
Чуднова Ольга Владимировна
Сахалинский государственный университет
старший преподаватель кафедры социологии
Аннотация
Статья посвящена описанию процесса обработки первичной социологической информации, получаемой в ходе интервью, анкетирования и иных количественных методов с помощью прикладной компьютерной программы Microsoft Office Excel. Проведенный анализ позволяет утверждать, что высокая адаптивность и простота работы с данным программным обеспечением позволяет решать множество разнообразных задач, необходимых для социолога-практика.
Chudnova Olga Vladimirovna
Sakhalin State University
Senior Lecturer, Sociology Department
Abstract
The article describes processing of primary sociological information obtained through interviews, questionnaires and other quantitative methods using Microsoft Office Excel application. Performed analysis allows to state that high adaptability and ease of use of this software enable to solve a wide variety of Sociological Practitioner’s tasks.
Библиографическая ссылка на статью:
Чуднова О.В. Алгоритм базового анализа данных социологического опроса в программе MS Excel // Современные научные исследования и инновации. 2015. № 4. Ч. 5 [Электронный ресурс]. URL: https://web.snauka.ru/issues/2015/04/45596 (дата обращения: 07.04.2023).
В ходе проведения массовых социологических опросов перед исследователями нередко возникает проблема, связанная с обработкой больших совокупностей полученных данных и их преобразованием из рукописного вида в электронный, машиночитаемый формат.
К сожалению, практически все специализированные программы для обработки социологической информации (SPSS, Statistica, Vortex, PolyAnalyst и др.) распространяются на коммерческой основе, предъявляют серьезные требования к техническим характеристикам персональных компьютеров и зачастую не имеют русифицированного файла помощи.
В связи с этим возрастает необходимость обращения к программному обеспечению, имеющемуся на большинстве современных ЭВМ и позволяющему решать различные задачи необходимые социологу-практику. Одной из таковых программ является Microsoft Office Excel (Excel).
Обработка первичной социологической информации полученной в ходе опроса происходит в Excel в несколько этапов.На первом этапе необходимо пронумеровать все анкеты подлежащие анализу, для постоянного контроля ввода данных и возможности их своевременного корректирования. Далее необходимо «закрыть» все открытые вопросы анкеты, объединив ответы респондентов в группы [1, с. 434-437].Так, при ответе на открытый вопрос «Сколько лет Вы трудитесь в вузе?» человек может указать точный стаж, который социолог для удобства анализа отнесет в группы: «менее 5 лет», «5-10 лет», «11-16 лет», «17-22 года», «23 и более лет» (рис.1, вопрос 1).
Рис. 1 Фрагмент анкеты
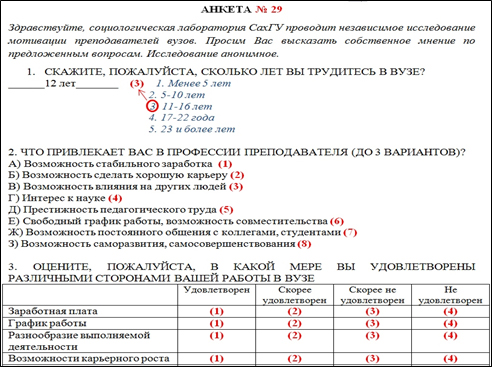
Когда все открытые вопросы анкеты приведены в «закрытый» вид, следует присвоить числовой код каждому варианту ответа в каждом вопросе, то есть закодировать его. Если вопрос задан в виде таблицы (рис 1, вопрос 3), то при его анализе необходимо каждую строку ответа кодировать как отдельный вопрос. Ведь, по сути, каждый вопрос таблицы задается респонденту как отдельный: «Насколько Вы удовлетворены заработной платой?», «Насколько Вы удовлетворены графиком работы?» и т.д. Если же респондент пропустил вопрос или не смог ответить на него, то код отсутствию ответа не присваивается.
На втором этапе происходит формирование базы данных социологического опроса в Excel.
В первый столбец матрицы необходимо внести номера анкет, а в первую строку – краткие формулировки вопросов или их номера. Таким образом, каждой строке матрицы соответствует одна анкета, а каждому столбцу – один вопрос или подвопрос (рис. 2).
Рис. 2. Фрагмент базы данных социологического опроса в Excel
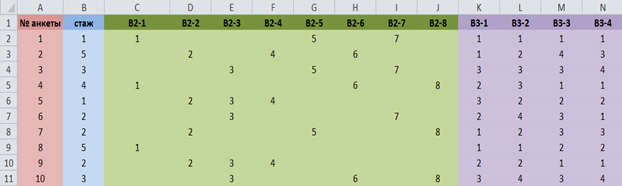
Поскольку во втором вопросе анкеты (рис.1) респондент может выбрать несколько вариантов, вопрос необходимо разбить на колонки по числу вариантов ответа (подвопросы).
При обработке вопроса заданного в виде таблицы, следует разбивать его на подвопросы по количеству строк.
Затем в матрицу вносятся данные всех анкет в соответствии с ранее произведенным кодированием.
Таким образом, согласно нашей матрице, респондент заполнивший анкету № 2, имеющий стаж работы более 23 лет, выбрал в качестве ответов на второй вопрос варианты №2, 4, 6 (возможность сделать хорошую карьеру, интерес к науке, свободный график работы и возможность совместительства). Он же удовлетворен заработной платой; скорее удовлетворен графиком работы; не удовлетворен разнообразием выполняемой деятельности; скорее не удовлетворен возможностями карьерного роста.
Для удобства формирования базы данных социологического опроса рекомендуется закреплять первую строку матрицы (вкладка «Вид» → «Закрепить области» → «Закрепить верхнюю строку») (рис. 3), что позволит всегда видеть заголовок таблицы.
Рис. 3 Матрица данных с закрепленным заголовком
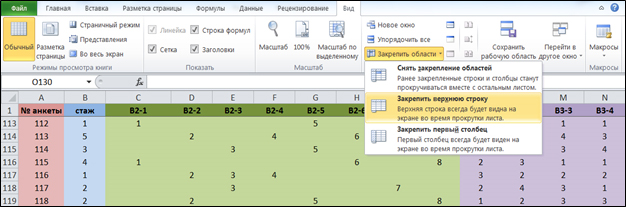
Кроме того, если в анкете присутствует значительное количество вопросов, требующих разбивки в матрице данных, эти вопросы желательно выделять одним цветом (щелчок левой кнопкой мыши по столбцу выделяет его, далее во вкладке «Главная» выбираем «Заливка» и необходимый цвет).
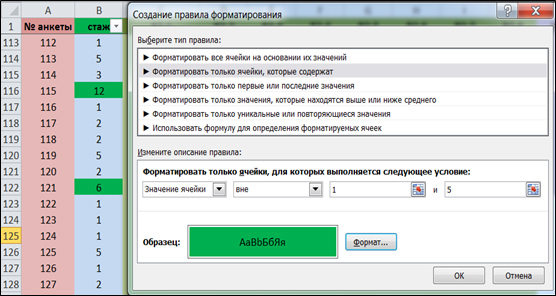
На третьем этапе исследователем должен быть осуществлен поиск и устранение ввода ошибочных значений. Реализуется такая процедура с помощью функции «Условное форматирование», она позволяет выделить цветом все ячейки, содержащие ошибку. Согласно нашей кодировке в вопросе № 1 в матрице данных могут присутствовать только значения 1-5. Все иные цифры являются ошибочными и должны быть исправлены. Для поиска иных значений в вопросе №1 выделим его щелчком мыши. Далее перейдем во вкладку «Главная» → «Условное форматирование» → «Создать правило». В открывшемся окне отметим «Форматировать только ячейки, которые содержат» в полях раздела «Форматировать только ячейки, для которых выполняется следующее условие», выберем «значение ячейки», «вне», «1», «5». Затем выберем требуемый формат, например фон. При нажатии кнопки «OK», Excel выделит зеленым ошибочные значения. (Рис. 4).
Рис. 4. Поиск ошибок ввода данных
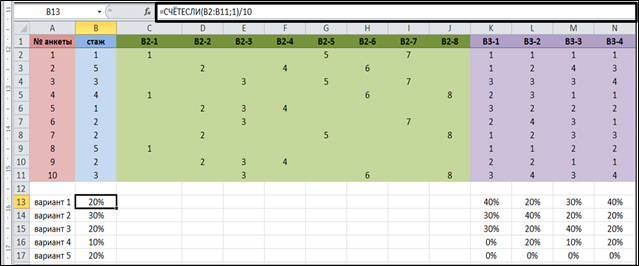
На четвертом этапе происходит непосредственная обработка социологической информации. Для подсчета процентного распределения ответов на вопросы, предполагающие только один ответ, необходимо пользоваться функцией «СЧЕТЕСЛИ». Для этого под таблицей, в столбце «№ анкеты» прописываем номера вариантов ответа на вопросы. Во втором столбце прописываем формулу (рис. 5). В нашем примере формула подсчета первого варианта ответа на вопрос о стаже работы будет иметь следующий вид:
=СЧЁТЕСЛИ(B2:B11;1)/10, где
B2:B11- столбец, в котором находятся интересующие нас ответы;
1 – номер варианта ответа, процент которого необходимо посчитать;
10 – общее количество анкет.
Для подсчета второго варианта, формула приобретет значение: =СЧЁТЕСЛИ(B2:B11;2)/10. Полученное число необходимо перевести в процентный формат: вкладка «Главная» → «Процентный формат».
Когда все варианты ответа в первом столбце просчитаны, формулу можно растянуть вправо для подсчета процентов по всем вопросам, предполагающим один ответ.
Рис. 5 Подсчет процентного распределения ответов на вопросы, предполагающие один вариант
Если вопрос предполагает множественный ответ, то расчет процентного соотношения ответов рассчитывается следующим образом: сначала необходимо узнать, сколько всего ответов дали респонденты при ответе на вопрос. Для этого воспользуемся счетом заполненных ячеек, с помощью формулы: =СЧЁТЗ(C2:J11), где C2:J11- диапазон столбцов, в которых находятся интересующие нас ответы.
Далее применим формулу использованную ранее. Для подсчета процентного распределения первого варианта ответа во втором вопросе анкеты, формула будет иметь вид:
=СЧЁТЕСЛИ(C2:C11;1)/27, где
C2:C11 – диапазон столбцов, в которых находятся интересующие нас ответы;
1- номер варианта ответа, процент которого необходимо посчитать;
27 – сумма всех ответов на вопрос № 2. (Рис.6)
Рис. 6 Подсчет процентного распределения ответов на вопрос, предполагающий множественный ответ.

Если в ходе исследования социологу необходимо определить связь между признаками, например, выяснить, сколько респондентов со стажем работы от 5 до 10 лет полностью удовлетворены заработной платой (столбец В3-1), необходимо пользоваться формулой вида:
=СЧЁТЕСЛИМН(B2:B11;2;K2:K11;1)/СЧЁТЕСЛИ(B2:B11;2), где
B2:B11 – диапазон столбцов, в которых находятся ответы о стаже работы;
2 – код ответа, обозначающий стаж работы от 5 до 10 лет;
K2:K11- диапазон столбцов, в которых находятся ответы об удовлетворенностью заработной платой;
1 – код ответа, обозначающий полную удовлетворенность заработной платой.
Таким образом, с помощью программы MS Excel, социолог может в сжатые сроки базовый анализ данных, интерпретировать значительные числовые массивы, полученные в ходе эмпирических исследований. Высокая адаптивность и простота работы, легкость экспорта данных, как между пользователями, так и между другими программными продуктами, позволяет реализовать на практике любой метод количественных исследований и решить большую часть задач, встречающихся в работе социолога.
Библиографический список
- Рабочая книга социолога / под ред. Г.В. Осипова. Изд. 4-е, стереотипное. – М.: КомКнига, 2006. – 480 с.
Количество просмотров публикации: Please wait
Все статьи автора «Чуднова Ольга Владимировна»
Собранные данные сводятся в табл. Таблица 7
и Таблица 8. В них дан пример ответов
пяти респондентов, на котором и
рассматривается процесс расчетов.
Эти таблицы удобно ввести в Excel для
дальнейшей обработки, которая заключается
в построении еще двух таблиц.
В табл. Объясните, почему берется именно взвешенная неудовлетворенность.
рассчитывается оценка неудовлетворенности
респондентов:
Dij = Smax –
Sij,
где Dij
– неудовлетворенность i-го
респондента j-й
характеристикой; Smax
– максимальная оценка удовлетворенности
(в предлагаемом варианте опроса она
равна 5);
Sij
– оценка удовлетворенности i-го
респондента j-й
характеристикой (в предлагаемом варианте
опроса берется из табл. Таблица 7 и
находится в пределах от 1
до 5).
Таблица
7
Оценки
важности характеристик товара
респондентами. Пример
|
Респондент |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Цена |
1 |
3 |
5 |
4 |
2 |
… |
||||
|
Долговечность |
2 |
3 |
4 |
5 |
1 |
… |
||||
|
Удобство |
5 |
4 |
3 |
1 |
3 |
… |
||||
|
Внешний |
5 |
5 |
5 |
5 |
5 |
… |
||||
|
Потребляемая |
1 |
1 |
1 |
1 |
1 |
… |
Оценки
важности характеристик товара
респондентами
|
Респондент |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Цена |
||||||||||
|
Долговечность |
||||||||||
|
Удобство |
||||||||||
|
Внешний |
||||||||||
|
Потребляемая |
Таблица
8
Оценки
респондентами характеристик лучшего
из товаров-аналогов. Пример
|
Респондент |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Цена |
4 |
4 |
2 |
5 |
1 |
… |
||||
|
Долговечность |
3 |
3 |
3 |
3 |
3 |
… |
||||
|
Удобство |
5 |
1 |
3 |
2 |
4 |
… |
||||
|
Внешний |
5 |
4 |
3 |
2 |
1 |
… |
||||
|
Потребляемая |
1 |
2 |
3 |
4 |
5 |
… |
Оценки
респондентами характеристик лучшего
из товаров-аналогов
|
Респондент |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
Цена |
||||||||||
|
Долговечность |
||||||||||
|
Удобство |
||||||||||
|
Внешний |
||||||||||
|
Потребляемая |
Табл. Таблица 10 содержит оценку взвешенной
неудовлетворенности:
Wij = Dij ×
wij,
где Wij
– взвешенная неудовлетворенность i-го
респондента j-й
характеристикой; wij
– важность для i-го
респондента j-й
характеристики (в предлагаемом варианте
опроса берется из табл. 6 и находится в
пределах от 1
до 5).
Объясните, почему берется именно
взвешенная неудовлетворенность.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Если на листе есть список данных опроса, как показано ниже, и вам нужно проанализировать этот опрос и создать отчет о результатах опроса в Excel, как вы могли бы это сделать? Теперь я расскажу об этапах анализа данных опроса и создания отчета о результатах в Microsoft Excel.
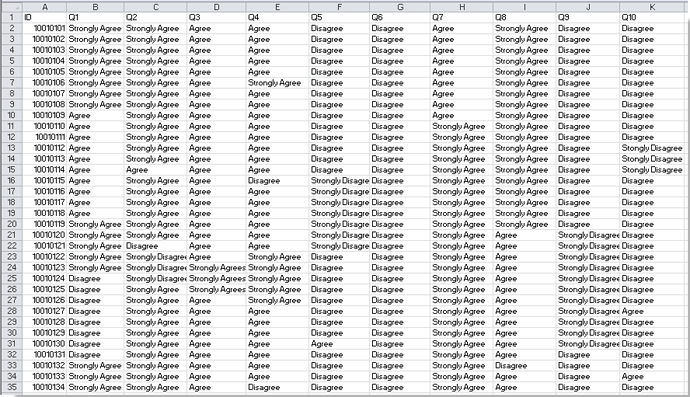
Анализируйте данные опроса в Excel
Часть 1. Подсчитайте все виды отзывов в опросе
Часть 2. Рассчитайте процентное соотношение всех отзывов.
Часть 3. Создание отчета об опросе с расчетными результатами выше
 Часть 1. Подсчитайте все виды отзывов в опросе
Часть 1. Подсчитайте все виды отзывов в опросе
Во-первых, вам нужно посчитать общее количество отзывов в каждом вопросе.
1. Выберите пустую ячейку, например ячейку B53, введите эту формулу = СЧИТАТЬПУСТОТЫ (B2: B51) (диапазон B2: B51 — это диапазон отзывов по вопросу 1, вы можете изменить его по своему усмотрению) в нем и нажмите Enter кнопку на клавиатуре. Затем перетащите маркер заполнения в диапазон, в котором вы хотите использовать эту формулу, здесь я заполняю его до диапазона B53: K53. Смотрите скриншот:

2. В ячейке B54 введите эту формулу = СЧЁТ (B2: B51) (диапазон B2: B51 — это диапазон отзывов по вопросу 1, вы можете изменить его по своему усмотрению) в него и нажмите Enter кнопку на клавиатуре. Затем перетащите маркер заполнения в диапазон, в котором вы хотите использовать эту формулу, здесь я заполняю его до диапазона B54: K54. Смотрите скриншот:
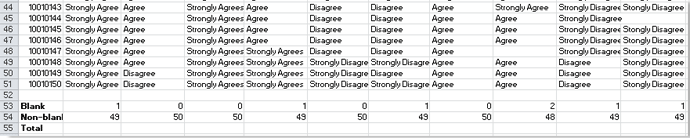
3. В ячейке B55 введите эту формулу = СУММ (B53: B54) (диапазон B2: B51 — это диапазон обратной связи по вопросу 1, вы можете изменить его по своему усмотрению) и нажмите кнопку Enter на клавиатуре, затем перетащите маркер заполнения в диапазон, в котором вы хотите использовать эту формулу , вот и заливаю до диапазона B55: K55. Смотрите скриншот:
Затем подсчитайте количество ответов по каждому вопросу: «Полностью согласен», «Согласен», «Не согласен» и «Полностью не согласен».
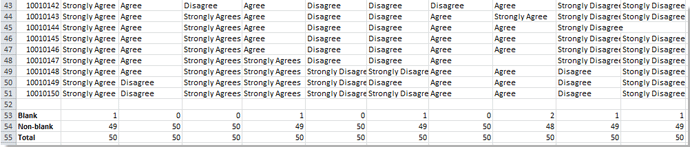
4. В ячейке B57 введите эту формулу = СЧЁТЕСЛИ (B2: B51; $ B $ 51) (диапазон B2: B51 — это диапазон отзывов по вопросу 1, ячейка $ B $ 51 — это критерии, которые вы хотите подсчитать, вы можете изменить их по своему усмотрению) и нажмите Enter на клавиатуре, затем перетащите маркер заполнения в диапазон, в котором вы хотите использовать эту формулу, здесь я заполняю его до диапазона B57: K57. Смотрите скриншот:
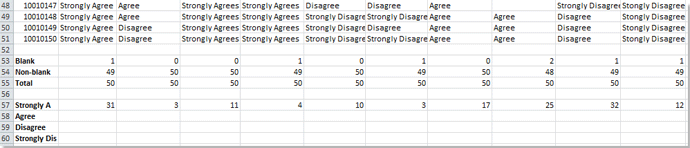
5. Тип = СЧЁТЕСЛИ (B2: B51; $ B $ 11) (диапазон B2: B51 — это диапазон отзывов по вопросу 1, ячейка $ B $ 11 — это критерии, которые вы хотите подсчитать, вы можете изменить их по своему усмотрению) в ячейку B58 и нажмите Enter на клавиатуре, затем перетащите маркер заполнения в диапазон, в котором вы хотите использовать эту формулу, здесь я заполняю его до диапазона B58: K58. Смотрите скриншот:

6. Повторите шаги 5 или 6, чтобы подсчитать количество отзывов по каждому вопросу. Смотрите скриншот:

7. В ячейке B61 введите эту формулу = СУММ (B57: B60) (диапазон B2: B51 — это диапазон отзывов по вопросу 1, вы можете изменить его по своему усмотрению), просуммируйте общий отзыв и нажмите Enter на клавиатуре, затем перетащите маркер заполнения в диапазон, в котором вы хотите использовать эту формулу, здесь я заполняю его до диапазона B61: K61. Смотрите скриншот:

Часть 2. Рассчитайте процентное соотношение всех отзывов.
Затем вам нужно рассчитать процент каждой обратной связи по каждому вопросу.
8. В ячейке B62 введите эту формулу = 57 бат / 61 млрд долларов (Ячейка B57 указывает на особую обратную связь, которую вы хотите подсчитать, ее количество, Ячейка $ B $ 61 обозначает общее количество отзывов, вы можете изменить их по своему усмотрению), чтобы просуммировать общую обратную связь и нажмите Enter на клавиатуре, затем перетащите маркер заполнения в диапазон, в котором вы хотите использовать эту формулу. Затем отформатируйте ячейку в процентах, щелкнув правой кнопкой мыши> Форматы ячеек > Процент. Смотрите скриншот:
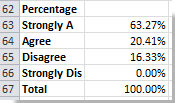
Вы также можете отобразить эти результаты в процентах, выбрав их и нажав % (Процентный стиль) в Число группы на Главная меню.
9. Повторите шаг 8, чтобы вычислить процент каждой обратной связи в каждом вопросе. Смотрите скриншот:

Часть 3. Создание отчета об опросе с расчетными результатами выше
Теперь вы можете составить отчет о результатах опроса.
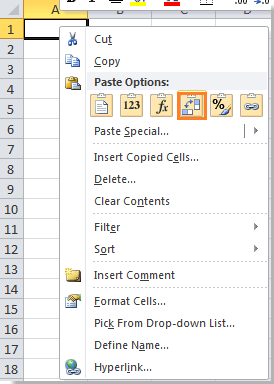
10 Выберите заголовки столбцов опроса (в данном случае A1: K1) и щелкните правой кнопкой мыши> Копировать а затем вставьте их в другой пустой лист, щелкнув правой кнопкой мыши> Транспонировать (T). Смотрите скриншот:
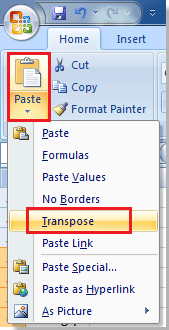
Если вы используете Microsoft Excel 2007, вы можете вставить эти рассчитанные проценты, выбрав пустую ячейку и нажав Главная > Вставить > транспонировать. См. Следующий снимок экрана:
11 Отредактируйте заголовок, как вам нужно, см. Снимок экрана:
12 Выберите часть, которую необходимо отобразить в отчете, и щелкните правой кнопкой мыши> Копировать, а затем перейдите на рабочий лист, который вам нужно вставить, и выберите одну пустую ячейку, например Ячейку B2, щелкните Главная > Вставить > Специальная вставка. Смотрите скриншот:
13 В разделе Специальная вставка диалог, проверьте Ценности и транспонирование в Вставить и транспонировать разделы и щелкните OK чтобы закрыть этот диалог. Смотрите скриншот:
Повторите шаги 10 и 11, чтобы скопировать и вставить нужные вам данные, после чего будет составлен отчет об исследовании. Смотрите скриншот:
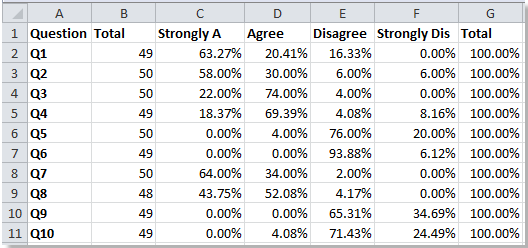
В школах или компаниях — опросы со скрытыми вопросами для выяснения общей атмосферы и мнений очень популярны. Однозначные ответы (да, нет, множественный выбор или деления шкалы) как раз и дают возможность быстрой обработки через Excel. И для расчета важных контрольных цифр по опросу специальных знаний в области статистики не требуется.
Дело в визуализации
Картинка может быть красноречивее слов, а умело подобранная диаграмма в одно мгновение передает результат опроса. В то время как линейчатая или круговая диаграммы являются удачным выбором для решений типа «да-нет», для опросов, при которых значения рассчитываются по фиксированной шкале, в качестве замечательной основы предлагается блочное графическое представление.
Оно интуитивно передает несколько видов данных одновременно: минимальное и максимальное значение отображается посредством антенн (точечных контактов), а сам блок обозначает область, где собрано 50% данных. Медиана делит блок пополам и своим положением отмечает среднее значение в представлении. Если она находится справа или слева от середины, статистики говорят о распределении с искажением вправо или влево.
Если при обработке опроса блок имеет вытянутую форму, а антенны или точечные контакты достигают соответствующих концов опросной шкалы, к тому же становится ясно, что решение у этого вопроса отнюдь не однозначное — результаты в таком случае распределяются по широкому спектру. Короткий блок с короткими антеннами, напротив, показывает концентрацию на определенной области шкалы.
Как это сделать: пошаговое руководство
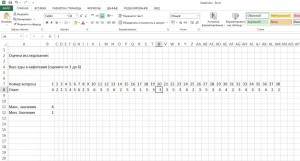
1. Собрать данные
Если данные еще на распознаны, вам понадобится перенести их на лист Excel. Если, как в нашем примере, идет шкала от 1 до 6 (оценочные баллы), то и задаваться должны только эти значения. Если у вас в списке присутствуют нулевые значения, например, для недействительных или отсутствующих записей, их следует удалить.
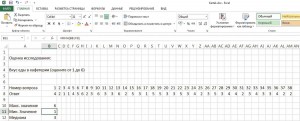
2. Рассчитать максимум и минимум
В первую очередь вам потребуется найти максимальное и минимальное значение числового ряда. Для этого используется следующая синтаксическая конструкция: «=МАКС(B8:JF8)» и, соответственно, «=МИН(B8:JF8)», причем диапазон данных вам, конечно же, придется настраивать под ваш проект.
3. Рассчитать медиану
Медиана обозначает среднее значение распределения или второй квартиль. Синтаксическая конструкция имеет вид «=медиана (B8:JF8)».
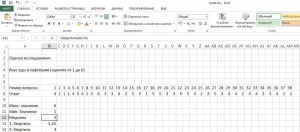
4. Определить оставшиеся квартили
Теперь нам еще понадобятся первый и третий квартили, чтобы можно было рассчитать блочные диаграммы. Синтаксическая конструкция: «=квартиль (B8:JF8;1)» и «=квартиль (B8:JF8;3)».
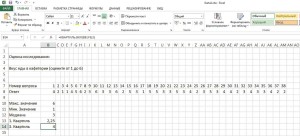
5. Рассчитать вспомогательные величины
Поскольку при построении блочной диаграммы речь идет о дополнительном представлении значений, нам еще потребуется несколько разностей в качестве вспомогательных величин: H1=минимум; H2=1-й квартиль-минимум; H3=медиана-1-й квартиль: H4=3-й квартиль-медиана; H5=максимум-3-й квартиль.
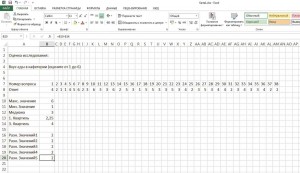
6. Начертить линейчатую диаграмму
Если вы рассчитали вспомогательные величины, как показано на иллюстрации, выделите небольшую таблицу, но без строки с пятой вспомогательной величиной. Перейдите в меню «Вставка | Диаграммы | Линейчатая | Линейчатая с накоплением». Теперь у вас отображается четыре одноцветных полосы. Нажмите на кнопку «Изменить строку | Cтолбец».
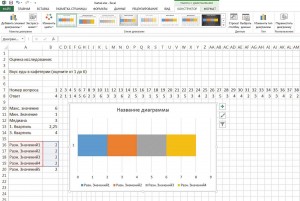
7. Откорректировать диаграмму
Теперь выделите самый левый столбец диаграммы и с помощью контекстного меню перейдите в пункт «Формат ряда данных». Отключите пункты «Заливка» и «Цвет контура». То же самое проделайте с крайним правым столбцом. Оставьте левый столбец выделенным.
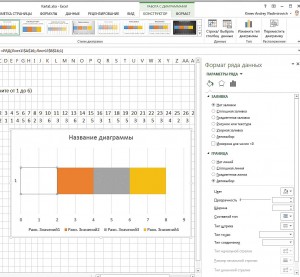
8. Нарисовать антенны
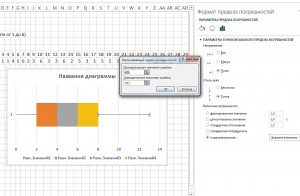
В строке меню перейдите к пункту «Работа с диаграммами | Макет | Планки погрешностей | Дополнительные параметры планок погрешностей…». Установите здесь направление на «Минус», а относительное значение на «100» (величина погрешности). После этого закройте меню настроек.
Теперь выделите крайний правый сегмент. Снова перейдите к контекстному меню для планок погрешностей. На этот раз установите направление на «Плюс», а в разделе «Величина погрешности» под пунктом «Пользовательская» задайте положительное значение погрешности «Вспомогательные данные 5».
Для этого вам понадобится просто кликнуть кнопкой мыши в таблице со вспомогательными величинами. Теперь, в завершение создания диаграммы, вы можете отключить легенду и линии координатной сетки, и у вас готово отличное блочное графическое представление для визуализации небольшого опроса.
Обработка результатов анкетирования в Excel
- Ошибки распознавателя. Не существует решений, которые могут распознавать информацию со 100% точностью. Можно добиться результата близкого к 100%.
- Человеческий фактор. Иногда люди игнорируют требования к полям документов и заполняют их на свое усмотрение.
Обработка анкет в Excel с использованием макроса
Наиболее приемлемым вариантом решения этой задачи является отображение части сканированной анкеты прямо в электронной таблице Excel по некоторому событию (двойной клик, выделение ячейки). Это позволит максимально быстро сопоставить информацию и убедиться в правильном ответе. Для реализации этой задачи потребуется создать макрос. Необходимым условием работы макроса является наличие файлов сканированных анкет и координат для каждого поля анкеты.
Лекция: Алгоритм базового анализа данных опроса
Базовый анализ статистических данных можно проводить и в распространенной системе MS Excel или ее бесплатных аналогах, таких как Open Office или online редакторах типа Google Docs.
Первоначально результаты опросов должны быть оцифрованы в виде таблицы в столбцах которой представлены ответы на вопросы, а в строках результаты анкет. Такой вариант представления данных соответсвует реляционным базам данных.

Для начала найдем распределение ответов при помощи функций СУММ, ЕСЛИ, СУММЕСЛИ, СУММЕСЛИМН, СЧЕТЕСЛИи СЧЕТЕСЛИМН.
Описание функций Excel
- СУММ(Диапазон) — функция для нахождения суммы значений указанного диапазона. Пример: =СУММ(B2:B25).
- ЕСЛИ(это истинно, то сделать это, в противном случае сделать что-то еще). У функции ЕСЛИ возможны два результата. Первый результат возвращается в случае, если сравнение истинно, второй — если сравнение ложно. Пример: =ЕСЛИ(E2=»Да»;1;2).
- СУММЕСЛИ(Диапазон;Условие) — функция для нахождения суммы значений указанного диапазона, соответствующие указанному условию. Пример: =СУММЕСЛИ(B2:B25;»>35″).
Есть возможность разделения диапазонов сравнения и суммирования, для этого диапазон суммирования указывается в качестве третьего параметра: =СУММЕСЛИ(D2:D5; «Теле2»; B2:B5) суммирует только те значения из диапазона B2:B5, для которых соответствующие значения из диапазона D2:D5 равны «Теле2». - Функция СУММЕСЛИМН(диапазон_суммирования; диапазон_условия1; условие1) похожа на второй вариант использования функции СУММЕСЛИ(диапазон_условия;Условие;диапазон_суммирования), только диапазон суммирования и диапазон условия переставлены местами.
Кроме этого есть возможность указания нескольких диапазонов условий СУММЕСЛИМН(диапазон_суммирования; диапазон_условия1; условие1; диапазон_условия2; условие2; . ). Можно ввести до 127 пар диапазонов и условий.
Пример: =СУММЕСЛИМН(B2:B9; D2:D9; «=М*»; C2:C9; «м») найдет сумму возрастов мужчин, оператор которых начинатеся на букву М. - Функции СЧЕТЕСЛИ и СЧЕТЕСЛИМН аналогичны функциям СУММЕСЛИ и СУММЕСЛИМН, только они ничего не суммируют, а просто считают количество ячеек, удовлетворяющих условиям.
Примеры: =СЧЁТЕСЛИ(C2:C10;$C$2) считает число мужчин.
=СЧЁТЕСЛИ(F2:F5;»<>»&$F$10) считает число анкет с графиком не равным «Свободный». Знак амперсанда (&) объединяет оператор сравнения «<>» (не равно) и значение в ячейке $F$10, в результате чего получается формула =СЧЁТЕСЛИ(F2:F5;»<>Свободный»).
На представленном рисунке приведен пример подсчета мужских и женских анкет. Аналогично можно проанализировать и другие дихотомические (т.е. принимающие одно из двух значений) параметры.

В приведенном примере только два дихотомических параметра: пол и замужество. Их можно проверить на зависимость. Для этого подсчитаем «Коэффициент контингенции Пирсона»
где (a), (b), (c), (d) — элементы четырехпольной корреляционной таблицы, в которой представлены частоты или количество совместных событий.
| Событие 1 | |||
| Событие 2 | (a) | (b) | (a+b) |
| (c) | (d) | (c+d) | |
| (a+c) | (b+d) |
Например, если за «событие 1» принять пол (м,ж), а за «событие 2» — замужество (да, нет), то (a) — это количество женатых мужчин, (b) — количество замужних женщин, (c) — количество неженатых мужчин, (d) — количество незамужних женщин.

В рассматриваемом примере Коээффициент контингенции Пирсона получился равным -0,29778. Если взглянуть на шкалу Чедокка, то видим, что имеется слабая обратная зависимость между параметрами.
| Коэффициент | 0,1 — 0,3 | 0,3 — 0,5 | 0,5 — 0,7 | 0,7 — 0,9 | 0,9 — 0,99 |
|---|---|---|---|---|---|
| Характеристика зависимости | Слабая | Умеренная | Заметная | Высокая | Весьма высокая |
Найдем ошибку коэффициента корреляции по формуле:
Она составила 0,100318. Ниже приведена таблица с исходными данными: