

HTML Cleaner – сервис очистки html тегов от «мусора», который остается в документе после сохранения страницы в формате html из программы MS Word.

Давным давно я написал подобный плагин, но он был сделан на скорую руку, сейчас механизм полностью переписан.
Очистка кода происходит методом перебора введенной строки из которой формируется новая, содержащая «чистый» код. Плагин удаляет абсолютно все из тегов, в том числе и из тегов html 5. В непарных тегах проставляется символ /(слеш). Удаляются пустые теги, например конструкция <p></p> будет удалена, так как она ничего не содержит.
Как работает html cleaner?
Есть два способа:
- В программе MS Word выберите данные, которые хотите очистить от мусора, чтобы выбрать все, нажмите Ctrl + A. Вставьте скопированный текст в поле ниже(должна быть выбрана вкладка «Вставить данные MS Office»), нажмите кнопку «Готово».
- Перед тем, как оптимизировать код выберите в Word «Сохранить как…», далее укажите Тип файла «Веб-страница с фильтром», затем откройте сохраненный файл в текстовом редакторе, скопируйте код и вставьте в поле ниже(должна быть выбрана вкладка «Вставить HTML»), нажмите кнопку «Готово».
В результате Вы получите девственно чистый html код.
Не тронутыми остаются следующие атрибуты:
colspan, rowspan, href, src, type, value, lang, tabindex, title, code, alt, target, dir, span, action, method, style
Включить форматирование HTML
Не забывайте оставлять свои комментарии, которые помогут мне исправить ошибки или сделать доработки.
Post Views: 109 879
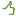 (5)
(5) (2)
(2)
Короткая ссылка на страницу:
-
Метки
clean. word, html, html 5, MS Word, автоматически, код, очистить html от word, чистка
Очистка HTML кода
При помощи нашего сервиса Вы можете конвертировать любой текст из Word в html-разметку, а также добавлять и удалять теги из html-кода. Полученный текст легко использовать для публикации контента в различных CMS. Также Вы можете использовать наш визуальный редактор для моментального просмотра и редактирования.
Описание функционала сервиса HTMLCleanup
Наш сервис позволяет превращать HTML-код в удобный читаемый текст, пригодный для публикации как обычный текстовый документ или при помощи редакторов CMS. Также доступна функция визуального редактирования.
Сервис предоставляет 16 опций очистки, которые могут быть использованы в различных комбинациях друг с другом.
1. Styles — удаление css-стилей для отдельных тегов и всего документа.
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Пример 2:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet
2. Classes and ID’s — удаление css-селекторов классов и Id.
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.Aenean commodo ligula eget dolor.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
Пример 2:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
3. Span tags — удаление всех тегов span.
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
4. Comments — удаление комментариев из html-кода.
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
5. Empty-attributes — удаление пустых селекторов атрибутов.
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
Пример 2:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
6. Empty new lines — удаление пустых строк.
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet
7. Empty tags — удаление пустых тегов.
Пример 1:
Исходный текст:
Text
После обработки:
Text
Пример 2:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Text text.
Text text.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Text text.
Text text.
8. Non-breaking spaces — удаление неразрывных пробелов ( ).
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.Lorem ipsum dolor.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.Lorem ipsum dolor.
9. Links — удаление ссылок (без удаления элементов-привязок).
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Loremipsum dolor sit amet.
Loremipsum dolor sit amet.

После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.

10. Tables — удаление таблиц.
Пример 1:
Исходный текст:
Table1
Table2
| Lorem ipsum | Lorem ipsum2 |
| Ipsum Lorem | Ipsum Lorem2 |
Table3
После обработки:
Table1
Table2
Table3
11. Forms — удаление тегов форм ввода.
Пример 1:
Исходный текст:
Lorem ipsum dolor sit amet.
First name:
Last name:
Aenean commodo ligula eget dolor.
После обработки:
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor./p>
12. Images — удаление изображений.
Пример 1:
Исходный текст:

Text
После обработки:
13. Tags with whitespace — удаление тегов с пробелами.
Пример 1:
Исходный текст:
Text
Text
Text
Text
Text
После обработки:
Text
Text
Text
Text
Text
14. All tag attributes (except href and src) — удаление атрибутов тегов (кроме href и src).
Пример 1:
Исходный текст:
Title
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Text

Lorem ipsum dolor.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
После обработки:
Title
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Text
Lorem ipsum dolor.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
Aenean commodo ligula eget dolor.
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
15. JS code scripts — удаление для js-скриптов.
Пример 1:
Исходный текст:
После обработки:
Пример 2:
Исходный текст:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
После обработки:
Lorem ipsum dolor sit amet.
Lorem ipsum dolor sit amet.
16. All tags — удаление всех html-тегов.
Пример 1:
Исходный текст:
Title
Title of text
1.Lorem ipsum Lorem ipsum.
2.Lorem ipsum dolor sit amet
- Text1
- Text2
- Test1
- Test2
Title of paragraph
3.Lorem ipsum dolor sit amet.
Image
Link image
| Lorem ipsum | Lorem ipsum2 |
| Ipsum Lorem | Ipsum Lorem2 |
4.Lorem ipsum dolor sit amet.
First input name:
Last input name:
После обработки:
Title of text
1.Lorem ipsum Lorem ipsum.
2.Lorem ipsum dolor sit amet.
Text1 Text2 Test1 Test2
Comment
Title of paragraph
3.Lorem ipsum dolor sit amet.
Image
Link image
Table name Lorem ipsum Lorem ipsum2 Ipsum Lorem Ipsum Lorem2
4.Lorem ipsum dolor sit amet.
First input name Last input name
Функция найти и заменить в HTML-коде
Функция позволяет находить и заменять в html-коде текстовые фрагменты и теги на заданные пользователем. Замена срабатывает в html-редакторе, изменения в котором передаются в визуальный редактор.
Политика конфиденциальности
HTMLCleanup использует cookie-файлы для улучшения взаимодействия с пользователями и сбора аналитики по анонимным посетителям. Все пользовательские операции выполняются на стороне клиента и не хранятся на наших серверах. Мы используем Google Analytics для сбора анонимной статистики и Google Adsense для показа персонализированной рекламы.
Когда текст
документа формируется из различных
источников, оформление скомпонованного
документа получается весьма «пестрым».
Кроме того, при копировании фрагментов
интернет-страниц из браузера или
фрагментов текста из других документов,
а так же при сканировании и распознавании
текста в итоговом документе очень часто
помимо различного оформления бывает
еще очень много не к месту использованных
символов оформления.
Для «очистки»
документа от подобного «мусора»
необходимо в первую очередь включить
режим отображения непечатаемых символов.
Этот режим позволяет наглядно видеть
некоторые нюансы оформления документа.
Далее необходимо выполнить следующие
действия, используя инструменты поиска
и замены:
-
Удалить все мягкие
переносы;
Мягкий перенос,
обозначающийся значком ¬, используется
для указания места для разрыва слова
или словосочетания, если оно попадет в
конец строки. Например, можно указать,
что слово «автоформат» должно быть
перенесено как «авто-формат», а не
«автофор-мат». Если слово, в которое
вставлен мягкий перенос, находится не
в конце строки, этот перенос будет виден
только при включенном параметре
Отобразить все знаки. Чтобы создать
мягкий перенос, нужно в нужном месте
нажать сочетание клавиш Cntrl+Дефис.
Главная
задача переноса слов —
эстетическая.
Недостатком мягкого переноса является
его фиксированность, так что при
копировании или форматировании текста
перенос остаётся, хотя данный перенос
может быть уже не нужен.
1.1 Удалить
автоматическую расстановку переносов
На вкладке Разметка
страницы в группе Параметры страницы
нужно выбирать команду Расстановка
переносов, а затем — команду Нет
(Рис. 27).
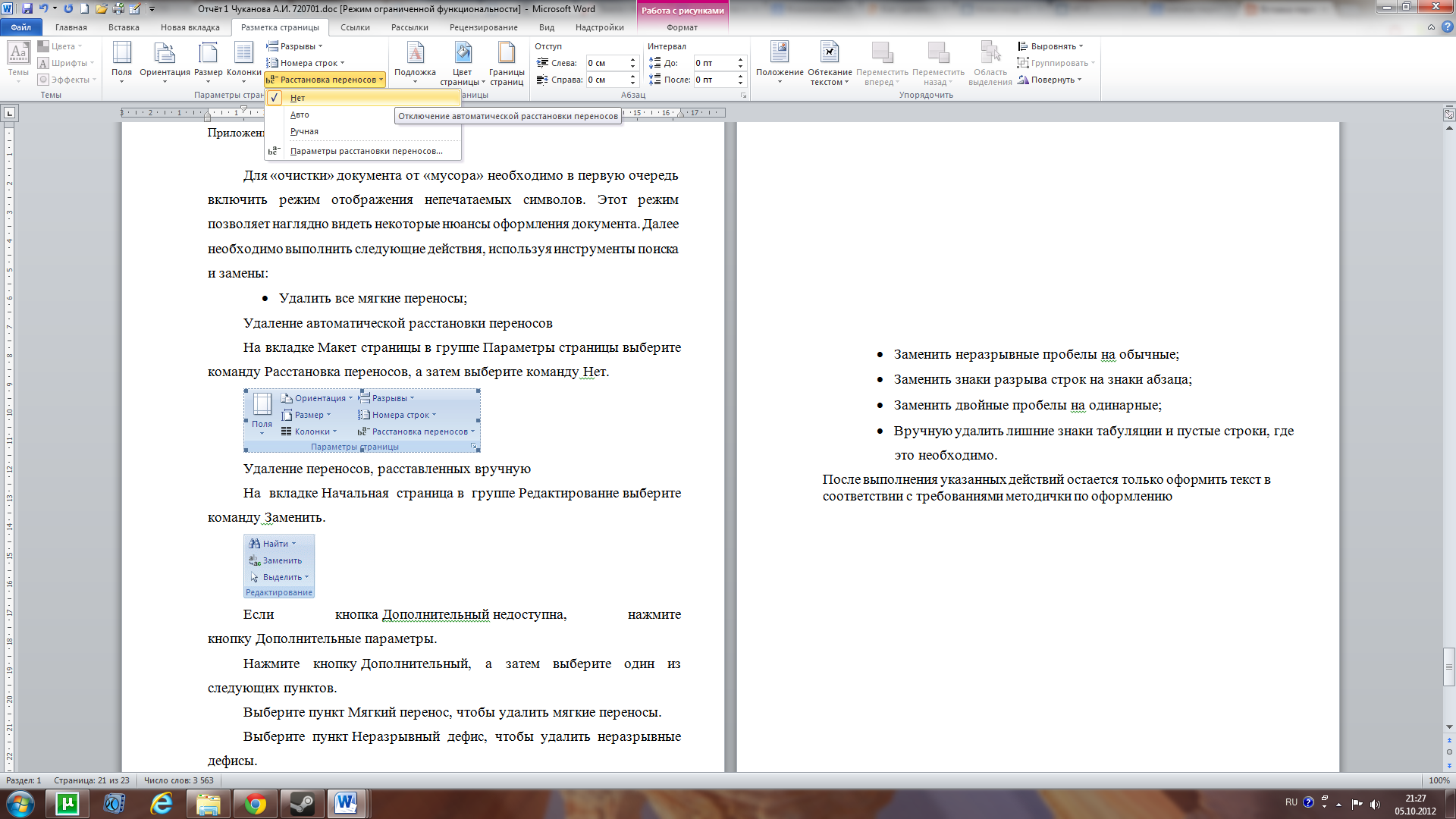
Рис. 27 –
Удаление автоматической расстановки
переносов
в MS Word 2010
1.2 Удалить переносы,
расставленные вручную
На вкладке Начальная
страница в группе Редактирование
нужно выбрать команду Заменить
(Рис. 28).

Рис. 28 —
Удаление переносов, расставленных
вручную
Нажимаем кнопку
Больше, а затем выбираем один из
нужных пунктов (Рис. 29).

Рис. 29 –
Открытие расширенной версии окна Найти
и заменить
Откроем пункт
Специальный (Рис. 30).
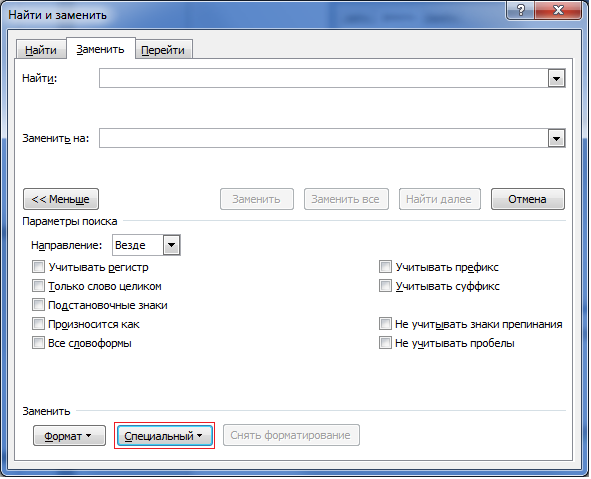
Рис. 30 – Пункт
Специальный
Выберем пункт
Мягкий перенос в поле Найти,
чтобы удалить мягкие переносы (Рис. 31).

Рис. 31 – Мягкий
перенос в поле Найти
Оставим поле
Заменить на пустым (Рис. 32).
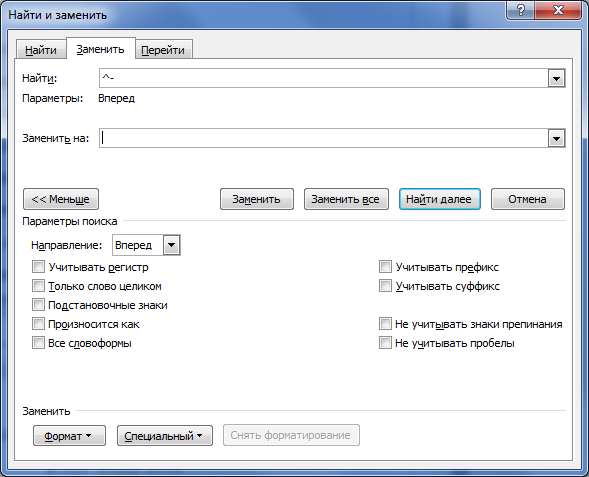
Рис. 32 – Пустое
поле заменить на
Нажмём кнопку
Заменить все.
-
Заменить неразрывные
пробелы на обычные;
При редактировании
документов часто возникают ситуации,
когда разбивается и переносится на
следующую строку информация, которую
по правилам правописания недопустимо
разрывать (инициалы, нумерация, единицы
измерения и т.п.). В этом случае используют
неразрывный пробел, предотвращающий
нежелательные переносы и разрывы строк.
Он ставится
посредством одновременного нажатия
Ctrl + Shift + Space bar (пробел).
Если мы посмотрим
на непечатаемые знаки, то он изображается
в виде маленького кружка:
![]()
Недостаток
неразрывного пробела состоит в том, что
фраза становится единым целым и ни
поддаётся никакому форматированию.
В поле Найти
выберем пункт неразрывные пробелы.
В поле Заменить
на нажмём один раз на пробел.
Нажмём кнопку
Заменить все (Рис. 33).

Рис. 33 — Замена
неразрывных пробелов на обычные
3. Заменить знаки
разрыва строк на знаки абзаца;
При вставке
принудительного разрыва строки текущая
строка обрывается, и текст продолжается
на следующей строке. Предположим,
например, что стиль абзаца включает в
себя отступ перед первой строкой. Чтобы
избежать появления отступа перед
короткими строками текста (например, в
написании адреса или в стихотворении),
каждый раз, когда нужно начать новую
строку, вместо того чтобы нажимать
клавишу Enter, можно вставить
знак разрыва строки (![]()
)
с помощью сочетания клавиш Shift+Enter.
Данный знак неудобен
тем, что при любом форматировании он
оставляет текст «стихотворением».
Заменяя знак
разрыва строки на знак абзаца (¶) (
вызывается клавишей Enter),
можно привести текст к нормальному
виду.
В поле Найти
выберем пункт разрыв строки.
В поле Заменить
на выберем пункт знак абзаца.
Нажмём кнопку
Заменить все (Рис. 34).

Рис. 34 — Замена
знаков разрыва строк на знаки абзаца
4. Заменить двойные
пробелы на одинарные;
Двойной пробел в
MS Word не
имеет смысла, так как редактор регулирует
длину пробела самостоятельно, если
выбрано выравнивание по ширине.
Знак пробела
обозначается в виде ·.
В поле Найти
вводим двойной пробел, в поле Заменить
на одиночный пробел.
Нажмём кнопку
Заменить все (Рис. 35).

Рис. 35 — Замена
двойных пробелов на одинарные
Важно! Необходимо
проводить замену до тех пор, пока Word
не сообщит, что число выполненных замен
равно 0. Так же необходимо проверять,
чтобы в полях Найти и Заменить на
действительно были два и один пробел
соответственно.
5. Вручную удалить
лишние знаки табуляции и пустые строки,
где это необходимо.
Нажатие клавиши
Tab при вводе текста перемещает курсор
ввода и следующий за ним текст на новую
позицию табулятора. Выравнивание текста
соответствует виду данного табулятора.
В тексте появляется непечатаемый символ
табуляции →, который отмечает место
нажатия клавиши Tab.
Ранее знаки
табуляции использовали для упрощения
форматирования документа (отступа на
первой строке к примеру) и создания
таблиц, но начиная с Word
2003 табуляцию в основном используют при
нумерации.
Пустые строки для
визуального выделения частей текста,
но при неправильном применении они
могут превратить текст в набор строк.
Необходимо вручную
удалять лишние знаки табуляции и пустые
строки, так как полное удаление данных
знаков нанесёт не меньший вред тексту,
чем наличие лишних знаков.
После
выполнения указанных действий остается
только оформить текст в соответствии
с требованиями методички по оформлению
[1].
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
-

-
September 26 2009, 12:05
- IT
- Cancel
Как вы знаете, от современного письменного переводчика все чаще и чаще требуется выполнение работ с использованием различных CAT-программ. Нередко бюро переводов требуют сдачи работы в неочищенном виде (билингв со скрытой разметкой, uncleaned file) и в очищенном виде (монолингв, т.е. без разметки, чистый перевод, cleaned file). Как показывает практика, подготовка очищенного варианта работы вызывает у переводчиков затруднения.
MS Word дает возможность получения работ в двух из этих видах. Ниже привожу скриншот неочищенного файла и очищенного. Обращаю ваше внимание, что для отображения разметки в неочищенном файле необходимо включить функцию «Отображение скрытого текста» (значок ¶).
Неочищенный текст:

Соответственно очищенный вариант данного фрагмента будет:
Итак, для подготовки очищенного варианта используются три способа.
I. Стандартный: Очистка с помощью Trados Workbench
Порядок действий:
— запускаем Trados Workbench;
— запускаем модуль очистки через Tools>Clean Up…;

— в диалоговом окне выбираем файл(ы) для очистки, устанавливаем необходимые опции (напр. добавить очищенные сегменты в базу данных — Update TM), и нажимаем Clean Up;

— в результате получаем очищенный файл с расширением DOC, старую версию файла, сохраненную с расширением bak, и обновленную базу переводов (Translation Memory).
II. Обходной: Очистка с помощью макроса Trados Workbench
— запускаем MS Word;
— вызываем перечень макросов через Сервис>Макрос>Макросы (комбинация клавиш ALT + F8);
— выбираем макрос под названием tw4winClean.Main и жмем кнопку «Выполнить»;
— через пару секунд получаем очищенный файл (желательно его сохранить под другим именем).

III. Против лома нет приема!
— запускаем MS Word;
— вызываем диалоговое окно «Найти и заменить» (комбинация клавиш CTRL + H);

— в диалоговом окне нажимаем кнопку «Больше» — получаем две дополнительные кнопки «Формат» и «Специальный»;

— устанавливаем курсор в поле «Найти»
— выбираем «Формат» > «Шрифт…», в открывшемся диалоговом окне устанавливаем флажок «Скрытый», жмем «ОК»

— выбираем «Специальный» > «Любой знак»;
— получается в итоге следующее диалоговое окно, в котором остается нажать только «Заменить все».
Надеюсь, эти способы помогут вам избежать любых затруднений при очистке даже самых сложных и «глюкавых» файлов.
Страницы 1
Чтобы отправить ответ, вы должны войти или зарегистрироваться
1 31.03.2015 17:05:30
- карандаш
- сержант
- Неактивен
- Зарегистрирован: 12.03.2015
- Сообщений: 22
- Поблагодарили: 5
Тема: обработка абзацев (чистка от мусора и форматирование)
приходится править несколько документов (типа договора) каждый день
хотелось бы автоматизировать
прошу помочь преобразовать алгоритм в работоспособный макрос
Суть обработки:
нумерация пунктов, подпунктов, подподрунктов проставлена вручную + отбивка отступа делается пробелами (или табуляцией)
необходимо убрать мусор и отформатировать абзацы
Алгоритм макроса рассчитан на обработку одного абзаца (где стоит курсор).
Обработка по замыслу должна заключаться в клике мышкой по нужному абзацу и нажатием клавиш, вызывающих макрос
попытка описания алгоритма:
Dim Flag_Number, Count_Simbol, Count_Level
Flag_Number = false // флаг чисел
Count_Simbol = 0 // счетчик символов
Count_Level = 0 // счетчик уровня
Selection.HomeKey Unit:=wdStory // указатель в начало абзаца
If "Кол-во_символов_в_параграфе" < 3 then GoTo Last // не нуждается в обработке
For ... // Цикл для каждого знака текущего параграфа
If Символ(i)<>[#, ".", " ", Tab] then GoTo LastOp // ВыходИзЦикла
Inc(Count_Simbol)
If Символ(i) = "#" then
If Flag_Number = False then
Flag_Number = True
Inc(Count_Level)
Next // в начало цикла
End If
Else If Символ(i) = "." then
Flag_Number = false
End If
End For
LastOp:
If Count_Simbol > 0 then Удалить первые символы в кол-ве Count_Simbol
If Count_Level = 0 then Применить_Стиль "Обычный"
If Count_Level = 1 then Применить_Стиль "Раздел 1"
If Count_Level = 2 then Применить_Стиль "Раздел 2"
If Count_Level = 3 then Применить_Стиль "Раздел 3"2 Ответ от Александр Б. 01.04.2015 18:55:16
- Александр Б.
- генерал-майор
- Неактивен
- Откуда: Москва
- Зарегистрирован: 16.02.2013
- Сообщений: 275
- Поблагодарили: 60
Re: обработка абзацев (чистка от мусора и форматирование)
Немного не по теме, но вот:
Удаление лишних пробелов в тексте документа
http://wordexpert.ru/page/udalenie-lish … -dokumenta
Мой шаблон/макросы для автоматической нумерации Word 2003, 2007, 2010 и т.д. (стили, названия, перекрестные ссылки, LISTNUM). Делюсь: http://vk.com/club_alex_bir
3 Ответ от карандаш 02.04.2015 09:36:32
- карандаш
- сержант
- Неактивен
- Зарегистрирован: 12.03.2015
- Сообщений: 22
- Поблагодарили: 5
Re: обработка абзацев (чистка от мусора и форматирование)
к сожалению, это совсем не по теме, увы (((
таких макросов у меня куча. И они хорошо работают (удаления общего мусора типа множественных пробелов, выравнивание тире и прочее)
интересует конкретно правильное оформление (нотификация) в VBA циклов и прочее, что отвечает за «точечную» правку именно вплоть до символов.
4 Ответ от Александр Б. 02.04.2015 23:01:38
- Александр Б.
- генерал-майор
- Неактивен
- Откуда: Москва
- Зарегистрирован: 16.02.2013
- Сообщений: 275
- Поблагодарили: 60
- За сообщение: 1
Re: обработка абзацев (чистка от мусора и форматирование)
Вы когда копируете макросы, включите русскую раскладку клавиатуры, чтобы не было абракадабры вместо русских комментариев.
Мой шаблон/макросы для автоматической нумерации Word 2003, 2007, 2010 и т.д. (стили, названия, перекрестные ссылки, LISTNUM). Делюсь: http://vk.com/club_alex_bir
5 Ответ от Alex_Gur 03.04.2015 09:25:10
")
- Alex_Gur
- Модератор
- Неактивен
- Откуда: Москва
- Зарегистрирован: 28.07.2011
- Сообщений: 2,758
- Поблагодарили: 492
- За сообщение: 2
Re: обработка абзацев (чистка от мусора и форматирование)
Александр Б. пишет:
Вы когда копируете макросы, включите русскую раскладку клавиатуры, чтобы не было абракадабры вместо русских комментариев.
Исправил абракадабру. ![]()
Удобной и приятной работы в Word!
Перевести спасибо на Яндекс кошелёк — 41001162202962; на WebMoney — R581830807057.
6 Ответ от карандаш 03.04.2015 11:47:59
- карандаш
- сержант
- Неактивен
- Зарегистрирован: 12.03.2015
- Сообщений: 22
- Поблагодарили: 5
Re: обработка абзацев (чистка от мусора и форматирование)
Александру: спасибо. Никак не мог вспомнить как избавиться от абракадабры.
Sub DelSpace()
' DelSpace Макрос
'
' УДАЛЯЕМ лишние пробелы (заменяем 2 и более пробелов одним)
'
Selection.WholeStory
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = " {2;}"
.Replacement.Text = " "
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchAllWordForms = False
.MatchWildcards = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.MoveRight Unit:=wdCharacter, Count:=1
'
'УДАЛЯЕМ пробел ПЕРЕД знаками пунктуации, ), % и концом абзаца
'
Selection.WholeStory
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = " {1;}([.,:;!?%)^0013])"
.Replacement.Text = "1"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.MoveLeft Unit:=wdCharacter, Count:=1
'
'УДАЛЯЕМ пробел ПОСЛЕ "(" и в начале абзаца (кроме первого)
'
Selection.WholeStory
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "([(^0013])^0032"
.Replacement.Text = "1"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.MoveLeft Unit:=wdCharacter, Count:=1
'
'ВСТАВЛЯЕМ пробел ПОСЛЕ знаков пунктуации, % и ), если после них нет пробела, цифры или конца абзаца
'
Selection.WholeStory
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "([.,:;!?)%])([!^0032^00130123456789])"
.Replacement.Text = "1^00322"
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.MoveLeft Unit:=wdCharacter, Count:=1
'
'ВСТАВЛЯЕМ пробел ПЕРЕД "(", если это не начало абзаца
'
Selection.WholeStory
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = "([!^0032^0013])("
.Replacement.Text = "1 ("
.Forward = True
.Wrap = wdFindContinue
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchAllWordForms = False
.MatchSoundsLike = False
.MatchWildcards = True
End With
Selection.Find.Execute Replace:=wdReplaceAll
Selection.MoveLeft Unit:=wdCharacter, Count:=1
End Sub7 Ответ от карандаш 03.04.2015 11:58:06
- карандаш
- сержант
- Неактивен
- Зарегистрирован: 12.03.2015
- Сообщений: 22
- Поблагодарили: 5
Re: обработка абзацев (чистка от мусора и форматирование)
просьба подсказать как указывается путь к стандартной почти системной папке.
Например, «Документы», «Видео» и прочее в VBA
если винда установлена, например на диске d: или папок несколько (если несколько пользователей), то существует способ записи через %
что-то типа %username% или %App…%
система тогда обращается к реестру и от туда вытягивает «абсолютный» путь
А как этот путь выглядит в «относительном» исполнении?
Это чтобы макрос с указанием пути был универсален для любого пользователя.
8 Ответ от Александр Б. 03.04.2015 19:10:50
- Александр Б.
- генерал-майор
- Неактивен
- Откуда: Москва
- Зарегистрирован: 16.02.2013
- Сообщений: 275
- Поблагодарили: 60
Re: обработка абзацев (чистка от мусора и форматирование)
Alex_Gur пишет:
Исправил абракадабру.
Я тоже хочу так научится…
карандаш пишет:
просьба подсказать как указывается путь
Я ответил в другой теме, потому что эта тема посвящена другому вопросу. Хотя, и та другая тема тоже была посвящена другому вопросу. Мне не нравится, что вы задаете свои вопросы где хотите, выходя за рамки тем. Я, если честно, вообще за жесткую модерацию, поскольку это форум, где люди ищут информацию, а не чат какой-нибудь.
В этой теме я выложу макрос для очистки одного или нескольких выделенных абзацев от мусора, на основе ваших наработок.
Мой шаблон/макросы для автоматической нумерации Word 2003, 2007, 2010 и т.д. (стили, названия, перекрестные ссылки, LISTNUM). Делюсь: http://vk.com/club_alex_bir
9 Ответ от Alex_Gur 03.04.2015 20:53:22
- Alex_Gur
- Модератор
- Неактивен
- Откуда: Москва
- Зарегистрирован: 28.07.2011
- Сообщений: 2,758
- Поблагодарили: 492
Re: обработка абзацев (чистка от мусора и форматирование)
Александр Б. пишет:
Alex_Gur пишет:
Исправил абракадабру.
Я тоже хочу так научится…
Я использовал Декодер Артемия Лебедева:
внешняя ссылка
Александр Б. пишет:
Мне не нравится, что вы задаете свои вопросы где хотите, выходя за рамки тем. Я, если честно, вообще за жесткую модерацию, поскольку это форум, где люди ищут информацию, а не чат какой-нибудь.
Александр, насколько я знаю, на этом сайте не принята жесткая модерация.
Главное, чтобы обсужение относилось к Word и к Office, а не к чему-то другому.
Вопросы, не относящиеся к этим темам, обычно удалаются, а их авторы — «банятся».
Здесь же обсуждение идет по «профильному» вопросу.
Если же Вы считаете это принципиальным, то можете предложить пользователю создать новую ветку. Или дайте ссылку на ту ветку, где этот вопрос рассматривался.
Удобной и приятной работы в Word!
Перевести спасибо на Яндекс кошелёк — 41001162202962; на WebMoney — R581830807057.
10 Ответ от Александр Б. 04.04.2015 12:21:18
- Александр Б.
- генерал-майор
- Неактивен
- Откуда: Москва
- Зарегистрирован: 16.02.2013
- Сообщений: 275
- Поблагодарили: 60
Re: обработка абзацев (чистка от мусора и форматирование)
Ниже приведен макрос для очистки от мусора выделенного текста. Ниже даны три процедуры. Лучше их засунуть в отдельный модуль.
Выделяете фрагмент текста и запускаете процедуру X_TempMacro.
Основная неприятность с заменами заключается в том, что после точки не всегда нужно вставлять пробел. Поэтому в конец процедуры WildcardsReplaceProcedures нужно добавить исключения, вроде таких:
Call ReplaceSomeText("([Тт].)[^0032^s](к.)", "12") 'заменить "т. к." на "т.к."Когда наберется несколько исключений, скажем, пять-десять, можно их в этой теме сообщить, и они будут учтены.
Я немного изменил поисковые слова Карандаша; в комментариях это описано. В дальнейшем этот макрос будет доделан в части обработки начал абзацев.
Sub WildcardsReplaceProcedures()
'Несколько процедур поиска и замены с использованием подстановочных знаков
' 1) Ищем два и более пробелов подряд " {2;}" и заменяем на пробел " " (пробел можно записать как " " или "^0032").
Call ReplaceSomeText("^0032{2;}", "^0032") '
'Примечание - Искомый символ (пробел) задан перед фигурной скобкой, точка с запятой означает "и более" _
Точка с запятой в операторах {n;} и {n;m} — это не просто точка с запятой, а так называемый List separator _
(Разделитель элементов списка). В США это запятая, в России — точка с запятой. _
Чтобы узнать, какой символ играет роль разделителя элементов списка в вашей конфигурации, _
загляните в Control Panel | Regional Settings | Numbers | List separator _
(Панель управления | Язык и стандарты | Числа | Разделитель элементов списка).
' 2) Удаляем один и более пробелов ПЕРЕД знаками пунктуации, перед символами ")", "%" и перед концом абзаца.
Call ReplaceSomeText(" {1;}([.,:;!?%)^0013])", "1")
'Примечание - Квадратные скобки означают ИЛИ, т.е. ищется любой из символов в кв. скобках. _
Единица "1" означает порядковый номер выражения _
(выражение это то, что заключается в круглые скобки; здесь выражение одно). _
^0013 это знак абзаца (код ASCII). _
Вместо ) можно было бы написать просто курглую скобку ), в этом случае тоже работает.
' 3) Удаляем пробел ПОСЛЕ символа "(".
Call ReplaceSomeText("( ", "(")
'Внимание - Здесь я не хочу удалять пробел в начале абзаца, что записывается так: _
.Text = "([(^0013])^0032" _
.Replacement.Text = "1" _
Это удалило бы пробел в начале абзацев, кроме первого. _
Причина в том, что я прочитал в интеренете следующее сообщение: _
"...впечатываем в поле "Найти" ^0013^0032{1;} в поле "Заменить на" ^0013 и в результате _
удаляется любое количество пробелов в начале абзаца. _
Но есть одна проблема: если к абзацам применены разные стили, то стиль предшествующего абзаца _
заменяется на стиль последующего." _
Пробел в начале абзацев я удалю другими способами (кстати, в начале абзаца может потребоваться удалить _
не только пробел, но и, например, "жесткий" номер заголовка 1.1.1 и табуляцию).
' 4) Вставляем пробел ПОСЛЕ знаков пунктуации и после ")", "%", если после них нет пробела, НЕРАЗРЫВНОГО_ПРОБЕЛА, _
цифры или конца абзаца
''' Call ReplaceSomeText("([.,:;!?)%])([!^0032^00130123456789])", "1^00322") 'вариант Карандаша
Call ReplaceSomeText("([.,:;!?)%])([!^0032^s^00130-9])", "1^00322") 'мой вариант с неразрывным пробелом ^s
'Внимание - Вставка пробела после точки не всегда нужна. Например: _
"т.е." заменяется на "т. е.", _
"т.к." на "т. к.", _
"А.А. Бирюков" на "А. А. Бирюков" _
Поэтому далее нужно удалить лишние вставленные пробелы _
(либо, как вариант, можно просто убрать точку из квадратных скобок в текущей процедуре).
' 5) Вставляем пробел ПЕРЕД скобкой "(", если перед ней нет пробела ^0032 или неразрывного пробела ^s
Call ReplaceSomeText("([!^0032^s])(", "1 (")
' Примечание - Восклицательный знак в [!^0032^s] означает, что символ не является пробелом или _
неразрывным пробелом _
' Круглые скобки (выражение) тут обязательно нужны, чтобы не удалять символ найденный слева от "("
'''''''' Начало процедур удаления лишних вставленных пробелов
' Заменить выражение типа "А. А. Бирюков" на "А.А.^sБирюков" _
(между буквами может быть пробел ^0032 или неразрывный пробел ^s)
Call ReplaceSomeText("([А-ЯЁ].)[^0032^s]([А-ЯЁ].)[^0032^s]([А-ЯЁ])", "12^s3")
Call ReplaceSomeText("([Тт].)[^0032^s](к.)", "12") 'заменить "т. к." на "т.к."
Call ReplaceSomeText("([Тт].)[^0032^s](е.)", "12") 'заменить "т. е." на "т.е."
Call ReplaceSomeText("())[^0032^s](.)", "12") 'заменить ") ." на ")."
' *** ДОБАВЬТЕ ДОПОЛНИТЕЛЬНЫЕ ПРОЦЕДУРЫ ReplaceSomeText ДЛЯ ИСПРАВЛЕНИЯ ВСЕХ ИСКЛЮЧЕНИЙ ***
'''''''' Конец процедур удаления лишних вставленных пробелов
End Sub
Sub ReplaceSomeText(s1 As String, s2 As String, Optional blnWildcards As Boolean = True)
'Найти и заменить некий текст
'Ищет в текущем выделении фрагменты текста s1 и заменяет их на s2
'blnWildcards - необязательный агрумент, если не указан, то равен True, и подстановочные знаки включены.
Selection.Find.ClearFormatting
Selection.Find.Replacement.ClearFormatting
With Selection.Find
.Text = s1 'искомый текст
.Replacement.Text = s2 'текст для замены
.Forward = True
.Wrap = wdFindStop 'в конце останавливаем поиск без переспросов
.Format = False
.MatchCase = False
.MatchWholeWord = False
.MatchAllWordForms = False
.MatchWildcards = blnWildcards 'подстановочные знаки включены (True) или отключены (False)
End With
Selection.Find.Execute Replace:=wdReplaceAll
End Sub
Sub X_TempMacro()
' Очистка выделенного текста от "мусора"
Dim x1, x2
x1 = Selection.Range.Start 'левая граница выделения
x2 = Selection.Range.End 'правая граница выделения
If x1 = x2 Then Exit Sub 'если границы совпадают, то завершаем процедуру _
(это защита от дурака, чтобы случайно не очистить весь документ целиком)
Application.ScreenUpdating = False 'отключаем обновление экрана _
(для увеличения скорости выполнения замен)
'Несколько процедур поиска и замены, с использованием подстановочных знаков
Call WildcardsReplaceProcedures
Application.ScreenUpdating = True 'включаем обновление экрана
' *** НИЖЕ ДОБАВЛЮ ПРОЦЕДУРУ ОБРАБОТКИ НАЧАЛ АБЗАЦЕВ ***
''переходим в начало абзаца
'Dim oRng As Range
' Set oRng = Selection.Paragraphs(1).Range
' oRng.Collapse wdCollapseStart
' oRng.Select
'
''выделяем один символ в начале абзаца
' Selection.MoveRight Unit:=wdCharacter, Count:=1, Extend:=wdExtend
' If Selection.Text = " " Then
' Selection.Delete Unit:=wdCharacter, Count:=1 'если это пробел, то удаляем
' Else
' Selection.MoveLeft Unit:=wdCharacter, Count:=1 'иначе, влево на один
' End If
End SubМой шаблон/макросы для автоматической нумерации Word 2003, 2007, 2010 и т.д. (стили, названия, перекрестные ссылки, LISTNUM). Делюсь: http://vk.com/club_alex_bir
11 Ответ от Александр Б. 04.04.2015 15:03:51
- Александр Б.
- генерал-майор
- Неактивен
- Откуда: Москва
- Зарегистрирован: 16.02.2013
- Сообщений: 275
- Поблагодарили: 60
Re: обработка абзацев (чистка от мусора и форматирование)
Возможно, я ошибся, и правильно писать «т. е.«, а не «т.е.», но все равно в некоторых случаях вставляется лишний пробел (как, например, в конце этого предложения) .
Мой шаблон/макросы для автоматической нумерации Word 2003, 2007, 2010 и т.д. (стили, названия, перекрестные ссылки, LISTNUM). Делюсь: http://vk.com/club_alex_bir
12 Ответ от Настаев 13.04.2015 02:36:25
- Настаев
- подполковник
- Неактивен
- Зарегистрирован: 14.07.2011
- Сообщений: 176
- Поблагодарили: 54
Re: обработка абзацев (чистка от мусора и форматирование)
Вот вам готовый цикл по всем спискам в документе. Если надо только для выделения, измените в коде ActiveDocument на Selection.
Обратите внимание на то, что я в код прописал настройку шрифта и настройку параграфа (предположил, что у вас сканированные тексты ![]() )
)
На счёт превращения списков, написанных вручную в автоматизированные — это другая тема. Как по мне, то не стоит это автоматизировать.
Public Const отступ As Single = 0.95
Sub Вычитка_списков()
Dim j As Object
Dim p As Object
Dim i, i2 As Integer 'только для строки состояния
'запоминаем количество списков в документе
i2 = Application.ActiveDocument.Lists.Count
'для каждого списка
For Each j In Application.ActiveDocument.Lists
'счётчик
i += 1
'строка состояния
Application.StatusBar = "Вычитка списков: " & i & " из " & i2
'для каждого элемента списка
For Each p In j.ListParagraphs
'выделить маркировку
p.Range.Paragraphs(1).SelectNumber()
'настройка шрифта
With Application.Selection.Font
.Size = 14
.Name = "Times New Roman"
.Bold = False
End With
Next p
'настройка параграфа
With j.Range.ParagraphFormat
'выступ
.LeftIndent = Application.CentimetersToPoints(отступ)
'отступ
.FirstLineIndent = Application.CentimetersToPoints(-отступ)
'правый выступ
.RightIndent = Application.CentimetersToPoints(0)
'табулятор
.TabStops.ClearAll() 'если в обрабатываемом списке табуляторы имеют разные значения, возникает ошибка. Поэтому я их удаляю, чтобы задать заново единое значение.
.TabStops(Application.CentimetersToPoints(отступ)).Position = Application.CentimetersToPoints(отступ)
End With
Next j
End Sub13 Ответ от карандаш 14.04.2015 01:30:35
- карандаш
- сержант
- Неактивен
- Зарегистрирован: 12.03.2015
- Сообщений: 22
- Поблагодарили: 5
- За сообщение: 2
Re: обработка абзацев (чистка от мусора и форматирование)
может пригодится: Автоматизация перенумерования абзацев
Макрос форматирует текущий абзац (абзац, на котором стоит указатель) одним из 4-х видов стилей: обычный абзац (стиль .стандартный), абзац с многоуровневой нумерацией (от 1-го до 3-го уровня). Автоматически обнаруживает каким стилем форматировать текущий абзац по одному из признаков: — к абзацу уже применена нуменрация уровня от 1 до 3- в начале абзаца имеются числа с точками. Кол-во сочетаний цифры-точки определяет уровень. Последней точки может не быть. Кол-во пробелов и табуляций в начале абзаца роли не играет.- не обнаружив ничего из вышеописанного применяется стиль «.стандартный»Кол-во уровней можно легко увеличить, дописав соответственные строки в макросе.
Sub LoadTemplate()
ActiveDocument.CopyStylesFromTemplate (Environ("HOMEPATH") & "Documents!СтилиДоговора1.docx")
End Sub
Sub reNumber()
'
'проверка отсутствие выделения
If Selection.Type <> 1 Then
MsgBox "Просто установите курсор внутри абзаца, который хотите преобразовать", 64
Exit Sub
End If
'
'проверка наличия нужных стилей (чтобы не было ошибки применения несуществующего стиля)
Dim p As Style, MyStyleIs As Boolean
MyStyleIs = False
For i = 1 To ActiveDocument.Styles.Count ' так почему-то быстрее, чем с конца
Set p = ActiveDocument.Styles(i)
If Left$(p.NameLocal, 1) = "." Then
MyStyleIs = True
Exit For
End If
Next i
If Not MyStyleIs Then LoadTemplate ' загрузка стилей, если они не нашлись
'
' если уже есть нумерация многоуровневыми стилями
If Selection.Range.ListFormat.ListType = wdListOutlineNumbering Then
Lev = Selection.Range.ListFormat.ListLevelNumber
Selection.Expand wdParagraph
Select Case Lev
Case 1
Selection.Style = ActiveDocument.Styles(".Раздел 1")
Case 2
Selection.Style = ActiveDocument.Styles(".Раздел 2")
Case 3
Selection.Style = ActiveDocument.Styles(".Раздел 3")
End Select
Selection.Collapse
Selection.MoveDown Unit:=wdParagraph, Count:=1
Exit Sub
End If
'
' если обычный текст с/без нумерации в начале абзаца вручную
Dim ch As String, Flag_Number As Boolean, Count_Level, Count_Simbol As Integer, r
Flag_Number = False
Count_Level = 0
Count_Simbol = 0
With Selection
.StartOf Unit:=wdParagraph, Extend:=wdMove
.Expand wdParagraph
n = .Characters.Count
For i = 1 To n
ch = .Characters(i)
If (ch Like "[!0-9. ]") And (ch <> Chr(9)) Then Exit For
Count_Simbol = Count_Simbol + 1
If ch Like "[0-9]" Then
If Flag_Number = False Then
Flag_Number = True
Count_Level = Count_Level + 1
'Next '// в начало цикла
End If
ElseIf ch = "." Then
Flag_Number = False
End If
Next i
End With
Selection.End = Selection.Start + Count_Simbol
If Count_Simbol > 0 Then Selection.Delete
Selection.Expand wdParagraph
Select Case Count_Level
Case 0
Selection.Style = ActiveDocument.Styles(".стандартный")
Case 1
Selection.Style = ActiveDocument.Styles(".Раздел 1")
Case 2
Selection.Style = ActiveDocument.Styles(".Раздел 2")
Case 3
Selection.Style = ActiveDocument.Styles(".Раздел 3")
End Select
'Selection.Collapse
Selection.MoveDown Unit:=wdParagraph, Count:=1 ' автоматически переходим к следующему абзацу (чтобы не надо было жать Ctrl+СтрелкаВниз)
End SubСтраницы 1
Чтобы отправить ответ, вы должны войти или зарегистрироваться