
Рассмотрим использование MS EXCEL при проверке статистических гипотез о разнице средних значений 2-х распределений в случае неизвестных дисперсий (парный тест). Вычислим значение тестовой статистики
t
0
, рассмотрим соответствующую процедуру «двухвыборочный
t
-тест», вычислим Р-значение (Р-
value
). С помощью надстройки Пакет анализа сделаем «Парный двухвыборочный t-тест для средних».
Здесь рассмотрен специальный случай
двухвыборочного t-теста
, когда наблюдения случайных величин из двух распределений производятся не независимо, а парами.
Примечание
: Процедура
двухвыборочного t-теста
также изложена в статьях
Двухвыборочный t-тест с одинаковыми дисперсиями
и
Двухвыборочный t-тест с различными дисперсиями
, где
выборки
из распределений считались независимыми.
СОВЕТ
: При первом знакомстве с процедурой
двухвыборочного
t
-теста
может быть полезным освежить в памяти
процедуру одновыброчного t-теста для среднего при неизвестной дисперсии
.
СОВЕТ
: Для
проверки гипотез
нам потребуется знание следующих понятий:
-
дисперсия и стандартное отклонение
,
-
выборочное распределение статистики
,
-
уровень доверия/ уровень значимости
,
-
нормальное распределение
,
-
t-распределение Стьюдента
и
его квантили
.
Приведем пример
. Имеется 2 прибора измеряющих твердость металлических образцов. Необходимо проверить, что эти приборы показывают одинаковые результаты на одном и том же образце (
нулевая гипотеза
).
Если для испытания на приборах образцы отбирать случайным образом: половину для проверки на приборе №1, другую на приборе №2, и использовать для проверки
нулевой
гипотезы
t-тест с одинаковыми (или различающимися) дисперсиями,
то можно сделать ошибочное заключение. Дело в том, что металлические образцы могут быть изготовлены из различных заготовок, прошедших различную термообработку и, следовательно, они могут иметь различную твердость. Таким образом, наблюденная разность между средними значениями твердости, полученными на каждом из приборов (Х
ср1
и Х
ср2
), будет также включать различие в твердости, обусловленную самими образцами. Другими словами, при таком методе исследования у нас имеется 2 источника неопределенности (случайности): несовершенство приборов и случайные колебания твердости самих образцов.
Чтобы исключить случайность, обусловленную различием образцов, и тем самым увеличить мощность
t
-теста
, используют парные
выборки
. В нашем случае, измерения одного и того же образца будем проводить сначала на одном, затем на другом приборе (предполагается, что после измерения твердости на первом приборе, образец не портится).
Таким образом, процедура
проверки гипотезы
сводится к определению разности твердостей полученных приборами на одном и том же образце. Если приборы настроены одинаково, то среднее разностей должно быть около 0 (отклонение не должно быть статистически значимым).
Пусть имеется набор из n пар наблюдений (n образцов). Т.к. результат каждого наблюдения является случайной величиной (приборы не идеальны, присутствует случайная ошибка измерений), то эти случайные величины имеют распределения с неизвестными средними значениями μ
1
и μ
2
(измерения полученные на приборе №1 и №2, соответственно). Дисперсии этих распределений неизвестны (обозначим их σ
1
2
и σ
2
2
).
Будем рассматривать не сами наблюдения, а их разницу. Обозначим D
i
– разницу измерений, полученную приборами №1 и №2 на i-м образце. Разницу между μ
1
и μ
2
, которую нам необходимо оценить, обозначим μ
D
.
Проведем
проверку гипотезы
о равенстве μ
D
заданному значению Δ
0
, т.е.
парный
t
-тест
(англ. The Paired t-Test). Если Δ
0
равно 0, то речь идет о проверке равенства средних двух распределений.
На самом деле, этот
t
-тест
сводится к
одновыборочному t-тесту
:
Нулевая гипотеза
H
0
: μ
D
=Δ
0
Альтернативная гипотеза
H
1
:
μ
D
<>Δ
0
Т.е. нам требуется проверить
двухстороннюю гипотезу
.
Тестовой статистикой
является случайная величина t:
![]()
где D
ср
– среднее значение разностей, S
d
– стандартное отклонение этих разностей.
Как известно из статьи про
одновыборочный t-тест
, данная
тестовая статистика
, имеет
t-распределение
c n-1 степенью свободы. Значение, которое приняла эта
t
-статистика,
обозначим t
0
.
Установим требуемый
уровень значимости
α (альфа) = 0,05 (допустимую для данной задачи
ошибку первого рода
, т.е. вероятность отклонить
нулевую гипотезу
, когда она верна).
Если вычисленное на основе
выборок
значение t
0
, в случае
двухсторонней гипотезы
, не попадет в область значений ограниченной
нижним
и
верхним α/2-квантилями
t
—
распределения
с n–1
степенями свободы,
то у нас будет основание отвергнуть
нулевую гипотезу.
Это утверждение эквивалентно случаю, когда D
ср
окажется вне пределов соответствующего
доверительного интервала.
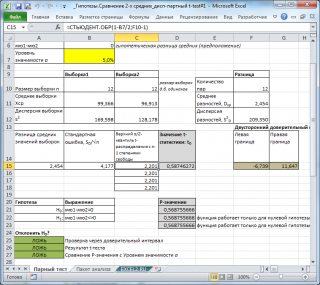
В
файле примера на листе Парный тест
показана эквивалентность
доверительного интервала
и соответствующего
t
-теста.
Примечание
:
Верхний α/2-квантиль
— этотакое значение случайной величины
t
n–1
,
что
P
(
t
n-1
>=t
α/2
,
n-1
)
=α/2. Верхний α/2-квантиль
t
—
распределения с
n
-1 степенью свободы
обычно обозначают
t
α
/2,
n-1
. Подробнее о
квантилях
распределений см. статью
Квантили распределений MS EXCEL
.
В нашем случае, необходимо будет вычислить только верхний α/2-квантиль, т.к. он равен соответствующему нижнему
квантилю
со знаком минус. Следовательно, условие отклонения
нулевой гипотезы
можно записать как |t
0
|>t
α/2
,
n-1
.
Чтобы в MS EXCEL вычислить значение t
α/2
,
n-1
для различных
уровней значимости
(10%; 5%; 1%) и
степеней свобод
можно использовать несколько формул:
=СТЬЮДЕНТ.ОБР.2Х(α; n-1) =СТЬЮДЕНТ.ОБР(1- α/2; n-1) =-СТЬЮДЕНТ.ОБР(α/2; n-1) =СТЬЮДРАСПОБР(α; n-1)
Примечание
: Подробнее про функции MS EXCEL, связанные с
t
—
распределением
см.
статью t-распределение
.
Итак, если при проверке
двухсторонней гипотезы
формула
=ABS(t
0
)
вернет значение больше, чем результат формулы
=СТЬЮДЕНТ.ОБР.2Х(α; n-1)
, то это означает, что необходимо отвергнуть
нулевую гипотезу
(вычисления приведены в
файле примера на листе Парный тест
)
.
Для
односторонней
альтернативной гипотезы
μ
D
>Δ
0
,
нулевая гипотеза
будет отвергнута в случае t
0
> t
α
,
n-1
.
Для
односторонней
альтернативной гипотезы
μ
D
<Δ
0
,
нулевая гипотеза
будет отвергнута в случае t
0
<-t
α
,
n-1
.
Примечание
: Вышеуказанные распределения не обязательно должны быть
нормальными
. Однако, требуется чтобы выполнялись условия применимости
Центральной предельной теоремы
. Если размеры
выборок
меньше 30, то для справедливости сделанных здесь выводов, необходимо, чтобы
выборки
были сделаны из
нормального распределения
.
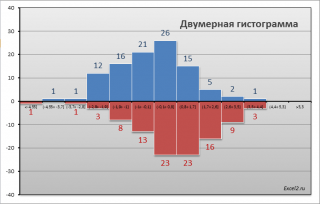
СОВЕТ
: Перед
проверкой гипотез
о равенстве средних значений
полезно построить
двумерную гистограмму
, чтобы визуально определить
центральную тенденцию
и
разброс данных
в обеих
выборок
.
Р-значение
При
проверке гипотез,
помимо
t
-теста,
большое распространение получил еще один эквивалентный подход, основанный на вычислении
p
-значения
(p-value).
Если
p-значение
меньше чем заданный
уровень значимости α
, то
нулевая гипотеза
отвергается и принимается
альтернативная гипотеза
. И наоборот, если
p-значение
больше α, то
нулевая гипотеза
не отвергается.
В случае
двусторонней гипотезы
p-значение
равно суммарной вероятности, что
t
-статистика
примет значение больше |t
0
| и меньше -|t
0
|.
Подробнее про
p
-значение
см., например,
статью про двухвыборочный z-тест
.
В MS EXCEL
p
-значение
для
двухсторонней гипотезы
в случае
парного
t
-теста
вычисляется по формуле:
=2*(1-СТЬЮДЕНТ.РАСП(ABS(t
0
); n-1;ИСТИНА))
Примечание
: Вычисления приведены в
файле примера на листе Парный тест
.
Для
односторонней гипотезы
μ
1
-μ
2
>Δ
0
p
-значение
вычисляется по формуле:
=1-СТЬЮДЕНТ.РАСП(t
0
; n-1;ИСТИНА)
В этом случае
p-значение
равно вероятности, что
t
-статистика
примет значение больше t
0
.
Для
односторонней гипотезы
μ
1
-μ
2
<Δ
0
p
-значение
вычисляется по формуле:
= СТЬЮДЕНТ.РАСП(t
0
; n-1;ИСТИНА)
В этом случае
p-значение
равно вероятности, что
t
-статистика
примет значение меньше t
0
.
В
файле примера на листе Парный
тест показана эквивалентность
проверки гипотезы
через
доверительный интервал
,
статистику t
0
(
t
-тест)
и
p
-значение
.
В MS EXCEL есть функция
СТЬЮДЕНТ.TEСT()
, которая вычисляет
p-значение
для 3-х различных
двухвыборочных
t
-тестов
(см. следующий раздел статьи)
.
К сожалению, эта функция может быть использована только для
проверки гипотез
с Δ
0
=0, то есть для
проверки гипотез
о равенстве средних μ
1
=μ
2
. Об этом легко догадаться, т.к. среди ее параметров отсутствует параметр
Гипотетическая разность средних
, т.е. Δ
0
.
Функция
СТЬЮДЕНТ.ТЕСТ()
Функция
СТЬЮДЕНТ.ТЕСТ()
используется для оценки различия двух
выборочных средних
. До
MS EXCEL 2010
имелась аналогичная функция
ТТЕСТ()
.
Примечание
: В английской версии функция носит название T.TEST(), старая версия — TTEST().
Функция
СТЬЮДЕНТ.ТЕСТ()
имеет 4 параметра. Первые два – это ссылки на диапазоны ячеек, содержащие
выборки
из 2-х сравниваемых распределений.
Третий параметр имеет название «хвосты». Этот параметр задает тип проверяемой гипотезы: односторонняя (=1) или двухсторонняя (=2). Если мы проверяем
двухстороннюю гипотезу
, то смотрим, не попало ли значение
тестовой статистики
в один из 2-х хвостов соответствующего
t-распределения
. Если мы проверяем
одностороннюю гипотезу
(имеется ввиду гипотеза μ
1
<μ
2
), то «хвост» всего один.
Как было сказано выше, эта функция вычисляет
p
-значение
для 3-х различных
двухвыборочных
t
-тестов
. За это отвечает четвертый параметр функции, который принимает значения от 1 до 3:
Парный двухвыборочный t-тест для средних;
-
Двухвыборочный t-тест с одинаковыми дисперсиями
;
-
Двухвыборочный t-тест с разными дисперсиями
.
Таким образом,
p
-значение
для
двухсторонней гипотезы
(равные
дисперсии
) вычисляется по формуле (см.
файл примера
):
=СТЬЮДЕНТ.ТЕСТ(
выборка1
;
выборка2
; 2; 1)
или
=2*(1-СТЬЮДЕНТ.РАСП(ABS(t
0
); n-1;ИСТИНА))
Для
односторонней гипотезы
μ
1
<μ
2
p
-значение
вычисляется по формуле:
=СТЬЮДЕНТ.ТЕСТ(
выборка1
;
выборка2
; 1; 1)
или
=СТЬЮДЕНТ.РАСП(t
0
; n-1;ИСТИНА)
Для
односторонней гипотезы
μ
1
>μ
2
p
-значение
вычисляется по формуле:
=1-СТЬЮДЕНТ.ТЕСТ(
выборка1
;
выборка2
; 1; 1)
или
=1-СТЬЮДЕНТ.РАСП(t
0
; n-1;ИСТИНА)
Пакет анализа
В
надстройке Пакет анализа
для проведения
Парного
двухвыборочного
t
-теста
имеется одноименный инструмент:
Парный
двухвыборочный
t
-тест для средних
(t-Test: Paired Two-Sample for Means).
После выбора инструмента откроется окно, в котором требуется заполнить следующие поля (см.
файл примера лист Пакет анализа
):
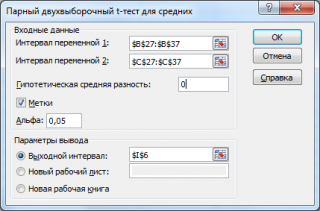
интервал переменной 1
: ссылка на значения первой
выборки
. Ссылку указывать лучше с заголовком. В этом случае, при выводе результата надстройка выводит заголовки, которые делают результат нагляднее (в окне требуется установить галочку
Метки
);
интервал переменной 2
: ссылка на значения второй
выборки
;
гипотетическая средняя разность
: укажите значение Δ
0
, т.е. μ
1
-μ
2
. В нашем случае, введем 0;
Метки:
если в полях
интервал переменной 1
и
интервал переменной 2
указаны ссылки вместе с заголовками столбцов, то эту галочку нужно установить. В противном случае надстройка не позволит провести вычисления и пожалуется, что «
входной интервал содержит нечисловые данные
»;
Альфа:
уровень значимости;
Выходной интервал:
диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
В результате вычислений будет заполнен указанный
Выходной интервал.
Тот же результат можно получить с помощью формул (см.
файл примера лист Пакет анализа
):
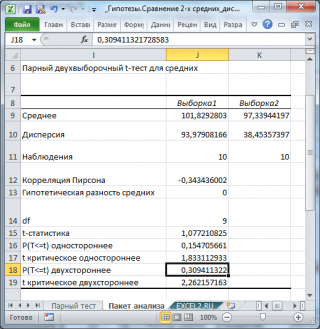
Разберем результаты вычислений, выполненных надстройкой:
Среднее
:
средние значения
обеих
выборок
Хср
1
и Хср
2
. Вычисления можно сделать с помощью функции
СРЗНАЧ()
;
Дисперсия
:
дисперсии
обеих
выборок.
Вычисления можно сделать с помощью функции
ДИСП.В()
Наблюдения
: размер
выборок.
Вычисления можно сделать с помощью функции
СЧЁТ()
Корреляция Пирсона
: коэффициент корреляции двух
выборок
. Вычисления можно сделать с помощью функции
КОРРЕЛ()
или
PEARSON()
Df
: число
степеней свободы
: n-1, где n размер
выборок
;
t
-статистика
: значение
тестовой статистики
t
(в наших обозначениях – это t
0
). Вычисление t
0
приведено в ячейке
Е1
5
;
P(T<=t) одностороннее
:
р-значение
в случае
односторонней альтернативной гипотезы
μ
1
-μ
2
>Δ
0
. Эквивалентная формула
=1-СТЬЮДЕНТ.РАСП(t
0
; n-1;ИСТИНА)
;
t критическое одностороннее
: Верхний α-квантиль t-распределения. Эквивалентная формула
=СТЬЮДЕНТ.ОБР(1- α; n-1)
;
P(T<=t) двухстороннее: р-значение
в случае
двухсторонней альтернативной гипотезы
μ
1
-μ
2
<>Δ
0
. Эквивалентная формула
=2*(1-СТЬЮДЕНТ.РАСП(ABS(t
0
); n-1;ИСТИНА))
;
t критическое двухстороннее: Верхний α/2-Квантиль t-распределения
. Эквивалентная формула
=СТЬЮДЕНТ.ОБР(1- α/2; n-1)
.
СОВЕТ
: О проверке других видов гипотез см. статью
Проверка статистических гипотез в MS EXCEL
.
17 авг. 2022 г.
читать 3 мин
Стьюдентный критерий для парных выборок используется для сравнения средних значений двух выборок, когда каждое наблюдение в одной выборке может быть сопоставлено с наблюдением в другой выборке.
В этом руководстве объясняется, как провести t-критерий парных выборок в Excel.
Как провести t-тест для парных выборок в Excel
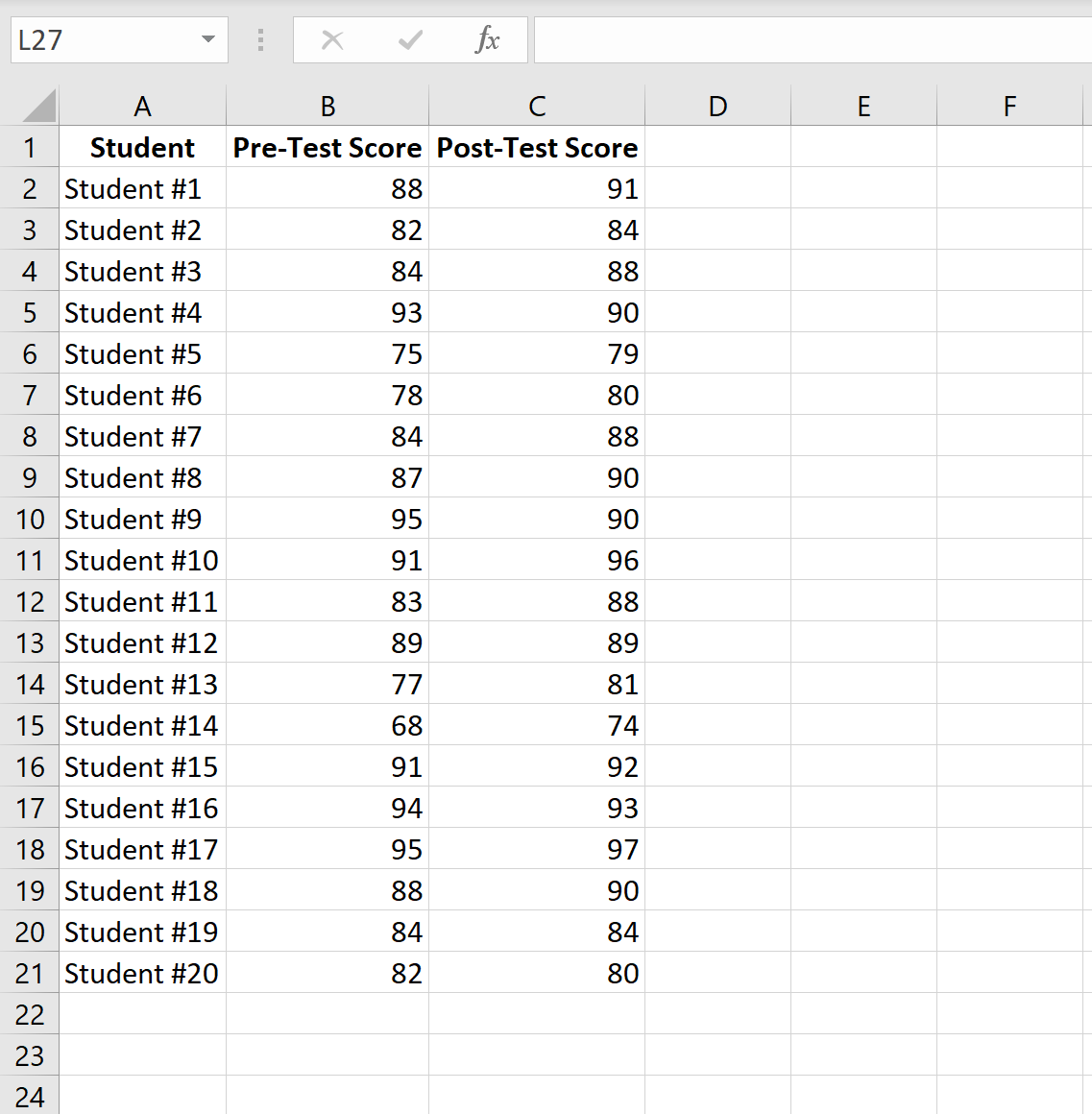
Предположим, мы хотим знать, значительно ли влияет определенная учебная программа на успеваемость студента на конкретном экзамене. Чтобы проверить это, у нас есть 20 учеников в классе, которые проходят предварительный тест. Затем каждый из студентов участвует в учебной программе в течение двух недель. Затем учащиеся пересдают тест аналогичной сложности.
Чтобы сравнить разницу между средними баллами по первому и второму тесту, мы используем t-критерий для парных выборок, потому что для каждого учащегося его балл за первый тест можно сопоставить с баллом за второй тест.
На следующем изображении показана оценка до теста и оценка после теста для каждого учащегося:
Выполните следующие шаги, чтобы провести t-критерий для парных выборок, чтобы определить, существует ли значительная разница в средних результатах теста между предварительным тестом и посттестом.
Шаг 1: Откройте пакет инструментов анализа данных.
На вкладке «Данные» на верхней ленте нажмите «Анализ данных».

Если вы не видите этот вариант для выбора, вам необходимо сначала загрузить пакет инструментов анализа , который является совершенно бесплатным.
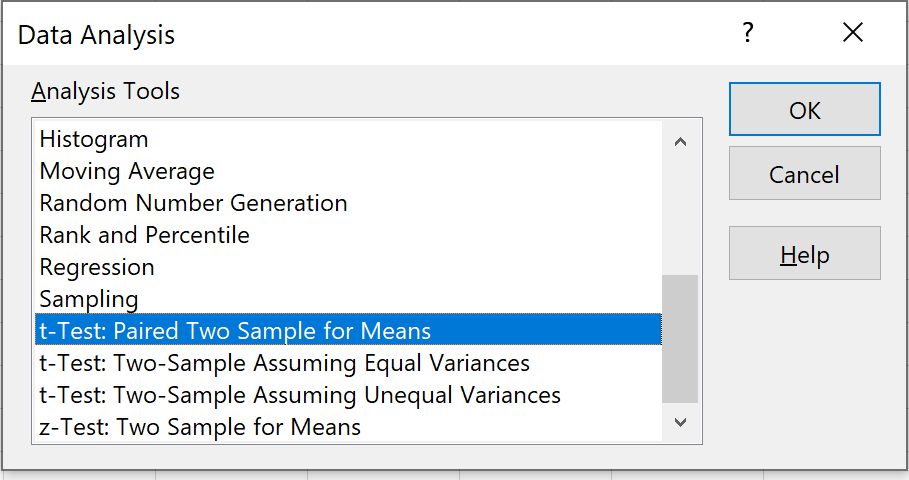
Шаг 2: Выберите подходящий тест для использования.
Выберите вариант с надписью t-Test: Paired Two Sample for Means и нажмите OK.
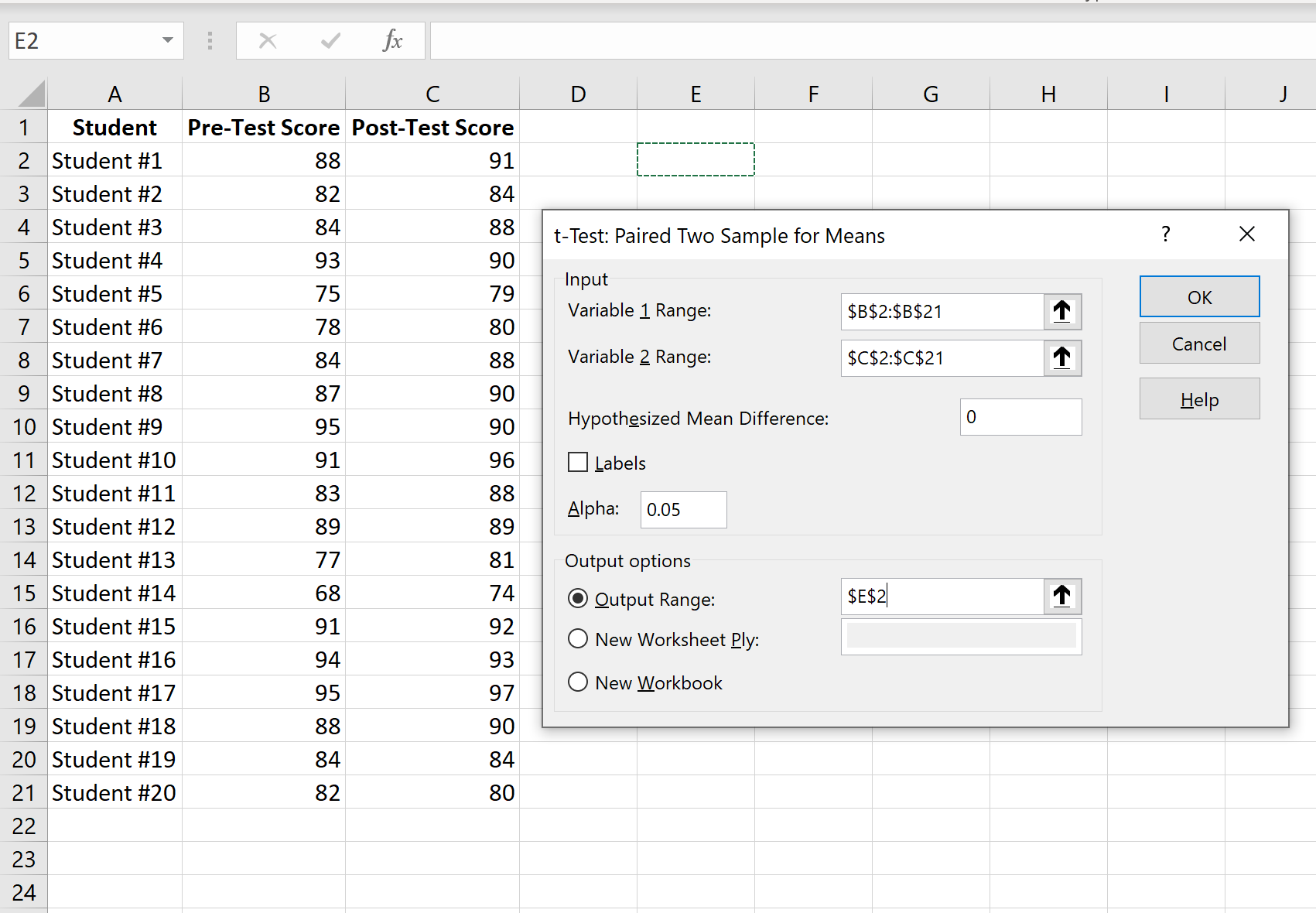
Шаг 3: Введите необходимую информацию.
Введите диапазон значений для Переменной 1 (оценки до теста), Переменной 2 (оценки после теста), гипотетической средней разницы (в этом случае мы поместили «0», потому что мы хотим знать, является ли истинная средняя разница между оценки до теста и оценки после теста равны 0), а выходной диапазон, в котором мы хотели бы видеть результаты теста, отображаются. Затем нажмите ОК.
Шаг 4: Интерпретируйте результаты.
После того, как вы нажмете OK на предыдущем шаге, отобразятся результаты t-теста.
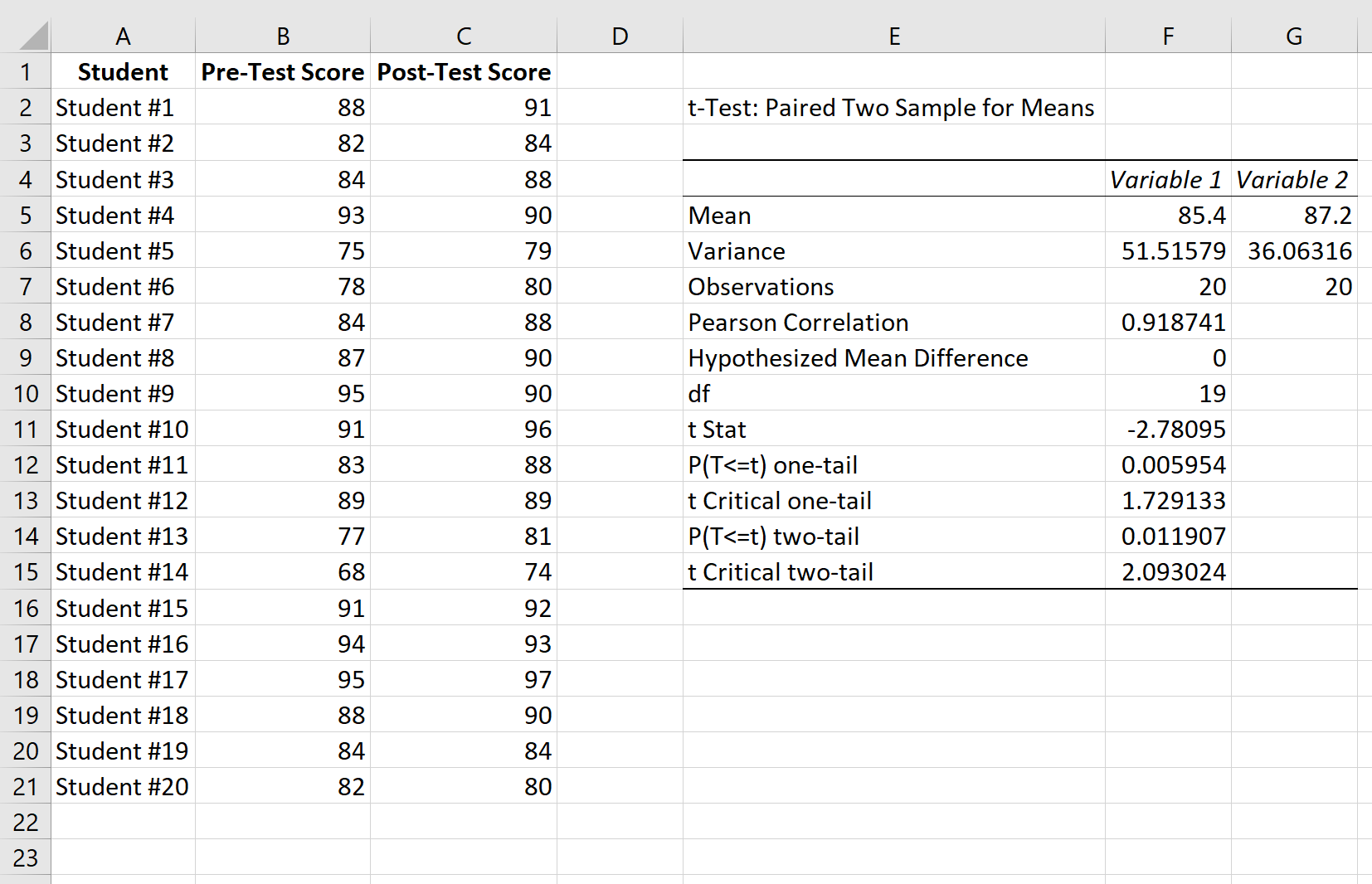
Вот как интерпретировать результаты:
Среднее значение: это среднее значение для каждого образца. Средний балл до теста — 85,4 , а средний балл после теста — 87,2 .
Дисперсия: это дисперсия для каждого образца. Дисперсия оценок до теста составляет 51,51 , а дисперсия оценок после теста — 36,06 .
Наблюдения: это количество наблюдений в каждой выборке. Обе выборки имеют по 20 наблюдений.
Корреляция Пирсона: корреляция между результатами до и после теста. Получается 0,918 .
Гипотетическая средняя разница: число, которое мы «предполагаем», представляет собой разницу между двумя средними значениями. В данном случае мы выбрали 0 , потому что хотим проверить, есть ли вообще какая-либо разница между результатами до и после теста.
df: Степени свободы для t-критерия. Это рассчитывается как n-1, где n — количество пар. В этом случае df = 20 – 1 = 19 .
t Stat: тестовая статистика t , которая оказывается равной -2,78 .
P(T<=t) двухсторонний: значение p для двустороннего t-критерия. В этом случае р = 0,011907.Это меньше, чем альфа = 0,05, поэтому мы отвергаем нулевую гипотезу. У нас есть достаточно доказательств, чтобы сказать, что существует статистически значимая разница между средним баллом до и после теста.
t Критический двухсторонний: это критическое значение теста, найденное путем определения значения в таблице распределения t , которое соответствует двустороннему тесту с альфа = 0,05 и df = 19. Получается 2,093024.Поскольку абсолютное значение нашей тестовой статистики t больше этого значения, мы отвергаем нулевую гипотезу. У нас есть достаточно доказательств, чтобы сказать, что существует статистически значимая разница между средним баллом до и после теста.
Обратите внимание, что подход с использованием p-значения и критического значения приведет к одному и тому же выводу.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие t-тесты в Excel:
Как провести одновыборочный t-тест в Excel
Как провести двухвыборочный t-тест в Excel
Microsoft Excel имеет мощные инструменты для анализа и визуализации статистики. В этой статье мы продемонстрируем их на примере классической статистической процедуры: теста Стьюдента или t-теста.
t-тест: что это такое, и зачем это нужно?
t-тест или тест Стьюдента был разработан английским математиком Уильямом Госсетом. В начале XX века он трудился на пивоваренном заводе «Гиннесс» в Ирландии, разрабатывая математические методы оценки качества сырья, из которого варят пиво.
По условиям контракта, Госсет не имел права публиковать свои разработки под собственным именем. Поэтому первая публикация методики теста появилась в журнале «Биометрика» под псевдонимом Student, что значит «студент». Так тест и остался в истории под названием теста Стьюдента.
Тест Стьюдента позволяет сравнивать случайные выборки данных — либо с некой нормой, либо между собой. Например, завод выпускает шурупы, и нужно оценить, соответствуют ли они в норме по длине. Или в больнице ведется клиническое исследование лекарства, и нужно оценить его эффект на пациентах до и после приема.
В обоих случаях должно выполняться требование нормальности распределения исследуемого признака в каждой из сравниваемых групп. Результатом выполнения теста является число, отражающее данный показатель — t-критерий, или критерий Стьюдента.
t-тест: как выполнить в MS Excel?
Вне зависимости от того, для чего вам может понадобиться вычислить критерий Стьюдента, в Microsoft Excel есть функция TTEST, которая позволяет это сделать. Она доступна в надстройке Пакет анализа. Рассмотрим, как использовать функцию на примере Microsoft Excel 2013 в Windows 7.
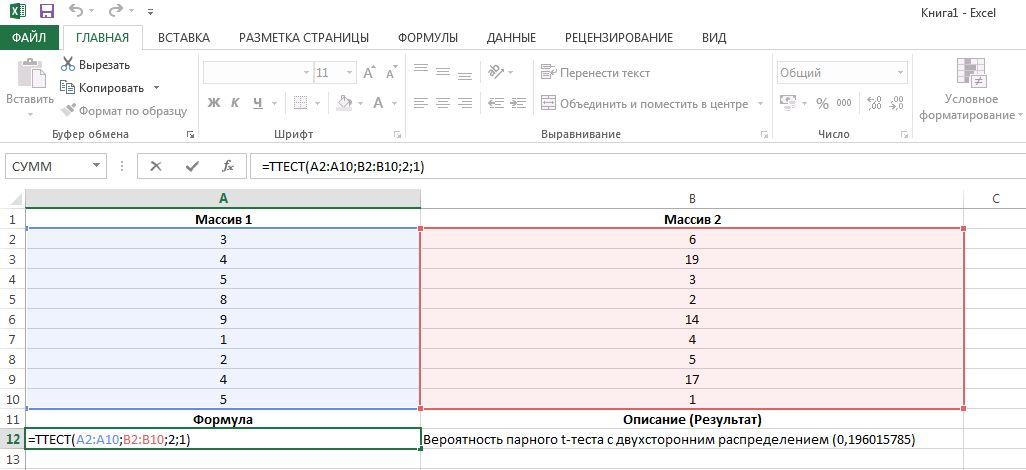
Синтаксис функции следующий: ТТЕСТ(массив1;массив2;хвосты;тип). Скопируйте эту формулу в любое поле вашего документа Excel.
- Первый набор данных называется «массив1», а «массив2», соответственно, обозначает второй набор данных. В примере (см. изображение) «массив1» имеет значение «A2:A10».
- Переменная «хвосты» определяет тип распределения. Если в ячейке имеется значение «1», используется одностороннее распределение; если имеется значение «2», то используется двустороннее распределение.
- Переменная «тип» указывает, какой тип теста применять. Если значение равно «1», используется тест «Парный». Если выбрать «2», то будет использоваться тип «Двухпарный», если 3 — «Двухпарный с неравным отклонением».
Читайте также:
- Как выполнять расчеты времени в Excel
- Как сделать сводную таблицу в Excel
- Excel: 10 формул для работы в офисе
Фото: авторские, pxhere.com
Это средство анализа служит для проверки
гипотезы о равенстве средних парных
наблюдений, когда наблюдения собраны
в пары, и нужно исследовать разницу
между ними.
Для проверки необходимо заполнить
диалоговое окно, приведенное на рис.4.14.,
назначение всех полей очевидно. Результат
работы представлен на рис.4.15. Сравните
полученные результаты с результатами,
полученными вручную.

Рис.4.14 Диалоговое
окно средства анализа «Парный
двухвыборочный t-тест для средних»
надстройки «Пакет анализа»MSExcel

Рис.4.15. Результат
работы средства анализа «Парный
двухвыборочный t-тест для средних»
надстройки «Пакет анализа»MSExcel
ЗАДАНИЕ
Задача 1
Проверка гипотезы о согласии выборочных
данных с нормальным законом распределения.
Имеется выборка объема n
из непрерывно распределенной
генеральной совокупности.
Требуется проверить гипотезу, состоящую
в том, что выборочные данные получены
из нормально распределенной генеральной
совокупности.
Варианты
заданий взять из лабораторной работы
№ 3.
Решение
задачи 1 приведено выше (см. пример
4.2) .
Задача 2
Текст задачи в зависимости от варианта
приведен ниже.
Пример задачи 2
В рабочей книге MSExcelЛечебницы.xlsсодержатся статистические данные,
связанные с работой городских и загородных
лечебниц, собранные Отделом здравоохранения
штата Нью-Мексико. Фрагмент этой книги
приведен на рис. 4.16.

Рис.4.16 Фрагмент
рабочего листа Excelс
исходными данными для задачи 2
Выяснить, есть ли разница между доходами
городских и загородных лечебниц.
Решение
Выдвигаем гипотезу H0:
средние значения доходов городских
и загородных лечебниц выборок равны,
альтернативная гипотезаH1: доходы не равны. Чтобы проверить эту
гипотезу с помощьюt-критерия,
необходимо выполнить ряд операций:
-
Разделить всю выборку на две части: для
городских и для загородных лечебниц.
Считать эти выборки самостоятельными; -
Выяснить, имеют ли эти выборки одинаковую
дисперсию, если «да», то перейти к пункту
3, в противном случае перейти к пункту
4; -
Применить двухвыборочный t-тест с
одинаковыми дисперсиями; -
Применить двухвыборочный t-тест с
различными дисперсиями.
Пункт 1.Для разделения
выборки воспользоваться командойДанные![]() Сортировка. Результат приведен на
Сортировка. Результат приведен на
рис.4.17. В интервале строк 59:76 содержатся
данные, относящиеся к городским
лечебницам. В интервале строк 77:110 —
данные, относящиеся к загородным
лечебницам.

Рис.4.17 Фрагмент
рабочего листа Excelс
данными для задачи 2 после сортировки
Пункт 2.Для проверки
предположения, что эти выборки имеют
одинаковую дисперсию, воспользуемся
критерием Фишера.
Выдвигаем гипотезу H0:
дисперсии выборок равны, альтернативная
гипотезаH1:
дисперсии не равны.
Воспользуемся надстройкой MSExcel«Пакет анализа»
«Двухвыборочный F-тест для дисперсии».
Результат расчета приведен на рис. 4.18.

Рис.4.18.
Фрагмент рабочего листа MSExcelс данными для проверки
равенства
дисперсий
Поскольку
![]() (вычисленное значение критерия
(вычисленное значение критерия![]()
не больше критического),
то принимается гипотезаH0(дисперсии выборок равны). Отсюда следует,
что можно применить двухвыборочныйt-тест с одинаковыми дисперсиями.
Выдвигаем гипотезу H0:
средние арифметические значения
выборок равны, альтернативная гипотезаH1: эти
значения не равны. Воспользуемся
надстройкойMSExcel«Пакет анализа» «Двухвыборочныйt-тест
с одинаковыми дисперсиями»; результат
работы приведен на рис. 4.19.

Рис. 4.19. Фрагмент
рабочего листа MSExcelс данными для проверки равенства
средних
В качестве
![]() следует рассматривать двустороннее
следует рассматривать двустороннее
значение. Так как![]() ,
,![]() ,
,
то![]() ,
,
следовательно, гипотезаH0
отклоняется, гипотезаH1—
принимается. Из этого делаем вывод о
том, что средние значения доходов
городских и загородных лечебниц различны.
Соседние файлы в папке Эконометрика 1 лекция
- #
- #
- #
- #
- #
- #
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функции ТТЕСТ в Microsoft Excel.
Возвращает вероятность, соответствующую критерию Стьюдента. Функция ТТЕСТ позволяет определить, вероятность того, что две выборки взяты из генеральных совокупностей, которые имеют одно и то же среднее.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Дополнительные сведения о новом варианте этой функции см. в статье Функция СТЬЮДЕНТ.ТЕСТ.
Синтаксис
ТТЕСТ(массив1;массив2;хвосты;тип)
Аргументы функции ТТЕСТ описаны ниже.
-
Массив1 Обязательный. Первый набор данных.
-
Массив2 Обязательный. Второй набор данных.
-
Хвосты Обязательный. Число хвостов распределения. Если значение «хвосты» = 1, функция ТТЕСТ возвращает одностороннее распределение. Если значение «хвосты» = 2, функция ТТЕСТ возвращает двустороннее распределение.
-
Тип Обязательный. Вид выполняемого t-теста.
|
Тип |
Выполняемый тест |
|
1 |
Парный |
|
2 |
Двухвыборочный с равными дисперсиями (гомоскедастический) |
|
3 |
Двухвыборочный с неравными дисперсиями (гетероскедастический) |
Замечания
-
Если аргументы «массив1» и «массив2» имеют различное число точек данных, а тип = 1 (парный), то функция ТТЕСТ возвращает значение ошибки #Н/Д.
-
Аргументы «хвосты» и «тип» усекаются до целых значений.
-
Если аргумент «хвосты» или «тип» не является числом, функция ТТЕСТ возвращает значение ошибки #ЗНАЧ!.
-
Если аргумент «хвосты» имеет значение, отличное от 1 и 2, функция ТТЕСТ возвращает значение ошибки #ЧИСЛО!.
-
Функция ТТЕСТ использует данные аргументов «массив1» и «массив2» для вычисления неотрицательной t-статистики. Если хвосты = 1, ТТЕСТ возвращает вероятность более высокого значения t-статистики, исходя из предположения, что «массив1» и «массив2» являются выборками, принадлежащими генеральной совокупности с одним и тем же средним. Значение, возвращаемое функцией ТТЕСТ в случае, когда хвосты = 2, вдвое больше значения, возвращаемого, когда хвосты = 1, и соответствует вероятности более высокого абсолютного значения t-статистики, исходя из предположения, что «массив1» и «массив2» являются выборками, принадлежащими генеральной совокупности с одним и тем же средним.
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные 1 |
Данные 2 |
|
|
3 |
6 |
|
|
4 |
19 |
|
|
5 |
3 |
|
|
8 |
2 |
|
|
9 |
14 |
|
|
1 |
4 |
|
|
2 |
5 |
|
|
4 |
17 |
|
|
5 |
1 |
|
|
Формула |
Описание (результат) |
Результат |
|
=ТТЕСТ(A2:A10;B2:B10;2;1) |
Вероятность, соответствующая парному критерию Стьюдента, с двусторонним распределением. Используются значения в диапазонах А2:А10 и В2:В10 |
0,19602 |