
stesl писал(а): ↑23 мар 2021, 10:37
Тип Word — это целочисленный беззнаковый тип данных, в два байта. Диапазон 0-65535. Используется везде, где оказывается нужным.
Не путайте Word с UInt (unsigned integer16), он не относится к целочисленным, так как не кодирует числовые значения и не совместим с математическими операциями.
Потому что:
Sergy6661 писал(а): ↑23 мар 2021, 12:54
Вот для упаковки-распаковки битовых переменных и используется в основном.
Но не в основном, а только для этого. Если конечно в конкретном ПЛК не срабатывает неявное преобразование, из-за которого кажется, что Word — это целое число.
Отправлено спустя 21 минуту 7 секунд:
Не, иначе объясню:
Word — это когда ты в 16 бит записал 16 булевых значений, каждый из которых что-то значит в смысле true/false. Например, при управлении сервоприводом или частотником.
Int16, UInt16 — это числа, отдельные биты не представляют интереса (хотя бывают редкие исключения).
Математические операции умеют работать с числами, то есть Add(), Sub(), Mul(), Div() работают с Int16/UInt16, а с Word работает подозрительно, подсвечивает типа «глянь, что за дрянь ты задумал?», но воспринимает как число 0-65535. Извините, правда, зачем вы складываете слово управления частотника с числом -85?
Зато сдвиговые операции и операции со словами типа ANDW(), ORW(), NOT(W), XORW() работают именно со словами и подозрительно с целыми числами.
Это разные типы данных, хотя все они 16 бит.
Уважаемые коллеги, мы рады предложить вам, разрабатываемый нами учебный курс по программированию ПЛК фирмы Beckhoff с применением среды автоматизации TwinCAT. Курс предназначен исключительно для самостоятельного изучения в ознакомительных целях. Перед любым применением изложенного материала в коммерческих целях просим связаться с нами. Текст из предложенных вам статей скопированный и размещенный в других источниках, должен содержать ссылку на наш сайт heaviside.ru. Вы можете связаться с нами по любым вопросам, в том числе создания для вас систем мониторинга и АСУ ТП.
Типы данных в языках стандарта МЭК 61131-3
Уважаемые коллеги, в этой статье мы будем рассматривать важнейшую для написания программ тему — типы данных. Чтобы читатели понимали, в чем отличие одних типов данных от других и зачем они вообще нужны, мы подробно разберем, каким образом данные представлены в процессоре. В следующем занятии будет большая практическая работа, выполняя которую, можно будет потренироваться объявлять переменные и на практике познакомится с особенностями выполнения математических операций с различными типами данных.
Простые типы данных
В прошлой статье мы научились записывать цифры в двоичной системе счисления. Именно такую систему счисления используют все компьютеры, микропроцессоры и прочая вычислительная техника. Теперь мы будем изучать типы данных.
Любая переменная, которую вы используете в своем коде, будь то показания датчиков, состояние выхода или выхода, состояние катушки или просто любая промежуточная величина, при выполнении программы будет хранится в оперативной памяти. Чтобы под каждую используемую переменную на этапе компиляции проекта была выделена оперативная память, мы объявляем переменные при написании программы. Компиляция, это перевод исходного кода, написанного программистом, в команды на языке ассемблера понятные процессору. Причем в зависимости от вида применяемого процессора один и тот же исходный код может транслироваться в разные ассемблерные команды (вспомним что ПЛК Beckhoff, как и персональные компьютеры работают на процессорах семейства x86).
Как помните, из статьи Знакомство с языком LD, при объявлении переменной необходимо указать, к какому типу данных будет принадлежать переменная. Как вы уже можете понять, число B016 будет занимать гораздо меньший объем памяти чем число 4 C4E5 01E7 7A9016. Также одни и те же операции с разными типами данных будут транслироваться в разные ассемблерные команды. В TwinCAT используются следующие типы данных:
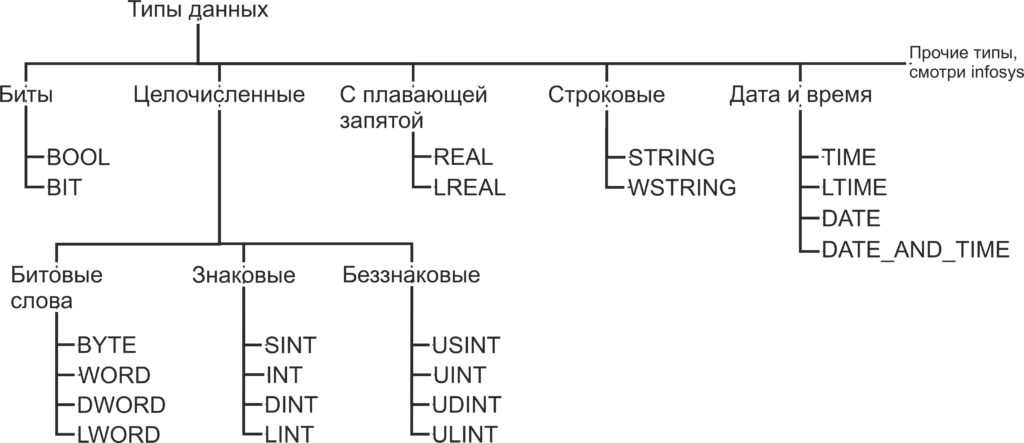
Биты
BOOL — это простейший тип данных, как уже было сказано, этот тип данных может принимать только два значения 0 и 1. Так же в TwinCAT, как и в большинстве языков программирования, эти значения, наравне с 0 и 1, обозначаются как TRUE и FALSE и несут в себе количество информации, соответствующее одному биту. Минимальным объемом данных, который читается из памяти за один раз, является байт, то есть восемь бит. Поэтому, для оптимизации скорости доступа к данным, переменная типа BOOL занимает восемь бит памяти. Для хранения самой переменной используется нулевой бит, а биты с первого по седьмой заполнены нулями. Впрочем, на практике о таком нюансе приходится вспоминать достаточно редко.
BIT — то же самое, что и BOOL, но в памяти занимает 1 бит. Как можно догадаться, операции с этим типом данных медленнее чем с типом BOOL, но он занимает меньше места в памяти. Тип данных BIT отсутствует в стандарте МЭК 61131-3 и поддерживается исключительно в TwinCAT, поэтому стоит отдавать предпочтение типу BOOL, когда у вас нет явных поводов использовать тип BIT.
Целочисленные типы данных
BYTE — тип данных, по размеру соответствующий одному байту. Хоть с типом BYTE можно производить математические операции, но в первую очередь он предназначен для хранения набора из 8 бит. Иногда в таком виде удобнее, чем побитно, передавать данные по цифровым интерфейсам, работать с входами выходами и так далее. С такими вопросами мы будем знакомится далее по мере изучения курса. В переменную типа BYTE можно записать числа из диапазона 0..255 (0..28-1).
WORD — то же самое, что и BYTE, но размером 16 бит. В переменную типа WORD можно записать числа из диапазона 0..65 535 (0..216-1). Тип данных WORD переводится с английского как «слово». Давным-давно термином машинное слово называли группу бит, обрабатываемых вычислительной машиной за один раз. Была уместна фраза «Программа состоит из машинных слов.». Со временем этим термином перестали пользоваться в прямом его значении, и сейчас под термином «машинное слово» обычно подразумевается группа из 16 бит.
DWORD — то же самое, что и BYTE, но размером 32 бит. В переменную типа DWORD можно записать числа из диапазона 0..4 294 967 295 (0..232-1). DWORD — это сокращение от double word, что переводится как двойное слово. Довольно часто буква «D» перед каким-либо типом данных значит, что этот тип данных в два раза длиннее, чем исходный.
LWORD — то же самое, что и BYTE, но размером 64 ;бит. В переменную типа LWORD можно записать числа из диапазона 0..18 446 744 073 709 551 615 (0..264-1). LWORD — это сокращение от long word, что переводится как длинное слово. Приставка «L» перед типом данных, как правило, означает что такой тип имеет длину 64 бита.
SINT — знаковый тип данных, длинной 8 бит. В переменную типа SINT можно записать числа из диапазона -128..127 (-27..27-1). В отличии от всех предыдущих типов данных этот тип данных предназначен для хранения именно чисел, а не набора бит. Слово знаковый в описании типа означает, что такой тип данных может хранить как положительные, так и отрицательные значения. Для хранения знака числа предназначен старший, в данном случае седьмой, разряд числа. Если старший разряд имеет значение 0, то число интерпретируется как положительное, если 1, то число интерпретируется как отрицательное. Приставка «S» означает short, что переводится с английского как короткий. Как вы догадались, SINT короткий вариант типа INT.
USINT — беззнаковый тип данных, длинной 8 бит. В переменную типа USINT можно записать числа из диапазона 0..255 (0..28-1). Приставка «U» означает unsigned, переводится как беззнаковый.
Остальные целочисленные типы аналогичны уже описанным и отличаются только размером. Сведем все целочисленные типы в таблицу.
| Тип данных | Нижний предел | Верхний предел | Занимаемая память |
| BYTE | 0 | 255 | 8 бит |
| WORD | 0 | 65 535 | 16 бит |
| DWORD | 0 | 4 294 967 295 | 32 бит |
| LWORD | 0 | 264-1 | 64 бит |
| SINT | -128 | 127 | 8 бит |
| USINT | 0 | 255 | 8 бит |
| INT | -32 768 | 32 767 | 16 бит |
| UINT | 0 | 65 535 | 16 бит |
| DINT | -2 147 483 648 | 2 147 483 647 | 32 бит |
| UDINT | 0 | 4 294 967 295 | 32 бит |
| LINT | -263 | -263-1 | 64 бит |
| ULINT | 0 | -264-1 | 64 бит |
Выше мы рассматривали целочисленные типы данных, то есть такие типы данных, в которых отсутствует запятая. При совершении математических операций с целочисленными типами данных есть некоторые особенности:
- Округление при делении: округление всегда выполняется вниз. То есть дробная часть просто отбрасывается. Если делимое меньше делителя, то частное всегда будет равно нулю, например, 10/11 = 0.
- Переполнение: если к целочисленной переменной, например, SINT, имеющей значение 255, прибавить 1, переменная переполнится и примет значение 0. Если прибавить 2, переменная примет значение 1 и так далее. При операции 0 — 1 результатом будет 255. Это свойство очень схоже с устройством стрелочных часов. Если сейчас 2 часа, то 5 часов назад было 9 часов. Только шкала часов имеет пределы не 1..12, а 0..255. Иногда такое свойство может использоваться при написании программ, но как правило не стоит допускать переполнения переменных.
Подробно такие нюансы разбираются в пособиях по дискретной математике. Мы на них пока что останавливаться не будем, но о приведенных двух особенностях не стоит забывать при написании программ.
Можно встретить упоминания о данных с фиксированной запятой, это такие данные, в которых количество знаков после запятой строго фиксировано. В TwinCAT типы данных с фиксированной запятой отсутствуют в чистом виде. TwinCAT поддерживает типы данных с плавающей запятой, то есть количество знаков до и после запятой может быть любым в пределах поддерживаемого диапазона.
Типы данных с плавающей запятой
REAL — тип данных с плавающей запятой длинной 32 бита. В переменную типа REAL можно записать числа из диапазона -3.402 82*1038..3.402 82*1038.
LREAL — тип данных с плавающей запятой длинной 64 бита. В переменную типа LREAL можно записать числа из диапазона -1.797 693 134 862 315 8*10308..1.797 693 134 862 315 8*10308.
При присваивании значения типам REAL и LREAL присваиваемое значение должно содержать целую часть, разделительную точку и дробную часть, например, 7.4 или 560.0.
Так же при записи значения типа REAL и LREAL использовать экспоненциальную (научную) форму. Примером экспоненциальной формы записи будет Me+P, в этом примере
- M называется мантиссой.
- e называется экспонентой (от англ. «exponent»), означающая «·10^» («…умножить на десять в степени…»),
- P называется порядком.
Примерами такой формы записи будет:
- 1.64e+3 расшифровывается как 1.64e+3 = 1.64*103 = 1640.
- 9.764e+5 расшифровывается как 9.764e+5 = 9.764*105 = 976400.
- 0.3694e+2 расшифровывается как 0.3694e+2 = 0.3694*102 = 36.94.
Еще один способ записи присваиваемого значения переменной типа REAL и LREAL, это добавить к числу префикс REAL#, например, REAL#7.4 или REAL#560. В таком случае можно не указывать дробную часть.
Старший, 31-й бит переменной типа REAL представляет собой знак. Следующие восемь бит, с 30-го по 23-й отведены под экспоненту. Оставшиеся 23 бита, с 22-го по 0-й используются для записи мантиссы.
В переменной типа LREAL старший, 63-й бит также используется для записи знака. В следующие 11 бит, с 62 по 52-й, записана экспонента. Оставшиеся 52 бита, с 51-го по 0-й, используются для записи мантиссы.
При записи числа с большим количеством значащих цифр в переменные типа REAL и LREAL производится округление. Необходимо не забывать об этом в расчетах, к которым предъявляются строгие требования по точности. Еще одна особенность, вытекающая из прошлой, если вы хотите сравнить два числа типа REAL или LREAL, прямое сравнение мало применимо, так как если в результате округления числа отличаются хоть на малую долю результат сравнения будет FALSE. Чтобы выполнить сравнение более корректно, можно вычесть одно число из другого, а потом оценить больше или меньше модуль получившегося результата вычитания, чем наибольшая допустимая разность. Поведение системы при переполнении переменных с плавающей запятой не определенно стандартом МЭК 61131-3, допускать его не стоит.
Строковые типы данных
STRING — тип данных для хранения символов. Каждый символ в переменной типа STRING хранится в 1 байте, в кодировке Windows-1252, это значит, что переменные такого типа поддерживают только латинские символы. При объявлении переменной количество символов в переменной указывается в круглых или квадратных скобках. Если размер не указан, при объявлении по умолчанию он равен 80 символам. Для данных типа STRING количество содержащихся в переменной символов не ограниченно, но функции для обработки строк могут принять до 255 символов.
Объем памяти, необходимый для переменной STRING, всегда составляет 1 байт на символ +1 дополнительный байт, например, переменная объявленная как «STRING [80]» будет занимать 81 байт. Для присвоения константного значения переменной типа STRING присваемый текст необходимо заключить в одинарные кавычки.
Пример объявления строки на 35 символов:
sVar : STRING(35) := 'This is a String'; (*Пример объявления переменной типа STRING*)
WSTRING — этот тип данных схож с типом STRING, но использует по 2 байта на символ и кодировку Unicode. Это значит что переменные типа WSTRING поддерживают символы кириллицы. Для присвоения константного значения переменной типа WSTRING присваемый текст необходимо заключить в двойные кавычки.
Пример объявления переменной типа WSTRING:
wsVar : WSTRING := "This is a WString"; (*Пример объявления переменной типа WSTRING*)Если значение, присваиваемое переменной STRING или WSTRING, содержит знак доллара ($), следующие два символа интерпретируются как шестнадцатеричный код в соответствии с кодировкой Windows-1252. Код также соответствует кодировке ASCII.
| Код со знаком доллара | Его значение в переменной |
| $<восьмибитное число> | Восьмибитное число интерпретируется как символ в кодировке ISO / IEC 8859-1 |
| ‘$41’ | A |
| ‘$9A’ | © |
| ‘$40’ | @ |
| ‘$0D’, ‘$R’, ‘$r’ | Разрыв строки |
| ‘$0A’, ‘$L’, ‘$l’, ‘$N’, ‘$n’ | Новая строка |
| ‘$P’, ‘$p’ | Конец страницы |
| ‘$T’, ‘$t’ | Табуляция |
| ‘$$’ | Знак доллара |
| ‘$’ ‘ | Одиночная кавычка |
Такое разнообразие кодировок связанно с тем, что у всех из них первые 128 символов соответствуют кодовой таблице ASCII, но в статье для каждого случая кодировка указывалась так же, как она указана в infosys.
Пример:
VAR CONSTANT
sConstA : STRING :='Hello world';
sConstB : STRING :='Hello world $21'; (*Пример объявления переменной типа STRING с спец символом*)
END_VAR
Типы данных времени
TIME — тип данных, предназначенный для хранения временных промежутков. Размер типа данных 32 бита. Этот тип данных интерпретируется в TwinCAT, как переменная типа DWORD, содержащая время в миллисекундах. Нижний допустимый предел 0 (0 мс), верхний предел 4 294 967 295 (49 дней, 17 часов, 2 минуты, 47 секунд, 295 миллисекунд). Для записи значений в переменные типа TIME используется префикс T# и суффиксы d: дни, h: часы, m: минуты, s: секунды, ms: миллисекунды, которые должны располагаться в порядке убывания.
Примеры корректного присваивания значения переменной типа TIME:
TIME1 : TIME := T#14ms;
TIME1 : TIME := T#100s12ms; // Допускается переполнение в старшем отрезке времени.
TIME1 : TIME := t#12h34m15s;Примеры некорректного присваивания значения переменной типа TIME, при компиляции будет выдана ошибка:
TIME1 : TIME := t#5m68s; // Переполнение не в старшем отрезке времени недопустимо
TIME1 : TIME := 15ms; // Пропущен префикс T#
TIME1 : TIME := t#4ms13d; // Не соблюден порядок записи временных отрезокLTIME — тип данных аналогичен TIME, но его размер составляет 64 бита, а временные отрезки хранятся в наносекундах. Нижний допустимый предел 0, верхний предел 213 503 дней, 23 часов, 34 минуты, 33 секунд, 709 миллисекунд, 551 микросекунд и 615 наносекунд. Для записи значений в переменные типа LTIME используется префикс LTIME#. Помимо суффиксов, используемых для записи типа TIME для LTIME, используются µs: микросекунды и ns: наносекунды.
Пример:
LTIME1 : LTIME := LTIME#1000d15h23m12s34ms2us44ns; (*Пример объявления переменной типа LTIME*)TIME_OF_DAY (TOD) — тип данных для записи времени суток. Имеет размер 32 бита. Нижнее допустимое значение 0, верхнее допустимое значение 23 часа, 59 минут, 59 секунд, 999 миллисекунд. Для записи значений в переменные типа TOD используется префикс TIME_OF_DAY# или TOD#, значение записывается в виде <часы : минуты : секунды> . В остальном этот тип данных аналогичен типу TIME.
Пример:
TIME_OF_DAY#15:36:30.123
tod#00:00:00Date — тип данных для записи даты. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106), да, здесь присутствует возможный компьютерный апокалипсис, но учитывая запас по верхнему пределу, эта проблема не слишком актуальна. Для записи значений в переменные типа TOD используется префикс DATE# или D#, значение записывается в виде <год — месяц — дата>. В остальном этот тип данных аналогичен типу TIME.
DATE#1996-05-06
d#1972-03-29DATE_AND_TIME (DT) — тип данных для записи даты и времени. Имеет размер 32 бита. Нижнее допустимое значение 0 (01.01.1970), верхнее допустимое значение 4 294 967 295 (7 февраля 2106, 6:28:15). Для записи значений в переменные типа DT используется префикс DATE_AND_TIME # или DT#, значение записывается в виде <год — месяц — дата — час : минута : секунда>. В остальном этот тип данных аналогичен типу TIME.
DATE_AND_TIME#1996-05-06-15:36:30
dt#1972-03-29-00:00:00На этом раз мы заканчиваем рассмотрение типов данных. Сейчас мы разобрали не все типы данных, остальные можно найти в infosys по пути TwinCAT 3 → TE1000 XAE → PLC → Reference Programming → Data types.
Следующая статья будет целиком состоять из практической работы, мы напишем калькулятор на языке LD.
In computer science, an integer is a datum of integral data type, a data type that represents some range of mathematical integers. Integral data types may be of different sizes and may or may not be allowed to contain negative values. Integers are commonly represented in a computer as a group of binary digits (bits). The size of the grouping varies so the set of integer sizes available varies between different types of computers. Computer hardware nearly always provides a way to represent a processor register or memory address as an integer.
Value and representation[edit]
The value of an item with an integral type is the mathematical integer that it corresponds to. Integral types may be unsigned (capable of representing only non-negative integers) or signed (capable of representing negative integers as well).[1]
An integer value is typically specified in the source code of a program as a sequence of digits optionally prefixed with + or −. Some programming languages allow other notations, such as hexadecimal (base 16) or octal (base 8). Some programming languages also permit digit group separators.[2]
The internal representation of this datum is the way the value is stored in the computer’s memory. Unlike mathematical integers, a typical datum in a computer has some minimal and maximum possible value.
The most common representation of a positive integer is a string of bits, using the binary numeral system. The order of the memory bytes storing the bits varies; see endianness. The width or precision of an integral type is the number of bits in its representation. An integral type with n bits can encode 2n numbers; for example an unsigned type typically represents the non-negative values 0 through 2n−1. Other encodings of integer values to bit patterns are sometimes used, for example binary-coded decimal or Gray code, or as printed character codes such as ASCII.
There are four well-known ways to represent signed numbers in a binary computing system. The most common is two’s complement, which allows a signed integral type with n bits to represent numbers from −2(n−1) through 2(n−1)−1. Two’s complement arithmetic is convenient because there is a perfect one-to-one correspondence between representations and values (in particular, no separate +0 and −0), and because addition, subtraction and multiplication do not need to distinguish between signed and unsigned types. Other possibilities include offset binary, sign-magnitude, and ones’ complement.
Some computer languages define integer sizes in a machine-independent way; others have varying definitions depending on the underlying processor word size. Not all language implementations define variables of all integer sizes, and defined sizes may not even be distinct in a particular implementation. An integer in one programming language may be a different size in a different language or on a different processor.
Some older computer architectures used decimal representations of integers, stored in binary-coded decimal (BCD) or other format. These values generally require data sizes of 4 bits per decimal digit (sometimes called a nibble), usually with additional bits for a sign. Many modern CPUs provide limited support for decimal integers as an extended datatype, providing instructions for converting such values to and from binary values. Depending on the architecture, decimal integers may have fixed sizes (e.g., 7 decimal digits plus a sign fit into a 32-bit word), or may be variable-length (up to some maximum digit size), typically occupying two digits per byte (octet).
Common integral data types[edit]
| Bits | Name | Range (assuming two’s complement for signed) | Decimal digits | Uses | Implementations | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C/C++ | C# | Pascal and Delphi | Java | SQL[a] | FORTRAN | D | Rust | |||||
| 4 | nibble, semioctet | Signed: From −8 to 7, from −(23) to 23 − 1 | 0.9 | Binary-coded decimal, single decimal digit representation | — | — | — | — | — | — | — | — |
| Unsigned: From 0 to 15, which equals 24 − 1 | 1.2 | |||||||||||
| 8 | byte, octet, i8, u8 | Signed: From −128 to 127, from −(27) to 27 − 1 | 2.11 | ASCII characters, code units in the UTF-8 character encoding | int8_t, signed char[b] | sbyte | Shortint | byte | tinyint | integer(1) | byte | i8 |
| Unsigned: From 0 to 255, which equals 28 − 1 | 2.41 | uint8_t, unsigned char[b] | byte | Byte | — | unsigned tinyint | — | ubyte | u8 | |||
| 16 | halfword, word, short, i16, u16 | Signed: From −32,768 to 32,767, from −(215) to 215 − 1 | 4.52 | UCS-2 characters, code units in the UTF-16 character encoding | int16_t, short[b], int[b] | short | Smallint | short | smallint | integer(2) | short | i16 |
| Unsigned: From 0 to 65,535, which equals 216 − 1 | 4.82 | uint16_t, unsigned[b], unsigned int[b] | ushort | Word | char[c] | unsigned smallint | — | ushort | u16 | |||
| 32 | word, long, doubleword, longword, int, i32, u32 | Signed: From −2,147,483,648 to 2,147,483,647, from −(231) to 231 − 1 | 9.33 | UTF-32 characters, true color with alpha, FourCC, pointers in 32-bit computing | int32_t, int[b], long[b] | int | LongInt; Integer[d] | int | int | integer(4) | int | i32 |
| Unsigned: From 0 to 4,294,967,295, which equals 232 − 1 | 9.63 | uint32_t, unsigned[b], unsigned int[b], unsigned long[b] | uint | LongWord; DWord; Cardinal[d] | — | unsigned int | — | uint | u32 | |||
| 64 | word, doubleword, longword, long long, quad, quadword, qword, int64, i64, u64 | Signed: From −9,223,372,036,854,775,808 to 9,223,372,036,854,775,807, from −(263) to 263 − 1 | 18.96 | Time (milliseconds since the Unix epoch), pointers in 64-bit computing | int64_t, long[b], long long[b] | long | Int64 | long | bigint | integer(8) | long | i64 |
| Unsigned: From 0 to 18,446,744,073,709,551,615, which equals 264 − 1 | 19.27 | uint64_t, unsigned long long[b] | ulong | UInt64; QWord | — | unsigned bigint | — | ulong | u64 | |||
| 128 | octaword, double quadword, i128, u128 | Signed: From −170,141,183,460,469,231,731,687,303,715,884,105,728 to 170,141,183,460,469,231,731,687,303,715,884,105,727, from −(2127) to 2127 − 1 | 38.23 | Complex scientific calculations,
IPv6 addresses, |
C: only available as non-standard compiler-specific extension | — | — | — | — | integer(16) | cent[e] | i128 |
| Unsigned: From 0 to 340,282,366,920,938,463,463,374,607,431,768,211,455, which equals 2128 − 1 | 38.53 | — | ucent[e] | u128 | ||||||||
| n | n-bit integer (general case) |
Signed: −(2n−1) to (2n−1 − 1) | (n − 1) log10 2 | C23: _BitInt(n), signed _BitInt(n) | Ada: range -2**(n-1)..2**(n-1)-1 | |||||||
| Unsigned: 0 to (2n − 1) | n log10 2 | C23: unsigned _BitInt(n) | Ada: range 0..2**n-1, mod 2**n; standard libraries’ or third-party arbitrary arithmetic libraries’ BigDecimal or Decimal classes in many languages such as Python, C++, etc. |
Different CPUs support different integral data types. Typically, hardware will support both signed and unsigned types, but only a small, fixed set of widths.
The table above lists integral type widths that are supported in hardware by common processors. High level programming languages provide more possibilities. It is common to have a ‘double width’ integral type that has twice as many bits as the biggest hardware-supported type. Many languages also have bit-field types (a specified number of bits, usually constrained to be less than the maximum hardware-supported width) and range types (that can represent only the integers in a specified range).
Some languages, such as Lisp, Smalltalk, REXX, Haskell, Python, and Raku, support arbitrary precision integers (also known as infinite precision integers or bignums). Other languages that do not support this concept as a top-level construct may have libraries available to represent very large numbers using arrays of smaller variables, such as Java’s BigInteger class or Perl’s «bigint» package.[5] These use as much of the computer’s memory as is necessary to store the numbers; however, a computer has only a finite amount of storage, so they, too, can only represent a finite subset of the mathematical integers. These schemes support very large numbers; for example one kilobyte of memory could be used to store numbers up to 2466 decimal digits long.
A Boolean or Flag type is a type that can represent only two values: 0 and 1, usually identified with false and true respectively. This type can be stored in memory using a single bit, but is often given a full byte for convenience of addressing and speed of access.
A four-bit quantity is known as a nibble (when eating, being smaller than a bite) or nybble (being a pun on the form of the word byte). One nibble corresponds to one digit in hexadecimal and holds one digit or a sign code in binary-coded decimal.
Bytes and octets[edit]
The term byte initially meant ‘the smallest addressable unit of memory’. In the past, 5-, 6-, 7-, 8-, and 9-bit bytes have all been used. There have also been computers that could address individual bits (‘bit-addressed machine’), or that could only address 16- or 32-bit quantities (‘word-addressed machine’). The term byte was usually not used at all in connection with bit- and word-addressed machines.
The term octet always refers to an 8-bit quantity. It is mostly used in the field of computer networking, where computers with different byte widths might have to communicate.
In modern usage byte almost invariably means eight bits, since all other sizes have fallen into disuse; thus byte has come to be synonymous with octet.
Words[edit]
The term ‘word’ is used for a small group of bits that are handled simultaneously by processors of a particular architecture. The size of a word is thus CPU-specific. Many different word sizes have been used, including 6-, 8-, 12-, 16-, 18-, 24-, 32-, 36-, 39-, 40-, 48-, 60-, and 64-bit. Since it is architectural, the size of a word is usually set by the first CPU in a family, rather than the characteristics of a later compatible CPU. The meanings of terms derived from word, such as longword, doubleword, quadword, and halfword, also vary with the CPU and OS.[6]
Practically all new desktop processors are capable of using 64-bit words, though embedded processors with 8- and 16-bit word size are still common. The 36-bit word length was common in the early days of computers.
One important cause of non-portability of software is the incorrect assumption that all computers have the same word size as the computer used by the programmer. For example, if a programmer using the C language incorrectly declares as int a variable that will be used to store values greater than 215−1, the program will fail on computers with 16-bit integers. That variable should have been declared as long, which has at least 32 bits on any computer. Programmers may also incorrectly assume that a pointer can be converted to an integer without loss of information, which may work on (some) 32-bit computers, but fail on 64-bit computers with 64-bit pointers and 32-bit integers. This issue is resolved by C99 in stdint.h in the form of intptr_t.
Short integer[edit]
A short integer can represent a whole number that may take less storage, while having a smaller range, compared with a standard integer on the same machine.
In C, it is denoted by short. It is required to be at least 16 bits, and is often smaller than a standard integer, but this is not required.[7][8] A conforming program can assume that it can safely store values between −(215−1)[9] and 215−1,[10] but it may not assume that the range is not larger. In Java, a short is always a 16-bit integer. In the Windows API, the datatype SHORT is defined as a 16-bit signed integer on all machines.[6]
| Programming language | Data type name | Signedness | Size in bytes | Minimum value | Maximum value |
|---|---|---|---|---|---|
| C and C++ | short | signed | 2 | −32,767[f] | +32,767 |
| unsigned short | unsigned | 2 | 0 | 65,535 | |
| C# | short | signed | 2 | −32,768 | +32,767 |
| ushort | unsigned | 2 | 0 | 65,535 | |
| Java | short | signed | 2 | −32,768 | +32,767 |
| SQL | smallint | signed | 2 | −32,768 | +32,767 |
Long integer[edit]
A long integer can represent a whole integer whose range is greater than or equal to that of a standard integer on the same machine.
In C, it is denoted by long. It is required to be at least 32 bits, and may or may not be larger than a standard integer. A conforming program can assume that it can safely store values between −(231−1)[9] and 231−1,[10] but it may not assume that the range is not larger.
| Programming language | Approval Type | Platforms | Data type name | Storage in bytes | Signed range | Unsigned range |
|---|---|---|---|---|---|---|
| C ISO/ANSI C99 | International Standard | Unix,16/32-bit systems[6] Windows,16/32/64-bit systems[6] |
long[g] | 4 (minimum requirement 4) |
−2,147,483,647 to +2,147,483,647 | 0 to 4,294,967,295 (minimum requirement) |
| C ISO/ANSI C99 | International Standard | Unix, 64-bit systems[6][8] |
long[g] | 8 (minimum requirement 4) |
−9,223,372,036,854,775,807 to +9,223,372,036,854,775,807 | 0 to 18,446,744,073,709,551,615 |
| C++ ISO/ANSI | International Standard | Unix, Windows, 16/32-bit system |
long[g] | 4 [12] (minimum requirement 4) |
−2,147,483,648 to +2,147,483,647 | 0 to 4,294,967,295 (minimum requirement) |
| C++/CLI | International Standard ECMA-372 |
Unix, Windows, 16/32-bit systems |
long[g] | 4 [13] (minimum requirement 4) |
−2,147,483,648 to +2,147,483,647 | 0 to 4,294,967,295 (minimum requirement) |
| VB | Company Standard | Windows | Long | 4 [14] | −2,147,483,648 to +2,147,483,647 | — |
| VBA | Company Standard | Windows, Mac OS X | Long | 4 [15] | −2,147,483,648 to +2,147,483,647 | — |
| SQL Server | Company Standard | Windows | BigInt | 8 | −9,223,372,036,854,775,808 to +9,223,372,036,854,775,807 | 0 to 18,446,744,073,709,551,615 |
| C#/ VB.NET | ECMA International Standard | Microsoft .NET | long or Int64 | 8 | −9,223,372,036,854,775,808 to +9,223,372,036,854,775,807 | 0 to 18,446,744,073,709,551,615 |
| Java | International/Company Standard | Java platform | long | 8 | −9,223,372,036,854,775,808 to +9,223,372,036,854,775,807 | — |
| Pascal | ? | Windows, UNIX | int64 | 8 | −9,223,372,036,854,775,808 to +9,223,372,036,854,775,807 | 0 to 18,446,744,073,709,551,615 (Qword type) |
Long long[edit]
In the C99 version of the C programming language and the C++11 version of C++, a long long type is supported that has double the minimum capacity of the standard long. This type is not supported by compilers that require C code to be compliant with the previous C++ standard, C++03, because the long long type did not exist in C++03. For an ANSI/ISO compliant compiler, the minimum requirements for the specified ranges, that is, −(263−1)[9] to 263−1 for signed and 0 to 264−1 for unsigned,[10] must be fulfilled; however, extending this range is permitted.[16][17] This can be an issue when exchanging code and data between platforms, or doing direct hardware access. Thus, there are several sets of headers providing platform independent exact width types. The C standard library provides stdint.h; this was introduced in C99 and C++11.
Syntax[edit]
Literals for integers can be written as regular Arabic numerals, consisting of a sequence of digits and with negation indicated by a minus sign before the value. However, most programming languages disallow use of commas or spaces for digit grouping. Examples of integer literals are:
4210000-233000
There are several alternate methods for writing integer literals in many programming languages:
- Many programming languages, especially those influenced by C, prefix an integer literal with
0Xor0xto represent a hexadecimal value, e.g.0xDEADBEEF. Other languages may use a different notation, e.g. some assembly languages append anHorhto the end of a hexadecimal value. - Perl, Ruby, Java, Julia, D, Go, Rust and Python (starting from version 3.6) allow embedded underscores for clarity, e.g.
10_000_000, and fixed-form Fortran ignores embedded spaces in integer literals. C (starting from C23) and C++ use single quotes for this purpose. - In C and C++, a leading zero indicates an octal value, e.g.
0755. This was primarily intended to be used with Unix modes; however, it has been criticized because normal integers may also lead with zero.[18] As such, Python, Ruby, Haskell, and OCaml prefix octal values with0Oor0o, following the layout used by hexadecimal values. - Several languages, including Java, C#, Scala, Python, Ruby, OCaml, C (starting from C23) and C++ can represent binary values by prefixing a number with
0Bor0b.
See also[edit]
- Arbitrary-precision arithmetic
- Binary-coded decimal (BCD)
- C data types
- Integer overflow
- Signed number representations
Notes[edit]
- ^ Not all SQL dialects have unsigned datatypes.[3][4]
- ^ a b c d e f g h i j k l m n The sizes of char, short, int, long and long long in C/C++ are dependent upon the implementation of the language.
- ^ Java does not directly support arithmetic on char types. The results must be cast back into char from an int.
- ^ a b The sizes of Delphi’s Integer and Cardinal are not guaranteed, varying from platform to platform; usually defined as LongInt and LongWord respectively.
- ^ a b Reserved for future use. Not implemented yet.
- ^ The ISO C standard allows implementations to reserve the value with sign bit 1 and all other bits 0 (for sign–magnitude and two’s complement representation) or with all bits 1 (for ones’ complement) for use as a «trap» value, used to indicate (for example) an overflow.[9]
- ^ a b c d The terms long and int are equivalent[11]
References[edit]
- ^ Cheever, Eric. «Representation of numbers». Swarthmore College. Retrieved 2011-09-11.
- ^ Madhusudhan Konda (2011-09-02). «A look at Java 7’s new features — O’Reilly Radar». Radar.oreilly.com. Retrieved 2013-10-15.
- ^ «Sybase Adaptive Server Enterprise 15.5: Exact Numeric Datatypes».
- ^ «MySQL 5.6 Numeric Datatypes».
- ^ «BigInteger (Java Platform SE 6)». Oracle. Retrieved 2011-09-11.
- ^ a b c d e Fog, Agner (2010-02-16). «Calling conventions for different C++ compilers and operating systems: Chapter 3, Data Representation» (PDF). Retrieved 2010-08-30.
- ^ Giguere, Eric (1987-12-18). «The ANSI Standard: A Summary for the C Programmer». Retrieved 2010-09-04.
- ^ a b Meyers, Randy (2000-12-01). «The New C: Integers in C99, Part 1». drdobbs.com. Retrieved 2010-09-04.
- ^ a b c d «ISO/IEC 9899:201x» (PDF). open-std.org. section 6.2.6.2, paragraph 2. Retrieved 2016-06-20.
- ^ a b c «ISO/IEC 9899:201x» (PDF). open-std.org. section 5.2.4.2.1. Retrieved 2016-06-20.
- ^ «ISO/IEC 9899:201x» (PDF). open-std.org. Retrieved 2013-03-27.
- ^ «Fundamental types in C++». cppreference.com. Retrieved 5 December 2010.
- ^ «Chapter 8.6.2 on page 12» (PDF). ecma-international.org.
- ^ VB 6.0 help file
- ^ «The Integer, Long, and Byte Data Types (VBA)». microsoft.com. Retrieved 2006-12-19.
- ^ Giguere, Eric (December 18, 1987). «The ANSI Standard: A Summary for the C Programmer». Retrieved 2010-09-04.
- ^ «American National Standard Programming Language C specifies the syntax and semantics of programs written in the C programming language». Archived from the original on 2010-08-22. Retrieved 2010-09-04.
- ^ ECMAScript 6th Edition draft: https://people.mozilla.org/~jorendorff/es6-draft.html#sec-literals-numeric-literals Archived 2013-12-16 at the Wayback Machine
It is true that the expressiveness of the Haskell type system encourages users to assign precise types to entities they define. However, seasoned Haskellers will readily acknowledge that one must strike a balance between ultimate type precision (which besides isn’t always attainable given the current limits of Haskell type system) and convenience. In short, precise types are only useful to a point. Beyond that point, they often just cause extra bureaucracy for little to no gain.
Let’s illustrate the problem with an example. Consider the factorial function. For all n bigger than 1, the factorial of n is an even number, and the factorial of 1 isn’t terribly interesting so let’s ignore that one. Therefore, in order to make sure that our implementation of the factorial function in Haskell is correct, we might be tempted to introduce a new numeric type, that can only represent unsigned even integers:
module (Even) where
newtype Even = Even Integer
instance Num Even where
...
fromInteger x | x `mod` 2 == 0 = Even x
| otherwise = error "Not an even number."
instance Integral Even where
...
toInteger (Even x) = x
We seal this datatype inside a module that doesn’t export the constructor, to make it abstract, and make it an instance of the all the relevant type classes that Int is an instance of. Now we can give the following signature to factorial:
factorial :: Int -> Even
The type of factorial sure is more precise than if we just said that it returns Int. But you’ll find that definining factorial with such a type is really quite annoying, because you need a version of multiplication that multiplies an (even or odd) Int with an Even and produces and Even. What’s more, you might have to introduce extraneous calls to toInteger on the result of a call to factorial in client code, which can be a significant source of clutter and noise for little gain. Besides, all these conversion functions could potentially have a negative impact on performance.
Another problem is that when introducing a new, more precise type, you often end up having to duplicate all manner of library functions. For instance, if you introduce the type List1 a of non-empty lists, then you will have to reimplement many of the functions that Data.List already provides, but for [a] only. Sure, one can then make these functions methods of ListLike type class. But you quickly end up with all manner of adhoc type classes and other boilerplate, with again not much gain.
One final point is that one shouldn’t consider Word to be an unsigned variant of Int. The Haskell report leaves the actual size of Int unspecified, and only guarantees that this type should be capable of representing integers in the range [− 229, 229 − 1]. The type Word is said to provide unsigned integers of unspecified width. It isn’t guaranteed that in any conforming implementation the width of a Word corresponds to the width of an Int.
Though I make a point guarding against excessive type proliferation, I do acknowledge that introducing a type of Natural of naturals could be nice. Ultimately, though, whether Haskell should have a dedicated type for natural numbers, in addition to Int, Integer, and the various Word* types, is largely a matter of taste. And the current state of affairs is probably in very large part just an accident of history.