
The new version of Pandas uses the following interface to load Excel files:
read_excel('path_to_file.xls', 'Sheet1', index_col=None, na_values=['NA'])
but what if I don’t know the sheets that are available?
For example, I am working with excel files that the following sheets
Data 1, Data 2 …, Data N, foo, bar
but I don’t know N a priori.
Is there any way to get the list of sheets from an excel document in Pandas?
![]()
denfromufa
5,97612 gold badges77 silver badges138 bronze badges
asked Jul 31, 2013 at 17:57
![]()
You can still use the ExcelFile class (and the sheet_names attribute):
xl = pd.ExcelFile('foo.xls')
xl.sheet_names # see all sheet names
xl.parse(sheet_name) # read a specific sheet to DataFrame
see docs for parse for more options…
![]()
answered Jul 31, 2013 at 18:01
![]()
Andy HaydenAndy Hayden
353k101 gold badges619 silver badges531 bronze badges
3
You should explicitly specify the second parameter (sheetname) as None. like this:
df = pandas.read_excel("/yourPath/FileName.xlsx", None);
«df» are all sheets as a dictionary of DataFrames, you can verify it by run this:
df.keys()
result like this:
[u'201610', u'201601', u'201701', u'201702', u'201703', u'201704', u'201705', u'201706', u'201612', u'fund', u'201603', u'201602', u'201605', u'201607', u'201606', u'201608', u'201512', u'201611', u'201604']
please refer pandas doc for more details: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html
answered Aug 10, 2017 at 1:59
![]()
3
The easiest way to retrieve the sheet-names from an excel (xls., xlsx) is:
tabs = pd.ExcelFile("path").sheet_names
print(tabs)
Then to read and store the data of a particular sheet (say, sheet names are «Sheet1», «Sheet2», etc.), say «Sheet2» for example:
data = pd.read_excel("path", "Sheet2")
print(data)
![]()
answered Aug 12, 2021 at 20:13
![]()
This is the fastest way I have found, inspired by @divingTobi’s answer. All The answers based on xlrd, openpyxl or pandas are slow for me, as they all load the whole file first.
from zipfile import ZipFile
from bs4 import BeautifulSoup # you also need to install "lxml" for the XML parser
with ZipFile(file) as zipped_file:
summary = zipped_file.open(r'xl/workbook.xml').read()
soup = BeautifulSoup(summary, "xml")
sheets = [sheet.get("name") for sheet in soup.find_all("sheet")]
answered Sep 6, 2019 at 21:10
![]()
S.E.AS.E.A
1211 silver badge3 bronze badges
#It will work for Both '.xls' and '.xlsx' by using pandas
import pandas as pd
excel_Sheet_names = (pd.ExcelFile(excelFilePath)).sheet_names
#for '.xlsx' use only openpyxl
from openpyxl import load_workbook
excel_Sheet_names = (load_workbook(excelFilePath, read_only=True)).sheet_names
![]()
Suraj Rao
29.3k11 gold badges96 silver badges103 bronze badges
answered Dec 7, 2021 at 11:58
![]()
1
I have tried xlrd, pandas, openpyxl and other such libraries and all of them seem to take exponential time as the file size increase as it reads the entire file. The other solutions mentioned above where they used ‘on_demand’ did not work for me. If you just want to get the sheet names initially, the following function works for xlsx files.
def get_sheet_details(file_path):
sheets = []
file_name = os.path.splitext(os.path.split(file_path)[-1])[0]
# Make a temporary directory with the file name
directory_to_extract_to = os.path.join(settings.MEDIA_ROOT, file_name)
os.mkdir(directory_to_extract_to)
# Extract the xlsx file as it is just a zip file
zip_ref = zipfile.ZipFile(file_path, 'r')
zip_ref.extractall(directory_to_extract_to)
zip_ref.close()
# Open the workbook.xml which is very light and only has meta data, get sheets from it
path_to_workbook = os.path.join(directory_to_extract_to, 'xl', 'workbook.xml')
with open(path_to_workbook, 'r') as f:
xml = f.read()
dictionary = xmltodict.parse(xml)
for sheet in dictionary['workbook']['sheets']['sheet']:
sheet_details = {
'id': sheet['@sheetId'],
'name': sheet['@name']
}
sheets.append(sheet_details)
# Delete the extracted files directory
shutil.rmtree(directory_to_extract_to)
return sheets
Since all xlsx are basically zipped files, we extract the underlying xml data and read sheet names from the workbook directly which takes a fraction of a second as compared to the library functions.
Benchmarking: (On a 6mb xlsx file with 4 sheets)
Pandas, xlrd: 12 seconds
openpyxl: 24 seconds
Proposed method: 0.4 seconds
Since my requirement was just reading the sheet names, the unnecessary overhead of reading the entire time was bugging me so I took this route instead.
answered May 27, 2019 at 5:43
![]()
3
Building on @dhwanil_shah ‘s answer, you do not need to extract the whole file. With zf.open it is possible to read from a zipped file directly.
import xml.etree.ElementTree as ET
import zipfile
def xlsxSheets(f):
zf = zipfile.ZipFile(f)
f = zf.open(r'xl/workbook.xml')
l = f.readline()
l = f.readline()
root = ET.fromstring(l)
sheets=[]
for c in root.findall('{http://schemas.openxmlformats.org/spreadsheetml/2006/main}sheets/*'):
sheets.append(c.attrib['name'])
return sheets
The two consecutive readlines are ugly, but the content is only in the second line of the text. No need to parse the whole file.
This solution seems to be much faster than the read_excel version, and most likely also faster than the full extract version.
answered Jul 1, 2019 at 14:01
![]()
divingTobidivingTobi
1,9349 silver badges24 bronze badges
1
If you:
- care about performance
- don’t need the data in the file at execution time.
- want to go with conventional libraries vs rolling your own solution
Below was benchmarked on a ~10Mb xlsx, xlsb file.
xlsx, xls
from openpyxl import load_workbook
def get_sheetnames_xlsx(filepath):
wb = load_workbook(filepath, read_only=True, keep_links=False)
return wb.sheetnames
Benchmarks: ~ 14x speed improvement
# get_sheetnames_xlsx vs pd.read_excel
225 ms ± 6.21 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
3.25 s ± 140 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
xlsb
from pyxlsb import open_workbook
def get_sheetnames_xlsb(filepath):
with open_workbook(filepath) as wb:
return wb.sheets
Benchmarks: ~ 56x speed improvement
# get_sheetnames_xlsb vs pd.read_excel
96.4 ms ± 1.61 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
5.36 s ± 162 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Notes:
- This is a good resource —
http://www.python-excel.org/ xlrdis no longer maintained as of 2020
answered Nov 9, 2020 at 21:24
![]()
Glen ThompsonGlen Thompson
8,7834 gold badges49 silver badges50 bronze badges
from openpyxl import load_workbook
sheets = load_workbook(excel_file, read_only=True).sheetnames
For a 5MB Excel file I’m working with, load_workbook without the read_only flag took 8.24s. With the read_only flag it only took 39.6 ms. If you still want to use an Excel library and not drop to an xml solution, that’s much faster than the methods that parse the whole file.
answered Jun 4, 2020 at 20:54
![]()
flutefreak7flutefreak7
2,2915 gold badges28 silver badges38 bronze badges
-
With the load_workbook readonly option, what was earlier seen as a execution seen visibly waiting for many seconds happened with milliseconds. The solution could however be still improved.
import pandas as pd from openpyxl import load_workbook class ExcelFile: def __init__(self, **kwargs): ........ ..... self._SheetNames = list(load_workbook(self._name,read_only=True,keep_links=False).sheetnames) -
The Excelfile.parse takes the same time as reading the complete xls in order of 10s of sec. This result was obtained with windows 10 operating system with below package versions
C:>python -V Python 3.9.1 C:>pip list Package Version --------------- ------- et-xmlfile 1.0.1 numpy 1.20.2 openpyxl 3.0.7 pandas 1.2.3 pip 21.0.1 python-dateutil 2.8.1 pytz 2021.1 pyxlsb 1.0.8 setuptools 49.2.1 six 1.15.0 xlrd 2.0.1
answered Apr 8, 2021 at 12:19
![]()
if you read excel file
dfs = pd.ExcelFile('file')
then use
dfs.sheet_names
dfs.parse('sheetname')
another variant
df = pd.read_excel('file', sheet_name='sheetname')
![]()
Dominique
15.9k15 gold badges52 silver badges104 bronze badges
answered Aug 10, 2021 at 5:12
![]()
import pandas as pd
path = "\DB\Expense\reconcile\"
file_name = "202209-v01.xlsx"
df = pd.read_excel(path + file_name, None)
print(df)
sheet_names = list(df.keys())
# print last sheet name
print(sheet_names[len(sheet_names)-1])
last_month = df.get(sheet_names[len(sheet_names)-1])
print(last_month)
answered Nov 8, 2022 at 0:00
![]()
Last Updated on July 14, 2022 by
In the previous post, we touched on how to read an Excel file into Python. Here we’ll attempt to read multiple Excel sheets (from the same file) with Python pandas. We can do this in two ways: use pd.read_excel() method, with the optional argument sheet_name; the alternative is to create a pd.ExcelFile object, then parse data from that object.
pd.read_excel() method
In the below example:
- Select sheets to read by index:
sheet_name = [0,1,2]means the first three sheets. - Select sheets to read by name:
sheet_name = ['User_info', 'compound']. This method requires you to know the sheet names in advance. - Select all sheets: sheet_name = None.
import pandas as pd
df = pd.read_excel('users.xlsx', sheet_name = [0,1,2])
df = pd.read_excel('users.xlsx', sheet_name = ['User_info','compound'])
df = pd.read_excel('users.xlsx', sheet_name = None) # read all sheetsWe will read all sheets from the sample Excel file, then use that dataframe for the examples going forward.
The df returns a dictionary of dataframes. The keys of the dictionary contain sheet names, and values of the dictionary contain sheet content.
>>> df.keys()
dict_keys(['User_info', 'purchase', 'compound', 'header_row5'])
>>> df.values()
dict_values([ User Name Country City Gender Age
0 Forrest Gump USA New York M 50
1 Mary Jane CANADA Tornoto F 30
2 Harry Porter UK London M 20
3 Jean Grey CHINA Shanghai F 30,
ID Customer purchase Date
0 101 Forrest Gump Dragon Ball 2020-08-12
1 102 Mary Jane Evangelion 2020-01-01
2 103 Harry Porter Kill la Kill 2020-08-01
3 104 Jean Grey Dragon Ball 1999-01-01
4 105 Mary Jane Evangelion 2019-12-31
5 106 Harry Porter Ghost in the Shell 2020-01-01
6 107 Jean Grey Evangelion 2018-04-01,
....
]To obtain data from a specific sheet, simply reference the key in the dictionary. For example, df['header_row5'] returns the sheet in which data starts from row 5.
>>> df['header_row5']
Unnamed: 0 Unnamed: 1 Unnamed: 2 Unnamed: 3
0 NaN NaN NaN NaN
1 NaN NaN NaN NaN
2 NaN NaN NaN NaN
3 ID Customer purchase Date
4 101 Forrest Gump Dragon Ball 2020-08-12 00:00:00
5 102 Mary Jane Evangelion 2020-01-01 00:00:00
6 103 Harry Porter Kill la Kill 2020-08-01 00:00:00
7 104 Jean Grey Dragon Ball 1999-01-01 00:00:00
8 105 Mary Jane Evangelion 2019-12-31 00:00:00
9 106 Harry Porter Ghost in the Shell 2020-01-01 00:00:00
10 107 Jean Grey Evangelion 2018-04-01 00:00:00pd.ExcelFile()
With this approach, we create a pd.ExcelFile object to represent the Excel file. We do not need to specify which sheets to read when using this method. Note that the previous read_excel() method returns a dataframe or a dictionary of dataframes; whereas pd.ExcelFile() returns a reference object to the Excel file.
f = pd.ExcelFile('users.xlsx')
>>> f
<pandas.io.excel._base.ExcelFile object at 0x00000138DAE66670>To get sheet names, we can all the sheet_names attribute from the ExcelFile object, which returns a list of the sheet names (string).
>>> f.sheet_names
['User_info', 'purchase', 'compound', 'header_row5']
To get data from a sheet, we can use the parse() method, and provide the sheet name.
>>> f.parse(sheet_name = 'User_info')
User Name Country City Gender Age
0 Forrest Gump USA New York M 50
1 Mary Jane CANADA Tornoto F 30
2 Harry Porter UK London M 20
3 Jean Grey CHINA Shanghai F 30One thing to note is that the pd.ExcelFile.parse() method is equivalent to the pd.read_excel() method, so that means you can pass in the same arguments used in read_excel().
Moving on…
We have learned how to read data from Excel or CSV files, next we’ll cover how to save a dataframe back into an Excel (or CSV) file.
In this tutorial, you’ll learn how to use Python and Pandas to read Excel files using the Pandas read_excel function. Excel files are everywhere – and while they may not be the ideal data type for many data scientists, knowing how to work with them is an essential skill.
By the end of this tutorial, you’ll have learned:
- How to use the Pandas read_excel function to read an Excel file
- How to read specify an Excel sheet name to read into Pandas
- How to read multiple Excel sheets or files
- How to certain columns from an Excel file in Pandas
- How to skip rows when reading Excel files in Pandas
- And more
Let’s get started!
The Quick Answer: Use Pandas read_excel to Read Excel Files
To read Excel files in Python’s Pandas, use the read_excel() function. You can specify the path to the file and a sheet name to read, as shown below:
# Reading an Excel File in Pandas
import pandas as pd
df = pd.read_excel('/Users/datagy/Desktop/Sales.xlsx')
# With a Sheet Name
df = pd.read_excel(
io='/Users/datagy/Desktop/Sales.xlsx'
sheet_name ='North'
)In the following sections of this tutorial, you’ll learn more about the Pandas read_excel() function to better understand how to customize reading Excel files.
Understanding the Pandas read_excel Function
The Pandas read_excel() function has a ton of different parameters. In this tutorial, you’ll learn how to use the main parameters available to you that provide incredible flexibility in terms of how you read Excel files in Pandas.
| Parameter | Description | Available Option |
|---|---|---|
io= |
The string path to the workbook. | URL to file, path to file, etc. |
sheet_name= |
The name of the sheet to read. Will default to the first sheet in the workbook (position 0). | Can read either strings (for the sheet name), integers (for position), or lists (for multiple sheets) |
usecols= |
The columns to read, if not all columns are to be read | Can be strings of columns, Excel-style columns (“A:C”), or integers representing positions columns |
dtype= |
The datatypes to use for each column | Dictionary with columns as keys and data types as values |
skiprows= |
The number of rows to skip from the top | Integer value representing the number of rows to skip |
nrows= |
The number of rows to parse | Integer value representing the number of rows to read |
.read_excel() functionThe table above highlights some of the key parameters available in the Pandas .read_excel() function. The full list can be found in the official documentation. In the following sections, you’ll learn how to use the parameters shown above to read Excel files in different ways using Python and Pandas.
As shown above, the easiest way to read an Excel file using Pandas is by simply passing in the filepath to the Excel file. The io= parameter is the first parameter, so you can simply pass in the string to the file.
The parameter accepts both a path to a file, an HTTP path, an FTP path or more. Let’s see what happens when we read in an Excel file hosted on my Github page.
# Reading an Excel file in Pandas
import pandas as pd
df = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/Sales.xlsx')
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969If you’ve downloaded the file and taken a look at it, you’ll notice that the file has three sheets? So, how does Pandas know which sheet to load? By default, Pandas will use the first sheet (positionally), unless otherwise specified.
In the following section, you’ll learn how to specify which sheet you want to load into a DataFrame.
How to Specify Excel Sheet Names in Pandas read_excel
As shown in the previous section, you learned that when no sheet is specified, Pandas will load the first sheet in an Excel workbook. In the workbook provided, there are three sheets in the following structure:
Sales.xlsx
|---East
|---West
|---NorthBecause of this, we know that the data from the sheet “East” was loaded. If we wanted to load the data from the sheet “West”, we can use the sheet_name= parameter to specify which sheet we want to load.
The parameter accepts both a string as well as an integer. If we were to pass in a string, we can specify the sheet name that we want to load.
Let’s take a look at how we can specify the sheet name for 'West':
# Specifying an Excel Sheet to Load by Name
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='West')
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255Similarly, we can load a sheet name by its position. By default, Pandas will use the position of 0, which will load the first sheet. Say we wanted to repeat our earlier example and load the data from the sheet named 'West', we would need to know where the sheet is located.
Because we know the sheet is the second sheet, we can pass in the 1st index:
# Specifying an Excel Sheet to Load by Position
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=1)
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255We can see that both of these methods returned the same sheet’s data. In the following section, you’ll learn how to specify which columns to load when using the Pandas read_excel function.
How to Specify Columns Names in Pandas read_excel
There may be many times when you don’t want to load every column in an Excel file. This may be because the file has too many columns or has different columns for different worksheets.
In order to do this, we can use the usecols= parameter. It’s a very flexible parameter that lets you specify:
- A list of column names,
- A string of Excel column ranges,
- A list of integers specifying the column indices to load
Most commonly, you’ll encounter people using a list of column names to read in. Each of these columns are comma separated strings, contained in a list.
Let’s load our DataFrame from the example above, only this time only loading the 'Customer' and 'Sales' columns:
# Specifying Columns to Load by Name
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols=['Customer', 'Sales'])
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969We can see that by passing in the list of strings representing the columns, we were able to parse those columns only.
If we wanted to use Excel changes, we could also specify columns 'B:C'. Let’s see what this looks like below:
# Specifying Columns to Load by Excel Range
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols='B:C')
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969Finally, we can also pass in a list of integers that represent the positions of the columns we wanted to load. Because the columns are the second and third columns, we would load a list of integers as shown below:
# Specifying Columns to Load by Their Position
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols=[1,2])
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969In the following section, you’ll learn how to specify data types when reading Excel files.
How to Specify Data Types in Pandas read_excel
Pandas makes it easy to specify the data type of different columns when reading an Excel file. This serves three main purposes:
- Preventing data from being read incorrectly
- Speeding up the read operation
- Saving memory
You can pass in a dictionary where the keys are the columns and the values are the data types. This ensures that data are ready correctly. Let’s see how we can specify the data types for our columns.
# Specifying Data Types for Columns When Reading Excel Files
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
dtype={'date':'datetime64', 'Customer': 'object', 'Sales':'int'})
print(df.head())
# Returns:
# Customer Sales
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969It’s important to note that you don’t need to pass in all the columns for this to work. In the next section, you’ll learn how to skip rows when reading Excel files.
How to Skip Rows When Reading Excel Files in Pandas
In some cases, you’ll encounter files where there are formatted title rows in your Excel file, as shown below:
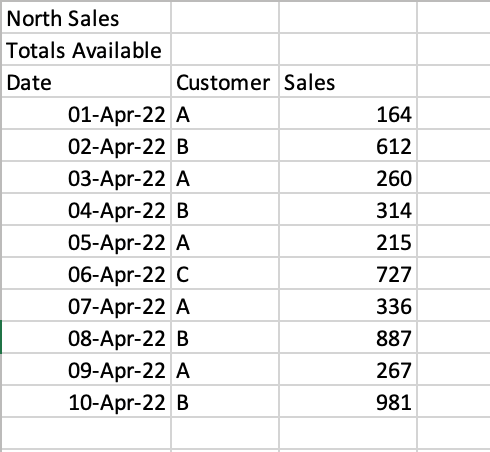
If we were to read the sheet 'North', we would get the following returned:
# Reading a poorly formatted Excel file
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='North')
print(df.head())
# Returns:
# North Sales Unnamed: 1 Unnamed: 2
# 0 Totals Available NaN NaN
# 1 Date Customer Sales
# 2 2022-04-01 00:00:00 A 164
# 3 2022-04-02 00:00:00 B 612
# 4 2022-04-03 00:00:00 A 260Pandas makes it easy to skip a certain number of rows when reading an Excel file. This can be done using the skiprows= parameter. We can see that we need to skip two rows, so we can simply pass in the value 2, as shown below:
# Reading a Poorly Formatted File Correctly
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='North',
skiprows=2)
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 164
# 1 2022-04-02 B 612
# 2 2022-04-03 A 260
# 3 2022-04-04 B 314
# 4 2022-04-05 A 215This read the file much more accurately! It can be a lifesaver when working with poorly formatted files. In the next section, you’ll learn how to read multiple sheets in an Excel file in Pandas.
How to Read Multiple Sheets in an Excel File in Pandas
Pandas makes it very easy to read multiple sheets at the same time. This can be done using the sheet_name= parameter. In our earlier examples, we passed in only a single string to read a single sheet. However, you can also pass in a list of sheets to read multiple sheets at once.
Let’s see how we can read our first two sheets:
# Reading Multiple Excel Sheets at Once in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=['East', 'West'])
print(type(dfs))
# Returns: <class 'dict'>In the example above, we passed in a list of sheets to read. When we used the type() function to check the type of the returned value, we saw that a dictionary was returned.
Each of the sheets is a key of the dictionary with the DataFrame being the corresponding key’s value. Let’s see how we can access the 'West' DataFrame:
# Reading Multiple Excel Sheets in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=['East', 'West'])
print(dfs.get('West').head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255You can also read all of the sheets at once by specifying None for the value of sheet_name=. Similarly, this returns a dictionary of all sheets:
# Reading Multiple Excel Sheets in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=None)In the next section, you’ll learn how to read multiple Excel files in Pandas.
How to Read Only n Lines When Reading Excel Files in Pandas
When working with very large Excel files, it can be helpful to only sample a small subset of the data first. This allows you to quickly load the file to better be able to explore the different columns and data types.
This can be done using the nrows= parameter, which accepts an integer value of the number of rows you want to read into your DataFrame. Let’s see how we can read the first five rows of the Excel sheet:
# Reading n Number of Rows of an Excel Sheet
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
nrows=5)
print(df)
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969Conclusion
In this tutorial, you learned how to use Python and Pandas to read Excel files into a DataFrame using the .read_excel() function. You learned how to use the function to read an Excel, specify sheet names, read only particular columns, and specify data types. You then learned how skip rows, read only a set number of rows, and read multiple sheets.
Additional Resources
To learn more about related topics, check out the tutorials below:
- Pandas Dataframe to CSV File – Export Using .to_csv()
- Combine Data in Pandas with merge, join, and concat
- Introduction to Pandas for Data Science
- Summarizing and Analyzing a Pandas DataFrame
sheet_name param on pandas.read_excel() is used to read multiple sheets from excel. This supports reading excel sheets by name or position. When you read multiple sheets, it creates a Dict of DataFrame, each key in Dictionary is represented as Sheet name and DF for Dict value.
sheet_name param also takes a list of sheet names as values that can be used to read multiple sheets into pandas DataFrame. Not that while reading multiple sheets it returns a Dict of DataFrame. The key in Dict is a sheet name and the value would be DataFrame.
This param takes values str, int, list, or None, default 0. When None is used it reads all sheets from excel. By default, it is set to 0 meaning the first sheet.
Let’s see with an example, I have an excel file with two sheets named 'Technologies' and 'Schedule'.
import pandas as pd
# Read excel file with sheet name
dict_df = pd.read_excel('c:/apps/courses_schedule.xlsx',
sheet_name=['Technologies','Schedule'])
Since we are reading two sheets from excel, this function returns Dict of DataFrame. You can get the DataFrames from Dict as follows.
# Get DataFrame from Dict
technologies_df = dict_df .get('Technologies')
schedule_df = df.get('Schedule')
# Print DataFrame's
print(technologies_df)
print(schedule_df)
The 'Technologies' sheet is converted into DataFrame as follows. Note that empty values are converted into NaN on DataFrame.
Courses Fee Duration Discount
0 Spark 25000 50 Days 2000
1 Pandas 20000 35 Days 1000
2 Java 15000 NaN 800
3 Python 15000 30 Days 500
4 PHP 18000 30 Days 800
And the 'Schedule' sheet is converted into DataFrame as follows.
Courses Days Time
0 Spark MON, THU 7:00 AM to 9:00 AM
1 Pandas MON, WED 8:00 AM to 10:00 AM
2 Java WEN, FRI 7:00 PM to 9:00 PM
3 Python TUE, THU 6:00 PM to 8:00 PM
4 PHP WEN, THU 8:00 AM to 10:00 AM
Conclusion
In this article, you have learned how to read an excel with multiple sheets and convert it to pandas DataFrame. Since it returns a Dict of DataFrame, you have also learned how to get each DF from the dict.
Happy Learning !!
Related Articles
Naveen (NNK)
SparkByExamples.com is a Big Data and Spark examples community page, all examples are simple and easy to understand and well tested in our development environment Read more ..

Microsoft Excel is one of the most powerful spreadsheet software applications in the world, and it has become critical in all business processes. Companies across the world, both big and small, are using Microsoft Excel to store, organize, analyze, and visualize data.
As a data professional, when you combine Python with Excel, you create a unique data analysis bundle that unlocks the value of the enterprise data.
In this tutorial, we’re going to learn how to read and work with Excel files in Python.
After you finish this tutorial, you’ll understand the following:
- Loading Excel spreadsheets into pandas DataFrames
- Working with an Excel workbook with multiple spreadsheets
- Combining multiple spreadsheets
- Reading Excel files using the
xlrdpackage
In this tutorial, we assume you know the fundamentals of pandas DataFrames. If you aren’t familiar with the pandas library, you might like to try our Pandas and NumPy Fundamentals – Dataquest.
Let’s dive in.
Reading Spreadsheets with Pandas
Technically, multiple packages allow us to work with Excel files in Python. However, in this tutorial, we’ll use pandas and xlrd libraries to interact with Excel workbooks. Essentially, you can think of a pandas DataFrame as a spreadsheet with rows and columns stored in Series objects. Traversability of Series as iterable objects allows us to grab specific data easily. Once we load an Excel workbook into a pandas DataFrame, we can perform any kind of data analysis on the data.
Before we proceed to the next step, let’s first download the following spreadsheet:
Sales Data Excel Workbook — xlsx ver.
The Excel workbook consists of two sheets that contain stationery sales data for 2020 and 2021.
NOTE
Although Excel spreadsheets can contain formula and also support formatting, pandas only imports Excel spreadsheets as flat files, and it doesn’t support spreadsheet formatting.
To import the Excel spreadsheet into a pandas DataFrame, first, we need to import the pandas package and then use the read_excel() method:
import pandas as pd
df = pd.read_excel('sales_data.xlsx')
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 | True |
| 1 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 2 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 3 | 2020-04-01 | East | Jones | Binder | 60 | 4.99 | 299.40 | False |
| 4 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
| 5 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 6 | 2020-07-12 | East | Howard | Binder | 29 | 1.99 | 57.71 | False |
| 7 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 8 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 9 | 2020-10-05 | Central | Morgan | Binder | 28 | 8.99 | 251.72 | True |
| 10 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 11 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
If you want to load only a limited number of rows into the DataFrame, you can specify the number of rows using the nrows argument:
df = pd.read_excel('sales_data.xlsx', nrows=5)
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 | True |
| 1 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 2 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 3 | 2020-04-01 | East | Jones | Binder | 60 | 4.99 | 299.40 | False |
| 4 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
Skipping a specific number of rows from the begining of a spreadsheet or skipping over a list of particular rows is available through the skiprows argument, as follows:
df = pd.read_excel('sales_data.xlsx', skiprows=range(5))
display(df)| 2020-05-05 00:00:00 | Central | Jardine | Pencil | 90 | 4.99 | 449.1 | True | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 1 | 2020-07-12 | East | Howard | Binder | 29 | 1.99 | 57.71 | False |
| 2 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 3 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 4 | 2020-10-05 | Central | Morgan | Binder | 28 | 8.99 | 251.72 | True |
| 5 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 6 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
The code above skips the first five rows and returns the rest of the data. Instead, the following code returns all the rows except for those with the mentioned indices:
df = pd.read_excel('sales_data.xlsx', skiprows=[1, 4,7,10])
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 1 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 2 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
| 3 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 4 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 5 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 6 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 7 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
Another useful argument is usecols, which allows us to select spreadsheet columns with their letters, names, or positional numbers. Let’s see how it works:
df = pd.read_excel('sales_data.xlsx', usecols='A:C,G')
display(df)| OrderDate | Region | Rep | Total | |
|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | 189.05 |
| 1 | 2020-02-09 | Central | Jardine | 179.64 |
| 2 | 2020-03-15 | West | Sorvino | 167.44 |
| 3 | 2020-04-01 | East | Jones | 299.40 |
| 4 | 2020-05-05 | Central | Jardine | 449.10 |
| 5 | 2020-06-08 | East | Jones | 539.40 |
| 6 | 2020-07-12 | East | Howard | 57.71 |
| 7 | 2020-08-15 | East | Jones | 174.65 |
| 8 | 2020-09-01 | Central | Smith | 250.00 |
| 9 | 2020-10-05 | Central | Morgan | 251.72 |
| 10 | 2020-11-08 | East | Mike | 299.85 |
| 11 | 2020-12-12 | Central | Smith | 86.43 |
In the code above, the string assigned to the usecols argument contains a range of columns with : plus column G separated by a comma. Also, we’re able to provide a list of column names and assign it to the usecols argument, as follows:
df = pd.read_excel('sales_data.xlsx', usecols=['OrderDate', 'Region', 'Rep', 'Total'])
display(df)| OrderDate | Region | Rep | Total | |
|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | 189.05 |
| 1 | 2020-02-09 | Central | Jardine | 179.64 |
| 2 | 2020-03-15 | West | Sorvino | 167.44 |
| 3 | 2020-04-01 | East | Jones | 299.40 |
| 4 | 2020-05-05 | Central | Jardine | 449.10 |
| 5 | 2020-06-08 | East | Jones | 539.40 |
| 6 | 2020-07-12 | East | Howard | 57.71 |
| 7 | 2020-08-15 | East | Jones | 174.65 |
| 8 | 2020-09-01 | Central | Smith | 250.00 |
| 9 | 2020-10-05 | Central | Morgan | 251.72 |
| 10 | 2020-11-08 | East | Mike | 299.85 |
| 11 | 2020-12-12 | Central | Smith | 86.43 |
The usecols argument accepts a list of column numbers, too. The following code shows how we can pick up specific columns using their indices:
df = pd.read_excel('sales_data.xlsx', usecols=[0, 1, 2, 6])
display(df)| OrderDate | Region | Rep | Total | |
|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | 189.05 |
| 1 | 2020-02-09 | Central | Jardine | 179.64 |
| 2 | 2020-03-15 | West | Sorvino | 167.44 |
| 3 | 2020-04-01 | East | Jones | 299.40 |
| 4 | 2020-05-05 | Central | Jardine | 449.10 |
| 5 | 2020-06-08 | East | Jones | 539.40 |
| 6 | 2020-07-12 | East | Howard | 57.71 |
| 7 | 2020-08-15 | East | Jones | 174.65 |
| 8 | 2020-09-01 | Central | Smith | 250.00 |
| 9 | 2020-10-05 | Central | Morgan | 251.72 |
| 10 | 2020-11-08 | East | Mike | 299.85 |
| 11 | 2020-12-12 | Central | Smith | 86.43 |
Working with Multiple Spreadsheets
Excel files or workbooks usually contain more than one spreadsheet. The pandas library allows us to load data from a specific sheet or combine multiple spreadsheets into a single DataFrame. In this section, we’ll explore how to use these valuable capabilities.
By default, the read_excel() method reads the first Excel sheet with the index 0. However, we can choose the other sheets by assigning a particular sheet name, sheet index, or even a list of sheet names or indices to the sheet_name argument. Let’s try it:
df = pd.read_excel('sales_data.xlsx', sheet_name='2021')
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2021-01-15 | Central | Gill | Binder | 46 | 8.99 | 413.54 | True |
| 1 | 2021-02-01 | Central | Smith | Binder | 87 | 15.00 | 1305.00 | True |
| 2 | 2021-03-07 | West | Sorvino | Binder | 27 | 19.99 | 139.93 | True |
| 3 | 2021-04-10 | Central | Andrews | Pencil | 66 | 1.99 | 131.34 | False |
| 4 | 2021-05-14 | Central | Gill | Pencil | 53 | 1.29 | 68.37 | False |
| 5 | 2021-06-17 | Central | Tom | Desk | 15 | 125.00 | 625.00 | True |
| 6 | 2021-07-04 | East | Jones | Pen Set | 62 | 4.99 | 309.38 | True |
| 7 | 2021-08-07 | Central | Tom | Pen Set | 42 | 23.95 | 1005.90 | True |
| 8 | 2021-09-10 | Central | Gill | Pencil | 47 | 1.29 | 9.03 | True |
| 9 | 2021-10-14 | West | Thompson | Binder | 57 | 19.99 | 1139.43 | False |
| 10 | 2021-11-17 | Central | Jardine | Binder | 11 | 4.99 | 54.89 | False |
| 11 | 2021-12-04 | Central | Jardine | Binder | 94 | 19.99 | 1879.06 | False |
The code above reads the second spreadsheet in the workbook, whose name is 2021. As mentioned before, we also can assign a sheet position number (zero-indexed) to the sheet_name argument. Let’s see how it works:
df = pd.read_excel('sales_data.xlsx', sheet_name=1)
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2021-01-15 | Central | Gill | Binder | 46 | 8.99 | 413.54 | True |
| 1 | 2021-02-01 | Central | Smith | Binder | 87 | 15.00 | 1305.00 | True |
| 2 | 2021-03-07 | West | Sorvino | Binder | 27 | 19.99 | 139.93 | True |
| 3 | 2021-04-10 | Central | Andrews | Pencil | 66 | 1.99 | 131.34 | False |
| 4 | 2021-05-14 | Central | Gill | Pencil | 53 | 1.29 | 68.37 | False |
| 5 | 2021-06-17 | Central | Tom | Desk | 15 | 125.00 | 625.00 | True |
| 6 | 2021-07-04 | East | Jones | Pen Set | 62 | 4.99 | 309.38 | True |
| 7 | 2021-08-07 | Central | Tom | Pen Set | 42 | 23.95 | 1005.90 | True |
| 8 | 2021-09-10 | Central | Gill | Pencil | 47 | 1.29 | 9.03 | True |
| 9 | 2021-10-14 | West | Thompson | Binder | 57 | 19.99 | 1139.43 | False |
| 10 | 2021-11-17 | Central | Jardine | Binder | 11 | 4.99 | 54.89 | False |
| 11 | 2021-12-04 | Central | Jardine | Binder | 94 | 19.99 | 1879.06 | False |
As you can see, both statements take in either the actual sheet name or sheet index to return the same result.
Sometimes, we want to import all the spreadsheets stored in an Excel file into pandas DataFrames simultaneously. The good news is that the read_excel() method provides this feature for us. In order to do this, we can assign a list of sheet names or their indices to the sheet_name argument. But there is a much easier way to do the same: to assign None to the sheet_name argument. Let’s try it:
all_sheets = pd.read_excel('sales_data.xlsx', sheet_name=None)Before exploring the data stored in the all_sheets variable, let’s check its data type:
type(all_sheets)dictAs you can see, the variable is a dictionary. Now, let’s reveal what is stored in this dictionary:
for key, value in all_sheets.items():
print(key, type(value))2020 <class 'pandas.core.frame.DataFrame'>
2021 <class 'pandas.core.frame.DataFrame'>The code above shows that the dictionary’s keys are the Excel workbook sheet names, and its values are pandas DataFrames for each spreadsheet. To print out the content of the dictionary, we can use the following code:
for key, value in all_sheets.items():
print(key)
display(value)2020| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 | True |
| 1 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 2 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 3 | 2020-04-01 | East | Jones | Binder | 60 | 4.99 | 299.40 | False |
| 4 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
| 5 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 6 | 2020-07-12 | East | Howard | Binder | 29 | 1.99 | 57.71 | False |
| 7 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 8 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 9 | 2020-10-05 | Central | Morgan | Binder | 28 | 8.99 | 251.72 | True |
| 10 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 11 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
2021| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2021-01-15 | Central | Gill | Binder | 46 | 8.99 | 413.54 | True |
| 1 | 2021-02-01 | Central | Smith | Binder | 87 | 15.00 | 1305.00 | True |
| 2 | 2021-03-07 | West | Sorvino | Binder | 27 | 19.99 | 139.93 | True |
| 3 | 2021-04-10 | Central | Andrews | Pencil | 66 | 1.99 | 131.34 | False |
| 4 | 2021-05-14 | Central | Gill | Pencil | 53 | 1.29 | 68.37 | False |
| 5 | 2021-06-17 | Central | Tom | Desk | 15 | 125.00 | 625.00 | True |
| 6 | 2021-07-04 | East | Jones | Pen Set | 62 | 4.99 | 309.38 | True |
| 7 | 2021-08-07 | Central | Tom | Pen Set | 42 | 23.95 | 1005.90 | True |
| 8 | 2021-09-10 | Central | Gill | Pencil | 47 | 1.29 | 9.03 | True |
| 9 | 2021-10-14 | West | Thompson | Binder | 57 | 19.99 | 1139.43 | False |
| 10 | 2021-11-17 | Central | Jardine | Binder | 11 | 4.99 | 54.89 | False |
| 11 | 2021-12-04 | Central | Jardine | Binder | 94 | 19.99 | 1879.06 | False |
Combining Multiple Excel Spreadsheets into a Single Pandas DataFrame
Having one DataFrame per sheet allows us to have different columns or content in different sheets.
But what if we prefer to store all the spreadsheets’ data in a single DataFrame? In this tutorial, the workbook spreadsheets have the same columns, so we can combine them with the concat() method of pandas.
If you run the code below, you’ll see that the two DataFrames stored in the dictionary are concatenated:
combined_df = pd.concat(all_sheets.values(), ignore_index=True)
display(combined_df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 | True |
| 1 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 2 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 3 | 2020-04-01 | East | Jones | Binder | 60 | 4.99 | 299.40 | False |
| 4 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
| 5 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 6 | 2020-07-12 | East | Howard | Binder | 29 | 1.99 | 57.71 | False |
| 7 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 8 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 9 | 2020-10-05 | Central | Morgan | Binder | 28 | 8.99 | 251.72 | True |
| 10 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 11 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
| 12 | 2021-01-15 | Central | Gill | Binder | 46 | 8.99 | 413.54 | True |
| 13 | 2021-02-01 | Central | Smith | Binder | 87 | 15.00 | 1305.00 | True |
| 14 | 2021-03-07 | West | Sorvino | Binder | 27 | 19.99 | 139.93 | True |
| 15 | 2021-04-10 | Central | Andrews | Pencil | 66 | 1.99 | 131.34 | False |
| 16 | 2021-05-14 | Central | Gill | Pencil | 53 | 1.29 | 68.37 | False |
| 17 | 2021-06-17 | Central | Tom | Desk | 15 | 125.00 | 625.00 | True |
| 18 | 2021-07-04 | East | Jones | Pen Set | 62 | 4.99 | 309.38 | True |
| 19 | 2021-08-07 | Central | Tom | Pen Set | 42 | 23.95 | 1005.90 | True |
| 20 | 2021-09-10 | Central | Gill | Pencil | 47 | 1.29 | 9.03 | True |
| 21 | 2021-10-14 | West | Thompson | Binder | 57 | 19.99 | 1139.43 | False |
| 22 | 2021-11-17 | Central | Jardine | Binder | 11 | 4.99 | 54.89 | False |
| 23 | 2021-12-04 | Central | Jardine | Binder | 94 | 19.99 | 1879.06 | False |
Now the data stored in the combined_df DataFrame is ready for further processing or visualization. In the following piece of code, we’re going to create a simple bar chart that shows the total sales amount made by each representative. Let’s run it and see the output plot:
total_sales_amount = combined_df.groupby('Rep').Total.sum()
total_sales_amount.plot.bar(figsize=(10, 6))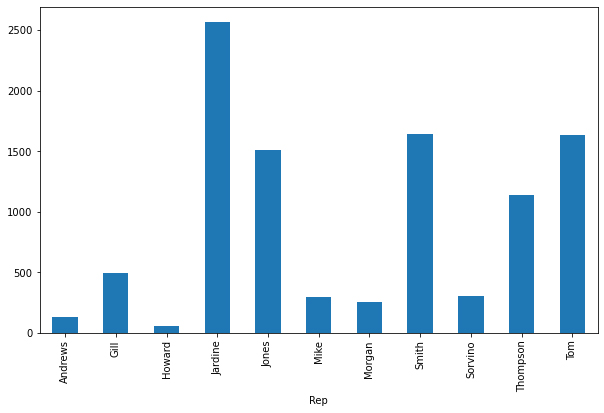
Reading Excel Files Using xlrd
Although importing data into a pandas DataFrame is much more common, another helpful package for reading Excel files in Python is xlrd. In this section, we’re going to scratch the surface of how to read Excel spreadsheets using this package.
NOTE
The xlrd package doesn’t support xlsx files due to a potential security vulnerability. So, we use the xls version of the sales data. You can download the xls version from the link below:
Sales Data Excel Workbook — xls ver.
Let’s see how it works:
import xlrd
excel_workbook = xlrd.open_workbook('sales_data.xls')Above, the first line imports the xlrd package, then the open_workbook method reads the sales_data.xls file.
We can also open an individual sheet containing the actual data. There are two ways to do so: opening a sheet by index or by name. Let’s open the first sheet by index and the second one by name:
excel_worksheet_2020 = excel_workbook.sheet_by_index(0)
excel_worksheet_2021 = excel_workbook.sheet_by_name('2021')Now, let’s see how we can print a cell value. The xlrd package provides a method called cell_value() that takes in two arguments: the cell’s row index and column index. Let’s explore it:
print(excel_worksheet_2020.cell_value(1, 3))PencilWe can see that the cell_value function returned the value of the cell at row index 1 (the 2nd row) and column index 3 (the 4th column).
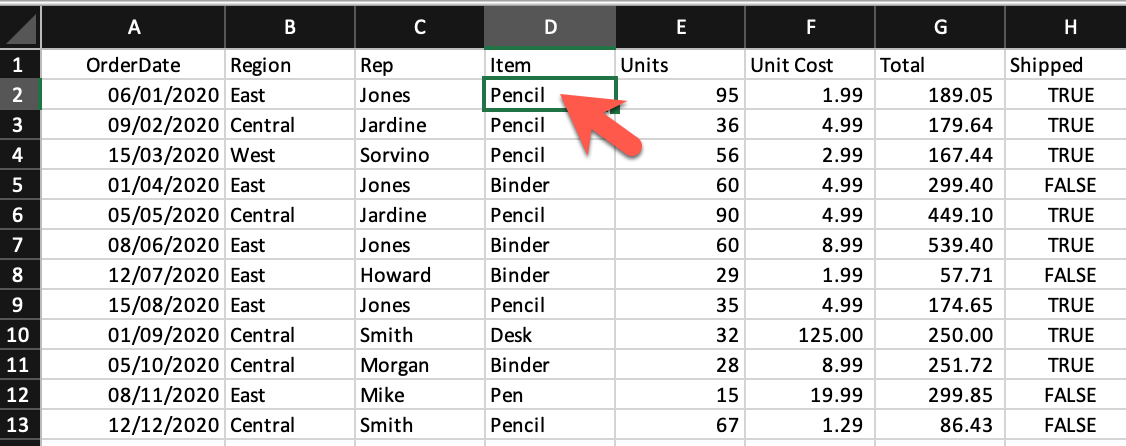
The xlrd package provides two helpful properties: nrows and ncols, returning the number of nonempty spreadsheet’s rows and columns respectively:
print('Columns#:', excel_worksheet_2020.ncols)
print('Rows#:', excel_worksheet_2020.nrows)Columns#: 8
Rows#: 13Knowing the number of nonempty rows and columns in a spreadsheet helps us with iterating over the data using nested for loops. This makes all the Excel sheet data accessible via the cell_value() method.
Conclusion
This tutorial discussed how to load Excel spreadsheets into pandas DataFrames, work with multiple Excel sheets, and combine them into a single pandas DataFrame. We also explored the main aspects of the xlrd package as one of the simplest tools for accessing the Excel spreadsheets data.