
I want to use excel files to store data elaborated with python. My problem is that I can’t add sheets to an existing excel file. Here I suggest a sample code to work with in order to reach this issue
import pandas as pd
import numpy as np
path = r"C:UsersfedelDesktopexcelDataPhD_data.xlsx"
x1 = np.random.randn(100, 2)
df1 = pd.DataFrame(x1)
x2 = np.random.randn(100, 2)
df2 = pd.DataFrame(x2)
writer = pd.ExcelWriter(path, engine = 'xlsxwriter')
df1.to_excel(writer, sheet_name = 'x1')
df2.to_excel(writer, sheet_name = 'x2')
writer.save()
writer.close()
This code saves two DataFrames to two sheets, named «x1» and «x2» respectively. If I create two new DataFrames and try to use the same code to add two new sheets, ‘x3’ and ‘x4’, the original data is lost.
import pandas as pd
import numpy as np
path = r"C:UsersfedelDesktopexcelDataPhD_data.xlsx"
x3 = np.random.randn(100, 2)
df3 = pd.DataFrame(x3)
x4 = np.random.randn(100, 2)
df4 = pd.DataFrame(x4)
writer = pd.ExcelWriter(path, engine = 'xlsxwriter')
df3.to_excel(writer, sheet_name = 'x3')
df4.to_excel(writer, sheet_name = 'x4')
writer.save()
writer.close()
I want an excel file with four sheets: ‘x1’, ‘x2’, ‘x3’, ‘x4’.
I know that ‘xlsxwriter’ is not the only «engine», there is ‘openpyxl’. I also saw there are already other people that have written about this issue, but still I can’t understand how to do that.
Here a code taken from this link
import pandas
from openpyxl import load_workbook
book = load_workbook('Masterfile.xlsx')
writer = pandas.ExcelWriter('Masterfile.xlsx', engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
data_filtered.to_excel(writer, "Main", cols=['Diff1', 'Diff2'])
writer.save()
They say that it works, but it is hard to figure out how. I don’t understand what «ws.title», «ws», and «dict» are in this context.
Which is the best way to save «x1» and «x2», then close the file, open it again and add «x3» and «x4»?
В Pandas есть встроенная функция для сохранения датафрейма в электронную таблицу Excel. Все очень просто:
|
df.to_excel( path ) # где path это путь до файла, куда будем сохранять |
Как записать в лист с заданным именем
В этом случае будет создан xls / xlsx файл, а данные сохранятся на лист с именем Sheet1. Если хочется сохранить на лист с заданным именем, то можно использовать конструкцию:
|
df.to_excel( path, sheet_name=«Лист 1») # где sheet_name название листа |
Как записать в один файл сразу два листа
Но что делать, если хочется записать в файл сразу два листа? Логично было бы использовать две команды
df.to_excel друг за другом, но с одним путем до файла и разными
sheet_name , однако в Pandas это так не работает. Для решения этой задачи придется использовать конструкцию посложнее:
|
from pandas.io.excel import ExcelWriter with ExcelWriter(path) as writer: df.sample(10).to_excel(writer, sheet_name=«Лист 1») df.sample(10).to_excel(writer, sheet_name=«Лист 2») |
В результате будет создан файл Excel, где будет два листа с именами Лист 1 и Лист 2.
Как добавить ещё один лист у уже существующему файлу
Если использовать предыдущий код, то текущий файл будет перезаписан и в него будет записан новый лист. Старые данные при этом, ожидаемо, будут утеряны. Выход есть, достаточно лишь добавить модификатор «a» (append):
|
with ExcelWriter(path, mode=«a») as writer: df.sample(10).to_excel(writer, sheet_name=«Лист 3») |
Но что, если оставить этот код, удалить существующий файл Excel и попробовать выполнить код? Получим ошибку Файл не найден. В Python существует модификатор «a+», который создает файл, если его нет, и открывает его на редактирование, если файл существует. Но в Pandas такого модификатора не существует, поэтому мы должны выбрать модификатор для ExcelWriter в зависимости от наличия или отсутствия файла. Но это не сложно:
|
with ExcelWriter(path, mode=«a» if os.path.exists(path) else «w») as writer: df.sample().to_excel(writer, sheet_name=«Лист 4») |
К сожалению в Pandas, на момент написания поста, такого функционала нет. Но это можно реализовать с помощью пакета openpyxl. Вот пример такой функции:
|
def update_spreadsheet(path : str, _df, starcol : int = 1, startrow : int = 1, sheet_name : str =«ToUpdate»): »’ :param path: Путь до файла Excel :param _df: Датафрейм Pandas для записи :param starcol: Стартовая колонка в таблице листа Excel, куда буду писать данные :param startrow: Стартовая строка в таблице листа Excel, куда буду писать данные :param sheet_name: Имя листа в таблице Excel, куда буду писать данные :return: »’ wb = ox.load_workbook(path) for ir in range(0, len(_df)): for ic in range(0, len(_df.iloc[ir])): wb[sheet_name].cell(startrow + ir, starcol + ic).value = _df.iloc[ir][ic] wb.save(path) |
Как работает код и пояснения смотри в видео
Если у тебя есть вопросы, что-то не получается или ты знаешь как решить задачи в посте лучше и эффективнее (такое вполне возможно) то смело пиши в комментариях к видео.
Skip to content
![]()
Home » Python » Add new sheet to excel using pandas
A data frame can be added as a new sheet to an existing excel sheet. For this operation, the library required is openpyxl.
You can install this library using below command in Jupyter notebook. The same command can be executed in command prompt without the exclamation character “!”.
|
# Installing library for excel interaction using pandas !pip install openpyxl |
You can add the data from multiple DataFrames, each becoming one sheet.
Below snippet loads a pre-existing excel sheet and adds two more sheets to it using two different data frames.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import pandas as pd import numpy as np from openpyxl import load_workbook # Defining the path which excel needs to be created # There must be a pre-existing excel sheet which can be updated FilePath = «/Users/farukh/Python ML IVY-May-2020/CarPricesData.xlsx» # Generating workbook ExcelWorkbook = load_workbook(FilePath) # Generating the writer engine writer = pd.ExcelWriter(FilePath, engine = ‘openpyxl’) # Assigning the workbook to the writer engine writer.book = ExcelWorkbook # Creating first dataframe DataSample1= [[10,‘value1’], [20,‘value2’], [30,‘value3’]] SimpleDataFrame1=pd.DataFrame(data=DataSample1, columns=[‘Col1’,‘Col2’]) print(SimpleDataFrame1) # Creating second dataframe DataSample2= [[100,‘A’], [200,‘B’], [300,‘C’]] SimpleDataFrame2=pd.DataFrame(data=DataSample2, columns=[‘colA’,‘colB’]) print(SimpleDataFrame2) # Adding the DataFrames to the excel as a new sheet SimpleDataFrame1.to_excel(writer, sheet_name = ‘Data1’) SimpleDataFrame2.to_excel(writer, sheet_name = ‘Data2’) writer.save() writer.close() |

Lead Data Scientist
Farukh is an innovator in solving industry problems using Artificial intelligence. His expertise is backed with 10 years of industry experience. Being a senior data scientist he is responsible for designing the AI/ML solution to provide maximum gains for the clients. As a thought leader, his focus is on solving the key business problems of the CPG Industry. He has worked across different domains like Telecom, Insurance, and Logistics. He has worked with global tech leaders including Infosys, IBM, and Persistent systems. His passion to teach inspired him to create this website!
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, we will see how to export different DataFrames to different excel sheets using python.
Pandas provide a function called xlsxwriter for this purpose. ExcelWriter() is a class that allows you to write DataFrame objects into Microsoft Excel sheets. Text, numbers, strings, and formulas can all be written using ExcelWriter(). It can also be used on several worksheets.
Syntax:
pandas.ExcelWriter(path, date_format=None, mode=’w’)
Parameter:
- path: (str) Path to xls or xlsx or ods file.
- date_format: Format string for dates written into Excel files (e.g. ‘YYYY-MM-DD’). str, default None
- mode: {‘w’, ‘a’}, default ‘w’. File mode to use (write or append). Append does not work with fsspec URLs.
The to_excel() method is used to export the DataFrame to the excel file. To write a single object to the excel file, we have to specify the target file name. If we want to write to multiple sheets, we need to create an ExcelWriter object with target filename and also need to specify the sheet in the file in which we have to write. The multiple sheets can also be written by specifying the unique sheet_name. It is necessary to save the changes for all the data written to the file.
Syntax:
DataFrame.to_excel(excel_writer, sheet_name=’Sheet1′,index=True)
Parameter:
- excel_writer: path-like, file-like, or ExcelWriter object (new or existing)
- sheet_name: (str, default ‘Sheet1’). Name of the sheet which will contain DataFrame.
- index: (bool, default True). Write row names (index).
Create some sample data frames using pandas.DataFrame function. Now, create a writer variable and specify the path in which you wish to store the excel file and the file name, inside the pandas excelwriter function.
Example: Write Pandas dataframe to multiple excel sheets
Python3
import pandas as pd
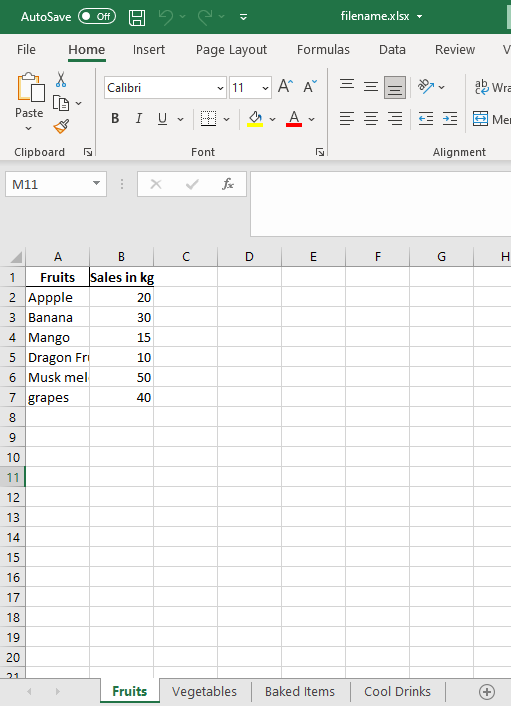
data_frame1 = pd.DataFrame({'Fruits': ['Appple', 'Banana', 'Mango',
'Dragon Fruit', 'Musk melon', 'grapes'],
'Sales in kg': [20, 30, 15, 10, 50, 40]})
data_frame2 = pd.DataFrame({'Vegetables': ['tomato', 'Onion', 'ladies finger',
'beans', 'bedroot', 'carrot'],
'Sales in kg': [200, 310, 115, 110, 55, 45]})
data_frame3 = pd.DataFrame({'Baked Items': ['Cakes', 'biscuits', 'muffins',
'Rusk', 'puffs', 'cupcakes'],
'Sales in kg': [120, 130, 159, 310, 150, 140]})
print(data_frame1)
print(data_frame2)
print(data_frame3)
with pd.ExcelWriter("path to filefilename.xlsx") as writer:
data_frame1.to_excel(writer, sheet_name="Fruits", index=False)
data_frame2.to_excel(writer, sheet_name="Vegetables", index=False)
data_frame3.to_excel(writer, sheet_name="Baked Items", index=False)
Output:

The output showing the excel file with different sheets got saved in the specified location.

Example 2: Another method to store the dataframe in an existing excel file using excelwriter is shown below,
Create dataframe(s) and Append them to the existing excel file shown above using mode= ‘a’ (meaning append) in the excelwriter function. Using mode ‘a’ will add the new sheet as the last sheet in the existing excel file.
Python3
import pandas as pd
data_frame1 = pd.DataFrame({'Fruits': ['Appple', 'Banana', 'Mango',
'Dragon Fruit', 'Musk melon', 'grapes'],
'Sales in kg': [20, 30, 15, 10, 50, 40]})
data_frame2 = pd.DataFrame({'Vegetables': ['tomato', 'Onion', 'ladies finger',
'beans', 'bedroot', 'carrot'],
'Sales in kg': [200, 310, 115, 110, 55, 45]})
data_frame3 = pd.DataFrame({'Baked Items': ['Cakes', 'biscuits', 'muffins',
'Rusk', 'puffs', 'cupcakes'],
'Sales in kg': [120, 130, 159, 310, 150, 140]})
data_frame4 = pd.DataFrame({'Cool drinks': ['Pepsi', 'Coca-cola', 'Fanta',
'Miranda', '7up', 'Sprite'],
'Sales in count': [1209, 1230, 1359, 3310, 2150, 1402]})
with pd.ExcelWriter("path_to_file.xlsx", mode="a", engine="openpyxl") as writer:
data_frame4.to_excel(writer, sheet_name="Cool drinks")
Output:

Writing Large Pandas DataFrame to excel file in a zipped format.
If the output dataframe is large, you can also store the excel file as a zipped file. Let’s save the dataframe which we created for this example. as excel and store it as a zip file. The ZIP file format is a common archive and compression standard.
Syntax:
ZipFile(file, mode=’r’)
Parameter:
- file: the file can be a path to a file (a string), a file-like object, or a path-like object.
- mode: The mode parameter should be ‘r’ to read an existing file, ‘w’ to truncate and write a new file, ‘a’ to append to an existing file, or ‘x’ to exclusively create and write a new file.
Import the zipfile package and create sample dataframes. Now, specify the path in which the zip file has to be stored, This creates a zip file in the specified path. Create a file name in which the excel file has to be stored. Use to_excel() function and specify the sheet name and index to store the dataframe in multiple sheets
Example: Write large dataframes in ZIP format
Python3
import zipfile
import pandas as pd
data_frame1 = pd.DataFrame({'Fruits': ['Appple', 'Banana', 'Mango',
'Dragon Fruit', 'Musk melon', 'grapes'],
'Sales in kg': [20, 30, 15, 10, 50, 40]})
data_frame2 = pd.DataFrame({'Vegetables': ['tomato', 'Onion', 'ladies finger',
'beans', 'bedroot', 'carrot'],
'Sales in kg': [200, 310, 115, 110, 55, 45]})
data_frame3 = pd.DataFrame({'Baked Items': ['Cakes', 'biscuits', 'muffins',
'Rusk', 'puffs', 'cupcakes'],
'Sales in kg': [120, 130, 159, 310, 150, 140]})
data_frame4 = pd.DataFrame({'Cool drinks': ['Pepsi', 'Coca-cola', 'Fanta',
'Miranda', '7up', 'Sprite'],
'Sales in count': [1209, 1230, 1359, 3310, 2150, 1402]})
with zipfile.ZipFile("path_to_file.zip", "w") as zf:
with zf.open("filename.xlsx", "w") as buffer:
with pd.ExcelWriter(buffer) as writer:
data_frame1.to_excel(writer, sheet_name="Fruits", index=False)
data_frame2.to_excel(writer, sheet_name="Vegetables", index=False)
data_frame3.to_excel(writer, sheet_name="Baked Items", index=False)
data_frame4.to_excel(writer, sheet_name="Cool Drinks", index=False)
Output:
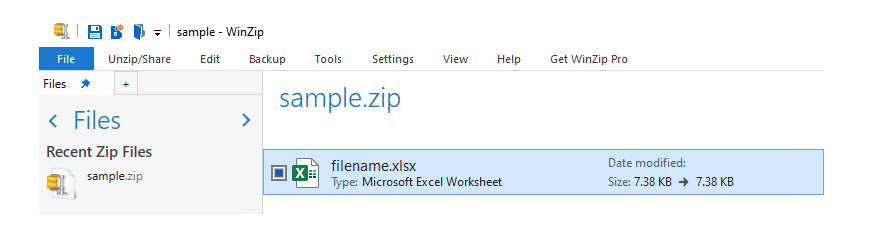
Sample output of zipped excel file
Like Article
Save Article
Write Excel with Python Pandas. You can write any data (lists, strings, numbers etc) to Excel, by first converting it into a Pandas DataFrame and then writing the DataFrame to Excel.
To export a Pandas DataFrame as an Excel file (extension: .xlsx, .xls), use the to_excel() method.
Related course: Data Analysis with Python Pandas
installxlwt, openpyxl
to_excel() uses a library called xlwt and openpyxl internally.
- xlwt is used to write .xls files (formats up to Excel2003)
- openpyxl is used to write .xlsx (Excel2007 or later formats).
Both can be installed with pip. (pip3 depending on the environment)
1 |
$ pip install xlwt |
Write Excel
Write DataFrame to Excel file
Importing openpyxl is required if you want to append it to an existing Excel file described at the end.
A dataframe is defined below:
1 |
import pandas as pd |
You can specify a path as the first argument of the to_excel() method.
Note: that the data in the original file is deleted when overwriting.
The argument new_sheet_name is the name of the sheet. If omitted, it will be named Sheet1.
1 |
df.to_excel('pandas_to_excel.xlsx', sheet_name='new_sheet_name') |
Related course: Data Analysis with Python Pandas
If you do not need to write index (row name), columns (column name), the argument index, columns is False.
1 |
df.to_excel('pandas_to_excel_no_index_header.xlsx', index=False, header=False) |
Write multiple DataFrames to Excel files
The ExcelWriter object allows you to use multiple pandas. DataFrame objects can be exported to separate sheets.
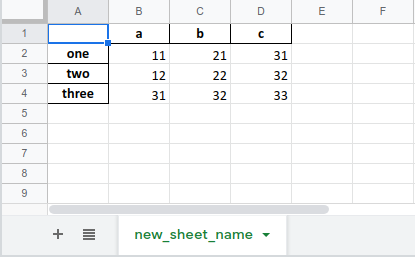
As an example, pandas. Prepare another DataFrame object.
1 |
df2 = df[['a', 'c']] |
Then use the ExcelWriter() function like this:
1 |
with pd.ExcelWriter('pandas_to_excel.xlsx') as writer: |
You don’t need to call writer.save(), writer.close() within the blocks.
Append to an existing Excel file
You can append a DataFrame to an existing Excel file. The code below opens an existing file, then adds two sheets with the data of the dataframes.
Note: Because it is processed using openpyxl, only .xlsx files are included.
1 |
path = 'pandas_to_excel.xlsx' |
Related course: Data Analysis with Python Pandas
Use pandas to_excel() function to write a DataFrame to an excel sheet with extension .xlsx. By default it writes a single DataFrame to an excel file, you can also write multiple sheets by using an ExcelWriter object with a target file name, and sheet name to write to.
Note that creating an ExcelWriter object with a file name that already exists will result in the contents of the existing file being erased.
Related: pandas read Excel Sheet
pandas to Excel key Points
- By default, it uses xlsxwriter if it is installed otherwise it uses openpyxl
- Supports saving multiple DataFrames to single sheet.
- Save multiple sheets, append existing sheet or file.
- Use ExcelWriter()
Let’s create a pandas DataFrame from list and explore usingto_excel() function by using multiple parameters.
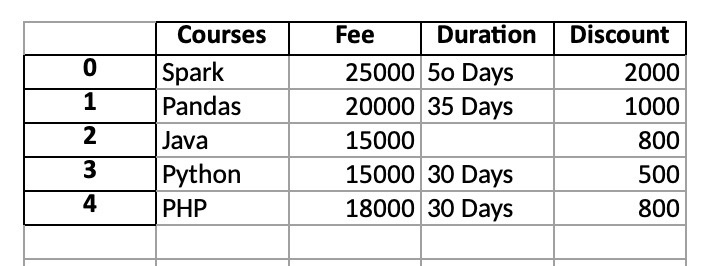
import pandas as pd
import numpy as np
# Create multiple lists
technologies = ['Spark','Pandas','Java','Python', 'PHP']
fee = [25000,20000,15000,15000,18000]
duration = ['5o Days','35 Days',np.nan,'30 Days', '30 Days']
discount = [2000,1000,800,500,800]
columns=['Courses','Fee','Duration','Discount']
# Create DataFrame from multiple lists
df = pd.DataFrame(list(zip(technologies,fee,duration,discount)), columns=columns)
print(df)
# Outputs
# Courses Fee Duration Discount
#0 Spark 25000 5o Days 2000
#1 Pandas 20000 35 Days 1000
#2 Java 15000 NaN 800
#3 Python 15000 30 Days 500
#4 PHP 18000 30 Days 800
1. pandas DataFrame to Excel
Use to_excel() function to write or export pandas DataFrame to excel sheet with extension xslx. Using this you can write excel files to the local file system, S3 e.t.c. Not specifying any parameter it default writes to a single sheet.
to_excel() takes several optional params that can be used skip columns, skip rows, not to write index, set column names, formatting, and many more.
# Write DataFrame to Excel file
df.to_excel('Courses.xlsx')
This creates an excel file with the contents as below. By default, It exports column names, indexes, and data to a sheet named 'Sheet1'.
You can change the name of the sheet from Sheet1 to something that makes sense to your data by using sheet_name param. The below example exports it to the sheet named ‘Technologies‘.
# Write DataFrame to Excel file with sheet name
df.to_excel('Courses.xlsx', sheet_name='Technologies')
2. Write to Multiple Sheets
The ExcelWriter class allows you to write or export multiple pandas DataFrames to separate sheets. First, you need to create an object for ExcelWriter.
The below example writes data from df object to a sheet named Technologies and df2 object to a sheet named Schedule.
# Write to Multiple Sheets
with pd.ExcelWriter('Courses.xlsx') as writer:
df.to_excel(writer, sheet_name='Technologies')
df2.to_excel(writer, sheet_name='Schedule')
3. Append to Existing Excel File
ExcelWriter can be used to append DataFrame to an excel file. Use mode param with value 'a' to append. The code below opens an existing file and adds data from the DataFrame to the specified sheet.
# Append DataFrame to existing excel file
with pd.ExcelWriter('Courses.xlsx',mode='a') as writer:
df.to_excel(writer, sheet_name='Technologies')
4. Save Selected Columns
use param columns to save selected columns from DataFrame to excel file. The below example only saves columns Fee, Duration to excel file.
# Save Selected Columns to Excel File
df.to_excel('Courses.xlsx', columns = ['Fee','Duration'])
Use header param with a list of values if you wanted to write with different column names.
5. Skip Index
To skip Index from writing use index=False param. By default, it is set to True meaning write numerical Index to excel sheet.
# Skip Index
df.to_excel('Courses.xlsx', index = False)
Conclusion
In this article, you have learned how to write pandas DataFrame to excel file by using to_excel(). Also explored how to write to specific sheets, multiple sheets, and append to existing excel file.
Related Articles
- pandas ExcelWriter Usage with Examples
- pandas write CSV file
- pandas read Excel
- Pandas ExcelWriter Explained with Examples
- Pandas Read Multiple CSV Files into DataFrame
- How to Read Excel Multiple Sheets in Pandas
- Pretty Print Pandas DataFrame or Series?
- Pandas Handle Missing Data in Dataframe
- How to read CSV without headers in pandas
References
- https://stackoverflow.com/questions/38074678/append-existing-excel-sheet-with-new-dataframe-using-python-pandas/38075046#38075046
In this tutorial, you’ll learn how to save your Pandas DataFrame or DataFrames to Excel files. Being able to save data to this ubiquitous data format is an important skill in many organizations. In this tutorial, you’ll learn how to save a simple DataFrame to Excel, but also how to customize your options to create the report you want!
By the end of this tutorial, you’ll have learned:
- How to save a Pandas DataFrame to Excel
- How to customize the sheet name of your DataFrame in Excel
- How to customize the index and column names when writing to Excel
- How to write multiple DataFrames to Excel in Pandas
- Whether to merge cells or freeze panes when writing to Excel in Pandas
- How to format missing values and infinity values when writing Pandas to Excel
Let’s get started!
The Quick Answer: Use Pandas to_excel
To write a Pandas DataFrame to an Excel file, you can apply the .to_excel() method to the DataFrame, as shown below:
# Saving a Pandas DataFrame to an Excel File
# Without a Sheet Name
df.to_excel(file_name)
# With a Sheet Name
df.to_excel(file_name, sheet_name='My Sheet')
# Without an Index
df.to_excel(file_name, index=False)Understanding the Pandas to_excel Function
Before diving into any specifics, let’s take a look at the different parameters that the method offers. The method provides a ton of different options, allowing you to customize the output of your DataFrame in many different ways. Let’s take a look:
# The many parameters of the .to_excel() function
df.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options=None)Let’s break down what each of these parameters does:
| Parameter | Description | Available Options |
|---|---|---|
excel_writer= |
The path of the ExcelWriter to use | path-like, file-like, or ExcelWriter object |
sheet_name= |
The name of the sheet to use | String representing name, default ‘Sheet1’ |
na_rep= |
How to represent missing data | String, default '' |
float_format= |
Allows you to pass in a format string to format floating point values | String |
columns= |
The columns to use when writing to the file | List of strings. If blank, all will be written |
header= |
Accepts either a boolean or a list of values. If a boolean, will either include the header or not. If a list of values is provided, aliases will be used for the column names. | Boolean or list of values |
index= |
Whether to include an index column or not. | Boolean |
index_label= |
Column labels to use for the index. | String or list of strings. |
startrow= |
The upper left cell to start the DataFrame on. | Integer, default 0 |
startcol= |
The upper left column to start the DataFrame on | Integer, default 0 |
engine= |
The engine to use to write. | openpyxl or xlsxwriter |
merge_cells= |
Whether to write multi-index cells or hierarchical rows as merged cells | Boolean, default True |
encoding= |
The encoding of the resulting file. | String |
inf_rep= |
How to represent infinity values (as Excel doesn’t have a representation) | String, default 'inf' |
verbose= |
Whether to display more information in the error logs. | Boolean, default True |
freeze_panes= |
Allows you to pass in a tuple of the row, column to start freezing panes on | Tuple of integers with length 2 |
storage_options= |
Extra options that allow you to save to a particular storage connection | Dictionary |
.to_excel() methodHow to Save a Pandas DataFrame to Excel
The easiest way to save a Pandas DataFrame to an Excel file is by passing a path to the .to_excel() method. This will save the DataFrame to an Excel file at that path, overwriting an Excel file if it exists already.
Let’s take a look at how this works:
# Saving a Pandas DataFrame to an Excel File
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx')Running the code as shown above will save the file with all other default parameters. This returns the following image:
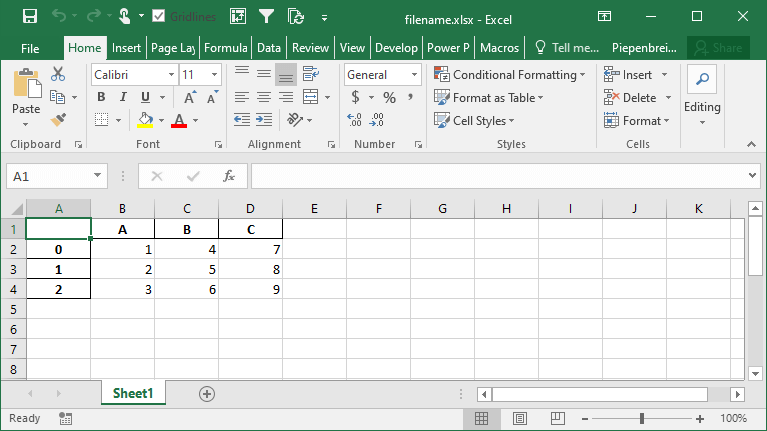
You can specify a sheetname by using the sheet_name= parameter. By default, Pandas will use 'sheet1'.
# Specifying a Sheet Name When Saving to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', sheet_name='Your Sheet')This returns the following workbook:
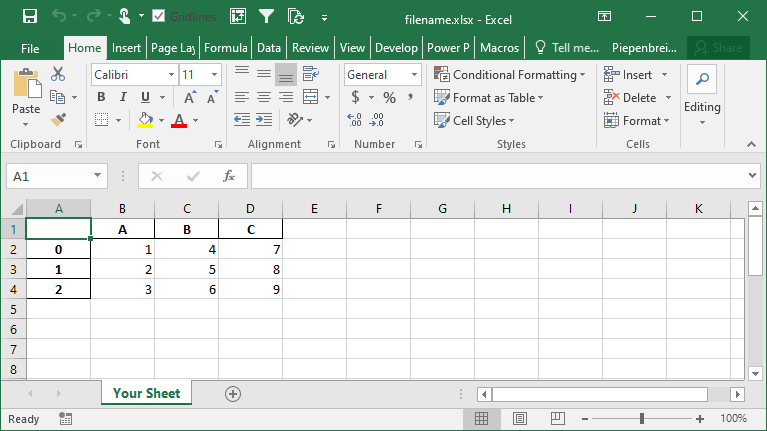
In the following section, you’ll learn how to customize whether to include an index column or not.
How to Include an Index when Saving a Pandas DataFrame to Excel
By default, Pandas will include the index when saving a Pandas Dataframe to an Excel file. This can be helpful when the index is a meaningful index (such as a date and time). However, in many cases, the index will simply represent the values from 0 through to the end of the records.
If you don’t want to include the index in your Excel file, you can use the index= parameter, as shown below:
# How to exclude the index when saving a DataFrame to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', index=False)This returns the following Excel file:
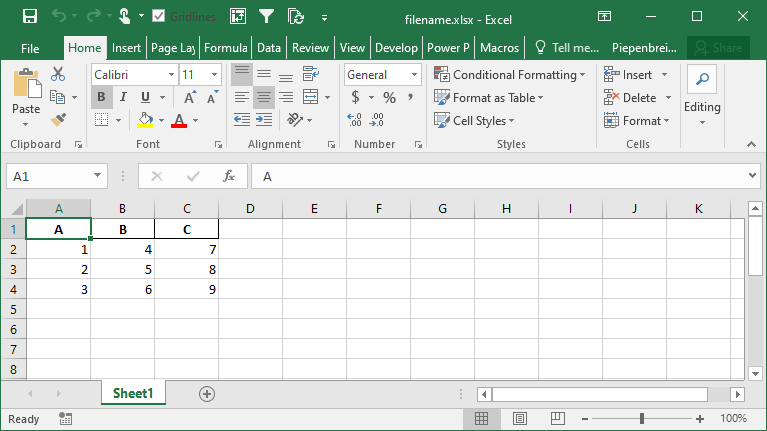
In the following section, you’ll learn how to rename an index when saving a Pandas DataFrame to an Excel file.
How to Rename an Index when Saving a Pandas DataFrame to Excel
By default, Pandas will not named the index of your DataFrame. This, however, can be confusing and can lead to poorer results when trying to manipulate the data in Excel, either by filtering or by pivoting the data. Because of this, it can be helpful to provide a name or names for your indices.
Pandas makes this easy by using the index_label= parameter. This parameter accepts either a single string (for a single index) or a list of strings (for a multi-index). Check out below how you can use this parameter:
# Providing a name for your Pandas index
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', index_label='Your Index')This returns the following sheet:
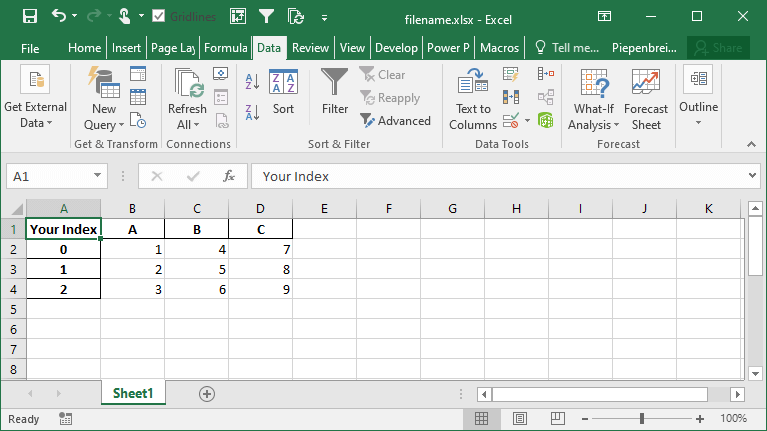
How to Save Multiple DataFrames to Different Sheets in Excel
One of the tasks you may encounter quite frequently is the need to save multi Pandas DataFrames to the same Excel file, but in different sheets. This is where Pandas makes it a less intuitive. If you were to simply write the following code, the second command would overwrite the first command:
# The wrong way to save multiple DataFrames to the same workbook
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', sheet_name='Sheet1')
df.to_excel('filename.xlsx', sheet_name='Sheet2')Instead, we need to use a Pandas Excel Writer to manage opening and saving our workbook. This can be done easily by using a context manager, as shown below:
# The Correct Way to Save Multiple DataFrames to the Same Workbook
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
with pd.ExcelWriter('filename.xlsx') as writer:
df.to_excel(writer, sheet_name='Sheet1')
df.to_excel(writer, sheet_name='Sheet2')This will create multiple sheets in the same workbook. The sheets will be created in the same order as you specify them in the command above.
This returns the following workbook:
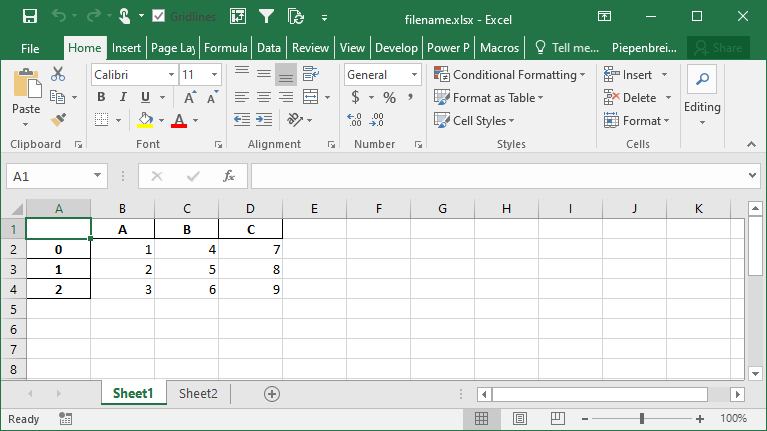
How to Save Only Some Columns when Exporting Pandas DataFrames to Excel
When saving a Pandas DataFrame to an Excel file, you may not always want to save every single column. In many cases, the Excel file will be used for reporting and it may be redundant to save every column. Because of this, you can use the columns= parameter to accomplish this.
Let’s see how we can save only a number of columns from our dataset:
# Saving Only a Subset of Columns to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', columns=['A', 'B'])This returns the following Excel file:
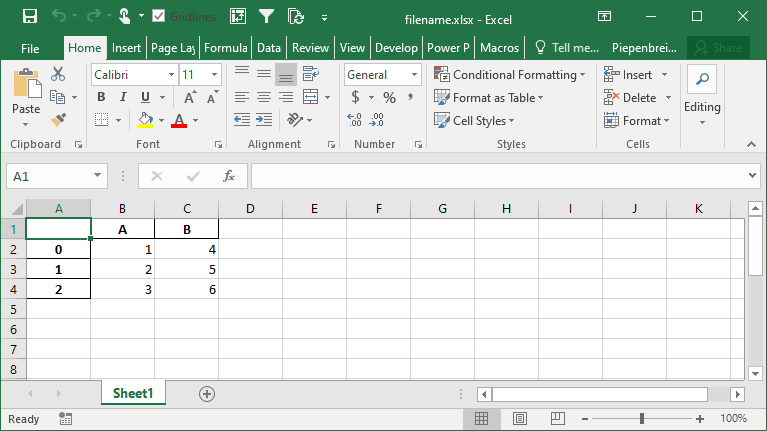
How to Rename Columns when Exporting Pandas DataFrames to Excel
Continuing our discussion about how to handle Pandas DataFrame columns when exporting to Excel, we can also rename our columns in the saved Excel file. The benefit of this is that we can work with aliases in Pandas, which may be easier to write, but then output presentation-ready column names when saving to Excel.
We can accomplish this using the header= parameter. The parameter accepts either a boolean value of a list of values. If a boolean value is passed, you can decide whether to include or a header or not. When a list of strings is provided, then you can modify the column names in the resulting Excel file, as shown below:
# Modifying Column Names when Exporting a Pandas DataFrame to Excel
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', header=['New_A', 'New_B', 'New_C'])This returns the following Excel sheet:
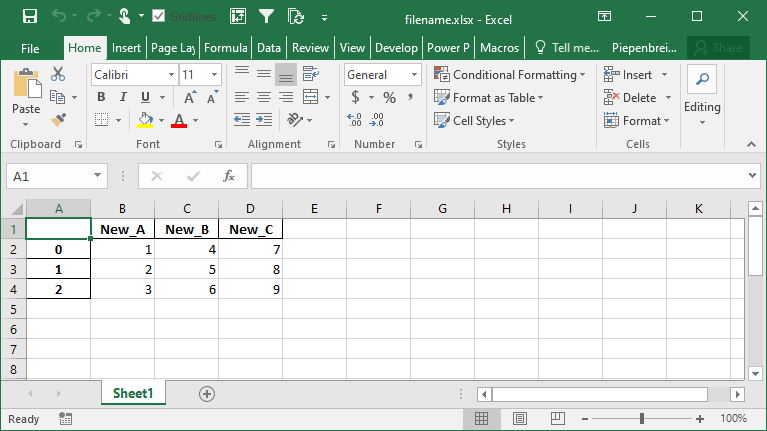
How to Specify Starting Positions when Exporting a Pandas DataFrame to Excel
One of the interesting features that Pandas provides is the ability to modify the starting position of where your DataFrame will be saved on the Excel sheet. This can be helpful if you know you’ll be including different rows above your data or a logo of your company.
Let’s see how we can use the startrow= and startcol= parameters to modify this:
# Changing the Start Row and Column When Saving a DataFrame to an Excel File
import pandas as pd
df = pd.DataFrame.from_dict(
{'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
)
df.to_excel('filename.xlsx', startcol=3, startrow=2)This returns the following worksheet:
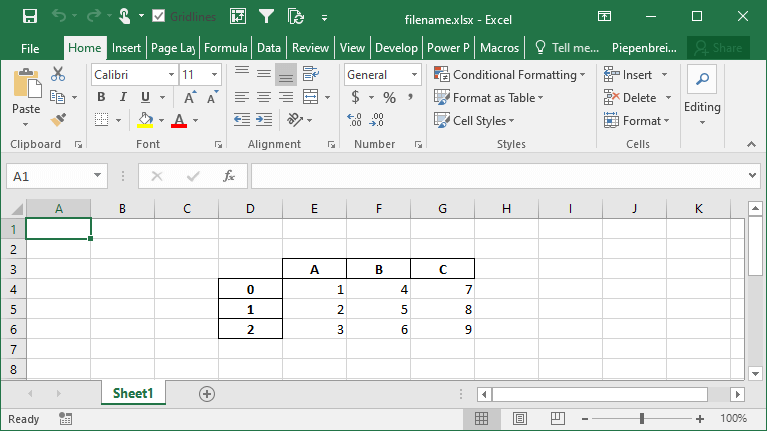
How to Represent Missing and Infinity Values When Saving Pandas DataFrame to Excel
In this section, you’ll learn how to represent missing data and infinity values when saving a Pandas DataFrame to Excel. Because Excel doesn’t have a way to represent infinity, Pandas will default to the string 'inf' to represent any values of infinity.
In order to modify these behaviors, we can use the na_rep= and inf_rep= parameters to modify the missing and infinity values respectively. Let’s see how we can do this by adding some of these values to our DataFrame:
# Customizing Output of Missing and Infinity Values When Saving to Excel
import pandas as pd
import numpy as np
df = pd.DataFrame.from_dict(
{'A': [1, np.NaN, 3], 'B': [4, 5, np.inf], 'C': [7, 8, 9]}
)
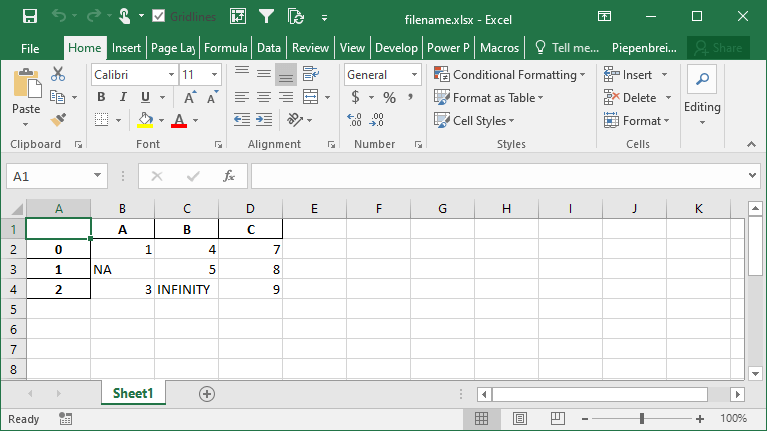
df.to_excel('filename.xlsx', na_rep='NA', inf_rep='INFINITY')This returns the following worksheet:
How to Merge Cells when Writing Multi-Index DataFrames to Excel
In this section, you’ll learn how to modify the behavior of multi-index DataFrames when saved to Excel. By default Pandas will set the merge_cells= parameter to True, meaning that the cells will be merged. Let’s see what happens when we set this behavior to False, indicating that the cells should not be merged:
# Modifying Merge Cell Behavior for Multi-Index DataFrames
import pandas as pd
import numpy as np
from random import choice
df = pd.DataFrame.from_dict({
'A': np.random.randint(0, 10, size=50),
'B': [choice(['a', 'b', 'c']) for i in range(50)],
'C': np.random.randint(0, 3, size=50)})
pivot = df.pivot_table(index=['B', 'C'], values='A')
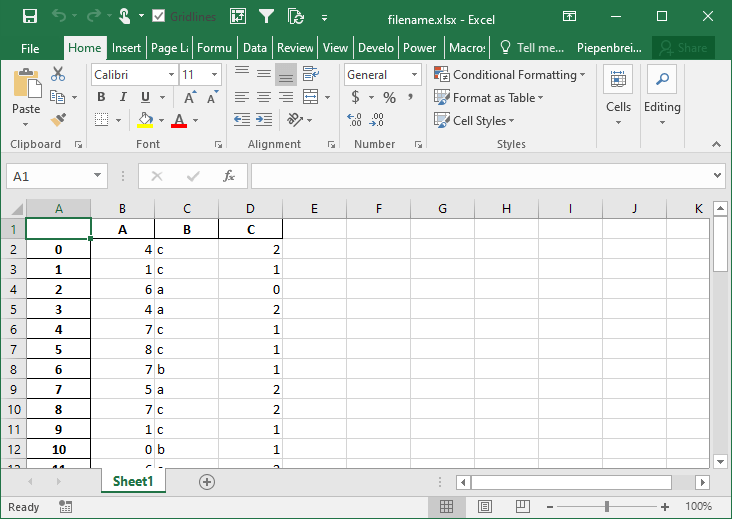
pivot.to_excel('filename.xlsx', merge_cells=False)This returns the Excel worksheet below:
How to Freeze Panes when Saving a Pandas DataFrame to Excel
In this final section, you’ll learn how to freeze panes in your resulting Excel worksheet. This allows you to specify the row and column at which you want Excel to freeze the panes. This can be done using the freeze_panes= parameter. The parameter accepts a tuple of integers (of length 2). The tuple represents the bottommost row and the rightmost column that is to be frozen.
Let’s see how we can use the freeze_panes= parameter to freeze our panes in Excel:
# Freezing Panes in an Excel Workbook Using Pandas
import pandas as pd
import numpy as np
df = pd.DataFrame.from_dict(
{'A': [1, np.NaN, 3], 'B': [4, 5, np.inf], 'C': [7, 8, 9]}
)
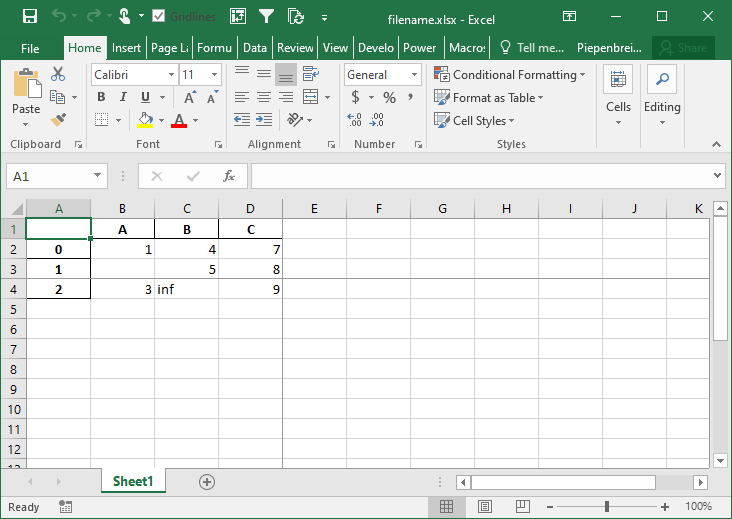
df.to_excel('filename.xlsx', freeze_panes=(3,4))This returns the following workbook:
Conclusion
In this tutorial, you learned how to save a Pandas DataFrame to an Excel file using the to_excel method. You first explored all of the different parameters that the function had to offer at a high level. Following that, you learned how to use these parameters to gain control over how the resulting Excel file should be saved. For example, you learned how to specify sheet names, index names, and whether to include the index or not. Then you learned how to include only some columns in the resulting file and how to rename the columns of your DataFrame. You also learned how to modify the starting position of the data and how to freeze panes.
Additional Resources
To learn more about related topics, check out the tutorials below:
- How to Use Pandas to Read Excel Files in Python
- Pandas Dataframe to CSV File – Export Using .to_csv()
- Introduction to Pandas for Data Science
- Official Documentation: Pandas to_excel
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
Comments
![]()
The ability of ExcelWriter to save different dataframes to different worksheets is great for sharing those dfs with the python-deficient. But this quickly leads to a need to add worksheets to an existing workbook, not just creating one from scratch; something like:
df0=pd.DataFrame(np.arange(3))
df0.to_excel('foo.xlsx','Data 0')
df1=pd.DataFrame(np.arange(2))
df1.to_excel('foo.xlsx','Data 1')
The following little diff to io/parsers.py implements this behavior for *.xlsx files:
diff --git a/pandas/io/parsers.py b/pandas/io/parsers.py
index 89f892d..7f010ee 100644
--- a/pandas/io/parsers.py
+++ b/pandas/io/parsers.py
@@ -2099,12 +2099,19 @@ class ExcelWriter(object):
self.fm_date = xlwt.easyxf(num_format_str='YYYY-MM-DD')
else:
from openpyxl.workbook import Workbook
- self.book = Workbook() # optimized_write=True)
- # open pyxl 1.6.1 adds a dummy sheet remove it
- if self.book.worksheets:
- self.book.remove_sheet(self.book.worksheets[0])
+ from openpyxl.reader.excel import load_workbook
+
+ try:
+ self.book=load_workbook(filename = path)
+ self.sheets={wks.title:wks for wks in self.book.worksheets}
+ except InvalidFileException:
+ self.book = Workbook() # optimized_write=True)
+ # open pyxl 1.6.1 adds a dummy sheet remove it
+ if self.book.worksheets:
+ self.book.remove_sheet(self.book.worksheets[0])
+ self.sheets = {}
+
self.path = path
- self.sheets = {}
self.cur_sheet = None
Doing this for *.xls files is a little harder.
![]()
@jtratner is this still a bug/needed enhancement?
![]()
Because of how to_excel is set up, this would mean reading in and then writing the file each time (because to_excel with a path argument saves the file). The right way to do this is to use ExcelWriter:
import pandas as pd writer = pd.ExcelWriter('foo.xlsx') df.to_excel(writer, 'Data 0') df.to_excel(writer, 'Data 1') writer.save()
I could see (eventually) adding an option to ExcelWriter that doesn’t overwrite the file. But, yet again, that may mean writing in the entire file first. I don’t know.
![]()
I’m going to add something to the docs about this, maybe a test case with this, and I’ll look into adding an option to read in the file, but it depends on how xlwt and openpyxl work.
![]()
@jtratner what about a context manager get_excel?
with get_excel('foo.xlsx') as e:
df.to_excel(e,'Data 0)
df.to_excel(e,'Data 1)
?
![]()
how about we just make ExcelWriter into a contextmanager instead? it’ll just call save at the end. Much simpler.
![]()
@ligon you can do this now this way:
with ExcelWriter('foo.xlsx') as writer: df.to_excel(writer, 'Data 0') df2.to_excel(writer, 'Data 1')
If you don’t use the with statement, just have to call save() at the end.
![]()
Copy link
Author
ligon
commented
Sep 23, 2013
•
edited by jorisvandenbossche
ligon
commented
Sep 23, 2013
•
edited by jorisvandenbossche
Excellent. And great that it has an exit method.
Thanks,
-Ethan Ligon
Ethan Ligon, Associate Professor
Agricultural & Resource Economics
University of California, Berkeley
![]()
I was extremely interesting by the request made by @ligon — but seems this is already there.
However using 0.12.0 pd version, when I am doing:
df = DataFrame([1,2,3])
df2 = DataFrame([5,5,6])
with ExcelWriter(‘foo.xlsx’) as writer:
df.to_excel(writer, ‘Data 0’)
df2.to_excel(writer, ‘Data 1’)
Assumning foo.xlsx was containing a sheet named ‘bar’, basgot delete after the command run. While as per your comment, i was expecting to keep it in my foo excel file. Is that a bug?
![]()
is it hard to add sheets to an existing excel file on the disk?
import pandas as pd
import numpy as np
a=pd.DataFrame(np.random.random((3,1)))
excel_writer=pd.ExcelWriter(‘c:excel.xlsx’)
a.to_excel(excel_writer, ‘a1’)
excel_writer.save()
excel_writer=pd.ExcelWriter(‘c:excel.xlsx’)
a.to_excel(excel_writer, ‘a2’)
excel_writer.save()
here only sheet ‘a2″ is save, but I like to save both ‘a1’ and ‘a2’.
I know it is possible to add sheets to an existing workbook.
![]()
Copy link
Contributor
jtratner
commented
Apr 4, 2014
•
edited by jorisvandenbossche
jtratner
commented
Apr 4, 2014
•
edited by jorisvandenbossche
It’s definitely possible to add sheets to an existing workbook, but it’s
not necessarily easy to do it with pandas. I think you’d have to read the
workbook separately and then pass it into the ExcelWriter class… That
would be something we could consider supporting.
![]()
Copy link
Contributor
jtratner
commented
Apr 4, 2014
•
edited by jorisvandenbossche
jtratner
commented
Apr 4, 2014
•
edited by jorisvandenbossche
And I think if you subclass the ExcelWriter instance you want to use and
overwrite its__init__ method, as long as you set self.book it should work.
That said, no guarantee that this would continue to work in future
versions, since it’s only a quasi-public API
![]()
This stackoverflow workaround, which is based in openpyxl, may work
(EDIT: indeed works, checked with pandas-0.17.0):
import pandas from openpyxl import load_workbook book = load_workbook('Masterfile.xlsx') writer = pandas.ExcelWriter('Masterfile.xlsx', engine='openpyxl') writer.book = book writer.sheets = dict((ws.title, ws) for ws in book.worksheets) data_filtered.to_excel(writer, "Main", cols=['Diff1', 'Diff2']) writer.save()
YangJian1992 and luckyzachary reacted with laugh emoji
YangJian1992 and luckyzachary reacted with heart emoji
![]()
this would be pretty easy to implement inside ExcelWriter (Oder patch above)
prob just need to add a mode=kw and default to w and make a be append
![]()
![]()
it seems that you can work around it (see above), but I suppose would be nice to actually do it from pandas.
![]()
Hi, any follow up on this issue?
I can provide a use case: I have excel files with pivot tables and pivot graphs that I need to reach out people not proficient in Python.
My idea was to use pandas to add a sheet that contains the data for the pivot. But up to know I am stuck and the proposed workaround, thought not difficult, sounds a bit cumbersome . It would make sense to jsut have an option whether overwrite an existing file.
![]()
Let me echo @jreback , it would be super nice if I could just add a sheet to an excel workbook from pandas.
![]()
To be clear, we agree that this would be a nice functionality, and would certainly welcome a contribution from the community.
Best way to have this in pandas is to make a PR!
![]()
@jmcnamara how to use pandas.to_excel(Writer maybe use pandas.ExcelWriter) to add some data to an existed file , but not rewrite it??
![]()
@aa3222119 That is exactly what this issue is about: an enhancement request to add this ability, which is not yet possible today.
(BTW, it is not needed to post the same question in multiple issues)
![]()
![]()
BTW will that be possible some day later? @jmcnamara
This isn’t and won’t be possible when using XlsxWriter as the engine. It should be possible when using OpenPyXL. I’ve seen some examples on SO like this one: jmcnamara/excel-writer-xlsx#157
![]()
3Q very much! @jmcnamara
it is exactly what you said . use openpyxl 👍
import pandas as pd
from openpyxl import load_workbook
book = load_workbook(‘text.xlsx’)
writer = pd.ExcelWriter(‘text.xlsx’, engine=’openpyxl’)
writer.book = book
pd.DataFrame(userProfile,index=[1]).to_excel(writer,’sheet111′,startrow=7,startcol=7)
pd.DataFrame(userProfile,index=[1]).to_excel(writer,’sheet123′,startrow=0,startcol=0)
writer.save()
pd.DataFrame(userProfile,index=[1]).to_excel(writer,’sheet123′,startrow=3,startcol=3)
writer.save()
all can be added to text.xlsx.
https://github.com/pandas-dev/pandas/issues/3441
![]()
![]()
@ankostis, @aa3222119 when I follow the steps you comment, I always reach the following error:
Traceback (most recent call last):
File «./name_manipulation.py», line 60, in
df.to_excel(excel_writer, ‘iadatasheet’, startcol=0, startrow=5, columns=[‘codes’, ‘Zona Basica de Salud’, month+»-«+year], index=False)
File «/Users/jgonzalez.iacs/Projects/SIIDI/PYTHON_ETLs/venv/lib/python3.4/site-packages/pandas/core/frame.py», line 1464, in to_excel
startrow=startrow, startcol=startcol)
File «/Users/jgonzalez.iacs/Projects/SIIDI/PYTHON_ETLs/venv/lib/python3.4/site-packages/pandas/io/excel.py», line 1306, in write_cells
wks = self.book.create_sheet()
AttributeError: ‘str’ object has no attribute ‘create_sheet’
So, there is not solution yet, right?
Thanks
![]()
Maybe the API has changed — it definitely worked back then.
![]()
![]()
@jgonzale by what python said , your excel_writer.book maybe just a str but not a workbook?
![]()
@aa3222119 Oh geez! You were right! Messing around with very similar names!
Thank you very much! 👏 👏 👏
![]()
![]()
Hello
I have some use case where it would be useful:
Even with the ExcelWriter trick as:
with ExcelWriter(‘foo.xlsx’) as writer:
df.to_excel(writer, ‘Data 0’)
df2.to_excel(writer, ‘Data 1’)
you can’t add a plot that you need without saving the file and reopening it. With the risk of meddling with any formatting you have in the workbook.
There is indeed the workaround to use the plotting functions from pandas to save these in the files, but (there is a but), when you need something a little more sophisticated like showing a PCA components graph you built from scikitlearn PCA and matplotlib, then it becomes tedious.
Hence
a pandas.nondf_manager (non df object or filename).to_excel(usual syntax)
would be exceedingly fine.
Thanks.
![]()
I don’t know how it is possible, however, it works for me
create_excel = 0
if plot_spectra != 0:
for x in range(min_sigma, max_sigma, step_size):
# apply gaussian
df1 = gaussian_filter(df, sigma=x, mode=padding_mode)
df2 = pd.DataFrame(df1)
if save_file:
if save_csv:
df2.to_csv('{} {}{}.csv'.format(Output_file, 'sigma_', x,))
if save_xlsx:
if os.path.isfile('{}.xlsx'.format(Output_file)):
print("Warning! Excel file is exist")
break
if create_excel == 0:
xlsx_writer = pd.ExcelWriter('{}.xlsx'.format(Output_file), engine='xlsxwriter')
create_excel += 1
df2.to_excel(xlsx_writer, '{}{}'.format('sigma_', x))
if x == max_sigma-1:
xlsx_writer.save()
At the end, I got the excel file which have several work sheets.
![]()
@orbitalz you are creating an excel file the first time (xlsx_writer = pd.ExcelWriter(..)), and then adding multiple sheets to that file object. That is supported, but this issue is about adding sheets to an existing excel file.
![]()
I’m sorry for misunderstanding the topic and Thank you for pointing me out 
![]()
@orbitalz You solve my problem ,but I don’t known how it works
![]()
mode={‘a’} does not work as the documentation suggests
this is still a buggy mess
![]()
Appending in the existing worksheet seems to work with
writer = pd.ExcelWriter(‘filename.xlsx’, mode=’a’)
But, this only appends and does not overwrite sheets with the same sheetname
Example, my existing workbook has a sheetname ‘mySheet’
If I try to do:
df.to_excel(writer, ‘mySheet’)
It will create a new sheet ‘mySheet1’ instead of rewriting the existing ‘mySheet’
I wonder if there’s any other way to append in the existing workbook, but overwriting sheets that you want to overwrite.
Hope someone helps.
![]()
By using openpyxl as engine in ExcelWriter
writer = pd.ExcelWriter(filename, engine=’openpyxl’)
df.to_excel(writer, sheet_name)
at writer.save() i am getting this error
TypeError: got invalid input value of type <class ‘xml.etree.ElementTree.Element’>, expected string or Element
![]()
By using openpyxl as engine in ExcelWriter
writer = pd.ExcelWriter(filename, engine=’openpyxl’)
df.to_excel(writer, sheet_name)
at writer.save() i am getting this error
TypeError: got invalid input value of type <class ‘xml.etree.ElementTree.Element’>, expected string or Element
I have met the same error. Has anyone solved this issue?
![]()
engine should change to openyxl,because the default engine’xlsxwriter’ NOT support append mode !
`
import pandas as pd
df= pd.DataFrame({‘lkey’: [‘foo’, ‘bar’, ‘baz’, ‘foo’], ‘value’: [1, 2, 3, 5]})
#engine should change to openyxl,because the default engine’xlsxwriter’ NOT support append mode !
writer = pd.ExcelWriter(‘exist.xlsx’,mode=’a’,engine=’openpyxl’)
df.to_excel(writer, sheet_name =’NewSheet’)
writer.save()
writer.close()
`
Pandas chooses an Excel writer via two methods:
the engine keyword argument
the filename extension (via the default specified in config options)
By default, pandas uses the XlsxWriter for .xlsx, openpyxl for .xlsm, and xlwt for .xls files. If you have multiple engines installed, you can set the default engine through setting the config options io.excel.xlsx.writer and io.excel.xls.writer. pandas will fall back on openpyxl for .xlsx files if Xlsxwriter is not available.
To specify which writer you want to use, you can pass an engine keyword argument to to_excel and to ExcelWriter. The built-in engines are:
- openpyxl: version 2.4 or higher is required
- xlsxwriter
- xlwt
![]()
Hello,
I have an issue with the use of Pandas + ExcelWriter + load_workbook.
My need is to be able to modify data from an existing excel file (without deleting the rest).
It works partly, but when I check the size of the produced file and the original one the size is quite different.
Moreover, it seems to lack some properties. Which leads to an error message when I want to integrate the modified file into an application.
The code bellow :
data_filtered = pd.DataFrame([date, date, date, date], index=[2,3,4,5])
book = openpyxl.load_workbook(file_origin)
writer = pd.ExcelWriter(file_modif, engine=’openpyxl’,datetime_format=’dd/mm/yyyy hh:mm:ss’, date_format=’dd/mm/yyyy’)
writer.book = book
## ExcelWriter for some reason uses writer.sheets to access the sheet.
## If you leave it empty it will not know that sheet Main is already there
## and will create a new sheet.
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
data_filtered.to_excel(writer, sheet_name=»PCA pour intégration», index=False, startrow=2, startcol=5, header=False, verbose=True)
writer.save()`
- Syntax of
pandas.DataFrame.to_excel() - Example Codes: Pandas
DataFrame.to_excel() - Example Codes: Pandas
DataFrame.to_excel()WithExcelWriter - Example Codes: Pandas
DataFrame.to_excelto Append to an Existing Excel File - Example Codes: Pandas
DataFrame.to_excelto Write Multiple Sheets - Example Codes: Pandas
DataFrame.to_excelWithheaderParameter - Example Codes: Pandas
DataFrame.to_excelWithindex=False - Example Codes: Pandas
DataFrame.to_excelWithindex_labelParameter - Example Codes: Pandas
DataFrame.to_excelWithfloat_formatParameter - Example Codes: Pandas
DataFrame.to_excelWithfreeze_panesParameter
Python Pandas DataFrame.to_excel(values) function dumps the dataframe data to an Excel file, in a single sheet or multiple sheets.
Syntax of pandas.DataFrame.to_excel()
DataFrame.to_excel(excel_writer,
sheet_name='Sheet1',
na_rep='',
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
startrow=0,
startcol=0,
engine=None,
merge_cells=True,
encoding=None,
inf_rep='inf',
verbose=True,
freeze_panes=None)
Parameters
excel_writer |
Excel file path or the existing pandas.ExcelWriter |
sheet_name |
Sheet name to which the dataframe dumps |
na_rep |
Representation of null values. |
float_format |
Format of floating numbers |
header |
Specify the header of the generated excel file. |
index |
If True, write dataframe index to the Excel. |
index_label |
Column label for index column. |
startrow |
The upper left cell row to write the data to the Excel. Default is 0 |
startcol |
The upper left cell column to write the data to the Excel. Default is 0 |
engine |
Optional parameter to specify the engine to use. openyxl or xlswriter |
merge_cells |
Merge MultiIndex to merged cells |
encoding |
Encoding of the output Excel file. Only necessary if xlwt writer is used, other writers support Unicode natively. |
inf_rep |
Representation of infinity. Default is inf |
verbose |
If True, error logs consist of more information |
freeze_panes |
Specify the bottommost and rightmost of the frozen pane. It is one-based, but not zero-based. |
Return
None
Example Codes: Pandas DataFrame.to_excel()
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
dataframe.to_excel('test.xlsx')
The caller DataFrame is
Attendance Name Marks
0 60 Olivia 90
1 100 John 75
2 80 Laura 82
3 78 Ben 64
4 95 Kevin 45
test.xlsx is created.
Example Codes: Pandas DataFrame.to_excel() With ExcelWriter
The above example uses the file path as the excel_writer, and we could also use pandas.Excelwriter to specify the excel file the dataframe dumps.
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx') as writer:
dataframe.to_excel(writer)
Example Codes: Pandas DataFrame.to_excel to Append to an Existing Excel File
import pandas as pd
import openpyxl
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx', mode='a', engine='openpyxl') as writer:
dataframe.to_excel(writer, sheet_name="new")
We should specify the engine as openpyxl but not default xlsxwriter; otherwise, we will get the error that xlswriter doesn’t support append mode.
ValueError: Append mode is not supported with xlsxwriter!
openpyxl shall be installed and imported because it is not part of pandas.
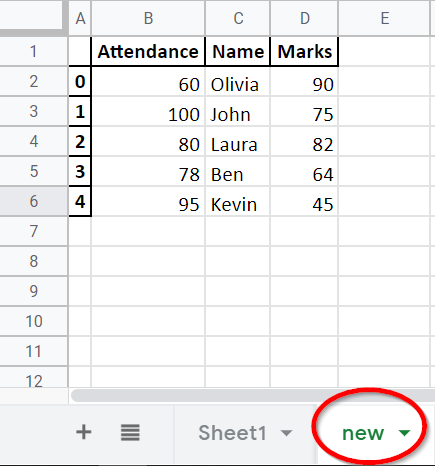
Example Codes: Pandas DataFrame.to_excel to Write Multiple Sheets
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx') as writer:
dataframe.to_excel(writer, sheet_name="Sheet1")
dataframe.to_excel(writer, sheet_name="Sheet2")
It dumps the dataframe object to both Sheet1 and Sheet2.
You could also write different data to multiple sheets if you specify the columns parameter.
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx') as writer:
dataframe.to_excel(writer,
columns=["Name","Attendance"],
sheet_name="Sheet1")
dataframe.to_excel(writer,
columns=["Name","Marks"],
sheet_name="Sheet2")
Example Codes: Pandas DataFrame.to_excel With header Parameter
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx') as writer:
dataframe.to_excel(writer, header=["Student", "First Name", "Score"])
The default header in the created Excel file is the same as dataframe’s column names. The header parameter specifies the new header to replace the default one.
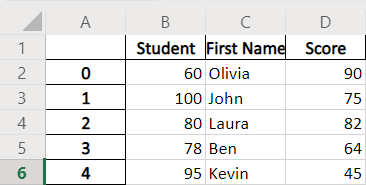
Example Codes: Pandas DataFrame.to_excel With index=False
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx') as writer:
dataframe.to_excel(writer, index=False)
index = False specifies that DataFrame.to_excel() generates an Excel file without header row.
Example Codes: Pandas DataFrame.to_excel With index_label Parameter
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx') as writer:
dataframe.to_excel(writer, index_label='id')
index_label='id' sets the column name of the index column to be id.
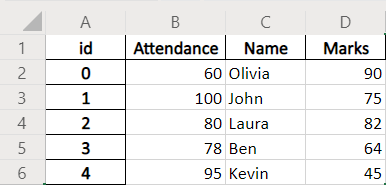
Example Codes: Pandas DataFrame.to_excel With float_format Parameter
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx') as writer:
dataframe.to_excel(writer, float_format="%.1f")
float_format="%.1f" specifies the floating number to have two floating digits.
Example Codes: Pandas DataFrame.to_excel With freeze_panes Parameter
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
with pd.ExcelWriter('test.xlsx') as writer:
dataframe.to_excel(writer, freeze_panes=(1,1))
freeze_panes=(1,1) specifies that the excel file has the frozen top row and frozen first column.