

Word to HTML
phpdocx Advanced and Premium licenses include the functionality of transforming DOCX files to HTML with native PHP classes.
There are currently two ways to transform Word to HTML with phpdocx:
- With the conversion plugin
- With the TransformDocAdvHTML native PHP class
The conversion plugin executes LibreOffice or OpenOffice to perform the conversion. This method has a disadvantage: it is not native PHP and requires calling external programs, besides, it doesn’t allow to customize the output but with PHP DOM modifications after the conversion.
Native PHP classes included in Advanced and Premium licenses allow to transform DOCX to HTML with PHP exclusively. The main features of this functionality are the following:
- Conversion of contents, styles and properties
- Native PHP classes
- Easily customizable
- Transform DOCX created from scratch and templates
The transformation can be done using just three lines of code:
where document.docx can be a DOCX created with phpdocx or from other source (MS Word, LibreOffice, etc). Premium licenses can also transform in-memory documents.
Supported OOXML tags and attributes
phpdocx parses contents, styles, properties and other XML contents.
The list of currently parsed contents and styles include (OOXML content/style and HTML/CSS transformation):
-
document (w:body) : <body>
- background color (w:background) => w:color (background-color)
- background image (v:background) => id (background-image)
- border (w:pgBorders) => w:top (border-top), w:bottom (border-bottom), w:left (border-left), w:right (border-right): w:color (border-color: #HEX), w:sz (border-width), w:val (border-style: nil, none, dashed, dotted, double, solid), w:space (padding)
-
sections (w:sectPr) : <section>
- size (w:pgSz) => w:w (max-width)
- margin (w:pgMar) => w:top (margin-top), w:bottom (margin-bottom), w:left (margin-left), w:right (margin-right)
- columns (w:cols) => w:num (columns)
-
title and metas (cp:coreProperties) : <title>, <meta>
- title (dc:title) => <title>
- author (dc:creator) => <meta> (author)
- description (dc:description) => <meta> (description)
- keywords (cp:keywords) => <meta> (keywords)
-
text strings (w:t) and text styles (w:rPr) : <span>
- text (w:t) => <span>
- bold (w:b) => w:val (font-weight: bold)
- color (w:color) => w:val (color: #HEX)
- double line through (w:dstrike) => w:val (text-decoration-style: double)
- font family (w:rFonts) => w:ascii (font-family), w:cs (font-family)
- font size (w:sz) => w:val (font-size)
- highlight (w:highlight) => w:val (background-color)
- italic (w:i) => w:val (font-style: italic)
- line through (w:strike) => w:on (text-decoration: line-through)
- lower case (w:smallCaps) => w:val (text-transform: uppercase; font-size: small)
- text decoration (w:u) => w:val (text-decoration: none or underline; text-decoration-style: dashed, dotted, double, solid, wavy, none)
- upper case (w:caps) => w:val (text-transform: uppercase)
- vanish (w:vanish) => w:val (visibility: hidden; visibility: visibility)
- vertical align (w:vertAlign) => w:val (vertical-align: sub; vertical-align: super)
-
paragraphs (w:pPr) : <p>
- background color (w:shd) => w:shd (background-color)
- bold (w:b) => w:val (font-weight: bold)
- border (w:pBdr) => w:top (border-top), w:bottom (border-bottom), w:left (border-left), w:right (border-right), w:color (border-color: #HEX), w:sz (border-width), w:val (border-style: nil, none, dashed, dotted, double, solid), w:space (padding)
- color (w:color) => w:val (color: #HEX)
- double line-through (w:dstrike) => w:val (text-decoration-style: double)
- font family (w:rFonts) => w:ascii (font-family)
- font size (w:sz) => w:val (font-size)
- heading (w:outlineLvl) => w:val (h1, h2, h3, h4, h5, h6)
- highlight (w:highlight) => w:val (background-color)
- italic (w:i) => w:val (font-style: italic)
- line height (w:spacing) => w:line (line-height)
- line through (w:strike) => w:on (text-decoration: line-through)
- lower case (w:smallCaps) => w:val (text-transform: lowercase)
- margin (w:ind, w:spacing) => w:left (margin-left), w:start (margin-left), w:right (margin-right), w:end (margin-right), w:after (margin-bottom), w:before (margin-top)
- padding (w:hanging) => w:hanging (padding-left, text-indent)
- page break (w:pageBreakBefore) => w:val (page-break-before: always)
- text align (w:jc) => w:val (text-align: left, justify, center, right)
- text decoration (w:u) => w:val (text-decoration: none or underline; text-decoration-style: dashed, dotted, double, solid, wavy, none)
- text indent (w:firstLine) => w:firstLine (text-indent)
- text direction (w:textDirection) => w:val tbRl (direction: rtl; text-align: right;)
- upper case (w:caps) => w:val (text-transform: uppercase)
- vertical-align (w:vertAlign) => w:val (vertical-align: sub; vertical-align: super)
- word wrap (w:wordWrap) => w:val (word-wrap: break-word)
-
lists (w:numPr) : <ul>, <ol>, <li>
- type (w:numId) => w:val and w:ilvl (list-style-type: circle, disc, decimal, lower-alpha, lower-roman, upper-alpha, upper-roman)
- view paragraphs elements for other styles
- some styles such as color or font sizes can be inherited to the li content from the li symbol. In this case, the content must have its own style
-
links : <a>
- bookmark (w:bookmarkStart, w:bookmarkEnd) => w:name (<a>)
- cross-reference (w:instrText) => PAGEREF (<a>)
- link (w:instrText) => HYPERLINK (<a>)
-
form elements
- checkbox (w:instrText) => (<input> checkbox)
- date (w:date) => (<input> date)
- input (w:instrText) => (<input> text)
- select (w:instrText, w:comboBox) => (<select>)
-
styles (view elements on this same page for supported styles)
- character/run (w:rPr)
- paragraph (w:pPr)
- list (w:pPr, w:numId, w:ilvl)
- table (w:style, w:pPr, w:rPr)
- styles file (w:styles) => character/run (w:rStyle), paragraph and list (w:pStyle), table
- numbering file => list (w:abstractNum)
- default styles (w:docDefaults, w:style w:default=»1″) => w:pPr, w:rPr
-
tables (w:tbl) : <table>
- align (w:jc) => w:val (margin-left, margin-right)
- border (w:tblBorders) => w:top, w:right, w:bottom, w:left (border-: width style [dashed, dotted, double, none, solid] color)
- layout (w:tblLayout) => w:type fixed (table-layout)
- margin (w:tblInd, w:tblpPr) => w:w (margin-left), w:bottomFromText (margin-bottom), w:topFromText (margin-top)
- width (w:tblW) => w:type pct, dxa w:w (width)
- first col style (w:tblStylePr) => w:type (w:rPr styles)
- first row style (w:tblStylePr) => w:type (w:rPr and w:pPr styles)
- last col style (w:tblStylePr) => w:type (w:rPr styles)
- last row style (w:tblStylePr) => w:type (w:rPr and w:pPr styles)
- band1Horz style (w:tblStylePr) => w:type (w:rPr and w:pPr styles)
- band2Horz style (w:tblStylePr) => w:type (w:rPr and w:pPr styles)
- row height (w:trPr) => w:trHeight (height)
- rowspan (w:vMerge) => w:val restart, continue (rowspan)
- cell background color (w:shd) => w:fill (background-color)
- cell border (w:tcPr) => w:top, w:right, w:bottom, w:left (border-: width style [dashed, dotted, double, none, solid] color)
- cell padding (w:tblCellMar) => w:top (padding-top), w:right (padding-right), w:bottom (padding-bottom), w:left (padding-left)
- cell vertical align (w:vAlign) => top, bottom, center, both and default w:val (vertical-align)
- cell width (w:tcW) => w:w (width)
- colspan (w:gridSpan) => w:val (colspan)
- text direction (w:textDirection) => w:val btLr, tbLrV, tbRl and tbRlV (writing-mode, transform, white-space)
-
images (w:drawing) : <img>
- Supported image formats: png, jpg and other formats supported by web browsers. Wmf is supported if ImageImagick is installed
- border (a:ln, a:noFill) => w (width), a:prstDash (style: dashed, dotted, solid), a:srgbClr (color)
- float (wp:positionH, wp:align) => right (float: right), left (float: left), center (display:block; margin-left: auto; margin-right: auto)
- height (wp:extent) => cy (height)
- link (a:hlinkClick) => r:id (href)
- margin (wp:effectExtent, wp:positionH, wp:positionV) => t (margin-top), r (margin-right), b (margin-bottom), l (margin-left), wp:positionH wp:posOffset (margin-left), wp:positionV wp:posOffset (margin-top)
- text wrapping (wp:inline, wp:anchor) => wp:inline (display: inline), wp:wrapSquare (float: left), wp:wrapNone behindDoc (position: absolute; z-index: -1)
- width (wp:extent) => cx (width)
- src (r:embed, r:link) => embedded and linked images
- saved as files or as base64 (only for embedded images)
-
charts (w:drawing) : <div>
- Supported charts: bar (group, stack and percent), column (group, stack and percent), pie, doughnut and line charts
- Plotly JS library (MIT license) [https://plotly.com/javascript/] is used as default chart library
- height (cy)
- labels (c:cat)
- legends (c:tx)
- orientation (h, v)
- values (c:val)
- width (cx)
- Plotly default colors are used
-
other elements
- break (w:br) => (<br>)
- comment (w:commentReference, w:comment) => added to the bottom of the page (<span>)
- date (w:instrText) => TIME (<span>)
- endnote (w:endnoteReference, w:endnote) => added to the bottom of the page (<span>)
- external file (w:altChunk) => r:id (<a>)
- footer (w:footerReference, w:ftr) => (<footer>) added to the bottom of its section
- header (w:headerReference, w:hdr) => (<header>) added to the top of its section
- footnote (w:footnoteReference) => added to the bottom of the page (<span>)
- math equations => Office MathML
- simple fields (w:fldSimple) => AUTHOR, COMMENTS, LASTSAVEDBY, TITLE
- tabs (w:tab) => (<span>) margin-left default
- textbox (v:textbox) => (<div>), style (min-height, float, width), fillcolor (background-color), margin-top (margin-top), strokecolor (border-color, border-style), strokeweight (border-width)
- tracked contents (w:ins, w:del) => (<ins>, <del>)
- The fact that a tag is not parsed does not mean its content disappears from the HTML output. It only implies that their associated OOXML properties are not taken directly into account. Their children and text content will be parsed and rendered with their corresponding styles into the HTML output.
WARNING:
The transforming features included in phpdocx allow to transform complex DOCX documents generated from scratch or using templates. Let’s take a look at some samples and their HTML output.
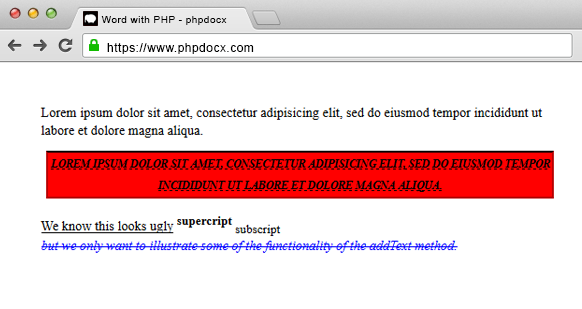
DOCX with an A4 section and paragraphs:
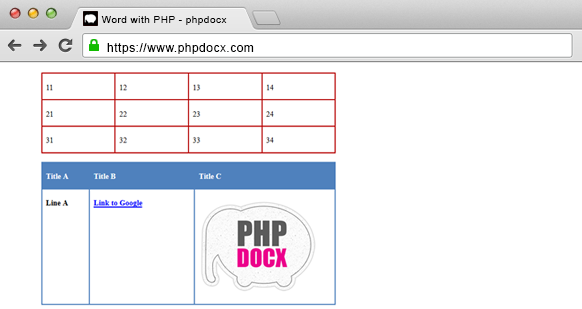
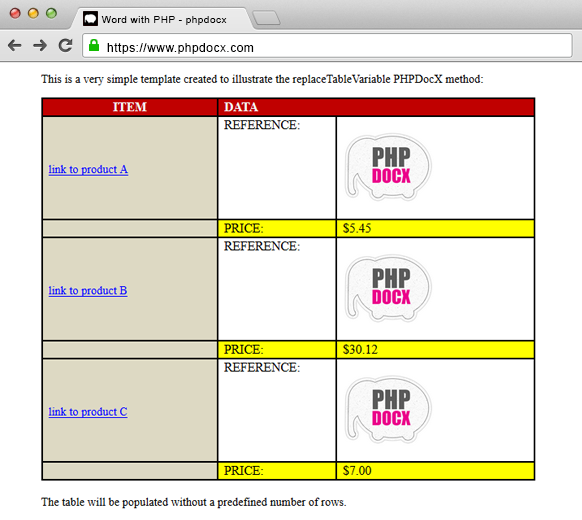
DOCX with tables:
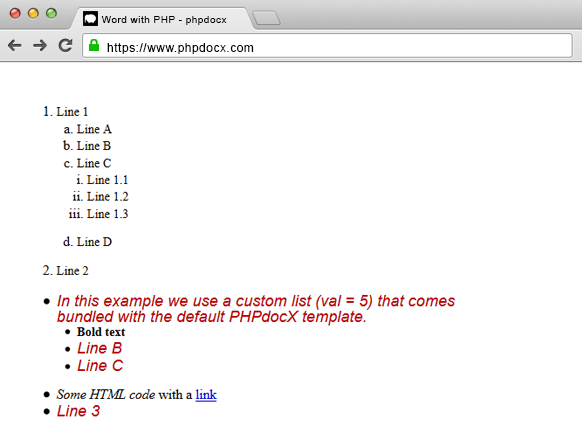
DOCX with lists and text styles:
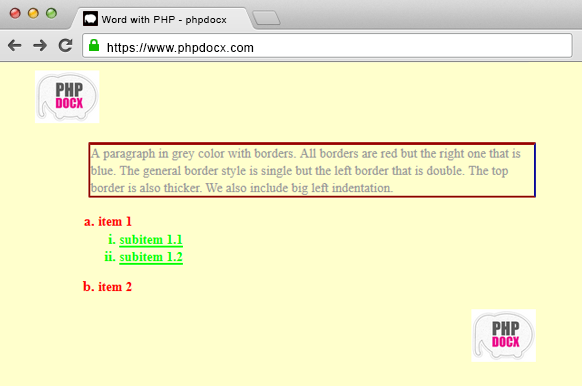
DOCX with headers and footers:
DOCX from a template:
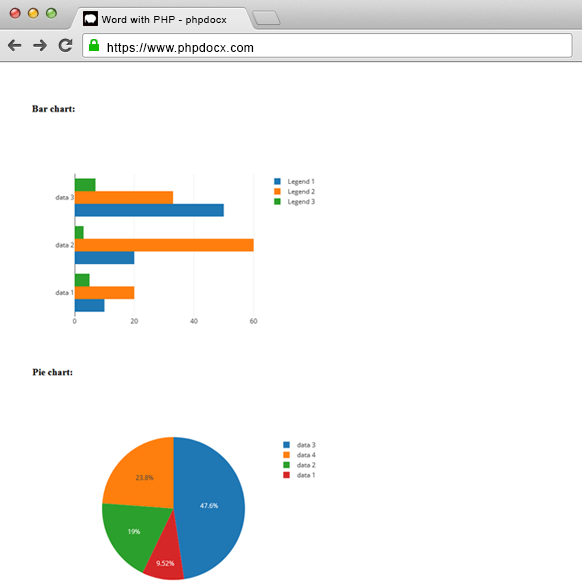
DOCX with charts:
How to customize transformations
Nearly all the functionalities available for performing DOCX to HTML transformations can be customized.
The two main classes for transformations are: TransformDocAdvHTML and TransformDocAdvHTMLPlugin.
TransformDocAdvHTML is the class for parsing DOCX structures and performs the transformation to HTML. Its constructor receives an object of the TransformDocAdvHTMLPlugin type that sets the export options. This class can be extended to customize the transformation of each element, e.g., transformW_BOOKMARKSTART for bookmarks or transformW_SECTPR for sections.
TransformDocAdvHTMLPlugin allows to generate transformation plugins according to the project requirements. E.g.: inserting images as base64, ignoring sections, customizing conversion factors, setting the method to set export sizes and set CSS, JavaScript and custom HTML. phpdocx includes the TransformDocAdvHTMLDefaultPlugin, the default plugin to perform transformations.
All the available options are thoroughly explained in the API documentation page of the transformDocAdvHTML method.
Ok Im in very late, but thought I’d post this to save you all some time.
This is some php code I have put together not just to read the text from docx but the images too, currently it does not support floating images / text, but what I have done so far is a massive move forwards to whats already been posted on here — note you need to update https://example.co.uk to YOUR domain name.
<?php
class Docx_ws_imglnk {
public $originalpath = '';
public $extractedpath = '';
}
class Docx_ws_rel {
public $Id = '';
public $Target = '';
}
class Docx_ws_def {
public $styleId = '';
public $type = '';
public $color = '000000';
}
class Docx_p_def {
public $data = array();
public $text = "";
}
class Docx_p_item {
public $name = "";
public $value = "";
public $innerstyle = "";
public $type = "text";
}
class Docx_reader {
private $fileData = false;
private $errors = array();
public $rels = array();
public $imglnks = array();
public $styles = array();
public $document = null;
public $paragraphs = array();
public $path = '';
private $saveimgpath = 'docimages';
public function __construct() {
}
private function load($file) {
if (file_exists($file)) {
$zip = new ZipArchive();
$openedZip = $zip->open($file);
if ($openedZip === true) {
$this->path = $file;
//read and save images
for ( $i = 0; $i < $zip->numFiles; $i ++ ) {
$zip_element = $zip->statIndex( $i );
if ( preg_match( "([^s]+(.(?i)(jpg|jpeg|png|gif|bmp))$)", $zip_element['name'] ) ) {
$imglnk = new Docx_ws_imglnk;
$imglnk->originalpath = $zip_element['name'];
$imagename = explode( '/', $zip_element['name'] );
$imagename = end( $imagename );
$imglnk->extractedpath = dirname( __FILE__ ) . '/' . $this->savepath . $imagename;
$putres = file_put_contents( $imglnk->extractedpath, $zip->getFromIndex( $i ));
$imglnk->extractedpath = str_replace('var/www/', 'https://example.co.uk/', $imglnk->extractedpath);
$imglnk->extractedpath = substr($imglnk->extractedpath, 1);
array_push($this->imglnks, $imglnk);
}
}
//read relationships
if (($styleIndex = $zip->locateName('word/_rels/document.xml.rels')) !== false) {
$stylesRels = $zip->getFromIndex($styleIndex);
$xml = simplexml_load_string($stylesRels);
$XMLTEXT = $xml->saveXML();
$doc = new DOMDocument();
$doc->loadXML($XMLTEXT);
foreach($doc->documentElement->childNodes as $childnode)
{
$nodename = $childnode->nodeName;
if($childnode->hasAttributes())
{
$rel = new Docx_ws_rel;
for ($a = 0; $a < $childnode->attributes->count(); $a++)
{
$attrNode = $childnode->attributes->item($a);
if (strcmp( $attrNode->nodeName, 'Id') == 0)
{
$rel->Id = $attrNode->nodeValue;
}
if (strcmp( $attrNode->nodeName, 'Target') == 0)
{
$rel->Target = $attrNode->nodeValue;
}
}
array_push($this->rels, $rel);
}
}
}
//attempt to load styles:
if (($styleIndex = $zip->locateName('word/styles.xml')) !== false) {
$stylesXml = $zip->getFromIndex($styleIndex);
$xml = simplexml_load_string($stylesXml);
$XMLTEXT = $xml->saveXML();
$doc = new DOMDocument();
$doc->loadXML($XMLTEXT);
foreach($doc->documentElement->childNodes as $childnode)
{
$nodename = $childnode->nodeName;
//get style
if (strcmp($nodename, "w:style") == 0)
{
$ws_def = new Docx_ws_def;
for ($a=0; $a < $childnode->attributes->count(); $a++ )
{
$item = $childnode->attributes->item($a);
//style id
if (strcmp($item->nodeName, "w:styleId") == 0)
{
$ws_def->styleId = $item->nodeValue;
}
//style type
if (strcmp($item->nodeName, "w:type") == 0)
{
$ws_def->type = $item->nodeValue;
}
}
}
//push style to the array of styles
if (strcmp($ws_def->styleId, "") != 0 && strcmp($ws_def->type, "") != 0)
{
array_push($this->styles, $ws_def);
}
}
}
if (($index = $zip->locateName('word/document.xml')) !== false) {
$stylesDoc = $zip->getFromIndex($index);
$xml = simplexml_load_string($stylesDoc);
$XMLTEXT = $xml->saveXML();
$this->document = new DOMDocument();
$this->document->loadXML($XMLTEXT);
}
$zip->close();
} else {
switch($openedZip) {
case ZipArchive::ER_EXISTS:
$this->errors[] = 'File exists.';
break;
case ZipArchive::ER_INCONS:
$this->errors[] = 'Inconsistent zip file.';
break;
case ZipArchive::ER_MEMORY:
$this->errors[] = 'Malloc failure.';
break;
case ZipArchive::ER_NOENT:
$this->errors[] = 'No such file.';
break;
case ZipArchive::ER_NOZIP:
$this->errors[] = 'File is not a zip archive.';
break;
case ZipArchive::ER_OPEN:
$this->errors[] = 'Could not open file.';
break;
case ZipArchive::ER_READ:
$this->errors[] = 'Read error.';
break;
case ZipArchive::ER_SEEK:
$this->errors[] = 'Seek error.';
break;
}
}
} else {
$this->errors[] = 'File does not exist.';
}
}
public function setFile($path) {
$this->fileData = $this->load($path);
}
public function to_plain_text() {
if ($this->fileData) {
return strip_tags($this->fileData);
} else {
return false;
}
}
public function processDocument() {
$html = '';
foreach($this->document->documentElement->childNodes as $childnode)
{
$nodename = $childnode->nodeName;
//get the body of the document
if (strcmp($nodename, "w:body") == 0)
{
foreach($childnode->childNodes as $subchildnode)
{
$pnodename = $subchildnode->nodeName;
//process every paragraph
if (strcmp($pnodename, "w:p") == 0)
{
$pdef = new Docx_p_def;
foreach($subchildnode->childNodes as $pchildnode)
{
//process any inner children
if (strcmp($pchildnode, "w:pPr") == 0)
{
foreach($pchildnode->childNodes as $prchildnode)
{
//process text alignment
if (strcmp($prchildnode->nodeName, "w:pStyle") == 0)
{
$pitem = new Docx_p_item;
$pitem->name = 'styleId';
$pitem->value = $prchildnode->attributes->getNamedItem('val')->nodeValue;
array_push($pdef->data, $pitem);
}
//process text alignment
if (strcmp($prchildnode->nodeName, "w:jc") == 0)
{
$pitem = new Docx_p_item;
$pitem->name = 'align';
$pitem->value = $prchildnode->attributes->getNamedItem('val')->nodeValue;
if (strcmp($pitem->value, "left") == 0)
{
$pitem->innerstyle .= "text-align:" . $pitem->value . ";";
}
if (strcmp($pitem->value, "center") == 0)
{
$pitem->innerstyle .= "text-align:" . $pitem->value . ";";
}
if (strcmp($pitem->value, "right") == 0)
{
$pitem->innerstyle .= "text-align:" . $pitem->value . ";";
}
if (strcmp($pitem->value, "both") == 0)
{
$pitem->innerstyle .= "word-spacing:" . 10 . "px;";
}
array_push($pdef->data, $pitem);
}
//process drawing
if (strcmp($prchildnode->nodeName, "w:drawing") == 0)
{
$pitem = new Docx_p_item;
$pitem->name = 'drawing';
$pitem->value = '';
$pitem->type = 'graphic';
$extents = $prchildnode->getElementsByTagName('extent')[0];
$cx = $extents->attributes->getNamedItem('cx')->nodeValue;
$cy = $extents->attributes->getNamedItem('cy')->nodeValue;
$pcx = (int)$cx / 9525;
$pcy = (int)$cy / 9525;
$pitem->innerstyle .= "width:" . $pcx . "px;";
$pitem->innerstyle .= "height:" . $pcy . "px;";
$blip = $prchildnode->getElementsByTagName('blip')[0];
$pitem->value = $blip->attributes->getNamedItem('embed')->nodeValue;
array_push($pdef->data, $pitem);
}
//process spacing
if (strcmp($prchildnode->nodeName, "w:spacing") == 0)
{
$pitem = new Docx_p_item;
$pitem->name = 'paragraphSpacing';
$bval = $prchildnode->attributes->getNamedItem('before')->nodeValue;
if (strcmp($bval, '') == 0)
$bval = 0;
$pitem->innerstyle .= "padding-top:" . $bval . "px;";
$aval = $prchildnode->attributes->getNamedItem('after')->nodeValue;
if (strcmp($aval, '') == 0)
$aval = 0;
$pitem->innerstyle .= "padding-bottom:" . $aval . "px;";
array_push($pdef->data, $pitem);
}
}
}
if (strcmp($pchildnode, "w:r") == 0)
{
foreach($pchildnode->childNodes as $rchildnode)
{
//process text
if (strcmp($rchildnode->nodeName, "w:t") == 0)
{
$pdef->text .= $rchildnode->nodeValue;
if (count($pdef->data) == 0)
{
$pitem = new Docx_p_item;
$pitem->name = 'styleId';
$pitem->value = '';
array_push($pdef->data, $pitem);
}
}
if (strcmp($rchildnode->nodeName, "w:rPr") == 0)
{
foreach($rchildnode->childNodes as $rPrchildnode)
{
if (strcmp($rPrchildnode->nodeName, "w:b") == 0 )
{
$pitem = new Docx_p_item;
$pitem->name = 'textBold';
$pitem->value = '';
$pitem->innerstyle .= "text-weight: 500;";
array_push($pdef->data, $pitem);
}
if (strcmp($rPrchildnode->nodeName, "w:i") == 0 )
{
$pitem = new Docx_p_item;
$pitem->name = 'textItalic';
$pitem->value = '';
$pitem->innerstyle .= "text-style: italic;";
array_push($pdef->data, $pitem);
}
if (strcmp($rPrchildnode->nodeName, "w:u") == 0 )
{
$pitem = new Docx_p_item;
$pitem->name = 'textUnderline';
$pitem->value = '';
$pitem->innerstyle .= "text-decoration: underline;";
array_push($pdef->data, $pitem);
}
if (strcmp($rPrchildnode->nodeName, "w:sz") == 0 )
{
$pitem = new Docx_p_item;
$pitem->name = 'textSize';
$sz = $rPrchildnode->attributes->getNamedItem('val')->nodeValue;
if ($sz == '')
{
$sz=0;
}
$pitem->value = $sz;
array_push($pdef->data, $pitem);
}
}
}
}
}
}
array_push($this->paragraphs, $pdef);
}
}
}
}
}
public function to_html()
{
$html = '';
foreach($this->paragraphs as $para)
{
$styleselect = null;
$type = 'text';
$content = $para->text;
$sz = 0;
$extent = '';
$embedid = '';
$pinnerstylesid = '';
$pinnerstylesunderline = '';
$pinnerstylessz = '';
if (count($para->data) > 0)
{
foreach($para->data as $node)
{
if (strcmp($node->name, "styleId") == 0)
{
$type = $node->type;
$pinnerstylesid = $node->innerstyle;
foreach($this->styles as $style)
{
if (strcmp ($node->value, $style->styleId) == 0)
{
$styleselect = $style;
}
}
}
if (strcmp($node->name, "align") == 0)
{
$pinnerstylesid .= $node->innerstyle. ";";
}
if (strcmp($node->name, "drawing") == 0)
{
$type = $node->type;
$extent = $node->innerstyle;
$embedid = $node->value;
}
if (strcmp($node->name, "textSize") == 0)
{
$sz = $node->value;
}
if (strcmp($node->name, "textUnderline") == 0)
{
$pinnerstylesunderline = $node->innerstyle;
}
}
}
if (strcmp($type, 'text') == 0)
{
//echo "has valid para";
//echo "<br>";
if ($styleselect != null)
{
//echo "has valid style";
//echo "<br>";
if (strcmp($styleselect->color, '') != 0)
{
$pinnerstylesid .= "color:#" . $styleselect->color. ";";
}
}
if ($sz != 0)
{
$pinnerstylesid .= 'font-size:' . $sz . 'px;';
//echo "sz<br>";
}
$span = "<p style='". $pinnerstylesid . $pinnerstylesunderline ."'>";
$span .= $content;
$span .= "</p>";
//echo $span;
$html .= $span;
}
if (strcmp($type, 'graphic') == 0)
{
$imglnk = '';
foreach($this->rels as $rel)
{
if(strcmp($embedid, '') != 0 && strcmp($rel->Id, $embedid) == 0)
{
foreach($this->imglnks as $imgpathdef)
{
if (strpos($imgpathdef->extractedpath, $rel->Target) >= 0)
{
$imglnk = $imgpathdef->extractedpath;
//echo "has img link<br>";
//echo $imglnk . "<br>";
}
}
}
}
if ($styleselect != null)
{
//echo "has valid style";
//echo "<br>";
if (strcmp($styleselect->color, '') != 0)
{
$pinnerstylesid .= "color:#" . $styleselect->color. ";";
}
}
if ($sz != 0)
{
$pinnerstylesid .= 'font-size:' . $sz . 'px;';
//echo "sz<br>";
}
$span = "<p style='". $pinnerstylesid . $pinnerstylesunderline ."'>";
$span .= "<img style='". $extent ."' alt='image coming soon' src ='". $imglnk ."'/>";
$span .= "</p>";
//echo $span;
$html .= $span;
}
}
return $html;
}
public function get_errors() {
return $this->errors;
}
private function getStyles() {
}
}
function getDocX($path)
{
//echo $path;
$doc = new Docx_reader();
$doc->setFile($path);
if(!$doc->get_errors()) {
$doc->processDocument();
$html = $doc->to_html();
echo $html;
}
return "";
}
?>
Convert a docx (OOXML) file to semantic HTML.
All of Word formatting nonsense is stripped away and
you’re left with a cleanly-formatted version of the content.
Usage
>>> from docx2html import convert
>>> html = convert('path/to/docx/file')
Running Tests for Development
$ virtualenv path/to/new/virtualenv $ source path/to/new/virtualenv/bin/activate $ cd path/to/workspace $ git clone git://github.com/PolicyStat/docx2html.git $ cd docx2html $ pip install . $ pip install -r test_requirements.txt $ ./run_tests.sh
Description
docx2html is designed to take a docx file and extract the content out and
convert that content to html. It does not care about styles or fonts or
anything that changes how the content is displayed (with few exceptions). Below
is a list of what currently works:
-
- Paragraphs
-
-
Bold
-
Italics
-
Underline
-
Hyperlinks
-
-
- Lists
-
-
Nested lists
-
List styles (letters, roman numerals, etc.)
-
Tables
-
Paragraphs
-
-
- Tables
-
-
Rowspans
-
Colspans
-
Nested tables
-
Lists
-
-
- Images
-
-
Resizing
-
Converting to smaller formats (for bitmaps and tiffs)
-
There is a hook to allow setting the src of the image tag out of context,
more on this later
-
-
- Headings
-
-
Simple headings
-
Root level lists that are upper case roman numerals get converted to h2
tags
-
Handling embedded images
docx2html allows you to specify how you would like to handle image uploading.
For example, you might be uploading your images to Amazon S3 eg:
Note: This documentation sucks, so you might need to read the source.
import os.path
from shutil import copyfile
from docx2html import convert
def handle_image(image_id, relationship_dict):
image_path = relationship_dict[image_id]
# Now do something to the image. Let's move it somewhere.
_, filename = os.path.split(image_path)
destination_path = os.path.join('/tmp', filename)
copyfile(image_path, destination_path)
# Return the `src` attribute to be used in the img tag
return 'file://%s' % destination
html = convert('path/to/docx/file', image_handler=handle_image)
Naming Conventions
There are two main naming conventions in the source for docx2html there are
build functions, which will return an etree element that represents HTML. And
there are get_content functions which return string representations of HTML.
Changelog
-
- 0.2.3
-
-
There was a bug with hyperlinks that had a break tag in them. The
document would fail to convert. This issue has been fixed.
-
-
- 0.2.2
-
-
There was a bug with hyperlinks that were missing text. The document
would fail to convert. This issue has been fixed.
-
-
- 0.2.1
-
-
If a list had an inconsistency in the ilvls, the content for the
inconsistent ilvl would be lost. Now we roll that inconsistent list into
the root, no longer losing the content.
-
-
- 0.2.0
-
-
If a list had a numId that was not stored in the numbering dict, then a
key error would be thrown. Now if either the numId or the ilvl for a
given list tag is invalid it defaults to returning a list type of
decimal.
-
-
- 0.1.11
-
-
Sometimes in the OOXML an image will have a height or width of 0. If this
happens we are now ignoring the height and width in the OOXML and using
the full image instead.
-
-
- 0.1.10
-
-
Added a user facing version
-
-
- 0.1.9
-
-
There was a problem for some lists that would cause missing content if
the list id’s were not well behaved. This issue has been addressed.
-
-
- 0.1.8
-
-
Fixed missing content with hyperlinks with more than one run tag and
smartTags. -
Certain image types are now being ignored. These include: emf, wmf and
svg.
-
-
- 0.1.7
-
-
If the indentation level of a set of lists (with the same list id) were
mangled (Starting off with a higher indentation level followed by a
lower) then the entire sub list (the list with the lower indentation
level) would not be added to the root list. This would result in removing
the mangled list from the final output. This issue has been addressed.
-
-
- 0.1.6
-
-
Header detection was relying on case. However it is possible for a lower
case version of headers to show up. Those are now handled correctly.
-
-
- 0.1.4
-
-
Added a function to remove tags, in addition stripped ‘sectPr’ tags since
they have to do with headers and footers.
-
-
- 0.1.3
-
-
Hyperlinks with no text no longer throw an error
-
Fixed a bug with determining the font size with an incomplete styles dict
-
-
- 0.1.2
-
-
Fixed a bug with determining the font size of a paragraph tag
-
-
- 0.1.1
-
-
Added a changelog
-
Styles are now stripped from hyperlinks
-
jinja2 is now used to render test xml
-
-
- 0.1.0
-
-
Correctly handle tables and paragraphs in lists. Before if there was a
table in a list it would break the list into two halves, the half before
the table and the half after the table (with the table inbetween them). Now
if there is a table or paragraph in a list those elements get rolled into
the list.
-

Здравствуйте, пытаюсь распарсить word-файл (вытащить таблицу). Уже вторую неделю бьюсь над этим
Перепробывал кучу вариантов, различных библиотек, прогуглил и русскоязычный и англоязычный интернет, — нашел несколько рабочих способов:
1) Word to html посредством COM-модуля.
*
Недостаток 1:
сервер может быть линуксовый (обычно так и есть), поэтому тут нужно искать альтернативу в Linux
*
Недостаток 2:
Распарсив таким образом word, я получил html-документ, имеющий структуру, которая не совсем правильная с точки зрения построения таблиц (некоторые из ячеек выравнивались с помощью инлайновых стилей), — парсить такую штуку не удобно, а городить свои костыли не хотелось бы.
Пример html-файла сгенерированного
Кликните здесь для просмотра всего текста
| HTML5 | ||
|
2) Конвертирование утилитами на стороне сервера, выполнив консольные команды
На стороне сервера передаем в функции команду конвертации файла и в какой
| PHP | ||
|
Эту тему особо не прогугливал, возможно, кто-то пробовал играться с этим
3) Какое-нибудь прикручивание сторонней библиотеки (например, на python) word to html
4) Word to xml
* Аналогично недостаткам парсинга, как и в пункте 1), плюс в xml-формате стандартно docx, на doc нужно другое решение
Может быть кто-то знает как решить данную проблему, хотелось бы решить ее на php, но, судя по тому, что я нагуглил, такие задачи легко решаются на java / c# / python, т.к там уже есть легкоуправляемые библиотеки
Прикрепляю word-файл таблички, которую нужно распарсить и ее скриншот