
Все знакомы с табличным процессором Excel, который входит в стандартный пакет Microsoft Office. Напрямую в Excel очень удобно и приятно работать, но мало кто знает, что в Java этот процесс не менее приятный и увлекательный.
Последнее время мне приходилось программно парсить файлы формата .xls и .xlsx. Чтобы осуществить парсинг Excel-файла, понадобилась библиотека Apache POI. С помощью этой библиотеки можно парсить не только файлы в формате .xls, но и DOC, PPT, а также форматы, которые появились в версии Microsoft Office 2007.
В этой статье мы познакомимся с чтением данных из xls или xlsx файла в Java с помощью библиотеки Apache POI. Как всегда, немного теории по основам и практика на примере чтения простого xls файла. Пример создания нового Excel файла представлен здесь.
Подключаем библиотеку для работы с Excel в Java
Для начала нужно создать Maven-проект и в файле pom.xml прописать следующий код зависимостей
|
<dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>3.11</version> </dependency> |
Чтение Excel файла на Java
Библиотека Apache POI предоставляет простой в использовании API для чтения любого xls файла. Ниже мы рассмотрим наиболее используемые классы для чтения содержимого Excel таблиц:
Код для чтения Excel документов в формате xls
В листинге ниже приведен типичный пример инициализации HSSFWorkbook и HSSFSheet для считывания данных из .xls файлов.
|
// получаем файл в формате xls FileInputStream file = new FileInputStream(new File(«C:\simplexcel.xls»)); // формируем из файла экземпляр HSSFWorkbook HSSFWorkbook workbook = new HSSFWorkbook(file); // выбираем первый лист для обработки // нумерация начинается с 0 HSSFSheet sheet = workbook.getSheetAt(0); // получаем Iterator по всем строкам в листе Iterator<Row> rowIterator = sheet.iterator(); // получаем Iterator по всем ячейкам в строке Iterator<Cell> cellIterator = row.cellIterator(); |
Код для чтения Excel документов в формате .xlsx
Ниже приведен фрагмент кода для инициализации работы с Excel файлами в формате .xlsx:
|
// получаем файл в формате xlsx FileInputStream file = new FileInputStream(new File(«C:\simplexcelx.xlsx»)); // получаем экземпляр XSSFWorkbook для обработки xlsx файла XSSFWorkbook workbook = new XSSFWorkbook (file); // выбираем первый лист для обработки // нумерация начинается из 0 XSSFSheet sheet = workbook.getSheetAt(0); // получаем Iterator по всем строкам в листе Iterator<Row> rowIterator = sheet.iterator(); // получаем Iterator по всем ячейкам в строке Iterator<Cell> cellIterator = row.cellIterator(); |
Практика. Создаем простой Excel для работы
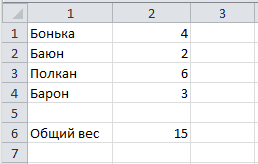
Пишем парсер на Java
Назовем класс ExcelParser.java с методом parse, который принимает текстовый параметр fileName
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
package ua.com.prologistic.excel; import org.apache.poi.hssf.usermodel.HSSFWorkbook; import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStream; import java.util.Iterator; public class ExcelParser { public static String parse(String fileName) { //инициализируем потоки String result = «»; InputStream inputStream = null; HSSFWorkbook workBook = null; try { inputStream = new FileInputStream(fileName); workBook = new HSSFWorkbook(inputStream); } catch (IOException e) { e.printStackTrace(); } //разбираем первый лист входного файла на объектную модель Sheet sheet = workBook.getSheetAt(0); Iterator<Row> it = sheet.iterator(); //проходим по всему листу while (it.hasNext()) { Row row = it.next(); Iterator<Cell> cells = row.iterator(); while (cells.hasNext()) { Cell cell = cells.next(); int cellType = cell.getCellType(); //перебираем возможные типы ячеек switch (cellType) { case Cell.CELL_TYPE_STRING: result += cell.getStringCellValue() + «=»; break; case Cell.CELL_TYPE_NUMERIC: result += «[« + cell.getNumericCellValue() + «]»; break; case Cell.CELL_TYPE_FORMULA: result += «[« + cell.getNumericCellValue() + «]»; break; default: result += «|»; break; } } result += «n»; } return result; } } |
Создаем главный класс-ранер, где и запустим парсер:
|
package ua.com.prologistic; import ua.com.prologistic.excel.ExcelParser; public class MainClass { public static void main(String[] args){ System.out.println(Parser.parse(«excel.xls»)); } } |
Результат выполнения парсера Excel
|
Бонька=[4.0] Баюн=[2.0] Полкан=[6.0] Барон=[3.0] Общий вес=[15.0] |
Работа с запароленным Excel файлом
В Apache POI с каждой новой версией добавляются новые возможности по работе с закрытыми/запароленными файлами. Например, мы может работать с защищенными файлами XLS (используя org.apache.poi.hssf.record.crypt) и защищенными файлами XLSX (с помощью org.apache.poi.poifs.crypt).
Если вы используете HSSF (для файла XLS), то проверить является ли он запаролленым нам поможет метод isWriteProtected(). А для работы с ним необходимо указать пароль перед самым открытием файла:
|
... org.apache.poi.hssf.record.crypto.Biff8EncryptionKey.setCurrentUserPassword(«здесь пароль»); |
После этого можем работать с файлом.
Для XSSF нам понадобится что-то вроде такого:
|
POIFSFileSystem fs = new POIFSFileSystem(new FileInputStream(«protected.xlsx»)); EncryptionInfo info = new EncryptionInfo(fs); Decryptor d = new Decryptor(info); d.verifyPassword(Decryptor.DEFAULT_PASSWORD); XSSFWorkbook wb = new XSSFWorkbook(d.getDataStream(fs)); |
При работе с более новыми версиями Apache POI, можно просто указать пароль при создании Workbook:
|
Workbook wb = WorkbookFactory.create(new File(«protected.xls»), «здесь пароль»)); |
Этот код будет работать как для HSSF, так и для XSSF.
Также смотрите примеры чтения Word документа и создания нового документа Word с помощью Apache POI.
Подписывайтесь на обновления!

Excel Parser Examples
HSSF — Horrible Spreadsheet Format – not anymore. With few annotations, excel parsing can be done in one line.
We had a requirement in our current project to parse multiple excel sheets and store the information to database. I hope most of the projects involving excel sheet parsing would be doing the same. We built a extensible framework to parse multiple sheets and populate JAVA objects with annotations.
Usage
This JAR is currently available in Sonatype maven repository.
Maven:
<dependency> <groupId>org.javafunk</groupId> <artifactId>excel-parser</artifactId> <version>1.0</version> </dependency>
Gradle:
compile 'org.javafunk:excel-parser:1.0'
Thanks to tobyclemson for publishing this to Maven repository.
Student Information Example
Consider we have an excel sheet with student information.
While parsing this excel sheet, we need to populate one “Section” object and multiple “Student” objects related to a Section. You can see that Student information is available in multiple rows whereas the Section details (Year, Section) is available in column B.
Step 1: Annotate Domain Classes
First we will see the steps to annotate Section object:
@ExcelObject(parseType = ParseType.COLUMN, start = 2, end = 2) public class Section { @ExcelField(position = 2) private String year; @ExcelField(position = 3) private String section; @MappedExcelObject private List <Student> students; }
You can find three different annotation in this class.
ExcelObject: This annotation tells the parser about the parse type (Row or Column), number of objects to create (start, end). Based on the above annotation, Section value should be parsed Columnwise and information can be found in Column 2 (“B”) of the Excelsheet.ExcelField: This annotation tells the parser to fetch “year” information from Row 2 and “section” information from Row 3.MappedExcelObject: Apart from Simple datatypes like “Double”,”String”, we might also try to populate complex java objects while parsing. In this case, each section has a list of student information to be parsed from excel sheet. This annotation will help the parser in identifying such fields.
Then, annotate the Student class:
@ExcelObject(parseType = ParseType.ROW, start = 6, end = 8) public class Student { @ExcelField(position = 2) private Long roleNumber; @ExcelField(position = 3) private String name; @ExcelField(position = 4) private Date dateOfBirth; @ExcelField(position = 5) private String fatherName; @ExcelField(position = 6) private String motherName; @ExcelField(position = 7) private String address; @ExcelField(position = 8) private Double totalScore; }
ExcelObject: As shown above, this annotation tells parser to parse Rows 6 to 8 (create 3 student objects). NOTE: Optional field “zeroIfNull” , if set to true, will populate Zero to all number fields (Double,Long,Integer) by default if the data is not available in DB.ExcelField: Student class has 7 values to be parsed and stored in the database. This is denoted in the domain class as annotation.MappedExcelObject: Student class does not have any complex object, hence this annoation is not used in this domain class.
Step 2: Invoke Sheet Parser
Once the annotation is done, you have just invoke the parser with the Sheet and the Root class you want to populate.
//Get the sheet using POI API. String sheetName = "Sheet1"; SheetParser parser = new SheetParser(); InputStream inputStream = getClass().getClassLoader().getResourceAsStream("Student Profile.xls"); Sheet sheet = new HSSFWorkbook(inputStream).getSheet(sheetName); //Invoke the Sheet parser. List entityList = parser.createEntity(sheet, sheetName, Section.class);
Thats all it requires. Parser would populate all the fields based on the annotation for you.
Development
- JDK 8
- Run «gradle idea» to setup the project
- Install Lombok plugin
- Enable «Enable annotation processing» as this project uses Lombok library. [Compiler > Annotation Processors > Enable annotation processing: checked ]
Contributors
- @nvenky
- @cv
- @tobyclemson
1. Introduction
In this article, we are going to present a custom XLSX parser based on Java annotations. The application will be using the Apache POI library to read the structure of the Excel file and then map all entries into the POJO object.
2. Setup project
The project will use several dependencies from apache-poi. We also used Lombok to generate common methods for POJO classes like setters, getters, and constructors.
The pom.xml file will contain the following items:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>libraries</artifactId>
<groupId>com.frontbackend.libraries</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>apache-poi</artifactId>
<properties>
<lombok.version>1.16.22</lombok.version>
<apache.poi.version>3.17</apache.poi.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>${apache.poi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${apache.poi.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
</project>
The latest versions of used libraries could be found in our Maven Repository:
- apache-poi latest libraries,
- Lombok Maven artifacts.
3. Project structure
The project is organized in the following structure:
├── pom.xml
├── src
│ ├── main
│ │ ├── java
│ │ │ └── com
│ │ │ └── frontbackend
│ │ │ └── libraries
│ │ │ └── apachepoi
│ │ │ ├── MainParseXLSXUsingAnnotations.java
│ │ │ ├── model
│ │ │ │ └── Post.java
│ │ │ └── parser
│ │ │ ├── XLSXField.java
│ │ │ ├── XLSXHeader.java
│ │ │ └── XLSXParser.java
│ │ └── resources
│ │ └── posts.xlsx
4. XLSX Parser classes
We can distinguish three classes responsible for processing XLSX files:
XLSXField— custom annotation used to mark field in POJO class and connect it with the column from XLSX document,XLSXHeader— is a wrapper class used to hold information about fields, columns, and columns positions in the Excel file,XLSXParser— the main class responsible for parsing XLSX files and set values into POJO objects.
Starting with the XLSXField — which is an annotation used to connect column with a field in Java class:
package com.frontbackend.libraries.apachepoi.parser;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface XLSXField {
String column() default "";
}
The XLSXHeader is a helper class that wraps data like class field name, column name from XLSX file, and column index:
package com.frontbackend.libraries.apachepoi.parser;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.ToString;
@AllArgsConstructor
@Getter
@ToString
public class XLSXHeader {
private final String fieldName;
private final String xlsxColumnName;
private final int columnIndex;
}
And finally the base utility class responsible for parsing Excel files — XLSXParser:
package com.frontbackend.libraries.apachepoi.parser;
import java.io.InputStream;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.CellType;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
public class XLSXParser<T> {
private static final int HEADER_ROW_INDEX = 0;
private static final int SHEET_INDEX = 0;
public List<T> parse(InputStream inputStream, Class<T> cls) throws Exception {
List<T> out = new ArrayList<>();
XSSFWorkbook workbook = new XSSFWorkbook(inputStream);
Sheet sheet = workbook.getSheetAt(SHEET_INDEX);
List<XLSXHeader> xlsxHeaders = modelObjectToXLSXHeader(cls, sheet);
for (Row row : sheet) {
if (row.getRowNum() > HEADER_ROW_INDEX) {
out.add(createRowObject(xlsxHeaders, row, cls));
}
}
return out;
}
private T createRowObject(List<XLSXHeader> xlsxHeaders, Row row, Class<T> cls) throws Exception {
T obj = cls.newInstance();
Method[] declaredMethods = obj.getClass()
.getDeclaredMethods();
for (XLSXHeader xlsxHeader : xlsxHeaders) {
Cell cell = row.getCell(xlsxHeader.getColumnIndex());
String field = xlsxHeader.getFieldName();
Optional<Method> setter = Arrays.stream(declaredMethods)
.filter(method -> isSetterMethod(field, method))
.findFirst();
if (setter.isPresent()) {
Method setMethod = setter.get();
setMethod.invoke(obj, cell.getStringCellValue());
}
}
return obj;
}
private boolean isSetterMethod(String field, Method method) {
return method.getName()
.equals("set" + field.substring(0, 1)
.toUpperCase()
+ field.substring(1));
}
private List<XLSXHeader> modelObjectToXLSXHeader(Class<T> cls, Sheet sheet) {
return Stream.of(cls.getDeclaredFields())
.filter(field -> field.getAnnotation(XLSXField.class) != null)
.map(field -> {
XLSXField importField = field.getAnnotation(XLSXField.class);
String xlsxColumn = importField.column();
int columnIndex = findColumnIndex(xlsxColumn, sheet);
return new XLSXHeader(field.getName(), xlsxColumn, columnIndex);
})
.collect(Collectors.toList());
}
private int findColumnIndex(String columnTitle, Sheet sheet) {
Row row = sheet.getRow(HEADER_ROW_INDEX);
if (row != null) {
for (Cell cell : row) {
if (CellType.STRING.equals(cell.getCellTypeEnum()) && columnTitle.equals(cell.getStringCellValue())) {
return cell.getColumnIndex();
}
}
}
return 0;
}
}
Note that for the sake of simplicity we assume that the first row in an Excel file will be our table header, and also the first sheet will contain all the data:
private static final int HEADER_ROW_INDEX = 0;
private static final int SHEET_INDEX = 0;
The parse(...) method is responsible for reading XLSX documents using the Apache POI library and parsing values from it into a specific Java model instance.
In the first step, we create a list of helper classes that contains all the necessary information like field name, related column, and column index:
List<XLSXHeader> xlsxHeaders = modelObjectToXLSXHeader(cls, sheet);
In modelObjectToXLSXHeader() method we iterate over all declared in specified class fields and filter all marked with XLSXField annotation. Then we are searching for a column in an Excel file with the same name as provided in the annotation column property. The method returns the list of wrapped objects XLSXHeader.
private List<XLSXHeader> modelObjectToXLSXHeader(Class<T> cls, Sheet sheet) {
return Stream.of(cls.getDeclaredFields())
.filter(field -> field.getAnnotation(XLSXField.class) != null)
.map(field -> {
XLSXField importField = field.getAnnotation(XLSXField.class);
String xlsxColumn = importField.column();
int columnIndex = findColumnIndex(xlsxColumn, sheet);
return new XLSXHeader(field.getName(), xlsxColumn, columnIndex);
})
.collect(Collectors.toList());
}
The createRowObject() method creates an instance of a specified POJO object and filled the fields with values according to the data from the XLSX file.
As a result parse() method returns a list of POJO objects.
5. Run and test a sample program
In order to test the implementation of the XLSX parser, we created a simple object with three fields marked with @XLSXField annotation:
package com.frontbackend.libraries.apachepoi.model;
import com.frontbackend.libraries.apachepoi.parser.XLSXField;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
@Setter
@Getter
@ToString
public class Post {
@XLSXField(column = "Title")
private String title;
@XLSXField(column = "Content")
private String content;
@XLSXField(column = "URL")
private String url;
}
Fields will be related with the following column from the Excel file:
| Field | Column |
| title | Title |
| content | Content |
| url | URL |
Our sample XLSX file with have the following structure:
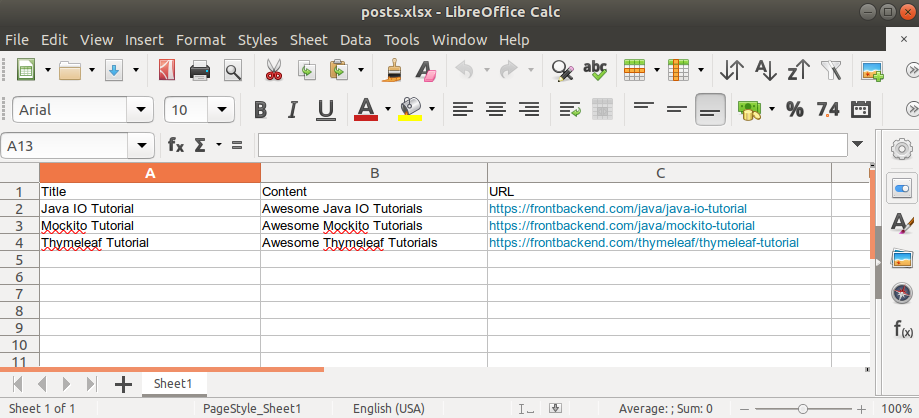
The sample Java program that will parse the posts.xlsx file located in the project resource folder looks as follows:
package com.frontbackend.libraries.apachepoi;
import java.io.InputStream;
import java.util.List;
import com.frontbackend.libraries.apachepoi.model.Post;
import com.frontbackend.libraries.apachepoi.parser.XLSXParser;
public class MainParseXLSXUsingAnnotations {
public static void main(String[] args) {
XLSXParser<Post> postsXLSXParser = new XLSXParser<>();
InputStream xlsxFile = postsXLSXParser.getClass()
.getClassLoader()
.getResourceAsStream("posts.xlsx");
try {
List<Post> list = postsXLSXParser.parse(xlsxFile, Post.class);
System.out.println(list);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Here:
- first, we created an instance of
XLSXParserdedicated for thePostclass, - in the next step we retrieved data from the
posts.xlsxfile, - then file stream is used to parse the file using the
XLSXParser.parse(...)method.
As a result, we have a list of three POJO instances that correspond to the rows in the Excel document:
[Post(title=Java IO Tutorial, content=Awesome Java IO Tutorials, url=https://frontbackend.com/java/java-io-tutorial),
Post(title=Mockito Tutorial, content=Awesome Mockito Tutorials, url=https://frontbackend.com/java/mockito-tutorial),
Post(title=Thymeleaf Tutorial, content=Awesome Thymeleaf Tutorials, url=https://frontbackend.com/thymeleaf/thymeleaf-tutorial)]
6. Conclusion
In this article, we presented how to create an XLSX parser based on annotations in Java using the Apache POI library. Note that we showed a simple example of an Excel file, also we convert all values into strings, but it a good point to start some more complex functionality.
As always the code used in this article is available in our GitHub repository.

Часто ли вам приходилось на живую работать с Excel? Думаю, что несколько раз приходилось. Так вот, на днях у меня для собственного проекта появилась необходимость распарсить Excel файл.
Как известно то формат Excel файла *.xsl, но после выхода Microsoft Office 2007 появился новый формат Excel файла *.xlsx, так вот для того, чтобы иметь возможность парсить Excel я использую библиотеку Apache POI все мои пожелания по поводу Excel файла она удовлетворила.
Шаг 1
Для начало создадим Maven проект и добавим следующую зависимость:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.9</version>
</dependency>
Шаг 2
Теперь создадим Excel файл и добавим в него несколько записей.

Файл прикреплен к исходнику.
Шаг 3
Теперь попробуем распарсить файл testfile.xls, для этого напишем парсер.
Создаем класс Parser.java и в нем создадим статический метод parse(String name);
package com.devcolibri.excel;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
public class Parser {
public static String parse(String name) {
String result = "";
InputStream in = null;
HSSFWorkbook wb = null;
try {
in = new FileInputStream(name);
wb = new HSSFWorkbook(in);
} catch (IOException e) {
e.printStackTrace();
}
Sheet sheet = wb.getSheetAt(0);
Iterator<Row> it = sheet.iterator();
while (it.hasNext()) {
Row row = it.next();
Iterator<Cell> cells = row.iterator();
while (cells.hasNext()) {
Cell cell = cells.next();
int cellType = cell.getCellType();
switch (cellType) {
case Cell.CELL_TYPE_STRING:
result += cell.getStringCellValue() + "=";
break;
case Cell.CELL_TYPE_NUMERIC:
result += "[" + cell.getNumericCellValue() + "]";
break;
case Cell.CELL_TYPE_FORMULA:
result += "[" + cell.getNumericCellValue() + "]";
break;
default:
result += "|";
break;
}
}
result += "n";
}
return result;
}
}
Шаг 4
Теперь давайте проверим все это, создаем класс Main.java со следующим содержимым:
package com.devcolibri;
import com.devcolibri.excel.Parser;
public class Main {
public static void main(String... args){
System.out.println(Parser.parse("testfile.xls"));
}
}
Шаг 5
Запускаем все это дело, и получаем следующий результат:
Александр Барчук=[5000.0] Виктор Пупкин=[10000.0] Дмитрий Федкин=[1500.0] Максим Панков=[300.0] Данил Муев=[8000.0] Анастасия Валяева=[8900.0] Екатерина Максимова=[7000.0] Company=[40700.0]
- None Found
I have the code below which reads excel files and displays it in java.
I’d like to implement the code after reading the data from the excel file to java, it will to convert in XML format and save it on XML file.
Any code sample or reference will be thankful;
public class POIExcelReader {
public POIExcelReader (){
}
public void displayFromExcel (String xlsPath)
{
InputStream inputStream = null;
try
{
inputStream = new FileInputStream (xlsPath);
}
catch (FileNotFoundException e)
{
System.out.println ("File not found in the specified path.");
e.printStackTrace ();
}
POIFSFileSystem fileSystem = null;
try {
fileSystem = new POIFSFileSystem (inputStream);
HSSFWorkbook workBook = new HSSFWorkbook (fileSystem);
HSSFSheet sheet = workBook.getSheetAt (0);
Iterator<?> rows = sheet.rowIterator ();
while (rows.hasNext ())
{
HSSFRow row = (HSSFRow) rows.next();
// display row number
System.out.println ("Row No.: " + row.getRowNum ());
// get a row, iterate through cells.
Iterator<?> cells = row.cellIterator ();
while (cells.hasNext ())
{
HSSFCell cell = (HSSFCell) cells.next ();
//System.out.println ("Cell : " + cell.getCellNum ());
switch (cell.getCellType ())
{
case HSSFCell.CELL_TYPE_NUMERIC :
{
// NUMERIC CELL TYPE
System.out.println ("Numeric: " + cell.getNumericCellValue ());
break;
}
case HSSFCell.CELL_TYPE_STRING :
{
// STRING CELL TYPE
HSSFRichTextString richTextString = cell.getRichStringCellValue ();
System.out.println ("String: " + richTextString.getString ());
break;
}
default:
{
// types other than String and Numeric.
System.out.println ("Type not supported.");
break;
}
}
}
}
}
catch(IOException e)
{
e.printStackTrace ();
}
}
public static void main (String[] args)
{
POIExcelReader poiExample = new POIExcelReader ();
String xlsPath ="c://Users//Secured//Desktop//artikli.xls";
poiExample.displayFromExcel (xlsPath);
}
}
asked Dec 3, 2013 at 17:20
![]()
1
You can use the classes in the package: javax.xml.parsers. The package provides classes allowing the processing of XML documents. e.g. DocumentBuilder, DocumentBuilderFactory, to mention a few.
Using the java code (extended your original code) below and the file located in this location: http://base.google.com/base/products.xls
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.Iterator;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRichTextString;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.poifs.filesystem.POIFSFileSystem;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class POIExcelReader {
public POIExcelReader (){
}
public void displayFromExcel (String xlsPath)
{
InputStream inputStream = null;
try
{
inputStream = new FileInputStream (xlsPath);
}
catch (FileNotFoundException e)
{
System.out.println ("File not found in the specified path.");
e.printStackTrace ();
}
POIFSFileSystem fileSystem = null;
try {
//Initializing the XML document
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.newDocument();
Element rootElement = document.createElement("products");
document.appendChild(rootElement);
fileSystem = new POIFSFileSystem (inputStream);
HSSFWorkbook workBook = new HSSFWorkbook (fileSystem);
HSSFSheet sheet = workBook.getSheetAt (0);
Iterator<?> rows = sheet.rowIterator ();
ArrayList<ArrayList<String>> data = new ArrayList<ArrayList<String>>();
while (rows.hasNext ())
{
HSSFRow row = (HSSFRow) rows.next();
int rowNumber = row.getRowNum ();
// display row number
System.out.println ("Row No.: " + rowNumber);
// get a row, iterate through cells.
Iterator<?> cells = row.cellIterator ();
ArrayList<String> rowData = new ArrayList<String>();
while (cells.hasNext ())
{
HSSFCell cell = (HSSFCell) cells.next ();
//System.out.println ("Cell : " + cell.getCellNum ());
switch (cell.getCellType ())
{
case HSSFCell.CELL_TYPE_NUMERIC :
{
// NUMERIC CELL TYPE
System.out.println ("Numeric: " + cell.getNumericCellValue ());
rowData.add(cell.getNumericCellValue () + "");
break;
}
case HSSFCell.CELL_TYPE_STRING :
{
// STRING CELL TYPE
HSSFRichTextString richTextString = cell.getRichStringCellValue ();
System.out.println ("String: " + richTextString.getString ());
rowData.add(richTextString.getString ());
break;
}
default:
{
// types other than String and Numeric.
System.out.println ("Type not supported.");
break;
}
} // end switch
} // end while
data.add(rowData);
} //end while
int numOfProduct = data.size();
for (int i = 1; i < numOfProduct; i++){
Element productElement = document.createElement("product");
rootElement.appendChild(productElement);
int index = 0;
for(String s: data.get(i)) {
String headerString = data.get(0).get(index);
if( data.get(0).get(index).equals("image link") ){
headerString = "image_link";
}
if( data.get(0).get(index).equals("product type") ){
headerString = "product_type";
}
Element headerElement = document.createElement(headerString);
productElement.appendChild(headerElement);
headerElement.appendChild(document.createTextNode(s));
index++;
}
}
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer();
//Add indentation to output
transformer.setOutputProperty
(OutputKeys.INDENT, "yes");
transformer.setOutputProperty(
"{http://xml.apache.org/xslt}indent-amount", "2");
DOMSource source = new DOMSource(document);
StreamResult result = new StreamResult(new File("products.xml"));
//StreamResult result = new StreamResult(System.out);
transformer.transform(source, result);
}
catch(IOException e)
{
System.out.println("IOException " + e.getMessage());
} catch (ParserConfigurationException e) {
System.out.println("ParserConfigurationException " + e.getMessage());
} catch (TransformerConfigurationException e) {
System.out.println("TransformerConfigurationException "+ e.getMessage());
} catch (TransformerException e) {
System.out.println("TransformerException " + e.getMessage());
}
}
public static void main (String[] args)
{
POIExcelReader poiExample = new POIExcelReader ();
String xlsPath ="products.xls";
poiExample.displayFromExcel (xlsPath);
}
}
answered Dec 3, 2013 at 17:58
![]()
openmikeopenmike
2721 silver badge9 bronze badges
3
import java.io.*;
import java.util.*;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.FactoryConfigurationError;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRichTextString;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class MyExp {
protected DocumentBuilderFactory domFactory = null;
protected DocumentBuilder domBuilder = null;
public MyExp(){
try {
domFactory = DocumentBuilderFactory.newInstance();
domBuilder = domFactory.newDocumentBuilder();
} catch (FactoryConfigurationError exp) {
System.err.println(exp.toString());
} catch (ParserConfigurationException exp) {
System.err.println(exp.toString());
} catch (Exception exp) {
System.err.println(exp.toString());
}
}
public void convertFile(String xlsFileName, String xmlFileName){
try {
Document newDoc = domBuilder.newDocument();
Element rootElement = newDoc.createElement("XMLCreators");
newDoc.appendChild(rootElement);
InputStream InputStream=new FileInputStream(new File(xlsFileName));
HSSFWorkbook workBook = new HSSFWorkbook (InputStream);
HSSFSheet sheet = workBook.getSheetAt (0);
Iterator<?> rows = sheet.rowIterator ();
List<String> headers = new ArrayList<String>(5);
while (rows.hasNext ())
{
HSSFRow row = (HSSFRow) rows.next();
int rowNumber = row.getRowNum ();
Iterator<?> cells = row.cellIterator ();
ArrayList<String> rowData = new ArrayList<String>();
while (cells.hasNext ())
{
HSSFCell cell = (HSSFCell) cells.next ();
switch (cell.getCellType ())
{
case HSSFCell.CELL_TYPE_NUMERIC :
{
// NUMERIC CELL TYPE
rowData.add(cell.getNumericCellValue () + "");
break;
}
case HSSFCell.CELL_TYPE_STRING :
{
// STRING CELL TYPE
HSSFRichTextString richTextString = cell.getRichStringCellValue();
rowData.add(richTextString.getString ());
break;
}
default:
{
break;
}
}
} // end while
if(rowNumber==1){
headers.addAll(rowData);
}
else
{
Element rowElement = newDoc.createElement("row");
rootElement.appendChild(rowElement);
for (int col = 0; col < headers.size(); col++) {
String header = headers.get(col);
String value = null;
if (col < rowData.size()) {
value = rowData.get(col);
} else {
value = "";
}
Element curElement = newDoc.createElement(header);
curElement.appendChild(newDoc.createTextNode(value));
rowElement.appendChild(curElement);
}
}
} //end while
ByteArrayOutputStream baos = null;
OutputStreamWriter osw = null;
try {
baos = new ByteArrayOutputStream();
osw = new OutputStreamWriter(baos);
TransformerFactory tranFactory = ransformerFactory.newInstance();
Transformer aTransformer = tranFactory.newTransformer();
aTransformer.setOutputProperty(OutputKeys.INDENT, "yes");
aTransformer.setOutputProperty(OutputKeys.METHOD, "xml");
aTransformer.setOutputProperty("http://xml.apache.org/xslt}indent-amount", "4");
Source src = new DOMSource(newDoc);
Result result = new StreamResult(new File(xmlFileName));
aTransformer.transform(src, result);
osw.flush();
System.out.println(new String(baos.toByteArray()));
} catch (Exception exp) {
exp.printStackTrace();
} finally {
try {
osw.close();
} catch (Exception e) {
}
try {
baos.close();
} catch (Exception e) {
}
}
}
catch(IOException e)
{
System.out.println("IOException " + e.getMessage());
}
}
public static void main (String[] args)
{
MyExp poiExample = new MyExp ();
poiExample.convertFile("srcfile.xls", "destfile.xml");
}
}
answered Jul 24, 2015 at 10:13
![]()
0