
I read an Excel Sheet into a pandas DataFrame this way:
import pandas as pd
xl = pd.ExcelFile("Path + filename")
df = xl.parse("Sheet1")
the first cell’s value of each column is selected as the column name for the dataFrame, I want to specify my own column names, How do I do this?
asked Jun 27, 2013 at 6:05
![]()
This thread is 5 years old and outdated now, but still shows up on the top of the list from a generic search. So I am adding this note. Pandas now (v0.22) has a keyword to specify column names at parsing Excel files. Use:
import pandas as pd
xl = pd.ExcelFile("Path + filename")
df = xl.parse("Sheet 1", header=None, names=['A', 'B', 'C'])
If header=None is not set, pd seems to consider the first row as header and delete it during parsing. If there is indeed a header, but you dont want to use it, you have two choices, either (1) use «names» kwarg only; or (2) use «names» with header=None and skiprows=1. I personally prefer the second option, since it clearly makes note that the input file is not in the format I want, and that I am doing something to go around it.
answered Apr 20, 2018 at 14:21
![]()
1
I think setting them afterwards is the only way in this case, so if you have for example four columns in your DataFrame:
df.columns = ['W','X','Y','Z']
If you know in advance what the headers in the Excelfile are its probably better to rename them, this would rename W into A, etc:
df.rename(columns={'W':'A', 'X':'B', etc})
answered Jun 27, 2013 at 6:12
![]()
Rutger KassiesRutger Kassies
60.2k17 gold badges111 silver badges97 bronze badges
1
As Ram said, this post comes on the top and may be useful to some….
In pandas 0.24.2 (may be earlier as well), read_excel itself has the capability of ignoring the source headers and giving your own col names and few other good controls:
DID = pd.read_excel(file1, sheet_name=0, header=None, usecols=[0, 1, 6], names=['A', 'ID', 'B'], dtype={2:str}, skiprows=10)
# for example....
# usecols => read only specific col indexes
# dtype => specifying the data types
# skiprows => skip number of rows from the top.
answered Apr 11, 2019 at 0:40
![]()
LokuLoku
2012 silver badges5 bronze badges
call .parse with header=None keyword argument.
df = xl.parse("Sheet1", header=None)
answered Jun 27, 2013 at 6:25
![]()
falsetrufalsetru
352k62 gold badges715 silver badges630 bronze badges
In case the excel sheet only contains the data without headers:
df=pd.read_excel("the excel file",header=None,names=["A","B","C"])
In case the excel sheet already contains header names, then use skiprows to skip the line:
df=pd.read_excel("the excel file",header=None,names=["A","B","C"],skiprows=1)
![]()
Wtower
18.4k11 gold badges106 silver badges80 bronze badges
answered Aug 4, 2020 at 6:11
![]()
code-freezecode-freeze
4457 silver badges8 bronze badges
In this tutorial, you’ll learn how to use Python and Pandas to read Excel files using the Pandas read_excel function. Excel files are everywhere – and while they may not be the ideal data type for many data scientists, knowing how to work with them is an essential skill.
By the end of this tutorial, you’ll have learned:
- How to use the Pandas read_excel function to read an Excel file
- How to read specify an Excel sheet name to read into Pandas
- How to read multiple Excel sheets or files
- How to certain columns from an Excel file in Pandas
- How to skip rows when reading Excel files in Pandas
- And more
Let’s get started!
The Quick Answer: Use Pandas read_excel to Read Excel Files
To read Excel files in Python’s Pandas, use the read_excel() function. You can specify the path to the file and a sheet name to read, as shown below:
# Reading an Excel File in Pandas
import pandas as pd
df = pd.read_excel('/Users/datagy/Desktop/Sales.xlsx')
# With a Sheet Name
df = pd.read_excel(
io='/Users/datagy/Desktop/Sales.xlsx'
sheet_name ='North'
)In the following sections of this tutorial, you’ll learn more about the Pandas read_excel() function to better understand how to customize reading Excel files.
Understanding the Pandas read_excel Function
The Pandas read_excel() function has a ton of different parameters. In this tutorial, you’ll learn how to use the main parameters available to you that provide incredible flexibility in terms of how you read Excel files in Pandas.
| Parameter | Description | Available Option |
|---|---|---|
io= |
The string path to the workbook. | URL to file, path to file, etc. |
sheet_name= |
The name of the sheet to read. Will default to the first sheet in the workbook (position 0). | Can read either strings (for the sheet name), integers (for position), or lists (for multiple sheets) |
usecols= |
The columns to read, if not all columns are to be read | Can be strings of columns, Excel-style columns (“A:C”), or integers representing positions columns |
dtype= |
The datatypes to use for each column | Dictionary with columns as keys and data types as values |
skiprows= |
The number of rows to skip from the top | Integer value representing the number of rows to skip |
nrows= |
The number of rows to parse | Integer value representing the number of rows to read |
.read_excel() functionThe table above highlights some of the key parameters available in the Pandas .read_excel() function. The full list can be found in the official documentation. In the following sections, you’ll learn how to use the parameters shown above to read Excel files in different ways using Python and Pandas.
As shown above, the easiest way to read an Excel file using Pandas is by simply passing in the filepath to the Excel file. The io= parameter is the first parameter, so you can simply pass in the string to the file.
The parameter accepts both a path to a file, an HTTP path, an FTP path or more. Let’s see what happens when we read in an Excel file hosted on my Github page.
# Reading an Excel file in Pandas
import pandas as pd
df = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/Sales.xlsx')
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969If you’ve downloaded the file and taken a look at it, you’ll notice that the file has three sheets? So, how does Pandas know which sheet to load? By default, Pandas will use the first sheet (positionally), unless otherwise specified.
In the following section, you’ll learn how to specify which sheet you want to load into a DataFrame.
How to Specify Excel Sheet Names in Pandas read_excel
As shown in the previous section, you learned that when no sheet is specified, Pandas will load the first sheet in an Excel workbook. In the workbook provided, there are three sheets in the following structure:
Sales.xlsx
|---East
|---West
|---NorthBecause of this, we know that the data from the sheet “East” was loaded. If we wanted to load the data from the sheet “West”, we can use the sheet_name= parameter to specify which sheet we want to load.
The parameter accepts both a string as well as an integer. If we were to pass in a string, we can specify the sheet name that we want to load.
Let’s take a look at how we can specify the sheet name for 'West':
# Specifying an Excel Sheet to Load by Name
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='West')
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255Similarly, we can load a sheet name by its position. By default, Pandas will use the position of 0, which will load the first sheet. Say we wanted to repeat our earlier example and load the data from the sheet named 'West', we would need to know where the sheet is located.
Because we know the sheet is the second sheet, we can pass in the 1st index:
# Specifying an Excel Sheet to Load by Position
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=1)
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255We can see that both of these methods returned the same sheet’s data. In the following section, you’ll learn how to specify which columns to load when using the Pandas read_excel function.
How to Specify Columns Names in Pandas read_excel
There may be many times when you don’t want to load every column in an Excel file. This may be because the file has too many columns or has different columns for different worksheets.
In order to do this, we can use the usecols= parameter. It’s a very flexible parameter that lets you specify:
- A list of column names,
- A string of Excel column ranges,
- A list of integers specifying the column indices to load
Most commonly, you’ll encounter people using a list of column names to read in. Each of these columns are comma separated strings, contained in a list.
Let’s load our DataFrame from the example above, only this time only loading the 'Customer' and 'Sales' columns:
# Specifying Columns to Load by Name
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols=['Customer', 'Sales'])
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969We can see that by passing in the list of strings representing the columns, we were able to parse those columns only.
If we wanted to use Excel changes, we could also specify columns 'B:C'. Let’s see what this looks like below:
# Specifying Columns to Load by Excel Range
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols='B:C')
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969Finally, we can also pass in a list of integers that represent the positions of the columns we wanted to load. Because the columns are the second and third columns, we would load a list of integers as shown below:
# Specifying Columns to Load by Their Position
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols=[1,2])
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969In the following section, you’ll learn how to specify data types when reading Excel files.
How to Specify Data Types in Pandas read_excel
Pandas makes it easy to specify the data type of different columns when reading an Excel file. This serves three main purposes:
- Preventing data from being read incorrectly
- Speeding up the read operation
- Saving memory
You can pass in a dictionary where the keys are the columns and the values are the data types. This ensures that data are ready correctly. Let’s see how we can specify the data types for our columns.
# Specifying Data Types for Columns When Reading Excel Files
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
dtype={'date':'datetime64', 'Customer': 'object', 'Sales':'int'})
print(df.head())
# Returns:
# Customer Sales
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969It’s important to note that you don’t need to pass in all the columns for this to work. In the next section, you’ll learn how to skip rows when reading Excel files.
How to Skip Rows When Reading Excel Files in Pandas
In some cases, you’ll encounter files where there are formatted title rows in your Excel file, as shown below:
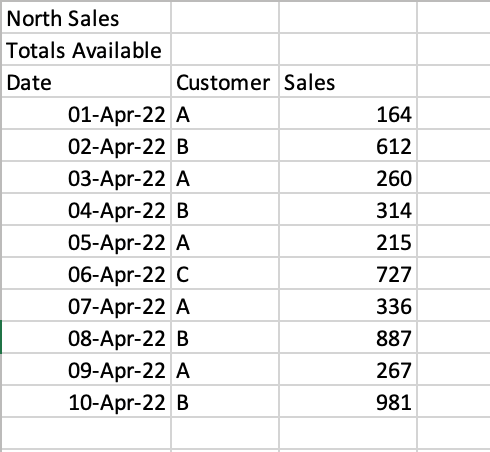
If we were to read the sheet 'North', we would get the following returned:
# Reading a poorly formatted Excel file
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='North')
print(df.head())
# Returns:
# North Sales Unnamed: 1 Unnamed: 2
# 0 Totals Available NaN NaN
# 1 Date Customer Sales
# 2 2022-04-01 00:00:00 A 164
# 3 2022-04-02 00:00:00 B 612
# 4 2022-04-03 00:00:00 A 260Pandas makes it easy to skip a certain number of rows when reading an Excel file. This can be done using the skiprows= parameter. We can see that we need to skip two rows, so we can simply pass in the value 2, as shown below:
# Reading a Poorly Formatted File Correctly
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='North',
skiprows=2)
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 164
# 1 2022-04-02 B 612
# 2 2022-04-03 A 260
# 3 2022-04-04 B 314
# 4 2022-04-05 A 215This read the file much more accurately! It can be a lifesaver when working with poorly formatted files. In the next section, you’ll learn how to read multiple sheets in an Excel file in Pandas.
How to Read Multiple Sheets in an Excel File in Pandas
Pandas makes it very easy to read multiple sheets at the same time. This can be done using the sheet_name= parameter. In our earlier examples, we passed in only a single string to read a single sheet. However, you can also pass in a list of sheets to read multiple sheets at once.
Let’s see how we can read our first two sheets:
# Reading Multiple Excel Sheets at Once in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=['East', 'West'])
print(type(dfs))
# Returns: <class 'dict'>In the example above, we passed in a list of sheets to read. When we used the type() function to check the type of the returned value, we saw that a dictionary was returned.
Each of the sheets is a key of the dictionary with the DataFrame being the corresponding key’s value. Let’s see how we can access the 'West' DataFrame:
# Reading Multiple Excel Sheets in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=['East', 'West'])
print(dfs.get('West').head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255You can also read all of the sheets at once by specifying None for the value of sheet_name=. Similarly, this returns a dictionary of all sheets:
# Reading Multiple Excel Sheets in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=None)In the next section, you’ll learn how to read multiple Excel files in Pandas.
How to Read Only n Lines When Reading Excel Files in Pandas
When working with very large Excel files, it can be helpful to only sample a small subset of the data first. This allows you to quickly load the file to better be able to explore the different columns and data types.
This can be done using the nrows= parameter, which accepts an integer value of the number of rows you want to read into your DataFrame. Let’s see how we can read the first five rows of the Excel sheet:
# Reading n Number of Rows of an Excel Sheet
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
nrows=5)
print(df)
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969Conclusion
In this tutorial, you learned how to use Python and Pandas to read Excel files into a DataFrame using the .read_excel() function. You learned how to use the function to read an Excel, specify sheet names, read only particular columns, and specify data types. You then learned how skip rows, read only a set number of rows, and read multiple sheets.
Additional Resources
To learn more about related topics, check out the tutorials below:
- Pandas Dataframe to CSV File – Export Using .to_csv()
- Combine Data in Pandas with merge, join, and concat
- Introduction to Pandas for Data Science
- Summarizing and Analyzing a Pandas DataFrame
You can use the following basic syntax to set the column names of a DataFrame when importing an Excel file into pandas:
colnames = ['col1', 'col2', 'col3'] df = pd.read_excel('my_data.xlsx', names=colnames)
The names argument takes a list of names that you’d like to use for the columns in the DataFrame.
By using this argument, you also tell pandas to use the first row in the Excel file as the first row in the DataFrame instead of using it as the header row.
The following example shows how to use this syntax in practice.
Suppose we have the following Excel file called players_data.xlsx:

From the file we can see that the first row does not contain any column names.
If we import the Excel file using the read_excel() function, pandas will attempt to use the values in the first row as the column names for the DataFrame:
import pandas as pd #import Excel file df = pd.read_excel('players_data.xlsx') #view resulting DataFrame print(df) A 22 10 0 B 14 9 1 C 29 6 2 D 30 2 3 E 22 9 4 F 31 10
However, we can use the names argument to specify our own column names when importing the Excel file:
import pandas as pd #specify column names colnames = ['team', 'points', 'rebounds'] #import Excel file and use specified column names df = pd.read_excel('players_data.xlsx', names=colnames) #view resulting DataFrame print(df) team points rebounds 0 B 14 9 1 C 29 6 2 D 30 2 3 E 22 9 4 F 31 10
Notice that the first row in the Excel file is no longer used as the header row.
Instead, the column names that we specified using the names argument are now used as the column names.
Note: You can find the complete documentation for the pandas read_excel() function here.
Additional Resources
The following tutorials explain how to perform other common tasks in pandas:
Pandas: How to Read Excel File with Merged Cells
Pandas: Skip Specific Columns when Importing Excel File
Pandas: How to Specify dtypes when Importing Excel File
Pandas: How to Skip Rows when Reading Excel File
- io:str, bytes, ExcelFile, xlrd.Book, path object, or file-like object
-
Any valid string path is acceptable. The string could be a URL. Valid URL schemes include http, ftp, s3, and file. For file URLs, a host is expected. A local file could be:
file://localhost/path/to/table.xlsx.If you want to pass in a path object, pandas accepts any
os.PathLike.By file-like object, we refer to objects with a
read()method, such as a file handle (e.g. via builtinopenfunction) orStringIO. - sheet_name:str, int, list, or None, default 0
-
Strings are used for sheet names. Integers are used in zero-indexed sheet positions (chart sheets do not count as a sheet position). Lists of strings/integers are used to request multiple sheets. Specify None to get all worksheets.
Available cases:
-
Defaults to
0: 1st sheet as aDataFrame -
1: 2nd sheet as aDataFrame -
"Sheet1": Load sheet with name “Sheet1” -
[0, 1, "Sheet5"]: Load first, second and sheet named “Sheet5” as a dict ofDataFrame -
None: All worksheets.
-
- header:int, list of int, default 0
-
Row (0-indexed) to use for the column labels of the parsed DataFrame. If a list of integers is passed those row positions will be combined into a
MultiIndex. Use None if there is no header. - names:array-like, default None
-
List of column names to use. If file contains no header row, then you should explicitly pass header=None.
- index_col:int, list of int, default None
-
Column (0-indexed) to use as the row labels of the DataFrame. Pass None if there is no such column. If a list is passed, those columns will be combined into a
MultiIndex. If a subset of data is selected withusecols, index_col is based on the subset.Missing values will be forward filled to allow roundtripping with
to_excelformerged_cells=True. To avoid forward filling the missing values useset_indexafter reading the data instead ofindex_col. - usecols:str, list-like, or callable, default None
-
-
If None, then parse all columns.
-
If str, then indicates comma separated list of Excel column letters and column ranges (e.g. “A:E” or “A,C,E:F”). Ranges are inclusive of both sides.
-
If list of int, then indicates list of column numbers to be parsed (0-indexed).
-
If list of string, then indicates list of column names to be parsed.
-
If callable, then evaluate each column name against it and parse the column if the callable returns
True.
Returns a subset of the columns according to behavior above.
-
- squeeze:bool, default False
-
If the parsed data only contains one column then return a Series.
Deprecated since version 1.4.0: Append
.squeeze("columns")to the call toread_excelto squeeze the data. - dtype:Type name or dict of column -> type, default None
-
Data type for data or columns. E.g. {‘a’: np.float64, ‘b’: np.int32} Useobjectto preserve data as stored in Excel and not interpret dtype. If converters are specified, they will be applied INSTEAD of dtype conversion.
- engine:str, default None
-
If io is not a buffer or path, this must be set to identify io. Supported engines: “xlrd”, “openpyxl”, “odf”, “pyxlsb”. Engine compatibility :
-
“xlrd” supports old-style Excel files (.xls).
-
“openpyxl” supports newer Excel file formats.
-
“odf” supports OpenDocument file formats (.odf, .ods, .odt).
-
“pyxlsb” supports Binary Excel files.
Changed in version 1.2.0: The engine xlrd now only supports old-style
.xlsfiles. Whenengine=None, the following logic will be used to determine the engine:-
If
path_or_bufferis an OpenDocument format (.odf, .ods, .odt), then odf will be used. -
Otherwise if
path_or_bufferis an xls format,xlrdwill be used. -
Otherwise if
path_or_bufferis in xlsb format,pyxlsbwill be used.New in version 1.3.0.
-
Otherwise
openpyxlwill be used.Changed in version 1.3.0.
-
- converters:dict, default None
-
Dict of functions for converting values in certain columns. Keys can either be integers or column labels, values are functions that take one input argument, the Excel cell content, and return the transformed content.
- true_values:list, default None
-
Values to consider as True.
- false_values:list, default None
-
Values to consider as False.
- skiprows:list-like, int, or callable, optional
-
Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file. If callable, the callable function will be evaluated against the row indices, returning True if the row should be skipped and False otherwise. An example of a valid callable argument would be
lambda.
x: x in [0, 2] - nrows:int, default None
-
Number of rows to parse.
- na_values:scalar, str, list-like, or dict, default None
-
Additional strings to recognize as NA/NaN. If dict passed, specific per-column NA values. By default the following values are interpreted as NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘<NA>’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’.
- keep_default_na:bool, default True
-
Whether or not to include the default NaN values when parsing the data. Depending on whetherna_valuesis passed in, the behavior is as follows:
-
Ifkeep_default_nais True, andna_valuesare specified,na_valuesis appended to the default NaN values used for parsing.
-
Ifkeep_default_nais True, andna_valuesare not specified, only the default NaN values are used for parsing.
-
Ifkeep_default_nais False, andna_valuesare specified, only the NaN values specifiedna_valuesare used for parsing.
-
Ifkeep_default_nais False, andna_valuesare not specified, no strings will be parsed as NaN.
Note that ifna_filteris passed in as False, thekeep_default_naandna_valuesparameters will be ignored.
-
- na_filter:bool, default True
-
Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file.
- verbose:bool, default False
-
Indicate number of NA values placed in non-numeric columns.
- parse_dates:bool, list-like, or dict, default False
-
The behavior is as follows:
-
bool. If True -> try parsing the index.
-
list of int or names. e.g. If [1, 2, 3] -> try parsing columns 1, 2, 3 each as a separate date column.
-
list of lists. e.g. If [[1, 3]] -> combine columns 1 and 3 and parse as a single date column.
-
dict, e.g. {‘foo’ : [1, 3]} -> parse columns 1, 3 as date and call result ‘foo’
If a column or index contains an unparsable date, the entire column or index will be returned unaltered as an object data type. If you don`t want to parse some cells as date just change their type in Excel to “Text”. For non-standard datetime parsing, use
pd.to_datetimeafterpd.read_excel.Note: A fast-path exists for iso8601-formatted dates.
-
- date_parser:function, optional
-
Function to use for converting a sequence of string columns to an array of datetime instances. The default uses
dateutil.parser.parserto do the conversion. Pandas will try to calldate_parserin three different ways, advancing to the next if an exception occurs: 1) Pass one or more arrays (as defined byparse_dates) as arguments; 2) concatenate (row-wise) the string values from the columns defined byparse_datesinto a single array and pass that; and 3) calldate_parseronce for each row using one or more strings (corresponding to the columns defined byparse_dates) as arguments. - thousands:str, default None
-
Thousands separator for parsing string columns to numeric. Note that this parameter is only necessary for columns stored as TEXT in Excel, any numeric columns will automatically be parsed, regardless of display format.
- decimal:str, default ‘.’
-
Character to recognize as decimal point for parsing string columns to numeric. Note that this parameter is only necessary for columns stored as TEXT in Excel, any numeric columns will automatically be parsed, regardless of display format.(e.g. use ‘,’ for European data).
New in version 1.4.0.
- comment:str, default None
-
Comments out remainder of line. Pass a character or characters to this argument to indicate comments in the input file. Any data between the comment string and the end of the current line is ignored.
- skipfooter:int, default 0
-
Rows at the end to skip (0-indexed).
- convert_float:bool, default True
-
Convert integral floats to int (i.e., 1.0 –> 1). If False, all numeric data will be read in as floats: Excel stores all numbers as floats internally.
Deprecated since version 1.3.0: convert_float will be removed in a future version
- mangle_dupe_cols:bool, default True
-
Duplicate columns will be specified as ‘X’, ‘X.1’, …’X.N’, rather than ‘X’…’X’. Passing in False will cause data to be overwritten if there are duplicate names in the columns.
Deprecated since version 1.5.0: Not implemented, and a new argument to specify the pattern for the names of duplicated columns will be added instead
- storage_options:dict, optional
-
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to
urllib.request.Requestas header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded tofsspec.open. Please seefsspecandurllibfor more details, and for more examples on storage options refer here.New in version 1.2.0.
В Python данные из файла Excel считываются в объект DataFrame. Для этого используется функция read_excel() модуля pandas.
Лист Excel — это двухмерная таблица. Объект DataFrame также представляет собой двухмерную табличную структуру данных.
- Пример использования Pandas read_excel()
- Список заголовков столбцов листа Excel
- Вывод данных столбца
- Пример использования Pandas to Excel: read_excel()
- Чтение файла Excel без строки заголовка
- Лист Excel в Dict, CSV и JSON
- Ресурсы

Предположим, что у нас есть документ Excel, состоящий из двух листов: «Employees» и «Cars». Верхняя строка содержит заголовок таблицы.

Ниже приведен код, который считывает данные листа «Employees» и выводит их.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Employees')
# print whole sheet data
print(excel_data_df)
Вывод:
EmpID EmpName EmpRole 0 1 Pankaj CEO 1 2 David Lee Editor 2 3 Lisa Ray Author
Первый параметр, который принимает функция read_excel ()— это имя файла Excel. Второй параметр (sheet_name) определяет лист для считывания данных.
При выводе содержимого объекта DataFrame мы получаем двухмерные таблицы, схожие по своей структуре со структурой документа Excel.
Чтобы получить список заголовков столбцов таблицы, используется свойство columns объекта Dataframe. Пример реализации:
print(excel_data_df.columns.ravel())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Мы можем получить данные из столбца и преобразовать их в список значений. Пример:
print(excel_data_df['EmpName'].tolist())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Можно указать имена столбцов для чтения из файла Excel. Это потребуется, если нужно вывести данные из определенных столбцов таблицы.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print(excel_data_df)
Вывод:
Car Name Car Price 0 Honda City 20,000 USD 1 Bugatti Chiron 3 Million USD 2 Ferrari 458 2,30,000 USD
Если в листе Excel нет строки заголовка, нужно передать его значение как None.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Numbers', header=None)
Если вы передадите значение заголовка как целое число (например, 3), тогда третья строка станет им. При этом считывание данных начнется со следующей строки. Данные, расположенные перед строкой заголовка, будут отброшены.
Объект DataFrame предоставляет различные методы для преобразования табличных данных в формат Dict , CSV или JSON.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print('Excel Sheet to Dict:', excel_data_df.to_dict(orient='record'))
print('Excel Sheet to JSON:', excel_data_df.to_json(orient='records'))
print('Excel Sheet to CSV:n', excel_data_df.to_csv(index=False))
Вывод:
Excel Sheet to Dict: [{'Car Name': 'Honda City', 'Car Price': '20,000 USD'}, {'Car Name': 'Bugatti Chiron', 'Car Price': '3 Million USD'}, {'Car Name': 'Ferrari 458', 'Car Price': '2,30,000 USD'}]
Excel Sheet to JSON: [{"Car Name":"Honda City","Car Price":"20,000 USD"},{"Car Name":"Bugatti Chiron","Car Price":"3 Million USD"},{"Car Name":"Ferrari 458","Car Price":"2,30,000 USD"}]
Excel Sheet to CSV:
Car Name,Car Price
Honda City,"20,000 USD"
Bugatti Chiron,3 Million USD
Ferrari 458,"2,30,000 USD"
- Документы API pandas read_excel()
Дайте знать, что вы думаете по этой теме материала в комментариях. Мы крайне благодарны вам за ваши комментарии, дизлайки, подписки, лайки, отклики!
Microsoft Excel is software that enables users to manage, format, and organize data in the form of a spreadsheet. The data is presented as 2-dimensional tables in an Excel file. Pandas also have a data structure similar to tables, a data frame.
You have previously learned to read data from CSV, JSON, and HTML format files. In this tutorial, you will understand how you can read an Excel file into a Pandas DataFrame object by using the pandas.read_excel() method.
Recommended Reads:
- Pandas read_json
- Pandas read_csv
- Pandas to_excel
Prerequisites of read_excel()
You need to have Python and Pandas installed on your computer and your favorite IDE set up to start coding. If you don’t have Pandas installed, you can install it using the command:
If you are using the Anaconda distribution use the command:
Syntax of pandas.read_excel()
pandas.read_excel(io, sheet_name=0, *, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal='.', comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
Some of the important parameters are:
| Parameter | Description |
| io | Path of the Excel file to be read. A URL is also accepted. |
| sheet_name | Names or indexes of the sheets in the Excel file. |
| names | List of column names to be used. |
| usecols | Specify only selected columns to be displayed in the output. |
| skiprows | Specify the number of rows that are to be skipped in the output. |
| nrows | Specify the number of rows to be displayed in the output. |
Reading an Excel file using Pandas
Let us first have a look at the sample Excel sheets. The name of the Excel file here is ‘info.xlsx‘. It contains two sheets as shown below:
To read the Excel file, use the below code:
import pandas as pd
df = pd.read_excel('info.xlsx')
df
Since the data is in the form of a Pandas DataFrame now, you can operate it just like you operate any other DataFrame.
For example, if you want to get only the column names, you can write:
print(df['car'].to_list())
Output:
['ciaz', 'swift', 'i20', 'kia', 'brezza']
Specifying sheet names
By default, only the first sheet in the Excel workbook or file is read by the read_excel() function. To read multiple sheets from an Excel file, use the sheet_names parameter. You can mention an integer or a list of integers that represent the 0-indexed sheet number sequence to be read.
Since the above workbook has two sheets, the car has an index of 0 and the flower has an index of 1.
df = pd.read_excel('info.xlsx', sheet_name = 0)
df
df = pd.read_excel('info.xlsx', sheet_name = 1)
df
Displaying only some specific columns in the output
If you don’t want all the columns in the Excel sheet, you can select the columns that you need using the usecols parameter.
df = pd.read_excel('info.xlsx', sheet_name = 0, usecols=['car', 'price'])
df
As the code suggests, only the columns car and price from sheet 0 i.e. car are displayed and other columns are not included in the resulting DataFrame.
Changing column names
You can also change the column names for the Excel sheet, if needed, using the names parameter in the read_excel() function.
df = pd.read_excel('info.xlsx', sheet_name = 1, names=['col 1', 'col 2'])
df
The names of the columns from sheet 1 i.e. flower have been changed to col 1 and col 2.
Skipping rows
If you have any irrelevant or redundant data and do not want it in your DataFrame object, you can assign an integer or a list of integers to the skiprows parameter. If an integer n is given, it skips the first n rows, and if a list of 0-indexed integers is given, those rows are only skipped.
df = pd.read_excel('info.xlsx', sheet_name=1, skiprows=1)
df
One row from the flower sheet is skipped here.
Specifying a new header
When you use the header parameter with the read_excel() function, you assign an integer n to it and then the function treats the nth row as the header and displays only the data below it. The rows above it are discarded.
df = pd.read_excel('info.xlsx', sheet_name = 0, header = 3)
df
The third row from the car sheet is set as the header, and the two entries above it are discarded. Only the rows below it are displayed.
Selecting only ‘n’ rows
The nrows parameter lets you choose how many rows you want in your resulting Pandas DataFrame. It displays the first n rows, where n is the value assigned to the parameter.
df = pd.read_excel('info.xlsx', nrows=3)
df
Conclusion
The pandas.read_excel() function lets you read any Excel file into a Pandas DataFrame object. It also provides various parameters which you can use to customize the output as per your requirements, some of which were discussed in this tutorial.
Please visit askpython.com for more such tutorials on various Python-related topics.
Reference
- Pandas read_excel() Official Documentation