
The weird characters you got from reading the Excel file from the FileReader API comes from the structure of the file that differs a lot from a text file.
So reading it as text with the FileReader API will give those weirds character as a result.
What you can do is to use the FileReader API to read it as a binary string.
At this point if you try to log that binary string you will also get weirds characters.
In order to get your file content you need to parse that binary string to extract the data it contains. This can be done quite easily using SheetJS.
import { read, writeFileXLSX, utils } from "https://cdn.sheetjs.com/xlsx-0.18.7/package/xlsx.mjs";
const workbook = read(data, {
type:'binary',
});
data is the binary string resulting from reading an Excel file as a binary string with the FileReader API.
workbook is an object that contains all the data of your file.
The workbook.Sheets instruction will give you access to all the sheets that are in the file.
workbook.Sheets.sheet1 will give you access to the content of the first sheet of the file.
All the related arrays are from the {key:value} type.
The content of a sheet accessed this way is a single dimension object array wich contains all the cells of the sheet starting from the first cell of the header to the last cell wich contains data.
Each of those cells has a key like this 'A1', 'B250', 'J3'
This array also have two more entries with those keys '!margin' and '!ref':
'!margin' refers to cells margins so it may not represent any interest.
'!ref' is more interesting as it contains the plage of cells containing data wich is a string
like this 'A1:J215' from it you could get the amount of lines or the char of the last column.
If you want more informations you could check the SheetJS documentation and there is a more detailed example here : How to read an excel file contents on client side?
Note :
If you want to use this import statement in an html page you’ll need to do it inside those scripts tags : <script type="module" defer> ... </script>
Here is a codepen where you can test this method. There’s only the most basic method. There are some shorter ways to do the same by using the SheetJS utils functions to convert directly the sheet content to another format.
Парсинг нетабличных данных с сайтов
Проблема с нетабличными данными
С загрузкой в Excel табличных данных из интернета проблем нет. Надстройка Power Query в Excel легко позволяет реализовать эту задачу буквально за секунды. Достаточно выбрать на вкладке Данные команду Из интернета (Data — From internet), вставить адрес нужной веб-страницы (например, ключевых показателей ЦБ) и нажать ОК:

Power Query автоматически распознает все имеющиеся на веб-странице таблицы и выведет их список в окне Навигатора:

Дальше останется выбрать нужную таблицу методом тыка и загрузить её в Power Query для дальнейшей обработки (кнопка Преобразовать данные) или сразу на лист Excel (кнопка Загрузить).
Если с нужного вам сайта данные грузятся по вышеописанному сценарию — считайте, что вам повезло.
К сожалению, сплошь и рядом встречаются сайты, где при попытке такой загрузки Power Query «не видит» таблиц с нужными данными, т.е. в окне Навигатора попросту нет этих Table 0,1,2… или же среди них нет таблицы с нужной нам информацией. Причин для этого может быть несколько, но чаще всего это происходит потому, что веб-дизайнер при создании таблицы использовал в HTML-коде страницы не стандартную конструкцию с тегом <TABLE>, а её аналог — вложенные друг в друга теги-контейнеры <DIV>. Это весьма распространённая техника при вёрстке веб-сайтов, но, к сожалению, Power Query пока не умеет распознавать такую разметку и загружать такие данные в Excel.
Тем не менее, есть способ обойти это ограничение 
В качестве тренировки, давайте попробуем загрузить цены и описания товаров с маркетплейса Wildberries — например, книг из раздела Детективы:

Загружаем HTML-код вместо веб-страницы
Сначала используем всё тот же подход — выбираем команду Из интернета на вкладке Данные (Data — From internet) и вводим адрес нужной нам страницы:
https://www.wildberries.ru/catalog/knigi/hudozhestvennaya-literatura/detektivy
После нажатия на ОК появится окно Навигатора, где мы уже не увидим никаких полезных таблиц, кроме непонятной Document:

Дальше начинается самое интересное. Жмём на кнопку Преобразовать данные (Transform Data), чтобы всё-таки загрузить содержимое таблицы Document в редактор запросов Power Query. В открывшемся окне удаляем шаг Навигация (Navigation) красным крестом:

… и затем щёлкаем по значку шестерёнки справа от шага Источник (Source), чтобы открыть его параметры:

В выпадающием списке Открыть файл как (Open file as) вместо выбранной там по-умолчанию HTML-страницы выбираем Текстовый файл (Text file). Это заставит Power Query интерпретировать загружаемые данные не как веб-страницу, а как простой текст, т.е. Power Query не будет пытаться распознавать HTML-теги и их атрибуты, ссылки, картинки, таблицы, а просто обработает исходный код страницы как текст.
После нажатия на ОК мы этот HTML-код как раз и увидим (он может быть весьма объемным — не пугайтесь):

Ищем за что зацепиться
Теперь нужно понять на какие теги, атрибуты или метки в коде мы можем ориентироваться, чтобы извлечь из этой кучи текста нужные нам данные о товарах. Само-собой, тут всё зависит от конкретного сайта и веб-программиста, который его писал и вам придётся уже импровизировать.
В случае с Wildberries, промотав этот код вниз до товаров, можно легко нащупать простую логику:

- Строчки с ценами всегда содержат метку lower-price
- Строчки с названием бренда — всегда с меткой brand-name c-text-sm
- Название товара можно найти по метке goods-name c-text-sm
Иногда процесс поиска можно существенно упростить, если воспользоваться инструментами отладки кода, которые сейчас есть в любом современном браузере. Щёлкнув правой кнопкой мыши по любому элементу веб-страницы (например, цене или описанию товара) можно выбрать из контекстного меню команду Инспектировать (Inspect) и затем просматривать код в удобном окошке непосредственно рядом с содержимым сайта:

Фильтруем нужные данные
Теперь совершенно стандартным образом давайте отфильтруем в коде страницы нужные нам строки по обнаруженным меткам. Для этого выбираем в окне Power Query в фильтре [1] опцию Текстовые фильтры — Содержит (Text filters — Contains), переключаемся в режим Подробнее (Advanced) [2] и вводим наши критерии:

Добавление условий выполняется кнопкой со смешным названием Добавить предложение [3]. И не забудьте для всех условий выставить логическую связку Или (OR) вместо И (And) в выпадающих списках слева [4] — иначе фильтрация просто не сработает.
После нажатия на ОК на экране останутся только строки с нужной нам информацией:

Чистим мусор
Останется почистить всё это от мусора любым подходящим и удобным лично вам способом (их много). Например, так:
- Удалить заменой на пустоту начальный тег: <span class=»price»> через команду Главная — Замена значений (Home — Replace values).
- Разделить получившийся столбец по первому разделителю «>» слева командой Главная — Разделить столбец — По разделителю (Home — Split column — By delimiter) и затем ещё раз разделить получившийся столбец по первому вхождению разделителя «<» слева, чтобы отделить полезные данные от тегов:

- Удалить лишние столбцы, а в оставшемся заменить стандартную HTML-конструкцию " на нормальные кавычки.

В итоге получим наши данные в уже гораздо более презентабельном виде:

Разбираем блоки по столбцам
Если присмотреться, то информация о каждом отдельном товаре в получившемся списке сгруппирована в блоки по три ячейки. Само-собой, нам было бы гораздо удобнее работать с этой таблицей, если бы эти блоки превратились в отдельные столбцы: цена, бренд (издательство) и наименование.
Выполнить такое преобразование можно очень легко — с помощью, буквально, одной строчки кода на встроенном в Power Query языке М. Для этого щёлкаем по кнопке fx в строке формул (если у вас её не видно, то включите её на вкладке Просмотр (View)) и вводим следующую конструкцию:
= Table.FromRows(List.Split(#»Замененное значение1″[Column1.2.1],3))
Здесь функция List.Split разбивает столбец с именем Column1.2.1 из нашей таблицы с предыдущего шага #»Замененное значение1″ на кусочки по 3 ячейки, а потом функция Table.FromRows конвертирует получившиеся вложенные списки обратно в таблицу — уже из трёх столбцов:

Ну, а дальше уже дело техники — настроить числовые форматы столбцов, переименовать их и разместить в нужном порядке. И выгрузить получившуюся красоту обратно на лист Excel командой Главная — Закрыть и загрузить (Home — Close & Load…)

Вот и все хитрости 
Ссылки по теме
- Импорт курса биткойна с сайта через Power Query
- Парсинг текста регулярными выражениями (RegExp) в Power Query
- Параметризация путей к данным в Power Query

Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей.
Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
Пример использования парсера для мониторинга цен конкурентов
Дополнительные видеоинструкции, а также подробное описание функционала, можно найти в разделе Справка по программе
В программе можно настроить несколько парсеров (обработчиков сайтов).
Любой из парсеров настраивается и работает независимо от других.
Примеры настроенных парсеров (можно скачать, запустить, посмотреть настройки)
Видеоинструкция (2 минуты), как запустить готовый (уже настроенный) парсер
Настройка программы, — дело не самое простое (для этого, надо хоть немного разбираться в HTML)
Если вам нужен готовый парсер, но вы не хотите разбираться с настройкой,
— закажите настройку парсера разработчику программы. Стоимость настройки под конкретный сайт — от 2000 рублей.
(настройка под заказ выполняется только при условии приобретения лицензии на надстройку «Парсер» (3300 руб)
Инструкция (с видео) по заказу настройки парсера
По всем вопросам, готов проконсультировать вас в Скайпе.
Программа не привязана к конкретному файлу Excel.
Вы в настройках задаёте столбец с исходными данными (ссылками или артикулами),
настраиваете формирование ссылок и подстановку данных с сайта в нужные столбцы,
нажимаете кнопку, — и ваша таблица заполняется данными с сайта.
Программа «Парсер сайтов» может быть полезна для формирования каталога товаров интернет-магазинов,
поиска и загрузки фотографий товара по артикулам (если для получения ссылки на фото, необходимо анализировать страницу товара),
загрузки актуальных данных (цен и наличия) с сайтов поставщиков, и т.д. и т.п.
Справка по программе «Парсер сайтов»
Можно попробовать разобраться с работой программы на примерах настроенных парсеров
Пользовательские функции VBA Excel для парсинга сайтов, html-страниц и файлов, возвращающие их текстовое содержимое. Примеры записи текста в переменную.
Парсинг html-страниц (msxml2.xmlhttp)
Пользовательская функция GetHTML1 (VBA Excel) для извлечения (парсинга) текстового содержимого из html-страницы сайта по ее URL-адресу с помощью объекта «msxml2.xmlhttp»:
|
Function GetHTML1(ByVal myURL As String) As String On Error Resume Next With CreateObject(«msxml2.xmlhttp») .Open «GET», myURL, False .send Do: DoEvents: Loop Until .readyState = 4 GetHTML1 = .responseText End With End Function |
Парсинг сайтов (WinHttp.WinHttpRequest.5.1)
Пользовательская функция GetHTML2 (VBA Excel) для извлечения (парсинга) текстового содержимого из html-страницы сайта по ее URL-адресу с помощью объекта «WinHttp.WinHttpRequest.5.1»:
|
Function GetHTML2(ByVal myURL As String) As String On Error Resume Next With CreateObject(«WinHttp.WinHttpRequest.5.1») .Open «GET», myURL, False .send Do: DoEvents: Loop Until .readyState = 4 GetHTML2 = .responseText End With End Function |
Парсинг файлов (ADODB.Stream)
Пользовательская функция GetText (VBA Excel) для извлечения (парсинга) текстового содержимого из файла (.txt, .csv, .mhtml), сохраненного на диск компьютера, по его полному имени (адресу) с помощью объекта «ADODB.Stream»:
|
Function GetText(ByVal myFile As String) As String On Error Resume Next With CreateObject(«ADODB.Stream») .Charset = «utf-8» .Open .LoadFromFile myFile GetText = .ReadText .Close End With End Function |
Примеры записи текста в переменную
Общая формула записи текста, извлеченного с помощью пользовательских функций VBA Excel, в переменную:
|
Dim htmlText As String htmlText = GetHTML1(«Адрес сайта (html-страницы)») htmlText = GetHTML2(«Адрес сайта (html-страницы)») htmlText = GetText(«Полное имя файла») |
Конкретные примеры:
|
htmlText = GetHTML1(«https://internettovary.ru/nabor-dlya-vyrashchivaniya-veshenki/») htmlText = GetHTML2(«https://internettovary.ru/nabor-dlya-vyrashchivaniya-veshenki/») htmlText = GetText(«C:UsersEvgeniyDownloadsНовый текстовый документ.txt») htmlText = GetText(«C:UsersEvgeniyDownloadsИспользование msxml2.xmlhttp в Excel VBA.mhtml») |
В понятие «парсинг», кроме извлечения текстового содержимого сайтов, html-страниц или файлов, входит поиск и извлечение конкретных данных из всего полученного текстового содержимого.
Пример извлечения email-адресов из текста, присвоенного переменной, смотрите в последнем параграфе статьи: Регулярные выражения (объекты, свойства, методы).
Парсинг содержимого тегов
Извлечение содержимого тегов с помощью метода getElementsByTagName объекта HTMLFile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Sub Primer1() Dim myHtml As String, myFile As Object, myTag As Object, myTxt As String ‘Извлекаем содержимое html-страницы в переменную myHtml с помощью функции GetHTML1 myHtml = GetHTML1(«https://internettovary.ru/sadovaya-nozhovka-sinitsa/») ‘Создаем объект HTMLFile Set myFile = CreateObject(«HTMLFile») ‘Записываем в myFile текст из myHtml myFile.body.innerHTML = myHtml ‘Присваиваем переменной myTag коллекцию одноименных тегов, имя которого ‘указанно в качестве аргумента метода getElementsByTagName Set myTag = myFile.getElementsByTagName(«p») ‘Выбираем, содержимое какого тега по порядку, начинающегося с 0, нужно извлечь myTxt = myTag(5).innerText MsgBox myTxt ‘Большой текст может не уместиться в MsgBox, тогда для просмотра используйте окно Immediate ‘Debug.Print myTxt End Sub |
С помощью этого кода извлекается текст, расположенный между открывающим и закрывающим тегами. В примере — это текст 6-го абзаца (p) между 5-й (нумерация с 0) парой отрывающего <p> и закрывающего </p> тегов.
Примеры тегов, используемых в html: "p", "title", "h1", "h2", "table", "div", "script".
Пример извлечения содержимого тега "title":
|
Sub Primer2() Dim myHtml As String, myFile As Object, myTag As Object, myTxt As String myHtml = GetHTML1(«https://internettovary.ru/sadovaya-nozhovka-sinitsa/») Set myFile = CreateObject(«HTMLFile») myFile.body.innerHTML = myHtml Set myTag = myFile.getElementsByTagName(«title») myTxt = myTag(0).innerText MsgBox myTxt End Sub |
Парсинг содержимого Id
Извлечение текстового содержимого html-элементов, имеющих уникальный идентификатор — Id, с помощью метода getElementById объекта HTMLFile:
|
Sub Primer3() Dim myHtml As String, myFile As Object, myTag As Object, myTxt As String myHtml = GetHTML1(«https://internettovary.ru/sadovaya-nozhovka-sinitsa/») Set myFile = CreateObject(«HTMLFile») myFile.body.innerHTML = myHtml ‘Присваиваем переменной myTag html-элемент по указанному в скобках Id Set myTag = myFile.getElementById(«attachment_465») ‘Присваиваем переменной myTxt текстовое содержимое html-элемента с Id myTxt = myTag.innerText MsgBox myTxt ‘Большой текст может не уместиться в MsgBox, тогда для просмотра используйте окно Immediate ‘Debug.Print myTxt End Sub |
Для реализации представленных здесь примеров могут понадобиться дополнительные библиотеки. В настоящее время у меня подключены следующие (к данной теме могут относиться последние шесть):
- Visual Basic For Applications
- Microsoft Excel 16.0 Object Library
- OLE Automation
- Microsoft Office 16.0 Object Library
- Microsoft Forms 2.0 Object Library
- Ref Edit Control
- Microsoft Scripting Runtime
- Microsoft Word 16.0 Object Library
- Microsoft Windows Common Controls 6.0 (SP6)
- Microsoft ActiveX Data Objects 6.1 Library
- Microsoft ActiveX Data Objects Recordset 6.0 Library
- Microsoft HTML Object Library
- Microsoft Internet Controls
- Microsoft Shell Controls And Automation
- Microsoft XML, v6.0
С этим набором библиотек все примеры работают. Тестирование проводилось в VBA Excel 2016.
Содержание
- VBA Excel. Парсинг сайтов, html-страниц и файлов
- Парсинг html-страниц (msxml2.xmlhttp)
- Парсинг сайтов (WinHttp.WinHttpRequest.5.1)
- Парсинг файлов (ADODB.Stream)
- Примеры записи текста в переменную
- Извлечение данных из html
- Парсинг содержимого тегов
- Парсинг содержимого Id
- Как Excel и VBA помогают отправлять тысячи HTTP REST API запросов
- Часть 1. Реализация решения под Windows
- Часть 2. Реализация решения под MacOS и Excel 64-bit
- Vba excel html запросы
- Scraping a website HTML in VBA
- Step 1 — Defining the problem
- Step 2 — Analysing the target website
- Step 3 — Referencing the required applications
- Step 4 — Getting at the underlying HTML
- Step 5 — Parsing the HTML
- I need a freelance data entry & admin Urgent /span>
- I need a freelance data entry & admin «
VBA Excel. Парсинг сайтов, html-страниц и файлов
Пользовательские функции VBA Excel для парсинга сайтов, html-страниц и файлов, возвращающие их текстовое содержимое. Примеры записи текста в переменную.
Парсинг html-страниц (msxml2.xmlhttp)
Пользовательская функция GetHTML1 (VBA Excel) для извлечения (парсинга) текстового содержимого из html-страницы сайта по ее URL-адресу с помощью объекта «msxml2.xmlhttp»:
Парсинг сайтов (WinHttp.WinHttpRequest.5.1)
Пользовательская функция GetHTML2 (VBA Excel) для извлечения (парсинга) текстового содержимого из html-страницы сайта по ее URL-адресу с помощью объекта «WinHttp.WinHttpRequest.5.1»:
Парсинг файлов (ADODB.Stream)
Пользовательская функция GetText (VBA Excel) для извлечения (парсинга) текстового содержимого из файла (.txt, .csv, .mhtml), сохраненного на диск компьютера, по его полному имени (адресу) с помощью объекта «ADODB.Stream»:
Примеры записи текста в переменную
Общая формула записи текста, извлеченного с помощью пользовательских функций VBA Excel, в переменную:
Извлечение данных из html
В понятие «парсинг», кроме извлечения текстового содержимого сайтов, html-страниц или файлов, входит поиск и извлечение конкретных данных из всего полученного текстового содержимого.
Пример извлечения email-адресов из текста, присвоенного переменной, смотрите в последнем параграфе статьи: Регулярные выражения (объекты, свойства, методы).
Парсинг содержимого тегов
Извлечение содержимого тегов с помощью метода getElementsByTagName объекта HTMLFile:
С помощью этого кода извлекается текст, расположенный между открывающим и закрывающим тегами. В примере — это текст 6-го абзаца (p) между 5-й (нумерация с 0) парой отрывающего
Примеры тегов, используемых в html: «p» , «title» , «h1» , «h2» , «table» , «div» , «script» .
Пример извлечения содержимого тега «title» :
Парсинг содержимого Id
Извлечение текстового содержимого html-элементов, имеющих уникальный идентификатор — Id, с помощью метода getElementById объекта HTMLFile:
Для реализации представленных здесь примеров могут понадобиться дополнительные библиотеки. В настоящее время у меня подключены следующие (к данной теме могут относиться последние шесть):
- Visual Basic For Applications
- Microsoft Excel 16.0 Object Library
- OLE Automation
- Microsoft Office 16.0 Object Library
- Microsoft Forms 2.0 Object Library
- Ref Edit Control
- Microsoft Scripting Runtime
- Microsoft Word 16.0 Object Library
- Microsoft Windows Common Controls 6.0 (SP6)
- Microsoft ActiveX Data Objects 6.1 Library
- Microsoft ActiveX Data Objects Recordset 6.0 Library
- Microsoft HTML Object Library
- Microsoft Internet Controls
- Microsoft Shell Controls And Automation
- Microsoft XML, v6.0
С этим набором библиотек все примеры работают. Тестирование проводилось в VBA Excel 2016.
Источник
Как Excel и VBA помогают отправлять тысячи HTTP REST API запросов
Работая в IoT-сфере и плотно взаимодействуя с одним из основных элементов данной концепции технологий – сетевым сервером, столкнулся вот с какой проблемой (задачей): необходимо отправлять много запросов для работы с умными устройствами на сетевой сервер. На сервере был реализован REST API с оболочкой Swagger UI, где из графической оболочки можно было отправлять только разовые запросы. Анализ сторонних клиентов, типа Postman или Insomnia показал, что простого визуального способа поместить в скрипт массив из необходимого перечня идентификаторов устройств (или любых других элементов сервера), для обращения к ним – не нашлось.
Так как большая часть работы с выгрузками и данными была в Excel, то решено было вспомнить навыки, полученные на учебе в университете, и написать скрипт на VBA, который бы мою задачку решал.
получать информацию по устройствам с различными параметрами фильтрации (GET);
применять изменения в конфигурации по устройствам: имя, профиль устройства, сетевые лицензии и пр. (PUT);
отправлять данные для конфигурации и взаимодействия с устройствами (POST).
И сегодня я расскажу вам про то, как с помощью Excel, пары формул и самописных функций на VBA можно реализовать алгоритм, отправляющий любое необходимое количество REST-API запросов с использованием авторизации Bearer Token.
Данная статья будет полезная тем, кто воспользуется данным решением под Windows, но еще больше она будет полезна тем людям, которые хотят использовать данное решение на MacOS (с Excel x64). Как вы уже догадались, ниже будут рассмотрены два варианта реализации под разные системы, так как с MacOS есть нюанс.
Часть 1. Реализация решения под Windows
GET
Начнем с самого простого: GET – запросов. В данном примере необходимо получить ответ (информацию) от сервера по заданному списку устройств.
Для реализации GET – запросов нам дано:
1) Ссылка, в которой указываются параметры запроса.
2) Заголовки запроса + Токен авторизации (Bearer Token)
—header ‘Accept: application/json’ —header ‘Authorization: Bearer
3) Параметр, указываемый в ссылке (в данном примере это идентификаторы устройств – DevEUI):
Имея такие данные на входе, делаем в Excel лист-шаблон, который заполняем в соответствии с тем, что имеем:
столбец А уходит вот значения параметров
столбец F уходит под ссылку-родителя
столбец H уходит под заголовки, где в ячейке H1 единоразово для текущего листа указывается токен:
=СЦЕП(«—header ‘Accept: application/json’ —header ‘Authorization: Bearer «;$H$1;»‘»)
столбец I уходит под URL (ссылки-дети, на основе ссылки-родителя)
столбец J уходит под результат (ответ от сервера)
 Шаблон листа для GET-запросов
Шаблон листа для GET-запросов
Далее, нам необходимо реализовать подпрограмму(макрос) отправки GET-запросов. Состоит она из четырех частей:
цикла, который считает количество строк для работы по листу, пробегая по столбцу А с 2 по первую пустую ячейку, чтобы у цикла был конец.
функции, для работы с REST API (используется стандартная, библиотека Msxml2.XMLHTTP.6.0, встроенная в Windows., поэтому сложностей с реализацией не возникает. Для MacOS есть альтернатива)
временной задержки, в случае если нужно отправлять запросы не сразу, после получения ответа, а задав время ожидания
таймером, который показывает время выполнения всего макроса после завершения
Привязываем подпрограмму к кнопкам для удобства и выполним скрипт. Получается:

Таким образом, скрипт проходит по столбцу I, забирая из значения каждой ячейки URL, для тех строк, где в столбце А есть значения (которые и подставляются в URL). Для удобства также сделаны кнопки очистки полей и подсветка запросов условным форматированием, в случае успешного ответа на запрос.
PUT
Чуть-чуть усложним задачу и перейдем к PUT-запросам. В данном примере необходимо изменить профиль устройства, чтобы сервер по-другому с ним взаимодействовал.
К исходным данным для GET – запроса добавляется тело запроса с ключем-значением (п4). Итого дано:
1) Ссылка, в которой указываются параметры запроса.
2) Заголовки запроса + Токен авторизации (Bearer Token)
—header ‘Content-Type: application/json’ —header ‘Accept: application/json’ —header ‘Authorization: Bearer
3) Параметр, указываемый в ссылке (в данном примере это внутренние идентификаторы устройств – hRef):
4) Тело запроса, с ключом и значением:
Немного дополняем новый PUT-лист в Excel по сравнению с GET (остальное без изменений):
новый столбец B теперь отвечает за ключ deviceProfileId (ячейка B1), а все значения ниже за его возможные значения)
столбец D отвечает за формирование итогового тела сообщения в формате JSON.
Немного поменяем макрос и вынесем его в отдельную подпрограмму:
Привяжем макрос к кнопке и выполним.
Логика абсолютно аналогична GET запросу.

POST
Для POST запросов все аналогично PUT. Только немного меняется код в части типа запроса. В данном примере на устройство отправляется команда-конфигурация с указанием тела посылки (payload_hex) и порта (fport) для конкретного устройства.
Получившаяся таблица выглядит следующим образом:

На этом часть для Windows заканчивается. Здесь все оказалось довольно просто: стандартная библиотека, простенький алгоритм перебора значений в цикле.
Часть 2. Реализация решения под MacOS и Excel 64-bit
В виду того, что работал я на двух машинах под управлением разных ОС, хотелось, чтобы решение было универсальным. В итоге, собрав по крупицам информацию по интернет-форумам с данной тематикой у меня вышло следующее решение. Принцип работы его остается схожим, а изменения были внесены в часть, где использовалась стандартная библиотека WindowsMsxml2.XMLHTTP.6.0, которой в MacOS не было по понятным причинам.
Чтобы обойти данное ограничение, был выбран единственный рабочий подход через cUrl, exec и функции. Данное решение точно работает под версией MacOS 10.14 и Excel 16.51. Функция ниже, в том или ином виде, встречается на различных форумах, однако на текущих версиях софта – не работает. В итоге, после небольших правок получили рабочий вариант:
Была отлажена функция вызова ExecShell:
И написаны отдельные функции для работы с различным методами GET / PUT / POST, которые на входе принимают URL и параметры):
Так как мы заменяем библиотеку Msxml2.XMLHTTP.6.0 – поменялась реализация макросов в этой части: мы заменили Msxml2 на написанные выше функции и получили следующее:
В итоге, у меня получилось аналогичное windows по работе и функционалу решение для MacOS c использованием Excel 64-bit.
На просторах интернета я не нашел какого-то сборного и единого описания, только фрагменты кода и подходов, которые в большинстве случаев не работали полностью или частично. Поэтому решил объединить все в рабочее решение и выложить на хабр для истории.
На текущий момент я все еще не встретил иного решения, которое бы позволяло в пару кликов копипастить тысячи идентификаторов и параметров из excel и массово их отправлять на сервер. Надеюсь, кому-то пригодится 🙂
Если такие сторонние решения есть, а я не в курсе, и все можно было сделать проще, быстрее и изящнее – делитесь опытом в комментариях.
Файл-пример, который можно потыкать, пока жив сервер и «бессрочный» токен:
Источник
Vba excel html запросы

Функция GetQueryRange предназначена для автоматизации загрузки данных с веб-страниц.
Например, нам надо из макроса Excel получить данные с нескольких однотипных страниц сайта .
Самый простой способ достичь этого — выполнять почти идентичные веб-запросы (где незначительно отличаться будет только URL страницы),
каждый раз анализируя данные, загруженные веб-запросом на лист Excel
Поскольку количество обращений ко мне, с просьбами сделать программу загрузки данных из интернета , с каждым днём растёт, я решил сделать для этих целей универсальную функцию:
Dim ra As Range: On Error Resume Next
Set ra = GetQueryRange( «http://ExcelVBA.ru/» , 6)
Debug. Print ra.Address ‘ переменная ra содержит ссылку на диапазон ячеек $A$1:$C$15,
‘ содержащий данные 6-й таблицы главной страницы сайта ExcelVBA.ru
Set ra = GetQueryRange( «http://excelvba.ru/sitemap.xml» )
Debug. Print ra.Address ‘ теперь переменная ra содержит ссылку на диапазон ячеек $A$1:$D$502,
‘ содержащий данные карты сайта ExcelVBA.ru
При запуске функции, создаётся скрытый лист с именем «tmpWQ» (если такой лист уже есть — используется существующий), и на этом листе выполняется веб-запрос к указанному сайту .
В качестве параметра можно задать номер интересующей нас таблицы сайта.
Номер (или номера) требуемых страниц можно узнать, записав макрорекордером код веб-запроса к нужной веб-странице.
Функция загружает данные на лист в формате HTML, — соответственно, мы можем получить доступ к гиперссылкам в результатах веб-запроса.
В большинстве случаев, эту функцию требуется использовать внутри цикла, формируя в теле цикла очередной URL, затем выполняя запрос к сформированному URL, получая необходимые данные с листа Excel, и т.д. для каждой из ссылок:
Dim ra As Range, cell As Range, n As Long : On Error Resume Next
URL$ = «http://www.planetaexcel.ru/forum.php?forum_id=129&page_forum=» & i
Set ra = GetQueryRange(URL$, 6) ‘ выполняем веб-запрос
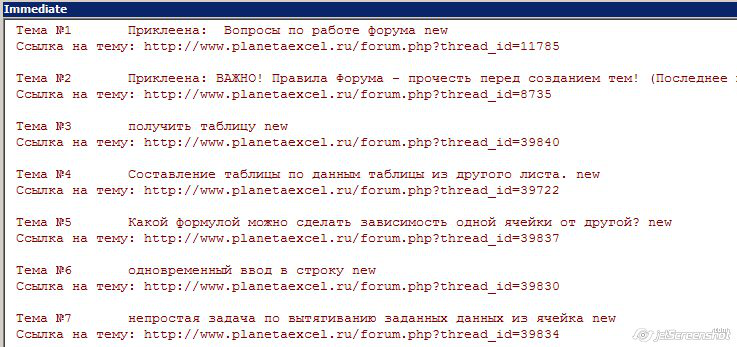
‘ перебирая ячейки таблицы-результата, выводим список тем в окно Immediate
For Each cell In ra.Columns(2).Cells
If cell.Hyperlinks.Count Then
n = n + 1: Debug. Print «Тема №» & n, cell.Text
Debug. Print «Ссылка на тему: » & cell.Hyperlinks(1).Address: Debug. Print
Скриншот результата этого макроса:
Код функции GetQueryRange:
Function GetQueryRange( ByVal SearchLink$, Optional ByVal Tables$) As Range
On Error Resume Next : Err.Clear
Dim tmpSheet As Worksheet: Set tmpSheet = ThisWorkbook.Worksheets( «tmpWQ» )
If tmpSheet Is Nothing Then
Set tmpSheet = ThisWorkbook.Worksheets.Add
If tmpSheet Is Nothing Then
msg$ = «Не удалось добавить скрытый лист «tmpWQ» в файл программы»
MsgBox msg, vbCritical, «Невозможно выполнить запрос к сайту» : End
tmpSheet.Cells.Delete: DoEvents: Err.Clear
With tmpSheet.QueryTables.Add( «URL;» & SearchLink$, tmpSheet.Range( «A1» ))
If Len(Tables$) Then
.FillAdjacentFormulas = False : .PreserveFormatting = True
.RefreshOnFileOpen = False : DoEvents
.Refresh BackgroundQuery:= False : DoEvents
Источник
Scraping a website HTML in VBA
This blog shows how to go through a website, making sense of its HTML within VBA. We’ll break the problem down into several chunks — to whit:
- Defining what we want to achieve.
- Analysing the target URL (the target website).
- Referencing the required applications.
- Getting at the underlying HTML.
- Parsing the data into Excel.
Don’t forget that websites change all the time, so this code may no longer work when you try it out as the format of the StackOverflow website may have changed. The following code also assumes that you have Internet Explorer on your computer (something which will be true of nearly all Windows computers).
Step 1 — Defining the problem
At the time of writing, here is what the above-mentioned StackOverflow website’s home page looks like:

The home page lists out the questions which have been asked most recently.
From this we want to extract the raw questions, with just the votes, views and author information:

What the answer should look like. The list of questions changes by the second, so the data is different!
To do this we need to learn the structure of the HTML behind the page.
To scrape websites you need to know a little HTML, and knowing a lot will help you enormously.
Step 2 — Analysing the target website
In any browser you can right-click and choose to show the underlying HTML for the page:

How to show the HTML for a webpage in FireFox (the Internet Explorer, Chrome, Safari and other browser options will be similar).
The web page begins with Top Questions, so let’s find that:

Press CTRL + F to find the given text.
Analysing the HTML which follows this shows that the questions are all encased in a div tag called question-mini-list:

We’ll loop over all of the HTML elements within this div tag.
Here’s the HTML for a single question:

The question contains all of the data we want — we just have to get at it!
Here’s how we’ll get at the four bits of data we want:
| Data | Method |
|---|---|
| Id | We’ll find the div t ag with class question-summary narrow, and extract the question number from its id. |
| Votes | We’ll find the div tag with class name votes, and look at the inner text for this (ie the contents of the div tag, ignoring any HTML tags). By stripping out any blanks and the word vote or votes, we’ll end up with the data we want. |
| Views | An identical process, but using views instead of votes. |
| Author | We’ll find the tag with class name started, and look at the inner text of the second tag within this (since there are two hyperlinks, and it’s the second one which contains the author’s name). |
Step 3 — Referencing the required applications
To get this macro to work, we’ll need to:
- Create a new copy of Internet Explorer in memory; then
- Work with the elements on the HTML page we find.
To do this, you’ll need to reference two object libraries:
| Library | Used for |
|---|---|
| Microsoft Internet Controls | Getting at Internet Explorer in VBA |
| Microsoft HTML Object Library | Getting at parts of an HTML page |
To do this, in VBA choose from the menu Tools —> References, then tick the two options shown:

You’ll need to scroll down quite a way to find each of these libraries to reference.
Now we can begin writing the VBA to get at our data!
Step 4 — Getting at the underlying HTML
Let’s now show some code for loading up the HTML at a given web page. The main problem is that we have to wait until the web browser has responded, so we keep «doing any events» until it returns the correct state out of the following choices:
Here a subroutine to get at the text behind a web page:
‘to refer to the running copy of Internet Explorer
Dim ie As InternetExplorer
‘to refer to the HTML document returned
Dim html As HTMLDocument
‘open Internet Explorer in memory, and go to website
Set ie = New InternetExplorer
‘Wait until IE is done loading page
Do While ie.readyState <> READYSTATE_COMPLETE
Application.StatusBar = «Trying to go to StackOverflow . «
‘show text of HTML document returned
Set html = ie.document
‘close down IE and reset status bar
Set ie = Nothing
What this does is:
- Creates a new copy of Internet Explorer to run invisibly in memory.
- Navigates to the StackOverflow home page.
- Waits until the home page has loaded.
- Loads up an HTML document, and shows its text.
- Closes Internet Explorer.
You could now parse the HTML using the Document Object Model (for those who know this), but we’re going to do it the slightly harder way, by finding tags and then looping over their contents.
Step 5 — Parsing the HTML
Here’s the entire subroutine, in parts, with comments for the HTML bits. Start by getting a handle on the HTML document, as above:
‘to refer to the running copy of Internet Explorer
Dim ie As InternetExplorer
‘to refer to the HTML document returned
Dim html As HTMLDocument
‘open Internet Explorer in memory, and go to website
Set ie = New InternetExplorer
‘Wait until IE is done loading page
Do While ie.readyState <> READYSTATE_COMPLETE
Application.StatusBar = «Trying to go to StackOverflow . «
‘show text of HTML document returned
Set html = ie.document
‘close down IE and reset status bar
Set ie = Nothing
Now put titles in row 3 of the spreadsheet:
‘clear old data out and put titles in
‘put heading across the top of row 3
Range(«A3»).Value = «Question id»
We’re going to need a fair few variables (I don’t guarantee that this is the most efficient solution!):
Dim QuestionList As IHTMLElement
Dim Questions As IHTMLElementCollection
Dim Question As IHTMLElement
Dim RowNumber As Long
Dim QuestionId As String
Dim QuestionFields As IHTMLElementCollection
Dim QuestionField As IHTMLElement
Dim votes As String
Dim views As String
Dim QuestionFieldLinks As IHTMLElementCollection
Start by getting a reference to the HTML element which contains all of the questions (this also initialises the row number in the spreadsheet to 4, the one after the titles):
Set QuestionList = html.getElementById(«question-mini-list»)
Set Questions = QuestionList.Children
Now we’ll loop over all of the child elements within this tag, finding each question in turn:
For Each Question In Questions
‘if this is the tag containing the question details, process it
If Question.className = «question-summary narrow» Then
Each question has a tag giving its id, which we can extract:
‘first get and store the question id in first column
QuestionId = Replace(Question.ID, «question-summary-«, «»)
Cells(RowNumber, 1).Value = CLng(QuestionId)
Now we’ll loop over all of the child elements within each question’s containing div tag:
‘get a list of all of the parts of this question,
‘and loop over them
Set QuestionFields = Question.all
For Each QuestionField In QuestionFields
For each element, extract its details (either the integer number of votes cast, the integer number of views or the name of the author):
‘if this is the question’s votes, store it (get rid of any surrounding text)
If QuestionField.className = «votes» Then
votes = Replace(QuestionField.innerText, «votes», «»)
votes = Replace(votes, «vote», «»)
Cells(RowNumber, 2).Value = Trim(votes)
‘likewise for views (getting rid of any text)
If QuestionField.className = «views» Then
views = Replace(views, «views», «»)
views = Replace(views, «view», «»)
Cells(RowNumber, 3).Value = Trim(views)
‘if this is the bit where author’s name is .
If QuestionField.className = «started» Then
‘get a list of all elements within, and store the
‘text in the second one
Set QuestionFieldLinks = QuestionField.all
Cells(RowNumber, 4).Value = QuestionFieldLinks(2).innerHTML
Time now to finish this question, increase the spreadsheet row count by one and go on to the next question:
‘go on to next row of worksheet
RowNumber = RowNumber + 1
Set html = Nothing
Finally, we’ll tidy up the results and put a title in row one:
‘do some final formatting
Range(«A1»).Value = «StackOverflow home page questions»
And that’s the complete macro!
As the above shows, website scraping can get quite messy. If you’re going to be doing much of this, I recommend learning about the HTML DOM (Document Object Model), and taking advantage of this in your code.
If you’ve learnt something from this blog and wonder how much more we could teach you, have a look at our online and classroom VBA courses.
- Two ways to get data from websites using Excel VBA
- Extracting a table of data from a website using a VBA query
- Scraping a website HTML in VBA (this blog)
I have been trying to follow your videos and extract data from an HTML file and I was able to do so on my system. BUT when I try to use the same code/module to extract data from the html file from my Friend’s system it shows me an «error 91: object variable or with block not set» at line 2 and sometime even at line 1. Basically it is not reading the html document on a different system. The HTMLButton1 and HTMLButton2 when tried in debug.print show nothing
Public Type MyType
date As String
protocol As String
Dim file As String
Dim IE As New SHDocVw.InternetExplorerMedium
Dim HTMLDoc As MSHTML.HTMLDocument
Dim HTMLButton1
Dim HTMLButton2
IE.Visible = False
IE.navigate file ‘line 1
Do While IE.Busy = True
Loop
Set HTMLDoc = IE.Document
Set HTMLButton1 = HTMLDoc.elementFromPoint(338, 462)
Set HTMLButton2 = HTMLDoc.elementFromPoint(314, 490)
array_objects(index).date = HTMLButton1.innerText ‘line2
array_objects(index).protocol = HTMLButton2.innerText
IE.Quit
Set IE = Nothing
Thank you so much for your quick response !!
We both are using the same IE versions and same screen resolution, the destination system is not able to parse the html document due to some reason.As a result I have decided to try reading the html document as a text file without using IE, hopefully that should work !!
Really appreciate your help.
No problem! Sorry that the suggestions didn’t work — it’s frustrating to not know why!
I hope you have more success with your workaround.
Hi, I’m not familiar the ElementFromPoint method but, after reading the documentation here, I wonder if it’s due to a difference in the configuration of your friend’s display. Are they using the same screen resolution as your machine?
There is also some suggestion here that the version of IE being used can affect how the method works.
I hope that helps!
Hello Andy Brown,
Thank you so much for this great and well explained post.
I have one question: When I tried to implement your code, I only managed to make it work by changing the following line, as bellow:
Set Questions = QuestionList.all (instead of Set Questions = QuestionList.Children)
Do you know why can’t I get access to the elements using the Children property?
Thanks in advance,
I don’t, sadly! Anyone else have any light to throw on the subject?
First, thanks for the code. It is very useful.
Second, I experienced the same issue. The cause is that i found there is one extra
I solved it by getting the children of the children (something like QuestionList.Children.Item(0).Children).
QuestionList.All is also working but the «for» loop will have much more cycles as «all» will drill down the children/grandchildren of element and treats them as independent.
I want to fetch a detail from a webpage using Excel macros. When I click a button in the web page, It opens a new tab, there I will have the detail to be fetched. But my macro is clicking the button in the current web page — it is not going to the next newly opened tab. I’ve published the full code on StackOverflow.
Many thanks for a great post which I’ve now successfully modified to scrape 2 sites I need data from. I can get the innertext but am struggling to get some additional data like an href giving the URL.
In the past, I have copied the HTML into a spreadsheet and parsed the html lines there to get at what I want. I now want to automate this hence my interest in your post. Two questions:
Downloading the HTML of one line so I can manually parse it
Using the element.innerText, I can extract the innerText from the following but what I want to do is to get the URL and each piece of innerText individually to put in fields in Excel:
I need a freelance data entry & admin
Urgent
/span>
The innerText shows:
Title, Urgent, Time ago posted, Remote, # proposals, etc.
Is there a command I can use to get all the source html text from the «
Downloading the Full HTML into Excel
A I mentioned, I can manipulate HTML once I paste it into Excel. If I cannot easily do the above, is there a way of pasting all the HTML from a webpage into Excel so I can use my manual methods?
Many thanks in advance for your help; I have spent many hours trawling the Internet for answers but couldn’t find anything!
Parsing HTML in VBA is a bit tedious. To start you off, here is some code to read through HTML to pick out the hyperlinks:
I need a freelance data entry & admin «
Const AngleStart As String = » «
Dim StartAngle As Integer
Dim EndAngle As Integer
StartAngle = InStr(1, Html, AngleStart)
‘having found first angle bracket, keep going till find last one
Do Until StartAngle Reply to demhaReply
Hi! First of all, thanks so much for your post. I have next to no experience with VBA or any coding really and I’ve found this very useful as I try to build up an excel sheet. I haven’t gotten my version to work yet, mainly I’m trying to loop through a list with a ul tag with li containers but cant seem to get it to work. Im trying to pull the tips for each horse racing meeting from this site but am unable to. Any guidance would be very appreciated!
Thanks for your kind comments. No particular tips I’m afraid! For you (or anyone else) who does this sort of thing for a living, I would consider writing the code in Visual Basic in .NET, using Windows Forms. You’d have to download Visual Studio Community edition (which is free), and there is a LONG learning curve, but you can then add in a reference to something called the HTML Agility Pack, which makes it easier to parse HTML tags.
For anyone who hasn’t got a spare month or two to learn how to program in .NET, just keep working at it and everything will gradually become easier!
Is there a way to scrape pages when you have to click something to get access? It’s beyond web scraping, but i would like for example to enter a user name and a password, display a menu, select an item, and finally get access to the page with the information i want to scrape. (Even though i don’t know how to code it, i heard about Selenium and Beautiful soup for Python). So, could this be done from vba excel?
Also, where can i find a reference to the library Internet Object Control and Internet HTML, methods, functions, etc please?
It would be difficult — I think impossible — to initiate a chain of actions like this using VBA. The problem is that interaction with a web page has two parts: server and client. Typically when you request a web page, the web server creates a page of HTML and sends this to your client computer, where the browser (Firefox, Chrome, IE, etc) presents it as a web page.
At this point there is no remaining link with the web server, and the only way you can interact with the web page is by running client script (typically using JavaScript or a derivative language called JQuery). However, there’s no way to get VBA to run JavaScript on a web page to mimic user interaction.
With regard to your other post, I don’t know of any library of functions, but I’m sure Googling it would throw one up.
I’m using VBA for Office. Mostly from MSAccess 2016.
I’ve been trying to scrape some info from a screen. The info is/are all the items in a dropdown list box. When I ‘Inspect Element’ I can see this:
However, I still haven’t figured out how to retrieve the options between the tags.
I think I know how to use the info after I get it. Any help would be very much appreciated!!
A newbie on this site
I don’t know the answer to your question, but here’s a thought. The dropdown list has no id and no class name, so it’s hard to identify. However, it will be contained within an outer item which WILL have an id. You could always locate this (adapting the code in the blog), then loop over the elements within it to find the SELECT tag you want.
I realise that’s only the outline of a solution; can anyone else improve on this?
I am trying to pull just one row of data from an HTML table. Using Data- > Get External Data -> From Web option is very tedious, there are over 30 individual tables. These tables reside on my pc. I can open them in a web browser, but I do not how to parse them since they are not located on the web. I am trying to automate the process to bring the data into Excel. So far, I have not found any info relating to this specifc case. I would appreciate any info on this subject.
I think you’re probably reading the wrong post! If your data are in HTML format, the best thing to do would be to write a macro to open each file, and save it again, but this time in Excel format. You’d then be able to write a macro to loop over the Excel files, getting the first row of each.
If, on the other hand, your data’s already in CSV or even XLS format, you can just write a VBA macro to loop over all of the files opening each in turn. This is beyond the scope of this reply, although you might find this video useful.
Thanks Andy. Ithink I have the solution. I have recorded macro when I used the Data->Get External Data->From Web and looked at the code I have noticed that
it uses QueryTables.Add(Connection:=»URL;file:///L:/T420/F/01%20(2).htm». Since the local files I have are in the HTM format (very basic structure) the query recognizes that. So, all I have to do is put those tables in an array, use loop and I,m in business. Once again thank you very much for Your help.
I have been scraping some supermarket products with code similar to the code in this blog, but I can ‘t figure out how to parse this site (I can’t figure out how to go to a child). I would be so thankful if i could get an indication about what i’m doing wrong, or what is the way to get each product price.
I can’t help you in this much detail, but can give you a couple of hints. The first is that we’ve got a new video tutorial on our site (here), which you may find helpful, and the second is that to scrape websites effectively you need to understand the document object model of the site in question, and also have a pretty good understanding of HTML.
I wish you luck!
«You could now parse the HTML using the Document Object Model (for those who know this). «
Anyone know where I can find more information about this?
Hi, here’s the link to MIcrosoft’s documentation for the Document Object Model
Источник