

Надстройка Parser для Excel — простое и удобное решение для парсинга любых сайтов (интернет-магазинов, соцсетей, площадок объявлений) с выводом данных в таблицу Excel (формата XLS* или CSV), а также скачивания файлов.
Особенность программы — очень гибкая настройка постобработки полученных данных (множество текстовых функций, всевозможные фильтры, перекодировки, работа с переменными, разбиение значения на массив и обработка каждого элемента в отдельности, вывод характеристик в отдельные столбцы, автоматический поиск цены товара на странице, поддержка форматов JSON и XML).
В парсере сайтов поддерживается авторизация на сайтах, выбор региона, GET и POST запросы, приём и отправка Cookies и заголовков запроса, получение исходных данных для парсинга с листа Excel, многопоточность (до 200 потоков), распознавание капчи через сервис RuCaptcha.com, работа через браузер (IE), кеширование, рекурсивный поиск страниц на сайте, сохранение загруженных изображений товара под заданными именами в одну или несколько папок, и многое другое.
Поиск нужных данных на страницах сайта выполняется в парсере путем поиска тегов и/или атрибутов тегов (по любому свойству и его значению). Специализированные функции для работы с HTML позволяют разными способами преобразовывать HTML-таблицы в текст (или пары вида название-значение), автоматически находить ссылки пейджера, чистить HTML от лишних данных.
За счёт тесной интеграции с Excel, надстройка Parser может считывать любые данные из файлов Excel, создавать отдельные листы и файлы, динамически формировать столбцы для вывода, а также использовать всю мощь встроенных в Excel возможностей.
Поддерживается также сбор данных из текстовых файлов (формата Word, XML, TXT) из заданной пользователем папки, а также преобразование файлов Excel из одного формата таблицы в другой (обработка и разбиение данных на отдельные столбцы)
В программе «Парсер сайтов» можно настроить обработку нескольких сайтов. Перед запуском парсинга (кнопкой на панели инструментов Excel) можно выбрать ранее настроенный сайт из выпадающего списка.
Пример использования парсера для мониторинга цен конкурентов
Дополнительные видеоинструкции, а также подробное описание функционала, можно найти в разделе Справка по программе
В программе можно настроить несколько парсеров (обработчиков сайтов).
Любой из парсеров настраивается и работает независимо от других.
Примеры настроенных парсеров (можно скачать, запустить, посмотреть настройки)
Видеоинструкция (2 минуты), как запустить готовый (уже настроенный) парсер
Настройка программы, — дело не самое простое (для этого, надо хоть немного разбираться в HTML)
Если вам нужен готовый парсер, но вы не хотите разбираться с настройкой,
— закажите настройку парсера разработчику программы. Стоимость настройки под конкретный сайт — от 2000 рублей.
(настройка под заказ выполняется только при условии приобретения лицензии на надстройку «Парсер» (3300 руб)
Инструкция (с видео) по заказу настройки парсера
По всем вопросам, готов проконсультировать вас в Скайпе.
Программа не привязана к конкретному файлу Excel.
Вы в настройках задаёте столбец с исходными данными (ссылками или артикулами),
настраиваете формирование ссылок и подстановку данных с сайта в нужные столбцы,
нажимаете кнопку, — и ваша таблица заполняется данными с сайта.
Программа «Парсер сайтов» может быть полезна для формирования каталога товаров интернет-магазинов,
поиска и загрузки фотографий товара по артикулам (если для получения ссылки на фото, необходимо анализировать страницу товара),
загрузки актуальных данных (цен и наличия) с сайтов поставщиков, и т.д. и т.п.
Справка по программе «Парсер сайтов»
Можно попробовать разобраться с работой программы на примерах настроенных парсеров
Есть excel-файлы, несколько сотен.
Из них нужно как-то извлечь некоторые строки, по заданному принципу (текст в них отличается).
И залить эти строки в один новый экселевский файл.
Можно сделать руками, но лень. И еще есть вариант, что данная задача будет периодически повторяться.
Подскажите, пожалуйста, какими инструментами лучше это программно сделать? Автоматически по очереди пооткрывать все файлы в директории, пропарсить, взять нужные строки, залить в новый файл.
Может, был у кого похожий опыт.
Я начал смотреть в сторону python и www.python-excel.org
Может лучше сделать это visual basic’ом? Или вообще в самом экселе есть такая возможность?
Спасибо!
P.S. Все сделал так: сперва нашел плагин для эксель, бесплатно и быстро сливающий много эксель файлов в один. Вот он.
Затем искал конкретные макросы, удаляющие строки по различным критериям, типа — пустая ячейка, текст в ячейке, цифры в ячейке.
В общем, даже не пришлось сильно разбираться с VBA, все сделал готовыми средствами.
Добавить это приложение в закладки
Нажмите Ctrl + D, чтобы добавить эту страницу в избранное, или Esc, чтобы отменить действие.
Отправьте ссылку для скачивания на
Отправьте нам свой отзыв
Ой! Произошла ошибка.
Недопустимый файл. Убедитесь, что загружается правильный файл.
Ошибка успешно зарегистрирована.
Вы успешно сообщили об ошибке. Вы получите уведомление по электронной почте, когда ошибка будет исправлена.
Нажмите эту ссылку, чтобы посетить форумы.
Немедленно удалите загруженные и обработанные файлы.
Вы уверены, что хотите удалить файлы?
Введите адрес
Разобрать файл XLSX и извлечь данные с помощью любого современного браузера
Loading…
Обработка Пожалуйста, подождите…
Копировать ссылку
![]()
![]()
Обработка Пожалуйста, подождите…
Файл отправлен на
![]()
Ваше мнение важно для нас, пожалуйста, оцените это приложение.
★
★
★
★
★
Спасибо за оценку нашего приложения!
XLSX parser
XLSX Parser – это бесплатный инструмент, который позволяет извлекать текст и таблицы из XLSX файлов, управлять содержимым документов без установки дополнительного программного обеспечения, из любого браузера и с любого устройства. Извлекайте текст из XLS, XLSX, PPT, PPTX, PDF, DOC, DOCX, RTF, HTML, EPUB и многих других форматов файлов и документов.
![]()
Скоро будет
Как Разобрать XLSX
- Щелкните внутри области перетаскивания или перетащите файл.
- Дождитесь завершения загрузки и обработки.
- После завершения загрузки и обработки файла вы увидите страницу результатов.
- На странице результатов нажмите кнопку «Синтаксический анализ», чтобы начать анализ вашего файла.
- Вы также можете поделиться своим файлом с помощью ссылки для копирования или электронной почты.
![]()
часто задаваемые вопросы
Q: Как разобрать файл XLSX?
A: Во-первых, вам нужно загрузить файл: перетащите файл или щелкните внутри области загрузки, чтобы выбрать файл, чтобы начать его обработку. После завершения обработки нажмите кнопку «Разобрать», чтобы начать анализ вашего документа.
Q: Нужно ли мне устанавливать дополнительное программное обеспечение, чтобы иметь возможность анализировать файл XLSX?
A: Нет, приложение для анализа документов Conholdate — это полностью облачная служба, которая не требует установки дополнительного программного обеспечения.
Q: Могу ли я анализировать файлы в ОС Linux, Mac или Android?
A: Конечно, Conholdate Parser — это полностью облачный сервис, который не требует установки какого-либо программного обеспечения и может использоваться в любой операционной системе с веб-браузером.
Q: Безопасно ли анализировать файлы XLSX с помощью бесплатного Conholdate.App?
A: Да, это абсолютно безопасно. Ваши файлы хранятся на нашем защищенном сервере и защищены от любого несанкционированного доступа. Через 24 часа все файлы удаляются безвозвратно.
Q: Можно ли разобрать текст из документа XLSX?
A: Да, выберите инструмент текстового поля на верхней панели инструментов синтаксического анализатора XLSX, выберите нужную область на странице документа XLSX и нажмите кнопку синтаксического анализа.
Q: Могу ли я разобрать таблицу из документа XLSX?
A: Да, выберите инструмент таблицы на верхней панели инструментов синтаксического анализатора XLSX, выберите таблицу на странице документа XLSX и нажмите кнопку синтаксического анализа.
Q: Как получить XLSX результатов синтаксического анализа?
A: Вы можете загрузить результаты в виде файла CSV, нажав кнопку загрузки, расположенную в верхней части диалогового окна анализатора XLSX. Также вы можете сохранить шаблон синтаксического анализа для дальнейшего использования, для этого просто щелкните значок загрузки, расположенный в верхней правой части панели инструментов синтаксического анализатора.
Еще приложений
Еще parser приложений
Выбрать язык
Парсить сайты в Excel достаточно просто если использовать облачную версию софта Google Таблицы (Sheets/Doc), которые без труда позволяют использовать мощности поисковика для отправки запросов на нужные сайты.
- Подготовка;
- IMPORTXML;
- IMPORTHTML;
- Обратная конвертация.
Видеоинструкция
Подготовка к парсингу сайтов в Excel (Google Таблице)
Для того, чтобы начать парсить сайты потребуется в первую очередь перейти в Google Sheets, что можно сделать открыв страницу:
https://www.google.com/intl/ru_ru/sheets/about/
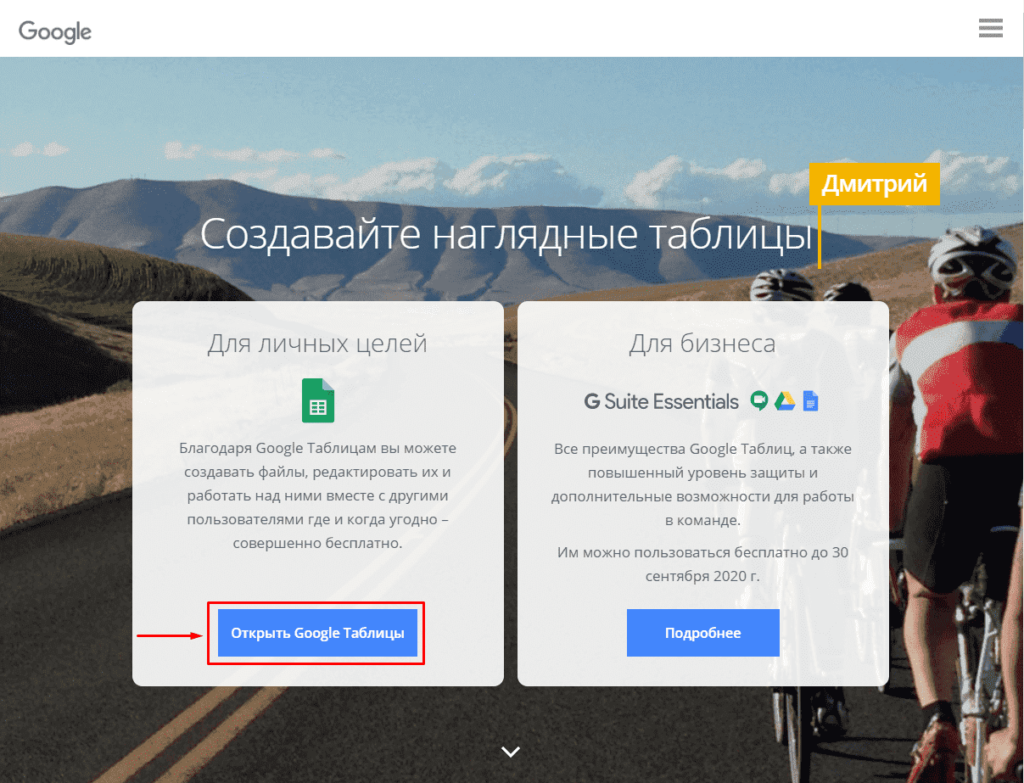
Потребуется войти в Google Аккаунт, после чего нажать на «Создать» (+).
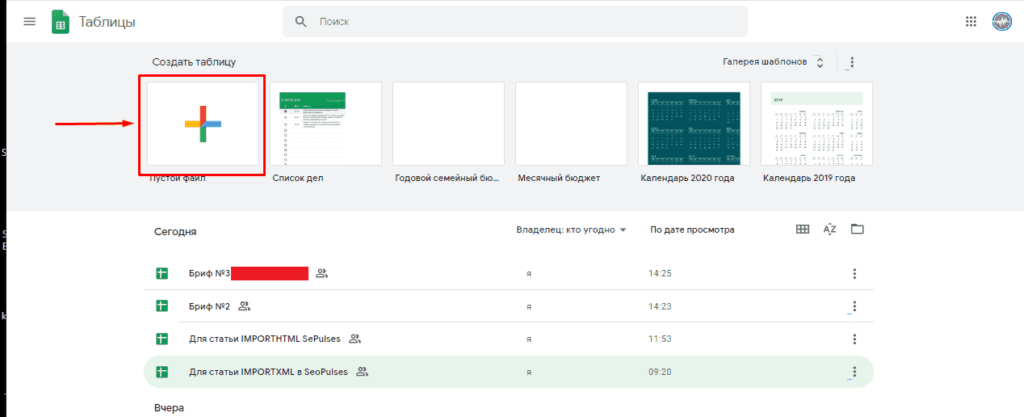
Теперь можно переходить к парсингу, который можно выполнить через 2 основные функции:
- IMPORTXML. Позволяет получить практически любые данные с сайта, включая цены, наименования, картинки и многое другое;
- IMPORTHTML. Позволяет получить данные из таблиц и списков.
Однако, все эти методы работают на основе ссылок на страницы, если таблицы с URL-адресами нет, то можно ускорить этот сбор через карту сайта (Sitemap). Для этого добавляем к домену сайта конструкцию «/robots.txt». Например, «seopulses.ru/robots.txt».
Здесь открываем URL с картой сайта:
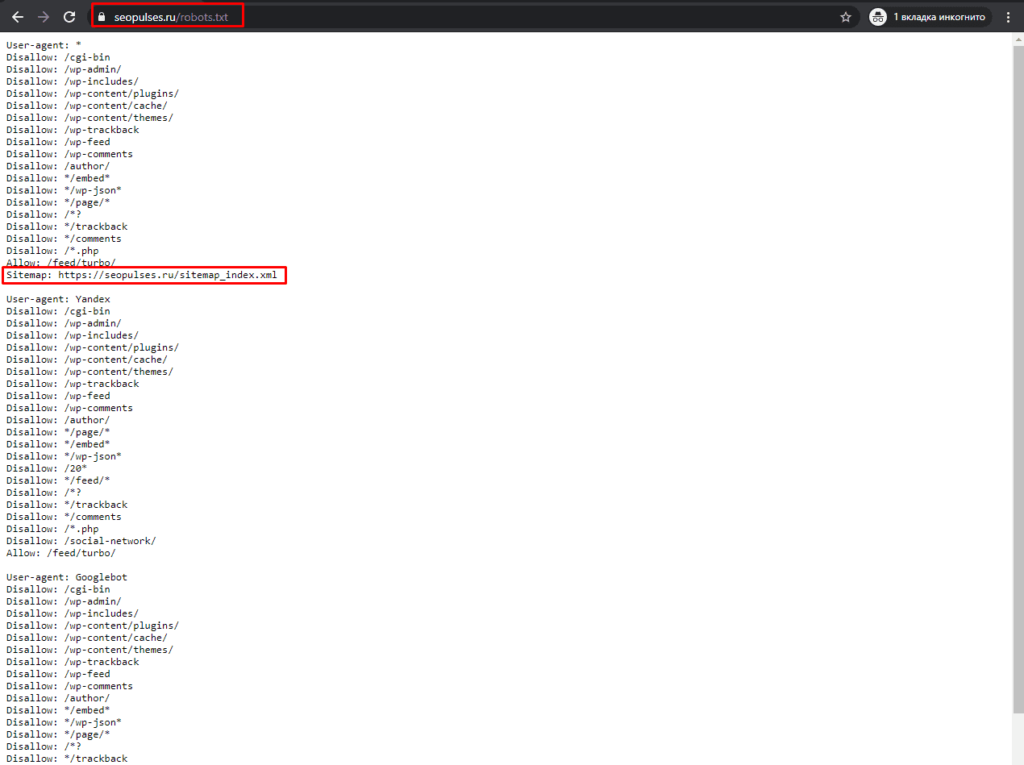
Нас интересует список постов, поэтому открываем первую ссылку.
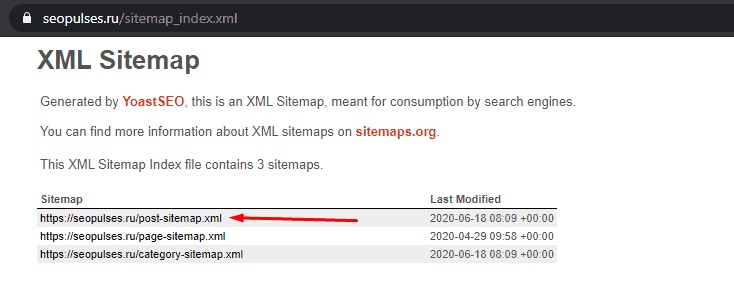
Получаем полный список из URL-адресов, который можно сохранить, кликнув правой кнопкой мыши и нажав на «Сохранить как» (в Google Chrome).
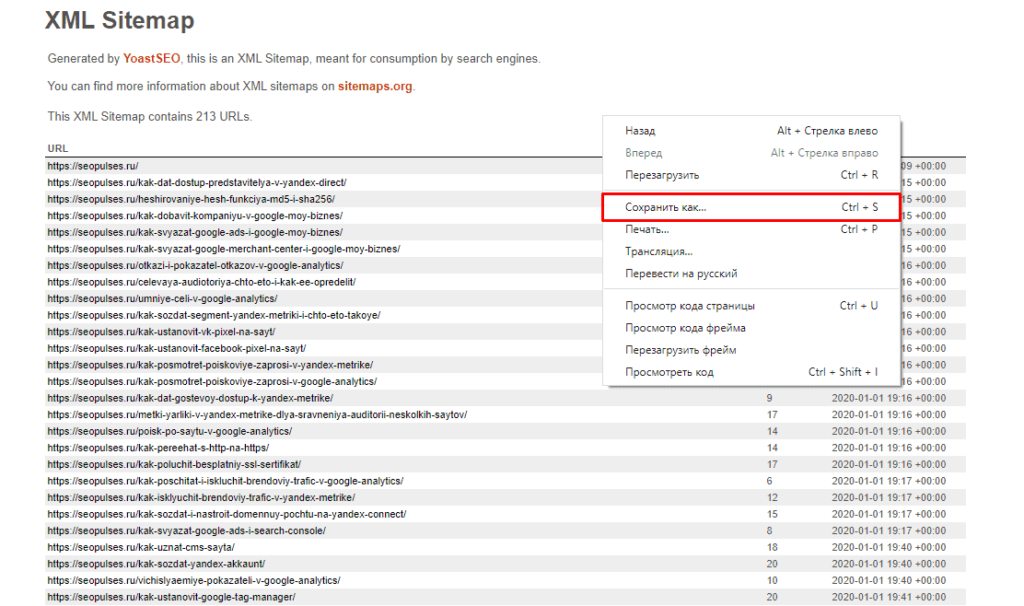
Теперь на компьютере сохранен файл XML, который можно открыть через текстовые редакторы, например, Sublime Text или NotePad++.
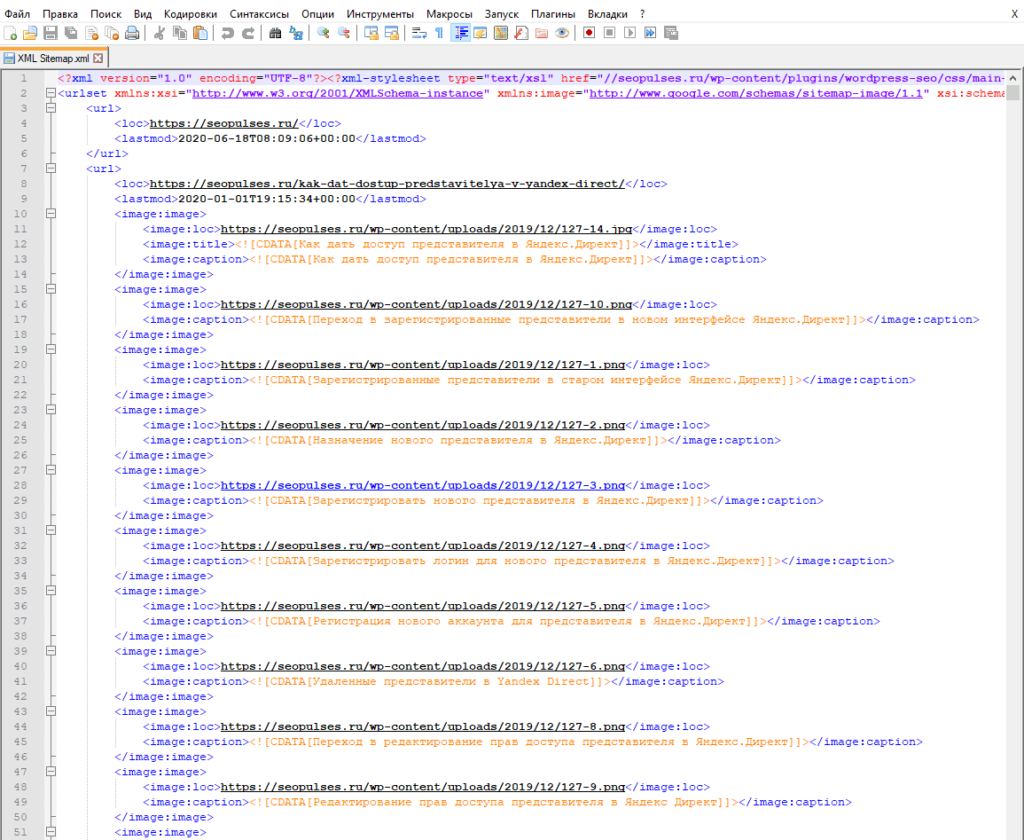
Чтобы обработать информацию корректно следует ознакомиться с инструкцией открытия XML-файлов в Excel (или создания), после чего данные будут поданы в формате таблицы.
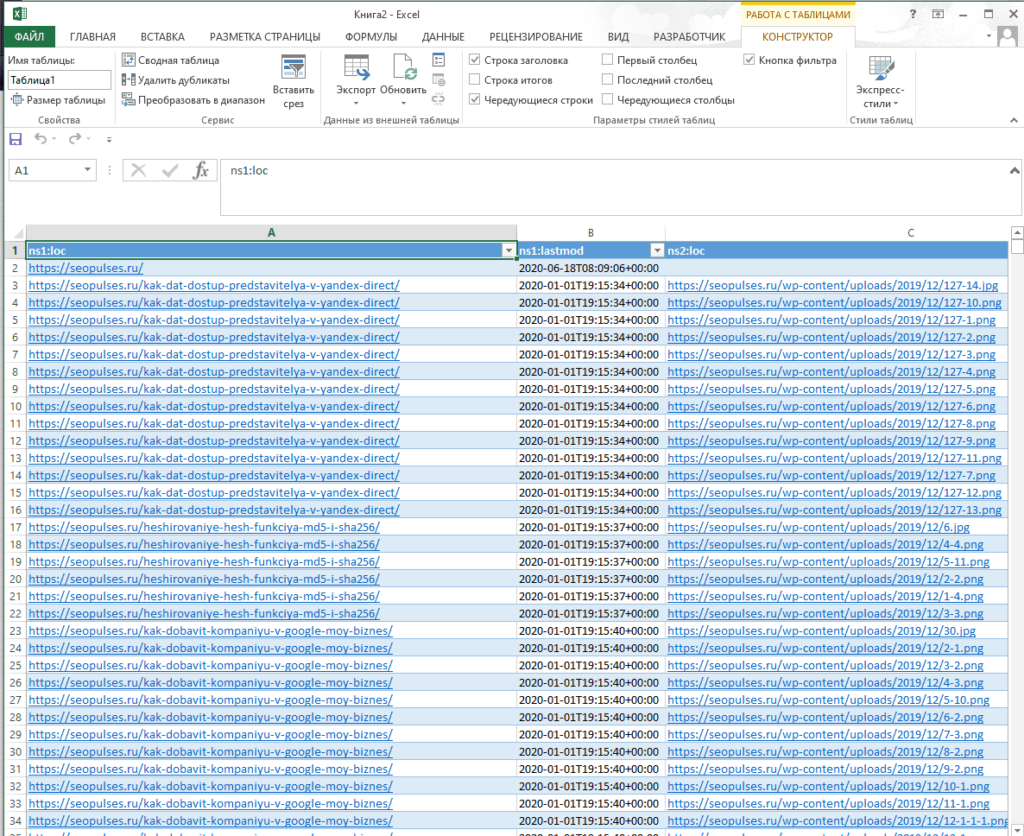
Все готово, можно переходить к методам парсинга.
IPMORTXML для парсинга сайтов в Excel
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос)
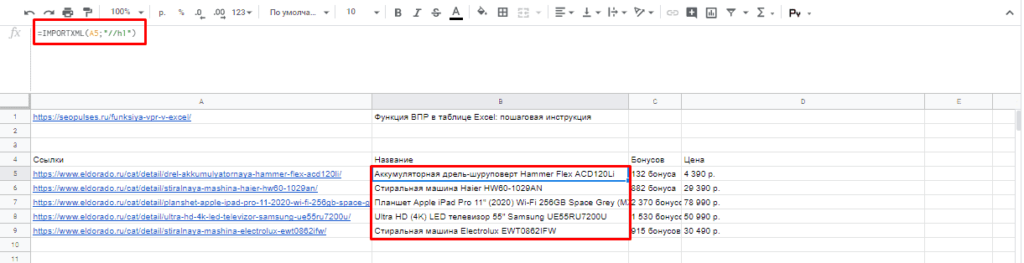
Где:
- Ссылка — URL-адрес страницы;
- Запрос – в формате XPath.
С примером можно ознакомиться в:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit#gid=0
Примеры использования IMPORTXML в Google Doc
Парсинг названий
Для работы с парсингом через данную функцию потребуется знание XPATH и составление пути в этом формате. Сделать это можно открыв консоль разработчика. Для примера будет использоваться сайт крупного интернет-магазина и в первую очередь необходимо в Google Chrome открыть окно разработчика кликнув правой кнопкой мыли и в выпавшем меню выбрать «Посмотреть код» (сочетание клавиш CTRL+Shift+I).
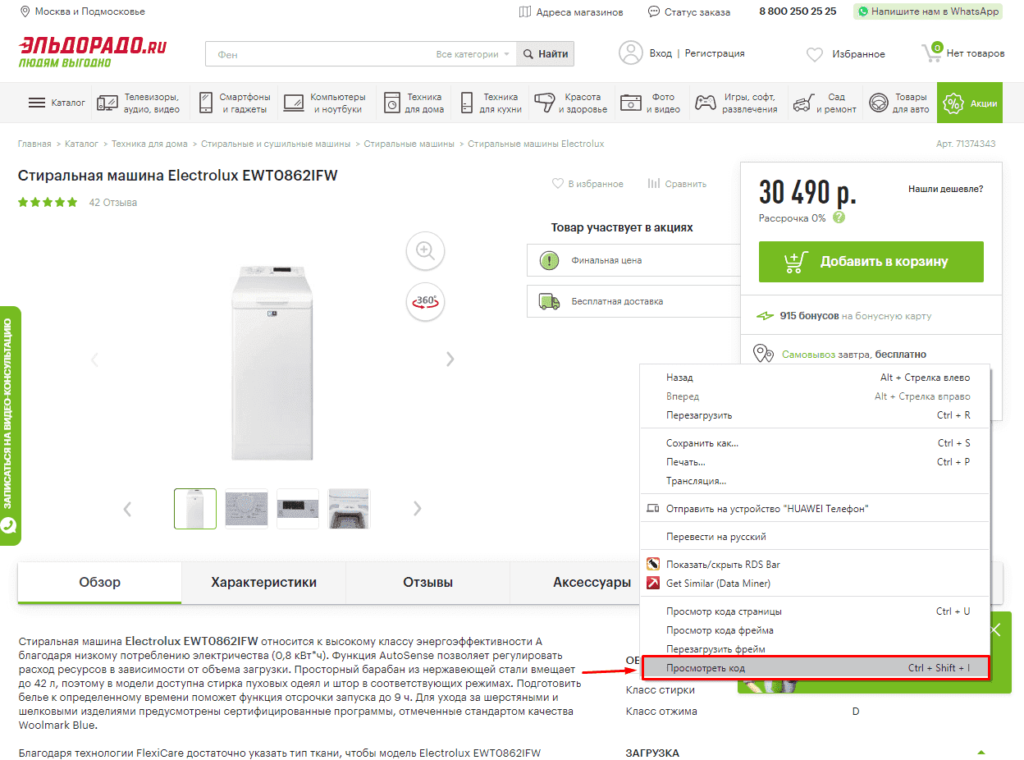
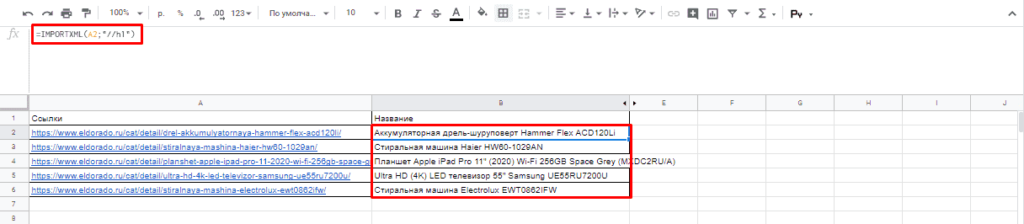
После этого пытаемся получить название товара, которое содержится в H1, единственным на странице, поэтому запрос должен быть:
//h1
И как следствие формула:
=IMPORTXML(A2;»//h1″)
Важно! Запрос XPath пишется в кавычках «запрос».
Парсинг различных элементов
Если мы хотим получить баллы, то нам потребуется обратиться к элементу div с классом product-standart-bonus поэтому получаем:
//div[@class=’product-standart-bonus’]
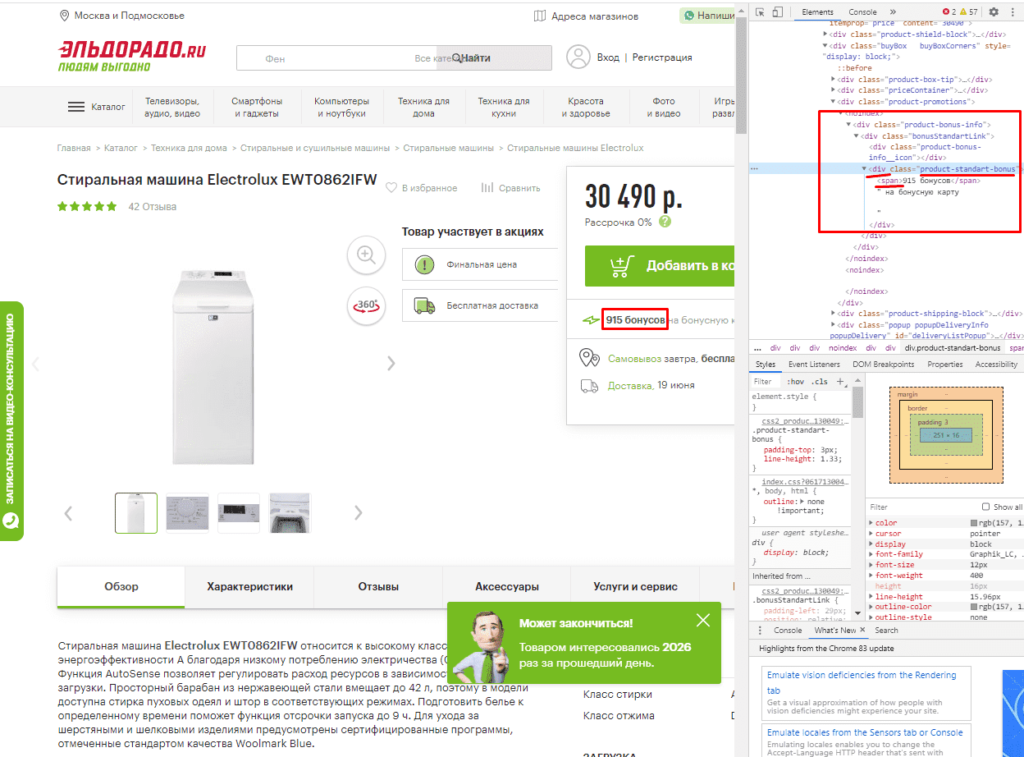
В этом случае первый тег div обозначает то, откуда берутся данные, когда в скобках [] уточняется его уникальность.
Для уточнения потребуется указать тип в виде @class, который может быть и @id, а после пишется = и в одинарных кавычках ‘значение’ пишется запрос.
Однако, нужное нам значение находиться глубже в теге span, поэтому добавляем /span и вводим:
//div[@class=’product-standart-bonus’]/span
В документе:

Парсинг цен без знаний XPath
Если нет знаний XPath и необходимо быстро получить информацию, то требуется выбрав нужный элемент в консоли разработчика кликнуть правой клавишей мыши и в меню выбрать «Copy»-«XPath». Например, при поиске запроса цены получаем:
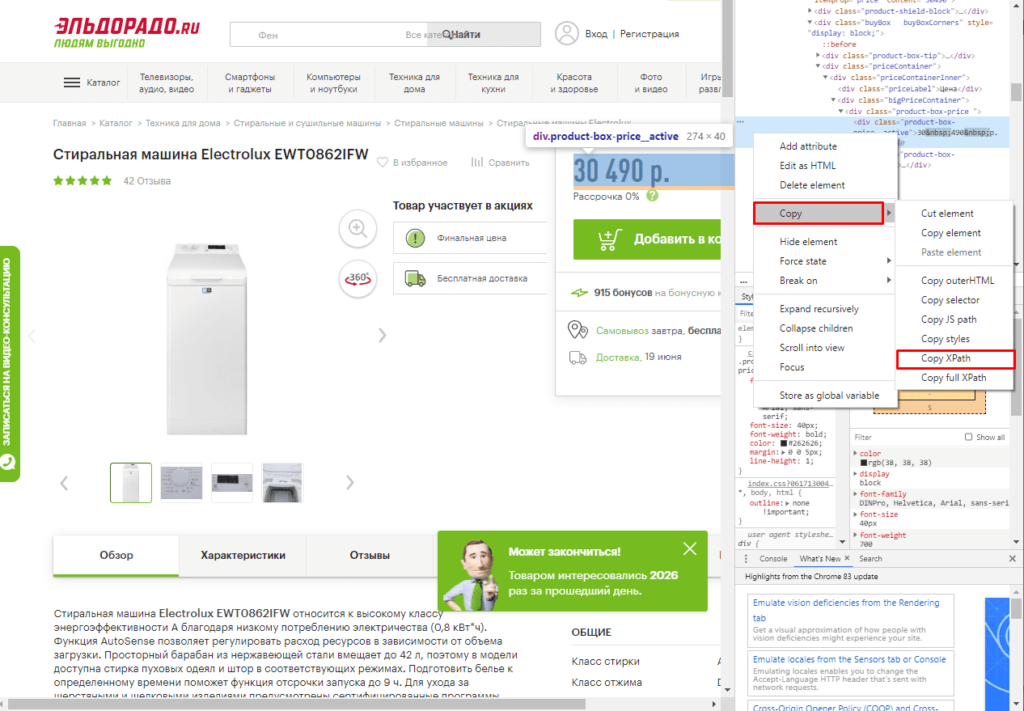
//*[@id=»showcase»]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div/div[1]
Важно! Следует изменить » на одинарные кавычки ‘.
Далее используем ее вместе с IMPORTXML.
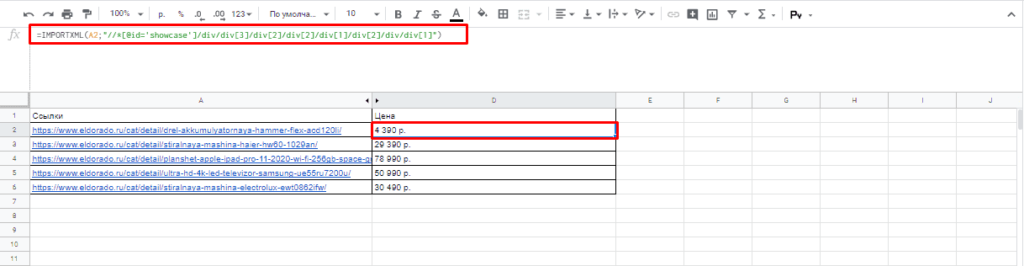
Все готово цены получены.
Простые формулы с IMPORTXML в Google Sheets
Чтобы получить title страницы необходимо использовать запрос:
=IMPORTXML(A3;»//title»)
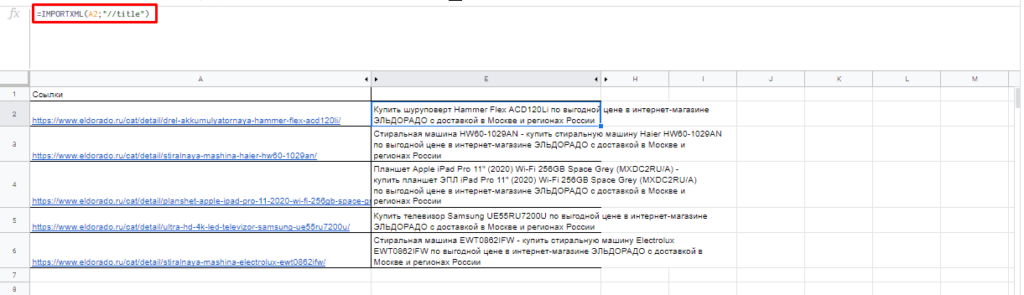
Для вывода description стоит использовать:
=IMPORTXML(A3;»//description»)
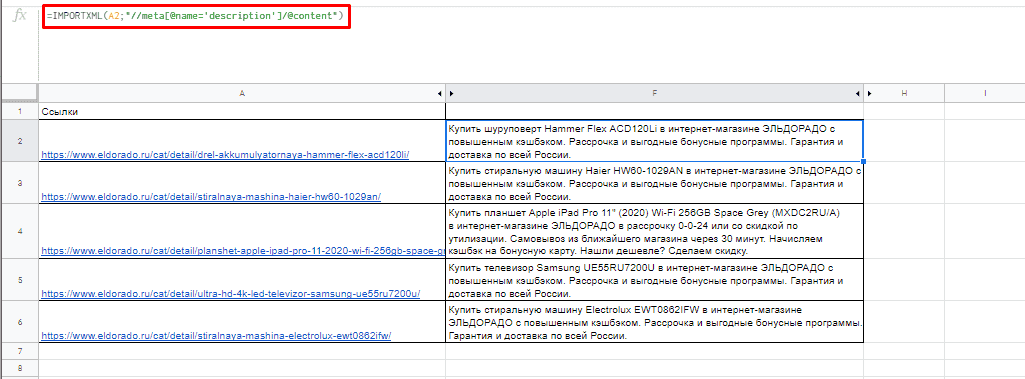
Первый заголовок (или любой другой):
=IMPORTXML(A3;»//h1″)

IMPORTHTML для создания парсера веи-ресурсов в Эксель
Синтаксис IMPORTXML в Google Таблице
Для того, чтобы использовать данную функцию потребуется в таблице написать формулу:
=IMPORTXML(Ссылка;Запрос;Индекс)
Где:
- Ссылка — URL-адрес страницы;
- Запрос – может быть в формате «table» или «list», выгружающий таблицу и список, соответственно.
- Индекс – порядковый номер элемента.
С примерами можно ознакомиться в файле:
https://docs.google.com/spreadsheets/d/1GpcGZd7CW4ugGECFHVMqzTXrbxHhdmP-VvIYtavSp4s/edit#gid=0
Пример использования IMPORTHTML в Google Doc
Парсинг таблиц
В примерах будет использоваться данная статья, перейдя на которую можно открыть консоль разработчика (в Google Chrome это можно сделать кликнув правой клавишей мыши и выбрав пункт «Посмотреть код» или же нажав на сочетание клавиш «CTRL+Shift+I»).
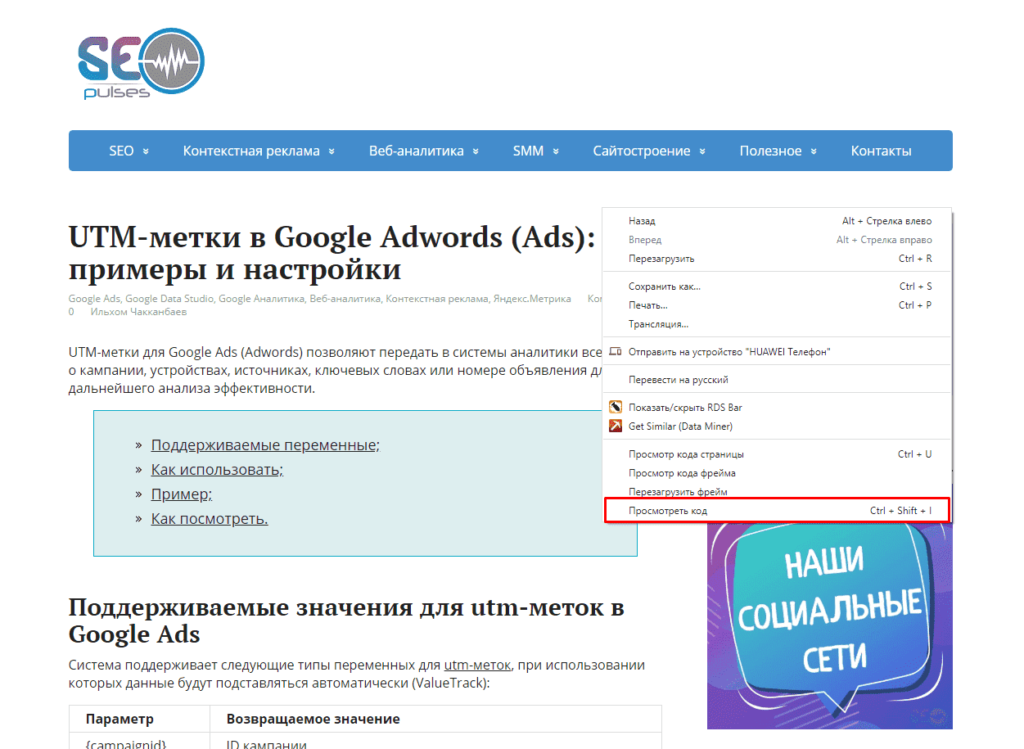
Теперь просматриваем код таблицы, которая заключена в теге <table>.
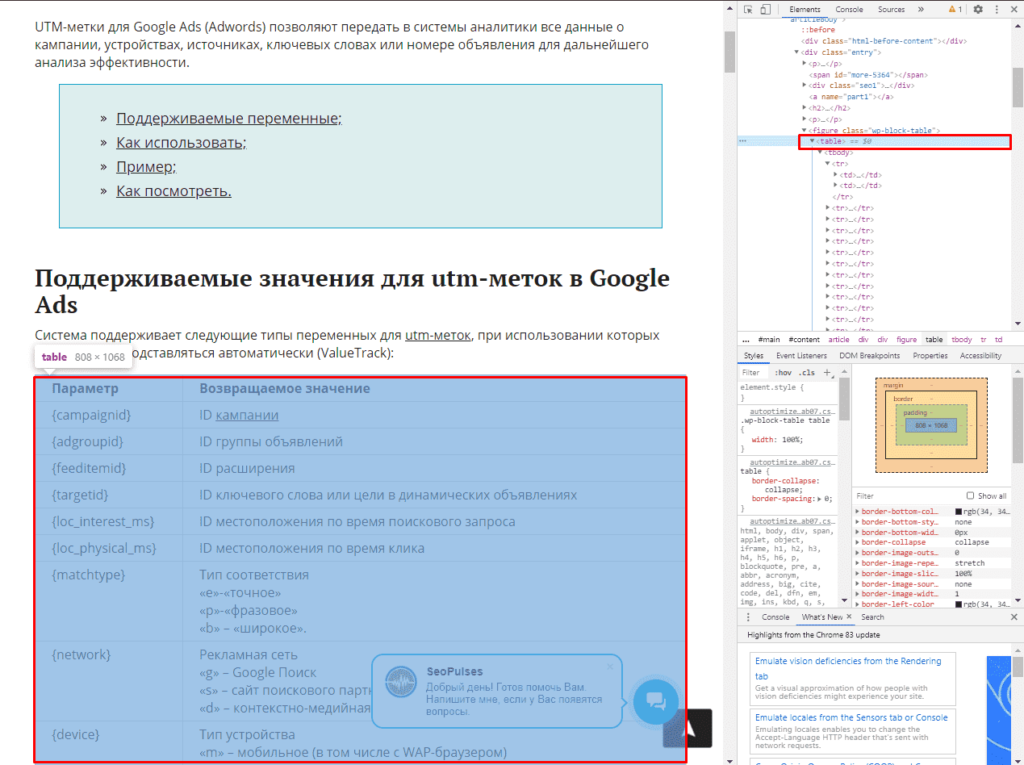
Данный элемент можно будет выгрузить при помощи конструкции:
=IMPORTHTML(A2;»table»;1)
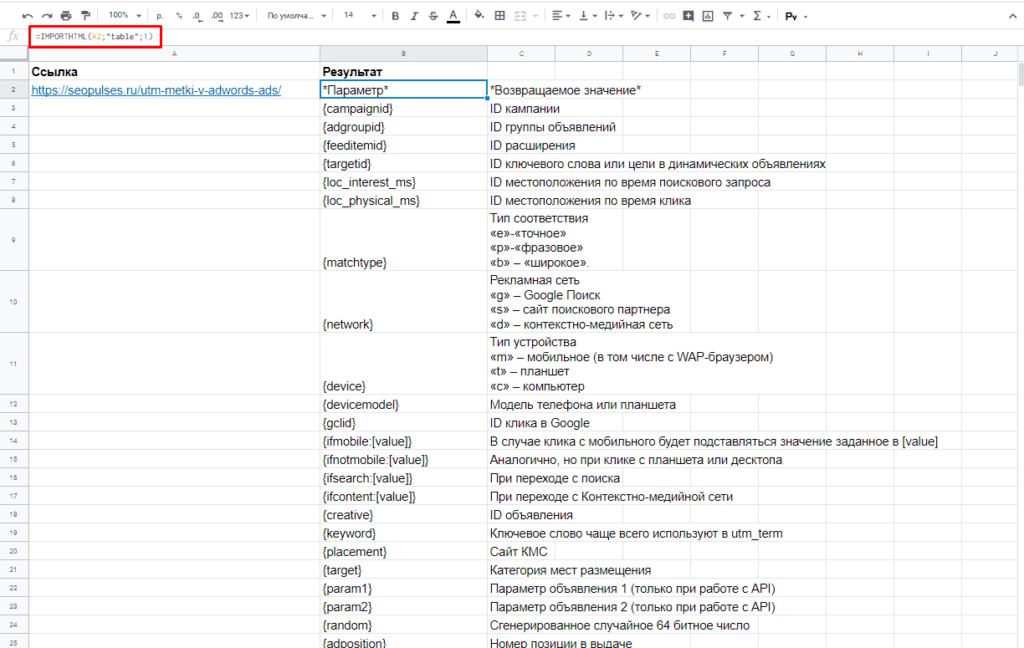
- Где A2 ячейка со ссылкой;
- table позволяет получить данные с таблицы;
- 1 – номер таблицы.
Важно! Сам запрос table или list записывается в кавычках «запрос».
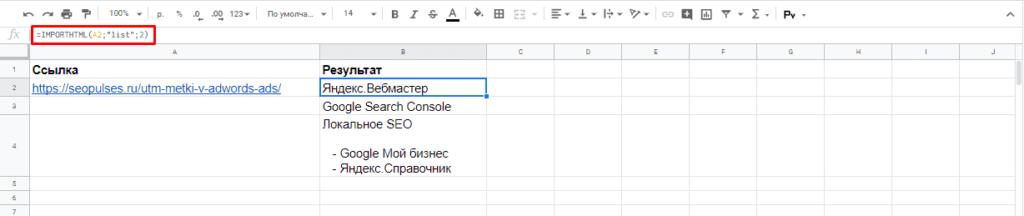
Парсинг списков
Получить список, заключенный в тегах <ul>…</ul> при помощи конструкции.
=IMPORTHTML(A2;»list»;1)
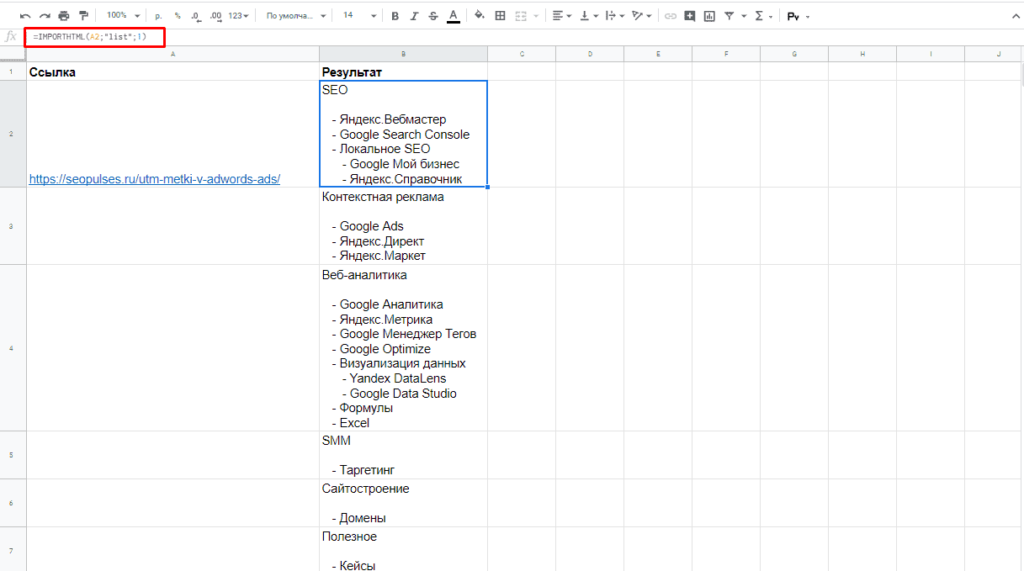
В данном случае речь идет о меню, которое также представлено в виде списка.
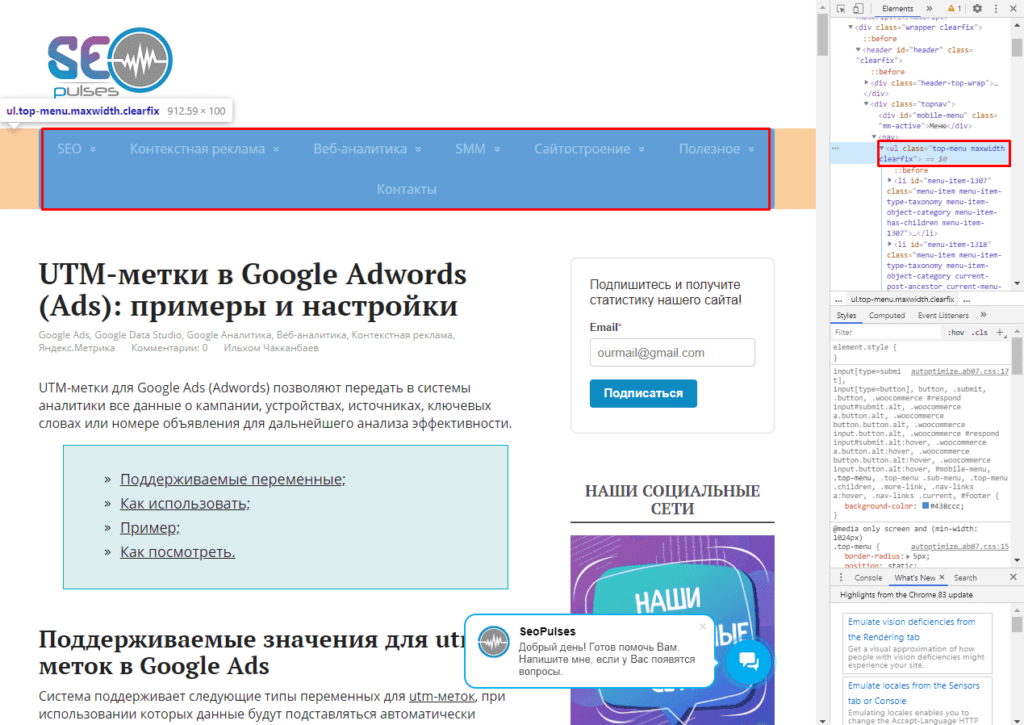
Если использовать индекс третей таблицы, то будут получены данные с третей таблицы в меню:
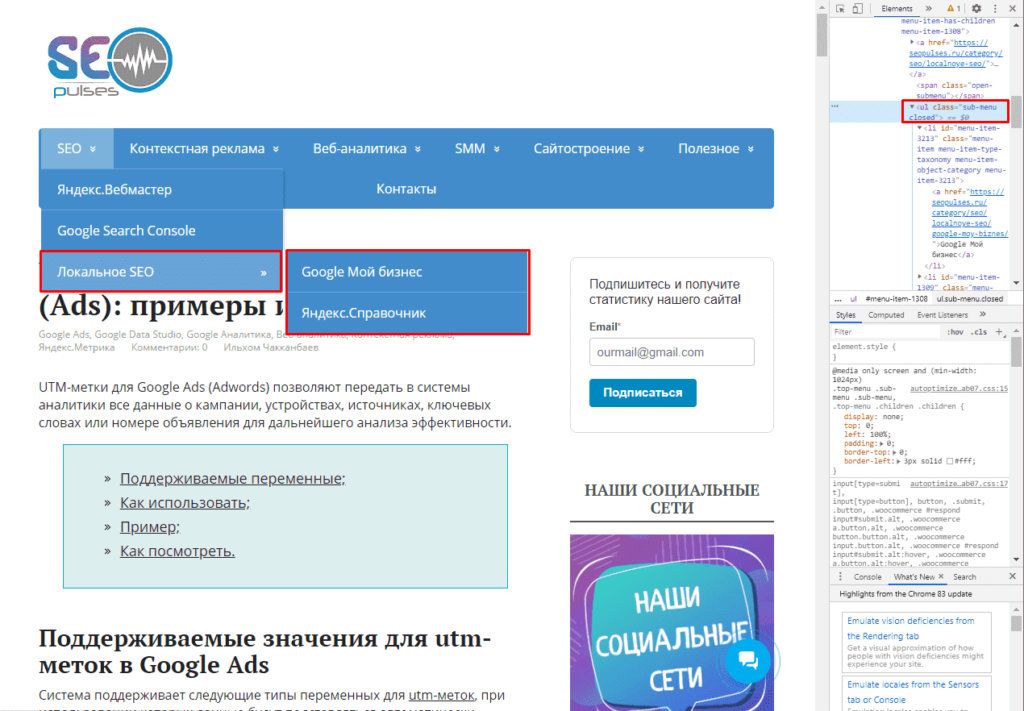
Формула:
=IMPORTHTML(A2;»list»;2)
Все готово, данные получены.
Обратная конвертация
Чтобы превратить Google таблицу в MS Excel потребуется кликнуть на вкладку «Файл»-«Скачать»-«Microsoft Excel».
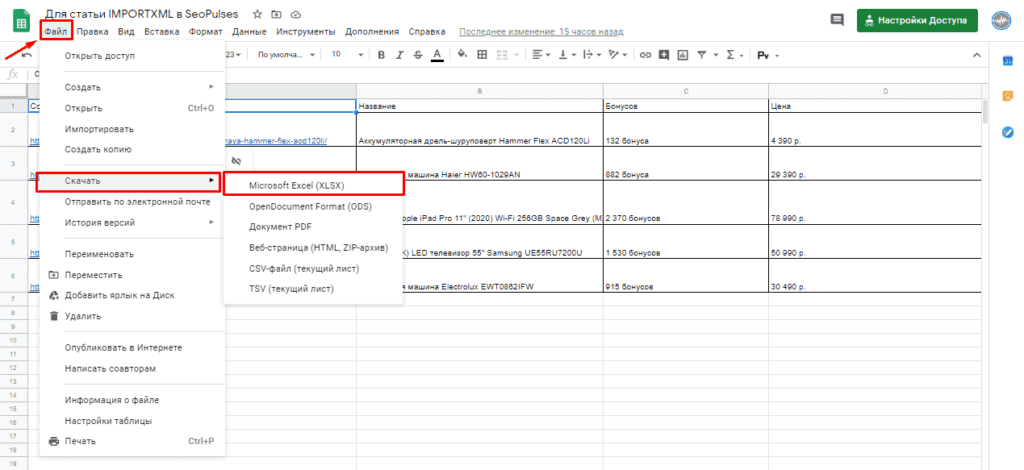
Все готово, пример можно скачать ниже.
Пример:
https://docs.google.com/spreadsheets/d/1xmzdcBPap6lA5Gtwm1hjQfDHf3kCQdbxY3HM11IqDqY/edit