
import pandas as pd
from pandas import ExcelWriter
trans=pd.read_csv('HMIS-DICR-2011-12-Manipur-Bishnupur.csv')
df=trans[["April 10-11","May 10-11","June 10-11","July 10-11","August 10-11","September 10-11","October 10-11","November 10-11","December 10-11","January 10-11","February 10-11","March 10-11","April 11-12","May 11-12","June 11-12","July 11-12","August 11-12","September 11-12","October 11-12","November 11-12","December 11-12","January 11-12","February 11-12","March 11-12"]]
writer1 = ExcelWriter('manipur1.xlsx')
df.to_excel(writer1,'Sheet1',index=False)
writer1.save()
this code successfully writes the data in a sheet 1 but how can append data of another data frame(df) from different excel file(mention below) into existing sheet(sheet1) «manipur1» excel file
for example:
my data frame is like:
trans=pd.read_csv('HMIS-DICR-2013-2014-Manipur-Bishnupur.csv')
df=trans[["April 12-13","May 12-13","June 12-13","July 12-13","August 12-13","September 12-13","October 12-13","November 12-13","December 12-13","January 12-13","February 12-13","March 12-13","April 13-14","May 13-14","June 13-14","July 13-14","August 13-14","September 13-14","October 13-14","November 13-14","December 13-14","January 13-14","February 13-14","March 13-14"]]
В этом уроке рассмотрим основные моменты при работе с пакетом Pandas, который позволяет работать с Excel данными, как с двухмерными таблицами. Мы изучим как работать с самой таблицей, как массивом данных, с отдельными столбцами и строками, а также научимся делать отборы по условиям.

Для начала подготовим Excel файл с примером, который будем использовать в качестве источника данных (всю обработку данных будем делать в Python, без сохранения в Excel, для ускорения работы). Файл должен содержать лист «Данные» с такой информацией:

Сохраните файл с названием «Excel_Python-3.xlsx». Теперь запускаем Spyder, создаем новый скрипт и туда вносим следующий код, который позволит нам прочитать данные из вышеуказанного Excel файла в DataFrame, который мы будем использовать сегодня в примерах. Скрипт сохраняем в ту же папку, куда сохранили Excel файл.
import xlwings as xw
import pandas as pdwb=xw.Book(‘Excel_Python-3.xlsx’)
data_excel = wb.sheets[‘Данные’]
data_pd = data_excel.range(‘A1:D7’).options(pd.DataFrame, header = 1, index = False).value
print (data_pd)
Итак, данные прочитаны, внесены в DataFrame data_pd, с которым мы будем работать в дальнейшем.
Таблица
data_pd.shape — функция показывается количество строк и количество столбцов в таблице. В нашем случае получим (6, 4), т.е. в нашей таблице 6 строк (заголовок не считается) и 4 столбца.
data_pd.info() — получаем общую сводку о таблицу, в т.ч. какие столбцы, их названия, тип данных в столбцах, количество не пустых элементов. При выполнении функции на обучающем примере мы получим:
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 6 entries, 0 to 5
Data columns (total 4 columns):
Фамилия 6 non-null object
Имя 6 non-null object
Возраст 6 non-null float64
Доход 6 non-null float64
dtypes: float64(2), object(2)
memory usage: 320.0+ bytes
Работа со строками
data_pd = data_pd.append({‘Фамилия’:’Егоров’, ‘Имя’:’Михаил’, ‘Возраст’:’37’,’Доход’:’40000′}, ignore_index=True) — Функция Append добавляет строку в таблицу. В качестве первого аргумента в фигурных скобках мы указываем те данные, что хотим добавить в формате ‘Название столбца’ : ‘Значение’, вторым аргументом мы говорим о том, что нам не важно в какое место таблицы добавится строка (по умолчанию в конец таблицы).
data_pd.drop([0, 1], axis=0, inplace=True) — Функция Drop удаляет строки. Первым параметром в квадратных скобках мы указываем номера строк, которые хотим удалить (нумерация строк начинается в Pandas с 0), вторым аргументом указываем что хотим удалить строку (axis=0) или столбец (axis=1), последним аргументом говорим о том, что измения должны быть произведены непосредственно в той таблице, с которой мы работаем (inplace=True), в противном случае (inplace=False) Pandas создаст копию таблицы, где удалит указанные строки, что может привести к путаницу и ошибкам.
data_pd.head(3) — Выводит указанное количество строк с начала таблицы, в данном случае 3.
data_pd[:3] — Функция аналогичная head, получаем указанное количество строк с начала таблицы.
data_pd[-3:] — Получаем указанное количество строк с конца таблицы.
Работа со столбцами
data_pd.columns — Выводит названия столбцов в таблице. В нашем случае при выполнении функции получим следующее: Index([‘Фамилия’, ‘Имя’, ‘Возраст’, ‘Доход’], dtype=’object’)
data_pd.dtypes — Выводит тип данных в столбцах. В нашем случае:
Фамилия object
Имя object
Возраст float64
Доход float64
dtype: object
data_pd[‘Пол’] =[‘Муж.’,’Муж.’,’Муж.’,’Муж.’,’Муж.’,’Муж.’] — Добавляем новый столбец. В левой части в квадратных скобках указываем название столбца, в правой части — что в этом столбце должно содержаться. Обратите внимание, что количество записей должно равняться количеству строк в таблице, иначе получите ошибку «Length of values does not match length of index».
data_pd.drop([‘Фамилия’], axis=1, inplace=True) — Функция Drop, как и говорилось ранее, удаляет столбец или строку. В данном случае в качестве первого параметра в квадратных скобках указываем название столбца, далее указываем что удаляем именно столбец (axis=1), и не забываем указать что измения должны быть произведены непосредственно в той таблице, с которой мы работаем (inplace=True).
data_pd[[‘Фамилия’, ‘Имя’]] — Получаем данные только по отдельным столбцам, а не по всей таблице в целом.
Работа со строками и столбцами
data_pd.loc[[0, 1], [‘Фамилия’, ‘Имя’]] — Функция loc позволяет получить данные только по конкретным строкам и столбцам. Первым агрументом указываем номера строк, которых хотим получить, вторым — названия столбцов.
data_pd.iloc[[0, 1], [0, 1]] — Функция iloc позволяет получить данные обращаясь и к строкам и к столбцам по номерам. Показанный пример вернет теже данные, что и вариант выше (обратите внимание, что номерация столбцов, как и строк, в Pandas начинается с 0).
Отбор данных по условию
data_pd[(data_pd[‘Доход’] >= 30000) & (data_pd[‘Фамилия’] == ‘Петров’)] — Отбираем данные по двум условиям. В первом говорим о том, что доход должен быть больше 30 000, а фамилия сотрудника должна быть Петров. Обратите внимание, что используется логическое условие И (&) — это значит, что данные будут получены, если выполнены оба условия. При использовании логического условия ИЛИ (|), будут отобраны те строки, в которых выполняется хоть одно из указанных условий.
На сегодня все. Есть вопросы — задавайте в комментариях ниже.
Время на прочтение
5 мин
Количество просмотров 63K
Excel — это чрезвычайно распространённый инструмент для анализа данных. С ним легко научиться работать, есть он практически на каждом компьютере, а тот, кто его освоил, может с его помощью решать довольно сложные задачи. Python часто считают инструментом, возможности которого практически безграничны, но который освоить сложнее, чем Excel. Автор материала, перевод которого мы сегодня публикуем, хочет рассказать о решении с помощью Python трёх задач, которые обычно решают в Excel. Эта статья представляет собой нечто вроде введения в Python для тех, кто хорошо знает Excel.

Загрузка данных
Начнём с импорта Python-библиотеки pandas и с загрузки в датафреймы данных, которые хранятся на листах sales и states книги Excel. Такие же имена мы дадим и соответствующим датафреймам.
import pandas as pd
sales = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'sales')
states = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/pythonexcel.xlsx', sheet_name = 'states')
Теперь воспользуемся методом .head() датафрейма sales для того чтобы вывести элементы, находящиеся в начале датафрейма:
print(sales.head())
Сравним то, что будет выведено, с тем, что можно видеть в Excel.
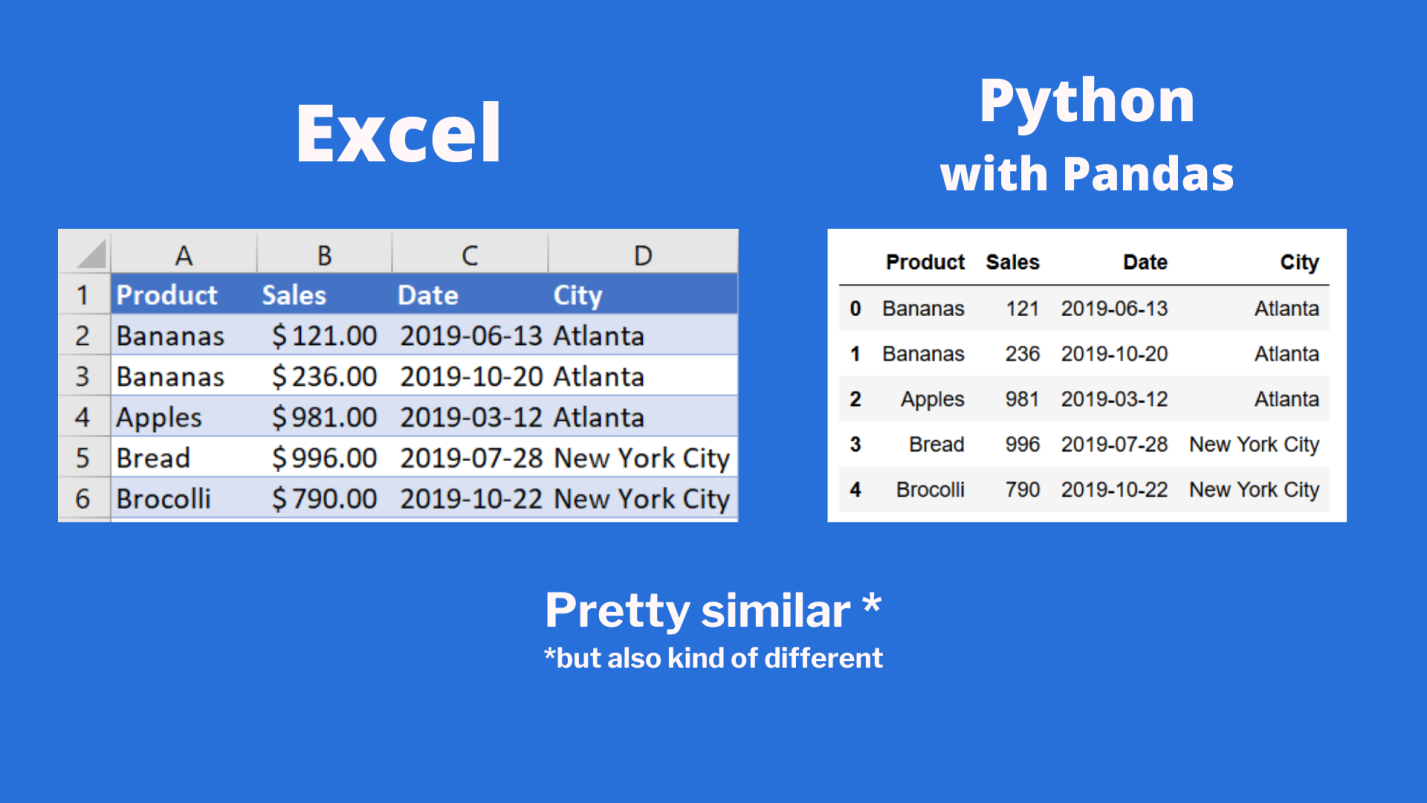
Сравнение внешнего вида данных, выводимых в Excel, с внешним видом данных, выводимых из датафрейма pandas
Тут можно видеть, что результаты визуализации данных из датафрейма очень похожи на то, что можно видеть в Excel. Но тут имеются и некоторые очень важные различия:
- Нумерация строк в Excel начинается с 1, а в pandas номер (индекс) первой строки равняется 0.
- В Excel столбцы имеют буквенные обозначения, начинающиеся с буквы
A, а в pandas названия столбцов соответствуют именам соответствующих переменных.
Продолжим исследование возможностей pandas, позволяющих решать задачи, которые обычно решают в Excel.
Реализация возможностей Excel-функции IF в Python
В Excel существует очень удобная функция IF, которая позволяет, например, записать что-либо в ячейку, основываясь на проверке того, что находится в другой ячейке. Предположим, нужно создать в Excel новый столбец, ячейки которого будут сообщать нам о том, превышают ли 500 значения, записанные в соответствующие ячейки столбца B. В Excel такому столбцу (в нашем случае это столбец E) можно назначить заголовок MoreThan500, записав соответствующий текст в ячейку E1. После этого, в ячейке E2, можно ввести следующее:
=IF([@Sales]>500, "Yes", "No")
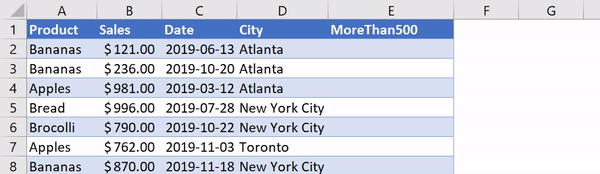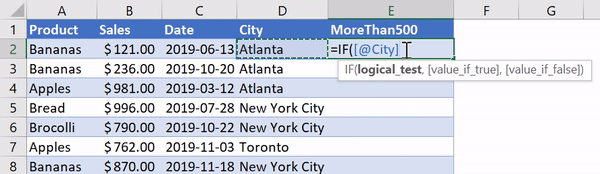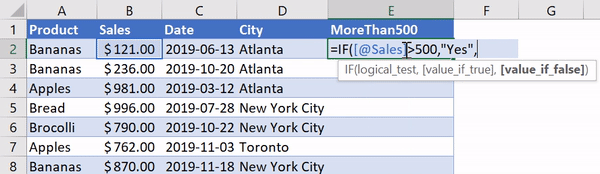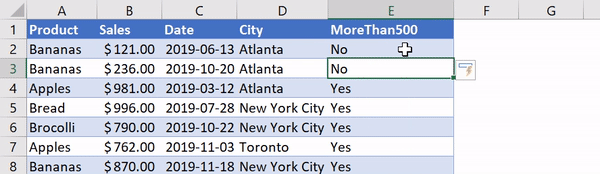
Использование функции IF в Excel
Для того чтобы сделать то же самое с использованием pandas, можно воспользоваться списковым включением (list comprehension):
sales['MoreThan500'] = ['Yes' if x > 500 else 'No' for x in sales['Sales']]

Списковые включения в Python: если текущее значение больше 500 — в список попадает Yes, в противном случае — No
Списковые включения — это отличное средство для решения подобных задач, позволяющее упростить код за счёт уменьшения потребности в сложных конструкциях вида if/else. Ту же задачу можно решить и с помощью if/else, но предложенный подход экономит время и делает код немного чище. Подробности о списковых включениях можно найти здесь.
Реализация возможностей Excel-функции VLOOKUP в Python
В нашем наборе данных, на одном из листов Excel, есть названия городов, а на другом — названия штатов и провинций. Как узнать о том, где именно находится каждый город? Для этого подходит Excel-функция VLOOKUP, с помощью которой можно связать данные двух таблиц. Эта функция работает по принципу левого соединения, когда сохраняется каждая запись из набора данных, находящегося в левой части выражения. Применяя функцию VLOOKUP, мы предлагаем системе выполнить поиск определённого значения в заданном столбце указанного листа, а затем — вернуть значение, которое находится на заданное число столбцов правее найденного значения. Вот как это выглядит:
=VLOOKUP([@City],states,2,false)
Зададим на листе sales заголовок столбца F как State и воспользуемся функцией VLOOKUP для того чтобы заполнить ячейки этого столбца названиями штатов и провинций, в которых расположены города.

Использование функции VLOOKUP в Excel
В Python сделать то же самое можно, воспользовавшись методом merge из pandas. Он принимает два датафрейма и объединяет их. Для решения этой задачи нам понадобится следующий код:
sales = pd.merge(sales, states, how='left', on='City')
Разберём его:
- Первый аргумент метода
merge— это исходный датафрейм. - Второй аргумент — это датафрейм, в котором мы ищем значения.
- Аргумент
howуказывает на то, как именно мы хотим соединить данные. - Аргумент
onуказывает на переменную, по которой нужно выполнить соединение (тут ещё можно использовать аргументыleft_onиright_on, нужные в том случае, если интересующие нас данные в разных датафреймах названы по-разному).
Сводные таблицы
Сводные таблицы (Pivot Tables) — это одна из самых мощных возможностей Excel. Такие таблицы позволяют очень быстро извлекать ценные сведения из больших наборов данных. Создадим в Excel сводную таблицу, выводящую сведения о суммарных продажах по каждому городу.
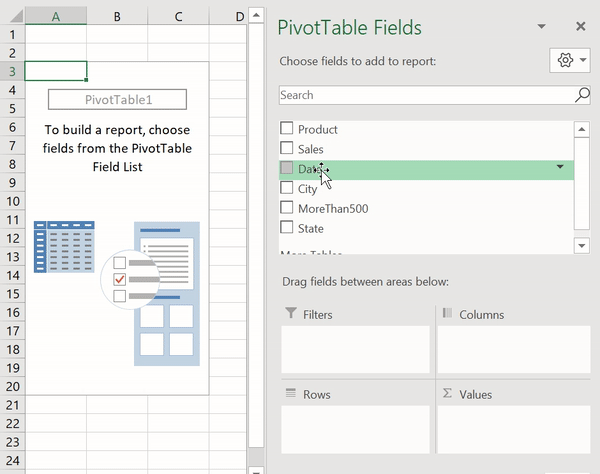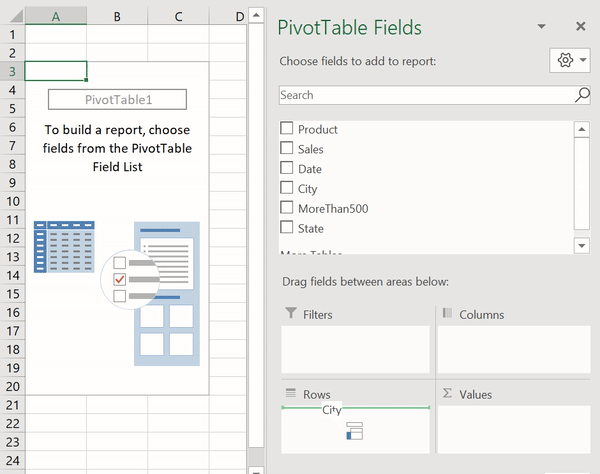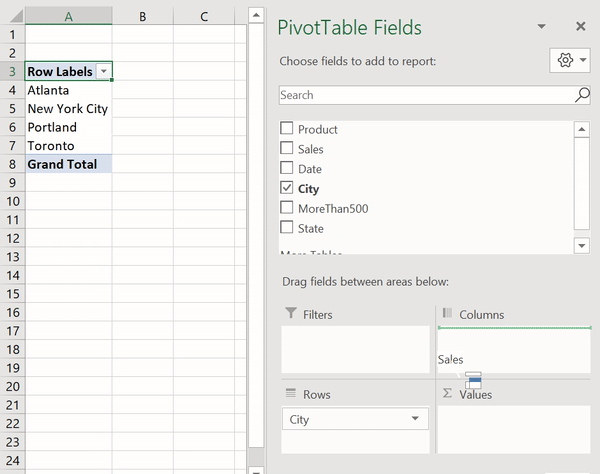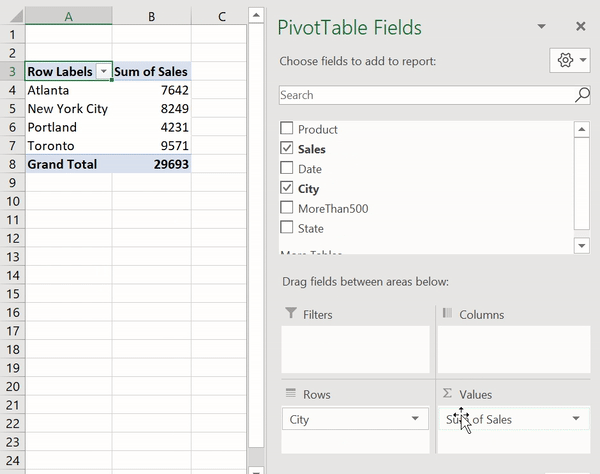
Создание сводной таблицы в Excel
Как видите, для создания подобной таблицы достаточно перетащить поле City в раздел Rows, а поле Sales — в раздел Values. После этого Excel автоматически выведет суммарные продажи для каждого города.
Для того чтобы создать такую же сводную таблицу в pandas, нужно будет написать следующий код:
sales.pivot_table(index = 'City', values = 'Sales', aggfunc = 'sum')
Разберём его:
- Здесь мы используем метод
sales.pivot_table, сообщая pandas о том, что мы хотим создать сводную таблицу, основанную на датафреймеsales. - Аргумент
indexуказывает на столбец, по которому мы хотим агрегировать данные. - Аргумент
valuesуказывает на то, какие значения мы собираемся агрегировать. - Аргумент
aggfuncзадаёт функцию, которую мы хотим использовать при обработке значений (тут ещё можно воспользоваться функциямиmean,max,minи так далее).
Итоги
Из этого материала вы узнали о том, как импортировать Excel-данные в pandas, о том, как реализовать средствами Python и pandas возможности Excel-функций IF и VLOOKUP, а также о том, как воспроизвести средствами pandas функционал сводных таблиц Excel. Возможно, сейчас вы задаётесь вопросом о том, зачем вам пользоваться pandas, если то же самое можно сделать и в Excel. На этот вопрос нет однозначного ответа. Python позволяет создавать код, который поддаётся тонкой настройке и глубокому исследованию. Такой код можно использовать многократно. Средствами Python можно описывать очень сложные схемы анализа данных. А возможностей Excel, вероятно, достаточно лишь для менее масштабных исследований данных. Если вы до этого момента пользовались только Excel — рекомендую испытать Python и pandas, и узнать о том, что у вас из этого получится.
А какие инструменты вы используете для анализа данных?
Напоминаем, что у нас продолжается конкурс прогнозов, в котором можно выиграть новенький iPhone. Еще есть время ворваться в него, и сделать максимально точный прогноз по злободневным величинам.

Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Let’s discuss how to add new columns to the existing DataFrame in Pandas. There are multiple ways we can do this task.
Method #1: By declaring a new list as a column.
Python3
import pandas as pd
data = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Height': [5.1, 6.2, 5.1, 5.2],
'Qualification': ['Msc', 'MA', 'Msc', 'Msc']}
df = pd.DataFrame(data)
address = ['Delhi', 'Bangalore', 'Chennai', 'Patna']
df['Address'] = address
print(df)
Output:
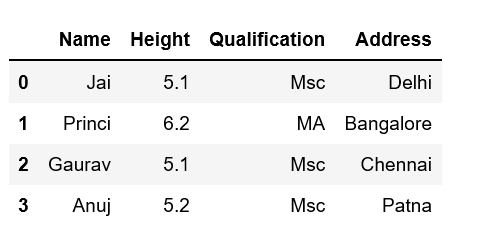
Note that the length of your list should match the length of the index column otherwise it will show an error.
Method #2: By using DataFrame.insert()
It gives the freedom to add a column at any position we like and not just at the end. It also provides different options for inserting the column values.
Example
Python3
import pandas as pd
data = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Height': [5.1, 6.2, 5.1, 5.2],
'Qualification': ['Msc', 'MA', 'Msc', 'Msc']}
df = pd.DataFrame(data)
df.insert(2, "Age", [21, 23, 24, 21], True)
print(df)
Output:
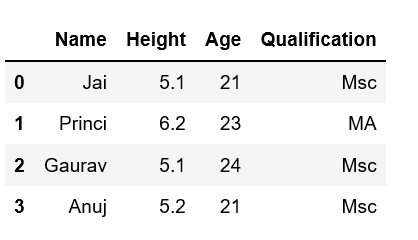
Method #3: Using Dataframe.assign() method
This method will create a new dataframe with a new column added to the old dataframe.
Example
Python3
import pandas as pd
data = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Height': [5.1, 6.2, 5.1, 5.2],
'Qualification': ['Msc', 'MA', 'Msc', 'Msc']}
df = pd.DataFrame(data)
df2 = df.assign(address=['Delhi', 'Bangalore', 'Chennai', 'Patna'])
print(df2)
Output:
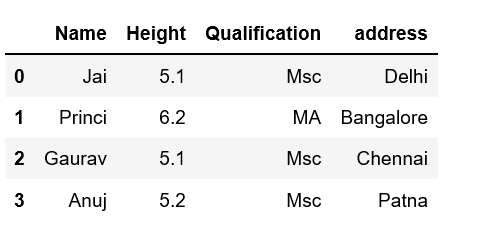
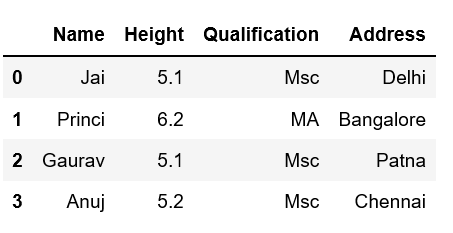
Method #4: By using a dictionary
We can use a Python dictionary to add a new column in pandas DataFrame. Use an existing column as the key values and their respective values will be the values for a new column.
Example
Python3
import pandas as pd
data = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Height': [5.1, 6.2, 5.1, 5.2],
'Qualification': ['Msc', 'MA', 'Msc', 'Msc']}
address = {'Delhi': 'Jai', 'Bangalore': 'Princi',
'Patna': 'Gaurav', 'Chennai': 'Anuj'}
df = pd.DataFrame(data)
df['Address'] = address
print(df)
Output:
Like Article
Save Article
state_to_code = {"VERMONT": "VT", "GEORGIA": "GA", "IOWA": "IA", "Armed Forces Pacific": "AP", "GUAM": "GU", "KANSAS": "KS", "FLORIDA": "FL", "AMERICAN SAMOA": "AS", "NORTH CAROLINA": "NC", "HAWAII": "HI", "NEW YORK": "NY", "CALIFORNIA": "CA", "ALABAMA": "AL", "IDAHO": "ID", "FEDERATED STATES OF MICRONESIA": "FM", "Armed Forces Americas": "AA", "DELAWARE": "DE", "ALASKA": "AK", "ILLINOIS": "IL", "Armed Forces Africa": "AE", "SOUTH DAKOTA": "SD", "CONNECTICUT": "CT", "MONTANA": "MT", "MASSACHUSETTS": "MA", "PUERTO RICO": "PR", "Armed Forces Canada": "AE", "NEW HAMPSHIRE": "NH", "MARYLAND": "MD", "NEW MEXICO": "NM", "MISSISSIPPI": "MS", "TENNESSEE": "TN", "PALAU": "PW", "COLORADO": "CO", "Armed Forces Middle East": "AE", "NEW JERSEY": "NJ", "UTAH": "UT", "MICHIGAN": "MI", "WEST VIRGINIA": "WV", "WASHINGTON": "WA", "MINNESOTA": "MN", "OREGON": "OR", "VIRGINIA": "VA", "VIRGIN ISLANDS": "VI", "MARSHALL ISLANDS": "MH", "WYOMING": "WY", "OHIO": "OH", "SOUTH CAROLINA": "SC", "INDIANA": "IN", "NEVADA": "NV", "LOUISIANA": "LA", "NORTHERN MARIANA ISLANDS": "MP", "NEBRASKA": "NE", "ARIZONA": "AZ", "WISCONSIN": "WI", "NORTH DAKOTA": "ND", "Armed Forces Europe": "AE", "PENNSYLVANIA": "PA", "OKLAHOMA": "OK", "KENTUCKY": "KY", "RHODE ISLAND": "RI", "DISTRICT OF COLUMBIA": "DC", "ARKANSAS": "AR", "MISSOURI": "MO", "TEXAS": "TX", "MAINE": "ME"}
Файлы к уроку:
- Для спонсоров Boosty
- Для спонсоров VK
- YouTube
- VK
Ссылки:
- Страница курса
- Плейлист YouTube
- Плейлист ВК
Описание
В этом уроке:
- Операции над столбцами датафрейма
- Импорт данных из DataFrame
- Переименование столбцов
- Добавление новых столбцов
- Изменение существующего столбца
- Удаление столбцов
Решение
Чтение CSV
# Чтение CSV
rus_alc = pd.read_csv('data.csv')
rus_alc[:4]Переименование столбцов
# Создадим новую переменную
rus_alc_2 = rus_alc.rename(columns={'region': 'federal_subject'})
rus_alc_2[:2]# Переименовать без создания новых переменных
rus_alc.rename(columns={'region': 'federal_subject'},
inplace=True)
rus_alc[:2]Добавление новых столбцов
# Добавим новый столбец
rus_alc_c['total_spirit'] = (rus_alc_c['wine']
+ rus_alc_c['beer']
+ rus_alc_c['vodka']
+ rus_alc_c['champagne']
+ rus_alc_c['brandy'])
rus_alc_c[:4]# Создать столбец с указанием места для этого столбца
rus_alc_c.insert(7, 'soft_total', (rus_alc_c['wine']
+ rus_alc_c['beer']
+ rus_alc_c['champagne']))
rus_alc_c[:2]Изменить существующий столбец
# Изменить существующий столбец
rus_alc_c['total_spirit'] = rus_alc_c['total_spirit'].round()
rus_alc_c[:4]Создать столбец из серии
# Создать серию со случайными значениями
np.random.seed(123456)
s_random = pd.Series(np.random.normal(size=1615),
index=rus_alc_c.index)
# Добавить столбец из серии
rus_alc_c.loc[:, 'sample_col'] = s_randomРасположить столбцы в обратном порядке
# Имена столбцов в обратном порядке
cols = rus_alc_c.columns[::-1]
# Расположить столбцы в обратном порядке
rus_alc_c[cols][:4]Удаление столбцов
del удаляет серию из объекта DataFrame.
pop() удаляет и возвращает в результате серию.
drop() возвращает новый датафрейм с удаленным столбцом.
# Удаляем столбец
del rus_alc_c_1['sample_col']
rus_alc_c_1[:3]# pop
poped_s = rus_alc_c_2.pop('sample_col')
poped_s[:3]# Получим новый датафрейм с удаленным столбцом sample_col
dropped_df = rus_alc_c_3.drop(['sample_col'],
axis=1)
dropped_df[:3]Примененные функции
- pandas.read_csv
- pandas.DataFrame.rename
- pandas.DataFrame.insert
- pandas.DataFrame.round
- pandas.Series
- numpy.random.seed
- numpy.random.normal
- pandas.DataFrame.copy
- pandas.DataFrame.pop
- del
- pandas.DataFrame.drop
Курс Pandas Базовый
| Номер урока | Урок | Описание |
|---|---|---|
| 1 | Pandas Базовый №1. Создание DataFrame и запись в CSV | Познакомимся с объектом DataFrame. Научимся его создавать двумя разными способами и научимся записывать его в файл. |
| 2 | Pandas Базовый №2. Создание DataFrame 2 | Изучим еще несколько способов создания объекта DataFrame. В этом уроке мы создадим DataFrame из массива numpy, Series, словаря Series. |
| 3 | Pandas Базовый №3. Отбор строк и столбцов, Размерность, Импорт CSV | Получить информацию о размере DataFrame, отбор строк и столбцов, индексация. |
| 4 | Pandas Базовый №4. Операции со столбцами DataFrame | Операции со столбцами в Pandas. Переименование столбцов, добавление новых столбцов, изменить существующий столбец, удаление столбцов. |
| 5 | Pandas Базовый №5. Операции со строками | Объединение по вертикали методами append и concat, Создание строк вручную, Удаление строк методом drop, Фильтрация строк условием или срезом. |
| 6 | Pandas Базовый №6. Индексы | Зачем нужны индексы, Как задать индекс, Как пользоваться индексами. |
| 7 | Pandas Базовый №7. Категории | Что такое категориальные переменные. |
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Для работы с табличными данными часто используют продукт Microsoft Excel. В таблицы Excel помещают как списки покупок, так и отчетности компаний. Благодаря распространенности данного формата разработчики создали инструменты для атоматизации обработки данных.
Pandas является средством работы с табличными данными и умеет работать с файлами формата Excel-таблиц: .xls и .xlsx. И каждый разработчик должен уметь работать с такими форматами наравне с текстовыми файлами и файлами формата json и html.
В этом уроке мы познакомимся с основными методами библиотеки Pandas для работы с табличными данными в формате Microsoft Excel: .xls и .xlsx. Мы научимся их читать и записывать. Также мы разберем работу с файлами, в которых есть несколько листов, а также форматированию данных при записи.
Обработка Excel файлов в Python
Среди форматов файлов Excel наиболее популярными являются:
- .xls — использовался в версиях Microsoft Excel до 2007
- .xlsx — используется во всех версиях после 2007
Для работы с обоими типами в Python есть ряд открытых библиотек:
xlwtopenpyxlXlsxWriterxlrd
В библиотеке Pandas не реализован свой функционал работы с Excel-файлами, но есть единый интерфейс для работы с каждой из указанных выше библиотек.
Чтобы использовать этот функционал, нужно установить указанные библиотеки в окружение, в котором установлена библиотека Pandas. Библиотеки не являются взаимозаменяемыми и дополняют друг друга — лучше установить их все.
Чтение таблиц из Excel файлов
Чтобы читать файлы в Pandas, используется метод read_excel(). Ему на вход подается путь к читаемому файлу:
import pandas as pd
df_orders = pd.read_excel('data_read/Shop_orders_one_week.xlsx')
print(df_orders.head())
# => weekday shop_1 shop_2 shop_3 shop_4
# 0 mon 7 1 7 8
# 1 tue 4 2 4 5
# 2 wed 3 5 2 3
# 3 thu 8 12 8 7
# 4 fri 15 11 13 9
# 5 sat 21 18 17 21
# 6 sun 25 16 25 17
В примере выше прочитан файл продаж четырех магазинов за неделю и размещен в объекте DataFrame. Pandas по умолчанию добавил столбец индексов — последовательность целых чисел от 0 до 6.
Чтобы указать, какой из столбцов является столбцом индексов, необходимо указать его номер в параметре index_col. В нашем случае это первый столбец, в котором указаны дни недели:
df_orders = pd.read_excel('data_read/Shop_orders_one_week.xlsx', index_col=0)
print(df_orders.head())
# => shop_1 shop_2 shop_3 shop_4
# weekday
# mon 7 1 7 8
# tue 4 2 4 5
# wed 3 5 2 3
# thu 8 12 8 7
# fri 15 11 13 9
# sat 21 18 17 21
# sun 25 16 25 17
Если перед таблицей некоторые строки содержали записи, то попытка прочтения не приведет к ожидаемому результату. Pandas будет стараться положить данные в строках до таблицы в качестве индексов столбцов:
df_orders = pd.read_excel('data_read/Shop_orders_one_week_with_head.xlsx')
print(df_orders.head())
# => Orders by shop Unnamed: 1 Unnamed: 2 Unnamed: 3 Unnamed: 4
# 0 NaN NaN NaN NaN NaN
# 1 weekday shop_1 shop_2 shop_3 shop_4
# 2 mon 7 1 7 8
# 3 tue 4 2 4 5
# 4 wed 3 5 2 3
Для корректного прочтения необходимо пропустить некоторое количество строк при прочтении. Для этого нужно использовать параметр skiprows и указать количество пропускаемых строк:
df_orders = pd.read_excel('data_read/Shop_orders_one_week_with_head.xlsx', skiprows=2)
print(df_orders.head())
# => weekday shop_1 shop_2 shop_3 shop_4
# 0 mon 7 1 7 8
# 1 tue 4 2 4 5
# 2 wed 3 5 2 3
# 3 thu 8 12 8 7
# 4 fri 15 11 13 9
Итоговый вариант корректного чтения, где пропущены две строки и использован один столбец в качестве столбца индексов, выглядит следующим образом:
df_orders = pd.read_excel('data_read/Shop_orders_one_week_with_head.xls', skiprows=2, index_col=0)
print(df_orders.head())
# => shop_1 shop_2 shop_3 shop_4
# weekday
# mon 7 1 7 8
# tue 4 2 4 5
# wed 3 5 2 3
# thu 8 12 8 7
# fri 15 11 13 9
Запись таблиц в Excel файл
Также в Excel-файл можно записывать результаты работы программы. Эту задачу можно разделить на два типа по сложности используемого синтаксиса:
- Быстрая запись на один лист — записывается одна таблица, которая будет размещена на одном листе файла Excel
- Создание файла с несколькими листами — если результаты работы программы располагаются в нескольких итоговых таблицах, то для формирования единого файла Excel с несколькими листами потребуется применить определенные правила создания
Быстрая запись на один лист
В качестве результатов работы программы используем среднее по магазинам за неделю:
df_orders_mean = pd.DataFrame(df_orders.mean()).T.round(1)
df_orders_mean.index = ['mean']
print(df_orders_mean)
# => shop_1 shop_2 shop_3 shop_4
# mean 11.9 9.3 10.9 10.0
Сформируем итоговую таблицу на основе исходной и добавим аналитические результаты:
df_analitic_results = pd.concat([
df_orders,
df_orders_mean
])
print(df_analitic_results)
# => shop_1 shop_2 shop_3 shop_4
# mon 7.0 1.0 7.0 8.0
# tue 4.0 2.0 4.0 5.0
# wed 3.0 5.0 2.0 3.0
# thu 8.0 12.0 8.0 7.0
# fri 15.0 11.0 13.0 9.0
# sat 21.0 18.0 17.0 21.0
# sun 25.0 16.0 25.0 17.0
# mean 11.9 9.3 10.9 10.0
Чтобы быстро записать данную таблицу, достаточно воспользоваться методом to_excel(). Формат файла .xls или .xlsx необходимо указать в расширении файла. Pandas автоматически определит, какой библиотекой воспользоваться для конкретного формата:
df_analitic_results.to_excel('data_read/Shop_orders_one_week_analitics.xlsx')
df_analitic_results.to_excel('data_read/Shop_orders_one_week_analitics.xls')
Создание файла с несколькими листами
Чтобы задать имя листа, на котором располагается таблица, необходимо указать его в параметре sheet_name. В данном примере получится лист Total:
path_for_analitic_results = 'data_read/Shop_orders_one_week_analitics.xlsx'
df_analitic_results.to_excel(
path_for_analitic_results,
sheet_name='Total'
)
Попробуем добавить к сформированному файлу лист итогов только для первого магазина:
df_analitic_results[['shop_1']].to_excel(
path_for_analitic_results,
sheet_name='shop_1',
)
Все выполнено без ошибок, но в итоговом файле листа Total нет. Чтобы перезаписать файл и удалить предыдущий, вызовем функцию to_excel().
Для корректной записи или дозаписи нужно использовать следующую конструкцию. В одном файле запишем итоговую таблицу на один лист, а для каждого магазина создадим отдельный лист только с его итогами:
with pd.ExcelWriter(
path_for_analitic_results,
engine="xlsxwriter",
mode='w') as excel_writer:
# Add total df
df_analitic_results.to_excel(excel_writer, sheet_name='Total')
# Add all shop df results
for shop_name in df_analitic_results.columns.to_list():
df_analitic_results[[shop_name]].to_excel(excel_writer, sheet_name=shop_name)
В коде выше создается экземпляр класса ExcelWriter на «движке» библиотеки xlsxwriter. Далее мы используем инициализированный экземпляр excel_writer в качестве первого параметра метода to_excel(). Конструкция with...as... позволяет безопасно работать с потоком данных и закрыть файл, даже когда возникают ошибки записи.
Чтение таблиц из Excel файлов с несколькими листами
Чтобы прочитать файл с несколькими листами, не хватит метода read_excel(), поскольку будет прочитан только первый лист из файла:
df_analitic_results_from_file = pd.read_excel(path_for_analitic_results, index_col=0)
print(df_analitic_results_from_file)
# => shop_1 shop_2 shop_3 shop_4
# mon 7.0 1.0 7.0 8
# tue 4.0 2.0 4.0 5
# wed 3.0 5.0 2.0 3
# thu 8.0 12.0 8.0 7
# fri 15.0 11.0 13.0 9
# sat 21.0 18.0 17.0 21
# sun 25.0 16.0 25.0 17
# mean 11.9 9.3 10.9 10
При этом можно прочитать конкретный лист, если указать его название в параметре sheet_name:
df_analitic_results_from_file = pd.read_excel(path_for_analitic_results, index_col=0, sheet_name='shop_1')
print(df_analitic_results_from_file)
# => shop_1
# mon 7.0
# tue 4.0
# wed 3.0
# thu 8.0
# fri 15.0
# sat 21.0
# sun 25.0
# mean 11.9
Чтобы прочитать несколько листов и не переоткрывать файл, достаточно использовать экземпляр класса ExcelFile и его метод parse(). В последнем указывается имя нужного листа и дополнительные параметры чтения, аналогичные методу read_excel().
excel_reader = pd.ExcelFile(path_for_analitic_results)
df_shop_1 = excel_reader.parse('shop_1', index_col=0)
df_shop_2 = excel_reader.parse('shop_2', index_col=0)
print(df_shop_1)
print(df_shop_2)
# => shop_1
# mon 7.0
# tue 4.0
# wed 3.0
# thu 8.0
# fri 15.0
# sat 21.0
# sun 25.0
# mean 11.9
# shop_2
# mon 1.0
# tue 2.0
# wed 5.0
# thu 12.0
# fri 11.0
# sat 18.0
# sun 16.0
# mean 9.3
Данный подход для чтения файла Excel удобен, чтобы получить список всех листов. Для этого нужно посмотреть на атрибут sheet_names:
print(excel_reader.sheet_names)
# => ['Total', 'shop_1', 'shop_2', 'shop_3', 'shop_4']
Если использовать наработки выше, можно собрать словарь из датафреймов, в которых будут располагаться все таблицы файла. Чтобы получить нужный датафрейм, нужно обратиться к словарю по ключу с соответствующим названием листа:
sheet_to_df_map = {}
for sheet_name in excel_reader.sheet_names:
sheet_to_df_map[sheet_name] = excel_reader.parse(sheet_name, index_col=0)
print(sheet_to_df_map['shop_1'])
print(sheet_to_df_map['Total'])
# => shop_1
# mon 7.0
# tue 4.0
# wed 3.0
# thu 8.0
# fri 15.0
# sat 21.0
# sun 25.0
# mean 11.9
# shop_1 shop_2 shop_3 shop_4
# mon 7.0 1.0 7.0 8
# tue 4.0 2.0 4.0 5
# wed 3.0 5.0 2.0 3
# thu 8.0 12.0 8.0 7
# fri 15.0 11.0 13.0 9
# sat 21.0 18.0 17.0 21
# sun 25.0 16.0 25.0 17
# mean 11.9 9.3 10.9 10
Форматирование таблиц
За время своего развития Excel накопил довольно мощный функционал, чтобы анализировать и презентовать данные: создание графиков, цветовая подсветка результатов по условию, настройка шрифтов и многое другое.
В примере ниже мы форматируем итоговые аналитические данные: если значения в таблице превышают порог в одиннадцать заказов, то они раскрашиваются в один цвет, иначе — в другой. Цветовая дифференциация данных удобна, чтобы быстро оценивать результаты и искать закономерности в данных:
with pd.ExcelWriter(
path_for_analitic_results,
engine="xlsxwriter",
mode='w') as excel_writer:
# Add total df
df_analitic_results.to_excel(excel_writer, sheet_name='Total')
# Formatting total df
threshold = 11
workbook = excel_writer.book
worksheet = excel_writer.sheets['Total']
format1 = workbook.add_format({'bg_color': '#FFC7CD',
'font_color': '#9C0006'})
format2 = workbook.add_format({'bg_color': '#C6EFCD',
'font_color': '#006100'})
worksheet.conditional_format('B2:E9', {
'type' : 'cell',
'criteria' : '>=',
'value' : threshold,
'format' : format1}
)
worksheet.conditional_format('B2:E9', {
'type' : 'cell',
'criteria' : '<',
'value' : threshold,
'format' : format2}
)
В примере выше используются методы движка xlsxwriter. Разбор всех возможностей форматирования данных при записи выходит за рамки данного урока. Можно глубже погрузиться в данную тему через документацию с примерами по следующей ссылке.
Выводы
Если DataFrame является основным типом данных библиотеки pandas, то очевидно, что главный навык, которым мы должны обладать при работе с этой библиотекой, заключается в том, как создавать DataFrame из данных.
Основная проблема заключается в том, что исходные данные обычно поступают в различных формах, будь то список, словарь, массив NumPy, обычный текстовый файл, файл CSV (значения, разделенные запятыми), файл JSON, база данных и так далее. В этой статье вы узнаете, как создать DataFrame из любого источника данных.
Для создания DataFrame используется функция-конструктор DataFrame(), которой предоставляется список или словарь с данными для ввода. Если данные находятся в файле или базе данных, вы должны использовать собственные функции, такие как read_csv, read_excel, read_json, read_html или read_sql.
Читайте дальше, чтобы получить общее представление о том, как генерировать DataFrame из любого источника данных. Я расскажу вам по порядку и приведу примеры, чтобы было понятно.
Содержание
- 1 DataFrame: таблица данных с маркированными строками и столбцами
- 2 Создание пустого DataFrame
- 3 Как добавить столбцы в DataFrame
- 4 Как вставить данные в DataFrame
- 5 Как создать DataFrame из массива
- 6 Как создать DataFrame из словаря
- 7 Как создать DataFrame из списка словарей
- 8 Как создать DataFrame из массива NumPy
- 9 Как создать DataFrame из файла CSV
- 10 Как создать DataFrame из данных буфера обмена
- 11 Как создать DataFrame из веб-страницы или HTML-файла
- 12 Как создать DataFrame из файла Excel
- 13 Как создать DataFrame из файла JSON
- 14 Как создать DataFrame из базы данных SQL
- 15 Как создать DataFrame из объектов pickle, parquet или Feather, файлов ORC, HDF, запросов SPSS, SAS, Stata или Google BigQuery.
- 16 Итоговая таблица
Прежде чем мы рассмотрим, как загружать различные источники данных в DataFrame, нам необходимо четко определить формат данных, который он представляет.
DataFrame представляет собой не что иное, как типичную двумерную таблицу данных со строками и столбцами. Кроме того, каждая строка и столбец могут иметь собственное имя или метку.
Так, например, мы можем сохранить в DataFrame расписание занятий, где столбцы – это дни, строки – часы, а значения – это каждый урок или предмет. Или мы можем также хранить список вылетов рейсов, где столбцы представляют номер рейса, время вылета и пункт назначения.
Обратите внимание, что таблица может иметь один столбец или одну строку, поэтому если вы встретите данные в таком формате, они также могут быть загружены в DataFrame. Они даже могут иметь одну строку и один столбец, т.е. одно значение!
Чтобы было понятнее, я приведу пример таблицы для наглядности моих слов:
| Имя | Возраст |
| Иван | 37 |
| Петр | 42 |
| Алексей | 40 |
Мы будем использовать таблицу, подобную этой, в некоторых примерах данной статьи.
Создание пустого DataFrame
Первая ситуация, в которой мы можем оказаться – это то, что мы должны создать DataFrame даже если у нас еще нет данных.
Лучшим вариантом для этого является создание пустого DataFrame. После создания мы можем добавлять в него данные, чтобы он постепенно рос.
Первое, что нужно понять, это то, что наш DataFrame будет экземпляром или объектом класса DataFrame библиотеки pandas. Поэтому мы будем использовать самый прямой способ создания объекта – с помощью его конструктора.
Убедитесь, что у вас установлена библиотека. Вы можете использовать команду pip install pandas.
В этом случае мы можем вызвать конструктор без каких-либо параметров, и у нас будет наш DataFrame, готовый принимать данные:
Code language: JavaScript (javascript)
import pandas as pd df = pd.DataFrame()
Обратите внимание, что необходимо импортировать библиотеку, чтобы иметь возможность работать с ней. Мы также переименуем его в pd, чтобы получить более короткий код.
Прежде чем вводить данные, мы должны определить некоторые колонки, потому что не может быть таблицы без колонок.
Как добавить столбцы в DataFrame
Обратите внимание, что основным измерением DataFrame являются столбцы, поэтому доступ к столбцам всегда немного более прямой, чем к строкам. На самом деле, используя типичную скобочную нотацию, мы обращаемся к столбцам раньше, чем к строкам, что противоречит общепринятой практике.
Один из способов добавления нового столбца в DataFrame – присвоить ему непосредственно значения, которые должен иметь столбец, как это делается в словаре и в скобочной нотации. Поскольку в данном случае мы не хотим вводить значения, мы просто указываем None.
Code language: PHP (php)
df['Name'] = None print(df)
В результате выполнения приведенного выше кода получается следующее, где видно, что в DataFrame, хотя он и пуст, появился новый столбец под названием Name. Кроме того, вы можете увидеть Index, но мы можем пока проигнорировать ее:
Code language: CSS (css)
Empty DataFrame Columns: [Name] Index: []
Другим способом добавления столбцов является использование функции assign в DataFrame. Эта функция позволяет нам добавлять колонки к уже созданным. Однако она не добавляет их в исходный DataFrame, а возвращает новый, содержащий новые плюс исходные столбцы:
Code language: PHP (php)
df['Name'] = None df = df.assign(Age=None) print(df)
Результатом выполнения приведенного выше кода будет:
Code language: CSS (css)
Empty DataFrame Columns: [Name, Age] Index: []
Будьте осторожны! Если вы назначите уже существующие колонки, вы перезапишете их значения. В данном случае это не имеет большого значения, потому что у нас пока нет данных, но имейте в виду, что они уже могут быть.
Итак, мы знаем, как добавить столбцы, но… вы согласитесь со мной, что от DataFrame без данных тоже мало толку. Давайте посмотрим, как добавить данные.
Как вставить данные в DataFrame
Когда у нас уже создан DataFrame со своими столбцами, нам остается только добавить в него данные. Существует несколько способов сделать это. Давайте посмотрим на некоторые из них.
Предположим, что у нас есть данные, которые нужно вставить в списки, то есть список для каждого столбца со значениями каждой строки для этого столбца. Мы можем сделать простое отображение следующим образом:
Code language: PHP (php)
names = ['Иван', 'Петр', 'Алексей'] ages = [42, 40, 37] df['Name'] = names df['Age'] = ages print(df)
Результат этой операции будет следующим:
Name Age 0 Иван 42 1 Петр 40 2 Алексей 37
Будьте осторожны! Если вы присваиваете значения DataFrame таким образом, все списки должны иметь одинаковую длину.
Обратите внимание, что если вы присваиваете значения таким образом, вам не нужно предварительно создавать столбцы, так как присвоение само создает столбец, если он не был определен. Обратите внимание, что таким же образом вы можете смешивать старые значения с новыми, если колонка уже существует.
Когда у нас есть некоторые значения, мы можем добавить новые значения, вставляя полные строки. Это полезно, как я уже говорил, чтобы иметь возможность вставлять значения постепенно, по мере их получения или генерации. Для этого можно воспользоваться функцией append объектов DataFrame, которая добавляет строку в конец таблицы.
Вы можете предоставить этой функции объект типа Series of pandas, который представляет собой список значений, или объект типа dictionary, где каждое значение соответствует имени столбца в таблице в качестве ключа. Рассмотрим оба способа на одном примере:
names = ['Иван, 'Петртрр', 'Алексей'] ages = [42, 40, 37] df['Name'] = names df['Age'] = ages new_row = { 'Name': 'Александр', 'Age': 29} # словарь df = df.append(new_row, ignore_index=True) new_row = pd.Series(['Аннанаа', 33], index=df.columns) # объект Series df = df.append(new_row, ignore_index=True) print(df)Code language: PHP (php)
Обратите внимание на несколько моментов:
- Функция append возвращает новый объект с новыми значениями, поэтому мы должны выполнить присваивание df = df.append(…).
- Мы должны указать параметр ignore_index, установленный в False в функции append, чтобы она не учитывала индексы новых данных, которые могли бы быть указаны (хотя в данном случае они этого не делают). Помните, что мы можем добавить данные из другого DataFrame, у которого есть индексы.
- При создании объекта Series, помимо новых данных, необходимо указать столбцы (в том же порядке, что и данные). Для этого я использую параметр index и атрибут columns фрейма DataFrame, чтобы не писать их вручную.
Результатом приведенного выше кода является:
0 Иван 42 1 Петр 40 2 Алексей 37 3 Александр 29 4 Анна 33
Вы можете добавить сразу несколько строк, предоставив функции append список словарей или Series, по одному на строку. Это будет более эффективно, чем несколько вызовов функции, по одному вызову на строку.
Подобно столбцам, строки тоже могут иметь имя. Каждый ряд может иметь собственное название или метку. Вы можете представить себе еженедельный календарь, в котором каждая строка представляет собой день недели. Таким образом, мы можем обозначить каждый ряд названиями “понедельник”, “вторник”, “среда” и так далее.
Это делает очень удобным доступ к определенным строкам без необходимости знать их положение в таблице. Создадим DataFrame для хранения, например, лекарств, которые человек должен принимать утром, днем и вечером для каждого дня недели.
Другим способом добавления данных является использование атрибута loc фрейма DataFrame. loc позволяет получить доступ к определенной строке (или нескольким строкам) через ее имя.
Рассмотрим пример:
Code language: PHP (php)
import pandas as pd df = pd.DataFrame() # создаем столбцы df['Утро'] = None df['Обед'] = None df['Вечер'] = None # добавляем строки по имени строки df.loc['Понедельник'] = ['Витамины', 'Против алергии', 'Седативные'] df.loc['Вторник'] = ['Витамины', None, 'Против алергии'] df.loc['Среда'] = ['Седативные', 'Против алергии', 'Витамины'] print(df)
Преимущество этой формы в том, что нам не нужно указывать имена столбцов для каждого значения. Однако необходимо указывать значения в соответствующем порядке. Результат получается следующим:
Утро Обед Вечер Понедельник Витамины Против аллергии Седативные Вторник Витамины None Против аллергии Среда Седативные Против аллергии Витамины
Обратите внимание, что во вторник во второй половине дня лекарств нет. В этом случае я могу указать значение None.
Это имена меток или строк, являющиеся набором индексов, которые print(df) намеревался вывести на экран, когда DataFrame был пуст.
Обратите внимание, что loc переписывает существующую строку в том случае, если указанный индекс уже существует в таблице.
Конечно, существует еще много способов вставки данных, но рассмотрение всех этих способов не является целью данной статьи, мы рассматриваем различные способы создания DataFrame. Теперь, когда мы увидели, как создать пустой и как создать еще один из значений столбцов, давайте рассмотрим другие способы.
Как создать DataFrame из массива
Если создание пустого DataFrame может быть первой идеей, которая приходит нам в голову, когда мы начинаем изучать pandas, то вторая идея – создать его из таблицы данных, уже созданной как массив.
Чтобы создать DataFrame из массива, называемого, например, data, просто вызовите конструктор, передав ему в качестве параметра список data следующим образом: DataFrame(data). Этот вызов вернет объект DataFrame, созданный с указанными данными и готовый к использованию.
Предположим, что у вас есть список из трех списков с четырьмя значениями в каждом, представляющий, например, следующую таблицу данных:
10 11 12 13 20 21 22 23 30 31 32 33
Давайте теперь создадим DataFrame из этого массива. Мы можем сделать следующее:
Code language: JavaScript (javascript)
import pandas as pd data = [[10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33]] df = pd.DataFrame(data) print(df)
Этот код генерирует вывод на экран, где видно, что по умолчанию имена столбцов равны 0, 1, 2 и 3, а имена строк – 0, 1 и 2.
0 1 2 3 0 10 11 12 13 1 20 21 22 23 2 30 31 32 33
Обратите внимание, что каждая строка в DataFrame соответствует каждой строке в исходном массива.
Если вы хотите, чтобы каждая строка в вашем списке списков стала столбцом в DataFrame, вам придется транспонировать DataFrame, то есть поменять строки на столбцы, при его создании, используя функцию transpose, как показано ниже df = pd.DataFrame(data).transpose().
Если вам нужны собственные имена столбцов, вы можете добавить параметр columns в вызов конструктора, чтобы перечислить имена столбцов.
Аналогично, если вы хотите дать имена строкам, вы можете сделать то же самое, но с параметром index:
Code language: PHP (php)
import pandas as pd data = [[10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33]] columns = ['C1', 'C2', 'C3', 'C4'] # определяем названия столбцов rows = ['F1', 'F2', 'F3'] # определяем названия строк df = pd.DataFrame(data, columns=columns, index=rows) print(df)
Таким образом, результат будет следующим:
C1 C2 C3 C4 F1 10 11 12 13 F2 20 21 22 23 F3 30 31 32 33
Как создать DataFrame из словаря
Другой распространенный случай – хранить данные каждого столбца нужной таблицы в словаре, помеченном именем столбца.
Чтобы создать DataFrame из словаря, просто предоставьте словарь конструктору класса DataFrame следующим образом: DataFrame(dictionary). Этот вызов возвращает объект DataFrame с данными из словаря, ключи которого являются именами столбцов.
Предположим, у вас есть словарь, в котором хранятся три списка, индексированные ключами Name, Age и Department. Вы просто предоставляете этот словарь конструктору DataFrame следующим образом:
Code language: JavaScript (javascript)
import pandas as pd data = { 'Name' : ['Иван', 'Петр', 'Алексей'], 'Age': [42, 40, 37], 'Department': ['Коммуникации', 'Администрация', 'Отдел продаж'] } df = pd.DataFrame(data) print(df)
И это все! Вот так просто можно получить следующий результат:
Name Age Department 0 Иван 42 Коммуникации 1 Петр 40 Администрация 2 Алексей 37 Отдел продаж
Убедитесь, что все списки словарей имеют одинаковую длину.
Как создать DataFrame из списка словарей
Чтобы создать DataFrame из списка словарей, просто предоставьте список конструктору класса DataFrame следующим образом: DataFrame(list). Этот вызов возвращает объект DataFrame, содержащий данные списка с ключами в виде имен столбцов.
В данном случае пример выглядит следующим образом:
Code language: JavaScript (javascript)
import pandas as pd data = [ {'Name': 'Иван', 'Age': 42, 'Department': 'Коммуникации'}, {'Name': 'Петр', 'Age': 44, 'Department': 'Администрация'}, {'Name': 'Алексей', 'Age': 37, 'Department': 'Отдел продаж'} ] df = pd.DataFrame(data) print(df)
Результатом приведенного выше кода будет:
Name Age Department 0 Иван 42 Коммуникации 1 Петр 40 Администрация 2 Алексей 37 Отдел продаж
Основная проблема этого решения заключается в том, что вы должны убедиться, что ключи в каждом словаре корректны и согласованы друг с другом. В целевом DataFrame будет создано столько столбцов, сколько различных ключей в словарях. Если, например, ключ, связанный с именем, в одном словаре – Name, в другом – name, а в третьем – NAME, то в итоге мы получим три разных колонки (с учетом регистра) для данных об имени, что нам не нужно. Кроме того, у нас будет много значений None, потому что если в других словарях нет значений для определенного ключа, то по умолчанию у нас будет именно None.
Как создать DataFrame из массива NumPy
Часто бывает, что данные, которые нам нужно обработать как DataFrame, хранятся в массиве NumPy.
Чтобы создать DataFrame из массива NumPy, необходимо вызвать конструктор DataFrame, снабдив его таким массивом следующим образом: DataFrame(array). Если мы хотим указать имена столбцов, они должны быть указаны в параметре columns.
В данном случае все очень просто.
Перед созданием DataFrame мы создадим массив NumPy (убедитесь, что у вас установлена библиотека numpy):
Code language: PHP (php)
import pandas as pd import numpy as np array = np.array([ [10, 11, 12, 13], [20, 21, 22, 23], [30, 31, 32, 33] ]) columns = ['C1', 'C2', 'C3', 'C4'] # этот список также может быть массивом NumPy df = pd.DataFrame(array, columns = columns) print(df)
В результате, где каждая строка массива соответствует строке DataFrame, получается:
C1 C2 C3 C4 0 10 11 12 13 1 20 21 22 23 2 30 31 32 33
Как создать DataFrame из файла CSV
Часто мы храним данные в CSV-файле (Comma Separated Values), который представляет собой не что иное, как текстовый файл в виде таблицы, где значения разделены запятыми (или другим символом). Кроме того, эти файлы обычно имеют первую строку, которая выступает в качестве заголовка с названиями столбцов.
Для создания DataFrame из значений файла CSV можно использовать функции pandas read_csv или read_table, указав им файл и символ разделителя. Эти функции создают новый DataFrame с данными, содержащимися в файле.
Предположим, что у нас есть текстовый файл data.csv, который имеет следующее содержание:
Name, Age, Department Иван, 42, Коммуникации Петр, 40, Администрация Алексей, 37, Отдел продаж
Это данные, из которых мы создадим DataFrame.
Один из вариантов – использовать функцию read_csv, которая представляет собой функцию, специально разработанную для чтения файлов CSV. Он имеет множество параметров, но для простых файлов нам нужно указать только имя файла и символ, который используется в этом файле в качестве разделителя. В данном случае таким символом является запятая.
Рассмотрим пример:
Code language: PHP (php)
import pandas as pd df = pd.read_csv('data.csv', delimiter=',') # вы также можете использовать функцию read_table print(df)
Результат на экране будет выглядеть следующим образом:
Name Age Department 0 Иван 42 Коммуникации 1 Петр 40 Администрация 2 Алексей 37 Отдел продаж
В этом простом случае вы можете использовать функцию read_table аналогичным образом, и результат будет таким же.
Если файл для чтения приходит без имен колонок, мы должны указать их через параметр names следующим образом: pd.read_csv(‘data.csv’, delimiter=’,’, names=[‘Name’,’Age’,’Department’]). Если нам не нужны имена столбцов, мы можем задать параметр header=None.
Еще одна функция, похожая на те, которые я только что представил, это read_fwf, которая генерирует таблицу данных из текстового файла, где поля имеют фиксированную ширину, поэтому нет необходимости использовать символ-разделитель, но операция очень похожа.
Как создать DataFrame из данных буфера обмена
Если у вас есть данные в формате таблицы, подобном предыдущему случаю, разделенные запятыми (или другим разделителем) в системном буфере обмена, pandas позволяет читать их прямо оттуда без необходимости создавать для этого файл. Это интересно, поскольку позволяет нам динамически и очень быстро создавать DataFrame из данных, полученных из различных источников, просто копируя данные в буфер обмена.
Для создания DataFrame из значений, разделенных запятыми, скопированных в системный буфер обмена, можно использовать функцию pandas read_clipboard, указав символ-разделитель. Эта функция создает новый DataFrame с данными, содержащимися в буфере обмена.
Попробуйте это сделать, выбрав данные из следующего примера и скопировав их:
Name, Age, Department Иван, 42, Коммуникации Петр, 40, Администрация Алексей, 37, Отдел продаж
Теперь просто используйте функцию read_clipboard, и у вас есть DataFrame – почти магия!
Code language: JavaScript (javascript)
import pandas as pd df = pd.read_clipboard(',') print(df)
Результат будет таким же, как и выше.
Если символ-разделитель полей не является одним или несколькими пробелами, вы должны указать нужный символ или строку, передав параметр функции, например, read_clipboard(‘,’). Если вы вызываете функцию без параметров, в качестве разделителей будут использоваться пробелы.
Как создать DataFrame из веб-страницы или HTML-файла
Если мы хотим получить данные из HTML-таблицы файла или веб-страницы, pandas упрощает задачу. Да, даже в этом случае, который может показаться сложнее.
Для создания DataFrame из таблиц веб-страницы или HTML-файла можно использовать функцию pandas read_html, указав файл или URL для чтения. Эта функция ищет теги и создает список DataFrames с каждой из таблиц в документе.
Функция read_html ищет теги <table> и элементы <tr> (строка), <th> (заголовок) и <td> (данные) и генерирует DataFrame для каждой из найденных таблиц, поэтому она всегда возвращает список со сгенерированными DataFrame.
Помните обо всех проблемах, связанных с разбором и чтением веб-страниц. Скорее всего, придется выполнить некоторую очистку ваших DataFrames после чтения.
Нам понадобится библиотека lxml, которая используется для обработки и разбора XML и HTML файлов в Python. Убедитесь, что вы установили его с помощью команды pip install lxml.
Ниже приведен небольшой HTML-файл, который я создал с двумя различными таблицами и назвал data.html.
Code language: HTML, XML (xml)
<html> <head> <meta charset="UTF-8"> <title>Тестовая страница с таблицами HTML</title> </head> <body> <h1>Как создать DataFrames из файлов HTML<h1> <h2>Таблица 1</h2> <table> <tr> <th>Name</th> <th>Age</th> </tr> <tr> <td>Иван</td> <td>42</td> </tr> <tr> <td>Петр</td> <td>40</td> </tr> <tr> <td>Алексей</td> <td>37</td> </tr> </table> <h2>Таблица 2</h2> <table> <tr> <th>A</th> <th>B</th> <th>C</th> </tr> <tr> <td>4</td> <td>4</td> <td>3</td> </tr> <tr> <td>5</td> <td>9</td> <td>0</td> </tr> <tr> <td>6</td> <td>5</td> <td>2</td> </tr> <tr> <td>0</td> <td>6</td> <td>3</td> </tr> <tr> <td>9</td> <td>1</td> <td>8</td> </tr> </table> </body> </html>
С этим документом, который вы можете скопировать и вставить в пустой файл, мы выполним следующий пример. Вы можете открыть HTML-файл с помощью веб-браузера, чтобы увидеть его содержимое и созданные таблицы. В примере создается список DataFrame с двумя объектами, по одному для каждой таблицы в HTML-документе. Затем этот список выводится на экран:
Code language: JavaScript (javascript)
import pandas as pd dfs = pd.read_html('data.html') for df in dfs: print(df, 'n')
Результат, который мы получаем, следующий:
Name Age 0 Иван 42 1 Петр 40 2 Алексей 37 A B C 0 4 4 3 1 5 9 0 2 6 5 2 3 0 6 3 4 9 1 8
Возможно, что из-за различных факторов чтение с помощью библиотеки lxml может быть неудачным, в этом случае будут использоваться библиотеки html5lib или bs4, которые у вас также должны быть установлены. Если вы предпочитаете, чтобы чтение выполнялось непосредственно с этими библиотеками, вы можете задать функции параметр flavor=’bs4′.
Как создать DataFrame из файла Excel
Другим распространенным случаем является наличие данных в файле Microsoft Excel или в совместимой электронной таблице, например, в таблицах открытого формата из пакета LibreOffice.
Чтобы создать DataFrame из электронной таблицы или файла Excel, вы можете использовать функцию pandas read_excel, указав ей имя файла. Эта функция открывает и считывает файл и создает DataFrame с его содержимым, готовый к использованию.
На изображении ниже показаны данные, содержащиеся в электронной таблице, в данном случае созданной с помощью Google Drive и сохраненной в формате xlsx с именем data.xlsx.
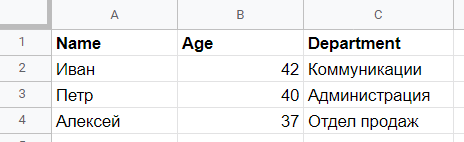
Для загрузки данных из файла и создания DataFrame мы будем использовать функцию read_excel. Эта функция выполняет чтение данных из исходного файла с помощью другой библиотеки. Так как в данном случае формат файла – Excel, используемая библиотека – openpyxl, которую необходимо установить с помощью команды pip install openpyxl. Если нам нужно прочитать файл в формате Open Document Format (например, в LibreOffice), то библиотека для установки – odf.
После установки необходимой библиотеки мы можем использовать функцию read_excel следующим простым способом:
Code language: JavaScript (javascript)
import pandas as pd df = pd.read_excel('data.xlsx') print(df)
Легко, не так ли? Результат на экране будет выглядеть следующим образом:
Name Age Department 0 Иван 42 Коммуникации 1 Петр 40 Администрация 2 Алексей 37 Отдел продаж
Может случиться так, что таблица, которую мы хотим прочитать, находится в определенной строке и столбце файла. В этом случае нам придется указать ему, какие строки игнорировать с помощью параметра skiprows и какие столбцы читать с помощью параметра usecols.
Также возможно, что таблица, которую нам нужно загрузить, находится не на первом листе документа. Мы можем использовать параметр sheet_name для указания листа, на котором он должен искать данные. Мы можем указать номер листа, учитывая, что первый из них – 0, или название листа.
Например, если таблица данных начинается со строки 3 и столбца B листа с названием Employees в файле data.xlsx, мы можем загрузить данные следующим образом: df = pd.read_excel(‘data.xlsx’, sheet_name=’Employees’, usecols=’B:D’, skiprows=2).
Как создать DataFrame из файла JSON
Другой вариант – хранить данные в файле JSON, что очень популярно в настоящее время.
Для создания DataFrame из файла JSON можно использовать функцию pandas read_json, задав ей имя файла следующим образом pandas.read_jason(‘data.json’). Эта функция создает новый DataFrame с данными, содержащимися в предоставленном файле.
Создадим DataFrame с теми же данными, что и в предыдущих примерах, только в этом случае исходный файл будет в формате JSON:
Code language: JSON / JSON with Comments (json)
[ { "Name": "Иван", "Age": 42, "Department": "Коммуникации" }, { "Name": "Петр", "Age": 40, "Department": "Администрация" }, { "Name": "Алексей", "Age": 37, "Department": "Отдел продаж" } ]
Теперь вам остается только использовать функцию read_json, которая будет считывать данные из файла и создавать DataFrame:
Code language: JavaScript (javascript)
import pandas as pd df = pd.read_json('data.json') print(df)
И чтобы не повторяться, результат будет таким же, как и в предыдущих случаях.
Как создать DataFrame из базы данных SQL
Давайте рассмотрим немного более сложный пример, использующий возможности баз данных SQL.
Для создания DataFrame из базы данных SQL можно использовать функцию pandas read_sql, которой необходимо предоставить имя таблицы или SQL-запрос и соединение с базой данных. Функция вернет DataFrame с соответствующими данными, готовый к использованию.
Предположим, что на этот раз у нас есть две разные таблицы в базе данных. Одна из сотрудников и одна из отделов. Таблица сотрудников содержит такие столбцы, как код сотрудника, имя, возраст и код отдела, в котором работает сотрудник. Таблица отдела имеет в качестве столбцов код отдела, название и местоположение.
Мы хотим создать DataFrame, в котором будут столбцы обеих таблиц, которые мы должны объединить с помощью операции объединения в столбце кода отдела.
В вашем случае база данных уже создана в определенной системе управления базами данных, такой как MariaDB или PostgreSQL. В этом примере я буду работать с SQLite.
Убедитесь, что у вас установлена библиотека SQLAlchemy, поскольку она необходима pandas для подключения к базе данных. Вы можете установить его с помощью команды pip install sqlalchemy.
Я создал базу данных под названием database_base.db (оригинально, не правда ли?) со структурой, которую я описал выше. Я также вставил некоторые данные в эти две таблицы. Я оставляю здесь SQL-код, позволяющий создать базу данных в точности как у меня, так что вы можете попробовать этот пример, если вам интересно:
Code language: PHP (php)
BEGIN TRANSACTION; CREATE TABLE IF NOT EXISTS "employees" ( "code" INTEGER NOT NULL, "name" TEXT, "age" INTEGER, "department" INTEGER, PRIMARY KEY("code" AUTOINCREMENT) ); CREATE TABLE IF NOT EXISTS "departments" ( "code" INTEGER NOT NULL, "name" TEXT, "location" TEXT, PRIMARY KEY("code" AUTOINCREMENT) ); INSERT INTO "employees" VALUES (1,'Иван',42,1); INSERT INTO "employees" VALUES (2,'Петр',40,2); INSERT INTO "employees" VALUES (3,'Алексей',37,3); INSERT INTO "employees" VALUES (4,'Анна',29,2); INSERT INTO "employees" VALUES (5,'Мария',32,3); INSERT INTO "departments" VALUES (1,'Коммуникации','Первый этаж'); INSERT INTO "departments" VALUES (2,'Администрация','Второй этаж'); INSERT INTO "departments" VALUES (3,'Отдел продаж','Первый этаж'); COMMIT;
После создания базы данных нам остается только создать несколько DataFrames. Начнем с самого прямого варианта, который заключается в загрузке DataFrame с каждой из таблиц.
Для этого нам просто нужно использовать функцию read_sql, которой мы должны передать два параметра. Первое – это имя таблицы, которую мы хотим прочитать. Второй – это строка подключения к базе данных, которая в нашем случае будет в стиле sqlite:///database_name.db. Мы это видим:
Code language: PHP (php)
import pandas as pd df_employees = pd.read_sql('employees', 'sqlite:///database_base.db') df_departments = pd.read_sql('departments', 'sqlite:///database_base.db') print('Сотрудники:', df_employees, sep='n') print('Отделы:', df_departments, sep='n')
Если вы заметили, теперь у нас есть два DataFrames, это df_employees и df_departments. Когда мы выводим их на экран, то получаем следующее:
Сотрудники: code name age department 0 1 Иван 42 1 1 2 Петр 40 2 2 3 Алексей 37 3 3 4 Анна 29 2 4 5 Мария 32 3 Отделы: code name location 0 1 Коммуникации Первый этаж 1 2 Администрация Второй этаж 2 3 Отдел продаж Первый этаж
Так просто и так быстро. Но теперь давайте сделаем кое-что более сложное, потому что я хочу получить один DataFrame со всеми полями обеих таблиц, объединенными так, чтобы за каждым сотрудником следовала информация его отдела, а не только его код.
Я могу решить это с помощью простой операции объединения между двумя таблицами, которую можно выполнить следующим образом, где я также выбираю только некоторые поля, потому что меня не интересуют коды. SQL-запрос выглядит следующим образом:
Code language: JavaScript (javascript)
select e.name, e.age, d.name as department, d.location from employees as e inner join departments as d on e.department = d.code;
Сила функции read_sql заключается в том, что она позволяет нам задать SQL-запрос для получения нужных нам данных и затем как можно меньше манипулировать DataFrame. Просто введите запрос вместо имени таблицы, и все готово. Код:
Code language: PHP (php)
import pandas as pd query = ''' select e.name, e.age, d.name as department, d.location from employees as e inner join departments as d on e.department = d.code; ''' df = pd.read_sql(query, 'sqlite:///database_base.db') print(df)
Результат следующий:
name age department location 0 Иван 42 Коммуникации Первый этаж 1 Петр 40 Администрация Второй этаж 2 Алексей 37 Отдел продаж Первый этаж 3 Анна 29 Администрация Второй этаж 4 Мария 32 Отдел продаж Первый этаж
Как создать DataFrame из объектов pickle, parquet или Feather, файлов ORC, HDF, запросов SPSS, SAS, Stata или Google BigQuery.
Существуют и другие менее распространенные или более специализированные объекты или файлы данных, из которых также может быть сгенерирован DataFrame.
Если вы прочитали часть этой статьи, вы уже поняли общий подход к созданию DataFrame. Поэтому я не буду приводить примеры всех этих форматов, потому что статья будет слишком длинной (а я думаю, что она и так слишком длинная), но я хочу дать вам список функций, используемых для чтения этих объектов и файлов, чтобы вы знали об их существовании.
Со всеми этими функциями, а также со всеми теми, о которых я уже рассказал, можно ознакомиться в официальной документации pandas.
| Объект или файл | Функция |
| Pickle | read_pickle |
| PyTables, HDF5 | read_hdf |
| Feather | read_feather |
| Parquet | read_parquet |
| ORC | read_orc |
| SAS | read_sas |
| SPSS | read_spss |
| Google BigQuery | read_gbq |
| Stata | read_stata |
Итоговая таблица
Мы рассмотрели несколько способов создания DataFrame с помощью pandas и Python. Если вы прочитали всю статью, то увидели, что все способы очень похожи, хотя каждый из них имеет свои особенности. Идея здесь в том, что пандас хочет сделать нашу жизнь проще, как вы видите.
В качестве резюме я привожу здесь таблицу со всеми рассмотренными нами способами и функциями для создания DataFrame.
| Источник данных | Пример |
| Данные отсутствуют | df = pd.DataFrame(columns=['Столбец 1', 'Столбец 2'])df['Столбец 3'] = Nonedf['Столбец 4'] = None |
| Список списков, список словарей |
df = pd.DataFrame(list) |
| Словарь списков | df = pd.DataFrame(dictionary) |
| Массив NumPy | df = pd.DataFrame(array) |
| Формат CSV | df = pd.read_csv('data.csv')df = pd.read_table('data.csv', delimiter=',') |
| Файл с полями поля фиксированной ширины |
df = pd.read_fwf(‘data.fwf’) |
| Данные в буфере обмена | df = pd.read_clipboard() |
| Веб-файлы или файлы HTML | dfs = pd.read_html('data.html')dfs = pd.read_html(url) |
| Электронная таблица | df = pd.read_excel(‘data.xlsx’) |
| JSON-файл | df = pd.read_json(‘data.json’) |
| База данных SQL | df = pd.read_sql(table, connection_bd)df = pd.read_sql(query, connection_bd) |
| Другие форматы | См. таблицу 2 |