

Системная биология принимает и интегрирует многопрофильные подходы для понимания биологии человека. Быстрое развитие инструментов омики, включая геномику, транскриптомику, протеомику и метаболомику, наряду с биоинформатикой и информатикой, очень помогло нам в понимании биологических систем на молекулярном уровне, обеспечивая более глубокое понимание механизмов нашего понимания здоровья и болезней человека.
Технологии высокой пропускной способности сделали сбор данных намного проще, чем раньше. Однако анализ и интеграция больших данных становятся все более сложными. Возникает более фундаментальный вопрос: достаточно ли Microsoft Excel для анализа данных или необходимо ли изучение Python для получения более глубокого понимания данных? Чтобы ответить на этот вопрос, нам нужно расшифровать ситуации, когда использование Python превосходит Excel.
Здесь я рассмотрел 5 различных возможностей, чтобы обосновать, почему стоит рассмотреть возможность изучения Python для анализа больших наборов данных:
1. Python позволяет пользователям назначать обрабатываемые наборы данных в кодах или переменных, уменьшая необходимость в хранении нескольких файлов или электронных таблиц.
Большую часть данных необходимо будет предварительно обработать, прежде чем можно будет выполнить анализ данных. Примеры включают в себя вменение значений для отсутствующих данных, удаление строк или столбцов со слишком большим количеством отсутствующих данных и масштабирование данных, чтобы модели машинного обучения работали лучше.
Эти задачи можно легко выполнить в Microsoft Excel, если набор данных небольшой. Однако при анализе набора данных с размерами 20 переменных с 20000 генами (всего 400000 числовых значений) пользователям обычно приходится сохранять индивидуально обработанные файлы в разных таблицах и файлах Excel, чтобы уменьшить проблемы с запаздыванием.
В Python обработка этих больших наборов данных намного проще с помощью всего нескольких строк кода с использованием библиотеки pandas в Python.
2. Python более согласован и менее подвержен ошибкам по сравнению с Excel.
Использование файлов Excel для анализа небольших наборов данных удобно и, следовательно, обычно предпочтительнее. Однако с большими наборами данных функция перетаскивания не идеальна. Например, требуется много времени и усилий, чтобы перетащить ячейки, если у вас есть большое количество переменных. Функция перетаскивания также бесполезна, если в вашем наборе данных есть пустые ячейки.
Наконец, комбинирование функций «фильтрации» или «сортировки» с формулами в Excel обременительно, особенно для больших наборов данных. Однако в Python фильтрация, группировка, сортировка и управление таблицами могут быть легко выполнены в пандах.
3. Python более экономичен по времени и пространству при обработке больших наборов данных.
Максимальный предел Excel составляет 1 048 576 строк на 16 384 столбца, что означает, что вам придется хранить все свои гены с микрочипа или RNAseq в строках. Даже если вы сохранили все свои гены в строках, выполнение функций Excel в больших наборах данных может занять много времени (может занять несколько минут).
В некоторых сценариях из-за длительного времени обработки программа Excel может отключиться, что приведет к потере обновленного файла. Это означает, что вам придется регулярно сохранять файлы, и каждый раз, когда вы нажимаете «сохранить», это занимает несколько минут, а это означает, что вы тратите много времени на ожидание.
В Python коды автоматически сохраняются, а размеры DataFrame безграничны, что означает, что вы можете управлять файлами и переносить их в любое время, а обработка обычно завершается в течение нескольких секунд.
Также следует отметить, что все коды могут быть сохранены и опубликованы, что означает, что одни и те же коды можно использовать для сравнения с другим большим набором данных. Это экономит много времени и снижает потребность в управлении большим количеством файлов.
4. Поиск переменных в разных наборах данных в Python выполняется быстрее, чем в Excel.
В одном наборе данных Excel может выполнять несколько запросов генов с помощью функции ИНДЕКС. Однако для нескольких больших наборов данных это неэффективно. Сначала вам нужно будет открыть несколько электронных таблиц, а затем использовать функцию ИНДЕКС для запроса каждой таблицы. В целом, если у вас много таблиц, это может занять много времени.
В Python после назначения столбца (столбцов) индекса вы можете использовать функции iloc для выполнения конкретного запроса для каждого набора данных. Вы даже можете использовать функцию множественных запросов в Streamlit для выполнения функций запросов. Следовательно, запрос данных большого количества переменных в нескольких наборах данных обычно более эффективен с Python, чем с Excel.
5. Python может рисовать более интерактивные и сложные графики, чем Excel.
Поскольку все больше людей делятся своими кодами и разрабатывают пакеты, Python может строить более сложные графики, что важно для визуализации данных больших наборов данных. Например, Python может выполнять иерархическую кластеризацию и тепловые карты проще, чем Excel. Сложные функции, включающие неконтролируемую кластеризацию, такие как анализ главных компонентов, также легче выполнять в Python. Наконец, библиотеки Plotly и Altair в Python делают графики интерактивными, позволяя пользователям наводить курсор на точки данных для получения характеристик отдельных точек данных.
Другие причины дают Python конкурентное преимущество, в том числе простота реализации моделей машинного обучения, создания информационных панелей для клиентов и совместного использования рабочих процессов анализа данных. Я верю, что сначала нужно изучить основы, прежде чем углубляться в сложные модели и рамки. Хорошее место для начала — прочитать документацию по пандам. Другой веб-сайт с хорошей вводной частью также можно найти здесь.
Таким образом, мы можем сделать вывод, что Python лучше, чем Excel для анализа данных.
Надеюсь, это поможет вам сделать свой выбор. Спасибо за чтение!
После запуска нового курса «Python для анализа данных» нам стали часто задавать вопрос: «Зачем вообще нужен Python, если есть Excel?».
Содержание:
- Автоматизация и масштаб
- Воспроизводимость
- Бесконечные возможности
- Широкие возможности
- Легкость обучения Python
- Итоги
Excel является самым популярным программным обеспечением для баз данных, хотя сегодня доступно множество альтернативных и более эффективных решений. Пять лет назад у Excel было более 750 миллионов пользователей. Население Земли на тот момент — примерно 7,6 миллиарда человека. Таким образом, около 10% людей пользовались Excel, можно предположить, что основная задача — анализ данных.
Excel являлся востребованным инструментом для многих компаний, его используют ученые и аналитики данных, однако для большей части их работы есть более эффективный софт — Python. И я вам это докажу.
Если вы еще не начали изучать Python и не вывели свои скилы по визуализации и анализу данных на новый уровень, я расскажу вам о пяти причинах, по которым вам необходимо начать изучать его прямо сейчас. Не сомневаюсь, что к концу статьи вы точно захотите перенести большую часть своей работы из Excel в Python.
Автоматизация и масштаб
В вопросе автоматизации Python становится действительно удивительным языком программирования. Вы сможете решить следующие задачи:
- подключить Python к любому источнику данных;
- составлять отчеты;
- запланировать задание, повторно извлекающее ваши данные с любыми обновлениями;
- выполнять необходимые расчеты;
- создавать динамическую панель мониторинга.
Python поможет вам сэкономить массу времени. Excel, напротив, требует слишком большого количества ручного труда, а также в нем не доступны автоматические обновления [комментарий HOCK Training: возможно, здесь речь идет о сложности обновлений данных стандартными инструментами Excel. Периодические обновления в Excel легко можно выполнять при помощи VBA (макросами)].

Python способен напрямую подключаться к вашей базе данных для проведения автоматических обновлений. Изображение: NobleDesktop.
Excel подходит для выполнения быстрого специального анализа небольших данных, однако, когда вы решите перейти к более крупному масштабу, он не будет работать. Общее количество строк на странице Excel — до 1 048 576, столбцов — до 16 384. Python же масштабируется до любых размеров и ограничен только памятью вашего устройства, а также для него доступно множество инструментов, которые поддерживают вычисления за ее пределами.
Пример — библиотека Dask. Она позволяет масштабировать вычисления не только на ПК, но и для запуска на кластере. Для тех, кто знаком с Pandas, это похожий код для чтения в CSV:

Это только строчка кода, однако благодаря ней вы сможете читать данные, чей объем намного больше объема памяти вашего компьютера. Я бы с удовольствием показал, как сделать то же самое в Excel, если бы это было возможно.
Если этот код показался вам сложным, начните учиться с помощью нашего курса. В нем есть все необходимое для начала работы с Python.
Python также масштабируется для нескольких источников данных. Excel — это хранилище и в то же время — механизм вычислений. Python же абсолютно не зависит от данных. Если вы нашли метод чтения имеющихся данных в Python, это значит, что вы сможете работать с ними. В Python есть множество библиотек, поэтому процесс считывания данных из целого ряда источников (например — базы данных CSV, Excel, JSON и SQL) является обычным.
Воспроизводимость
Воспроизводимость является концепцией, согласно которой любые созданные вами аналитические данные и визуализации могут быть без проблем воспроизведены кем-нибудь еще. Важны обе составляющие процесса:
Конечный результат. Кто-то другой должен суметь повторно запустить ваш процесс, чтобы получить такой же результат.
Путь достижения цели. Кто-то другой должен суметь пройти через ваши шаги. Только так можно обеспечить точность результата.
Важность этой концепции обусловлена тем, что она позволяет полагаться на автоматические процессы. Автоматизация полезна, когда работает правильно. Если же она неверна, автоматические отчеты могут стать настоящим кошмаром.
В Excel воспроизводимость крайне сложна. Результаты вычислений в ячейках практически не поддаются проверке при любом масштабировании. Типы данных очень запутаны. Картина, которую видит пользователь, часто не соответствует необработанным данным. VBA лишь делает воспроизводимость чуть лучше, поэтому вам гораздо выгоднее инвестировать в освоение Python.
Давайте обратимся к этому Excel-документу:

Нам известно, что столбец Sum — это сумма значений из колонок a и b, как нам подтвердить это? Можно проверить любую формулу, чтобы убедиться, что перед нами действительно сумма. Однако каждая ячейка может содержать отдельную формулу, что будет, если все они неверны? Если бы я не обратил ваше внимание на шестую строку, вы бы заметили что в ней другая формула?
Но в Python ваша сумма будет выглядеть так:

Простой и понятный код с легкостью подтверждает, что сумма всегда будет рассчитываться верно.
Python открывает доступ ко всем инструментам, необходимым для улучшения воспроизводимости и совместной работы разработчиков программного обеспечения. Python позволяет анализировать данные в облаке, мгновенно повторяя процесс, поэтому он лучше всего подходит для подключения к данным.
В сообществе Python широко распространены:
- Git;
- документация и стандарты форматирования кода;
- модульное тестирование.
В Python 3 есть функция статической типизации, облегчающая чтение кода. Такие инструменты упрощают правильное написание кода. Если в дальнейшем его будет использовать кто-то другой, ему будет легко воспроизвести и понять каждую строку.
Бесконечные возможности
Если пользователь умеет работать в Excel, эти навыки полезны, но больше их нигде нельзя применить. Пожалуй, в этом заключается существенное отличие и главный плюс Python. Это удобный инструмент для анализа и визуализации данных, он также является надежным языком программирования, подходящим для других целей.
Python поможет вам:
- заняться машинным или глубоким обучением;
- создать сайт;
- настроить автоматизацию системы умного дома и многое другое.
Python больше похож на другие языки программирования, с которыми вы можете столкнуться, чем Excel. Это значительно упрощает их изучение. Python более перспективен, чем Excel.
Спрос на специалистов, владеющих Python, очень высок. Согласно StackOverflow, в 2019 году этот язык программирования — четвертый по уровню популярности в мире среди разработчиков ПО. По информации Indeed от 2020 года, в США средняя годовая заработная плата разработчиков Python — 120 000 долларов.
Широкие возможности
Одно из преимуществ Excel — большое число встроенных формул, но возможности Python намного шире. В Python доступно множество библиотек, которые значительно упрощают расширенную статистику и аналитику. Визуализация выведена на новый уровень. При помощи Matplotlib, Seaborn, Plotly, Streamlit можно создавать:
- интерактивные информационные панели;
- необычные визуализации данных;
- графики.
Scikit-learn помогает обучать алгоритмы машинного обучения: машины повышения градиента, деоевья решений и т. д. Scipy и Numpy полезны для векторных и научных вычислений, а также для линейной алгебры. Xkcd отлично выразил мои мысли:

У Python при сравнении с Excel намного больше возможностей, но значит ли это, что его трудно освоить? К счастью, нет! Это Java-версия Hello World самой простой программы:

Python — это буквально одна строка: print(“Hello World!”). Что может быть проще? Python входит в группу самых простых языков программирования. Также у него одно из самых активных сообществ, особенно — в сфере аналитики данных.
Язык программирования Python можно понять интуитивно. Его легко освоит даже человек с минимальным опытом работы в области программирования. Кому-то кривая обучения Excel, возможно, кажется более предпочтительной, но от нее намного меньше отдачи. Обучение Python стоит затраченного времени и приложенных усилий, а его универсальный дизайн оставляет Excel далеко позади.
Простой в использовании, Python имеет большое сообщество поддержки. Обучение никогда не было более простым.
Итоги
Время перейти на Python настало. Хватит придумывать оправдания! Я надеюсь, что в статье мне удалось показать вам плюсы изучения Python и помочь обойти некоторые препятствия на пути к обучению.
Учитесь и развивайте свои навыки владения Python!
Оригинал статьи:
https://towardsdatascience.com/stop-using-excel-for-data-analytics-upgrade-to-python
In this tutorial, we’ll compare Excel and Python by looking at how to perform basic analysis tasks across both platforms.
Excel is the most commonly used data analysis software in the world. Why? It’s easy to get the hang of and fairly powerful once you master it. In contrast, Python’s reputation is that it’s more difficult to use, though what you can do with it is once you’ve learned it is almost unlimited.
But how do these two data analysis tools actually compare? Their reputations don’t really reflect reality. In this tutorial, we’ll take a look at some common data analysis tasks to demonstrate how accessible Python data analysis can be.
This tutorial assumes you have an intermediate-level knowledge of Excel, including using formulas and pivot tables.
We’ll be using the Python library pandas, which is designed facilitate data analysis in Python, but you don’t need any Python or pandas knowledge for this tutorial.
Why Use Python vs Excel?
Before we start, you might be wondering why Python is even worth considering. Why couldn’t you just keep using Excel?
Even though Excel is great, there are some areas that make a programming language like Python better for certain types of data analysis. Here are some reasons from our post 9 Reasons Excel Users Should Consider Learning Programming:
- You can read and work with almost any kind of data.
- Automated and repetitive tasks are easier.
- Working with large data sets is much faster and easier.
- It’s easier for others to reproduce and audit your work.
- Finding and fixing errors is easier.
- Python is open source, so you can see what’s behind the libraries you use.
- Advanced statistics and machine learning capabilities.
- Advanced data visualization capabilities.
- Cross-platform stability — your analysis can be run on any computer.
To be clear, we don’t advocate leaving Excel behind — it’s a powerful tool with many uses! But as an Excel user, being able to also leverage the power of Python can save you hours of time and open up career advancement opportunities.
It’s worth remembering the two tools can work well in tandem, and you may find that some tasks are best left in Excel, while others would benefit from the power, flexibility, and transparency that’s offered by Python.
Importing Our Data
Let’s start by familiarizing ourselves with the data we’ll be working with for this tutorial. We’ll use fictional data about a company with salespeople. Here’s what our data looks like in Excel:
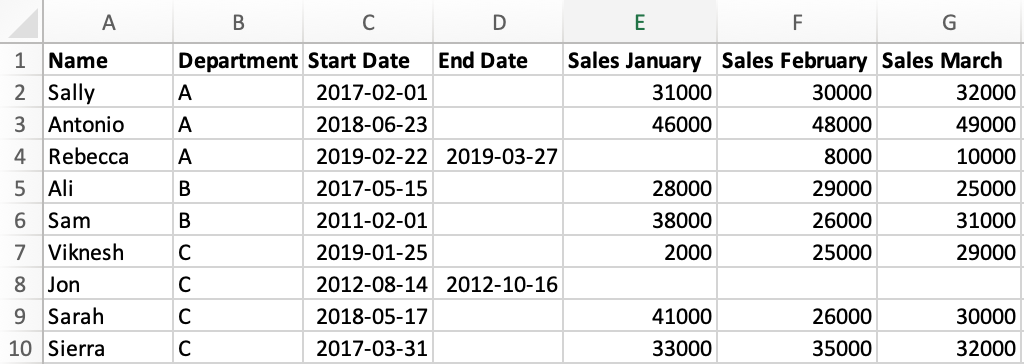
Our data is saved as a CSV file called sales.csv. In order to import our data in pandas, we need to start by importing the pandas library itself.
The code above imports pandas and aliases it to the syntax pd. That may sound complicated, but it’s actually just a kind of nickname — it means that in the future we can just use pd to refer to pandas so that we don’t have to type out the full word each time.
To read our file we use pd.read_csv():
We assigned the result of pd.read_csv() to a variable called sales, which we’ll use to refer to our data. We also put the variable name on its own in the last line of our code, which prints the data in a nicely formatted table.
Immediately, we can notice a few differences between how pandas represents the data vs what we saw in Excel:
- In pandas, the row numbers start at 0 versus 1 in Excel.
- The column names in pandas are taken from the data, versus Excel where columns are labelled using letters.
- Where there is a missing value in the original data, pandas has the placeholder
NaNwhich indicates that the value is missing, or null. - The sales data has a decimal point added to each value, because pandas stores numeric values that include null (
NaN) values as numeric type known as float (this doesn’t effect anything for us, but we just wanted to explain why this is).
Before we learn our first pandas operation, we’ll quickly learn a little about how our data is stored.
Let’s use the type() function to look at the type of our sales variable:
This output tells us that our sales variable is a DataFrame object, which is a specific type of object in pandas. Most of the time in pandas when we want to modify a dataframe, we’ll use special syntax called a dataframe method, which allows us to access specific functionality that relates to the dataframe objects. We’ll see an example of that in a moment when we complete our first task in pandas!
Sorting Data
Let’s learn how to sort our data in Excel and Python. Currently, our data isn’t sorted. In Excel, if we wanted to sort our data by the "Start Date" column, we would:
- Select our data.
- Click the ‘Sort’ button on the toolbar.
- Select ‘Start Date’ in the dialog box that opens.
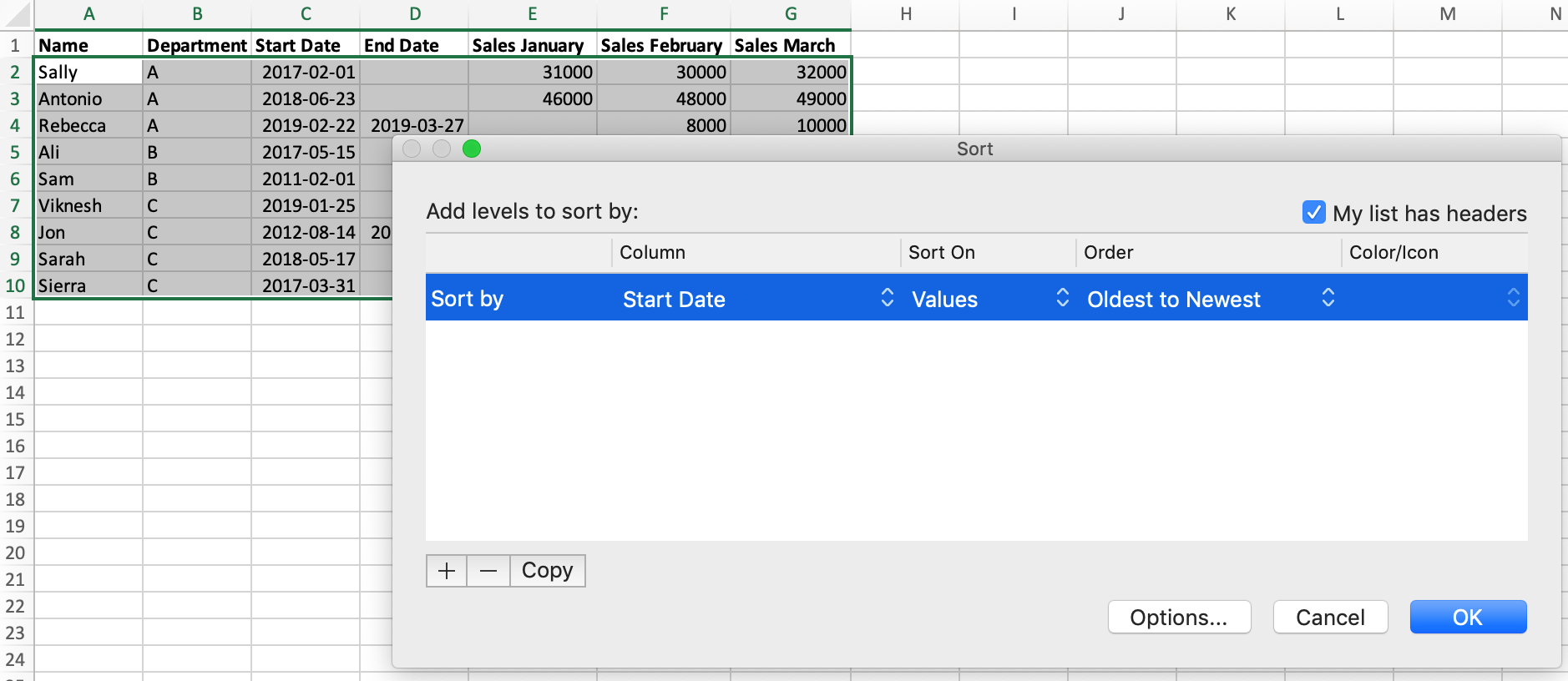
In pandas, we use the DataFrame.sort_values() method. We mentioned methods briefly a moment ago. In order to use them we have to replace DataFrame with the name of the dataframe we want to apply the method to — in this case sales. If you’ve worked with lists in Python, you will be familiar with this pattern from the list.append() method.
We provide the column name to the method to tell it which column to sort by:
The values in our dataframe have been sorted with one simple line of pandas code!
Summing the Sales Values
The last three columns of our data contain sales values for the first three months of the year, known as the first quarter. Our next task will be to sum those values in both Excel and Python.
Let’s start by looking at how we achieve this in Excel:
- Enter a new column name
"Sales Q1"in cellH1. - In cell H2, use the
SUM()formula and specify the range of cells using their coordinates. - Drag the formula down to all rows.
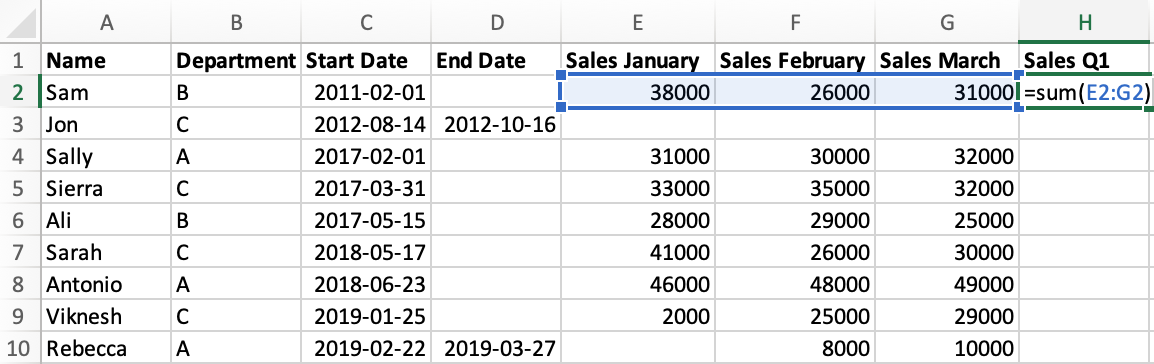
In pandas, when we perform an operation it automatically applies it to every row at once. We’ll start by selecting the three column by using their names in a list:
Next, we’ll use the DataFrame.sum() method and specify axis=1, which tells pandas that we want to sum the rows and not the columns. We’ll specify the new column name by providing it inside brackets:
In pandas, the «formula» we used isn’t stored. Instead the resulting values are added directly to our dataframe. If we wanted to make an adjustment to the values in our new column, we’d need to write new code to do it.
Joining Manager Data
In our spreadsheet, we also have a small table of data on who manages each team:
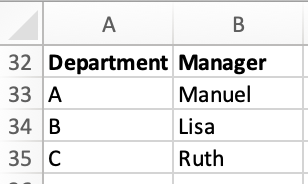
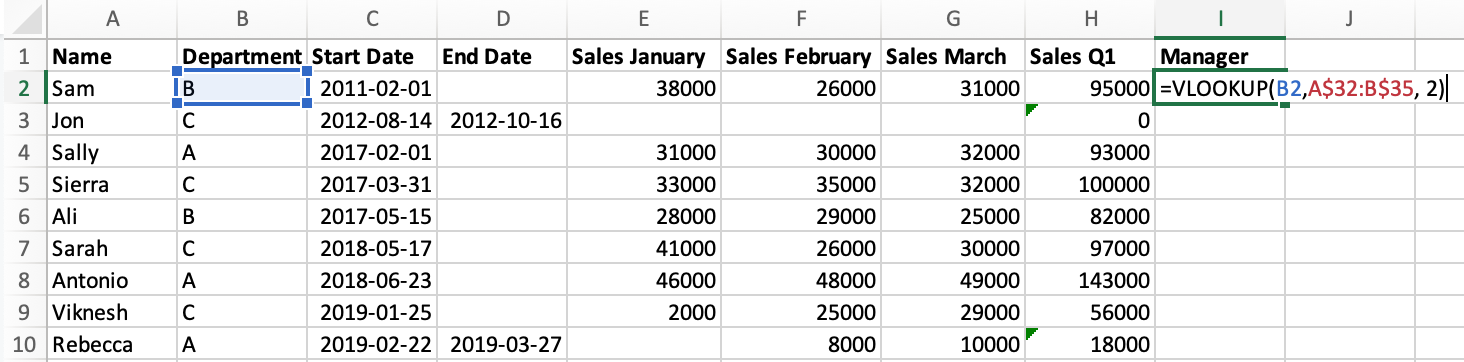
Let’s look at how to join this data in a "Manager" column in Excel and Python. In Excel, we:
- start by adding the column name to cell
I1. - use the
VLOOKUP()formula in cellI2, specifying:- to lookup the value from cell
B2(the Department) - in the selection of manager data, which we specify using coordinates
- and that we want to select the value from the second column of that data.
- to lookup the value from cell
- Click and drag the formula down to all cells.
To work with this data in pandas, first we’ll need to import it from a second CSV, managers.csv:
In order to join mangers data to sales using pandas, we’ll use the pandas.merge() function. We provide the following arguments, in order:
sales: the name of the first, or left, dataframe we want to mergemanagers: the name of the second, or right, dataframe we want to mergehow='left': the method we want to use to join the data. Theleftjoin specifies that no matter what, we want to keep all the rows from our left (first) dataframe.on='Department': The name of the column in both dataframes that we will join on.
If this seems is a bit confusing at first, that’s OK. The model for joining data in Python is different to what is used in Excel, but it’s also a lot more powerful. Note that in Python we get to specify exactly how we join our data using clear syntax and column names.
Adding a Conditional Column
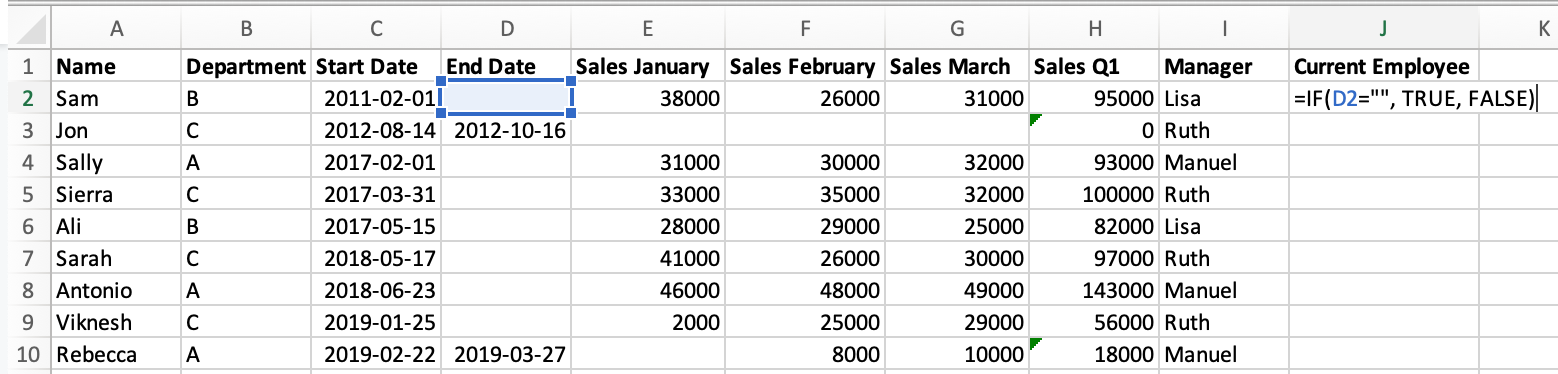
If we look at the "End Date" column, we can see that not all employees are still with the company — those with a missing value are still employed but the rest have left. Our next task will be to create a column which tells us if each salesperson is a current employee. We’ll perform this in Excel and Python.
Starting with Excel, to add this column we:
- Add a new column name to cell
J1. - Use the
IF()formula to check if cellD1(End Date) is empty, and if so fillJ2withTRUE, otherwiseFALSE. - Drag the formula down to the cells below.
In pandas, we use the pandas.isnull() function to check for null values in the "End Date" column, and assign the result to a new column:
Pivot Tables
One of the most powerful Excel features is pivot tables, which facilitate data analysis using aggregation. We’re going to look at two different pivot table applications in Excel and Python.
We’ll start with a pivot table in Excel that counts the number of employees in each department:
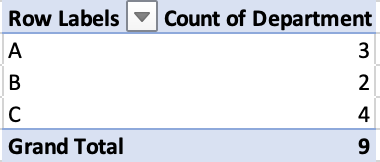
This operation — counting the number of times a value occurs in a column — is so common that in pandas it has its own syntax: Series.value_counts().
The series type is new to this tutorial, but it’s quite similar to a DataFrame, which we’ve already learned about. Series is just the pandas representation of a single row or column.
Let’s use the pandas method to calculate the number of employees in each department:
The second pivot table example also aggregates by department, but instead calculates the average Q1 sales:
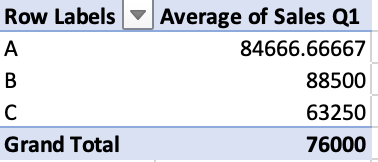
In order to calculate this in pandas, we’ll use the DataFrame.pivot_table() method. We need to specify some arguments:
index: the column to aggregate by.values: the column we want to use the values for.aggfunc: the aggregation function we want to use, in this case'mean'average.
Excel vs Python: Summary
In this tutorial we learned Python equivalents for the following Excel functionality:
- Sorting data
SUM()VLOOKUP()IF()- Pivot Tables
For each example we looked at, the pandas syntax was of similar complexity to the formulas or menu options you would use in Excel. But Python offers some advantages, like much faster processing of large data sets, more customization and complexity, and more transparency for error-checking and auditing (since everything you’ve done is clearly laid out in code, rather than hidden in cells).
Someone proficient in Excel is more than capable of making the leap to working in Python. Adding Python skills to your skill set will make you a faster and more powerful analyst in the long run, and you’ll discover new workflows that take advantage of both Excel and Python for more efficient and powerful data analysis than you could do with Excel alone.
If you’d like to learn how to analyze data in Python, our Data Analyst in Python path is design to teach you everything you need to know, even if you’ve never coded before. You’ll start with two courses that teach you the Python fundamentals before you move onto learn the pandas library that we’ve worked with in this tutorial.
You know the sum column should be the sum of a and b, but how do you confirm that? You could check one of the formulas and see that it is in fact the sum, but since every cell can be its own formula, what if they all are not correct? If you were not paying attention, you might have missed that row x was wrong.
But in Python, your sum would look like this:
a = [1,2,3,4]
b = [5,6,7,8]
sum = []
for i in range(a):
sum.append(a[i] + b[i])
This code is clear and easy to confirm that the sum is always calculated correctly.
With Python, you get all the tools developed to make reproducibility and collaboration better for software engineers. On top of that, Python is superior for data connectivity, allowing us to analyze data in the cloud and repeat a process instantly. Git, unit testing, documentation, and code formatting standards are all prevalent in the Python community. With Python 3, you can even add static typing to make your code even more clear.
All of these tools make it easier to ensure your code is written well and correctly. So that the next time you look at your code or someone else picks it up, it’s easy to reproduce and understand.
In Supply Chain, data management and processing are vital. To be able to pilot physical flows, it is essential to master information flows: the processing and analysis of these flows is done through Information Systems.
Very often, Excel serves as an intermediary between information systems and users. It is sometimes used fully as a supply chain management tool for small companies that have not invested in Planning Software or ERP packages. Microsoft Excel has therefore naturally taken a very important position for flow controllers, forecasters, procurement managers, … up to project managers and Supply Chain directors.
However, another tool has been in the news a lot in recent years: Python. Supply chain professionals are learning about Python, and some are using it daily to analyze their ERP data.
This trend was confirmed in my recent survey on strategic programming languages in Supply Chain:
I sometimes even hear it said that “Python is the new Excel.” What is it really like? Can we consider this tool to be indispensable for the Supply Chain professions? Will it make our old Excel spreadsheets obsolete?
Python and Excel do not have the same purpose
When I hear people comparing both tools, I realize that they are missing a key point: they were designed for very different functionality.
Excel is first and foremost a spreadsheet: the simplicity of its graphical interface allows any user to manipulate data, without any notion of the underlying code.
Python is a programming language: its use is not limited to data management; one can develop extremely varied programs. It is obviously necessary to learn to code in order to use Python.
So why do we often equate these two tools?
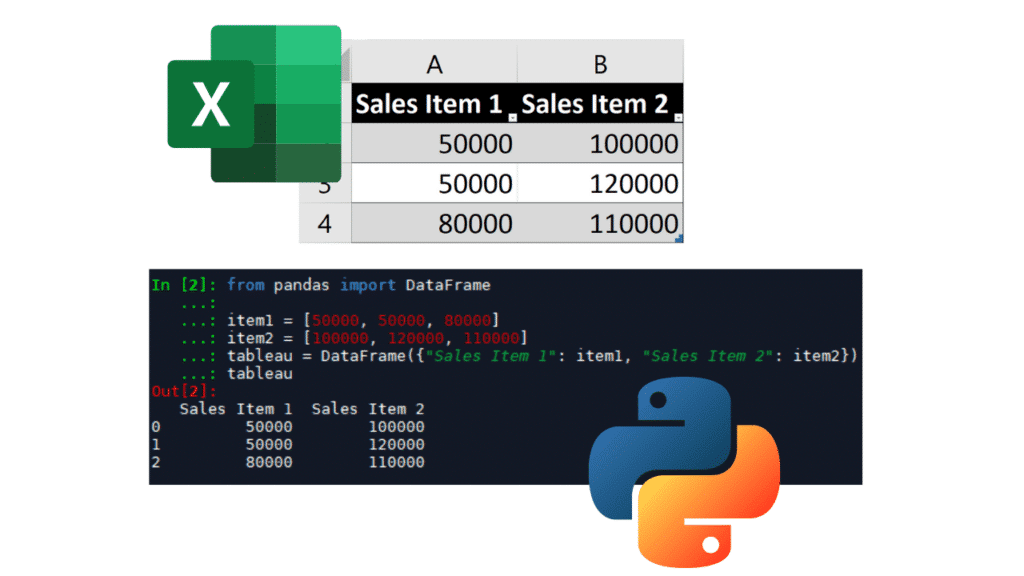
Simply because Python’s great versatility allows it to reproduce quite quickly the main features of Excel: storing values on a row, on a column, on a table, and performing calculations on those same values. You can even use libraries to visualize data, draw graphs… Python has no limits in terms of data analysis.
For example, here is a simple linear regression on a Yearly Sales dataset of 2 items:
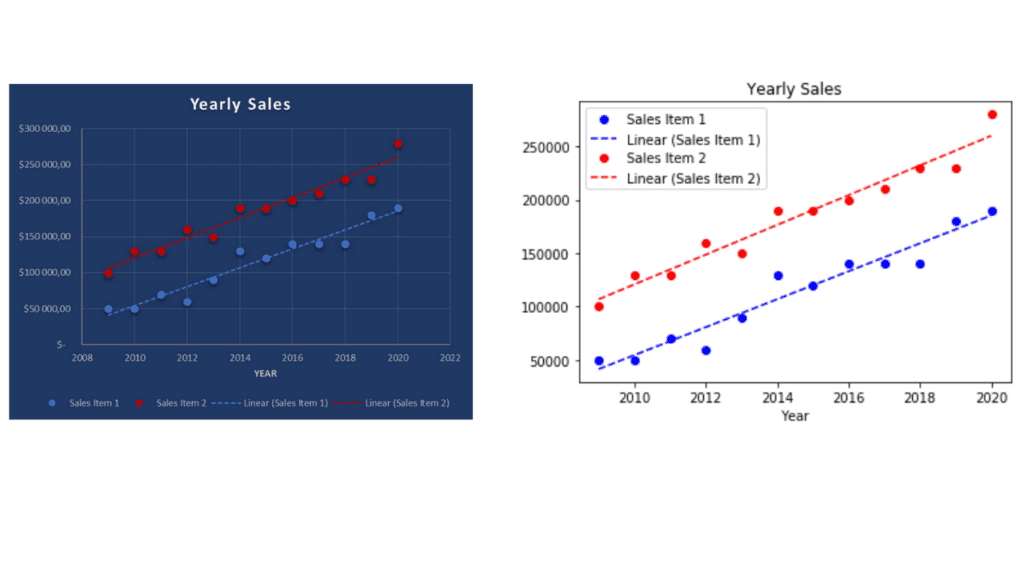
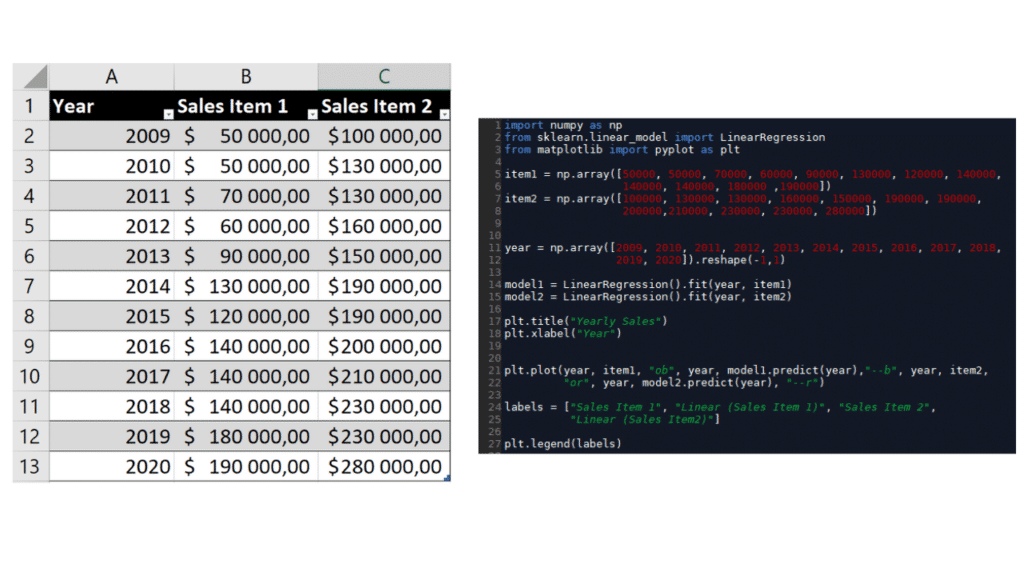
In Excel, all is interactive: we can write down data right away on a table and make the regression with the tendency curve option of Excel graphs. With Python, everything must be coded using open-source packages:
So we can perform data analysis on both tools, but Python is all about programming and development, and is not meant to be used by any random Business User. What could happen in the future is that Automation led by Python programming teams would remove the need to have some tasks performed by Supply Chain professionals on Excel. But it would be a high-level business consequence, not just substituting one software for another at the user level.
Python: more strategic, but more complex
Python is a strategic language in Supply Chain.
The volumes of data managed by companies are only increasing, and supply chain professionals have access to more data in both quantity and variety. The larger the volumes, the more difficult it becomes to manage them with simple desktop tools. Python is an excellent solution for handling large amounts of information. Its computational power is nothing like that of Excel.
It also brings an opportunity to bring more intelligence via Machine Learning algorithms. Python excels in this area.
It has a relatively simple syntax with few lines of code compared to other languages. It is popular in the scientific community, as it benefits from numerous open-source libraries that allow statistical and machine learning models to be applied fairly quickly.
However, Python is much more complex to get to grips with. To give you an order of magnitude, I’d say it takes at least 50 hours of learning to start getting results (assuming you already know how to code!). Since it is only a programming language, it does not have a standard graphical interface of its own and suffers from the comparison with the very intuitive interface of Excel. This was one of my main difficulties when I was starting with Python.

Another crucial point: you won’t have many people around you who can understand and update your programs in Python. Unless you collaborate with a team of Python developers or Data Scientists, the maintainability of your programs will be difficult. And you’ll be on your own when your algorithms crash.
Excel is still evolving
We tend to forget that Microsoft continues to innovate fairly consistently in the features of its office tools. Excel modules such as Power Query and Power Pivot have reached a good level of maturity in recent years.They are particularly well-suited for the issues we encounter in logistics.
Whatever the context in Supply Chain, it is often necessary to go through these 7 steps when analyzing data:
- Import the data
- Clean it up
- Consolidate it
- Shape it
- Set up KPIs and calculations
- Consolidate it on dashboards
- And analyze it to make the right decisions
Power Query is used for importing data and Power Pivot for building data models (you can see more details on how they work on the official Microsoft website). So the two modules are very complementary and allow you to automate steps 1 to 4. Many formerly complex automation projects, which required a lot of VBA code, can now be done with much more intuitive tools.
Besides, Power Query and Power Pivot are making Visual Basic Macros obsoletes, which are more complex and less efficient.
We see this clearly on Google search volumes:
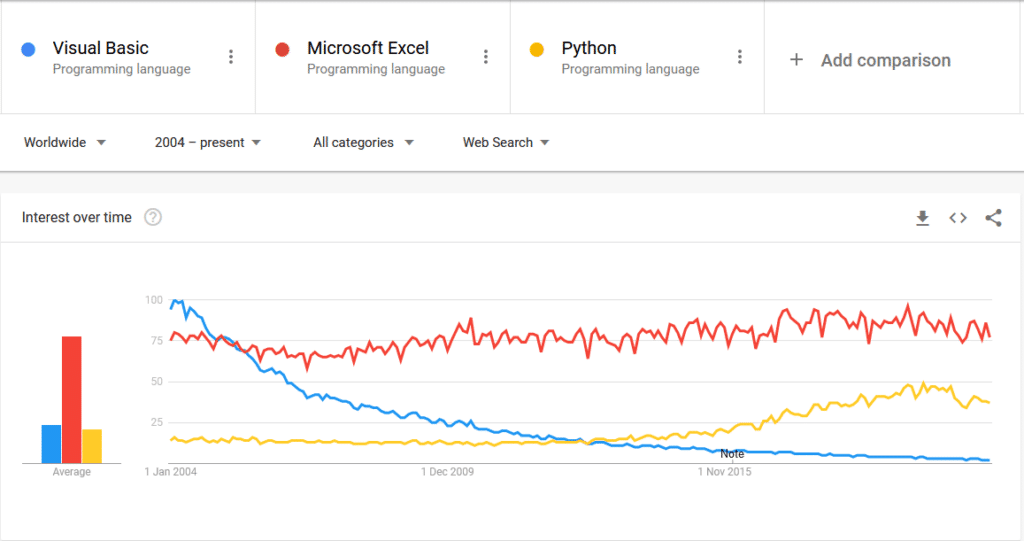
So Microsoft Excel still has many years ahead of it. I know from experience that many people do not use it to its full potential, often without realizing it.
Conclusion
So… Python or Excel? We can’t say that one can substitute for the other, because they are two very different tools. Nevertheless, they are comparable in Supply Chain, in the sense that they can be used for the same purposes for extracting, processing and analyzing data from Information Systems. Where Excel provides simplicity, visualizations, and quick analysis, Python offers solutions in terms of scalability, computational power, and complex algorithms.
Depending on your programming level and your business needs, it may be worthwhile to get into Python. However, my speech is always the same, first master the foundations of your business before getting into the complexity.
Start with mastering Excel at a very advanced level and automating as much as possible. Particularly with Power Query/Pivot. This way, you will gain a lot of productivity and stand out in the job market. Only then, if you have an affinity for numbers, you can start training in Python. If you’re a Data Scientist today, obviously you need to master Python, but the majority of Data Scientists I know are already excellent at Excel.
In any case, you should make your own opinion, test Power Query/Pivot and Python for yourself.
To go further
If you want to develop your skills and increase your attractiveness, check out my articles:
- How to Become a Supply Chain Manager: 6 Pillars
- Programming languages for Supply Chain
- Supply Chain Software & ERP

Founder of AbcSupplyChain | Supply Chain Expert | 15 years experience in 6 different countries –> Follow me on LinkedIn