного диапазона.
Многие пользователи при указании массива используют конструкцию вида A:C, указывая столбцы целиком. Этот подход имеет право на существование, так как вы избавлены от необходимости отслеживать тот факт, что ваш массив включает все необходимые строки. Если вы добавите строки на лист с первоначальным массивом, то диапазон, указанный как A:C, не придётся корректировать. Безусловно, эта синтаксическая конструкция заставляет Excel проводить несколько большую работу, чем при точном указании диапазона, но данными накладными расходами можно пренебречь. Речь идёт о сотых долях секунды.
Ну и на грани гениальности — оформить массив в виде умной таблицы.
Использование функции СТОЛБЕЦ для указания колонки извлечения
Если таблица, в которую вы извлекаете данные при помощи ВПР, имеет ту же самую структуру, что и справочная таблица, но просто содержит меньшее количество строк, то в ВПР можно использовать функцию СТОЛБЕЦ() для автоматического расчёта номеров извлекаемых столбцов. При этом все ВПР-формулы будут одинаковыми (с поправкой на первый параметр, который меняется автоматически)! Обратите внимание, что у первого параметра координата столбца абсолютная.
Создание составного ключа через &»|»&
Если возникает необходимость искать по нескольким столбцам одновременно, то необходимо делать составной ключ для поиска. Если бы возвращаемое значение было не текстовым (как тут в случае с полем «Код»), а числовым, то для этого подошла бы более удобная формула СУММЕСЛИМН (SUMIFS) и составной ключ столбца не потребовался бы вовсе.
Это моя первая статья для Лайфхакера. Если вам понравилось, то приглашаю вас посетить мой сайт, а также с удовольствием прочту в комментариях о ваших секретах использования функции ВПР и ей подобных. Спасибо.