
- Click to view our Accessibility Policy
- Skip to content
DBA: Data Warehousing & Integration
by Casimir Saternos
Take advantage of open source technology and external tables to load data into Oracle from an Excel spreadsheet.
Downloads for this article:
Sample code
Oracle Database 10g
Apache Jakarta POI
The scenario: You receive an email with an attached Excel spreadsheet from your manager. Your task? Get the data in the spreadsheet loaded into the company Oracle 9i/10g database. How will you proceed? Will you write a custom application to load the data? Will you use the SQL*Loader utility? But wait a minutethe spreadsheet contains several sheets of data. First you will have to save each sheet in a delimited format. This is beginning to get more complicated than it seemed at first glance….
DBAs and application developers frequently face the task of loading data from Excel spreadsheets into Oracle databases. With the advent of Oracle 10g‘s spreadsheet-like model capabilities, it is likely that more data that is currently stored and viewed in spreadsheets will be loaded into Oracle databases for manipulation and processing.
Oracle provides a variety of methods for loading data from a spreadsheet into a database. Most Oracle DBAs and developers are familiar with the capabilities of SQL*Loader. Oracle HTML DB can be used to load Excel data in batch as well. This article presents and alternative method for loading data from an Excel spreadsheet that takes advantage of open source technology and external tables.
In this article you will learn how to use the Apache Jakarta POI open-source project to create external tables referencing data contained in an Excel spreadsheet with multiple sheets of data. During this process you will create a custom utility named ExternalTableGenerator to accomplish this goal.
Given an Excel spreadsheet containing one or more sheets with data, the ExternalTableGenerator utility generates flat datafiles and a DDL script that users can run to view the data as an external table. This project can also help clarify external table concepts for those who are new to the feature.
The article includes the source code for the ExternalTableGenerator, which can be used as a standalone application or as a basis for a more sophisticated and robust solution, and a sample spreadsheet for testing the process.
Jakarta POI
Jakarta POI FileSystem APIs implement the OLE 2 Compound Document format in pure Java, and HSSF APIs allow for the reading and writing of Excel files using Java POI is included in the sample code file and is referenced in the Java CLASSPATH when you are running the ExternalTableGenerator.
The ExternalTableGenerator The ExternalTableGenerator uses three classes that utilize the POI APIs to process a spreadsheet.
ExternalTable.java-This class represents the external table. An ExternalTable object has a name,
references a directory and files on the file system, and has a list of columns with appropriate column types. The class also has attributes
that describe the badfile name, logfile name, directory location, and constants for the various filename extensions. The class is populated with
these attribute values and is then used to generate the DDL for an external table that corresponds to the structure of a given sheet of a spreadsheet.The constructor takes a parameter that is used to derive the table name (all spaces in the name are replaced with underscores.
TheExternalTableGeneratorclass uses the name of a particular sheet for setting the
nameis used for the table name as
well as the badfile and the logfile. When all the columns and other attributes of theExternalTable
class have been populated (based on the first two rows in the spreadsheet), a call can be made to
getDdl() ,which returns the DDL for creating the external table. The structure of this DDL is described in the «DDL Script»
section of this article.ExternalTableColumn.java-This class represents a single column of an external table.
Its attributes include the name of the column and its type. For the purposes of the current application, the type is limited to
VARCHAR2 or NUMBER, and you use the constants POI provides for these types. The VARCHAR2 length is determined by
the values of the second row in a sheet. When called by theExternalTableGeneratorclass,
column names are determined by the first row in a sheet. This class replaces any spaces in column names with underscores to ensure valid DDL.ExternalTableGenerator.java-This is the class that does the actual work. It reads a spreadsheet passed to it as an argument.
For every sheet in the spreadsheet, it generates a comma-separated-value file (.csv extension) in the current directory. It also creates the DDL for creating
a directory and the external tables.
The POI-specific calls required for processing are as follows:
In the execute() method, the following two lines access the spreadsheet from the file system and create a new workbook object
that allows you to manipulate the spreadsheet.
POIFSFileSystem fs = new POIFSFileSystem(new FileInputStream(spreadsheet));
HSSFWorkbook wb = new HSSFWorkbook(fs);
have access to the HSSFWorkbook object, you can process it by iterating through all of the
sheets, rows, and columns. The processWorkbook() method iterates through each of the sheets in the workbook,
creates ExternalTable objects using the sheet name, processes each sheet, and extracts the relevant data for populating the ExternalTable objects.
private void processWorkbook(HSSFWorkbook wb) {
for (int i = 0; i < wb.getNumberOfSheets(); i++)
{
HSSFSheet sheet = wb.getSheetAt(i);
ExternalTable table = new ExternalTable(wb.getSheetName(i));
processSheet(sheet, table);
System.out.println("...Table "+ table.getName()+ " processed." );
}
}
The processSheet() method gets that table information from the sheet, writes a .csv file that will be the actual data
the ExternalTable references, and continues to append to the string that holds the contents of the DDL.
The getColumns() method contains relevant calls to the POI API for retrieving data about
particular cells. Different method calls are required, depending on the type of cell being accessed. Note that cells with no
data ( SSFCell.CELL_TYPE_BLANK ) have to be accounted for when the data in our example is being processed.
To write the data in a particular sheet, writeCsv() iterates through relevant rows and
columns and creates a string that contains the data in comma-delimited format. It does not write out the column names or
the row that contains the data that indicates VARCHAR2 size. The write() method contains the code that writes the data to a file on the file system.
You must run the DDL script (named ExternalTables.sql ) separately through SQL*Plus to actually create the directory and external tables.
External Tables
Beginning with Oracle 9i, external tables were implemented as an alternative to SQL*Loader. Unlike traditional database tables, external tables are read-only tables that reference data stored outside of the database. These tables can be queried in the same manner that standard Oracle tables can and often serve as an early stage in a larger ETL (extract/transform/load) process. External tables are of great assistance in referencing data outside of the database, but creating them requires a fairly large amount of DDL code to create the table that references the datafile, its column definition, and other files (badfiles and logfiles).
Creating external tables requires knowledge of the file format and record format of the datafiles as well as an understanding of SQL. The ExternalTableGenerator automates this process and provides some insight into the syntax for creating external tables that access delimited files.
DDL Script
Here is a brief description of the DDL script generated by the ExternalTableGenerator when you run it with the sample spreadsheet as an argument:
CREATE OR REPLACE DIRECTORY load_dir AS 'C:workspacestestXL2ExternalTables'
;
The CREATE OR REPLACE DIRECTORY statement creates a directory object that allows Oracle to access an operating system directory. This directory contains the datafile referenced by the external table as well as the badfiles and logfiles. The ExternalTableGenerator uses the current working directory as the operating system directory to reference.
CREATE TABLE PA_Zip_Code_Locations
(
ZIP VARCHAR2(10),
AREANAME VARCHAR2(30),
LATITUDE NUMBER,
LONGITUDE NUMBER,
POPULATION NUMBER
)
ORGANIZATION EXTERNAL
(
TYPE oracle_loader
DEFAULT DIRECTORY load_dir
ACCESS PARAMETERS
(
RECORDS DELIMITED BY NEWLINE
badfile load_dir:'PA_Zip_Code_Locations.bad'
logfile load_dir:'PA_Zip_Code_Locations.log'
FIELDS TERMINATED BY ','
MISSING FIELD VALUES ARE NULL
(
ZIP,
AREANAME,
LATITUDE,
LONGITUDE,
POPULATION
))
LOCATION ('PA_Zip_Code_Locations.csv')
)REJECT LIMIT UNLIMITED;
The CREATE TABLE syntax and column definitions look like a typical DDL statement
for creating a regular Oracle table. ORGANIZATION EXTERNAL identifies this table as an external table.
The TYPE clause is for specifying the driver type. Subsequent clauses describe the structure
of the file and the location of the logfile, badfile, and datafile. For more information on EXTERNAL TABLE
syntax, see the Oracle Documentation .
The ExternalTableGenerator generates this portion of the DDL according to the following rules:
- The name of the table is based on the name of a given sheet. The name of the sheet is also used to determine the name of the badfile, logfile, and datafile the external table references.
- The name of the column is based on the values in the first row of a sheet. These names are also used in the FIELDS definition section of the external table.
- The length of a VARCHAR2 is dictated by the second row in the spreadsheet.
- A column type is defined as either a VARCHAR2 or a NUMBER, depending on the cell in the subsequent spreadsheet row.
- Because each .xls sheet is exported as comma-separated-value (.csv) file, you include the RECORDS DELIMITED BY NEWLINE and FIELDS TERMINATED BY ‘,’ information.
The new_departments and new_employees tables have the same basic
structure as the pa_zip_code_locations table shown above.
Excel Spreadsheets
Data that needs loading comes frequently in a simple format of comma-, pipe-, or tab-delimited values, and loading it is a relatively straightforward task. However, data can also be provided in an Excel spreadsheet, which can contain multiple sheets. A spreadsheet is stored in a binary format that is not accessible directly with SQL*Loader or external tables. One benefit of Excel spreadsheets over traditional flat files is that the data can be typed (as numeric, string, and so on). As mentioned above, you can take advantage of this fact in the ExternalTableGenerator to determine column types.
There are a few requirements for spreadsheets the ExternalTableGenerator processes:
- They can contain one or more spreadsheets.
- The name of the spreadsheet is used for table name definition . The external table name, datafile name, logfile name, and badfile name are dictated by the name of the spreadsheet.
- Each sheet in a spreadsheet is used to generate one block of the external table DDL and one .csv datafile.
- The first row in each spreadsheet is the column name definition row . The name of a column is used in the column name and field name sections of the EXTERNAL TABLE block. This row is not included in the .csv datafile.
- The second row in each spreadsheet is used to determine the length of a VARCHAR2 field. This row is also not included in the .csv datafile.
Because you use parts of the spreadsheet to determine table and column names, take care to choose names that will allow generation of valid SQL. In other words, avoid illegal characters, SQL keywords, existing table names, and the like in spreadsheets to be processed by the ExternalTableGenerator.
Excel is not required for running the project, but it is necessary for viewing the .xls file. Screen shots of the sample data appear below:
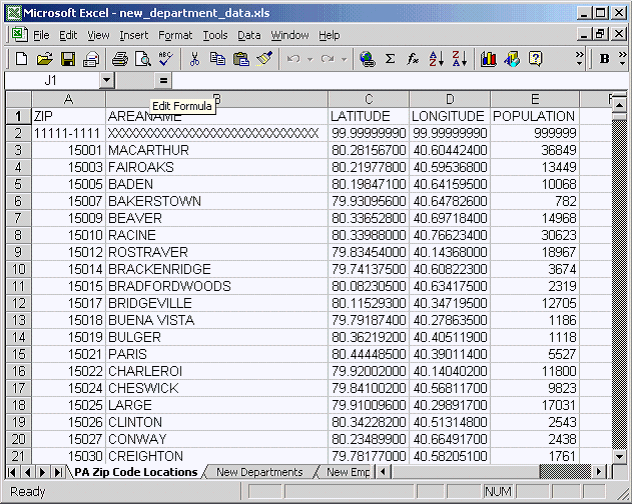
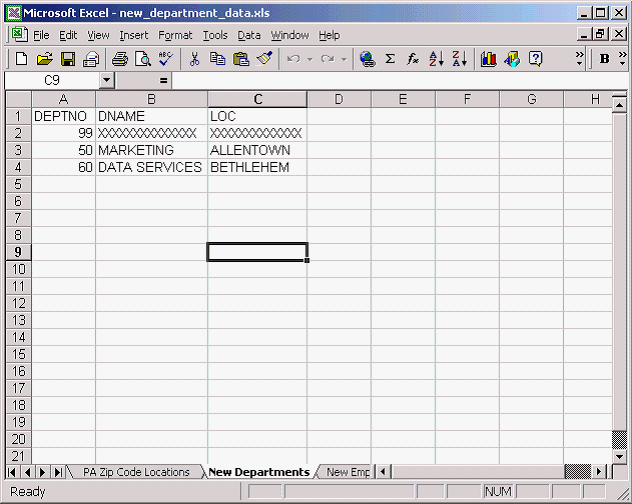
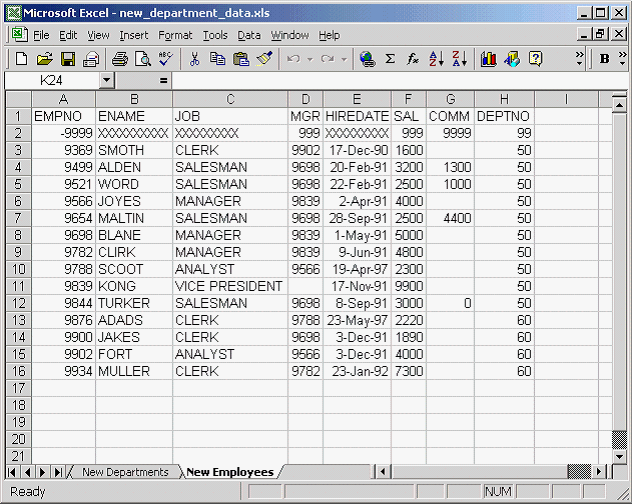
The data in the example represents two new departments, their employees, and a list of relevant zip codes that need to be added to the database. The employee and department data is based on the tables in the scott/tiger schema and can be imported there for experimentation, provided you grant all necessary permissions to scott. The zip code information demonstrates the ability of the ExternalTableGenerator to handle a bit more data.
Running the Project
The project was tested with Java Runtime Environment (JRE) 1.4.2_03 but should work with any JRE that can run POI. You can run the ExternalTableGenerator by executing runSample.bat. This batch file includes the relevant jars in the classpath (XL2ExternalTables.jar;jakarta-poi-1.5.1-final-20020615.jar;jakarta-poi-contrib-1.5.1-final-20020615.jar) and runs the appropriate Java class, com.saternos.database.utilities.ExternalTableGenerator, using the Excel worksheet specified in the argument.
Sample output from a successful run should resemble the following (with the paths based on your working directory.
C:Documents and SettingsAdministratorDesktopXL2ETB>runExample
C:Documents and SettingsAdministratorDesktopXL2ETB>
java -cp XL2ExternalTables.jar;jakarta-poi-1.5.1-final-20020615.jar;
jakarta-poi-contrib-1.5.1-final-20020
615.jar com.saternos.database.utilities.ExternalTableGenerator new_department_data.xls
Begin processing.
Using working directory C:Documents and SettingsAdministratorDesktopXL2ETB
...File PA_Zip_Code_Locations.csv created.
...Table PA_Zip_Code_Locations processed.
...File New_Departments.csv created.
...Table New_Departments processed.
...File New_Employees.csv created.
...Table New_Employees processed.
...File ExternalTables.sql created.
Processing complete.
This code creates three datafiles (designated with the .csv extension) and generates a single SQL script that contains the DDL for creating the external tables.
Here is a sample of running the DDL script and testing the results. Begin by connecting to the database via SQL*Plus from the directory where the
ExternalTables.sql script was created.
C:XL2ETB>SQL*Plus testuser/mypassword@orcladm
SQL*Plus: Release 10.1.0.2.0 - Production on Tue Dec 21 09:36:25 2004
Copyright (c) 1982, 2004, Oracle. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.1.0 - Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.1.0 - Production
SQL> select * from tab;
no rows selected
Although this example is an empty schema, the script can be run in any schema, providing that the user has appropriate permissions and that there are no name collisions.
SQL> @ExternalTables
Directory created.
Table created.
Table created.
Table created.
The script is executed, and the directory object and three external tables are created.
SQL> select * from tab;
TNAME TABTYPE CLUSTERID
------------------------------ ------- ----------
NEW_DEPARTMENTS TABLE
NEW_EMPLOYEES TABLE
PA_ZIP_CODE_LOCATIONS TABLE
SQL> select count(*) from new_departments;
COUNT(*)
----------
2
SQL> select count(*) from new_employees;
COUNT(*)
----------
14
SQL> select count(*) from pa_zip_code_locations;
COUNT(*)
----------
1458
SQL> select * from new_employees;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
------ ---------- --------- ---------- ------------ -------- ---------- ----------
9499 ALDEN SALESMAN 9698 33289.0 3200 1300 50
9521 WORD SALESMAN 9698 33291.0 2500 1000 50
9654 MALTIN SALESMAN 9698 33509.0 2500 4400 50
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
------ ---------- --------- ---------- ------------- -------- ---------- ----------
9844 TURKER SALESMAN 9698 33489.0 3000 0 50
SQL>
Conclusion
This article introduced POI but has only scratched the surface of the functionality available through this API. There are a number of ways the ExternalTableGenerator utility described in this article could be enhanced:
- A JDBC connection could be made within the utility allowing the External Table DDL to be executed within the utility itself.
- Additional column types and precisions based on the spreadsheet types could be added.
- The utility could add functionality to manipulate other attributes of External Tables (PARALLEL, etc).
- Alternative methods of translating spreadsheet types to Oracle data types could be devised.
Hopefully this article has whetted your appetite to explore the possibilities of using POI and Oracle together to facilitate data manipulation between Excel and Oracle.
Casimir Saternos is an Oracle Certified DBA, IBM Certified Enterprise Developer and Sun Certified Java Programmer based in Allentown,
Pa.
I’ve been thinking about it for quite a long time and never really had time to implement it, but it’s finally there : a pipelined table interface to read an Excel file (.xlsx) as if it were an external table.
It’s entirely implemented in PL/SQL using an object type (for the ODCI routines) and a package supporting the core functionalities.
Available for download on GitHub :
 /mbleron/ExcelTable
/mbleron/ExcelTable
Usage
ExcelTable.getRows table function :
This is the actual SQL interface, to be used in conjunction with the TABLE operator.
It returns an ANYDATASET instance whose structure is defined by the p_cols parameter.
function getRows (
p_file in blob
, p_sheet in varchar2
, p_cols in varchar2
, p_range in varchar2 default null
)
return anydataset pipelined
using ExcelTableImpl;
| Arg | Data type | Desc | Mandatory |
|---|---|---|---|
p_file |
BLOB | Input Excel file in Office Open XML format (.xlsx or .xlsm). A helper function ( ExcelTable.getFile) is available to directly reference the file from a directory. |
Yes |
p_sheet |
VARCHAR2 | Worksheet name | Yes |
p_cols |
VARCHAR2 | Column list (see specs below) | Yes |
p_range |
VARCHAR2 | Excel-like range expression that defines the table boundaries in the worksheet (see specs below) | No |
Range syntax specification
range_expr ::= ( cell_ref [ ":" cell_ref ] | col_ref ":" col_ref | row_ref ":" row_ref )
cell_ref ::= col_ref row_ref
col_ref ::= { "A".."Z" }
row_ref ::= integer
If the range is empty, the table implicitly starts at cell A1.
Otherwise, there are four ways to specify the table range :
- Range of rows :
'1:100'
In this case the range of columns implicitly starts at A. - Range of columns :
'B:E'
In this case the range of rows implicitly starts at 1. - Range of cells (top-left to bottom-right) :
'B2:F150' - Single cell anchor (top-left cell) :
'C3'
Columns syntax specification
The syntax is similar to the column list in a CREATE TABLE statement, with a couple of specifics :
column_list ::= column_expr { "," column_expr }
column_expr ::= ( identifier datatype [ "column" string_literal ] | identifier for_ordinality )
datatype ::= ( number_expr | varchar2_expr | date_expr | clob_expr )
number_expr ::= "number" [ "(" ( integer | "*" ) [ "," [ "-" ] integer ] ")" ]
varchar2_expr ::= "varchar2" "(" integer [ "char" | "byte" ] ")"
date_expr ::= "date" [ "format" string_literal ]
clob_expr ::= "clob"
for_ordinality ::= "for" "ordinality"
identifier ::= """ { char } """
string_literal ::= "'" { char } "'"
Column names must be declared using a quoted identifier.
Supported data types are :
- NUMBER – with optional precision and scale specs
- VARCHAR2 – including CHAR/BYTE semantics
Values larger than the maximum length declared are silently truncated and no error is reported. - DATE – with optional format mask
The format mask is used if the value is stored as text in the spreadsheet, otherwise the date value is assumed to be stored as date in Excel’s internal serial format. - CLOB
A special “FOR ORDINALITY” clause (like XMLTABLE or JSON_TABLE’s one) is also available to autogenerate a sequence number.
Each column definition (except for the one qualified with FOR ORDINALITY) may be complemented with an optional “COLUMN” clause to explicitly target a named column in the spreadsheet, instead of relying on the order of the declarations (relative to the range).
Positional and named column definitions cannot be mixed.
For instance :
"RN" for ordinality , "COL1" number , "COL2" varchar2(10) , "COL3" varchar2(4000) , "COL4" date format 'YYYY-MM-DD' , "COL5" number(10,2) , "COL6" varchar2(5)
"COL1" number column 'A' , "COL2" varchar2(10) column 'C' , "COL3" clob column 'D'
Examples
Using this sample file :
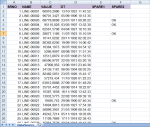
1- Loading all six columns, starting at cell A2, in order to skip the header :
SQL> select t.*
2 from table(
3 ExcelTable.getRows(
4 ExcelTable.getFile('TMP_DIR','ooxdata3.xlsx')
5 , 'DataSource'
6 , ' "SRNO" number
7 , "NAME" varchar2(10)
8 , "VAL" number
9 , "DT" date
10 , "SPARE1" varchar2(6)
11 , "SPARE2" varchar2(6)'
12 , 'A2'
13 )
14 ) t
15 ;
SRNO NAME VAL DT SPARE1 SPARE2
---------- ---------- ---------- ------------------- ------ ------
1 LINE-00001 66916.2986 13/10/1923 11:45:52
2 LINE-00002 96701.3427 05/09/1906 10:12:35
3 LINE-00003 68778.8698 23/01/1911 09:26:22 OK
4 LINE-00004 95110.028 03/05/1907 13:52:30 OK
5 LINE-00005 62561.5708 04/04/1927 18:10:39
6 LINE-00006 28677.1166 11/07/1923 15:10:59 OK
7 LINE-00007 16141.0202 20/11/1902 02:02:24
8 LINE-00008 80362.6256 19/09/1910 14:06:42
9 LINE-00009 10384.1973 16/07/1902 04:54:12
10 LINE-00010 5266.9097 08/08/1921 11:51:34
11 LINE-00011 12513.0679 01/07/1908 21:53:55
12 LINE-00012 66596.9707 22/03/1913 05:20:10
...
95 LINE-00095 96274.2193 08/04/1914 22:48:31
96 LINE-00096 29783.146 06/04/1915 23:49:23
97 LINE-00097 19857.7661 16/02/1909 21:21:52
98 LINE-00098 19504.3969 05/12/1917 01:56:05
99 LINE-00099 98675.8673 05/06/1906 17:41:10
100 LINE-00100 24288.2885 22/07/1920 13:25:59
100 rows selected.
2- Loading columns B and F only, from rows 2 to 10, with a generated sequence :
SQL> select t.*
2 from table(
3 ExcelTable.getRows(
4 ExcelTable.getFile('TMP_DIR','ooxdata3.xlsx')
5 , 'DataSource'
6 , q'{
7 "R_NUM" for ordinality
8 , "NAME" varchar2(10) column 'B'
9 , "SPARE2" varchar2(6) column 'F'
10 }'
11 , '2:10'
12 )
13 ) t
14 ;
R_NUM NAME SPARE2
---------- ---------- ------
1 LINE-00001
2 LINE-00002
3 LINE-00003 OK
4 LINE-00004 OK
5 LINE-00005
6 LINE-00006 OK
7 LINE-00007
8 LINE-00008
9 LINE-00009
9 rows selected.
Lately I had a customer, who needed to load xlsx files into the database on regular basis.
Unlikely csv or other text format xlsx is a proprietary binary format, that Oracle seem to be reluctant to support at least until lately. So, you can’t just read an Excel file through an external table using native Oracle drivers, unless you can install APEX 19.1+. There are also other solutions using data cartridge, java and pl/sql. But both options were overkill for me, especially getting DBAs to install APEX, which was considered a system level change and needed to undergo a lot of approvals and paperwork.
Suddenly I recalled, that we have Python installed on almost all servers in the network, since it’s widely used across the organisation. Then, what if I write a Python script that takes xlsx files and yields plain text, and use it as preprocessor in external table? That should be elegant and simple enough, and also seem to conform to security the organisation’s requirements.
Preprocessor is an embedded feature of Oracle that lets you run an OS level executable against the data files before reading them into the database. For example, if you have a compressed file, you could run GZIP or UNZIP command as preprocessor to get uncompressed version right in the moment of querying your external table. The limitation here is that the preprocessor must return result as stdout, and accept only one input argument, that is the file name to be processed. If you need more arguments for your preprocessor, then you could just wrap the whole thing in a shell script, and specify additional arguments inside.
Now we need the Python script that would perform conversion for us. At this point we might start digging into xlsx specification details, write some simple snippets to prove the concept etc. Or, would it be wise to recall, that Python has a huge library of everything, from simple math tools to AI scripts, already implemented for you? And in our case, googling “Python xlsx to csv” quickly gets us a very neat tool xlsx2csv. Small and simple Python script with some advanced capabilities to convert documents with multiple sheets, adjust encodings, data formats, quotes, delimiters and a lot more. It’s a very simple installation using PIP:
pip install xlsx2csv
And now we can try it out right from our shell:
xlsx2csv input_file.xlsx output_file.csv
For the next example I exported standard EMP table as an xlsx file. Now let’s try what happens if we specify it as the only argument for the script (pretty much what Oracle would do when it’s involved as a preprocessor):
[oracle@ora122 ~]$ xlsx2csv emp.xlsx emp,,,,,,, EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO 7369,SMITH,CLERK,7902,17.12.80,800,,20 7499,ALLEN,SALESMAN,7698,20.02.81,1600,300,30 7521,WARD,SALESMAN,7698,22.02.81,1250,500,30 7566,JONES,MANAGER,7839,02.04.81,2975,,20 ...
I cut the output slightly to save space, but already we can see that it does exactly what we need: produces csv data as standard output. Now it shouldn’t be harder than that to specify the preprocessor clause for the external table:
preprocessor preprocessor_dir:'xlsx2csv'
But we need to take a closer look at the first two lines of the output: the second one represents column names, but the first one looks like a table/file name in the first cell with all other cells empty (’emp,,,,,,,’). Is that a part of original file or a feature of xlsx2csv? Let’s take a look at the xlsx file first:
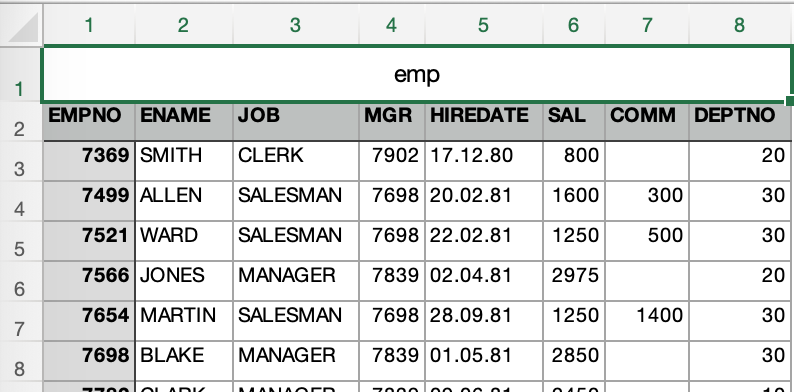
Ok, found the culprit at the first try. It’s an export glitch. But for our case, let’s assume that we always get the file with this heading , and we need to process it correctly. So, we basically need to skip first two lines to get to the actual data. Xlsx2csv won’t provide us with a parameter to skip lines, though it’s fully open sourced, so we could review the code, and add the parameter. But it seems like a lot of wasteful effort, given that Oracle allows us to skip lines with a single option of external table access parameters (skip n), so let’s stick with it.
Now to the actual implementation. To get the external table working we need a preprocessor to be copied in the special Oracle directory, where you have EXECUTE privilege. Defining /usr/bin as such is probably a very bad idea. Putting the script into the same directory where your data resides is not all that better as well. Oracle recommends to create a dedicated directory for preprocessors, and carefully control who has access to it. Let us follow the recommendation (connected to 12.2 db as andzhi4):
SQL> create directory preprocessor_dir as '/home/oracle/preprocessor'; Directory PREPROCESSOR_DIR created.
Now we need our xlsx2csv script copied into that directory:
[oracle@ora122 ~]$ pwd /home/oracle [oracle@ora122 ~]$ mkdir preprocessor [oracle@ora122 ~]$ which xlsx2csv /usr/bin/xlsx2csv [oracle@ora122 ~]$ cp /usr/bin/xlsx2csv preprocessor/
Assume we already have xlsx file in our data directory (my_data), we could start creating the external table:
create table "ANDZHI4"."EX_EMP" (
"EMPNO" number(4, 0) not null enable,
"ENAME" varchar2(10 byte),
"JOB" varchar2(9 byte),
"MGR" number(4, 0),
"HIREDATE" date,
"SAL" number(7, 2),
"COMM" number(7, 2),
"DEPTNO" number(2, 0)
)
organization EXTERNAL ( type oracle_loader
default directory "MY_DATA"
access parameters (
records skip 2
BADFILE 'emp_%p.bad'
noDISCARDFILE
LOGFILE 'emp_%p.log'
preprocessor PREPROCESSOR_DIR:'xlsx2csv'
FIELDS TERMINATED BY "," OPTIONALLY ENCLOSED BY '"' LDRTRIM
ALL FIELDS OVERRIDE
MISSING FIELD VALUES ARE NULL
REJECT ROWS WITH ALL NULL FIELDS
(hiredate date 'DD.MM.RR' )
)
location('emp.xlsx') );
That’s my regular external table template to load csv data, but modified to use preprocessor script. Note that we use ‘Records skip 2’ option in access parameters to reject first two lines of the file. Also, we don’t parse HIREDATE column on the Python level, but do it in table definition as column override (hiredate date ‘DD.MM.RR’ ) . The year is stored as 2 digits, thus we need to use RR in format mask to correctly represent years from the past century (YY would give us 2081 for 81).
And that’s pretty much it, now you have a way to put your xlsx file right in the folder accessible by your database server, and read data directly from there. This approach works fine for multiple data files and for wild characters in name. Oracle will run preprocessor for every file identified. Parallel execution is also supported, though the parallel degree is limited to the number of data files you have in your directory.
Also, pay attention to some restrictions Oracle possess for preprocessor use:
- The
PREPROCESSORclause is not available on databases that use the Oracle Database Vault feature. - The
PREPROCESSORclause does not work in conjunction with theCOLUMNTRANSFORMSclause.
I didn’t hit neither of this in my recent deployment, though database vault might get in your way relatively often. Also, be aware that granting execute privilege on any Oracle directory means that database user can run custom OS level code, what might represent sensible security risk. Careful reader might have noticed that we never provided execute privilege on preprocessor_dir in this post. That’s because I run my examples as a user with DBA role (though for last releases Oracle warns “This role may not be created automatically by future releases of Oracle Database”, it still works in 12.2 ):
SQL> select granted_role from dba_role_privs where grantee = user; GRANTED_ROLE DBA CONNECT
This means, I can create directories, and thus I have all privileges on them by default:
SQL> select grantee, privilege from dba_tab_privs where table_name = 'PREPROCESSOR_DIR'; GRANTEE PRIVILEGE ANDZHI4 EXECUTE ANDZHI4 READ ANDZHI4 WRITE
Of course, this is not the case for production roll out, where you as a developer need to request explicit grant on appropriate directories from DBA.
Now that’s all I have for you today. Take care )
This entry was posted on October 14, 2019, 14:43 and is filed under Oracle. You can follow any responses to this entry through RSS 2.0.
You can leave a response, or trackback from your own site.
Содержание
- Generate External Tables from an Excel Spreadsheet Using Apache Jakarta POI
- Odie’s Oracle Blog
- XML & JSON functionalities in the database, and related stuff…
- Oracle SQL – Reading an Excel File (xlsx) as an External Table
- Usage
- Range syntax specification
- Columns syntax specification
- Examples
- Share this:
- Like this:
- Related
- 30 thoughts on “ Oracle SQL – Reading an Excel File (xlsx) as an External Table ”
- Leave a Reply Cancel reply
Generate External Tables from an Excel Spreadsheet Using Apache Jakarta POI
DBA: Data Warehousing & Integration
by Casimir Saternos
Take advantage of open source technology and external tables to load data into Oracle from an Excel spreadsheet.
Downloads for this article:
The scenario: You receive an email with an attached Excel spreadsheet from your manager. Your task? Get the data in the spreadsheet loaded into the company Oracle 9i/10g database. How will you proceed? Will you write a custom application to load the data? Will you use the SQL*Loader utility? But wait a minutethe spreadsheet contains several sheets of data. First you will have to save each sheet in a delimited format. This is beginning to get more complicated than it seemed at first glance.
DBAs and application developers frequently face the task of loading data from Excel spreadsheets into Oracle databases. With the advent of Oracle 10g‘s spreadsheet-like model capabilities, it is likely that more data that is currently stored and viewed in spreadsheets will be loaded into Oracle databases for manipulation and processing.
Oracle provides a variety of methods for loading data from a spreadsheet into a database. Most Oracle DBAs and developers are familiar with the capabilities of SQL*Loader. Oracle HTML DB can be used to load Excel data in batch as well. This article presents and alternative method for loading data from an Excel spreadsheet that takes advantage of open source technology and external tables.
In this article you will learn how to use the Apache Jakarta POI open-source project to create external tables referencing data contained in an Excel spreadsheet with multiple sheets of data. During this process you will create a custom utility named ExternalTableGenerator to accomplish this goal.
Given an Excel spreadsheet containing one or more sheets with data, the ExternalTableGenerator utility generates flat datafiles and a DDL script that users can run to view the data as an external table. This project can also help clarify external table concepts for those who are new to the feature.
The article includes the source code for the ExternalTableGenerator, which can be used as a standalone application or as a basis for a more sophisticated and robust solution, and a sample spreadsheet for testing the process.
Jakarta POI FileSystem APIs implement the OLE 2 Compound Document format in pure Java, and HSSF APIs allow for the reading and writing of Excel files using Java POI is included in the sample code file and is referenced in the Java CLASSPATH when you are running the ExternalTableGenerator.
The ExternalTableGenerator The ExternalTableGenerator uses three classes that utilize the POI APIs to process a spreadsheet.
- ExternalTable.java -This class represents the external table. An ExternalTable object has a name, references a directory and files on the file system, and has a list of columns with appropriate column types. The class also has attributes that describe the badfile name, logfile name, directory location, and constants for the various filename extensions. The class is populated with these attribute values and is then used to generate the DDL for an external table that corresponds to the structure of a given sheet of a spreadsheet.
The constructor takes a parameter that is used to derive the table name (all spaces in the name are replaced with underscores. The ExternalTableGenerator class uses the name of a particular sheet for setting the name attribute in this class. This name is used for the table name as well as the badfile and the logfile. When all the columns and other attributes of the ExternalTable class have been populated (based on the first two rows in the spreadsheet), a call can be made to getDdl() , which returns the DDL for creating the external table. The structure of this DDL is described in the «DDL Script» section of this article.
The POI-specific calls required for processing are as follows:
In the execute() method, the following two lines access the spreadsheet from the file system and create a new workbook object that allows you to manipulate the spreadsheet.
have access to the HSSFWorkbook object, you can process it by iterating through all of the sheets, rows, and columns. The processWorkbook() method iterates through each of the sheets in the workbook, creates ExternalTable objects using the sheet name, processes each sheet, and extracts the relevant data for populating the ExternalTable objects.
The processSheet() method gets that table information from the sheet, writes a .csv file that will be the actual data the ExternalTable references, and continues to append to the string that holds the contents of the DDL.
The getColumns() method contains relevant calls to the POI API for retrieving data about particular cells. Different method calls are required, depending on the type of cell being accessed. Note that cells with no data ( SSFCell.CELL_TYPE_BLANK ) have to be accounted for when the data in our example is being processed.
To write the data in a particular sheet, writeCsv() iterates through relevant rows and columns and creates a string that contains the data in comma-delimited format. It does not write out the column names or the row that contains the data that indicates VARCHAR2 size. The write() method contains the code that writes the data to a file on the file system.
You must run the DDL script (named ExternalTables.sql ) separately through SQL*Plus to actually create the directory and external tables.
Beginning with Oracle 9i, external tables were implemented as an alternative to SQL*Loader. Unlike traditional database tables, external tables are read-only tables that reference data stored outside of the database. These tables can be queried in the same manner that standard Oracle tables can and often serve as an early stage in a larger ETL (extract/transform/load) process. External tables are of great assistance in referencing data outside of the database, but creating them requires a fairly large amount of DDL code to create the table that references the datafile, its column definition, and other files (badfiles and logfiles).
Creating external tables requires knowledge of the file format and record format of the datafiles as well as an understanding of SQL. The ExternalTableGenerator automates this process and provides some insight into the syntax for creating external tables that access delimited files.
Here is a brief description of the DDL script generated by the ExternalTableGenerator when you run it with the sample spreadsheet as an argument:
The CREATE OR REPLACE DIRECTORY statement creates a directory object that allows Oracle to access an operating system directory. This directory contains the datafile referenced by the external table as well as the badfiles and logfiles. The ExternalTableGenerator uses the current working directory as the operating system directory to reference.
The CREATE TABLE syntax and column definitions look like a typical DDL statement for creating a regular Oracle table. ORGANIZATION EXTERNAL identifies this table as an external table. The TYPE clause is for specifying the driver type. Subsequent clauses describe the structure of the file and the location of the logfile, badfile, and datafile. For more information on EXTERNAL TABLE syntax, see the Oracle Documentation .
The ExternalTableGenerator generates this portion of the DDL according to the following rules:
- The name of the table is based on the name of a given sheet. The name of the sheet is also used to determine the name of the badfile, logfile, and datafile the external table references.
- The name of the column is based on the values in the first row of a sheet. These names are also used in the FIELDS definition section of the external table.
- The length of a VARCHAR2 is dictated by the second row in the spreadsheet.
- A column type is defined as either a VARCHAR2 or a NUMBER, depending on the cell in the subsequent spreadsheet row.
- Because each .xls sheet is exported as comma-separated-value (.csv) file, you include the RECORDS DELIMITED BY NEWLINE and FIELDS TERMINATED BY ‘,’ information.
The new_departments and new_employees tables have the same basic structure as the pa_zip_code_locations table shown above.
Data that needs loading comes frequently in a simple format of comma-, pipe-, or tab-delimited values, and loading it is a relatively straightforward task. However, data can also be provided in an Excel spreadsheet, which can contain multiple sheets. A spreadsheet is stored in a binary format that is not accessible directly with SQL*Loader or external tables. One benefit of Excel spreadsheets over traditional flat files is that the data can be typed (as numeric, string, and so on). As mentioned above, you can take advantage of this fact in the ExternalTableGenerator to determine column types.
There are a few requirements for spreadsheets the ExternalTableGenerator processes:
- They can contain one or more spreadsheets.
- The name of the spreadsheet is used for table name definition . The external table name, datafile name, logfile name, and badfile name are dictated by the name of the spreadsheet.
- Each sheet in a spreadsheet is used to generate one block of the external table DDL and one .csv datafile.
- The first row in each spreadsheet is the column name definition row . The name of a column is used in the column name and field name sections of the EXTERNAL TABLE block. This row is not included in the .csv datafile.
- The second row in each spreadsheet is used to determine the length of a VARCHAR2 field. This row is also not included in the .csv datafile.
Because you use parts of the spreadsheet to determine table and column names, take care to choose names that will allow generation of valid SQL. In other words, avoid illegal characters, SQL keywords, existing table names, and the like in spreadsheets to be processed by the ExternalTableGenerator.
Excel is not required for running the project, but it is necessary for viewing the .xls file. Screen shots of the sample data appear below:
The data in the example represents two new departments, their employees, and a list of relevant zip codes that need to be added to the database. The employee and department data is based on the tables in the scott/tiger schema and can be imported there for experimentation, provided you grant all necessary permissions to scott. The zip code information demonstrates the ability of the ExternalTableGenerator to handle a bit more data.
Running the Project
The project was tested with Java Runtime Environment (JRE) 1.4.2_03 but should work with any JRE that can run POI. You can run the ExternalTableGenerator by executing runSample.bat. This batch file includes the relevant jars in the classpath (XL2ExternalTables.jar;jakarta-poi-1.5.1-final-20020615.jar;jakarta-poi-contrib-1.5.1-final-20020615.jar) and runs the appropriate Java class, com.saternos.database.utilities.ExternalTableGenerator, using the Excel worksheet specified in the argument.
Sample output from a successful run should resemble the following (with the paths based on your working directory.
This code creates three datafiles (designated with the .csv extension) and generates a single SQL script that contains the DDL for creating the external tables.
Here is a sample of running the DDL script and testing the results. Begin by connecting to the database via SQL*Plus from the directory where the ExternalTables.sql script was created.
Although this example is an empty schema, the script can be run in any schema, providing that the user has appropriate permissions and that there are no name collisions.
This article introduced POI but has only scratched the surface of the functionality available through this API. There are a number of ways the ExternalTableGenerator utility described in this article could be enhanced:
- A JDBC connection could be made within the utility allowing the External Table DDL to be executed within the utility itself.
- Additional column types and precisions based on the spreadsheet types could be added.
- The utility could add functionality to manipulate other attributes of External Tables (PARALLEL, etc).
- Alternative methods of translating spreadsheet types to Oracle data types could be devised.
Hopefully this article has whetted your appetite to explore the possibilities of using POI and Oracle together to facilitate data manipulation between Excel and Oracle.
Casimir Saternos is an Oracle Certified DBA, IBM Certified Enterprise Developer and Sun Certified Java Programmer based in Allentown, Pa.
Источник
Odie’s Oracle Blog
XML & JSON functionalities in the database, and related stuff…
Oracle SQL – Reading an Excel File (xlsx) as an External Table
I’ve been thinking about it for quite a long time and never really had time to implement it, but it’s finally there : a pipelined table interface to read an Excel file (.xlsx) as if it were an external table.
It’s entirely implemented in PL/SQL using an object type (for the ODCI routines) and a package supporting the core functionalities.
Available for download on GitHub :
Usage
ExcelTable.getRows table function :
This is the actual SQL interface, to be used in conjunction with the TABLE operator.
It returns an ANYDATASET instance whose structure is defined by the p_cols parameter.
| Arg | Data type | Desc | Mandatory |
|---|---|---|---|
| p_file | BLOB | Input Excel file in Office Open XML format (.xlsx or .xlsm). A helper function ( ExcelTable.getFile ) is available to directly reference the file from a directory. |
Yes |
| p_sheet | VARCHAR2 | Worksheet name | Yes |
| p_cols | VARCHAR2 | Column list (see specs below) | Yes |
| p_range | VARCHAR2 | Excel-like range expression that defines the table boundaries in the worksheet (see specs below) | No |
Range syntax specification
If the range is empty, the table implicitly starts at cell A1.
Otherwise, there are four ways to specify the table range :
Range of rows : ‘1:100’
In this case the range of columns implicitly starts at A.
Range of columns : ‘B:E’
In this case the range of rows implicitly starts at 1.
Columns syntax specification
The syntax is similar to the column list in a CREATE TABLE statement, with a couple of specifics :
Column names must be declared using a quoted identifier.
Supported data types are :
- NUMBER – with optional precision and scale specs
VARCHAR2 – including CHAR/BYTE semantics
Values larger than the maximum length declared are silently truncated and no error is reported.
DATE – with optional format mask
The format mask is used if the value is stored as text in the spreadsheet, otherwise the date value is assumed to be stored as date in Excel’s internal serial format.
A special “FOR ORDINALITY” clause (like XMLTABLE or JSON_TABLE’s one) is also available to autogenerate a sequence number.
Each column definition (except for the one qualified with FOR ORDINALITY) may be complemented with an optional “COLUMN” clause to explicitly target a named column in the spreadsheet, instead of relying on the order of the declarations (relative to the range).
Positional and named column definitions cannot be mixed.
Examples
Using this sample file : 
1- Loading all six columns, starting at cell A2, in order to skip the header :
2- Loading columns B and F only, from rows 2 to 10, with a generated sequence :
Like this:
30 thoughts on “ Oracle SQL – Reading an Excel File (xlsx) as an External Table ”
This is an excellent piece of work on so many levels. The grammar for mapping types is excellent.
Odie,
I am trying to use your, Code for a POC, but I am stuck at the point in the oox_install.sql Script where there ina Anonymous Block,
declare
res boolean;
begin
res := DBMS_XDB.createFolder(‘/office’);
res := DBMS_XDB.createFolder(‘/office/excel’);
res := DBMS_XDB.createFolder(‘/office/excel/conf’);
res := DBMS_XDB.createFolder(‘/office/excel/temp’);
res := DBMS_XDB.createFolder(‘/office/excel/docs’);
end;
/
I am getting the Following Error
[Error] Execution (77: 1): ORA-31050: Access denied
ORA-06512: at “XDB.DBMS_XDB”, line 340
ORA-06512: at line 4
I requested my DBA to Provide XDBADMIN to my schema, still the Same.
What could be wrong.?
Seems like you want to use the demo from this post : https://odieweblog.wordpress.com/2012/01/28/xml-db-events-reading-an-open-office-xml-document-xlsx/
yet you’re posting your comment in another post.
What do you want to do?
Try EXCELTABLE package instead.
Odie,
Thanks for your Reply, I apologize for posting this Comment in the Wrong window, I had Opened Almost All your XML + Reading Excel file related article pages in my browser.
The solution sounds promising, but I followed your installation steps on GitHub, and I got following compilation errrors for “ExcelTable.pkb”:
Error(979,3): PL/SQL: Item ignored
Error(989,3): PLS-00311: the declaration of “db.office.spreadsheet.ReadContext.initialize(java.sql.Blob, java.sql.Blob, java.lang.String, int, int, int) return int” is incomplete or malformed
Error(992,3): PL/SQL: Item ignored
Error(995,3): PLS-00311: the declaration of “db.office.spreadsheet.ReadContext.iterate(int, int) return java.sql.Array” is incomplete or malformed
Error(998,3): PL/SQL: Item ignored
Error(1000,3): PLS-00311: the declaration of “db.office.spreadsheet.ReadContext.terminate(int)” is incomplete or malformed
What’s your database version? (select * from v$version)
Very useful package, thanks for sharing. I was trying to use as part of an ETL process written in PL/SQL. I have the call to your package within a cursor. When I run the SQL bit as SQL it works fine. But when I try to compile the exact same SQL but in a PL/SQL cursor (cursor xyz is select … from table(exceltable.getrows….) I get ORA-22905, cannot access rows from a non-nested table item. Any clues? Thanks again.
Hi Robert, thanks for your feedback.
It is a known error (unfortunately) when trying to use table functions returning AnyDataset within PL/SQL.
Apparently, Oracle is not able to call the ODCITableDescribe routine at compile time and therefore cannot retrieve the projection from the SELECT statement.
The workaround is to use dynamic SQL :
OPEN my_refcursor FOR ‘SELECT . ‘ USING
Thanks for feedback – that’s exactly how I got around the issue. Good to know I’m not totally stupid 🙂
FYI, in ExcelTable 1.4, I’ve added a new function getCursor() with same parameters as getRows() and returning a REF cursor.
The solution seems to have everything we need for our problem. I just have one question. Our Excel files are stored in a table as BLOB. Can you please post an example how getRows() can be used with BLOB?
That’s easy. Just pass your BLOB column to the p_file parameter :
Hi, this is excellent work. Could you provide an example using getCursor() fetched into a record variable? Thanks.
Hello. I’m trying to use your code with example 1 to test but I can’t run it. Surely a mistake from my side, but i don’t find the clue …
Directory created and granted sur my user REF
file ooxdata3.xlsx exists and test of function getfile is OK
select t.*
from table(
ExcelTable.getRows(
ExcelTable.getFile(‘TMP_DIR’,’ooxdata3.xlsx’)
, ‘DataSource’
, ‘ “SRNO” number
, “NAME” varchar2(10)
, “VAL” number
, “DT” date
, “SPARE1” varchar2(6)
, “SPARE2” varchar2(6)’
, ‘A2’
)
) t
;
return a PLS-00225 : line 4 col 6 subprogram of cursor ‘REF’ is out of scope.
I’m on oracle 11.2.0.3 x64 and windows 2008 R2 … All is well compiled, I don’t know where to search.
I’ve done another test on oracle 12c and it works.
Hello. I’m trying to use your code with example 1 to test but I can’t run it.
select t.*
from table(
ExcelTable.getRows(
ExcelTable.getFile(‘TMP_DIR’,’ooxdata3.xlsx’)
, ‘DataSource’
, ‘ “SRNO” number
, “NAME” varchar2(10)
, “VAL” number
, “DT” date
, “SPARE1” varchar2(6)
, “SPARE2” varchar2(6)’
, ‘A2’
)
) t
;
return ORA-00955: name is already used by an existing object al line 1121 in EXCELTABLE object.
At line 1121 your code tries to create a global temporary table.
WHat can i do?
Thanks
How can we use This query inside SP or PL/SQL block? I get error always cannot access rows from non-nested table
It’s explained in one of the comments above : use dynamic SQL, or ExcelTable.getCursor() if you want to use the query in a cursor (see the README).
Great work. It helped me a lot. Thank you for sharing.
It’s working nicely for small file for me but
while inserting a large excel file 200000 rows into oracle table, I getting
insert /+APPEND/ into REASSIGNMENT_tmp
*
ERROR at line 1:
ORA-31011: XML parsing failed
ORA-19202: Error occurred in XML processing
LPX-00664: VM Node-Stack overflow.
ORA-06512: at “XDB.DBMS_XSLPROCESSOR”, line 743
ORA-06512: at “XDB.DBMS_XSLPROCESSOR”, line 771
ORA-06512: at “HARI.EXCELTABLE”, line 1760
ORA-06512: at “HARI.EXCELTABLE”, line 1862
ORA-06512: at “HARI.EXCELTABLE”, line 2295
ORA-06512: at “HARI.EXCELTABLEIMPL”, line 60
ORA-06512: at line 1
Please advice;
2) I need to commit every 10000 record, what method you suggest ?
For large files, you’ll have to use the streaming read method (requires Java).
See the README for instructions, and this post.
About your other question, I’ve never understood the need for any “COMMIT every N record” requirement.
Anyway, it’s not possible with a single INSERT/SELECT statement, let alone with the APPEND hint.
I suggest you use the cursor-based approach. See procedure ExcelTable.getCursor() and insert in a loop, then you’ll be able to implement your commit-every stuff.
How we have to specify the Boolean data type
What do you mean? Boolean data type from Excel?
I am trying to create a materialized view from the select of the table. The direct select works fine, but when I place into the materialized view the it only takes the first column (for each column …
Has Anyone come across this issue? is there a way to resolve?
Is there something in my code I could use to fix this?
In the following example, the Materialized view give the value of the row_number in each column…
SELECT xl.*
FROM TABLE (IDATA.PAK_ExcelTable.F_getRows (
IDATA.PAK_ExcelTable.F_getFile (‘IDATA_DATA’, ‘EMIDB.XLSX’),
‘Sheet1’,
‘”ROW_NUMBER” for ordinality
, “OPEN_INCIDENT_FLAG” varchar2(5) column ”A”
, “BAND_NUMBER” number(10, 0) column ”B”
, “EMAP_ELIGIBLE_FLAG” varchar2(1) column ”C”
, “MAIN_CATEGORY” varchar2(5) column ”D”’,
‘A2’)) xl;
ROW_NUMBER OPEN_INCIDENT_FLAG BAND_NUMBER EMAP_ELIGIBLE_FLAG MAIN_CATEGORY
CREATE MATERIALIZED VIEW BB_TEST (ROW_NUMBER,OPEN_INCIDENT_FLAG,BAND_NUMBER,EMAP_ELIGIBLE_FLAG,MAIN_CATEGORY)
BUILD IMMEDIATE
REFRESH FORCE ON DEMAND
WITH PRIMARY KEY
AS
/* Formatted on 8/15/2018 11:52:16 AM (QP5 v5.269.14213.34746) /
SELECT xl.
FROM TABLE (IDATA.PAK_ExcelTable.F_getRows (
IDATA.PAK_ExcelTable.F_getFile (‘IDATA_DATA’, ‘EMIDB.XLSX’),
‘Sheet1’,
‘”ROW_NUMBER” for ordinality
, “OPEN_INCIDENT_FLAG” varchar2(5) column ”A”
, “BAND_NUMBER” number(10, 0) column ”B”
, “EMAP_ELIGIBLE_FLAG” varchar2(1) column ”C”
, “MAIN_CATEGORY” varchar2(5) column ”D”’,
‘A2’)) xl;
select * from bb_test
;
ROW_NUMBER OPEN_INCIDENT_FLAG BAND_NUMBER EMAP_ELIGIBLE_FLAG MAIN_CATEGORY
I can’t reproduce the problem. What’s your exact database version please?
Hello, please help with the error:
ORA-20722: Error at position 1 : unexpected symbol ” instead of ”
ORA-06512: на “DWH.EXCELTABLE”, line 1041
ORA-06512: на “DWH.EXCELTABLE”, line 1414
ORA-06512: на “DWH.EXCELTABLE”, line 1427
ORA-06512: на “DWH.EXCELTABLE”, line 1574
ORA-06512: на “DWH.EXCELTABLE”, line 1585
ORA-06512: на “DWH.EXCELTABLE”, line 1597
ORA-06512: на “DWH.EXCELTABLE”, line 2688
ORA-06512: на “DWH.EXCELTABLEIMPL”, line 16
ORA-06512: на line 4
select t.*
from table(
ExcelTable.getRows(
ExcelTable.getFile(‘TMP_DIR’,’ooxdata3.xlsx’)
, ‘DataSource’
, ‘ “SRNO” number
, “NAME” varchar2(10)
, “VAL” number
, “DT” date
, “SPARE1” varchar2(6)
, “SPARE2” varchar2(6)’
, ‘A2’
)
) t
;
Hello,
Just found this post and it’s exactly what I for my requirement. However, it seems the Excel file must be on the DB server for the store function to work, correct? How can we load the Excel file that reside on Window client since I don’t have access to the DB server? Thank you in advance,
Hi, sorry for the late reply.
You are correct, the file must reside in a location the DB server has access to, not necessarily the DB server itself though, could be a NFS (Network File System) for example.
To address your situation, a classical approach is to mount a shared Windows directory on the DB server, so that end users may deposit files to be read by the DB.
If such a setup is not possible, the only other option I see is to send the file to the server as a separate step (e.g. SFTP/FTP protocol), or directly load the file in a BLOB in a temp table using SQL*Loader, you’ll then be able to use ExcelTable over the BLOB.
This is really cool Thank you for sharing.
DATE type columns gave me some trouble initially, but turns out that was related to the header row not being a valid DATE format.
Is there a good way to have this ignore the row of headers, specifically when the column needs to be DATE type?
I just answered my own question. Adding ,’A2′ at the end of the selection, as you show in an example, will resolve the header situation.
Leave a Reply Cancel reply
This site uses Akismet to reduce spam. Learn how your comment data is processed.
Источник
I’ve seen this over and over. Is it possible to load Excel to Oracle database some easy to automate way? Of course there is, there are actually many ways. My favorite is (7).
1. client side executed solution – VBA macro or COM to directly write to Oracle Database (some manual file manipulation required each time you want to load the file )
This is certainly possible and is not complex to code, but I don’t like it at all for two reasons – first you need to install (if its COM) or at least run (in case of VBA) script on client machine and either hardcode uid/psw or allow the user access directly to Oracle Database. Certainly a lot of places where things can go wrong. One place where I used this was ESSBASE – it has decent excel plug-in and allows to write back to essbase cube (yeah I know essbase is not oracle database).
2. client side executed solution – web app (some manual file manipulation required each time you want to upload the file)
This is a bit nicer solution simply because there is nothing to install and even authentication can be very seamless. If you use for example Oracle Apex, you can use transparent AD authentication. The app can work the way Oracle Apex imports excel data (copy-paste from excel to a text field in the page) which basically pastes the data as tab delimited structure (and saves probably as CLOB if you use Apex).
3. ask for a file in CSV format (some manual file manipulation required each time you want to load the file)
OK, this is obvious easy to deal with format, I’ve used this method many many times and burned my fingers over and over. You would be surprised how many users have problems with SAVE-AS CSV
4. ask for XML file (no manual work required if excel is kept in XML format)
This is very interesting solution since XML is somewhat natural excel format. If the user keeps his/her file in XML then there is no special file manipulation required on his/her side. Oracle can easily load XML. If you start digging into this, you might see how complex the XML is and how “not so easy” this can be.
5. server side VBScript (can be very easily automated)
If you are lucky and have Windows server with Excel installed then you can easily use Worksheet.SaveAs Method to convert excel to CSV. One strong advantage I see here is the fact that you use Excel object model to manipulate Excel file and thus it should be easy to move to new Excel format (in case of any future company wide conversion).
6. JAVA in Oracle JVM (can be very easily automated)
I’m really not JAVA guru, but … there are few easy to use conversion classes. Since Java can run in Oracle JVM and you can use PL/SQL to execute it, it can be painless very easy to use solution. Please note JVM is isolated from Oracle database and thus most of the out-of-the-box classes out there are going to create CSV file in the file system. I found very nice sample here http://www.dynamicpsp.com/!go?ln=nfaq&faq=FAQ9
7. unix SCRIPT executed either stand alone or using 11.2 external table preprocessor (can be very easily automated)
You can either use JAVA (similar to above) or PERL or … this is really easy to use solution and if you are lucky and have oracle 11.2 then you can utilize preprocessor and simple SELECT * FROM MY_EXTERNAL_TABLE is going to take care of conversion as well as loading to oracle – this is the way I like !! No scripts to execute, no special manual manipulations, simple SELECT * FROM … is taking care of everything.
here is small how-to for (7) in 11.2
1. take the sample below and create Book1.xls

2. create four oracle directories pointing to four unix directories (you can of course create one for all files, but let’s try to keep the security tight)
CREATE DIRECTORY dir_sample_data as '/home/jiri/Desktop/sample/data'; CREATE DIRECTORY dir_sample_log as '/home/jiri/Desktop/sample/log'; CREATE DIRECTORY dir_sample_bad as '/home/jiri/Desktop/sample/bad'; CREATE DIRECTORY dir_sample_exec as '/home/jiri/Desktop/sample/execute'; GRANT READ on DIRECTORY dir_sample_data to JIRI; GRANT READ, WRITE on DIRECTORY dir_sample_log to JIRI; GRANT READ, WRITE on DIRECTORY dir_sample_bad to JIRI; GRANT EXECUTE on DIRECTORY dir_sample_exec to JIRI;
3. place Book1.xls to /home/jiri/Desktop/sample/data
4. download and install xls2csv perl script – http://search.cpan.org/~ken/xls2csv-1.06/script/xls2csv
5. place script below to /home/jiri/Desktop/sample/execute/run_convert.sh – the script executes perl conversion script and spools the output file to stdout (source for oracle external table)
#!/bin/bash currentDir="/home/oracle/Desktop/sample/data" /usr/bin/xls2csv -q -x $currentDir/Book1.xls -w Sheet1 -c $currentDir/Book1.dat /bin/cat $currentDir/Book1.dat
6. create external table with preprocessor and load the data. Please note the script above is going to be executed every time you run SELECT * FROM jiri.sample_01_ext
CREATE TABLE JIRI.SAMPLE_01_EXT ( CUSTOMER_ID NUMBER(10), CUSTOMER_NM VARCHAR2(60), CUSTOMER_SSN VARCHAR2(12) ) ORGANIZATION EXTERNAL ( TYPE ORACLE_LOADER DEFAULT DIRECTORY dir_sample_data ACCESS PARAMETERS ( RECORDS DELIMITED BY NEWLINE PREPROCESSOR dir_sample_exec:'run_convert.sh' SKIP 1 LOGFILE dir_sample_log:'Book1.log' BADFILE dir_sample_bad:'Book1.bad' NODISCARDFILE FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' MISSING FIELD VALUES ARE NULL ) LOCATION (dir_sample_data:'Book1.xls') ) REJECT LIMIT 0 NOPARALLEL NOMONITORING;
It cannot be easier than that. There is one small issue with the script. It is really not that critical, but as you can see run_convert.sh creates CSV file first and thus if two users run the select at the same time, you can might have a conflict. You can of course create unique file name each time or even better change the perl script a bit (this is actually very very easy change) and run the output to stdout instead of a file.
8. odbc driver
BluShadow pointed this out on OTN Oracle discussion (thank you for the comment). Oracle allows to use OCDB driver to connect to well any source which supports ODBC. Excel ODBC driver is free on Windows and thus this probably would be preferred solution if you run Oracle on Windows machine. It is possible to run it on unix if you have the driver (DataDirect are most common unix drivers – not cheap).
Here is how to create the link (this is copy-paste solution from OTN BlueShadow posted – thank you again for the info), you can find more details on AskTom http://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:4406709207206
1- Go to Control Panel>Administrative Tools>Data Sources (ODBC)>System DSN and create a data source with appropriate driver. Name it EXCL.
2- In %ORACLE_HOME%NetworkAdminTnsnames.ora fie add entry:
EXCL = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = 10.12.0.24)(PORT = 1521)) ) (CONNECT_DATA = (SID = EXCL) ) (HS = OK) )
Here SID is the name of data source that you have just created.
3- In %ORACLE_HOME%NetworkAdminListener.ora file add:
(SID_DESC = (PROGRAM = hsodbc) (SID_NAME = <hs_sid>) (ORACLE_HOME = <oracle home>) )
under SID_LIST_LISTENER like:
SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = d:ORA9DB) (PROGRAM = extproc) ) (SID_DESC = (GLOBAL_DBNAME = ORA9DB) (ORACLE_HOME = d:ORA9DB) (SID_NAME = ORA9DB) ) (SID_DESC = (PROGRAM = hsodbc) (SID_NAME = EXCL) (ORACLE_HOME = D:ora9db) ) )
Dont forget to reload the listener
C:> lsnrctl reload
4- In %ORACLE_HOME%hsadmin create init<HS_SID>.ora. For our sid EXCL we create file initexcl.ora.
In this file set following two parameters:
HS_FDS_CONNECT_INFO = excl HS_FDS_TRACE_LEVEL = 0
5- Now connect to Oracle database and create database link with following command:
SQL> CREATE DATABASE LINK excl 2 USING 'excl' 3 / Database link created.
Now you can perform query against this database like you would for any remote database.
SQL> SELECT table_name FROM all_tables@excl; TABLE_NAME ------------------------------ DEPT EMP
 На протяжении многих лет администраторы баз данных Oracle пользовались практически только утилитой SQL*Loader для выполнения загрузки данных в таблицы Oracle из внешних источников, применяя ее либо в обычном, либо в прямом режиме загрузки. Предлагаемый Oracle механизм внешних таблиц является шагом вперед и позволяет использовать функциональные возможности SQL*Loader для получения доступа к данным, хранящимся в файлах операционной системы, без выполнения загрузки в реальные таблицы Oracle.
На протяжении многих лет администраторы баз данных Oracle пользовались практически только утилитой SQL*Loader для выполнения загрузки данных в таблицы Oracle из внешних источников, применяя ее либо в обычном, либо в прямом режиме загрузки. Предлагаемый Oracle механизм внешних таблиц является шагом вперед и позволяет использовать функциональные возможности SQL*Loader для получения доступа к данным, хранящимся в файлах операционной системы, без выполнения загрузки в реальные таблицы Oracle.
Если исходные данные не нуждаются ни в каких преобразованиях перед загрузкой в базу, утилиты SQL*Loader для выполнения их загрузки в обычном или прямом режиме вполне достаточно. Внешние таблицы дополняют функциональные возможности SQL*Loader. Поэтому если необходимо выполнить серьезные преобразования перед загрузкой данных, рекомендуется использовать именно внешние таблицы.
За счет применения механизма внешних таблиц внешние данные можно визуализировать так, будто бы они хранятся в таблице Oracle. При создании внешней таблицы столбцы перечисляются тем же самым образом, как и при создании обычной таблицы. Однако поля данных из внешнего файла просто отображаются на столбцы внешней таблицы, но не загружаются в них на самом деле.
Внешние таблицы в действительности не существуют нигде ни внутри, ни за пределами базы данных Oracle. Под термином внешняя таблица (external table) подразумевается просто отображение заданной табличной структуры на файл данных, который находится в файле операционной системы. При создании внешней таблицы единственное, что происходит в базе данных, так это создание для новой таблицы в словаре данных новых записей с метаданными. Изменять содержимое файла данных во время получения доступа к его содержимому из базы данных никоим образом не допускается. Другими словами, при взаимодействии с внешними таблицами разрешается пользоваться только командой SELECT, но не командами INSERT, UPDATE и DELETE.
Фактически, внешняя таблица представляет собой своего рода интерфейс к внешнему файлу данных. Однако к ней можно выполнять запросы так, будто бы она является виртуальной таблицей, точно таким же образом, как и к любой обычной таблице Oracle, что делает ее очень мощным инструментом для осуществления ETL-операций в хранилищах данных. Кроме того, из внешних таблиц можно легко создавать другие обычные таблицы или представления, что может быть очень удобным при заполнении хранилищ данных.
Утилита SQL*Loader и механизм внешних таблиц в большинстве случаев работают одинаково в том, что касается скорости выполнения загрузки данных. Обе эти технологии представляют собой альтернативные методы для загрузки данных в базу из внешних источников. Ниже перечислены некоторые общие преимущества, которые предоставляет метод выполнения загрузки при помощи внешних таблиц по сравнению с методом выполнения загрузки с помощью утилиты SQL*Loader.
- К данным во внешних файлах можно получать доступ перед их загрузкой в таблицы.
- Над данными можно выполнять широкий спектр различных преобразований прямо во время самого процесса загрузки. Утилита SQL*Loader позволяет выполнять лишь очень ограниченный набор преобразований.
- При желании преобразование данных можно выполнять одновременно с их загрузкой в таблицы. Этот прием называется конвейеризацией (pipelining) двух этапов. В случае применения утилиты SQL*Loader для выполнения загрузки данных прямо в таблицы, в ходе процесса загрузки не допускается выполнять ничего, кроме самого минимального преобразования данных, из-за чего, следовательно, серьезные преобразования требуется производить на отдельном от загрузки данных этапе.
- Внешние таблицы подходят для загрузки больших объемов данных, которые могут иметь в базе данных одноразовое применение.
- Внешние таблицы экономят время, связанное с созданием реальных таблиц базы данных и затем агрегированием размеров данных для выполнения их загрузки в другие таблицы.
- Внешние таблицы исключают необходимость в создании вспомогательных или временных таблиц, которые являются практически обязательными в случае применения для выполнения загрузки данных из внешних источников утилиты SQL*Loader.
- Никакого физического пространства выделять не требуется, даже для самых больших внешних таблиц. После загрузки файлов данных в операционную систему можно создавать внешние таблицы и сразу же приступать к выполнению в отношении них необходимых SQL-запросов.
При наличии потребности в выполнении загрузки данных удаленным образом или отсутствии необходимости в подвергании данных серьезным преобразованиям, применение утилиты SQL*Loader, бесспорно, является наилучшим вариантом. Внешние таблицы никак не являются такими же универсальными, как и обычные таблицы базы данных, поскольку они доступны только для чтения. Более того, внешние таблицы страдают от ограничения, не позволяющего их индексировать, что делает выполнение насыщенной запросами работы с ними очень непрактичным занятием. Если имеется потребность в индексировании данных во вспомогательных таблицах по какой-то причине, применение утилиты SQL*Loader является единственной достойной внимания альтернативной. Настоящую пользу внешние таблицы приносят главным образом в средах с хранилищами данных или в ситуациях, когда требуется выполнять загрузку и преобразование огромных объемов данных при первой загрузке приложения.
Внимание! При желании иметь возможность создавать индексы на уровне вспомогательной таблицы, лучше применять для загрузки данных утилиту SQL*Loader. Индексировать внешние таблицы нельзя!
Например, предположим, что есть внешний файл данных по имени sales_data, в котором содержится детальная информация по произведенным фирмой продажам за последний год, и что фирма хочет провести на основании этих исходных данных анализ затрат по продуктам и времени. Для выполнения этого анализа создается специальная таблица затрат. Теперь в файле данных sales_data содержится масса детальной информации по затратам, но компания хочет, чтобы данные были объединены, скажем, по регионам. Внешние таблицы замечательно подходят для такой ситуации, когда есть много доступных исходных данных, но преобразовать требуется только какие-то конкретные их части.
Раньше администраторам баз данных, занимающимся хранилищами данных, приходилось создавать вспомогательные таблицы для выполнения преобразования данных перед их загрузкой в хранилище. В случае применения одной лишь утилиты SQL*Loader им требовалось сначала загружать исходные данные в базу и только затем выполнять над ними необходимые преобразования. В случае применения внешней таблицы операции по загрузке и преобразованию данных могут выполняться на одном этапе!
Создание внешней таблицы
Описание внешней таблицы еще также называется слоем (уровнем) внешней таблицы (external table layer) и, по сути, представляет собой описание входящих в состав внешней таблицы столбцов. Этот уровень, вместе драйвером доступа, обеспечивает отображение данных из внешнего файла на определение внешней таблицы.
В листинге 1 ниже приведен пример создания внешней таблицы.
SQL> CREATE TABLE sales_ext(
2 product_id NUMBER(6),
3 sale_date DATE,
4 store_id NUMBER(8),
5 quantity_sold NUMBER(8),
6 unit_cost NUMBER(10,2),
7 unit_price NUMBER(10,2))
8 ORGANIZATION EXTERNAL (
9 TYPE ORACLE_LOADER
10 DEFAULT DIRECTORY ext_data_dir
11 ACCESS PARAMETERS
12 (RECORDS DELIMITED BY NEWLINE
13 BADFILE log_file_dir:'sales.bad_xt'
14 LOGFILE log_file_dir:'sales.log_xt'
15 FIELDS TERMINATED BY "|" LDRTRIM
16 MISSING FIELD VALUES ARE NULL)
17 LOCATION ('sales.data'))
18* REJECT LIMIT UNLIMITED;
Table created.
SQL>
Давайте проанализируем этот оператор более детально, чтобы разобраться в различных компонентах внешней таблицы.
Оператор CREATE TABLE…ORGANIZATION EXTERNAL
Оператор CREATE TABLE sales_ext (. . .) описывает структуру внешней таблицы, а идущая за ним конструкция ORGANIZATION EXTERNAL как раз и обозначает, что это будет не обычная таблица Oracle, а внешняя.
Оператор CREATE, который применяется для создания внешней таблицы, в принципе очень похож на тот, что применяется для создания обычной таблицы, за исключением разве что того, что в нем помимо определений столбцов требуется также предоставлять схему отображения этих столбцов на поля данных во внешнем файле данных, а также указывать место размещения внешнего файла данных в операционной системе.
Параметры доступа
Конструкция ACCESS PARAMETERS чем-то напоминает конструкцию OPTIONS, которая используется в управляющем файле SQL*Loader. Она тоже позволяет указывать различные выбираемые параметры, а также место размещения файла некорректных записей и файла журнала. Есть несколько параметров, которые можно использовать в этой конструкции для задания формата данных во внешней таблице. Наиболее важные из них перечислены ниже.
- RECORD_FORMAT_INFO. Эта конструкция является необязательной. По умолчанию для нее устанавливается значение RECORDS DELIMITED BY NEWLINE.
- FIXED. Эта конструкция позволяет определять фиксированную длину и тем самым указывать, что все записи во внешнем файле имеет одинаковую длину.
ACCESS PARAMETERS (RECORD FIXED 20 FIELDS (...))
- VARIABLE. Конструкция VARIABLE позволяет указывать, что все записи могут иметь разный размер, обозначаемый при помощи идущего в начале каждой из них ряда цифр.
ACCESS PARAMETERS (RECORDS VARIABLE 2)
- То есть в случае использования конструкции VARIABLE каждая запись в наборе данных будет иметь следующий вид, где первые два байта будут обозначать ее длину:
22samalapati1999dallastx
- DELIMITED BY. Эта конструкция позволяет указывать символ, которым завершается каждая запись. Чаще всего роль разделителей исполняют символы конвейера (|) или запятой (,).
- LOAD WHEN. Эта конструкция позволяет указывать условия, которые должны обязательно удовлетворяться перед загрузкой записи в таблицу.
LOAD WHEN (job != MANAGER)
- LOG FILE, BAD FILE и DISCARD FILE. Эти параметры являются необязательными, но файл журнала (LOG FILE) все равно всегда создается по умолчанию. Файлы некорректных (BAD FILE) и отвергнутых записей (DISCARD FILE) создаются только в случае отклонения данных или не удовлетворения ими условия, указанного в конструкции LOAD WHEN.
- Condition. Эта переменная позволяет сравнивать все поле или только какую-то его часть с произвольной постоянной строкой.
Драйвер доступа
Параметры доступа описывают внешние данные, содержащиеся в файлах данных. Драйвер доступа (access driver) заботится о том, чтобы обработка этих внешних данных соответствовала описанию внешней таблицы.
Драйверы доступа бывают двух типов, и каждых из них указывается за счет использования в операторе создания внешней таблицы атрибута TYPE. К первому типу относится драйвер доступа ORACLE_LOADER, который выбирается по умолчанию. В примере, приведенном в листинге 1, внешняя таблица создавалась с использованием именного такого драйвера. Драйвер доступа ORACLE_LOADER позволяет только загружать данные в таблицу из внешнего текстового файла.
Ко второму типу относится новый драйвер доступа ORACLE_DATAPUMP, и этот драйвер позволяет не только загружать, но и выгружать данные за счет применения внешних файлов дампа. С его помощью можно выполнять считывание данных в таблицы базы данных из внешнего файла данных, а также извлекать данные из таблиц Oracle в файл дампа внешней таблицы.
Объекты каталогов и их размещение
Конструкция DEFAULT DIRECTORY указывает на принятое по умолчанию место размещения всех файлов, из которых внешним таблицам необходимо считывать или в которые им необходимо записывать данные. Размещать внешние файлы данных в случайном каталоге операционной системы нельзя по вполне очевидным связанным с безопасностью причинам. Для успешного выполнения оператора создания внешней таблицы нужно сначала создавать объект каталога (directory object) и затем предоставлять конкретным пользователям права на доступ к нему.
Параметр LOCATION, расположенный ближе к концу показанного в листинге 1 оператора, указывает, где находятся файлы данных, необходимые для создания внешней таблицы. В параметре LOCATION может указываться и объект каталога, и имя файла. В общем, синтаксис этого параметра выглядит как каталог: файл, где на месте каталог указывается объект каталога, созданный в базе данных, а не путь к настоящему каталогу в операционной системе. Если объект каталога не задан, тогда по умолчанию предполагается, что файл или файлы данных находятся в том каталоге, на который указывает конструкция DEFAULT DIRECTORY. При желании синтаксисом каталог: файл можно также пользоваться и для указания файлов данных прямо в конструкции ACCESS PARAMETERS.
Утилита SQL*Loader использует объект (или объекты) каталога для обозначения места размещения файлов данных, а также для хранения своих выходных файлов, наподобие файлов некорректных или отвергнутых записей. Пользователь должен обязательно обладать привилегиями на выполнение чтения в объекте каталога, содержащем файлы данных, и привилегиями на выполнение записи в объекте каталога, содержащем выходные файлы. При желании разместить файлы данных и выходные файлы одном и том же объекте каталога можно предоставлять пользователю привилегии на выполнение в этом объекте каталога как чтения, так и записи. Ниже приведен один такой пример:
SQL> CREATE DIRECTORY ext_data_dir AS '/u01/oradata/ext_data'; Directory created. SQL> GRANT READ, WRITE ON DIRECTORY ext_data_dir TO samalapati; Grant succeeded. SQL>
После создания объекта каталога ext_data_dir и предоставления надлежащих прав доступа к нему, можно далее начинать использовать его как принятый по умолчанию каталог для размещения всех внешних файлов данных, а также любых выходных файлов. Параметр LOCATION в операторе создания внешней таблицы, показанном в листинге 1, указывает лишь на внешний файл данных, находиться который будет в принятом по умолчанию каталоге, на который ссылается ext_data_dir.
В целях демонстрации давайте создадим новую таблицу по имени costs, чтобы впоследствии выполнить в нее загрузку из внешнего файла данных (внешней таблицы) агрегированных данных (а именно — совокупных значений столбцов unit_cost и unit_price):
SQL> CREATE TABLE costs 2 (sale_date DATE, 3 product_id NUMBER(6), 4 unit_cost NUMBER (10,2), 5 unit_price NUMBER(10,2)); Table created.
Теперь можно приступать непосредственно к вставке в эту новую таблицу costs необходимых агрегированных данных из внешней таблицы (фактически, представляющей собой внешний файл) с именем sales_ext. Этот процесс подразумевает выполнение сначала считывания данных из внешней таблицы и только потом их загрузку в обычную таблицу базы данных и называется загрузкой данных. В листинге 2 показан пример осуществления вставки данных из внешней таблицы в обычную. В этом примере предполагается, что внешняя таблица имеет имя sales_ext, а обычная таблица Oracle — costs.
SQL> INSERT INTO costs (sale_date, product_id, unit_cost, unit_price) SELECT sale_date, product_id, sum(unit_cost), sum(unit_price) FROM sales_ext GROUP BY time_id, prod_id; SQL>
Обратите внимание на то, что при желании можно вставлять только некоторые из столбцов внешней таблицы и что выполнять преобразование данных можно еще до их загрузки в таблицы Oracle. В этом как раз и заключается главное отличие между применением внешних таблиц и применением утилиты SQL*Loader. Утилита SQL*Loader позволяет выполнять преобразование данных, но ее возможности в этой области чрезвычайно ограничены, как было показано ранее в этой статье. При создании внешней таблицы для данных можно применять практически любые SQL-преобразования.
Заполнение внешних таблиц
Термины загрузка (loading) и выгрузка (unloading) в контексте внешних таблиц могут вызывать путаницу, поэтому давайте остановимся на них более подробно и устраним любую связанную с ними неоднозначность. В частности, при работе с внешними таблицами эти термины означают следующее.
- Под загрузкой данных подразумевается считывание данных из внешней таблицы и затем их загрузка в обычную таблицу. Oracle сначала считывает поток данных из тех файлов, которые указываются, а потом переводит их из внешнего представления в вид внутренних данных Oracle и передает далее интерфейсу внешней таблицы.
- Под выгрузкой данных подразумевается считывание данных из обычной таблицы Oracle и затем помещение их во внешнюю таблицу. По сути, под этим процессом понимается выполнение загрузки данных во внешний файл. В Oracle Database 11g появилась возможность загружать и преобразовывать большие объемы данных в не зависящие от платформы собственные плоские файлы Oracle для распространения или хранения данных.
Драйвер доступа ORACLE_DATAPUMP умеет как загружать, так и извлекать данные, т.е. он может и загружать внешнюю таблицу из плоского файла, и извлекать данные из обычной таблицы базы данных во внешний плоский файл. Данные в такой внешний плоский файл записываются в специальном формате, который может понимать только драйвер доступа ORACLE_DATAPUMP. Далее этот созданный новый файл можно использовать для создания внешней таблицы как в той же, так и в другой базе данных.
При загрузке таблицы Oracle из внешней таблицы (загрузка данных) применяется конструкция INSERT INTO…SELECT, как было показано в листинге 2. А при заполнении внешней таблицы данными из обычной таблицы Oracle (выгрузка данных) применяется конструкция CREATE TABLE…AS SELECT (также сокращенно называемая CTAS), как будет показано позже в этой статье, в листинге 4.
Ниже перечислены некоторые преимущества наличия возможности заполнять таблицы данными при помощи внешних таблиц.
- Загрузка табличных данных в плоские файлы означает, что далее их можно легко хранить или перемещать в другие базы данных. Внешние таблицы помогают перемещать большие объемы данных между платформами, поскольку они не зависят от используемой платформы.
- В средах с хранилищами данных часто возникает необходимость в выполнении сложных заданий ETL. Данными во внешних таблицах можно легко манипулировать за счет применения различных SQL-трансформаций перед их загрузкой снова в ту же или другую базу данных.
Обратите внимание на то, что когда говорится о выполнении записи во внешние таблицы, на самом деле имеется в виду выполнение записи во внешний файл. Для извлечения данных в этот находящийся в операционной системе файл применяется оператор SELECT. Драйвер доступа ORACLE_DATAPUMP записывает в него данные в двоичном и понятном только Oracle формате Data Pump, после чего его можно использовать для загрузки еще одной внешней таблицы в другой базе данных.
Создание внешней таблицы с использованием драйвера доступа ORACLE_DATAPUMP
В листинге 3 приведен пример, демонстрирующий создание внешней таблицы и заполнение ее данными из внешнего плоского файла с использованием драйвера доступа ORACLE_DATAPUMP, а не ORACLE_LOADER.
SQL> CREATE TABLE test_xt(
2 product_id NUMBER(6),
3 warehouse_id NUMBER(3),
4 quantity_on_hand NUMBER(8))
5 ORGANIZATION EXTERNAL(
6 TYPE ORACLE_DATAPUMP
7 DEFAULT DIRECTORY ext_data_dir
8 LOCATION ('test_xt.dmp'));
Table created.
SQL>
Для выполнения загрузки данных этой внешней таблицы в существующую таблицу в базе данных можно применить конструкцию INSERT INTO…SELECT, как было показано ранее в листинге 2
Запись данных во внешнюю таблицу
В листинге 4 представлен пример, показывающий, как выполнять запись данных во внешнюю таблицу.
SQL> CREATE TABLE test_xt
ORGANIZATION EXTERNAL(
TYPE ORACLE_DATAPUMP
DEFAULT DIRECTORY ext_data_dir
LOCATION ('test_xt.dmp'))
AS
SELECT * FROM scott.dept;
Обратите внимание на то, что в операторе создания внешней таблицы для выполнения во внешнюю таблицу (файл) записи данных из таблицы scott.dept используется конструкция SELECT * FROM. Если в новую внешнюю таблицу нужно включить лишь некоторые, а не все столбцы из таблицы scott.dept, вместо оператора SELECT*FROM применялся бы соответствующий оператор SELECT.
На заметку! Запомните, что при загрузке таблицы Oracle данными из внешней таблицы (загрузка данных) применяется конструкция INTO…SELECT, а при заполнении внешней таблицы данными из таблицы Oracle (выгрузка данных) — конструкция CREATE TABLE…AS SELECT.
Если теперь заглянуть в место, указанное для принятого по умолчанию каталога (ext_data_dir), то можно будет увидеть следующее:
SQL> ls -altr Total 24 drwxr-xr-x 5 root root 4096 March 4 14:08 .. -rw-r--r-- 1 oracle oinstall 41 March 5 10:08 TEST_XT_28637.log -rw-r------- 1 oracle oinstall 12288 March 5 10:08 test_xt.dmp
Первый файл (test_xt_28637.log) предназначен для сведений о самом процессе создания данной внешней таблицы, а во второй (test_xt.dmp) — для данных из таблицы. Таблица test_xt создается как внешняя таблица. Табличная структура и данные для нее берутся из обычной таблицы Oracle по имени scott.dept. При желании далее полученный файл дампа может использоваться как в той же, так и в другой базе данных для загрузки других таблиц. Обратите внимание на то, что для успешного выполнения данного оператора создания внешней таблицы, принятый по умолчанию каталог (ext_data_dir) должен быть обязательно создан заранее. Само выполнение этого оператора CTAS приведет к загрузке данных из таблицы scott.dept в новую внешнюю таблицу dept_xt_dmp, а точнее — просто к сохранению данных этой таблицы во внешнем файле по имени dept_xt_dmp. Следовательно, получается, что внешняя таблица на самом деле образуется из плоских файлов, имеющих специальный формат и не зависящих от используемой операционной системы.
Драйвер доступа ORACLE_DATAPUMP также можно применять и для извлечения данных таблицы Oracle в несколько файлов, как показано ниже:
SQL> CREATE TABLE extract_cust
ORGANIZATION EXTERNAL
(TYPE ORACLE_DATAPUMP DEFAULT DIRECTORY ext_data_dir ACCESS PARAMETERS
(NOBADFILE NOLOGFILE)
LOCATION ('extract_cust1.exp', 'extract_cust2.exp', 'extract_cust3.exp',
'extract_cust4.exp'))
PARALLEL 4 REJECT LIMIT UNLIMITED AS
SELECT c.*, co.country_name, co.country_subregion, co.country_region
FROM customers c, countries co where co.country_id=c.country_id;
Параметр PARALLEL ускорит процесс выгрузки данных в четыре указанных файла данных. Обратите внимание, что количество указываемых файлов накладывает ограничение на степень параллелизма. Например, в случае установки для параметра PARALLEL значения 8 (PARALLEL=8) и указания только четырех файлов, степень параллелизма будет равняться четырем, а не восьми.
Сжатие и шифрование данных
Для обеспечения сжатия и шифрования данных при их записи в набор файлов дампа можно применять параметры COMPRESSION и ENCRYPTION. По умолчанию база данных не сжимает и не шифрует данные. В следующих подразделах рассказывается о том, как именно применять каждый из этих двух параметров.
Параметр COMPRESSION
Параметр COMPRESSION позволяет указывать, должны ли данные сжиматься перед их записью в набор файлов дампа. По умолчанию функция сжатия отключена (COMPRESSION DISABLED). Включать ее на время всей операции выгрузки можно, установив для параметра COMPRESSION значение ENABLED. В следующем примере показано, как это сделать:
SQL> CREATE TABLE table TEST
ORGANIZATION EXTERNAL (TYPE ORACLE_DATAPUMP DEFAULT DIRECTORY def_dir1
ACCESS PARAMETERS (COMPRESSION ENABLED) LOCATION ('test.dmp'));
Наличие конструкции COMPRESSION ENABLED в приведенной выше команде гарантирует, что все данные будут записываться в файл test.dmp в сжатом формате.
Параметр ENCRYPTION
Параметр ENCRYPTION позволяет указывать, должна ли база данных шифровать данные перед их записью в набор файлов дампа. По умолчанию функция шифрования отключена и включить ее можно, установив для параметра ENCRYPITON значение ENABLED, как показано в следующем примере:
SQL> CREATE TABLE TEST
ORGANIZATION EXTERNAL (TYPE ORACLE_DATAPUMP DEFAULT DIRECTORY test_dir1
ACCESS PARAMETERS (ENCRYPTION ENABLED) LOCATION ('test.dmp'));
Наличие в приведенной выше команде конструкции ENCRYPTION ENABLED гарантирует, что перед записью в файл дампа test.dmp все данные будут обязательно шифроваться.
Использование внешней таблицы
После создания новой внешней таблицы за счет заполнения внешнего файла данными из таблицы Oracle к ней можно выполнять запросы, точно так же, как к любой обычной таблице Oracle. Например, запрос к внешней таблице test_xt приведет к получению тех же данных, что и запрос к исходной таблице scott.dept:
SQL> SELECT * FROM test_xt;
В качестве владельца этой новой таблицы test_xt будет тоже отображаться пользователь samalapati, как показано ниже:
SQL> SELECT owner FROM dba_tables WHERE table_name='TEST_XT'; OWNER ----------- SAMALAPATI
Важно обратить внимание на то, что, как и в версии Oracle9i, в которой механизм внешних таблиц появился впервые, данные можно только выбирать (select) из внешней таблицы. Вставлять, удалять или обновлять данные во внешней таблице нельзя. Поэтому термин “записываемые внешние таблицы” (writable external tables) имеет очень ограниченный смысл: выполнять запись во внешние таблицы допускается только при их первоначальном создании. Ниже приведен пример, показывающий, что бы произошло при попытке вставить в новую внешнюю таблицу test_xt какие-то данные:
SQL> INSERT INTO test_xt (product_id) VALUES (222222); INSERT INTO test_xt * ERROR at line 1: ORA-30657: operation not supported on external organized table операция не поддерживается на внешних таблицах SQL>
При попытке выполнить операцию DELETE или UPDATE тоже было бы выдано похожее сообщение об ошибке.
Еще важно обратить внимание на то, что в случае применения механизма внешних таблицы для извлечения табличных данных в файл экспортируются только сами данные. Экспортировать метаданные при применении внешних таблиц нельзя. При желании извлечь метаданные для какого-нибудь объекта, нужно просто использовать DBMS_METADATA, как показано ниже:
SET LONG 2000
SELECT DBMS_METADATA.GET_DDL('TABLE','EXTRACT_CUST') FROM DUAL;
Использование SQL*Loader для генерации операторов создания внешних таблиц
Как уже можно было видеть в предыдущих разделах, правильное создание внешних таблиц и выбор подходящих параметров доступа может оказаться довольно утомительным занятием. К счастью, для выполнения всего этого существует и более простой способ, который заключается в генерировании всего необходимого для создания внешних таблиц DDL-кода и всех необходимых для загрузки их данными SQL-операторов утилитой SQL*Loader.
Генерировать DDL-код, необходимый для создания всех внешних таблиц, в SQL*Loader позволяет параметр командной строки EXTERNAL_TABLE. По умолчанию для него используется значение NOT_USED, при котором утилита SQL*Loader выполняет стандартную загрузку данных либо в обычном, либо в прямом режиме. В случае использования этого параметра со значением GENERATE_ONLY утилита SQL*Loader никакой загрузки данных не выполняет; вместо этого она генерирует все SQL-операторы, которые требуются для загрузки описанных в управляющем файле внешних таблиц, и размещает их в своем журнальном файле. В случае применения параметра EXTERNAL_TABLE со значением EXECUTE она пытаться выполнить эти SQL-операторы, чтобы создать внешние таблицы и загрузить их данными.
В частности, в результате применения опции EXTERNAL_TABLE=GENERATE_ONLY в журнальном файле SQL*Loader генерируются следующие операторы.
- Оператор CREATE DIRECTORY.
- Полный оператор CREATE TABLE, требуемый для создания внешней таблицы, со всеми необходимыми параметрами доступа.
- Все операторы INSERT, которые необходимы для выполнения загрузки данных из внутренних таблиц.
- Все операторы DELETE, которые требуются для каталога и внешней таблицы.
Давайте рассмотрим пример, показывающий, как генерировать связанные с созданием внешней таблицы операторы с помощью утилиты SQL*Loader. В этом примере предполагается, что внутренняя таблица называется test_emp. Эта таблица должна либо уже существовать, либо быть создана перед использованием SQL*Loader. Имя генерируемой SQL*Loader внешней таблицы выглядит как sys_sqlldr_x_ext_test_emp. Используемый для SQL*Loader управляющий файл носит имя test.ctl и имеет следующий вид:
LOAD DATA INFILE * INTO TABLE test_emp FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' (employee_id,first_name,last_name,hire_date,salary,manager_id) BEGINDATA 12345,"sam","alapati",sysdate,50000,99999 23456,"mark","potts",sysdate,50000,99999
Первое, что нужно сделать — это вызвать утилиту SQL*Loader с указанием test.ctl в качестве управляющего файла. Не следует забывать о том, что производится лишь генерация операторов CREATE TABLE и INSERT, а не фактическая загрузка таблиц.
$ sqlldr USERID=system/sammyy1 CONTROL=test.ctl
EXTERNAL_TABLE=GENERATE_ONLY
SQL*Loader: Release 10.2.0.0.0 - Beta on Sun Mar 6 13:49:39 2009
Copyright (c) 1982, 2008, Oracle. All rights reserved.
Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript. [/u01/app/oracle/dba]
$
Поскольку для журнального файла не был указан никакой каталог, он будет создан в том же каталоге, из которого была запущена утилита SQL*Loader. В данном случае он будет называться test.log и содержать всю необходимую информацию, а именно — и операторы для создания внешней таблицы и каталога для нее, и фактические операторы INSERT для загрузки этой таблицы данными. После этого с помощью этих SQL-операторов внешнюю таблицу можно будет создать и загрузить напрямую данными уже без использования SQL*Loader. В листинге 5 ниже показано, как будет выглядеть содержимое журнального файла, сгенерированного в результате указания параметра EXTERNAL_TABLE=GENERATE_ONLY.
SQL*Loader: Release 10.2.0.0.0 - Beta on Sun Mar 9 13:49:39 2008
Copyright (c) 1982, 2008, Oracle. All rights reserved.
Control File: test.ctl
Data File: test.ctl
Bad File: test.bad
Discard File: none specified
(Allow all discards)
Number to load: ALL
Number to skip: 0
Errors allowed: 50
Continuation: none specified
Path used: External Table
Table TEST_EMP, loaded from every logical record.
Insert option in effect for this table: INSERT
Column Name Position Len Term Encl Datatype
------------------------- ---------- ----- ---- ---- ---------
EMPLOYEE_ID FIRST * , O(") CHARACTER
FIRST_NAME NEXT * , O(") CHARACTER
LAST_NAME NEXT * , O(") CHARACTER
HIRE_DATE NEXT * , O(") CHARACTER
SALARY NEXT * , O(") CHARACTER
MANAGER_ID NEXT * , O(") CHARACTER
CREATE DIRECTORY statements needed for files
------------------------------------------------------------------------
CREATE DIRECTORY SYS_SQLLDR_XT_TMPDIR_00000 AS '/u01/app/oracle/dba'
CREATE TABLE statement for external table:
------------------------------------------------------------------------
CREATE TABLE "SYS_SQLLDR_X_EXT_TEST_EMP"
(
"EMPLOYEE_ID" NUMBER,
"FIRST_NAME" VARCHAR2(20),
"LAST_NAME" VARCHAR2(20),
"HIRE_DATE" DATE,
"SALARY" NUMBER,
"MANAGER_ID" NUMBER
)
ORGANIZATION external
(
TYPE oracle_loader
DEFAULT DIRECTORY SYS_SQLLDR_XT_TMPDIR_00000
ACCESS PARAMETERS
(
RECORDS DELIMITED BY NEWLINE CHARACTERSET US7ASCII
BADFILE 'SYS_SQLLDR_XT_TMPDIR_00000':'test.bad'
LOGFILE 'test.log_xt'
READSIZE 1048576
SKIP 6
FIELDS TERMINATED BY "," OPTIONALLY ENCLOSED BY '"' LDRTRIM
REJECT ROWS WITH ALL NULL FIELDS
(
"EMPLOYEE_ID" CHAR(255)
TERMINATED BY "," OPTIONALLY ENCLOSED BY '"',
"FIRST_NAME" CHAR(255)
TERMINATED BY "," OPTIONALLY ENCLOSED BY '"',
"LAST_NAME" CHAR(255)
TERMINATED BY "," OPTIONALLY ENCLOSED BY '"',
"HIRE_DATE" CHAR(255)
TERMINATED BY "," OPTIONALLY ENCLOSED BY '"',
"SALARY" CHAR(255)
TERMINATED BY "," OPTIONALLY ENCLOSED BY '"',
"MANAGER_ID" CHAR(255)
TERMINATED BY "," OPTIONALLY ENCLOSED BY '"'
)
)
location
(
'test.ctl'
)
)REJECT LIMIT UNLIMITED
INSERT statements used to load internal tables:
--------------------------------------------------------------
INSERT /*+ append */ INTO TEST_EMP
(
EMPLOYEE_ID,
FIRST_NAME,
LAST_NAME,
HIRE_DATE,
SALARY,
MANAGER_ID
)
SELECT
"EMPLOYEE_ID",
"FIRST_NAME",
"LAST_NAME",
"HIRE_DATE",
"SALARY",
"MANAGER_ID"
FROM "SYS_SQLLDR_X_EXT_TEST_EMP"
Run began on Sun Mar 06 13:49:39 2009
Run ended on Sun Mar 06 13:49:40 2009
Elapsed time was: 00:00:01.22
CPU time was: 00:00:00.27
Не трудно заметить, что генерировать операторы CREATE TABLE для внешних таблиц таким способом гораздо легче, чем создавать их с нуля.