
Хотя многие Data Scientist’ы больше привыкли работать с CSV-файлами, на практике очень часто приходится сталкиваться с обычными Excel-таблицами. Поэтому сегодня мы расскажем, как читать Excel-файлы в Pandas, а также рассмотрим основные возможности Python-библиотеки OpenPyXL для чтения метаданных ячеек.
Дополнительные зависимости для возможности чтения Excel таблиц
Для чтения таблиц Excel в Pandas требуются дополнительные зависимости:
- xlrd поддерживает старые и новые форматы MS Excel [1];
- OpenPyXL поддерживает новые форматы MS Excel (.xlsx) [2];
- ODFpy поддерживает свободные форматы OpenDocument (.odf, .ods и .odt) [3];
- pyxlsb поддерживает бинарные MS Excel файлы (формат .xlsb) [4].
Мы рекомендуем установить только OpenPyXL, поскольку он нам пригодится в дальнейшем. Для этого в командной строке прописывается следующая операция:
pip install openpyxl
Затем в Pandas нужно указать путь к Excel-файлу и одну из установленных зависимостей. Python-код выглядит следующим образом:
import pandas as pd
pd.read_excel(io='temp1.xlsx', engine='openpyxl')
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
Читаем несколько листов
Excel-файл может содержать несколько листов. В Pandas, чтобы прочитать конкретный лист, в аргументе нужно указать sheet_name. Можно указать список названий листов, тогда Pandas вернет словарь (dict) с объектами DataFrame:
dfs = pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
sheet_name=['Sheet1', 'Sheet2'])
dfs
#
{'Sheet1': Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64,
'Sheet2': Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78}
Если таблицы в словаре имеют одинаковые атрибуты, то их можно объединить в один DataFrame. В Python это выглядит так:
pd.concat(dfs).reset_index(drop=True)
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
3 Gosha 43 95
4 Anna 24 65
5 Lena 22 78
Указание диапазонов
Таблицы могут размещаться не в самом начале, а как, например, на рисунке ниже. Как видим, таблица располагается в диапазоне A:F.
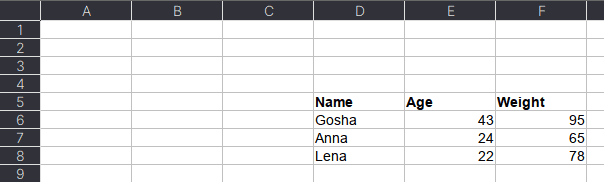
Чтобы прочитать такую таблицу, нужно указать диапазон в аргументе usecols. Также дополнительно можно добавить header — номер заголовка таблицы, а также nrows — количество строк, которые нужно прочитать. В аргументе header всегда передается номер строки на единицу меньше, чем в Excel-файле, поскольку в Python индексация начинается с 0 (на рисунке это номер 5, тогда указываем 4):
pd.read_excel(io='temp1.xlsx',
engine='openpyxl',
usecols='D:F',
header=4, # в excel это №5
nrows=3)
#
Name Age Weight
0 Gosha 43 95
1 Anna 24 65
2 Lena 22 78
Читаем таблицы в OpenPyXL
Pandas прочитывает только содержимое таблицы, но игнорирует метаданные: цвет заливки ячеек, примечания, стили таблицы и т.д. В таком случае пригодится библиотека OpenPyXL. Загрузка файлов осуществляется через функцию load_workbook, а к листам обращаться можно через квадратные скобки:
from openpyxl import load_workbook
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
type(ws)
# openpyxl.worksheet.worksheet.Worksheet
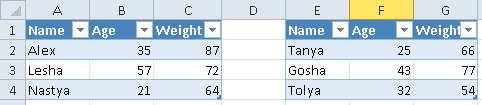
Допустим, имеется Excel-файл с несколькими таблицами на листе (см. рисунок выше). Если бы мы использовали Pandas, то он бы выдал следующий результат:
pd.read_excel(io='temp2.xlsx',
engine='openpyxl')
#
Name Age Weight Unnamed: 3 Name.1 Age.1 Weight.1
0 Alex 35 87 NaN Tanya 25 66
1 Lesha 57 72 NaN Gosha 43 77
2 Nastya 21 64 NaN Tolya 32 54
Можно, конечно, заняться обработкой и привести таблицы в нормальный вид, а можно воспользоваться OpenPyXL, который хранит таблицу и его диапазон в словаре. Чтобы посмотреть этот словарь, нужно вызвать ws.tables.items. Вот так выглядит Python-код:
ws.tables.items()
wb = load_workbook('temp2.xlsx')
ws = wb['Лист1']
ws.tables.items()
#
[('Таблица1', 'A1:C4'), ('Таблица13', 'E1:G4')]
Обращаясь к каждому диапазону, можно проходить по каждой строке или столбцу, а внутри них – по каждой ячейке. Например, следующий код на Python таблицы объединяет строки в список, где первая строка уходит на заголовок, а затем преобразует их в DataFrame:
dfs = []
for table_name, value in ws.tables.items():
table = ws[value]
header, *body = [[cell.value for cell in row]
for row in table]
df = pd.DataFrame(body, columns=header)
dfs.append(df)
Если таблицы имеют одинаковые атрибуты, то их можно соединить в одну:
pd.concat(dfs)
#
Name Age Weight
0 Alex 35 87
1 Lesha 57 72
2 Nastya 21 64
0 Tanya 25 66
1 Gosha 43 77
2 Tolya 32 54
Сохраняем метаданные таблицы
Как указано в коде выше, у ячейки OpenPyXL есть атрибут value, который хранит ее значение. Помимо value, можно получить тип ячейки (data_type), цвет заливки (fill), примечание (comment) и др.
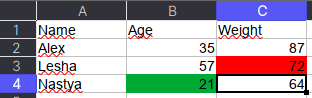
Например, требуется сохранить данные о цвете ячеек. Для этого мы каждую ячейку с числами перезапишем в виде <значение,RGB>, где RGB — значение цвета в формате RGB (red, green, blue). Python-код выглядит следующим образом:
# _TYPES = {int:'n', float:'n', str:'s', bool:'b'}
data = []
for row in ws.rows:
row_cells = []
for cell in row:
cell_value = cell.value
if cell.data_type == 'n':
cell_value = f"{cell_value},{cell.fill.fgColor.rgb}"
row_cells.append(cell_value)
data.append(row_cells)
Первым элементом списка является строка-заголовок, а все остальное уже значения таблицы:
pd.DataFrame(data[1:], columns=data[0])
#
Name Age Weight
0 Alex 35,00000000 87,00000000
1 Lesha 57,00000000 72,FFFF0000
2 Nastya 21,FF00A933 64,00000000
Теперь представим атрибуты в виде индексов с помощью метода stack, а после разобьём все записи на значение и цвет методом str.split:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
)
#
0 1
Name
Alex Age 35 00000000
Weight 87 00000000
Lesha Age 57 00000000
Weight 72 FFFF0000
Nastya Age 21 FF00A933
Weight 64 0000000
Осталось только переименовать 0 и 1 на Value и Color, а также добавить атрибут Variable, который обозначит Вес и Возраст. Полный код на Python выглядит следующим образом:
(pd.DataFrame(data[1:], columns=data[0])
.set_index('Name')
.stack()
.str.split(',', expand=True)
.set_axis(['Value', 'Color'], axis=1)
.rename_axis(index=['Name', 'Variable'])
.reset_index()
)
#
Name Variable Value Color
0 Alex Age 35 00000000
1 Alex Weight 87 00000000
2 Lesha Age 57 00000000
3 Lesha Weight 72 FFFF0000
4 Nastya Age 21 FF00A933
5 Nastya Weight 64 00000000
Ещё больше подробностей о работе с таблицами в Pandas, а также их обработке на реальных примерах Data Science задач, вы узнаете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Источники
- https://xlrd.readthedocs.io/en/latest/
- https://openpyxl.readthedocs.io/en/latest/
- https://github.com/eea/odfpy
- https://github.com/willtrnr/pyxlsb
Excel sheets are very instinctive and user-friendly, which makes them ideal for manipulating large datasets even for less technical folks. If you are looking for places to learn to manipulate and automate stuff in excel files using Python, look no more. You are at the right place.
Python Pandas With Excel Sheet
In this article, you will learn how to use Pandas to work with Excel spreadsheets. At the end of the article, you will have the knowledge of:
- Necessary modules are needed for this and how to set them up in your system.
- Reading data from excel files into pandas using Python.
- Exploring the data from excel files in Pandas.
- Using functions to manipulate and reshape the data in Pandas.
Installation
To install Pandas in Anaconda, we can use the following command in Anaconda Terminal:
conda install pandas
To install Pandas in regular Python (Non-Anaconda), we can use the following command in the command prompt:
pip install pandas
Getting Started
First of all, we need to import the Pandas module which can be done by running the command: Pandas
Python3
Input File: Let’s suppose the excel file looks like this
Sheet 1:
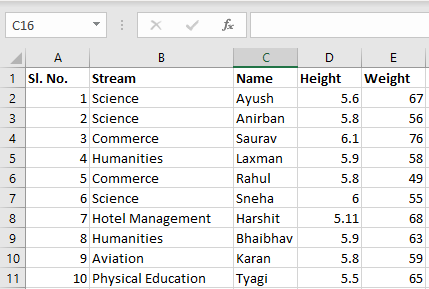
Sheet 2:
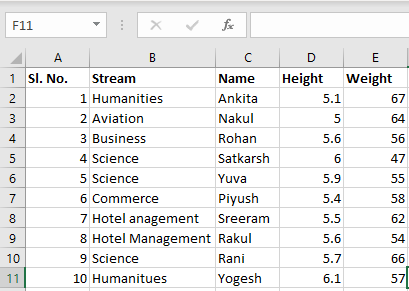
Now we can import the excel file using the read_excel function in Pandas. The second statement reads the data from excel and stores it into a pandas Data Frame which is represented by the variable newData. If there are multiple sheets in the excel workbook, the command will import data of the first sheet. To make a data frame with all the sheets in the workbook, the easiest method is to create different data frames separately and then concatenate them. The read_excel method takes argument sheet_name and index_col where we can specify the sheet of which the data frame should be made of and index_col specifies the title column, as is shown below:
Python3
file =('path_of_excel_file')
newData = pds.read_excel(file)
newData
Output:
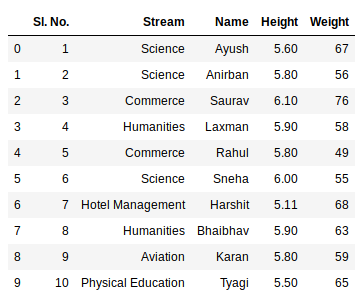
Example:
The third statement concatenates both sheets. Now to check the whole data frame, we can simply run the following command:
Python3
sheet1 = pds.read_excel(file,
sheet_name = 0,
index_col = 0)
sheet2 = pds.read_excel(file,
sheet_name = 1,
index_col = 0)
newData = pds.concat([sheet1, sheet2])
newData
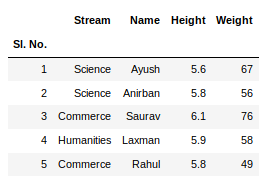
Output:
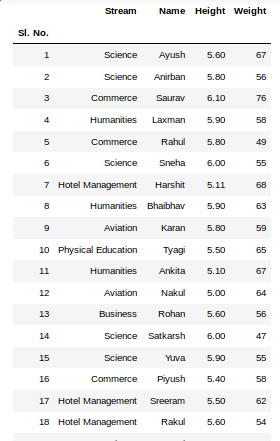
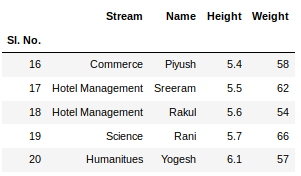
To view 5 columns from the top and from the bottom of the data frame, we can run the command. This head() and tail() method also take arguments as numbers for the number of columns to show.
Python3
newData.head()
newData.tail()
Output:
The shape() method can be used to view the number of rows and columns in the data frame as follows:
Python3
Output:
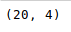
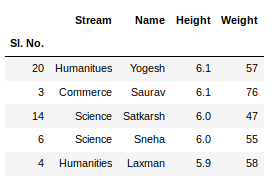
If any column contains numerical data, we can sort that column using the sort_values() method in pandas as follows:
Python3
sorted_column = newData.sort_values(['Height'], ascending = False)
Now, let’s suppose we want the top 5 values of the sorted column, we can use the head() method here:
Python3
sorted_column['Height'].head(5)
Output:
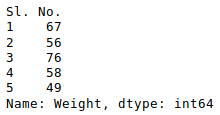
We can do that with any numerical column of the data frame as shown below:
Python3
Output:
Now, suppose our data is mostly numerical. We can get the statistical information like mean, max, min, etc. about the data frame using the describe() method as shown below:
Python3
Output:
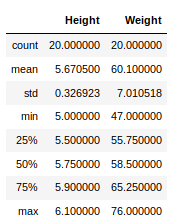
This can also be done separately for all the numerical columns using the following command:
Python3
Output:
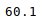
Other statistical information can also be calculated using the respective methods. Like in excel, formulas can also be applied and calculated columns can be created as follows:
Python3
newData['calculated_column'] =
newData[“Height”] + newData[“Weight”]
newData['calculated_column'].head()
Output:
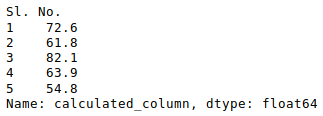
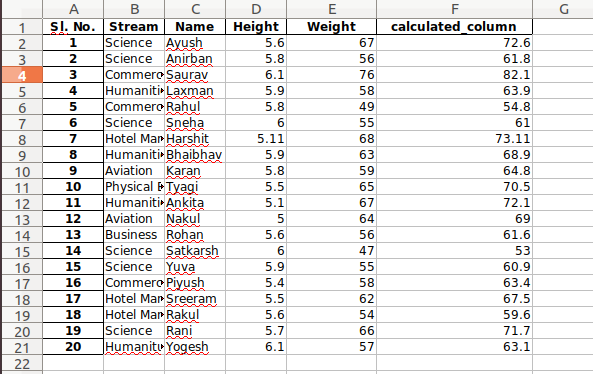
After operating on the data in the data frame, we can export the data back to an excel file using the method to_excel. For this we need to specify an output excel file where the transformed data is to be written, as shown below:
Python3
newData.to_excel('Output File.xlsx')
Output:
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Для работы с табличными данными часто используют продукт Microsoft Excel. В таблицы Excel помещают как списки покупок, так и отчетности компаний. Благодаря распространенности данного формата разработчики создали инструменты для атоматизации обработки данных.
Pandas является средством работы с табличными данными и умеет работать с файлами формата Excel-таблиц: .xls и .xlsx. И каждый разработчик должен уметь работать с такими форматами наравне с текстовыми файлами и файлами формата json и html.
В этом уроке мы познакомимся с основными методами библиотеки Pandas для работы с табличными данными в формате Microsoft Excel: .xls и .xlsx. Мы научимся их читать и записывать. Также мы разберем работу с файлами, в которых есть несколько листов, а также форматированию данных при записи.
Обработка Excel файлов в Python
Среди форматов файлов Excel наиболее популярными являются:
- .xls — использовался в версиях Microsoft Excel до 2007
- .xlsx — используется во всех версиях после 2007
Для работы с обоими типами в Python есть ряд открытых библиотек:
xlwtopenpyxlXlsxWriterxlrd
В библиотеке Pandas не реализован свой функционал работы с Excel-файлами, но есть единый интерфейс для работы с каждой из указанных выше библиотек.
Чтобы использовать этот функционал, нужно установить указанные библиотеки в окружение, в котором установлена библиотека Pandas. Библиотеки не являются взаимозаменяемыми и дополняют друг друга — лучше установить их все.
Чтение таблиц из Excel файлов
Чтобы читать файлы в Pandas, используется метод read_excel(). Ему на вход подается путь к читаемому файлу:
import pandas as pd
df_orders = pd.read_excel('data_read/Shop_orders_one_week.xlsx')
print(df_orders.head())
# => weekday shop_1 shop_2 shop_3 shop_4
# 0 mon 7 1 7 8
# 1 tue 4 2 4 5
# 2 wed 3 5 2 3
# 3 thu 8 12 8 7
# 4 fri 15 11 13 9
# 5 sat 21 18 17 21
# 6 sun 25 16 25 17
В примере выше прочитан файл продаж четырех магазинов за неделю и размещен в объекте DataFrame. Pandas по умолчанию добавил столбец индексов — последовательность целых чисел от 0 до 6.
Чтобы указать, какой из столбцов является столбцом индексов, необходимо указать его номер в параметре index_col. В нашем случае это первый столбец, в котором указаны дни недели:
df_orders = pd.read_excel('data_read/Shop_orders_one_week.xlsx', index_col=0)
print(df_orders.head())
# => shop_1 shop_2 shop_3 shop_4
# weekday
# mon 7 1 7 8
# tue 4 2 4 5
# wed 3 5 2 3
# thu 8 12 8 7
# fri 15 11 13 9
# sat 21 18 17 21
# sun 25 16 25 17
Если перед таблицей некоторые строки содержали записи, то попытка прочтения не приведет к ожидаемому результату. Pandas будет стараться положить данные в строках до таблицы в качестве индексов столбцов:
df_orders = pd.read_excel('data_read/Shop_orders_one_week_with_head.xlsx')
print(df_orders.head())
# => Orders by shop Unnamed: 1 Unnamed: 2 Unnamed: 3 Unnamed: 4
# 0 NaN NaN NaN NaN NaN
# 1 weekday shop_1 shop_2 shop_3 shop_4
# 2 mon 7 1 7 8
# 3 tue 4 2 4 5
# 4 wed 3 5 2 3
Для корректного прочтения необходимо пропустить некоторое количество строк при прочтении. Для этого нужно использовать параметр skiprows и указать количество пропускаемых строк:
df_orders = pd.read_excel('data_read/Shop_orders_one_week_with_head.xlsx', skiprows=2)
print(df_orders.head())
# => weekday shop_1 shop_2 shop_3 shop_4
# 0 mon 7 1 7 8
# 1 tue 4 2 4 5
# 2 wed 3 5 2 3
# 3 thu 8 12 8 7
# 4 fri 15 11 13 9
Итоговый вариант корректного чтения, где пропущены две строки и использован один столбец в качестве столбца индексов, выглядит следующим образом:
df_orders = pd.read_excel('data_read/Shop_orders_one_week_with_head.xls', skiprows=2, index_col=0)
print(df_orders.head())
# => shop_1 shop_2 shop_3 shop_4
# weekday
# mon 7 1 7 8
# tue 4 2 4 5
# wed 3 5 2 3
# thu 8 12 8 7
# fri 15 11 13 9
Запись таблиц в Excel файл
Также в Excel-файл можно записывать результаты работы программы. Эту задачу можно разделить на два типа по сложности используемого синтаксиса:
- Быстрая запись на один лист — записывается одна таблица, которая будет размещена на одном листе файла Excel
- Создание файла с несколькими листами — если результаты работы программы располагаются в нескольких итоговых таблицах, то для формирования единого файла Excel с несколькими листами потребуется применить определенные правила создания
Быстрая запись на один лист
В качестве результатов работы программы используем среднее по магазинам за неделю:
df_orders_mean = pd.DataFrame(df_orders.mean()).T.round(1)
df_orders_mean.index = ['mean']
print(df_orders_mean)
# => shop_1 shop_2 shop_3 shop_4
# mean 11.9 9.3 10.9 10.0
Сформируем итоговую таблицу на основе исходной и добавим аналитические результаты:
df_analitic_results = pd.concat([
df_orders,
df_orders_mean
])
print(df_analitic_results)
# => shop_1 shop_2 shop_3 shop_4
# mon 7.0 1.0 7.0 8.0
# tue 4.0 2.0 4.0 5.0
# wed 3.0 5.0 2.0 3.0
# thu 8.0 12.0 8.0 7.0
# fri 15.0 11.0 13.0 9.0
# sat 21.0 18.0 17.0 21.0
# sun 25.0 16.0 25.0 17.0
# mean 11.9 9.3 10.9 10.0
Чтобы быстро записать данную таблицу, достаточно воспользоваться методом to_excel(). Формат файла .xls или .xlsx необходимо указать в расширении файла. Pandas автоматически определит, какой библиотекой воспользоваться для конкретного формата:
df_analitic_results.to_excel('data_read/Shop_orders_one_week_analitics.xlsx')
df_analitic_results.to_excel('data_read/Shop_orders_one_week_analitics.xls')
Создание файла с несколькими листами
Чтобы задать имя листа, на котором располагается таблица, необходимо указать его в параметре sheet_name. В данном примере получится лист Total:
path_for_analitic_results = 'data_read/Shop_orders_one_week_analitics.xlsx'
df_analitic_results.to_excel(
path_for_analitic_results,
sheet_name='Total'
)
Попробуем добавить к сформированному файлу лист итогов только для первого магазина:
df_analitic_results[['shop_1']].to_excel(
path_for_analitic_results,
sheet_name='shop_1',
)
Все выполнено без ошибок, но в итоговом файле листа Total нет. Чтобы перезаписать файл и удалить предыдущий, вызовем функцию to_excel().
Для корректной записи или дозаписи нужно использовать следующую конструкцию. В одном файле запишем итоговую таблицу на один лист, а для каждого магазина создадим отдельный лист только с его итогами:
with pd.ExcelWriter(
path_for_analitic_results,
engine="xlsxwriter",
mode='w') as excel_writer:
# Add total df
df_analitic_results.to_excel(excel_writer, sheet_name='Total')
# Add all shop df results
for shop_name in df_analitic_results.columns.to_list():
df_analitic_results[[shop_name]].to_excel(excel_writer, sheet_name=shop_name)
В коде выше создается экземпляр класса ExcelWriter на «движке» библиотеки xlsxwriter. Далее мы используем инициализированный экземпляр excel_writer в качестве первого параметра метода to_excel(). Конструкция with...as... позволяет безопасно работать с потоком данных и закрыть файл, даже когда возникают ошибки записи.
Чтение таблиц из Excel файлов с несколькими листами
Чтобы прочитать файл с несколькими листами, не хватит метода read_excel(), поскольку будет прочитан только первый лист из файла:
df_analitic_results_from_file = pd.read_excel(path_for_analitic_results, index_col=0)
print(df_analitic_results_from_file)
# => shop_1 shop_2 shop_3 shop_4
# mon 7.0 1.0 7.0 8
# tue 4.0 2.0 4.0 5
# wed 3.0 5.0 2.0 3
# thu 8.0 12.0 8.0 7
# fri 15.0 11.0 13.0 9
# sat 21.0 18.0 17.0 21
# sun 25.0 16.0 25.0 17
# mean 11.9 9.3 10.9 10
При этом можно прочитать конкретный лист, если указать его название в параметре sheet_name:
df_analitic_results_from_file = pd.read_excel(path_for_analitic_results, index_col=0, sheet_name='shop_1')
print(df_analitic_results_from_file)
# => shop_1
# mon 7.0
# tue 4.0
# wed 3.0
# thu 8.0
# fri 15.0
# sat 21.0
# sun 25.0
# mean 11.9
Чтобы прочитать несколько листов и не переоткрывать файл, достаточно использовать экземпляр класса ExcelFile и его метод parse(). В последнем указывается имя нужного листа и дополнительные параметры чтения, аналогичные методу read_excel().
excel_reader = pd.ExcelFile(path_for_analitic_results)
df_shop_1 = excel_reader.parse('shop_1', index_col=0)
df_shop_2 = excel_reader.parse('shop_2', index_col=0)
print(df_shop_1)
print(df_shop_2)
# => shop_1
# mon 7.0
# tue 4.0
# wed 3.0
# thu 8.0
# fri 15.0
# sat 21.0
# sun 25.0
# mean 11.9
# shop_2
# mon 1.0
# tue 2.0
# wed 5.0
# thu 12.0
# fri 11.0
# sat 18.0
# sun 16.0
# mean 9.3
Данный подход для чтения файла Excel удобен, чтобы получить список всех листов. Для этого нужно посмотреть на атрибут sheet_names:
print(excel_reader.sheet_names)
# => ['Total', 'shop_1', 'shop_2', 'shop_3', 'shop_4']
Если использовать наработки выше, можно собрать словарь из датафреймов, в которых будут располагаться все таблицы файла. Чтобы получить нужный датафрейм, нужно обратиться к словарю по ключу с соответствующим названием листа:
sheet_to_df_map = {}
for sheet_name in excel_reader.sheet_names:
sheet_to_df_map[sheet_name] = excel_reader.parse(sheet_name, index_col=0)
print(sheet_to_df_map['shop_1'])
print(sheet_to_df_map['Total'])
# => shop_1
# mon 7.0
# tue 4.0
# wed 3.0
# thu 8.0
# fri 15.0
# sat 21.0
# sun 25.0
# mean 11.9
# shop_1 shop_2 shop_3 shop_4
# mon 7.0 1.0 7.0 8
# tue 4.0 2.0 4.0 5
# wed 3.0 5.0 2.0 3
# thu 8.0 12.0 8.0 7
# fri 15.0 11.0 13.0 9
# sat 21.0 18.0 17.0 21
# sun 25.0 16.0 25.0 17
# mean 11.9 9.3 10.9 10
Форматирование таблиц
За время своего развития Excel накопил довольно мощный функционал, чтобы анализировать и презентовать данные: создание графиков, цветовая подсветка результатов по условию, настройка шрифтов и многое другое.
В примере ниже мы форматируем итоговые аналитические данные: если значения в таблице превышают порог в одиннадцать заказов, то они раскрашиваются в один цвет, иначе — в другой. Цветовая дифференциация данных удобна, чтобы быстро оценивать результаты и искать закономерности в данных:
with pd.ExcelWriter(
path_for_analitic_results,
engine="xlsxwriter",
mode='w') as excel_writer:
# Add total df
df_analitic_results.to_excel(excel_writer, sheet_name='Total')
# Formatting total df
threshold = 11
workbook = excel_writer.book
worksheet = excel_writer.sheets['Total']
format1 = workbook.add_format({'bg_color': '#FFC7CD',
'font_color': '#9C0006'})
format2 = workbook.add_format({'bg_color': '#C6EFCD',
'font_color': '#006100'})
worksheet.conditional_format('B2:E9', {
'type' : 'cell',
'criteria' : '>=',
'value' : threshold,
'format' : format1}
)
worksheet.conditional_format('B2:E9', {
'type' : 'cell',
'criteria' : '<',
'value' : threshold,
'format' : format2}
)
В примере выше используются методы движка xlsxwriter. Разбор всех возможностей форматирования данных при записи выходит за рамки данного урока. Можно глубже погрузиться в данную тему через документацию с примерами по следующей ссылке.
Выводы
В Python данные из файла Excel считываются в объект DataFrame. Для этого используется функция read_excel() модуля pandas.
Лист Excel — это двухмерная таблица. Объект DataFrame также представляет собой двухмерную табличную структуру данных.
- Пример использования Pandas read_excel()
- Список заголовков столбцов листа Excel
- Вывод данных столбца
- Пример использования Pandas to Excel: read_excel()
- Чтение файла Excel без строки заголовка
- Лист Excel в Dict, CSV и JSON
- Ресурсы

Предположим, что у нас есть документ Excel, состоящий из двух листов: «Employees» и «Cars». Верхняя строка содержит заголовок таблицы.

Ниже приведен код, который считывает данные листа «Employees» и выводит их.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Employees')
# print whole sheet data
print(excel_data_df)
Вывод:
EmpID EmpName EmpRole 0 1 Pankaj CEO 1 2 David Lee Editor 2 3 Lisa Ray Author
Первый параметр, который принимает функция read_excel ()— это имя файла Excel. Второй параметр (sheet_name) определяет лист для считывания данных.
При выводе содержимого объекта DataFrame мы получаем двухмерные таблицы, схожие по своей структуре со структурой документа Excel.
Чтобы получить список заголовков столбцов таблицы, используется свойство columns объекта Dataframe. Пример реализации:
print(excel_data_df.columns.ravel())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Мы можем получить данные из столбца и преобразовать их в список значений. Пример:
print(excel_data_df['EmpName'].tolist())
Вывод:
['Pankaj', 'David Lee', 'Lisa Ray']
Можно указать имена столбцов для чтения из файла Excel. Это потребуется, если нужно вывести данные из определенных столбцов таблицы.
import pandas
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print(excel_data_df)
Вывод:
Car Name Car Price 0 Honda City 20,000 USD 1 Bugatti Chiron 3 Million USD 2 Ferrari 458 2,30,000 USD
Если в листе Excel нет строки заголовка, нужно передать его значение как None.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Numbers', header=None)
Если вы передадите значение заголовка как целое число (например, 3), тогда третья строка станет им. При этом считывание данных начнется со следующей строки. Данные, расположенные перед строкой заголовка, будут отброшены.
Объект DataFrame предоставляет различные методы для преобразования табличных данных в формат Dict , CSV или JSON.
excel_data_df = pandas.read_excel('records.xlsx', sheet_name='Cars', usecols=['Car Name', 'Car Price'])
print('Excel Sheet to Dict:', excel_data_df.to_dict(orient='record'))
print('Excel Sheet to JSON:', excel_data_df.to_json(orient='records'))
print('Excel Sheet to CSV:n', excel_data_df.to_csv(index=False))
Вывод:
Excel Sheet to Dict: [{'Car Name': 'Honda City', 'Car Price': '20,000 USD'}, {'Car Name': 'Bugatti Chiron', 'Car Price': '3 Million USD'}, {'Car Name': 'Ferrari 458', 'Car Price': '2,30,000 USD'}]
Excel Sheet to JSON: [{"Car Name":"Honda City","Car Price":"20,000 USD"},{"Car Name":"Bugatti Chiron","Car Price":"3 Million USD"},{"Car Name":"Ferrari 458","Car Price":"2,30,000 USD"}]
Excel Sheet to CSV:
Car Name,Car Price
Honda City,"20,000 USD"
Bugatti Chiron,3 Million USD
Ferrari 458,"2,30,000 USD"
- Документы API pandas read_excel()
Pandas можно использовать для чтения и записи файлов Excel с помощью Python. Это работает по аналогии с другими форматами. В этом материале рассмотрим, как это делается с помощью DataFrame.
Помимо чтения и записи рассмотрим, как записывать несколько DataFrame в Excel-файл, как считывать определенные строки и колонки из таблицы и как задавать имена для одной или нескольких таблиц в файле.
Установка Pandas
Для начала Pandas нужно установить. Проще всего это сделать с помощью pip.
Если у вас Windows, Linux или macOS:
pip install pandas # или pip3В процессе можно столкнуться с ошибками ModuleNotFoundError или ImportError при попытке запустить этот код. Например:
ModuleNotFoundError: No module named 'openpyxl'В таком случае нужно установить недостающие модули:
pip install openpyxl xlsxwriter xlrd # или pip3Будем хранить информацию, которую нужно записать в файл Excel, в DataFrame. А с помощью встроенной функции to_excel() ее можно будет записать в Excel.
Сначала импортируем модуль pandas. Потом используем словарь для заполнения DataFrame:
import pandas as pd
df = pd.DataFrame({'Name': ['Manchester City', 'Real Madrid', 'Liverpool',
'FC Bayern München', 'FC Barcelona', 'Juventus'],
'League': ['English Premier League (1)', 'Spain Primera Division (1)',
'English Premier League (1)', 'German 1. Bundesliga (1)',
'Spain Primera Division (1)', 'Italian Serie A (1)'],
'TransferBudget': [176000000, 188500000, 90000000,
100000000, 180500000, 105000000]})
Ключи в словаре — это названия колонок. А значения станут строками с информацией.
Теперь можно использовать функцию to_excel() для записи содержимого в файл. Единственный аргумент — это путь к файлу:
df.to_excel('./teams.xlsx')
А вот и созданный файл Excel:

Стоит обратить внимание на то, что в этом примере не использовались параметры. Таким образом название листа в файле останется по умолчанию — «Sheet1». В файле может быть и дополнительная колонка с числами. Эти числа представляют собой индексы, которые взяты напрямую из DataFrame.
Поменять название листа можно, добавив параметр sheet_name в вызов to_excel():
df.to_excel('./teams.xlsx', sheet_name='Budgets', index=False)
Также можно добавили параметр index со значением False, чтобы избавиться от колонки с индексами. Теперь файл Excel будет выглядеть следующим образом:
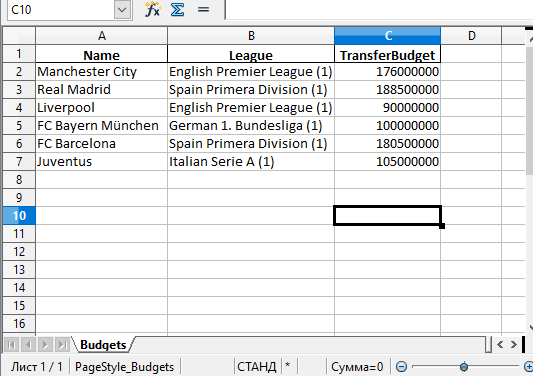
Запись нескольких DataFrame в файл Excel
Также есть возможность записать несколько DataFrame в файл Excel. Для этого можно указать отдельный лист для каждого объекта:
salaries1 = pd.DataFrame({'Name': ['L. Messi', 'Cristiano Ronaldo', 'J. Oblak'],
'Salary': [560000, 220000, 125000]})
salaries2 = pd.DataFrame({'Name': ['K. De Bruyne', 'Neymar Jr', 'R. Lewandowski'],
'Salary': [370000, 270000, 240000]})
salaries3 = pd.DataFrame({'Name': ['Alisson', 'M. ter Stegen', 'M. Salah'],
'Salary': [160000, 260000, 250000]})
salary_sheets = {'Group1': salaries1, 'Group2': salaries2, 'Group3': salaries3}
writer = pd.ExcelWriter('./salaries.xlsx', engine='xlsxwriter')
for sheet_name in salary_sheets.keys():
salary_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
Здесь создаются 3 разных DataFrame с разными названиями, которые включают имена сотрудников, а также размер их зарплаты. Каждый объект заполняется соответствующим словарем.
Объединим все три в переменной salary_sheets, где каждый ключ будет названием листа, а значение — объектом DataFrame.
Дальше используем движок xlsxwriter для создания объекта writer. Он и передается функции to_excel().
Перед записью пройдемся по ключам salary_sheets и для каждого ключа запишем содержимое в лист с соответствующим именем. Вот сгенерированный файл:
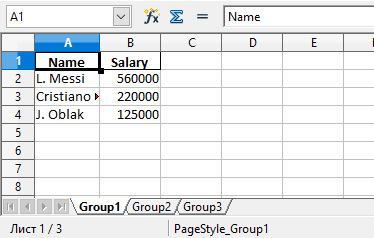
Можно увидеть, что в этом файле Excel есть три листа: Group1, Group2 и Group3. Каждый из этих листов содержит имена сотрудников и их зарплаты в соответствии с данными в трех DataFrame из кода.
Параметр движка в функции to_excel() используется для определения модуля, который задействуется библиотекой Pandas для создания файла Excel. В этом случае использовался xslswriter, который нужен для работы с классом ExcelWriter. Разные движка можно определять в соответствии с их функциями.
В зависимости от установленных в системе модулей Python другими параметрами для движка могут быть openpyxl (для xlsx или xlsm) и xlwt (для xls). Подробности о модуле xlswriter можно найти в официальной документации.
Наконец, в коде была строка writer.save(), которая нужна для сохранения файла на диске.
Чтение файлов Excel с python
По аналогии с записью объектов DataFrame в файл Excel, эти файлы можно и читать, сохраняя данные в объект DataFrame. Для этого достаточно воспользоваться функцией read_excel():
top_players = pd.read_excel('./top_players.xlsx')
top_players.head()
Содержимое финального объекта можно посмотреть с помощью функции head().
Примечание:
Этот способ самый простой, но он и способен прочесть лишь содержимое первого листа.
Посмотрим на вывод функции head():
| Name | Age | Overall | Potential | Positions | Club | |
|---|---|---|---|---|---|---|
| 0 | L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| 1 | Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| 2 | J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| 3 | K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| 4 | Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
Pandas присваивает метку строки или числовой индекс объекту DataFrame по умолчанию при использовании функции read_excel().
Это поведение можно переписать, передав одну из колонок из файла в качестве параметра index_col:
top_players = pd.read_excel('./top_players.xlsx', index_col='Name')
top_players.head()
Результат будет следующим:
| Name | Age | Overall | Potential | Positions | Club |
|---|---|---|---|---|---|
| L. Messi | 33 | 93 | 93 | RW,ST,CF | FC Barcelona |
| Cristiano Ronaldo | 35 | 92 | 92 | ST,LW | Juventus |
| J. Oblak | 27 | 91 | 93 | GK | Atlético Madrid |
| K. De Bruyne | 29 | 91 | 91 | CAM,CM | Manchester City |
| Neymar Jr | 28 | 91 | 91 | LW,CAM | Paris Saint-Germain |
В этом примере индекс по умолчанию был заменен на колонку «Name» из файла. Однако этот способ стоит использовать только при наличии колонки со значениями, которые могут стать заменой для индексов.
Чтение определенных колонок из файла Excel
Иногда удобно прочитать содержимое файла целиком, но бывают случаи, когда требуется получить доступ к определенному элементу. Например, нужно считать значение элемента и присвоить его полю объекта.
Это делается с помощью функции read_excel() и параметра usecols. Например, можно ограничить функцию, чтобы она читала только определенные колонки. Добавим параметр, чтобы он читал колонки, которые соответствуют значениям «Name», «Overall» и «Potential».
Для этого укажем числовой индекс каждой колонки:
cols = [0, 2, 3]
top_players = pd.read_excel('./top_players.xlsx', usecols=cols)
top_players.head()
Вот что выдаст этот код:
| Name | Overall | Potential | |
|---|---|---|---|
| 0 | L. Messi | 93 | 93 |
| 1 | Cristiano Ronaldo | 92 | 92 |
| 2 | J. Oblak | 91 | 93 |
| 3 | K. De Bruyne | 91 | 91 |
| 4 | Neymar Jr | 91 | 91 |
Таким образом возвращаются лишь колонки из списка cols.
В DataFrame много встроенных возможностей. Легко изменять, добавлять и агрегировать данные. Даже можно строить сводные таблицы. И все это сохраняется в Excel одной строкой кода.
Рекомендую изучить DataFrame в моих уроках по Pandas.
Выводы
В этом материале были рассмотрены функции read_excel() и to_excel() из библиотеки Pandas. С их помощью можно считывать данные из файлов Excel и выполнять запись в них. С помощью различных параметров есть возможность менять поведение функций, создавая нужные файлы, не просто копируя содержимое из объекта DataFrame.