
Одной из самых интересных задач, с которыми нам пришлось столкнуться в процессе работы над компонентом Spreadsheet, стал механизм вычисления формул. Работая над ним, мы основательно углубились в механику функционирования аналогичного механизма в MS Excel.
И сегодня я хочу рассказать вам о принципах его работы, хитростях и подводных камнях. А чтобы не сводиться к сухим пересказам документации, разбавленным дополнениями «из жизни» — я заодно вкратце расскажу, как мы реализовывали подобный механизм.
Итак, в этой статье пойдет речь о трех основных частях классического калькулятора формул – разборе выражения, хранении и вычислении.
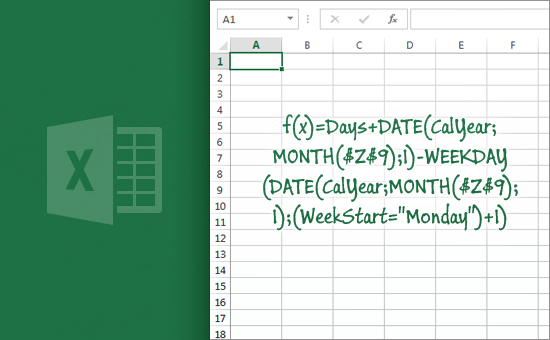
Внутреннее представление выражения
Выражение в Excel хранится в обратной польской записи, RPN. Выражение в RPN форме представляет из себя простой массив, элементы которого называются ParsedThing.
Полный набор ParsedThing состоит из следующих элементов:
Операнды – константы, массивы, ссылки;
Константы:
- ParsedThingNumeric
- ParsedThingInt
- ParsedThingString
- ParsedThingBool
- ParsedThingMissingArg
- ParsedThingError
Массивы:
- ParsedThingArray
Ссылки:
- ParsedThingName, ParsedThingNameX
- ParsedThingArea, ParsedThingAreaErr, ParsedThingArea3d, ParsedThingAreaErr3d, ParsedThingAreaN, ParsedThingArea3dRel
- ParsedThingRef, ParsedThingRefErr, ParsedThingRef3d, ParsedThingErr3d, ParsedThingRefRel, ParsedThingRef3dRel
- ParsedThingTable, ParsedThingTableExt
Операторы – математические, логические, ссылочные, а так же вызовы функций;
Вызовы функций:
- ParsedThingFunc
- ParsedThingFuncVar
Бинарные операторы:
- ParsedThingAdd
- ParsedThingSubtract
- ParsedThingMultiply
- ParsedThingDivide
- ParsedThingPower
- ParsedThingConcat
- ParsedThingLess
- ParsedThingLessEqual
- ParsedThingEqual
- ParsedThingGreaterEqual
- ParsedThingGreater
- ParsedThingNotEqual
- ParsedThingIntersect
- ParsedThingUnion
- ParsedThingRange
Унарные операторы:
- ParsedThingUnaryPlus
- ParsedThingUnaryMinus
- ParsedThingPercent
Вспомогательные элементы и атрибуты (для оптимизации скорости вычислений, сохранения пробелов и переводов строк в выражении, т.е. не влияющие на результат вычисления выражения).
Вспомогательные:
- ParsedThingMemArea
- ParsedThingMemNoMem
- ParsedThingMemErr
- ParsedThingMemFunc
- ParsedThingParentheses
Атрибуты:
- ParsedThingAttrSemi
- ParsedThingAttrIf
- ParsedThingAttrChoose
- ParsedThingAttrGoto
- ParsedThingAttrSum
- ParsedThingAttrSpace
Приведу пару примеров.
- «=A1*(1+true)». Во внутреннем представлении будет выглядеть так: {ParsedThingRef(A1), ParsedThingInt(1), ParsedThingBool(true), ParsedThingAdd, ParsedThingMultiply}
- «=SUM(A1,1,”2”,)». Во внутреннем представлении будет выглядеть так: {ParsedThingRef(A1), ParsedThingInt(1), ParsedThingString(“2”), ParsedThingMissing, ParsedThingFuncVar(“SUM”, 4 аргумента)}
Вычисления
Вычисление выражения, записанного в обратной польской записи, выполняется с использованием стековой машины. Хороший пример приведен в википедии.
Но в вычислении выражений из Excel не обошлось и без хитростей. Разработчики наделили все операнды свойством «тип значения». Это свойство указывает, как должен быть преобразован операнд перед вычислением оператора или функции. Например, обычные математические операторы не могут выполняться над ссылками, а могут только над простыми значениями (числовыми, логическими и т.д.). Чтобы выражение “A1 + B1:C1” работало корректно, Excel указывает для ссылок A1 и B1:C1, что те должны быть преобразованы к простому значению перед помещением результата вычисления в стек.
Существует три типа операндов:
- Reference;
- Value;
- Array.
Каждый операнд имеет тип «по умолчанию»:
| Все виды ссылок | Reference |
| Константы кроме массивов | Value |
| Массивы | Array |
| Вызовы функций | Value, Reference, Array |
Результат вычисления функции может быть любого типа. Большинство функций возвращают Value, некоторые (например, INDIRECT) -Reference, остальные — Array(MMULT).
Конечным пользователям не нужно забивать голову типами данных: Excel сам подбирает нужный тип операнда уже на этапе разбора выражения. А на этапе вычисления не обойтись без «неявного приведения типов». Оно происходит в соответствии со следующей схемой:
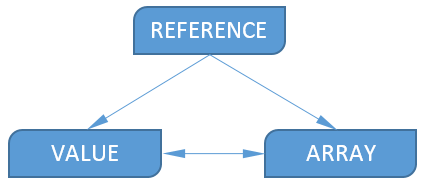
Значение типа Value можно преобразовать к Array, в этом случае создастся массив из одного значения. В обратном направлении (Array->Value) преобразование тоже достаточно простое — из массива берется первый элемент.
Как видно из схемы, значение типа Reference невозможно получить из Value или Array. Это вполне логично, из числа, строки и т.п. получить ссылку не получится.
При преобразовании Reference к Array все значения из ячеек, входящих в диапазон, переписываются в массив. В случае когда диапазон комплексный (состоящий из двух или более других диапазонов) — результат преобразования равен ошибке #VALUE!
Интересным образом происходит преобразование Reference к Value. Между собой это правило мы прозвали «Кроссинг». Проще всего объяснить его суть на примере:
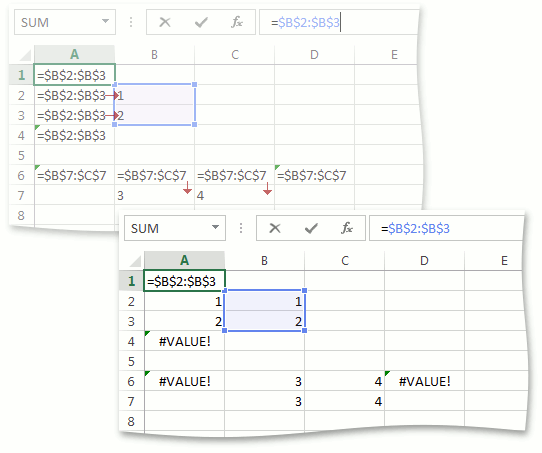
Пусть мы хотим привести к Value значения ячеек с A1 по A4, в которых находится одинаковая формула “=B2:B3”, имеющая тип Reference. Диапазон B2:B3 состоит из одной колонки. Если бы это было не так и колонок было бы больше, преобразование Reference к Value для всех ячеек с A1 по A4 вернуло бы #VALUE! и на этом бы завершилось. Ячейки A2 и A3 находятся в строках, пересекающихся с диапазоном B2:B3. Преобразование Reference->Value для этих ячеек вернет соответствующее значение из диапазона B2:B3, т.е. преобразование для A2 вернет 1, а для A3 вернет 2. Для остальных ячеек, таких как A1 и A4, преобразование вернет #VALUE!
Точно таким же поведение будет и для диапазона B7:C7, состоящего из одной строки. Для ячеек B6 и C6 преобразование вернет значения 3 и 4 соответственно, а для A6 и — D6 #VALUE! Аналогично, если бы строк в диапазоне было больше, преобразование вернуло бы #VALUE! для всех ячеек с A6 по D6
Существует несколько правил преобразования типов.
Значения всех формул, находящихся внутри ячеек, всегда приводятся к типу Value.
Например:
- «=123» В этой формуле задана константа, она уже типа Value. Ничего преобразовывать не надо.
- «={1,2,3}» Тут задан массив. Преобразование к Value по правилу дает нам первый элемент массива — 1. Он и будет результатом вычисления выражения.
- Формула «=A1:B1» находящаяся в ячейке B2. Операнд-ссылка на диапазон по умолчанию имеет тип Reference. При вычислении он будет приведен к Value по правилу «кроссинг». Результатом в данном случае будет значение из ячейки B1.
Математические, логические и текстовые операторы не могут работать со ссылками. Поэтому аргументы для них подготавливаются и приводятся либо к Value либо к Array. Второй вариант при этом возможен только внутри Array формул. Например, при вычислении выражения «=B1:B2+A3:B3», записанного в ячейку A1, оба аргумента математического оператора сложения сначала будут приведены к типу Value по правилу «Кроссинг», а затем результаты будут сложены. Т.е. значение будет равно сумме значений ячеек B1 и A3.
Операторы ссылки не могут работать ни с каким другим типом, кроме Reference. К примеру, формула «=A1:«test»» будет неправильной, ввод такой формулы приведет к ошибке — Excel просто не даст такую формулу записать в ячейку.
Выражения внутри “имен” и некоторых других конструкций приводятся к типу «по умолчанию». В отличие от формул внутри ячеек, выражения в которых приводятся к типу Value. Выражение внутри некоторого “имени” name «=A1:B1» в результате вычисления будет равно диапазону A1:B1. Это же выражение в ячейке будет вычисляться и в результате будет либо одно значение, либо ошибка #VALUE! Но выражение в ячейке «=name» уже будет иметь тип Value и будет вычисляться в зависимости от текущей ячейки.
Парсер
Написав на коленке первый вариант парсера мы поняли, что монстр слишком велик и слабо поддается модернизации. А она в нашем случае была неизбежна, поскольку большое количество тонкостей мы познавали уже когда парсер худо-бедно работал. Для интереса решил попробовать другие методы и вооружился для этого генератором трансляторов Coco/R. Выбор на него в тот момент пал в основном из-за того, что я был с ним уже неплохо знаком. Coco/R оправдал мои надежды. Сгенеренный им парсер показал весьма неплохие результаты по скорости работы, поэтому решили остановиться на этом варианте.
Конечно, в рамках этой статьи я не стану останавливаться на описании возможностей и пересказе документации Coco/R. Благо, что документация написана на мой взгляд весьма понятно. Кроме этого рекомендую почитать статью на хабре.
Собираем Coco/R из исходников
В некоторых местах Coco/R генерирует не CLS-compliant код.
Проблема в публичных константах, имя которых начинается со знака подчеркивания. Правильный выход из ситуации только один — поправить Coco/R, благо полный исходный код его доступен на сайте разработчиков.
Покопавшись в исходниках нашел три места, где создаются публичные константы. Все они в файле ParserGen.cs. Например:
void GenTokens() {
foreach (Symbol sym in tab.terminals) {
if (Char.IsLetter(sym.name[0]))
gen.WriteLine("tpublic const int _{0} = {1};", sym.name, sym.n);
}
}
Далее, получившийся код продолжает быть невалидным, теперь уже по мнению FxCop. В нашей компании сборки постоянно тестируются на соответствие большому числу правил. Конечно, поскольку код сгенерирован, можно было бы сделать для него исключение и подавить проверку сгенерированных классов. Но это не лучший выход. К счастью, проблема только одна – публичные поля не соответствуют правилу Microsoft.Design: CA1051. Чтобы все исправить достаточно внести необходимые правки в файлы Parser.frame и Scanner.frame, которые располагаются рядом с файлом грамматики. То есть, сам Coco/R пересобирать не надо. Вот примеры:
public Scanner scanner;
public Errors errors;
public Token t; // last recognized token
public Token la; // lookahead token
Некоторые из этих полей вообще не используются за пределами класса – их просто делаем приватными, остальным – создаем публичные свойства.
При разработке грамматики для Coco/R я пользовался плагином для студии.
Его плюшки
- Подсветка синтаксиса для файла с грамматикой;
- Автоматический запуск генератора при сохранении файла с грамматикой;
- Intellisense для ключевых слов;
- Показывает ошибки компиляции, возникающие в файле парсера в соответствующем месте в файле с грамматикой
Последняя фича была бы весьма удобна, но, к сожалению, у меня она работала некорректно — показывала ошибки не там где надо.
Плагин тоже пришлось научить генерировать CLS compliant код. Скачиваем исходный код плагина, и повторяем те же операции, что и с самим Coco/R.
Модернизируем сканер и парсер
Напомню, что для разбора выражения Coco/R создает пару классов – Parser и Scanner. Оба они создаются заново для каждого нового выражения. Поскольку в нашем случае выражений много, то пересоздание сканера может занять дополнительное время на большом количестве вызовов. В целом, нам достаточно одного комплекта парсер-сканер. Первая модернизация коснулась именно этого.
Вторая модернизация коснулась вспомогательного класса Buffer, который создается сканером для чтения входящего потока символов. “Из коробки” Coco/R содержит пару реализаций Buffer и UTF8Buffer. Оба они работают с потоком. Нам же поток не нужен: достаточно работы со строкой. Для этого создадим третью реализацию StringBuffer, попутно выделив интерфейс IBuffer:
public interface IBuffer {
string GetString(int beg, int end);
int Peek();
int Pos { get; set; }
int Read();
}
Сама реализация StringBuffer простая:
public class StringBuffer : IBuffer {
int stringLen;
int bufPos;
string str;
public StringBuffer(string str) {
stringLen = str.Length;
this.str = str;
if (stringLen > 0)
Pos = 0;
else
bufPos = 0;
}
public int Read() {
if (bufPos < stringLen)
return str[bufPos++];
else
return StreamBuffer.EOF;
}
public int Peek() {
int curPos = Pos;
int ch = Read();
Pos = curPos;
return ch;
}
public string GetString(int beg, int end) {
return str.Substring(beg, end - beg);
}
public int Pos {
get { return bufPos; }
set {
if (value < 0 || value > stringLen)
throw new FatalError("buffer out of bounds access, position: " + value);
bufPos = value;
}
}
}
Тестируем
На всякий случай проверяем, что создали дополнительный класс не зря. Запускаем тестирование трех сценариев для строки длиной N:
- инициализация из строки;
- чтение символа (вызов метода IBuffer.Read() N раз) ;
- получение 10 символов из строки(вызов IBuffer.GetString(i-10, i) (N-10) раз).
При N = 100:
Init x 100000:
Buffer: 171 мс
StringBuffer: 2 мс
Read xNx10000:
Buffer: 14 мс
StringBuffer: 8мс
GetString x (N-10) x 10000:
Buffer: 250 мс
StringBuffer: 20 мс
Разработка грамматики
Грамматика для Coco/R описывается в РБНФ(EBNF). Разработка грамматики для Coco/R сводится к построению РБНФ и оформлению ее в соответсвии с грамматикой Coco/R в файле с расширением atg.
Парсер строится на основе рекурсивного спуска, грамматика должна удовлетворять LL(k). Сканер основывается на детерминированном конечном автомате.
Итак, приступим. Первым в файле грамматики идет название будущего компилятора:
COMPILER FormulaParserGrammar
Далее должна следовать спецификация сканера. Сканер будет case-insensitive, указываем это при помощи ключевого слова IGNORECASE. Теперь надо определиться с символами. Нам надо отделить цифры, буквы, управляющие символы. Получилось следующее:
CHARACTERS
digit = "0123456789".
chars = "~!@#$%^&*()_-+={[]}|\:;"',./?<> ".
eol = 'r'.
blank = ' '.
letter = ANY - digit - chars - eol - blank + '_'.
Coco/R позволяет не только складывать множества символов, но и вычитать. Так, в описании letter применено ключевое слово ANY, которое подставляет все множество символов, из которого вычитаются определенные выше другие множества.
Важной задачей сканера является идентификация токенов во входной последовательности. Во время работы над парсером набор токенов постоянно менялся и в итоге выглядит так:
TOKENS
ident = letter {letter | digit | '.'}.
wideident = letter {letter | digit} ('?'|'\') {letter | digit | '?'|'\'}.
positiveinumber = digit {digit}.
fnumber =
"." digit {digit} [("e" | "E") ["+" | "-"] digit {digit}]
|
digit {digit}
(
"." digit {digit}
[("e" | "E" ) ["+" | "-"] digit {digit} ]
|
("e" | "E") ["+" | "-"] digit {digit}
).
space = blank.
quotedOpenBracket = "'[".
quotedSymbol = "''" | "']" | "'@" | "'#".
pathPart = ":\".
trueConstant = "TRUE".
falseConstant = "FALSE".
Обратите внимание, что идентификатор может содержать одну или несколько символов “точка”. Таким, например, может быть имя листа в ссылке на диапазон. Так же необходим дополнительный, расширенный, идентификатор. Он отличается от обычного наличием знака вопроса или бекслеша. Отмечу, что в Excel понятие идентификатора достаточно сложное и его трудно описать в грамматике. Вместо этого все строчки, идентифированные сканером как ident и wideident, проверяю уже в коде на соответствие следующим правилам:
- Может содержать только буквы, цифры, и символы: _,.,,?;
- Не может быть равен TRUE или FALSE;
- Первый символ может быть только буквой, знаком подчеркивания, или бекслешем;
- Если первый символ строки – бекслеш, то второго символа может не быть, либо это должен быть один из: _,.,,?;
- Не должен быть схож с названием диапазона (например, A10);
- Не должен начинаться на строку, которая может быть воспринята как ссылка в формате R1C1. Природа этого условия сложнообъяснима, приведу только несколько примеров идентификаторов, которые ему не удовлетворяют: “R1_test”, “R1test”,“RC1test”,“R”,“C”. При этом «RCtest» – вполне подходит.
Выделение quotedOpenBracket, quotedSymbol и pathPart в отельный токен – не более чем хитрость. Она позволила пропустить символы в именах колонок в табличной ссылке, перед которыми должен следовать апостроф. Например, в выражении “=Table1[Column'[1′]]” имя колонки начинается после символа ‘[’ и продолжается до символа ‘]’. При этом первый такой символ вместе с предшествующим ему апострофом будет прочитан сканером как терминал quotedSymbol(‘]) и, тем самым, чтение имени колонки на нем не остановится.
Наконец, укажем сканеру, чтобы он пропускал переводы строк и табуляции.
IGNORE eol + ‘n’ + ‘t’. Сами выражения могут быть написаны в несколько строк, но на грамматику это не влияет.
Мы подошли к основному разделу PRODUCTIONS. В нем необходимо описать все нетерминалы. В примерах дальше я буду приводить упрощенный код, большинство семантических вставок вырезаю, т.к. они внесут сложности в понимание грамматики. Оставлю лишь места построения самого выражения, без оптимизаций.
По всем нетерминалам (из которых Coco/R сделает методы) будет передаваться ссылка на выражение в RPN форме, а так же тип данных, к которому надо его привести. При вызове парсера для формулы внутри ячейки начальный тип данных – Value. Далее во время разбора он будет меняться, и в ветви дерева разбора будет передаваться подготовленный тип. К примеру, при разборе выражения “=OFFSET(A1:B1, A1, A2)” элемент польской записи — функция OFFSET — получит тип Value, при разборе же аргументов первый будет приводиться к Reference, другие два к Value. Для всех функциий мы храним информацию, какие аргументы и каких типов должны в нее передаваться.
Задачей парсера также является проверка формулы на правильность. Формулу будем считать некорректной, если Excel не дает записать ее в ячейку. Кроме синтаксических ошибок формулу некорректной могут сделать и неправильное количество аргументов, переданное в функцию или же несовпадение типа данных запрошенному. Например, функция ROW либо вообще не нуждается в параметрах либо только в одном, и он должен быть исключительно Reference. Мы уже говорили, что к Reference невозможно привести ни один другой тип, а это значит, что выражения «=ROW(1)», «=ROW(“A1”)» будут невалидными.
Т.к. наша грамматика является усложненной грамматикой для обычных математических выражений, строится она так же в зависимости от старшинства операций. Первым следуют логические выражения, последним – операторы работы с диапазонами. Т.е. в порядке увеличения приоритета.
Для визуализации РБНФ использую небольшую программку EBNF Visualizer. Вот так будет выглядеть первый нетерминал в нашей грамматике – логическое выражение:
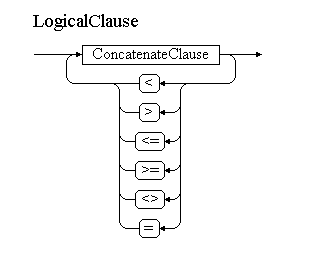
Далее грамматика для Coco/R. В семантических вставках, оформленных между “(.” и “.)” я добавлю нужный ParsedThing к выражению.
LogicalClause<OperandDataType dataType, ParsedExpression expression>
(. IParsedThing thing = null; .)
=
ConcatenateClause<dataType, expression>
{
(
'<' (.thing = ParsedThingLess.Instance; .)
| '>' (.thing = ParsedThingGreater.Instance; .)
| "<=" (.thing = ParsedThingLessEqual.Instance; .)
| ">=" (.thing = ParsedThingGreaterEqual.Instance; .)
| "<>" (.thing = ParsedThingNotEqual.Instance; .)
| '=' (.thing = ParsedThingEqual.Instance; .)
)
ConcatenateClause<dataType, expression>
(. expression.Add(thing); .)
}
.
По этому принципу будут строится: ConcatenateClause, AddClause, MultipyClause, PowerClause, UnaryClause, PercentClause, RangeUnionClause, RangeIntersectionClause, CellRangeClause. На CellRangeClause заканчиваются нетерминалы, описывающие операторы. За ним следует первый операнд – OperandCommonClause. Он будет выглядеть примерно так:
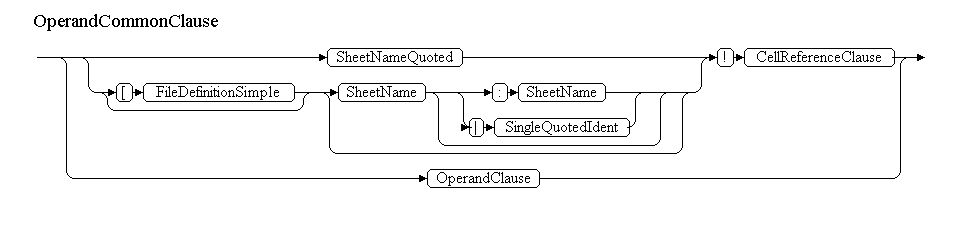
Однако, в приведенной грамматике есть неоднозначность. Она заключается в том, что SheetName и OperandClause могут начинаться с одного и того же терминала — с идентификатора. Например, может следовать выражение “=Sheet!A1”, а может “=name”. Тут “Sheet” и “name” – идентификаторы. К счастью, Coco/R позволяет разрешать конфликты, просматривая входящий поток сканером на несколько терминалов вперед. Т.е. мы можем просмотреть в поисках символа ‘!’, если таковой будет найден – то мы разбираем SheetName, иначе – OperandClause. Вот так будет выглядеть грамматика:
OperandCommonClause<OperandDataType dataType, ParsedExpression expression>
=
(
IF(IsSheetDefinition())
(
(
SheetNameQuoted<sheetDefinitionContext>
|
[ '[' FileDefinitionSimple ]
[
SheetName<out sheetName>
[
':' SheetName<out sheetName>
|
'|'
SingleQuotedIdent<out ddeTopic>
]
]
)
'!'
CellReferenceClause<dataType, expression>
)
|
OperandClause<dataType, expression>
)
.
Для разрешения конфликта используется метод IsSheetDefinition(), определенный в классе Parser. Подобные методы удобно писать в отдельном файле, пометив класс как partial.
Нетерминал SheetName может начинаться с цифры или состоять только из цифр. В этом случае, имя листа должно быть заключено в апострофы. В противном случае, Excel добавляет недостающие апрострофы.
SheetName<out string sheetName>
(. int sheetNameStart = la.pos;.)
=
(
[positiveinumber | fnumber]
[ident]
)
(. sheetName = scanner.Buffer.GetString(sheetNameStart, la.pos); .)
.
В этой грамматике есть пара ошибок. Во-первых, все терминалы внутри нетерминала необязательны. А во вторых, она позволяет между числом и идентификатором вставить пробел или любой символ, описанный в разделе IGNORE. Проблему можно решить при помощи механизма разрешения конфликтов, но уже без дополнительных функций. Прямо в грамматике проверяем на наличие разрыва между числом и следующим за ним идентификатором:
SheetName<out string sheetName>
(. int sheetNameStart = la.pos;.)
=
(
positiveinumber | fnumber
[
IF(la.pos - t.pos == t.val.Length)
ident
]
|
ident
)
(. sheetName = scanner.Buffer.GetString(sheetNameStart, la.pos); .)
.
В OperandClause мы будем попадать из OperandCommonClause, если нет ссылки на лист, внешнюю книгу или источник DDE. Из этого нетерминала мы можем попасть в ArrayClause, StringConstant(оба не могут иметь перед собой ссылку на лист), CellReferenceClause, либо встретим скобку и перейдем к началу всего дерева разбора – к LogicalClause.
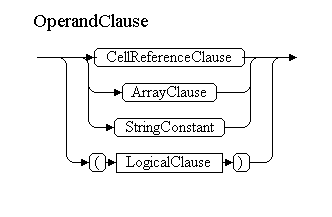
OperandClause<OperandDataType dataType, ParsedExpression expression>
=
(
CellReferenceClause<dataType, expression>
|
ArrayClause<dataType, expression>
|
StringConstant<expression, dataType>
)
|
'('
CommonCellReference<dataType, expression>
')'
(. expression.Add(ParsedThingParentheses.Instance);.)
.
CellReferenceClause наверно самый большой нетерминал, в нем собраны почти все виды операндов:
CellReferenceClause<OperandDataType dataType, ParsedExpression expression>
=
(
IF (IsTableDefinition())
TableReferenceExpressionClause<dataType, expression>
|
IF (IsFunctionDefinition())
FunctionClause<dataType, expression>
|
IF (IsDefinedNameDefinition())
DefinedNameClause<dataType, expression>
|
IF(IsRCCellPosition())
CellPositionRCClause<dataType, expression>
|
IF(IsA1CellPosition())
CellPositionA1Clause<dataType, expression>
|
CellError<dataType, expression>
|
TermNumber<expression>
|
BoolConstant<expression, dataType>
|
wideident
(. expression.Add(new ParsedThingName(t.val);.)
)
.
Для большинства нетерминалов приходится создавать методы разрешения конфликтов. Дальше описываем грамматики для всех оставшихся нетерминалов.
Парсинг неполных выражений и «предсказания»
Рассмотрим задачу подсветки диапазонов, участвующих в формуле.
Проблемой здесь является то, что выражение может быть невалидное, а подсвечивать диапазоны надо все равно. На тот момент парсер, не осилив выражение, возврашал всегда null. Конечно, можно было бы попробовать разобраться в частично прочитанном выражении и собрать ссылки с него, но как узнать на каких местах в выражении стоит конкретная ссылка? Поэтому решили научить парсер сразу по ходу чтения складывать все интересное по местам. Так, все ссылки по типам оказались в специально предназначенных коллекциях. Парсер при обнаружении, например, ссылки на диапазон вызывает соответствующий метод
void RegisterCellRange(CellRange range, int sheetDefinitionIndex, int position, int length)
После чтения, вне зависимости удачно оно завершилось или нет, у нас есть набор ссылок.
На этом же стал основываться еще один механизм – предсказания. В выражении “=1*(1+2” нарушен баланс скобок, но, с большой вероятностью, пользователь забыл поставить скобку именно в конце выражения. То есть можно попробовать исправить эту формулу, дописав к ней недостающую скобку. Конечно, парсер сам этим заниматься не будет, он только скажет где и чего по его мнению не хватает. Так, например, в уже знаком нам OperandClause появилась следующие строки:
'('
CommonCellReference<dataType, expression>
(.
if(la.val != ")")
parserContext.RegisterSuggestion(new FunctionCloseBracketSuggestion(la.pos));
.)
')'
Конечно, все эти действия делаются только тогда, когда выражение вводят вручную и есть необходимость рисовать задействованные диапазоны или пробовать исправить недописанную формулу.
Оптимизация производительности вычислений
Excel, еще на этапе разбора выражения, старается облегчить себе дальнейшую жизнь. Для этого он, по возможности, наполняет выражения всяческими вспомогательными элементами. Давайте рассмотрим их.
Атрибут AttrSemi. Этот атрибут добавляется первым элементом в те выражения, которые содержат volatile-функции.
Класс атрибутов Mem. Сюда входят сразу несколько атрибутов. Их объединяет то, что они созданы для оптимизации вычисления ссылок. По сути, они являются оберткой над некоторым выражением. Во время вычисления внутреннее выражение может и не вычисляться, за него результат выдаст Mem. Отличительной особенностью этих элементов является то, что они вставляются в обратной польской записи до выражения, которое оптимизируют.
- ParsedThingMemFunc — указывает на то, что выражение внутри должно вычисляться каждый раз и не результат не может быть закеширован. Например, все выражение =INDIRECT(«A1»):B1 будет обернуто в MemFunc, т.к. функция INDIRECT является volatile функцией и при следующем расчете может вернуть уже другое значение.
- ParsedThingMemArea. Заключает в себе выражение, значение которого уже посчитано и не будет меняться. Это значение сохранится внутри атрибута и при следующем расчете в стек будет добавлено именно оно, а внутреннее выражение вычисляться вообще не будет.
- ParsedThingMemErr. Заключает в себе выражение, значение которого посчитано, не будет меняться и равно ошибке.
- ParsedThingMemNoMem. При вычислении выражения внутри Excel столкнулся с нехваткой памяти. На практике я такое ни разу не встречал.
Атрибут AttrSum применяется в качестве упрощенной формы записи функции SUM в том случае, когда в функцию передан только один аргумент.
Атрибут AttrIf применяется совместно с одним или двумя операторами Goto для оптимизации вычисления функции IF. Напомню синтаксис функции IF: IF(условие, значение_истина, [значение_ложь]). Из двух значений можно вычислить только одно и сэкономить время на вычислении другого, если сразу после вычисления условия перейти к нужному значению. Тем самым, простое выражение =IF(condition,”v_true”,”v_false”) Excel густо разбавляет атрибутами. Получается примерно следующее:

Вычисление идет так. Значение condition помещается в стек. Следующим на очереди идет атрибут IF. Он смотрит на значение на вершине стека. Если оно истинно — ничего не делает. Если ложно, прибавляет текущий счетчик элементов в выражении на записанное внутри смещение, тем самым счетчик начинает указывать на “v_false”. Следующим рассчитывается либо “v_true”, либо “v_false” и результат помещается в стек. Далее идет Goto, первый или второй. Но оба они ссылаются на конец выражения (либо на следующие операторы в выражении, если таковые имеются).
AttrChoose работает очень похожим образом. Напомню, функция CHOOSE выбирает из аргументов один, порядковый номер которого указан в первом аргументе.
Тем самым на дальнейший результат расчета влияет только один аргумент, все остальные можно пропустить. В AttrChoose хранится набор смешений, каждое из которых указывает на начало каждого следующего аргумента. После аргумента следует уже знакомый AttrGoto, который указывает на конец выражения или следующий за функцией CHOOSE элемент.
Атрибут Space используется для сохранения формата введенного пользователем выражения, а именно переводов строк и пробелов. Каждый такой атрибут кроме количества имеет тип. Типов всего шесть:
- SpaceBeforeBaseExpression,
- CarriageReturnBeforeBaseExpression,
- SpaceBeforeOpenParentheses,
- CarriageReturnBeforeOpenParentheses,
- SpaceBeforeCloseParentheses,
- CarriageReturnBeforeCloseParentheses,
- SpaceBeforeExpression;
Взглянув на эти типы можно догадаться, что Excel не умеет сохранять пробелы в конце строки и перед знаком ‘=’. Кроме этого пробелы внутри структурированных ссылок и массивов так же сохранены не будут.
Тестирование
Когда наш контрол только-только научился читать и писать файлы в формате OpenXML, мы поспешили проверить его в деле. И самый лучший для этого способ – найти много- много файлов и попробовать погонять чтение и запись этих файлов. Так мы накачали около 10к случайных OpenXML файлов и написали несложную программку. Создали для нее задачу на тестовой ферме. Каждую ночь задача автоматически запускается и читает-пишет файлы. При возникновении каких либо ошибок вся необходимая информация записывается в лог. Так мы смогли отладить огромное количество ошибок.
По мере развития контрола добавлялись как поддерживаемые форматы, так и фичи. Так сейчас постоянно тестируются 20к xls файлов и 15к csv файлов. И тестируются не только на чтение-запись, но и проверяются сторонними утилитами, которые также нам очень помогают.
Огромное количество знаний о работе формул в Excel мы получили, когда запустили задачу на тестирование вычислений формул из тех же 10к OpenXML и 20к xls файлов. Файл открывается, записывается в модель данных. Затем поочередно мы начинаем помечать ячейки на листе как не посчитанные, вычисляем и сравниваем новое значение с тем значением, которое было прочитано из файла. Тем самым мы убили двух зайцев – отладили парсер формул и привели результаты вычислений максимально близко к тем, что получаются при использовании Excel.
Конечно, мы не избавились от всех проблем, связанных с формулами – уж слишком обширная тема. Но уже очень много всего изучили и реализовали, и не останавливаемся на достигнутом. Лично мне было интересно работать над ним, надеюсь, что и Вам было интересно читать эту статью.
Спасибо за внимание!
Парсинг нетабличных данных с сайтов
Проблема с нетабличными данными
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet), вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:

Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:

Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2… или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом <TABLE>, а её аналог — вложенные друг в друга теги-контейнеры <DIV>. Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel.
Тем не менее, есть способ обойти это ограничение 
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:

Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
https://www.wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:

Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data), чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:

… и затем щёлкаем по значку шестерёнки справа от шага Источник (Source), чтобы открыть его параметры:

В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file). Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):

Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:

- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:

Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains), переключаемся в режим Подробнее (Advanced) [2] и вводим наши критерии:

Добавление условий выполняется кнопкой со смешным названием Добавить предложение [3]. И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:

Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: <span class=»price»> через команду Главная — Замена значений (Home — Replace values).
- Разделить получившийся столбец по первому разделителю «>» слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя «<» слева, чтобы отделить полезные данные от тегов:

- Удалить лишние столбцы, а в оставшемся заменить стандартную HTML-конструкцию " на нормальные кавычки.

В итоге получим наши данные в уже гораздо более презентабельном виде:

Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View)) и вводим следующую конструкцию:
= Table.FromRows(List.Split(#»Замененное значение1″[Column1.2.1],3))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:

Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load…)

Вот и все хитрости 
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query
- Формулы Excel
- текстовые строки
- Разное

Пользовательская функция ParseFormula предназначена для отображения промежуточных результатов вычисления простейших формул в Excel.
В данной версии функции ParseFormula поддерживаются только 2 формулы: СУММ и ПРОИЗВЕД
Пример её использования — в прикреплённом файле.
В примере в голубых ячейках — исходные данные для формул,
в оранжевых ячейках — формулы типа =ПРОИЗВЕД(A1;B1) для получения промежуточных результатов
в зеленой ячейке подсчитывается сумма произведений формулой =СУММ(C1:C10)
Функция анализирует диапазоны, заданные в качестве параметров этих формул, и возвращает результат промежуточных вычислений в виде
123*2,85 + 156*2,94 + 189*3,03 + 222*3,12 + 255*3,21 + 288*3,3 + 321*3,39 + 354*3,48 + 387*3,57 + 420*3,66 = 9082,35
Для использования функции добавьте в стандартный модуль вашего файла (или любой подключенной надстройки) следующий код:
Option Compare Text Function ParseFormula(ByRef cell As Range, Optional SubItem As Boolean = False) On Error Resume Next fo = cell.Formula: fu = Split(Split(fo, "=")(1), "(")(0) Dim cel As Range, ra As Range: Set ra = Range(Split(Split(fo, "(")(1), ")")(0)) Select Case fu Case "PRODUCT": s = "*" Case "SUM": s = " + " Case Else: s = " ??? ": fu = "" End Select If fu = "" Then ParseFormula = cell.Value: Exit Function For Each cel In ra.Cells ParseFormula = ParseFormula & s & IIf(fu = "", cel.Value, ParseFormula(cel, True)) Next cel ParseFormula = Mid(ParseFormula, Len(s) + 1) If Not SubItem Then ParseFormula = "" & ParseFormula & " = " & cell.Value End Function
После добавления кода поместите в нужную ячейку формулу вида =ParseFormula(a1)
где a1 — ссылка на ячейку с обрабатываемой формулой.
Результат работы функции можно использовать и из кода VBA:
Sub ПримерИспользованияParseFormula() ' выводим промежуточные результаты вычисления для формулы из активной ячейки РезультатВычислений = ParseFormula(ActiveCell) Debug.Print РезультатВычислений End Sub
- 17281 просмотр
Не получается применить макрос? Не удаётся изменить код под свои нужды?
Оформите заказ у нас на сайте, не забыв прикрепить примеры файлов, и описать, что и как должно работать.
Парсить сайты в Excel достаточно просто если использовать облачную версию софта Google Таблицы (Sheets/Doc), которые без труда позволяют использовать мощности поисковика для отправки запросов на нужные сайты.
- Подготовка;
- IMPORTXML;
- IMPORTHTML;
- Обратная конвертация.
Видеоинструкция
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/
Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).
Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML. Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
- IMPORTHTML. Позволяет получить данные из таблиц и списков.
Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:
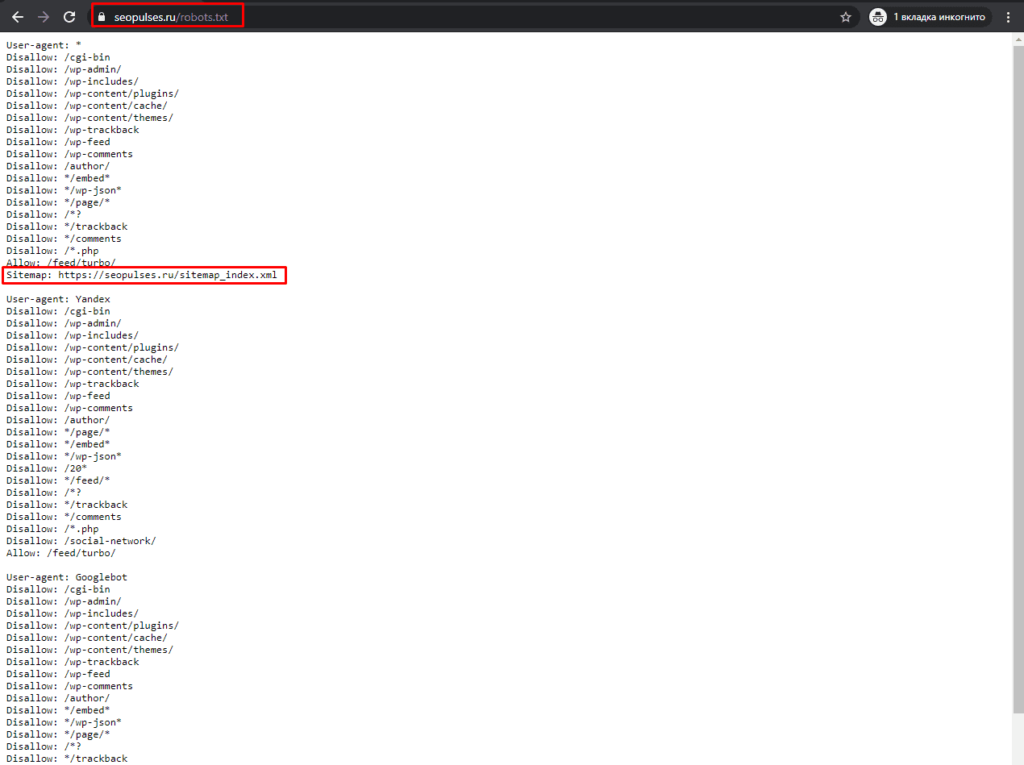
Нас интересует список постов, поэтому открываем первую ссылку.
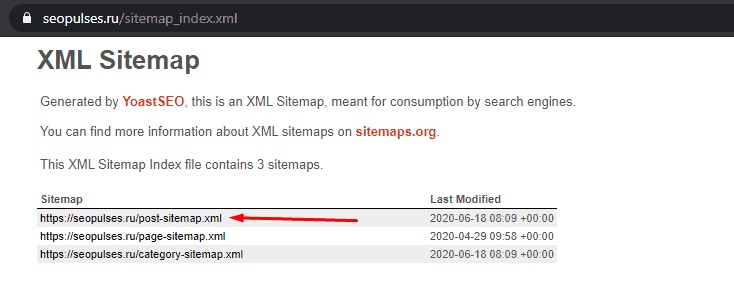
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).
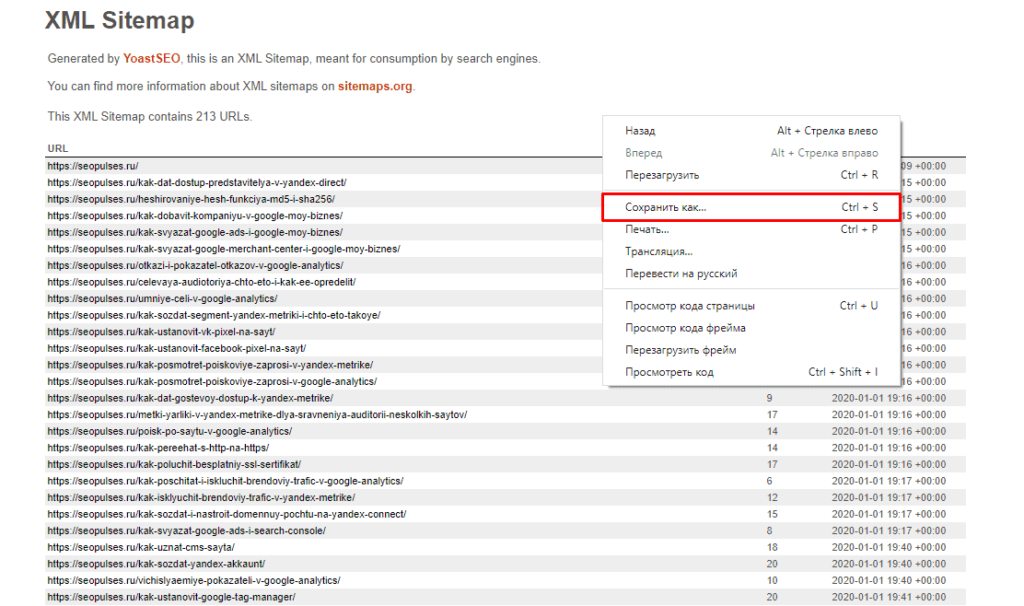
Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.
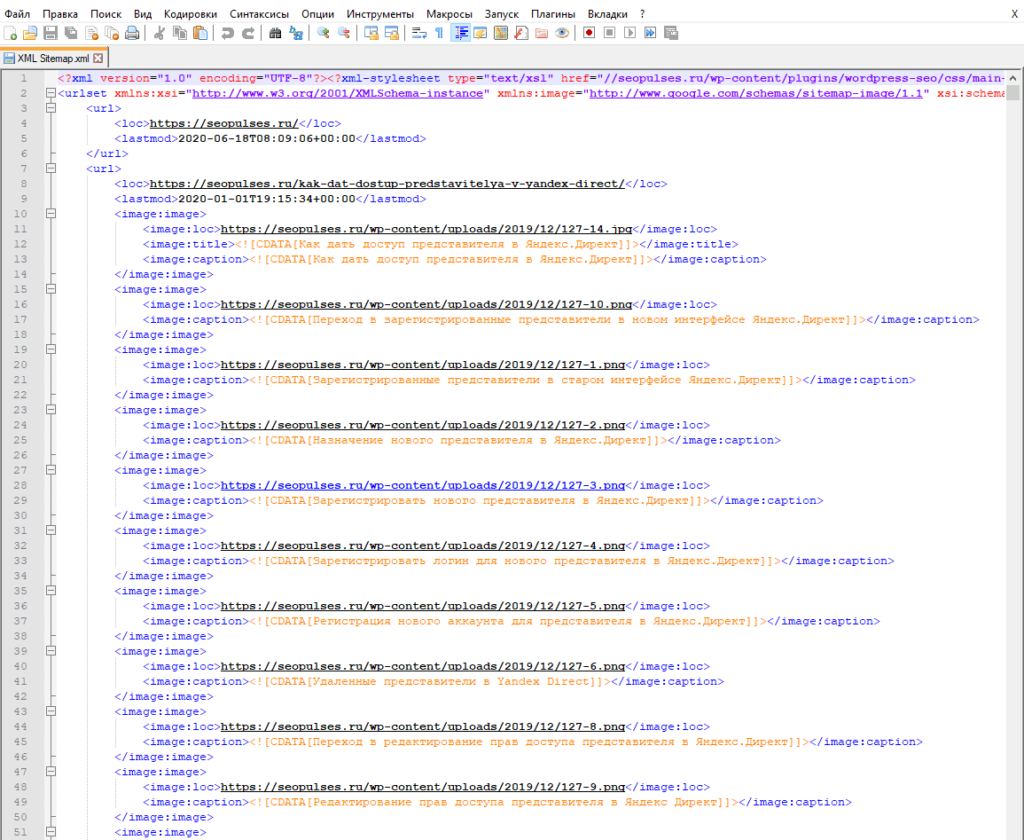
Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.
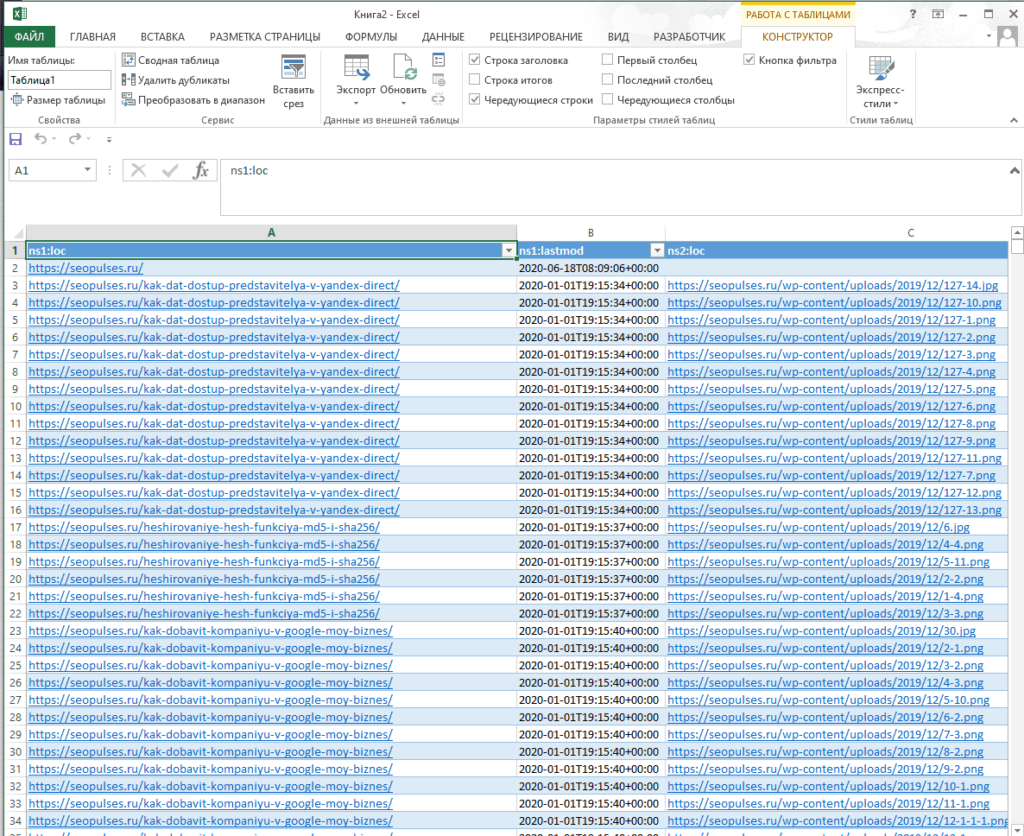
Все готово, можно переходить к методам парсинга.
IPMORTXML для парсинга сайтов в Excel
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос)
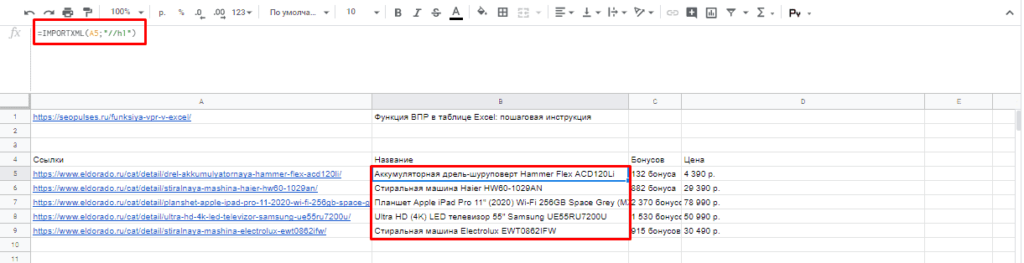
Где:
- Ссылка — URL-адрес страницы;
- Запрос – в формате XPath.
С примером можно ознакомиться в:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit#gid=0
Примеры использования IMPORTXML в Google Doc
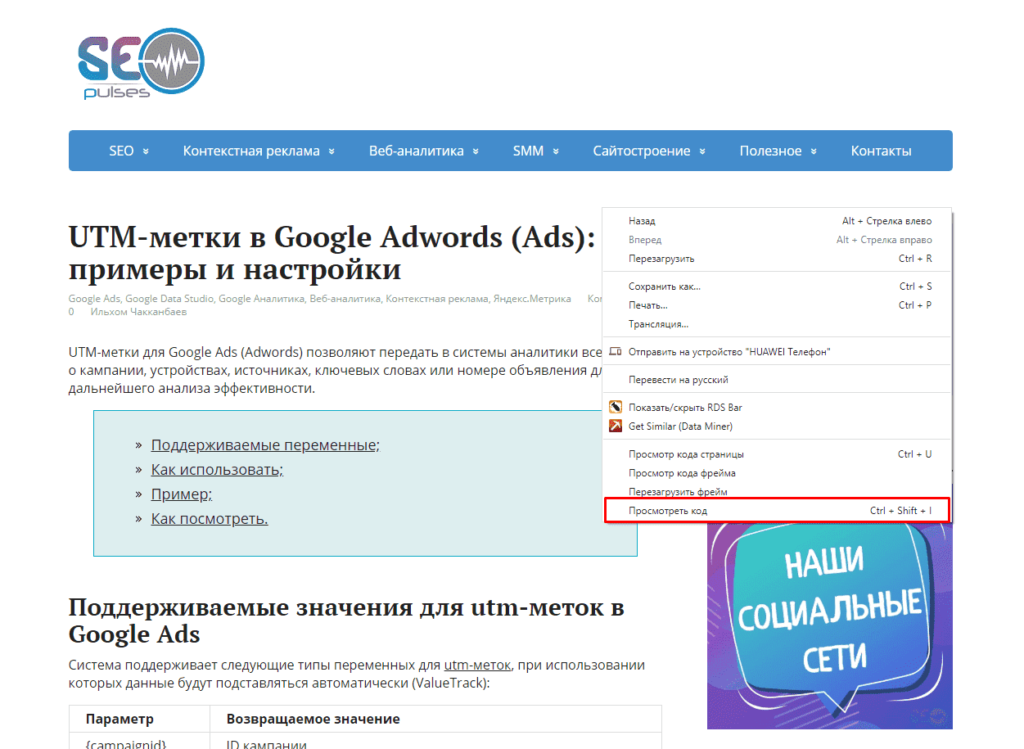
Парсинг названий
Для работы с парсингом через данную функцию потребуется знание XPATH и составление пути в этом формате. Сделать это можно открыв консоль разработчика. Для примера будет использоваться сайт крупного интернет-магазина и в первую очередь необходимо в Google Chrome открыть окно разработчика кликнув правой кнопкой мыли и в выпавшем меню выбрать «Посмотреть код» (сочетание клавиш CTRL+Shift+I).
После этого пытаемся получить название товара, которое содержится в H1, единственным на странице, поэтому запрос должен быть:
//h1
И как следствие формула:
=IMPORTXML(A2;»//h1″)
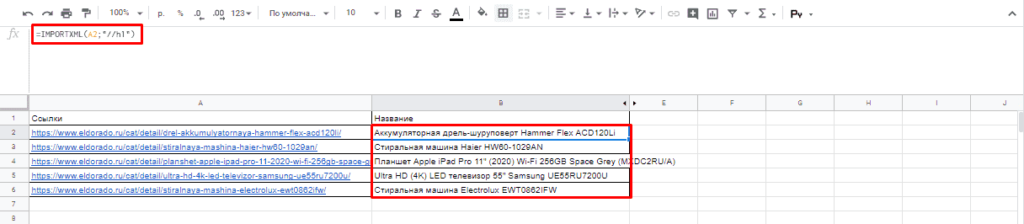
Важно! Запрос XPath пишется в кавычках «запрос».
Парсинг различных элементов
Если мы хотим получить баллы, то нам потребуется обратиться к элементу div с классом product-standart-bonus поэтому получаем:
//div[@class=’product-standart-bonus’]
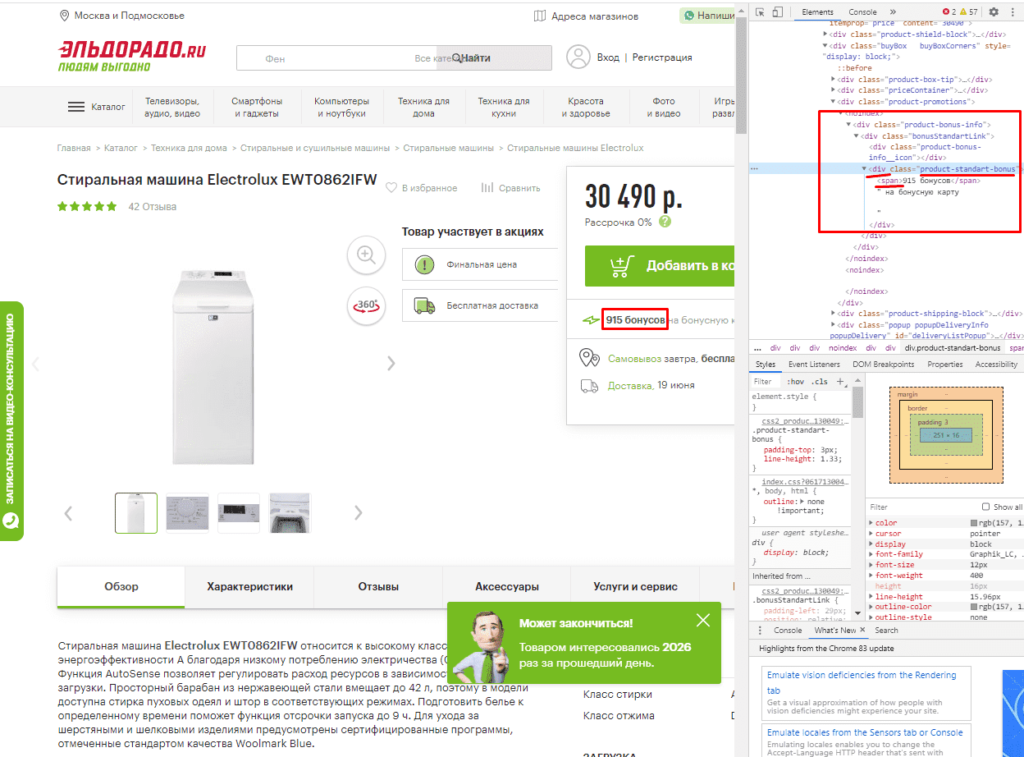
В этом случае первый тег div обозначает то, откуда берутся данные, когда в скобках [] уточняется его уникальность.
Для уточнения потребуется указать тип в виде @class, который может быть и @id, а после пишется = и в одинарных кавычках ‘значение’ пишется запрос.
Однако, нужное нам значение находиться глубже в теге span, поэтому добавляем /span и вводим:
//div[@class=’product-standart-bonus’]/span
В документе:

Парсинг цен без знаний XPath
Если нет знаний XPath и необходимо быстро получить информацию, то требуется выбрав нужный элемент в консоли разработчика кликнуть правой клавишей мыши и в меню выбрать «Copy»-«XPath». Например, при поиске запроса цены получаем:
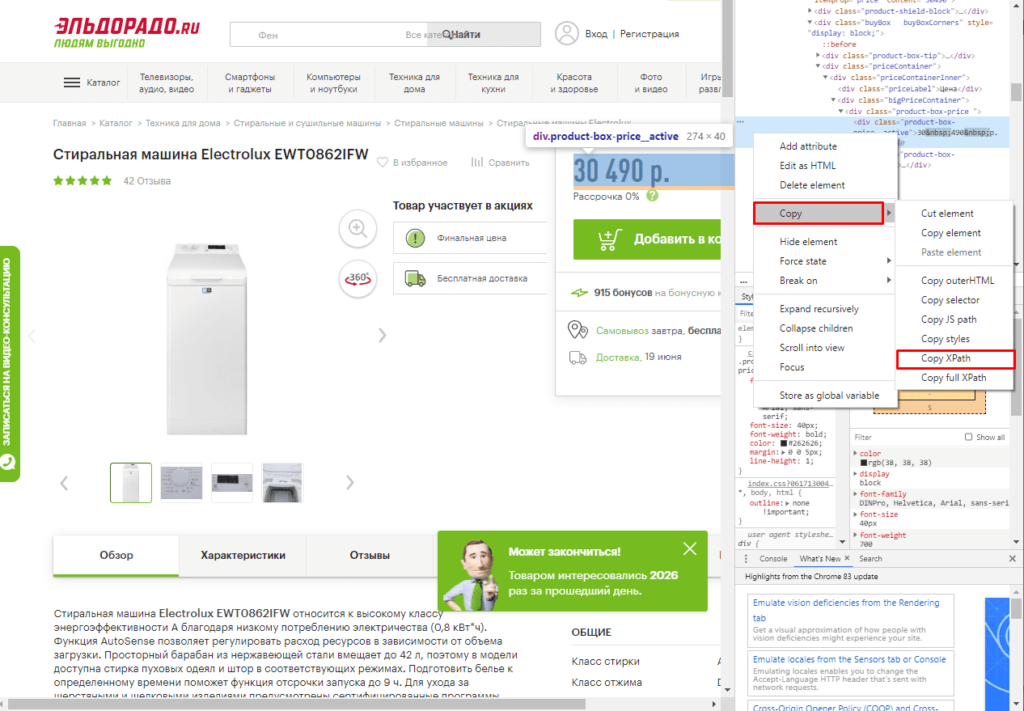
//*[@id=»showcase»]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div/div[1]
Важно! Следует изменить » на одинарные кавычки ‘.
Далее используем ее вместе с IMPORTXML.
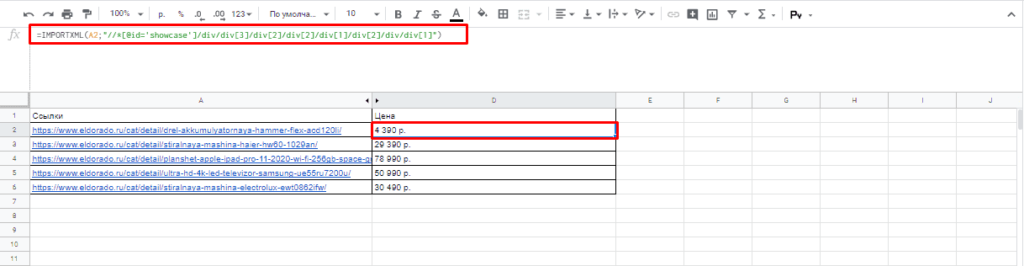
Все готово цены получены.
Простые формулы с IMPORTXML в Google Sheets
Чтобы получить title страницы необходимо использовать запрос:
=IMPORTXML(A3;»//title»)
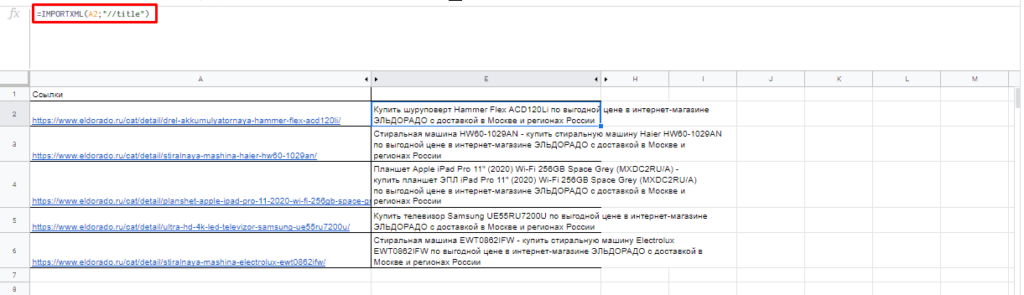
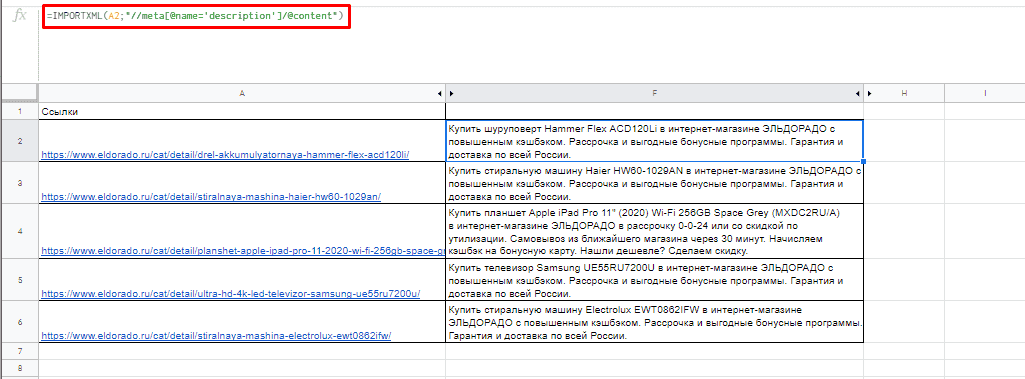
Для вывода description стоит использовать:
=IMPORTXML(A3;»//description»)
Первый заголовок (или любой другой):
=IMPORTXML(A3;»//h1″)

IMPORTHTML для создания парсера веи-ресурсов в Эксель
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос;Индекс)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – может быть в формате «table» или «list», выгружающий таблицу и список, соответственно.
- Индекс – порядковый номер элемента.
С примерами можно ознакомиться в файле:
https://docs.google.com/spreadsheets/d/1GpcGZd7CW4ugGECFHVMqzTXrbxHhdmP-VvIYtavSp4s/edit#gid=0
Пример использования IMPORTHTML в Google Doc
Парсинг таблиц
В примерах будет использоваться данная статья, перейдя на которую можно открыть консоль разработчика (в Google Chrome это можно сделать кликнув правой клавишей мыши и выбрав пункт «Посмотреть код» или же нажав на сочетание клавиш «CTRL+Shift+I»).
Теперь просматриваем код таблицы, которая заключена в теге <table>.
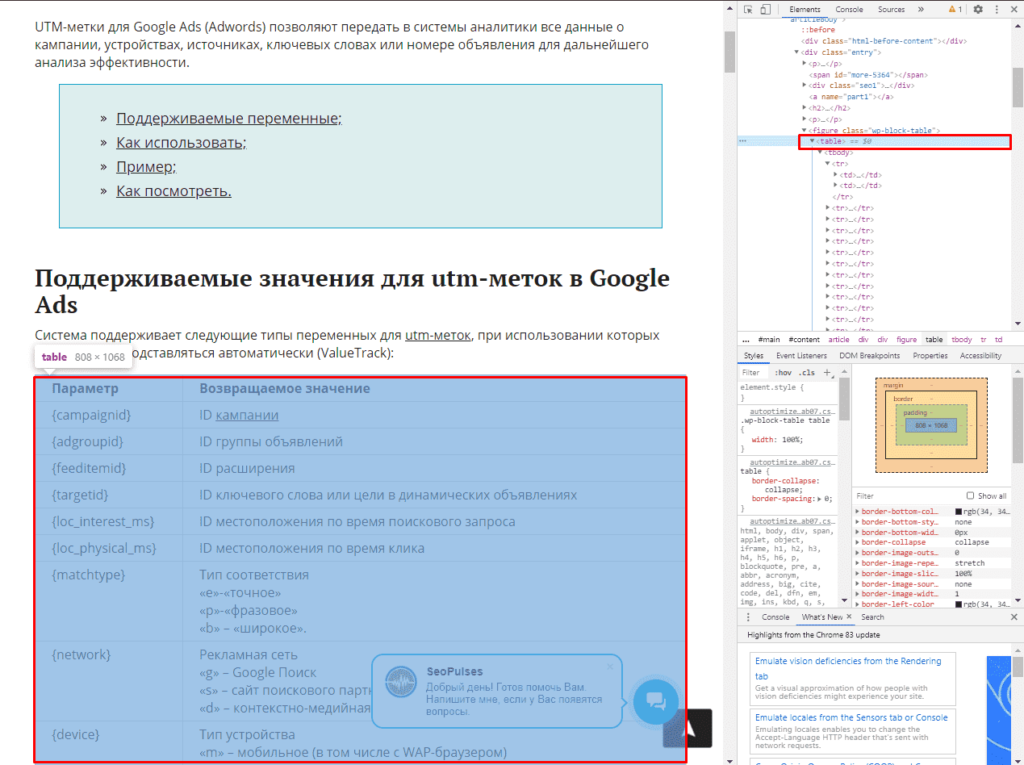
Данный элемент можно будет выгрузить при помощи конструкции:
=IMPORTHTML(A2;»table»;1)
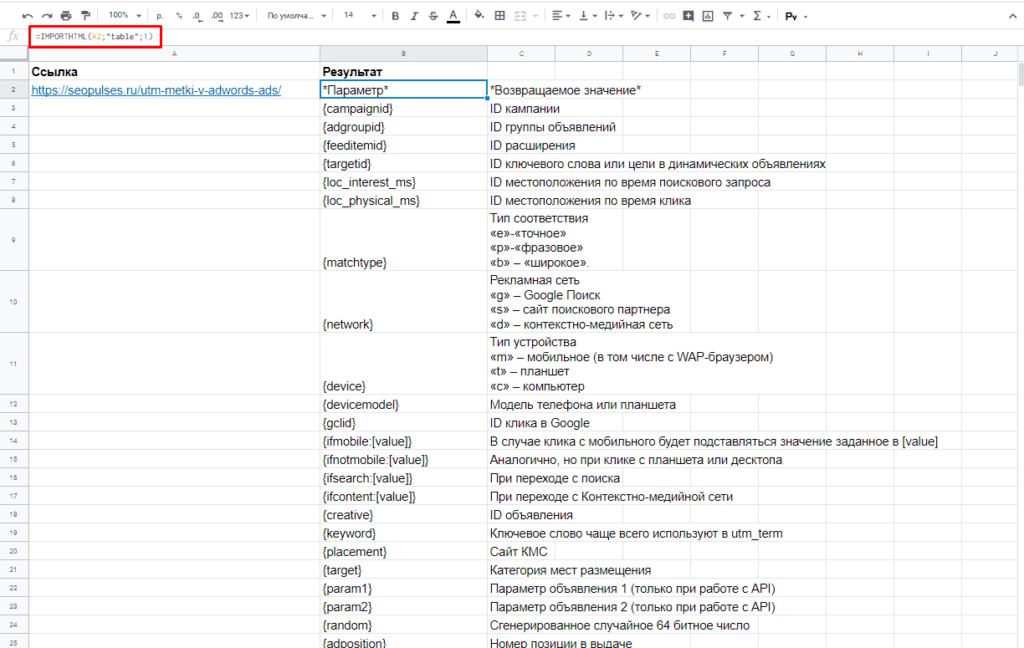
- Где A2 ячейка со ссылкой;
- table позволяет получить данные с таблицы;
- 1 – номер таблицы.
Важно! Сам запрос table или list записывается в кавычках «запрос».
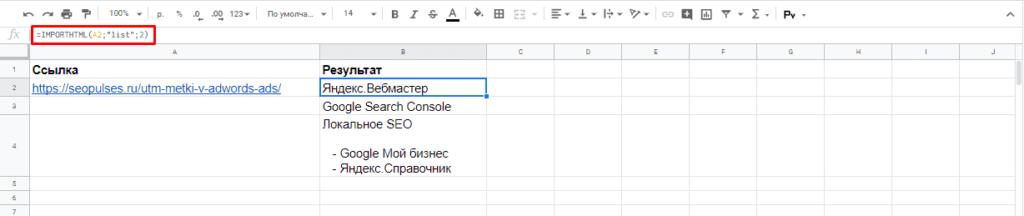
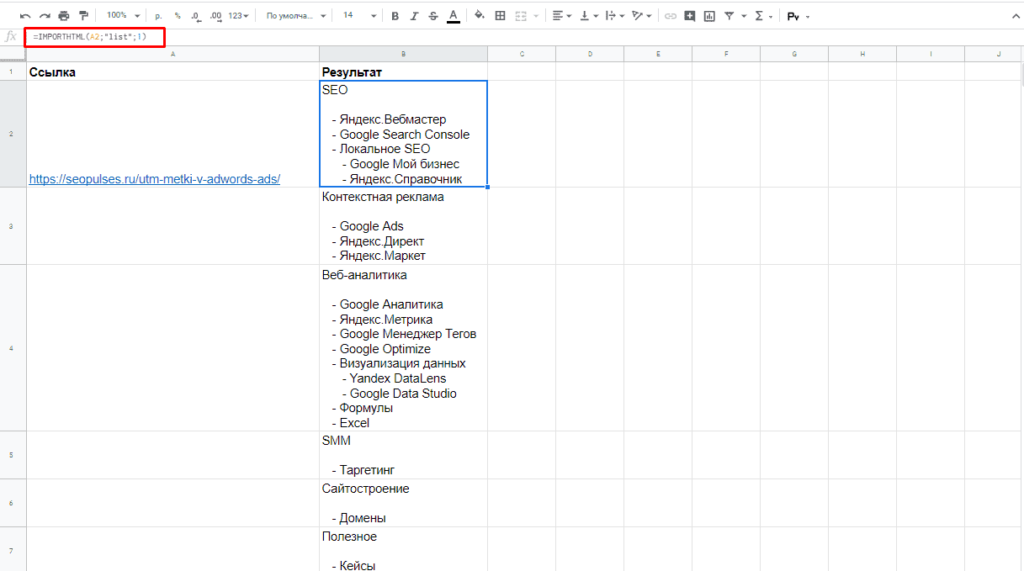
Парсинг списков
Получить список, заключенный в тегах <ul>…</ul> при помощи конструкции.
=IMPORTHTML(A2;»list»;1)
В данном случае речь идет о меню, которое также представлено в виде списка.
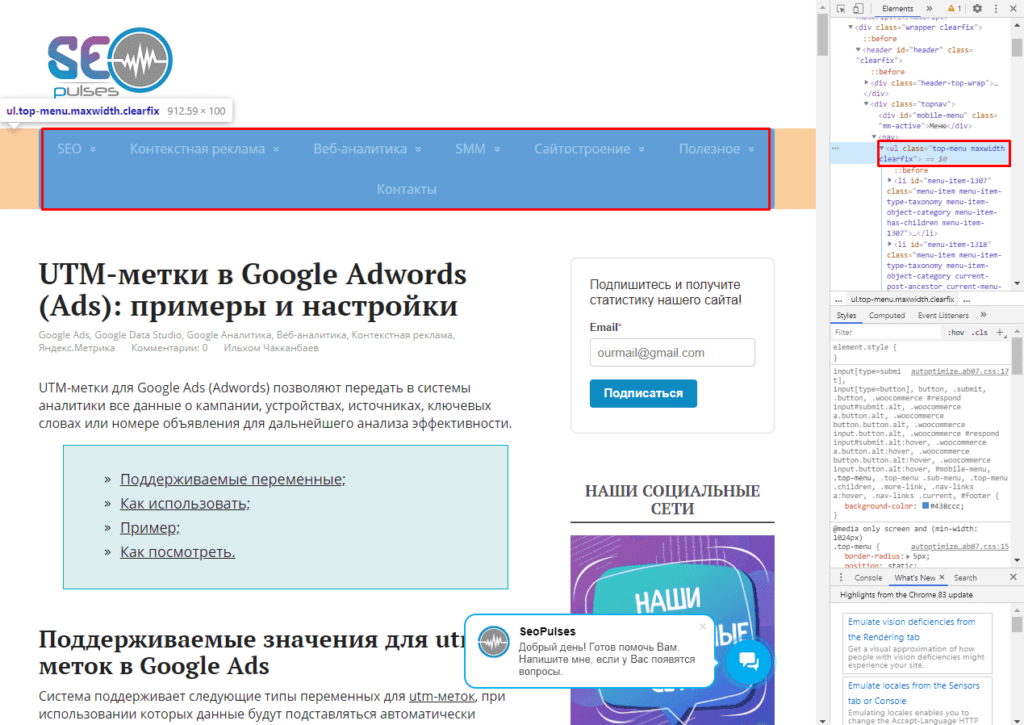
Если использовать индекс третей таблицы, то будут получены данные с третей таблицы в меню:
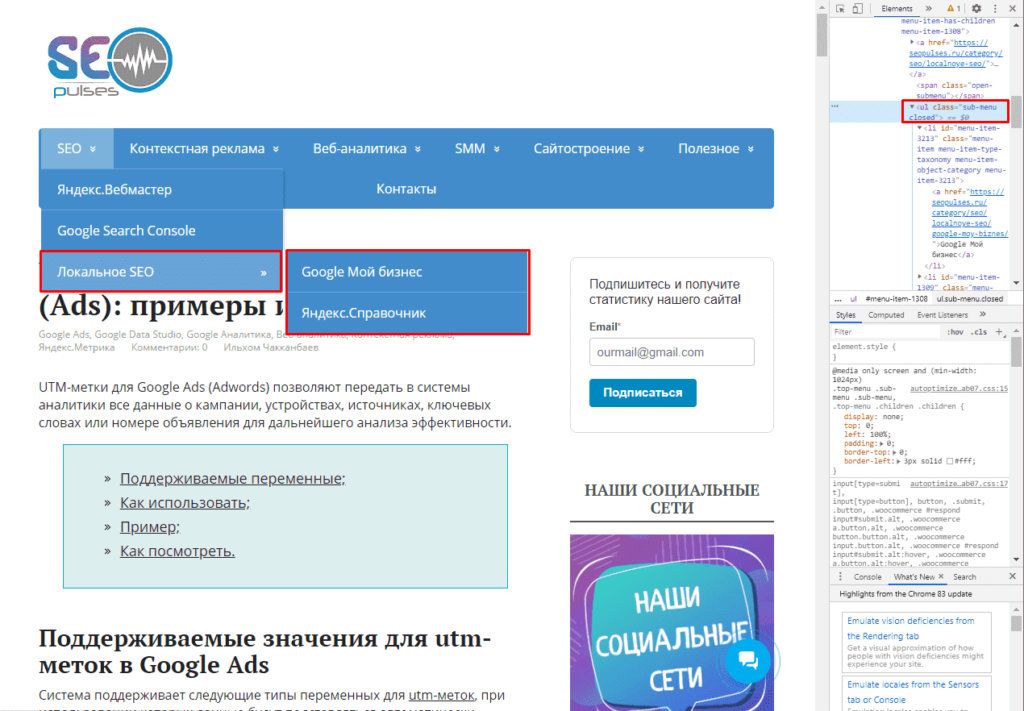
Формула:
=IMPORTHTML(A2;»list»;2)
Все готово, данные получены.
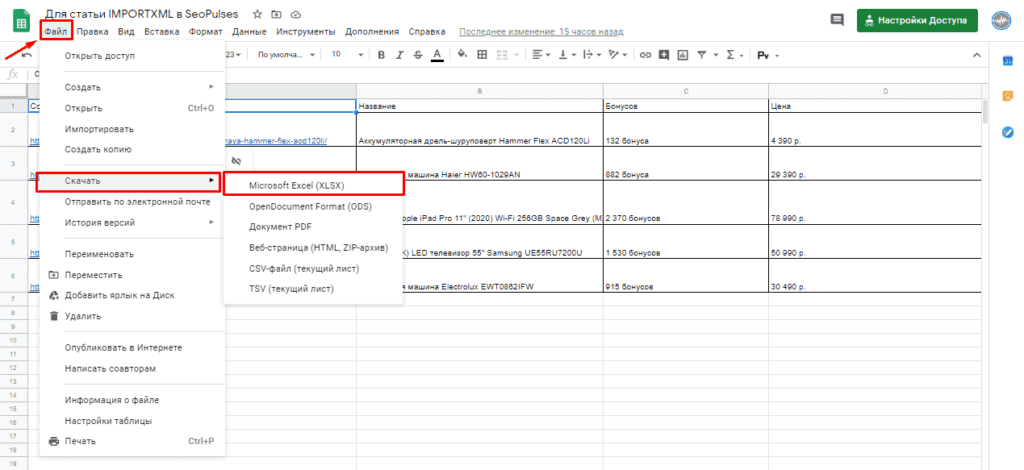
Обратная конвертация
Чтобы превратить Google таблицу в MS Excel потребуется кликнуть на вкладку «Файл»-«Скачать»-«Microsoft Excel».
Все готово, пример можно скачать ниже.
Пример:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit
⚠️ This repository is deprecated. We’ve released new and improved HyperFormula engine.
Formula Parser 
Library provides a Parser class that evaluates excel and mathematical formulas.
Install
A recommended way to install Formula Parser is through NPM using the following command:
$ npm install hot-formula-parser --save
Node.js:
var FormulaParser = require('hot-formula-parser').Parser; var parser = new FormulaParser(); parser.parse('SUM(1, 6, 7)'); // It returns `Object {error: null, result: 14}`
Browser:
<script src="/node_modules/hot-formula-parser/dist/formula-parser.min.js"></script> <script> var parser = new formulaParser.Parser(); parser.parse('SUM(1, 6, 7)'); // It returns `Object {error: null, result: 14}` </script>
Features
It supports:
- Any numbers, negative and positive as float or integer;
- Arithmetic operations like
+,-,/,*,%,^; - Logical operations like
AND(),OR(),NOT(),XOR(); - Comparison operations like
=,>,>=,<,<=,<>; - All JavaScript Math constants like
PI(),E(),LN10(),LN2(),LOG10E(),LOG2E(),SQRT1_2(),SQRT2(); - String operations like
&(concatenation eq.parser.parse('-(2&5)');will return-25); - All excel formulas defined in formula.js;
- Relative and absolute cell coordinates like
A1,$A1,A$1,$A$1; - Build-in variables like
TRUE,FALSE,NULL - Custom variables;
- Custom functions/formulas;
- Node and Browser environment.
API (methods)
var parser = new formulaParser.Parser();
.parse(expression)
Parses and evaluates provided expression. It always returns an object with result and error properties. result property
always keep evaluated value. If error occurs error property will be set as:
#ERROR!General error;#DIV/0!Divide by zero error;#NAME?Not recognised function name or variable name;#N/AIndicates that a value is not available to a formula;#NUM!Occurs when formula encounters an invalid number;#VALUE!Occurs when one of formula arguments is of the wrong type.
parser.parse('(1 + 5 + (5 * 10)) / 10'); // returns `Object {error: null, result: 5.6}` parser.parse('SUM(MY_VAR)'); // returns `Object {error: "#NAME?", result: null}` parser.parse('1;;1'); // returns `Object {error: "#ERROR!", result: null}`
.setVariable(name, value)
Set predefined variable name which can be visible while parsing formula expression.
parser.setVariable('MY_VARIABLE', 5); parser.setVariable('fooBar', 10); parser.parse('(1 + MY_VARIABLE + (5 * fooBar)) / fooBar'); // returns `5.6`
.getVariable(name)
Get variable name.
parser.setVariable('fooBar', 10); parser.getVariable('fooBar'); // returns `10`
.setFunction(name, fn)
Set custom function which can be visible while parsing formula expression.
parser.setFunction('ADD_5', function(params) { return params[0] + 5; }); parser.setFunction('GET_LETTER', function(params) { var string = params[0]; var index = params[1] - 1; return string.charAt(index); }); parser.parse('SUM(4, ADD_5(1))'); // returns `10` parser.parse('GET_LETTER("Some string", 3)'); // returns `m`
.getFunction(name)
Get custom function.
parser.setFunction('ADD_5', function(params) { return params[0] + 5; }); parser.getFunction('ADD_5')([1]); // returns `6`
.SUPPORTED_FORMULAS
List of all supported formulas function.
require('hot-formula-parser').SUPPORTED_FORMULAS; // An array of formula names
API (hooks)
‘callVariable’ (name, done)
Fired while retrieving variable. If variable was defined earlier using setVariable you can overwrite it by this hook.
parser.on('callVariable', function(name, done) { if (name === 'foo') { done(Math.PI / 2); } }); parser.parse('SUM(SIN(foo), COS(foo))'); // returns `1`
‘callFunction’ (name, params, done)
Fired while calling function. If function was defined earlier using setFunction you can overwrite it’s result by this hook.
You can also use this to override result of build-in formulas.
parser.on('callFunction', function(name, params, done) { if (name === 'ADD_5') { done(params[0] + 5); } }); parser.parse('ADD_5(3)'); // returns `8`
‘callCellValue’ (cellCoord, done)
Fired while retrieving cell value by its label (eq: B3, B$3, B$3, $B$3).
parser.on('callCellValue', function(cellCoord, done) { // using label if (cellCoord.label === 'B$6') { done('hello'); } // or using indexes if (cellCoord.row.index === 5 && cellCoord.row.isAbsolute && cellCoord.column.index === 1 && !cellCoord.column.isAbsolute) { done('hello'); } if (cellCoord.label === 'C6') { done(0.75); } }); parser.parse('B$6'); // returns `"hello"` parser.parse('B$6&" world"'); // returns `"hello world"` parser.parse('FISHER(C6)'); // returns `0.9729550745276566`
‘callRangeValue’ (startCellCoord, endCellCoord, done)
Fired while retrieving cells range value (eq: A1:B3, $A1:B$3, A$1:B$3, $A$1:$B$3).
parser.on('callRangeValue', function(startCellCoord, endCellCoord, done) { var data = [ [1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15], [16, 17, 18, 19, 20], ]; var fragment = []; for (var row = startCellCoord.row.index; row <= endCellCoord.row.index; row++) { var rowData = data[row]; var colFragment = []; for (var col = startCellCoord.column.index; col <= endCellCoord.column.index; col++) { colFragment.push(rowData[col]); } fragment.push(colFragment); } if (fragment) { done(fragment); } }); parser.parse('JOIN(A1:E2)'); // returns `"1,2,3,4,5,6,7,8,9,10"` parser.parse('COLUMNS(A1:E2)'); // returns `5` parser.parse('ROWS(A1:E2)'); // returns `2` parser.parse('COUNT(A1:E2)'); // returns `10` parser.parse('COUNTIF(A1:E2, ">5")'); // returns `5`
Want to help?
Please see CONTRIBUTING.md.
Changelog
To see the list of recent changes, see Releases section.
License
The MIT License (see the LICENSE file for the full text).
Contact
You can contact us at hello@handsontable.com.