
Situation:
I am using pandas to parse in separate Excel (.xlsx) sheets from a workbook with the following setup: Python 3.6.0 and Anaconda 4.3.1 on Windows 7 x64.
Problem:
I have been unable to find how to set a variable to a specific Excel sheet cell value e.g. var = Sheet['A3'].value from 'Sheet2' using pandas?
Question:
Is this possible? If so, how?
What i have tried:
I have searched through the pandas documentation on dataframe and various forums but haven’t found an answer to this.
I know i can work around this using openpyxl (where i can specify a cell co-ordinate) but I want:
- To use
pandas-if possible; - Only read in the file once.
I have imported numpy, as well as pandas, so was able to write:
xls = pd.ExcelFile(filenamewithpath)
data = xls.parse('Sheet1')
dateinfo2 = str(xls.parse('Sheet2', parse_cols = "A", skiprows = 2, nrows = 1, header = None)[0:1]).split('0n0')[1].strip()
'Sheet1' being read into 'data' is fine as i have a function to collect the range i want.
I am also trying to read in from a separate sheet ('sheet2'), the value in cell "A3", and the code i have at present is clunky. It gets the value out as a string, as required, but is in no way pretty. I only want this cell value and as little additional sheet info as possible.
Contents
A brief summary of how to read and write excel files using Pandas package.
First we need to install pandas and pre-requisite:
pip install pandas
pip install openpyxl # in order to read xlsx files
pip install xlrd
Read xlsx files
Note that in order to read xlsx files, we need to install openpyxl and use it like this:
import pandas as pd
df = pd.read_excel('test.xlsx', sheet_name=0, engine='openpyxl')
For param sheet_name, either the literal sheet name or the sheet index is okay.
sheet_name=0 means to read the 1st sheet.
Convert text in each cell to string type
When the sheet contains date and numbers, read_excel() will convert it to Timestamps and numbers by default,
if we would like to convert all text to strings, we can use the dtype parameter:
df = pd.read_excel('test.xlsx', sheet_name=0, dtype=str, engine='openpyxl')
Read empty cell as empty string
It seems that pandas will by default read empty cell as NAN values.
To read empty cell as empty string, use keep_default_na=False when reading excel:
df = pd.read_excel('test.xlsx', sheet_name=0, dtype=str, engine='openpyxl', keep_default_na=False)
Or after reading the sheet, use fillna() to replace the nan values with empty string:
df = pd.read_excel('test.xlsx', sheet_name=0, dtype=str, engine='openpyxl').fillna('')
Convert panda data frame to numpy array
Use to_numpy():
df = pd.read_excel('test.xlsx', sheet_name=0, dtype=str, engine='openpyxl').fillna('')
data = df.to_numpy() # data is now numpy array
Convert list to excel files
To convert a list of list (each sub-list has the same number of elements) to excel files, use to_excel():
import pandas as pd
my_list = [[1, 2, 3], [4, 5, 6]]
df = pd.DataFrame(my_list)
df.to_excel('my_list.xlsx')
To remove row index, use index=False:
df.to_excel('my_list.xlsx', index=False)
To add header for each column, we can provide a list of strings for each column using header parameter.
import pandas as pd
my_list = [[1, 2, 3], [4, 5, 6]]
df = pd.DataFrame(my_list)
header = ['c1', 'c2', 'c3']
df.to_excel('my_list.xlsx', index=False, header=header)
References
- pandas can not open xlsx files: https://stackoverflow.com/q/65250207/6064933
- pandas replace nan with blank:
- https://stackoverflow.com/q/45148292/6064933
- https://stackoverflow.com/q/10867028/6064933
- pandas how to read cell value as string: https://stackoverflow.com/q/32591466/6064933
- Remove row index: https://stackoverflow.com/q/22089317/6064933
Author
jdhao
LastMod
2022-06-15
License
CC BY-NC-ND 4.0
Хотя многие Data Scientist’ы больше привыкли работать с CSV-файлами, на практике очень часто приходится сталкиваться с обычными Excel-таблицами. Поэтому сегодня мы расскажем, как читать Excel-файлы в Pandas, а также рассмотрим основные возможности Python-библиотеки OpenPyXL для чтения метаданных ячеек.
Дополнительные зависимости для возможности чтения Excel таблиц
Для чтения таблиц Excel в Pandas требуются дополнительные зависимости:
- xlrd поддерживает старые и новые форматы MS Excel [1];
- OpenPyXL поддерживает новые форматы MS Excel (.xlsx) [2];
- ODFpy поддерживает свободные форматы OpenDocument (.odf, .ods и .odt) [3];
- pyxlsb поддерживает бинарные MS Excel файлы (формат .xlsb) [4].
Мы рекомендуем установить только OpenPyXL, поскольку он нам пригодится в дальнейшем. Для этого в командной строке прописывается следующая операция:
pip install openpyxl
Затем в Pandas нужно указать путь к Excel-файлу и одну из установленных зависимостей. Python-код выглядит следующим образом:
import pandas as pd
pd.read_excel(io='temp1.xlsx', engine='openpyxl')
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
Читаем несколько листов
Excel-файл может содержать несколько листов. В Pandas, чтобы прочитать конкретный лист, в аргументе нужно указать sheet_name. Можно указать список названий листов, тогда Pandas вернет словарь (dict) с объектами DataFrame:
dfs = pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
sheet_name=['Sheet1', 'Sheet2'])
dfs
#
{'Sheet1': Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64,
'Sheet2': Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78}
Если таблицы в словаре имеют одинаковые атрибуты, то их можно объединить в один DataFrame. В Python это выглядит так:
pd.concat(dfs).reset_index(drop=True)
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
3 Gosha 43 95
4 Anna 24 65
5 Lena 22 78
Указание диапазонов
Таблицы могут размещаться не в самом начале, а как, например, на рисунке ниже. Как видим, таблица располагается в диапазоне A:F.
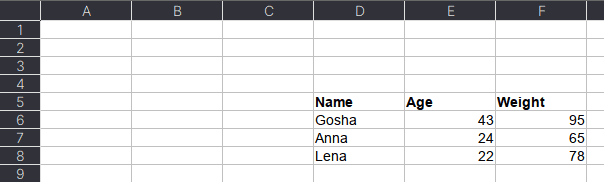
Чтобы прочитать такую таблицу, нужно указать диапазон в аргументе usecols. Также дополнительно можно добавить header — номер заголовка таблицы, а также nrows — количество строк, которые нужно прочитать. В аргументе header всегда передается номер строки на единицу меньше, чем в Excel-файле, поскольку в Python индексация начинается с 0 (на рисунке это номер 5, тогда указываем 4):
pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
usecols='D:F',
header=4, # в excel это №5
nrows=3)
#
Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78
Читаем таблицы в OpenPyXL
Pandas прочитывает только содержимое таблицы, но игнорирует метаданные: цвет заливки ячеек, примечания, стили таблицы и т.д. В таком случае пригодится библиотека OpenPyXL. Загрузка файлов осуществляется через функцию load_workbook, а к листам обращаться можно через квадратные скобки:
from openpyxl import load_workbook
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
type(ws)
# openpyxl.worksheet.worksheet.Worksheet
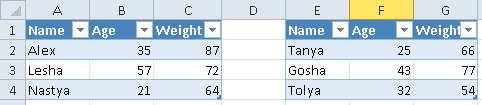
Допустим, имеется Excel-файл с несколькими таблицами на листе (см. рисунок выше). Если бы мы использовали Pandas, то он бы выдал следующий результат:
pd.read_excel(io='temp2.xlsx',
engine='openpyxl')
#
Name Age Weight Unnamed: 3 Name.1 Age.1 Weight.1
0 Alex 35 87 NaN Tanya 25 66
1 Lesha 57 72 NaN Gosha 43 77
2 Nastya 21 64 NaN Tolya 32 54
Можно, конечно, заняться обработкой и привести таблицы в нормальный вид, а можно воспользоваться OpenPyXL, который хранит таблицу и его диапазон в словаре. Чтобы посмотреть этот словарь, нужно вызвать ws.tables.items. Вот так выглядит Python-код:
ws.tables.items()
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
ws.tables.items()
#
[('Таблица1', 'A1:C4'), ('Таблица13', 'E1:G4')]
Обращаясь к каждому диапазону, можно проходить по каждой строке или столбцу, а внутри них – по каждой ячейке. Например, следующий код на Python таблицы объединяет строки в список, где первая строка уходит на заголовок, а затем преобразует их в DataFrame:
dfs = []
for table_name, value in ws.tables.items():
table = ws[value]
header, *body = [[cell.value for cell in row]
for row in table]
df = pd.DataFrame(body, columns=header)
dfs.append(df)
Если таблицы имеют одинаковые атрибуты, то их можно соединить в одну:
pd.concat(dfs)
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
0 Tanya 25 66
1 Gosha 43 77
2 Tolya 32 54
Сохраняем метаданные таблицы
Как указано в коде выше, у ячейки OpenPyXL есть атрибут value, который хранит ее значение. Помимо value, можно получить тип ячейки (data_type), цвет заливки (fill), примечание (comment) и др.
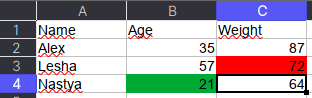
Например, требуется сохранить данные о цвете ячеек. Для этого мы каждую ячейку с числами перезапишем в виде <значение,RGB>, где RGB — значение цвета в формате RGB (red, green, blue). Python-код выглядит следующим образом:
# _TYPES = {int:'n', float:'n', str:'s', bool:'b'}
data = []
for row in ws.rows:
row_cells = []
for cell in row:
cell_value = cell.value
if cell.data_type == 'n':
cell_value = f"{cell_value},{cell.fill.fgColor.rgb}"
row_cells.append(cell_value)
data.append(row_cells)
Первым элементом списка является строка-заголовок, а все остальное уже значения таблицы:
pd.DataFrame(data[1:], columns=data[0])
#
Name Age Weight
0 Alex 35,00000000 87,00000000
1 Lesha 57,00000000 72,FFFF0000
2 Nastya 21,FF00A933 64,00000000
Теперь представим атрибуты в виде индексов с помощью метода stack, а после разобьём все записи на значение и цвет методом str.split:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
)
#
0 1
Name
Alex Age 35 00000000
Weight 87 00000000
Lesha Age 57 00000000
Weight 72 FFFF0000
Nastya Age 21 FF00A933
Weight 64 0000000
Осталось только переименовать 0 и 1 на Value и Color, а также добавить атрибут Variable, который обозначит Вес и Возраст. Полный код на Python выглядит следующим образом:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
.set_axis(['Value', 'Color'], axis=1)
.rename_axis(index=['Name', 'Variable'])
.reset_index()
)
#
Name Variable Value Color
0 Alex Age 35 00000000
1 Alex Weight 87 00000000
2 Lesha Age 57 00000000
3 Lesha Weight 72 FFFF0000
4 Nastya Age 21 FF00A933
5 Nastya Weight 64 00000000
Ещё больше подробностей о работе с таблицами в Pandas, а также их обработке на реальных примерах Data Science задач, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники
- https://xlrd.readthedocs.io/en/latest/
- https://openpyxl.readthedocs.io/en/latest/
- https://github.com/eea/odfpy
- https://github.com/willtrnr/pyxlsb
Last updated on
Jul 18, 2021
In this post you can learn how to read Excel files (ext xls, xlsx etc) with Python and Pandas. We will import one or several sheets from an Excel file to a Pandas DataFrame.
The list of the supported file extensions:
xlsxlsxxlsmxlsbodfodsodt
Note for ods, ods and odt please check: Read Excel(OpenDocument ODS) with Python Pandas
Step 1: Install Pandas and odfpy
Python offers many different modules for reading and manipulating Excel files. In this guide we are going to use pandas and odfpy:
pip install pandas
pip install odfpy
Step 2: Read the one sheet of Excel(XLS) file
Pandas offers a powerful method for reading any type of Excel files read_excel(). It’s pretty easy to be used and requires only the file path:
import pandas as pd
pd.read_excel('animals.xls')
It will read and return all non empty cells from the Excel file:
| Rank | Animal | Maximum speed | Class | Notes | |
|---|---|---|---|---|---|
| 0 | 1 | Peregrine falcon | 389 km/h (242 mph)108 m/s (354 ft/s)[2][6] | Flight-diving | The peregrine falcon is the fastest aerial ani… |
| 1 | 2 | Golden eagle | 240–320 km/h (150–200 mph)67–89 m/s (220–293 f… | Flight-diving | Assuming the maximum size at 1.02 m, its relat… |
| 2 | 3 | White-throated needletail swift | 169 km/h (105 mph)[8][9][10] | Flight | NaN |
| 3 | 4 | Eurasian hobby | 160 km/h (100 mph)[11] | Flight | Can sometimes outfly the swift |
| 4 | 5 | Mexican free-tailed bat | 160 km/h (100 mph)[12] | Flight | It has been claimed to have the fastest horizo… |
| 5 | 6 | Frigatebird | 153 km/h (95 mph) | Flight | The frigatebird’s high speed is helped by its … |
| 6 | 7 | Rock dove (pigeon) | 148.9 km/h (92.5 mph)[13] | Flight | Pigeons have been clocked flying 92.5 mph (148… |
| 7 | 8 | Spur-winged goose | 142 km/h (88 mph)[14] | Flight | NaN |
| 8 | 9 | Gyrfalcon | 128 km/h (80 mph)[citation needed] | Flight | NaN |
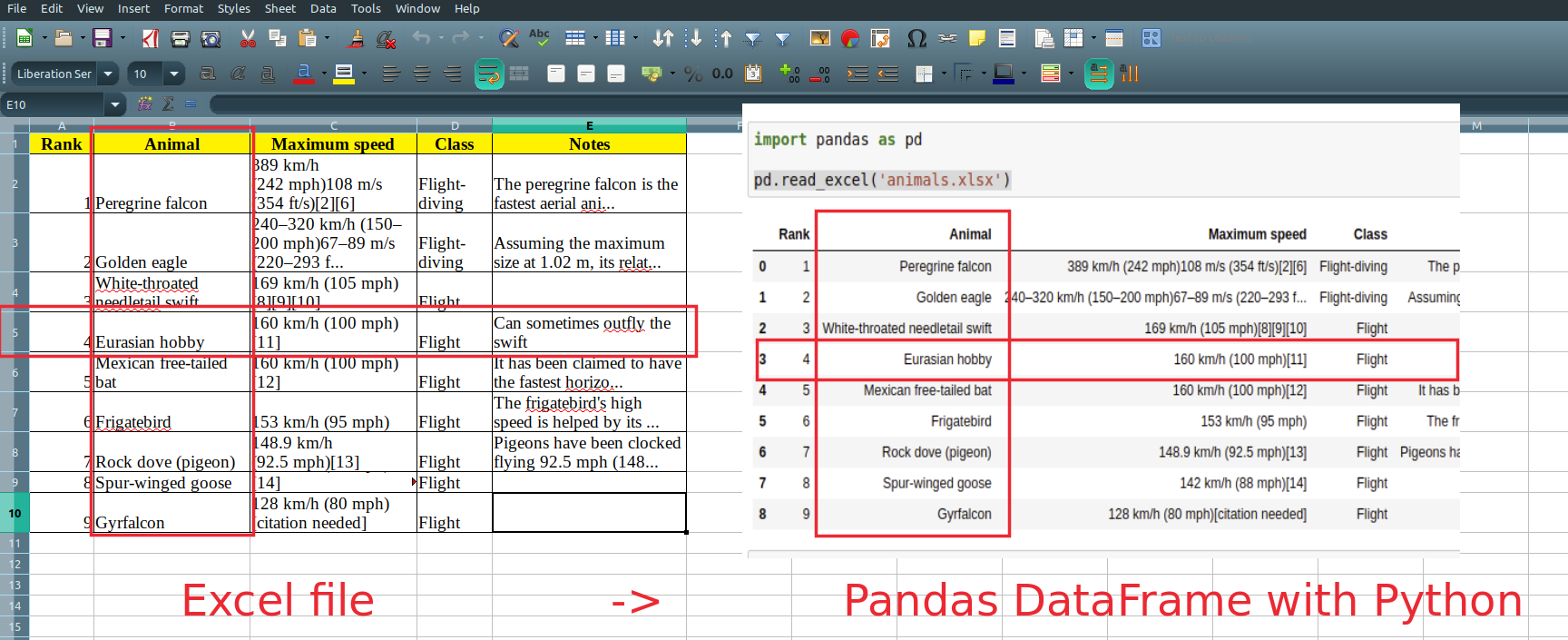
Step 3: Read the second sheet of Excel file by name
If you like to read data from a specific sheet — for example Sheet 2 then you can specify the name as a parameter — sheet_name:
pd.read_excel('animals.xlsx', sheet_name="Sheet2")
Which will result in:
| Blackbuck | Unnamed: 1 | |
|---|---|---|
| 0 | NaN | NaN |
| 1 | Male blackbuck | Male blackbuck |
| 2 | NaN | NaN |
| 3 | Female with young at the National Zoological Park Delhi | Female with young at the National Zoological P… |
| 4 | Conservation status | Conservation status |
| 5 | Least Concern (IUCN 3.1)[1] | Least Concern (IUCN 3.1)[1] |
| 6 | Scientific classification | Scientific classification |
Step 4: Python read excel file — specify columns and rows
If you like to read a range of data and not the whole sheet — read_excel offers several very useful parameters.
Python read excel file select rows
Next code example will show you how to read 3 rows skipping the first two rows. In this way Pandas will read only some rows from the whole sheet:
pd.read_excel('animals.xlsx', skiprows=2, nrows=3)
which will result in:
| 2 | Golden eagle | 240–320 km/h (150–200 mph)67–89 m/s (220–293 f… | Flight-diving | Assuming the maximum size at 1.02 m, its relat… | |
|---|---|---|---|---|---|
| 0 | 3 | White-throated needletail swift | 169 km/h (105 mph)[8][9][10] | Flight | NaN |
| 1 | 4 | Eurasian hobby | 160 km/h (100 mph)[11] | Flight | Can sometimes outfly the swift |
| 2 | 5 | Mexican free-tailed bat | 160 km/h (100 mph)[12] | Flight | It has been claimed to have the fastest horizo… |
Python read excel file select columns
If you like to** work with few columns** and not the whole sheet — then parameter use_cols can be used as shown:
pd.read_excel('animals.xlsx', usecols='C:D')
Python read excel file specify columns and rows
Finally if you like to select a range from specific columns and rows than you can use:
Which will result into:
| 240–320 km/h (150–200 mph)67–89 m/s (220–293 f… | Flight-diving | |
|---|---|---|
| 0 | 169 km/h (105 mph)[8][9][10] | Flight |
| 1 | 160 km/h (100 mph)[11] | Flight |
| 2 | 160 km/h (100 mph)[12] | Flight |
Step 5. Read multiple sheets from Excel file
What if you like to read with Pandas multiple sheets from Excel. It’s possible with pd.read_excel by providing a list of all sheets to be read as follows:
pd.read_excel('animals.xlsx', sheet_name=["Sheet1", "Sheet2"])
Note that a dictionary of
- keys — sheet names
- values — resulted DataFrames
will be returned.
In order to access data you can access it by a sheet name as:
pd.read_excel('animals.xlsx', sheet_name=["Sheet1", "Sheet2"]).get('Sheet1')
which will return the data for Sheet1 as a DataFrame.
Read All Sheets
For loading all sheets from Excel file use sheet_name=None:
pd.read_excel('animals.xlsx', sheet_name=None)
Step 6. Pandas read excel data with conversion, NA values and parsing
Finally let’s check what we can do if we need to convert data, drop or fill missing values, parse dates and numbers.
Pandas offers several parameters for this purpose:
- converters — dict of functions for converting values in certain columns
- keep_default_na — whether or not to include the default NaN values
- parse_dates
- ate_parser — converting a sequence of string columns to an array of datetime instances.
- thousands
- convert_float
You can check the Notebook in the resources for more examples of the above.
Resources
- Python Pandas Reading Excel files
- pandas.read_excel
- Notebook —
Read Excel ODS with Python Pandas