
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов
|
Остаточная сумма квадратов
|



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Содержание
- Вычисление дисперсии
- Способ 1: расчет по генеральной совокупности
- Способ 2: расчет по выборке
- Вопросы и ответы

Среди множества показателей, которые применяются в статистике, нужно выделить расчет дисперсии. Следует отметить, что выполнение вручную данного вычисления – довольно утомительное занятие. К счастью, в приложении Excel имеются функции, позволяющие автоматизировать процедуру расчета. Выясним алгоритм работы с этими инструментами.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
=ДИСП.Г(Число1;Число2;…)
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
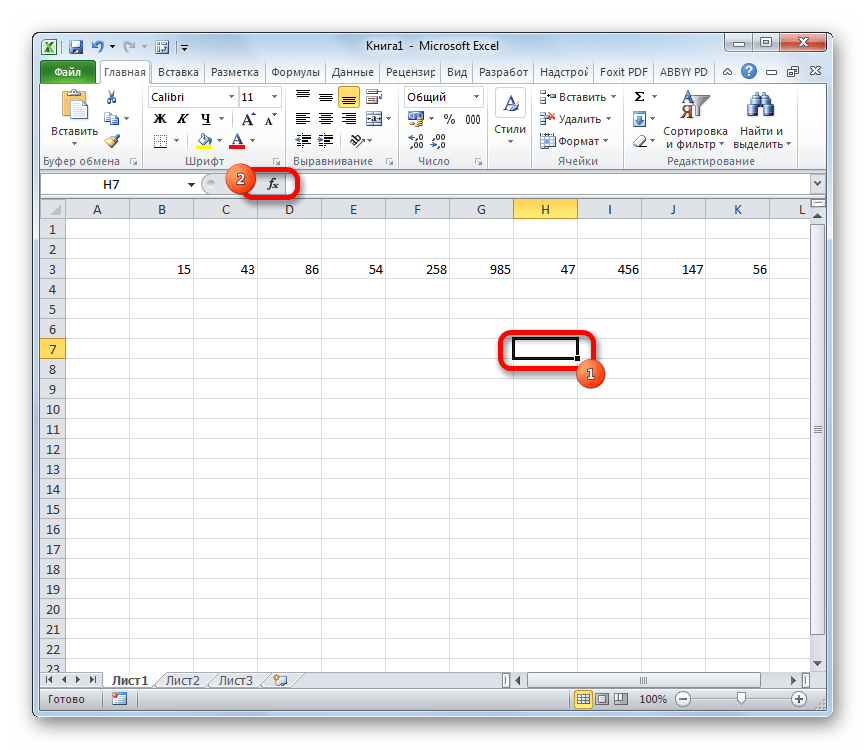
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.
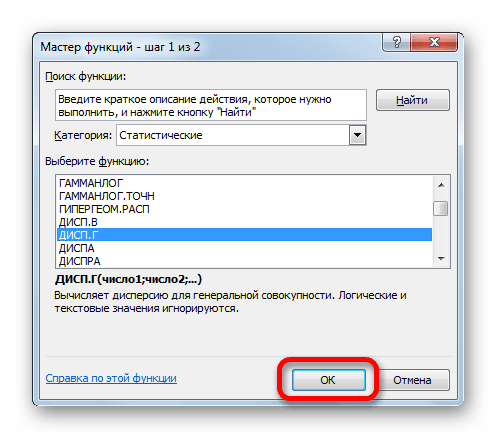
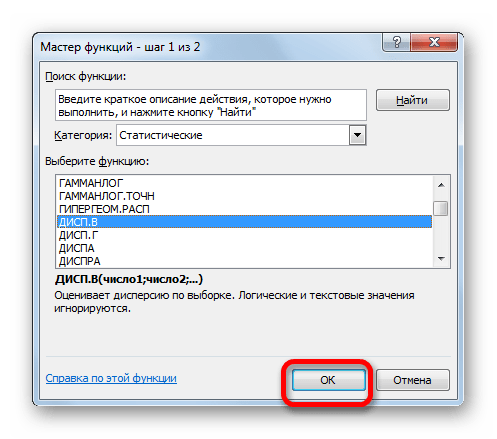
- Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
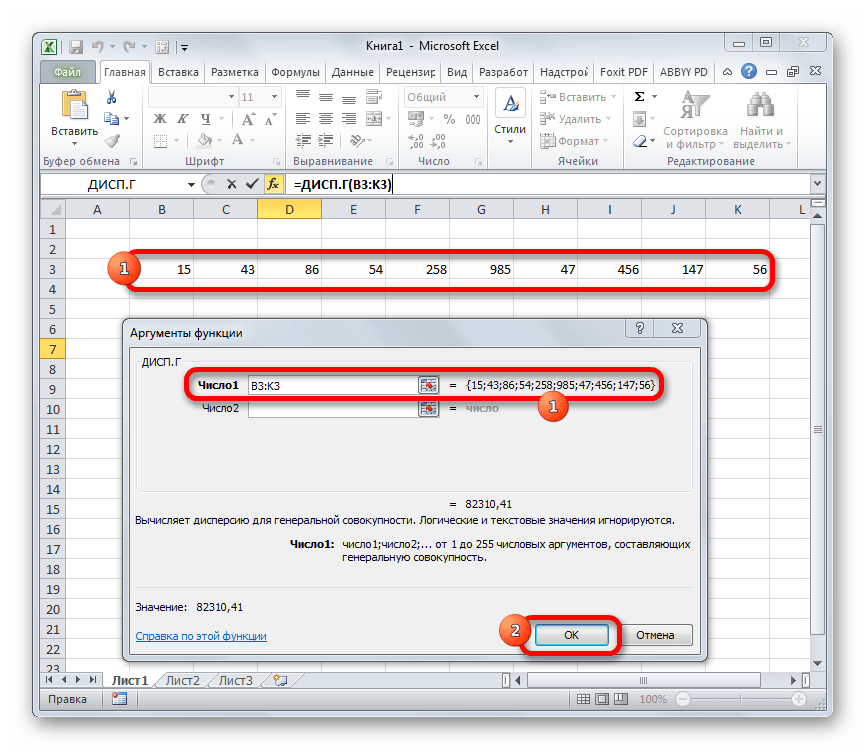
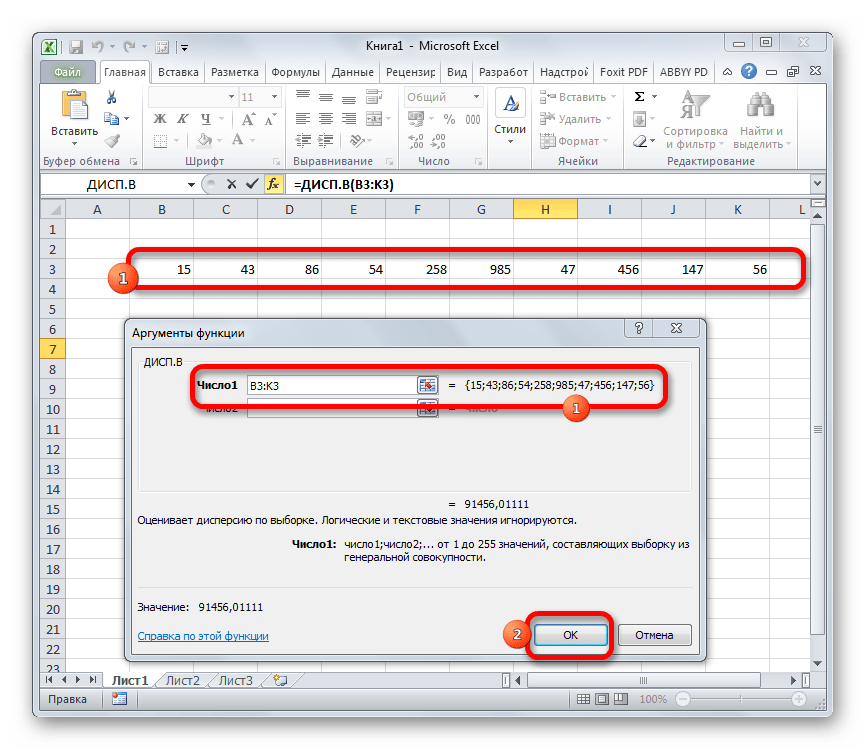
- Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».
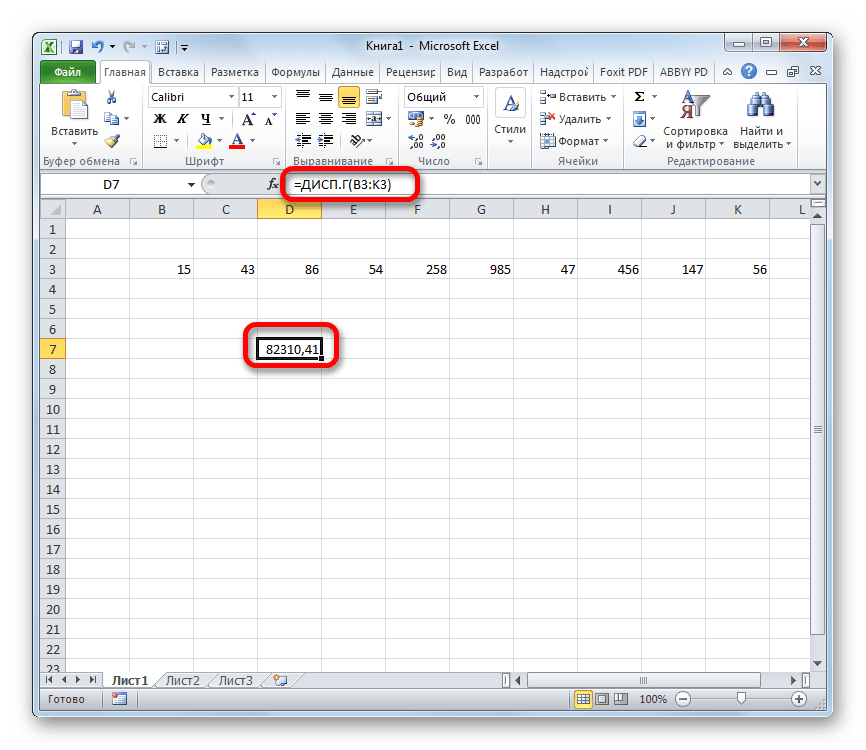
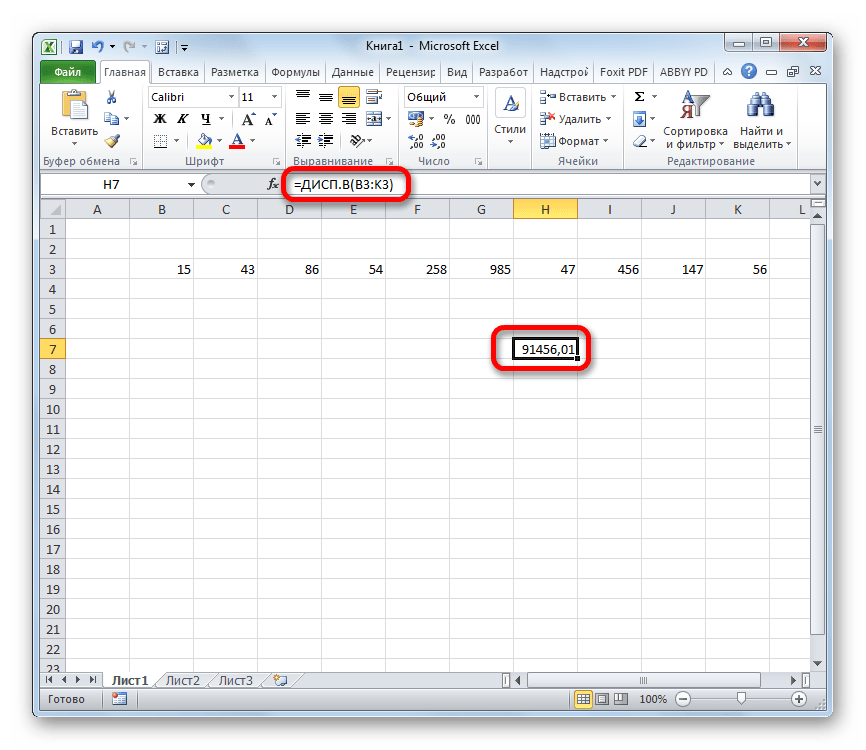
- Как видим, после этих действий производится расчет. Итог вычисления величины дисперсии по генеральной совокупности выводится в предварительно указанную ячейку. Это именно та ячейка, в которой непосредственно находится формула ДИСП.Г.
Урок: Мастер функций в Эксель
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
=ДИСП.В(Число1;Число2;…)
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.

- Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.
- В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
- Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».
- Результат вычисления будет выведен в отдельную ячейку.
Урок: Другие статистические функции в Эксель
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Еще статьи по данной теме:
Помогла ли Вам статья?
Итак, вас попросили рассчитать дисперсию с помощью Excel, но вы не знаете, что это значит и как это сделать. Не волнуйтесь, это простая концепция и еще более простой процесс. Вы станете профессионалом в дисперсии в кратчайшие сроки!
Что такое дисперсия?
«Дисперсия» — это способ измерения среднего расстояния от среднего. «Среднее» — это сумма всех значений в наборе данных, деленная на количество значений. Дисперсия дает нам представление о том, имеют ли значения в этом наборе данных тенденцию в среднем равномерно придерживаться среднего значения или разбросаны повсюду.
Математически дисперсия не так уж сложна:
- Вычислите среднее значение набора значений. Чтобы вычислить среднее значение, возьмите сумму всех значений, разделенную на количество значений.
- Возьмите каждое значение в вашем наборе и вычтите его из среднего.
- Возведите полученные значения в квадрат (чтобы исключить отрицательные числа).
- Сложите все квадраты значений вместе.
- Вычислите среднее квадратов значений, чтобы получить дисперсию.
Как видите, вычислить это значение несложно. Однако если у вас есть сотни или тысячи значений, на то, чтобы сделать это вручную, уйдет целая вечность. Так что хорошо, что Excel может автоматизировать этот процесс!
Для чего вы используете дисперсию?
Сама по себе дисперсия имеет ряд применений. С чисто статистической точки зрения это хороший способ обозначить, насколько разрознен набор данных. Инвесторы используют дисперсию для оценки риска данной инвестиции.
Например, взяв стоимость акции за определенный период времени и вычислив ее дисперсию, вы получите хорошее представление о ее волатильности в прошлом. Если предположить, что прошлое предсказывает будущее, это будет означать, что что-то с низкой дисперсией более безопасно и предсказуемо.
Вы также можете сравнить отклонения чего-либо в разные периоды времени. Это может помочь обнаружить, когда другой скрытый фактор на что-то влияет, изменяя его дисперсию.
Дисперсия также сильно связана с другой статистикой, известной как стандартное отклонение. Помните, что значения, используемые для расчета дисперсии, возведены в квадрат. Это означает, что отклонение не выражается в той же единице исходного значения. Стандартное отклонение требует извлечения квадратного корня из дисперсии, чтобы вернуть значение в исходную единицу. Таким образом, если данные были в килограммах, стандартное отклонение тоже.
Выбор между совокупностью и дисперсией выборки
В Excel есть два подтипа дисперсии с немного разными формулами. Какой из них выбрать, зависит от ваших данных. Если ваши данные включают всю «генеральную совокупность», вам следует использовать дисперсию генеральной совокупности. В этом случае «популяция» означает, что у вас есть все значения для каждого члена целевой группы населения.
Например, если вы посмотрите на вес левшей, то в популяцию войдут все левши на Земле. Если вы их все взвесите, вы воспользуетесь дисперсией населения.
Конечно, в реальной жизни мы обычно соглашаемся на меньшую выборку из большей совокупности. В этом случае вы должны использовать выборочную дисперсию. Дисперсия совокупности по-прежнему актуальна для небольших популяций. Например, в компании может быть несколько сотен или несколько тысяч сотрудников с данными о каждом сотруднике. Они представляют собой «население» в статистическом смысле.
Выбор правильной формулы дисперсии
В Excel есть три типовых формулы дисперсии и три формулы дисперсии генеральной совокупности:
- VAR, VAR.S и VARA для выборочной дисперсии.
- VARP, VAR.P и VARPA для дисперсии совокупности.
Вы можете игнорировать VAR и VARP. Они устарели и существуют только для совместимости с устаревшими электронными таблицами.
Остается VAR.S и VAR.P, которые предназначены для вычисления дисперсии набора числовых значений, а также VARA и VARPA, которые включают текстовые строки.
VARA и VARPA преобразуют любую текстовую строку в числовое значение 0, за исключением «ИСТИНА» и «ЛОЖЬ». Они преобразуются в 1 и 0 соответственно.
Самая большая разница в том, что VAR.S и VAR.P пропускают любые нечисловые значения. Это исключает эти случаи из общего количества значений, что означает, что среднее значение будет другим, потому что вы делите на меньшее количество случаев, чтобы получить среднее значение.
Все, что вам нужно для расчета дисперсии в Excel, — это набор значений. Мы собираемся использовать VAR.S в приведенном ниже примере, но формула и методы точно такие же, независимо от того, какую формулу дисперсии вы используете:
- Предполагая, что у вас есть готовый диапазон или дискретный набор значений, выберите пустую ячейку по вашему выбору.
- В поле формулы введите = VAR.S (XX: YY), где значения X и Y заменяются номерами первой и последней ячеек диапазона.
- Нажмите Enter, чтобы завершить расчет.
В качестве альтернативы вы можете указать конкретные значения, и в этом случае формула будет иметь вид = VAR.S (1,2,3,4). С числами, замененными на все, что вам нужно для расчета дисперсии. Вы можете ввести до 254 значений вручную таким образом, но если у вас есть только несколько значений, почти всегда лучше вводить данные в диапазоне ячеек, а затем использовать версию формулы, описанную выше, для диапазона ячеек.
Вы можете Excel в, Er, Excel
Вычисление дисперсии — полезный прием для тех, кому нужно выполнить статистическую работу в Excel. Но если какая-либо терминология Excel, которую мы использовали в этой статье, сбивала с толку, подумайте о том, чтобы ознакомиться с Руководством по основам Microsoft Excel — Обучение использованию Excel.
Если, с другой стороны, вы готовы к большему, ознакомьтесь с разделом «Добавить линию тренда линейной регрессии на точечную диаграмму Excel», чтобы вы могли визуализировать дисперсию или любой другой аспект вашего набора данных по отношению к среднему арифметическому.
Министерство
образования и науки Российской Федерации
Федеральное
агентство по образованию
Саратовский
государственный технический университет
Балаковский
институт техники, технологии и управления
Методическое
указание к выполнению лабораторной
работы
по дисциплине
“Идентификация и диагностика систем
управления”
для студентов
специальности 220201
очной и заочной
форм обучения
Одобрено
редакционно-издательским
советом
Балаковского
института техники,
технологии
и управления
Балаково 2010
Цель работы:
Освоение регрессионного анализа в
пакете EXCEL.
ОСНОВНЫЕ ПОНЯТИЯ
Задачами
регрессионного анализа являются:
установление формы зависимости между
переменными, оценка функций регрессии,
оценка неизвестных значений зависимой
переменной (прогноз).
Односторонняя
зависимость случайной зависимой
переменной Y
от одной или нескольких независимых
переменных Х
называется объясняющей
регрессией.
Такая
зависимость может возникать тогда,
когда при каждом фиксированном значении
X,
соответствующее значение Y
подвержено случайному разбросу под
воздействием неконтролируемых факторов.
Такая зависимость Y(X)
называется регрессионной.
Она может
быть представлена в виде модельного
уравнения регрессии:

(1)
где
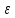
— случайная переменная характеризующая
отклонение функции регрессии.
Линейный
регрессионный анализ
— это анализ, для которого функция f(X)
линейна относительно оцениваемых
факторов. Уравнение линейной регрессии
имеет вид:

(2)
Регрессионный
анализ включает в себя две основные
компоненты:
1. оценка вектора
коэффициентов с помощью метода наименьших
квадратов:
 ;
;
2. дисперсионный
анализ.
Предпосылки
регрессионный анализ:
-
чтобы количество
экспериментальных данных было больше
либо равно 30 на один вход; -
распределение
выходной величины должно быть нормальным; -
в процессе
эксперимента дисперсия выходной
величины Y
не меняется:
 ;
; -
переменная X
изменяется с пренебрежительно малыми
ошибками, то есть является детерменированой; -
выходные переменные
Y1,
Y2,
… Yn
стохастически независимы между собой:
; -
дискретность
проведения экспериментов во времени
берется
таким образом, чтобы последовательно
взятые значения Y1,
Y2,
… Yn
были стохастически независимы, то есть
больше времени затухания автокорреляционной
функции; -
учет динамики в
регрессионном анализе производится в
виде транспортного запаздывания,
которое определяется как время нахождения
максимума взаимно корреляционной
функции X
и Y.
 ;
; ;
; берется
берется
На основании этих
предпосылок получают уравнение
регрессионной модели методом наименьших
квадратов.
Задача дисперсионного
анализа заключается в определении той
части экспериментальных данных, которая
описывается регрессионной моделью
(определяется коэффициент детерминации
R2
),
а также определение адекватности
регрессионной модели. Для этого
используется основное уравнение
дисперсионного анализа, которое имеет
вид:

(3)
где
 полная
полная
сумма квадратичных отклонений
характеризует разброс значений выходной
величины Y
вокруг его среднего значения;

— остаточная
сумма отклонений используется в качестве
критерия МНК;

сумма
обусловленная регрессией.
Коэффициент
детерминации R2
определяется
соотношением суммы обусловленной
регрессией и остаточной
суммы отклонений:

(4)
Коэффициент
детерминации изменяется от 0 до 1:

При

коэффициент детерминации

а при

коэффициент детерминации
 .
.
Чем ближе коэффициент детерминации к
1, тем точнее регрессионная модель.
При малых объемах
выборки используется коэффициент
множественной корреляции:
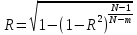
,
(5)
где N
– количество выборки; m
– количество входов.
Для оценки
адекватности регрессионной модели
используется критерий Фишера, который
определяется отношением дисперсии
обусловленной регрессией и остаточной
дисперсией:
 ,
,
(6)
Дисперсия,
обусловленная регрессией — среднее
значение квадратов отклонения
обусловленных регрессией определяется
выражением:

(7)
где fр
— число
степеней свободы суммы обусловленной
регрессией:
 ,
,
(8)
где m
– число
коэффициентов уравнения регрессии.
Остаточная дисперсия
определяется выражением:

(9)
где fост
— число
степеней свободы остаточной суммы:
 ,
,
(10)
где N
— число
экспериментов.
Для определения
адекватности регрессионной модели
сравнивают F-отношение,
рассчитанное по выражению (6), со значением
критерия Фишера выбранного из таблиц
для принятого уровня значимости

и числа степеней свободы сравниваемых
дисперсий
 и
и
 .
.

Если
 ,
,
то при соответствующем уровне значимости
регрессионная модель не адекватна.
Если
 ,
,
то при соответствующем уровне значимости
регрессионная модель адекватна.
Результаты
дисперсионного анализа сводятся в
таблицу 1.
Таблица
1.
Дисперсионный
анализ
|
SS |
f |
MS |
F |
P— |
F |
|
|
регрессия |
|
|
|
|
||
|
остатки |
|
|
|
|||
|
Итого |
|
|
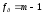


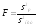





Интерпретация
результатов:
SS
— сумма квадратов; f
— число
степеней свободы; MS
— средний квадрат отклонений (дисперсия);
F—
расчетное значение отношения Фишера;
P—уровень
значимости для вычисленного значения
F;
Fкрит
— табличное значение отношения Фишера.
Если регрессионная
модель адекватна, определяют значимость
коэффициентов регрессии. Для проверки
значимости анализируется отношение
коэффициента регрессии и его
среднеквадратичного отклонения. Это
отношение является распределением
Стьюдента, то есть для определения
значимости используем t
– критерий:

(11)
где
 i,
i,
,
 —
—
значение коэффициента и его
среднеквадратичное отклонение.
Для определения
значимости коэффициента сравнивают
расчетное и табличное значение t
– критерия. Табличное значение t
– критерия определяется степенью
свободы
 и
и
значением заданной вероятности Р
: tтаб.
( ,
,
Р).
Если tрас.>tтаб.,
то коэффициент bi
является
значимым.
Доверительный
интервал определяется по формуле:
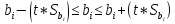
.
(12)
Если коэффициент
регрессии незначим, то соответствующий
ему входной фактор несущественно влияет
на выходную величину и его можно исключить
из регрессионной модели.
ПОРЯДОК ВЫПОЛНЕНИЯ
РАБОТЫ
-
Исходные данные
взять в таблицах(2,3) согласно варианту
(по номеру студента в журнале). -
Ввести исходные
данные в таблицу в пакете Excel. -
Подготовить два
столбца для ввода расчетных значений
Y
и остатков. -
Вызвать программу
«Регрессия»: Данные/ Анализ данных/
Регрессия. Диалоговое окно «Анализ
данных» представлено на рисунке 1.
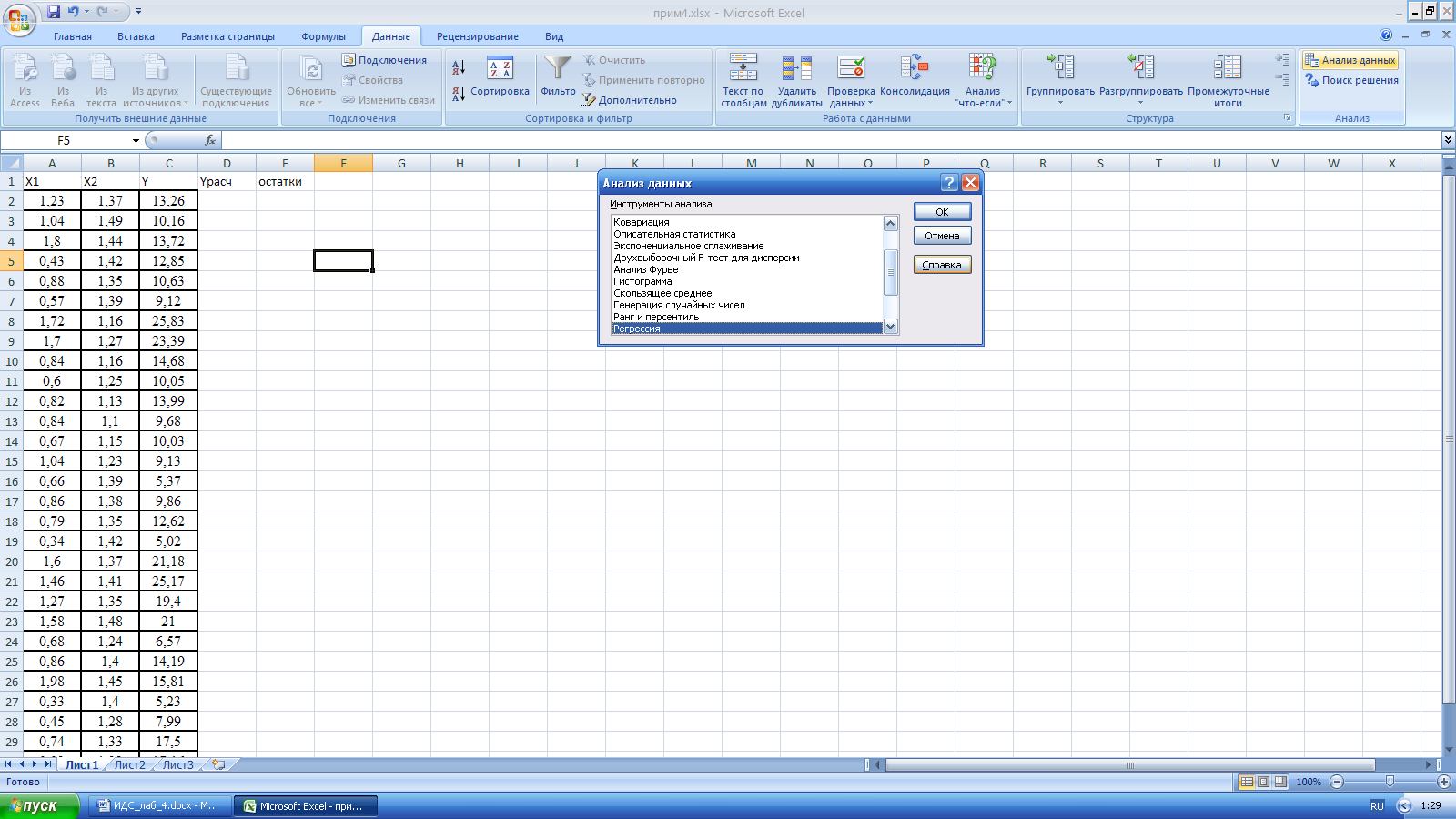
Рис. 1. Диалоговое окно «Анализ данных».
-
Ввести в диалоговое
окно «Регрессия» адреса исходных
данных:
-
входной интервал
Y,
входной интервал X
(3 столбца), -
установить уровень
надежности 95%, -
в опции «Выходной
интервал, указать левую верхнюю ячейку
места вывода данных регрессионного
анализа (первую ячейку на 2-странице
рабочего листа), -
включить опции
«Остатки» и «График остатков», -
нажать кнопку ОК
для запуска регрессионного анализа.
Диалоговое окно «Регрессия» представлено
на рисунке 2.

Рис. 2. Диалоговое окно
«Регрессия».
-
Excel выведет четыре
таблицы и два графика зависимости
остатков от переменных Х1
и Х2. -
Построить графики
для Yэксп,
Yрасч
и график ошибки прогноза (остатка). -
По полученным
графикам оценить правильность модели
по входам Х1,
Х2. -
Рассчитать
коэффициент множественной корреляции,
расчетные значения t-критериев,
доверительные интервалы коэффициентов
регрессии по выражениям (5,11,12). -
Сделать выводы
по результатам регрессионного анализа. -
Подготовить отчет
по работе.
ПРИМЕР ВЫПОЛНЕНИЯ
РАБОТЫ
Результаты
регрессионного анализа представлены
на рисунке 3.
Графики зависимости
остатков от переменных Х1
и Х2 представлены
на рисунке 4.
Графики расчетной
и экспериментальной выходной величины,
и график ошибки прогноза представлены
на рисунке 5.

Рис. 3. Пример регрессионного анализа в
пакете EXCEL


Рис.4 . Графики остатков переменных Х1,
Х2

Рис. 5. Графики Yэксп,
Yрасч и
ошибки прогноза (остатки).
По результатам
регрессионного анализа можно сказать:
-
Уравнение регрессии
полученное с помощью Excel,
имеет вид:
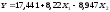
-
Коэффициент
детерминации:

Вариация результата
на 46,5% объясняется вариацией факторов.
-
Коэффициент
множественной корреляции:

-
Проверка на
адекватность модели. Анализ выполняется
при сравнении фактического и табличного
значения F-критерия
Фишера.
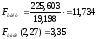
Фактическое
значение F-критерия Фишера
превышает табличное

— модель адекватна.
-
Проверка значимости
коэффициента b0.
Расчетное значение
t-критерия
для коэффициента
b0:

Табличное значение
t-критерия
tтаб.
(29, 0.975)=2.05
-
Доверительный
интервал коэффициента b0:


-
Проверка значимости
коэффициента b1.
Расчетное значение
t-критерия
для коэффициента
b1:

tрас.>tтаб.,
коэффициент b1
является значимым
-
Доверительный
интервал
коэффициента
b1:
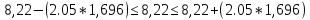

-
Проверка значимости
для коэффициентаb2.
Расчетное значение
t-критерия
для коэффициента
b2:

tрас.<tтаб.,
коэффициент b2
является не значимым, значит фактор X
2 незначительно влияет на выходную
величину Y,
и его можно исключить из уравнения
регрессии.
-
На основании
анализа значимости коэффициентов
уравнение регрессии примет вид:

Соседние файлы в папке LR-3
- #
- #
17.02.201457.34 Кб36Копия Xl0000004.xls
- #
Variance is a measurement of the spread between numbers in a data set. The variance measures how far each number in the set is from the mean. You can use Microsoft Excel to calculate the variance of the data you have entered into a spreadsheet.
How to Calculate Variance in Excel
To calculate variance in Excel, you will need to have your data set already entered into the software. Once you have your data, you can choose your formula based on the type of data set you have and the type of variance you need to calculate.
There are a few different options for the formula to calculate variance in Excel:
- =VAR.S(select data)
- =VARA(select data)
- =VAR.P(select data)
For each of these, you would select the range of cells you want to use after the parentheses. For example, you might enter =VAR.S(B12:B32) to find the variance for the data in cells B12 to B32.
Important
You must start with the «=» so that Excel knows you are entering a formula.
It is important to know what type of data you are working with in order to select the correct forumla. For example, if your data set contains any text values, VARA will interpret text as 0, TRUE as 1, and FALSE as 0, whereas VAR.S ignores all values other than numbers. This will change the result of your variance calculation.
VAR.P, on the other hand, is for calculating variance in a population based on the entire set of numbers. If you don’t have the entire population of data to use, you should use VAR.S in your formula.
In general, VAR.S is the formula you should most often rely on for calculation variance in Excel.
What Is Variance?
What are you actually calculating when you use Excel to find the variance of a data set?
Using a data set chart, we can observe what the linear relationship of the various data points, or numbers, is. We do this by drawing a regression line, which attempts to minimize the distance of any individual data point from the line itself. In the chart below, the data points are the blue dots and the orange line is the regression line. The red arrows are the distance from the observed data and the regression line.
When we calculate a variance, we are asking, given the relationship of all these data points, how much distance do we expect on the next data point? This «distance» is called the error term, and it’s what variance is measuring.
By itself, variance is not often useful because it does not have a unit, which makes it hard to measure and compare. However, the square root of variance is the standard deviation, and that is both practical and useful as a measurement.
Example of Calculating Variance in Excel
In the example below, we will calculate the variance of 20 days of daily returns in the highly popular exchange-traded fund (ETF) named SPY, which invests in the S&P 500. We will use the following formula:
=VAR.S(select data)
In this instance, if we had all returns in the history of the SPY ETF in our table, we could use the population measurement VAR.P. However, since we are only measuring the last 20 days to illustrate the concept, we will use VAR.S.
As you can see, the calculated variance value of .000018674 tells us little about the data set, by itself. If we went on to square root that value to get the standard deviation of returns, that would be more useful.