
I have Excel files with multiple sheets, each of which looks a little like this (but much longer):
Sample CD4 CD8
Day 1 8311 17.3 6.44
8312 13.6 3.50
8321 19.8 5.88
8322 13.5 4.09
Day 2 8311 16.0 4.92
8312 5.67 2.28
8321 13.0 4.34
8322 10.6 1.95
The first column is actually four cells merged vertically.
When I read this using pandas.read_excel, I get a DataFrame that looks like this:
Sample CD4 CD8
Day 1 8311 17.30 6.44
NaN 8312 13.60 3.50
NaN 8321 19.80 5.88
NaN 8322 13.50 4.09
Day 2 8311 16.00 4.92
NaN 8312 5.67 2.28
NaN 8321 13.00 4.34
NaN 8322 10.60 1.95
How can I either get Pandas to understand merged cells, or quickly and easily remove the NaN and group by the appropriate value? (One approach would be to reset the index, step through to find the values and replace NaNs with values, pass in the list of days, then set the index to the column. But it seems like there should be a simpler approach.)
When you read an Excel file with merged cells into a pandas DataFrame, the merged cells will automatically be filled with NaN values.
The easiest way to fill in these NaN values after importing the file is to use the pandas fillna() function as follows:
df = df.fillna(method='ffill', axis=0)
The following example shows how to use this syntax in practice.
Suppose we have the following Excel file called merged_data.xlsx that contains information about various basketball players:

Notice that the values in the Team column are merged.
Players A through D belong to the Mavericks while players E through H belong to the Rockets.
Suppose we use the read_excel() function to read this Excel file into a pandas DataFrame:
import pandas as pd #import Excel fie df = pd.read_excel('merged_data.xlsx') #view DataFrame print(df) Team Player Points Assists 0 Mavericks A 22 4 1 NaN B 29 4 2 NaN C 45 3 3 NaN D 30 7 4 Rockets E 29 8 5 NaN F 16 6 6 NaN G 25 9 7 NaN H 20 12
By default, pandas fills in the merged cells with NaN values.
To fill in each of these NaN values with the team names instead, we can use the fillna() function as follows:
#fill in NaN values with team names df = df.fillna(method='ffill', axis=0) #view updated DataFrame print(df) Team Player Points Assists 0 Mavericks A 22 4 1 Mavericks B 29 4 2 Mavericks C 45 3 3 Mavericks D 30 7 4 Rockets E 29 8 5 Rockets F 16 6 6 Rockets G 25 9 7 Rockets H 20 12
Notice that each of the NaN values has been filled in with the appropriate team name.
Note that the argument axis=0 tells pandas to fill in the NaN values vertically.
To instead fill in NaN values horizontally across columns, you can specify axis=1.
Note: You can find the complete documentation for the pandas fillna() function here.
Additional Resources
The following tutorials explain how to perform other common tasks in pandas:
Pandas: How to Skip Rows when Reading Excel File
Pandas: How to Specify dtypes when Importing Excel File
Pandas: How to Combine Multiple Excel Sheets
Содержание
- pandas.DataFrame.to_excel#
- Merge rows based on value (pandas to excel — xlsxwriter)
- 5 Answers 5
- Добавить заголовок с объединенными ячейками из одного Excel и вставить в другой Excel Pandas
- Читать объединенные ячейки в Excel с Python
- 3 ответа
- Объединить/разъединить ячейки модулем openpyxl.
- Содержание:
- Объединение/слияние нескольких ячеек и их разъединение.
- Оформление/стилизация разъединенных ячеек модулем openpyxl .
pandas.DataFrame.to_excel#
Write object to an Excel sheet.
To write a single object to an Excel .xlsx file it is only necessary to specify a target file name. To write to multiple sheets it is necessary to create an ExcelWriter object with a target file name, and specify a sheet in the file to write to.
Multiple sheets may be written to by specifying unique sheet_name . With all data written to the file it is necessary to save the changes. Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
Parameters excel_writer path-like, file-like, or ExcelWriter object
File path or existing ExcelWriter.
sheet_name str, default вЂSheet1’
Name of sheet which will contain DataFrame.
na_rep str, default вЂвЂ™
Missing data representation.
float_format str, optional
Format string for floating point numbers. For example float_format=»%.2f» will format 0.1234 to 0.12.
columns sequence or list of str, optional
Columns to write.
header bool or list of str, default True
Write out the column names. If a list of string is given it is assumed to be aliases for the column names.
index bool, default True
Write row names (index).
index_label str or sequence, optional
Column label for index column(s) if desired. If not specified, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
startrow int, default 0
Upper left cell row to dump data frame.
startcol int, default 0
Upper left cell column to dump data frame.
engine str, optional
Write engine to use, вЂopenpyxl’ or вЂxlsxwriter’. You can also set this via the options io.excel.xlsx.writer , io.excel.xls.writer , and io.excel.xlsm.writer .
Deprecated since version 1.2.0: As the xlwt package is no longer maintained, the xlwt engine will be removed in a future version of pandas.
Write MultiIndex and Hierarchical Rows as merged cells.
encoding str, optional
Encoding of the resulting excel file. Only necessary for xlwt, other writers support unicode natively.
Deprecated since version 1.5.0: This keyword was not used.
Representation for infinity (there is no native representation for infinity in Excel).
verbose bool, default True
Display more information in the error logs.
Deprecated since version 1.5.0: This keyword was not used.
Specifies the one-based bottommost row and rightmost column that is to be frozen.
storage_options dict, optional
Extra options that make sense for a particular storage connection, e.g. host, port, username, password, etc. For HTTP(S) URLs the key-value pairs are forwarded to urllib.request.Request as header options. For other URLs (e.g. starting with “s3://”, and “gcs://”) the key-value pairs are forwarded to fsspec.open . Please see fsspec and urllib for more details, and for more examples on storage options refer here.
New in version 1.2.0.
Write DataFrame to a comma-separated values (csv) file.
Class for writing DataFrame objects into excel sheets.
Read an Excel file into a pandas DataFrame.
Read a comma-separated values (csv) file into DataFrame.
Add styles to Excel sheet.
For compatibility with to_csv() , to_excel serializes lists and dicts to strings before writing.
Once a workbook has been saved it is not possible to write further data without rewriting the whole workbook.
Create, write to and save a workbook:
To specify the sheet name:
If you wish to write to more than one sheet in the workbook, it is necessary to specify an ExcelWriter object:
ExcelWriter can also be used to append to an existing Excel file:
To set the library that is used to write the Excel file, you can pass the engine keyword (the default engine is automatically chosen depending on the file extension):
Источник
Merge rows based on value (pandas to excel — xlsxwriter)
I’m trying to output a Pandas dataframe into an excel file using xlsxwriter. However I’m trying to apply some rule-based formatting; specifically trying to merge cells that have the same value, but having trouble coming up with how to write the loop. (New to Python here!)
See below for output vs output expected:

(As you can see based off the image above I’m trying to merge cells under the Name column when they have the same values).
Here is what I have thus far:
Any help is greatly appreciated!
5 Answers 5
Your logic is almost correct, however i approached your problem through a slightly different approach:
1) Sort the column, make sure that all the values are grouped together.
2) Reset the index (using reset_index() and maybe pass the arg drop=True).
3) Then we have to capture the rows where the value is new. For that purpose create a list and add the first row 1 because we will start for sure from there.
4) Then start iterating over the rows of that list and check some conditions:
4a) If we only have one row with a value the merge_range method will give an error because it can not merge one cell. In that case we need to replace the merge_range with the write method.
4b) With this algorithm you ‘ll get an index error when trying to write the last value of the list (because it is comparing it with the value in the next index postion, and because it is the last value of the list there is not a next index position). So we need to specifically mention that if we get an index error (which means we are checking the last value) we want to merge or write until the last row of the dataframe.
4c) Finally i did not take into consideration if the column contains blank or null cells. In that case code needs to be adjusted.
Lastly code might look a bit confusing, you have to take in mind that the 1st row for pandas is 0 indexed (headers are separate) while for xlsxwriter headers are 0 indexed and the first row is indexed 1.
Here is a working example to achieve exactly what you want to do:
Источник
Добавить заголовок с объединенными ячейками из одного Excel и вставить в другой Excel Pandas
Я искал, как добавить / вставить / конкатенировать строку из одного Excel в другой, но с объединенными ячейками. Мне не удалось найти то, что я ищу.
Что мне нужно получить, так это:
И добавьте в самую первую строку этого:
Я попытался использовать pandas append (), но он разрушил расположение столбцов.
Есть ли способ, которым панды могли это сделать? Мне просто нужно буквально вставить заголовок в верхнюю строку.
Хотя я все еще пытаюсь найти способ, для меня было бы нормально, если бы у этого вопроса был дубликат, если я могу найти ответы или совет.
Вы можете попробовать это — stackoverflow.com/questions/25418620/…





Вы можете использовать pd.read_excel для чтения в книге нужных вам данных, в вашем случае это test1.xlsx. Затем вы можете использовать openpyxl.load_workbook(), чтобы открыть существующую книгу с заголовком, в вашем случае это «merge1.xlsx». Наконец, вы можете сохранить новый workbbok под новым именем (test3.xlsx), не изменяя две существующие книги.
Ниже я привел полностью воспроизводимый пример того, как вы можете это сделать. Чтобы сделать этот пример полностью воспроизводимым, я создаю merge1.xlsx и test1.xlsx.
Обратите внимание, что если в вашем ‘merge1.xlsx’ у вас есть только нужный заголовок и ничего больше в файле, вы можете использовать две строки, которые я оставил закомментированными ниже. Это просто добавит ваши данные из test1.xlsx в заголовок в merge1.xlsx. Если это так, вы можете избавиться от двух for llops в конце. В противном случае, как в моем примере, все немного сложнее.
При создании test3.xlsx мы перебираем каждую строку и определяем количество столбцов, используя len(df3.columns). В моем примере это равно двум, но этот код также будет работать для большего количества столбцов.
Ожидаемый результат 3 рабочих тетрадей:
Спасибо за ваш ответ. Мне удалось использовать ваши коды с некоторыми изменениями. Не возражаете, если я спрошу, есть ли параметр для .save (), чтобы не включать / удалять индекс?
Мне удалось удалить индекс, запустив # ws.cell(row=row_index+3, column=1).value = int(row_index) и установив в столбце этой строки значение 1 ws.cell(row=row_index+3, column=1).value = int(row[‘col_1’]).
Отлично, вы правы. Комментирование этой строки приведет к удалению индекса.
Спасибо! Последний вопрос, для последнего цикла, есть ли способ повторить его со всеми существующими столбцами? У меня 72 определенных столбца, это не улучшит мой код, если я напишу каждый из них. У каждого столбца есть уникальное имя. Я думаю о создании цикла for для столбца, но у меня возникла проблема с повторением уникальных имен столбцов.
Хороший вопрос. Я собираюсь обновить ответ, чтобы отразить свой ответ на это. По сути, мы могли определить количество столбцов с помощью len(df3.columns). а затем прокрутите каждый столбец в каждой строке.
Я обновил ответ, чтобы отразить ваш вопрос. В моем примере результаты остались прежними.
Источник
Читать объединенные ячейки в Excel с Python
Я пытаюсь читать объединенные ячейки Excel с Python с помощью xlrd.
Мой Excel: (обратите внимание, что первый столбец объединен по трем строкам)
Я хотел бы прочитать третью строку первого столбца как равную 2 в этом примере, но он возвращает » . Вы не знаете, как добраться до значения объединенной ячейки?
Что я хотел бы получить:
3 ответа
Я просто попробовал это и, похоже, работает для ваших данных образца:
Он отслеживает значения из предыдущей строки и использует их, если соответствующее значение из текущей строки пуст.
Обратите внимание, что приведенный выше код не проверяет, действительно ли данная ячейка является частью объединенного набора ячеек, поэтому она может дублировать предыдущие значения в тех случаях, когда ячейка действительно должна быть пустой. Тем не менее, это может помочь.
Дополнительная информация:
Впоследствии я нашел страницу документации, в которой говорится об merged_cells , который можно использовать для определения ячеек, которые включены в различные диапазоны объединенных ячеек. В документации говорится, что это «Новое в версии 0.6.1», но когда я попытался использовать его с xlrd-0.9.3, как установлено pip , я получил ошибку
NotImplementedError: formatting_info = Истина еще не реализована
Я не очень хочу начинать преследовать разные версии xlrd, чтобы протестировать функцию merged_cells , но, возможно, вам может быть интересно это сделать, если приведенный выше код недостаточен для ваших нужд, и вы сталкиваетесь с той же ошибкой, что и Я сделал с formatting_info=True .
Источник
Объединить/разъединить ячейки модулем openpyxl.
В материале рассказывается о методах модуля openpyxl , которые отвечают за такие свойства электронной таблицы как объединение/разъединение ячеек таблицы, а также особенности стилизации объединенных ячеек.
Содержание:
Объединение/слияние нескольких ячеек и их разъединение.
Модуль openpyxl поддерживает слияние/объединение нескольких ячеек, что очень удобно при записи в них текста, с последующим выравниванием. При слиянии/объединении ячеек, все ячейки, кроме верхней левой, удаляются с рабочего листа. Для переноса информации о границах объединенной ячейки, граничные ячейки объединенной ячейки, создаются как ячейки слияния, которые всегда имеют значение None .
Информацию о форматировании объединенных ячеек смотрите ниже, в подразделе «Оформление объединенных ячеек«.
Пример слияния/объединения ячеек с модулем openpyxl :
При открытии сохраненного документа и перехода по любой ячейки из диапазона ‘B2:E2’ видно, что этот диапазон ячеек стал единым. Дополнительно исчезла возможность добавить значения к другим ячейкам этого диапазона.
Теперь разъединим ячейки, которые были объединены ранее, для этого загрузим сохраненный документ.
Пример разъединения ячеек с модулем openpyxl :
При открытии сохраненного документа и перехода по любой ячейки из диапазона ‘B2:E2’ видно, что текст, записанный ранее в ячейку ‘B2’ принадлежит только ей. Дополнительно появилась возможность добавить значения к другим ячейкам диапазона ‘B2:E2’ .
Методы слияния ws.merge_cells() и разъединения ws.unmerge_cells() ячеек, кроме диапазона/среза ячеек могут принимать аргументы:
- start_row : строка, с которой начинается слияние/разъединение.
- start_column : колонка, с которой начинается слияние/разъединение.
- end_row : строка, которой заканчивается слияние/разъединение.
- end_column : колонка, которой заканчивается слияние/разъединение.
Оформление/стилизация разъединенных ячеек модулем openpyxl .
Объединенная ячейка ведет себя аналогично другим объектам ячеек. Различие заключается лишь в том, что ее значение и формат записываются в левой верхней ячейке. Чтобы изменить, например, границу всей объединенной ячейки, необходимо изменить границу ее левой верхней ячейки.
Источник
В материале рассказывается о методах модуля openpyxl, которые отвечают за такие свойства электронной таблицы как объединение/разъединение ячеек таблицы, а также особенности стилизации объединенных ячеек.
Содержание:
- Объединение/слияние нескольких ячеек и их разъединение модулем
openpyxl. - Оформление/стилизация разъединенных ячеек модулем
openpyxl.
Объединение/слияние нескольких ячеек и их разъединение.
Модуль openpyxl поддерживает слияние/объединение нескольких ячеек, что очень удобно при записи в них текста, с последующим выравниванием. При слиянии/объединении ячеек, все ячейки, кроме верхней левой, удаляются с рабочего листа. Для переноса информации о границах объединенной ячейки, граничные ячейки объединенной ячейки, создаются как ячейки слияния, которые всегда имеют значение None.
Информацию о форматировании объединенных ячеек смотрите ниже, в подразделе «Оформление объединенных ячеек«.
Пример слияния/объединения ячеек с модулем openpyxl:
>>> from openpyxl import Workbook >>> wb = Workbook() >>> ws = wb.active # объединить ячейки, находящиеся # в диапазоне `B2 : E2` >>> ws.merge_cells('B2:E2') # записываем текст в оставшуюся # после объединения ячейку 'B2' >>> ws['B2'] = 'Объединенные ячейки `B2 : E2`' # сохраняем документ и смотрим что получилось >>> wb.save("merge.xlsx")
При открытии сохраненного документа и перехода по любой ячейки из диапазона 'B2:E2' видно, что этот диапазон ячеек стал единым. Дополнительно исчезла возможность добавить значения к другим ячейкам этого диапазона.
Теперь разъединим ячейки, которые были объединены ранее, для этого загрузим сохраненный документ.
Пример разъединения ячеек с модулем openpyxl:
>>> from openpyxl import load_workbook # загружаем сохраненный документ >>> wb = load_workbook(filename = 'merge.xlsx') >>> ws = wb.active # теперь разъединим ячейки, # в диапазоне `B2 : E2` >>> ws.unmerge_cells('B2:E2') # сохраняем документ и смотрим что получилось >>> wb.save("merge.xlsx")
При открытии сохраненного документа и перехода по любой ячейки из диапазона 'B2:E2' видно, что текст, записанный ранее в ячейку 'B2' принадлежит только ей. Дополнительно появилась возможность добавить значения к другим ячейкам диапазона 'B2:E2'.
Методы слияния ws.merge_cells() и разъединения ws.unmerge_cells() ячеек, кроме диапазона/среза ячеек могут принимать аргументы:
start_row: строка, с которой начинается слияние/разъединение.start_column: колонка, с которой начинается слияние/разъединение.end_row: строка, которой заканчивается слияние/разъединение.end_column: колонка, которой заканчивается слияние/разъединение.
Пример:
# объединение ячеек >>> ws.merge_cells(start_row=2, start_column=2, end_row=4, end_column=6) # посмотрите что получилось >>> wb.save("merge.xlsx") # и разъединение ячеек >>> ws.unmerge_cells(start_row=2, start_column=2, end_row=4, end_column=6)
Оформление/стилизация разъединенных ячеек модулем openpyxl.
Объединенная ячейка ведет себя аналогично другим объектам ячеек. Различие заключается лишь в том, что ее значение и формат записываются в левой верхней ячейке. Чтобы изменить, например, границу всей объединенной ячейки, необходимо изменить границу ее левой верхней ячейки.
Пример форматирования объединенной ячейки:
>>> from openpyxl import Workbook >>> from openpyxl.styles import Border, Side, PatternFill, Font, Alignment >>> wb = Workbook() >>> ws = wb.active # объединим ячейки в диапазоне `B2:E2` >>> ws.merge_cells('B2:E2') # в данном случае крайняя верхняя-левая ячейка это `B2` >>> megre_cell = ws['B2'] # запишем в нее текст >>> megre_cell.value = 'Объединенные ячейки `B2 : E2`' # установить высоту строки >>> ws.row_dimensions[2].height = 30 # установить ширину столбца >>> ws.column_dimensions['B'].width = 40 # определим стили границ >>> thins = Side(border_style="thin", color="0000ff") >>> double = Side(border_style="double", color="ff0000") # НАЧИНАЕМ ФОРМАТИРОВАНИЕ: # границы объединенной ячейки >>> megre_cell.border = Border(top=double, left=thins, right=thins, bottom=double) # заливка ячейки >>> megre_cell.fill = PatternFill("solid", fgColor="DDDDDD") # шрифт ячейки >>> megre_cell.font = Font(bold=True, color="FF0000", name='Arial', size=14) # выравнивание текста >>> megre_cell.alignment = Alignment(horizontal="center", vertical="center") # сохраняем и смотрим что получилось >>> wb.save("styled_megre.xlsx")
Дополнительно смотрите:
- Оформление/стилизация ячеек документа XLSX модулем
openpyxl. - Изменение размеров строки/столбца модулем
openpyxl.
I have two Excel sheets, sheet1, and sheet2. Sheet1 has the row id, First name, Last name, Description columns, etc. Sheet2 has also a column that stores the First name, Last name, and also two other columns, column D, and column E, that need to be merged in the Description column.
The combination of First name, Last name, exists only once in both sheets.
How could I merge the contents of column D, E from sheet 2, in column named Description, in sheet 1, based on the matching criteria First name and Last name are equal in row from sheet 1, and from sheet 2, using Python Pandas?
Sheet 1:
ID | columnB | column C | Column D
1 | John | Hingins | Somedescription
Sheet 2:
ID | column Z | column X | Column Y | Column W
1 | John | Hingins | description2 | Somemoredescription
Output:
Sheet 1:
ID | columnB | column C | Column D
1 | John | Hingins | description2-separator-Someotherdescription-separator-Somedescription
Время на прочтение
5 мин
Количество просмотров 63K
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
import pandas as pd
sales = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'sales')
states = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'states')
Теперь воспользуемся методом .head() датафрейма sales для того чтобы вывести элементы, находящиеся в начале датафрейма:
print(sales.head())
Сравним то, что будет выведено, с тем, что можно видеть в Excel.
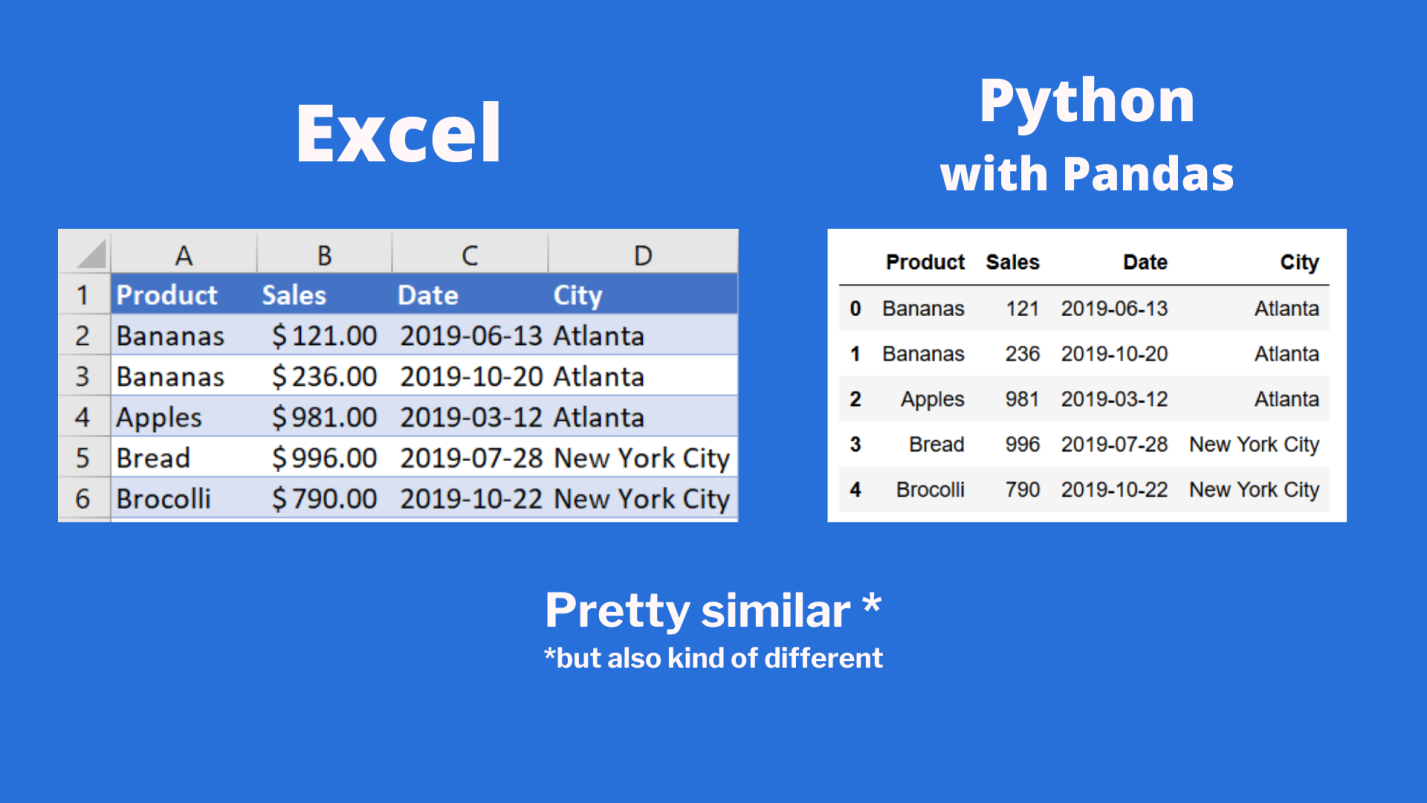
Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
- Нумерация строк в Excel начинается с 1, а в pandas номер (индекс) первой строки равняется 0.
- В Excel столбцы имеют буквенные обозначения, начинающиеся с буквы
A, а в pandas названия столбцов соответствуют именам соответствующих переменных.
Продолжим исследование возможностей pandas, позволяющих решать задачи, которые обычно решают в Excel.
Реализация возможностей Excel-функции IF в Python
В Excel существует очень удобная функция IF, которая позволяет, например, записать что-либо в ячейку, основываясь на проверке того, что находится в другой ячейке. Предположим, нужно создать в Excel новый столбец, ячейки которого будут сообщать нам о том, превышают ли 500 значения, записанные в соответствующие ячейки столбца B. В Excel такому столбцу (в нашем случае это столбец E) можно назначить заголовок MoreThan500, записав соответствующий текст в ячейку E1. После этого, в ячейке E2, можно ввести следующее:
=IF([@Sales]>500, "Yes", "No")
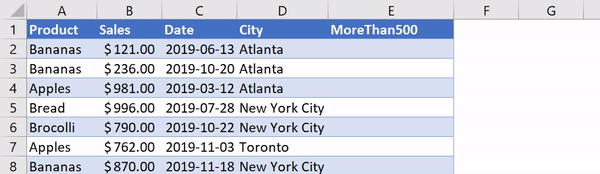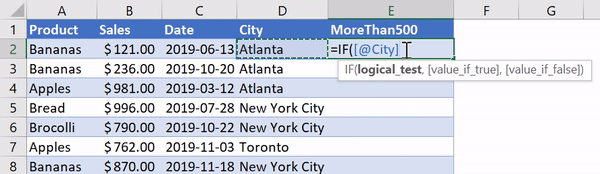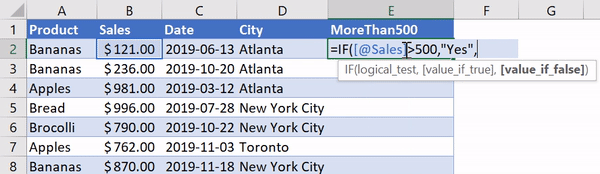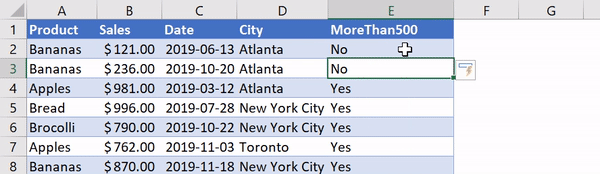
Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
sales['MoreThan500'] = ['Yes' if x > 500 else 'No' for x in sales['Sales']]

Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
В нашем наборе данных, на одном из листов Excel, есть названия городов, а на другом — названия штатов и провинций. Как узнать о том, где именно находится каждый город? Для этого подходит Excel-функция VLOOKUP, с помощью которой можно связать данные двух таблиц. Эта функция работает по принципу левого соединения, когда сохраняется каждая запись из набора данных, находящегося в левой части выражения. Применяя функцию VLOOKUP, мы предлагаем системе выполнить поиск определённого значения в заданном столбце указанного листа, а затем — вернуть значение, которое находится на заданное число столбцов правее найденного значения. Вот как это выглядит:
=VLOOKUP([@City],states,2,false)
Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.

Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
sales = pd.merge(sales, states, how='left', on='City')
Разберём его:
- Первый аргумент метода
merge— это исходный датафрейм. - Второй аргумент — это датафрейм, в котором мы ищем значения.
- Аргумент
howуказывает на то, как именно мы хотим соединить данные. - Аргумент
onуказывает на переменную, по которой нужно выполнить соединение (тут ещё можно использовать аргументыleft_onиright_on, нужные в том случае, если интересующие нас данные в разных датафреймах названы по-разному).
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
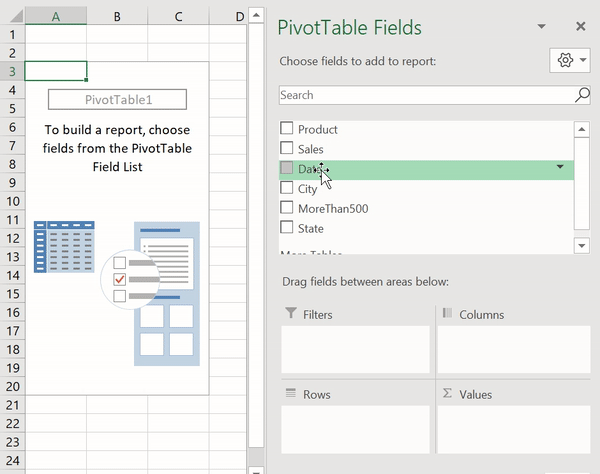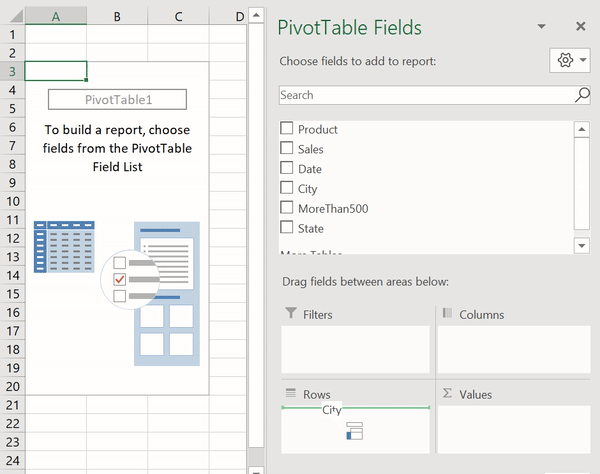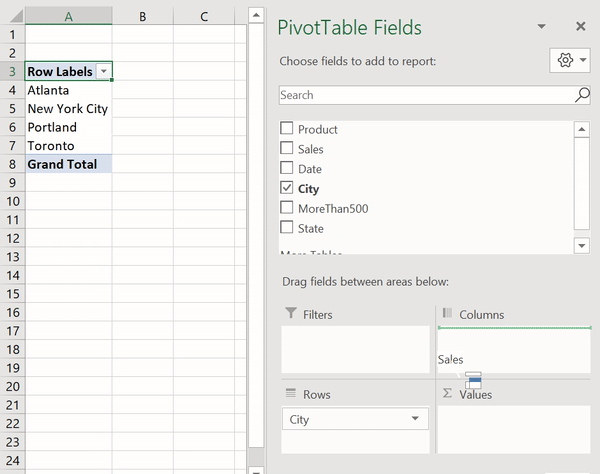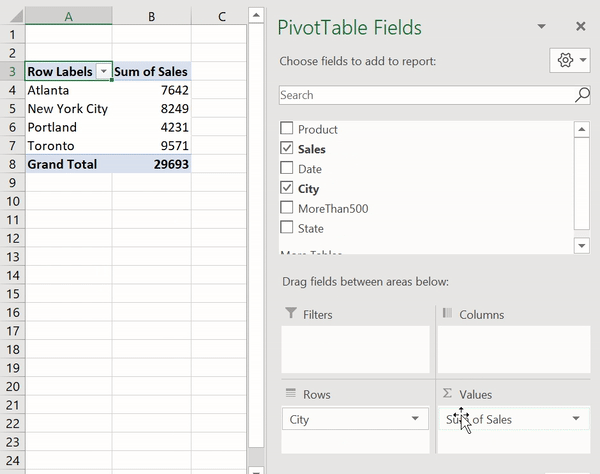
Создание сводной таблицы в Excel
Как видите, для создания подобной таблицы достаточно перетащить поле City в раздел Rows, а поле Sales — в раздел Values. После этого Excel автоматически выведет суммарные продажи для каждого города.
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
sales.pivot_table(index = 'City', values = 'Sales', aggfunc = 'sum')
Разберём его:
- Здесь мы используем метод
sales.pivot_table, сообщая pandas о том, что мы хотим создать сводную таблицу, основанную на датафреймеsales. - Аргумент
indexуказывает на столбец, по которому мы хотим агрегировать данные. - Аргумент
valuesуказывает на то, какие значения мы собираемся агрегировать. - Аргумент
aggfuncзадаёт функцию, которую мы хотим использовать при обработке значений (тут ещё можно воспользоваться функциямиmean,max,minи так далее).
Итоги
Из этого материала вы узнали о том, как импортировать Excel-данные в pandas, о том, как реализовать средствами Python и pandas возможности Excel-функций IF и VLOOKUP, а также о том, как воспроизвести средствами pandas функционал сводных таблиц Excel. Возможно, сейчас вы задаётесь вопросом о том, зачем вам пользоваться pandas, если то же самое можно сделать и в Excel. На этот вопрос нет однозначного ответа. Python позволяет создавать код, который поддаётся тонкой настройке и глубокому исследованию. Такой код можно использовать многократно. Средствами Python можно описывать очень сложные схемы анализа данных. А возможностей Excel, вероятно, достаточно лишь для менее масштабных исследований данных. Если вы до этого момента пользовались только Excel — рекомендую испытать Python и pandas, и узнать о том, что у вас из этого получится.
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.

Recipe Objective
In most of the big data scenarios , we need to merge multiple files or tables based on the various conditions to a unified data model for quicker data analysis purposes.in this recipe we are going to merge various excel files based on the certain conditions
Master the Art of Data Cleaning in Machine Learning
System requirements :
- Install pandas python module as follows:
pip install pandas - The below codes can be run in Jupyter notebook , or any python console
- In this scenario we are going to use 3 excel files to perform joins Products dataset , Orders dataset , Customers dataset
Table of Contents
- Recipe Objective
- System requirements :
- Step 1: Import the modules
- Step 2: Read the Excel Files
- Step 3: Join operations on the Data frames
- Step 4: write result to the csv file
Step 1: Import the modules
In this example we are going to use the pandas library , this library is used for data manipulation pandas data structures and operations for manipulating numerical tables and time series
Import pandas as pd
Step 2: Read the Excel Files
In the below code we are going read the data from excel files, and create dataframes using pandas library.
orders = pd. read_excel('orders.xlsx')
products =pd.read_excel("products.xlsx")
customers = pd.read_excel("customers.xlsx")
Step 3: Join operations on the Data frames
using the merge function in the pandas library , all database join operations between the pandas from the excel data. using the «how» parameter in the merge function we will perform the join operations like left, right,..etc.
Left Join :
import pandas as pd
orders = pd. read_excel('orders.xlsx')
products =pd.read_excel("products.xlsx")
customers = pd.read_excel("customers.xlsx")
result = pd.merge(orders,customers[["Product_id","Order_id","customer_name",'customer_email']],on='Product_id', how='left')
result.head()
Output of the above code:
Inner Join :
import pandas as pd
orders = pd. read_excel('orders.xlsx')
products =pd.read_excel("products.xlsx")
customers = pd.read_excel("customers.xlsx")
result= pd.merge(products,customers,on='Product_id',how='inner',indicator=True)
result.head()
Output of the above code:
Right Join :
import pandas as pd
orders = pd. read_excel('orders.xlsx')
products =pd.read_excel("products.xlsx")
customers = pd.read_excel("customers.xlsx")
result = pd.merge(orders, customers[["Product_id","Order_id","customer_name",'customer_email']],
on='Product_id',
how='right',
indicator=True)
result.head()
Output of the above code:
Outer Join :
import pandas as pd
orders = pd. read_excel('orders.xlsx')
products =pd.read_excel("products.xlsx")
customers = pd.read_excel("customers.xlsx")
result= pd.merge(products,customers,on='Product_id',how='outer',indicator=True)
result.head()
Output of the above code:
Step 4: write result to the csv file
After getting the result write to the hdfs or local file
import pandas as pd
orders = pd. read_excel('orders.xlsx')
products =pd.read_excel("products.xlsx")
customers = pd.read_excel("customers.xlsx")
result = pd.merge(orders,
customers[["Product_id","Order_id","customer_name",'customer_email']],
on='Product_id')
result.head()
# write the results to the hdfs/ local
result.to_excel("Results.xlsx", index = False)
Output of the above code : an excel file which will be written to current location of execution of the code and it looks like below