
Время на прочтение
11 мин
Количество просмотров 14K
Совсем недавно мне была поставлена задача, написать сервис, который будет заниматься всего лишь одной, но очень емкой задачей – собирать большой объем данных из базы, агрегировать и заполнять все это в Excel по определенному шаблону. В процессе поиска лучшего решения было опробовано несколько подходов, решены проблемы, связанные с памятью и производительностью. В этой статье я хочу поделиться с вами основными моментами и этапами реализации данной задачи.
1. Постановка задачи
В связи с тем, что мне нельзя разглашать подробности ТЗ, сущности, алгоритмы сбора данных и т. д. Пришлось придумать что-то аналогичное:
Итак представим, что у нас есть онлайн чат с высокой активностью, и заказчик хочет выгружать все сообщения, обогащенные данными о пользователе, за определенную дату в Excel. В день может копиться более 1 миллиона сообщений.
У нас есть 3 таблицы:
-
User. Хранит имя пользователя и его некий рейтинг (не важно откуда он берется и как считается)
-
Message. Хранит данные о сообщении – Имя пользователя, ДатуВремя, Текст сообщения.
-
Task. Задача на формирование отчета, которую создает заказчик. Хранит ID, Статус задачи (выполнено или нет), и два параметра: Дату сообщения начало, Дату сообщения конец.
Состав колонок будет следующим:
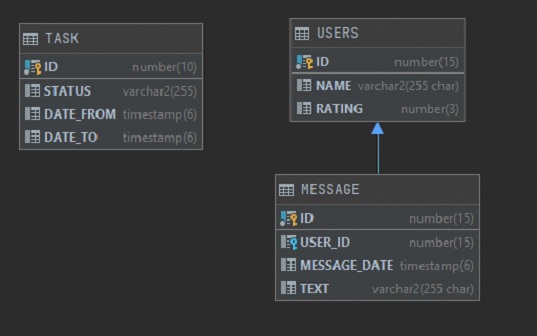
В Excel Заказчик хочет видеть 4 колонки 1) message_date. 2) name. 3) rating. 4) text. Ограничение по количеству строк 1 млн. Надо заполнить этими данными excel, а дальше заказчик уже будет работать с этими данными в екселе самостоятельно.
2. Задача понятна, начнем поиск решения
Так как в компании все стараются придерживаться единого стиля в разработке приложений, то и мне пришлось начать с самого обычного подхода, который используется во всех остальных микросервисах – это Spring + Hibernate для запуска приложения и работы с БД. В качестве БД используется Oracle, хотя использование любой другой СУБД будет плюс минус похожим.
Для старта приложения нам понадобится зависимость spring-boot-starter-data-jpa, которая объединяет в себе сразу Spring Data, Hibernate и JPA, все это нам понадобится для удобства работы с БД и нашими сущностями.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>2.4.5</version>
</dependency>Для тестирования добавим spring-boot-starter-test
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>И еще нам нужен сам драйвер для подключения к БД
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc10</artifactId>
<version>19.10.0.0</version>
</dependency>Далее нам нужно добавить некоторые настройки конфигурации. У нас будет один метод, который будет ходить в таблицу TASK, искать задачу в статусе “CREATED” и, если такая задача существует, то запускать генерацию отчета с параметрами. Предполагается, что генерация отчета может быть долгой, поэтому наш метод будет запускаться по расписанию в два потока асинхронными процессами. Так же для Spring Data укажем наш репозиторий для поиска соответствующих сущностей. Класс конфигурации будет выглядеть следующим образом:
package com.report.generator.demo.config;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.scheduling.TaskScheduler;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.concurrent.ThreadPoolTaskScheduler;
@Configuration
@EnableScheduling
@EnableAsync
@EnableJpaRepositories(basePackages = "com.report.generator.demo.repository")
@PropertySource({"classpath:application.properties"})
@ConditionalOnProperty(
value = "app.scheduling.enable", havingValue = "true", matchIfMissing = true
)
public class DemoConfig {
private static final int CORE_POOL_SIZE = 2;
@Bean(name = "taskScheduler")
public TaskScheduler getTaskScheduler() {
ThreadPoolTaskScheduler scheduler = new ThreadPoolTaskScheduler();
scheduler.setPoolSize(CORE_POOL_SIZE);
scheduler.initialize();
return scheduler;
}
}
Класс генерации отчетов содержит в себе @Scheduled метод, который раз в минуту ищет Task и, если находит, то запускает генерацию отчета с параметрами из этой таски.
@Async("taskScheduler")
@Scheduled(fixedDelay = 60000)
public void scheduledTask() {
log.info("scheduledTask is started");
Task task = getTask();
if (Objects.isNull(task)) {
log.info("task not found");
return;
}
log.info("task found");
generate(task);
}Класс стартер приложения не имеет ничего примечательного, весь код можно посмотреть на GitHub.
3. Выборка данных из БД
Т.к. в компании повсеместно используется Hibernate было решено использовать его. Добавлено entity MessageData с необходимым набором полей (id, name, rating, messageDate, test). Первой попыткой выбрать необходимые данные была попытка в лоб – выгрузить все в List<Message> с помощью простого метода:
List<Message> findAllByMessageDateBetween(Instant dateFrom, Instant dateTo);А дальше уже в цикле создавать объекты MessageData и обогащать их недостающими данными. Было очевидно, что данных подход в корне не верный и выгружать сразу миллион записей в List как минимум медленно. Но для эксперимента и замера скорости работы проверить хотелось, чтобы потом сравнить с другими вариантами. Но в результате данный набор записей выгружался около 30 минут после чего было получено OutOfMemoryError и на этом эксперимент завершился.
Даже если бы пользователь задал узкие рамки в параметрах и нам бы удалось выбрать все в один List, то дальше мы бы столкнулись со следующей проблемой – для заполнения всех необходимых колонок нужно было бы собирать id пользователей, идти снова в базу, получать их имена и рейтинги, и заполнить уже с полными данными. Сложность такого алгоритма вырастала в разы. Было понятно, что выборку надо производить по частям и переложить все возможные действия с данными на сторону бд. Чтобы не выбирать все разом и, чтобы не городить велосипедов, было решено использовать ScrollableResults. Это позволяет нам получить ссылку на курсор и итерироваться по результатам с определенным шагом. Далее пришлось переписать запрос так, чтобы он возвращал сразу все необходимые данные уже после всех джойнов, объединений, группировок и т. д.
Следующий вопрос – где хранить сам текст запроса. Это был не простая ситуация т.к. в действительности количество таблиц, которые участвовали в запросе было около десяти, количество джойнов и всяческих группировок было огромным, в результате чего текст запроса вышел на 200+ строк после ревью всевозможных коллег и утверждении самим тех лидом. Хранить такой запрос в java коде не хотелось, плюс в нем были захардкожены некоторые константы в условиях и светить ими в общем репозитории было бы неправильно. Для решения всех этих вопросов мне на помощь пришла идея использовать view. Весь текст запроса прекрасно туда вписывался, плюс на выходе мы получаем готовую сущность, с которой может работать hibernate как с обычной entity.
По началу все выглядело нормально, запрос на выборку 1 млн таких строк выполнялся за разумные 10 мин. или около того. Немного больше, чем хотелось бы, но заказчика это устраивало. Однако в процессе тестирования обнаружился серьезный минус такого подхода – когда мы выбираем 1 млн записей, запрос выполняется 10 минут, но когда мы хотим отчет по короче и указываем в параметрах границы даты поуже – у нас запрос так же выполняется 10 минут, но в результате мы можем получить хоть 1 запись, хоть миллион. Суть в том, что внутрь запроса view нельзя передавать параметры, мы можем только выполнить статический запрос и уже на результат наложить параметры. Поэтому не важно сколько будет в результате строк, в первую очередь будет выбрано все, что найдется в бд, а только потом будет применены параметры. Заказчику было все равно, его устраивало и то, что отчет с одной строкой будет формироваться практически за такое же время, что и отчет с 1 млн строк. Однако это излишне нагружало бд и было решено отказаться от этого варианта.
Оставался всего один вариант, который нам подходил – это хранимая в бд функция. В нее можно передавать параметры, она может вернуть ссылку на курсор и ее результат можно удобно маппить на нашу entity. Таким образом была описана функция, которая принимала на вход несколько параметров, и возвращала sys_refcursor, весь скрипт занял около 300 строк в реальности, а в упрощенном варианте здесь она выглядит так:
create function message_ref(
date_from timestamp,
date_to timestamp
) return sys_refcursor as
ret_cursor sys_refcursor;
begin
open ret_cursor for
select m.id,
u.name,
u.rating,
m.message_date,
m.text
from message m
left join users u on m.user_id = u.id
where m.message_date between date_from and date_to;
return ret_cursor;
end message_ref;Теперь как ее использовать? Для этого отлично подходит @NamedNativeQuery. Запрос для вызова функции выглядит следующим образом: «{ ? = call message_ref(?, ?) }», callable = true дает понять, что запрос представляет собой вызов функции, cacheMode = CacheModeType.IGNORE для указания не использовать кэш, т. к. скорость работы нам не так критична, как затрачиваемая память, ну и в конце resultClass = MessageData.class для маппинга результата на нашу entity. Класс MessageData выглядит следующим образом:
package com.report.generator.demo.repository.entity;
import lombok.Data;
import org.hibernate.annotations.CacheModeType;
import org.hibernate.annotations.NamedNativeQuery;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import java.io.Serializable;
import java.time.Instant;
import static com.report.generator.demo.repository.entity.MessageData.MESSAGE_REF_QUERY_NAME;
@Data
@Entity
@NamedNativeQuery(
name = MESSAGE_REF_QUERY_NAME,
query = "{ ? = call message_ref(?, ?) }",
callable = true,
cacheMode = CacheModeType.IGNORE,
resultClass = MessageData.class
)
public class MessageData implements Serializable {
public static final String MESSAGE_REF_QUERY_NAME = "MessageData.callMessageRef";
private static final long serialVersionUID = -6780765638993961105L;
@Id
private long id;
@Column
private String name;
@Column
private int rating;
@Column(name = "MESSAGE_DATE")
private Instant messageDate;
@Column
private String text;
}Для того чтобы не использовать кэш было решено выполнять запрос в StatelessSession. Однако есть важная особенность: если попытаться вызвать namedQuery то hibernate при попытке установить CacheMode выдаст UnsupportedOperationException. Чтобы этого избежать необходимо установить два хинта:
query.setHint(JPA_SHARED_CACHE_STORE_MODE, null);
query.setHint(JPA_SHARED_CACHE_RETRIEVE_MODE, null);В итоге наш метод генерации имеет следующий вид:
@Transactional
void generate(Task task) {
log.info("generating report is started");
try (
StatelessSession statelessSession = sessionFactory.openStatelessSession()
) {
ReportExcelStreamWriter writer = new ReportExcelStreamWriter();
Query<MessageData> query = statelessSession.createNamedQuery(MESSAGE_REF_QUERY_NAME, MessageData.class);
query.setParameter(1, task.getDateFrom());
query.setParameter(2, task.getDateTo());
query.setHint(JPA_SHARED_CACHE_STORE_MODE, null);
query.setHint(JPA_SHARED_CACHE_RETRIEVE_MODE, null);
ScrollableResults results = query.scroll(ScrollMode.FORWARD_ONLY);
int index = 0;
while (results.next()) {
index++;
writer.createRow(index, (MessageData) results.get(0));
if (index % 100000 == 0) {
log.info("progress {} rows", index);
}
}
writer.writeWorkbook();
task.setStatus(DONE.toString());
log.info("task {} complete", task);
} catch (Exception e) {
task.setStatus(FAIL.toString());
e.printStackTrace();
log.error("an error occurred with message {}. While executing the task {}", e.getMessage(), task);
} finally {
taskRepository.save(task);
}
}4. Запись данных в Excel
На данном этапе вопрос с выборкой данных из БД был решен и возник следующий вопрос – как теперь все это писать в excel так, чтобы это было быстро и не затратно по памяти. Первая попытка была самой очевидной – это использование библиотеки org.apache.poi. Тут все просто: подключаем зависимость
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.0.0</version>
</dependency>Создаем XSSFWorkbook далее XSSFSheet, из него уже row и так далее. Ничего примечательного, примерный код ниже:
package com.report.generator.demo.service;
import com.report.generator.demo.repository.entity.MessageData;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Instant;
public class ReportExcelWriter {
private final XSSFWorkbook wb;
private final XSSFSheet sheet;
public ReportExcelWriter() {
this.wb = new XSSFWorkbook();
this.sheet = wb.createSheet();
createTitle();
}
public void createRow(int index, MessageData data) {
XSSFRow row = sheet.createRow(index);
setCellValue(row.createCell(0), data.getMessageDate());
setCellValue(row.createCell(1), data.getName());
setCellValue(row.createCell(2), data.getRating());
setCellValue(row.createCell(3), data.getText());
}
public void writeWorkbook() throws IOException {
FileOutputStream fileOut = new FileOutputStream(Instant.now().getEpochSecond() + ".xlsx");
wb.write(fileOut);
fileOut.close();
}
private void createTitle() {
XSSFRow rowTitle = sheet.createRow(0);
setCellValue(rowTitle.createCell(0), "Date");
setCellValue(rowTitle.createCell(1), "Name");
setCellValue(rowTitle.createCell(2), "Rating");
setCellValue(rowTitle.createCell(3), "Text");
}
private void setCellValue(XSSFCell cell, String value) {
cell.setCellValue(value);
}
private void setCellValue(XSSFCell cell, long value) {
cell.setCellValue(value);
}
private void setCellValue(XSSFCell cell, Instant value) {
cell.setCellValue(value.toString());
}
}
Но такой подход оказался не очень оптимальным. Примерно 3 минуты потребовалось на выборку 1 млн строк из бд и запись их в excel. И в итоге приводил к OutOfMemoryError. Вот пример:

А когда я выполнял его на терминалке с выделенной оперативной памятью в 2Gb, то падал он с OutOfMemoryError примерно на 30% прогресса.
Грузить весь миллион строк в память в excel было так же плохой идеей, как и выгружать весь запрос в List, очевидно, здесь надо было использовать некий stream, но хоть какой-то годный пример google тогда мне не дал. Была попытка написать свое подобие I/O Stream для работы с excel, но мысль о том, что я пишу велосипед не давала мне покоя. В результате я стал изучать библиотеку org.apache.poi пристальней и оказалось, что там уже есть пакет streaming. В этом пакете уже есть весь необходимый набор классов для работы с большим объемом данных в excel. Оставалось только заменить все ключевые классы на аналогичные из пакета streaming и все:
package com.report.generator.demo.service;
import com.report.generator.demo.repository.entity.MessageData;
import org.apache.poi.xssf.streaming.SXSSFCell;
import org.apache.poi.xssf.streaming.SXSSFRow;
import org.apache.poi.xssf.streaming.SXSSFSheet;
import org.apache.poi.xssf.streaming.SXSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Instant;
public class ReportExcelStreamWriter {
private final SXSSFWorkbook wb;
private final SXSSFSheet sheet;
public ReportExcelStreamWriter() {
this.wb = new SXSSFWorkbook();
this.sheet = wb.createSheet();
createTitle();
}
public void createRow(int index, MessageData data) {
SXSSFRow row = sheet.createRow(index);
setCellValue(row.createCell(0), data.getMessageDate());
setCellValue(row.createCell(1), data.getName());
setCellValue(row.createCell(2), data.getRating());
setCellValue(row.createCell(3), data.getText());
}
public void writeWorkbook() throws IOException {
FileOutputStream fileOut = new FileOutputStream(Instant.now().getEpochSecond() + ".xlsx");
wb.write(fileOut);
fileOut.close();
}
private void createTitle() {
SXSSFRow rowTitle = sheet.createRow(0);
setCellValue(rowTitle.createCell(0), "Date");
setCellValue(rowTitle.createCell(1), "Name");
setCellValue(rowTitle.createCell(2), "Rating");
setCellValue(rowTitle.createCell(3), "Text");
}
private void setCellValue(SXSSFCell cell, String value) {
cell.setCellValue(value);
}
private void setCellValue(SXSSFCell cell, long value) {
cell.setCellValue(value);
}
private void setCellValue(SXSSFCell cell, Instant value) {
cell.setCellValue(value.toString());
}
}
Теперь сравним скорость обработки данных с этой библиотекой:

Вся обработка заняла пол минуты и, самое главное, никаких OutOfMemoryError.
5. Итог
В результате удалось добиться максимальной производительности за счет использования хранимой функции, StatelessSession, ScrollableResults и использования библиотеки org.apache.poi из пакета streaming. При большом желании можно улучшить производительность еще, если написать все на чистом jdbc, может быть есть еще варианты, как, что и где можно улучшить. Буду рад услышать комментарии от более опытных в этом экспертов. В данном примере не учтено ограничение на 1 млн. строк, т. к. это простая формальность и для примера не очень важна. Для наполнения БД тестовыми данными был добавлен тестовый класс DemoApplicationTests. Весь код можно посмотреть в репозитории на GitHub.
Содержание
- — Как я могу использовать в Excel более 1 миллиона строк?
- — Может ли Excel обрабатывать 4 миллиона строк?
- — Как заставить Excel обрабатывать больше данных?
- — Как открыть файл CSV с более чем 1 миллионом строк?
- — Какое максимальное количество строк в CSV-файле?
- — Есть ли ограничение на количество строк в Excel?
- — Как сохранить в Excel более 65536 строк?
- — Почему в Excel 65536 строк?
- — Что может быть мощнее Excel?
- — Как обойти ограничение на количество строк в Excel?
- — Как вы обрабатываете большие объемы данных?
Excel не может обрабатывать более 1 048 576 строк. Это максимум, который вы можете иметь на листе. @jstupl вам, конечно, потребуется использовать редактор запросов для текста.
Как загрузить большие наборы данных в модель?
- Шаг 1. Подключитесь к своим данным через Power Query. Перейдите на ленту данных и нажмите «Получить данные». …
- Шаг 2 — Загрузите данные в модель данных. В редакторе Power Query при необходимости выполните любые преобразования. …
- Шаг 3 — Проанализируйте данные с помощью сводных таблиц. Идите и вставьте сводную таблицу (Вставка> Сводная таблица)
Может ли Excel обрабатывать 4 миллиона строк?
Не многим людям нужно чтобы вывести в Excel 4 миллиона строк данных. Пункт принят. … Если вы когда-либо проверяли (нажмите End, затем клавишу со стрелкой вниз), в Excel чуть более 1 миллиона строк, но если вы начнете добавлять в эти строки одну или две формулы, вскоре у вас возникнут проблемы.
Как заставить Excel обрабатывать больше данных?
Сделать это, щелкните вкладку Power Pivot на ленте -> Управление данными -> Получить внешние данные. В списке источников данных есть много вариантов. В этом примере будут использоваться данные из другого файла Excel, поэтому выберите вариант Microsoft Excel внизу списка. Для больших объемов данных импорт займет некоторое время.
Как открыть файл CSV с более чем 1 миллионом строк?
Есть решение в Excel. Вы не можете открывать большие файлы стандартным способом, но вы может создать соединение с файлом CSV. Это работает путем загрузки данных в модель данных с сохранением ссылки на исходный файл CSV. Это позволит вам загрузить миллионы строк.
Какое максимальное количество строк в CSV-файле?
Файлы CSV не имеют ограничений на количество строк, которые вы можете добавить. им. Excel не будет содержать больше 1 миллиона строк данных, если вы импортируете файл CSV с большим количеством строк. Excel на самом деле спросит вас, хотите ли вы продолжить, если импортируете более 1 миллиона строк данных.
Есть ли ограничение на количество строк в Excel?
По данным службы поддержки Microsoft (2021 г.): максимальное количество строк в Excel составляет 1,048,576. Количество столбцов ограничено 16 384. Это относится к Excel для Microsoft 365, Excel 2019, Excel 2016, Excel 2013, Excel 2010 и Excel 2007. Еще в 2007 году немногим более миллиона строк казалось большим объемом данных.
Как сохранить в Excel более 65536 строк?
xlsx или. xlsm) имеет максимум около 1 миллиона (ровно 1048576) строк на листе. Если источник данных содержит более 65536 строк (и менее 1 миллиона строк) и вы используете ExcelWriter версии 7.0 или выше, вы можете использовать ExcelTemplate с шаблоном OOXML чтобы все данные поместились на одном листе.
Почему в Excel 65536 строк?
xls-файлы, которые вы открываете, будут ограничены этим количеством строк. Если вы указали, что хотите сохранять файлы в этом формате по умолчанию, тогда когда вы создаете новую книгу он будет ограничен 65536 строками, и [режим совместимости] появится в строке заголовка Excel.
Что может быть мощнее Excel?
Google Таблицы может быть самым популярным веб-приложением для работы с электронными таблицами, но Zoho Sheet имеет больше возможностей. И это также совершенно бесплатно. Это лучшая бесплатная альтернатива Excel, если вы ищете самое мощное решение. Как и Excel, Zoho Sheet действительно обладает множеством функций.
Как обойти ограничение на количество строк в Excel?
Предел строк в Excel
- Предел строк в Excel (содержание)
- Шаг 1. Выберите одну строку ниже, в которой вы хотите отобразить количество строк. …
- Шаг 2: Теперь удерживайте клавиши Shift и Ctrl> нажмите стрелку вниз; он перенесет вас до конца последней строки.
- Шаг 3: Щелкните правой кнопкой мыши заголовок столбца и выберите параметр скрытия.
Как вы обрабатываете большие объемы данных?
Вот 11 советов, как максимально эффективно использовать большие наборы данных.
- Берегите свои данные. «Храните необработанные данные в сыром виде: не манипулируйте ими, не имея копии», — говорит Тил. …
- Визуализируйте информацию.
- Покажите свой рабочий процесс. …
- Используйте контроль версий. …
- Запишите метаданные. …
- Автоматизируйте, автоматизируйте, автоматизируйте. …
- Считайте время вычислений. …
- Запечатлейте свое окружение.
Интересные материалы:
Как включить вспышку вне камеры с помощью выдвижной вспышки?
Как включить звук на камере?
Как включить звук срабатывания затвора камеры?
Как вручную прошить цифровую камеру?
Как вы читаете цвета на резервной камере?
Как вы держите камеру вертикально?
Как вы используете камеру на Canon 5D Mark III?
Как вы используете камеру рейнджера в юрском мире?
Как вы обслуживаете объектив камеры?
Как вы проверяете камеру?
It is known that Excel sheets can display a maximum of 1 million rows. Is there any row limit for csv data, i.e. does Excel allow more than 1 million rows in csv format?
One more question: About this 1 million limitation; Can Excel hold more than 1 million data rows, even though it only displays a maximum of 1 million data rows?
![]()
Andreass
3,1781 gold badge21 silver badges25 bronze badges
asked May 20, 2014 at 11:01
![]()
user1254579user1254579
3,87120 gold badges64 silver badges103 bronze badges
CSV files have no limit of rows you can add to them. Excel won’t hold more that the 1 million lines of data if you import a CSV file having more lines.
Excel will actually ask you whether you want to proceed when importing more than 1 million data rows. It suggests to import the remaining data by using the text import wizard again — you will need to set the appropriate line offset.
answered May 20, 2014 at 11:43
![]()
0
In my memory, excel (versions >= 2007) limits the power 2 of 20: 1.048.576 lines.
Csv is over to this boundary, like ordinary text file. So you will be care of the transfer between two formats.
![]()
Dherik
17.2k11 gold badges118 silver badges161 bronze badges
answered Jun 17, 2015 at 6:43
![]()
staticorstaticor
6109 silver badges18 bronze badges
Using the Excel Text import wizard to import it if it is a text file, like a CSV file, is another option and can be done based on which row number to which row numbers you specify. See: This link
![]()
Hasan Fathi
5,4604 gold badges42 silver badges56 bronze badges
answered Oct 18, 2017 at 11:54
![]()
ChrisChris
311 bronze badge
Существует ограничение в 1 048 576 строк, которое можно просматривать / просматривать в Excel 2007/2010.
В этом случае файл содержит 1,2 миллиона строк и, таким образом, хотя строки существуют в файле, их нельзя просмотреть / открыть в Excel.
Лицо, предоставляющее данные, предлагает не использовать Excel для открытия файлов.
Один из возможных подходов к просмотру необработанных данных — при условии, что это «распакованный файл.xslx»1) — использовать Блокнот для открытия файла (если Блокнот не работает, запись может). Вот несколько подходов сделать это:
- Щелкните правой кнопкой мыши по файлу и перейдите к «Открыть с помощью -> Выбрать программу по умолчанию..», затем выберите «Блокнот» (обязательно снимите флажок «Всегда использовать..»);
- Переименуйте расширение файла в «.txt», чтобы оно было связано с обычным редактором (возможно, «Блокнотом») по умолчанию;
- Запустите Блокнот, а затем «Открыть» указанный файл.
Если данные были предоставлены в CSV, все строки не могли быть просмотрены в Excel (например, после импорта) из-за указанного ограничения. Если этот файл является «распакованным.xsls», тогда данные уже являются обычным текстом, и файл с расширением.xsls (vs .txt) в значительной степени не имеет значения — расширение существует для ассоциации программы / файла.
Другой вариант — посмотреть, может ли другая программа для работы с электронными таблицами (например, Open Office Calc, Kingsoft Office Suite) отображать такое количество строк. YMMV.
1 Не все файлы «.xslx» одинаковы, и Excel довольно снисходительно относится к формату данных, содержащемуся в файлах с таким расширением, которые можно открыть. В этом случае другой человек кажется уверенным, что разумно рассматривать этот файл как необработанный текст — даже если работа с данными, вероятно, будет громоздкой.
Вопрос
Мне дали CSV-файл, содержащий больше, чем MAX Excel может обработать, и мне очень нужно иметь возможность видеть все данные. Я понял и попробовал метод «разделения», но он не работает.
Немного предыстории: CSV-файл — это файл Excel CSV, и человек, который дал файл, сказал, что в нем около `2 млн. строк данных.
Когда я импортирую его в Excel, я получаю данные до строки 1,048,576, затем повторно импортирую его в новой вкладке, начиная со строки 1,048,577 в данных, но это дает мне только одну строку, а я точно знаю, что их должно быть больше (не только из-за того, что «человек» сказал, что их больше 2 миллионов, но и из-за информации в последних нескольких наборах строк).
Я подумал, что, возможно, причина этого в том, что мне предоставили CSV-файл в формате Excel CSV, и поэтому вся информация после 1,048,576 потеряна (?).
Нужно ли мне запрашивать файл в формате базы данных SQL?
42
2013-06-05T16:37:49+00:00
12
![]()
Ответ на вопрос
30-го июня 2013 в 3:23
2013-06-30T15:23:08+00:00
#19566374
Попробуйте delimit, он может быстро открыть до 2 миллиардов строк и 2 миллионов столбцов, есть бесплатная 15-дневная пробная версия. Для меня это отличная работа!
![]()
Ответ на вопрос
30-го апреля 2014 в 9:19
2014-04-30T09:19:24+00:00
#19566377
Я бы предложил загрузить файл .CSV в MS-Access.
Затем в MS-Excel вы можете создать соединение данных с этим источником (без фактической загрузки записей в рабочий лист) и создать подключенную поворотную таблицу. Вы можете иметь практически неограниченное количество строк в таблице (в зависимости от процессора и памяти: у меня сейчас 15 миллионов строк при 3 Гб памяти).
Дополнительным преимуществом является то, что теперь вы можете создавать агрегированные представления в MS-Access. Таким образом, вы можете создавать обзоры из сотен миллионов строк и затем просматривать их в MS-Excel (помните об ограничении в 2 Гб для файлов NTFS в 32-битных ОС).
![]()
Ответ на вопрос
11-го сентября 2013 в 3:39
2013-09-11T15:39:03+00:00
#19566375
Сначала нужно изменить формат файла с csv на txt. Это легко сделать, просто отредактируйте имя файла и измените csv на txt. (Windows выдаст предупреждение о возможном повреждении данных, но все в порядке, просто нажмите OK). Затем сделайте копию txt-файла, чтобы теперь у вас было два файла с 2 миллионами строк данных. Затем откройте первый txt-файл, удалите второй миллион строк и сохраните файл. Затем откройте второй файл txt, удалите первый миллион строк и сохраните файл. Теперь измените оба файла обратно в csv так же, как вы изменили их в txt.
![]()
Ответ на вопрос
5-го июня 2013 в 4:49
2013-06-05T16:49:59+00:00
#19566372
Excel 2007+ ограничен количеством строк, несколько превышающим 1 миллион (2^20, если быть точным), поэтому он никогда не загрузит ваш файл с 2 миллионами строк. Я думаю, что техника, на которую вы ссылаетесь как на разделение, является встроенной в Excel, но afaik она работает только для ширины проблем, а не для длины проблем.
Действительно самый простой способ, который я вижу сразу, это использовать какой-нибудь инструмент для разделения файлов — их там ‘куча и использовать его для загрузки полученных частичных csv файлов в несколько рабочих листов.
ps: «excel csv файлы» не существуют, есть только файлы, создаваемые Excel, которые используют один из форматов, обычно называемых csv файлами…

Simple Text Splitter download | SourceForge.net
Download Simple Text Splitter for free. A very simple text splitter that can split text based files (txt, log, srt etc.) into smaller chunks.
sourceforge.net
Microsoft Support
Microsoft support is here to help you with Microsoft products. Find how-to articles, videos, and training for Office, Windows, Surface, and more.
office.microsoft.com
![]()
Ответ на вопрос
5-го апреля 2016 в 1:15
2016-04-05T13:15:51+00:00
#19566379
Если у вас есть Matlab, вы можете открывать большие файлы CSV (или TXT) через его импорт. Инструмент предоставляет различные параметры формата импорта, включая таблицы, векторы столбцов, числовую матрицу и т. Д. Однако, поскольку Matlab является пакетом интерпретаторов, для импорта такого большого файла требуется свое время, и я смог импортировать его с более чем 2 миллионами строк примерно за 10 минут.
Инструмент доступен через вкладку «Главная» Matlab, нажав кнопку «Импорт данных». Пример изображения большой загрузки файла показан ниже:

После импорта данные отображаются в рабочей области справа, которая затем может быть дважды щелкнута в формате Excel и даже нанесена на график в разных форматах.

![]()
Ответ на вопрос
18-го мая 2018 в 8:20
2018-05-18T20:20:52+00:00
#19566382
Я смог без проблем отредактировать большой файл csv объемом 17 ГБ в Sublime Text (нумерация строк позволяет намного легче отслеживать ручное разделение), а затем свалить его в Excel на куски размером менее 1 048 576 строк. Просто и довольно быстро — менее глупо, чем исследование, установка и обучение индивидуальных решений. Быстро и грязно, но это работает.
![]()
Ответ на вопрос
22-го ноября 2016 в 6:42
2016-11-22T06:42:00+00:00
#19566380
Используйте MS Access. У меня есть файл из 2 673 404 записей. Он не откроется в блокноте ++, и Excel не загрузит более 1 048 576 записей. Он ограничен вкладкой, поскольку я экспортировал данные из базы данных mysql, и они мне нужны в формате csv. Поэтому я импортировал его в Access. Измените расширение файла на .txt, чтобы MS Access провел вас через мастер импорта.
MS Access свяжется с вашим файлом, чтобы база данных оставалась неизменной и сохраняла файл csv
![]()
Ответ на вопрос
4-го сентября 2019 в 5:55
2019-09-04T05:55:25+00:00
#19566383
Я нашел этот предмет исследования.
Существует способ скопировать все эти данные в таблицу данных Excel.
(У меня есть эта проблема раньше с файлом CSV из 50 миллионов строк)
Если есть какой-либо формат, дополнительный код может быть включен.
Попробуй это.
![]()
Ответ на вопрос
5-го мая 2015 в 3:21
2015-05-05T15:21:05+00:00
#19566378
Разделите CSV на два файла в блокноте. Это боль, но после этого вы можете просто редактировать каждый из них по отдельности в Excel.
Похожие сообщества
2

