
Содержание
- 1 Использование описательной статистики
- 1.1 Подключение «Пакета анализа»
- 1.2 Применение инструмента «Описательная статистика»
- 1.3 Помогла ли вам эта статья?
- 1.4 Статистические процедуры Пакета анализа
- 1.5 Статистические функции библиотеки встроенных функций Excel

Пользователи Эксель знают, что данная программа имеет очень широкий набор статистических функций, по уровню которых она вполне может потягаться со специализированными приложениями. Но кроме того, у Excel имеется инструмент, с помощью которого производится обработка данных по целому ряду основных статистических показателей буквально в один клик.
Этот инструмент называется «Описательная статистика». С его помощью можно в очень короткие сроки, использовав ресурсы программы, обработать массив данных и получить о нем информацию по целому ряду статистических критериев. Давайте взглянем, как работает данный инструмент, и остановимся на некоторых нюансах работы с ним.
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».

После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Применение инструмента «Описательная статистика»
Теперь посмотрим, как инструмент описательная статистика можно применить на практике. Для этих целей используем готовую таблицу.
- Переходим во вкладку «Данные» и выполняем щелчок по кнопке «Анализ данных», которая размещена на ленте в блоке инструментов «Анализ».
- Открывается список инструментов, представленных в Пакете анализа. Ищем наименование «Описательная статистика», выделяем его и щелкаем по кнопке «OK».
- После выполнения данных действий непосредственно запускается окно «Описательная статистика».
В поле «Входной интервал» указываем адрес диапазона, который будет подвергаться обработке этим инструментом. Причем указываем его вместе с шапкой таблицы. Для того, чтобы внести нужные нам координаты, устанавливаем курсор в указанное поле. Затем, зажав левую кнопку мыши, выделяем на листе соответствующую табличную область. Как видим, её координаты тут же отобразятся в поле. Так как мы захватили данные вместе с шапкой, то около параметра «Метки в первой строке» следует установить флажок. Тут же выбираем тип группирования, переставив переключатель в позицию «По столбцам» или «По строкам». В нашем случае подходит вариант «По столбцам», но в других случаях, возможно, придется выставить переключатель иначе.
Выше мы говорили исключительно о входных данных. Теперь переходим к разбору настроек параметров вывода, которые расположены в этом же окне формирования описательной статистики. Прежде всего, нам нужно определиться, куда именно будут выводиться обработанные данные:
- Выходной интервал;
- Новый рабочий лист;
- Новая рабочая книга.
В первом случае нужно указать конкретный диапазон на текущем листе или его верхнюю левую ячейку, куда будет выводиться обработанная информация. Во втором случае следует указать название конкретного листа данной книги, где будет отображаться результат обработки. Если листа с таким наименованием в данный момент нет, то он будет создан автоматически после того, как вы нажмете на кнопку «OK». В третьем случае никаких дополнительных параметров указывать не нужно, так как данные будут выводиться в отдельном файле Excel (книге). Мы выбираем вывод результатов на новом рабочем листе под названием «Итоги».
Далее, если вы хотите чтобы выводилась также итоговая статистика, то нужно установить флажок около соответствующего пункта. Также можно установить уровень надежности, поставив галочку около соответствующего значения. По умолчанию он будет равен 95%, но его можно изменить, внеся другие числа в поле справа.
Кроме этого, можно установить галочки в пунктах «K-ый наименьший» и «K-ый наибольший», установив значения в соответствующих полях. Но в нашем случае этот параметр так же, как и предыдущий, не является обязательным, поэтому флажки мы не ставим.
После того, как все указанные данные внесены, жмем на кнопку «OK».
- После выполнения этих действий таблица с описательной статистикой выводится на отдельном листе, который был нами назван «Итоги». Как видим, данные представлены сумбурно, поэтому их следует отредактировать, расширив соответствующие колонки для более удобного просмотра.
- После того, как данные «причесаны» можно приступать к их непосредственному анализу. Как видим, при помощи инструмента описательной статистики были рассчитаны следующие показатели:
- Асимметричность;
- Интервал;
- Минимум;
- Стандартное отклонение;
- Дисперсия выборки;
- Максимум;
- Сумма;
- Эксцесс;
- Среднее;
- Стандартная ошибка;
- Медиана;
- Мода;
- Счет.

Если какие-то из вышеуказанных данных для конкретного вида анализа не нужны, то их можно удалить, чтобы они не мешали. Далее производится анализ с учетом статистических закономерностей.
Урок: Статистические функции в Excel
Как видим, с помощью инструмента «Описательная статистика» можно сразу получить результат по целому ряду критериев, которые в ином случае рассчитывались с применением отдельно предназначенной для каждого расчета функцией, что заняло бы значительное время у пользователя. А так, все эти расчеты можно получить практически в один клик, использовав соответствующий инструмент — Пакета анализа.
Мы рады, что смогли помочь Вам в решении проблемы.
Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
Да Нет
Сортировка данных в Excel
Таблицы Excel можно использовать для создания баз данных, т.е. совокупности определенным образом организованной информации. В таблицах хранят информацию о сотрудниках, клиентах, поставщиках различной продукции, ценах, книгах, фильмах, фотографиях и т.д. Как правило, для таких баз данных используется табличный способ организации. Они содержат большое количество данных, а с большим количеством данных не всегда просто работать. Для этого и необходима обработка данных.
- сортировку списков;
- выборку данных по определенным критериям;
- вычисление промежуточных сумм;
- вычисление средних значений;
- вычисление отклонений от определенного значения;
- построение сводных таблиц.
Как сделать фильтр в Excel
Базы данных очень удобны для хранения информации, но мы создаем их для того, чтобы получать нужную для нас справку, когда возникает подобная необходимость.
Например, нам нужно расписание железнодорожных поездов, которые отправляются в Москву в пятницу после четырех часов дня и т.п.
Поиск нужной информации осуществляется путем отбора строк, удовлетворяющих некоторому критерию. В большинстве случаев критерием отбора является равенство содержимого ячейки определенному значению.
Помимо сравнения на равенство, при отборе записей можно использовать и другие операции сравнения. Например, больше, меньше, больше или равно, меньше или равно. Использование этих операций позволяет сформулировать критерий запроса менее строго. Например, если требуется найти информацию о человеке, фамилия которого начинается с «Ку», то в качестве критерия можно использовать правило «содержимое ячейки Фамилия больше или равно Ку и содержимое ячейки Фамилия меньше Л».
Промежуточные итоги в Excel
Одним из методов обработки данных является подведение итогов. Пусть, например, есть таблица расходов. Для того чтобы узнать, сколько потрачено в каждом месяце, необходимо подвести итог за каждый месяц.
- 1. Выделить диапазон, содержащий данные и заголовки столбцов, в которых данные находятся. В рассматриваемом примере это вся таблица, на фото представлена только ее часть.
- 2. На вкладке Данные -> Структура выбрать команду Промежуточный итог.
- 3. В появившемся диалоговом окне Промежуточные итоги в поле — При каждом изменении в:, требуется задать столбец, при изменении содержимого которого будет вычислена промежуточная сумма. В данном случае это Дата. В поле Операция выбрать операцию из списка, которую нужно выполнить над обрабатываемыми данными. В нашем случае это Сумма. В поле — Добавить итоги по:, установить флажок в том столбце, в котором находятся обрабатываемые данные.
Сводные таблицы Excel 2010
Сводная таблица позволяет выполнить более тонкий анализ данных, чем простое подведение итога. Что такое сводная таблица и как ее построить, рассмотрим на примере.
Пусть есть таблица, в которой находится информация о расходах.

Основными средствами анализа статистических данных в Excel являются статистические процедуры надстройки Пакет анализа (Analysis ToolРак) и статистические функции библиотеки встроенных функций. Основные сведения обо всех этих средствах имеются в электронной справочной системе Excel.
Однако качество описаний статистических процедур и функций, приведенных в этой системе, заставляет желать лучшего. Некоторые из этих описаний не очень понятны, в них имеются неточности, а подчас и просто ошибки (это относится как к англоязычному оригиналу, так и к русскому переводу). Эти недостатки с завидным постоянством повторяются и во многих пособиях по Excel. Найти необходимые пособия в интернете можно быстро если скачать бесплатно Амиго браузер с усовершенствованным поисковым алгоритмом.
Статистические процедуры Пакета анализа
Наиболее развитыми средствами анализа данных являются статистические процедуры Пакета анализа. Они обладают большими возможностями, чем статистические функции. С их помощью можно решать более сложные задачи обработки статистических данных и выполнять более тонкий анализ этих данных.
В Пакет анализа входят следующие статистические процедуры:
- генерация случайных чисел (Random number generation);
- выборка (Sampling);
- гистограмма (Histogram);
- описательная статистика (Descriptive statistics);
- ранги персентиль (Rank and percentile);
- двухвыборочный z-тест для средних (z-Test: Two Sample for Means);
- двухвыборочный t-тест для средних с одинаковыми дисперсиями (t-Test: Two-Sample Assuming Equal Variances);
- двухвыборочный t-тест для средних с различными дисперсиями (t-Test: Two-Sample Assuming Unequal Variances);
- парный двухвыборочный t-тест для средних (t-Test: Paired Two Sample for Means);
- двухвыборочный F-тест да я дисперсий (F-Test: Two Sample for Variances);
- коварнация (Covariance);
- корреляция (Correlation);
- рецессия (Regression);
- однофакторный дисперсионный анализ (ANOVA: Single Factor);
- двухфакторный дисперсионный анализ без повторений (ANOVA: Two Factor Without Replication);
- двухфакторный дисперсионный анализ с повторениями (ANOVA: Two Factor With Replication);
- скользящее среднее (Moving Average);
- экспоненциальное сглаживание (Exponential Smoothing);
- анализ Фурье (Fourier Analysis).
Для доступа к процедурам Пакета анализа необходимо в меню Сервис (Tools) щелкнуть указателем мыши на строке Анализ данных (Data Analysis). Откроется диалоговое окно с соответствующим названием, в котором перечислены процедуры статистического анализа данных (рис. 1).

Рис.1. Диалоговое окно Анализ данных
Для того чтобы запустить в работу нужную статистическую процедуру, нужно выделить ее указателем мыши и щелкнуть на кнопке ОК. На экране появится диалоговое окно вызванной процедуры. На рис. 2 для примера показано диалоговое окно процедуры Описательная статистика (Descriptive statistics).

Рис.2. Диалоговое окно процедуры Описательная статистика
Диалоговое окно каждой процедуры содержит элементы управления: поля ввода, раскрывающиеся списки, переключатели, флажки и т. п. Эти элементы позволяют задать нужные параметры используемой процедуры. Некоторые элементы управления имеют специфический характер, присущий одной процедуре или небольшой группе процедур. Назначение таких элементов управления будет рассмотрено при описании соответствующих процедур. Другие элементы управления присутствуют в диалоговых окнах почти всех статистических процедур.
К числу общих для большинства процедур элементов управления относятся:
- поле ввода Входной интервал (Input Range). В это поле вводится ссылка на диапазон, содержащий статистические данные, подлежащие обработке. Входной диапазон может быть столбцом пли группой столбцов (строкой или группой строк);
- переключатель Группирование (Grouped By). В том случае, когда входной диапазон представляет собой столбец или группу столбцов, переключатель устанавливается в положение по столбцам (Columns). Если же входной диапазон представляет собой строку или группу строк, то переключатель устанавливается в положение по строкам (Rows). Более точным названием этого переключателя было бы название Расположение;
- флажок Метки (Labels in First Row). Флажок устанавливается в тех случаях, когда первая строка (первый столбец) входного диапазона содержит заголовки. Если такие заголовки отсутствуют, флажок Метки не устанавливают. При этом Excel автоматически создает и выводит на экран стандартные названия для данных выходного диапазона (Столбец1, Столбец2,… или Строка 1. Строка2,…);
- переключатели Выходной интервал/Новый рабочий лист/Новая книга (Output Range/New Worksheet/New Workbook). Эти переключатели определяют место вывода таблицы, содержащей результаты реализации статистической процедуры. В группе может быть выбран только одни переключатель.
При выборе переключателя Выходной интервал таблица результатов решения выводится на тот же рабочий лист, на котором находятся исходные данные. Справа от переключателя открывается поле ввода, в которое надо ввести ссылку на левую верхнюю ячейку таблицы результатов. Если возникает опасность наложения таблицы результатов на уже заполненные ячейки, на экране появляется сообщение о такой опасности. В ответ на это сообщение пользователь должен разрешить удаление старых данных и вывод на их место новых.
В положении Новый рабочий лист открывается новый лист рабочей книги. На этот лист, начиная с ячейки А1, и выводится таблица результатов решения. Справа от переключателя имеется поле ввода, в которое в случае необходимости можно ввести имя нового рабочего листа. При выборе переключателя Новая рабочая книга открывается новая рабочая книга. На первый лист этой новой книги, начиная с ячейки А1, выводится таблица результатов решения.
Следует заметить, что результаты;, получаемые с помощью статистических процедур Пакета анализа, не имеют постоянной связи с исходными данными — в случае изменения исходных данных результаты решения автоматически не изменяются. В том случае, когда необходимо получить результаты, автоматически изменяющиеся вместе с исходными данными, нужно использовать подходящие статистические функции библиотеки встроенных функций.
Эффективным и очень удобным в использовании средством парного регрессионного анализа и анализа временных рядов является процедура Добавить линию тренда (Add Trendline), входящая в комплекс графических средств Excel.
Статистические функции библиотеки встроенных функций Excel
Табличный процессор Excel имеет библиотеку встроенных функции рабочего листа (Worksheet function). Одним из разделов этой библиотеки является раздел Статистические функции. В этот раздел входят 83 функции, предназначенные для решения некоторых наиболее востребованных задач теории вероятностей и математической статистики.
Аргументы статистических функций должны быть числами или ссылками на диапазоны, которые содержат числа Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются, однако ячейки с нулевыми значениями учитываются.
Когда в качестве какого-либо аргумента встроенной статистической функции введен текст, функция выдает сообщение об ошибке #ЗНАЧ! (#VALUE!). Если в качестве аргумента, который по определению должен быть целым числом, введено число не целое, Excel использует в качестве аргумента целую часть этот числа. Никакие сообщения об этом «несанкционированном округлении» на экран не выводятся.

Дмитрий Михайлович Беляев
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Замечание 1
Статистическая обработка данных — это выполнение сбора, упорядочивания, обобщения и анализа информации с возможностью определить тенденции и сделать прогноз развития исследуемого явления.
Введение
Главными средствами, которые предназначены для выполнения операций по анализу статистических данных в программном приложении Excel, являются статистические операции надстройки «Пакет анализа» (Analysis ToolРак) и статистические функции, расположенные в библиотеке встроенных функций. Основная совокупность сведений обо всех названных выше средствах содержится в электронной справочной системе Excel. Однако необходимо подчеркнуть, что уровень качества описания статистических операций и функций, приводимых в этой системе, является довольно низким. Некоторые описания воспринимаются недостаточно ясно, в них могут присутствовать некоторые неточности, а иногда и просто ошибки, причем эти недостатки присущи как англоязычному варианту, так и варианту на русском языке.
![]()
Сделаем домашку
с вашим ребенком за 380 ₽
Уделите время себе, а мы сделаем всю домашку с вашим ребенком в режиме online
Бесплатное пробное занятие
*количество мест ограничено
Статистическая обработка данных в Excel
Наиболее эффективными средствами, которые предназначены для выполнения анализа информации, могут считаться статистические операции «Пакета анализа» в программном приложении Excel. Они обладают большой совокупностью возможностей, гораздо большей, чем статистические функции. С помощью «Пакета анализа» можно решать очень сложные задачи, связанные с обработкой статистической информации, а также выполнять расширенный анализ этих данных.
«Пакет анализа» имеет в своем составе следующие статистические операции:
- Операция, реализующая генерацию случайных чисел (Random number generation).
- Операция, предназначенная для осуществления выборки (Sampling).
- Операция построения гистограмм (Histogram).
- Операция, осуществляющая описательную статистику (Descriptive statistics).
- Операция по назначению рангов персентиль (Rank and percentile).
- Операция, реализующая двухвыборочный Z-тест для средних (z-Test: Two Sample for Means).
- Операция двухвыборочного T-теста для средних, имеющих одинаковую дисперсию (T-Test: Two-Sample Assuming Equal Variances).
- Операция двухвыборочного T-теста для средних, имеющих разную дисперсию (t-Test: Two-Sample Assuming Unequal Variances).
- Операция парного двухвыборочного T-теста для средних (t-Test: Paired Two Sample for Means).
- Операция двухвыборочного F-теста для дисперсий (F-Test: Two Sample for Variances).
- Операция коварнации (Covariance).
- Операция корреляции (Correlation).
- Операция рецессии (Regression).
- Операция однофакторного дисперсионного анализа (ANOVA: Single Factor).
- Операция двухфакторного дисперсионного анализа без присутствия повторений (ANOVA: Two Factor Without Replication).
- Операция двухфакторного дисперсионного анализа с наличием повторений (ANOVA: Two Factor With Replication).
- Операция скользящего среднего (Moving Average).
- Операция экспоненциального сглаживания (Exponential Smoothing).
- Операция анализа Фурье (Fourier Analysis).
«Статистическая обработка данных в Excel» 👇
Для получения доступа к операциям «Пакета анализа», необходимо в меню «Инструменты» (Tools) осуществить щелчок указателем мыши по строчке «Анализ данных» (Data Analysis). После этого открывается диалоговое окно, имеющее такое же название, в котором отображается весь перечень операций статистического информационного анализа. Вид данного окна показан на рисунке ниже.

Рисунок 1. Окно программы. Автор24 — интернет-биржа студенческих работ
Для того чтобы запустить выполнение необходимой статистической операции, необходимо выделить с помощью указателя мышки и осуществить щелчок по клавише ОК. На экране монитора появится диалоговое окно выбранной операции.
Диалоговое окно любой из возможных операций должно содержать следующий набор элементов управления:
- Совокупность полей ввода.
- Списки, которые можно раскрывать.
- Совокупность переключателей.
- Совокупность флажков и так далее.
Эти элементы могут предоставить возможность задания необходимых параметров исполняемой операции. Некоторые элементы управления обладают специфическим характером, который может быть присущ одной из операций или же их набору. Остальные элементы управления присутствуют в диалоговом окне фактически любой статистической процедуры. В качестве общих элементов управления для практически всех операций выступают следующие элементы:
- Элемент поля ввода, который обозначается как «Входной интервал» (Input Range). В этом поле следует вводить ссылку на диапазон, содержащий статистическую информацию, которая нуждается в обработке. Входной диапазон может быть в виде столбца или их совокупности, а также в виде строки или совокупности строк.
- Элемент переключатель «Группирование» (Grouped By). Когда входной диапазон задан в виде столбца или совокупности столбцов, то переключатель следует поставить в положение по столбцам (Columns). А если входной диапазон задан строкой или совокупностью строк, то переключатель следует поставить в положение по строкам (Rows). Некоторые специалисты полагают, что наиболее правильным наименованием этого переключателя было бы «Расположение».
- Элемент «флажок Метки» (Labels in First Row). Флажок необходимо установить в том случае, если первая строка или первый столбик входного диапазона состоят из заголовков. А если такие заголовки отсутствуют, то флажок Метки не устанавливается. При этом программа Excel может автоматически создать и вывести на экран монитора стандартные наименования для информации выходного диапазона, а именно, Столбец1, столбец 2, … или Строка1, Строка2, … .
- Элемент «Переключатели Выходной интервал/Новый рабочий лист/Новая книга (Output Range/New Worksheet/New Workbook). Эти переключатели способны задавать место для вывода таблицы, содержащей итоговые результаты исполнения статистической операции. В группе можно выбрать только один переключатель.
Если выбран переключатель «Выходной интервал», то таблица итогов решения будет отображаться на этом же рабочем листе, на котором расположены исходные данные.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Microsoft
Excel содержит большое число встроенных
функций категории Статистические,
а также
специализированные информационные
технологии статистического анализа,
реализуемые Пакетом анализа. «Пакет
анализа» – надстройка
Microsoft Excel, устанавливаемая с помощью
команды меню СервисНадстройка.
После
установки
надстройки
Пакет
анализа в меню команды Сервис
появляется
новый пункт – Анализ
данных.
Для
анализа наиболее часто используется
описательная статистика данных,
статистические методы прогнозирования
значений.
Описательная статистика
Это самый
распространенный прием анализа данных,
с помощью которого вычисляются
статистические характеристики массива
значений экономических показателей:
-
Средние
оценки, имеют ту же размерность, что и
сама случайная величина, в том числе:
-
Средняя
арифметическая – математическое
ожидание случайной величины, соответствует
встроенной функции СРЗНАЧ. -
Средняя
геометрическая – оценка средних темпов
роста, поиск значения, равноудаленного
от других значений, соответствует
встроенной функции СРГЕОМ. -
Средняя
гармоническая – оценка средней суммы
обратных величин, соответствует
встроенной функции СРГАРМ.
Между средними
величинами существует соотношение:
![]()
-
Показатели
вариации:
-
Общее
число значений в массиве, соответствует
встроенной функции СЧЕТ. -
Сумма
всех значений переменных в массиве,
соответствует встроенной функции СУММ. -
Дисперсия
случайной величины, соответствует
встроенной функции ДИСП
(дисперсия по выборке) или ДИСПР
(дисперсия
по генеральной совокупности). Дисперсия
имеет размерность в квадрате, характеризует
рассеивание значений случайной величины
относительно средней арифметической. -
Стандартное
отклонение, соответствует встроенной
функции СТАНДОТКЛОН
(стандартное
отклонение по выборке), СТАНДОТКЛОНП
(стандартное
отклонение по генеральной совокупности).
Стандартное отклонение имеет ту же
размерность, что и случайная величина. -
Средний
модуль отклонений, который нивелирует
знак отклонения от среднего и является
показателем силы вариации, соответствует
встроенной функции СРОТКЛ. -
Уровень
надежности (доверительный интервал)
для среднего значения, соответствует
встроенной функции ДОВЕРИТ. -
Средняя
квадратическая ошибка, вычисляется
как отношение СТАНДОТКЛОН
к корню квадратному из числа элементов
выборки. -
Минимальное
значение случайной величины, соответствует
встроенной функции МИН. -
Максимальное
значение случайной величины, соответствует
встроенной функции МАКС. -
Интервал
– размах вариации, равный разности
максимального и минимального значения
переменной (МАКС–МИН). -
Порядковое
наибольшее значений, соответствует
встроенной функции НАИБОЛЬШИЙ. -
Порядковое
наименьшее значение соответствует
встроенной функции – функция НАИМЕНЬШИЙ.
-
Мера
взаимного расположения данных в массиве
значений, соответствует встроенным
функциям: МОДА, КВАРТИЛЬ, МЕДИАНА,
ПЕРСЕНТИЛЬ, ПРОЦЕНТРАНГ.
Мода
– наиболее
вероятное значение случайной величины.
При симметричном распределении
относительно среднего мода совпадает
с математическим ожиданием. Мода может
отсутствовать, либо распределение может
быть многомодальным.
Квантили распределения
— величина
значения признака, делящая совокупность
на n равных
частей. Различают номера квантилей: 0 –
соответствует минимальному значению
величины; 1 — первая четверть (квартиль)
значений или (25-я персентиль; 2 – медиана
или 50-я персентиль; 3 — третья четверть
(квартиль) или 75-я персентиль; 4 –
максимальное значение величины.
-
Форма
распределения случайной величины,
соответствует встроенным функциям
СКОС,
ЭКСЦЕСС.
Асимметрия
(скос) – безразмерная величина,
характеристика асимметричности случайной
величины
![]() относительно ее математического
относительно ее математического
ожидания. Эксцесс
– безразмерный
коэффициент, характеристика формы
(островершинности или плосковершинности)
кривой распределения вероятности.
Эксцесс равен нулю для нормального
распределения, положителен для
островершинных и отрицателен для
плосковершинных кривых.
Пакет
анализа запускается командой меню
СервисАнализ
данных. В
диалоговом
окне Инструменты
анализа выбирается
Описательная
статистика. Исходные
данные для анализа располагаются в
ячейках строк или столбцов таблицы.
Описательная
статистика Пакета
анализа
вычисляет показатели:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Результаты
описательной статистики выводятся в
указанное место (текущий лист, другой
лист, новая книга).
Последовательность
действий (исходные данные для анализа
представлены на рабочем листе):
-
Команда
меню СервисАнализ
данных, выбрать
метод Описательная
статистика. -
Указать
параметры описательной статистики
(рис. 16):
-
Входной
интервал – блок ячеек, содержащий
анализируемые значения. Можно одновременно
выделить смежные столбцы исходных
данных.
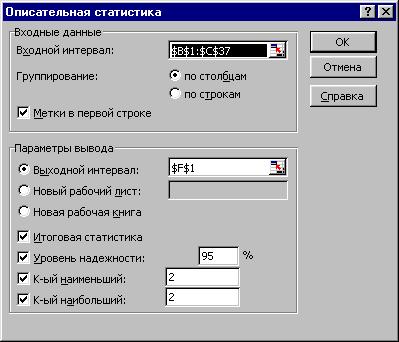
Рисунок
16
-
Группирование
– по столбцам/строкам. -
Флажок
Метки в первой строке выбран/не выбран. -
Выходной
интервал – Новый рабочий лист/Новая
книга/Определенная ячейка текущего
листа. -
Флажок
Итоговая статистика – выбран/не выбран
(выбор флажка обеспечивает вывод всей
описательной статистики). -
Уровень
надежности – 95% (стандартно, но можно
любой). -
K-й
наименьший – 2 (произвольно). -
K-й
наибольший – 2 (произвольно). -
Нажать
кнопку ОК.
Результаты
описательной статистики – табл. 14.
Таблица
14
|
Показатель |
Массив |
Массив |
|
Среднее |
13591,92 |
9564,75 |
|
Стандартная |
116,0136 |
127,61271 |
|
Медиана |
13821 |
9547,5 |
|
Мода |
#Н/Д |
9540 |
|
Стандартное |
696,0820303 |
765,6762604 |
|
Дисперсия |
484530,1929 |
586260,1357 |
|
Эксцесс |
-0,341929136 |
-0,809054 |
|
Асимметричность |
-0,823444644 |
0,016596 |
|
Интервал |
2441 |
2587 |
|
Минимум |
12054 |
8375 |
|
Максимум |
14495 |
10962 |
|
Сумма |
489309 |
344331 |
|
Счет |
36 |
36 |
|
Наибольший(2) |
14480 |
10932 |
|
Наименьший(2) |
12063 |
8377 |
|
Уровень |
235,52 |
259,07 |
Приведем алгоритм решения задачи. Предполагается, что теоретический материал уже освоен и решение задачи первичной статистической обработки данных уже известно.
1. Ввод данных. В диапазон ячеек А1:АN ввести выборочные значения .
2. Построение вариационного ряда.
• Скопировать содержимое ячеек А1:АN в ячейки В1:ВN.
• Упорядочить выборочные значения, используя кнопку сортировки по возрастанию.
3. Построение статистического ряда выборки.
• В ячейки С1:СК ввести k различных выборочных значений.
• В меню Данные выделить строку Анализ данных.
• В открывшемся диалоговом меню выделить процедуру Гистограмма и нажать кнопку OK.
• В поле Входной интервал диалогового окна Гистограмма ввести ссылку на диапазон А1:АN, в котором находятся значения исследуемой выборки.
• В поле Интервал карманов ввести ссылку на диапазон С1:СК, в котором помещены различные выборочные значения.
• Активизировать поле Выходной интервал щелчком мышки. Ввести в это поле ссылку – левая верхняя ячейка, в которую будет введена таблица результатов решений.
• Установить флажок Вывод графика и нажать OK.
• Составить таблицу 1 статистического ряда по следующему образцу:
различные
выборочные
значения
частота выборочного значения
относительная
частота выборочного значения
накопленная относительная частота
Первые столбцы заполнить копированием. Относительные и накопленные частоты вычислить с использованием формул, заполнить два последних столбца.
4. Построение полигонов относительных и накопленных частот.
• Скопировать первый и третий столбцы таблицы 1. Выделить их.
• Используя меню Вставка, применить к выделенным числам средство диаграммы Точечная. Полученный график есть полигон относительных частот.
• Скопировать первый и четвертый столбцы таблицы 1. Выделить их.
• Используя меню Вставка, применить к выделенным числам средство диаграммы Точечная. Полученный график есть полигон накопленных частот — сглаженный график эмпирической функции распределения.
5. Определение выборочных характеристик.
• В меню Данные выделить подменю Анализ данных.
• В открывшемся окне Анализ данных выделить процедуру Описательная статистика и нажать кнопку OK.
• На экране появится диалоговое окно Описательная статистика. В поле ввода Входной интервал ввести ссылку на диапазон ячеек, содержащий статистические данные А1:АN.
• Установить флажок Итоговая статистика.
• Активизировать поле Выходной интервал щелчком мышки. Ввести в это поле ссылку – левая верхняя ячейка, в которую будет введена таблица результатов решений.
6. Проверка гипотезы о виде распределения случайной величины с помощью критерия согласия Пирсона.
Заполнить таблицу 2:
различные
выборочные
значения
частота выборочного значения
теоретическая вероятность выборочного значения
теоретическая частота выборочного значения
Первые столбцы заполнить копированием, а оставшиеся — заполнить вычисленными по формулам значениями.
Если проверяется гипотеза о распределении Пуассона, то теоретические вероятности вычислить с помощью функции ПУАССОН . Здесь выборочное среднее, оно определяется в пункте 5, 0 – параметр, показывающий, что вычисляется вероятность того, что случайная величина, распределенная по закону Пуассона, принимает значение .
Если проверяется гипотеза о биномиальном распределении случайной величины, то теоретические вероятности вычислить с помощью функции БИНОМРАСП ,
при этом вероятность успеха в одном испытании определить по формуле где — выборочное среднее.
В случае других распределений, воспользоваться справкой о статистических функциях библиотеки встроенных функций.
Значение
является наблюдаемым значением случайной величины . Число степеней свободы этой случайной величины равно при проверке гипотезы о распределении Пуассона и , если проверяется гипотеза о биномиальном распределении. Критическое значение случайной величины определить с помощью функции ХИ2ОБР ,
где — уровень значимости.
Полученное наблюдаемое значение сравнить с :
• если , то гипотеза о виде распределения принимается при уровне значимости ,
• если , то гипотеза отвергается с уровнем значимости
Пример. Исследуется случайная величина — число правонарушений в течение одних суток в некотором городе N. Получены данные за первые 150 суток года
Построение рядов распределения
Любой ряд распределения характеризуется двумя элементами:
— варианта(хi) – это отдельные значения признака единиц выборочной совокупности. Для вариационного ряда варианта принимает числовые значения, для атрибутивного – качественные (например, х=«государственный служащий»);
— частота (ni) – число, показывающее, сколько раз встречается то или иное значение признака. Если частота выражена относительным числом (т.е. долей элементов совокупности, соответствующих данному значению варианты, в общем объеме совокупности), то она называется относительной частотойили частостью.
— дискретным, когда изучаемый признак характеризуется определенным числом (как правило целым).
— интервальным, когда определены границы «от» и «до» для непрерывно варьируемого признака. Интервальный ряд также строят если множество значений дискретно варьируемого признака велико.
Интервальный ряд может строиться как с интервалами равной длины (равноинтервальный ряд) так и с неодинаковыми интервалами, если это диктуется условиями статистического исследования. Например, может рассматриваться ряд распределения доходов населения со следующими интервалами:
где k – число интервалов, n – объем выборки. (Конечно, формула обычно дает число дробное, а в качестве числа интервалов выбирается ближайшее целое к полученному число.) Длина интервала в таком случае определяется по формуле
При работе в Excel для построения вариационных рядов могут быть использованы следующие функции:
— СЧЁТ(массив данных) – для определения объема выборки. Аргументом является диапазон ячеек, в котором находятся выборочные данные.
— СЧЁТЕСЛИ(диапазон; критерий) – может быть использована для построения атрибутивного или вариационного ряда. Аргументами являются диапазон массива выборочных значений признака и критерий – числовое или текстовое значение признака или номер ячейки, в которой оно находится. Результатом является частота появления этого значения в выборке.
Проиллюстрируем процесс первичной обработки данных на следующих примерах.
Пример 1.1. имеются данные о количественном составе 60 семей.
Построить вариационный ряд и полигон распределения
Рис.1.1 Пример 1. Первичная обработка статистических данных в таблицах Excel

Далее, подготовим таблицу для построения вариационного ряда, введя названия для столбца интервалов (значений варианты) и столбца частот. В столбец интервалов введем значения признака от минимального (1) до максимального (6), заняв диапазон В12:В17. Выделим столбец частот, введем формулу =ЧАСТОТА(А1:L5;В12:В17) и нажмем сочетание клавиш CTRL+SHIFT+ENTER

Для контроля вычислим сумму частот при помощи функции СУММ (значок функции S в группе «Редактирование» на вкладке «Главная»), вычисленная сумма должна совпасть с ранее вычисленным объемом выборки в ячейке В7.
Теперь построим полигон: выделив полученный диапазон частот, выберем команду «График» на вкладке «Вставка». По умолчанию значениями на горизонтальной оси будут порядковые числа — в нашем случае от 1 до 6, что совпадает со значениями варианты (номерами тарифных разрядов).
Название ряда диаграммы «ряд 1» можно либо изменить, воспользовавшись той же опцией «выбрать данные» вкладки «Конструктор», либо просто удалить.

Пример 1.2. Имеются данные о выбросах загрязняющих веществ из 50 источников:
| 10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
| 28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
| 18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
| 14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
| 12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Составить равноинтервальный ряд, построить гистограмму
Внесем массив данных в лист Excel, он займет диапазон А1:J5 Как и в предыдущей задаче, определим объем выборки n, минимальное и максимальное значения в выборке. Поскольку теперь требуется не дискретный, а интервальный ряд, и число интервалов в задаче не задано, вычислим число интервалов k по формуле Стерджесса. Для этого в ячейку В10 введем формулу =1+3,322*LOG10(B7).
Рис.1.4. Пример 2. Построение равноинтервального ряда

Полученное значение не является целым, оно равно примерно 6,64. Поскольку при k=7 длина интервалов будет выражаться целым числом (в отличие от случая k=6) выберем k=7, введя это значение в ячейку С10. Длину интервала d вычислим в ячейке В11, введя формулу =(В9-В8)/С10.
Рис.1.5. Пример 2. Построение равноинтервального ряда

Теперь заполним массив «карманов» при помощи функции ЧАСТОТА, как это было сделано в примере 1.
Рис.1.6. Пример 2. Построение равноинтервального ряда


Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Если выбор количества интервалов или их диапазонов не устраивает, то можно в диалоговом окне указать нужный массив интервалов если интервал карманов включает текстовый заголовок, то нужно установить галочку напротив поля Метка. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Расчет ширины интервала и таблица интервалов приведены в файле примера на листе Гистограмма . Для вычисления количества значений, попадающих в каждый интервал, использована формула массива на основе функции ЧАСТОТА() . О вводе этой функции см. статью Функция ЧАСТОТА() – Подсчет ЧИСЛОвых значений в MS EXCEL .

Для построений необходимо выделить всю таблицу вместе с заголовком и выполнить команду вкладка Вставка — инструмент Точечная. Выбираем вариант Точечная с гладкими кривыми и маркерами как более показательный.
| 10,4 | 18,6 | 10,3 | 26,0 | 45,0 | 18,2 | 17,3 | 19,2 | 25,8 | 18,7 |
| 28,2 | 25,2 | 18,4 | 17,5 | 41,8 | 14,6 | 10,0 | 37,8 | 10,5 | 16,0 |
| 18,1 | 16,8 | 38,5 | 37,7 | 17,9 | 29,0 | 10,1 | 28,0 | 12,0 | 14,0 |
| 14,2 | 20,8 | 13,5 | 42,4 | 15,5 | 17,9 | 19, | 10,8 | 12,1 | 12,4 |
| 12,9 | 12,6 | 16,8 | 19,7 | 18,3 | 36,8 | 15,0 | 37,0 | 13,0 | 19,5 |
Стиль и внешний вид гистограммы
После того, как вы создали гистограмму, вам может потребоваться внести корректировки в то, как выглядит ваш график. Для изменения дизайна и стиля используйте вкладку “Конструктор”. Эта вкладка отображается на Панели инструментов, когда вы выделяете левой клавишей мыши гистограмму. С помощью дополнительных настроек в разделе “Конструктор” вы сможете:
- добавить заголовок и другие дополнительные данные для отображения. Для того, чтобы добавить данные на график, кликните на пункт “Добавить элемент диаграммы”, затем, выберите нужный пункт из выпадающего списка:




Вы также можете использовать кнопки быстрого доступа к редактированию элементов гистограммы, стиля и фильтров:

Мнение эксперта
Витальева Анжела, консультант по работе с офисными программами
Со всеми вопросами обращайтесь ко мне!
Задать вопрос эксперту
Получили следующий набор данных 18,38,28,29,26,38,34,22,28,30,22,23,35,33,27,24,30,32,28,25,29,26,31,24,29,27,32,24,29,29 Постройте интервальный ряд и исследуйте его. Если же вам нужны дополнительные объяснения, обращайтесь ко мне!
Например:
Для распределения учеников по росту получаем: begin S^2=fraccdot 104,1approx 105,1\ sapprox 10,3 end Коэффициент вариации: $ V=fraccdot 100textapprox 6,0textlt 33text $ Выборка однородна. Найденное значение среднего роста (X_)=171,7 см можно распространить на всю генеральную совокупность (старшеклассников из других школ).
Интервальный вариационный ряд и его характеристики: построение, гистограмма, выборочная дисперсия и СКО
- автоматически рассчитаны интервалы значений (карманы);
- подсчитано количество значений из указанного массива данных, попадающих в каждый интервал (построена таблица частот);
- если поставлена галочка напротив пункта Вывод графика , то вместе с таблицей частот будет выведена гистограмма.
Ряды распределения одна из разновидностей статистических рядов (кроме них в статистике используются ряды динамики), используются для анализа данных о явлениях общественной жизни. Построение вариационных рядов вполне посильная задача для каждого. Однако есть правила, которые необходимо помнить.