
Всем привет!
Продолжаем серию уроков по разработке парсера на Python. Сегодня мы добавим сохранение результатов парсинга в Excel-таблицу, используя библиотеку xlsxwriter.
В предыдущем уроке мы собирали товары с тестового каталога с помощью библиотек requests и beautifulsoup4. Результат сохраняли в файл формата JSON, а сегодня добавим и в XLSX.
Библиотеки, используемые в данной статье:
1. xlsxwriter – ссылка на документацию.
По любым возникающим в ходе урока вопросам оставляйте комментарии ниже.
Ссылка на полный текст исходного кода находится в конце статьи.
Шаг 1. Подготовка
В дополнение к данным, которые мы собирали в словарь item по каждому товару, добавим URL-адрес:
item = {
'name': name,
'amount': amount,
'techs': techs,
# добавялем URL
'url': url,
}
Вынесем для удобства запись в JSON-файл в отдельный метод. Два позиционных аргумента:
1. filename – имя файла Excel-таблицы.
2. data – объект с результатом парсинга, список из данных по каждому товару.
А также именованные аргументы kwargs для передачи в json.dump().
def dump_to_json(filename, data, **kwargs):
kwargs.setdefault('ensure_ascii', False)
kwargs.setdefault('indent', 1)
with open(OUT_FILENAME, 'w') as f:
json.dump(data, f, **kwargs)
В основном коде в функции main() вызываем dump_to_json:
def main():
urls = crawl_products(PAGES_COUNT)
data = parse_products(urls)
# добавляем запись в JSON-фал функцией dump_to_json
dump_to_json(OUT_FILENAME, data)
Подготовка завершена, переходим к записи в Excel.
Шаг 2. Установка зависимостей
Установим библиотеку xlsxwriter командой:
pip install xlsxwriterШаг 3. Программирование
Импортируем библиотеку xlsxwriter:
import xslxwriter
Добавим глобальную переменную OUT_XLSX_FILENAME – имя Excel файла.
OUT_XLSX_FILENAME = 'out.xlsx'
Объявим функцию создания Excel файла и записи в него данных:
def dump_to_xlsx(filename, data):
pass
Создадим Excel файл с нашим именем и добавим один лист (worksheet).
Запишем в первую строку названия колонок (headers). Затем пройдемся по каждому товару и запишем данные в отдельные строки.
Характеристики разделим по колонкам так, чтобы каждая из них была в отдельной колонке.
Нам известно, что для всех товаров у нас одни и те же характеристики, поэтому для названия колонок возьмем названия из item[‘techs’] первого товара. Также перед записью проверим, есть ли товары для записи, если их нет, то функция возвращает None и не создает файл. Полный текст функции приведен ниже:
def dump_to_xlsx(filename, data):
if not len(data):
return None
with xlsxwriter.Workbook(filename) as workbook:
ws = workbook.add_worksheet()
bold = workbook.add_format({'bold': True})
headers = ['Название товара', 'Цена', 'Ссылка']
headers.extend(data[0]['techs'].keys())
for col, h in enumerate(headers):
ws.write_string(0, col, h, cell_format=bold)
for row, item in enumerate(data, start=1):
ws.write_string(row, 0, item['name'])
ws.write_string(row, 1, item['amount'])
ws.write_string(row, 2, item['url'])
for prop_name, prop_value in item['techs'].items():
col = headers.index(prop_name)
ws.write_string(row, col, prop_value)
Итог
Все!
Теперь достаточно вызвать функцию следующий образом для сохранения data в Excel:
dump_to_xlsx(OUT_XLSX_FILENAME, data)После прогона парсека по двум страницам (PAGES_COUNT = 2) видим, что в out.json к каждому товарному теперь добавился url.

Открываем файл out.xlsx и видим 24 товара, каждая характеристика в отдельной колонке. Первая строка жирным шрифтом. На этом сохранение в Excel завершено.

Ссылка на полный текст исходного кода – catalog.py
Если у вас возникли какие-то вопросы, можете задать их в комментариях к этой статье или под видео на YouTube. Предлагайте темы следующих уроков.
Спасибо за внимание!
Парсинг данных. Эта штука может быть настолько увлекательной, что порой затягивает очень сильно. Ведь всегда интересно найти способ, с помощью которого можно получить те или иные данные, да еще и структурировать их в нужном виде. В статье «Простой пример работы с Excel в Python» уже был рассмотрен один из способов получить данные из таблиц и сохранить их в формате Excel на разных листах. Для этого мы искали на странице все теги, которые так или иначе входят в содержимое таблицы и вытаскивали из них данные. Но, есть способ немного проще. И, давайте, о нем поговорим.

А состоит этот способ в использовании библиотеки pandas. Конечно же, ее простой не назовешь. Это очень мощный инструмент для аналитики самых разнообразных данных. И в рассмотренном ниже случае мы лишь коснемся небольшого фрагмента из того, что вообще умеет делать эта библиотека.
Что понадобиться?
Для того, чтобы написать данный скрипт нам понадобиться конечно же сам pandas. Библиотеки requests, BeautifulSoup и lxml. А также модуль для записи файлов в формате xlsx – xlsxwriter. Установить их все можно одной командой:
pip install requests bs4 lxml pandas xlsxwriter
А после установки импортировать в скрипт для дальнейшей работы с функциями, которые они предоставляют:
Python:
import requests
from bs4 import BeautifulSoup
import pandas as pdТак же с сайта, на котором расположены целевые таблицы нужно взять заголовки для запроса. Данные заголовки не нужны для pandas, но нужны для requests. Зачем вообще использовать в данном случае запросы? Тут все просто. Можно и не использовать вовсе. А полученные таблицы при сохранении называть какими-нибудь составными именами, вроде «Таблица 1» и так далее, но гораздо лучше и понятнее, все же собрать данные о том, как называется данная таблица в оригинале. Поэтому, с помощью запросов и библиотеки BeautifulSoup мы просто будем искать название таблицы.
Но, вернемся к заголовкам. Взял я их в инструментах разработчика на вкладке сеть у первого попавшегося запроса.
Python:
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.174 '
'YaBrowser/22.1.3.942 Yowser/2.5 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.9 '
}Теперь нужен список, в котором будут перечисляться года, которые представлены в виде таблиц на сайте. Эти года получаются из псевдовыпадающего списка. Я не стал использовать selenium для того, чтобы получить их со страницы. Так как обычный запрос не может забрать эти данные. Они подгружаются с помощью JS скриптов. В данном случае не так уж много данных, которые надо обработать руками. Поэтому я создал список, в которые эти данные и внес вручную:
Python:
num_year_dict = ['443', '442', '441', '440', '439', '438', '437', '436', '435', '434', '433', '432', '431', '426',
'425', '1', '2', '165', '884', '1851', '3226', '4385', '4959', '5582', '6297', '6886', '7371',
'8071', '8671']Теперь нам нужно будет создать пустой словарь вне всяких циклов. Именно, чтобы он был глобальной переменной. Этот словарь мы и будем наполнять полученными данными, а также сохранять их него данные в таблицу Excel. Поэтому, я подумал, что проще сделать его глобальной переменной, чем тасовать из функции в функцию.
df = {}
Назвал я его df, потому как все так называют. И увидев данное название в нужном контексте становиться понятно, что используется pandas. df – это сокращение от DataFrame, то есть, определенный набор данных.
Ну вот, предварительная подготовка закончена. Самое время получать данные. Давайте для начала сходим на одну страницу с таблицей и попробуем получить оттуда данные с помощью pandas.
tables = pd.read_html('https://www.sports.ru/rfpl/table/?s=443&table=0&sub=table')
Здесь была использована функция read_html. Pandas использует библиотеку для парсинга lxml. То есть, примерно это все работает так. Получаются данные со страницы, а затем в коде выполняется поиск с целью найти все таблицы, у которых есть тэг <table>, а далее, внутри таблиц ищутся заголовки и данные под тэгами <tr> и <td>, которые и возвращаются в виде списка формата DataFrame.
Давайте выполним запрос. Но вот печатать данные пока не будем. Нужно для начала понять, сколько таблиц нашлось в запросе. Так как на странице их может быть несколько. Помимо той, что на виду, в виде таблиц может быть оформлен подзаголовок или еще какая информация. Поэтому, давайте узнаем, сколько элементов списка содержится в запросе, а соответственно, столько и таблиц. Выполняем:
print(len(tables))
И видим, что найденных таблиц две. Если вывести по очереди элементы списка, то мы увидим, что нужная нам таблица, в данном случае, находиться под индексом 1. Вот ее и распечатаем для просмотра:
print(tables[1])
И вот она полученная таблица:

Как видим, в данной таблице помимо нужных нам данных, содержится так же лишний столбец, от которого желательно избавиться. Это, скажем так, можно назвать сопутствующим мусором. Поэтому, полученные данные иногда надо «причесать». Давайте вызовем метод drop и удалим ненужный нам столбец.
tables[1].drop('Unnamed: 0', axis=1, inplace=True)
На то, что нужно удалить столбец указывает параметр axis, который равен 1. Если бы нужно было удалить строку, он был бы равен 0. Ну и указываем название столбца, который нужно удалить. Параметр inplace в значении True указывает на то, что удалить столбец нужно будет в исходных данных, а не возвращать нам их копию с удаленным столбцом.
А теперь нужно получить заголовок таблицы. Поэтому, делаем запрос к странице, получаем ее содержимое и отправляем для распарсивания в BeautifulSoup. После чего выполняем поиск названия и обрезаем из него все лишние данные.
Python:
url = f'https://www.sports.ru/rfpl/table/?s={num}&table=0&sub=table'
req = requests.get(url=url, headers=headers)
soup = BeautifulSoup(req.text, 'lxml')
title_table = soup.find('h2', class_='titleH3').text.split("-")[2].strip().replace("/", "_")Теперь, когда у нас есть таблица и ее название, отправим полученные значения в ранее созданный глобально словарь.
df[title_table] = tables[1]
Вот и все. Мы получили данные по одной таблице. Но, не будем забывать, что их больше тридцати. А потому, нужен цикл, чтобы формировать ссылки из созданного ранее списка и делать запросы уже к страницам по ссылке. Давайте полностью оформим код функции. Назовем мы ее, к примеру, get_pd_table(). Ее полный код состоит из всех тех элементов кода, которые мы рассмотрели выше, плюс они запущены в цикле.
Python:
def get_pd_table():
for num in num_year_dict:
url = f'https://www.sports.ru/rfpl/table/?s={num}&table=0&sub=table'
req = requests.get(url=url, headers=headers)
soup = BeautifulSoup(req.text, 'lxml')
title_table = soup.find('h2', class_='titleH3').text.split("-")[2].strip().replace("/", "_")
print(f'Получаю данные из таблицы: "{title_table}"...')
tables = pd.read_html(url)
tables[1].drop('Unnamed: 0', axis=1, inplace=True)
df[title_table] = tables[1]Итак, когда цикл пробежится по всем ссылкам у нас будет готовый словарь с данными турниров, которые желательно бы записать на отдельные листы. На каждом листе по таблице. Давайте сразу создадим для этого функцию pd_save().
writer = pd.ExcelWriter('./Турнирная таблица ПЛ РФ.xlsx', engine='xlsxwriter')
Создаем объект писателя, в котором указываем имя записываемой книги, и инструмент, с помощью которого будем производить запись в параметре engine=’xlsxwriter’.
После запускаем цикл, в котором создаем объекты, то есть листы для записи из ключей списка с таблицами df, указываем, с помощью какого инструмента будет производиться запись, на какой лист. Имя листа берется из ключа словаря. А также указывается параметр index=False, чтобы не сохранялись индексы автоматически присваиваемые pandas.
df[df_name].to_excel(writer, sheet_name=df_name, index=False)
Ну и после всего сохраняем книгу:
writer.save()
Полный код функции сохранения значений:
Python:
def pd_save():
writer = pd.ExcelWriter('./Турнирная таблица ПЛ РФ.xlsx', engine='xlsxwriter')
for df_name in df.keys():
print(f'Записываем данные в лист: {df_name}')
df[df_name].to_excel(writer, sheet_name=df_name, index=False)
writer.save()Вот и все. Для того, чтобы было не скучно ждать, пока будет произведен парсинг таблиц, добавим принты с информацией о получаемой таблице в первую функцию.
print(f'Получаю данные из таблицы: "{title_table}"...')
И во вторую функцию, с сообщением о том, данные на какой лист записываются в данный момент.
print(f'Записываем данные в лист: {df_name}')
Ну, а дальше идет функция main, в которой и вызываются вышеприведенные функции. Все остальное, в виде принтов, это просто декорации, для того чтобы пользователь видел, что происходят какие-то процессы.
Python:
import requests
from bs4 import BeautifulSoup
import pandas as pd
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.174 '
'YaBrowser/22.1.3.942 Yowser/2.5 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.9 '
}
num_year_dict = ['443', '442', '441', '440', '439', '438', '437', '436', '435', '434', '433', '432', '431', '426',
'425', '1', '2', '165', '884', '1851', '3226', '4385', '4959', '5582', '6297', '6886', '7371',
'8071', '8671']
df = {}
def get_pd_table():
for num in num_year_dict:
url = f'https://www.sports.ru/rfpl/table/?s={num}&table=0&sub=table'
req = requests.get(url=url, headers=headers)
soup = BeautifulSoup(req.text, 'lxml')
title_table = soup.find('h2', class_='titleH3').text.split("-")[2].strip().replace("/", "_")
print(f'Получаю данные из таблицы: "{title_table}"...')
tables = pd.read_html(url)
tables[1].drop('Unnamed: 0', axis=1, inplace=True)
df[title_table] = tables[1]
def pd_save():
writer = pd.ExcelWriter('./Турнирная таблица ПЛ РФ.xlsx', engine='xlsxwriter')
for df_name in df.keys():
print(f'Записываем данные в лист: {df_name}')
df[df_name].to_excel(writer, sheet_name=df_name, index=False)
writer.save()
def main():
get_pd_table()
print(' ')
pd_save()
print('n[+] Данные записаны!')
if __name__ == '__main__':
main()И ниже результат работы скрипта с уже полученными и записанными таблицами:

Как видите, использовать библиотеку pandas, по крайней мере в данном контексте, не очень сложно. Конечно же, это только самая малая часть того, что она умеет. А умеет она собирать и анализировать данные из самых разных форматов, включая такие распространенные, как: cvs, txt, HTML, XML, xlsx.
Ну и думаю, что не всегда данные будут прилетать «чистыми». Скорее всего, периодически будут попадаться мусорные столбцы или строки. Но их не особо то трудно удалить. Нужно только понимать, что и откуда.
В общем, для себя я сделал однозначный вывод – если мне понадобиться парсить табличные значения, то лучше, чем использование pandas, пожалуй и не придумаешь. Можно просто на лету формировать данные из одного формата и переводить тут же в другой без утомительного перебора. К примеру, из формата csv в json.
Спасибо за внимание. Надеюсь, что данная информация будет вам полезна
Ранее мы рассмотрели основы парсинга данных с сайтов. Но знаете ли вы, что парсинг применим также для данных в табличном виде? Если вы часто сидите в Интернете, то, вероятно, заметили, что многие веб-сайты содержат таблицы. Например, расписание рейсов, характеристики продукта, дифференцирование услуг, расписание телепередач, рейтинг и многое другое.
В некоторых случаях можно легко скопировать таблицу и вставить в Excel без единой строчки кода. Но учтите, что специалисты по обработке и анализу данных работают с намного большими объемами данных, где метод копирования-вставки не очень эффективен. Итак, теперь мы покажем вам, как парсить таблицу с сайта на Python.
ШАГ 1. УСТАНОВКА БИБЛИОТЕК
Прежде всего, нужно установить в нашу среду разработки библиотеки:
- BeautifulSoup4
- Requests
- pandas
- lxml
Если у вас возникли проблемы на этом этапе, рекомендуем прочитать статью о парсинге сайтов на Python.
ШАГ 2. ИМПОРТИРОВАНИЕ БИБЛИОТЕК
Как только необходимые библиотеки установлены, мы можем открыть Spyder. Мы выбираем именно Spyder, потому что его удобнее использовать для проектов. Но вы можете иметь свои предпочтения.
Следующий этап парсинга таблицы на Python — это импортирование библиотеки:
# Import libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
ШАГ 3. ВЫБОР СТРАНИЦЫ
В этом проекте мы будем парсить таблицу данных covid с Worldometers. Как и в предыдущем руководстве, данный веб-сайт также создан с помощью HTML и считается более легким для понимания новичками.
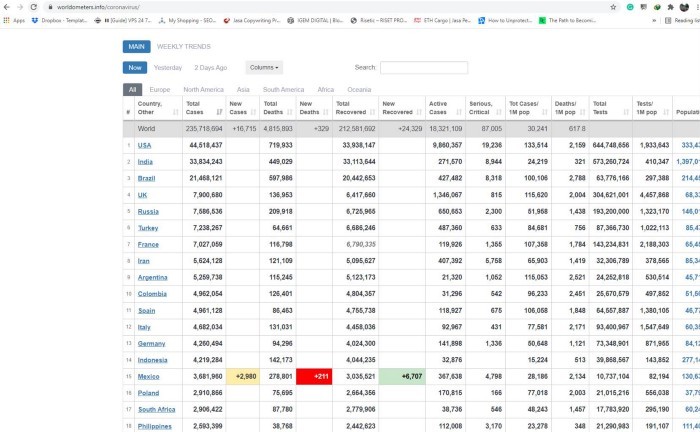
ШАГ 4. ЗАПРОС РАЗРЕШЕНИЯ
После выбора страницы для парсинга мы можем скопировать ее URL-адрес и использовать requests, чтобы запросить разрешение у сервера на получение данных с их сайта.
# Create an URL object
url = 'https://www.worldometers.info/coronavirus/'
# Create object page
page = requests.get(url)Результат <Response [200]> означает, что сервер позволяет нам собирать информацию. Дальше необходимо обработать HTML-код с помощью lxml, чтобы сделать его более доступным для чтения.
# parser-lxml = Change html to Python friendly format# Obtain page's information soup = BeautifulSoup(page.text, 'lxml') soup
ШАГ 5. ПРОСМОТР КОДА ЭЛЕМЕНТОВ ТАБЛИЦЫ
В предыдущей статье мы узнали, как просмотреть код каждого элемента на странице веб-сайта. Чтобы получить информацию о коде элементов таблицы, нам нужно сначала проверить ее расположение.
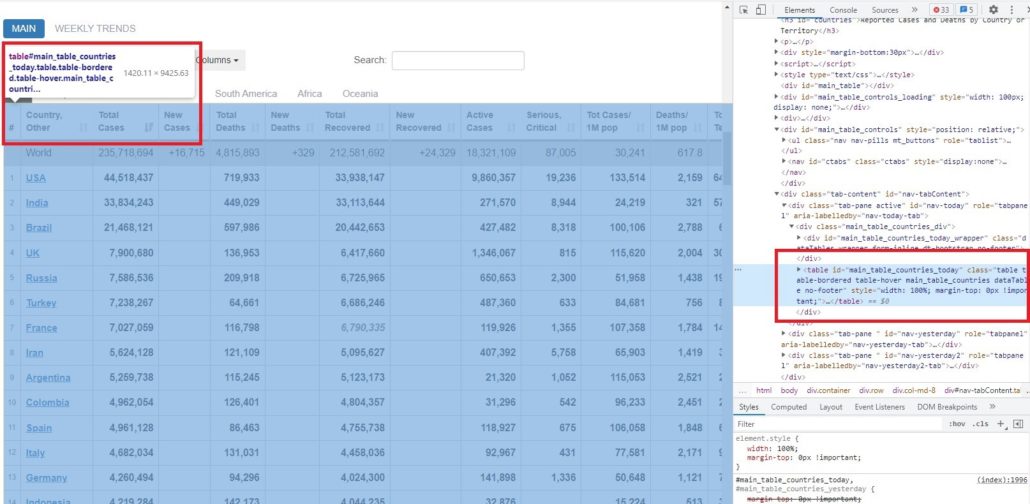
Как видно из рисунка выше, эта таблица находится внутри тега <table> и id = ‘main_table_countries_today’. Теперь мы можем определить переменную. В нашем случае мы определим таблицу как ‘table1’.
# Obtain information from tag <table>table1 = soup.find(‘table’, id=’main_table_countries_today’)
table1
ШАГ 6. СОЗДАНИЕ КОЛОНОК
После создания table1 мы можем посмотреть расположение каждой колонки. Если мы просмотрим все колонки, то заметим, что они имеют одну и ту же характеристику.
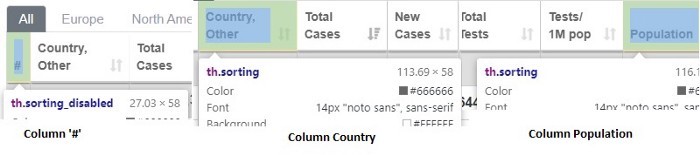
На рисунке видна общая характеристика каждой колонки — они расположены внутри тега <th>.
После нахождения тегов мы создаем цикл for, чтобы заполнить пустой список нашими колонками. Давайте определим пустой список как headers.
# Obtain every title of columns with tag <th>headers = []
for i in table1.find_all(‘th’):
title = i.text
headers.append(title)
Результат:

Список успешно заполнен и мы можем проверить его еще раз. Давайте посмотрим на индекс 13, здесь многострочный текст. Подобный перенос может быть проблемой, когда мы захотим сделать из него фрейм данных, поэтому необходимо преобразовать его в однострочный текст.
# Convert wrapped text in column 13 into one line text
headers[13] = ‘Tests/1M pop’
Результат:

ШАГ 7. СОЗДАНИЕ ФРЕЙМА ДАННЫХ
Следующий этап парсинга таблицы с помощью Python — это создание фрейма данных. Предлагаю определить фрейм данных как mydata.
# Create a dataframe
mydata = pd.DataFrame(columns = headers)
ШАГ 8. СОЗДАНИЕ ЦИКЛА FOR ДЛЯ ЗАПОЛНЕНИЯ ФРЕЙМА ДАННЫХ
Как только фрейм данных готов, мы можем заполнить его элементами в каждой колонке. До момента создания цикла for нам нужно еще определить место расположения строки и колонки элемента.
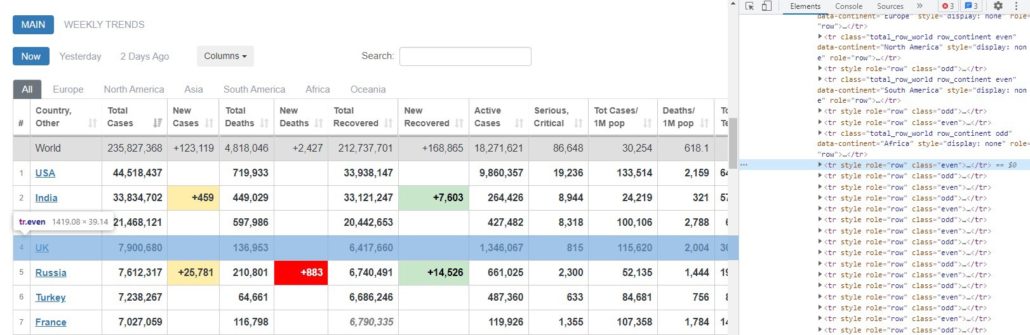

На рисунках выше видно, что строка находится внутри тега <tr>, а элементы — внутри тега <td>. Это применимо ко всем строкам и элементам в таблице.
Теги найдены и теперь можно создавать цикл for.
# Create a for loop to fill mydata
for j in table1.find_all(‘tr’)[1:]:
row_data = j.find_all(‘td’)
row = [i.text for i in row_data]
length = len(mydata)
mydata.loc[length] = row
Результат:

ШАГ 9. ОЧИСТКА ФРЕЙМА ДАННЫХ
Далее, как только фрейм данных будет успешно создан, мы можем удалить и очистить ненужные строки. В нашем случае мы удалим индекс 0–6, 222–228, затем вернем индекс в исходное состояние и удалим столбец «#».
# Drop and clearing unnecessary rowsmydata.drop(mydata.index[0:7], inplace=True) mydata.drop(mydata.index[222:229], inplace=True) mydata.reset_index(inplace=True, drop=True)# Drop “#” column mydata.drop(‘#’, inplace=True, axis=1)
Результат:

ШАГ 10. ЭКСПОРТ ДАННЫХ В CSV-ФАЙЛ
Когда фрейм данных будет готов, мы можем экспортировать данные в CSV-файл.
# Export to csv mydata.to_csv(‘covid_data.csv’, index=False)# Try to read csv mydata2 = pd.read_csv(‘covid_data.csv’)
Это был завершающий этап парсинга таблицы на Python и теперь данные можно использовать для работы в проектах по анализу и обработке данных, в машинном обучении и для получения другой необходимой информации. Надеемся, что это руководство будет полезно для вас, и особенно для тех, кто изучает веб-парсинг. До новых встреч в следующих проектах.
Просмотров статьи: 161
Очень простой скрипт для сбора товаров с интернет-магазина электроники Eldorado. По всем вопросам связанным с ошибками, неработоспособностью кода пишите в наше сообщество ВК
В данном парсере собраны и сохранены в Excel файл:
— название;
— артикул;
— цена;
— комментарии;
— ссылка.
1. Импорт используемых библиотек
from random import randint
import time
import requests
from bs4 import BeautifulSoup
import pandas as pd
from pandas import ExcelWriter2. Получение html страницы
Функция get_html. Получаем код страницы и статус ответа на наш запрос
def get_html(url, params=None):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Firefox/89.0',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br'}
response = requests.get(url, headers=headers, params=params)
html = response.text
print('Статус код: ', response.status_code)
return html3. Определяем количество страниц выдачи
Функция get_pages_count ищем на странице общее количество найденного товара и делит это число на 36, где 36 это количество позиций на странице и выводим принт
def get_pages_count(html):
soup = BeautifulSoup(html, 'html.parser')
try:
goods_count = int(soup.find('span', {"data-pc": "offers_cnt"}).text.replace(' ', ''))
print(f'Количество найденных позиций: {goods_count}')
pages = goods_count//36 + 1
except:
pages = 1
print('Количество страниц: ', pages)
return pages4. Собираем контент
Функция get_content. Со страницы будем брать название позиции, цену, рейтинг, количество отзывов, ссылку на товар. Цену и рейтинг вынес за словарь, включил в блок try-except, так как цена может быть не указана, например «скоро в продаже», а рейтинга может не быть, так как товар новый.
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
blocks = soup.find_all('li', {'data-dy': 'product'})
data = []
for block in blocks:
# столкнулся с позицией "скоро в продаже" ловим исключение
try:
price = block.find('span',{'data-pc': 'offer_price'}).text.replace(' ','').split('xa0')[-2]
except:
price = 0
try:
rating = block.find('span', class_='ms').text
except:
rating = '0'
data.append({
'title': block.find('a', {'data-dy': "title"}).get_text(),
'article': block.find('span', {"data-dy": "article"}).text.split(' ')[-1],
'price': int(price),
'rating': rating,
'review': int(block.find('a', {'data-dy': 'review'}).text.split()[0]),
'link': 'https://www.eldorado.ru' + block.find('a', {'data-dy': "title"}).get('href')
})
return data5. Сохраняем собранные данные
Функция save_data. Сохраняем через библиотеку pandas, через него же почистим от дубликатов, не знаю почему они есть, можете свои предложения написать в личку.
def save_data(data, file_name):
df = pd.DataFrame(data)
print(f'До удаления дубликатов: {len(df)} записей')
data_clear = df.drop_duplicates('article')
print(f'После удаления дубликатов: {len(data_clear)} записей')
writer = ExcelWriter(f'{file_name}.xlsx')
data_clear.to_excel(writer, f'{file_name[0:20]}')
writer.save()
print(f'Данные сохранены в "{file_name}.xlsx" файл')6. Основная функция.
Функция parser(url). file_name это заголовок страницы, которую парсим.
Обязательно! Выставляем задержку между страницами, иначе, статус код будет 403 (доступ к данным запрещен!)
Я поставил задержку от 4 до 8 секунд, краш-тест до 57 страниц проходил неоднократно.
def parser(url):
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
file_name = soup.h1.text
print(f'Выбранный раздел: {file_name}')
pages = get_pages_count(html)
data = []
for page in range(1, pages + 1):
#for page in range(14, 15):
html = get_html(url, params={"page": page})
data.extend(get_content(html))
print(f'Парсим страницу {page} из {pages}...Собрано {len(data)} позиций.')
time.sleep(randint(4, 8))
print('Найдено', len(data), 'позиций')
save_data(data, file_name)7. Ход выполнения и результаты
if __name__ == "__main__":
parser('https://www.eldorado.ru/c/vse-igry/f/dlya-sony-playstation-5/')
Запускаем код:

Смотрим полученный результат:

Спасибо, что прочли до конца, жду от вас обратной связи, пишите что нужно рассмотреть, что подробнее объяснить, рассказать, показать. Все ответы, любую помощь можно получить у нас в ВК
0
06.05.202012:4906.05.2020 12:49:12
Сегодня мы напишем с вами парсер сайтов на Python
Задача:
С сайта https://www.sds-group.ru/ загрузить изображения товаров в формате артикул_товара.jpg и описание товаров в формате артикул_товара.txt для последующей загрузки в 1С.
Файл Excel с артикулами которые нужно загрузить прилагается(в файле две колонки первая — артикула, вторая — наименование товара).
Для этой задачи нам понадобятся дополнительные библиотеки BeautifulSoup, requests, openpyxl и стандартная библиотека re, установим недостающее библиотеки:
pip install beautifulsoup4
pip install requests
pip install openpyxl
Для начала напишем загрузку картинок, создаем файл img.py и в начале файла импортируем нужные нам библиотеки:
from bs4 import BeautifulSoup
import requests
import re
import openpyxl
import urllib.requestПри анализе сайта выясняем что поиск на сайте работает через GET параметр search, и URL поиска будет выглядеть как https://www.sds-group.ru/search.htm?search=сюда_можно_подставить_артикул , занесем переменные в наш скрипт
# URL страницы поиска
url_src = 'https://www.sds-group.ru/search.htm?search='
# Файл артикулов
file = "sds-group.xlsx"Считываем значения колонок файла sds-group.xlsx
# Инициализируем библиотеку для работы с Excel и считываем значения колонок
wb_obj = openpyxl.load_workbook(file)
sheet_obj = wb_obj.active
m_row = sheet_obj.max_rowПишем цикл поиска товаров по артикулам на сайте из файла sds-group.xlsx и скачиванием картинок, я постарался максимально снабдить комментариями этот цикл:
for i in range(1, m_row + 1):
# Считываем значение ячейки
cell_obj = sheet_obj.cell(row=i, column=1)
print('-------------------------')
print('Артикул: ' + str(cell_obj.value))
# Формируем URL с поиском переменная url_src + значение ячейки
url = url_src + str(cell_obj.value)
# Делаем http запрос библиотекой requests и помещаем ответ сервера в переменную r
r = requests.get(url)
# Инициализируем парсер BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
# Находим на полученной странице с сайта элемент с классами flex-3 m-flex t-left(именно в этом элементе содержится ссылка на детальную страницу товара)
url_item = soup.find_all(class_='flex-3 m-flex t-left')
url_item_str = str(url_item)
item = re.findall('href=['"]?([^'" >]+)', url_item_str)
# Проверяем нашелся ли вообще нужный артикул на сайте? если нет то переходим к следующему артиклу из файла
try:
item_href = str(item[0])
print('https://www.sds-group.ru' + item_href)
except IndexError:
print('Артикул на сайте не найден')
continue
# Если артикул нашелся то переходим на страницу детального просмотра
r = requests.get('https://www.sds-group.ru' + item_href)
soup2 = BeautifulSoup(r.text, 'html.parser')
# Изображение находится в div с классом product-img, находим его и получаем прямую ссылку на картинку
img_item = soup2.find("div", {"class": "product-img"})
img = img_item.img['src']
img_src = 'https://www.sds-group.ru' + img
print(img_src)
# Скачиваем файл в папку img
try:
urllib.request.urlretrieve(img_src, './img/' + str(cell_obj.value) + '.jpg')
except:
print('Не получилось сохранить файл')Парсер текстового описание товаров выглядит аналогично, но с небольшими особенностями, я сделал его отдельным файлом — txt.py
Полный код парсера, со всеми файлами вы можете скачать в репозитории https://github.com/Nikovit/parser_site