
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
17 авг. 2022 г.
читать 2 мин
Всякий раз, когда мы подбираем модель линейной регрессии , модель принимает следующую форму:
Y = β 0 + β 1 X + … + β i X +ϵ
где ϵ — член ошибки, не зависящий от X.
Независимо от того, насколько хорошо можно использовать X для предсказания значений Y, в модели всегда будет какая-то случайная ошибка.
Одним из способов измерения дисперсии этой случайной ошибки является использование стандартной ошибки регрессионной модели , которая представляет собой способ измерения стандартного отклонения остатков ϵ.
В этом руководстве представлен пошаговый пример расчета стандартной ошибки регрессионной модели в Excel.
Шаг 1: Создайте данные
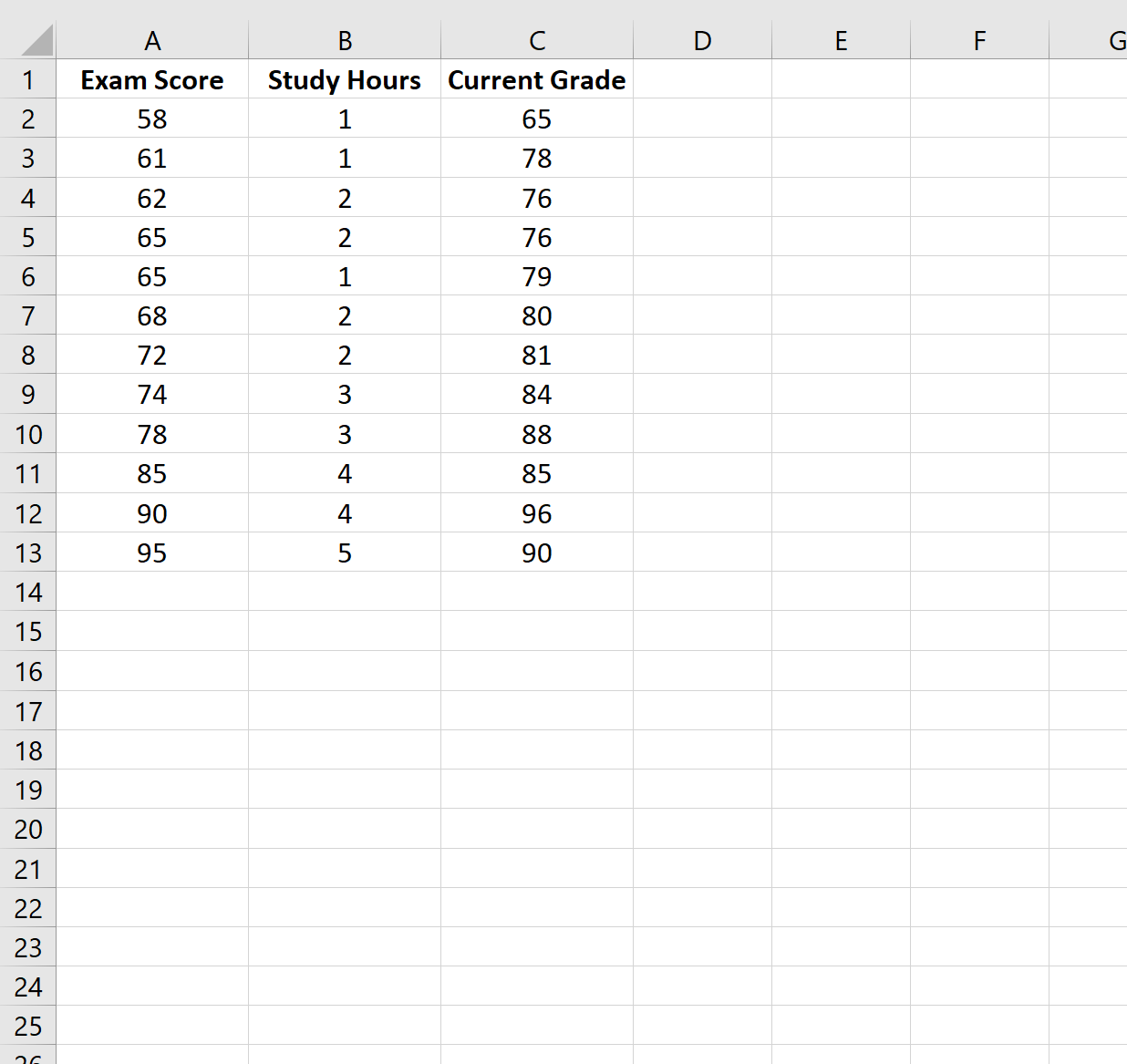
В этом примере мы создадим набор данных, содержащий следующие переменные для 12 разных учащихся:
- Оценка экзамена
- Часы, потраченные на учебу
- Текущая оценка
Шаг 2: Подгонка регрессионной модели
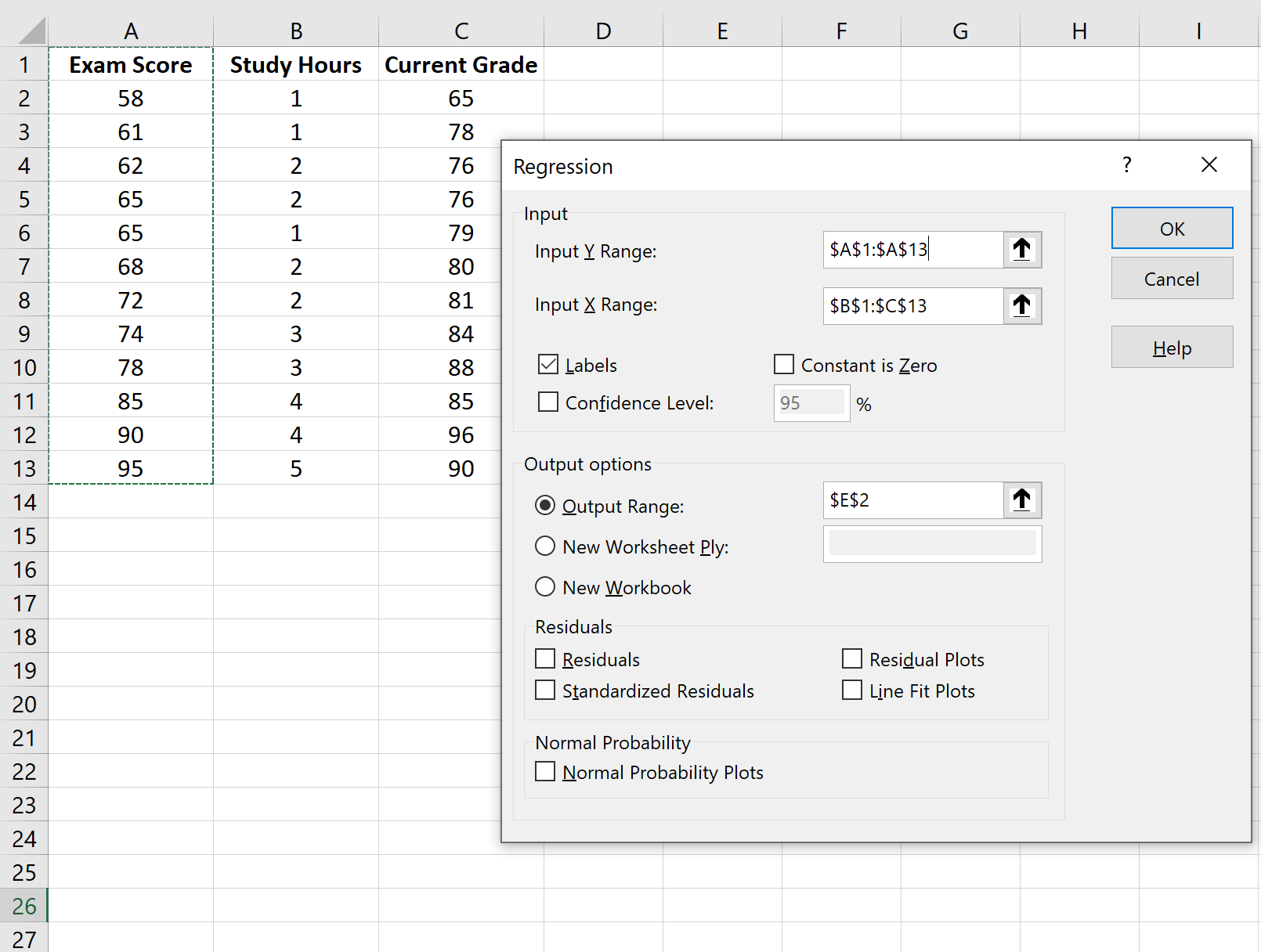
Далее мы подгоним модель множественной линейной регрессии , используя экзаменационный балл в качестве переменной ответа и часы обучения и текущую оценку в качестве переменных-предикторов.
Для этого щелкните вкладку « Данные » на верхней ленте, а затем щелкните « Анализ данных» :

Если вы не видите эту опцию доступной, вам нужно сначала загрузить Data Analysis ToolPak .
В появившемся окне выберите Регрессия.В появившемся новом окне заполните следующую информацию:
Как только вы нажмете OK , появится результат регрессионной модели:
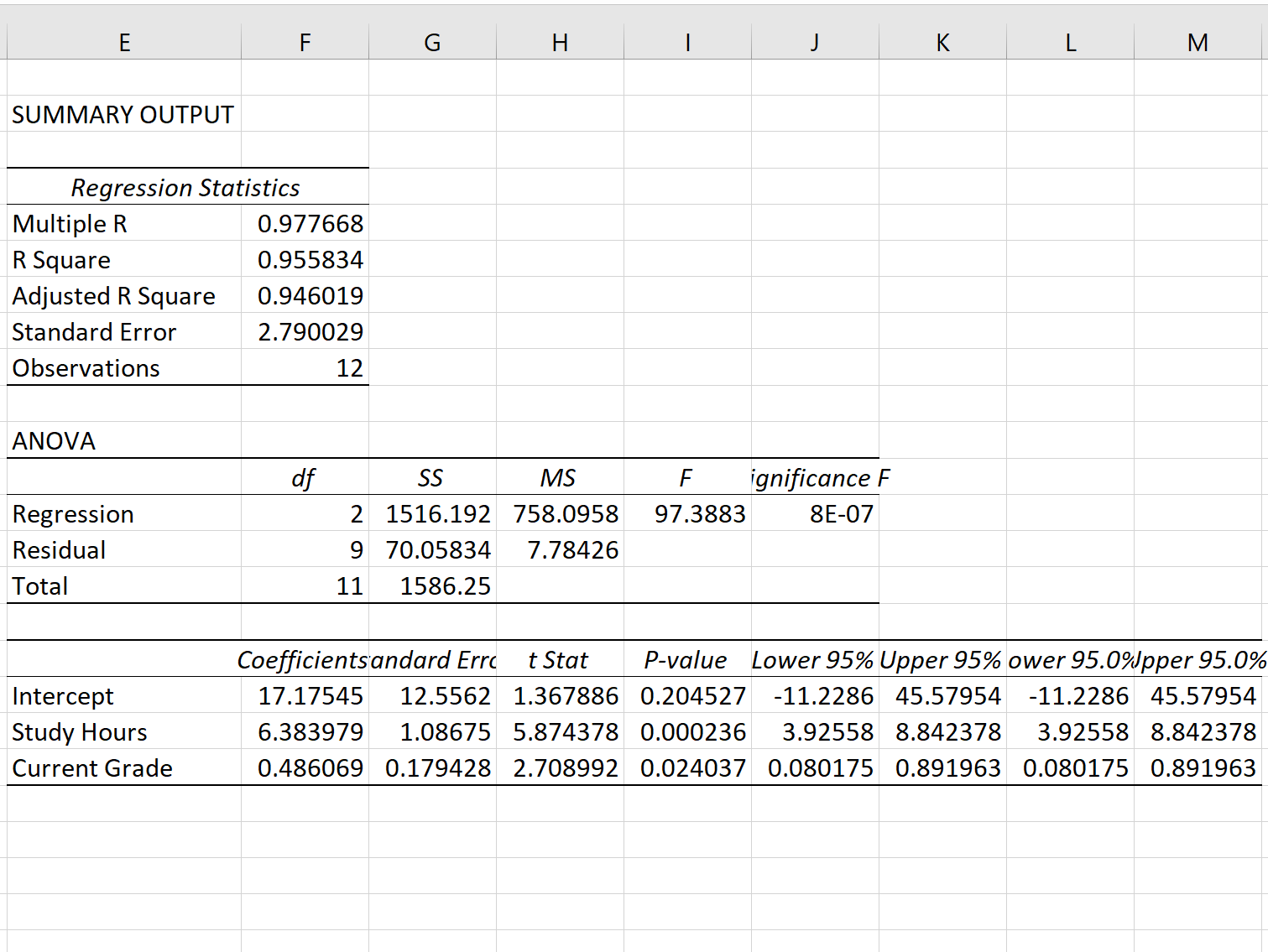
Шаг 3: Интерпретируйте стандартную ошибку регрессии
Стандартная ошибка модели регрессии — это число рядом со стандартной ошибкой :
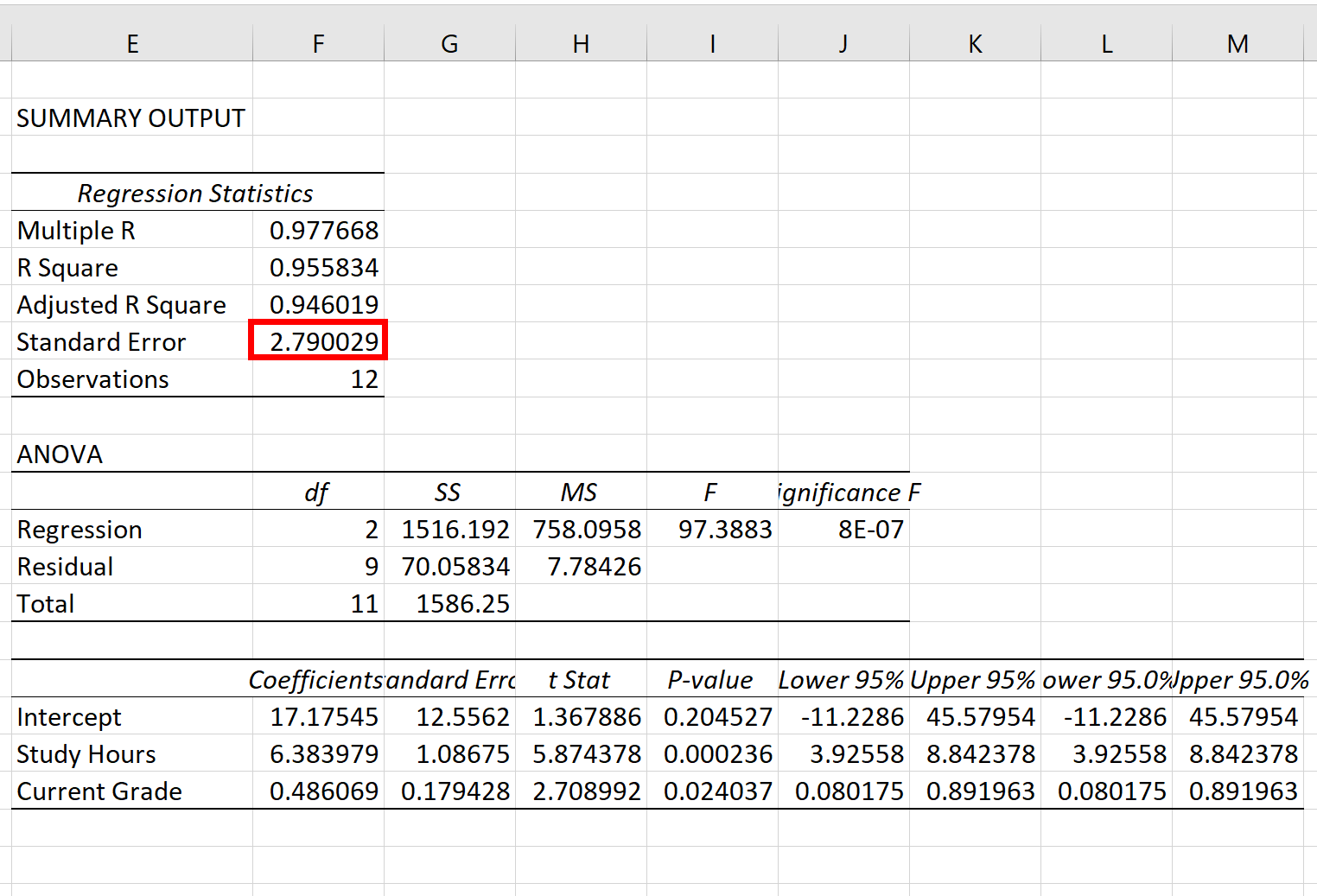
Стандартная ошибка этой конкретной модели регрессии оказывается равной 2,790029 .
Это число представляет собой среднее расстояние между фактическими результатами экзаменов и оценками экзаменов, предсказанными моделью.
Обратите внимание, что некоторые экзаменационные баллы будут отличаться от прогнозируемого более чем на 2,79 единицы, в то время как некоторые будут ближе. Но в среднем расстояние между реальными экзаменационными баллами и прогнозируемыми составляет 2,790029 .
Также обратите внимание, что меньшая стандартная ошибка регрессии указывает на то, что модель регрессии более точно соответствует набору данных.
Таким образом, если мы подгоним новую регрессионную модель к набору данных и получим стандартную ошибку, скажем, 4,53 , эта новая модель будет хуже предсказывать результаты экзаменов, чем предыдущая модель.
Дополнительные ресурсы
Другим распространенным способом измерения точности регрессионной модели является использование R-квадрата. Прочтите эту статью , чтобы получить хорошее объяснение преимуществ использования стандартной ошибки регрессии для измерения точности по сравнению с R-квадратом.
![]()
Загрузить PDF
![]()
Загрузить PDF
В этой статье мы расскажем вам, как в Excel вычислить стандартную ошибку среднего. Для этого стандартное отклонение (σ) нужно разделить на квадратный корень (√) из размера выборки (N).
Шаги
-
1
Запустите Excel. Нажмите на значок в виде белой буквы «Х» на зеленом фоне.
-
2
Откройте или создайте таблицу Excel. Чтобы открыть готовую таблицу с данными, нажмите «Открыть» на левой панели. Чтобы создать таблицу, нажмите «Создать» и введите данные.
-
3
Вычислите стандартное отклонение. Чтобы сделать это, нужно выполнить несколько действий, но в Excel можно просто ввести следующую формулу: =СТАНДОТКЛОН.В(''диапазон ячеек'').
- Например, если данные находятся в ячейках с A1 по A20, в пустой ячейке введите =СТАНДОТКЛОН.В(A1:A20), чтобы вычислить стандартное отклонение.
-
4
Введите формулу для вычисления стандартной ошибки среднего в пустой ячейке. Формула выглядит так:=СТАНДОТКЛОН.В(''диапазон ячеек'')/КОРЕНЬ(СЧЁТ("диапазон ячеек")).
- Например, если данные находятся в ячейках с A1 по A20, в пустой ячейке введите формулу =СТАНДОТКЛОН.В(A1:A20)/КОРЕНЬ(СЧЁТ(A1:A20)). Так вы вычислите стандартную ошибку среднего.
Реклама




Об этой статье
Эту страницу просматривали 31 569 раз.
Была ли эта статья полезной?
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
The standard error tells that how accurate the mean of any given sample from that population is likely to be compared to the true population mean.
Formula:
Standard Error=Standard Deviation/sqrt(n)
Where
- n= No. of samples.
Let’s follow the below steps and take a look at an example:
Step 1: The dataset is given as follow:
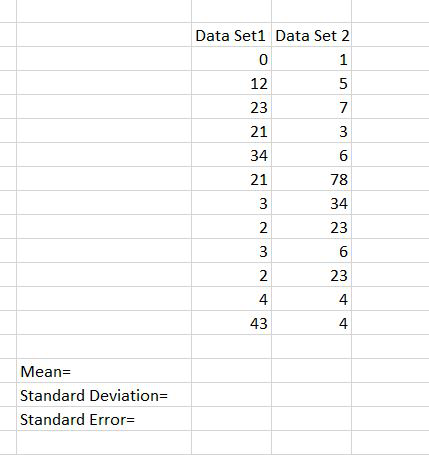
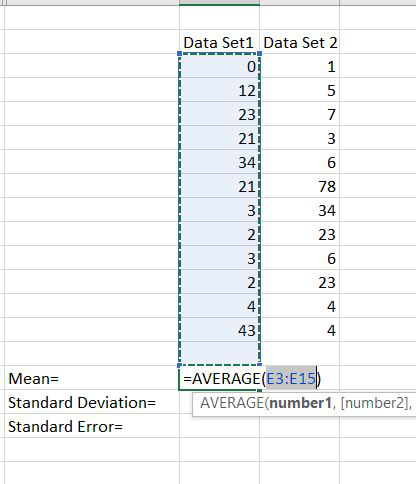
Step 2: Now for calculating the standard error we have to find the mean, standard deviation.
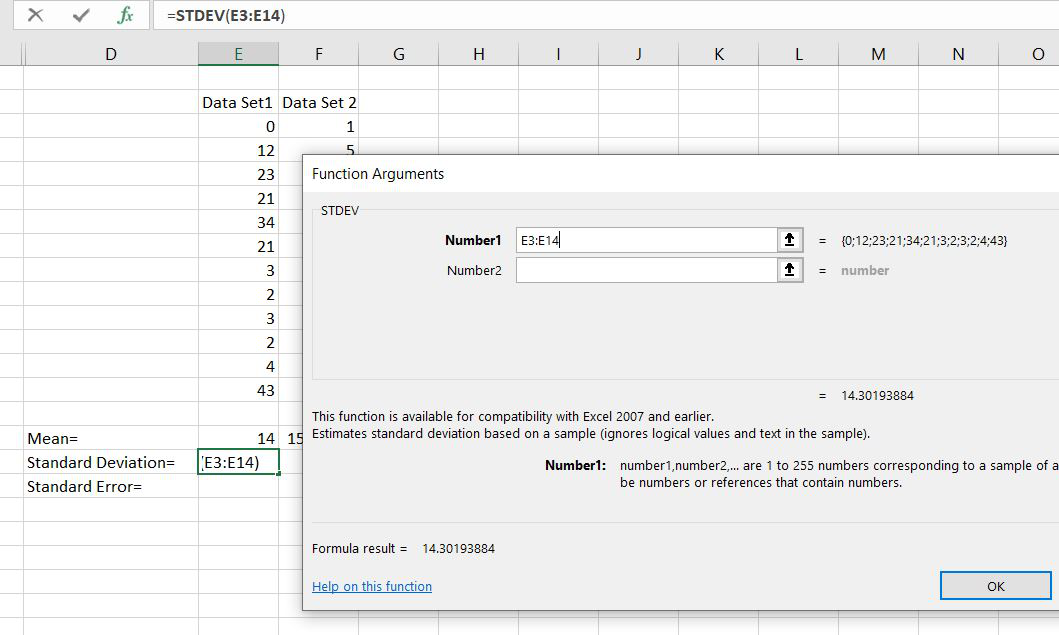
Step 3: Here we are calculating the standard deviation. And we have selected the rows whose standard deviation we have to calculate.
Step 4: Now for calculating the standard error we have divided the standard deviation with the square root of no. of samples. The no. of samples here are 12.
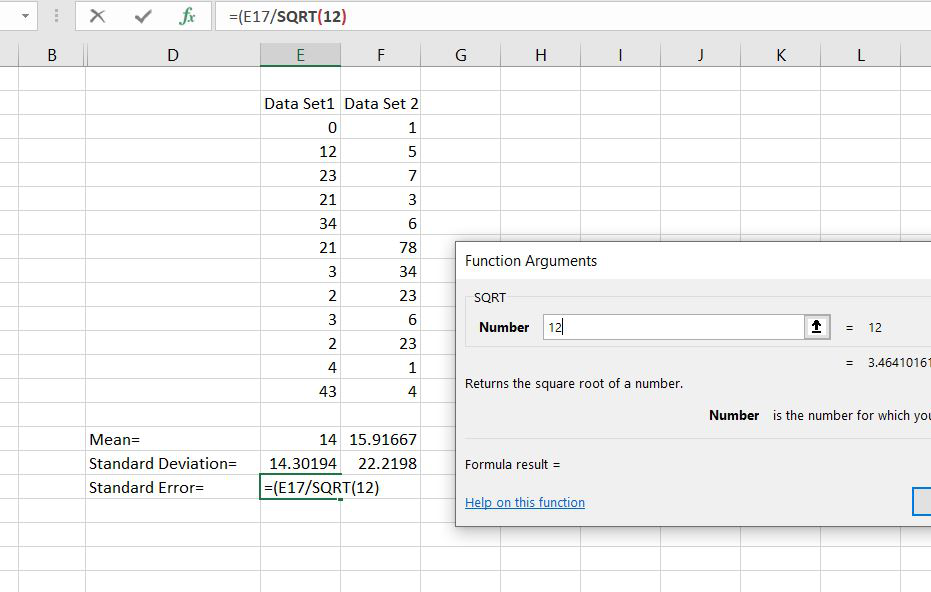
This is the way by which we have calculated the standard error. In this mean was optional.
Like Article
Save Article
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:
![]()
То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:
![]()
где
s2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
D(A) = 0
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
D(AX) = А2 D(X)
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
D(A + X) = D(X)
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
D(X+Y) = D(X) + D(Y)
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
D(X-Y) = D(X) + D(Y)
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:
![]()
На практике формула стандартного отклонения следующая:
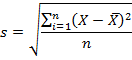
Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).
 отклонение в Excel")
Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:
![]()
По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
=СТАНДОТКЛОН.В()/СРЗНАЧ()
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
Поделиться в социальных сетях: